无题
ElasticSearch 概述

概述
Elasticsearch 是什么
Elasticsearch(简称ES)是一个基于Apache Lucene(TM)的开源搜索引擎
Elasticsearch 是一个高伸缩的开源全文搜索和分析引擎,是一个基于JSON的分布式搜索和分析引擎,基于restful web接口,Elasticsearch是用Java语言开发的,基于Apache协议的开源项目,是目前最受欢迎的企业搜索引擎。
它可以快速地、近实时的存储,搜索和分析大规模的数据。一般被用作底层引擎/技术,为具有复杂搜索功能和要求的应用提供强有力的支撑。
ElasticSearch特点
Elasticsearch是实时的分布式搜索分析引擎,内部使用Lucene做索引与搜索,有以下特点
- 近实时性:新增到 ES 中的数据在1秒后就可以被检索到,这种新增数据对搜索的可见性称为“近实时搜索”
- 全文检索:将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES
- 分布式:意味着可以动态调整集群规模,弹性扩容
- 集群规模:可以扩展到上百台服务器,处理PB级结构化或非结构化数据
- 开箱即用:对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES
- 不支持事务:数据库的功能面对很多领域是不够用的,事务,还有各种联机事务型的操作
使用场景
ElasticSearch广泛应用于各行业领域, 比如维基百科, GitHub的代码搜索,电商网站的大数据日志统计分析, BI系统报表统计分析等。
记录和日志分析
ELK结合使用可以实现日志数据的收集整理
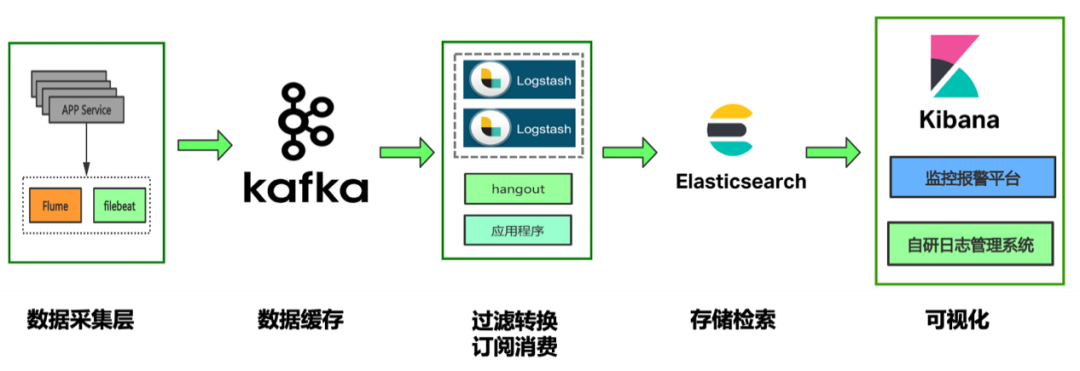
围绕Elasticsearch建立的生态系统使其成为实施和扩展日志记录解决方案最简单的系统之一,利用这一点将日志添加到他们的主要用例中,或者纯粹将我们用于日志记录。
从Beats到Logstash,再到Ingest Nodes,Elasticsearch为您提供了很多选择,可以随时随地获取数据并将其编入索引,从那里,像Kibana这样的工具使您能够创建丰富的仪表板和分析。
搜集和合并公共数据
像日志数据一样,Elastic Stack有很多工具可以使远程数据的获取和索引编制变得容易。
而且,像大多数文档存储一样,缺乏严格的架构也使Elasticsearch可以灵活地接收多种不同的数据源,并且仍然可以使所有数据源易于管理和搜索。
全文搜索
全文搜索作为Elasticsearch的核心功能,得到了广泛的应用,远远超出了传统的企业搜索或电子商务
从欺诈检测/安全性到协作及其他方面,Elasticsearch的搜索功能强大,灵活,并且包含许多工具,可以使搜索变得更加容易,Elasticsearch拥有自己的查询DSL以及内置的功能,可自动完成
事件数据和指标
Elasticsearch在如指标和应用程序事件之类的时间序列数据上也能很好地运行
这是巨大的Beats生态系统允许您轻松获取常见应用程序数据的另一个区域,无论您使用哪种技术,Elasticsearch都有很大的机会拥有可以立即获取指标和事件的组件。
可视化数据
Kibana拥有大量图表选项,用于地理数据的图块服务以及用于时间序列数据的TimeLion,是功能强大且易于使用的可视化工具。
对于上述每个用例,Kibana都会处理一些可视组件,熟悉了各种数据提取工具后,您会发现Elasticsearch + Kibana将成为您可视化试图包裹数据的必备工具。
能做什么
要使用ElasticSearch我们需要知道ElasticSearch能够做什么
提供快速查询
试想一下,当你打开一个博客网站,搜索一篇博客的时候,等待了一分钟才有搜索结果,那将会是一个极差的体验。
可想而知,这个博客网站肯定没有使用搜索引擎处理搜索的请求,而是使用了传统的关系型数据库查询,在庞大的数据面前,关系型数据库的查询就显得力不从心,相当耗时。Elasticsearch在这个时候可以帮上忙,使用博客数据建立索引库,依赖倒排索引的优势,为用户快速的呈现搜索的相关结果。
确保结果的相关性
接下来有一个难题: 如何将真正描述选举的帖子排序在前呢?有了 Elasticsearch,就可以使 用几个算法来计算相关性的得分( relevancy score ),然后根据分数来将结果逐个排序 。
默认情况下,计算文档相关性得分的算法是TF-IDF(term frequency-inverse document frequency),词频逆文档频率。我们将在后面讨论这个概念。除了选择算法,Elasticsearch还提供了很多其他内置的功能来计算概相关性得分,以满足定制需求。
处理错误的拼写
当我们在使用搜索时,会出现英文拼写错误,中文错别字等情况时有发生。
我们可以通过配置让Elasticsearch容忍一些错误,而不仅仅只是查找精确匹配,如我们输入“book”的时候由于手误输入了“bok”,如果搜索引擎能够意识到这一错误并且在搜索时帮我们修正这个错误,那么搜索会更快让人满意。
给予自动提示
当用户开始输入时,你可以帮助他们发现主流的查询和结果。
还可以通过自动提示技术预测 他们所要输入的内容,就像 Web 上很多搜索引擎做的那样,你同样可以展示主流的结果,通过 特殊的查询类型来匹配前缀、通配符或正则表达式。
使用统计信息
当用户不太清楚具体要搜索什么的时候,可以通过几种方式来协助他们 。
一种方法是聚集统计数据, 聚集是在搜索结果里得到一些统计数据,如每个分类有多少议题、每个分 类中“赞”和“分享”的平均数量。
假想一下,进入博客时,用户会在右侧看见最近流行的议题。 其中之一是自行车。 对其感兴趣的读者会点击这个标题,进一步缩小范围。 然后, 可能还有另外 的聚集方式 ,将自行车相关的帖子分为“ 自行车鉴赏”“自行车大事件”等。
ElasticSearch的发展
起源Lucene
Lucene 是一个用 Java 编写的非常古老的搜索引擎工具 包,用来构建倒排索引(一种数据结构)和对这些索引进行检索,从而实现全文检索功能。
缺点
Lucene,必须使用Java来作为开发语言并将其直接集成到你的应用中,并且Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它 是如何工作的,有以下缺点
- 只能在Java项目中使用,并且要以jar包的方式直接集成项目中
- 使用非常复杂-创建索引和搜索索引代码繁杂
- 不支持集群环境-索引数据不同步(不支持大型项目)
- 索引数据如果太多就不行,索引库和应用所在同一个服务器,共同占用硬盘,共用空间少。
lunce 单独占用内存?
诞生
ElasticSearch的创始人期初是为了能够为妻子开发一个菜谱搜索应用而接触的Lucene
它本身不是一个应用程序无法直接提供用户使用,同样对其他语言不友好的,那么ElastiSearch的开发者在使用过程中遇到的一系列问题,他就在Lucene的基础上对之进行不断的优化形成了自己的一套应用程序‘Compass’。
后来它自己在工作中同样遇到了一个需要高性能,分布式的搜索服务,所以他就在‘Compass’的基础之上重新构建起了ElasticSearch,从设计之初的目标就是打造成分布式、高性能、基于JSON、Restful的易用性可易用与其他语言的独立服务。
发展
围绕ElasticSearch后来成立一家公司(Elastic公司)全面围绕ElasticSearch或者说是数据生态进行发展,该公司已经在去年上市(ESTC),上市当天暴涨

ELasticSearch当前已经可以与多种客户端进行集成Python、PHP、.NET、Java等,当前同样支持与Hadoop、Spark等大数据分析平台进行集成。
ElasticSearch衍生出一系列的开源项目,例如业内较火的ELK Stack,ELK Stack是负责数据检索服务的ElasticSearch、数据采集解析服务的Logstash和负责数据可视化服务的Kibana的简称,Logstash是由Java语言编写的,同时负责数据的采集与解析工作,会导致服务的CPU与内存资源占用过高,后来ELastic又推出采用Go语言编写的Beats家族
ElasticSearch基本概念
索引类型
我们常见的索引包括正排索引和倒排索引
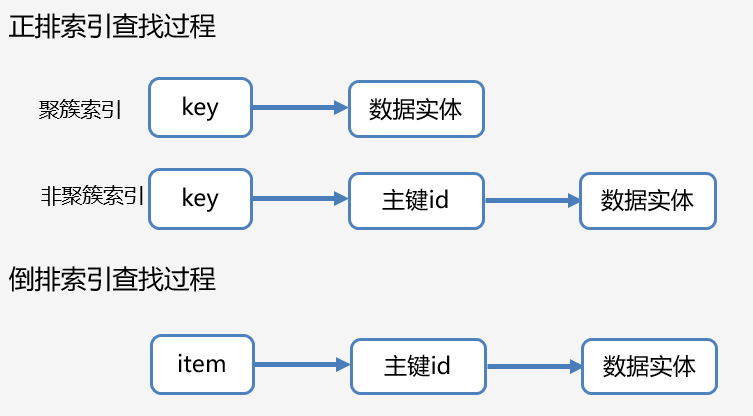
正排索引
正排索引是以文档的ID为关键字,表中记录文档中每个字段的位置信息,查找时扫描表中每个文档中字段的信息直到找出所有包含查询关键字的文档
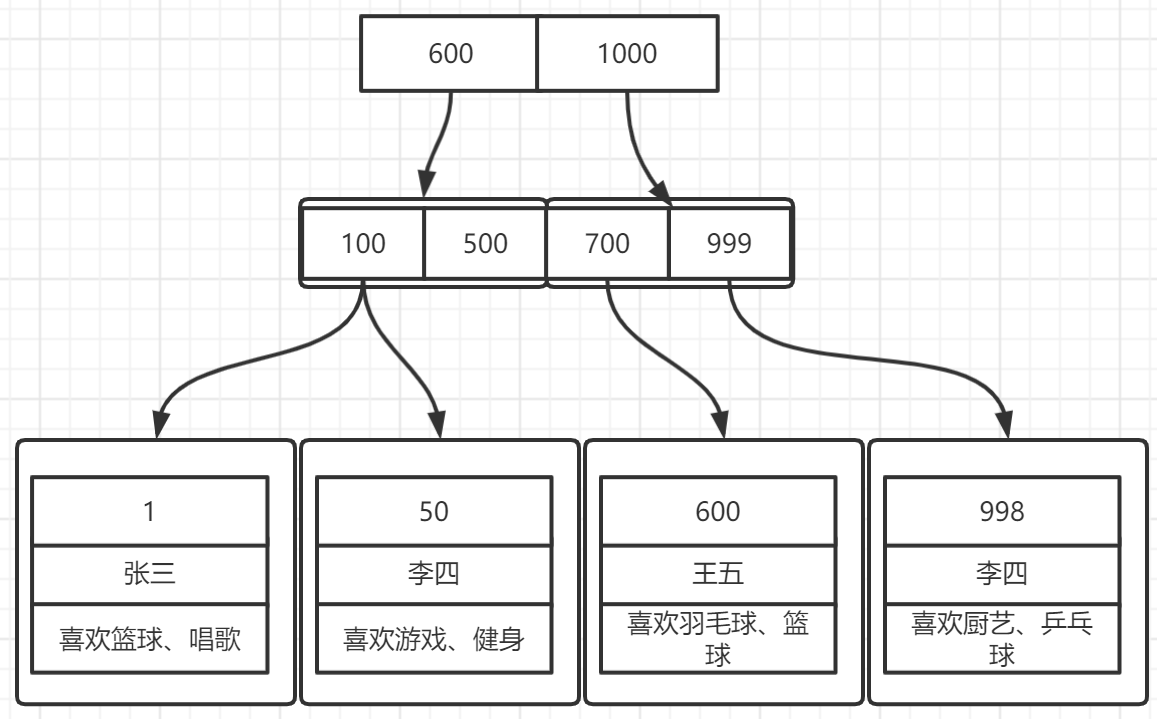
正排索引说明
拿MySQL Innodb的聚簇索引来说,如下图所示,一个极简版(无页属性)的B+树索引结构大概是这样,叶子节点存放完整数据,非叶子节点存放建立对应聚簇索引对应的字段(主键),一条可以使用到聚簇索引的SQL,会依次从上到下进行B+树的查找直到字段一致;
CREATE TABLE user_info (
id int,
name varchar(16),
hobby varchar(256)
);
索引查询
而对应非聚簇索引只是叶子节点的内容存放的是该表的主键信息,查询的顺序则是 先通过非聚簇索引的字段找到叶子节点中一致的 单个或者多个主键id,再使用这些主键id进行回表,最终获得对应的完整实体数据。
全表扫描
如果我们看上面在mysql中表的hobby爱好字段,如果我们有业务需求:根据用户爱好关键字如“篮球”去查询对应用户列表,我们怎么做,只能是写个字符串的like sql,全表扫描的逻辑。
SELECT *
FROM user_info
WHERE hobby LIKE '%篮球%';即使我们对hobby字段创建了普通索引,在Innodb引擎下,在查询中想使用字符串类型的索引也只能走最左前缀索引的逻辑,即 LIKE ‘篮球%’。
全文索引
幸好Innodb在5.6版本后支持了全文索引full text,在创建完全文索引后,查询中使用MATCH、AGAINST就能够使用全文索引了,比全表扫B+树效率会高很多,但是对应全文索引会占据相当的磁盘空间,全文索引与我们要说的倒排索引就是一个意思了。
SELECT *
FROM user_info
WHERE MATCH (hobby) AGAINST ('篮球');倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录,也就是说,不是由记录来确定属性值,而是由属性值来确定记录,因而称为倒排索引
相比B+树的正排索引,如果我们对hobby字段建立了索引,他的倒排索引极简的数据格式如下。
创建倒排索引的field,会通过分词器根据语义将字段中的field分成一个一个对应的词索引(term index),构成该类型数据的全部词索引集合,如“喜欢篮球、唱歌”会被分成 “篮球”和“唱歌”两个term index;
第二列是含有这些term index对应的文档Id,这个数据可以帮助我们最终溯源到完整实体数据;
第三列则是对应term index在该文档字段中的位置,0表示在开头的位置,这个可以帮助标注检索出来数据的高亮信息。

两种索引查找顺序
逻辑概念
假设我们在一个业务系统中选择MySQL做数据存储,那么我们需要先创建一个database,再创建一组相关的table,Elasticsearch同样具有这样的概念,使用index和mapping来组织数据,下面是Elasticsearch的一些基本概念
| 概念 | 关系型数据库 | 说明 |
|---|---|---|
| 索引库(indices) | Databases 数据库 | indices是index的复数,代表许多的索引 |
| 类型(type) | Table 数据表 | 类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同,不过这会导致索引库混乱,因此未来版本中会移除这个概念 |
| 文档(document) | Row 行 | 存入索引库原始的数据,比如每一条商品信息,就是一个文档 |
| 字段(field) | Columns 列 | 文档中的属性 |
| 映射配置(mappings) | 表结构 | 字段的数据类型、属性、是否索引、是否存储等特性 |
索引(Index)
一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
一个索引相当于数据库,是多个相似文档的集合,必须通过索引才能进行搜索,使用使用能够极大的提升查询速度,类似于词典里面的目录。
当然在底层,肯定用到了倒排索引,最基本的结构就是“keyword”和“PostingList”,Postinglist就是一个int的数组,存储了所有符合某个term的文档id,另外,这个倒排索引相比特定词项出现过的文档列表,会包含更多其它信息。
它会保存每一个词项出现过的文档总数,在对应的文档中一个具体词项出现的总次数,词项在文档中的顺序,每个文档的长度,所有文档的平均长度等等相关信息。
类型(Type)
一个类型过去是索引的逻辑类别/分区,允许你在同一索引中存储不同类型的文档
例如,一种类型用于用户,另一种类型用于博客文章,在索引中创建多个类型不再可能,类型的整个概念将在稍后的版本中删除,相当于sql领域中表的概念。
类型的变化
在不同的elasticsearch中,类型发生了不同的变化
| 版本 | Type |
|---|---|
| 5.x | 支持多种Type |
| 6.x | 只有一种Type |
| 7.x | 默认不在支持自定义的索引类型,默认类型为_doc |
文档(Document)
一个文档是可以被索引的一个基本单元,相当于数据库中的一条数据,索引和搜索数据的最小单位是文档
字段(Field)
相当于数据库表的字段,每个字段有不同的类型
映射(Mapping)
Mapping是对处理数据时的方式和规则作出一定的限制,如字段的类型、默认值、分析器、是否被索引等,映射定义了每个字段的类型、字段所使用的分词器等。
可以显式映射,由我们在索引映射中进行预先定义,也可以动态映射,在添加文档的时候,由es自动添加到索引,这个过程不需要事先在索引进行字段数据类型匹配等等,es会自己推断数据类型。
get itheima/_mapping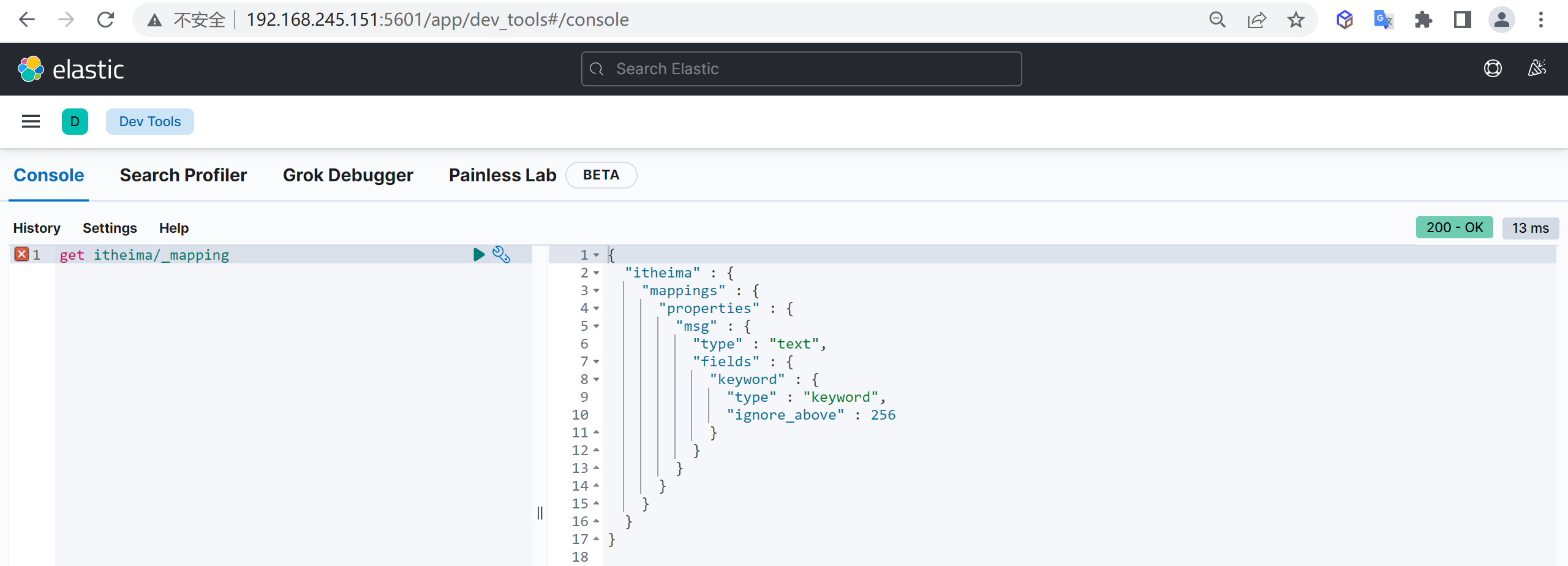
物理概念
Elasticsearch是一个分布式系统,其数据会分散存储到不同的节点上,为了实现这一点,需要将每个index中的数据划分到不同的块中,然后将这些数据块分配到不同的节点上存储
集群 (cluster)
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能
 集群(cluster)是一个或多个节点(node)的集合,这些节点 将共同拥有完整的数据,并跨节点提供联合索引、搜索和分析功能。
集群(cluster)是一个或多个节点(node)的集合,这些节点 将共同拥有完整的数据,并跨节点提供联合索引、搜索和分析功能。
一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”,这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
ES集群是一个 P2P类型(使用 gossip 协议)的分布式系统,除了集群状态管理以外,其他所有的请求都可以发送到集群内任意一台节点上,这个节点可以自己找到需要转发给哪些节点,并且直接跟这些节点通信,所以从网络架构及服务配置上来说,构建集群所需要的配置极其简单
集群中节点数量没有限制,一般大于等于2个节点就可以看做是集群了,一般处于高性能及高可用方面来考虑一般集群中的节点数量都是3个及3个以上。
节点(node)
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能
和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点
一个节点可以通过配置集群名称的方式来加入一个指定的集群,默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
分片(Shards)
分片的存在是为了解决单个索引大量文档的存储问题、以及搜索是响应慢等问题。
比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间,或者单个节点处理搜索请求,响应太慢,为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。
将一个索引划分成了多份,每一份就称之为分片,每个分片也是一个功能完善的“索引”,这个“索引”可以被放置到集群的任意节点上,通过”分”的思想,可以突破单机在存储空间和处理性能上的限制,这是分布式系统的核心目的
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
副本(Replicas)
而对于分布式存储而言,还有一个重要特性是”冗余”,因为分布式的前提是:接受系统中某个节点因为某些故障退出,为了保证在故障节点退出后数据不丢失,同一份数据需要拷贝多份存在不同节点上
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
段(segment)
segment来自于lucene,因为ES底层就是使用的lucene,一个shard包含一组segment,segment是最小的数据单元
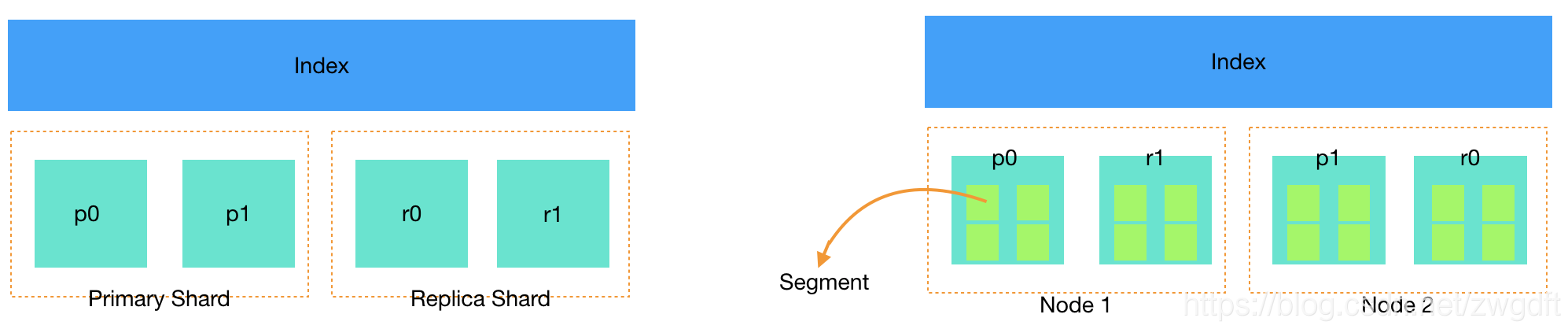
Elasticsearch每隔一段时间产生一个新的segment,里面包含了新写入的数据,lucene的数据写入会先写如到缓存(buffer)中,当达到一定数量以后,会flush成文一个segment,写入到磁盘当中,每个segement有自己独立的索引,可以单独查询。
segment不会被修改,数据的的写入都是进行批量的追加,避免了随机写的存在,提高了吞吐量,segement可以被删除,但也不是修改segement文件,而是由另外的文件记录需要被删除的documentId。
index的查询是对多个segement文件的查询,其中也包含了处理被删除文件的处理,并对查询结果进行合并,为了进行查询优化,lucene有策略对多个segment进行优化。
节点的角色
一个Elasticsearch实例代表了一个ES 节点,如果不通过 node.roles 设置节点的角色,一个ES节点默认的节点角色有:master 、data 、data_content、data_hot、data_warm、data_cold、ingest、ml、remote_cluster_client。
主节点介绍?元数据保存哪里,整体集群介绍
每个节点既可以是候选主节点也可以是数据节点,通过在配置文件../config/elasticsearch.yml中设置即可,默认都为true,ES节点有如下角色:
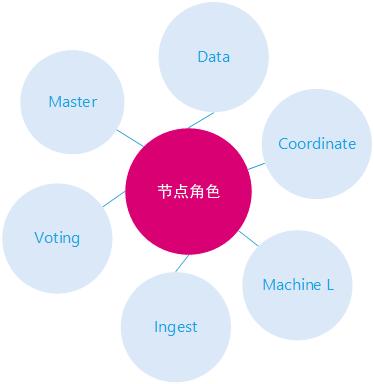
master角色
其实这个是master准确的来说是具有成为master节点资格的节点,即master-eligible node
候选主节点,master节点的职责是创建索引、删除索引、监控集群中的所有节点、决定分片应当分配到哪一个节点上,拥有一个稳定的主节点对集群非常重要,候选主节点可以通过节点选举过程被选举为主节点,主节点最好是专用的,不和其他角色共用,以免其他的操作对master节点负载造成影响,导致集群不可用
主节点负责轻量级集群范围的操作,例如创建或删除索引、跟踪哪些节点是集群的一部分以及决定将哪些分片分配给哪些节点,任何不是仅投票节点的主合格节点都可以通过主选举过程选举成为主节点。
主节点必须有一个path.data目录,其内容在重启后仍然存在,就像数据节点一样,因为这是存储集群元数据的地方,集群元数据描述了如何读取存储在数据节点上的数据,因此如果丢失,则无法读取存储在数据节点上的数据。
如果小型或轻负载集群的主节点具有其他角色和职责,则其可能运行良好,但是一旦您的集群包含多个节点,使用专用的主节点通常是有意义的。
voting_only 仅投票节点
只能参与主节点的投票选举环节,但是自己不能被选举为master
高可用性 (HA) 集群需要至少三个符合主节点的节点,其中至少两个不是仅投票节点,这样即使其中一个节点发生故障,集群也能够选举出一个主节点。
仅投票节点用来凑数的,如果只部署了两个候选主节点,当一个节点挂掉后集群将会不可用,加入了候选主节点则不一样,有了仅投票节点可以帮助快速选择一个主节点出来,并且仅投票节点不会选为主节点,不存储数据,所以消耗的资源也很小。
data 数据节点
负责数据的存储和相关的操作,例如对数据进行增、删、改、查和聚合等操作
保存包含已编入索引的文档的分片,数据节点处理数据相关操作,如 CRUD、搜索和聚合这些操作是 I/O 密集型、内存密集型和 CPU 密集型的,监控这些资源并在它们过载时添加更多数据节点非常重要
ingest 摄取节点
摄取节点可以执行由一个或多个摄取处理器组成的预处理管道
能执行预处理管道,有自己独立的任务要执行, 在索引数据之前可以先对数据做预处理操作, 不负责数据存储也不负责集群相关的事务,类似于 logstash 中 filter 的作用,功能相当强大。
在实际文档索引发生之前,使用Ingest节点预处理文档,Ingest节点拦截批量和索引请求,它应用转换,然后将文档传递回索引,在数据被索引之前,通过预定义好的处理管道对数据进行预处理。
coordinating 仅协调节点
如果您取消了处理主职责、保存数据和预处理文档的能力,那么您就剩下一个只能路由请求、处理搜索减少阶段和分发批量索引的协调节点
本质上,仅协调节点的行为就像智能负载均衡器,通过从数据和符合主节点的节点卸载协调节点角色,仅协调节点可以使大型集群受益,他们加入集群并接收完整的集群状态,就像其他每个节点一样,他们使用集群状态将请求直接路由到适当的地方。
配置节点类型
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| master eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| Coordianting only | 无 | 每个节点默认都是 Coordianting。设置其他类型为 false |
| machine learning | node.ml | true (需要 enable x-pack) |
ElasticSearch集群概念
集群角色
一个Elasticsearch实例代表了一个ES 节点,如果不通过
node.roles设置节点的角色,一个ES节点默认的节点角色有很多个不同的角色
每个节点既可以是候选主节点也可以是数据节点,通过在配置文件../config/elasticsearch.yml中设置即可,默认都为true,ES节点有如下角色:
Master节点
其实这个是master准确的来说是具有成为master节点资格的节点,即
master-eligible node
主要职责
Master角色的主要职责是负责集群层面的相关操作,管理集群变更,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。
拥有一个稳定的主节点对集群非常重要,候选主节点可以通过节点选举过程被选举为主节点,主节点最好是专用的,不和其他角色共用,以免其他的操作对master节点负载造成影响,导致集群不可用
角色介绍
主节点负责轻量级集群范围的操作,任何不是仅投票节点的合格节点都可以通过选举成为主节点
主节点必须有一个path.data目录,其内容在重启后仍然存在,就像数据节点一样,因为这是存储集群元数据的地方,集群元数据描述了如何读取存储在数据节点上的数据,因此如果丢失,则无法读取存储在数据节点上的数据。
仅投票节点
只能参与主节点的投票选举环节,但是自己不能被选举为master
主要职责
仅投票节点用来凑数的,如果只部署了两个候选主节点,当一个节点挂掉后集群将会不可用,加入了仅投票节点则不一样,有了仅投票节点可以帮助快速选择一个主节点出来,并且仅投票节点不会选为主节点,不存储数据,所以消耗的资源也很小。
角色介绍
高可用性 (HA) 集群需要至少三个符合主节点的节点,其中至少两个不是仅投票节点,这样即使其中一个节点发生故障,集群也能够选举出一个主节点。
数据节点
负责数据的存储和相关的操作,例如对数据进行增、删、改、查和聚合等操作
主要职责
数据节点主要是存储索引数据的节点,执行数据相关操作:CRUD、搜索,聚合操作等。
数据节点对cpu,内存,I/O要求较高, 在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
角色介绍
保存包含已编入索引的文档的分片,数据节点处理数据相关操作,如 CRUD、搜索和聚合这些操作是 I/O 密集型、内存密集型以及 CPU 密集型的,监控这些资源并在它们过载时添加更多数据节点非常重要
预处理节点
这是从5.0版本开始引入的概念,预处理节点可以执行由一个或多个摄取处理器组成的预处理管道
主要职责
预处理操作运行在索引文档之前,即写入数据之前,通过事先定义好的一系列processors(处理器)和pipeline(管道),对数据进行某种转换、富化
角色介绍
能执行预处理管道,有自己独立的任务要执行, 在索引数据之前可以先对数据做预处理操作, 不负责数据存储也不负责集群相关的事务,类似于 logstash 中 filter 的作用,功能相当强大。
在实际文档索引发生之前,使用Ingest节点预处理文档,Ingest节点拦截批量和索引请求,它应用转换,然后将文档传递回索引,在数据被索引之前,通过预定义好的处理管道对数据进行预处理。
仅协调节点
如果您取消了候选主节点的职责、保存数据和预处理文档的能力,那么您就剩下一个只能路由请求、处理搜索减少阶段和分发批量索引的协调节点
只要职责
协调节点将请求转发给保存数据的数据节点,每个数据节点在本地执行请求,并将结果返回给协调节点。
协调节点收集完数据合,将每个数据节点的结果合并为单个全局结果,对结果收集和排序的过程可能需要很多CPU和内存资源。
角色介绍
本质上,仅协调节点的行为就像智能负载均衡器,通过从数据和符合主节点的节点卸载协调节点角色,仅协调节点可以使大型集群受益,他们加入集群并接收完整的集群状态,就像其他每个节点一样,他们使用集群状态将请求直接路由到适当的地方。
节点配置方式
以下是个个节点的配置方式
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| master eligible | node.master | true |
| data | node.data | true |
| ingest | node.ingest | true |
| Coordianting only | 无 | 每个节点默认都是 Coordianting,设置其他类型为 false |
| machine learning | node.ml | true (需要 enable x-pack) |
集群脑裂问题
脑裂是因为集群中的节点失联导致的
脑裂分析
例如一个集群中,主节点与其它节点失联:
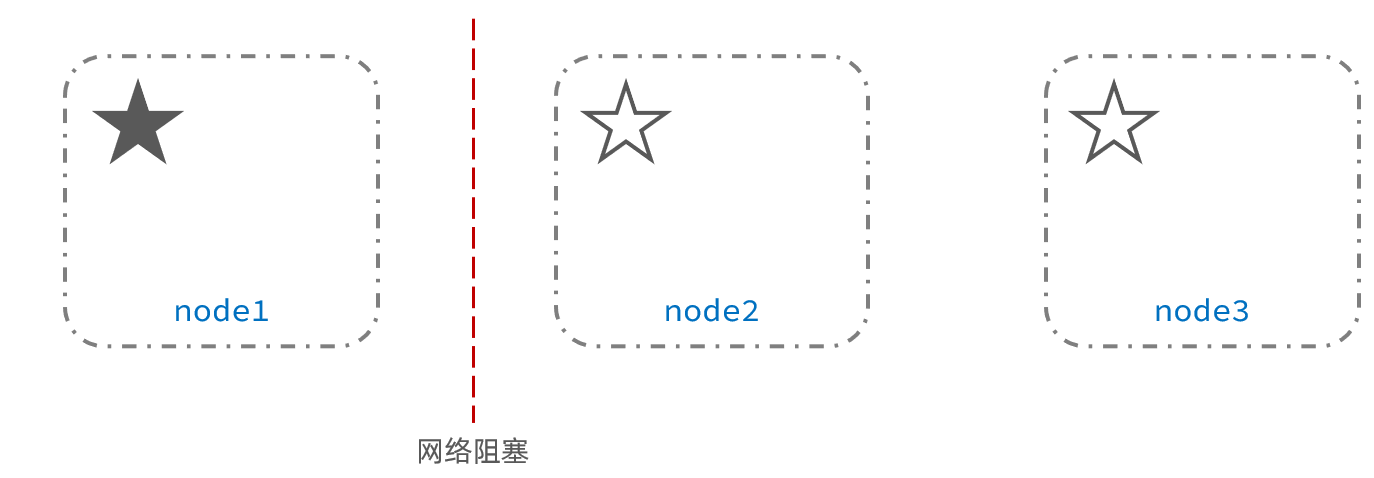
重新选主
此时,node2和node3认为node1宕机,就会重新选主:
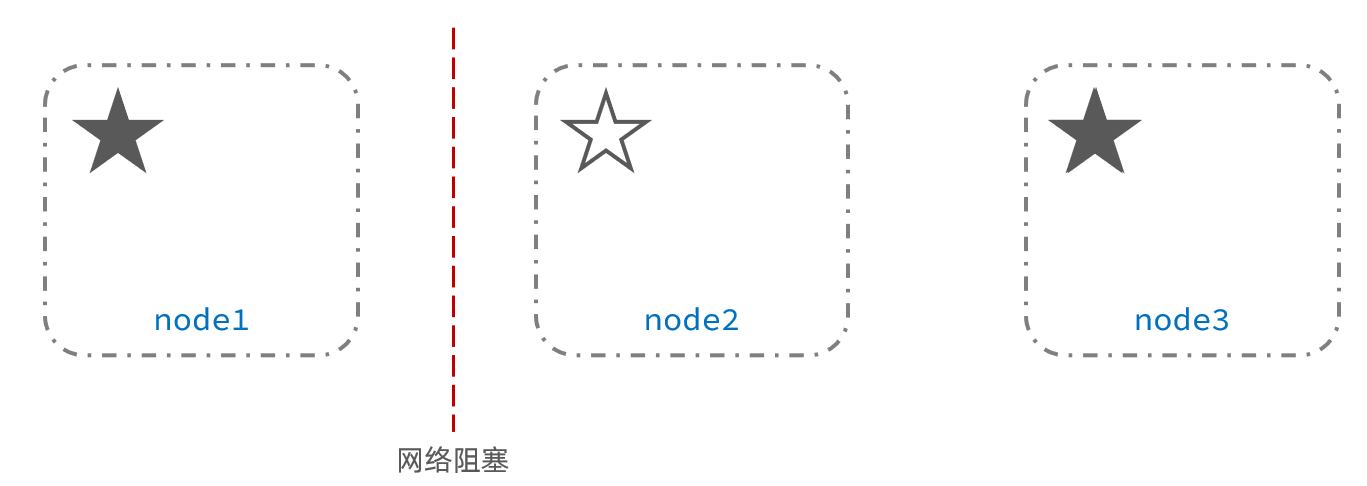
出现脑裂
当node3当选后,集群继续对外提供服务,node2和node3自成集群,node1自成集群,两个集群数据不同步,出现数据差异,当网络恢复后,因为集群中有两个master节点,集群状态的不一致,出现脑裂的情况:
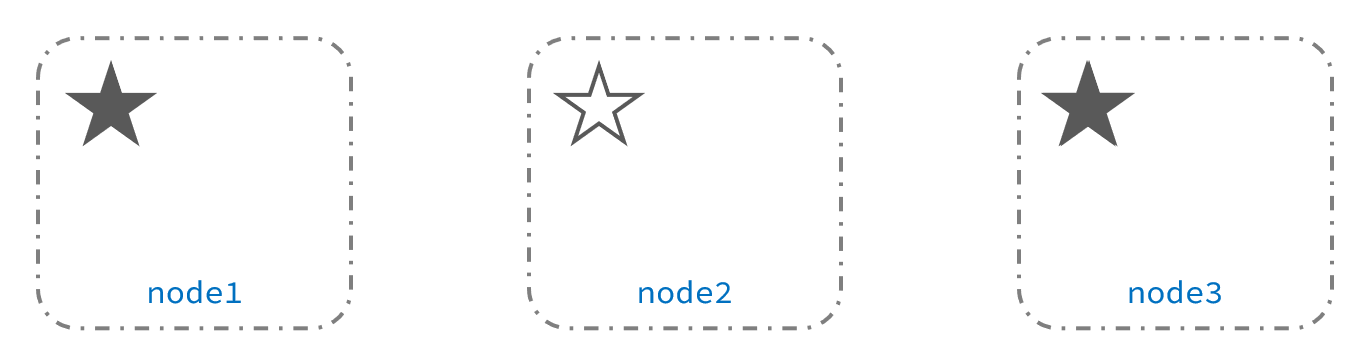
解决方案
解决脑裂的方案是,要求选票超过 ( 候选主节点数量 + 1 )/ 2 才能当选为主
因此候选主节点数量最好是奇数,对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
例如:3个节点形成的集群,选票必须超过 (3 + 1) / 2 ,也就是2票,node3得到node2和node3的选票,当选为主,node1只有自己1票,没有当选,集群中依然只有1个主节点,没有出现脑裂。
ElasticSearch 单机部署
单机部署
下载 Elasticsearch
我们下载的Elasticsearch 版本是 7.17.5,下载地址
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-17-5
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.5-linux-x86_64.tar.gz
tar -zvxf elasticsearch-7.17.5-linux-x86_64.tar.gz配置 Elasticsearch
关闭防火墙
systemctl status firewalld.service
systemctl stop firewalld.service
systemctl disable firewalld.service配置elasticsearch.yml
该配置文件是ES的主配置文件
vi elasticsearch.yml
#设置允许访问地址,配置位0.0.0.0允许任意主机访问
- #network.host: 192.168.0.1
+ network.host: 0.0.0.0
# 配置集群
# node.name: node-1
+ node.name: node-1
- #discovery.seed_hosts: ["host1", "host2"]
discovery.seed_hosts: ["node-1"]
- #cluster.initial_master_nodes: ["node-1", "node-2"]
+ cluster.initial_master_nodes: ["node-1"]修改Linux句柄数
查看当前最大句柄数
sysctl -a | grep vm.max_map_count修改句柄数
vi /etc/sysctl.conf
+ vm.max_map_count=262144生效配置
修改后需要重启才能生效,不想重启可以设置临时生效
sysctl -w vm.max_map_count=262144关闭swap
因为ES的数据大量都是常驻内存的,一旦使用了虚拟内存就会导致查询速度下降,一般需要关闭swap,但是要保证有足够的内存
临时关闭
swapoff -a永久关闭
vi /etc/fstab注释掉
swap这一行的配置

修改最大线程数
因为ES运行期间可能创建大量线程,如果线程数支持较少可能报错
配置修改
修改后需要重新登录生效
vi /etc/security/limits.conf
# 添加以下内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096重启服务
reboot创建ES用户
注意ES不能以 root 用户启动,否则会报错
添加用户
useradd elasticsearch
passwd elasticsearch增加管理员权限
增加sudoers权限
vi /etc/sudoers
+ elasticsearch ALL=(ALL) ALL修改Elasticsearch权限
给ES的安装目录进行授权
chown -R elasticsearch:elasticsearch elasticsearch-7.17.5JVM配置
根据自己的内存自行调整,内存不够则会启动失败
vi jvm.options
- ##-Xms4g
- ##-Xmx4g
+ -Xms4g
+ -Xmx4g添加IK分词器
因为后面要用到IK分词,所以我们要安装以下IK分词器
查找
在github中下载对应版本的分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases根据自己的ES版本选择相应版本的IK分词器,因为安装的ES是
7.17.5,所以也下载相应的IK分词器
解压
将下载的分词器复制到ES安装目录的
plugins目录中并进行解压
mkdir ik && cd ik
unzip elasticsearch-analysis-ik-7.17.5.zip启动ElasticSearch
切换用户
切换到刚刚创建的
elasticsearch用户
su elasticsearch启动命令
我们可以使用以下命令来进行使用
# 前台启动
sh bin/elasticsearch
# 后台启动
sh bin/elasticsearch -d访问测试
访问对应宿主机的
9200端口
http://192.168.245.151:9200/重启ElasticSearch
查找进程
先查找ElasticSearch的进程号
ps -ef | grep elastic杀死进程
杀死对应的进程
kill -9 49736启动ElasticSearch
注意不要使用ROOT用户启动
sh bin/elasticsearch -dkibana安装
下载安装 Kibana
kibana 版本 7.17.5
下载地址:https://www.elastic.co/cn/downloads/past-releases/kibana-7-17-5
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.5-linux-x86_64.tar.gz
tar -zvxf kibana-7.17.5-linux-x86_64.tar.gz
mv kibana-7.17.5-linux-x86_64 kibana-7.17.5配置 Kibana
vi config/kibana.yml
- #server.port: 5601
+ server.port: 5601
- #server.host: "localhost"
+ server.host: "0.0.0.0"
- #elasticsearch.hosts: ["http://localhost:9200"]
+ elasticsearch.hosts: ["http://localhost:9200"]启动 Kibana
切换用户
Kibana也不能以root用户运行,需要切换到
elasticsearch权限
su elasticsearch启动kibaba
#前台运行
sh bin/kibana
#后台运行
nohup sh bin/kibana >/dev/null 2>&1 &访问测试
访问对应宿主机的
5601端口
http://192.168.245.151:5601/ES快速入门
下面我们看下ES的一些基本使用
索引管理
我们使用数据库的第一步就是创建数据库,同样ES也是一样的,第一步也是对索引进行管理
列出索引
我们使用索引的第一步就是列出索引,查看当前数据库有哪些索引
GET /_cat/indices?v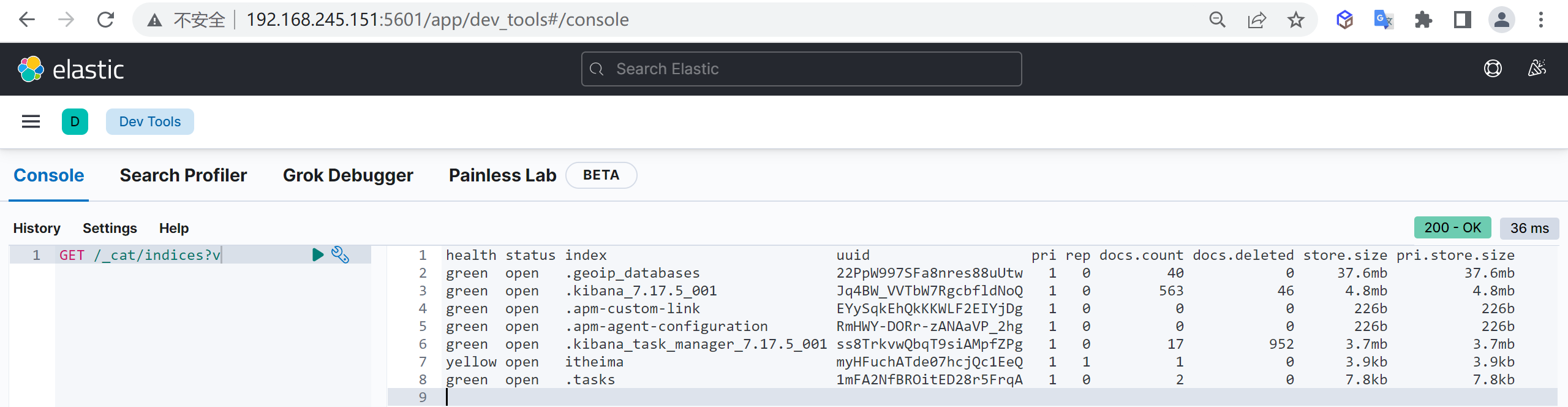
创建索引
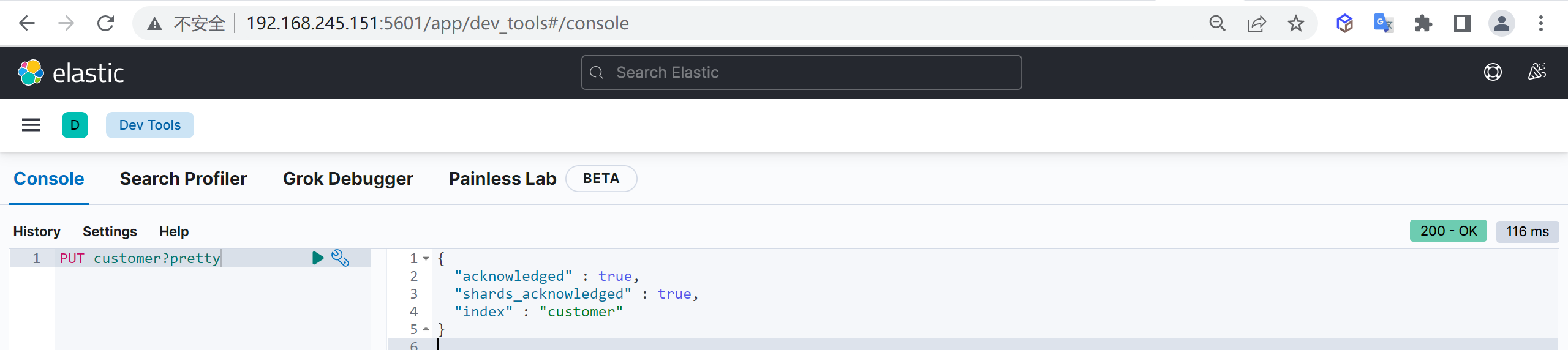
我们接下来要使用索引就需要创建索引了,Elasticsearch使用PUT方式来实现索引的新增
可以在创建索引的时候不添加任何参数,系统会为你创建一个默认的索引,当然你可以添加附加一些配置信息
PUT customer这样我们就创建了一个索引
查看索引
索引创建完成后,我们接下来就需要对索引进行查询
get customer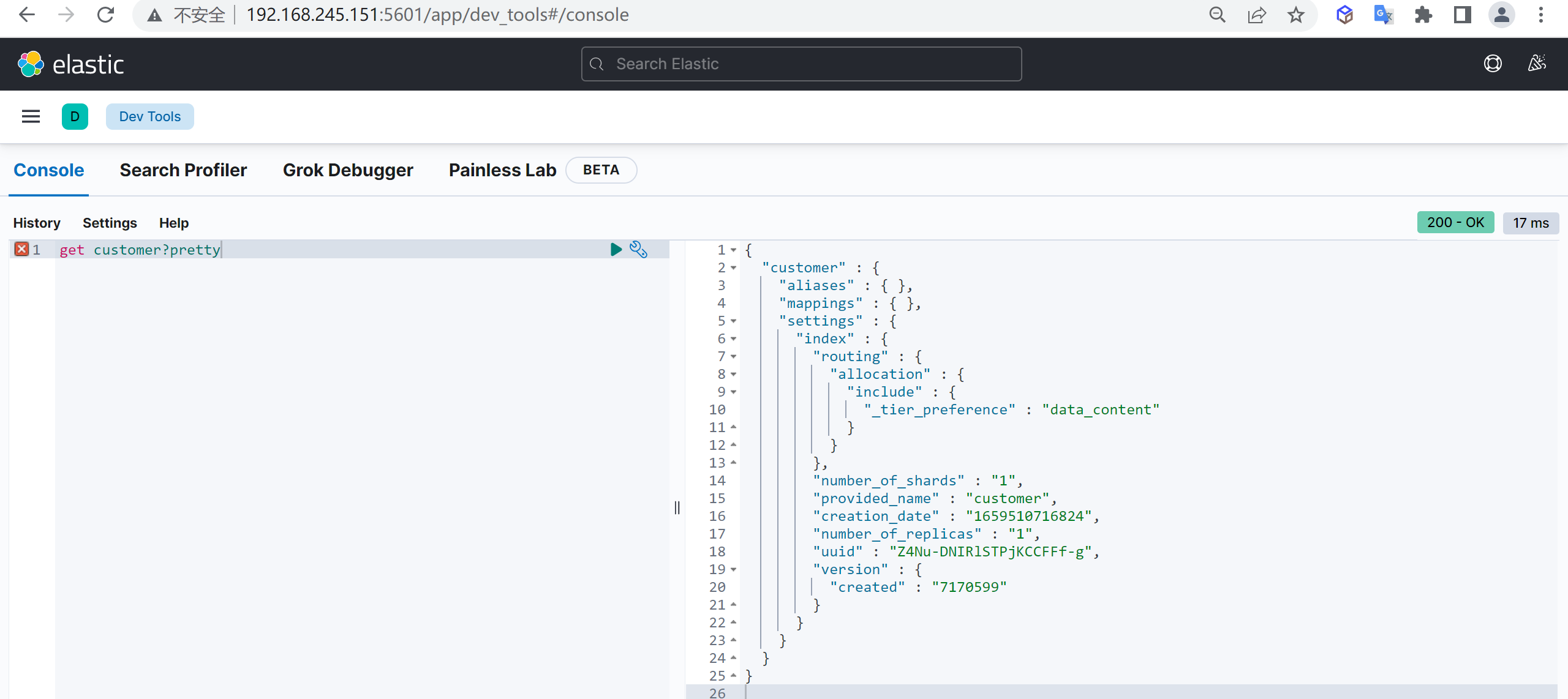
结果说明
这里返回了一堆数据,具体什么含义呢,我们需要查看字段的详细信息
| 字段 | 内容 |
|---|---|
| aliases | 别名 |
| mappings | 映射 |
| settings | 配置 |
| settings.index.creation_date | 创建时间 |
| settings.index.number_of_shards | 数据分片数,索引要做多少个分片,只能在创建索引时指定,后期无法修改 |
| settings.index.number_of_replicas | 数据备份数,每个分片有多少个副本,后期可以动态修改 |
| settings.index.uuid | 索引id |
| settings.index.provided_name | 名称 |
索引是否存在
有时候我们需要检查索引时候存在,我们可以使用HEAD命令验证索引是否存在
HEAD customer出现200表示索引存在

关闭索引
在一些业务场景,我们可能需要禁止掉某些索引的访问功能,但是又不想删除这个索引
post customer/_close这里我们就把这个索引给关闭了
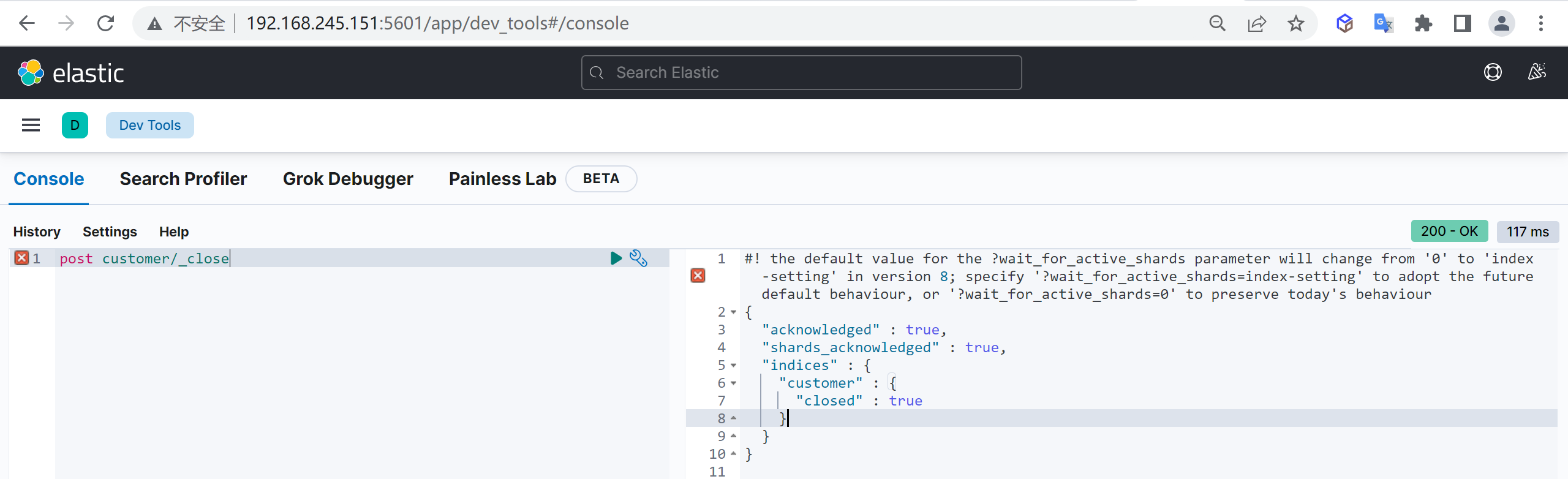
查看索引列表
再次查看索引列表,查看索引的状态
GET /_cat/indices?v我们发现索引已经被关闭了
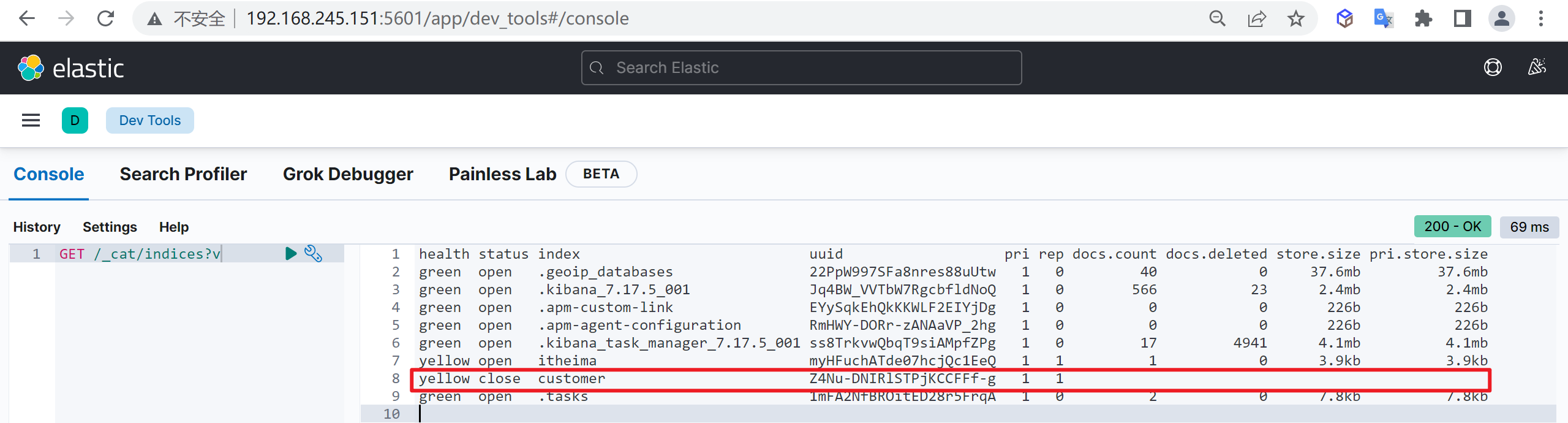
为什么关闭索引
如果关闭了一个索引,就无法通过Elasticsearch 来读取和写人其中的数据,直到再次打开它
在现实世界中,最好永久地保存应用日志,以防要查看很久之前的信息,另一方面,在Elasticsearch中存放大量数据需要增加资源,对于这种使用案例,关闭旧的索引非常有意义,你可能并不需要那些数据,但是也不想删除它们。
一旦索引被关闭,它在Elasticsearch内存中唯一的痕迹是其元数据,如名字以及分片的位置,如果有足够的磁盘空间,而且也不确定是否需要在那个数据中再次搜索,关闭索引要比删除索引更好,关闭它们会让你非常安心,随时可以重新打开被关闭的索引,然后在其中再次搜索
打开索引
如果我们需要继续启动索引可以直接打开索引
post customer/_open现在我们已经打开了索引
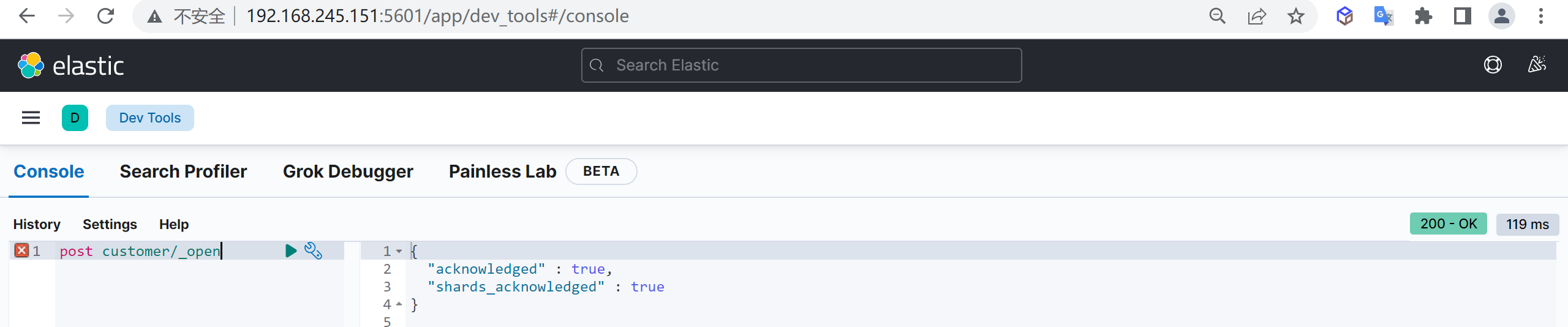
查看索引列表
GET /_cat/indices?v现在索引的状态已经是打开的状态了
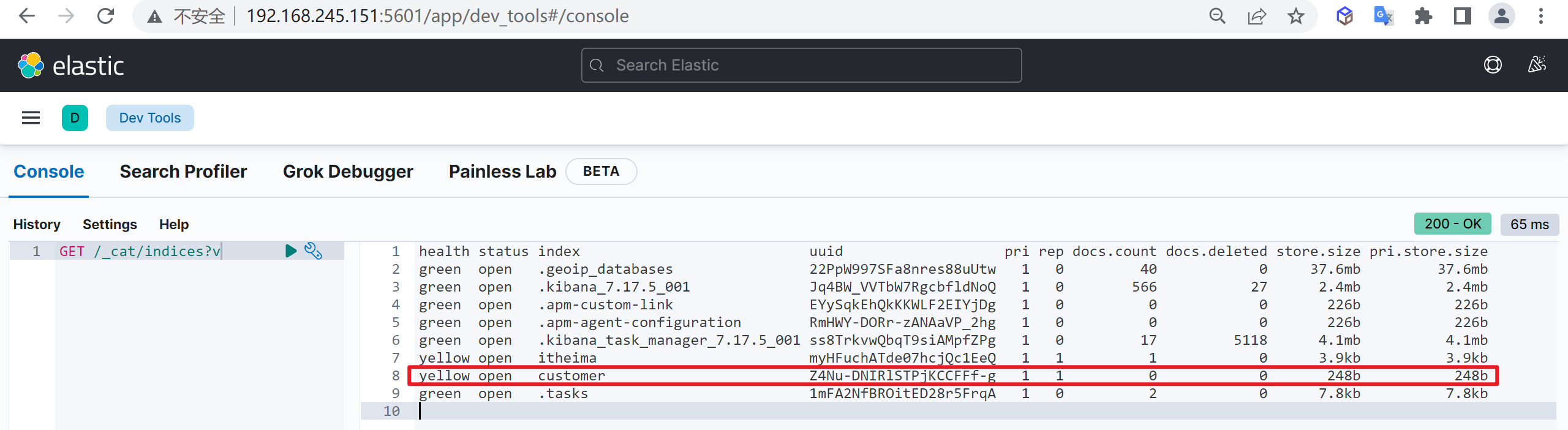
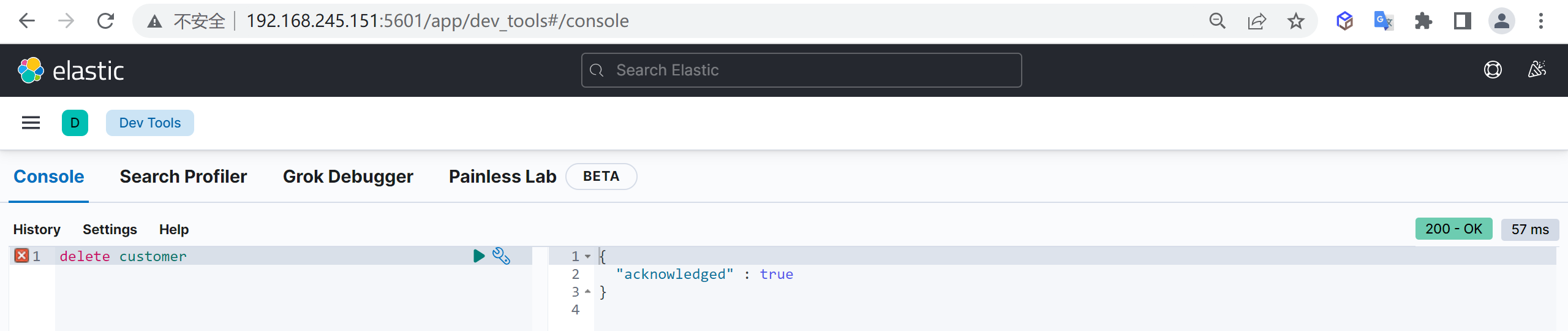
删除索引
如果索引中的数据已经不需要了,可以被删除,我们是可以删除索引的,使用以下命令可以删除索引
delete customer这样我们就把索引给删除了
映射管理
映射的创建时基于索引的,你必须要先创建索引才能创建映射,es中的映射相当于传统数据库中的表结构,数据存储的格式就是通过映射来规定的
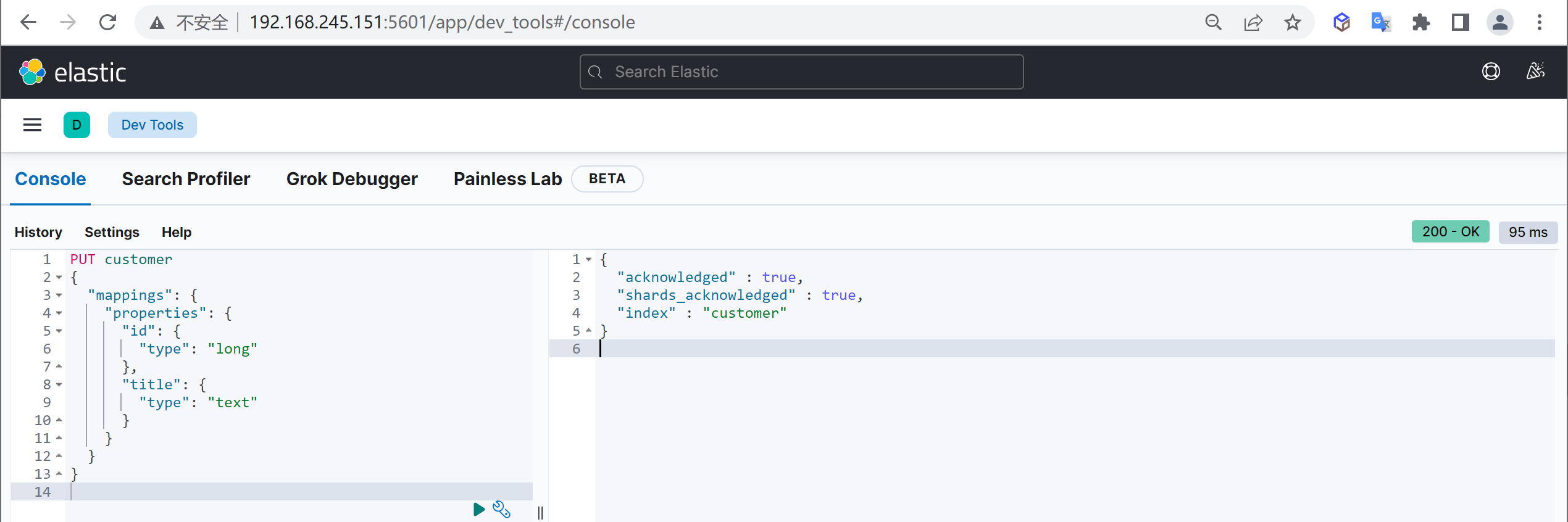
创建映射
可以在创建索引时指定映射,其中
mappings.properties为固定结构,指定创建映射属性
PUT customer
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "integer"
}
}
}
}
查看映射
查看索引完全信息,内容包含映射信息
GET customer/_mapping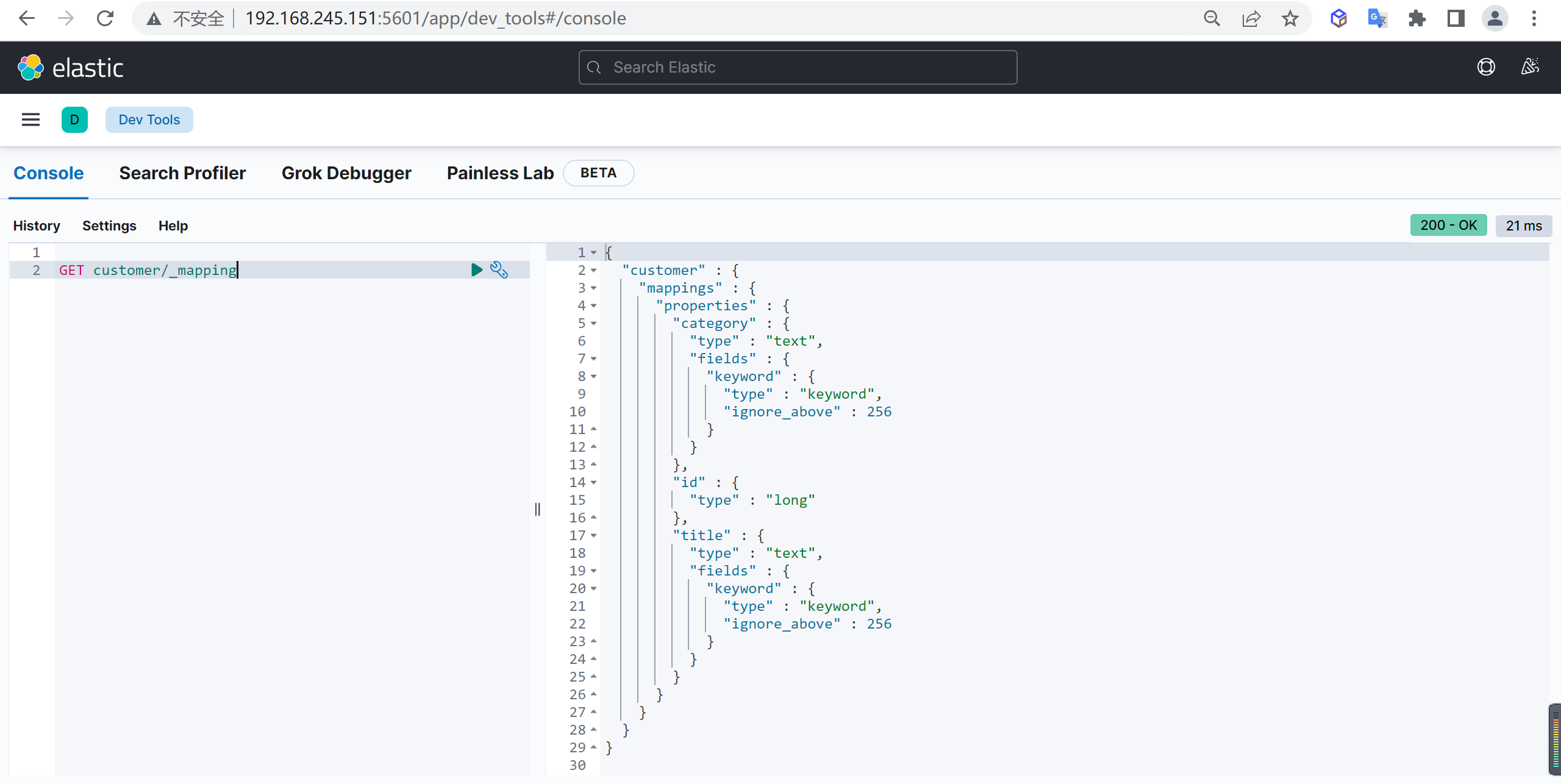
文档管理
创建文档(业务ID)
创建文档的时候我们可以手动来指定ID,但是一般不推荐,回对ES插入性能造成影响
如果手动指定ID,为了保证ID不冲突,会先查询一次文档库,如果不存在则进行插入,手动插入多了一次查询操作,性能会有损失。
操作说明
- 文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式
- 注意需要在索引后面添加
_doc,表示操作文档 - 在未指定id生成情况,每执行一次post将生成一个新文档
- 如果index不存在,将会默认创建
使用示例
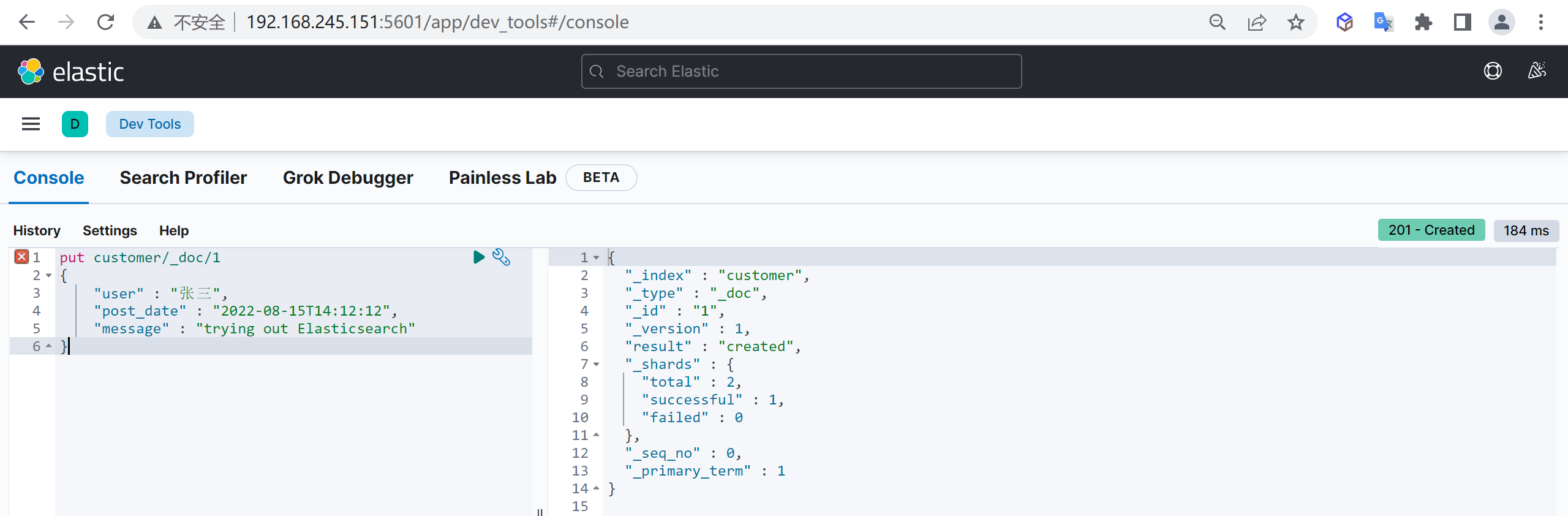
新增文档,自动生成文档id,并且如果如果添加文档的索引不存在时会自动创建索引
post customer/_doc/1
{
"name" : "张三",
"age" : 15
}这样我们就创建了一个文档
返回结果说明
{
"_index" : "customer", #所属索引
"_type" : "_doc", #所属mapping type
"_id" : "1", #文档id
"_version" : 1, #文档版本
"result" : "created", #文档创建成功
"_shards" : {
"total" : 2, #所在分片有两个分片
"successful" : 1, #只有一个副本成功写入,可能节点机器只有一台
"failed" : 0 #失败副本数
},
"_seq_no" : 0, #第几次操作该文档
"_primary_term" : 1 #词项数
}创建文档(自动ID)
为了提高插入文档效率,我们一般会使用自动生成ID,这样减少一次插入时的查询性能损耗,插入时不指定文档ID,ES就会自动生成ID
自动生成的ID是一个不会重复的随机数,使用GUID算法,可以保证在分布式环境下,不同节点同一时间创建的_id一定是不冲突的
post customer/_doc
{
"name" : "李四",
"age" : 50
}这样创建了一个文档,并且文档ID是系统自动生成的
_id
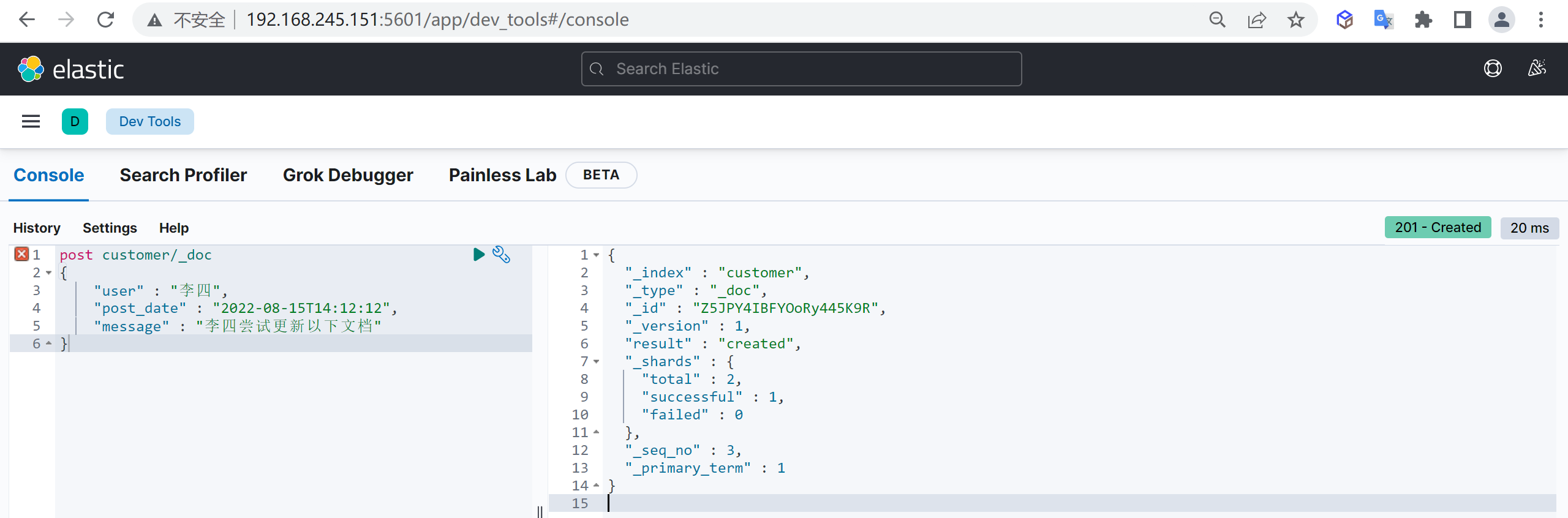
更新文档
更新文档和插入文档一样,如果文档ID一致则会进行覆盖更新,而更新又分为全量更新和增量更新
全量更新
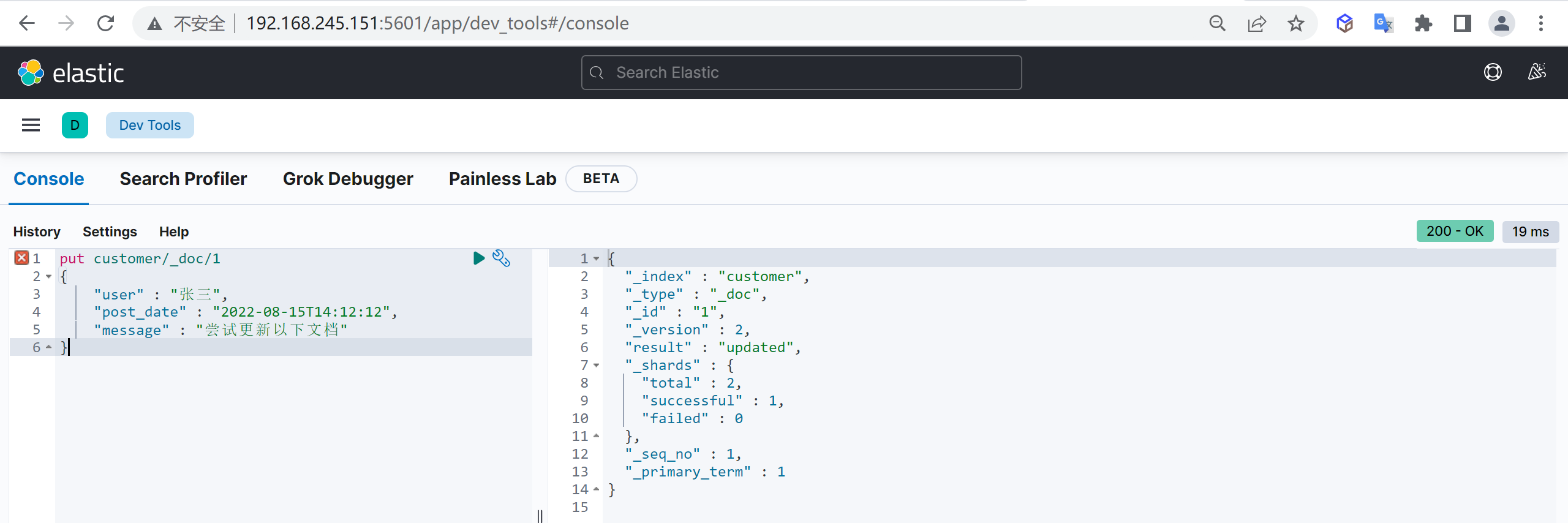
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖
post customer/_doc/1
{
"name" : "张三",
"age" : 50
}
增量更新
通过指定
_doc方式默认是全量更新,如果需要更新指定字段则需要将_doc改为_update,请求内容需要增加doc表示,原始{“key”: value},更新{“doc”: {“key”: value}}
post customer/_update/1
{
"doc": {
"age" : 55
}
}查询文档
验证是否存在
可以通过以下命令检查文档是否存在
HEAD customer/_doc/1 #查看是否存储,返回200表示已存储查询文档
GET customer/_doc/1 #返回源数据的查询不返回source
有时候只是查询,不需要具体的源文档字段,这样可以提高查询速度,可以使用以下方式
GET customer/_doc/1?_source=false查询所有
上述只能查询单个,可以查询所有文档,将
_doc替换为_search
GET customer/_search删除文档
根据文档ID删除
我们可以根据文档ID进行删除
DELETE customer/_doc/1 #指定文档id进行删除根据条件删除
根据查询条件删除,会先查询然后在删除,可能耗时会比较长
post customer/_delete_by_query
{
"query": {
"match": {
"age": "15"
}
}
}中文分词器
IKAnalyzer
IKAnalyzer是一个开源的,基于java的语言开发的轻量级的中文分词工具包
从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本,在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化
使用IK分词器
IK提供了两个分词算法:
- ik_smart:最少切分。
- ik_max_word:最细粒度划分。
ik_smart
使用案例
原始内容
传智教育的教学质量是杠杠的测试分词
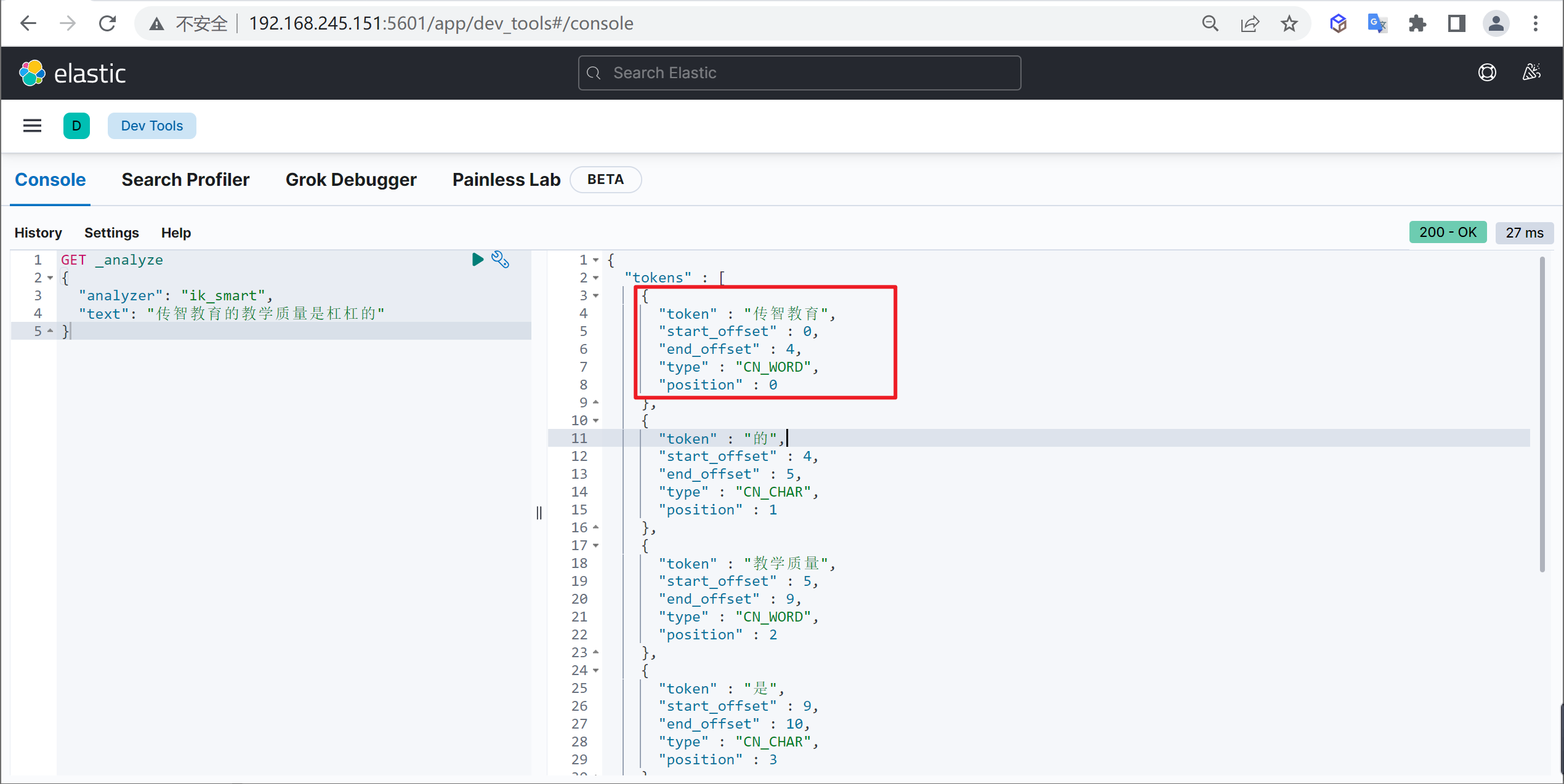
GET _analyze
{
"analyzer": "ik_smart",
"text": "传智教育的教学质量是杠杠的"
}
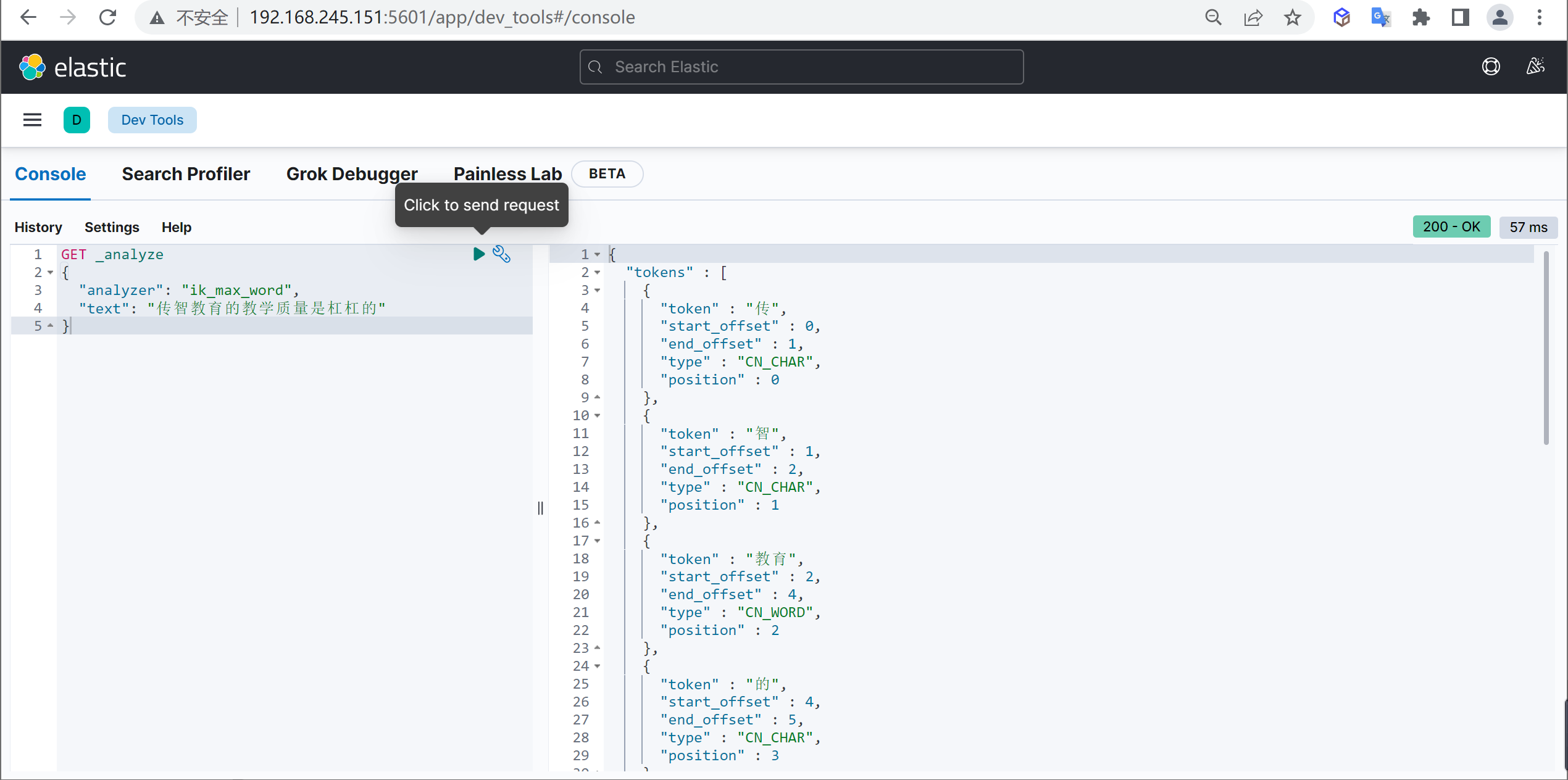
ik_max_word
使用案例
原始内容
传智教育的教学质量是杠杠的测试分词
GET _analyze
{
"analyzer": "ik_max_word",
"text": "传智教育的教学质量是杠杠的"
}
自定义词库
我们在使用IK分词器时会发现其实有时候分词的效果也并不是我们所期待的
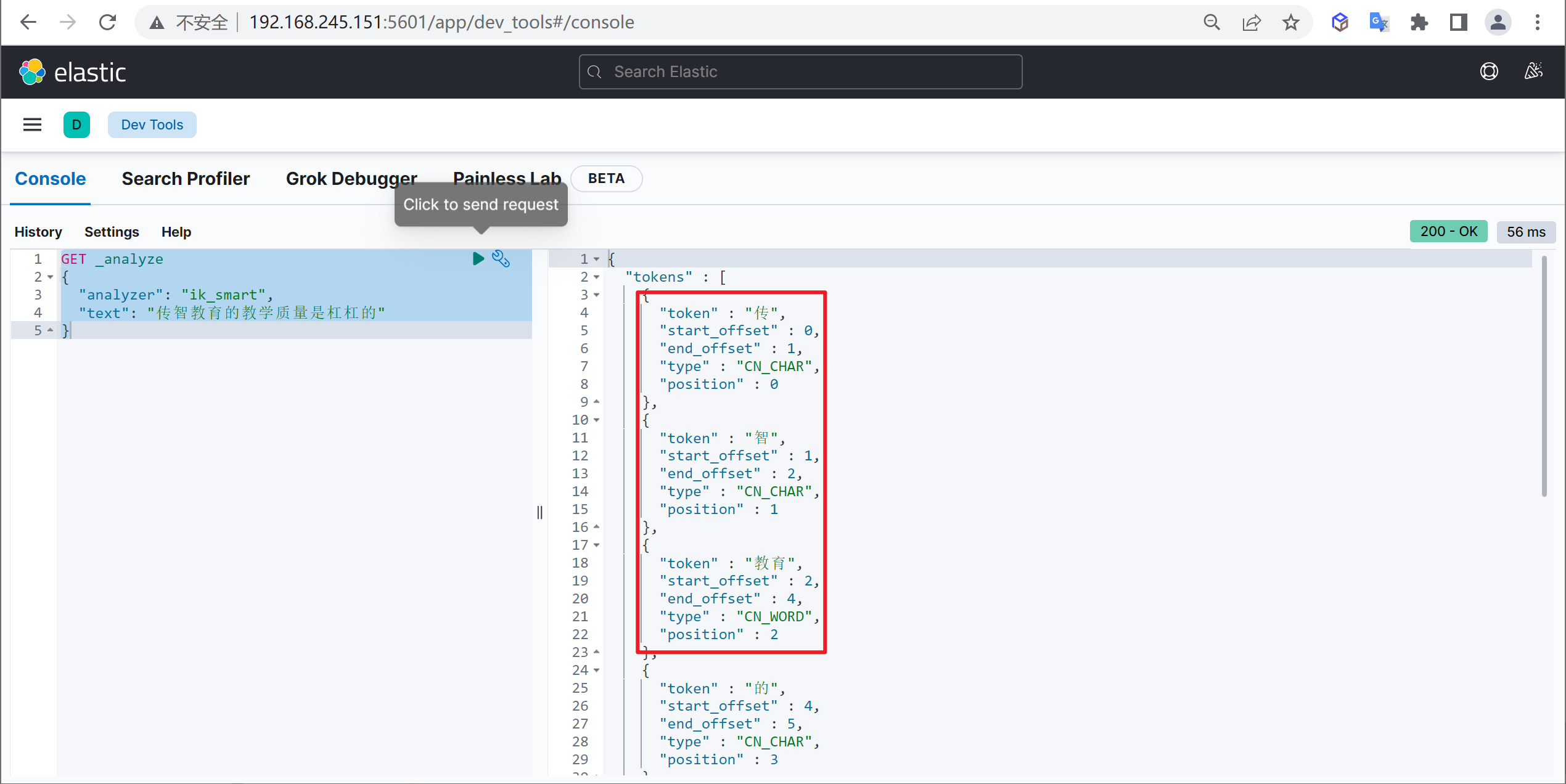
问题描述
例如我们输入“传智教育的教学质量是杠杠的”,但是分词器会把“传智教育”进行拆开,分为了“传”,“智”,“教育”,但我们希望的是“传智教育”可以不被拆开。
解决方案
对于以上的问题,我们只需要将自己要保留的词,加到我们的分词器的字典中即可
编辑字典内容
进入elasticsearch目录
plugins/ik/config中,创建我们自己的字典文件yixin.dic,并添加内容:
cd plugins/ik/config
echo "传智教育" > custom.dic
扩展字典
进入我们的elasticsearch目录 :
plugins/ik/config,打开IKAnalyzer.cfg.xml文件,进行如下配置:
vi IKAnalyzer.cfg.xml
#增加如下内容
<entry key="ext_dict">custom.dic</entry>再次测试
重启ElasticSearch,再次使用kibana测试
GET _analyze
{
"analyzer": "ik_max_word",
"text": "传智教育的教学质量是杠杠的"
}可以发现,现在我们的词汇”传智教育”就不会被拆开了,达到我们想要的效果了
ElasticSearch 集群部署
概述
我们将ES的服务部署和同步服务部署分为两套,因为后期我们数据同步完成可以将异构数据同步的服务停止掉
服务布局
我们整体采用Docker方式进行布局,以下是我们需要部署的服务
| 服务名称 | 服务名称 | 开放端口 | 内存限制 |
|---|---|---|---|
| ES-node1 | node-1 | 9200 | 1G |
| ES-node2 | node-2 | 9201 | 1G |
| ES-node3 | node-3 | 9202 | 1G |
| ES-cerebro | cerebro | 9100 | 不限 |
| kibana | kibana | 5601 | 不限 |
准备工作
创建挂载目录
#创建配置目录
mkdir -p /tmp/etc/elasticsearch/node-{1..3}/{config,plugins}
# 创建kibana的配置目录
mkdir -p /tmp/data/kibana/config
# 创建数据目录
mkdir -p /tmp/data/elasticsearch/node-{1..3}/{data,log}目录授权
chmod 777 /tmp/etc/elasticsearch/node-{1..3}/{config,plugins}
chmod 777 /tmp/etc/kibana/config
chmod 777 /tmp/data/elasticsearch/node-{1..3}/{data,log}修改Linux句柄数
查看当前最大句柄数
sysctl -a | grep vm.max_map_count修改句柄数
vi /etc/sysctl.conf
+ vm.max_map_count=262144生效配置
修改后需要重启才能生效,不想重启可以设置临时生效
sysctl -w vm.max_map_count=262144修改句柄数和最大线程数
配置修改
修改后需要重新登录生效
vi /etc/security/limits.conf
# 添加以下内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096重启服务
reboot添加IK分词器
因为后面要用到IK分词,所以我们要安装以下IK分词器
查找
在github中下载对应版本的分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases根据自己的ES版本选择相应版本的IK分词器,因为安装的ES是
7.17.5,所以也下载相应的IK分词器
解压
将下载的分词器复制到ES安装目录的
plugins目录中并进行解压
mkdir ik && cd ik
unzip elasticsearch-analysis-ik-7.17.5.zip安装
cp -R ik/ /tmp/etc/elasticsearch/node-1/plugins/
cp -R ik/ /tmp/etc/elasticsearch/node-2/plugins/
cp -R ik/ /tmp/etc/elasticsearch/node-3/plugins/编写配置文件
node-1
vi /tmp/data/elasticsearch/node-1/config/elasticsearch.yml
#集群名称
cluster.name: elastic
#当前该节点的名称
node.name: node-1
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#给当前节点自定义属性(可以省略)
#node.attr.rack: r1
#数据存档位置
path.data: /usr/share/elasticsearch/data
#日志存放位置
path.logs: /usr/share/elasticsearch/log
#是否开启时锁定内存(默认为是)
#bootstrap.memory_lock: true
#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,
#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0
network.host: 0.0.0.0
#设置映射端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上
discovery.seed_hosts: ["node-1","node-2","node-3"]
#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,
#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,
#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#在群集完全重新启动后阻止初始恢复,直到启动N个节点
#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,
gateway.recover_after_nodes: 2
#删除索引是是否需要显示其名称,默认为显示
#action.destructive_requires_name: true
# 禁用安全配置,否则查询的时候会提示警告
xpack.security.enabled: falsenode-2
vi /tmp/data/elasticsearch/node-2/config/elasticsearch.yml
#集群名称
cluster.name: elastic
#当前该节点的名称
node.name: node-2
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#给当前节点自定义属性(可以省略)
#node.attr.rack: r1
#数据存档位置
path.data: /usr/share/elasticsearch/data
#日志存放位置
path.logs: /usr/share/elasticsearch/log
#是否开启时锁定内存(默认为是)
#bootstrap.memory_lock: true
#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,
#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0
network.host: 0.0.0.0
#设置映射端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上
discovery.seed_hosts: ["node-1","node-2","node-3"]
#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,
#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,
#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#在群集完全重新启动后阻止初始恢复,直到启动N个节点
#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,
gateway.recover_after_nodes: 2
#删除索引是是否需要显示其名称,默认为显示
#action.destructive_requires_name: true
# 禁用安全配置,否则查询的时候会提示警告
xpack.security.enabled: falsenode-3
vi /tmp/data/elasticsearch/node-3/config/elasticsearch.yml
#集群名称
cluster.name: elastic
#当前该节点的名称
node.name: node-3
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#给当前节点自定义属性(可以省略)
#node.attr.rack: r1
#数据存档位置
path.data: /usr/share/elasticsearch/data
#日志存放位置
path.logs: /usr/share/elasticsearch/log
#是否开启时锁定内存(默认为是)
#bootstrap.memory_lock: true
#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,
#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0
network.host: 0.0.0.0
#设置映射端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上
discovery.seed_hosts: ["node-1","node-2","node-3"]
#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,
#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,
#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#在群集完全重新启动后阻止初始恢复,直到启动N个节点
#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,
gateway.recover_after_nodes: 2
#删除索引是是否需要显示其名称,默认为显示
#action.destructive_requires_name: true
# 禁用安全配置,否则查询的时候会提示警告
xpack.security.enabled: falsekibana
vi /tmp/data/kibana/config/kibana.yml
server.host: 0.0.0.0
# 监听端口
server.port: 5601
server.name: "kibana"
# kibana访问es服务器的URL,就可以有多个,以逗号","隔开
elasticsearch.hosts: ["http://node-1:9200","http://node-2:9201","http://node-3:9202"]
monitoring.ui.container.elasticsearch.enabled: true
# kibana访问Elasticsearch的账号与密码(如果ElasticSearch设置了的话)
elasticsearch.username: "kibana"
elasticsearch.password: "12345"
# kibana日志文件存储路径
logging.dest: stdout
# 此值为true时,禁止所有日志记录输出
logging.silent: false
# 此值为true时,禁止除错误消息之外的所有日志记录输出
logging.quiet: false
# 此值为true时,记录所有事件,包括系统使用信息和所有请求
logging.verbose: false
ops.interval: 5000
# kibana web语言
i18n.locale: "zh-CN"编写部署文档
vi docker-compose.yml
version: "3"
services:
node-1:
image: elasticsearch:7.17.5
container_name: node-1
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- "TZ=Asia/Shanghai"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- "9200:9200"
logging:
driver: "json-file"
options:
max-size: "50m"
volumes:
- /tmp/etc/elasticsearch/node-1/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /tmp/etc/elasticsearch/node-1/plugins:/usr/share/elasticsearch/plugins
- /tmp/data/elasticsearch/node-1/data:/usr/share/elasticsearch/data
- /tmp/data/elasticsearch/node-1/log:/usr/share/elasticsearch/log
networks:
- elastic
node-2:
image: elasticsearch:7.17.5
container_name: node-2
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- "TZ=Asia/Shanghai"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- "9201:9200"
logging:
driver: "json-file"
options:
max-size: "50m"
volumes:
- /tmp/etc/elasticsearch/node-2/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /tmp/etc/elasticsearch/node-2/plugins:/usr/share/elasticsearch/plugins
- /tmp/data/elasticsearch/node-2/data:/usr/share/elasticsearch/data
- /tmp/data/elasticsearch/node-2/log:/usr/share/elasticsearch/log
networks:
- elastic
node-3:
image: elasticsearch:7.17.5
container_name: node-3
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- "TZ=Asia/Shanghai"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- "9202:9200"
logging:
driver: "json-file"
options:
max-size: "50m"
volumes:
- /tmp/etc/elasticsearch/node-3/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /tmp/etc/elasticsearch/node-3/plugins:/usr/share/elasticsearch/plugins
- /tmp/data/elasticsearch/node-3/data:/usr/share/elasticsearch/data
- /tmp/data/elasticsearch/node-3/log:/usr/share/elasticsearch/log
networks:
- elastic
kibana:
container_name: kibana
image: kibana:7.17.5
volumes:
- /tmp/data/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
ports:
- 5601:5601
networks:
- elastic
elasticsearch-head:
image: wallbase/elasticsearch-head:6-alpine
container_name: elasticsearch-head
environment:
TZ: 'Asia/Shanghai'
ports:
- '9100:9100'
networks:
- elastic
networks:
elastic:
driver: bridge启动服务
使用以下命令就可以启动服务了
docker-compose up -dELK异构数据同步

概述
什么是ELK
ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件
- Elasticsearch是强大的数据搜索引擎,并且是分布式、能够通过restful方式进行交互的近实时搜索平台框架
- Logstash是免费且开源的服务器端数据处理通道,能够从多个来源收集数据,能够对数据进行转换和清洗,将转换数据后将数据发送到数据存储库中,并且不受格式和复杂度的影响。
- Kibana是针对Elasticsearch的开源分析及可视化平台,用于搜索、查看交互存储在Elasticsearch索引中的数据。
ELK能做什么
日志收集
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息
但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询,需要集中化的日志管理,所有服务器上的日志收集汇总,常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。

一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志分析平台。
异构数据同步
我们可以借助ELK来帮助我们将数据库中的数据同步到ES中
我们要将MySQL中的数据同步到ES中可能比较麻烦,但是我们借助ELK+Canal可以很轻易的就可以实现,我们现在要做一个全国小区房产的全文检索系统,但是使用MySQL进行全文检索会很麻烦,我们要使用ElasticSearch进行全文检索,就要涉及到异构数据的同步。
下面是我们的整体架构图

常用组件介绍
我们实现异构数据同步平台涉及到一下的组件
MySQL服务
MySQL是我们的主数据库,所有的操作都会写入到MySQL数据库,这个是我们的主要的数据库,因为MySQL不适合于全文检索,所以我们需要将数据同步的ES中,通过ES来进行全文检索
Canal
canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。
目前,canal主要支持了MySQL的binlog解析,解析完成后才利用canal client 用来处理获得的相关数据。(数据库同步需要阿里的otter中间件,基于canal)
我们这里使用Canal同步来将我们的MySQL的数据同步到ES中
canal 原理
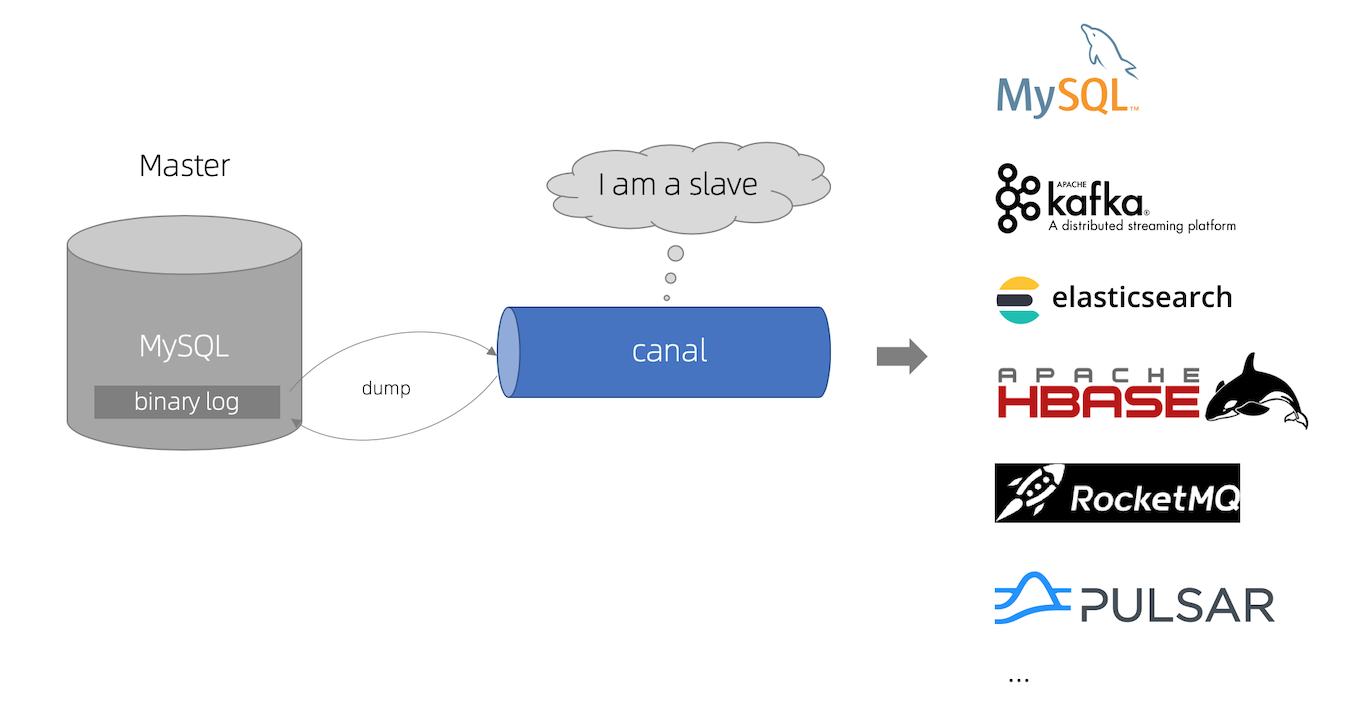
canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到canal发送过来的dump请求,开始推送binary log给canal,然后canal解析binary log,再发送到存储目的地,比如MySQL,Kafka,Elastic Search等等。
RabbitMQ
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)
我们这里使用RabbitMQ来进行消息的削峰填谷,因为全国的房产数据的操作会很频繁,数据量很大的情况下我们需要使用MQ来进行缓冲数据,这样可以进行大量数据的快速同步
Logstash
Logstash是具有实时流水线能力的开源的数据收集引擎
Logstash可以动态统一不同来源的数据,并将数据标准化到您选择的目标输出,它提供了大量插件,可帮助我们解析,丰富,转换和缓冲任何类型的数据。
我们需要使用logstash对RabbitMQ过来的数据进行解析以及清晰,并将清洗过的数据放进ES中
ElasticSearch
Elasticsearch 是一个分布式的开源搜索和分析引擎,在 Apache Lucene 的基础上开发而成。
我们使用ElasticSearch存储logstash清洗完成的数据,通过ES可以对数据进行全文检索,Elasticsearch还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,ES能够横向扩展至数以百计的服务器存储以及处理PB级的数据,可以在极短的时间内存储、搜索和分析大量的数据
kibana
针对es的ES的开源分析可视化工具,与存储在ES的数据进行交互
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的,你可以用kibana搜索、查看存放在Elasticsearch中的数据,Kibana与Elasticsearch的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。
ES物理部署
ES单机部署
下载 Elasticsearch
我们下载的Elasticsearch 版本是 7.17.5,下载地址
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-17-5
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.5-linux-x86_64.tar.gz
tar -zvxf elasticsearch-7.17.5-linux-x86_64.tar.gz配置 Elasticsearch
关闭防火墙
systemctl status firewalld.service
systemctl stop firewalld.service
systemctl disable firewalld.service配置elasticsearch.yml
该配置文件是ES的主配置文件
vi elasticsearch.yml
#设置允许访问地址,配置位0.0.0.0允许任意主机访问
- #network.host: 192.168.0.1
+ network.host: 0.0.0.0
# 配置集群
# node.name: node-1
+ node.name: node-1
- #discovery.seed_hosts: ["host1", "host2"]
discovery.seed_hosts: ["node-1"]
- #cluster.initial_master_nodes: ["node-1", "node-2"]
+ cluster.initial_master_nodes: ["node-1"]修改Linux句柄数
查看当前最大句柄数
sysctl -a | grep vm.max_map_count修改句柄数
vi /etc/sysctl.conf
+ vm.max_map_count=262144生效配置
修改后需要重启才能生效,不想重启可以设置临时生效
sysctl -w vm.max_map_count=262144关闭swap
因为ES的数据大量都是常驻内存的,一旦使用了虚拟内存就会导致查询速度下降,一般需要关闭swap,但是要保证有足够的内存
临时关闭
swapoff -a永久关闭
vi /etc/fstab注释掉
swap这一行的配置
修改最大线程数
因为ES运行期间可能创建大量线程,如果线程数支持较少可能报错
配置修改
修改后需要重新登录生效
vi /etc/security/limits.conf
# 添加以下内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096重启服务
reboot创建ES用户
注意ES不能以 root 用户启动,否则会报错
添加用户
useradd elasticsearch
passwd elasticsearch增加管理员权限
增加sudoers权限
vi /etc/sudoers
+ elasticsearch ALL=(ALL) ALL修改Elasticsearch权限
给ES的安装目录进行授权
chown -R elasticsearch:elasticsearch elasticsearch-7.17.5JVM配置
根据自己的内存自行调整,内存不够则会启动失败
vi jvm.options
- ##-Xms4g
- ##-Xmx4g
+ -Xms4g
+ -Xmx4g添加IK分词器
因为后面要用到IK分词,所以我们要安装以下IK分词器
查找
在github中下载对应版本的分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases根据自己的ES版本选择相应版本的IK分词器,因为安装的ES是
7.17.5,所以也下载相应的IK分词器
解压
将下载的分词器复制到ES安装目录的
plugins目录中并进行解压
mkdir ik && cd ik
unzip elasticsearch-analysis-ik-7.17.5.zip启动ElasticSearch
切换用户
切换到刚刚创建的
elasticsearch用户
su elasticsearch启动命令
我们可以使用以下命令来进行使用
# 前台启动
sh bin/elasticsearch
# 后台启动
sh bin/elasticsearch -d访问测试
访问对应宿主机的
9200端口
http://192.168.245.151:9200/重启ElasticSearch
查找进程
先查找ElasticSearch的进程号
ps -ef | grep elastic杀死进程
杀死对应的进程
kill -9 49736启动ElasticSearch
注意不要使用ROOT用户启动
sh bin/elasticsearch -dkibana安装
下载安装 Kibana
kibana 版本 7.17.5
下载地址:https://www.elastic.co/cn/downloads/past-releases/kibana-7-17-5
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.5-linux-x86_64.tar.gz
tar -zvxf kibana-7.17.5-linux-x86_64.tar.gz
mv kibana-7.17.5-linux-x86_64 kibana-7.17.5配置 Kibana
vi config/kibana.yml
- #server.port: 5601
+ server.port: 5601
- #server.host: "localhost"
+ server.host: "0.0.0.0"
- #elasticsearch.hosts: ["http://localhost:9200"]
+ elasticsearch.hosts: ["http://localhost:9200"]启动 Kibana
切换用户
Kibana也不能以root用户运行,需要切换到
elasticsearch权限
su elasticsearch启动kibaba
#前台运行
sh bin/kibana
#后台运行
nohup sh bin/kibana >/dev/null 2>&1 &访问测试
访问对应宿主机的
5601端口
http://192.168.245.151:5601/ES快速入门
下面我们看下ES的一些基本使用
索引管理
我们使用数据库的第一步就是创建数据库,同样ES也是一样的,第一步也是对索引进行管理
列出索引
我们使用索引的第一步就是列出索引,查看当前数据库有哪些索引
GET /_cat/indices?v
创建索引
我们接下来要使用索引就需要创建索引了,Elasticsearch使用PUT方式来实现索引的新增
可以在创建索引的时候不添加任何参数,系统会为你创建一个默认的索引,当然你可以添加附加一些配置信息
PUT customer这样我们就创建了一个索引
查看索引
索引创建完成后,我们接下来就需要对索引进行查询
get customer
结果说明
这里返回了一堆数据,具体什么含义呢,我们需要查看字段的详细信息
| 字段 | 内容 |
|---|---|
| aliases | 别名 |
| mappings | 映射 |
| settings | 配置 |
| settings.index.creation_date | 创建时间 |
| settings.index.number_of_shards | 数据分片数,索引要做多少个分片,只能在创建索引时指定,后期无法修改 |
| settings.index.number_of_replicas | 数据备份数,每个分片有多少个副本,后期可以动态修改 |
| settings.index.uuid | 索引id |
| settings.index.provided_name | 名称 |
索引是否存在
有时候我们需要检查索引时候存在,我们可以使用HEAD命令验证索引是否存在
HEAD customer出现200表示索引存在
关闭索引
在一些业务场景,我们可能需要禁止掉某些索引的访问功能,但是又不想删除这个索引
post customer/_close这里我们就把这个索引给关闭了
查看索引列表
再次查看索引列表,查看索引的状态
GET /_cat/indices?v我们发现索引已经被关闭了
为什么关闭索引
如果关闭了一个索引,就无法通过Elasticsearch 来读取和写人其中的数据,直到再次打开它
在现实世界中,最好永久地保存应用日志,以防要查看很久之前的信息,另一方面,在Elasticsearch中存放大量数据需要增加资源,对于这种使用案例,关闭旧的索引非常有意义,你可能并不需要那些数据,但是也不想删除它们。
一旦索引被关闭,它在Elasticsearch内存中唯一的痕迹是其元数据,如名字以及分片的位置,如果有足够的磁盘空间,而且也不确定是否需要在那个数据中再次搜索,关闭索引要比删除索引更好,关闭它们会让你非常安心,随时可以重新打开被关闭的索引,然后在其中再次搜索
打开索引
如果我们需要继续启动索引可以直接打开索引
post customer/_open现在我们已经打开了索引
查看索引列表
GET /_cat/indices?v现在索引的状态已经是打开的状态了
删除索引
如果索引中的数据已经不需要了,可以被删除,我们是可以删除索引的,使用以下命令可以删除索引
delete customer这样我们就把索引给删除了
映射管理
映射的创建时基于索引的,你必须要先创建索引才能创建映射,es中的映射相当于传统数据库中的表结构,数据存储的格式就是通过映射来规定的
创建映射
可以在创建索引时指定映射,其中
mappings.properties为固定结构,指定创建映射属性
PUT customer
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "integer"
}
}
}
}
查看映射
查看索引完全信息,内容包含映射信息
GET customer/_mapping
文档管理
创建文档(业务ID)
创建文档的时候我们可以手动来指定ID,但是一般不推荐,回对ES插入性能造成影响
如果手动指定ID,为了保证ID不冲突,会先查询一次文档库,如果不存在则进行插入,手动插入多了一次查询操作,性能会有损失。
操作说明
- 文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式
- 注意需要在索引后面添加
_doc,表示操作文档 - 在未指定id生成情况,每执行一次post将生成一个新文档
- 如果index不存在,将会默认创建
使用示例
新增文档,自动生成文档id,并且如果如果添加文档的索引不存在时会自动创建索引
post customer/_doc/1
{
"name" : "张三",
"age" : 15
}这样我们就创建了一个文档
返回结果说明
{
"_index" : "customer", #所属索引
"_type" : "_doc", #所属mapping type
"_id" : "1", #文档id
"_version" : 1, #文档版本
"result" : "created", #文档创建成功
"_shards" : {
"total" : 2, #所在分片有两个分片
"successful" : 1, #只有一个副本成功写入,可能节点机器只有一台
"failed" : 0 #失败副本数
},
"_seq_no" : 0, #第几次操作该文档
"_primary_term" : 1 #词项数
}创建文档(自动ID)
为了提高插入文档效率,我们一般会使用自动生成ID,这样减少一次插入时的查询性能损耗,插入时不指定文档ID,ES就会自动生成ID
自动生成的ID是一个不会重复的随机数,使用GUID算法,可以保证在分布式环境下,不同节点同一时间创建的_id一定是不冲突的
post customer/_doc
{
"name" : "李四",
"age" : 50
}这样创建了一个文档,并且文档ID是系统自动生成的
_id
更新文档
更新文档和插入文档一样,如果文档ID一致则会进行覆盖更新,而更新又分为全量更新和增量更新
全量更新
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖
post customer/_doc/1
{
"name" : "张三",
"age" : 50
}
增量更新
通过指定
_doc方式默认是全量更新,如果需要更新指定字段则需要将_doc改为_update,请求内容需要增加doc表示,原始{“key”: value},更新{“doc”: {“key”: value}}
post customer/_update/1
{
"doc": {
"age" : 55
}
}查询文档
验证是否存在
可以通过以下命令检查文档是否存在
HEAD customer/_doc/1 #查看是否存储,返回200表示已存储查询文档
GET customer/_doc/1 #返回源数据的查询不返回source
有时候只是查询,不需要具体的源文档字段,这样可以提高查询速度,可以使用以下方式
GET customer/_doc/1?_source=false查询所有
上述只能查询单个,可以查询所有文档,将
_doc替换为_search
GET customer/_search删除文档
根据文档ID删除
我们可以根据文档ID进行删除
DELETE customer/_doc/1 #指定文档id进行删除根据条件删除
根据查询条件删除,会先查询然后在删除,可能耗时会比较长
post customer/_delete_by_query
{
"query": {
"match": {
"age": "15"
}
}
}中文分词器
IKAnalyzer
IKAnalyzer是一个开源的,基于java的语言开发的轻量级的中文分词工具包
从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本,在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化
使用IK分词器
IK提供了两个分词算法:
- ik_smart:最少切分。
- ik_max_word:最细粒度划分。
ik_smart
使用案例
原始内容
传智教育的教学质量是杠杠的测试分词
GET _analyze
{
"analyzer": "ik_smart",
"text": "传智教育的教学质量是杠杠的"
}
ik_max_word
使用案例
原始内容
传智教育的教学质量是杠杠的测试分词
GET _analyze
{
"analyzer": "ik_max_word",
"text": "传智教育的教学质量是杠杠的"
}
自定义词库
我们在使用IK分词器时会发现其实有时候分词的效果也并不是我们所期待的
问题描述
例如我们输入“传智教育的教学质量是杠杠的”,但是分词器会把“传智教育”进行拆开,分为了“传”,“智”,“教育”,但我们希望的是“传智教育”可以不被拆开。
解决方案
对于以上的问题,我们只需要将自己要保留的词,加到我们的分词器的字典中即可
编辑字典内容
进入elasticsearch目录
plugins/ik/config中,创建我们自己的字典文件yixin.dic,并添加内容:
cd plugins/ik/config
echo "传智教育" > custom.dic
扩展字典
进入我们的elasticsearch目录 :
plugins/ik/config,打开IKAnalyzer.cfg.xml文件,进行如下配置:
vi IKAnalyzer.cfg.xml
#增加如下内容
<entry key="ext_dict">custom.dic</entry>再次测试
重启ElasticSearch,再次使用kibana测试
GET _analyze
{
"analyzer": "ik_max_word",
"text": "传智教育的教学质量是杠杠的"
}可以发现,现在我们的词汇”传智教育”就不会被拆开了,达到我们想要的效果了
ES服务集群部署
我们将ES的服务部署和同步服务部署分为两套,因为后期我们数据同步完成可以将异构数据同步的服务停止掉
服务布局
我们整体采用Docker方式进行布局,以下是我们需要部署的服务
| 服务名称 | 服务名称 | 开放端口 | 内存限制 |
|---|---|---|---|
| ES-node1 | node-1 | 9200 | 1G |
| ES-node2 | node-2 | 9201 | 1G |
| ES-node3 | node-3 | 9202 | 1G |
| ES-cerebro | cerebro | 9000 | 不限 |
| kibana | kibana | 5601 | 不限 |
准备工作
创建挂载目录
#创建ES的数据和配置目录
mkdir -p /tmp/data/elasticsearch/node-{1..3}/{config,plugins,data,log}
# 创建kibana的配置目录
mkdir -p /tmp/data/kibana/config目录授权
chmod 777 /tmp/data/elasticsearch/node-{1..3}/{config,plugins,data,log}
chmod 777 /tmp/data/kibana/config修改Linux句柄数
查看当前最大句柄数
sysctl -a | grep vm.max_map_count修改句柄数
vi /etc/sysctl.conf
+ vm.max_map_count=262144生效配置
修改后需要重启才能生效,不想重启可以设置临时生效
sysctl -w vm.max_map_count=262144关闭swap
因为ES的数据大量都是常驻内存的,一旦使用了虚拟内存就会导致查询速度下降,一般需要关闭swap,但是要保证有足够的内存
临时关闭
swapoff -a永久关闭
vi /etc/fstab注释掉
swap这一行的配置

修改最大线程数
因为ES运行期间可能创建大量线程,如果线程数支持较少可能报错
配置修改
修改后需要重新登录生效
vi /etc/security/limits.conf
# 添加以下内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096重启服务
reboot添加IK分词器
因为后面要用到IK分词,所以我们要安装以下IK分词器
查找
在github中下载对应版本的分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases根据自己的ES版本选择相应版本的IK分词器,因为安装的ES是
7.17.5,所以也下载相应的IK分词器
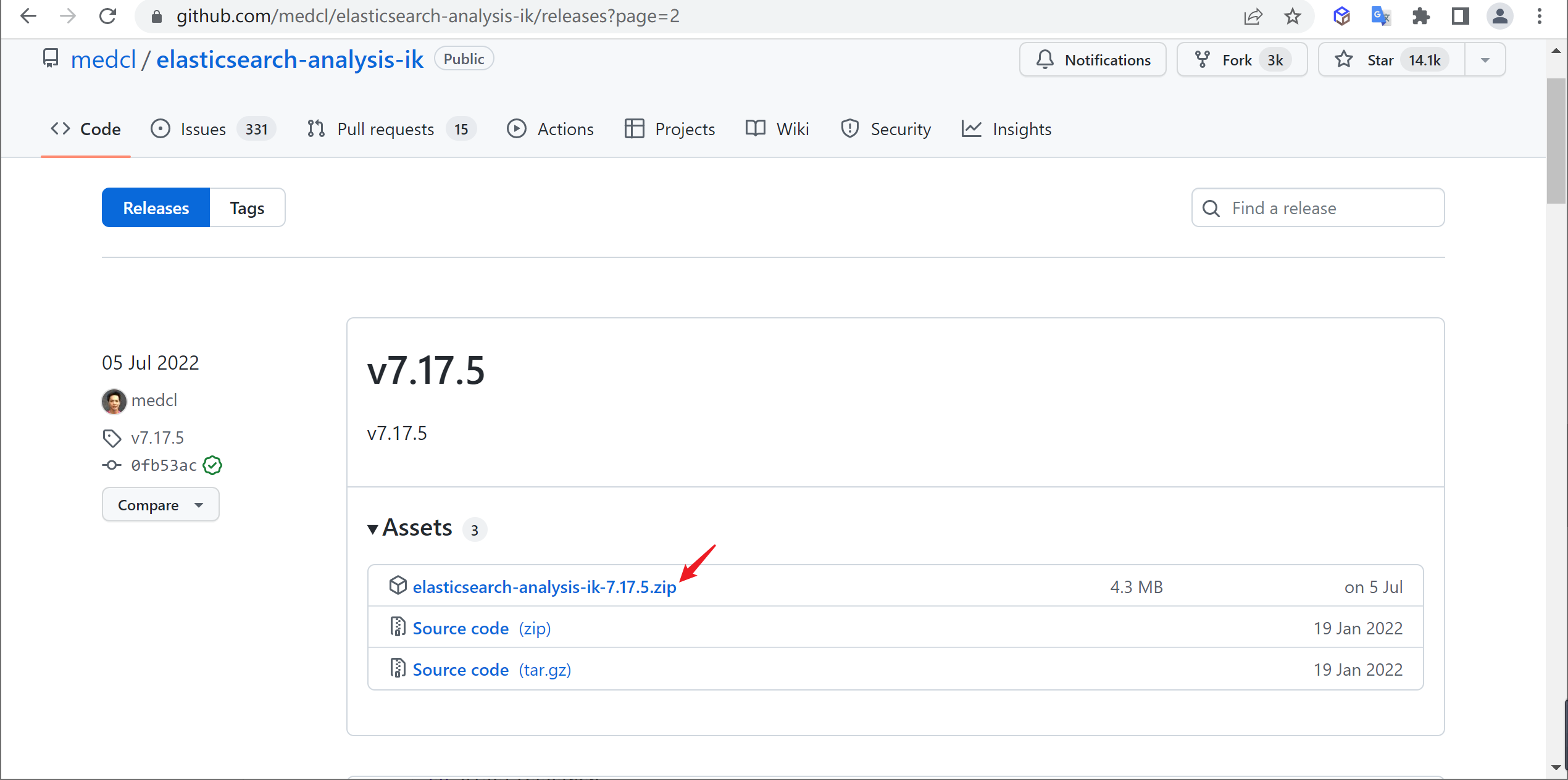
解压
将下载的分词器复制到ES安装目录的
plugins目录中并进行解压
mkdir ik && cd ik
unzip elasticsearch-analysis-ik-7.17.5.zip安装
cp -R ik/ /tmp/data/elasticsearch/node-1/plugins/
cp -R ik/ /tmp/data/elasticsearch/node-2/plugins/
cp -R ik/ /tmp/data/elasticsearch/node-3/plugins/编写配置文件
下面我们对三个节点的配置进行配置
node-1
vi /tmp/data/elasticsearch/node-1/config/elasticsearch.yml
#集群名称
cluster.name: elastic
#当前该节点的名称
node.name: node-1
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#给当前节点自定义属性(可以省略)
#node.attr.rack: r1
#数据存档位置
path.data: /usr/share/elasticsearch/data
#日志存放位置
path.logs: /usr/share/elasticsearch/log
#是否开启时锁定内存(默认为是)
#bootstrap.memory_lock: true
#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,
#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0
network.host: 0.0.0.0
#设置映射端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上
discovery.seed_hosts: ["node-1","node-2","node-3"]
#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,
#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,
#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#在群集完全重新启动后阻止初始恢复,直到启动N个节点
#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,
gateway.recover_after_nodes: 2
#删除索引是是否需要显示其名称,默认为显示
#action.destructive_requires_name: true
# 禁用安全配置,否则查询的时候会提示警告
xpack.security.enabled: falsenode-2
vi /tmp/data/elasticsearch/node-2/config/elasticsearch.yml
#集群名称
cluster.name: elastic
#当前该节点的名称
node.name: node-2
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#给当前节点自定义属性(可以省略)
#node.attr.rack: r1
#数据存档位置
path.data: /usr/share/elasticsearch/data
#日志存放位置
path.logs: /usr/share/elasticsearch/log
#是否开启时锁定内存(默认为是)
#bootstrap.memory_lock: true
#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,
#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0
network.host: 0.0.0.0
#设置映射端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上
discovery.seed_hosts: ["node-1","node-2","node-3"]
#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,
#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,
#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#在群集完全重新启动后阻止初始恢复,直到启动N个节点
#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,
gateway.recover_after_nodes: 2
#删除索引是是否需要显示其名称,默认为显示
#action.destructive_requires_name: true
# 禁用安全配置,否则查询的时候会提示警告
xpack.security.enabled: falsenode-3
vi /tmp/data/elasticsearch/node-3/config/elasticsearch.yml
#集群名称
cluster.name: elastic
#当前该节点的名称
node.name: node-3
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#给当前节点自定义属性(可以省略)
#node.attr.rack: r1
#数据存档位置
path.data: /usr/share/elasticsearch/data
#日志存放位置
path.logs: /usr/share/elasticsearch/log
#是否开启时锁定内存(默认为是)
#bootstrap.memory_lock: true
#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,
#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0
network.host: 0.0.0.0
#设置映射端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上
discovery.seed_hosts: ["node-1","node-2","node-3"]
#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,
#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,
#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#在群集完全重新启动后阻止初始恢复,直到启动N个节点
#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,
gateway.recover_after_nodes: 2
#删除索引是是否需要显示其名称,默认为显示
#action.destructive_requires_name: true
# 禁用安全配置,否则查询的时候会提示警告
xpack.security.enabled: falsekibana
vi /tmp/data/kibana/config/kibana.yml
server.host: 0.0.0.0
# 监听端口
server.port: 5601
server.name: "kibana"
# kibana访问es服务器的URL,就可以有多个,以逗号","隔开
elasticsearch.hosts: ["http://node-1:9200","http://node-2:9201","http://node-3:9202"]
monitoring.ui.container.elasticsearch.enabled: true
# kibana访问Elasticsearch的账号与密码(如果ElasticSearch设置了的话)
elasticsearch.username: "kibana"
elasticsearch.password: "12345"
# kibana日志文件存储路径
logging.dest: stdout
# 此值为true时,禁止所有日志记录输出
logging.silent: false
# 此值为true时,禁止除错误消息之外的所有日志记录输出
logging.quiet: false
# 此值为true时,记录所有事件,包括系统使用信息和所有请求
logging.verbose: false
ops.interval: 5000
# kibana web语言
i18n.locale: "zh-CN"编写部署文档
vi docker-compose.yml
version: "3"
services:
node-1:
image: elasticsearch:7.17.5
container_name: node-1
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- "TZ=Asia/Shanghai"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- "9200:9200"
logging:
driver: "json-file"
options:
max-size: "50m"
volumes:
- /tmp/data/elasticsearch/node-1/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /tmp/data/elasticsearch/node-1/plugins:/usr/share/elasticsearch/plugins
- /tmp/data/elasticsearch/node-1/data:/usr/share/elasticsearch/data
- /tmp/data/elasticsearch/node-1/log:/usr/share/elasticsearch/log
networks:
- elastic
node-2:
image: elasticsearch:7.17.5
container_name: node-2
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- "TZ=Asia/Shanghai"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- "9201:9200"
logging:
driver: "json-file"
options:
max-size: "50m"
volumes:
- /tmp/data/elasticsearch/node-2/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /tmp/data/elasticsearch/node-2/plugins:/usr/share/elasticsearch/plugins
- /tmp/data/elasticsearch/node-2/data:/usr/share/elasticsearch/data
- /tmp/data/elasticsearch/node-2/log:/usr/share/elasticsearch/log
networks:
- elastic
node-3:
image: elasticsearch:7.17.5
container_name: node-3
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- "TZ=Asia/Shanghai"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- "9202:9200"
logging:
driver: "json-file"
options:
max-size: "50m"
volumes:
- /tmp/data/elasticsearch/node-3/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /tmp/data/elasticsearch/node-3/plugins:/usr/share/elasticsearch/plugins
- /tmp/data/elasticsearch/node-3/data:/usr/share/elasticsearch/data
- /tmp/data/elasticsearch/node-3/log:/usr/share/elasticsearch/log
networks:
- elastic
kibana:
container_name: kibana
image: kibana:7.17.5
volumes:
- /tmp/data/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
ports:
- 5601:5601
networks:
- elastic
cerebro:
image: lmenezes/cerebro:0.9.4
container_name: cerebro
environment:
TZ: 'Asia/Shanghai'
ports:
- '9000:9000'
networks:
- elastic
networks:
elastic:
driver: bridge启动服务
使用以下命令就可以启动服务了
docker-compose up -d同步服务部署
下面我们来搭建以下同步服务,该服务主要用来进行将MySQL的数据同步到ES中
服务布局
我们整体采用Docker方式进行布局,以下是我们需要部署的服务
| 服务名称 | 服务名称 | 开放端口 |
|---|---|---|
| MySQL | MySQL | 3306 |
| Canal | Canal | 无 |
| RabbitMQ | RabbitMQ | 5672 |
| logstash | logstash | 无 |
准备工作
创建挂载目录
下面我们需要创建相关的挂载目录
mkdir -p /tmp/etc/{canal,logstash,mysql}
mkdir -p /tmp/data/{canal,logstash,mysql,rabbitmq}
# 创建canal日志目录
mkdir -p /tmp/data/canal/logs
# 创建logstash的pipeline配置目录
mkdir -p /tmp/etc/logstash/pipeline
# 创建logstash日志目录
mkdir -p /tmp/data/logstash/logs
chmod -R 777 /tmp/etc/{canal,logstash,mysql}创建配置文件
MySQL配置文件
我们需要开启binlog的row模式
vi /tmp/etc/mysql/my.cnf
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复Canan配置文件
配置canal.properties
配置Canal配置文件canal.properties的挂载文件
vi /tmp/etc/canal/canal.properties
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rabbitMQ
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations = village
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 127.0.0.1:9092
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host = rabbit
rabbitmq.virtual.host = /
rabbitmq.exchange = canal
rabbitmq.username = guest
rabbitmq.password = guest配置 instance.properties
配置Canal的数据源配置文件
instance.properties的挂载文件,路径在village/instance.properties
mkdir -p /tmp/etc/canal/village
vi /tmp/etc/canal/village/instance.properties
#################################################
## mysql serverId , v1.0.26+ will autoGen
## mysql slaveId v1.0.26 后的版本支持自动生成 可以不需要配置
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# position info
## 配置连接数据库的地址
canal.instance.master.address=mysql:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://172.18.0.10:3306/test
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
# 配置数据库用户名密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
# 配置 连接数据库的编码格式
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
#canal.instance.defaultDatabaseName=village
# table regex
## canal 收集表的 过滤正则表达式 这个表示收集所有表数据
#canal.instance.filter.regex=t_village
canal.instance.filter.regex=village\\..*
# table black regex
## canal 收集表的黑名单
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
#################################################Logstash配置文件
创建 logstash.yml
该配置文件时logstash的主要的配置文件
vi /tmp/etc/logstash/logstash.yml
http.host: 0.0.0.0
path.config: /usr/share/logstash/config/pipeline/*.conf
path.logs: /usr/share/logstash/logs
pipeline.batch.size: 10
xpack.monitoring.elasticsearch.hosts:
- http://192.168.245.151:9200
xpack.monitoring.enabled: false创建village.conf
该文件是logstash的pipeline的配置
vi /tmp/etc/logstash/pipeline/village.conf
input {
rabbitmq {
host => "rabbit" #RabbitMQ-IP地址
port => 5672 #端口号
vhost => "/" #虚拟主机
user => "guest" #用户名
password => "guest" #密码
exchange=> "canal" # rabbitmq中的交换器
key => ""
queue => "direct_queue" #队列
durable => false #持久化跟队列配置一致
codec => "json" #格式
}
}
filter {
if [type] == "DELETE" {
drop{}
}
split {
field => "data"
}
mutate {
remove_field => ["sqlType"]
remove_field => ["mysqlType"]
remove_field => ["database"]
remove_field => ["sql"]
remove_field => ["es"]
remove_field => ["ts"]
remove_field => ["pkNames"]
remove_field => ["isDdl"]
remove_field => ["table"]
remove_field => ["tags"]
remove_field => ["type"]
remove_field => ["old"]
remove_field => ["id"]
remove_field => ["sql"]
}
date {
match => ["create_date", "yyyy-MM-dd HH:mm:ss"]
locale => "en"
timezone => "Asia/Shanghai"
target => "@timestamp"
}
ruby {
code => "
event.set('@timestamp', LogStash::Timestamp.at(event.get('@timestamp').time.localtime + 8*60*60))
"
}
if [data][name] {
mutate {
add_field => { "name" => "%{[data][name]}"}
}
}
if [data][province]{
mutate {
add_field => { "province" => "%{[data][province]}"}
}
}
if [data][city]{
mutate {
add_field => { "city" => "%{[data][city]}"}
}
}
if [data][area]{
mutate {
add_field => { "area" => "%{[data][area]}"}
}
}
if [data][addr]{
mutate {
add_field => { "addr" => "%{[data][addr]}"}
}
}
if [data][lat_gps]{
mutate {
add_field => { "[location][lat]" => "%{[data][lat_gps]}"}
add_field => { "[location][lon]" => "%{[data][lon_gps]}"}
convert => { "[location][lat]" => "float" }
convert => { "[location][lon]" => "float" }
}
}
if [data][property_type]{
mutate {
add_field => { "property_type" => "%{[data][property_type]}"}
}
}
if [data][property_company]{
mutate {
add_field => { "property_company" => "%{[data][property_company]}"}
}
}
if [data][property_cost]{
mutate {
add_field => { "property_cost" => "%{[data][property_cost]}"}
}
}
if [data][floorage]{
mutate {
add_field => { "floorage" => "%{[data][floorage]}"}
}
}
if [data][houses]{
mutate {
add_field => { "houses" => "%{[data][houses]}"}
}
}
if [data][built_year]{
mutate {
add_field => { "built_year" => "%{[data][built_year]}"}
}
}
if [data][parkings]{
mutate {
add_field => { "parkings" => "%{[data][parkings]}"}
}
}
if [data][volume]{
mutate {
add_field => { "volume" => "%{[data][volume]}"}
}
}
if [data][greening]{
mutate {
add_field => { "greening" => "%{[data][greening]}"}
}
}
if [data][producer]{
mutate {
add_field => { "producer" => "%{[data][producer]}"}
}
}
if [data][school]{
mutate {
add_field => { "school" => "%{[data][school]}"}
}
}
if [data][info]{
mutate {
add_field => { "info" => "%{[data][info]}"}
}
}
# if [data][create_date]{
# mutate {
# add_field => { "create_date" => "%{[data][create_date]}"}
# }
# }
mutate {
remove_field => ["data"]
}
}
output {
elasticsearch {
hosts => ["192.168.245.151:9200"]
index => "logstash-village-%{+YYYY.MM.dd}"
}
# stdout { codec => rubydebug }
}编写部署文档
vi docker-compose.yml
version: '2'
services:
mysql:
image: mysql:5.7
hostname: mysql
container_name: mysql
networks:
- dockernetwork
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: root
volumes:
- "/tmp/etc/mysql:/etc/mysql/conf.d"
- "/tmp/data/mysql:/var/lib/mysql"
rabbit:
image: rabbitmq:management
hostname: rabbit
container_name: rabbit
networks:
- dockernetwork
ports:
- "15672:15672"
volumes:
- "/tmp/data/rabbitmq:/var/lib/rabbitmq"
canal:
image: canal/canal-server:v1.1.5
hostname: canal
container_name: canal
restart: always
networks:
- dockernetwork
volumes:
- "/tmp/etc/canal/canal.properties:/home/admin/canal-server/conf/canal.properties"
- "/tmp/etc/canal/village:/home/admin/canal-server/conf/village"
- "/tmp/data/canal/logs:/home/admin/canal-server/logs"
depends_on:
- mysql
- rabbit
logstash:
image: logstash:7.17.5
hostname: logstash
container_name: logstash
privileged: true
restart: always
networks:
- dockernetwork
environment:
XPACK_MONITORING_ENABLED: "false"
pipeline.batch.size: 10
volumes:
- "/tmp/etc/logstash/pipeline/:/usr/share/logstash/config/pipeline"
- "/tmp/etc/logstash/logstash.yml:/usr/share/logstash/config/logstash.yml"
- "/tmp/data/logstash/logs:/usr/share/logstash/logs"
depends_on:
- mysql
- rabbit
- canal
networks:
dockernetwork:
driver: bridge启动服务
执行下面的命令启动服务
docker-compose up -d初始化服务
初始化数据库
检查数据库
可以使用远程工具连接MySql检查是否能够正常连接
创建数据库
通过下面的脚本来创建数据库
CREATE DATABASE `village`
USE `village`;
DROP TABLE IF EXISTS `t_village`;
CREATE TABLE `t_village` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '小区名字',
`province` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '省',
`city` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '市',
`area` varchar(100) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '区',
`addr` varchar(200) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '地址',
`lon_baid` varchar(50) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '经度_百度',
`lat_baid` varchar(50) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '维度_百度',
`lon_gps` varchar(50) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '经度_GPS',
`lat_gps` varchar(50) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '维度_GPS',
`property_type` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '小区物业类型',
`property_cost` float DEFAULT NULL COMMENT '小区物业费用/平米',
`property_company` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '物业公司',
`floorage` float DEFAULT NULL COMMENT '总建筑面积',
`houses` int(11) DEFAULT NULL COMMENT '总户数',
`built_year` varchar(10) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '建造年代',
`parkings` int(11) DEFAULT NULL COMMENT '停车位数量',
`volume` float DEFAULT NULL COMMENT '容积率',
`greening` float DEFAULT NULL COMMENT '绿化率',
`producer` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '开发商',
`school` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '相关学校',
`info` varchar(15000) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT '小区介绍',
`create_date` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=334511 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;导入数据
通过服务连接Mysql服务,就可以将excel数据导入到mysql
创建Canal用户
canal的原理是模拟自己为mysql slave,所以这里一定需要做为mysql slave的相关权限
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;初始化RabbitMQ
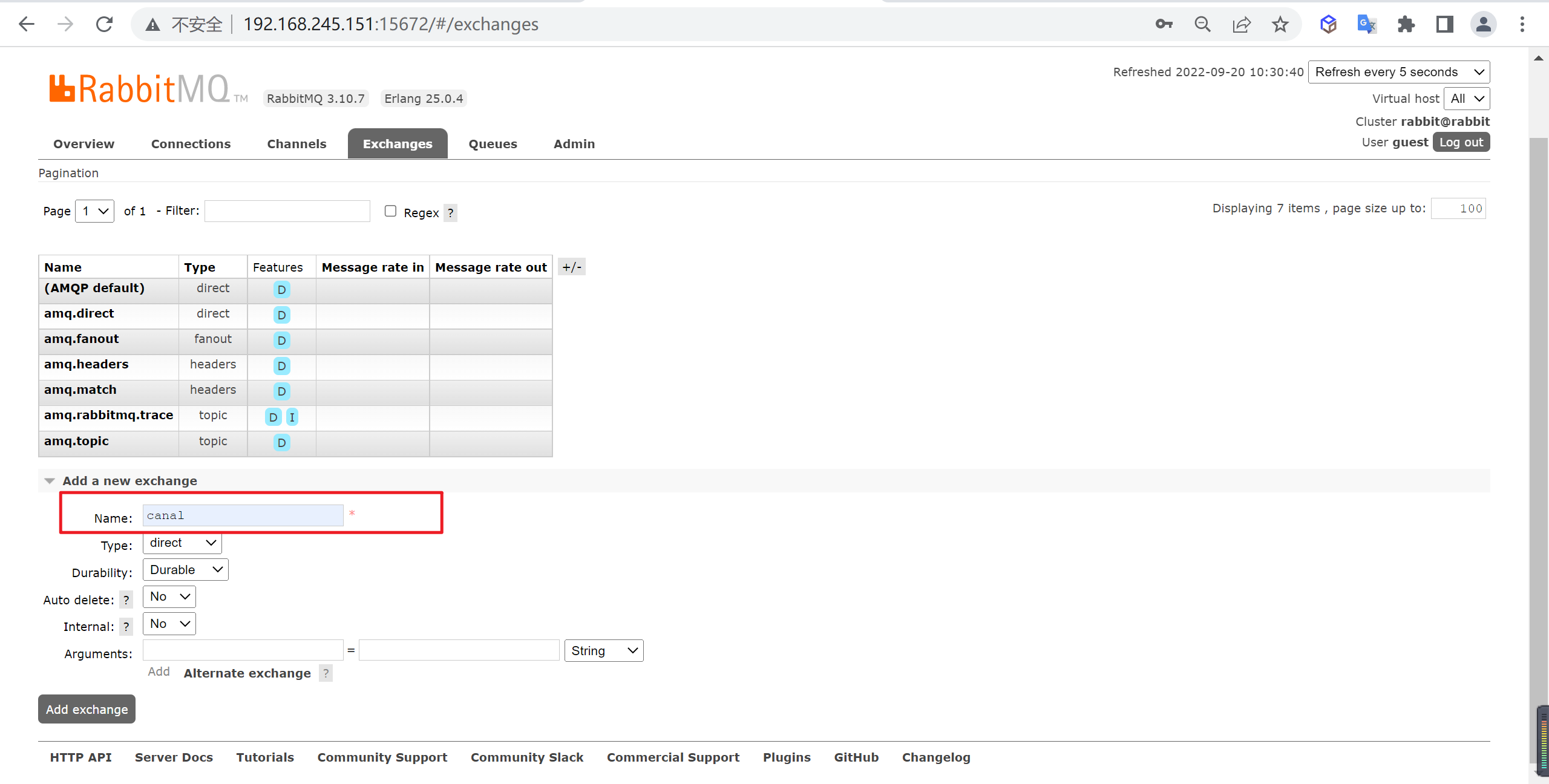
要将消息推送到RabbitMQ需要先添加交换器以及队列,登录
http://192.168.245.151:15672/进行操作
新增交换器
我们新增一个
canal的交换器
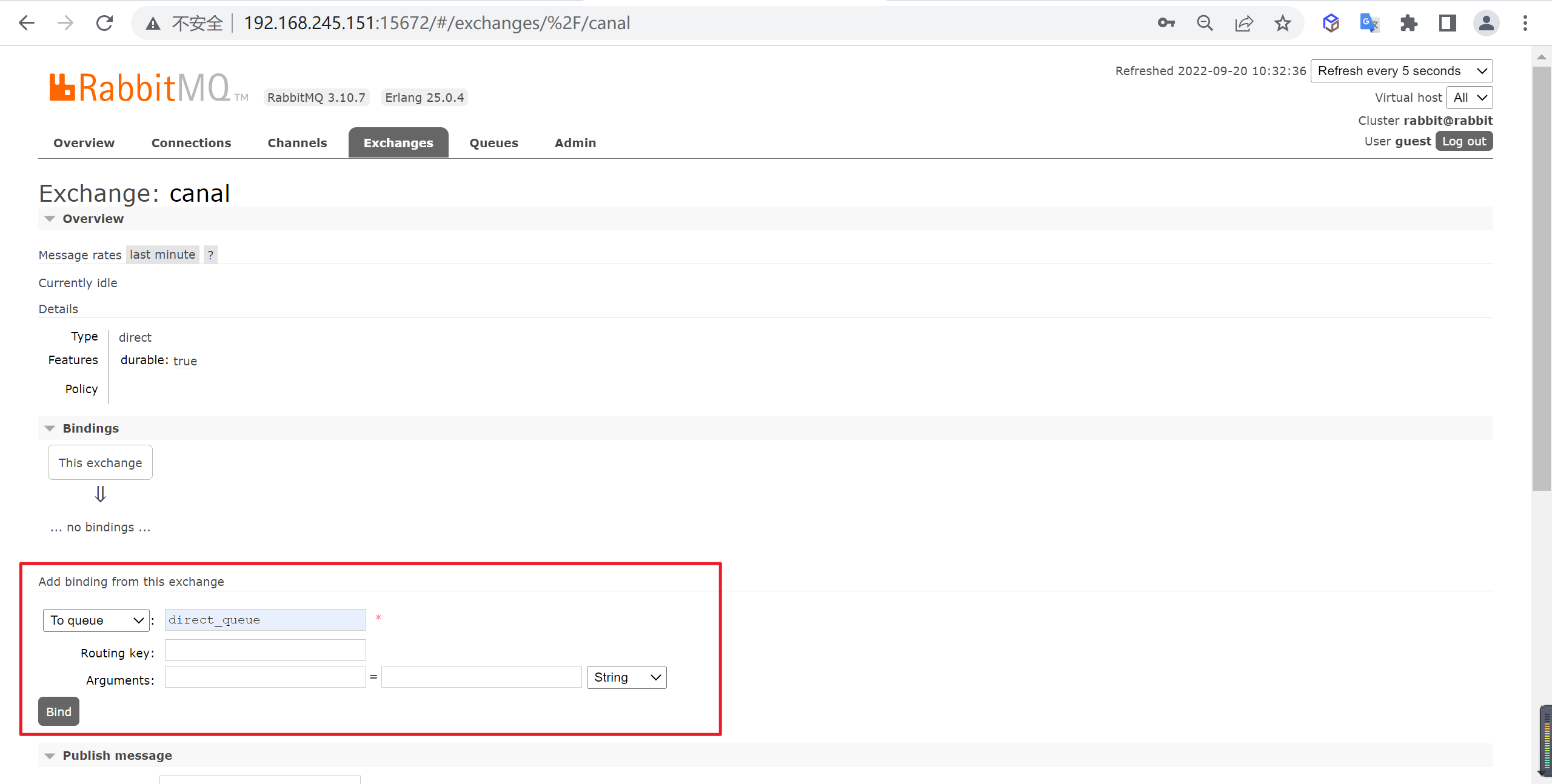
建立绑定关系
让
canal交换器和direct_queue队列建立绑定关系,路由键为空
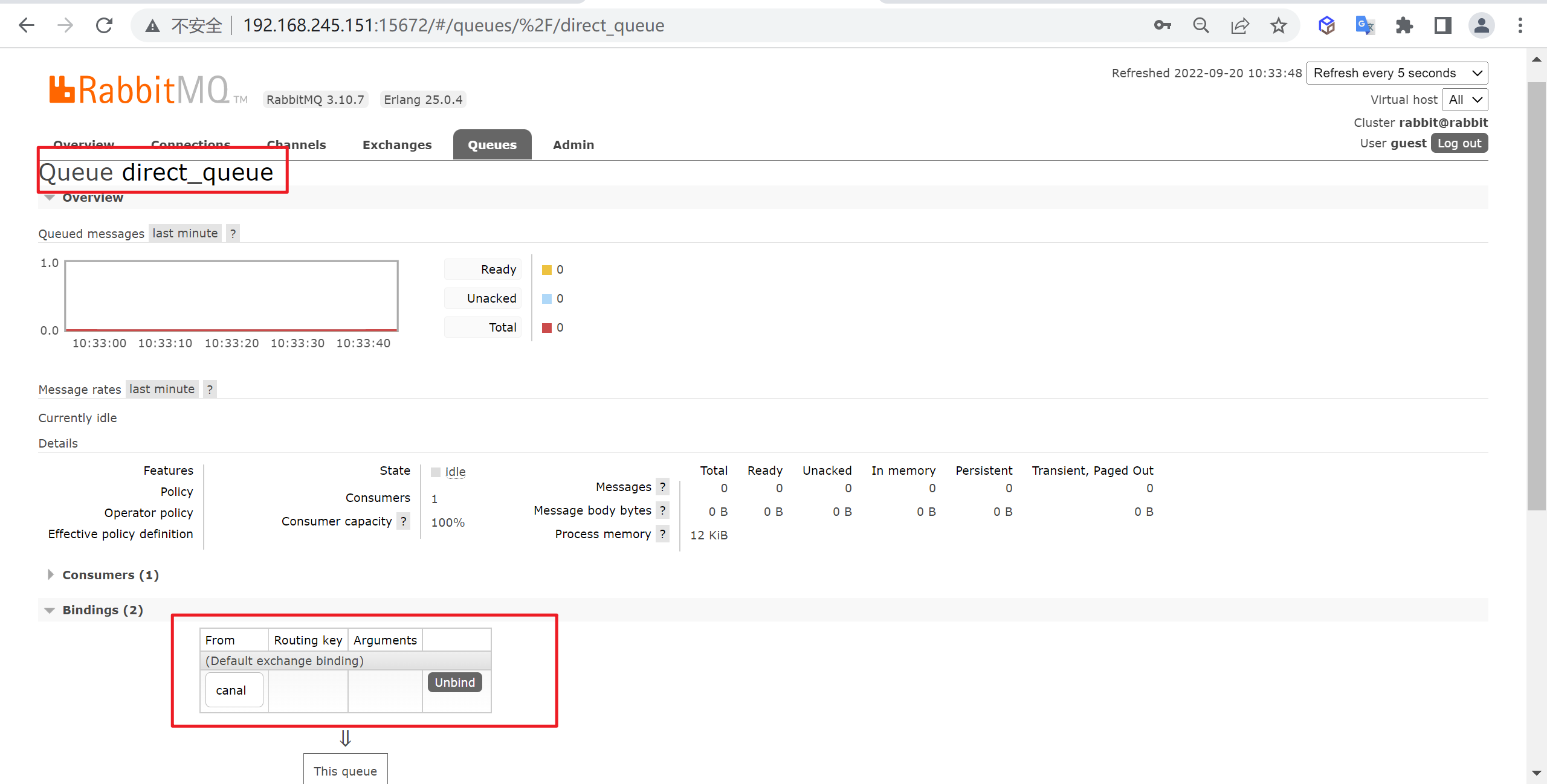
查看队列情况
我们绑定完成后,可以来查看一下队列的情况
ElasticSearch初始化
因为要导入ES,我们需要先创建索引
创建索引模板
创建一个有三个分片两个副本的索引
PUT _index_template/logstash-village
{
"index_patterns": [
"logstash-village-*" // 可以通过"logstash-village-*"来适配创建的索引
],
"template": {
"settings": {
"number_of_shards": "3", //指定模板分片数量
"number_of_replicas": "2" //指定模板副本数量
},
"aliases": {
"logstash-village": {} //指定模板索引别名
},
"mappings": { //设置映射
"dynamic": "strict", //禁用动态映射
"properties": {
"@timestamp": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis||yyyy-MM-dd HH:mm:ss"
},
"@version": {
"doc_values": false,
"index": "false",
"type": "integer"
},
"name": {
"type": "keyword"
},
"province": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"area": {
"type": "keyword"
},
"addr": {
"type": "text",
"analyzer": "ik_smart"
},
"location": {
"type": "geo_point"
},
"property_type": {
"type": "keyword"
},
"property_company": {
"type": "text",
"analyzer": "ik_smart"
},
"property_cost": {
"type": "float"
},
"floorage": {
"type": "float"
},
"houses": {
"type": "integer"
},
"built_year": {
"type": "integer"
},
"parkings": {
"type": "integer"
},
"volume": {
"type": "float"
},
"greening": {
"type": "float"
},
"producer": {
"type": "text",
"analyzer": "ik_smart"
},
"school": {
"type": "text",
"analyzer": "ik_smart"
},
"info": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
}导入数据进行同步
接下来我们就需要导入相关的Excel的数据进行同步了,logstash会自动的创建索引,并应用上面的模板
http://127.0.0.1:8080/api/import/crawler-data-4745655-1554808595755.xlsxKIBANA数据分析
我们的数据已经导入到了ES中了,我们来对数据进行一波分析
管理索引
下面我们看下kibana如何进行索引管理
创建索引模式
进入索引管理
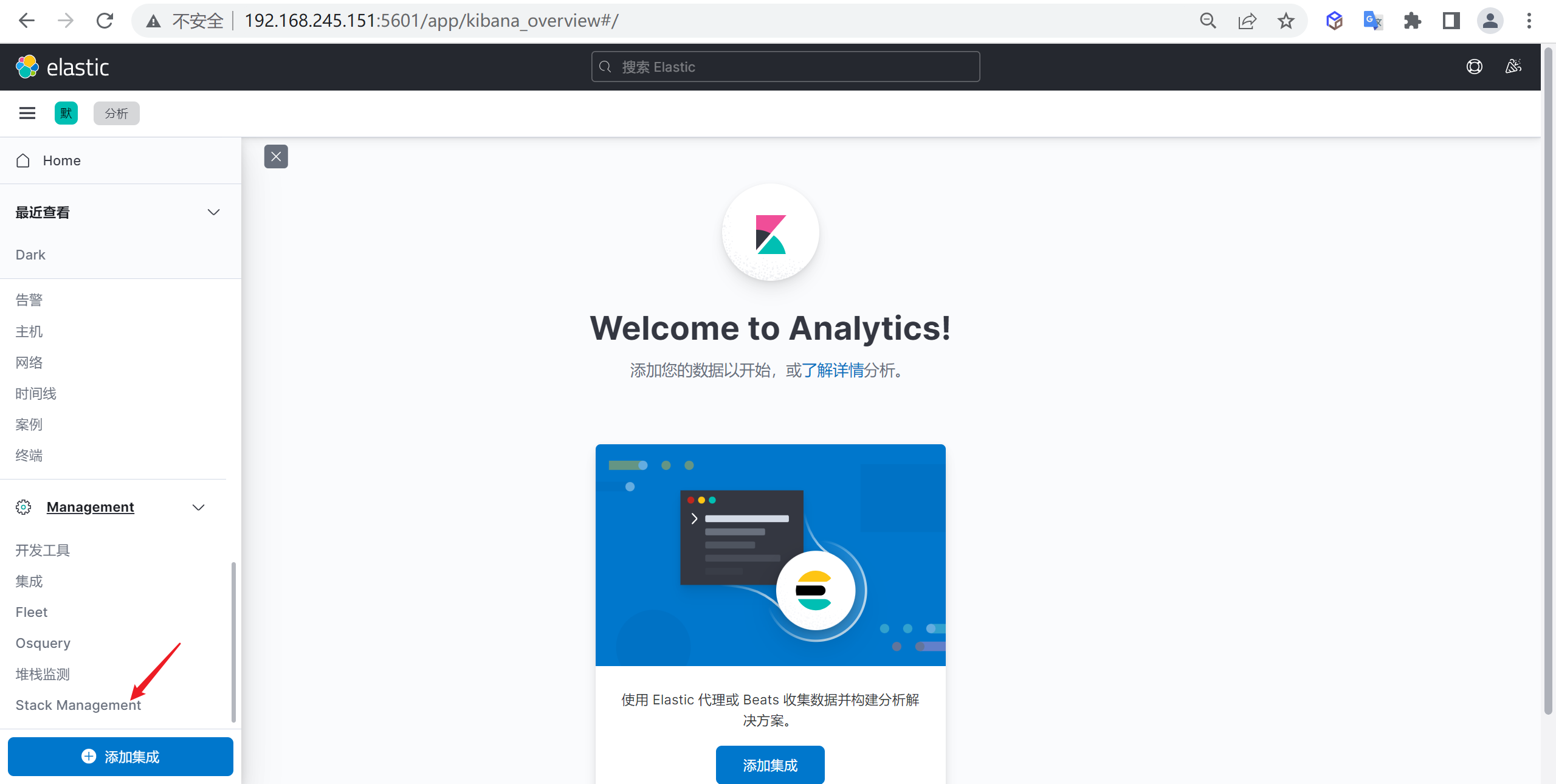
我们点击
Stack Management进入索引管理模块
查看当前索引
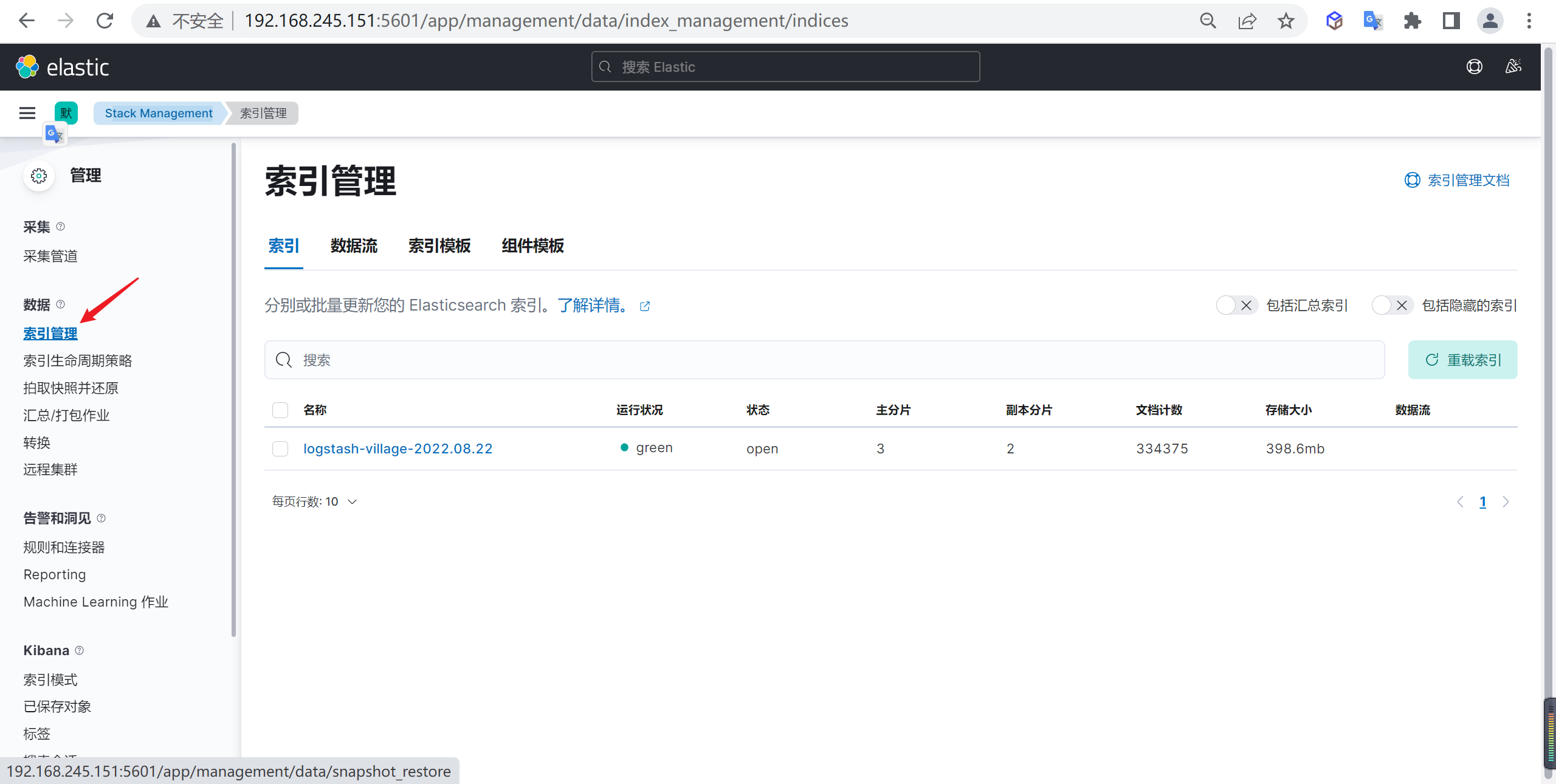
进入管理模块后,点击索引管理,可以看到我们创建的索引
创建索引模式
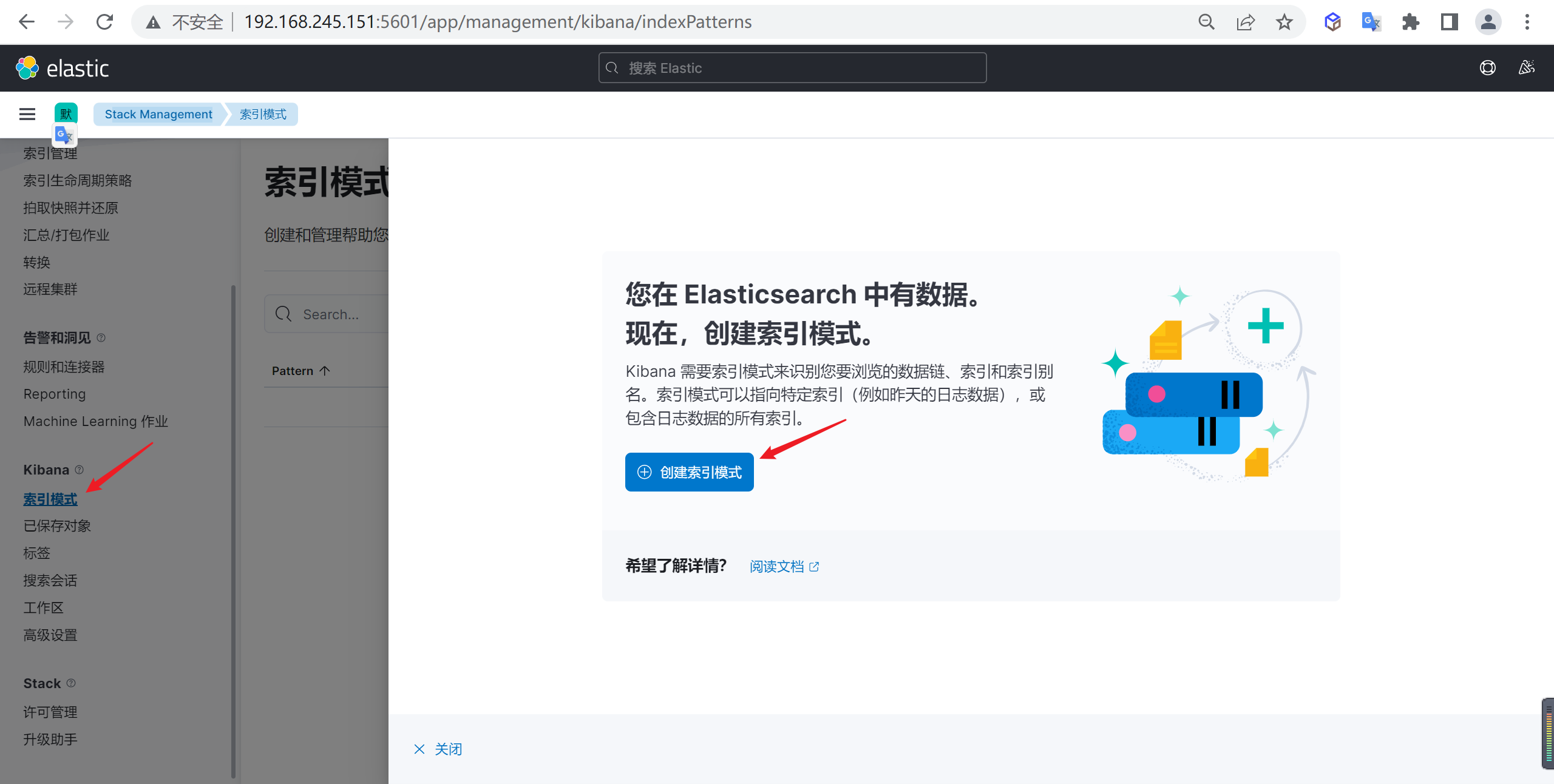
下面我们需要创建索引模式,因为当前的索引是一天一创建的,我们需要匹配所有的索引
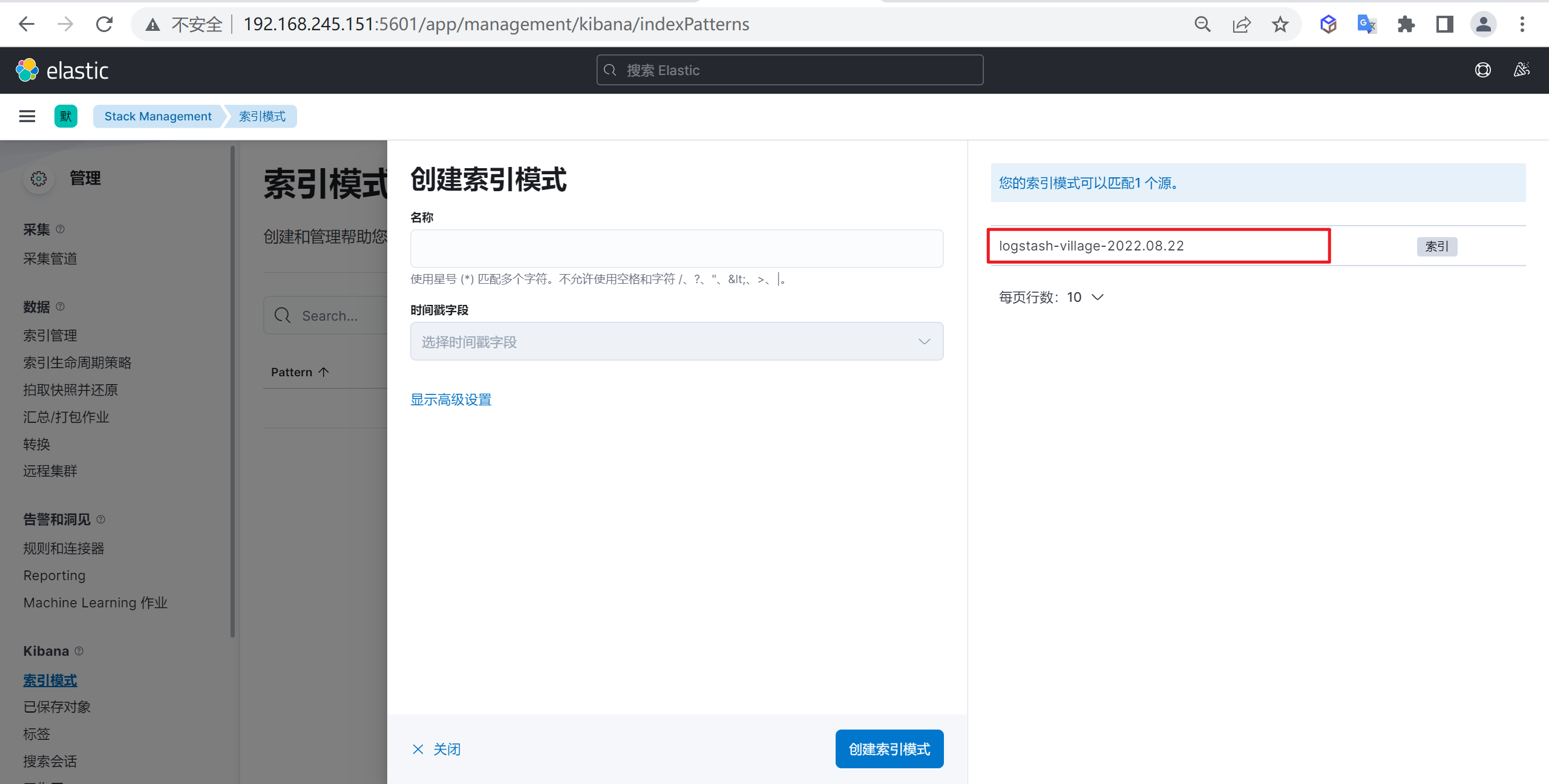
进入创建索引模式后,接下来就是创建索引匹配模式,我们需要匹配的就是标红的索引
接下来就是创建索引模式,我们使用通配符的方式来进行创建
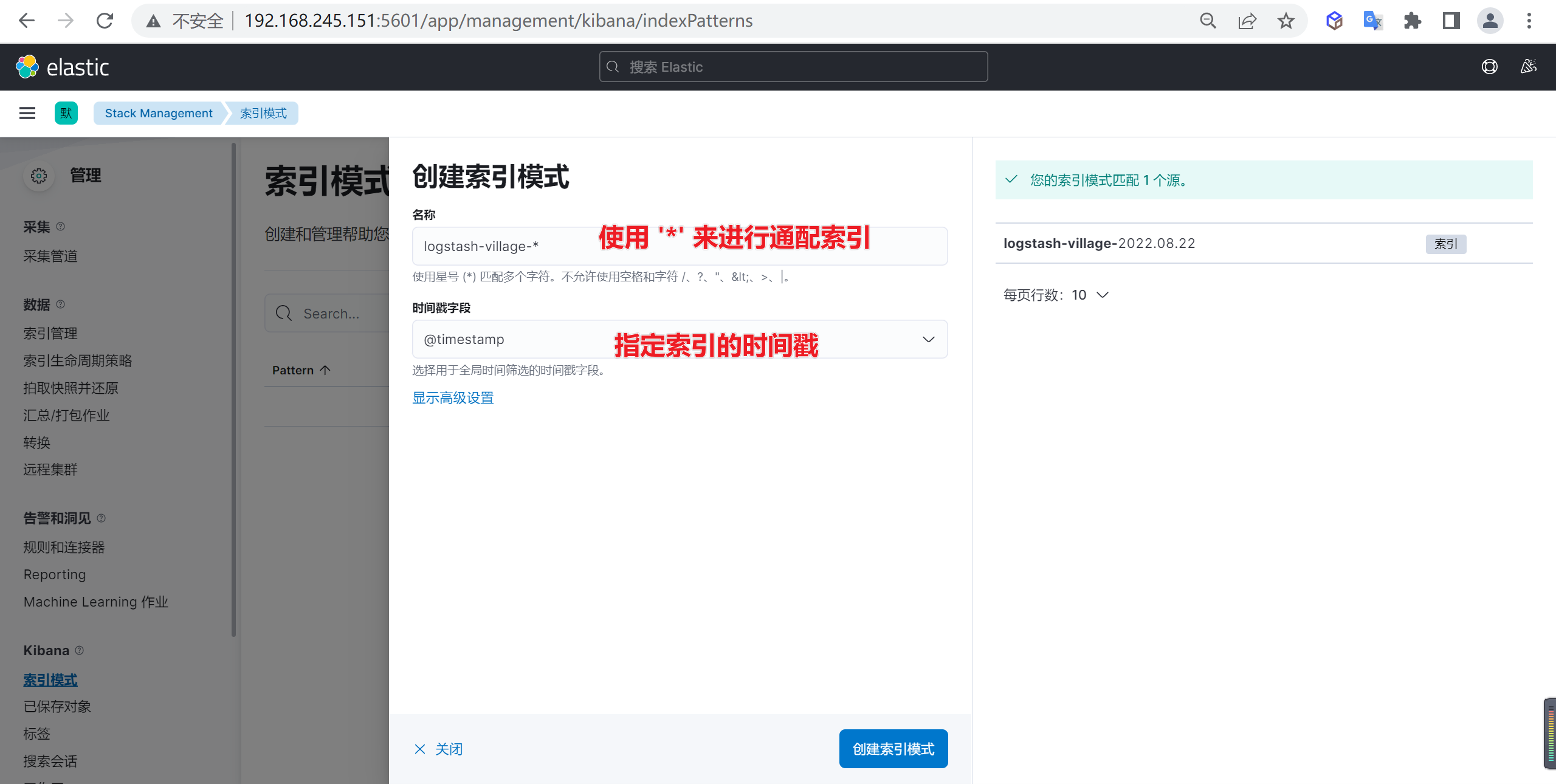
确定后我们就创建了一个索引模式,在这里我们可以编辑或者转换ES的字段
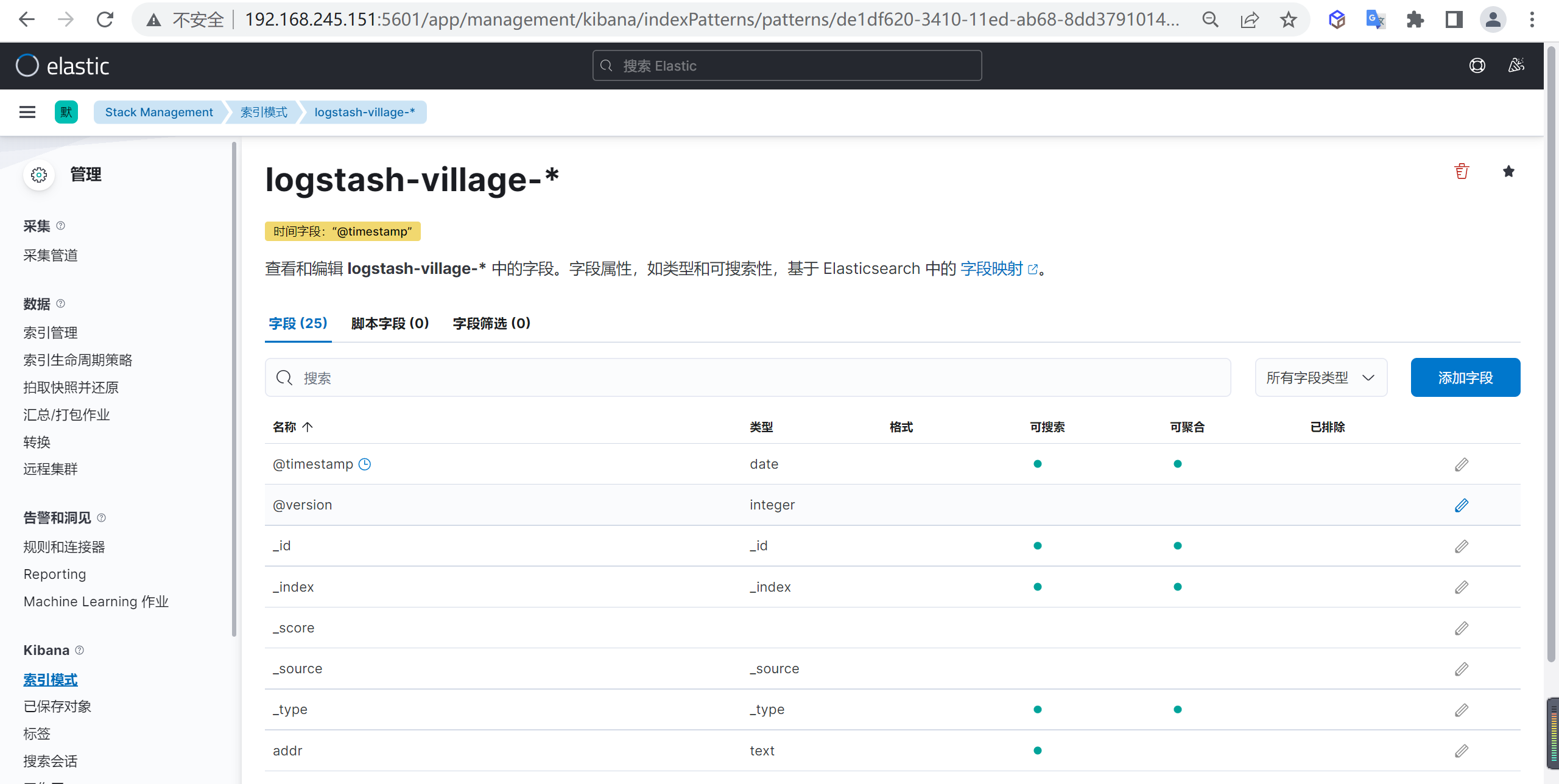
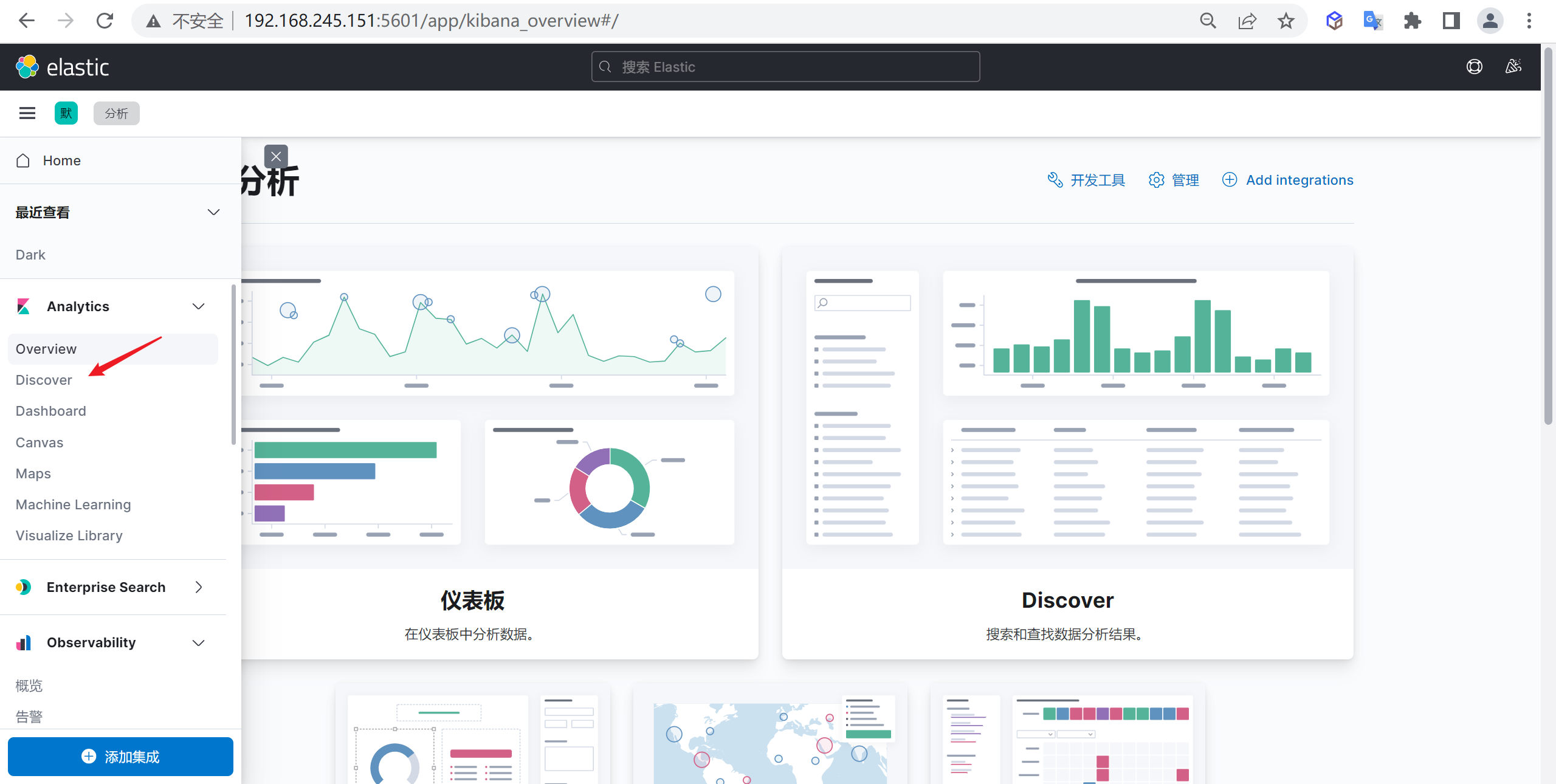
查看索引数据
我们点击
Discover就可以查看索引数据
如果看不到可以选择不同的时间范围
数据分析
接下来我们就按照这些数据进行一些图表分析
柱状图示例
下面我们演示以下柱状图,我们统计以下按照省份统计下个省份的总住户数量
打开仪表盘
下面我们需要到点击进入仪表盘管理节点
点击创建仪表盘
点击创建仪表盘,进入仪表盘管理界面
创建柱状图
点击
创建可视化我们就会打开一个可视化的管理界面
并且在这个管理界面选择对应的图形就好
水平轴数据配置
我们先配置水平轴的数据,选择
省份字段作为水平轴的参数
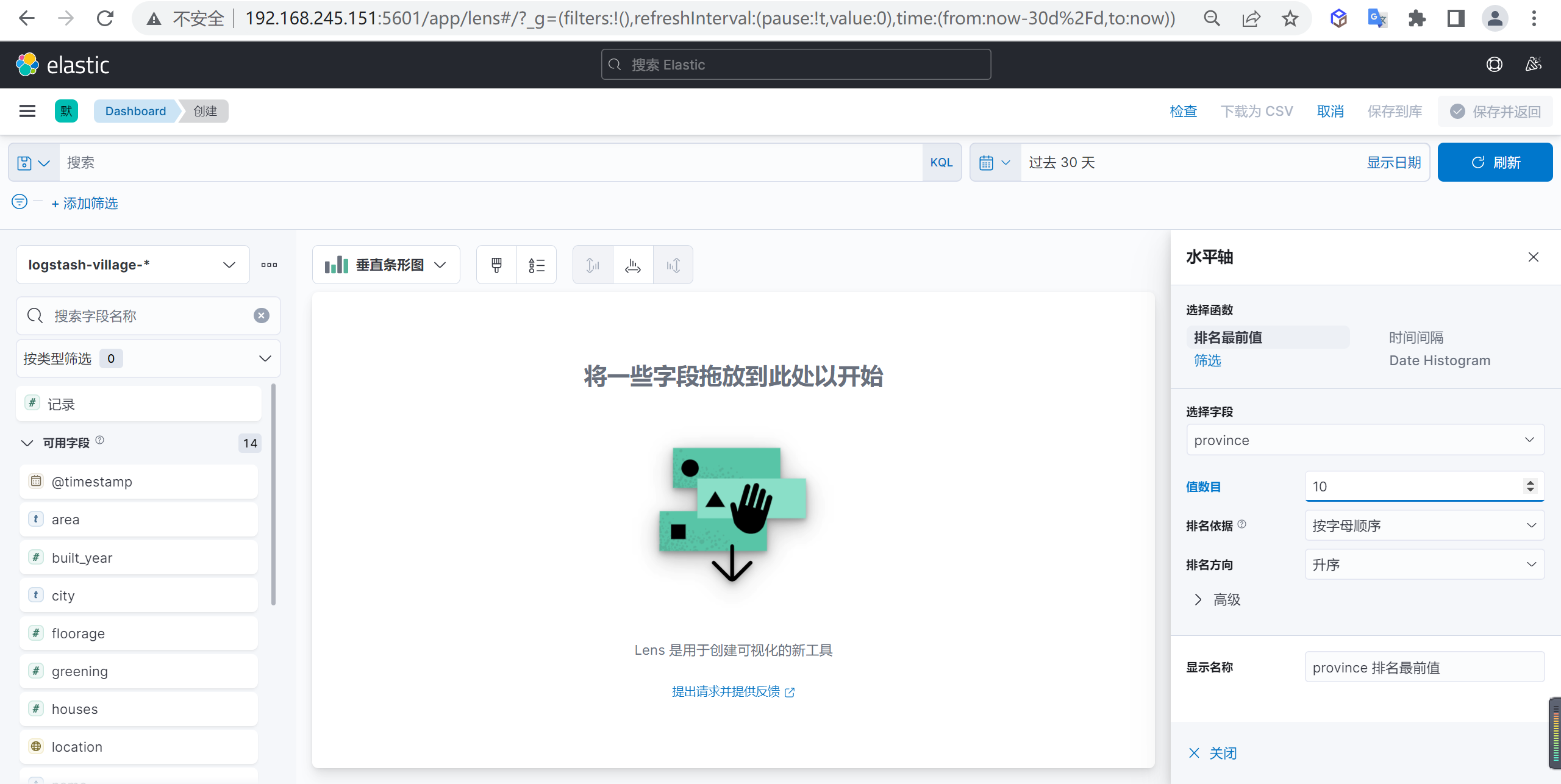
垂直轴数据配置
下面我们还需要配置垂直轴的数据,我们设置
总户数的平均值作为参数
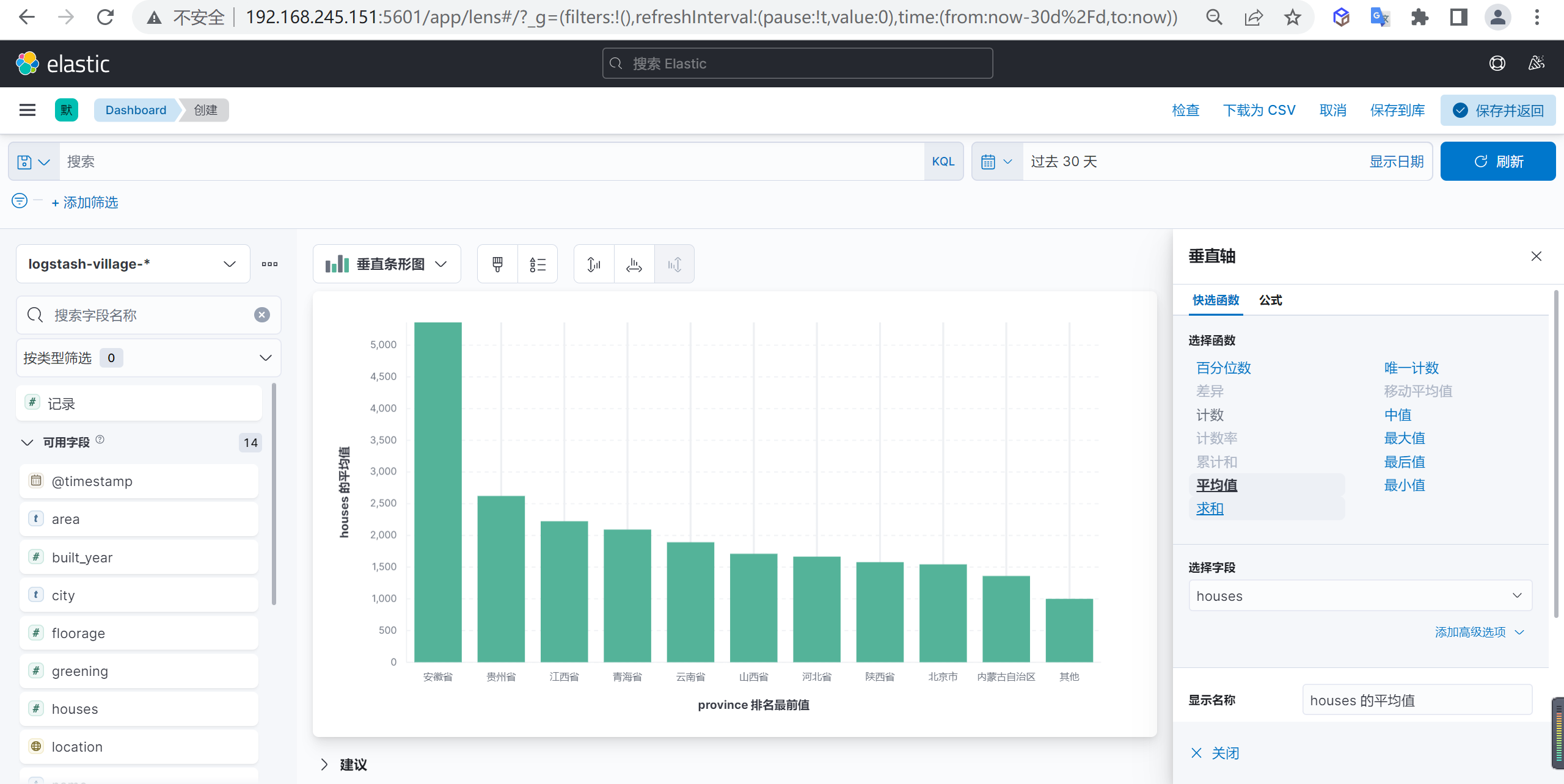
查看数据
这样我们就可以进行分析数据了,我们看到安徽省是小区住户平均数量最多的省份

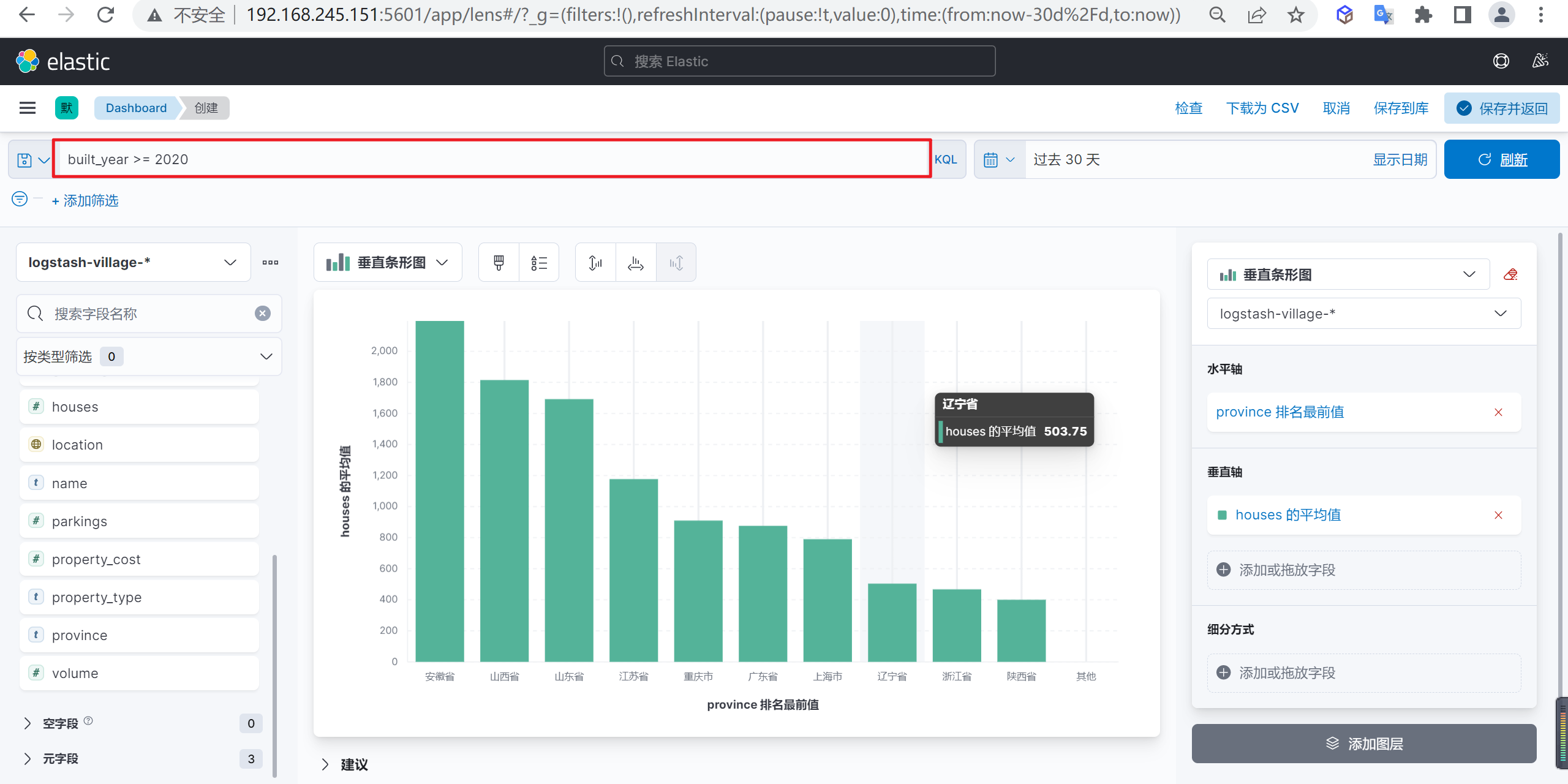
筛选数据
我们筛选以下2020年以后新建的小区住户平均数量最多的省份,我们可以使用表达式
built_year >= 2020进行筛选
折线图示例
我们分析下全国每年小区新建面试的走势图
创建折线图
点击
创建可视化我们创建一个折线图
水平轴数据配置
我们在水平轴配置小区新建的年份,并选择时间间隔

垂直轴数据配置
我们在垂直轴配置小区新建面积的总和
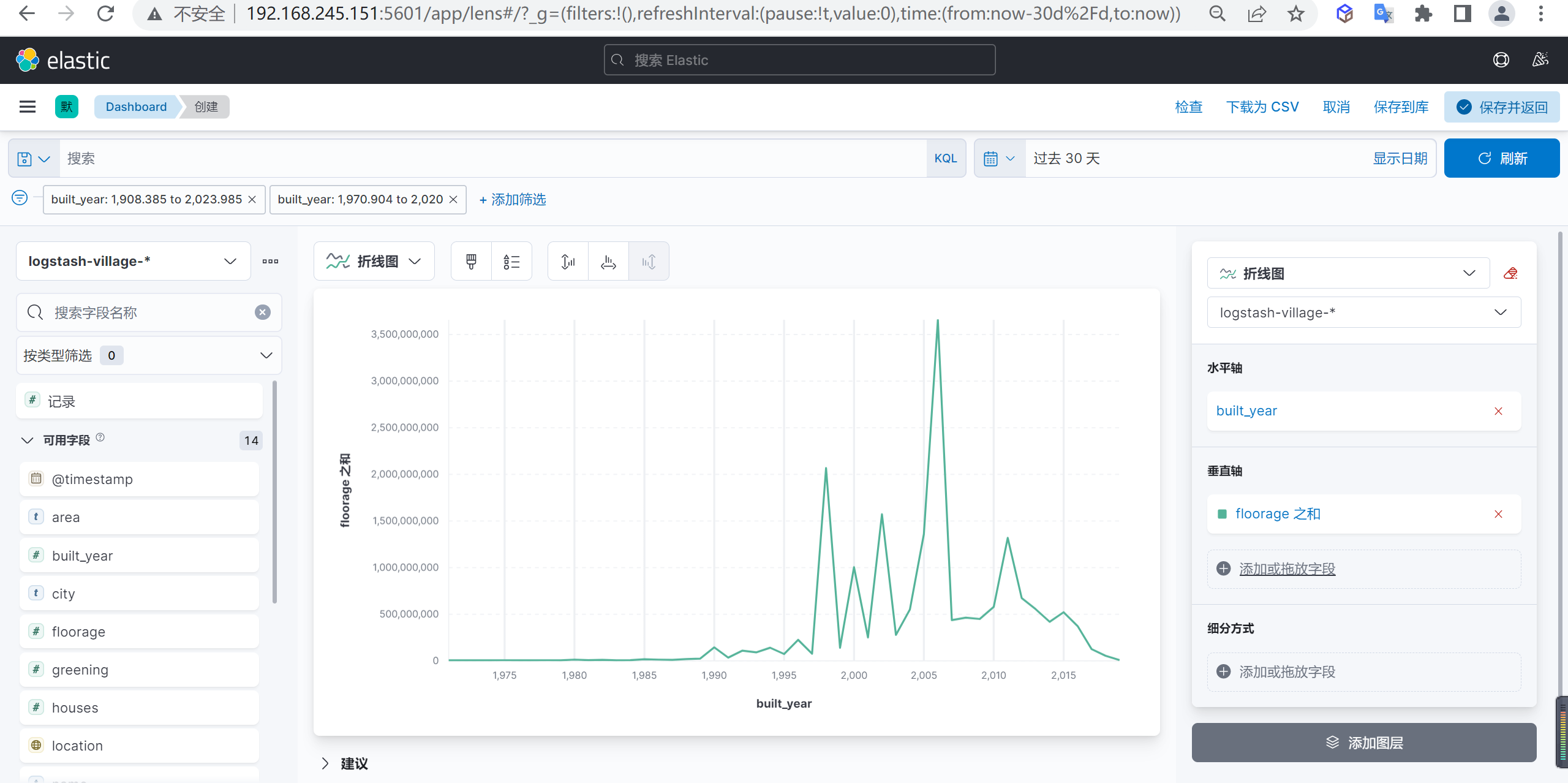
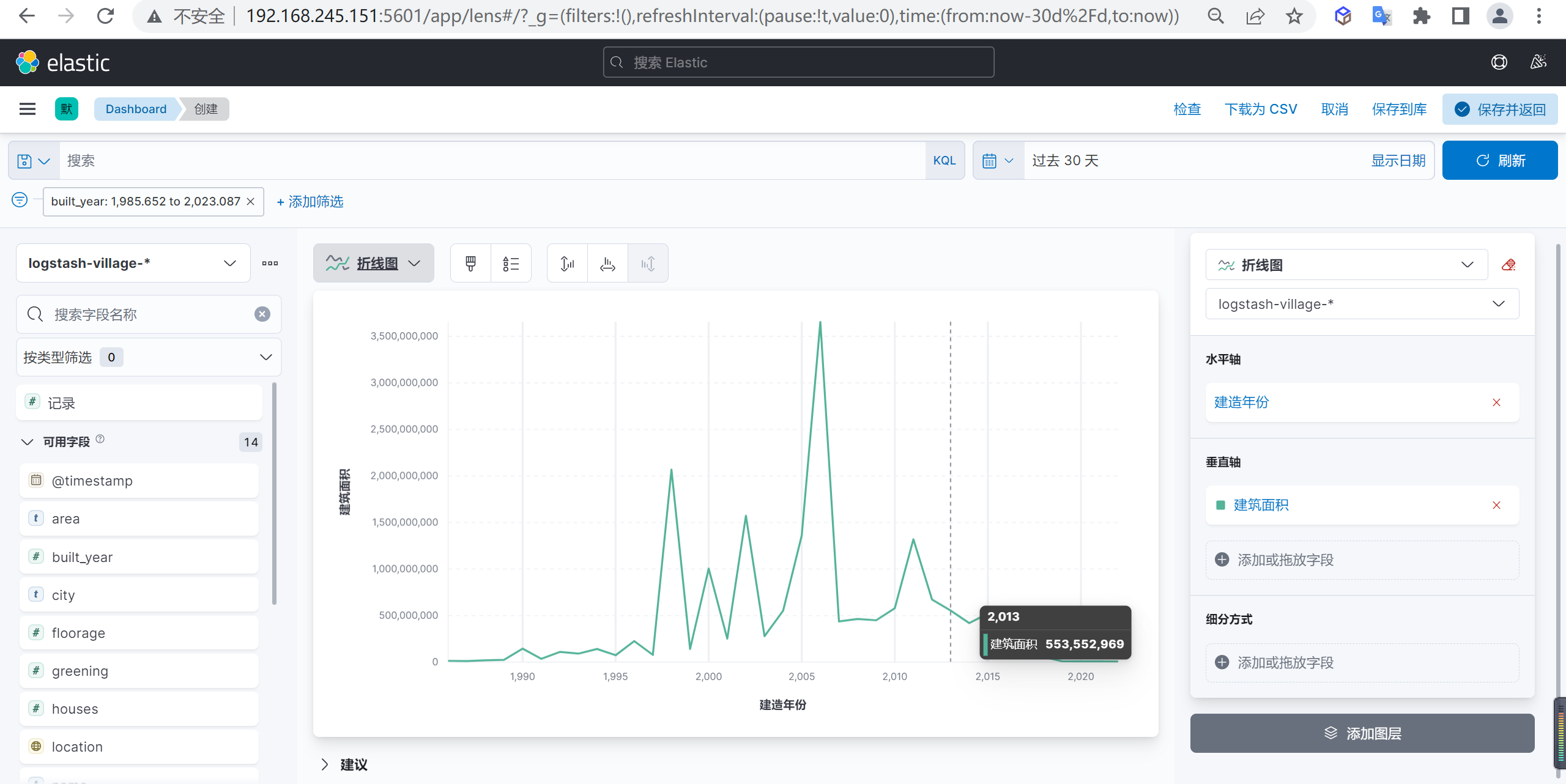
数据分析
我们分析出来数据后可以发现2006年是小区新建面积的高峰期,2006年后就开始慢慢回落了
树状图示例
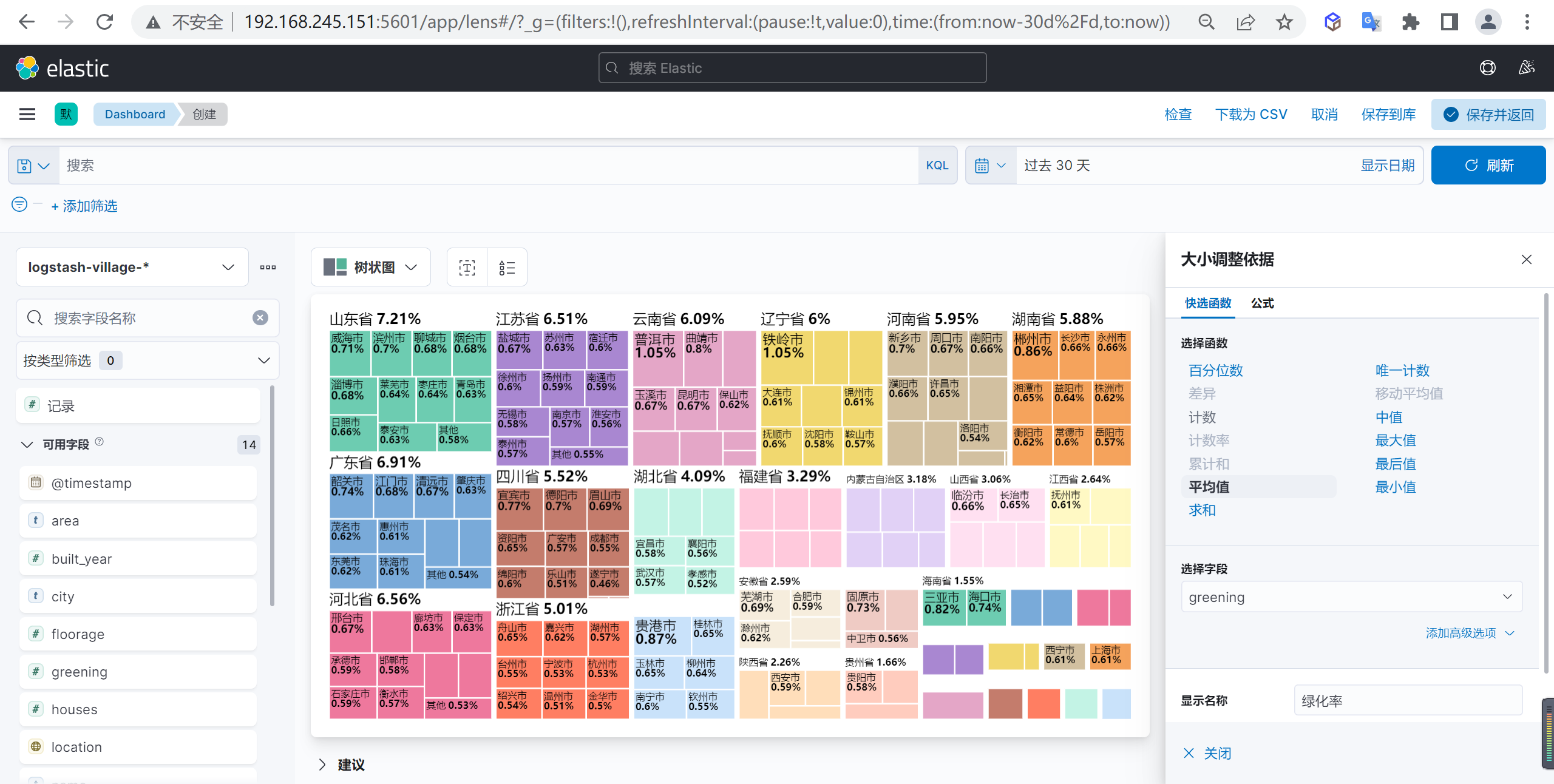
我们狂野配置一个按照省份的绿化率按照树状图进行展示
创建树状图
我们创建一个树状图
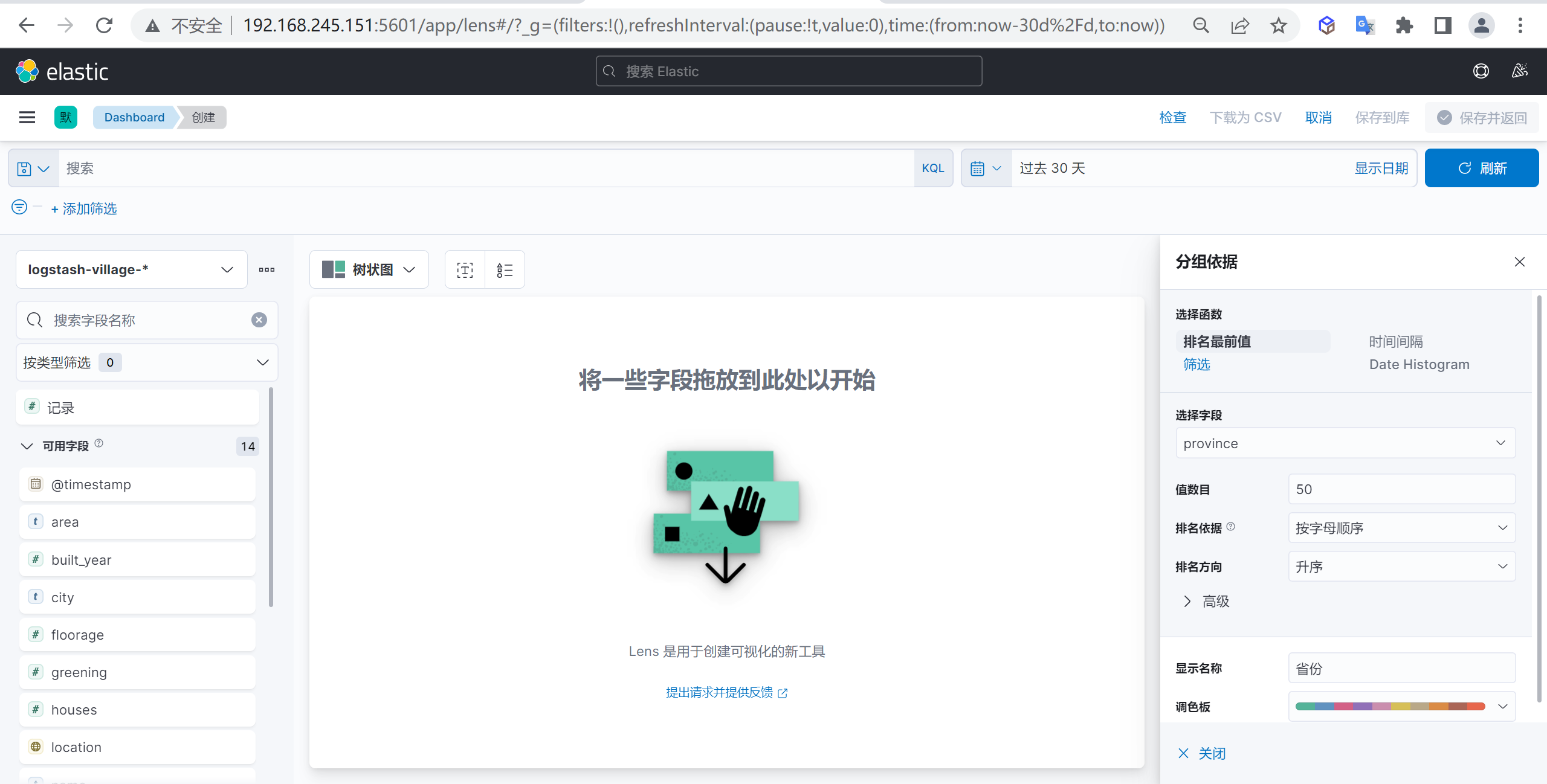
配置分组依据
我们可以配置一个分组依据,我们按照省份作为一个外部分组依据
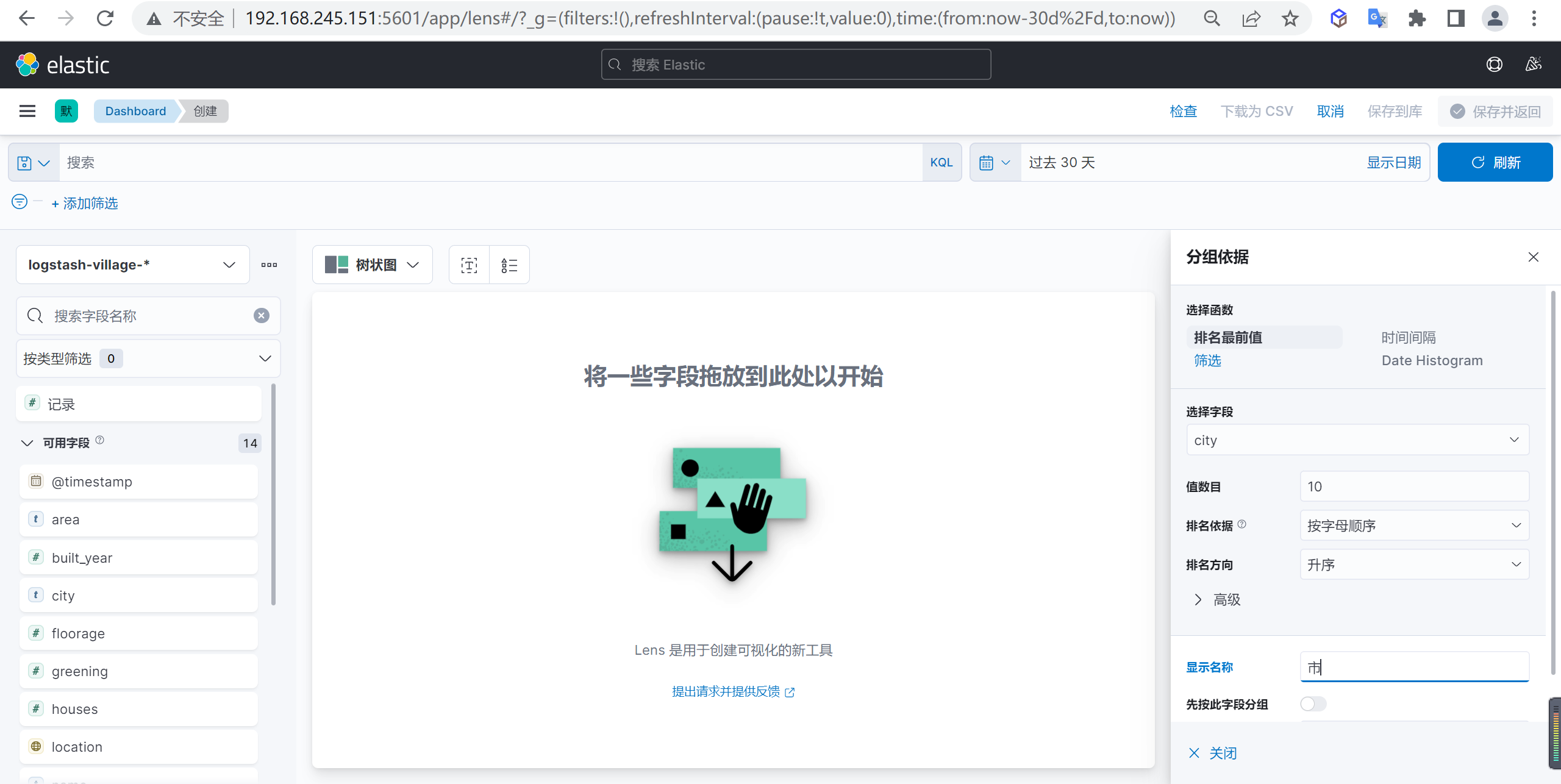
接下来我们再按照市级来作为下级的分组依据
配置大小依据
我们按照绿化率的平均值作为大小依据
创建地图示例
我们还可以使用GEO信息创建一个地图
创建一个地图
我们先创建一个地图,选择Maps来创建一个地图
添加图层
在地图上面添加一个图层
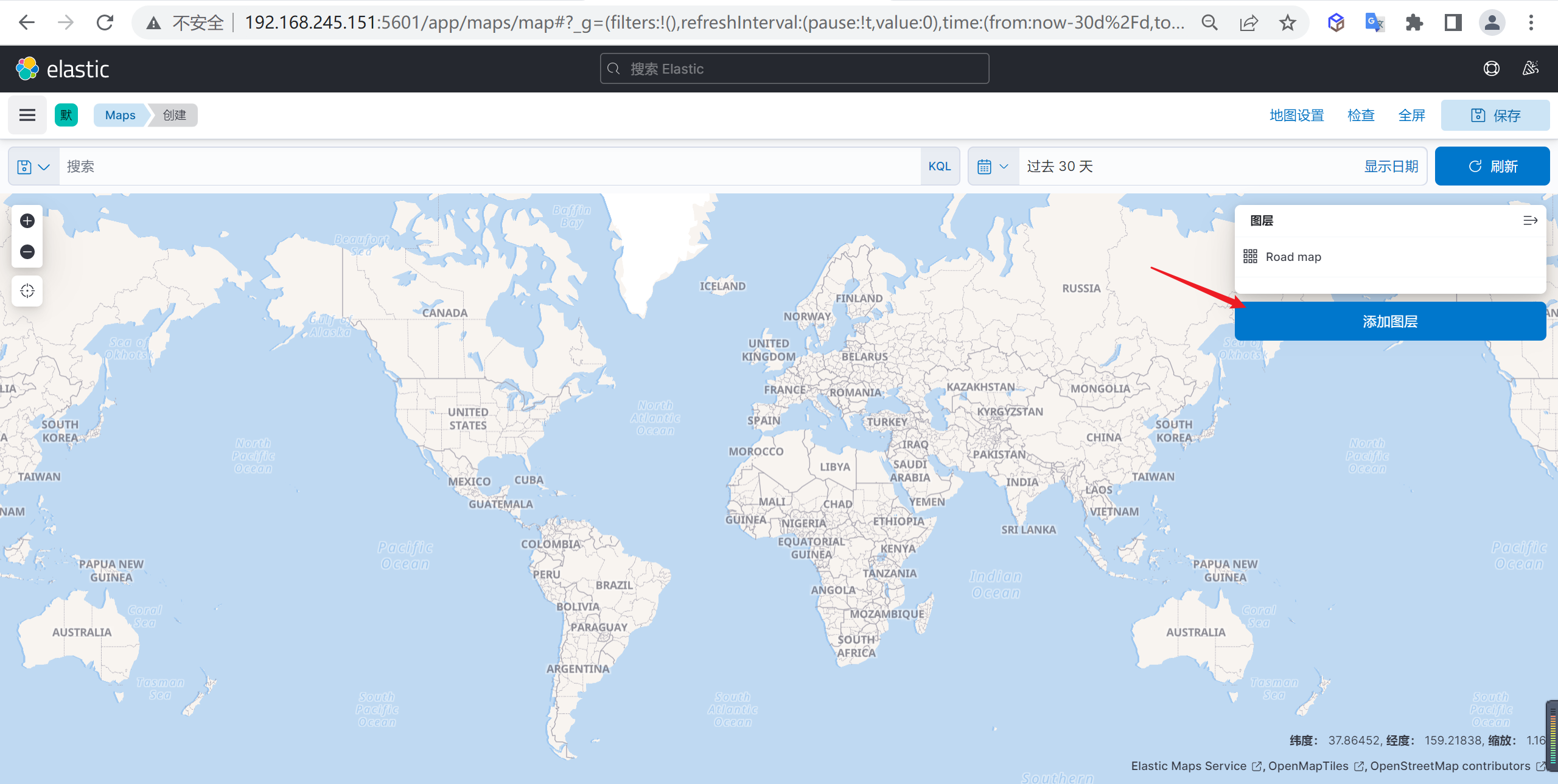
选择文档数据
添加图层后选择需要添加的文档数据
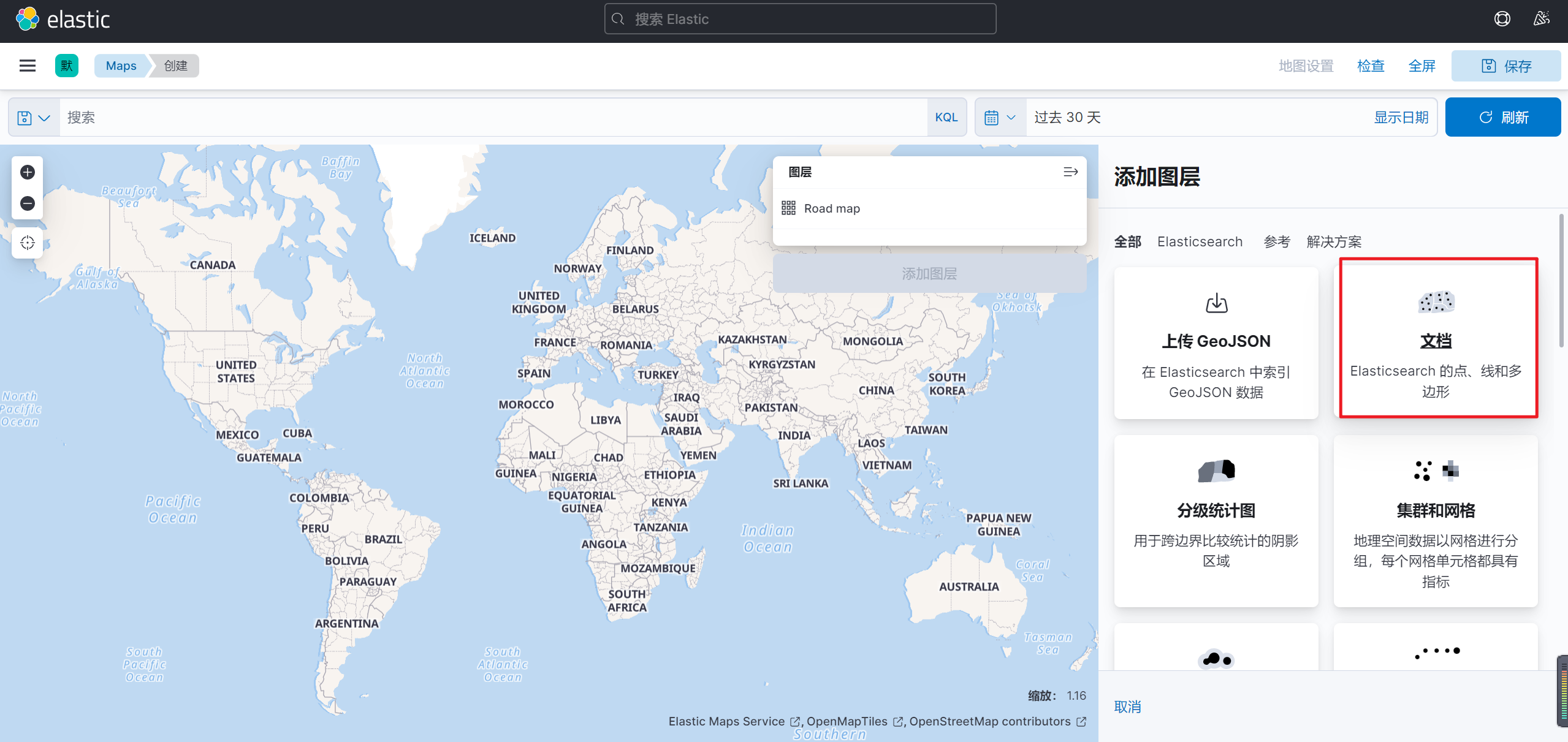
并且在在弹出的界面选择需要显示索引以及GEO字段

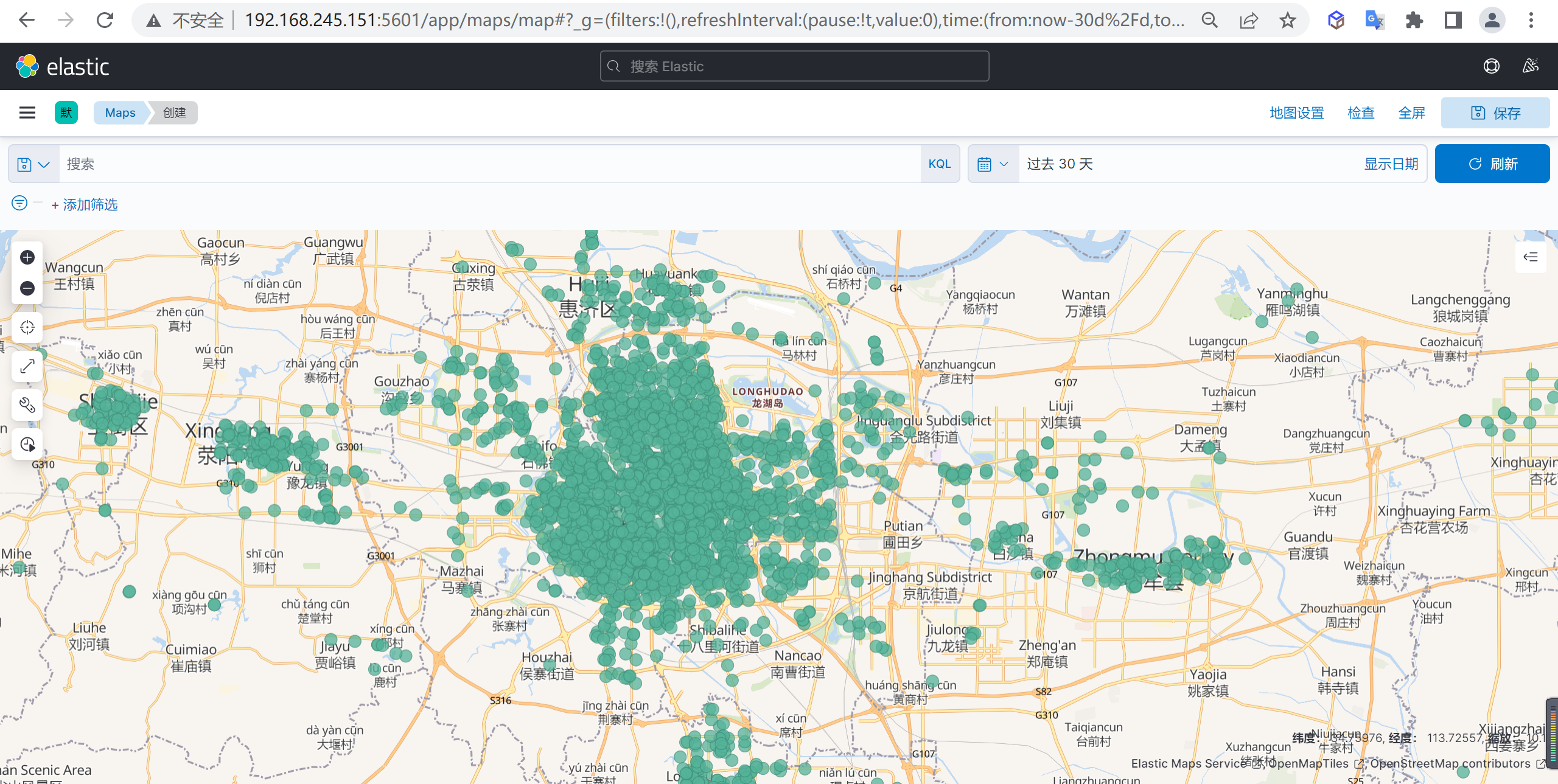
缩放显示数据
然后缩放地图可以看到就可以看到地图数据了
ElasticSearch 索引设计
在MySQL中数据库设计非常重要,同样在ES中数据库设计也是非常重要的
概述
我们创建索引就像创建表结构一样,必须非常慎重的,索引如果创建不好后面会出现各种各样的问题
索引设计的重要性
索引创建后,索引的分片只能通过
_split和_shrink接口对其进行成倍的增加和缩减
主要是因为es的数据是通过_routing分配到各个分片上面的,所以本质上是不推荐去改变索引的分片数量的,因为这样都会对数据进行重新的移动。
还有就是索引只能新增字段,不能对字段进行修改和删除,缺乏灵活性,所以每次都只能通过_reindex重建索引了,还有就是一个分片的大小以及所以分片数量的多少严重影响到了索引的查询和写入性能,所以可想而知,设计一个好的索引能够减少后期的运维管理和提高不少性能,所以前期对索引的设计是相当的重要的。
基于时间的Index设计
Index设计时要考虑的第一件事,就是基于时间对Index进行分割,即每隔一段时间产生一个新的Index
这样设计的目的
因为现实世界的数据是随着时间的变化而不断产生的,切分管理可以获得足够的灵活性和更好的性能
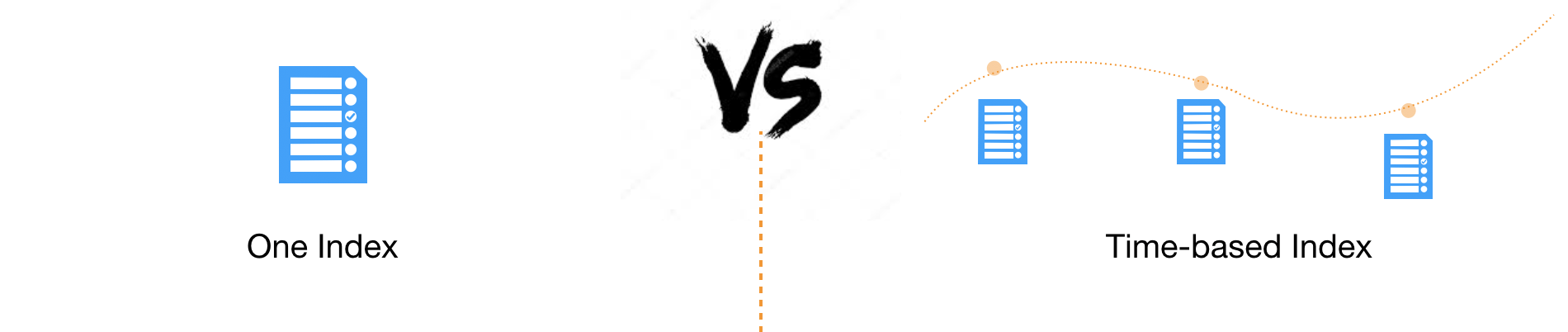
如果数据都存储在一个Index中,很难进行扩展和调整,因为Elasticsearch中Index的某些设置在创建时就设定好了,是不能更改的,比如Primary Shard的个数。
而根据时间来切分Index,则可以实现一定的灵活性,既可以在数据量过大时及时调整Shard个数,也可以及时响应新的业务需求。
大多数业务场景下,客户对数据的请求都会命中在最近一段时间上,通过切分Index,可以尽可能的避免扫描不必要的数据,提高性能。
时间间隔
根据上面的分析,自然是时间越短越能保持灵活性,但是这样做就会导致产生大量的Index,而每个Index都会消耗资源来维护其元信息的,因此需要在灵活性、资源和性能上做权衡
- 常见的间隔有小时、天、周和月:先考虑总共要存储多久的数据,然后选一个既不会产生大量Index又能够满足一定灵活性的间隔,比如你需要存储6个月的数据,那么一开始选择“周”这个间隔就会比较合适。
- 考虑业务增长速度:假如业务增长的特别快,比如上周产生了1亿数据,这周就增长到了10亿,那么就需要调低这个间隔来保证有足够的弹性能应对变化。
如何实现分割
切分行为是由客户端(数据的写入端)发起的,根据时间间隔与数据产生时间将数据写入不同的Index中,为了易于区分,会在Index的名字中加上对应的时间标识
创建新Index这件事,可以是客户端主动发起一个创建的请求,带上具体的Settings、Mappings等信息,但是可能会有一个时间错位,即有新数据写入时新的Index还没有建好,Elasticsearch提供了更优雅的方式来实现这个动作,即Index Template
分片设计
所谓分片设计,就是如何设定主分片的个数
看上去只是一个数字而已,也许在很多场景下,即使不设定也不会有问题(ES7默认是1个主分片一个副本分片),但是如果不提前考虑,一旦出问题就可能导致系统性能下降、不可访问、甚至无法恢复,换句话说,即使使用默认值,也应该是通过足够的评估后作出的决定,而非拍脑袋定的。
限制分片大小
单个Shard的存储大小不超过30GB
Elastic专家根据经验总结出来大家普遍认为30GB是个合适的上限值,实践中发现单个Shard过大(超过30GB)会导致系统不稳定。
其次,为什么不能超过30GB?主要是考虑Shard Relocate过程的负载,我们知道,如果Shard不均衡或者部分节点故障,Elasticsearch会做Shard Relocate,在这个过程中会搬移Shard,如果单个Shard过大,会导致CPU、IO负载过高进而影响系统性能与稳定性。
评估分片数量
单个Index的
Primary Shard个数 = k * 数据节点个数
在保证第一点的前提下,单个Index的Primary Shard个数不宜过多,否则相关的元信息与缓存会消耗过多的系统资源,这里的k,为一个较小的整数值,建议取值为1,2等,整数倍的关系可以让Shard更好地均匀分布,可以充分的将请求分散到不同节点上。
小索引设计
对于很小的Index,可以只分配1~2个Primary Shard的
有些情况下,Index很小,也许只有几十、几百MB左右,那么就不用按照第二点来分配了,只分配1~2个Primary Shard是可以,不用纠结。
使用索引模板
就是把已经创建好的某个索引的参数设置(settings)和索引映射(mapping)保存下来作为模板,在创建新索引时,指定要使用的模板名,就可以直接重用已经定义好的模板中的设置和映射
Elasticsearch基于与索引名称匹配的通配符模式将模板应用于新索引,也就是说通过索引进行匹配,看看新建的索引是否符合索引模板,如果符合,就将索引模板的相关设置应用到新的索引,如果同时符合多个索引模板呢,这里需要对参数priority进行比较,这样会选择priority大的那个模板进行创建索引。
在创建索引模板时,如果匹配有包含的关系,或者相同,则必须设置priority为不同的值,否则会报错,索引模板也是只有在新创建的时候起到作用,修改索引模板对现有的索引没有影响,同样如果在索引中设置了一些设置或者mapping都会覆盖索引模板中相同的设置或者mapping
索引模板的用途
索引模板一般用在时间序列相关的索引中。
也就是说, 如果你需要每间隔一定的时间就建立一次索引,你只需要配置好索引模板,以后就可以直接使用这个模板中的设置,不用每次都设置settings和mappings.
创建索引模板
PUT _index_template/logstash-village
{
"index_patterns": [
"logstash-village-*" // 可以通过"logstash-village-*"来适配创建的索引
],
"template": {
"settings": {
"number_of_shards": "3", //指定模板分片数量
"number_of_replicas": "2" //指定模板副本数量
},
"aliases": {
"logstash-village": {} //指定模板索引别名
},
"mappings": { //设置映射
"dynamic": "strict", //禁用动态映射
"properties": {
"@timestamp": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis||yyyy-MM-dd HH:mm:ss"
},
"@version": {
"doc_values": false,
"index": "false",
"type": "integer"
},
"name": {
"type": "keyword"
},
"province": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"area": {
"type": "keyword"
},
"addr": {
"type": "text",
"analyzer": "ik_smart"
},
"location": {
"type": "geo_point"
},
"property_type": {
"type": "keyword"
},
"property_company": {
"type": "text",
"analyzer": "ik_smart"
},
"property_cost": {
"type": "float"
},
"floorage": {
"type": "float"
},
"houses": {
"type": "integer"
},
"built_year": {
"type": "integer"
},
"parkings": {
"type": "integer"
},
"volume": {
"type": "float"
},
"greening": {
"type": "float"
},
"producer": {
"type": "keyword"
},
"school": {
"type": "keyword"
},
"info": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
}模板参数
下面是创建索引模板的一些参数
| 参数名称 | 参数介绍 |
|---|---|
| index_patterns | 必须配置,用于在创建期间匹配索引名称的通配符(*)表达式数组 |
| template | 可选配置,可以选择包括别名、映射或设置配置 |
| composed_of | 可选配置,组件模板名称的有序列表。组件模板按指定的顺序合并,这意味着最后指定的组件模板具有最高的优先级 |
| priority | 可选配置,创建新索引时确定索引模板优先级的优先级。选择具有最高优先级的索引模板。如果未指定优先级,则将模板视为优先级为0(最低优先级) |
| version | 可选配置,用于外部管理索引模板的版本号 |
| _meta | 可选配置,关于索引模板的可选用户元数据,可能有任何内容 |
映射配置
上面我们配置了映射模板,但是我们用到了映射,下面我们说下映射
什么是映射
在创建索引时,可以预先定义字段的类型(映射类型)及相关属性
数据库建表的时候,我们DDL依据一般都会指定每个字段的存储类型,例如:varchar、int、datetime等,目的很明确,就是更精确的存储数据,防止数据类型格式混乱,在Elasticsearch中也是这样,创建索引的时候一般也需要指定索引的字段类型,这种方式称为映射(Mapping)
被动创建(动态映射)
此时字段和映射类型不需要事先定义,只需要存在文档的索引,当向此索引添加数据的时候当遇到不存在的映射字段,ES会根据数据内容自动添加映射字段定义。
动态映射规则
使用动态映射的时候,根据传递请求数据的不同会创建对应的数据类型
| 数据类型 | Elasticsearch 数据类型 |
|---|---|
| null | 不添加任何字段 |
| true或者false | boolean类型 |
| 浮点数据 | float类型 |
| integer数据 | long类型 |
| object | object类型 |
| array | 取决于数组中的第一个非空值的类型。 |
| string | 如果此内容通过了日期格式检测,则会被认为是date数据类型 如果此值通过了数值类型检测则被认为是double或者long数据类型 带有关键字子字段会被认为一个text字段 |
禁止动态映射
一般生产环境下需要禁用动态映射,使用动态映射可能出现以下问题
- 造成集群元数据一直变更,导致不稳定;
- 可能造成数据类型与实际类型不一致;
如何禁用动态映射,动态
mapping的dynamic字段进行配置,可选值及含义如下
- true:支持动态扩展,新增数据有新的字段属性时,自动添加对于的mapping,数据写入成功
- false:不支持动态扩展,新增数据有新的字段属性时,直接忽略,数据写入成功
- strict:不支持动态扩展,新增数据有新的字段时,报错,数据写入失败
主动创建(显示映射)
动态映射只能保证最基础的数据结构的映射
所以很多时候我们需要对字段除了数据结构定义更多的限制的时候,动态映射创建的内容很可能不符合我们的需求,所以可以使用PUT {index}/mapping来更新指定索引的映射内容。
映射类型
我们要创建映射必须还要知道映射类型,否则就会走默认的映射类型,下面我们看看常用的映射类型
准备工作
我们先创建一个用于测试映射类型的索引
PUT mapping_demo字符串类型
字符串类型是我们最常用的类型之一,我们操作的时候字符串类型可以被设置为以下几种类型
text
当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型,text类型会被分词
设置text类型以后,字段内容会被分词,在生成倒排索引以前,字符串会被分析器分成一个一个词项,text类型的字段不用于排序,很少用于聚合
keyword
keyword类型不会被分词,常用于关键字搜索,比如姓名、email地址、主机名、状态码和标签等
如果字段需要进行过滤(比如查姓名是张三发布的博客)、排序、聚合,keyword类型的字段只能通过精确值搜索到,常常被用来过滤、排序和聚合
两者区别
它们的区别在于
text会对字段进行分词处理而keyword则不会进行分词
也就是说如果字段是text类型,存入的数据会先进行分词,然后将分完词的词组存入索引,而keyword则不会进行分词,直接存储,这样划分数据更加节省内存。
使用案例
我们先创建一个映射,name是keyword类型,描述是text类型的
PUT mapping_demo/_mapping
{
"properties": {
"name": {
"type": "keyword"
},
"city": {
"type": "text",
"analyzer": "ik_smart"
}
}
}插入数据
PUT mapping_demo/_doc/1
{
"name":"北京小区",
"city":"北京市昌平区回龙观街道"
}对于keyword的name字段进行精确查询
GET mapping_demo/_search
{
"query": {
"term": {
"name": "北京小区"
}
}
}对于text的city进行模糊查询
GET mapping_demo/_search
{
"query": {
"term": {
"city": "北京市"
}
}
}数字类型
数字类型也是我们最常用的类型之一,下面我们看下数字类型的使用
| 类型 | 取值范围 |
|---|---|
| long | -263 ~ 263 |
| integer | -231 ~ 231 |
| short | -215 ~ 215 |
| byte | -27 ~ 27 |
| double | 64位的双精度 IEEE754 浮点类型 |
| float | 32位的双精度 IEEE754 浮点类型 |
| half_float | 16位的双精度 IEEE754 浮点类型 |
| scaled_float | 缩放类型的浮点类型 |
注意事项
- 在满足需求的情况下,优先使用范围小的字段,字段长度越小,索引和搜索的效率越高。
日期类型
JSON表示日期
JSON没有表达日期的数据类型,所以在ES里面日期只能是下面其中之一
- 格式化的日期字符串,比如:
"2015-01-01"or"2015/01/01 12:10:30" - 用数字表示的从新纪元开始的毫秒数
- 用数字表示的从新纪元开始的秒数(epoch_second)
注意点:毫秒数的值是不能为负数的,如果时间在1970年以前,需要使用格式化的日期表达
ES如何处理日期
在ES的内部,时间会被转换为UTC时间(如果声明了时区)并使用从新纪元开始的毫秒数的长整形数字类型的进行存储,在日期字段上的查询,内部将会转换为使用长整形的毫秒进行范围查询,根据与字段关联的日期格式,聚合和存储字段的结果将转换回字符串
注意点:日期最终都会作为字符串呈现,即使最开始初始化的时候是利用JSON文档的long声明的
默认日期格式
日期的格式可以被定制化的,如果没有声明日期的格式,它将会使用默认的格式:
"strict_date_optional_time||epoch_millis" 这意味着它将会接收带时间戳的日期,它将遵守strict_date_optional_time限定的格式(yyyy-MM-dd'T'HH:mm:ss.SSSZ 或者 yyyy-MM-dd)或者毫秒数
日期格式示例
PUT mapping_demo/_mapping
{
"properties": {
"datetime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
# 添加数据
PUT mapping_demo/_doc/2
{
"name":"河北区",
"city":"河北省小区",
"datetime":"2022-02-21 11:35:42"
}日期类型参数
下面表格里的参数可以用在date字段上面
| 参数 | 说明 |
|---|---|
| doc_values | 该字段是否按照列式存储在磁盘上以便于后续进行排序、聚合和脚本操作,可配置 true(默认)或 false |
| format | 日期的格式 |
| locale | 解析日期中时使用了本地语言表示月份时的名称和/或缩写,默认是 ROOT locale |
| ignore_malformed | 如果设置为true,则奇怪的数字就会被忽略,如果是false(默认)奇怪的数字就会导致异常并且该文档将会被拒绝写入。需要注意的是,如果在脚本参数中使用则该属性不能被设置 |
| index | 该字段是否能快速的被查询,默认是true。date类型的字段只有在doc_values设置为true时才能被查询,尽管很慢。 |
| null_value | 替代null的值,默认是null |
| on_script_error | 定义在脚本中如何处理抛出的异常,fail(默认)则整个文档会被拒绝索引,continue:继续索引 |
| script | 如果该字段被设置,则字段的值将会使用该脚本产生,而不是直接从source里面读取。 |
| store | true or false(默认)是否在 _source 之外在独立存储一份 |
布尔类型
boolean类型用于存储文档中的true/false
范围类型
顾名思义,范围类型字段中存储的内容就是一段范围,例如年龄30-55岁,日期在2020-12-28到2021-01-01之间等
类型范围
es中有六种范围类型:
- integer_range
- float_range
- long_range
- double_range
- date_range
- ip_range
使用实例
PUT mapping_demo/_mapping
{
"properties": {
"age_range": {
"type": "integer_range"
}
}
}
# 指定年龄范围,可以使用 gt、gte、lt、lte。
PUT mapping_demo/_doc/3
{
"name":"张三",
"age_range":{
"gt":20,
"lt":30
}
}分词器
什么是分词器
分词器的主要作用将用户输入的一段文本,按照一定逻辑,分析成多个词语的一种工具
顾名思义,文本分析就是把全文本转换成一系列单词(term/token)的过程,也叫分词,在 ES 中,Analysis 是通过分词器(Analyzer) 来实现的,可使用 ES 内置的分析器或者按需定制化分析器。
举一个分词简单的例子:比如你输入 Mastering Elasticsearch,会自动帮你分成两个单词,一个是 mastering,另一个是 elasticsearch,可以看出单词也被转化成了小写的。
分词器构成
分词器是专门处理分词的组件,分词器由以下三部分组成:
character filter
接收原字符流,通过添加、删除或者替换操作改变原字符流
例如:去除文本中的html标签,或者将罗马数字转换成阿拉伯数字等,一个字符过滤器可以有零个或者多个
tokenizer
简单的说就是将一整段文本拆分成一个个的词
例如拆分英文,通过空格能将句子拆分成一个个的词,但是对于中文来说,无法使用这种方式来实现,在一个分词器中,有且只有一个tokenizeer
token filters
将切分的单词添加、删除或者改变
例如将所有英文单词小写,或者将英文中的停词a删除等,在token filters中,不允许将token(分出的词)的position或者offset改变,同时,在一个分词器中,可以有零个或者多个token filters。
分词顺序
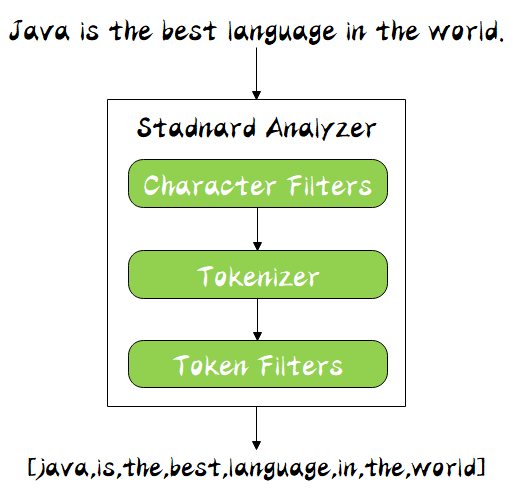
同时 Analyzer 三个部分也是有顺序的,从图中可以看出,从上到下依次经过 Character Filters,Tokenizer 以及 Token Filters,这个顺序比较好理解,一个文本进来肯定要先对文本数据进行处理,再去分词,最后对分词的结果进行过滤。
测试分词
可以通过
_analyzerAPI来测试分词的效果,我们使用下面的html过滤分词
POST _analyze
{
"text":"<b>hello world<b>" # 输入的文本
"char_filter":["html_strip"], # 过滤html标签
"tokenizer":"keyword", #原样输出
}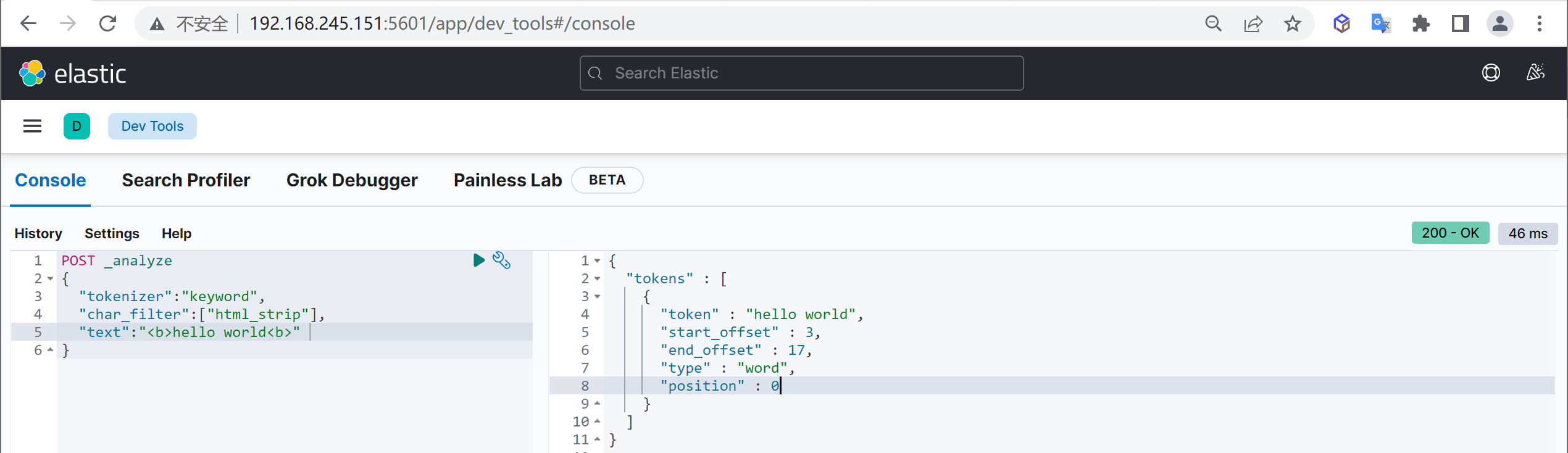
什么时候分词
文本分词会发生在两个地方:
创建索引:当索引文档字符类型为text时,在建立索引时将会对该字段进行分词。搜索:当对一个text类型的字段进行全文检索时,会对用户输入的文本进行分词。
创建索引时指定分词器
如果设置手动设置了分词器,ES将按照下面顺序来确定使用哪个分词器
- 先判断字段是否有设置分词器,如果有,则使用字段属性上的分词器设置
- 如果设置了
analysis.analyzer.default,则使用该设置的分词器 - 如果上面两个都未设置,则使用默认的
standard分词器
字段指定分词器
为addr属性指定分词器,这里我们使用的是中文分词器
PUT my_index
{
"mappings": {
"properties": {
"info": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}设置默认分词器
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
}
}
}
}
}搜索时指定分词器
在搜索时,通过下面参数依次检查搜索时使用的分词器,这样我们的搜索语句就会先分词,然后再来进行搜索
- 搜索时指定
analyzer参数 - 创建mapping时指定字段的
search_analyzer属性 - 创建索引时指定
setting的analysis.analyzer.default_search - 查看创建索引时字段指定的
analyzer属性 - 如果上面几种都未设置,则使用默认的
standard分词器。
指定analyzer
搜索时指定analyzer查询参数
GET my_index/_search
{
"query": {
"match": {
"message": {
"query": "Quick foxes",
"analyzer": "stop"
}
}
}
}指定字段analyzer
PUT my_index
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "whitespace",
"search_analyzer": "simple"
}
}
}
}指定默认default_seach
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
},
"default_seach":{
"type":"whitespace"
}
}
}
}
}内置分词器
es在索引文档时,会通过各种类型
Analyzer对text类型字段做分析
不同的 Analyzer 会有不同的分词结果,内置的分词器有以下几种,基本上内置的 Analyzer 包括 Language Analyzers 在内,对中文的分词都不够友好,中文分词需要安装其它 Analyzer
| 分析器 | 描述 | 分词对象 | 结果 |
|---|---|---|---|
| standard | 标准分析器是默认的分析器,如果没有指定,则使用该分析器。它提供了基于文法的标记化(基于 Unicode 文本分割算法,如 Unicode 标准附件 # 29所规定) ,并且对大多数语言都有效。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog’s, bone ] |
| simple | 简单分析器将文本分解为任何非字母字符的标记,如数字、空格、连字符和撇号、放弃非字母字符,并将大写字母更改为小写字母。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| whitespace | 空格分析器在遇到空白字符时将文本分解为术语 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog’s, bone. ] |
| stop | 停止分析器与简单分析器相同,但增加了删除停止字的支持。默认使用的是 _english_ 停止词。 |
The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ quick, brown, foxes, jumped, over, lazy, dog, s, bone ] |
| keyword | 不分词,把整个字段当做一个整体返回 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone.] |
| pattern | 模式分析器使用正则表达式将文本拆分为术语。正则表达式应该匹配令牌分隔符,而不是令牌本身。正则表达式默认为 w+ (或所有非单词字符)。 |
The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| 多种西语系 arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english等等 | 一组旨在分析特定语言文本的分析程序。 |
IK中文分词器
IKAnalyzer
IKAnalyzer是一个开源的,基于java的语言开发的轻量级的中文分词工具包
从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本,在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化
中文分词器算法
中文分词器最简单的是ik分词器,还有jieba分词,哈工大分词器等
| 分词器 | 描述 | 分词对象 | 结果 |
|---|---|---|---|
| ik_smart | ik分词器中的简单分词器,支持自定义字典,远程字典 | 学如逆水行舟,不进则退 | [学如逆水行舟,不进则退] |
| ik_max_word | ik_分词器的全量分词器,支持自定义字典,远程字典 | 学如逆水行舟,不进则退 | [学如逆水行舟,学如逆水,逆水行舟,逆水,行舟,不进则退,不进,则,退] |
ik_smart
原始内容
传智教育的教学质量是杠杠的测试分词
GET _analyze
{
"analyzer": "ik_smart",
"text": "传智教育的教学质量是杠杠的"
}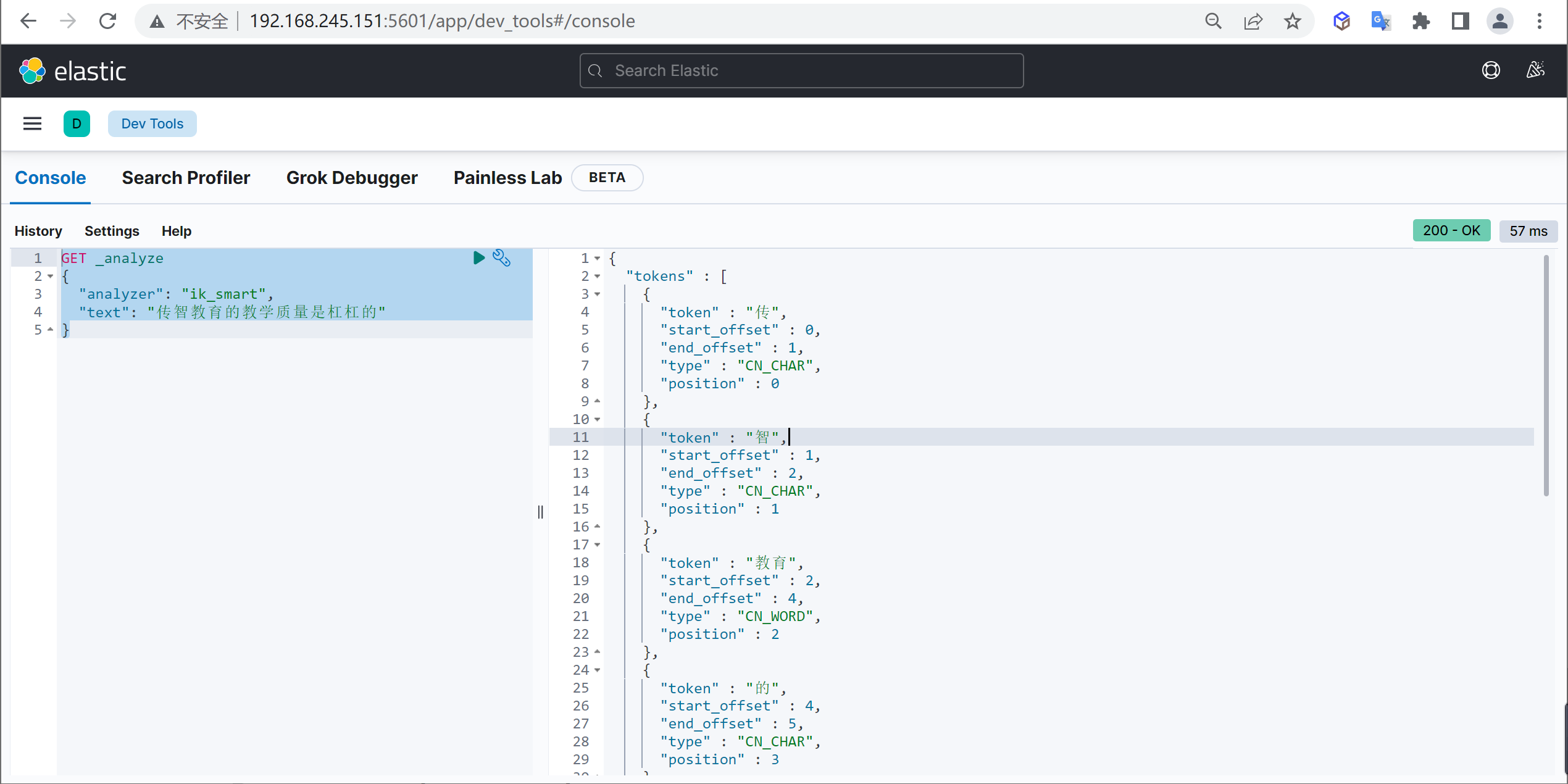
ik_max_word
原始内容
传智教育的教学质量是杠杠的测试分词
GET _analyze
{
"analyzer": "ik_max_word",
"text": "传智教育的教学质量是杠杠的"
}ElasticSearch 字段映射
概述
什么是映射
在创建索引时,可以预先定义字段的类型(映射类型,也就是type,一个索引可以有一个或多个类型)及相关属性
数据库建表的时候,我们DDL依据一般都会指定每个字段的存储类型,例如:varchar、int、datetime等,目的很明确,就是更精确的存储数据,防止数据类型格式混乱,在Elasticsearch中也是这样,创建爱你索引的时候一般也需要指定索引的字段类型,这种方式称为映射(Mapping)。
映射的作用
Elasticsearch会根据JSON源数据的基础类型猜测你想要的字段映射,将输入的数据转变成可搜索的索引项
Mapping就是我们定义的字段的数据类型,同时告诉Elasticsearch如何索引数据以及是否可以被搜索,会让索引建立的更加细致和完善
映射的创建
和传统数据库不同,传统的数据库我们尝试向表中插入数据的前提是这个表已经存在数据结构的定义,且插入数据的字段要在表结构中被定义,而ES的映射的创建支持主动和被动创建。
被动创建(动态映射)
此时字段和映射类型不需要事先定义,只需要存在文档的索引,当向此索引添加数据的时候当遇到不存在的映射字段,ES会根据数据内容自动添加映射字段定义。
动态映射规则
使用动态映射的时候,根据传递请求数据的不同会创建对应的数据类型
| JSON中数据类型 | Elasticsearch 数据类型 |
|---|---|
| null | 不添加任何字段 |
| true或者false | boolean类型 |
| 浮点数据 | float类型 |
| integer数据 | long类型 |
| object | object类型 |
| array | 取决于数组中的第一个非空值的类型。 |
| string | 如果此内容通过了日期格式检测,则会被认为是date数据类型。如果此值通过了数值类型检测则被认为是double或者long数据类型,带有关键字子字段会被认为一个text字段 |
主动创建(显示映射)
动态映射只能保证最基础的数据结构的映射,所以很多时候我们需要对字段除了数据结构定义更多的限制的时候,动态映射创建的内容很可能不符合我们的需求,所以可以使用
PUT {index}/mapping来更新指定索引的映射内容。
映射限制
为索引中的列定义太多太大的字段会使得映射变得十分臃肿,从而导致内存错误和难以恢复的情况。
尤其在使用动态映射的时候,新的数据中假如携带不存在的字段数据时系统会自动添加新的字段,假如不做出限制会使映射字段变得非常多。目前ES支持设置的参数有下面几个
| 参数 | 说明 |
|---|---|
| index.mapping.total_fields.limit | 限制索引中字段的最大数量,默认值是1000。 |
| index.mapping.depth.limit | 字段结构中定义的最大深度,基于根节点定义的字段深度为1,,如果有一个对象映射,则深度为2,依此类推。默认值是20。 |
| index.mapping.nested_fields.limit | 索引中嵌套类型的最大数目,默认为50。 |
| index.mapping.nested_objects.limit | 索引嵌套类型的单个文档内嵌套JSON对象的最大数量,默认为10000。 |
| index.mapping.field_name_length.limit | 自定名称的最大长度,模型情况下是没有限制的。 |
映射数据类型
核心类型
字符串类型
string
string类型在ElasticSearch 旧版本中使用较多,从ElasticSearch 5.x开始不再支持string,由text和keyword类型替代
text
当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型
设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项,text类型的字段不用于排序,很少用于聚合。
keyword
keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签
如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合,keyword类型的字段只能通过精确值搜索到,常常被用来过滤、排序和聚合
数字类型
以下是整数类型的取值范围
| 类型 | 取值范围 |
|---|---|
| long | -263 ~ 263 |
| integer | -231 ~ 231 |
| short | -215 ~ 215 |
| byte | -27 ~ 27 |
| double | 64位的双精度 IEEE754 浮点类型 |
| float | 32位的双精度 IEEE754 浮点类型 |
| half_float | 16位的双精度 IEEE754 浮点类型 |
| scaled_float | 缩放类型的浮点类型 |
注意事项
- 在满足需求的情况下,优先使用范围小的字段。字段长度越小,索引和搜索的效率越高。
- 浮点数,优先考虑使用scaled_float:例如保存一个价格为99.99的商品,当使用了scaled_float类型,定义比例因子scaling_factor为100,在底层保存的数据就是整数9999,可以提高效率。而在运算时,API还是以浮点类型进行运算。
日期类型
JSON中并没有日期类型
不管是什么样的格式,es 内部都会先将时间转为 UTC,然后将时间按照 millseconds-since-the-epoch 来存储成long类型,在查询的时候,再根据字段定义的格式转为字符串输出。
日期格式示例
日期类型默认的格式是:
strict_date_optional_time||epoch_millis,可以通过format属性来自定义日期格式
PUT mapping_demo/_mapping
{
"properties": {
"datetime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}日期格式
所以在es中日期类型可以表现成很多种:
- 日期格式字符串:“2020-12-28”或”2020/12/28 11:11:11”
- 毫秒级别的long类型
- 秒级别的integer类型
布尔类型
JSON 中的 “true”、“false”、true、false 都可以存储到布尔类型中。
二进制类型
二进制字段是指用base64来表示索引中存储的二进制数据
可用来存储二进制形式的数据,例如图像,默认情况下,该类型的字段只存储不索引,二进制类型只支持index_name属性。
范围类型
顾名思义,范围类型字段中存储的内容就是一段范围,例如年龄30-55岁,日期在2020-12-28到2021-01-01之间等
类型范围
es中有六种范围类型:
- integer_range
- float_range
- long_range
- double_range
- date_range
- ip_range
使用案例
PUT mapping_demo/_mapping
{
"properties": {
"age_range": {
"type": "integer_range"
}
}
}
# 指定年龄范围,可以使用 gt、gte、lt、lte。
PUT mapping_demo/_doc/3
{
"real_name":"大方哥",
"age_range":{
"gt":20,
"lt":30
}
}复合类型
数组类型
es 中没有专门的数组类型。
默认情况下,任何字段都可以有一个或者多个值,需要注意的是,数组中的元素必须是同一种类型。
使用示例
常用的数组类型是:
- 字符数组: [ “one”, “two” ]
- 整数数组: productid:[ 1, 2 ]
- 对象(文档)数组: “user”:[ { “name”: “Mary”, “age”: 12 }, { “name”: “John”, “age”: 10 }],ElasticSearch内部把对象数组展开为 {“user.name”: [“Mary”, “John”], “user.age”: [12,10]}
对象类型(object)
由于 JSON 本身具有层级关系,所以文档包含内部对象。内部对象中,还可以再包含内部对象。
使用案例
PUT test/my/1
{
"employee":{
"age":30,
"fullname":{
"first":"hadron",
"last":"cheng"
}
}
}嵌套类型(nested)
nested类型是一种特殊的对象object数据类型specialised version of the object datatype,允许对象数组彼此独立地进行索引和查询。
使用示例
Lucene中没有内部对象的概念,所以 es 会将对象层次扁平化,将一个对象转为字段名和值构成的简单列表,例如添加以下文档:
PUT nested/_doc/1
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}
user会被动态映射为object类型的,其内部转换成类似下面的文档格式:
{
"group" : "fans",
"user.first" : [ "alice", "john" ],
"user.last" : [ "smith", "white" ]
}扁平化处理后,用户名之间的关联关系没有,如果我们使用
alice和white查询,就会查询出不存在的用户
如果您需要索引对象数组并保持数组中每个对象的独立性,请使用nested数据类型,而不是object数据类型。
PUT nested
{
"mappings": {
"properties": {
"user": {
"type": "nested"
}
}
}
}在内部,嵌套对象将数组中的每个对象索引为一个单独的隐藏文档,这意味着每个嵌套对象都可以通过查询独立于其他对象进行nested查询。
优缺点
使用
nested类型的优缺点:
- 优点:文档存储在一起,读取性能高。
- 缺点:更新父或者子文档时需要更新更个文档
地理类型
geo_point
使用场景
- 查找某一个范围内的地理位置
- 通过地理位置或者相对中心点的距离来聚合文档
- 把距离整合到文档的评分中
- 通过距离对文档进行排序
定义类型
# 定义geo_point字段类型
PUT people
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}使用案例
可以通过5种方式来指定一个地理位置:
# object类型指定经纬度
PUT people/_doc/1
{
"text": "Geo-point as an object",
"location": {
"lat": 34.27,
"lon": 108.94
}
}
# 字符串形式指定经纬度,中间用逗号,分隔
PUT people/_doc/2
{
"text": "Geo-point as a string",
"location": "34.27,108.94"
}
# 将经纬度转个Geohash后储存
PUT people/_doc/3
{
"text": "Geo-point as a geohash",
"location": "uzbrgzfxuzup"
}
# 使用数组指定经纬度,注意经度在前,纬度在后
PUT people/_doc/4
{
"text": "Geo-point as an array",
"location": [108.94, 34.27]
}
# 使用WKT原点指定经纬度,注意经度在前,纬度在后
PUT people/_doc/5
{
"text": "Geo-point as a WKT POINT primitive",
"location": "POINT (108.94 34.27)"
}查询方式
通过经纬度来指定两左上角top_left和右下角bottom_rigth,来查询范围中的位置:
GET people/_search
{
"query": {
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 30,
"lon": 100
},
"bottom_right": {
"lat": 40,
"lon": 110
}
}
}
}
}字段参数
geo_point字段参数:
- ignore_malformed:默认为false,存储格式错误的地理位置将会抛出异常,并且文档也不会写入。true则忽略格式错误的地理位置。
- ignore_z_value:默认为true,接受并存储第三维z轴坐标,但仅索引经纬度。false则指接受二维经纬度,超过二维的地理坐标将会抛出异常。
- null_value:接受null值的地理位置,表示该字段被视为丢失。
geo_shape
GeoJson是什么
在学习
geo_shape之前,我们先要了解一下GeoJson。
GeoJSON是一种对各种地理数据结构进行编码的格式,基于Javascript对象表示法(JavaScript Object Notation, 简称JSON)的地理空间信息数据交换格式,GeoJSON对象可以表示几何、特征或者特征集合。GeoJSON支持下面几何类型:点、线、面、多点、多线、多面和几何集合。GeoJSON里的特征包含一个几何对象和其他属性,特征集合表示一系列特征
| GeoJson | geo_shape | 描述 |
|---|---|---|
| Point | point | 单个由经纬度描述的地理坐标。注意:Elasticsearch仅使用WGS-84坐标 |
| LineString | linestring | 一个任意的线条,由两个以上点组成 |
| Polygon | polygon | 一个封闭的多边形,其第一个点和最后一个点必须匹配,由四个以上点组成 |
| MultiPoint | multipoint | 一组不连续的点 |
| MultiLineString | multilinestring | 多个不关联的线条 |
| MultiPolygon | multipolygon | 多个多边形 |
| GeometryCollection | geometrycollection | 与JSON形状相似的GeoJSON形状, 可以同时存在多种几何对象类型(例如,Point和LineString)。 |
| N/A | envelope | 通过左上角和右下角两个点来指定一个矩形 |
| N/A | circle | 由中心点和半径指定的圆 |
定义类型
# 定义geo_shape字段类型
PUT people
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}添加数据
# point类型
PUT people/_doc/1
{
"location":{
"type": "point",
"coordinates": [108.94, 34.27]
}
}
# linestring类型
PUT people/_doc/2
{
"location":{
"type": "linestring",
"coordinates": [[108.94, 34.27], [100, 33]]
}
}
# polygon类型
POST /people/_doc/3
{
"location": {
"type": "polygon",
"coordinates": [
[[100.0, 0.0], [101.0, 0.0], [101.0, 1.0], [100.0, 1.0], [100.0, 0.0]]
]
}
}特殊类型
es中的特殊类型有很多种,下面主要介绍两种最常用的
ip类型
ip类型的字段用于存储IPv4或者IPv6的地址
PUT test
{
"mappings": {
"my":{
"properties": {
"nodeIP":{
"type": "ip"
}
}
}
}
}token_count
token_count用于统计字符串分词后的词项个数.
# 增加了length字段,用于统计词项个数
PUT blog
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"length": {
"type": "token_count",
"analyzer": "standard"
}
}
}
}
}
}
# 添加文档
PUT blog/_doc/1
{
"title": "zhang san"
}
# 使用token_count进行查询
GET blog/_search
{
"query": {
"term": {
"title.length": 2
}
}
}映射的元信息
在创建映射的时候我们定义的字段内容并非映射中所有的字段,每个文档都存在一些和系统有关的元数据,这些数据被存储在映射的元字段中,根据元数据的作用不同可以分为下面几部分:
文档特征元信息
| 字段 | 说明 |
|---|---|
| _index | 文档所属的索引 |
| _type | 文档的映射类型。6.X之后已删除 |
| _id | 文档的ID |
文档数据源元信息
需要注意的
_size并不是默认就存在的,此字段需要mapper-size插件提供,该字段会以字节为单位索引_source字段的大小。
| 字段 | 说明 |
|---|---|
| _source | 表示文档主体的原始JSON |
| _size | _source字段的大小(以字节为单位) |
索引原信息
| 字段 | 说明 |
|---|---|
| _field_names | 用来索引文档中包含除了null之外的任何值得字段的名称 |
| _ignored | 该字段索引并存储文档中因为格式错误而被忽略的字段的名称 |
路由原信息
| 字段 | 说明 |
|---|---|
| _routing | 将文档路由到特定碎片的自定义路由值 |
自定义元信息
| 字段 | 说明 |
|---|---|
| _meta | 此字段可以定义一些自定的信息,这些信息Elasticsearch不会使用他们,但是用户可以用其来保存特定的元数据,比如版本信息等。 |
映射参数
除了
type参数,Mapping中还有另外27种映射参数。
有些参数对于所有字段类型都是通用的,例如boost权重参数,而有些参数则只适用于特定字段,例如analyzer参数只能作用于text字段。
analyzer
将字符串转换成多个分词
例如,字符串 “The quick Brown Foxes.”,根据指定分词器可以得到分词:quick, brown, fox。分词器可以自定义,这使得可以有效地搜索大块文本中的单个单词。
此分析过程不仅需要在索引时进行,还需要在查询时进行:查询字符串需要指定相同或类似的分析器,以便在查询字符串分析得到的分词与索引中的分词格式相同。
Elasticsearch附带了需要预定义的分析器,无需进一步配置即可使用,它还附带了需要字符过滤器、分词器和分词过滤器,可以组合起来为每个索引配置自定义分析器。
analyzer参数定义text字段索引和查询所使用的分析器,默认使用es自带的Standard标准分析器。
查询分析时,除非使用search_analyzer映射参数覆盖,否则也是使用的也是analyzer定义的分析器。
英文分词
我们先创建一个索引,不配置任何类型
# 使用默认分词器
PUT blog
# 添加英文内容
PUT blog/_doc/1
{
"content": "Things in life are aften unpredictable,but the wise advance every step with confidence."
}
# 使用term vectors查看词条向量
GET blog/_termvectors/1
{
"fields": ["content"]
}我们发现英文默认按照单词空格进行分词的
中文分词
下面我们使用默认分词器为中文分词
# 首先不定义分析器
PUT blog
# 添加文档
PUT blog/_doc/1
{
"title": "中国人民解放军东部战区陆军部队在台湾海峡实施了远程火力实弹射击训练,取得了预期效果"
}
# 使用term vectors查看词条向量
GET blog/_termvectors/1
{
"fields": ["title"]
}通过
_termvectors词条向量可以看到,如果不使用分析器,es默认分析器会一个一个将中文拆分。这样的分词结果没有任何意义,因为只能使用单个汉字,而不能使用词语。
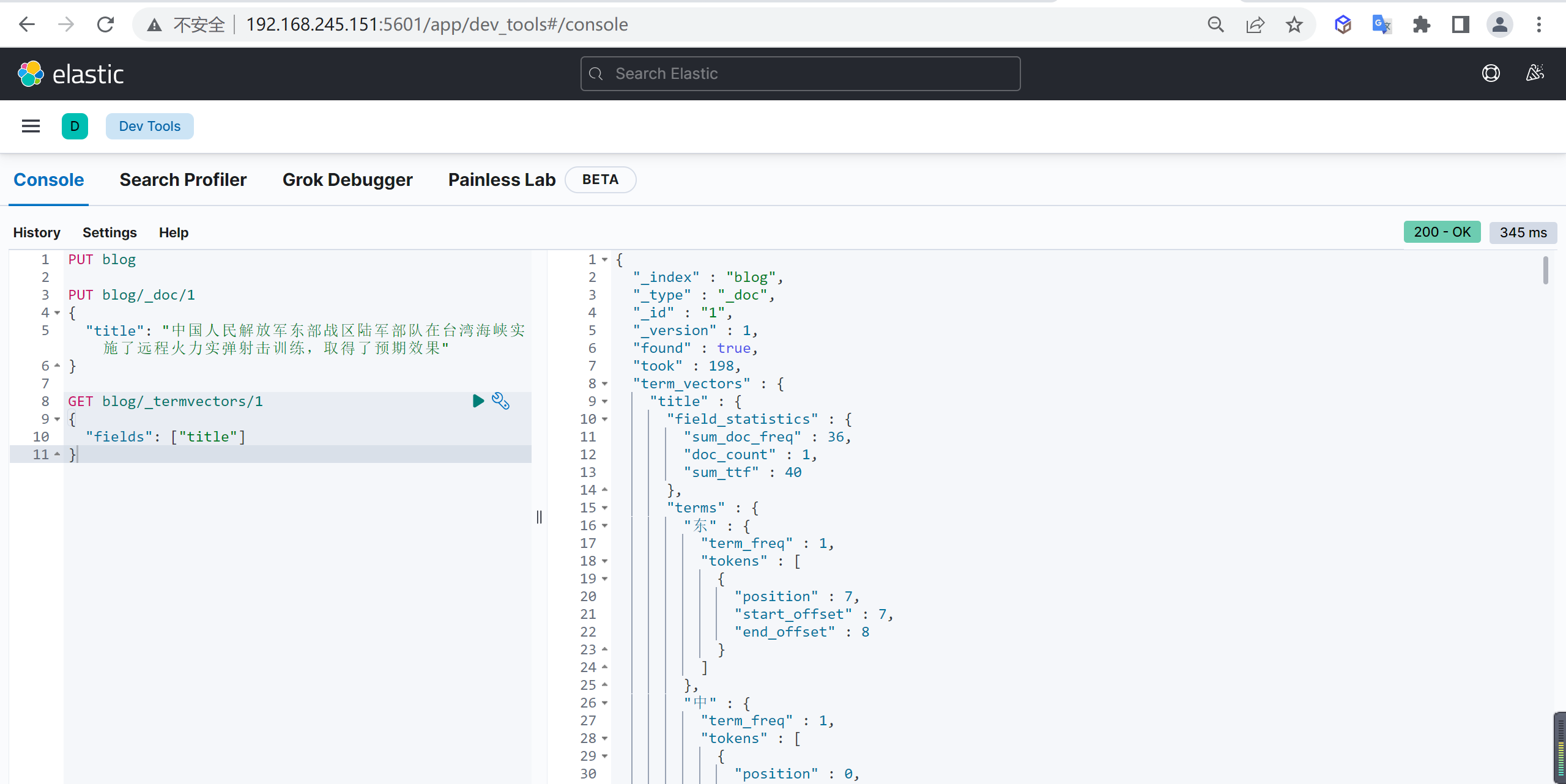
使用IK分词器
默认分词器不适合于中文分词,我们使用IK分词器试试
# 删除索引
DELETE blog
# 添加索引并设置title为text类型,并设置IK分词器
PUT blog
{
"mappings": {
"properties": {
"title": {
"type": "content",
"analyzer": "ik_smart"
}
}
}
}
# 添加文档
PUT blog/_doc/1
{
"title": "中国人民解放军东部战区陆军部队在台湾海峡实施了远程火力实弹射击训练,取得了预期效果"
}
# 使用term vectors查看词条向量
GET blog/_termvectors/1
{
"fields": ["content"]
}使用了正确的分词器,就可以将中文正确的分开了
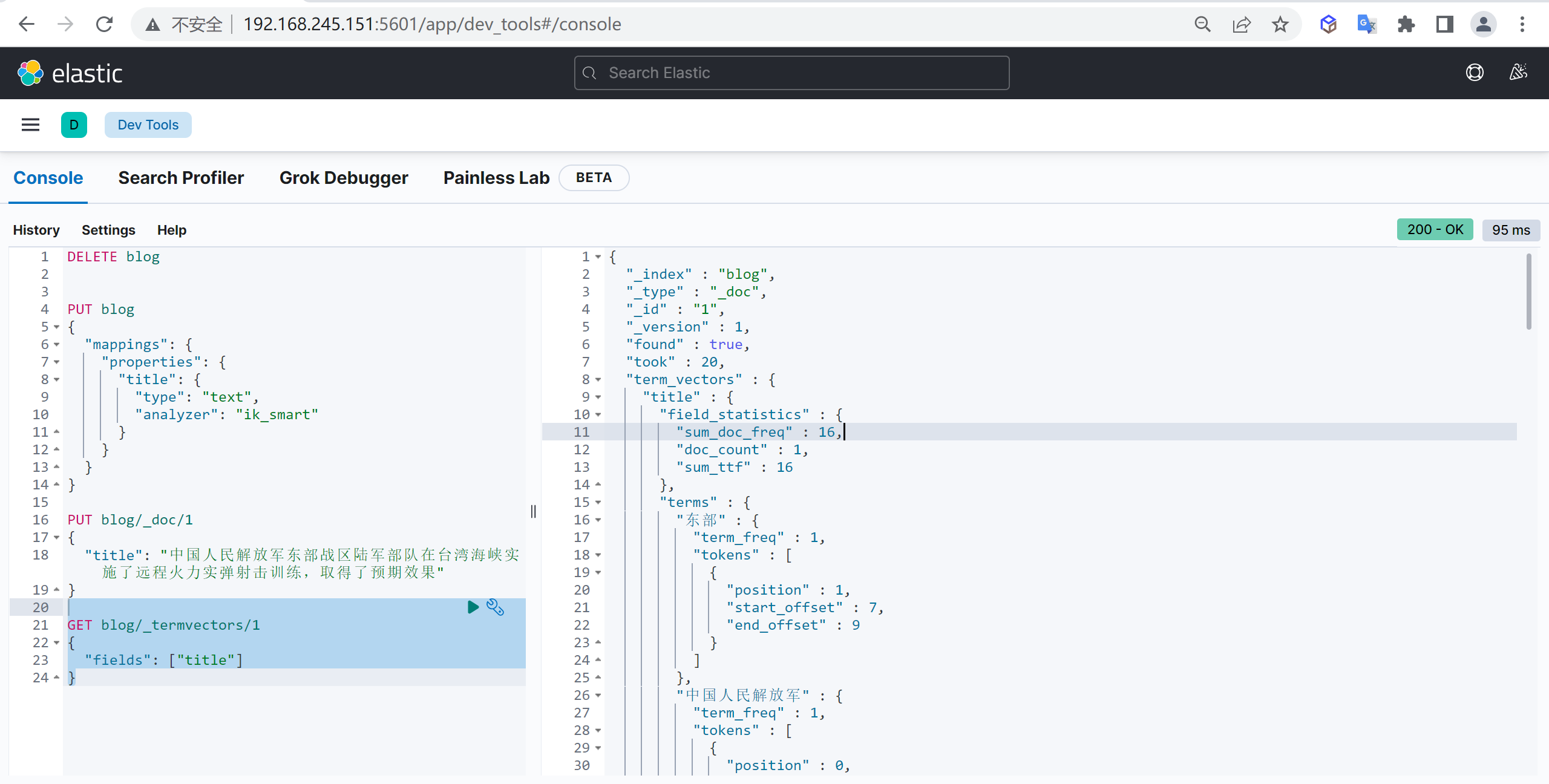
search_analyzer
通常情况下,索引和查询应该使用相同的分析器,以确保查询时的术语与倒排索引中的术语具有相同的格式
但有时,在搜索时使用不同的分析器是有意义的,例如在使用edge_ngrapm tokenizer自动补全。
默认情况下,查询时也是使用analyzer参数定义的分析器,但有些时候,为了查询更加精准,或是满足不同业务场景,可以通过search_analyzer参数来覆盖。
查询场景
我们看下下面的使用场景
PUT blog/_doc/1
{
"content": "普通高中生平均年龄15-18岁"
}
GET blog/_search
{
"query": {
"match": {
"content": "普通高中"
}
}
}使用
普通高中查询文档,此时查询默认也是使用analyzer定义的ik_smart分析器,查询失败!!
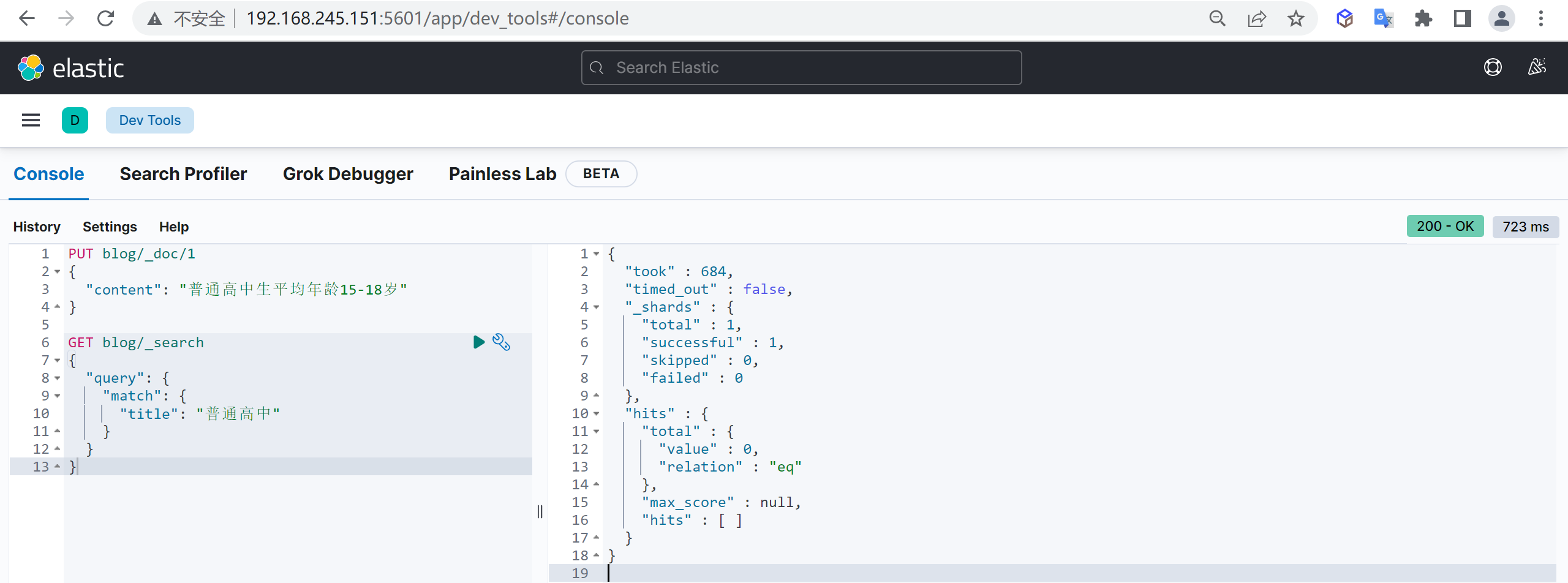
查询失败原因
首先我们使用
_termvectors查看词条向量,会发现ik_smart分析器将“普通高中生”分成“普通”和“高中生”两个词条
GET blog/_termvectors/1
{
"fields": ["content"]
}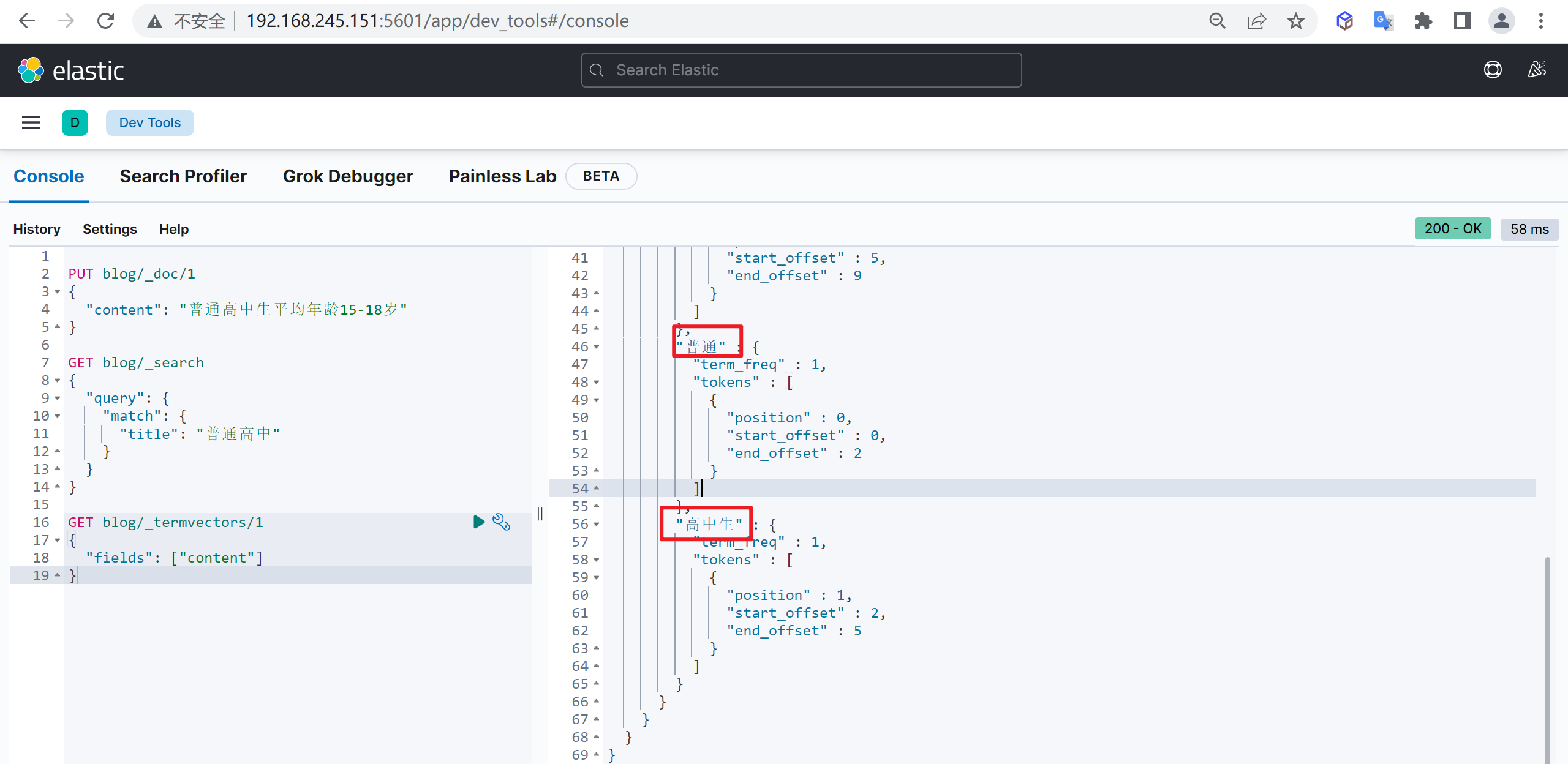
解析器分析
我们还可以使用ElasticSearch的解析器对文本进行分析,我们先来分析下
ik_smart的分词效果
POST _analyze
{
"analyzer": "ik_smart",
"text": "普通高中生平均年龄15-18岁"
}我们发现这个这个分词没有分出来
普通高中生
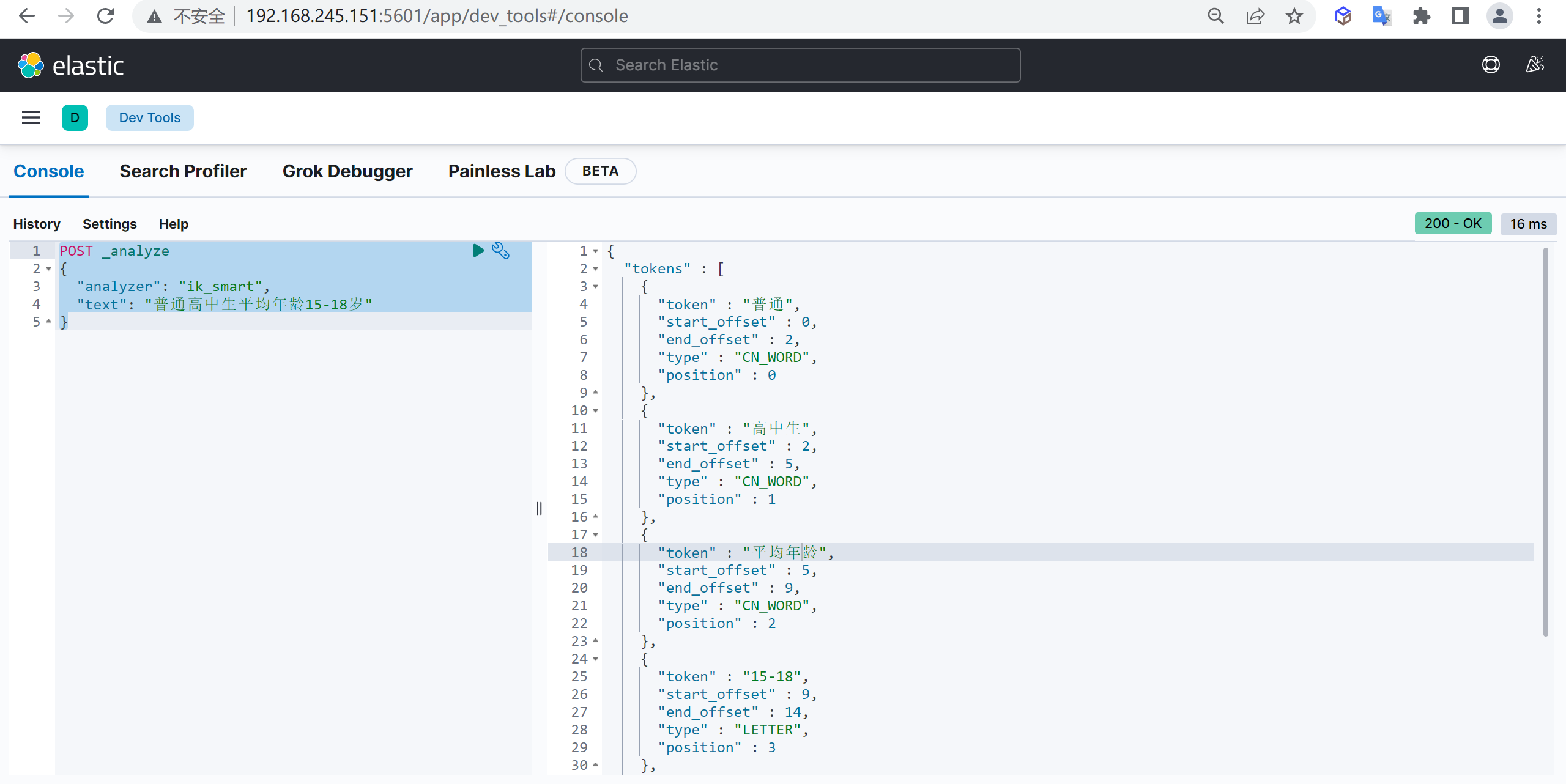
下面我们使用
ik_max_word来进行分词
POST _analyze
{
"analyzer": "ik_max_word",
"text": "普通高中生平均年龄15-18岁"
}我们发现这个分词效果符合我们的预期
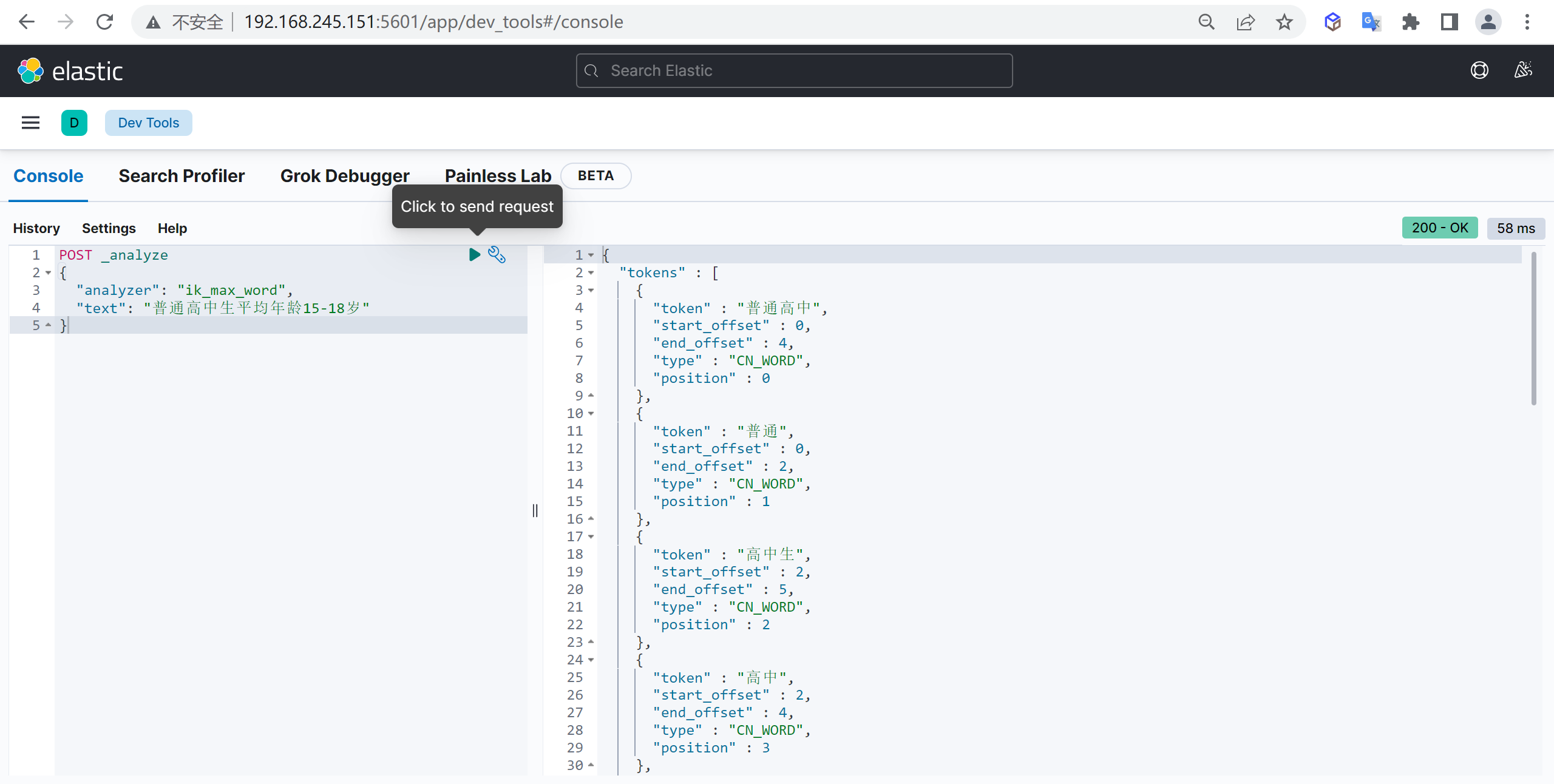
配置查询解析
对于“普通高中”,ik_smart分析器并不会分词,而是当做一个词条
当使用“普通高中”去查询时,自然查询失败,此时就可以设置查询的分析器为ik_max_word,查询时将“普通高中”分成“普通”和“高中”两个词条,进行精确查询
# 删除索引
DELETE blog
# 添加索引并设置title为text类型,并设置IK分词器
PUT blog
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_max_word"
}
}
}
}
PUT blog/_doc/1
{
"content": "普通高中生平均年龄15-18岁"
}
GET blog/_search
{
"query": {
"match": {
"title": "普通高中"
}
}
}我们发现这种已经有了命中数据了
search_quote_analyzer
通过参数search_quote_analyzer设置短语指定分析器,这在处理禁用短语查询的停用词时特别有用
禁用停用词
要禁用短语的停用词,需要使用三个分析器设置字段:
- 通过参数analyzer指定索引分词,包含停用词参数。分词中包含停用词
- 通过参数search_analyze指定非短语查询分词器,分词中删除停用词
- 通过参数search_quote_analyzer指定短语查询分词器,分词中包含停用词
添加文档
下面我们添加以下文档
# 删除索引
DELETE blog
# 定义文档格式
PUT blog
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_max_word",
"search_quote_analyzer": "ik_smart"
}
}
}
}
PUT blog/_doc/1
{
"content": "歌唱美好地祖国"
}
PUT blog/_doc/2
{
"content": "歌唱美好的祖国"
}非短语查询
下面我们使用非短语方式进行查询
GET blog/_search
{
"query": {
"match": {
"content": "歌唱美好的祖国"
}
}
}使用非短语查询时,
search_analyzer使用的ik_max_word会删除掉停止词“的”,导致两个文档都匹配,会查询出两条记录
短语查询
下面我们使用
query_string进行短语查询
GET blog/_search
{
"query": {
"query_string": {
"query": "\"歌唱美好的祖国\""
}
}
}当使用
query_string,并将查询短语用引号””引起来时,它被检测为短语查询,因此search_quote_analyzer启动,不会删除掉停用词“的”,只会查询出一条记录。
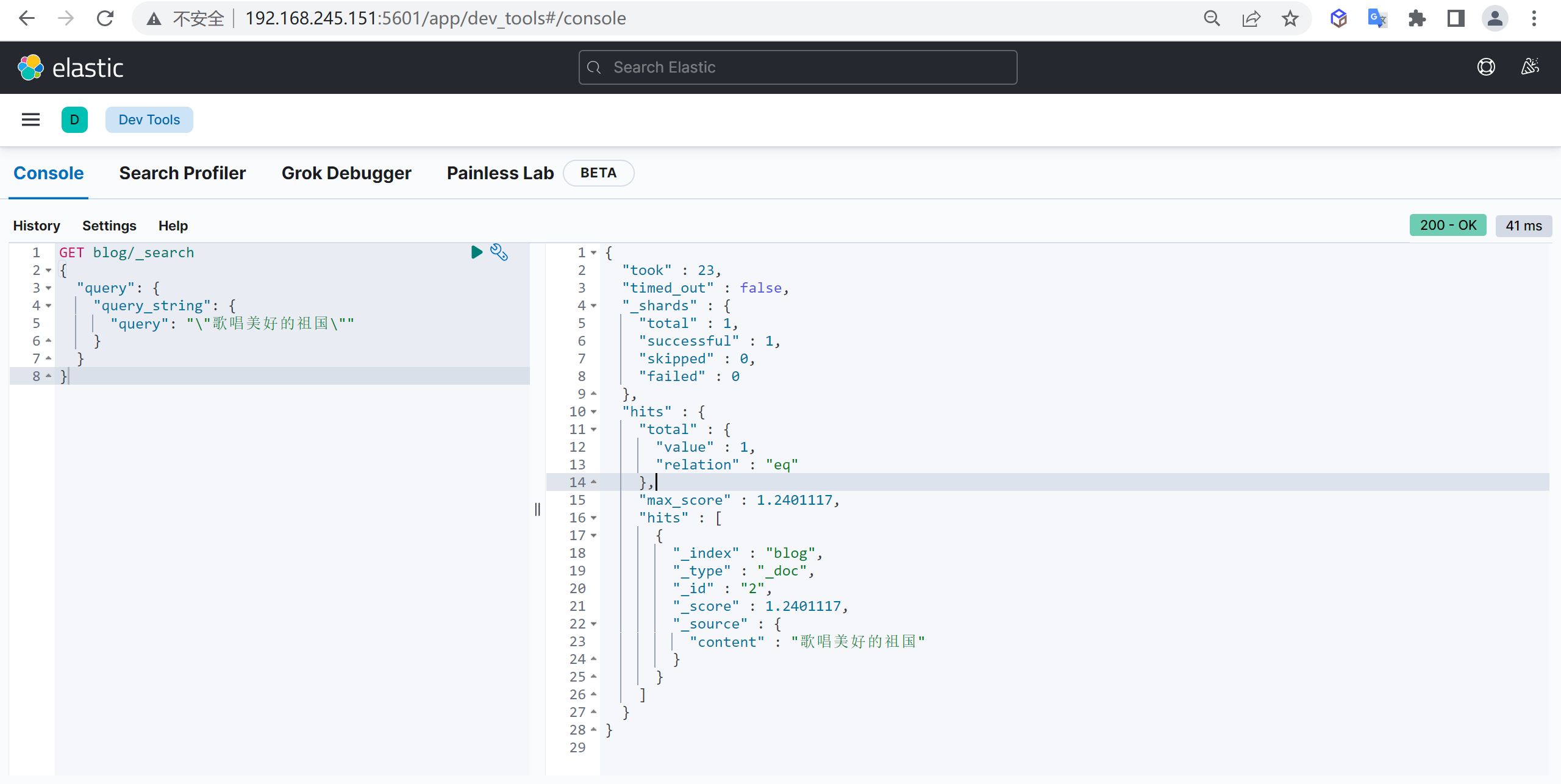
normalizer
normalizer作用于keyword字段类型,用于解析前(索引或者查询)的标准化配置。
归一化处理,主要针对 keyword 类型,在索引该字段或查询字段之前,可以先对原始数据进行一些简单的处理,然后再将处理后的结果当成一个词根存入倒排索 引中,默认为 null。
我们知道,keyword字段在索引或者查询时都不会进行分词,如果在索引前没有做好数据清洗,导致大小写不一致,例如 amby 和 Amby,使用 amby 就无法查询到 Amby 的文档,实际它们应该是相同的
创建文档
此时,我们就可以使用
normalizer在索引之前以及查询之前进行文档的标准化。
# 删除索引
DELETE blog
# 定义文档格式 自定义my_normalizer,并设置为author字段的normalizer参数值
PUT blog
{
"settings": {
"analysis": {
"normalizer":{
"my_normalizer":{
"type":"custom",
"filter":["lowercase"]
}
}
}
},
"mappings": {
"properties": {
"author":{
"type": "keyword",
"normalizer":"my_normalizer"
}
}
}
}
# 分别添加amby和Amby文档
PUT blog/_doc/1
{
"author":"amby"
}
PUT blog/_doc/2
{
"author":"Amby"
}文档查询
接下来不论是使用amby还是Amby,甚至是AMBY,都能查询出两个文档来
GET blog/_search
{
"query": {
"term": {
"author": "AMBY"
}
}
}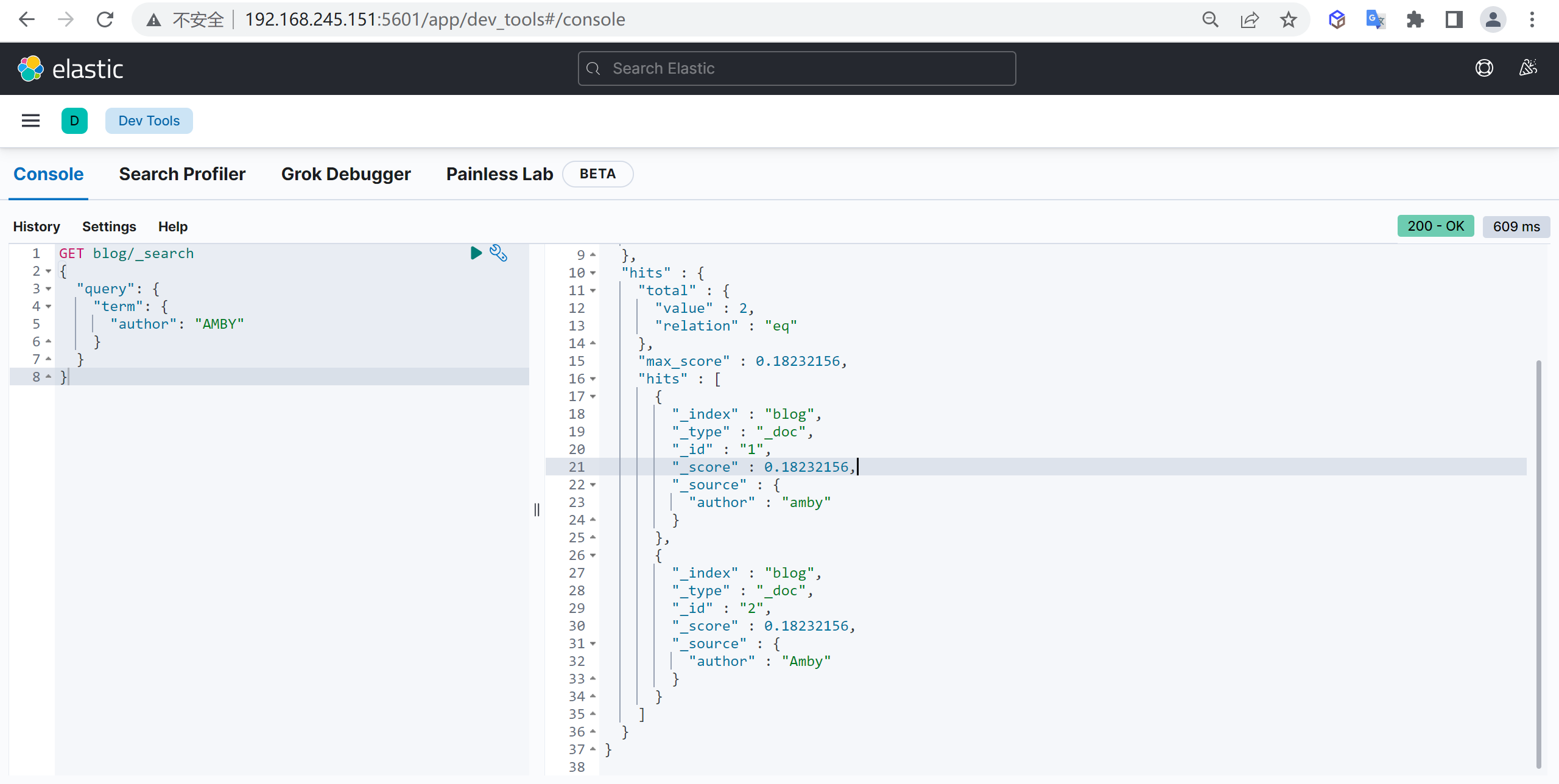
查看author字段的聚合返回归一化值,Amby在索引前已经被转成amby
GET blog/_search
{
"size": 0,
"aggs": {
"foo_terms": {
"terms": {
"field": "author"
}
}
}
} 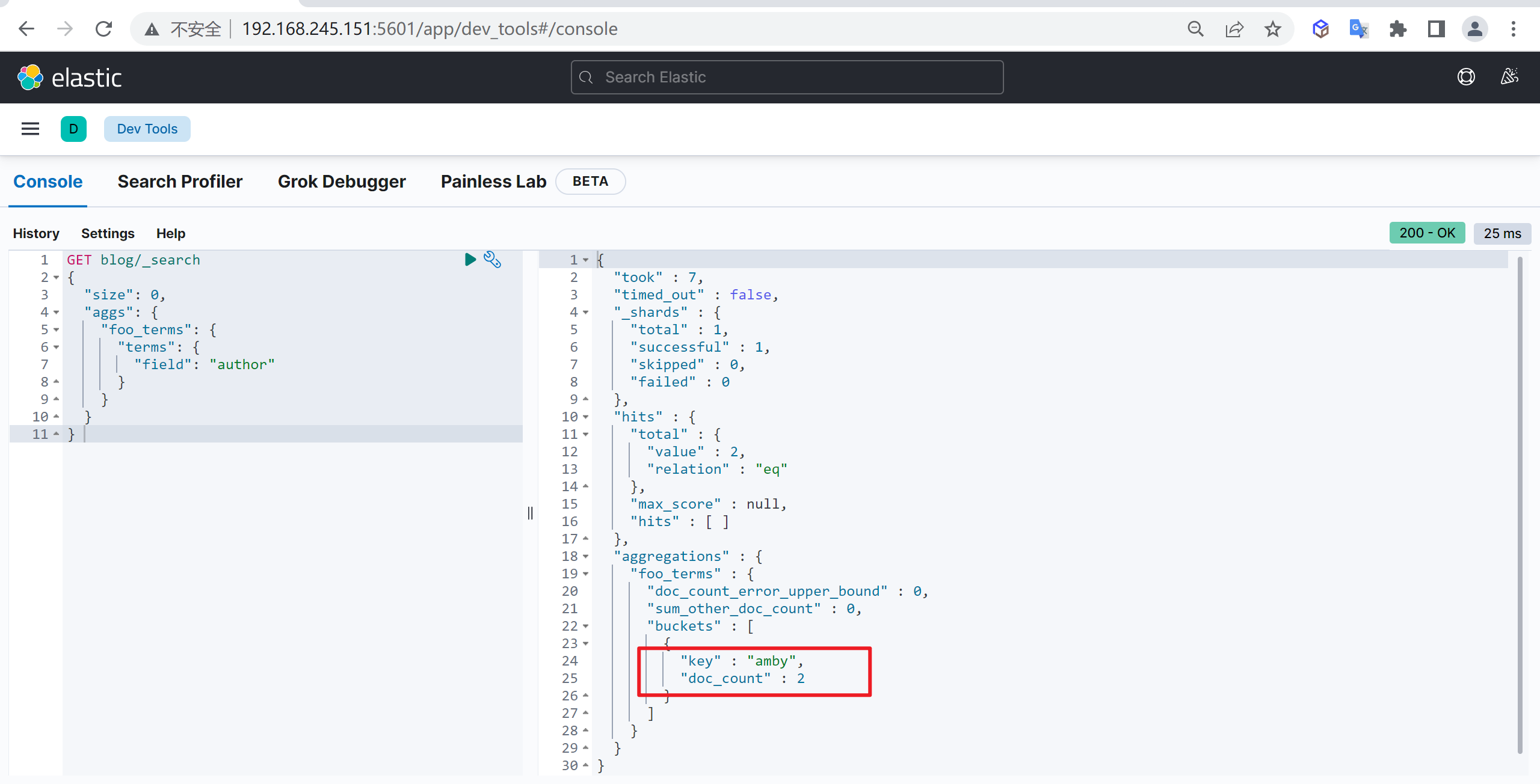
coerce
coerce参数用来清除脏数据,默认为 true。
数据不总是我们想要的,由于在转换 JSON body 为真正 JSON 的时候,整型数 字 5 有可能会被写成字符串”5”或者浮点数 5.0,这个参数可以将数值不合法的部分去除。
例如一个整数,在 JSON 中,用户可能输入了错误的类型:
{"age": "99"} # 字符串类型
{"age": 99.0} # 浮点类型使用场景
例如一个整数,在 JSON 中,用户可能输入了错误的类型:
{"age": "99"} # 字符串类型
{"age": 99.0} # 浮点类型这些都不是正确的数字格式,但是经过
coerce之后,都能正确的存储为整数类型
不进行过滤
默认情况下
coerce为rue,不对插入文档进行过滤
# 删除索引
DELETE blog
# 设置age为整数类型
PUT blog
{
"mappings": {
"properties": {
"age":{
"type": "integer"
}
}
}
}
# 无论是整数,还是字符串或浮点类型,都能正确的存储
POST blog/_doc
{
"age": 99
}
POST blog/_doc
{
"age": "99"
}
POST blog/_doc
{
"age": 99.0
}过滤文档
可以修改
coerce为 false ,修改之后,只有正确输入整数类型,才能存储,否则报错
# 删除索引
DELETE blog
# 设置age为整数类型
PUT blog
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"coerce": false
}
}
}
}
# 只有整数才能够被存储
POST blog/_doc
{
"age": 99
}
POST blog/_doc
{
"age": "99"
}
POST blog/_doc
{
"age": 99.0
}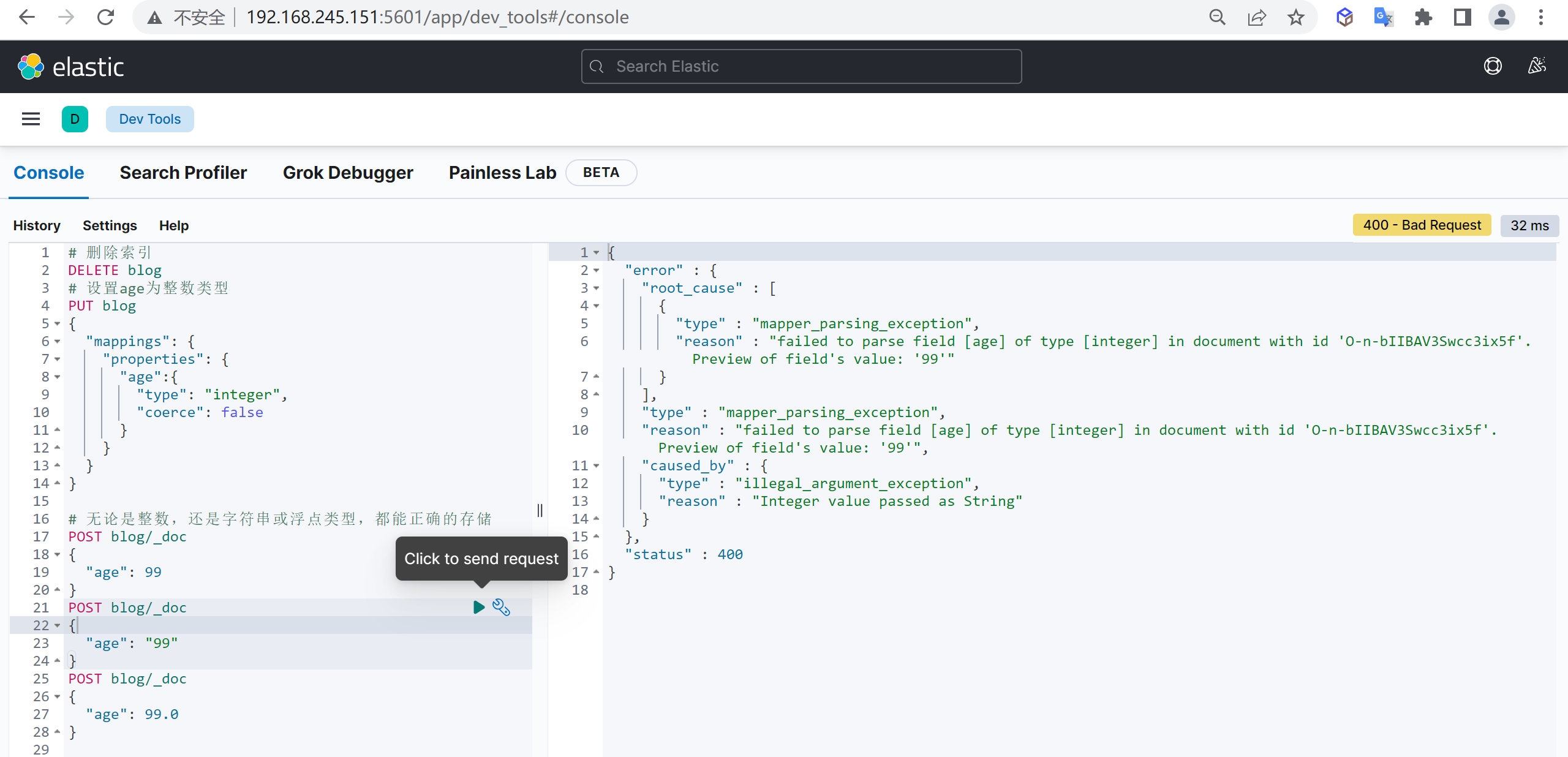
_to
_to 参数允许您创建自定义的
_all字段,这个参数可以将多个字段的值,复制到同一个字段中。
创建文档
我们创建一个文档
# 删除索引
DELETE blog
# 该索引会将type和content内容复制到full_content中
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"_to": "full_content"
},
"content":{
"type": "text",
"_to": "full_content"
},
"full_content":{
"type": "text"
}
}
}
}
# 添加文档
PUT blog/_doc/1
{
"title":"news ",
"content":"东部战区导弹全部精准命中目标"
}查询文档
我们根据生成的
full_content字段进行查询
GET blog/_search
{
"query": {
"term": {
"full_content": "news"
}
}
}
GET blog/_search
{
"query": {
"term": {
"full_content": "东"
}
}
}我们发现上面两个搜索都能够搜索到字段

doc_values 和 fielddata
es 中的搜索主要是用到倒排索引,
doc_values参数是为了加快排序、聚合操作而生的,当建立倒排索引的时候,会额外增加列式存储映射,以空间换时间,
doc_values 默认是开启的,如果确定某个字段不需要排序或者不需要聚合,那么可以关闭 doc_values,大部分的字段在索引时都会生成 doc_values,除了 text,text 字段在查询时会生成一个 fielddata 的数据结构,fieldata 在字段首次被聚合、排序的时候生成。
两者区别
下面简单对比一下两者的区别:
| doc_values | fieldata |
|---|---|
| 默认开启 | 默认关闭 |
| 索引时创建 | 使用时动态创建 |
| 磁盘 | 内存 |
| 不占用内存 | 不占用磁盘 |
| 索引速度降低一点 | 文档很多时,动态创建慢,占内存 |
fieldata参数使用场景很少,因为text字段一般都不用与排序和聚合,所以如果真的需要用到这个参数,一定要想清楚为什么,是否还有可替代方法。
排序效果
下面用
doc_values演示排序效果:
PUT users
PUT users/_doc/1
{
"age":100
}
PUT users/_doc/2
{
"age":99
}
PUT users/_doc/3
{
"age":98
}
PUT users/_doc/4
{
"age":101
}
GET users/_search
{
"query": {
"match_all": {}
},
"sort":[
{
"age":{
"order": "desc"
}
}
]
}下面就是排序后的效果
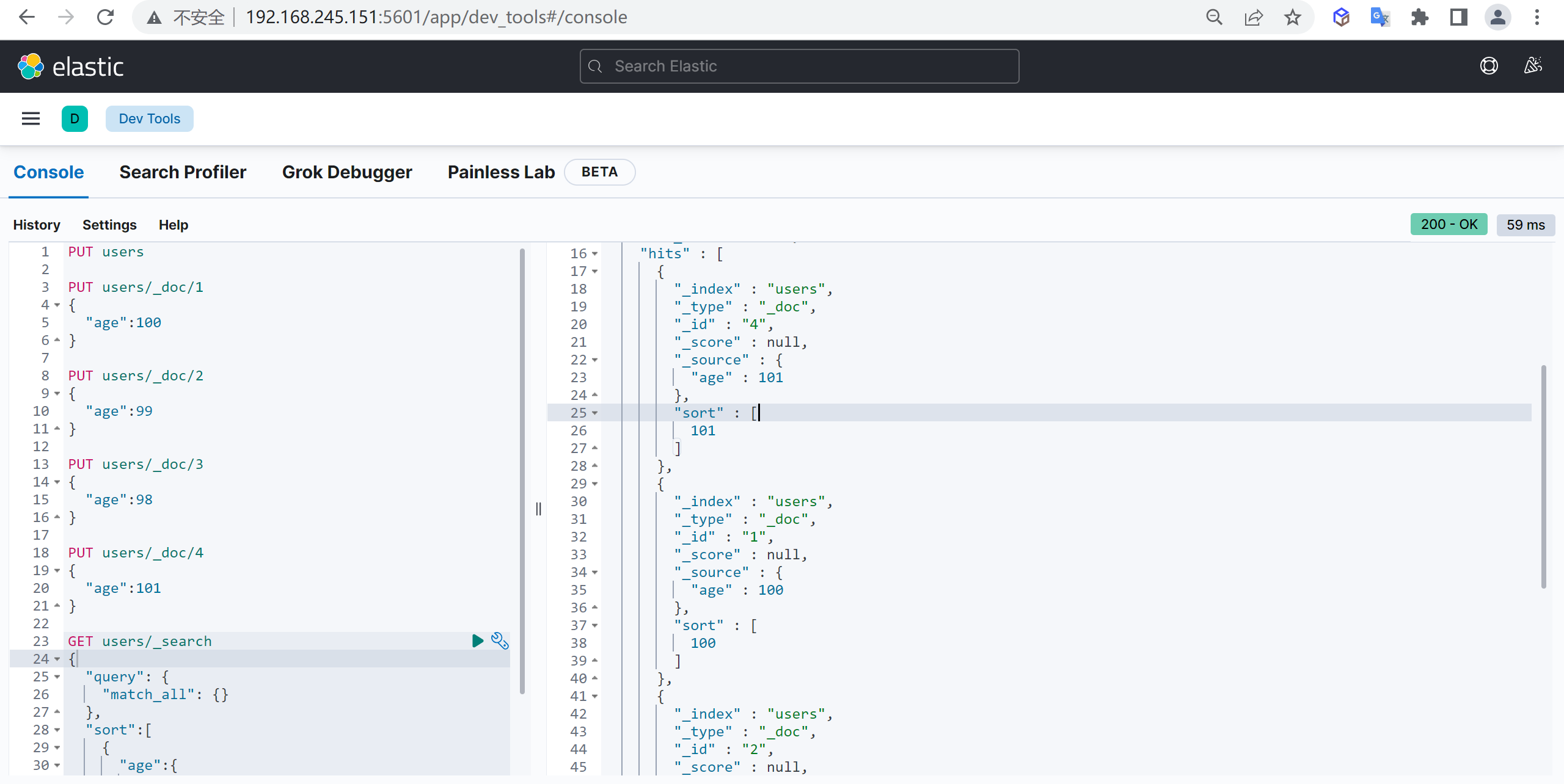
enabled
是否建立索引,默认情况下为 true
es 默认会索引所有的字段,但有时候某些类型的字段,无需建立索引,只是用来存储数据即可,例如图片url地址,此时可以通过 enabled 字段来控制,设置为 false 之后,就不能再通过该字段进行搜索了
创建文档
# 删除索引
DELETE blog
# 创建问题并设置title不建立索引
PUT blog
{
"mappings": {
"properties": {
"title":{
"enabled": false
}
}
}
}
# 创建文档
PUT blog/_doc/1
{
"title":"东部战区导弹全部精准命中目标"
}文档搜索
GET blog/_search
{
"query": {
"term": {
"title": "东部战区导弹全部精准命中目标"
}
}
}我们发现是无法进行索引查询的
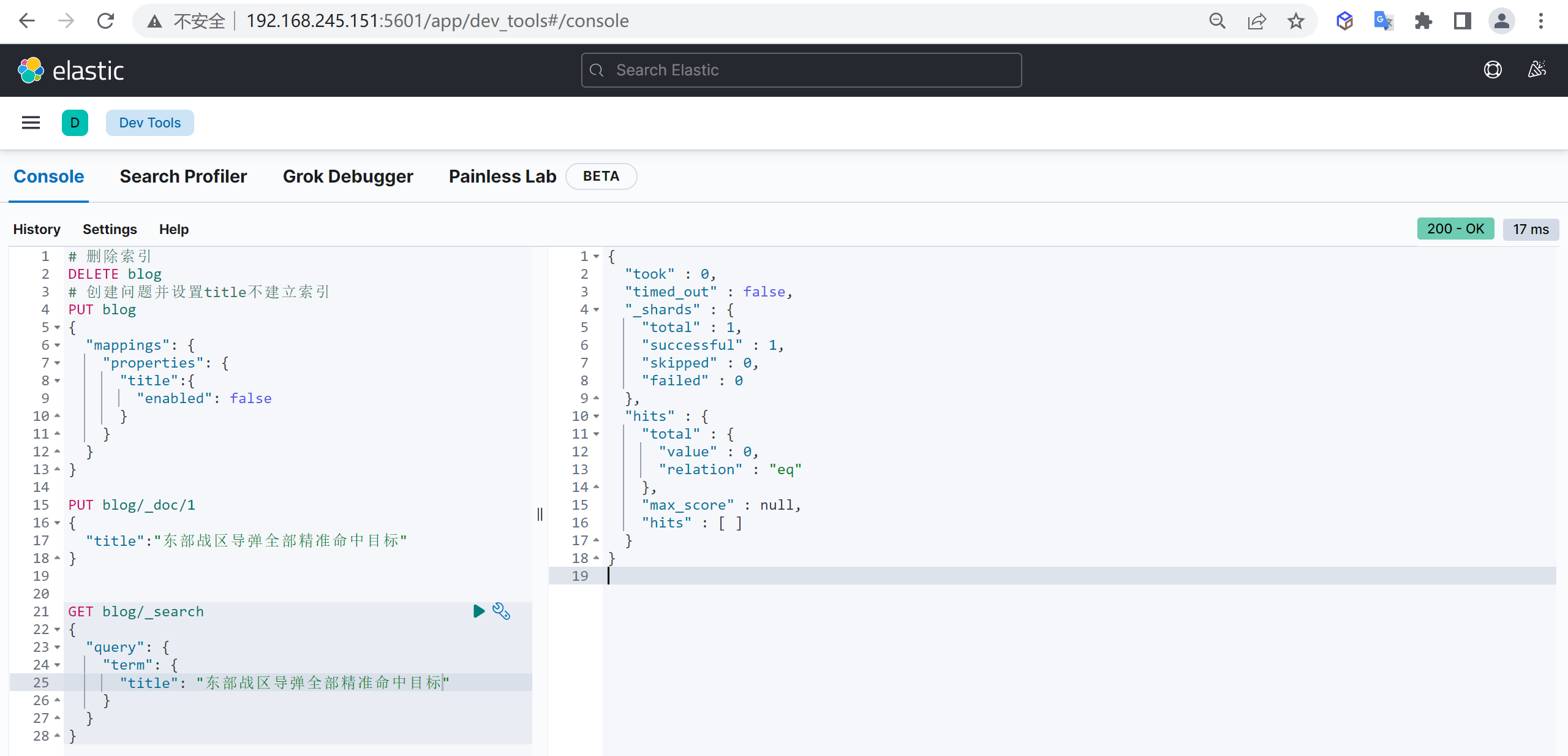
format
format用来对文档的日期类型进行识别以及格式化,如果格式不符合就会报错
在 JSON 文档中,日期表示为字符串,Elasticsearch 使用一组预先配置的格式来识别和解析这些字符串,并将其解析为 long 类型的数值(毫秒),支持自定义格式,一次可以定义多个 format,多个日期格式之间,使用 || 符号连接,注意没有空格,如果没有指定format,日期类型默认的格式是:strict_date_optional_time||epoch_millis
创建文档
# 删除索引
DELETE users
# 创建索引文件,类型是date指定格式化方式
PUT users
{
"mappings": {
"properties": {
"birthday":{
"type": "date",
"format": "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss"
}
}
}
}
# 添加文档
PUT users/_doc/1
{
"birthday":"2020-11-11"
}
PUT users/_doc/2
{
"birthday":"2020-11-11 11:11:11"
}
# 如果日期格式不是定义的格式就会插入错误
PUT users/_doc/3
{
"birthday":"2020-11-25T00:00:00"
}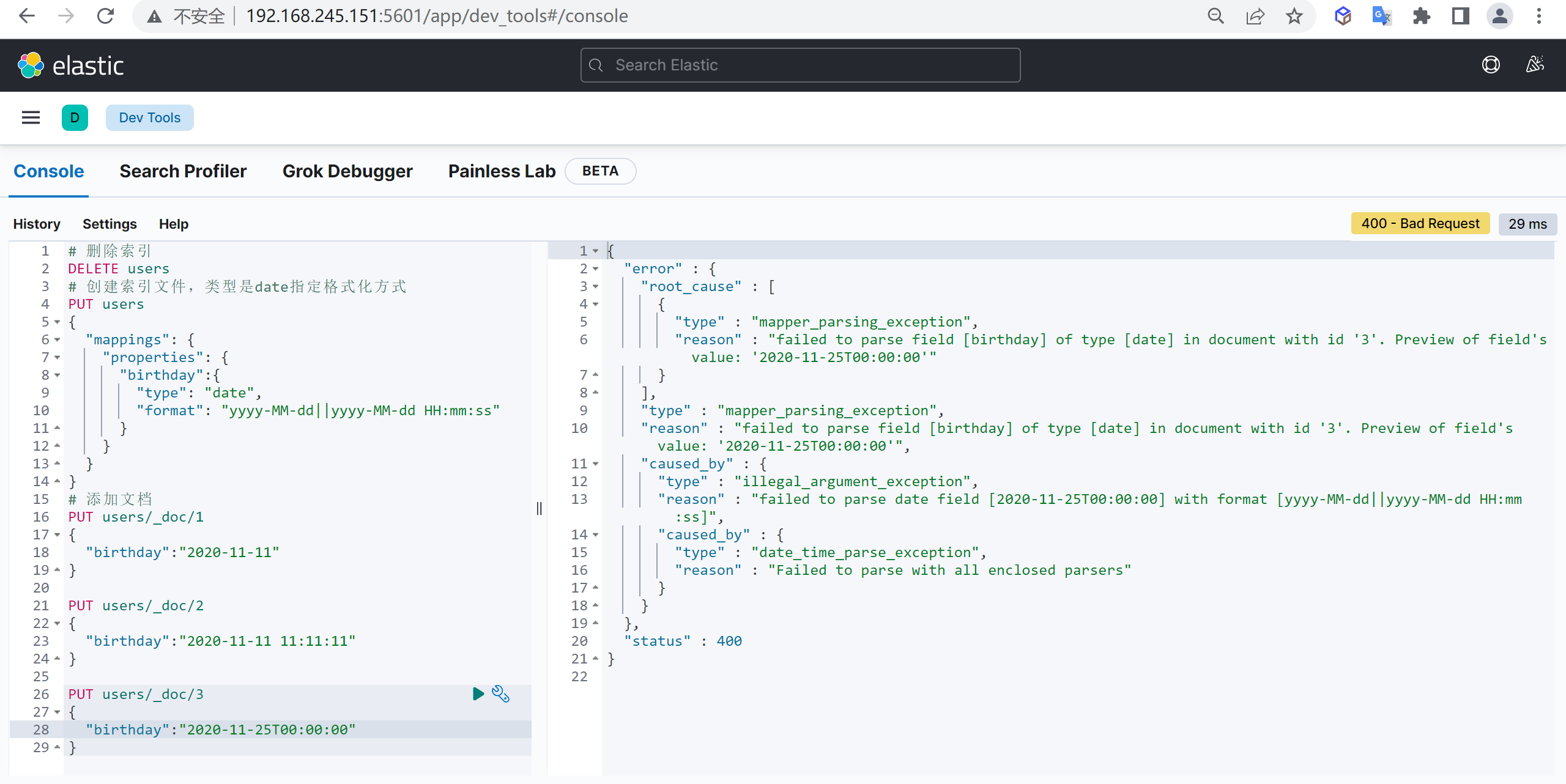
ignore_above
在ElasticSearch中keyword类型字段可以设置ignore_above属性(默认是10) ,表示最大的字段值长度,超出这个长度的字段将不会被索引,但是会存储,这个字段只适用于 keyword 类型。
创建文档
# 删除索引
DELETE blog
# 创建索引文件,设置title长度为10
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "keyword",
"ignore_above": 10
}
}
}
}
# 添加文档
PUT blog/_doc/1
{
"title":"东部战区"
}
PUT blog/_doc/2
{
"title":"东部战区导弹全部精准命中目标"
}查询文档
# 能够查询出来数据
GET blog/_search
{
"query": {
"term": {
"title": "东部战区"
}
}
}
# 查询不出来数据
GET blog/_search
{
"query": {
"term": {
"title": "东部战区导弹全部精准命中目标"
}
}
}
# 发现数据已经被存储了
GET blog/_doc/2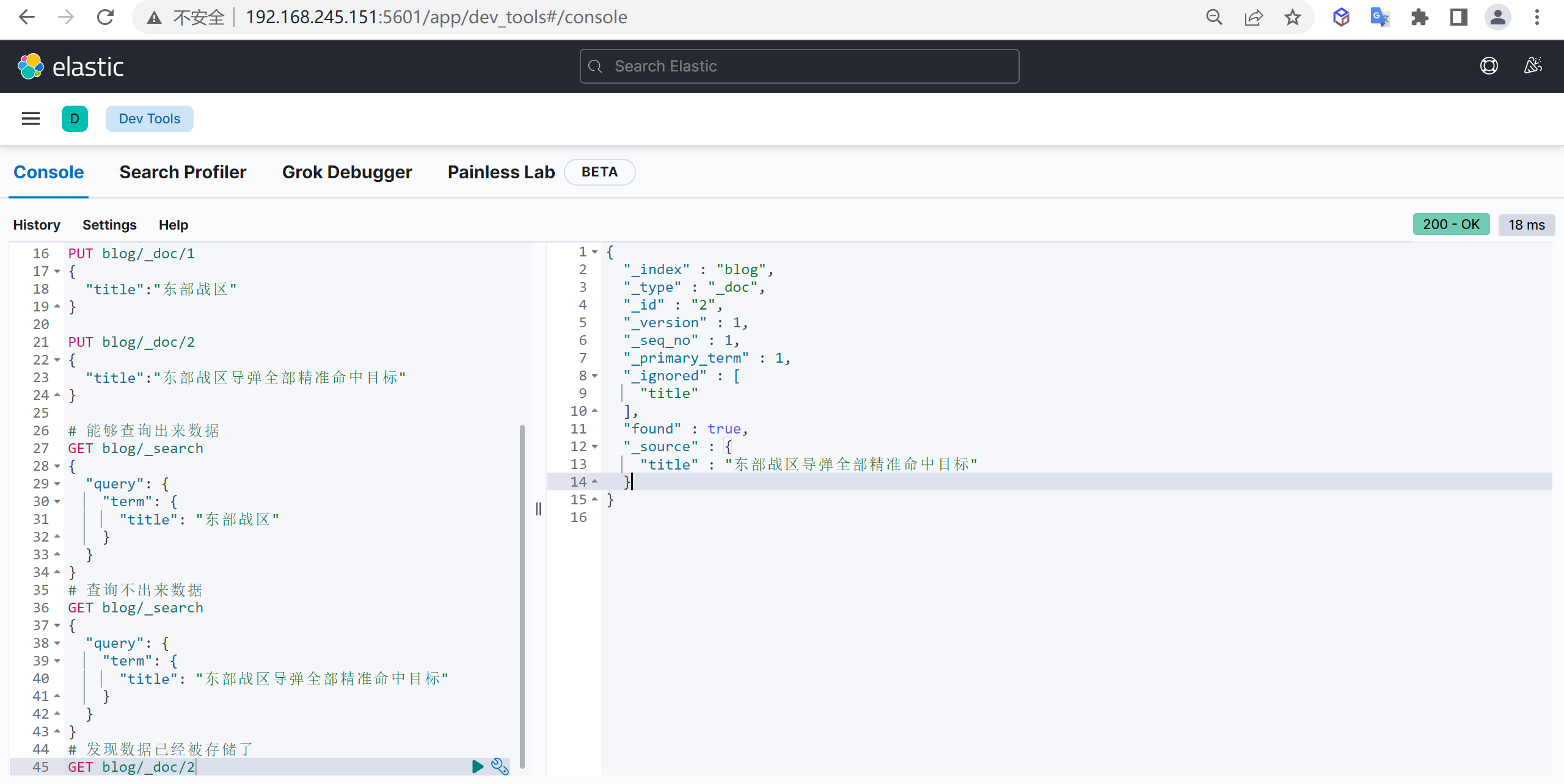
ignore_malformed
ignore_malformed参数可以忽略不规则的数据,该参数默认为 false
对于age字段,有人可能填写的是Integer类型,也有人填写的是字符串格式,给一个字段索引不合适的数据类型发生异常,导致整个文档索引失败,如果ignore_malformed参数设为true,异常会被忽略,出异常的字段不会被索引,其它字段正常索引。
创建文档
# 删除索引
DELETE users
# 创建索引文件
PUT users
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"ignore_malformed": true
}
}
}
}
PUT users/_doc/1
{
"age":99
}
PUT users/_doc/2
{
"age":"abc"
}
PUT users/_doc/2
{
"age":"abc"
}index
index参数用于指定一个字段是否被索引,为 true 表示字段被索引,false 表示字段不被索引
注意,如果字段不能被索引,也就不能通过该字段进行搜索。
创建文档
# 删除索引
DELETE users
PUT users
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"index": false
}
}
}
}
PUT users/_doc/1
{
"age":99
}查询
GET users/_search
{
"query": {
"term": {
"age": 99
}
}
}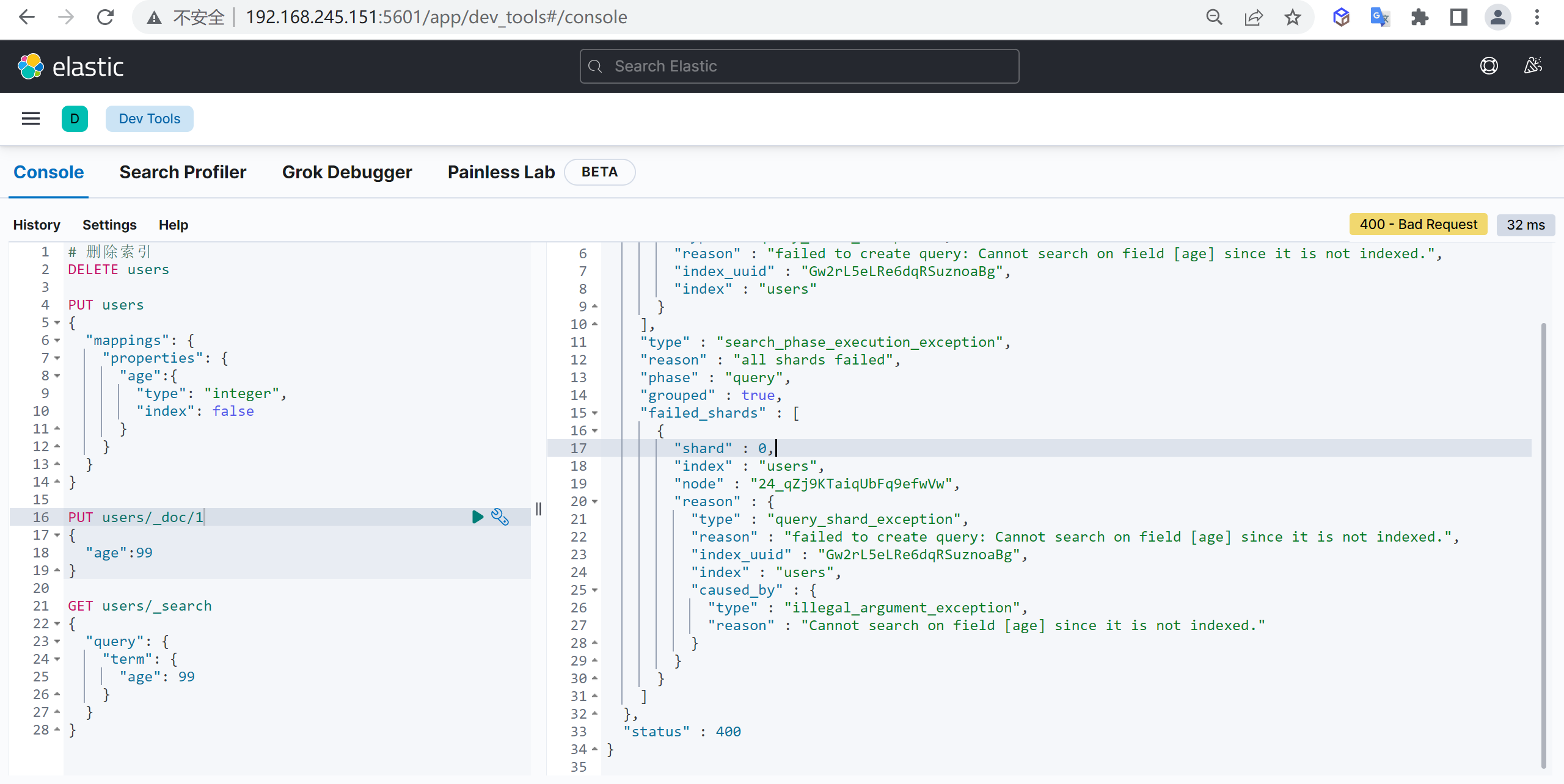
null_value
值为
null的字段不索引也不可以被搜索,null_value可以让值为null的字段显式的可索引、可搜索
创建文档
# 删除索引
DELETE users
# 创建索引设置name如果为null,设置值为null_value
PUT users
{
"mappings": {
"properties": {
"name":{
"type": "keyword",
"null_value": "null_value"
}
}
}
}
# 添加文档
PUT users/_doc/1
{
"name":null,
"age":99
}搜索文档
GET users/_search
{
"query": {
"term": {
"name": "null_value"
}
}
}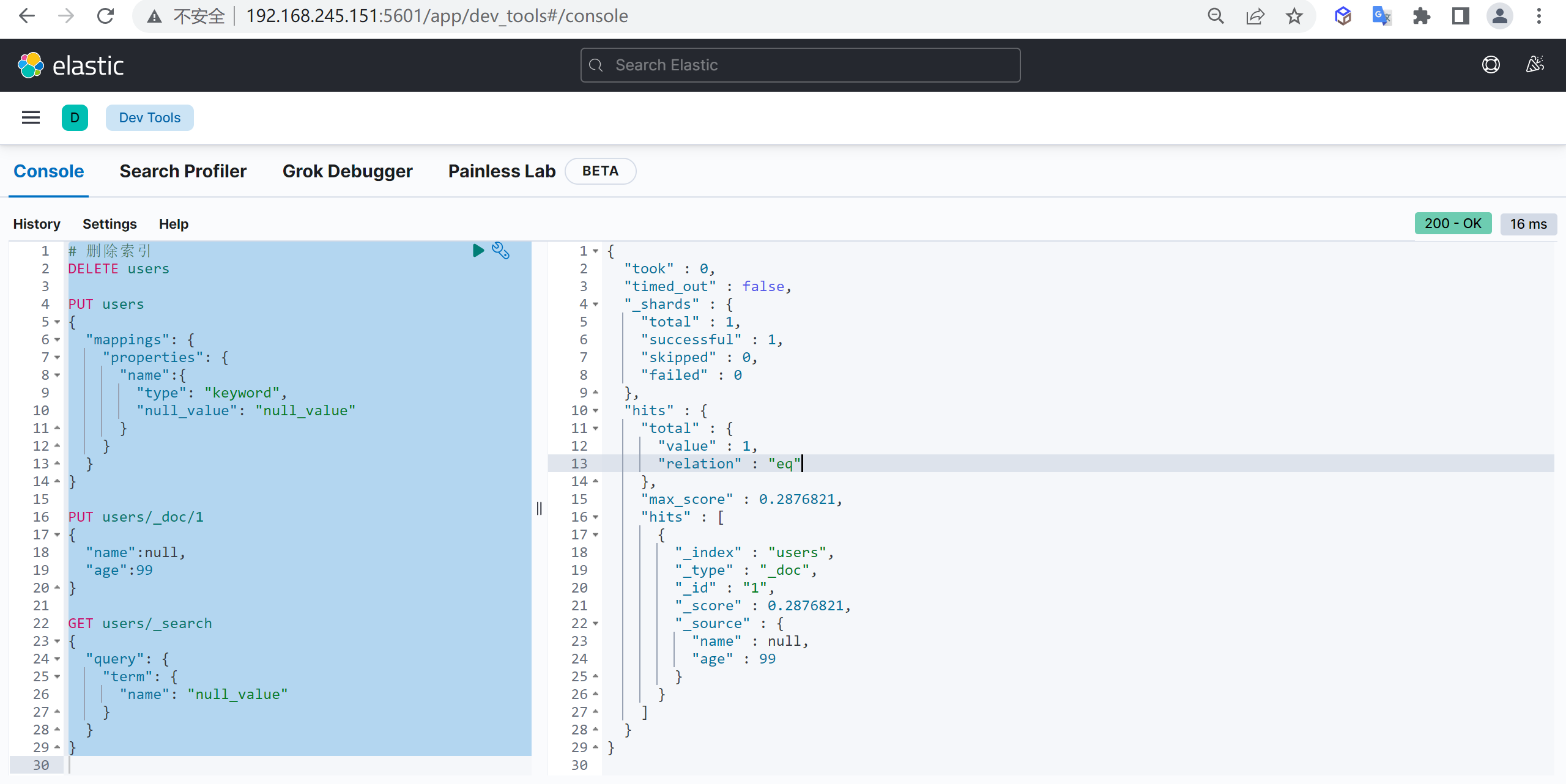
position_increment_gap
被解析的 text 字段会将 term 的位置考虑进去,目的是为了支持近似查询和短语查询
我们去索引一个含有多个值的 text 字段时,会在各个值之间添加一个假想的空间,将值隔开,这样就可以有效避免一些无意义的短语匹配,间隙大小通过 position_increment_gap 参数来控制,默认是 100
默认方式进行查询
# 删除索引
DELETE users
# 创建索引
PUT users
# 添加一个数组
PUT users/_doc/1
{
"name":["zhang san","li si"]
}
# 当我们使用“zhang san”或“li si”,可以查询到。如果使用“san li”则查询不了,因为数组中两个值之间间隔了100的空隙,需要指定空隙大小进行查询。
GET users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "san li"
}
}
}
}
# 查询时通过slop指定
GET users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "san li",
"slop": 100
}
}
}
}position_increment_gap查询
# 删除索引
DELETE users
# 创建索引
PUT users
{
"mappings": {
"properties": {
"name":{
"type": "text",
"position_increment_gap": 0
}
}
}
}
# 添加一个数组
PUT users/_doc/1
{
"name":["zhang san","li si"]
}
# 当我们使用“zhang san”或“li si”,可以查询到。如果使用“san li”则查询不了,因为数组中两个值之间间隔了100的空隙,需要指定空隙大小进行查询。
GET users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "san li"
}
}
}
}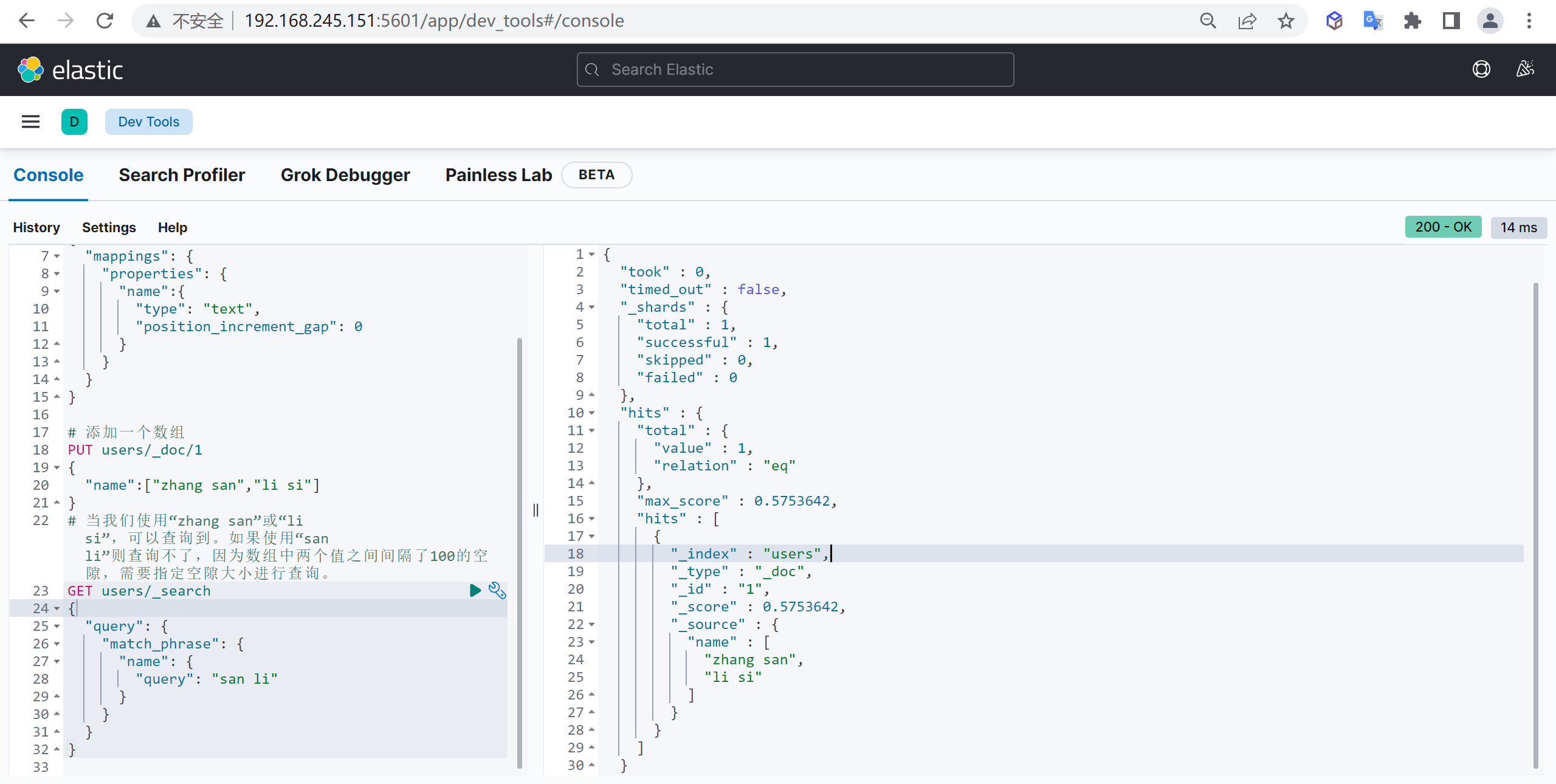
properties
properties是最常用的参数之一,可以作用于mappings、object字段、nested字段中,进行属性的添加,这些属性可以是任意字段类型,包括object和nested。可以通过以下三种方式添加属性:
使用方式
可以通过以下三种方式添加属性:
- 创建索引时定义。
- 使用PUT mapping 添加或更新字段类型时定义。
- 索引包含新字段的文档时,通过动态映射定义。
创建文档
PUT people
{
"mappings": {
"properties": {
"manager": {
"properties": {
"age": { "type": "integer" },
"name": { "type": "text" }
}
},
"employees": {
"type": "nested",
"properties": {
"age": { "type": "integer" },
"name": { "type": "text" }
}
}
}
}
}
PUT people/_doc/1
{
"manager": {
"name": "Alice White",
"age": 30
},
"employees": [
{
"name": "John Smith",
"age": 34
},
{
"name": "Peter Brown",
"age": 26
}
]
}fields
fields参数可以让同一字段有多种不同的索引方式,比如一个 String 类型的字段, 可以使用 text 类型做全文检索,使用 keyword 类型做聚合和排序
创建文档
# 删除索引
DELETE blog
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"fields": {
"raw":{
"type":"keyword"
}
}
}
}
}
}
# 添加数据
PUT blog/_doc/1
{
"title":"百度地图被搜崩了"
}全文检索
title字段用于全文检索
GET blog/_search
{
"query": {
"match": {
"title": "百度"
}
}
}关键字查询
title.raw用于关键字查询
GET blog/_search
{
"query": {
"term": {
"title.raw": "百度地图被搜崩了"
}
}
}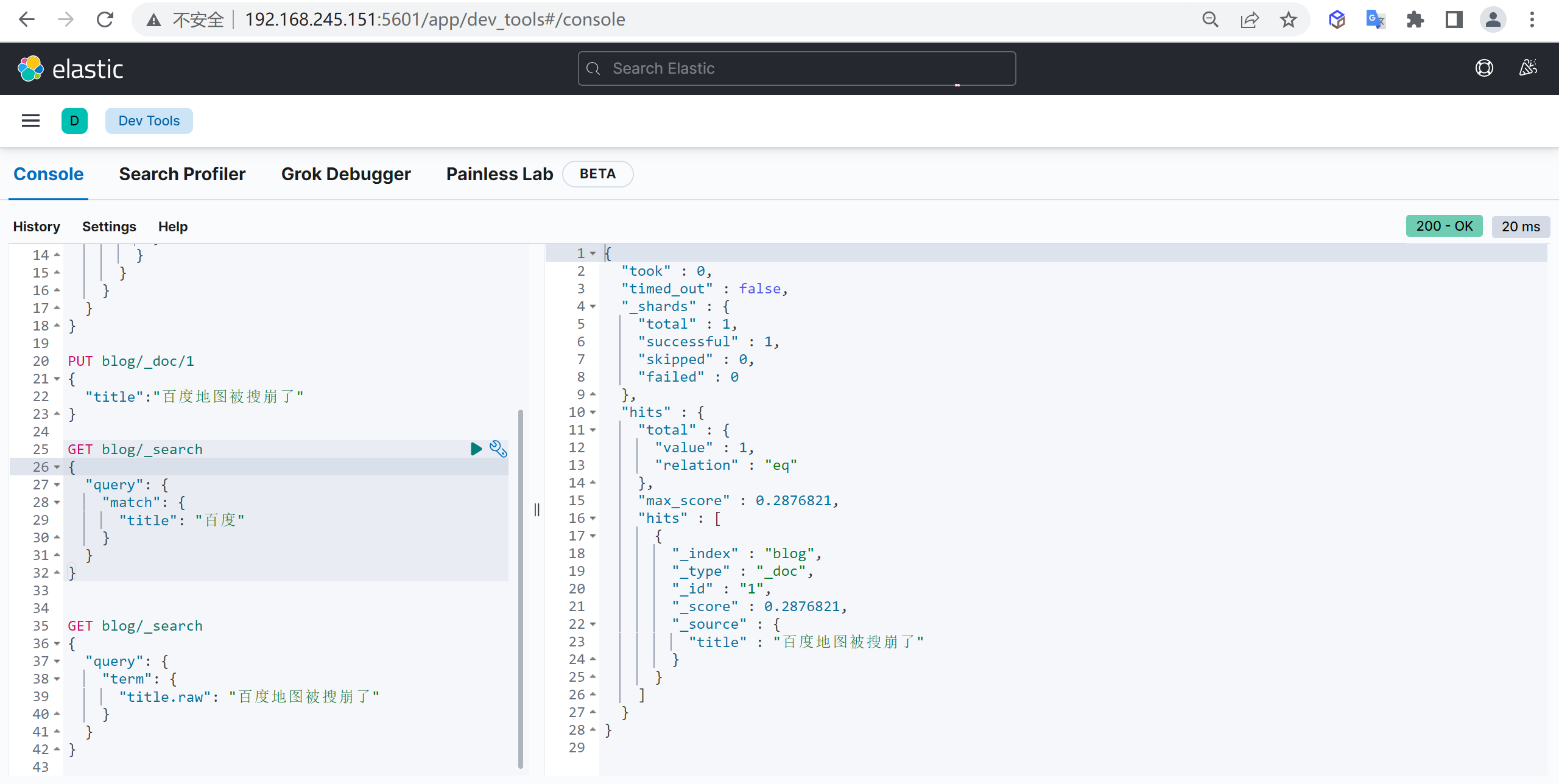
更多字段
还有更多字段,可以在这里进行查询
index_options
index_options参数用于控制索引时哪些信息被存储到倒排索引中,仅作用在 text 字段,有四种取值:
- docs:只存储文档编号。
- freqs:在docs基础上,存储词项频率。
- positions (默认):在freqs基础上,存储词项偏移位置。
- offsets:在positions基础上,存储词项开始和结束的字符位置。
norms
norms对字段评分有用,text 类型会默认开启,如果不是特别需要,不要开启norms。
similarity
similarity参数用于指定文档的评分模型,使用到的情况不多,默认有三种:
- BM25:es 和 Lucene 默认的评分模型。
- classic:TF/IDF 评分。
- boolean:boolean 评分模型。
store
默认情况下,字段会被索引,也可以搜索,但是不会存储,虽然不会被存储的,但是 _source 中有一个字段的备份。如果想将字段存储下来,可以通过配置 store 参数来实现。
term_vectors
term_vectors是通过分词器产生的词项信息,包括:
- 一组 terms
- 每个 term 的位置
- term 的首字符 / 尾字符与原始字符串原点的偏移量
| term_vectors取值 | |
|---|---|
| no | 不存储信息 |
| yes | 存储 term 信息 |
| with_positions | 存储 term 信息和位置信息 |
| with_offset | 存储 term 信息和偏移信息 |
| with_positions_offset | 存储 term 信息、位置信息和偏移信息 |
ElasticSearch 分词器
概述
分词器的主要作用将用户输入的一段文本,按照一定逻辑,分析成多个词语的一种工具
什么是分词器
顾名思义,文本分析就是把全文本转换成一系列单词(term/token)的过程,也叫分词。在 ES 中,Analysis 是通过分词器(Analyzer) 来实现的,可使用 ES 内置的分析器或者按需定制化分析器。
举一个分词简单的例子:比如你输入 Mastering Elasticsearch,会自动帮你分成两个单词,一个是 mastering,另一个是 elasticsearch,可以看出单词也被转化成了小写的。
分词器的构成
分词器是专门处理分词的组件,分词器由以下三部分组成:
组成部分
character filter
接收原字符流,通过添加、删除或者替换操作改变原字符流
例如:去除文本中的html标签,或者将罗马数字转换成阿拉伯数字等。一个字符过滤器可以有零个或者多个
tokenizer
简单的说就是将一整段文本拆分成一个个的词。
例如拆分英文,通过空格能将句子拆分成一个个的词,但是对于中文来说,无法使用这种方式来实现。在一个分词器中,有且只有一个tokenizeer
token filters
将切分的单词添加、删除或者改变
例如将所有英文单词小写,或者将英文中的停词a删除等,在token filters中,不允许将token(分出的词)的position或者offset改变。同时,在一个分词器中,可以有零个或者多个token filters.
分词顺序
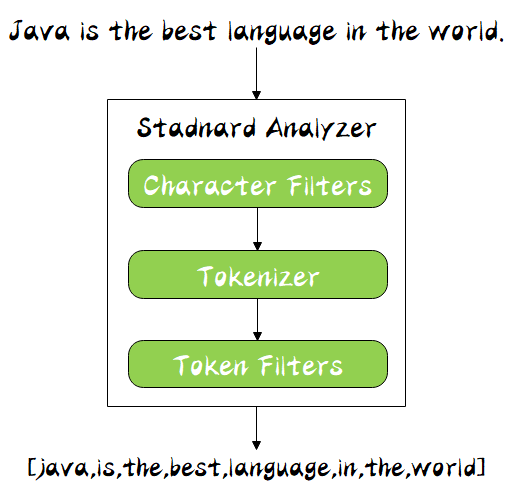
同时 Analyzer 三个部分也是有顺序的,从图中可以看出,从上到下依次经过 Character Filters,Tokenizer 以及 Token Filters,这个顺序比较好理解,一个文本进来肯定要先对文本数据进行处理,再去分词,最后对分词的结果进行过滤。
索引和搜索分词
文本分词会发生在两个地方:
创建索引:当索引文档字符类型为text时,在建立索引时将会对该字段进行分词。搜索:当对一个text类型的字段进行全文检索时,会对用户输入的文本进行分词。
配置分词器
默认ES使用
standard analyzer,如果默认的分词器无法符合你的要求,可以自己配置
分词器测试
可以通过
_analyzerAPI来测试分词的效果。
# 过滤html 标签
POST _analyze
{
"tokenizer":"keyword", #原样输出
"char_filter":["html_strip"], # 过滤html标签
"text":"<b>hello world<b>" # 输入的文本
}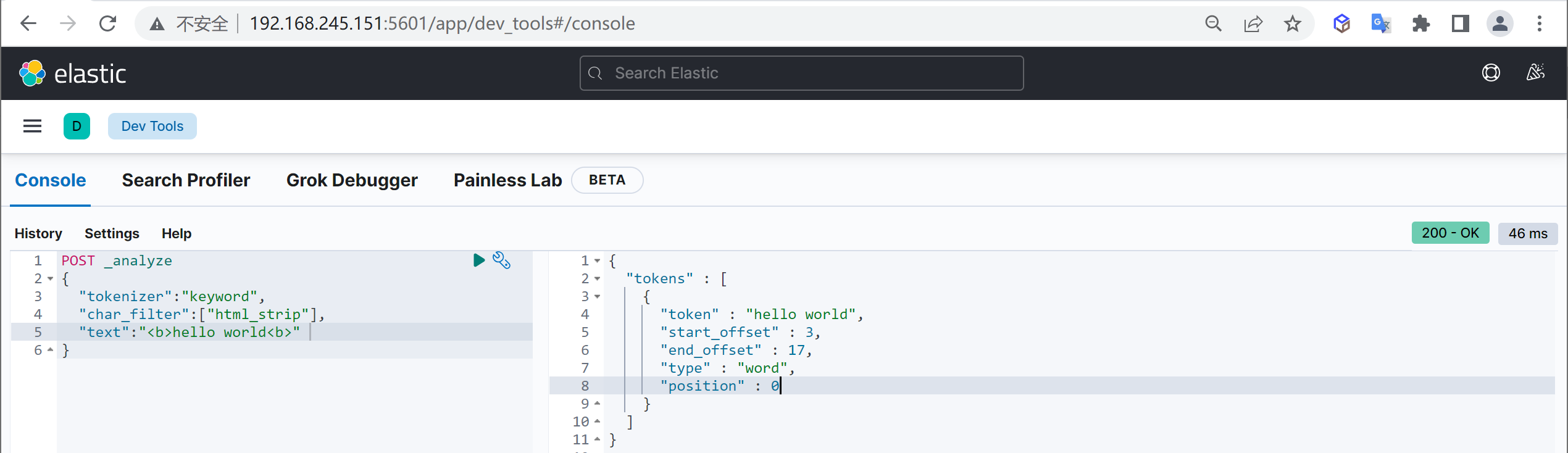
指定分词器
使用地方
分词器的使用地方有两个:
- 创建索引时
- 进行搜索时
创建索引时指定分词器
如果设置手动设置了分词器,ES将按照下面顺序来确定使用哪个分词器:
- 先判断字段是否有设置分词器,如果有,则使用字段属性上的分词器设置
- 如果设置了
analysis.analyzer.default,则使用该设置的分词器 - 如果上面两个都未设置,则使用默认的
standard分词器
字段指定分词器
为title属性指定分词器
PUT my_index
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "whitespace"
}
}
}
}设置默认分词器
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
}
}
}
}
}搜索时如何确定分词器
在搜索时,通过下面参数依次检查搜索时使用的分词器:
- 搜索时指定
analyzer参数 - 创建mapping时指定字段的
search_analyzer属性 - 创建索引时指定
setting的analysis.analyzer.default_search - 查看创建索引时字段指定的
analyzer属性 - 如果上面几种都未设置,则使用默认的
standard分词器。
指定analyzer
搜索时指定analyzer查询参数
GET my_index/_search
{
"query": {
"match": {
"message": {
"query": "Quick foxes",
"analyzer": "stop"
}
}
}
}指定字段analyzer
PUT my_index
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "whitespace",
"search_analyzer": "simple"
}
}
}
}指定默认default_seach
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"default":{
"type":"simple"
},
"default_seach":{
"type":"whitespace"
}
}
}
}
}内置分词器
es在索引文档时,会通过各种类型
Analyzer对text类型字段做分析,
不同的 Analyzer 会有不同的分词结果,内置的分词器有以下几种,基本上内置的 Analyzer 包括 Language Analyzers 在内,对中文的分词都不够友好,中文分词需要安装其它 Analyzer
| 分析器 | 描述 | 分词对象 | 结果 |
|---|---|---|---|
| standard | 标准分析器是默认的分析器,如果没有指定,则使用该分析器。它提供了基于文法的标记化(基于 Unicode 文本分割算法,如 Unicode 标准附件 # 29所规定) ,并且对大多数语言都有效。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog’s, bone ] |
| simple | 简单分析器将文本分解为任何非字母字符的标记,如数字、空格、连字符和撇号、放弃非字母字符,并将大写字母更改为小写字母。 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| whitespace | 空格分析器在遇到空白字符时将文本分解为术语 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ The, 2, QUICK, Brown-Foxes, jumped, over, the, lazy, dog’s, bone. ] |
| stop | 停止分析器与简单分析器相同,但增加了删除停止字的支持。默认使用的是 _english_ 停止词。 |
The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ quick, brown, foxes, jumped, over, lazy, dog, s, bone ] |
| keyword | 不分词,把整个字段当做一个整体返回 | The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone.] |
| pattern | 模式分析器使用正则表达式将文本拆分为术语。正则表达式应该匹配令牌分隔符,而不是令牌本身。正则表达式默认为 w+ (或所有非单词字符)。 |
The 2 QUICK Brown-Foxes jumped over the lazy dog’s bone. | [ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog, s, bone ] |
| 多种西语系 arabic, armenian, basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english等等 | 一组旨在分析特定语言文本的分析程序。 |
中文扩展分析器
中文分词器最简单的是ik分词器,还有jieba分词,哈工大分词器等
| 分词器 | 描述 | 分词对象 | 结果 |
|---|---|---|---|
| ik_smart | ik分词器中的简单分词器,支持自定义字典,远程字典 | 学如逆水行舟,不进则退 | [学如逆水行舟,不进则退] |
| ik_max_word | ik_分词器的全量分词器,支持自定义字典,远程字典 | 学如逆水行舟,不进则退 | [学如逆水行舟,学如逆水,逆水行舟,逆水,行舟,不进则退,不进,则,退] |
词语分词
标准分词器(Standard Tokenizer)
根据standardUnicode文本分段算法的定义,将文本划分为多个单词边界的上的术语
它是 ES 默认的分词器,它会对输入的文本按词的方式进行切分,切分好以后会进行转小写处理,默认的 stopwords 是关闭的。
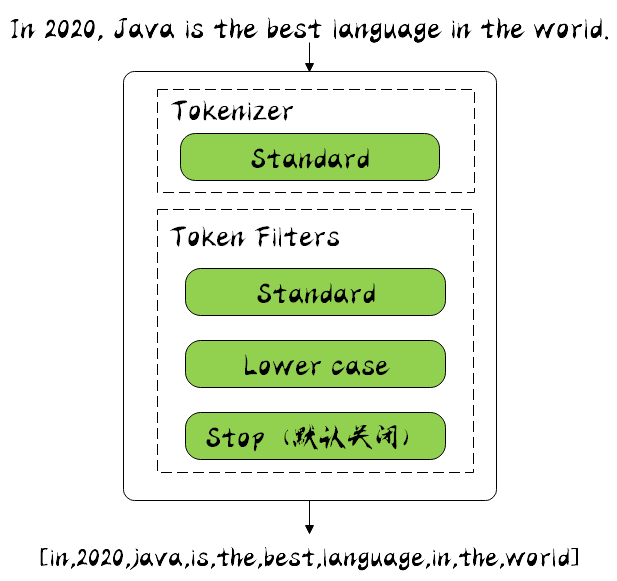
使用案例
下面使用 Kibana 看一下它是怎么样进行工作的
原始内容
In 2020, Java is the best language in the world.测试分词
在 Kibana 的开发工具(Dev Tools)中指定 Analyzer 为
standard,并输入文本In 2020, Java is the best language in the world.,然后我们运行一下:
GET _analyze
{
"text":"In 2020, Java is the best language in the world.",
"analyzer": "standard"
}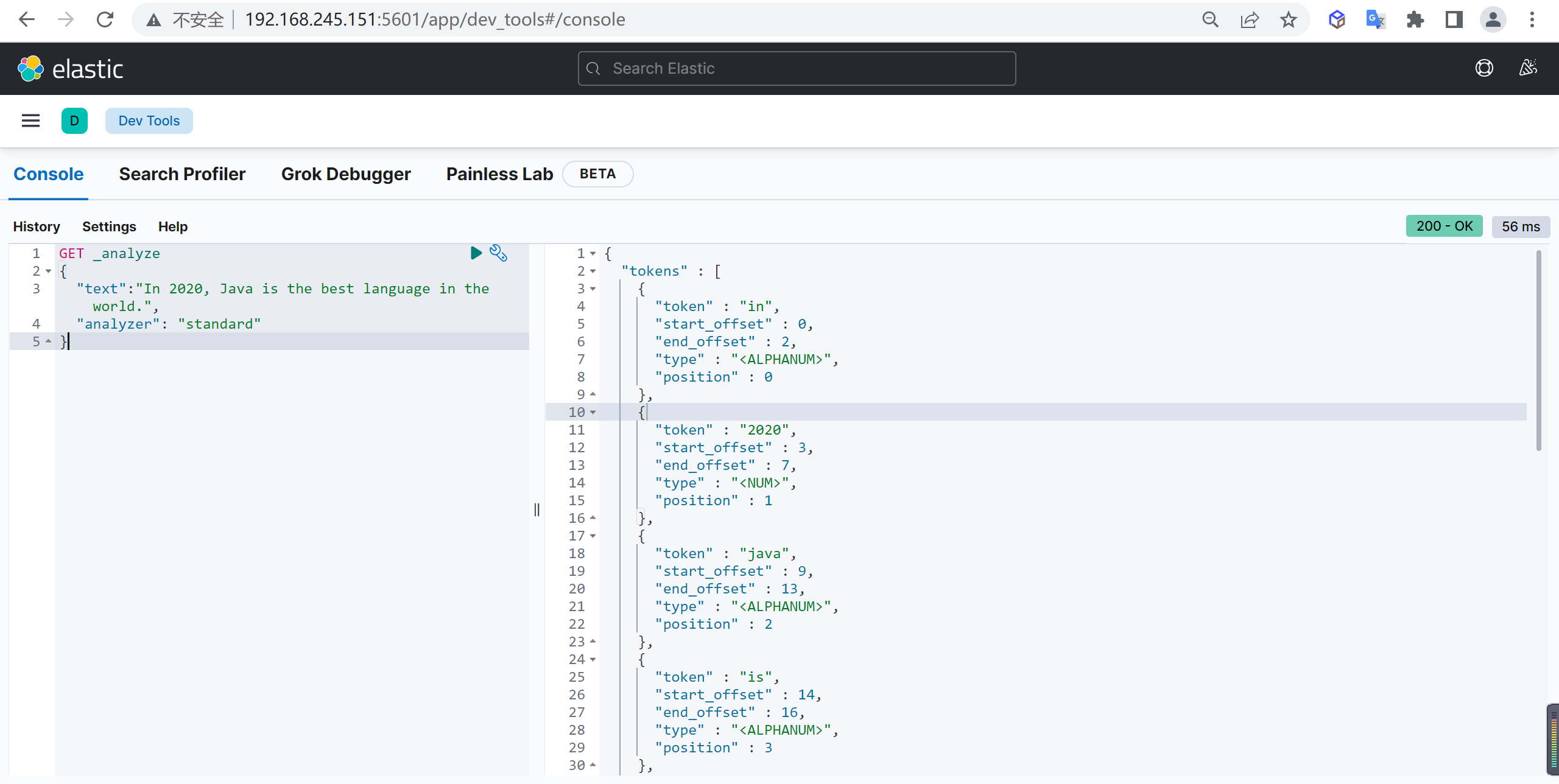
可以看出是按照空格、非字母的方式对输入的文本进行了转换,比如对 Java 做了转小写,对一些停用词也没有去掉,比如 in,其中 token 为分词结果;start_offset 为起始偏移;end_offset 为结束偏移;position 为分词位置。
可配置项
| 选项 | 描述 |
|---|---|
| max_token_length | 最大令牌长度。如果看到令牌超过此长度,则将其max_token_length间隔分割。默认为255。 |
| stopwords | 预定义的停用词列表,例如english或包含停用词列表的数组。默认为none。 |
| stopwords_path | 包含停用词的文件的路径。 |
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5,
"stopwords": "_english_"
}
}
}
}
}简单分词器(Letter Tokenizer)
当simple分析器遇到非字母的字符时,它会将文本划分为多个术语,它小写所有术语,对于中文和亚洲很多国家的语言来说是无用的
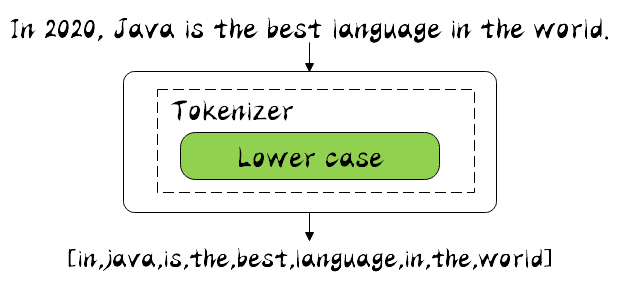
它只包括了 Lower Case 的 Tokenizer,它会按照非字母切分,非字母的会被去除,最后对切分好的做转小写处理,然后接着用刚才的输入文本,分词器换成 simple 来进行分词,运行结果如下:
使用案例
原始内容
In 2020, Java is the best language in the world.测试分词
GET _analyze
{
"text":"In 2020, Java is the best language in the world.",
"analyzer": "simple"
}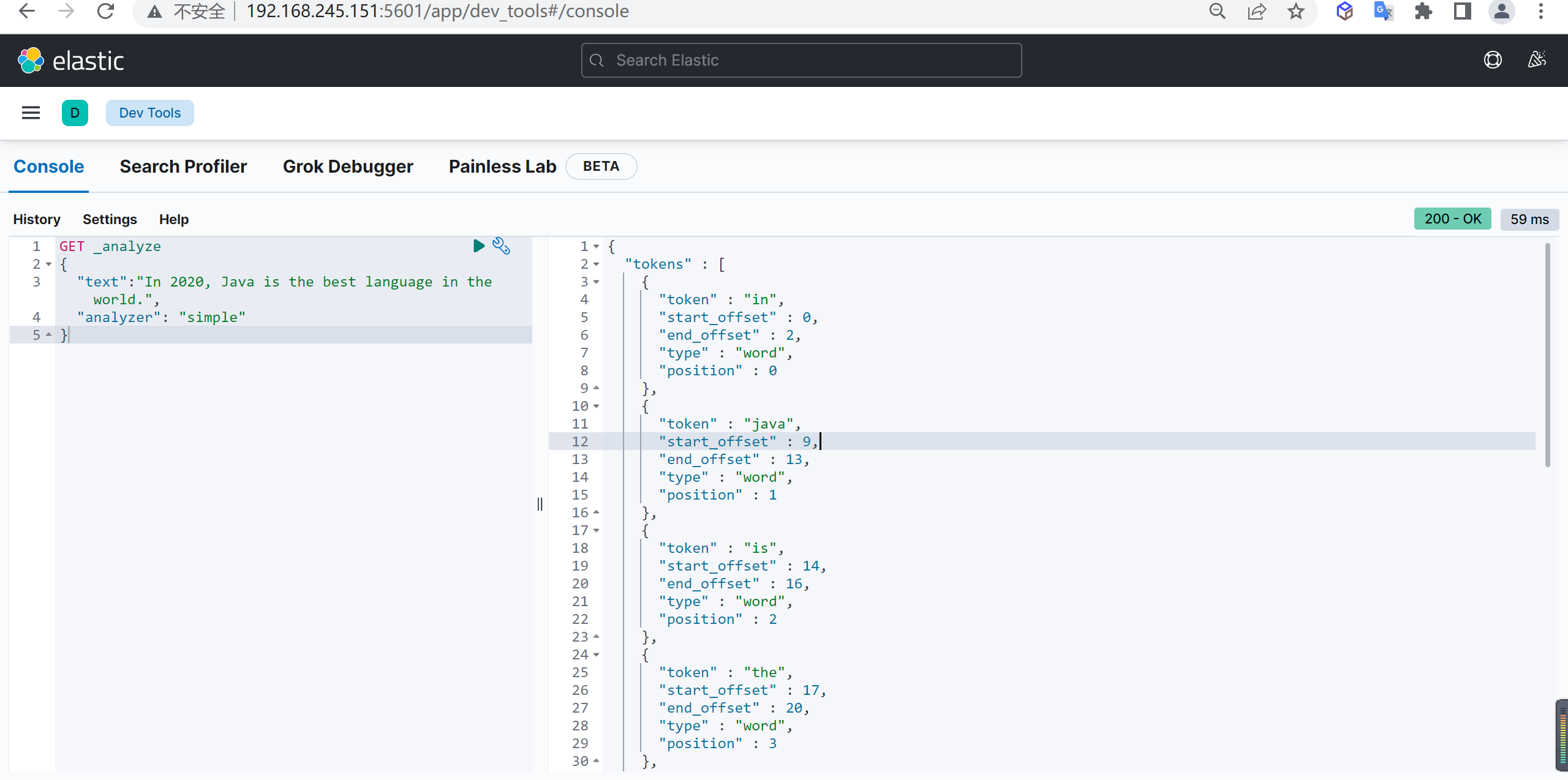
空白分词器(Whitespace Tokenizer)
它非常简单,根据名称也可以看出是按照空格进行切分的
该whitespace分析仪将文本分为方面每当遇到任何空白字符,和上面的分词器不同,空白分词器默认并不会将内容转换为小写。
使用案例
原始内容
In 2020, Java is the best language in the world.测试分词
GET _analyze
{
"text":"In 2020, Java is the best language in the world.",
"analyzer": "whitespace"
}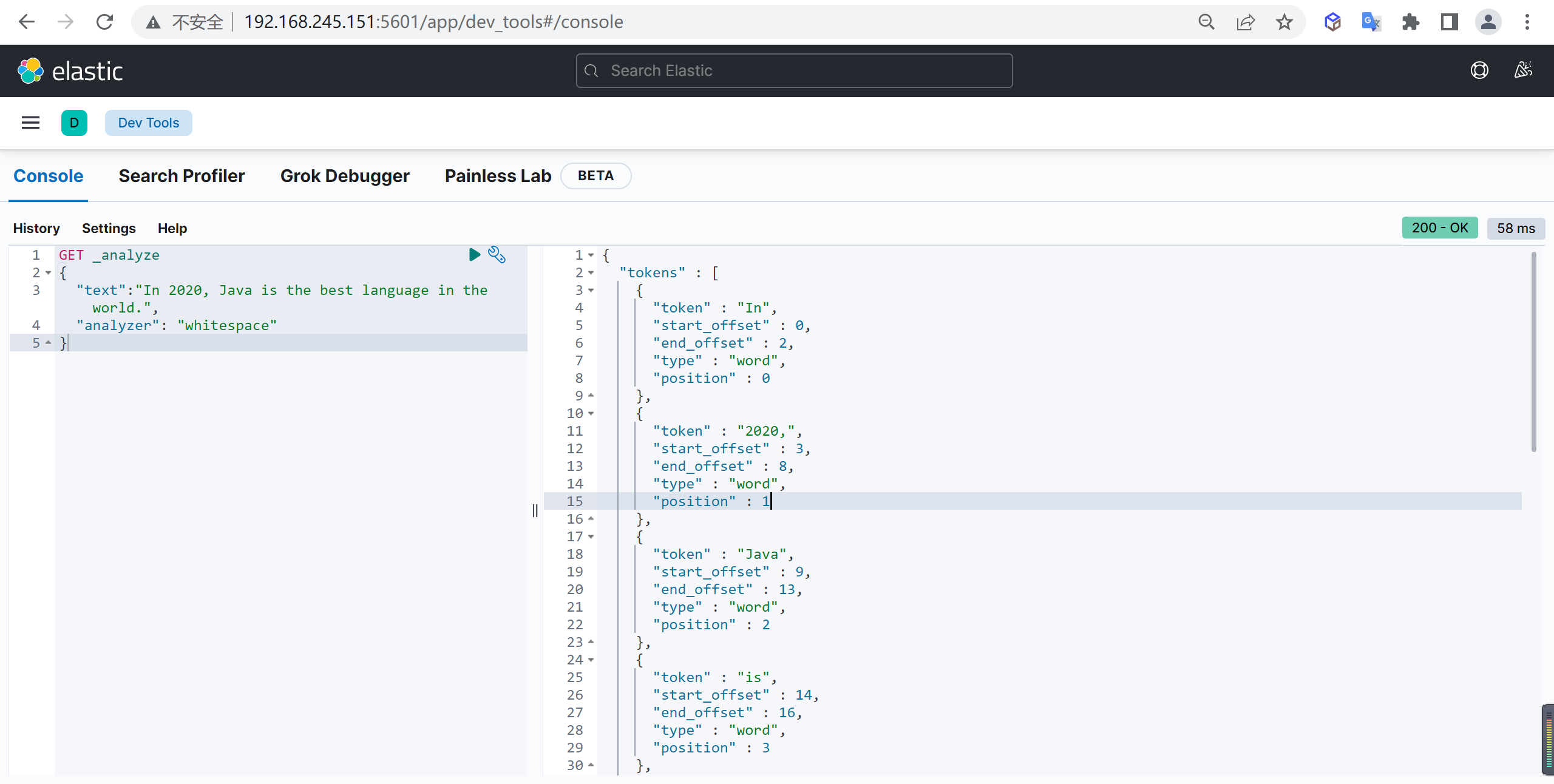
电子邮件分词器(UAX URL Email Tokenizer)
此分词器主要是针对email和url地址进行关键内容的标记。
使用案例
原始内容
"Email me at john.smith@global-international.com"测试分词
GET _analyze
{
"text":"Email me at john.smith@global-international.com",
"tokenizer": "uax_url_email"
}可配置项
max_token_length最大令牌长度。如果看到令牌超过此长度,则将其max_token_length间隔分割。默认为255
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5
}
}
}
}
}经典分词器(Classic Tokenizer)
可对首字母缩写词,公司名称,电子邮件地址和互联网主机名进行特殊处理,但是,这些规则并不总是有效,并且此关键词生成器不适用于英语以外的大多数其他语言
特点
- 它最多将标点符号拆分为单词,删除标点符号,但是,不带空格的点被认为是查询关键词的一部分
- 此分词器可以将邮件地址和URL地址识别为查询的term(词条)
使用案例
原始内容
"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."测试分词
GET _analyze
{
"text":"The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.",
"analyzer": "classic"
}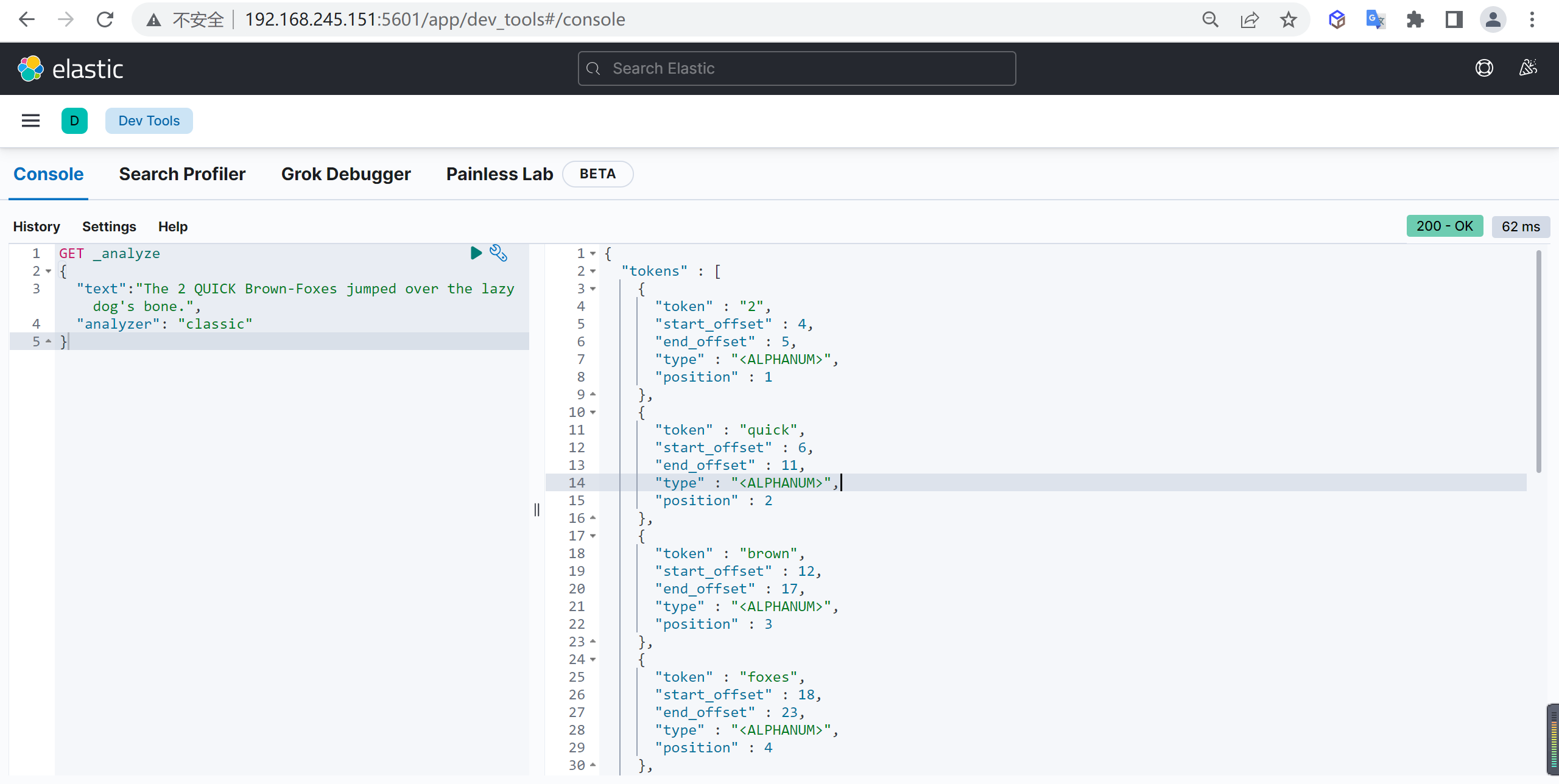
可配置项
max_token_length最大令牌长度。如果看到令牌超过此长度,则将其max_token_length间隔分割。默认为255。
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "classic",
"max_token_length": 5
}
}
}
}
}结构化文本分词
关键词分词器(Keyword Tokenizer)
它其实不做分词处理,只是将输入作为 Term 输出
关键词分词器其实是执行了一个空操作的分析,它将任何输入的文本作为一个单一的关键词输出。
使用案例
原始内容
"In 2020, Java is the best language in the world."测试分词
GET _analyze
{
"text":"In 2020, Java is the best language in the world.",
"analyzer": "keyword"
}会发现前后内容根本没有发生改变,这也是这个分词器的作用,有些时候我们针对一个需要分词查询的字段进行查询的时候,可能并不希望查询条件被分词,这个时候就可以使用这个分词器,整个查询条件作为一个关键词使用
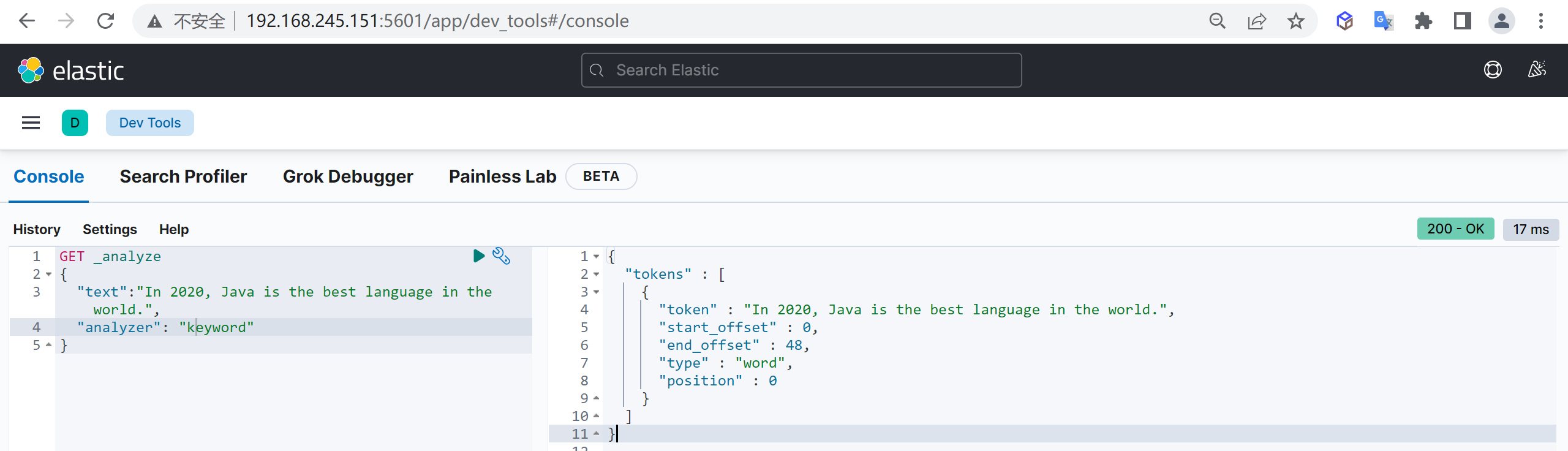
正则分词器(Pattern Tokenizer)
模式标记器使用 Java正则表达式。使用JAVA的正则表达式进行词语的拆分。
它可以通过正则表达式的方式进行分词,默认是用 \W+ 进行分割的,也就是非字母的符合进行切分的。
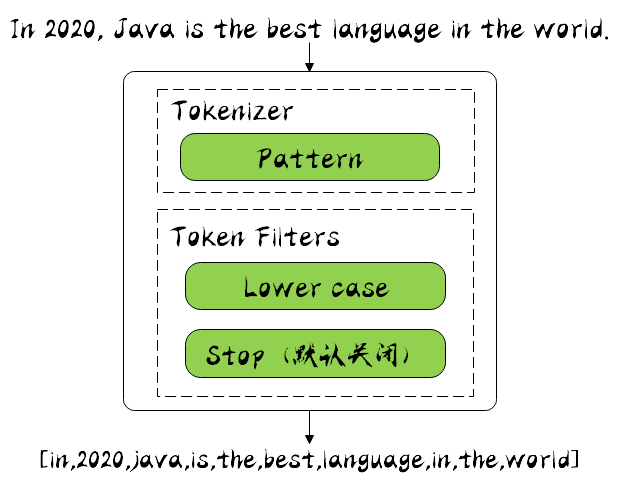
使用案例
原始内容
"In 2020, Java is the best language in the world."测试分词
GET _analyze
{
"text":"In 2020, Java is the best language in the world.",
"analyzer": "patter"
}
可配置项
正则分词器有以下的选项
| 选项 | 描述 |
|---|---|
| pattern | 正则表达式 |
| flags | 正则表达式标识 |
| lowercase | 是否使用小写词汇 |
| stopwords | 停止词的列表。 |
| stopwords_path | 定义停止词文件的路径。 |
{
"settings": {
"analysis": {
"analyzer": {
"my_email_analyzer": {
"type": "pattern",
"pattern": "\\W|_",
"lowercase": true
}
}
}
}
}路径分词器(Path Tokenizer)
可以对文件系统的路径样式的请求进行拆分,返回被拆分各个层级内容。
使用案例
原始内容
"/one/two/three"测试分词
GET _analyze
{
"text":"/one/two/three",
"tokenizer":"path_hierarchy"
}
可配置项
| 选项 | 描述 |
|---|---|
| delimiter | 用作路径分隔符的字符 |
| replacement | 用于定界符的可选替换字符 |
| buffer_size | 单次读取到术语缓冲区中的字符数。默认为1024。术语缓冲区将以该大小增长,直到所有文本都被消耗完为止。建议不要更改此设置。 |
| reverse | 正向还是反向获取关键词 |
| skip | 要忽略的内容 |
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "path_hierarchy",
"delimiter": "-",
"replacement": "/",
"skip": 2
}
}
}
}
}语言分词(Language Analyzer)
ES 为不同国家语言的输入提供了
Language Analyzer分词器,在里面可以指定不同的语言
支持语种
支持如下语种:
| 关键字 | 语种 |
|---|---|
| arabic | 美 /ˈærəbɪk/ 阿拉伯语 |
| armenian | 美 /ɑːrˈmiːniən/ 亚美尼亚语 |
| basque | 美 /bæsk,bɑːsk/ 巴斯克语 |
| bengali | 美 /beŋˈɡɑːli/ 孟加拉语 |
| brazilian | 美 /brəˈzɪliən/ 巴西语 |
| bulgarian | 美 /bʌlˈɡeriən/ 保加利亚语 |
| catalan | 美 /ˈkætəlæn/ 加泰罗尼亚语 |
| cjk | 中日韩统一表意文字 |
| czech | 美 /tʃek/ 捷克语 |
| danish | 美 /ˈdeɪnɪʃ/ 丹麦语 |
| dutch | 美 /dʌtʃ/ 荷兰语 |
| english | 美 /ˈɪŋɡlɪʃ/ 英语 |
| estonian | 美 /eˈstoʊniən/ 爱沙尼亚语 |
| finnish | 美 /ˈfɪnɪʃ/ 芬兰语 |
| french | 美 /frentʃ/ 法语 |
| galician | 美 /ɡəˈlɪʃn/ 加里西亚语 |
| german | 美 /ˈdʒɜːrmən/ 德语 |
| greek | 美 /ɡriːk/ 希腊语 |
| hindi | 美 /ˈhɪndi/ 北印度语 |
| hungarian | 美 /hʌŋˈɡeriən/ 匈牙利语 |
| indonesian | 美 /ˌɪndəˈniːʒn/ 印度尼西亚语 |
| irish | 美 /ˈaɪrɪʃ/ 爱尔兰语 |
| italian | 美 /ɪˈtæliən/ 意大利语 |
| latvian | 美 /ˈlætviən/ 拉脱维亚语 |
| lithuanian | 美 /ˌlɪθuˈeɪniən/ 立陶宛语 |
| norwegian | 美 /nɔːrˈwiːdʒən/ 挪威语 |
| persian | /‘pɜːrʒən/ 波斯语 |
| portuguese | 美 /ˌpɔːrtʃʊˈɡiːz/ 葡萄牙语 |
| romanian | 美 /ro’menɪən/ 罗马尼亚语 |
| russian | 美 /ˈrʌʃn/ 俄语 |
| sorani | 索拉尼语 |
| spanish | 美 /ˈspænɪʃ/ 西班牙语 |
| swedish | 美 /ˈswiːdɪʃ/ 瑞典语 |
| turkish | 美 /ˈtɜːrkɪʃ/ 土耳其语 |
| thai | 美 /taɪ/ 泰语 |
使用案例
下面我们使用英语进行分析
原始内容
"In 2020, Java is the best language in the world."测试分词
GET _analyze
{
"text":"In 2020, Java is the best language in the world.",
"analyzer":"english"
}
自定义分词器
当内置的分词器无法满足需求时,可以创建
custom类型的分词器。
配置参数
| 参数 | 描述 |
|---|---|
| tokenizer | 内置或定制的tokenizer.(必须) |
| char_filter | 内置或定制的char_filter(非必须) |
| filter | 内置或定制的token filter(非必须) |
| position_increment_gap | 当值为文本数组时,设置改值会在文本的中间插入假空隙。设置该属性,对与后面的查询会有影响。默认该值为100. |
创建索引
上面的示例中定义了一个名为
my_custom_analyzer的分词器
该分词器的type为custom,tokenizer为standard,char_filter为hmtl_strip,filter定义了两个分别为:lowercase和asciifolding
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer":{
"type":"custom",
"tokenizer":"standard",
"char_filter":["html_strip"],
"filter":["lowercase","asciifolding"]
}
}
}
}
}使用案例
原始内容
Is this <b>déjà vu</b>?测试分词
POST my_index/_analyze
{
"text": "Is this <b>déjà vu</b>?",
"analyzer": "my_custom_analyzer"
}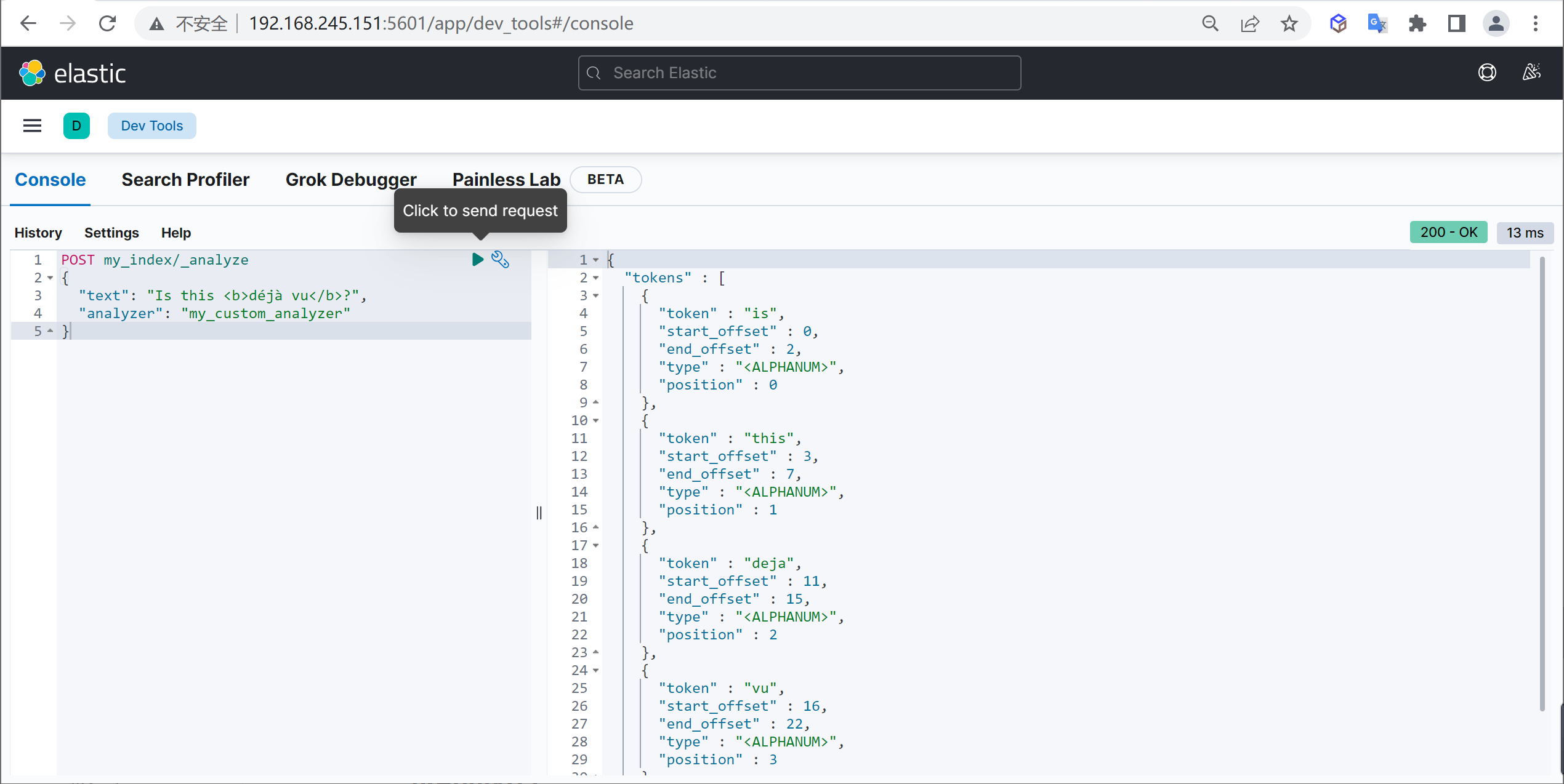
中文分词器
IKAnalyzer
IKAnalyzer是一个开源的,基于java的语言开发的轻量级的中文分词工具包
从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本,在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化
使用IK分词器
IK提供了两个分词算法:
- ik_smart:最少切分。
- ik_max_word:最细粒度划分。
ik_smart
使用案例
原始内容
传智教育的教学质量是杠杠的测试分词
GET _analyze
{
"analyzer": "ik_smart",
"text": "传智教育的教学质量是杠杠的"
}
ik_max_word
使用案例
原始内容
传智教育的教学质量是杠杠的测试分词
GET _analyze
{
"analyzer": "ik_max_word",
"text": "传智教育的教学质量是杠杠的"
}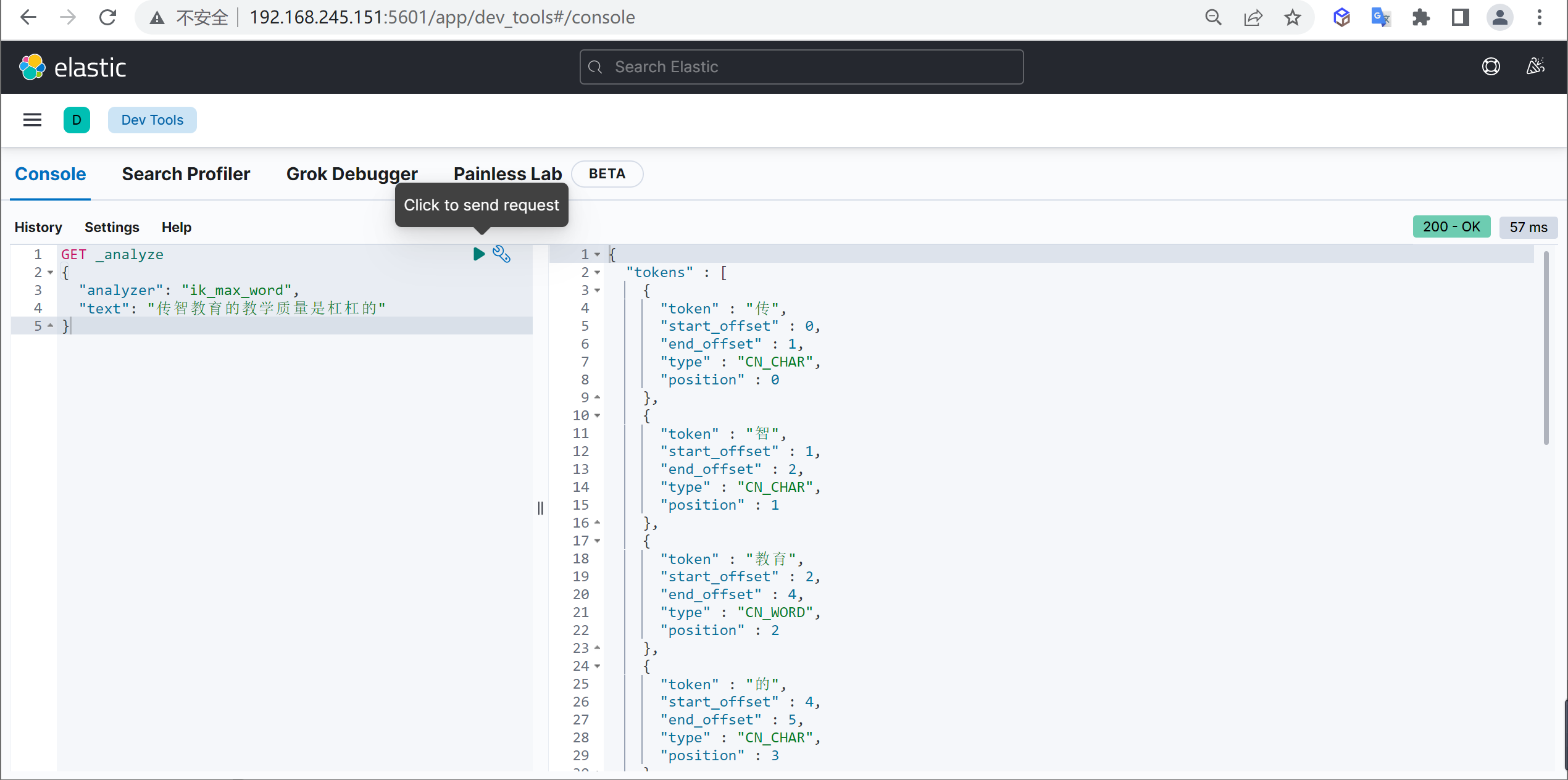
自定义词库
我们在使用IK分词器时会发现其实有时候分词的效果也并不是我们所期待的
问题描述
例如我们输入“传智教育的教学质量是杠杠的”,但是分词器会把“传智教育”进行拆开,分为了“传”,“智”,“教育”,但我们希望的是“传智教育”可以不被拆开。
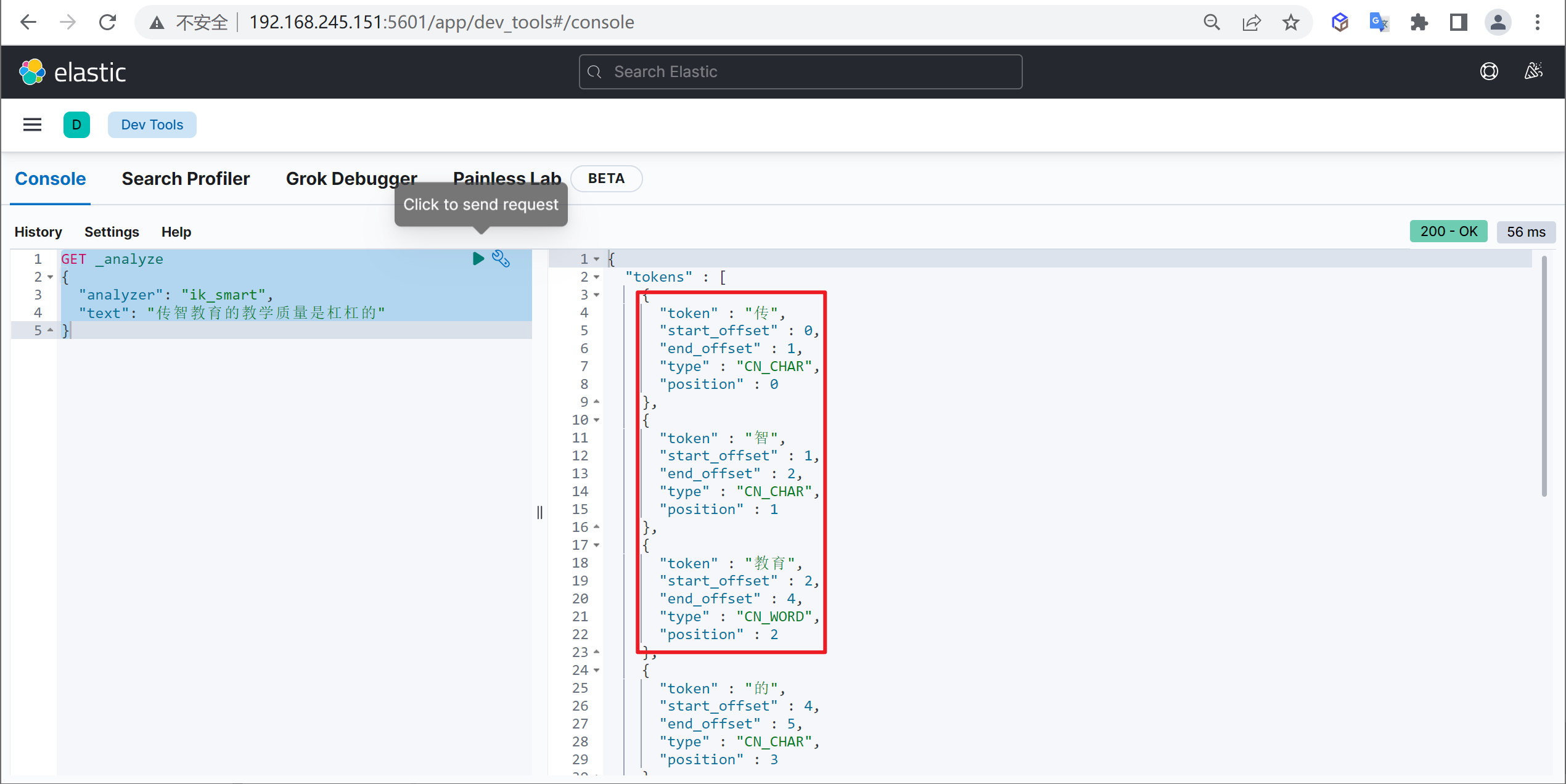
解决方案
对于以上的问题,我们只需要将自己要保留的词,加到我们的分词器的字典中即可
编辑字典内容
进入elasticsearch目录
plugins/ik/config中,创建我们自己的字典文件yixin.dic,并添加内容:
cd plugins/ik/config
echo "传智教育" > custom.dic扩展字典
进入我们的elasticsearch目录 :
plugins/ik/config,打开IKAnalyzer.cfg.xml文件,进行如下配置:
vi IKAnalyzer.cfg.xml
#增加如下内容
<entry key="ext_dict">custom.dic</entry>再次测试
重启ElasticSearch,再次使用kibana测试
GET _analyze
{
"analyzer": "ik_max_word",
"text": "传智教育的教学质量是杠杠的"
}可以发现,现在我们的词汇”传智教育”就不会被拆开了,达到我们想要的效果了
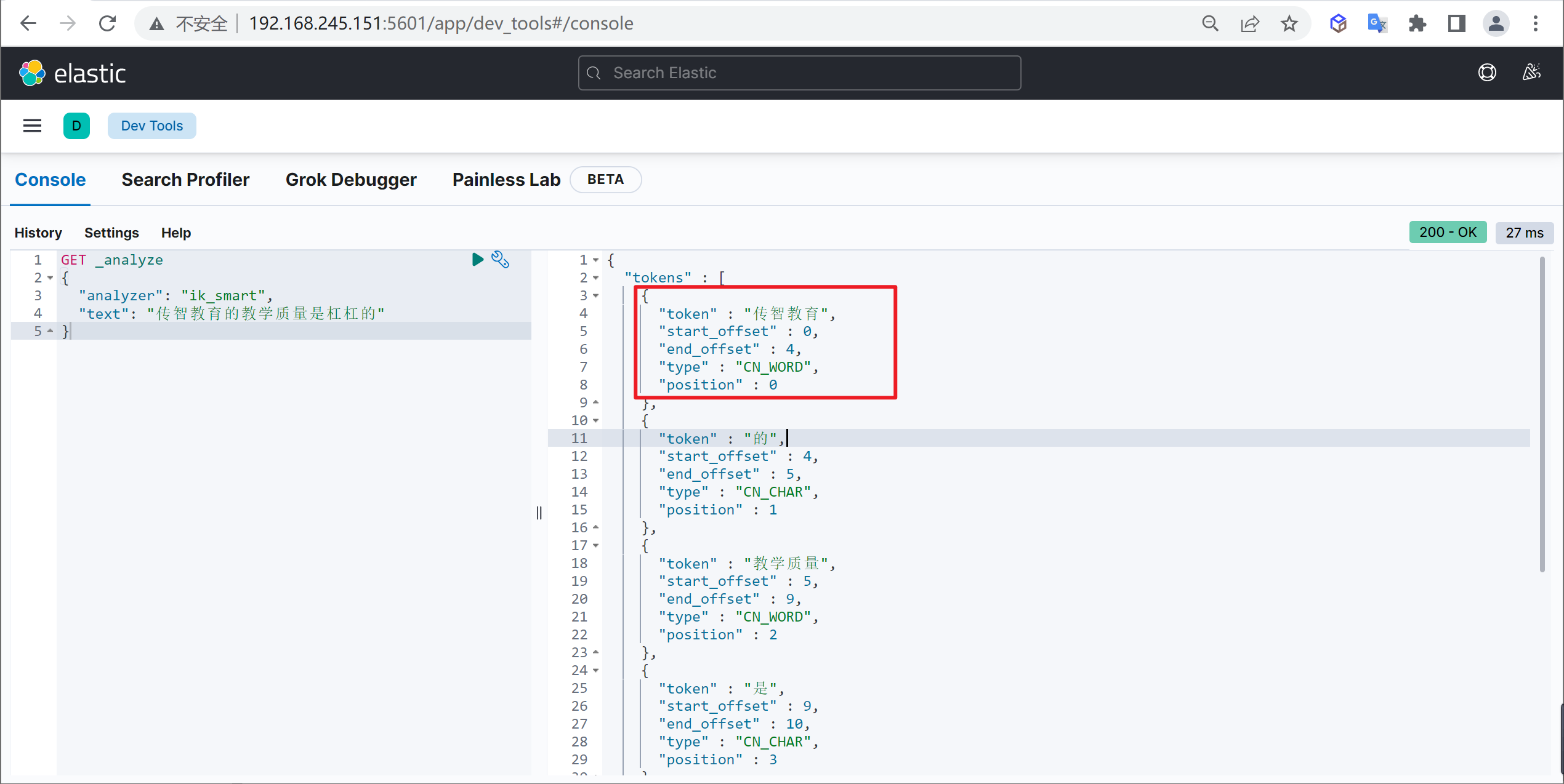
ElasticSearch 分布式文档
分布式文档原理
下面我们讲解下文档搜索的原理
索引的路由计算
当索引一个文档的时候,文档会被存储到一个主分片中, Elasticsearch如何知道一个文档应该存放到哪个分片中呢?

首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了,实际上,这个过程是根据下面这个算法决定的:
shard = hash(routing) % number_of_primary_shards- routing值是一个任意字符串,它默认是
_id,但也可以自定义。 - 这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是0到
number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
注意事项
通过上面的公式,我们理解并且也需要记住一个重要的规律
创建索引的时候就确定好主分片的数量,并且永远不会改变这个数量,数量的改变将导致上述公式的结果变化,最终会导致我们的数据无法被找到。
文档的写操作
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上
下图是数据写入P0主分片的过程,master在这里起到一个协调节点的作用
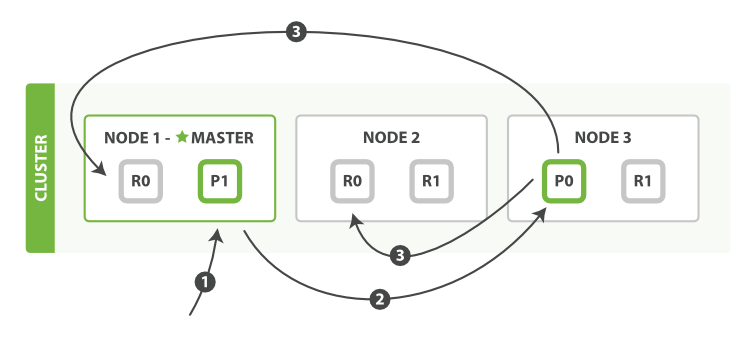
详细步骤
下面我们罗列在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:
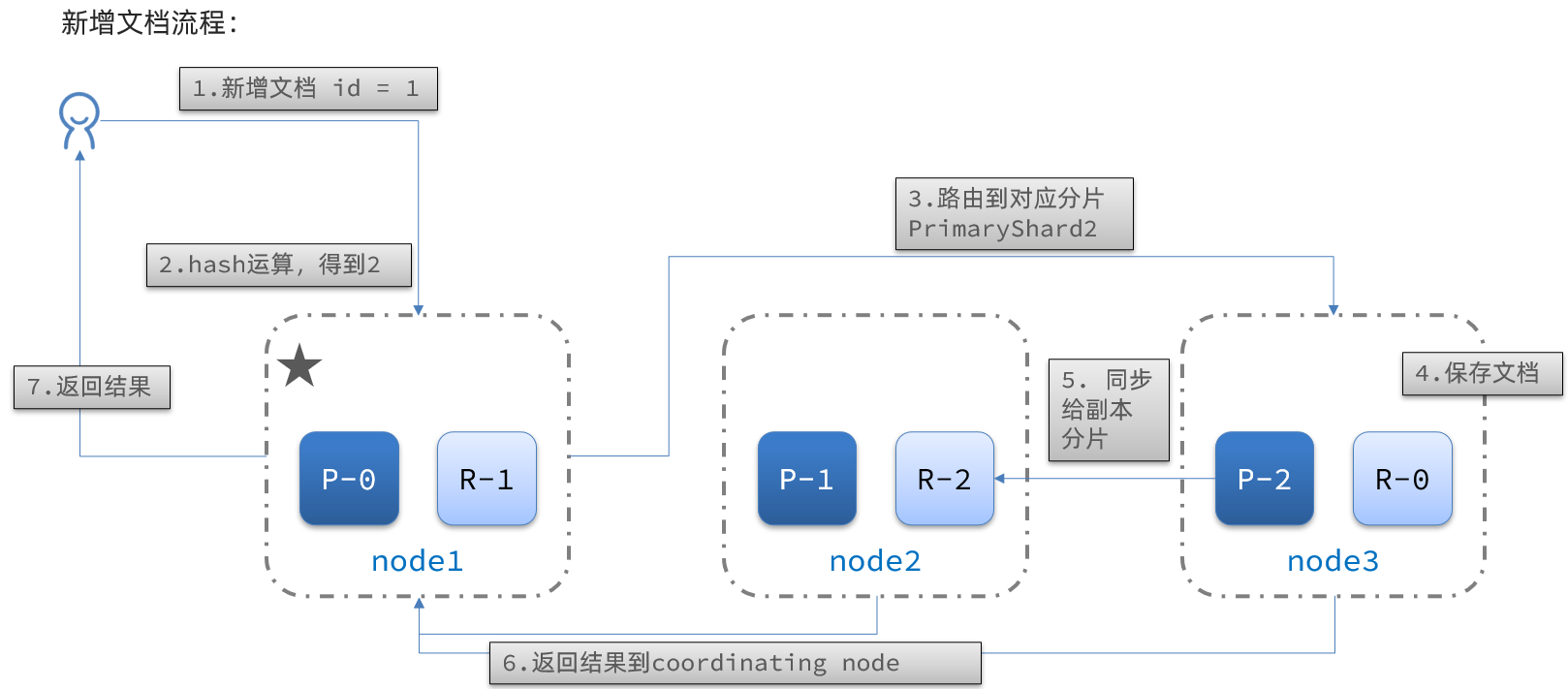
- 客户端给 Node 1 发送新建、索引或删除请求。
- 节点使用文档的
_id确定文档属于分片0,它转发请求到 Node 3 ,分片0位于这个节点上。 - Node 3 在主分片上执行请求
- Node 3保存文档,将数据保存到主分片
- 保存成功后,它转发请求到相应的位于 Node 1 和 Node 2 的复制节点上
- 当所有的复制节点报告成功, Node 3 报告成功到请求的节点
- 请求的节点再报告给客户端,客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片
注意事项
把文档存储写入到primary shard,如果设置了index.write.wait_for_active_shards=1,那么写完主节点,直接返回客户端,如果 index.write.wait_for_active_shards=all,那么必须要把所有的副本写入完成才返回客户端
实验验证
创建一个customer的索引
PUT /customer
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
}
}
},
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 2,
"write.wait_for_active_shards": "all"
}
}
}写入一条数据
POST customer/_doc
{
"name":"张三"
}暂时node2节点
docker pause node-2再尝试写入,发现写入阻塞,一直等到我们恢复node2节点
搜索文档(单个)
我们根据文档ID查询的时候ES是如何搜索到我们的文档的呢?
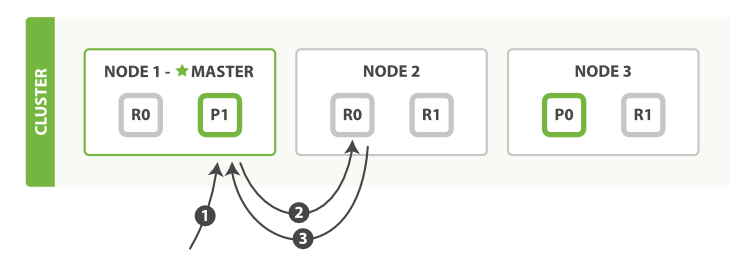
详细步骤
下面我们罗列在主分片或复制分片上检索一个文档必要的顺序步骤:
- 客户端给 Node 1 发送get请求。
- 节点使用文档的
_id确定文档属于分片0,对应的复制分片在三个节点上都有,此时它转发请求到Node2 - Node 2 返回文档(document)给 Node 1 然后返回给客户端
注意事项
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本
一个被索引的文档已经存在于主分片上却还没来得及同步到副本分片上,这时副本分片会报告文档未找到,如果查询主分片则会成功返回文档,这种情况下会产生读写不一致的情况
由于可能存在primary shard的数据还没同步到 replica shard上的情况,所以客户端可能查询到旧的数据,我们可以做相应的调整,保证读取到最新的数据。
更新文档(单个)
更新文档,必须先定位到主分片,修改文档后,再次同步到其他副本中才算完成

详细步骤
以下是部分更新一个文档的步骤:
- 客户端向
Node 1发送更新请求,发现主分片在Node 3 - 它将请求转发到主分片所在的
Node 3 Node 3从主分片检索文档,修改_source字段中的 JSON ,并且尝试重新索引主分片的文档, 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过retry_on_conflict次后放弃。- 如果
Node 3成功地更新文档,它将新版本的文档并行转发到Node 1和Node 2上的副本分片,重新建立索引, 一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。
文档复制
当主分片把更改转发到副本分片时, 它不会转发更新请求,相反,它转发完整文档的新版本
注意,这些更改将会异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达,如果Elasticsearch仅转发更改请求,则可能导致更新顺序错误,导致文档更新结果错误。
全文搜索
对于全文搜索而言,文档可能分散在各个节点上,那么在分布式的情况下,如何搜索文档呢?
搜索,分为2个阶段,搜索(query)+取回(fetch)
搜索(query)
在初始
查询阶段时, 查询会广播到索引中每一个分片拷贝(主分片或者副本分片), 每个分片在本地执行搜索并构建一个匹配文档的 优先队列。
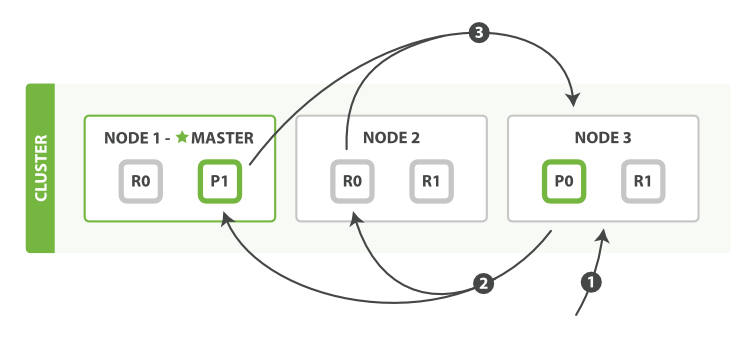
详细步骤
查询阶段包含以下三步:
- 客户端发送一个 search(搜索) 请求发送给
Node 3, 他会创建了一个长度为from+size的空优先级队 Node 3转发这个搜索请求到索引中每个分片的主分片或副本分片,每个分片在本地执行这个该查询并且结果将结果存储到一个大小为from+size的本地有序优先队列里去。- 每个分片返回
document的ID和该节点优先队列里的所有document的排序值给协调节点Node 3,而Node 3会把这些值合并到自己的优先队列里产生全局排序结果。
什么是优先级队列
一个
优先队列仅仅是一个存有top-n匹配文档的有序列表,优先队列的大小取决于分页参数from和size,如下搜索请求将需要足够大的优先队列来放入100条文档
GET /_search
{
"from": 90,
"size": 10
}注意事项
当一个搜索请求被发送到某个节点时,这个节点就变成了协调节点
这个节点的任务是广播查询请求到所有相关分片并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
第一步是广播请求到索引中每一个节点的分片拷贝, 查询请求可以被某个主分片或某个副本分片处理,这就是为什么更多的副本(当结合更多的硬件)能够增加搜索吞吐率, 协调节点将在之后的请求中轮询所有的分片来分摊负载。
每个分片在本地执行查询请求并且创建一个长度为 from + size 的本地优先队列,也就是说,每个分片创建的结果集足够大,均可以满足全局的搜索请求,分片返回一个轻量级的结果列表到协调节点,它仅包含文档 ID 集合以及任何排序需要用到的值,例如 _score
协调节点将这些分片级的结果合并到自己的有序优先队列里,它代表了全局排序结果集合,至此查询过程结束。
取回(fetch)
查询阶段标识哪些文档满足搜索请求,但是我们仍然需要取回这些文档
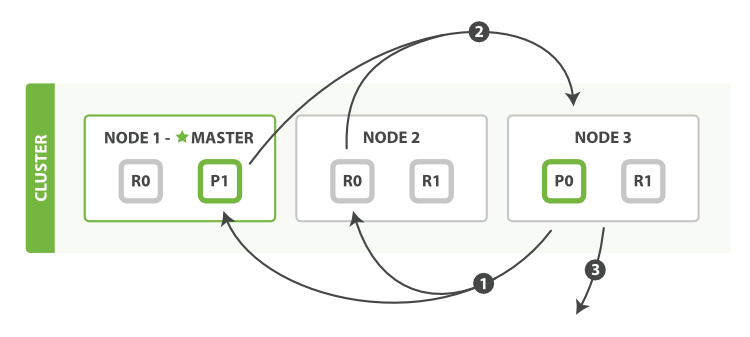
详细步骤
分发阶段由以下步骤构成:
- 协调节点辨别出哪个
document需要取回,并且向相关分片发出GET请求。 - 每个分片加载
document并且根据需要丰富它们,然后再将document返回协调节点。 - 一旦所有的
document都被取回,协调节点会将结果返回给客户端。
注意事项
协调节点首先决定哪些文档
确实需要被取回。
例如,如果我们的查询指定了 { "from": 90, "size": 10 } ,最初的90个结果会被丢弃,只有从第91个开始的10个结果需要被取回,这些文档可能来自和最初搜索请求有关的一个或者多个甚至全部分片。
协调节点给持有相关文档的每个分片创建一个 multi-get request ,并发送请求给同样处理查询阶段的分片副本
路由机制
假设你有一个100个分片的索引,当一个请求在集群上执行时会发生什么呢?
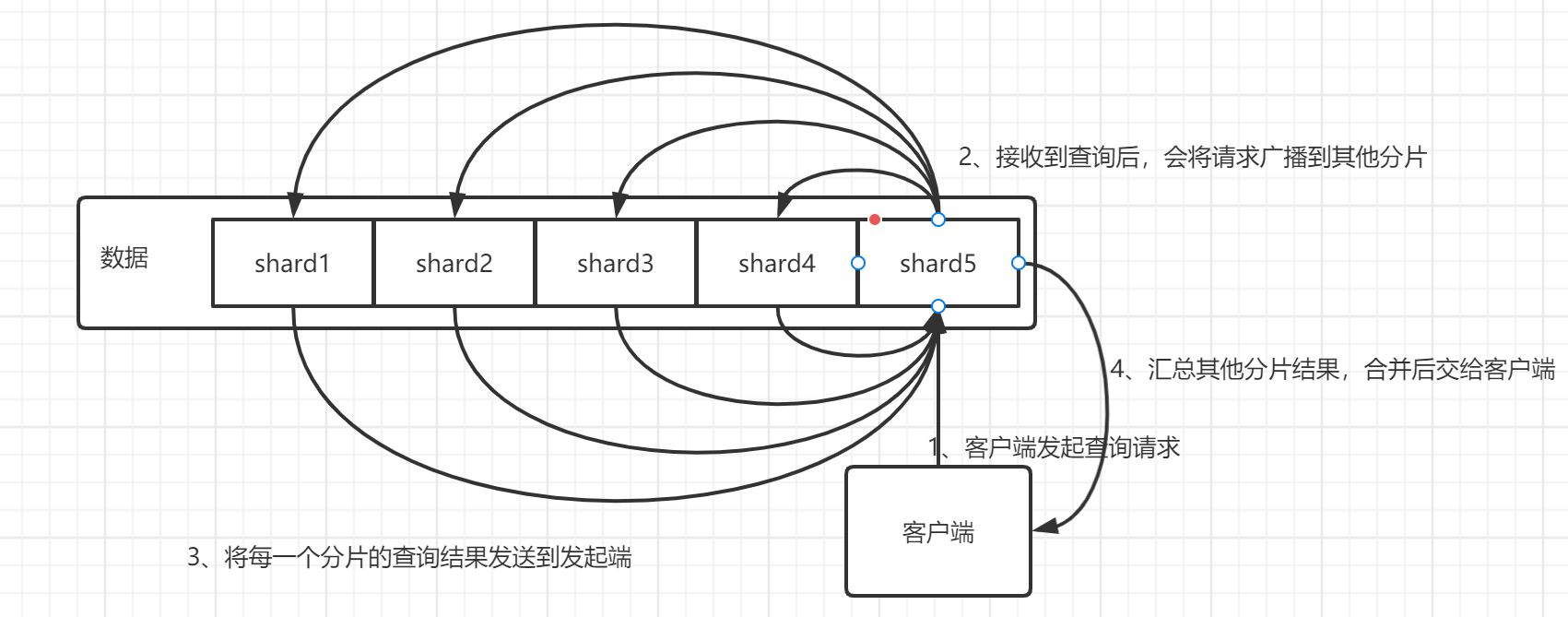
- 这个搜索的请求会被发送到一个节点
- 接收到这个请求的节点,将这个查询广播到这个索引的每个分片上(可能是主分片,也可能是复本分片)
- 每个分片执行这个搜索查询并返回结果
- 结果在通道节点上合并、排序并返回给用户
为什么使用路由
因为默认情况下,Elasticsearch使用文档的ID(类似于关系数据库中的自增ID),如果插入数据量比较大,文档会平均的分布于所有的分片上,如果不按照分片键进行搜索会导致了Elasticsearch不能确定文档的位置,所以它必须将这个请求广播到所有的N个分片上去执行 这种操作会给集群带来负担,增大了网络的开销。
如果你根本就不使用路由,Elasticsearch将确保你的文档以均衡的方式分布在所有不同的分片中,那么为什么还需要使用路由?定制路由允许你将同一个路由值得多篇文档归集到某一个分片中,而一旦这些文档放入到同一索引中,就可以路由某些查询,让它们可以在索引分片得子集中执行(简而言之:根据指定的散列值决定相关文档放在哪些分片上),类似于分库分表的路由键的概念。
路由查询
下面我们演示以下路由的使用
普通查询
下面我们介绍下不加路由的查询方式
GET logstash-village-2022.08.22/_search
{
"query": {
"match": {
"name": "龙苑居住区"
}
}
}我们发现查询的时候扫描了三个分片
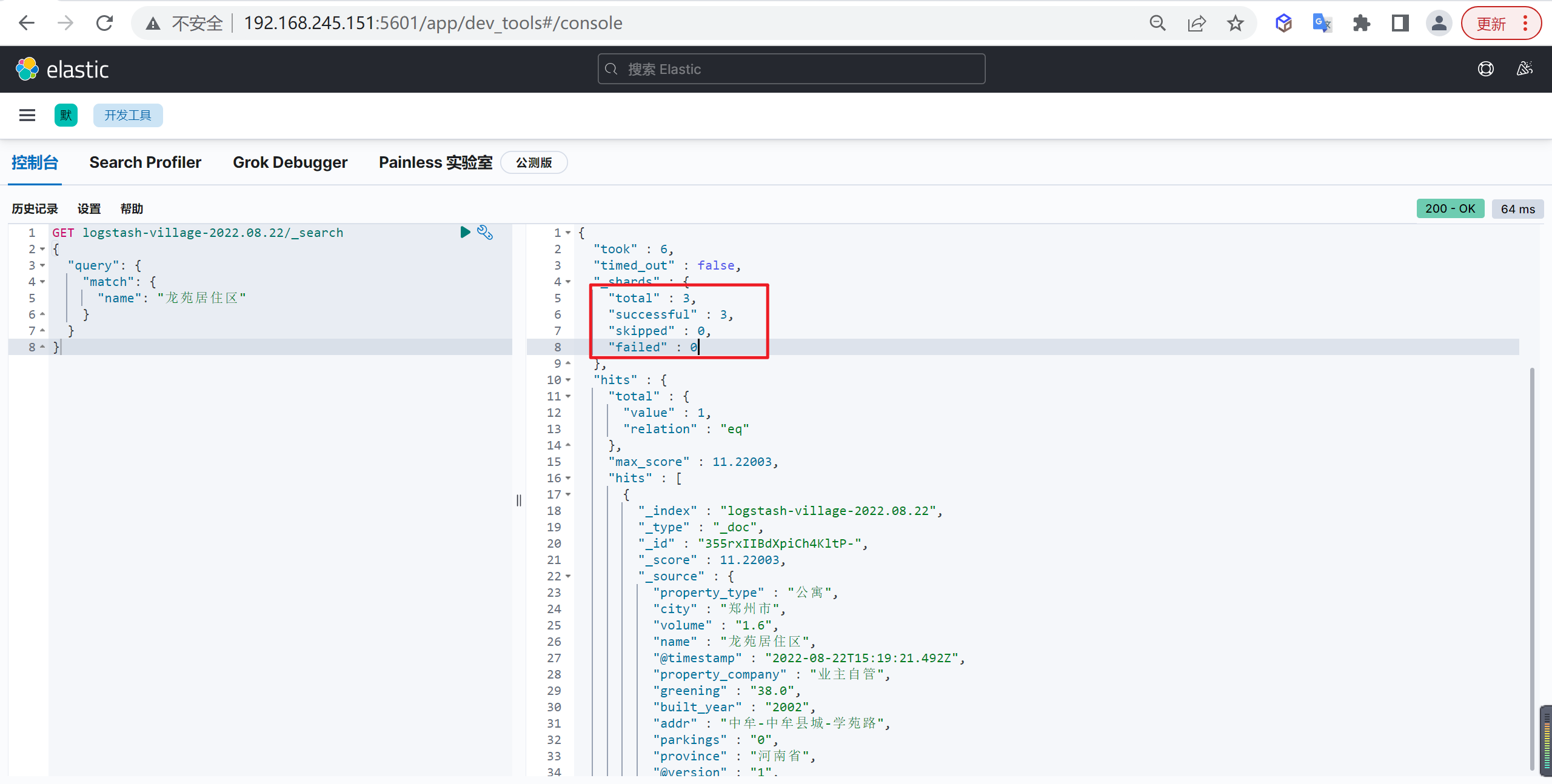
路由查询
下面我们通过路由的方式进行查询试试,路由查询只需要在请求后面加上路由key即可
GET logstash-village-2022.08.22/_search?routing=routingKey
{
"query": {
"match": {
"name": "龙苑居住区"
}
}
}这个路由key可以随意写,默认查询的路由key是
_id,现在我们就换成了routingKey
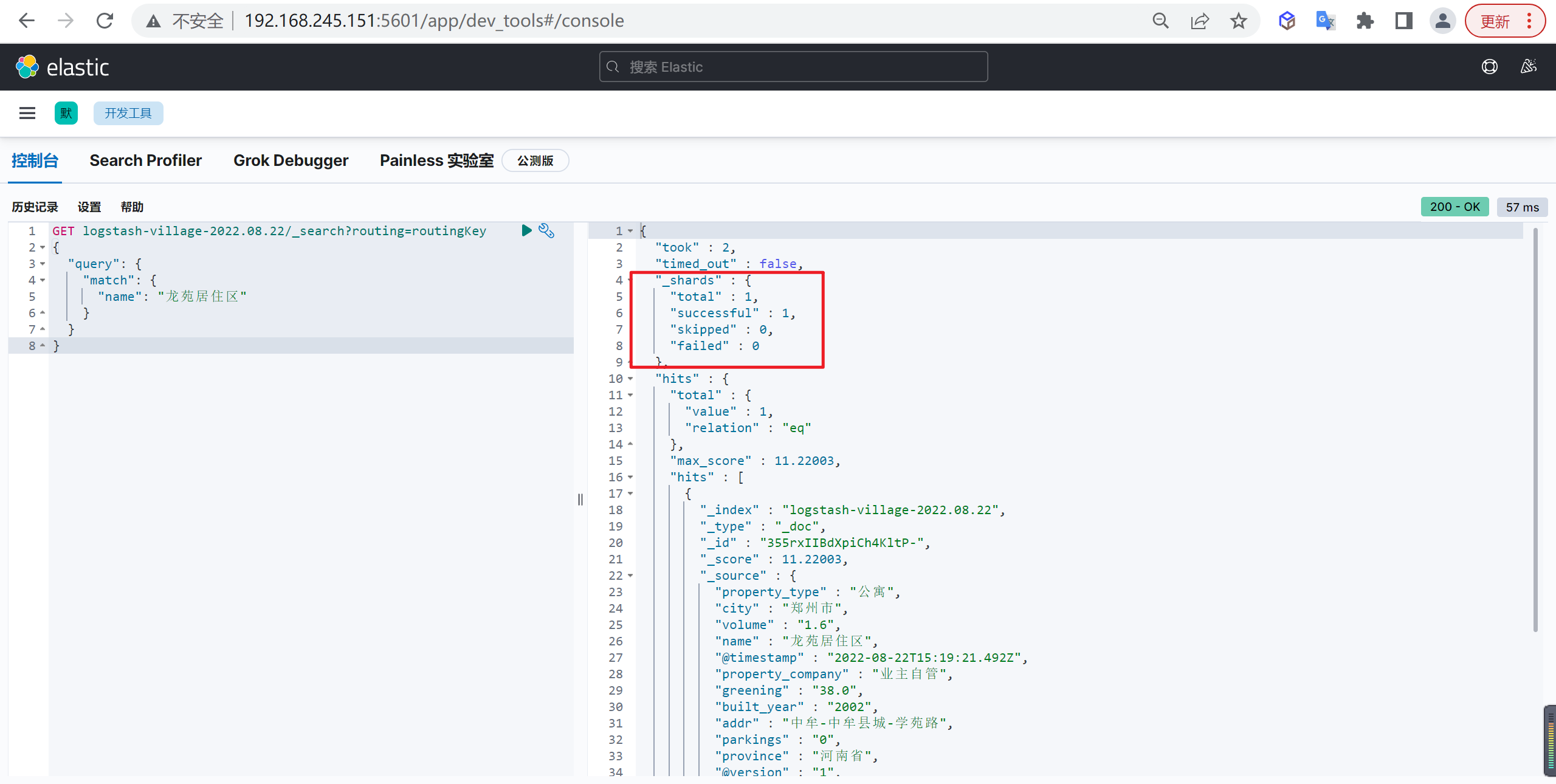
这样我们发现,查询只查询了一个分片,这样查询效率会更高,但是我们写入的时候是通过
_id写入的,查询的时候通过指定路由键,有些数据会查询不出来的,比如
GET logstash-village-2022.08.22/_search?routing=key
{
"query": {
"match": {
"name": "龙苑居住区"
}
}
}这样直接搜索是查不到数据的,根据
key路由键定位的分片是没有数据的,如何解决呢,就需要写和读都是用相同的路由键,再写入的时候也指定路由键即可
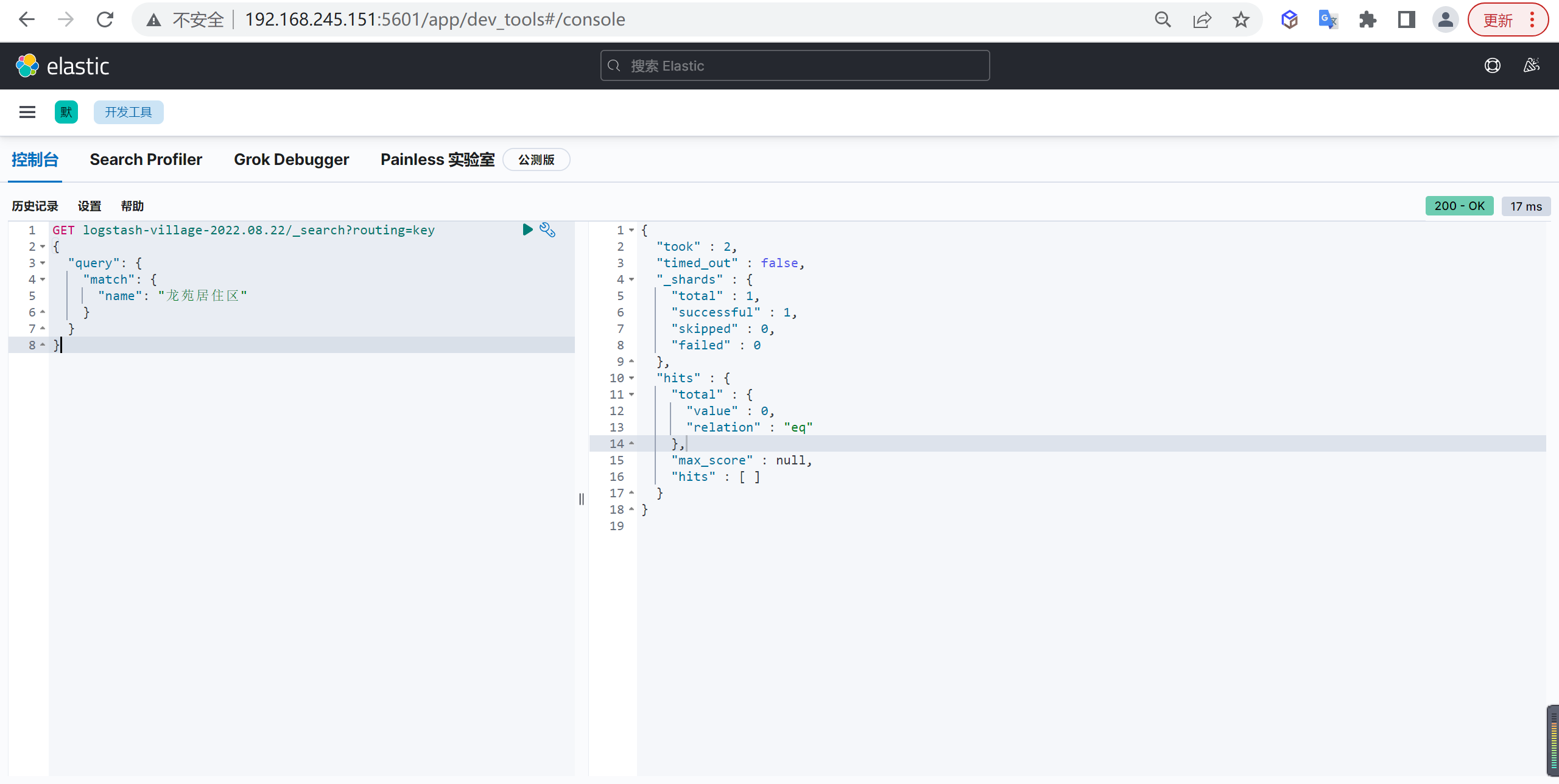
自定义路由(拓展)
自定义路由的方式非常简单,只需要在插入数据的时候指定路由的key即可,虽然使用简单,但有许多的细节需要注意
创建索引
先创建一个名为route_test的索引,该索引有3个shard,0个副本
PUT route_test/
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
}
}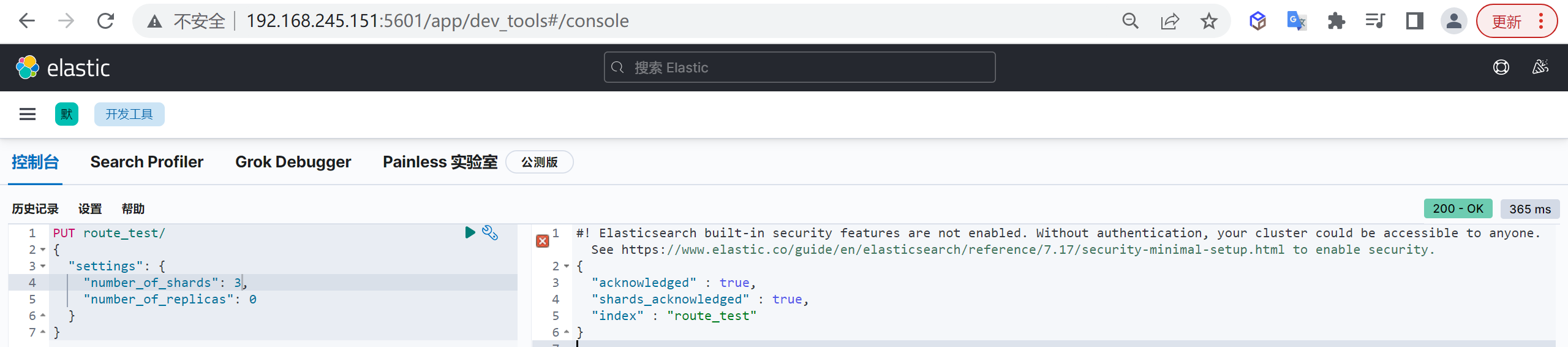
查看分片
我们接下来查看以下分片信息
GET _cat/shards/route_test?v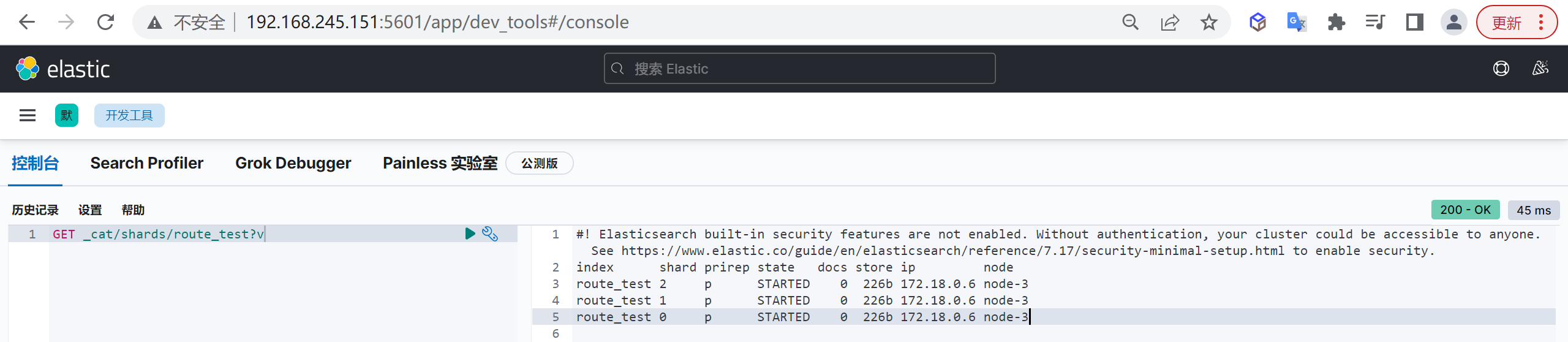
插入数据
接下来我们就需要插入数据
插入第一条数据
PUT route_test/_doc/a?refresh
{
"data": "A"
}
查看分片
我们插入数据后再次来查看分片信息
GET _cat/shards/route_test?v我们发现我们插入的数据加入了0分片
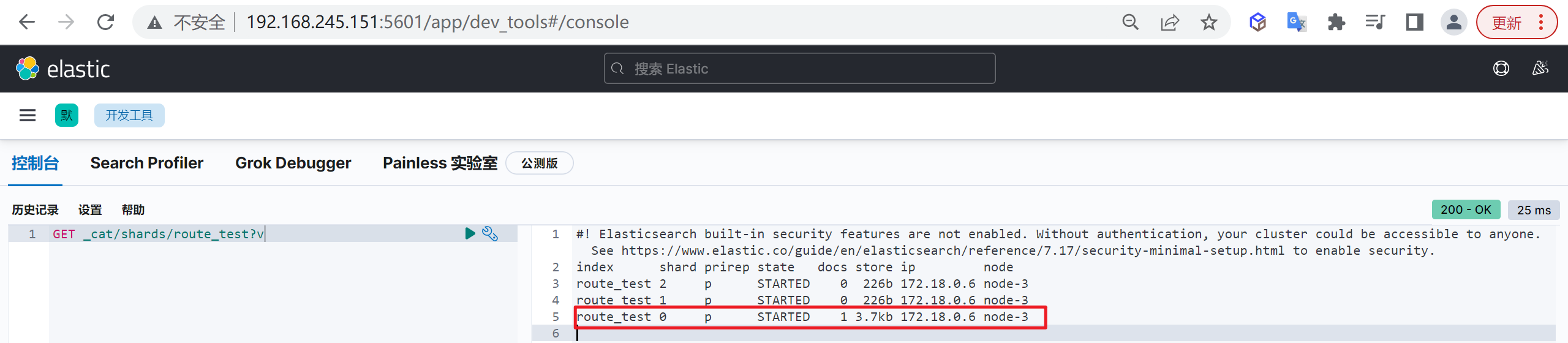
插入第二条数据
接下来我们插入第二条数据
PUT route_test/_doc/b?refresh
{
"data": "B"
}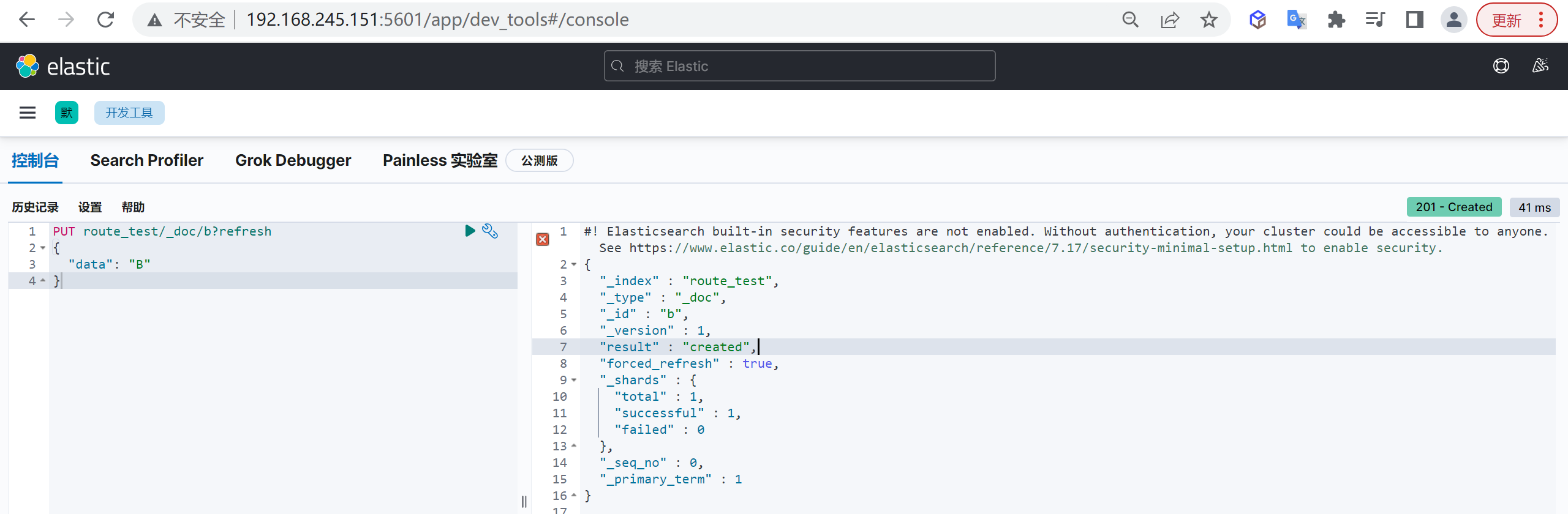
查看分片
我们插入数据后再次来查看分片信息
GET _cat/shards/route_test?v我们发现我们插入的数据加入了2分片
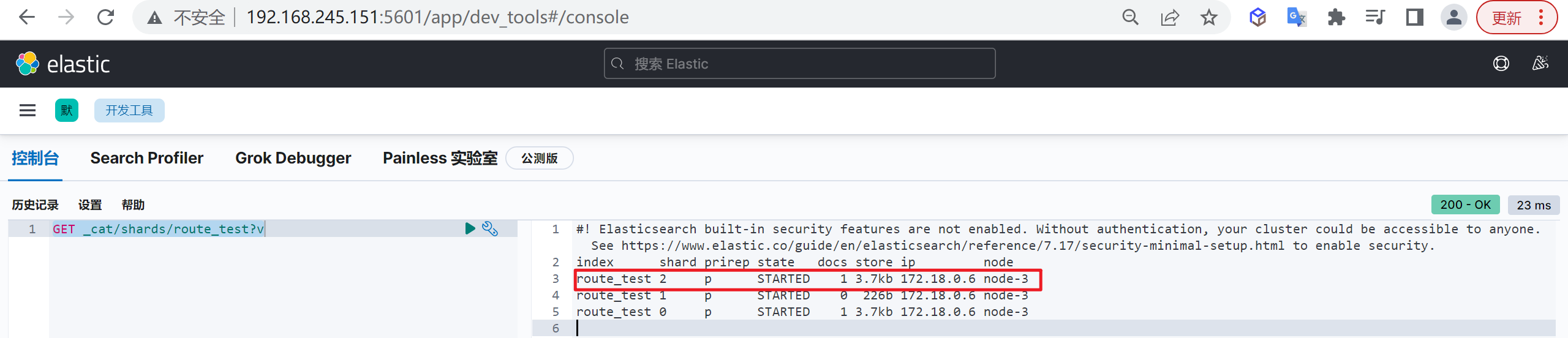
查询数据
接下来我们查询数据
GET route_test/_search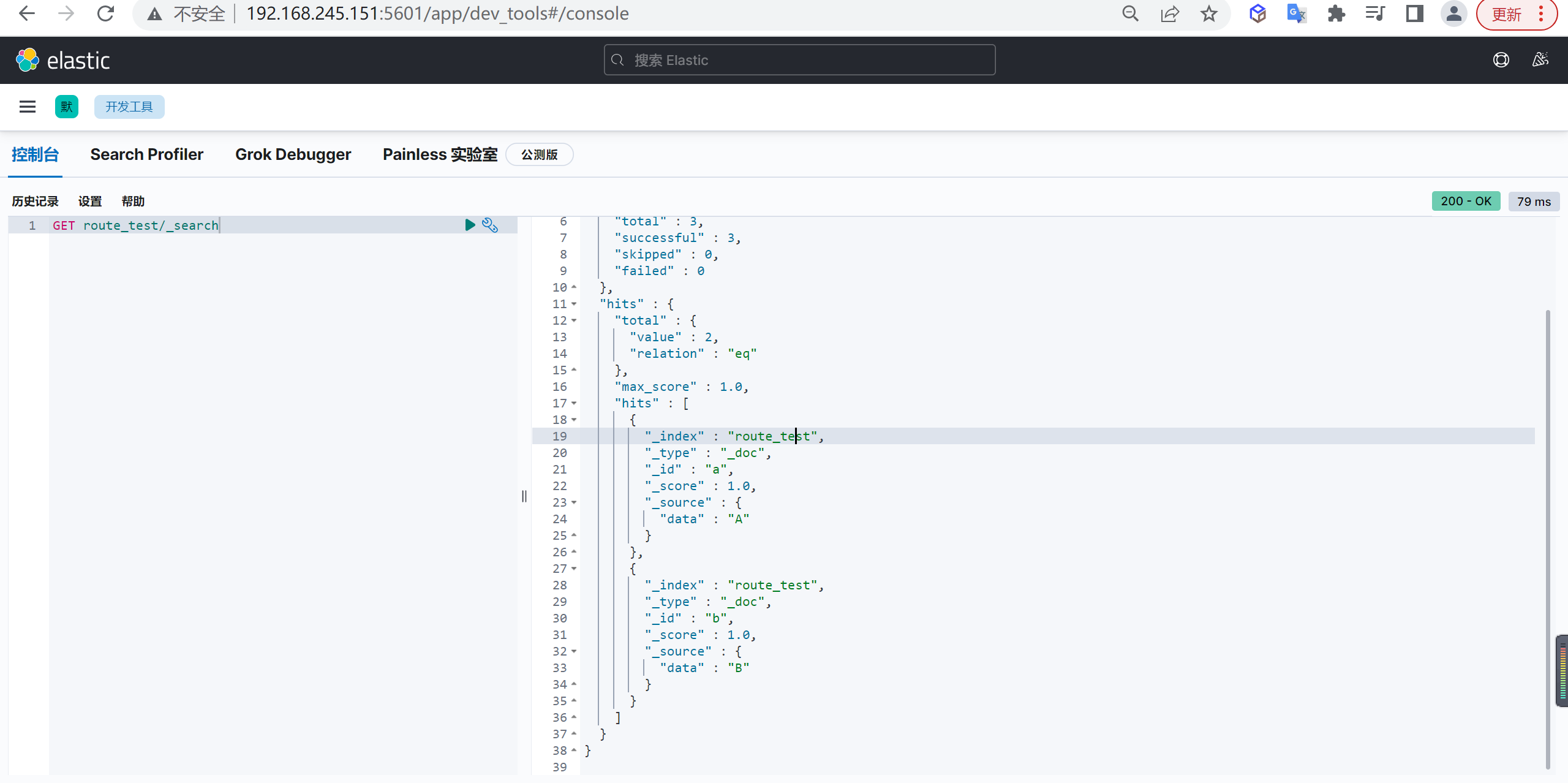
上面这个例子比较简单,先创建了一个拥有3个shard,0个副本(为了方便观察)的索引route_test ,创建完之后查看两个shard的信息,此时shard为空,里面没有任何文档(docs 列为0)。
接着我们插入了两条数据,每次插完之后,都检查shard的变化,通过对比可以发现 docid=a 的第一条数据写入了0号shard,docid=b 的第二条数据写入了2号 shard。
需要注意的是这里的doc_id我选用的是字母”a”和”b”,而非数字,原因是连续的数字很容易路由到一个shard中去,以上的过程就是不指定routing时候的默认行为。
指定路由
接着,我们指定routing,看看会发生什么
插入第三条数据
接下来我们插入第三条数据,但是这条数据我们加上一个路由键
PUT route_test/_doc/c?routing=key1&refresh
{
"data": "C"
}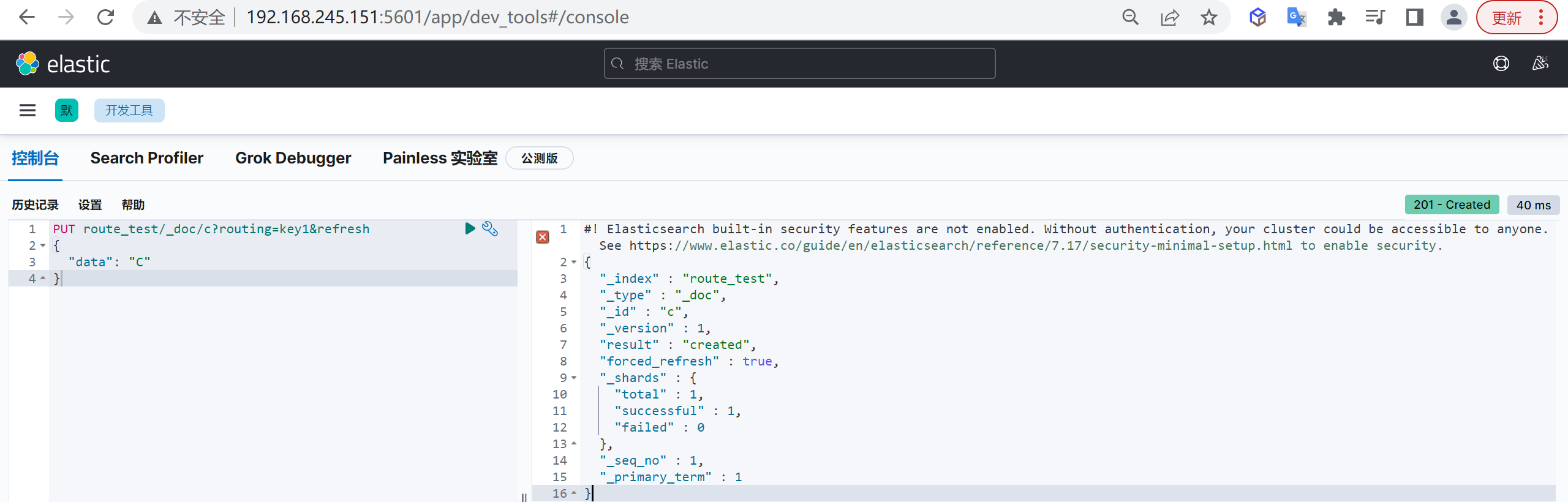
查看分片
我们插入数据后再次来查看分片信息
GET _cat/shards/route_test?v我们发现我们插入的数据加入了0分片
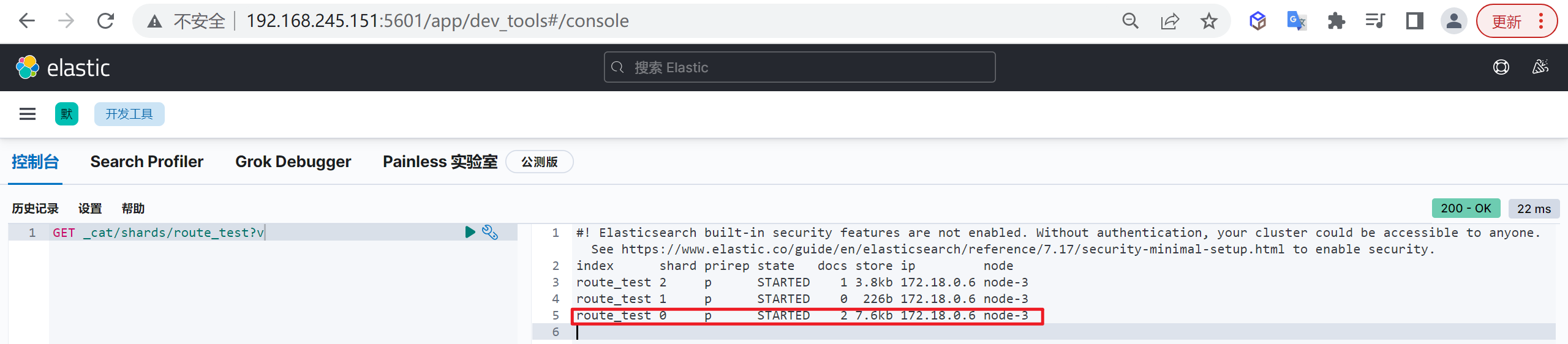
查询索引数据
GET route_test/_search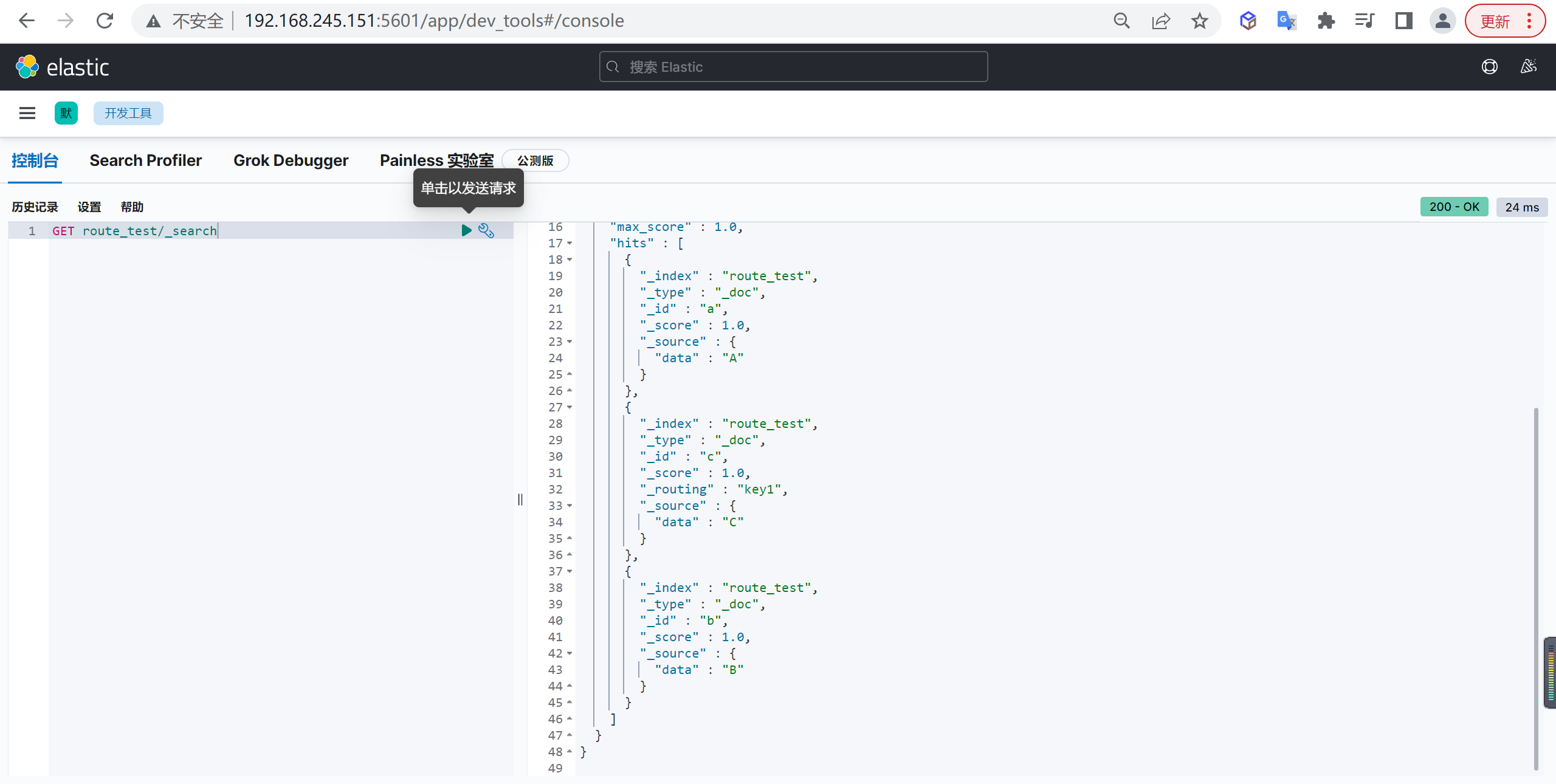
我们又插入了1条 docid=c 的新数据,但这次我们指定了路由,路由的值是一个字符串”key1”,通过查看shard信息,能看出这条数据路由到了0号shard,也就是说用”key1”做路由时,文档会写入到0号shard。
指定路由插入
接着我们使用该路由再插入两条数据,但这两条数据的 docid 分别为之前使用过的 “a”和”b”
再次插入数据
插入 docid=a 的数据,并指定 routing=key1
PUT route_test/_doc/a?routing=key1&refresh
{
"data": "A with routing key1"
}注意返回的状态为updated,之前的三次插入返回都为created
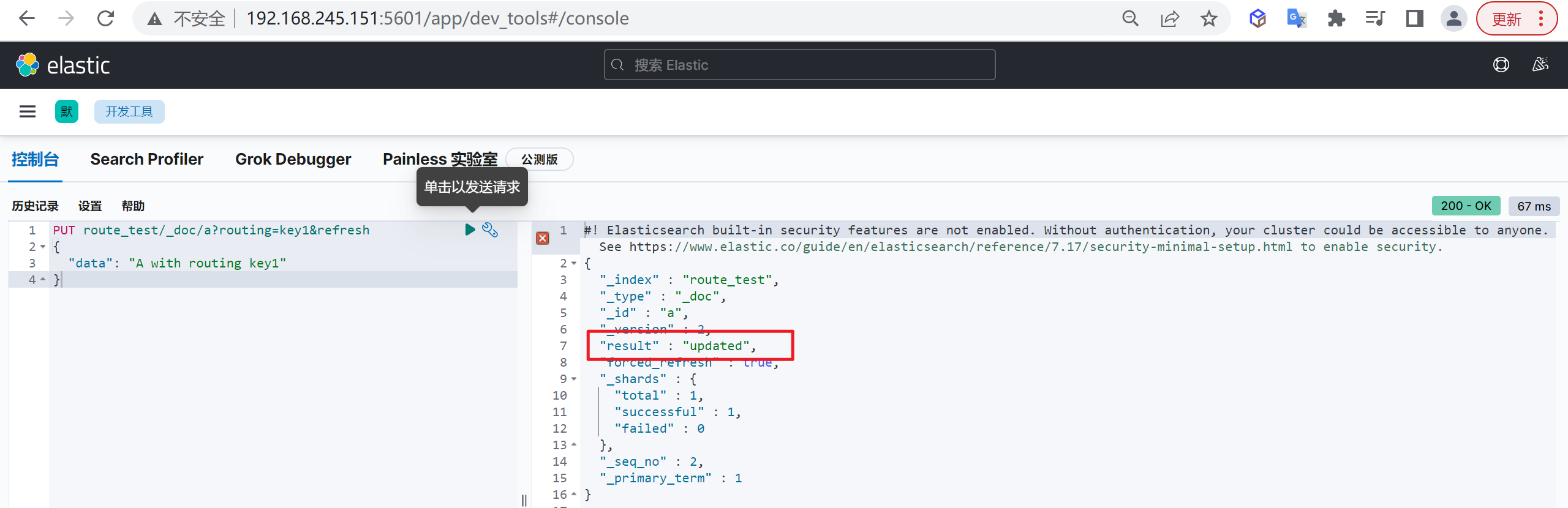
查看分片
我们插入数据后再次来查看分片信息
GET _cat/shards/route_test?v我们发现分片的数据没有变化
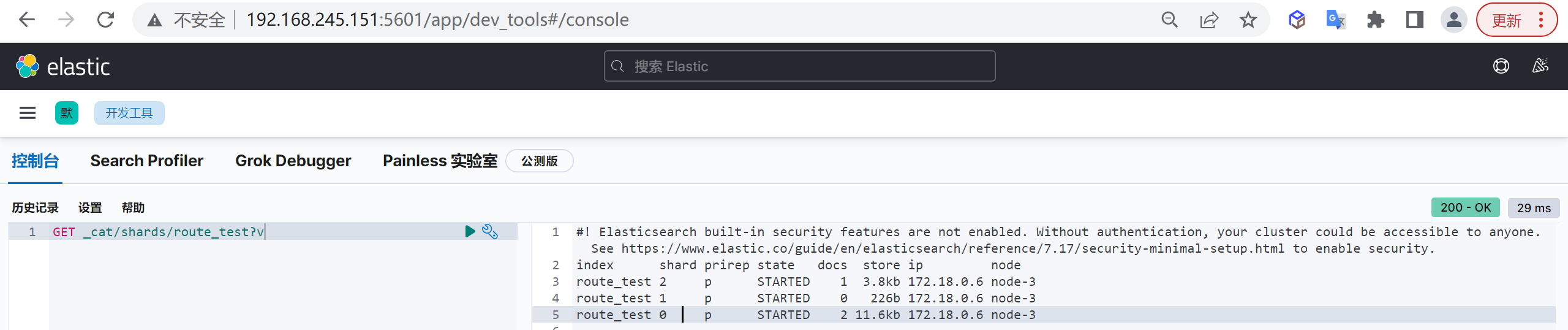
查询数据
GET route_test/_search之前 docid=a 的数据就在0号shard中,这次依旧写入到0号shard中了,因为docid重复,所以文档被更新了
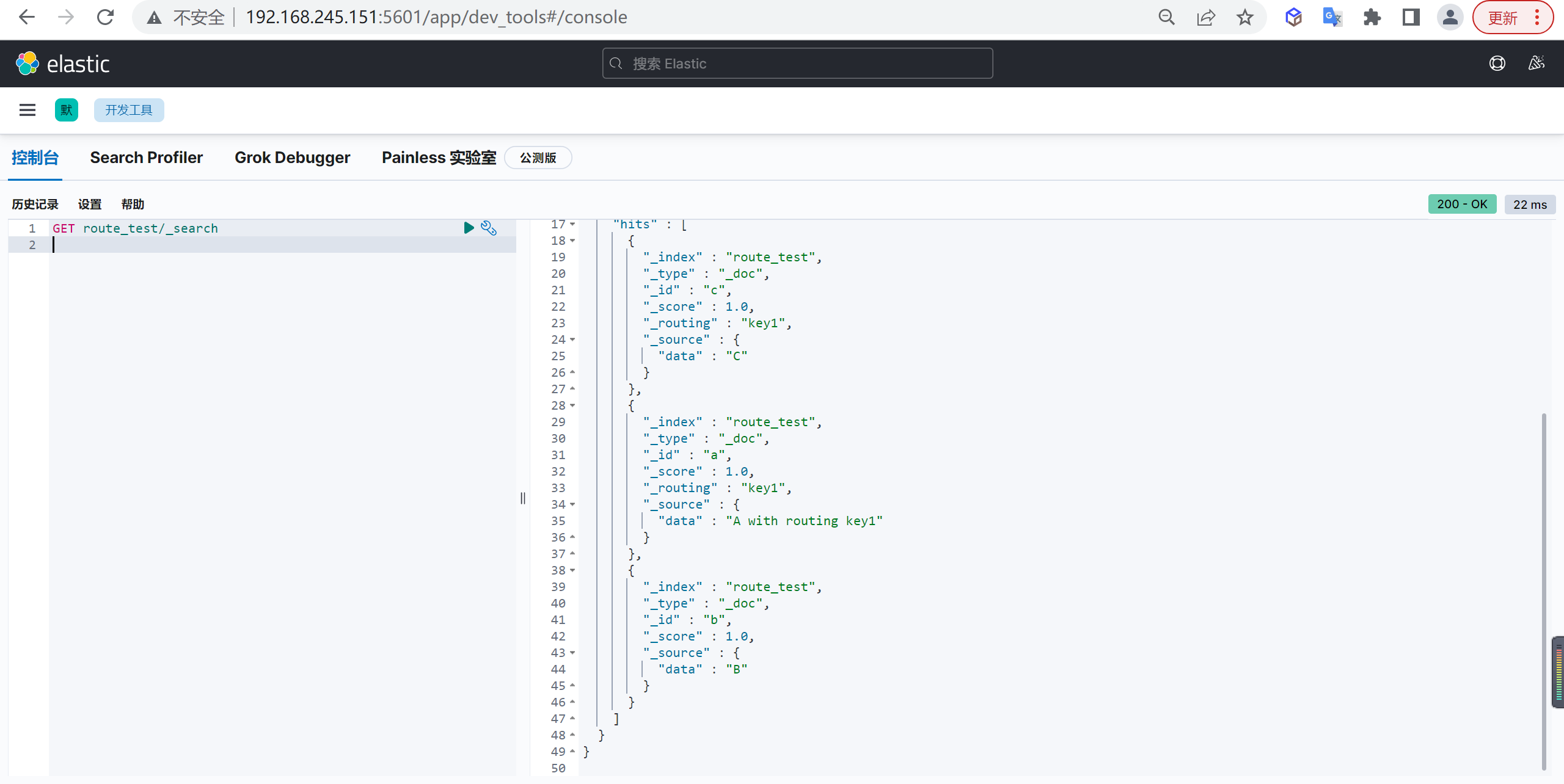
再次插入数据
这次插入 docid=b的数据,使用key1作为路由字段的值
PUT route_test/_doc/b?routing=key1&refresh
{
"data": "B with routing key1"
}我们发现这次变成创建了
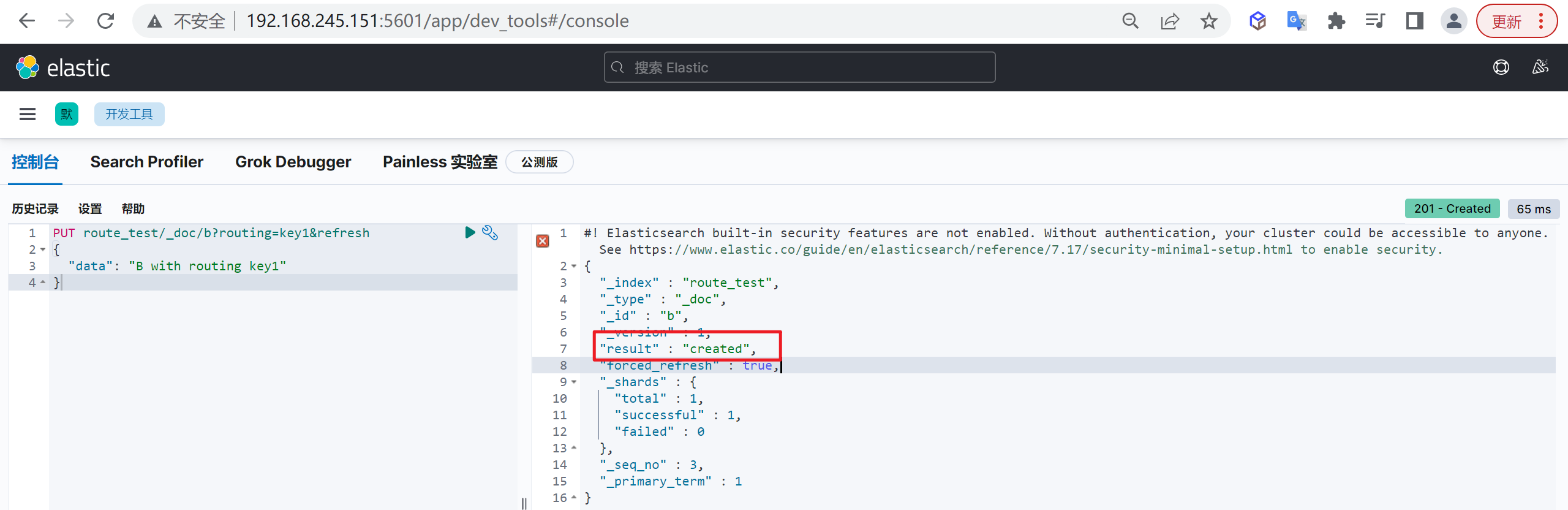
查看分片信息
我们再次查看分片信息
GET _cat/shards/route_test?v我们发现数据存储到了0分片中
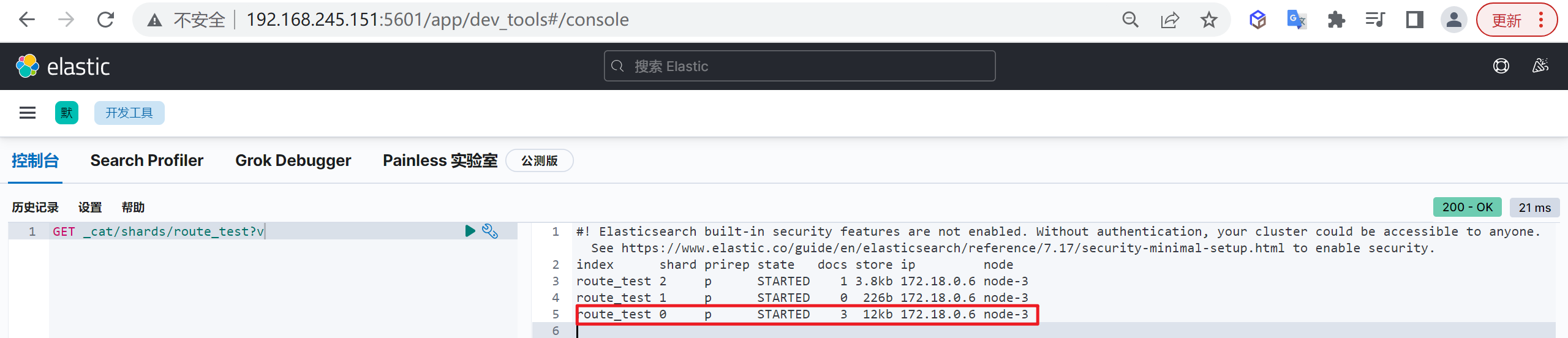
查询数据
我们再次来查询数据
GET route_test/_search和上面插入
docid=a的那条数据相比,这次这个有些不同,我们来分析一下
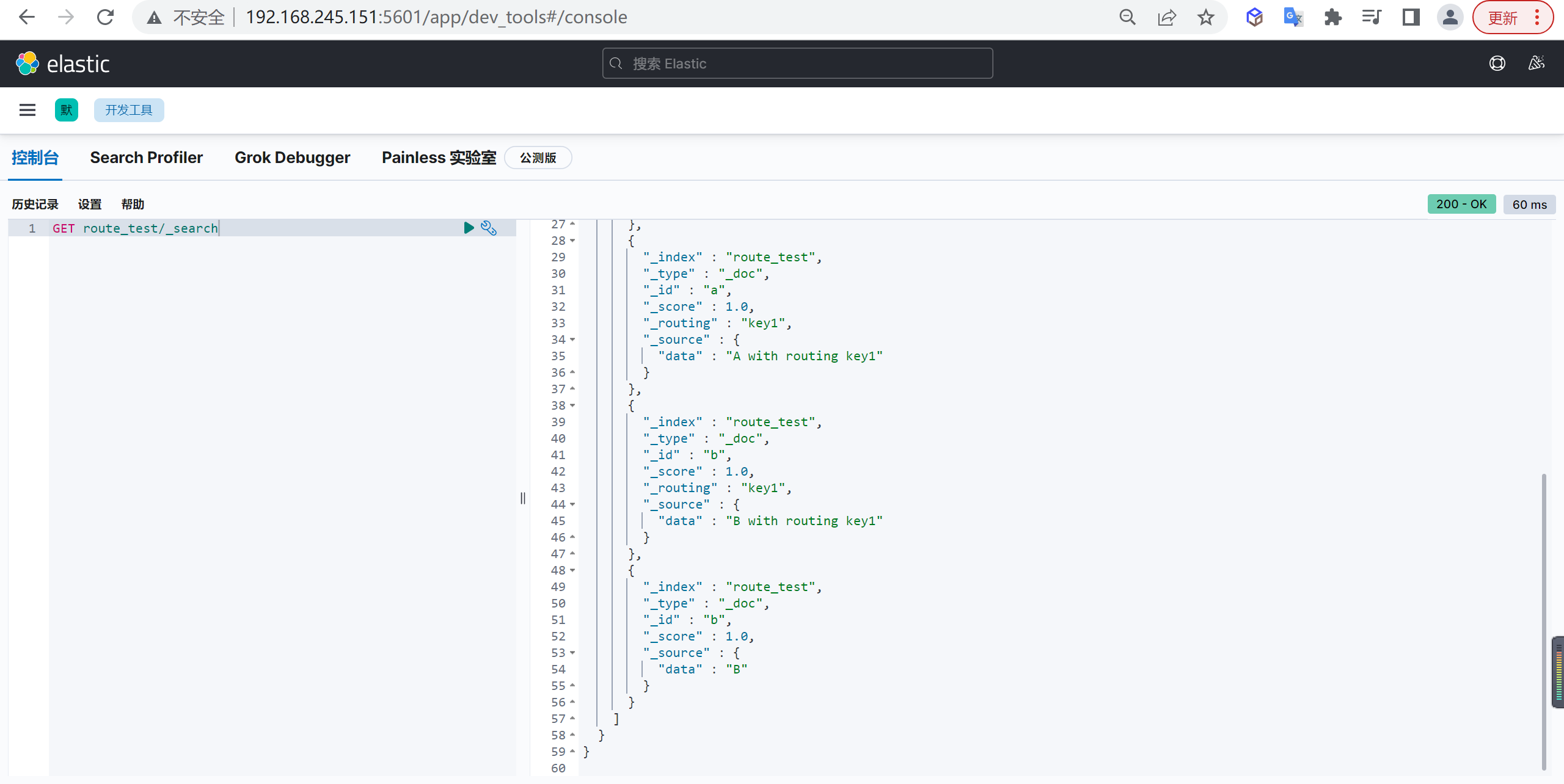
路由带来的问题
这个就是我们自定义routing后会导致的一个问题:docid不再全局唯一
ES shard的实质是Lucene的索引,所以其实每个shard都是一个功能完善的倒排索引,ES能保证docid全局唯一是采用docid作为了路由,所以同样的docid肯定会路由到同一个shard上面,如果出现docid重复,就会update或者抛异常,从而保证了集群内docid唯一标识一个doc。
但如果我们换用其它值做routing,那这个就保证不了了,如果用户还需要docid的全局唯一性,那只能自己保证了,因为docid不再全局唯一,所以doc的增删改查API就可能产生问题
索引别名
别名,有点类似数据库的视图,别名一般都会和一些过滤条件相结合,可以做到即使是同一个索引上,让不同人看到不同的数据
别名的作用
在开发中,一般随着业务需求的迭代,较老的业务逻辑就要面临更新甚至是重构,对于es来说为了适应新的业务逻辑,就要对原有的索引做一些修改,比如对某些字段做调整
而做这些操作的时候,可能会对业务造成影响,甚至是停机调整等问题,因为es提供了索引的别名来解决这个问题,索引的别名就像一个快捷方式或者是软连接,可以指向一个或者多个索引,也可以给任意一个需要索引名的API来使用
别名操作
下面我们看下别名的基本操作
查询别名
直接调用
_aliasAPI的GET方法可以看到索引的别名
GET logstash-village-2022.08.22/_alias我们看到现在可以看到当前的索引有一个别名
logstash-village
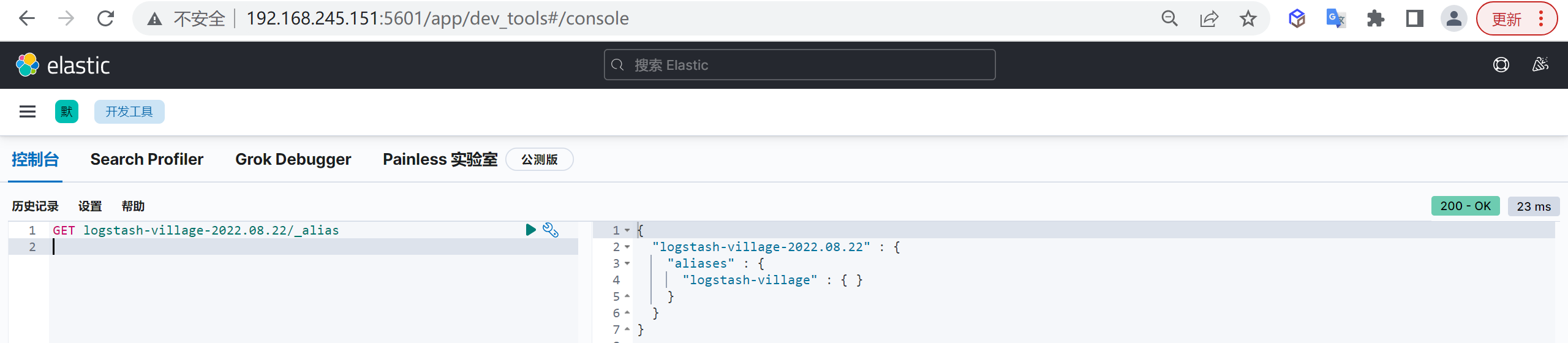
别名查询
我们查询的时候可以指定别名进行查询
GET logstash-village/_search
{
"query": {
"match": {
"name": "龙苑居住区"
}
}
}这样我们可以通过别名查询出来数据的
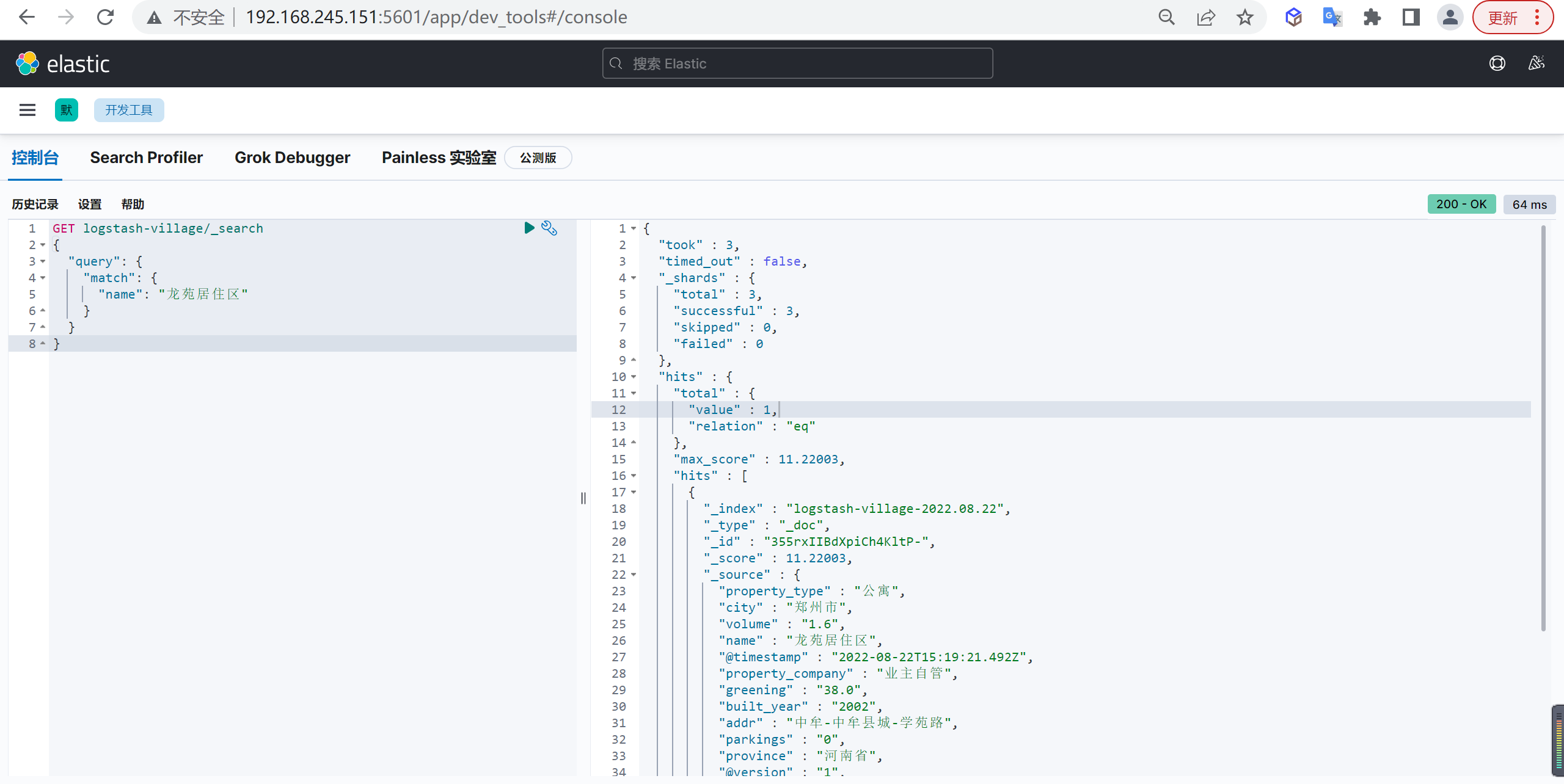
创建别名
我们还可以在建立一个别名,别名和索引的关系是多对多的关系,一个索引可以有多个别名,同样一个别名也可以有多个索引
POST /_aliases
{
"actions": [{
"add": {
"index": "logstash-village-2022.08.22",
"alias": "logstash-village-1.0"
}
}]
}这样我们就创建了一个别名
logstash-village-1.0
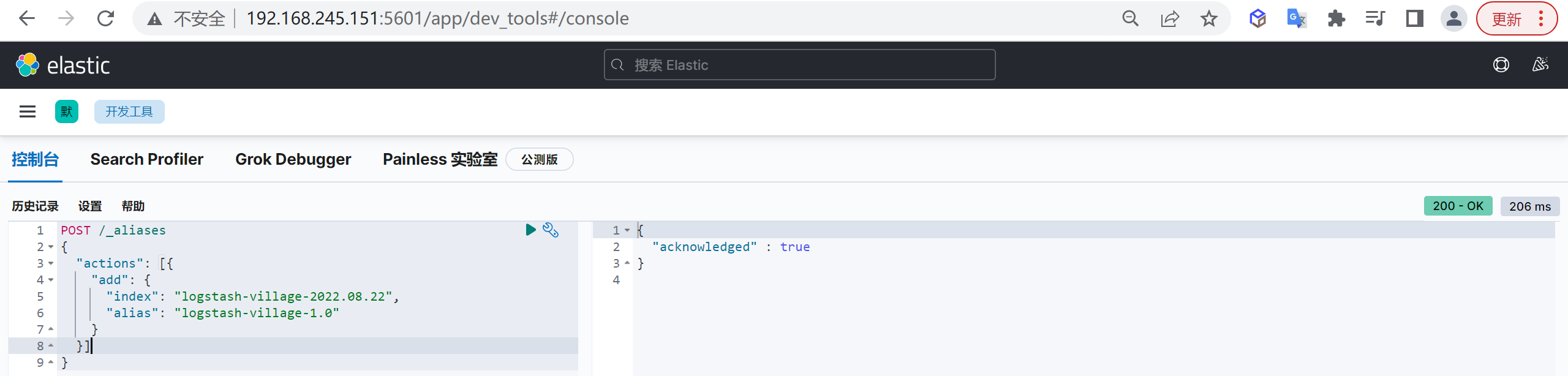
接下来我们直接进行别名查询就好
GET logstash-village-1.0/_search
{
"query": {
"match": {
"name": "龙苑居住区"
}
}
}这样就检索出来数据了
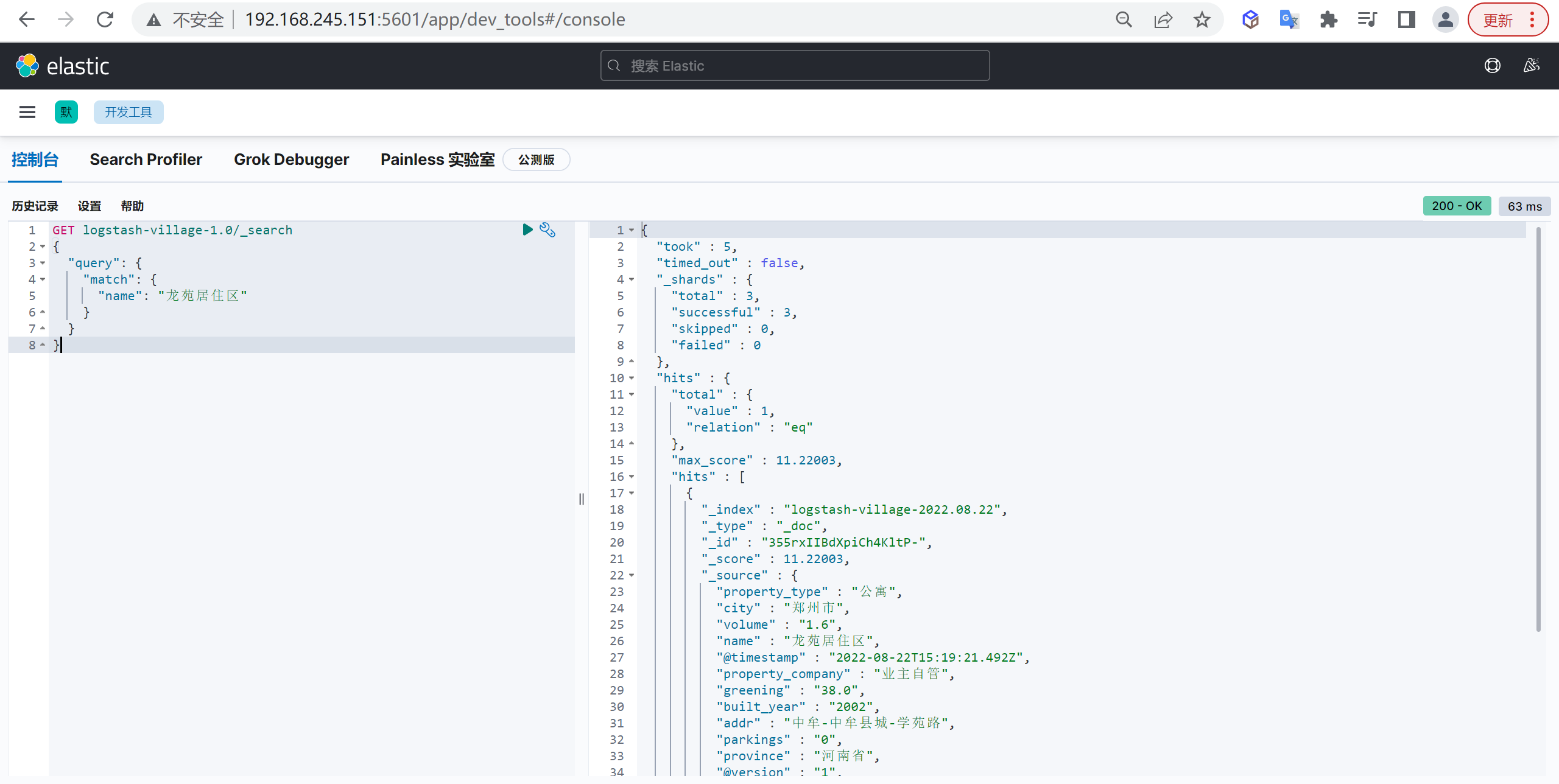
别名修改
有时候还需要修改别名,特别是涉及到索引迁移的时候,修改操作我们可以实现运行中的es集群无缝切换索引,我们可以将索引指向一个新准备的别名中,也可以为别名关联新的索引
POST /_aliases
{
"actions": [
{
"remove": {
"index": "logstash-village-2022.08.22",
"alias": "logstash-village-1.0"
}
},
{
"add": {
"index": "logstash-village-2022.08.22",
"alias": "logstash-village-2.0"
}
}
]
}这样我们就可以做到无缝的索引别名修改了
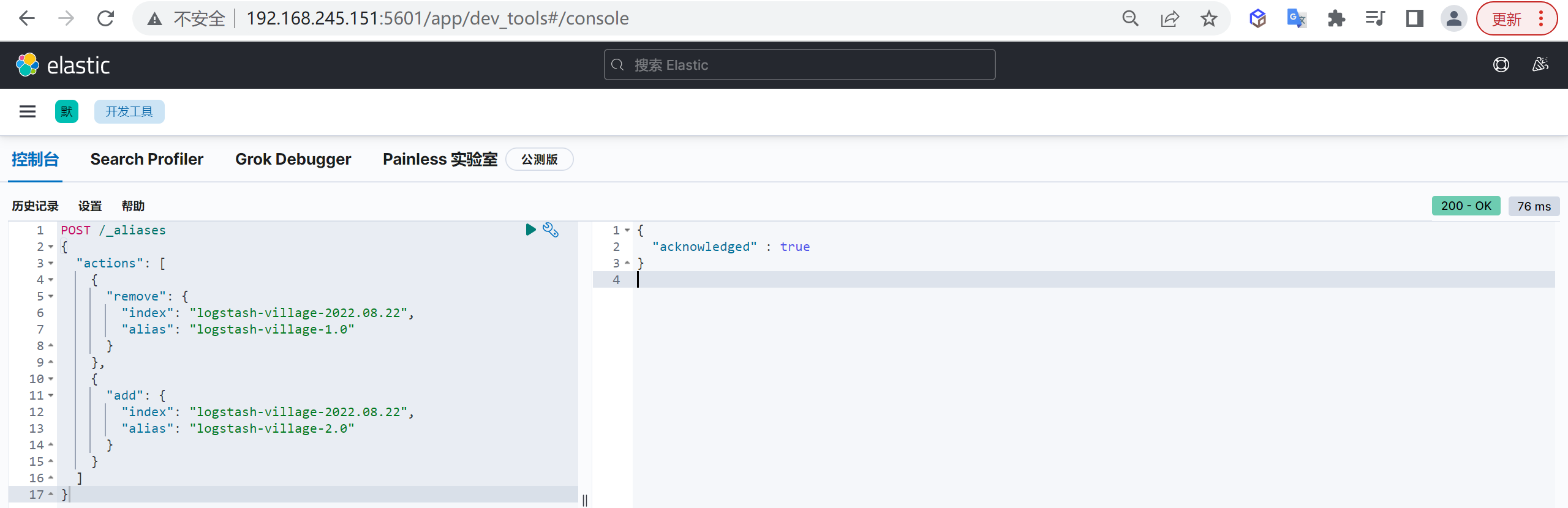
我们再来查询试试
GET logstash-village-2.0/_search
{
"query": {
"match": {
"name": "龙苑居住区"
}
}
}过滤器别名
我们可以创建一个带过滤器的别名,这样别人通过这个别名查询的时候,数据都是筛选过后的数据,起到一个数据权限的作用
创建别名
下面我们创建一个只能查询河南省房产信息的别名
POST /_aliases
{
"actions": [
{
"add": {
"index": "logstash-village-2022.08.22",
"alias": "logstash-village-hn",
"filter": {
"term": {
"province": "河南省"
}
}
}
}
]
}这样我们就创建了一个只能查询到河南省房产信息的别名
logstash-village-hn
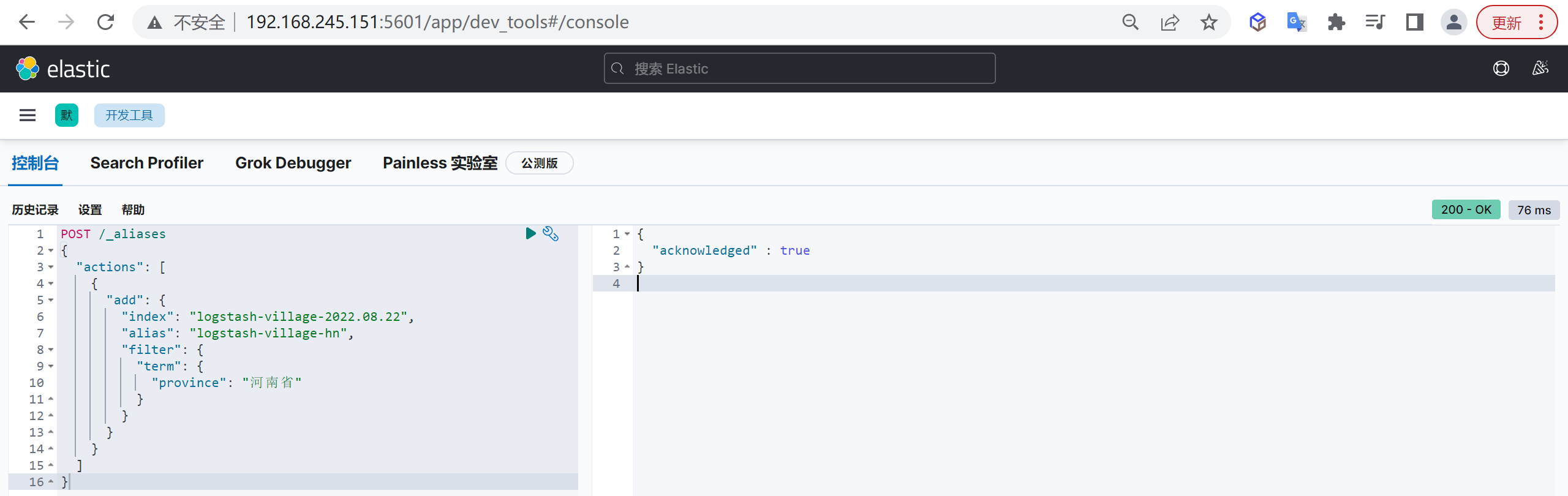
数据查询
下面我们通过这个别名查询北京
沁春家园的小区信息
GET logstash-village-hn/_search
{
"query": {
"match": {
"name": "沁春家园"
}
}
}我们发现根本就查询不出来
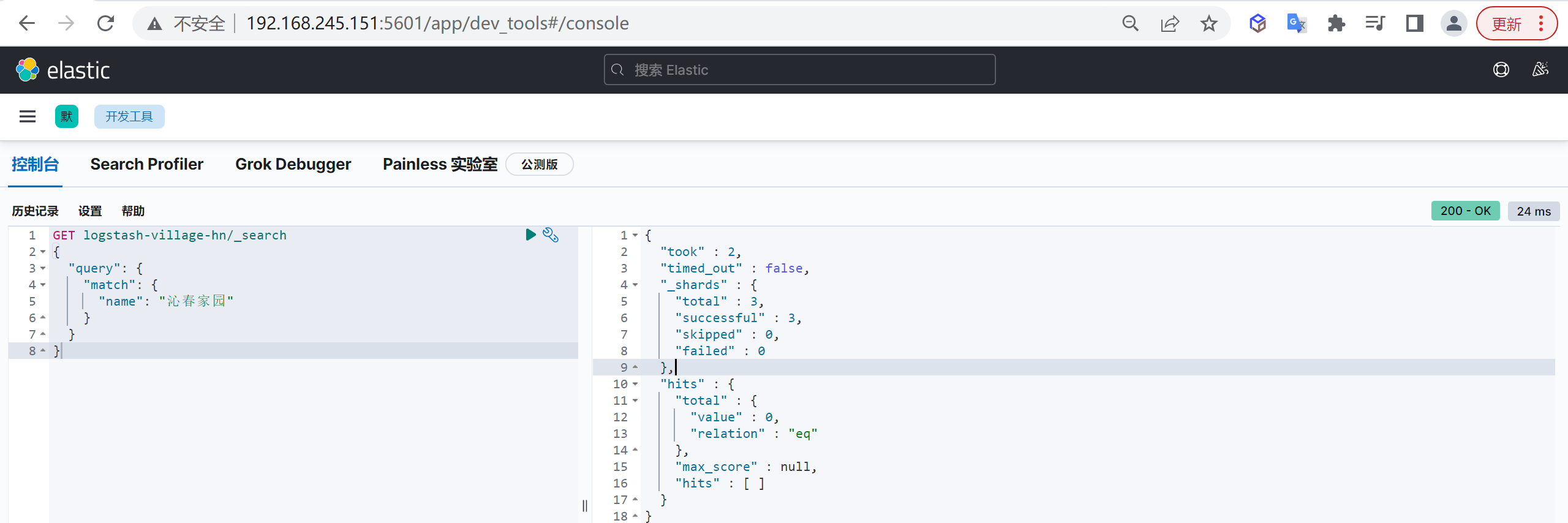
但是我们查询
龙苑居住区却可以查询出来
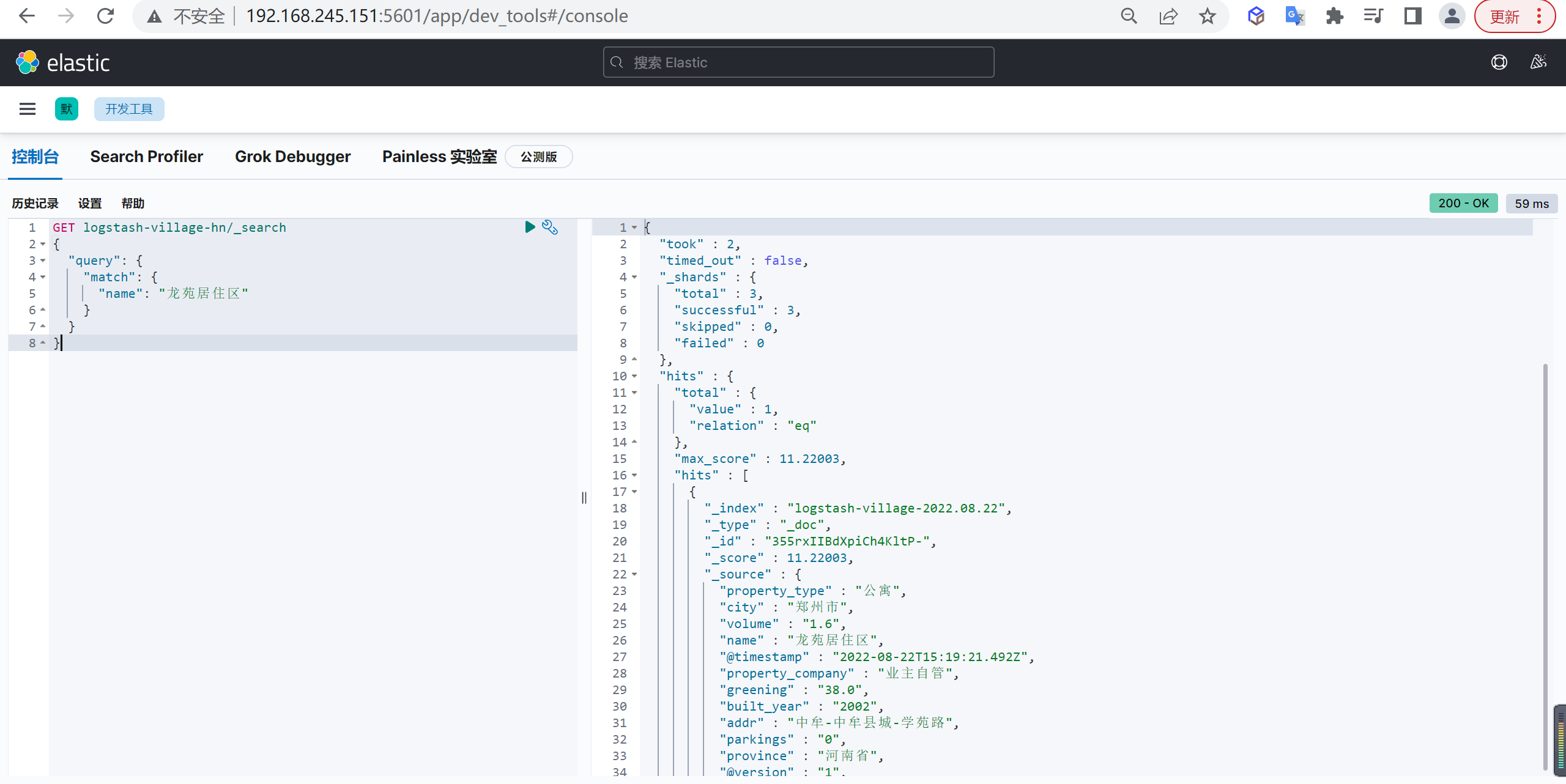
路由别名
我们上面介绍了路由的使用,但是有一个问题,我们查询的时候都需要携带路由参数,很麻烦,我们可以将我们的路由参数写进别名中,这样查询起来会更加方便
创建别名
下面我们就创建一个以
key为路由键
POST /_aliases
{
"actions": [
{
"add": {
"index": "logstash-village-2022.08.22",
"alias": "logstash-village-route_key",
"routing": "key"
}
}
]
}这样我们就以
key为路由键创建了一个索引
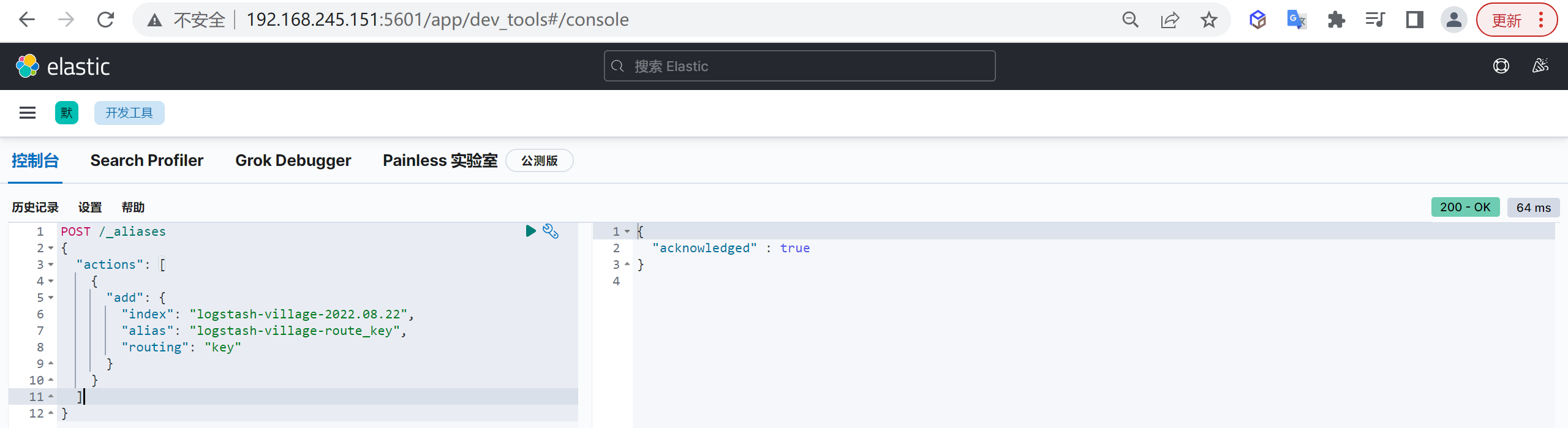
数据查询
下面我们就对索引进行一些查询
GET logstash-village-route_key/_search
{
"query": {
"match": {
"name": "沁春家园"
}
}
}我们看到查询
沁春家园是可以查询出来数据的,但是查询龙苑居住区是查询不出来数据的
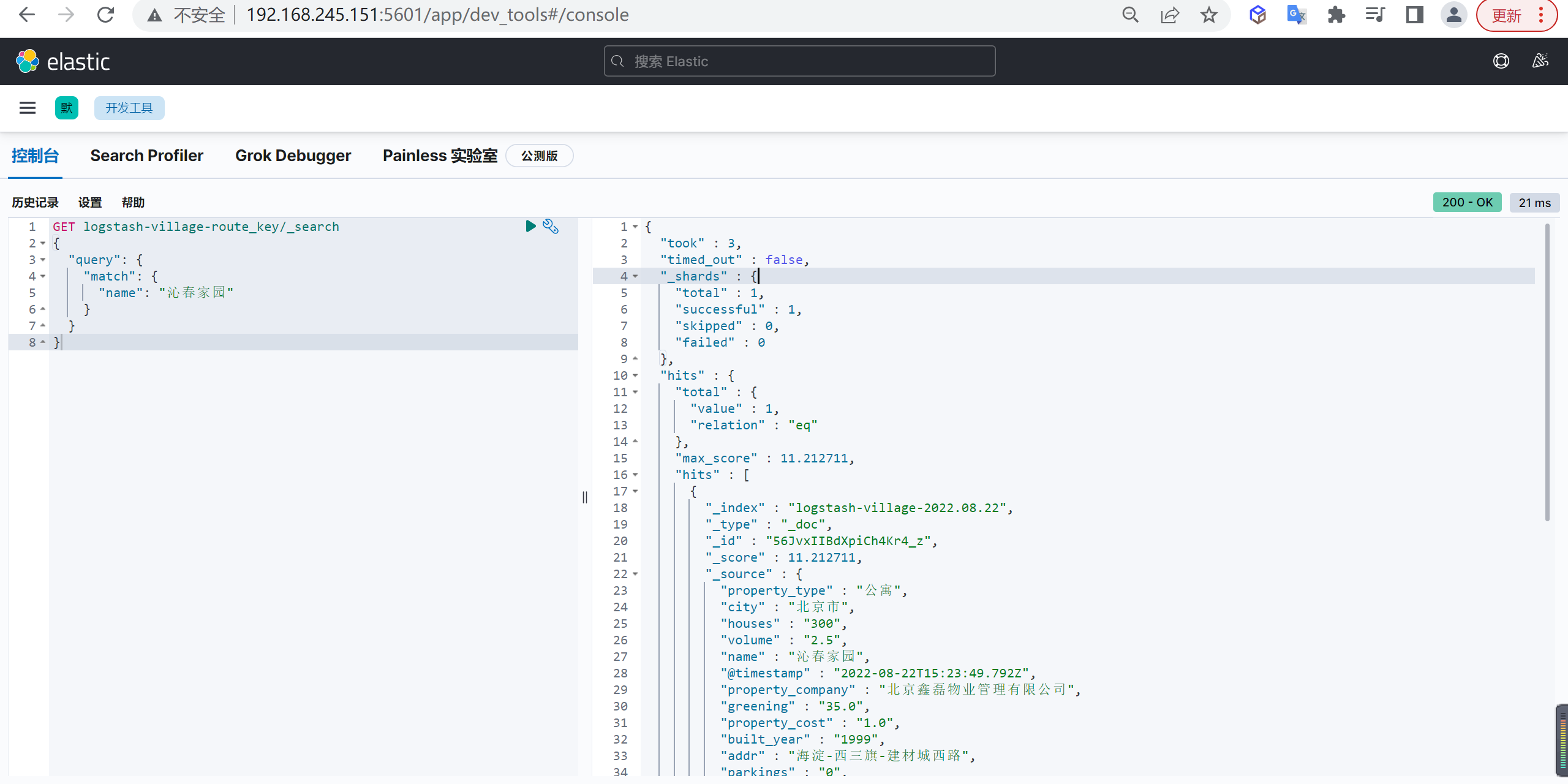
删除别名
创建了很多的别名,有时候别名不用了,需要定期删除以下
查看所有别名
现在我们查询以下当前索引下的别名有哪些
GET logstash-village-2022.08.22/_alias当前有这么多的别名,我们准备删除一些
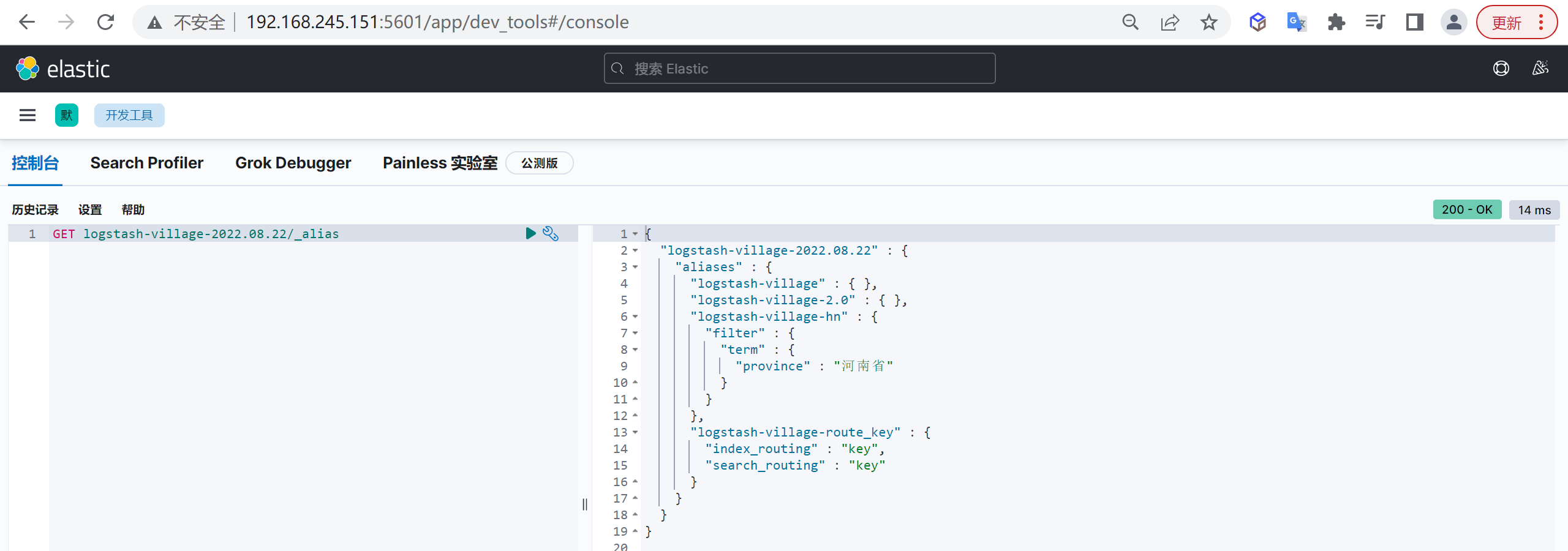
删除别名
删除的时候直接指定别名就可以的
DELETE logstash-village-2022.08.22/_alias/logstash-village-route_key这样我们就把当前这个别名删除了

重建索引
Elasticsearch使用时间长了后,到了后期可能有各种原因重建索引
ES是不支持索引字段类型变更的,不可变的原因是一个字段的类型进行修改之后,ES会重新建立对这个字段的索引信息,影响到ES对该字段分词方式,相关度,TF/IDF倒排索引创建等。
索引重建的步骤
- 创建旧索引
- 给索引创建别名
- 向oldindex中插入数据
- 创建新的索引newindex
- 重建索引
- 实现不重启服务索引的切换
创建旧索引
PUT oldindex
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"price": {
"type": "double"
}
}
}
}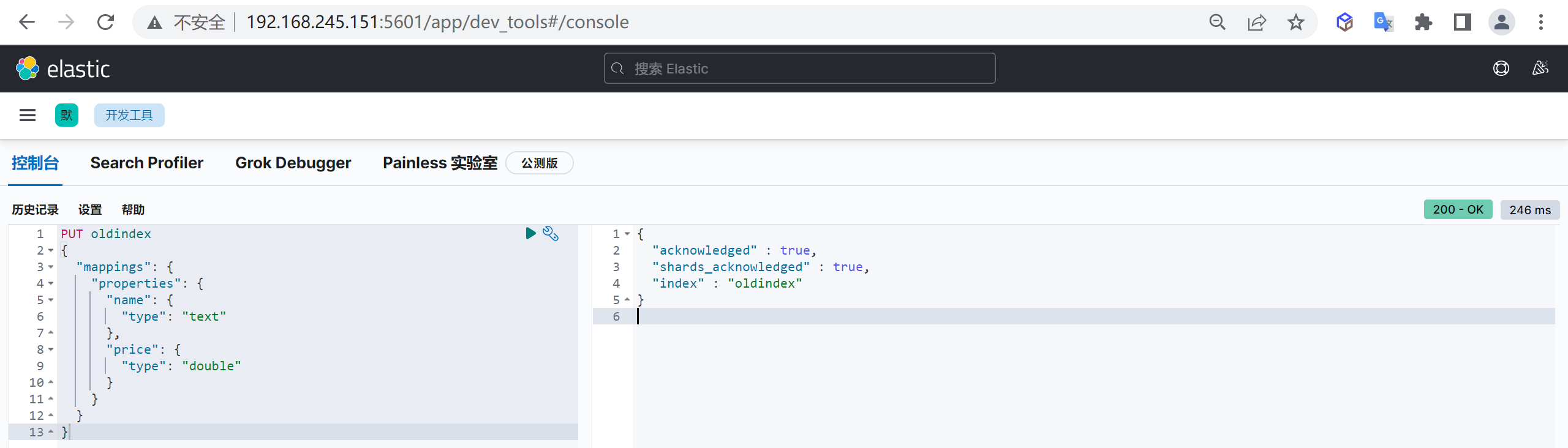
添加数据
POST oldindex/_doc/_bulk
{"create":{"_id":1}}
{"name":"name 01","price":1}
{"create":{"_id":2}}
{"name":"name 02","price":2}
{"create":{"_id":3}}
{"name":"name 03","price":3}
{"create":{"_id":4}}
{"name":"name 04","price":4}
{"create":{"_id":5}}
{"name":"name 05","price":5}
{"create":{"_id":6}}
{"name":"name 06","price":6}
{"create":{"_id":7}}
{"name":"name 07","price":7}
{"create":{"_id":8}}
{"name":"name 08","price":8}
{"create":{"_id":9}}
{"name":"name 09","price":9}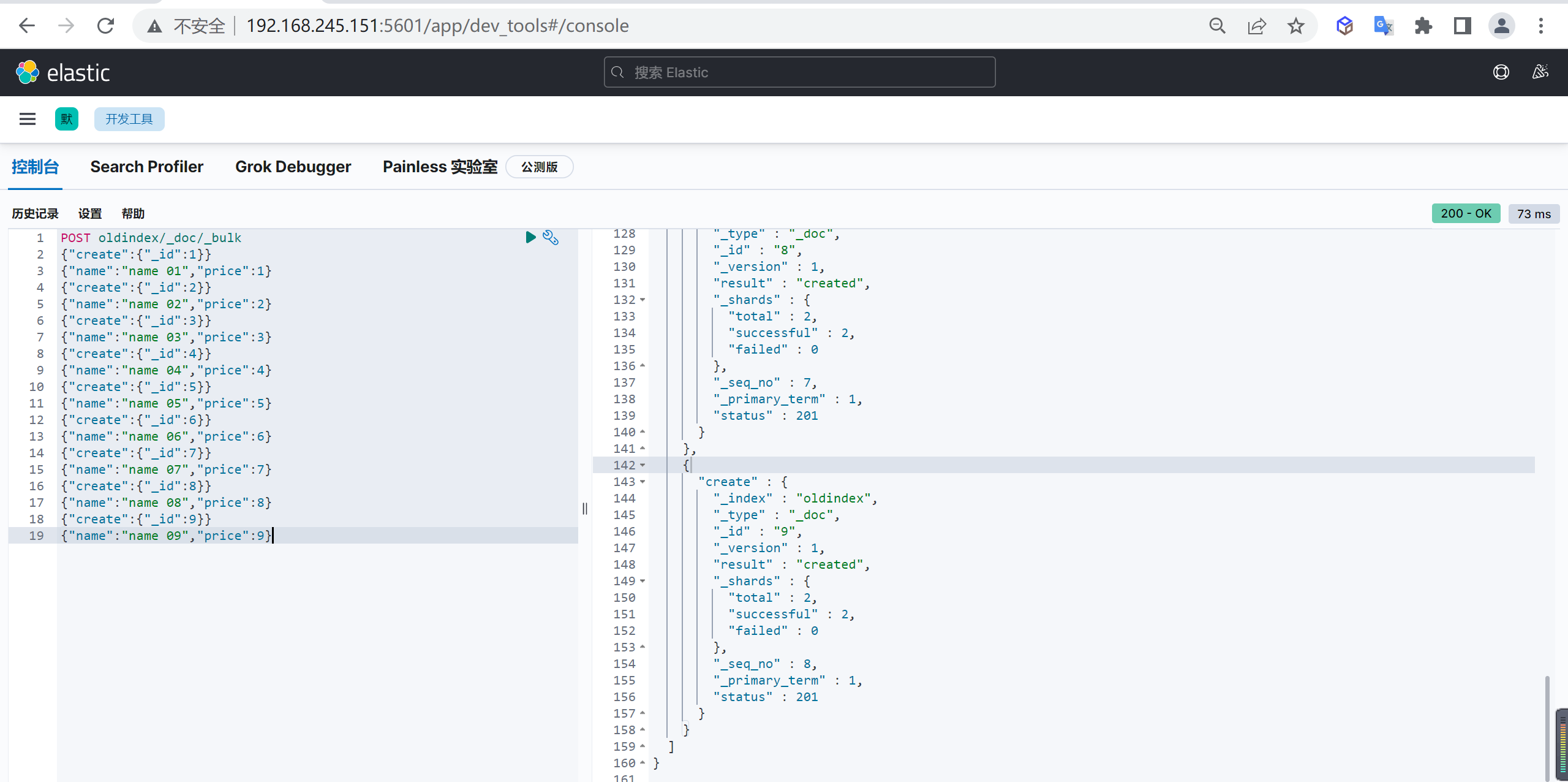
查询数据
GET oldindex/_search
{
}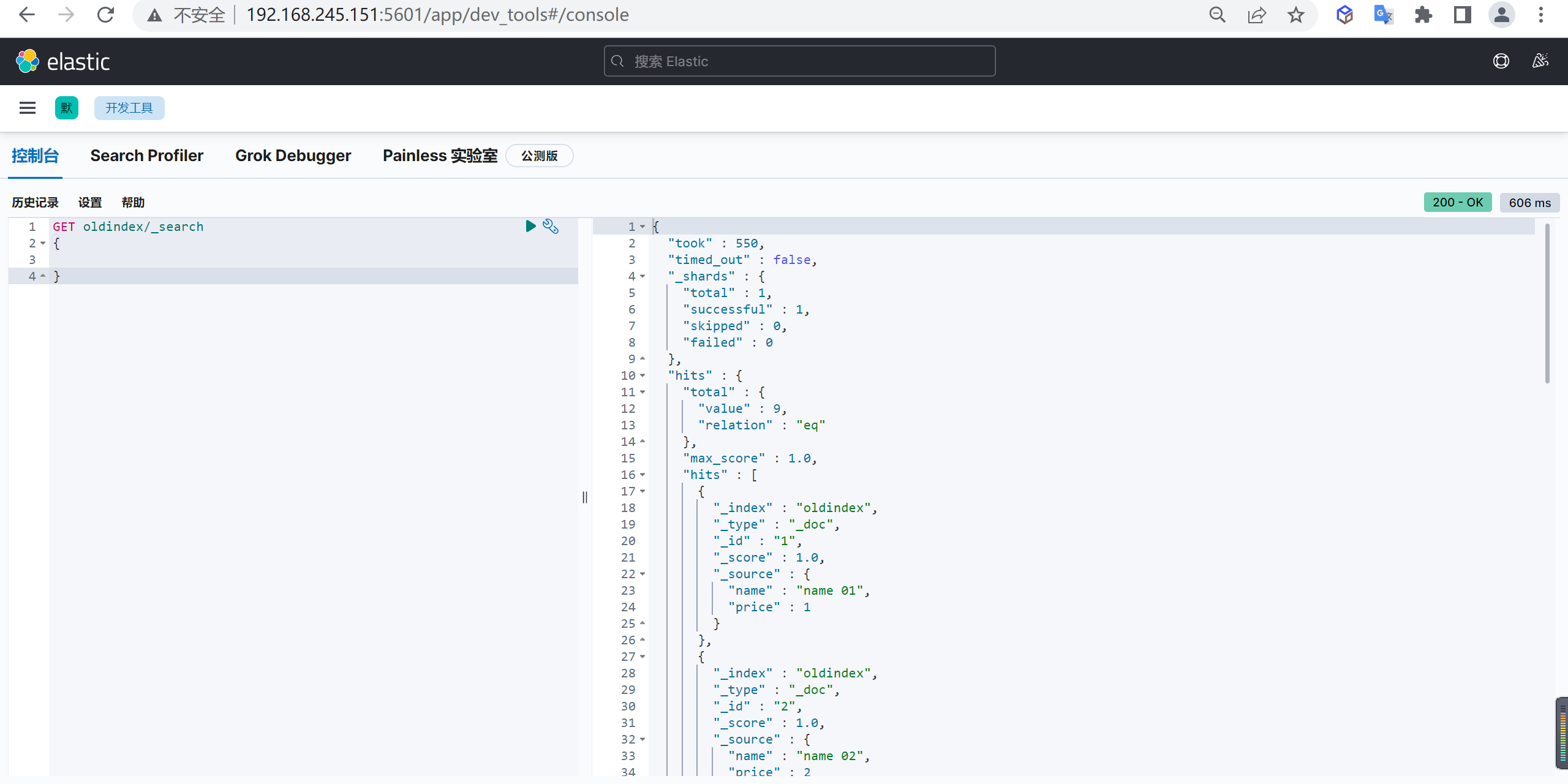
创建别名
POST /_aliases
{
"actions": [{
"add": {
"index": "oldindex",
"alias": "search_index"
}
}]
}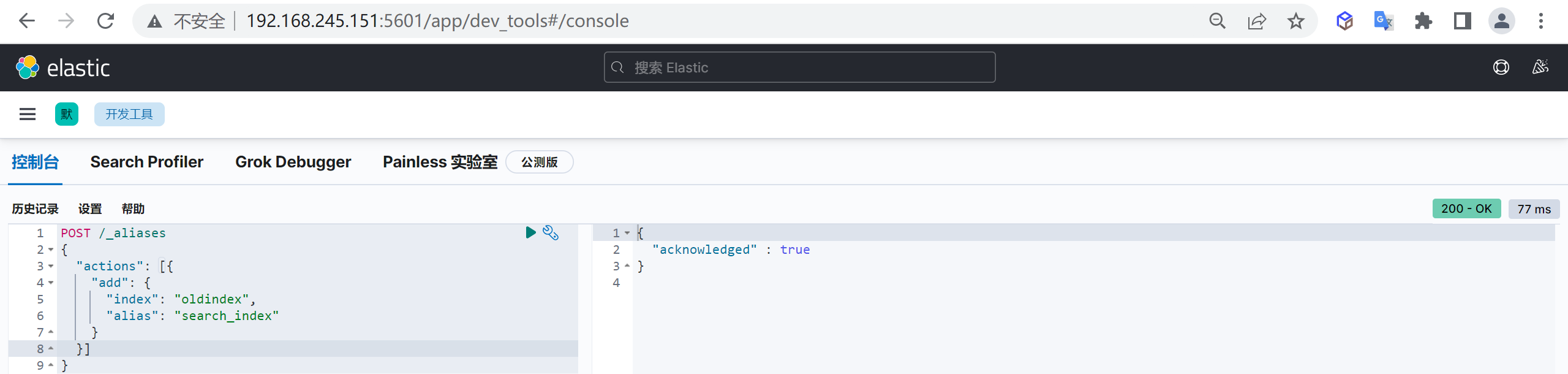
查询数据
我们使用别名查询数据
GET search_index/_search
创建新索引
根据需求我们创建一个新的索引,价格字段改为integer类型
PUT newindex
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"price": {
"type": "integer"
}
}
}
}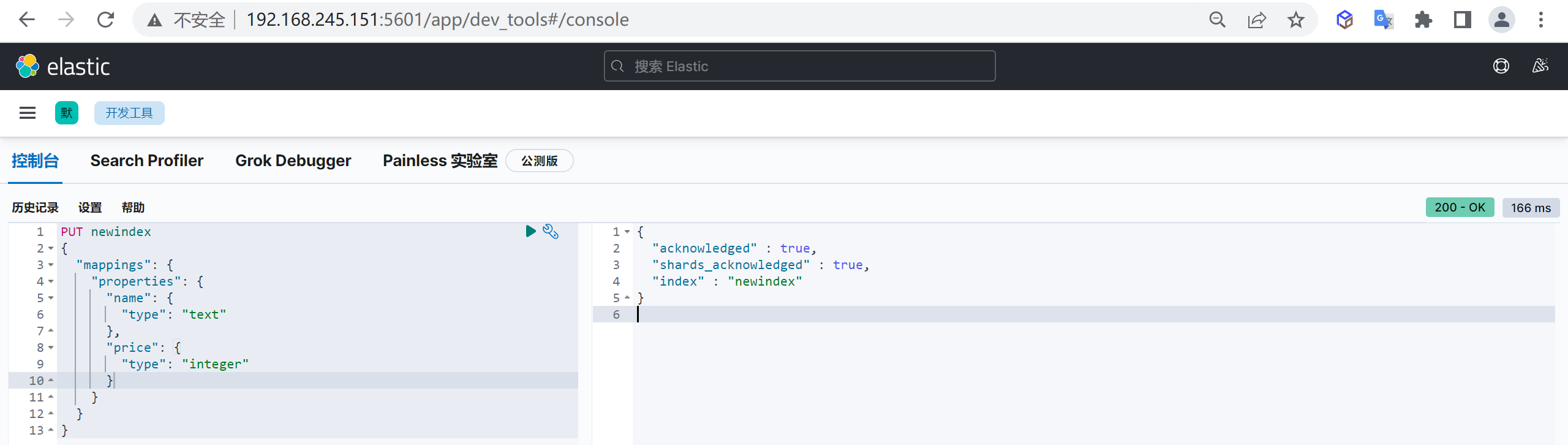
重建索引
数据量大的话可以异步执⾏,如果 reindex 时间过长,建议加上
wait_for_completion=false的参数条件,这样reindex将直接返回taskId
POST _reindex?wait_for_completion=false
{
"conflicts": "proceed", // 如果新的索引中数据冲突,程序继续往下执行,删除则会导致程序会终止
"source": {
"index": "oldindex" // 表示从oldindex中同步数据
},
"dest": {
"index": "newindex", // 表示数据插入新索引newindex中
"op_type": "create" // 数据插入的类型为创建,如果存在就会版本冲突
}
}更多参数
更高级的用法可以参考下下面的例子
POST _reindex?wait_for_completion=false
{
"size": 5, // 表示只获取5条数据插入到新的索引中
"conflicts": "proceed", // 如果新的索引中数据冲突,程序继续往下执行,删除则会导致程序会终止
"source": {
"size": 2, // 默认情况下,_reindex使用1000进行批量操作,调整批量插入2条
"index": "oldindex", // 表示从oldindex,类型product中查询出price字段的值
"_source": [
"price" //只需要同步price字段
],
"query": {
"range": {
"price": {
"gte": 2,
"lte": 8
}
}
}
},
"dest": {
"index": "newindex", // 表示数据插入新索引newindex中
"op_type": "create" // 数据插入的类型为创建,如果存在就会版本冲突
}
}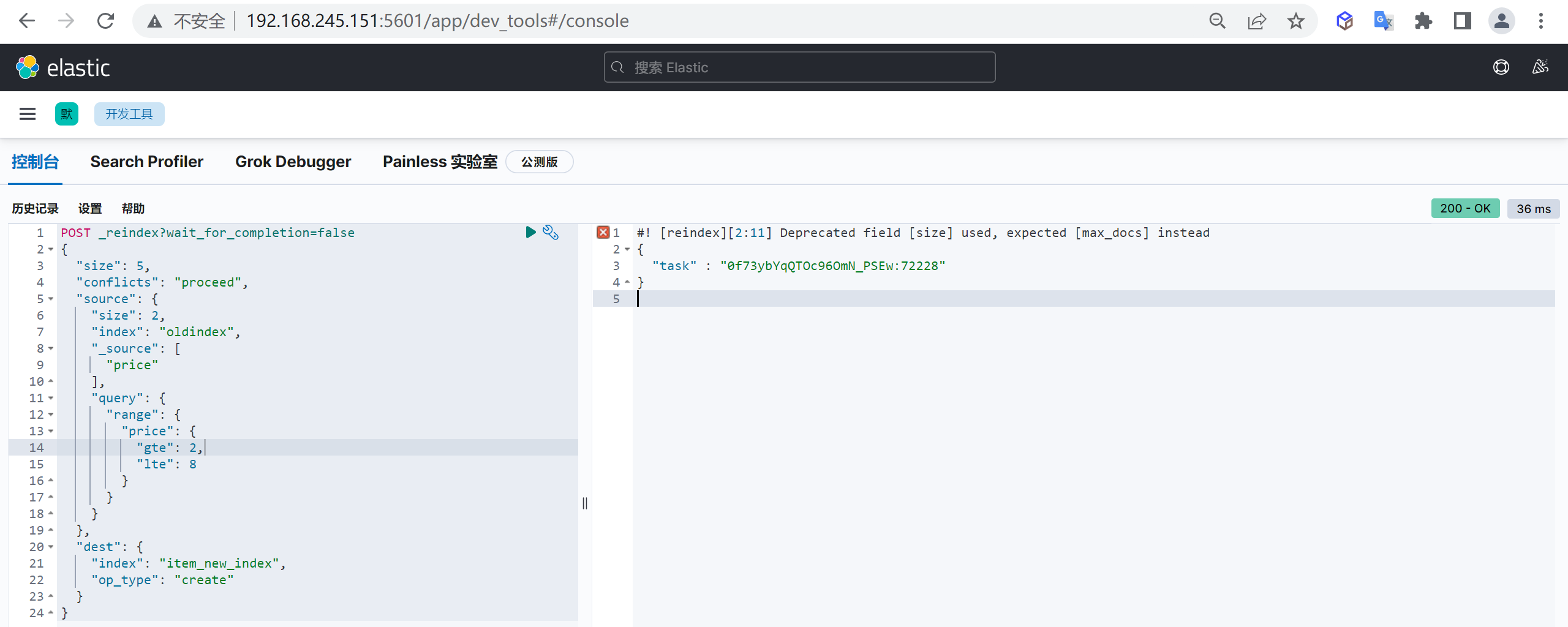
查看任务
GET _tasks/0f73ybYqQTOc96OmN_PSEw:72228
取消任务
如果任务还没有完成,需要取消任务可以使用如下的命令
POST _tasks/0f73ybYqQTOc96OmN_PSEw:72228/_cancel别名切换
我们需要将别名切换到另刚刚重建的索引上,切换索引可以实现不重启服务索引的切换
POST _aliases
{
"actions": [
{
"remove": {
"index": "oldindex",
"alias": "search_index"
}
},
{
"add": {
"index": "newindex",
"alias": "search_index"
}
}
]
}这样就实现了快速索引切换
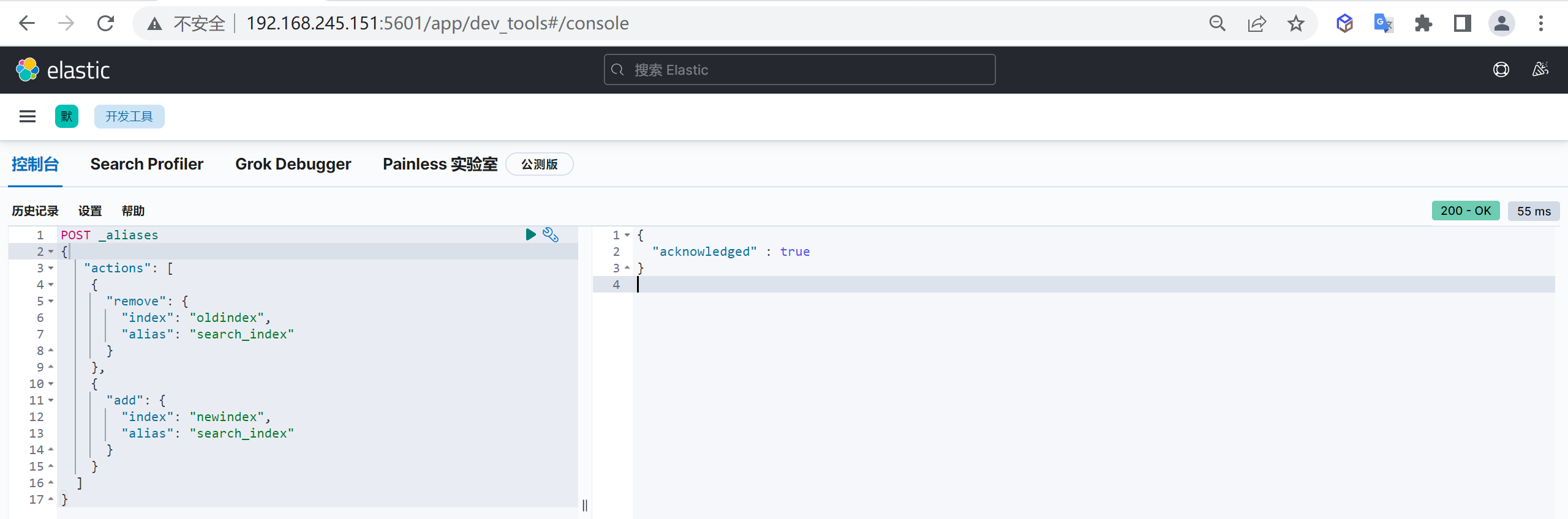
删除旧的索引
DELETE oldindex
查询数据
GET search_index/_search
{}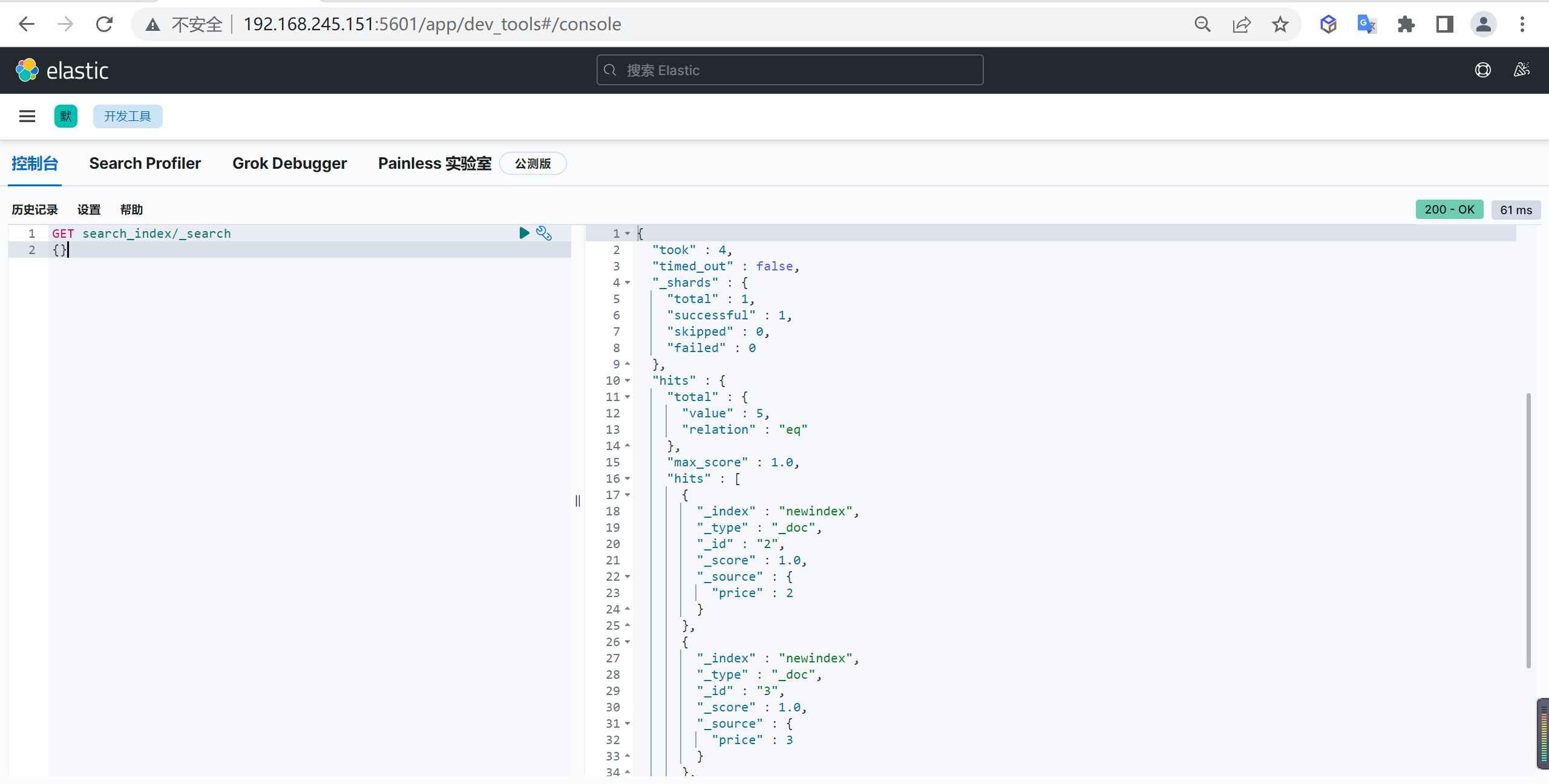
ElasticSearch 集群管理
集群模式
Elasticsearch节点设计支持多种角色,这个是实现集群最重要的前提,节点角色各司其职,也可以任意组合,职责重合。
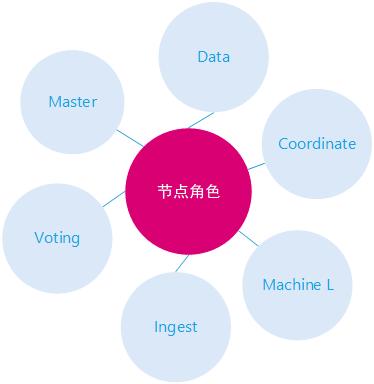
节点角色说明
- Master,集群管理
- Voting,投票选举节点
- Data,数据节点Ingest,数据编辑节点
- Coordinate,协调节点
- Machine Learning,集群学习节点
单节点
单节点模式默认开启所有节点特性,具备一个集群所有节点角色,可以认为是一个进程内部的集群
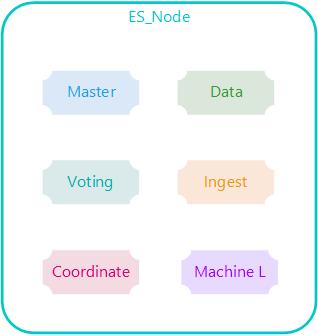
Elasticsearch在默认情况下,不用任何牌配置也可以运行,这也是它设计的精妙之处,相比其它很多数据产品集群配置,如Mongodb,简化了很多,起步入门容易。
基本高可用
elasticsearch集群要达到基本高可用,一般要至少启动3个节点,3个节点互相连接,单个节点包括所有角色,其中任意节点停机集群依然可用,为什么要至少3个节点?因为集群选举算法奇数法则。
数据与管理分离
Elasticserach管理节点职责是管理集群元数据、索引信息、节点信息等,自身不设计数据存储与查询,资源消耗低;相反数据节点是集群存储与查询的执行节点
管理节点与数据节点分离,各司其职,任意数据节点故障或者全部数据节点故障,集群仍可用;管理节点一般至少启动3个,任意节点停机,集群仍正常运行。
数据与协调分离
Elasticsearch内部执行查询或者更新操作时,需要路由,默认所有节点都具备此职能,特别是大的查询时,协调节点需要分发查询命令到各个数据节点,查询后的数据需要在协调节点合并排序,这样原有数据节点代价很大,所以分离职责
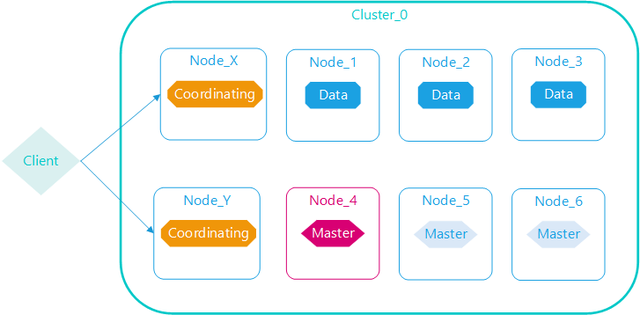
协调读写分离
Elasticsearch设置读写分离指的是在协调节点上,不是数据节点上,集群大量的查询需要消耗协调节点很大的内存与CPU合并结果,同时集群大量的数据写入会阻塞协调节点,所以在协调节点上做读写分离很少必要,也很简单,由集群设计搭建时规划好即可。
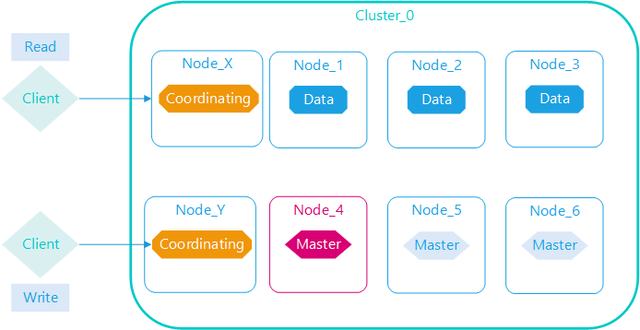
数据节点标签
Elasticsearch给数据节点标签,目的是分离索引数据的分布,在一个集群规模中等以上,索引数据用途多种多样,对于数据节点的资源需求不一样,数据节点的配置可以差异化,有的数据节点配置高做实时数据查询,有的数据节点配置低做历史数据查询,有的数据节点做专门做索引重建。
Elasticsearch集群部署时需要考虑基础硬件条件,集群规模越来越大,需要多个数据中心,多个网络服务、多个服务器机架,多个交换机等组成,索引数据的分布与这些基础硬件条件都密切相关
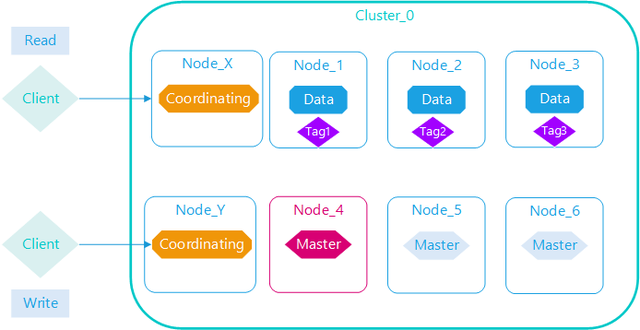
主副分片分离
Elasticsearch集群规模大了之后得考虑集群容灾,若某个机房出现故障,则可以迅速切换到另外的容灾机房
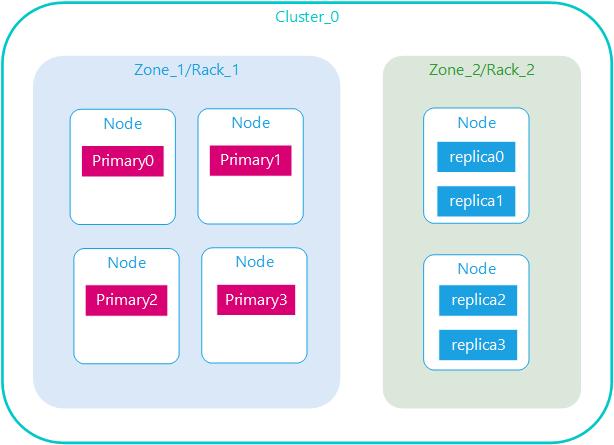
跨集群操作
Elasticsearch单个集群规模不能无限增长,理论上可以,实际很危险,通过创建多个分集群分解,集群直接建立直接连接,客户端可以通过一个代理集群访问任意集群,包括代理集群本身数据。
Elasticsearch集群支持异地容灾,采用的是跨集群复制的机制,与同一集群主分片副本分片分离是不同的概念,2个集群完全是独立部署运行,仅数据同步复制。
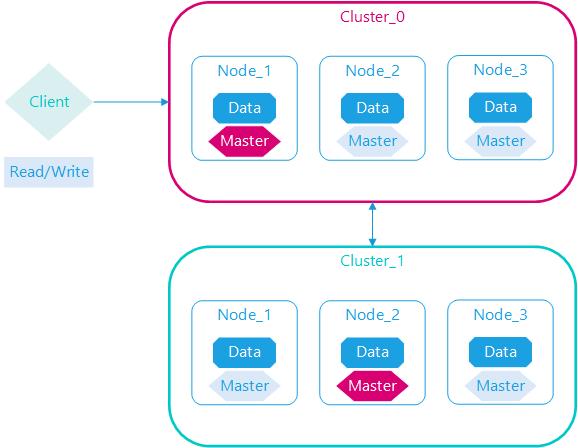
跨集群版本操作
elasticsearch版本更新很快,已知问题修复很快,新特性新功能推出很快,一日不学,如隔三秋。有的集群数据重要性很高,稳定第一,不能随意升级,有的业务场景刚好需要最新版本新功能新特性支持。
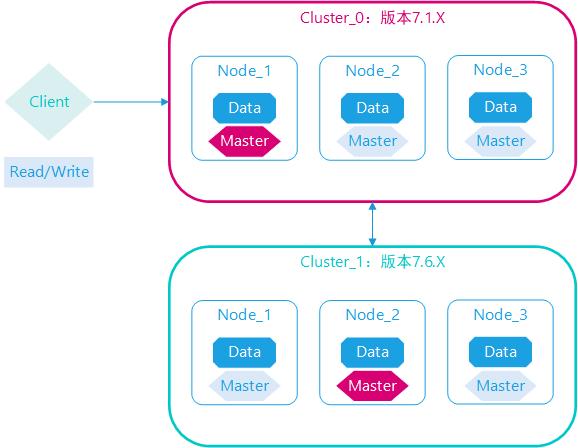
集群管理
集群健康检查
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是集群健康 , 它在
status字段中展示为green、yellow或者red
查看集群状态
可以通过如下的命令查看集群的状态
GET /_cluster/health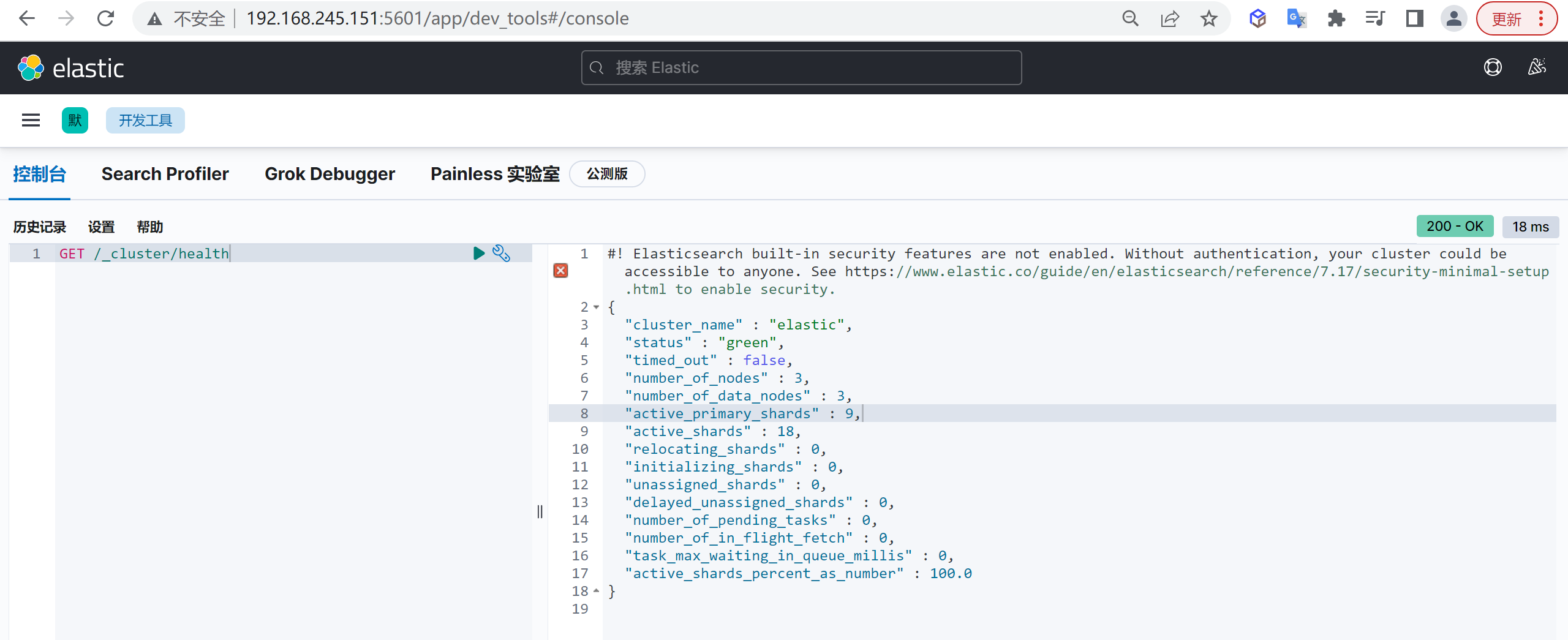
集群状态
status字段是我们最关心的,status字段指示着当前集群在总体上是否工作正常,它的三种颜色含义如下
green:所有的主分片和副本分片都正常运行yellow:所有数据可用,但有些副本尚未分配(集群功能完全)red:有主分片没能正常运行。
注意: 当集群处于红色状态时,正常的分片将继续提供搜索服务,但你可能要尽快修复它。
分片和副本
什么是分片
因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片,每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在,即:这个过程对用户来说是透明的
ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是20亿。
分片的意义
分片存在的重要原因有以下两个:
- 允许水平分扩展容量。
- 允许在分片之上进行分布式的,并行的操作,从而提高其吞吐量。
分片的本质
分片质上是一个lucene的索引,一个分片就是一个lucene索引
一个elasticsearch索引就是一个lucene索引的集合,当进行查询时,会将查询请求发送到每一个属于当前elasticsearch索引的分片上,然后将每个分片得到的结果进行合并返回。
什么是副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片,当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
ES默认为一个索引创建5个主分片,并分别为其创建一个副本分片, 也就是说每个索引都由5个主分片成本,而每个主分片都相应的有一个
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
副本的意义
副本存在的两个重要原因:
- 提高可用性:注意的是副本不能与主/原分片位于同一节点。
- 提高吞吐量:搜索操作可以在所有的副本上并行运行。
分片和副本的区别
分片与副本的区别在于:
分片
当你分片设置为5,数据量为30G时,es会自动帮我们把数据均衡地分配到5个分片上,即每个分片大概有6G数据,当你查询数据时,ES会把查询发送给每个相关的分片,并将结果组合在一起。
副本
而副本,就是对分布在5个分片的数据进行复制,因为分片是把数据进行分割而已,数据依然只有一份,这样的目的是保障查询的高效性,副本则是多复制几份分片的数据,这样的目的是保障数据的高可靠性,防止数据丢失。
分片验证
下面我们验证以下分片的使用
验证一个分片
首先我们通过建立索引的方式来看下什么是分片,会产生哪些变化。
创建索引
我们首先创建一个名为
test的索引,让它有一个分片,我们看看结果,在kibana执行以下命令
PUT test
{
"settings":{
"index":{
"number_of_shards" : "1",
"number_of_replicas" : "0"
}
}
}这样我们就创建了一个分片
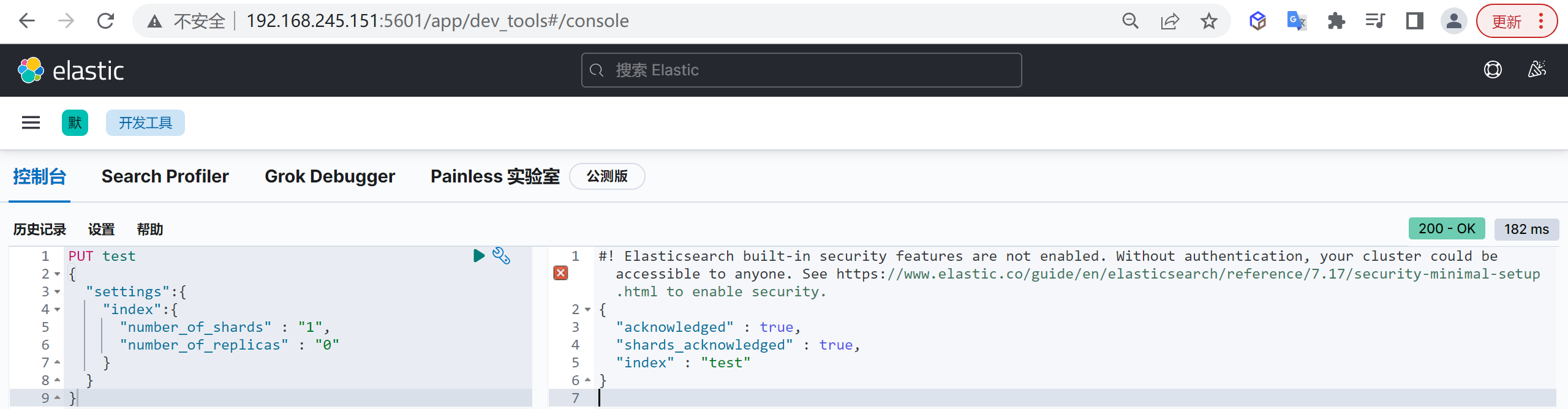
查看分片
我们在
cerebro中查看结果,我们看到test只在node-2节点上:
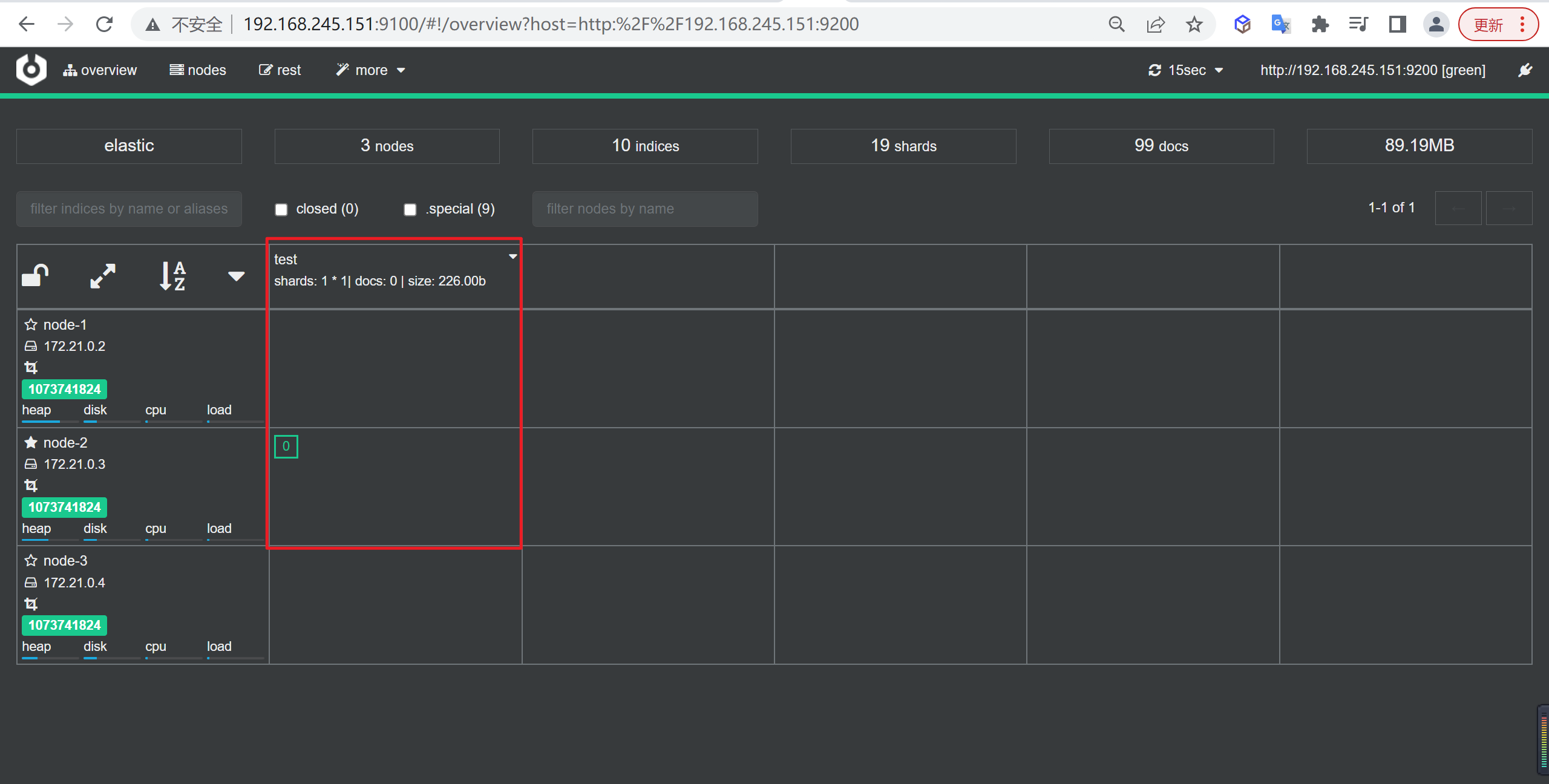
验证两个分片
我们再来创建两个分片看看会发生上面
创建索引
我们再次创建两个分片的test1
PUT test1
{
"settings":{
"index":{
"number_of_shards" : "2",
"number_of_replicas" : "0"
}
}
}这样我们就创建了一个索引
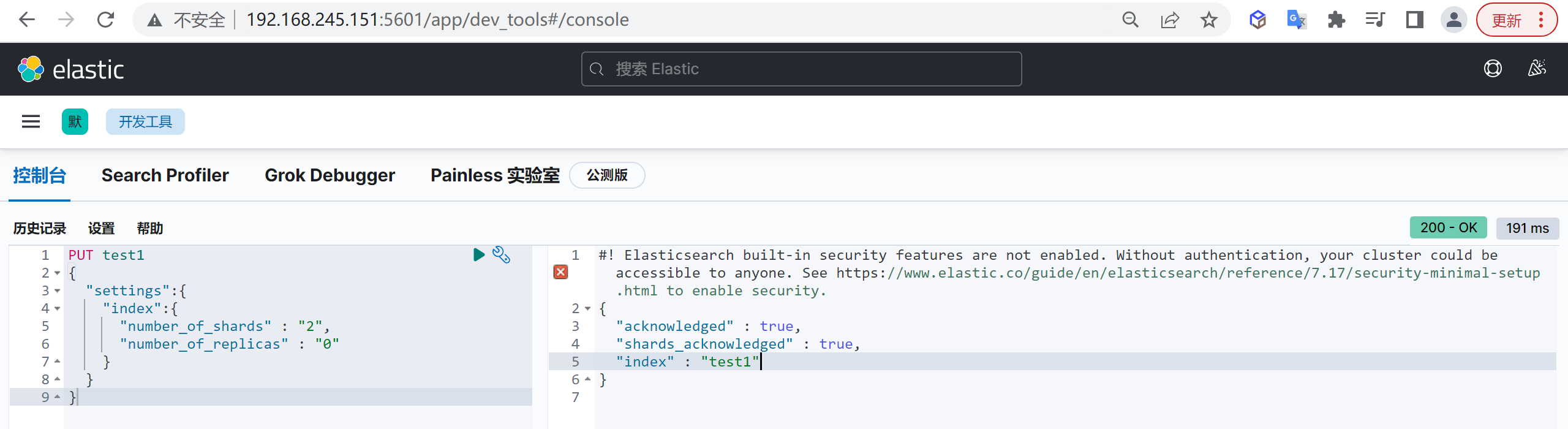
查看分片
我们在
cerebro中查看结果,我们看到test1在node-1和node-3上面
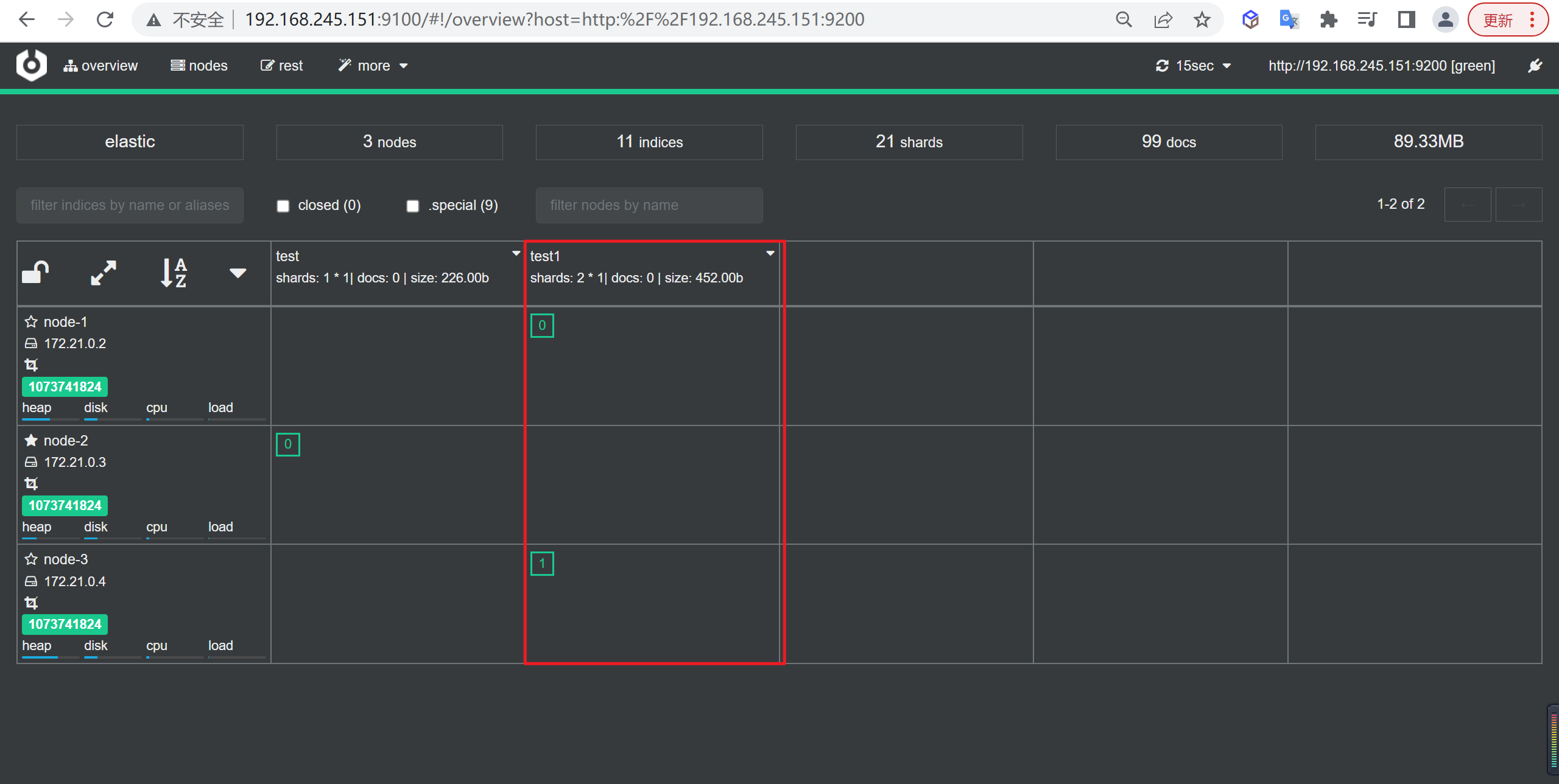
如上图看到分片分别分布在两个节点上,不用想,如果是3个那么肯定均匀分布在三个节点上
验证四个分片
如果我们创建四个分片,多于节点数会发生什么呢
创建索引
我们创建四个分片的索引
PUT test2
{
"settings":{
"index":{
"number_of_shards" : "4",
"number_of_replicas" : "0"
}
}
}这样我们就创建了一个索引
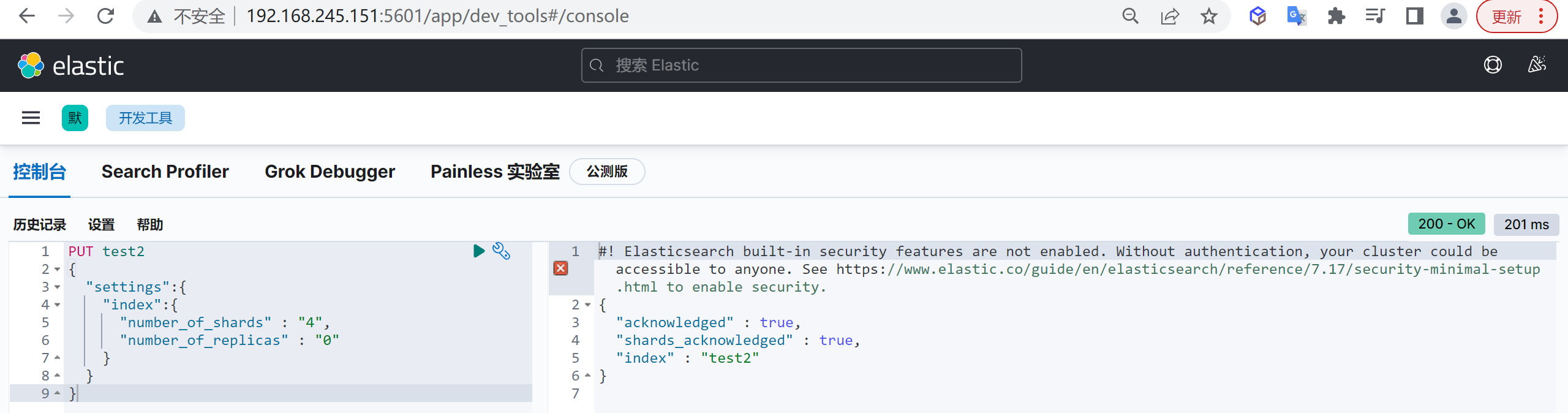
查看分片
我们发现有两个分片在
node-2的节点上
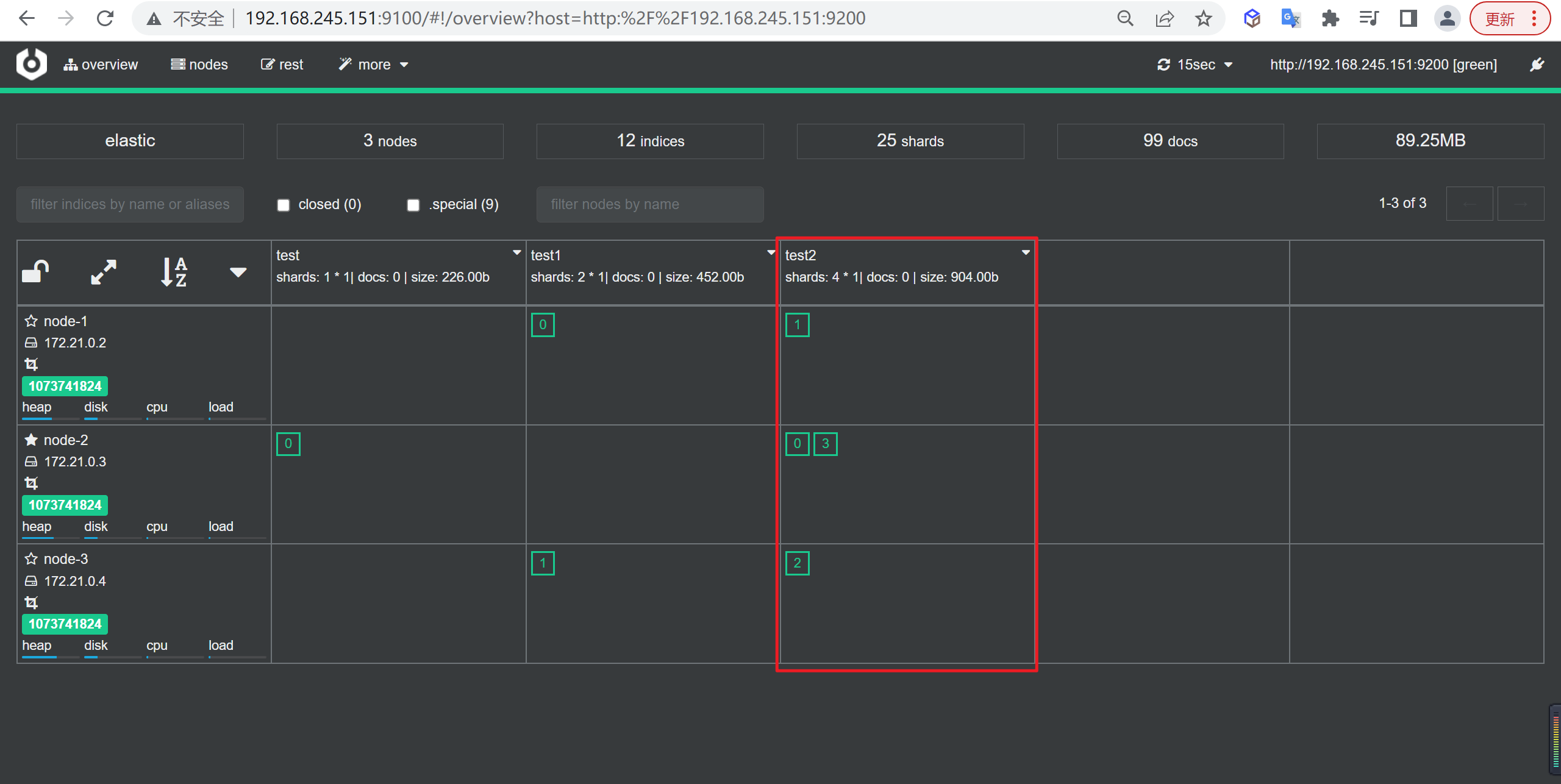
验证副本
下面我们对副本进行验证
验证两副本分片
创建索引
创建一个含有一个分片,两个副本的test3:
PUT test3
{
"settings":{
"index":{
"number_of_shards" : "1",
"number_of_replicas" : "2"
}
}
}这样我们就创建出来了一个分片带两个分片的索引
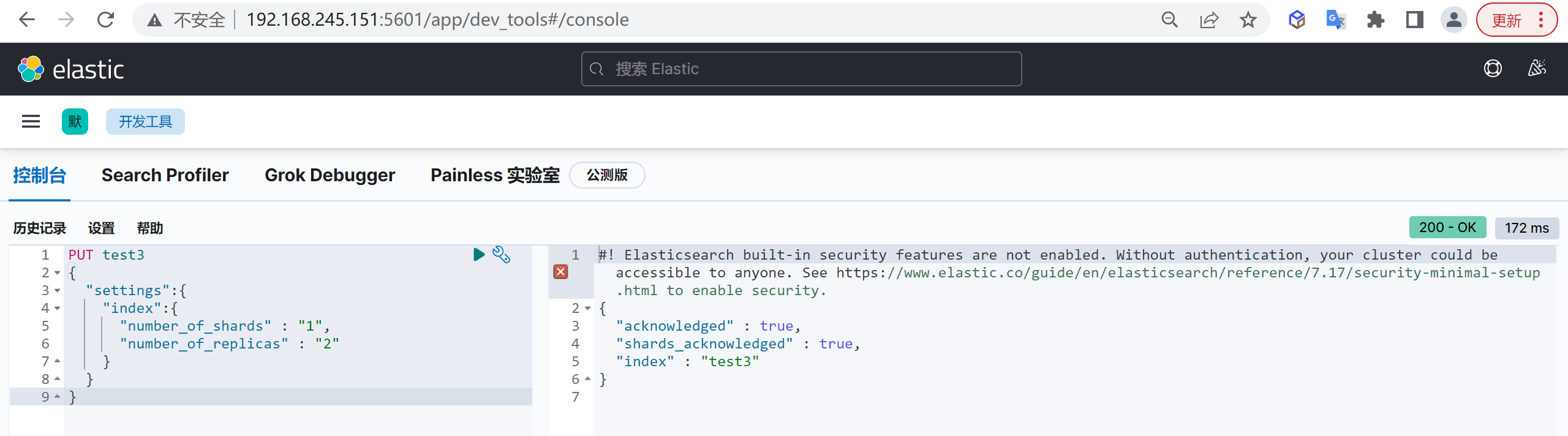
查看索引
如下图所示,我们看到了3个绿色的0,其中在
node-1节点的边框是粗体的,这个表示分片,而另外两个节点的0的边框是虚线的,这两个就是分片的副本。
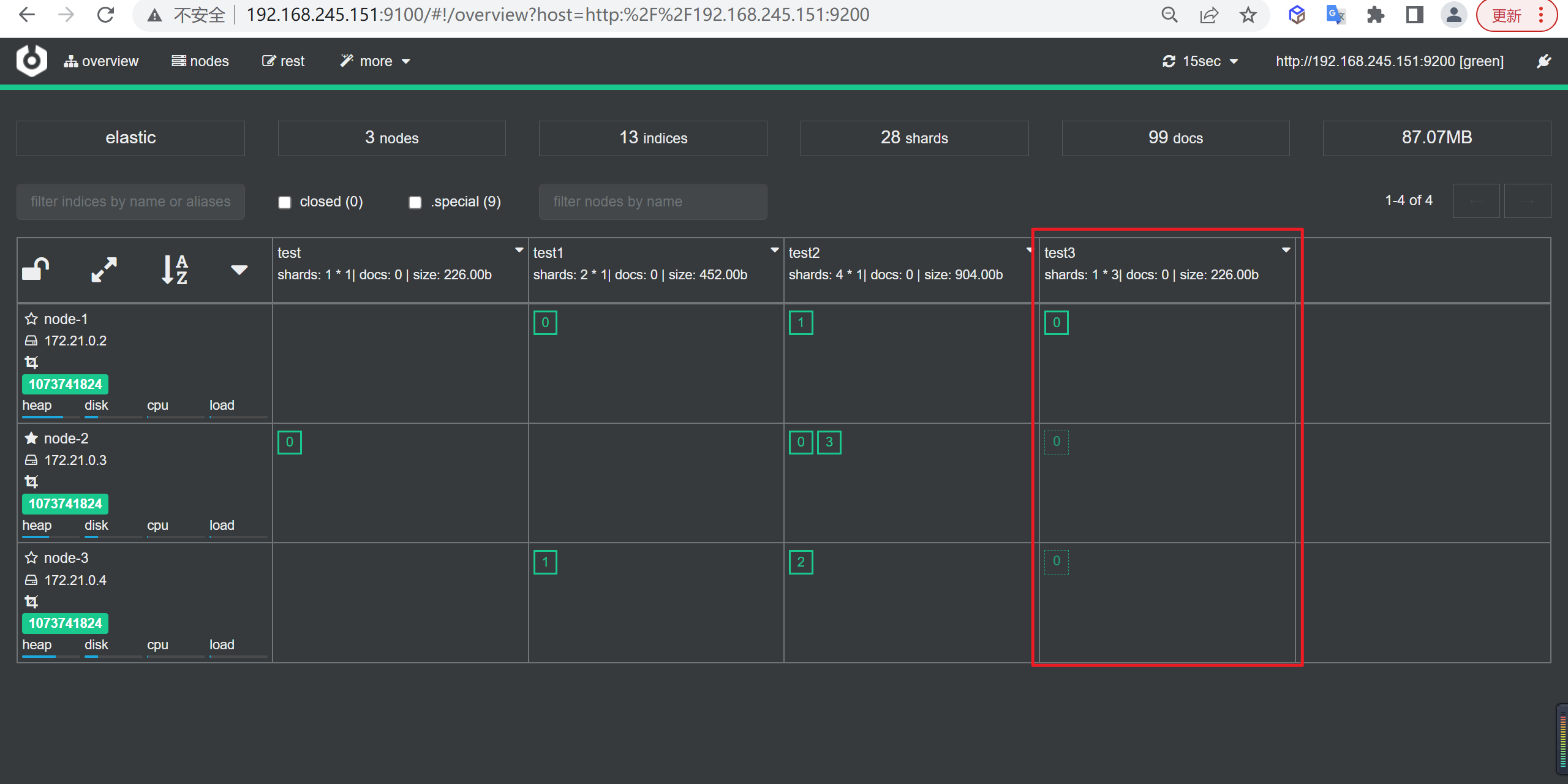
通常我们三个节点建立两个副本就可以了,三份数据均匀得到分布在三个节点
验证三副本分片
如果建立三个副本会怎么样呢?
创建索引
创建一个分片三个副本的索引
PUT test4
{
"settings":{
"index":{
"number_of_shards" : "1",
"number_of_replicas" : "3"
}
}
}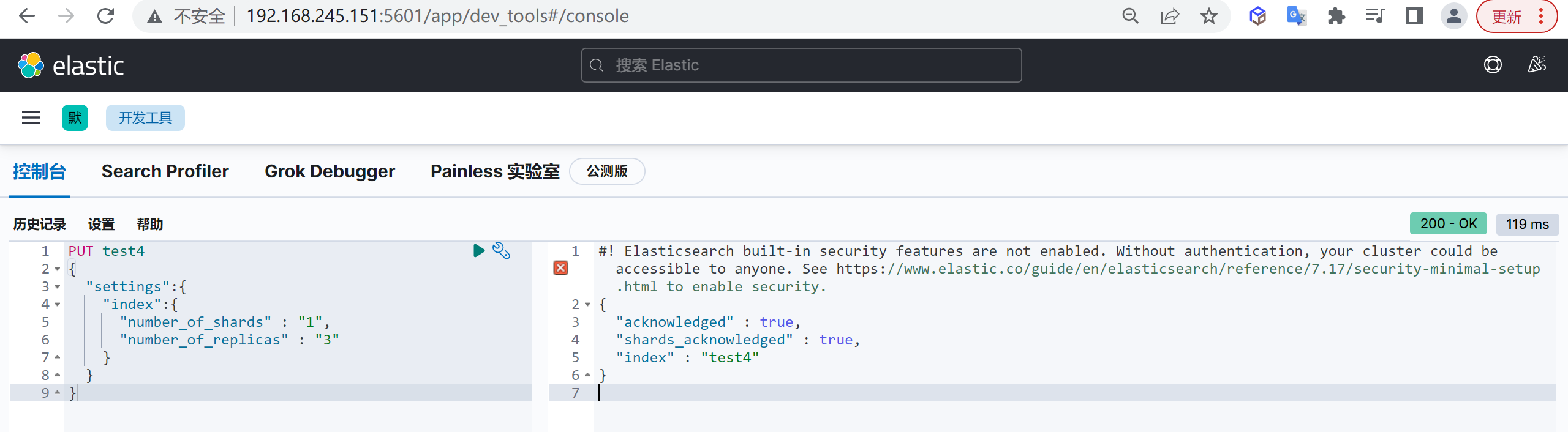
查看索引
如下所示我们看到多出一个Unassigned的副本,这个副本其实是多余的了,因为每个节点已经包含了分片的本身和其副本,多于这个没有意义!
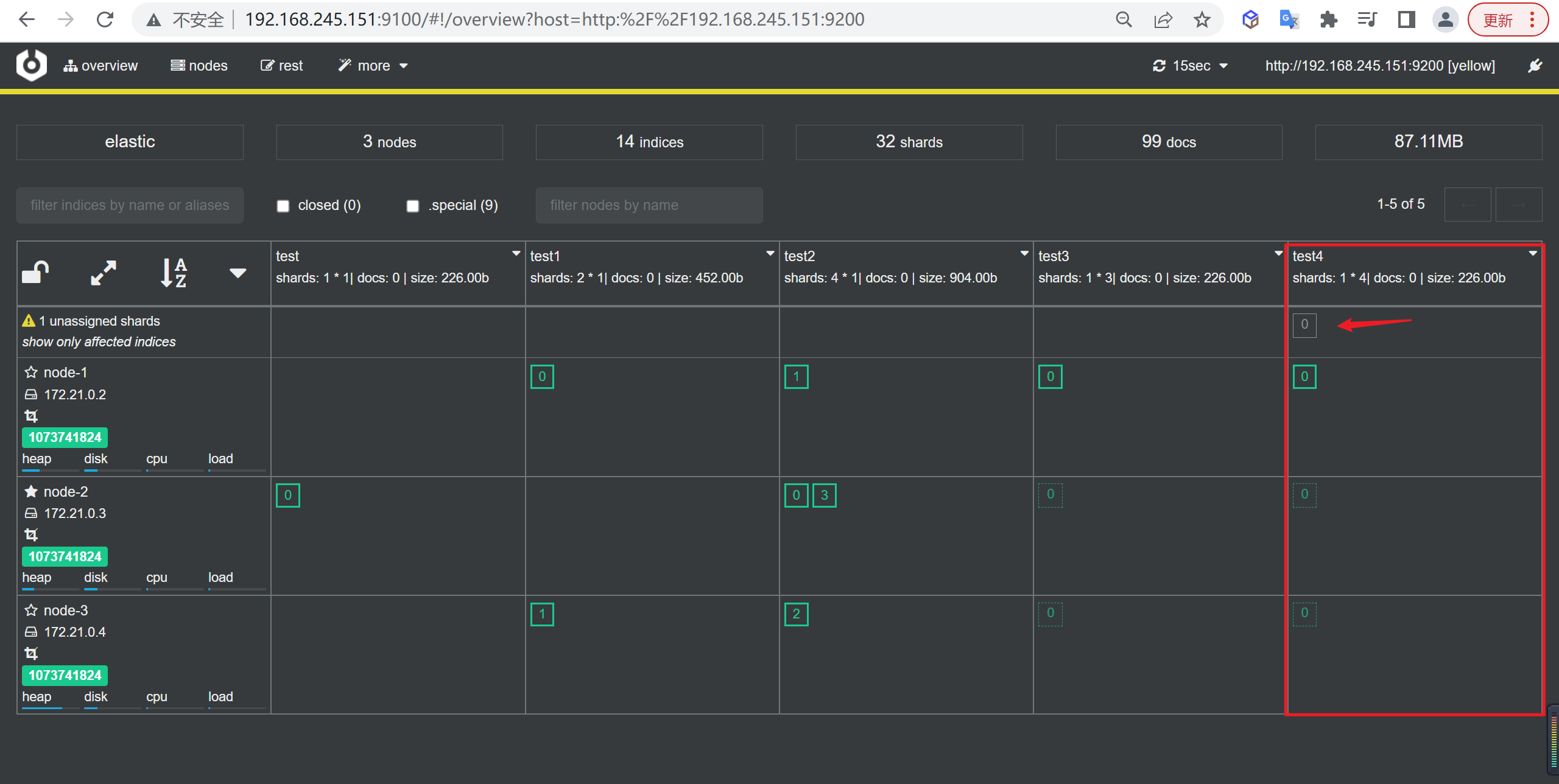
并且因为多出来了一个副本无法分配,整个集群都变成了
yellow的状态
分片与副本的组合
默认组合
如果不指定分片和副本会怎么样呢
创建索引
创建一个索引不指定副本和索引数量
PUT test5
{
"settings":{
"index":{
}
}
}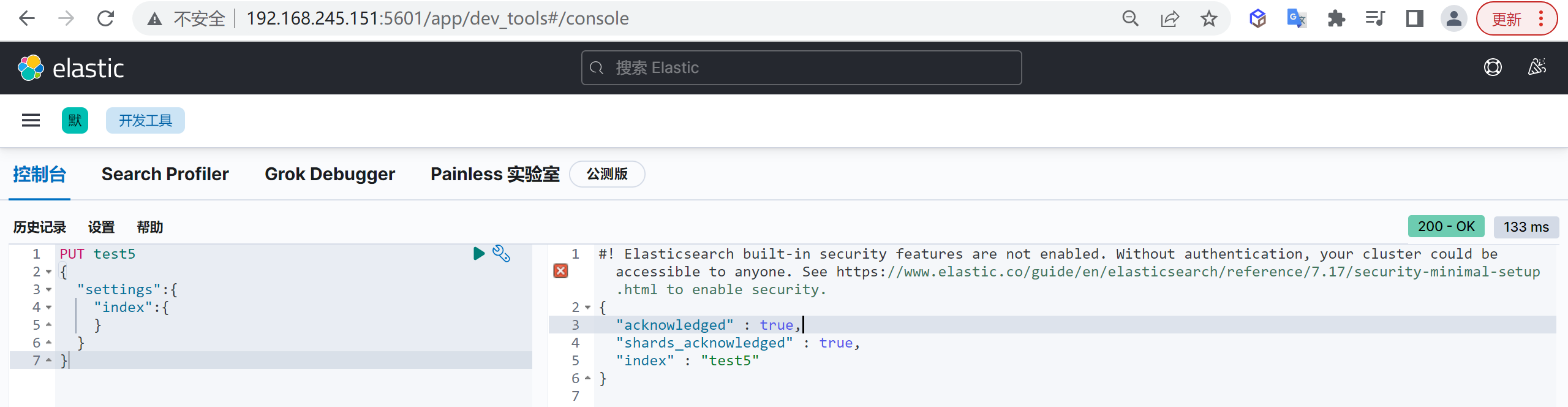
查看索引
如下图所示看到默认是有一个分片和一个副本的。
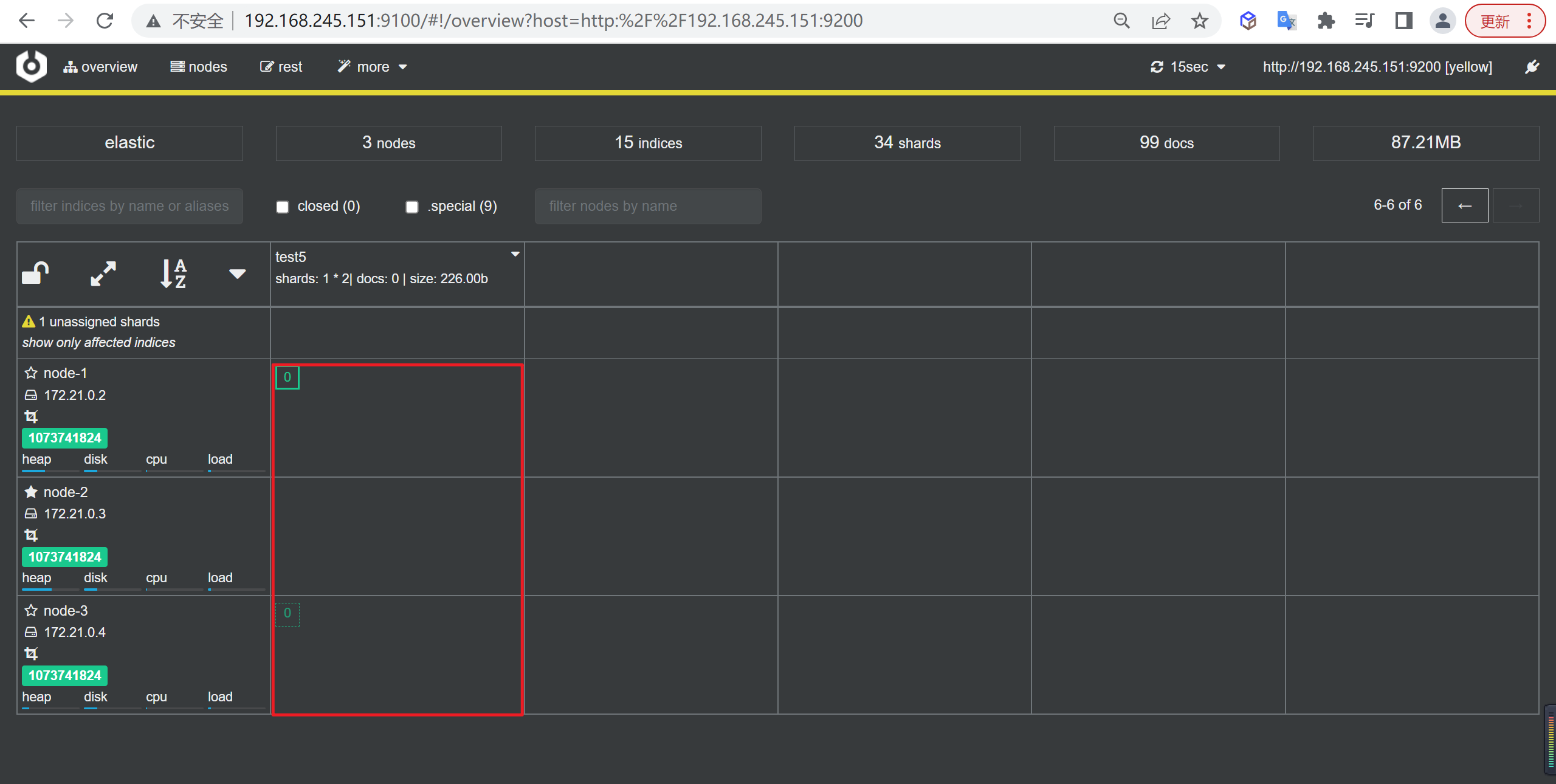
两副本两分片
下面我们试验一下两副本两分片,看看会发生什么
创建索引
下面我们创建两个分片和两个副本
PUT test6
{
"settings":{
"index":{
"number_of_shards" : "2",
"number_of_replicas" : "2"
}
}
}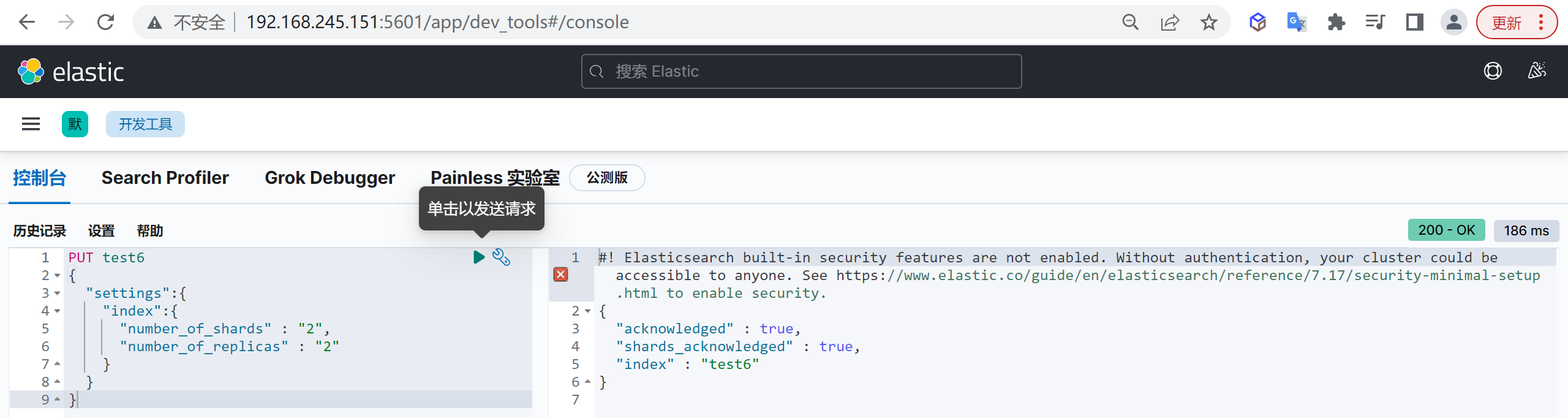
查看索引
我们看到下面就是两副本两分片的情况,每一个分片都有两个副本,如果再多一个副本就会无法再分配了
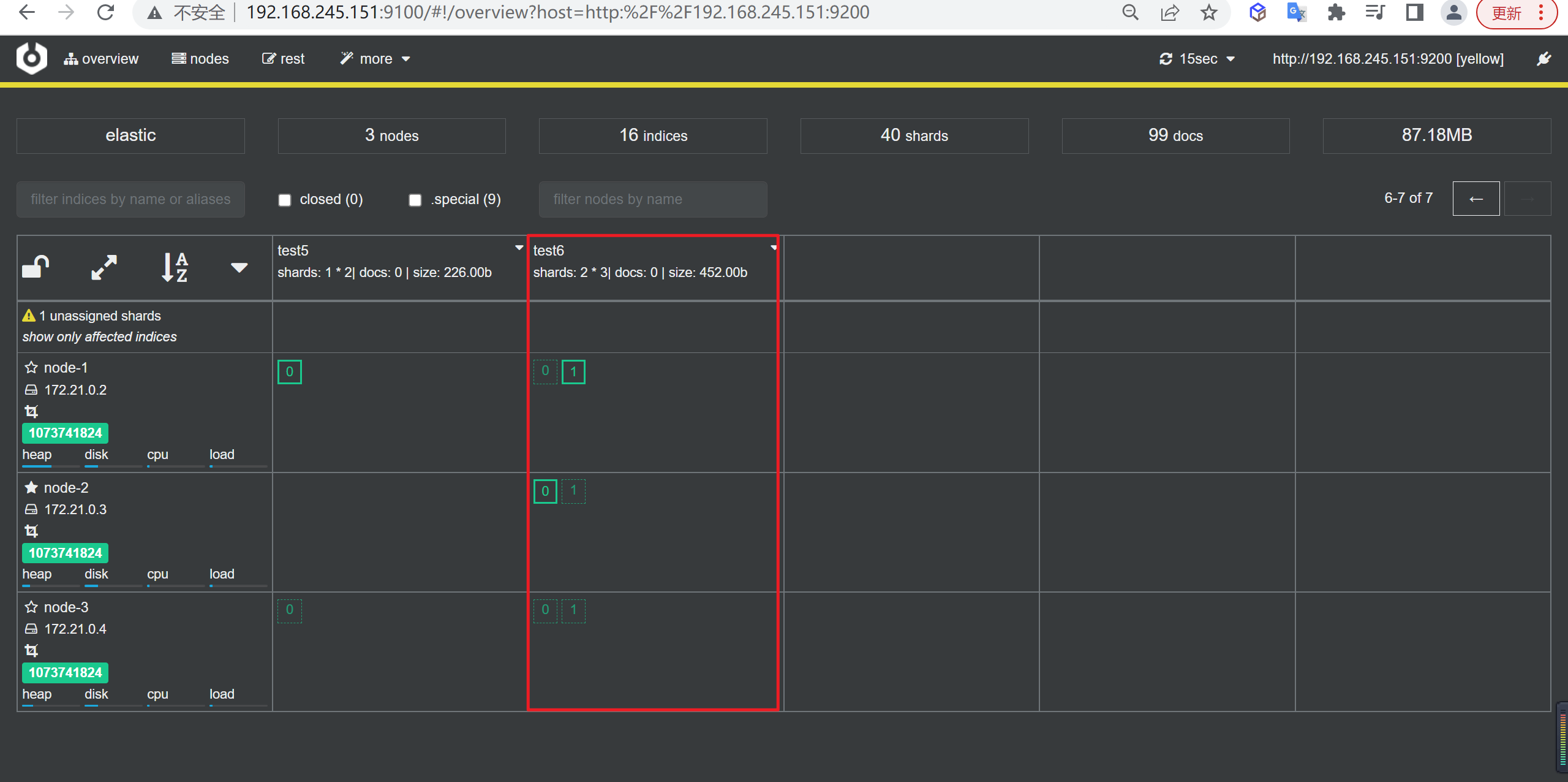
三分片两副本
下面我们验证以下三分片两副本的情况
创建索引
我们创建一个三个分片两个副本的索引
PUT test7
{
"settings":{
"index":{
"number_of_shards" : "3",
"number_of_replicas" : "2"
}
}
}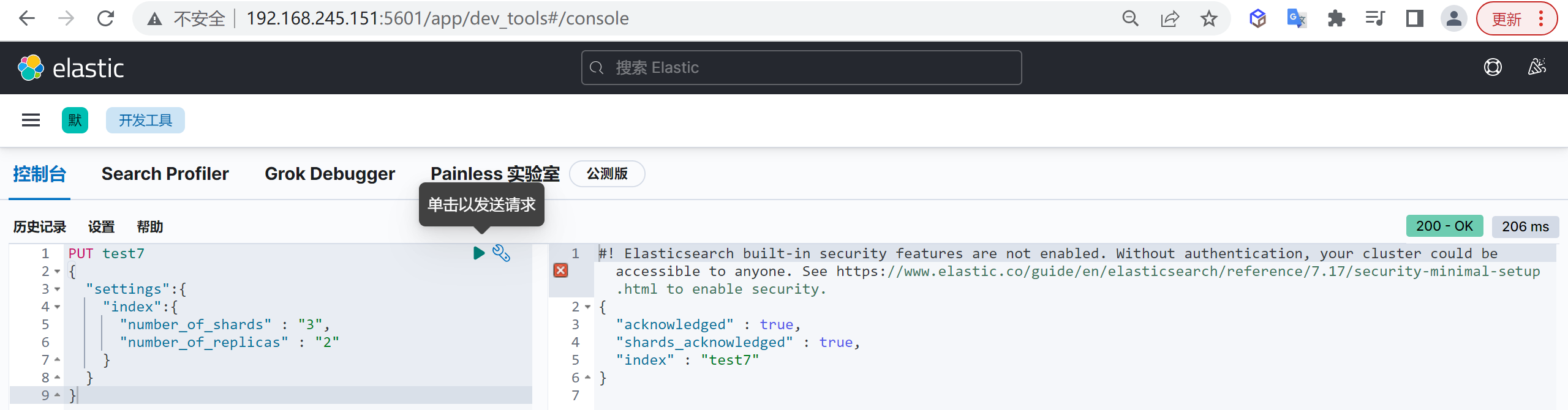
查看索引
如下所示看到分片和副本都均匀的分布在每个节点上。
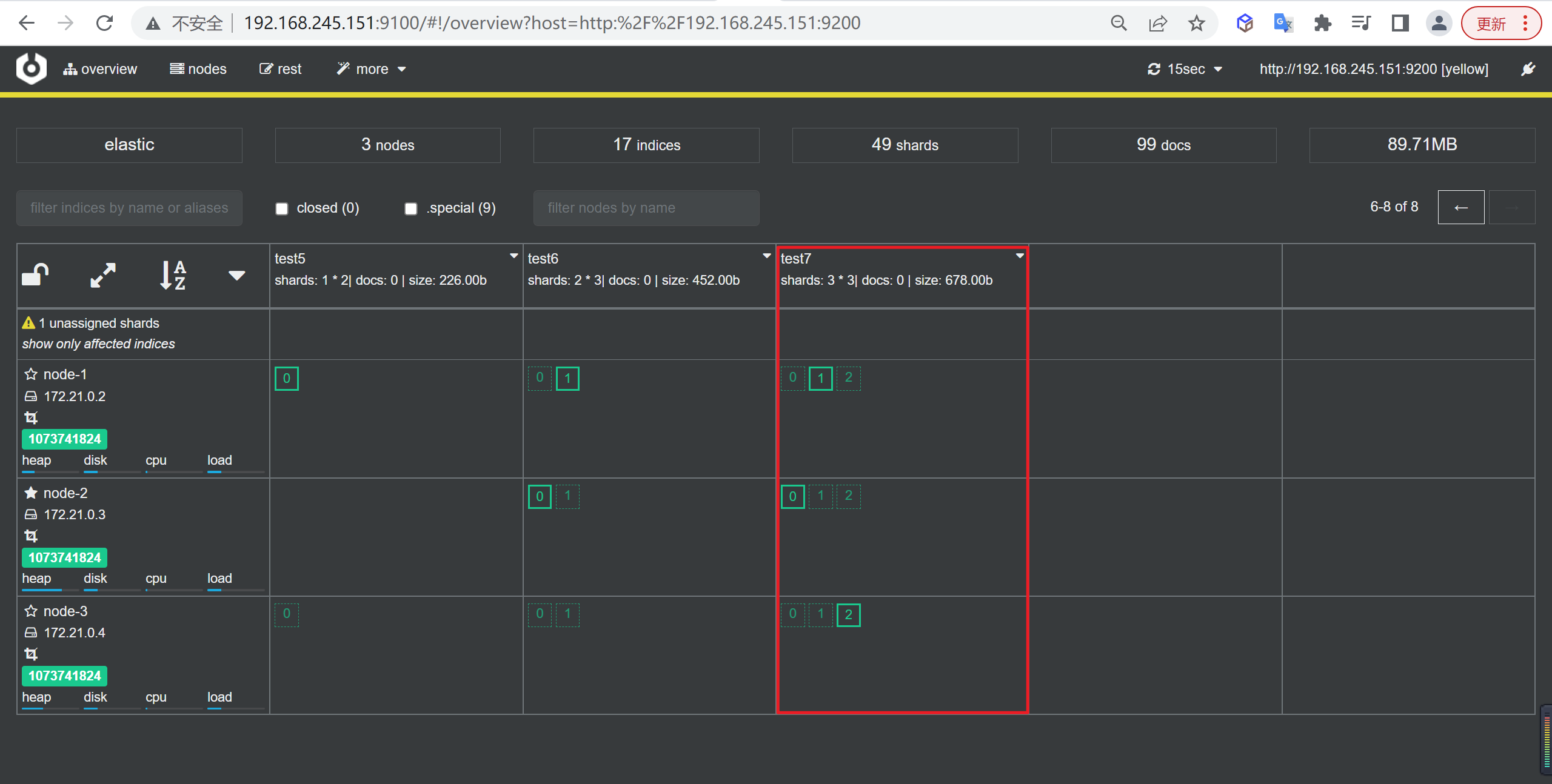
故障与恢复
故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
正常集群状态
下图是正常集群的状态,node1是主节点,其它两个节点是从节点
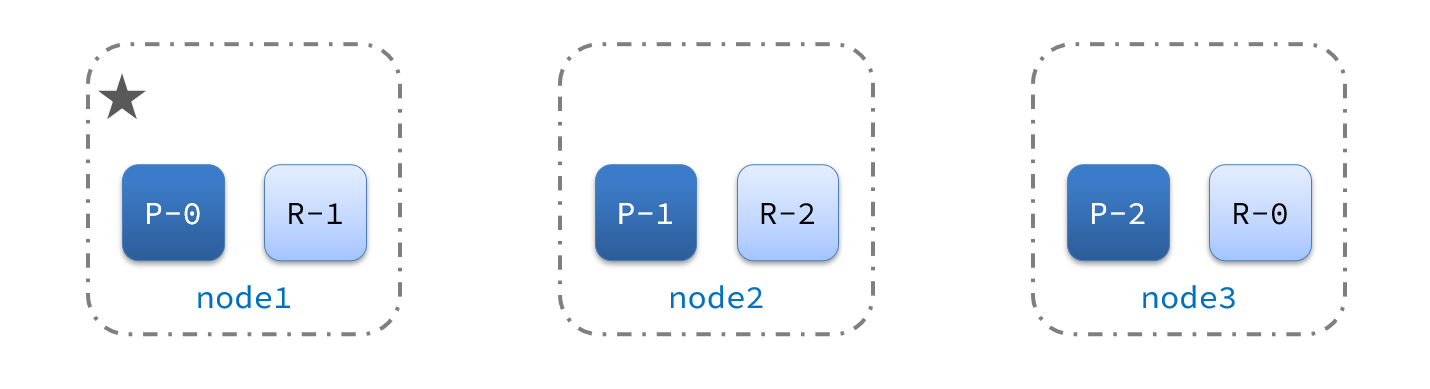
节点故障
突然,node1发生了故障
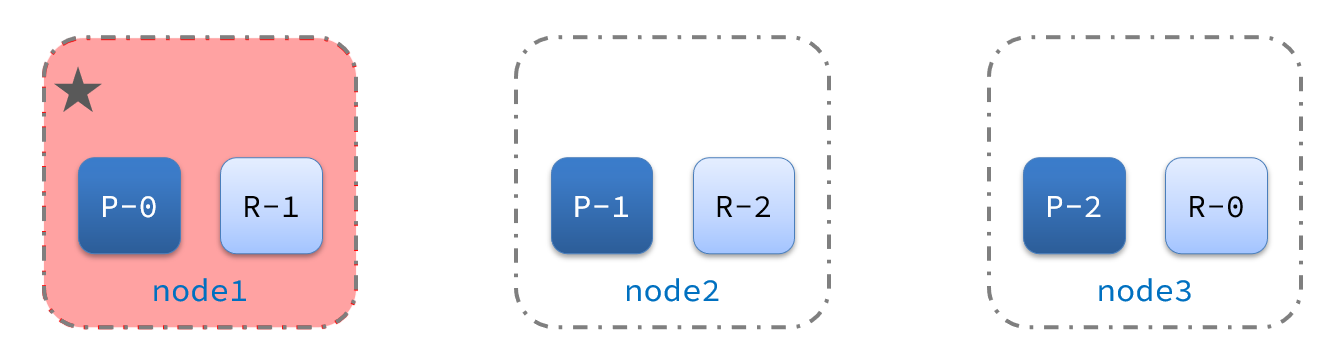
宕机后的第一件事,需要重新选主,例如选中了node2

数据迁移
node2成为主节点后,会检测集群监控状态,发现:shard-1、shard-0没有副本节点,因此需要将node1上的数据迁移到node2、node3
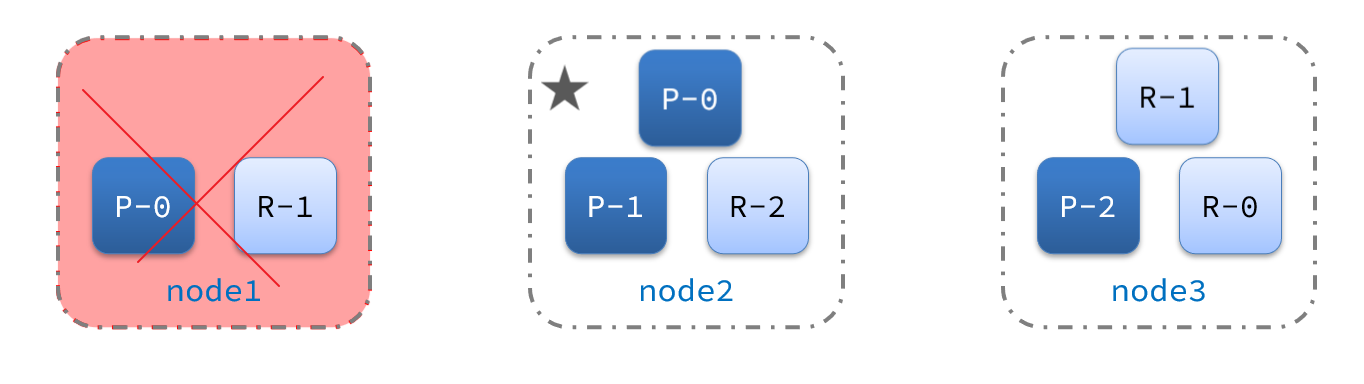
节点故障
我们观察下如果三个节点有一个节点宕机了,上文的
test7的分片和副本会有哪些变化
关闭node2节点
我们关闭
node-2节点
执行关闭命令
我们暂停
node-2节点
docker pause node-2查看索引
如下所示,原本的node-2节点变成了Unassigned
注意我标注的三个红框内的分片,这三个分片已经随着节点的宕机消息了,这就造成了数据的丢失,反观后面几个,虽然node2宕机了,但是由于我们做了分片与备份,索引仍然可以正常的工作,
原本在node-2的2号分片移动到了node-1节点,在使用es集群的过程中,一定要注意分片和副本的使用,保证我们整个集群的高可用性
关闭node3节点
我们关闭以下node-3节点看下情况
执行关闭命令
执行如下命令暂停node-3
docker pause node-3查看集群状态
通过
Cerebro我们发现整个集群已经无法进行访问了
当集群中的节点数少于半数,将导致整个集群不可用
节点恢复
经过上面的宕机试验后,我们现在要对宕机的服务进行启动
启动node2节点
我们先启动node2节点
执行启动命令
执行下面的命令恢复node-2节点
docker unpause node-2查看集群状态
如上发现集群已经能够恢复访问了

创建索引
此时我们在两个几点可用的情况下创建一个有三分片,两个副本的索引
PUT test8
{
"settings":{
"index":{
"number_of_shards" : "3",
"number_of_replicas" : "2"
}
}
}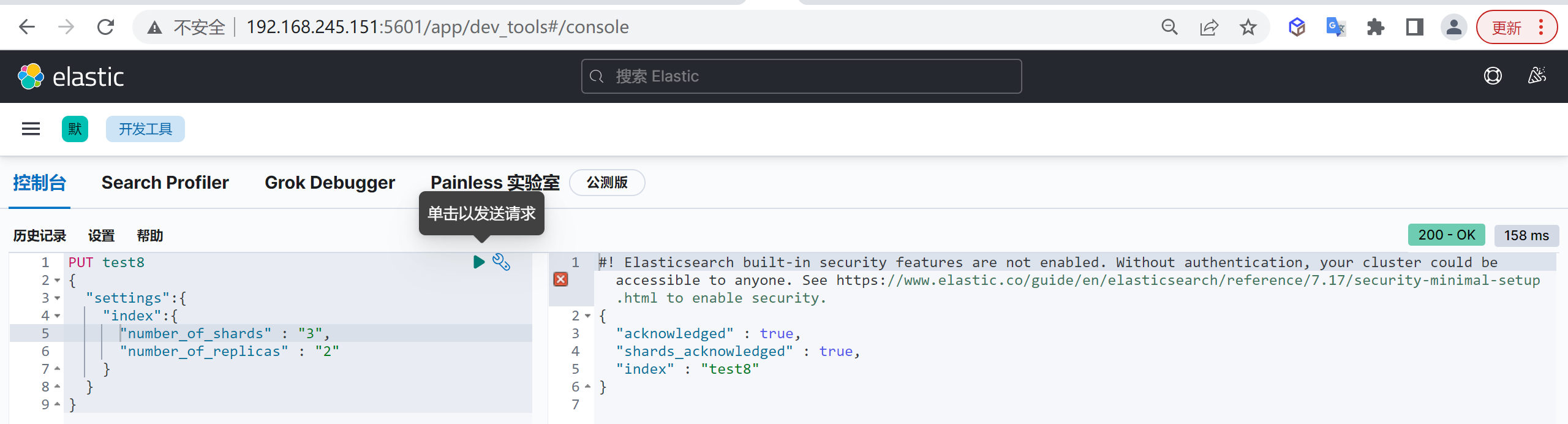
查看索引状态
如下所示,分片与副本的分布没有问题,有三个副本未分配
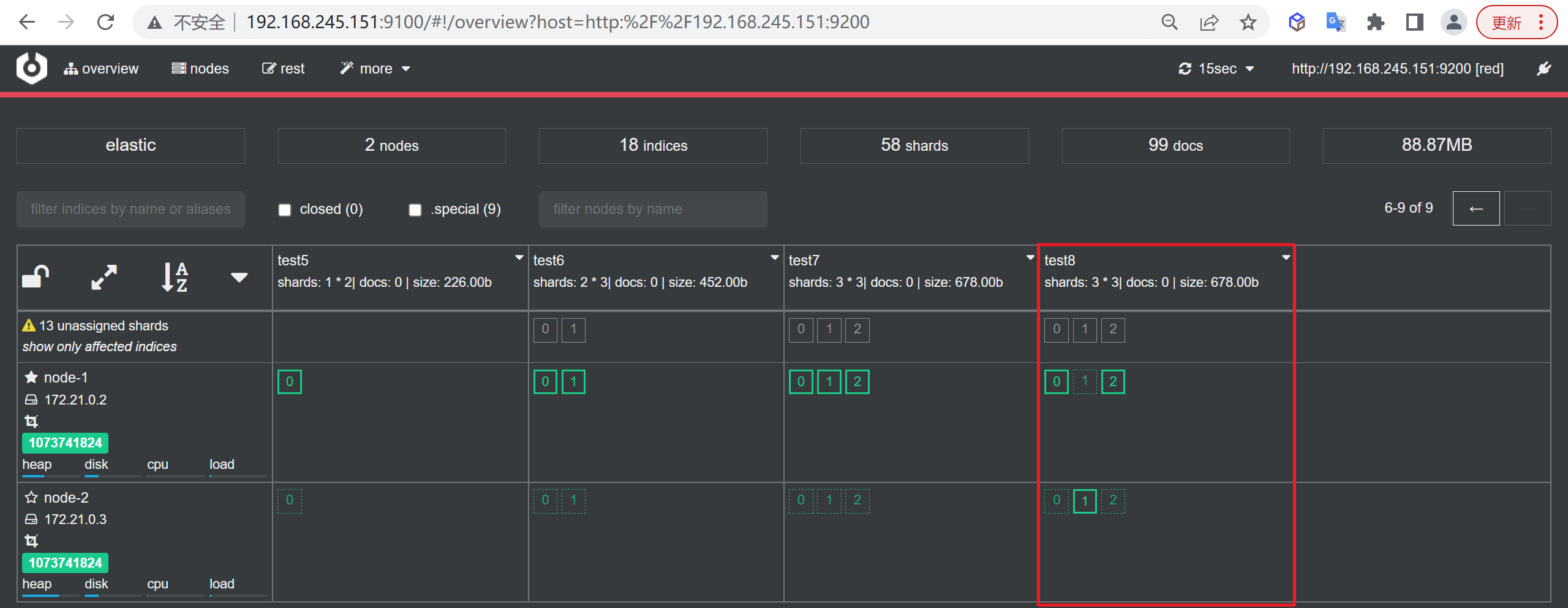
启动node3节点
下面我们就启动node3节点
执行启动命令
执行下面的命令恢复node-2节点
docker unpause node-3查看索引
所有的未分配副本移动到了node-3节点,并没有将分片移动到node-2上
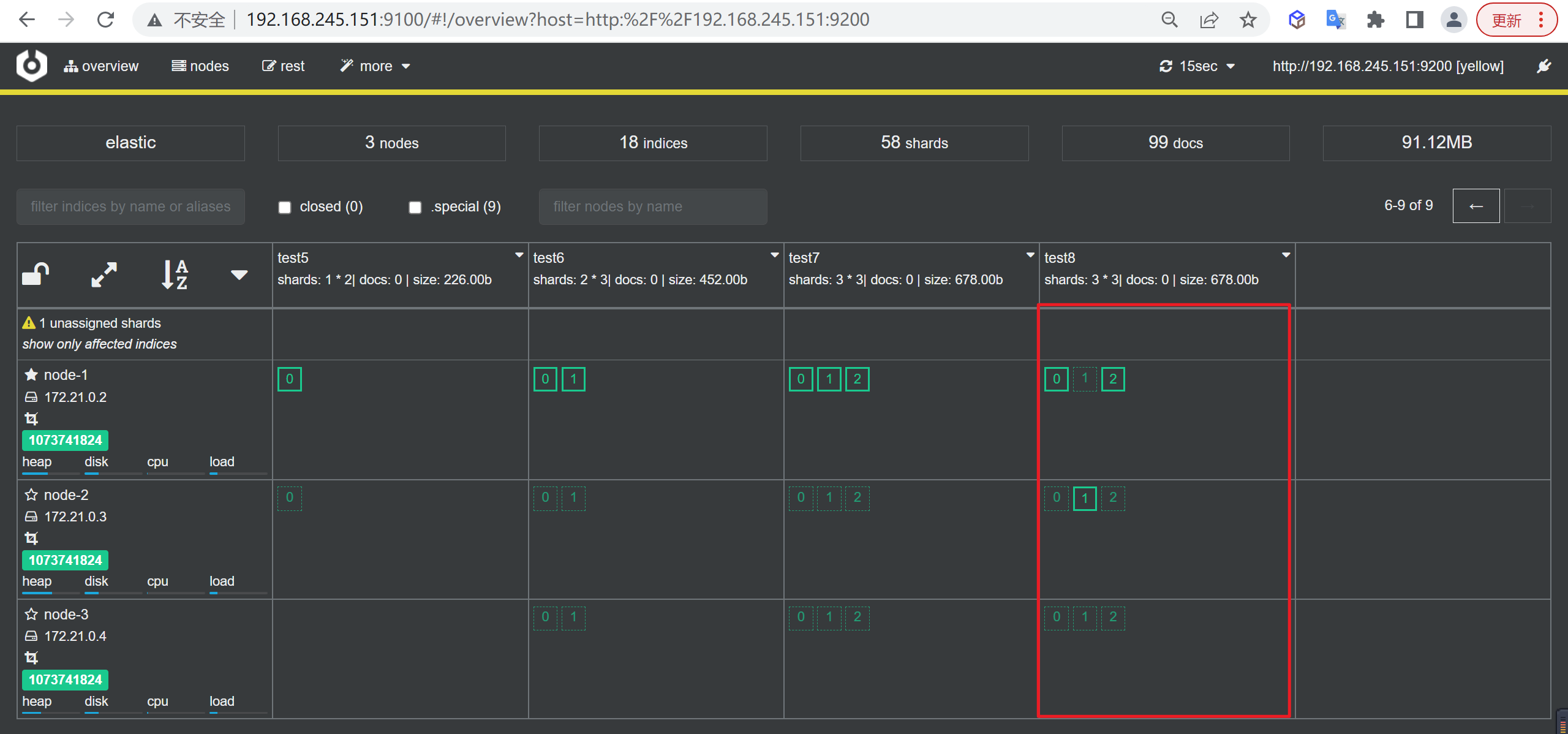
扩缩容
服务布局
我们整体采用Docker方式进行布局,以下是我们需要部署的服务,标红色的我们需要新增的节点
| 服务名称 | 服务名称 | 开放端口 | 内存限制 |
|---|---|---|---|
| ES-node1 | node-1 | 9200 | 1G |
| ES-node2 | node-2 | 9201 | 1G |
| ES-node3 | node-3 | 9202 | 1G |
| ES-node4 | node-4 | 9203 | 1G |
| ES-cerebro | cerebro | 9000 | 不限 |
| kibana |
扩容节点
创建节点目录
创建ES的节点目录
mkdir -p /tmp/data/elasticsearch/node-4/{config,plugins,data,log}
#进行授权
chmod 777 /tmp/data/elasticsearch/node-4/{config,plugins,data,log}添加IK分词器
只要将其他节点的IK分词器复制过来就可
cp -R ik/ /tmp/data/elasticsearch/node-4/plugins/编写配置文件
我们边界node4节点的配置文件
vi /tmp/data/elasticsearch/node-4/config/elasticsearch.yml
#集群名称
cluster.name: elastic
#当前该节点的名称
node.name: node-4
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#给当前节点自定义属性(可以省略)
#node.attr.rack: r1
#数据存档位置
path.data: /usr/share/elasticsearch/data
#日志存放位置
path.logs: /usr/share/elasticsearch/log
#是否开启时锁定内存(默认为是)
#bootstrap.memory_lock: true
#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,
#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0
network.host: 0.0.0.0
#设置映射端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上
discovery.seed_hosts: ["node-1","node-2","node-3"]
#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,
#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,
#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#在群集完全重新启动后阻止初始恢复,直到启动N个节点
#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,
gateway.recover_after_nodes: 2
#删除索引是是否需要显示其名称,默认为显示
#action.destructive_requires_name: true
# 禁用安全配置,否则查询的时候会提示警告
xpack.security.enabled: false编写部署文档
我们在部署脚本增加node-4节点
vi docker-compose.yml
version: "3"
services:
node-1:
image: elasticsearch:7.17.5
container_name: node-1
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- "TZ=Asia/Shanghai"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- "9200:9200"
logging:
driver: "json-file"
options:
max-size: "50m"
volumes:
- /tmp/data/elasticsearch/node-1/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /tmp/data/elasticsearch/node-1/plugins:/usr/share/elasticsearch/plugins
- /tmp/data/elasticsearch/node-1/data:/usr/share/elasticsearch/data
- /tmp/data/elasticsearch/node-1/log:/usr/share/elasticsearch/log
networks:
- elastic
node-2:
image: elasticsearch:7.17.5
container_name: node-2
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- "TZ=Asia/Shanghai"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- "9201:9200"
logging:
driver: "json-file"
options:
max-size: "50m"
volumes:
- /tmp/data/elasticsearch/node-2/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /tmp/data/elasticsearch/node-2/plugins:/usr/share/elasticsearch/plugins
- /tmp/data/elasticsearch/node-2/data:/usr/share/elasticsearch/data
- /tmp/data/elasticsearch/node-2/log:/usr/share/elasticsearch/log
networks:
- elastic
node-3:
image: elasticsearch:7.17.5
container_name: node-3
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- "TZ=Asia/Shanghai"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- "9202:9200"
logging:
driver: "json-file"
options:
max-size: "50m"
volumes:
- /tmp/data/elasticsearch/node-3/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /tmp/data/elasticsearch/node-3/plugins:/usr/share/elasticsearch/plugins
- /tmp/data/elasticsearch/node-3/data:/usr/share/elasticsearch/data
- /tmp/data/elasticsearch/node-3/log:/usr/share/elasticsearch/log
networks:
- elastic
node-4:
image: elasticsearch:7.17.5
container_name: node-4
environment:
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
- "TZ=Asia/Shanghai"
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
ports:
- "9203:9200"
logging:
driver: "json-file"
options:
max-size: "50m"
volumes:
- /tmp/data/elasticsearch/node-4/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
- /tmp/data/elasticsearch/node-4/plugins:/usr/share/elasticsearch/plugins
- /tmp/data/elasticsearch/node-4/data:/usr/share/elasticsearch/data
- /tmp/data/elasticsearch/node-4/log:/usr/share/elasticsearch/log
networks:
- elastic
kibana:
container_name: kibana
image: kibana:7.17.5
volumes:
- /tmp/data/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
ports:
- 5601:5601
networks:
- elastic
cerebro:
image: lmenezes/cerebro:0.9.4
container_name: cerebro
environment:
TZ: 'Asia/Shanghai'
ports:
- '9000:9000'
networks:
- elastic
networks:
elastic:
driver: bridge启动服务
我们完成配置后就可以启动服务了
docker-compose up -d查看节点信息
我们可以在监控界面看到节点的信息,我们发现节点4已经加入进来了
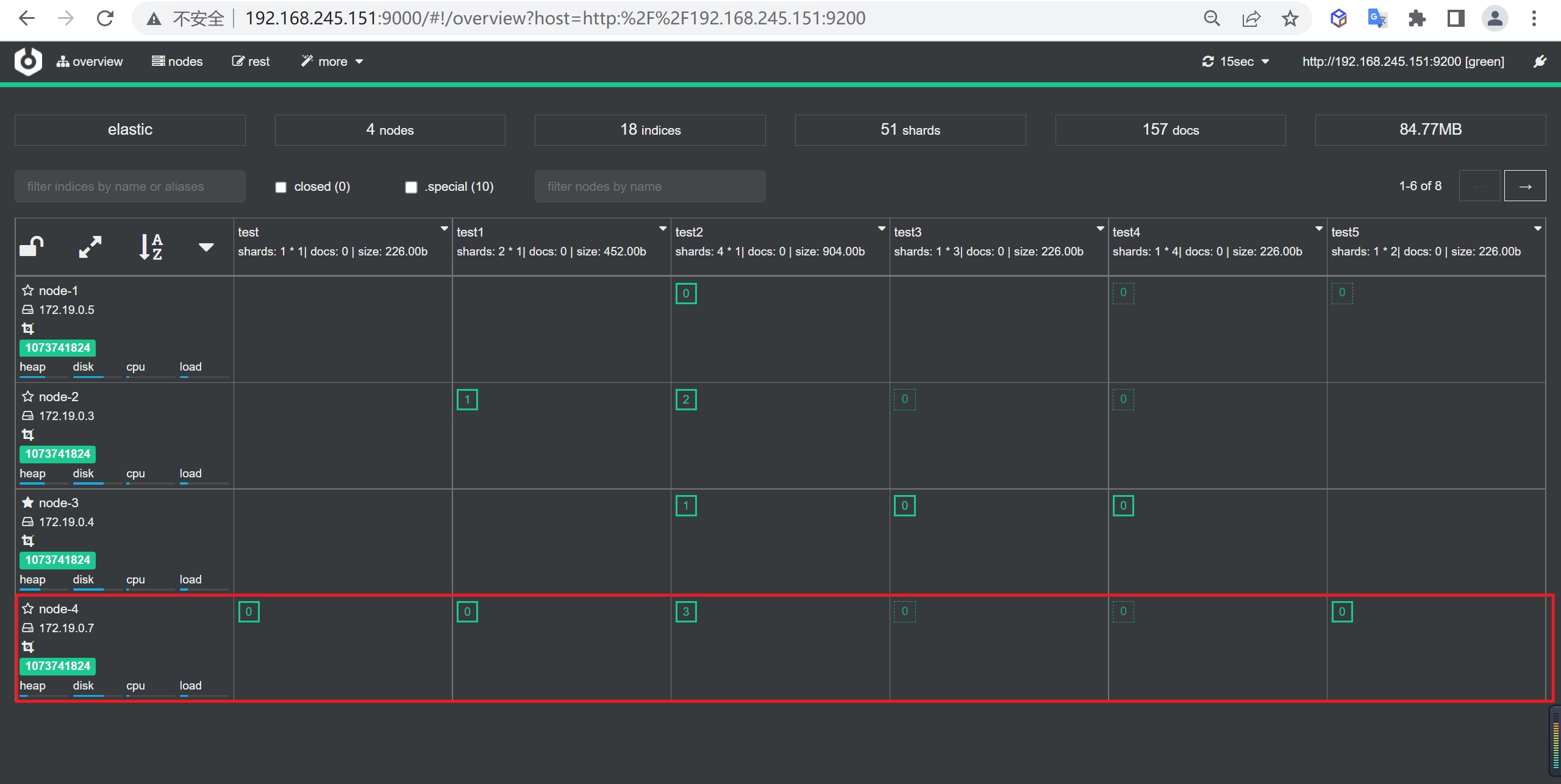
节点缩容
接下来我们要将node4节点去掉完成缩容操作
禁止数据分配
我们先排除node-4节点,禁止数据在该节点分配数据,然后才能停止节点,如果想正常缩容,这里填上所有要缩容的节点名称就可以了
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.exclude._name": "node-4"
}
}
检查数据分配
接下来检查一下缩容节点的数据迁移情况,我们发现数据已经全部迁移完成了
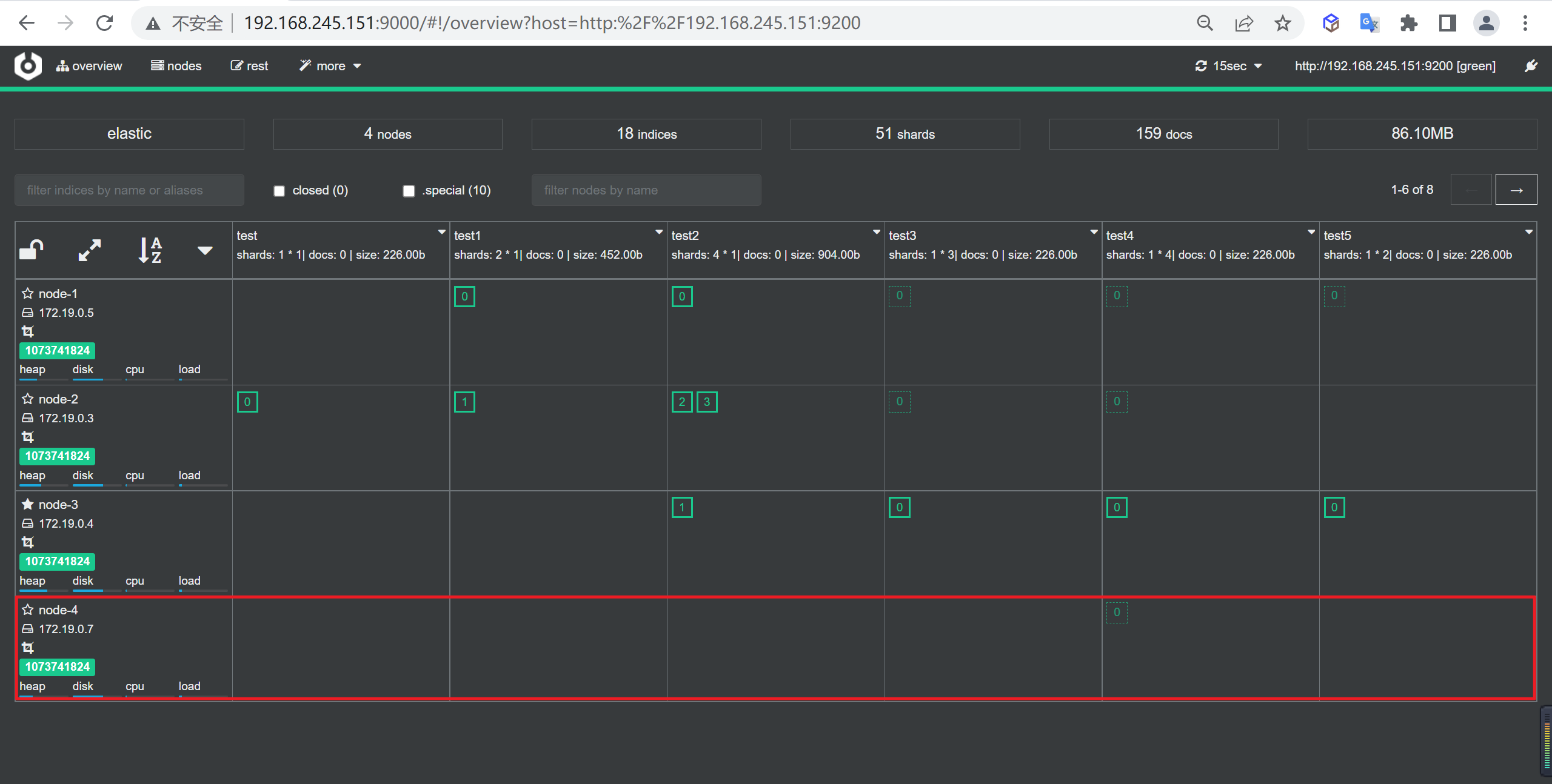
关闭节点
等到数据全部迁移完成后就可以进行缩容节点了
docker-compose stop node-4
查看集群情况
接下来看一下集群的情况,我们发现已经缩容成功了,并且没有出现主分片丢失的情况
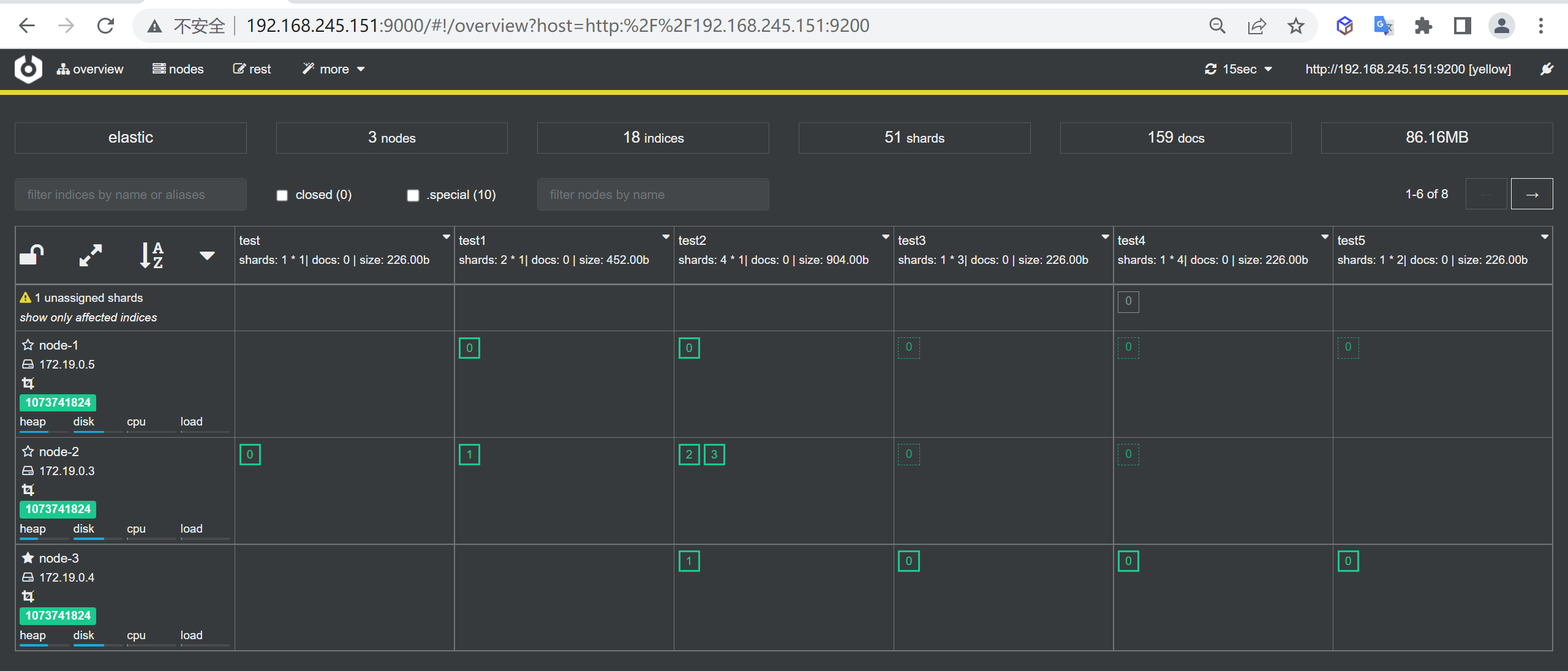
ElasticSearch 深度分页
深度分页问题
我们使用mysql的时候经常遇到分页查询的场景,在mysql中使用
limit关键字来实现分页,比如下面的示例
select * from orders_history where type=8 limit 100,100;
select * from orders_history where type=8 limit 1000,100;
select * from orders_history where type=8 limit 10000,100;在ElasticsSearch(以下简称ES)同样也有很多分页查询的场景,比如在数据量比较大的情况下,并且查询条件比较复杂,在mysql中无法命中索引,我们往往会选择使用ES的分页查询。
分页方式
在Elasticsearch中支持的三种分页查询方式
- From + Size 查询
- Scroll 查询
- Search After 查询
from/size
from+size的分页查询称为”浅”分页,它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据,这样其实白白浪费了前10条的查询
在深度分页的情况下,这种使用方式效率是非常低的,比如from = 50000, size=10, es 需要在各个分片上匹配排序并得到50010条数据,协调节点拿到这些数据再进行全局排序处理,然后结果集中取最后10条数据返回。
使用方式
这是ES分页最常用的一种方案,跟mysql类似
- from:未指定,默认值是 0,注意不是1,代表当前页返回数据的起始值。
- size:未指定,默认值是 10,代表当前页返回数据的条数
分页查询
查询小区数据中
0-10页的数据
GET logstash-village-2022.08.22/_search
{
"from": 0,
"size": 10,
"query": {
"match_all": {}
}
}优缺点
优点
- 支持随机翻页
缺点
- 受制于 max_result_window 设置,不能无限制翻页。
- 存在深度翻页问题,越往后翻页越慢。
适用场景
- 非常适合小型数据集或者大数据集返回 Top N(N <= 10000)结果集的业务场景
- 类似主流 PC 搜索引擎(谷歌、bing、百度、360、sogou等)支持随机跳转分页的业务场景

深度分页问题
Elasticsearch 在深度分页的情况下会限制最大分页数,避免大数据量的查询导致性能低下
深度分页限制
ES的
max_result_window默认值是10000,也就意味着:如果每页有 10 条数据,会最大翻页至1000页
实际主流搜索引擎都翻不了那么多页,举例:百度搜索“上海”,翻到第 76 页,就无法再往下翻页了,提示信息如下截图所示:
尝试深度分页
我们将上面的查询改造下,查询
9999页之后的十条数据
GET logstash-village-2022.08.22/_search
{
"from": 9999,
"size": 10,
"query": {
"match_all": {}
}
}我们发现查询后直接报错了,Result window is too large
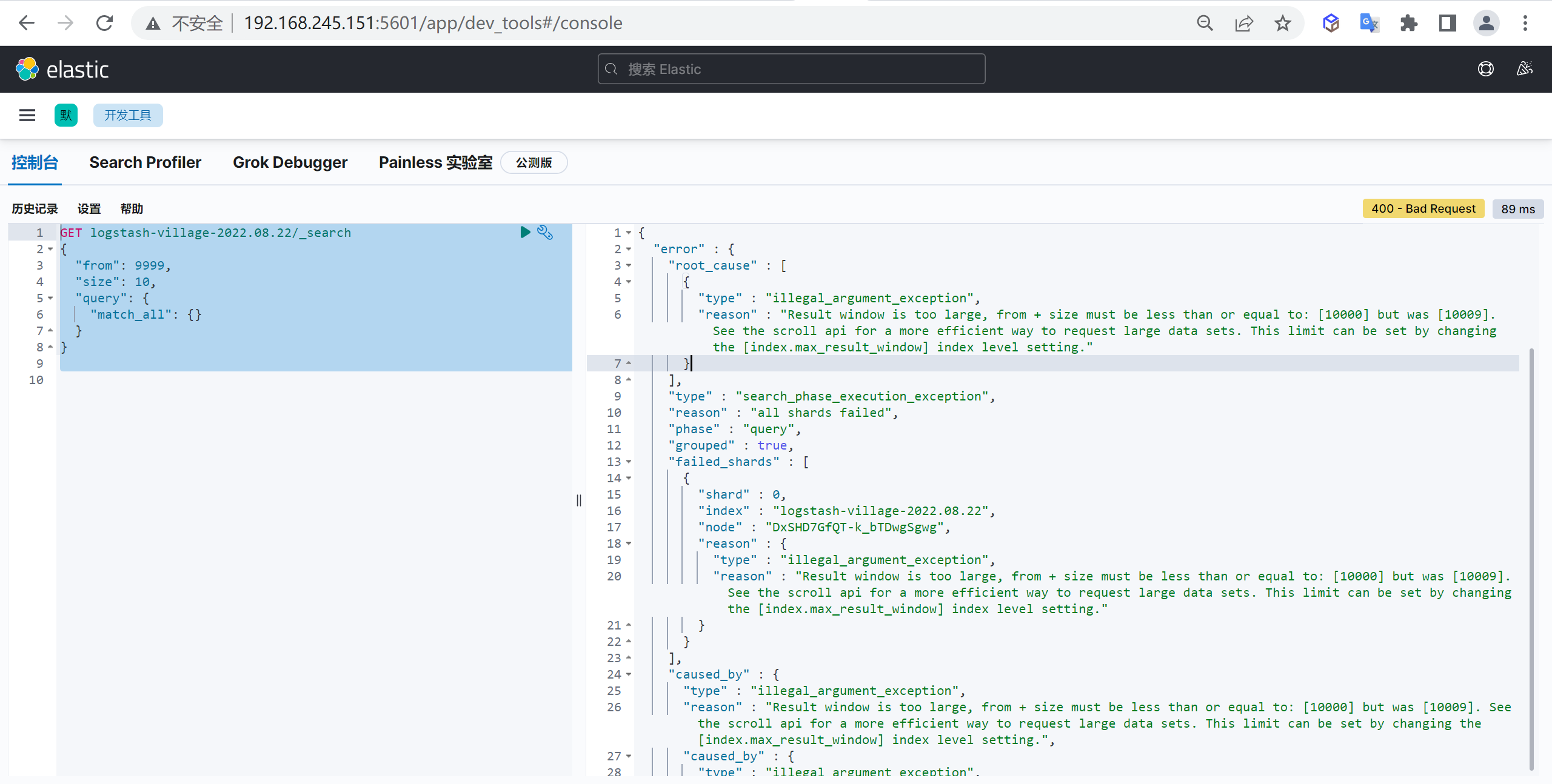
为什么限制深度分页
为了性能,es限制了我们分页的深度,es目前支持的最大的 max_result_window = 10000;
也就是说我们不能获取10000个以上的文档 , 当ES 分页查询超过一定的值(10000)后,会报错,如果数据量非常大的情况下进行查询可能会产生OOM
不推荐使用 from + size 做深度分页查询的核心原因:
- 搜索请求通常跨越多个分片,每个分片必须将其请求的命中内容以及任何先前页面的命中内容加载到内存中。
- 对于翻页较深的页面或大量结果,这些操作会显著增加内存和 CPU 使用率,从而导致性能下降或节点故障
分页查询步骤
- 协调节点或者客户端节点,需要将请求发送到所有的分片
- 每个分片把from + size个结果,返回给协调节点或者客户端节点
- 协调节点或者客户端节点进行结果合并,如果有n个分片,则查询数据是 n * (from+size) , 如果from很大的话,会造成oom或者网络资源的浪费。
问题分析
我么有三个shard(分片),每个分片有10w条数据如果要查询9999-10009的数据
查询的时候协调节点就会分别从每个分片中获取10009条数据,一共30027条数据,然后进行排序获取出10条数据,所以深度分页会给系统带来很大的压力
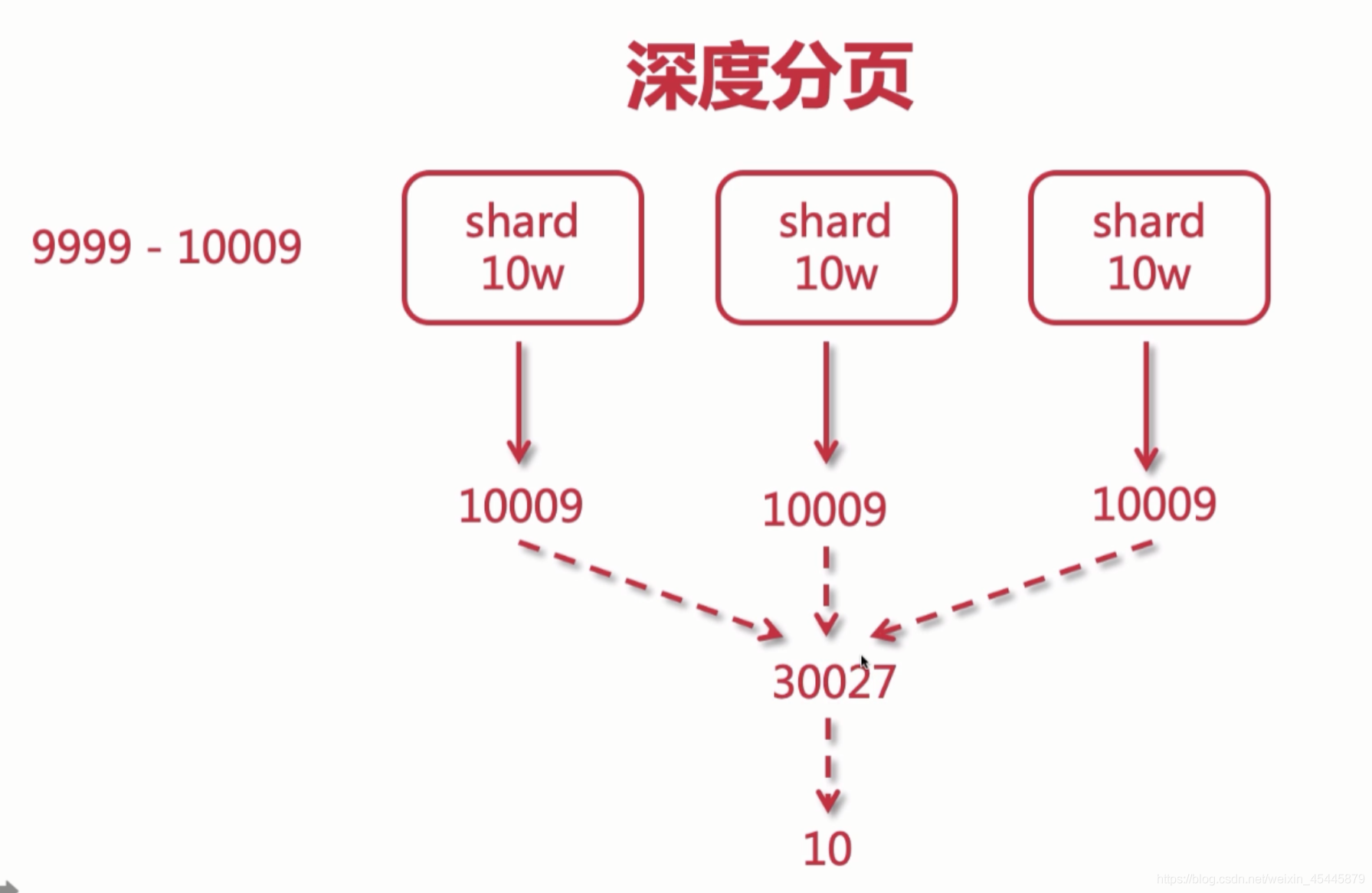
解决方案
限制分页数
我们可以限制分页的数量,而规避深度分页带来的性能影响,例如天猫会限制在80页

修改max_result_window初始值
怎么解决这个问题,首先能想到的就是调大这个window
PUT logstash-village/_settings
{
"index" : {
"max_result_window" : 20000
}
}但这种方法只是暂时解决问题,当数据量越来越大,分页也越来越深,而且越会出OOM问题的,所以当索引非常非常大(千万或亿),是无法使用from + size 做深分页的,分页越深则越容易OOM,即便不OOM,也很消耗CPU和内存资源
Scroll 遍历查询
ES为了避免深分页,不允许使用分页(from&size)查询10000条以后的数据,因此如果要查询第10000条以后的数据,要使用ES提供的 scroll(游标) 来查询
scroll 查询可以用来对 Elasticsearch 有效地执行大批量的文档查询,而又不用付出深度分页那种代价,游标查询允许我们先做查询初始化,然后再批量地拉取结果,这有点儿像传统数据库中的 cursor 。
如果把 From + size 和 search_after 两种请求看做近实时的请求处理方式,那么 scroll 滚动遍历查询显然是非实时的,数据量大的时候,响应时间可能会比较长。
使用方式
scroll 核心执行步骤如下
生成scroll_id
指定检索语句同时设置 scroll 上下文保留时间,如果文档不需要特定排序,可以指定按照文档创建的时间返回会使迭代更高效。
GET logstash-village-2022.08.22/_search?scroll=1m # 保持游标查询窗口一分钟
{
"query": { "match_all": {}},
"sort" : ["_doc"], #按照文件的创建顺序进行排序
"size": 10
}从 Scroll 请求返回的结果反映了发出初始搜索请求时索引的状态,类似在那一个时刻做了快照,随后对文档的更改(写入、更新或删除)只会影响以后的搜索请求。
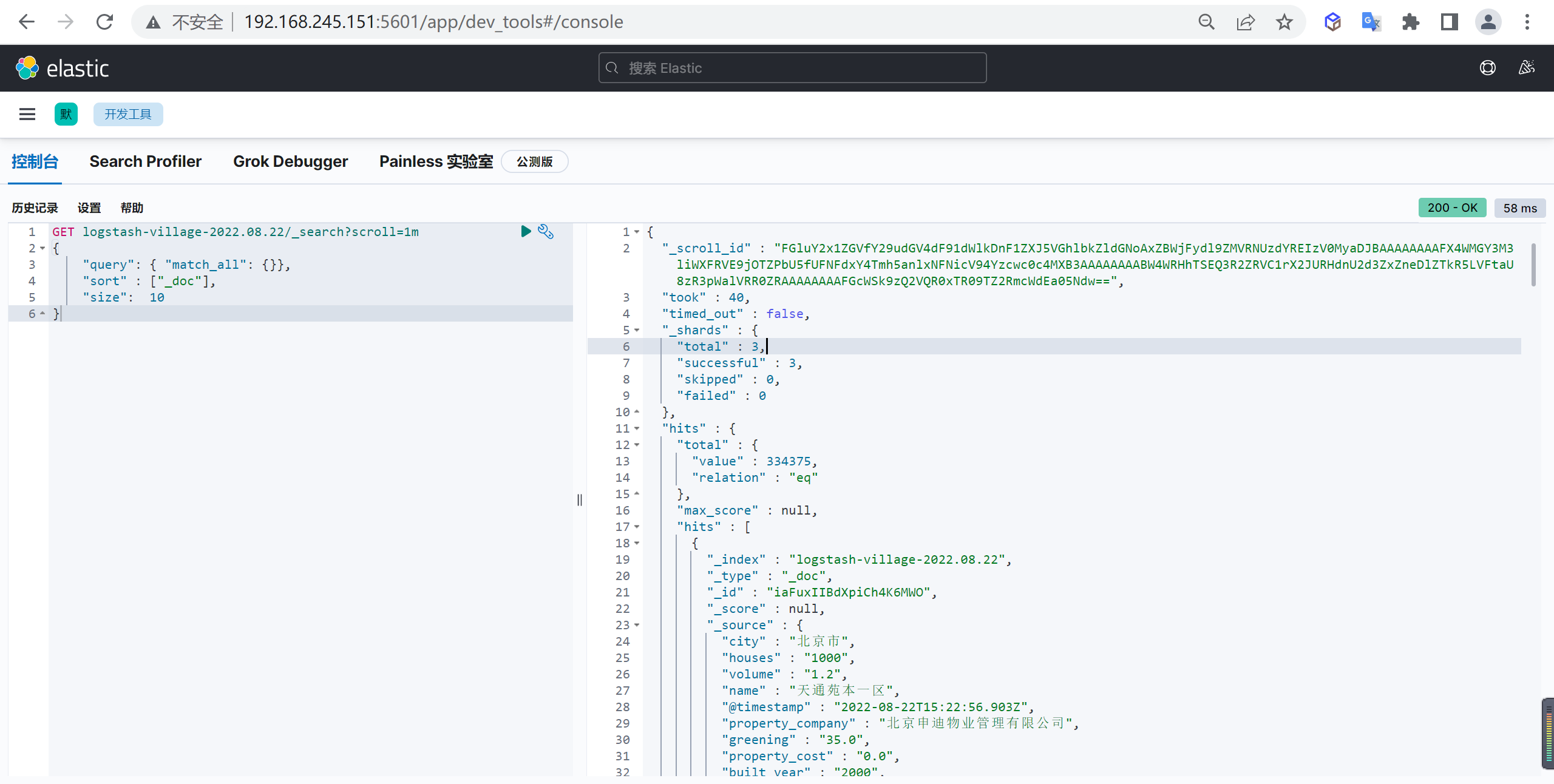
scroll就是把一次的查询结果缓存一定的时间,如scroll=1m则把查询结果在下一次请求上来时暂存1分钟,response比传统的返回多了一个scroll_id,下次带上这个scroll_id即可找回这个缓存的结果。
分页查询
后续翻页, 通过上一次查询返回的scroll_id 来不断的取下一页,请求指定的
scroll_id时就不需要索引条件等信息了,直到没有要返回的结果为止
GET /_search/scroll
{
"scroll": "1m",
"scroll_id":"FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAxZneDlZTkR5LVFtaU8zR3pWalVRR0ZRAAAAAAAAFK0WSk9zQ2VQR0xTR09TZ2RmcWdEa05NdxY4Tmh5anlxNFNicV94Yzcwc0c4MXB3AAAAAAAABYYWRHhTSEQ3R2ZRVC1rX2JURHdnU2d3ZxZBWjFydl9ZMVRNUzdYREIzV0MyaDJBAAAAAAAAFeEWMGY3M3liWXFRVE9jOTZPbU5fUFNFdw=="
}如果srcoll_id 的生存期很长,那么每次返回的 scroll_id 都是一样的,直到该 scroll_id 过期,才会返回一个新的 scroll_id
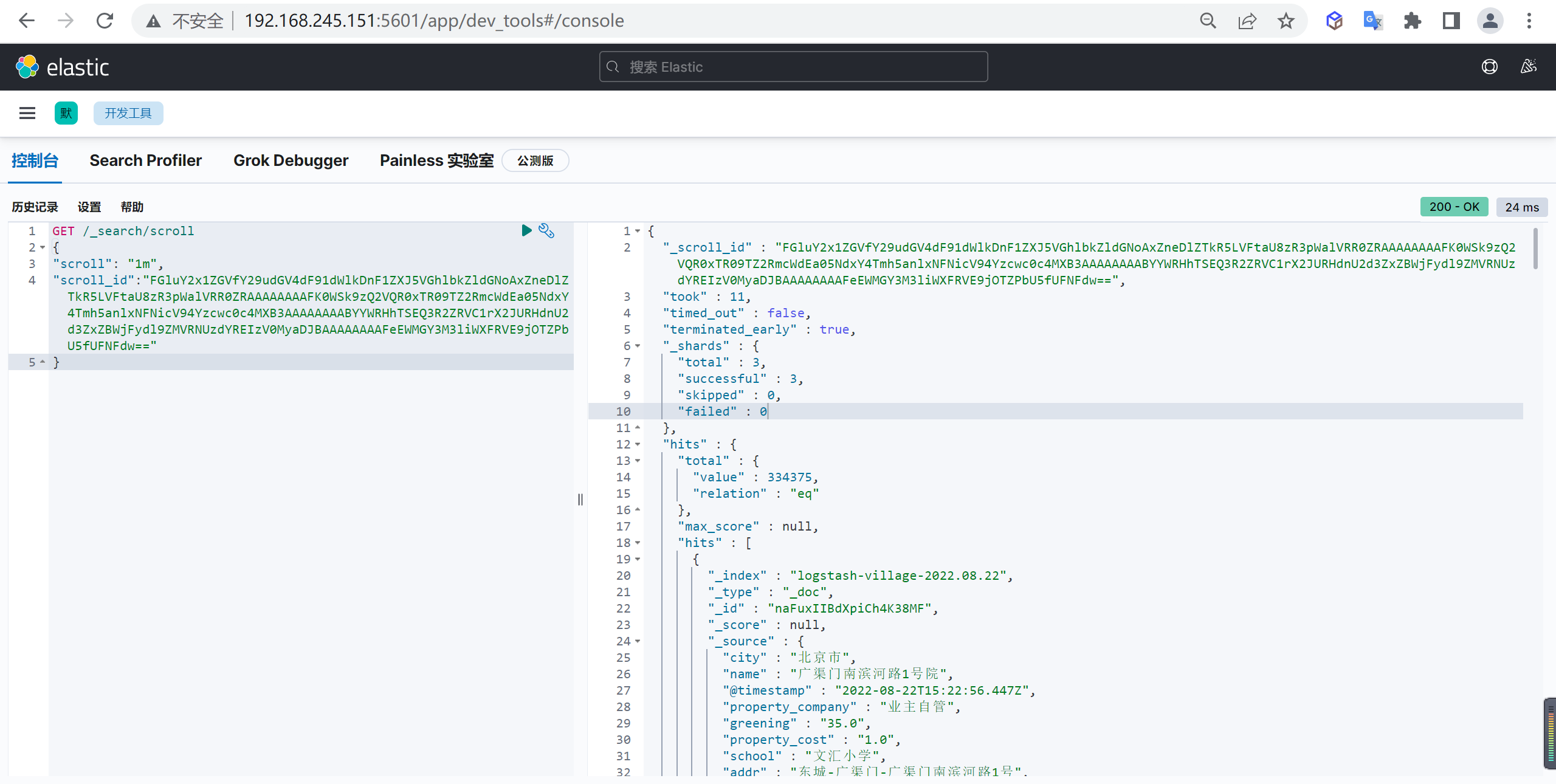
每读取一页都会重新设置 scroll_id 的生存时间,所以这个时间只需要满足读取当前页就可以,不需要满足读取所有的数据的时间,1 分钟足以。
注意事项
使用初始化返回的
_scroll_id来进行请求,每一次请求都会继续返回初始化中未读完数据,并且会返回一个_scroll_id,这个_scroll_id可能会改变,因此每一次请求应该带上上一次请求返回的_scroll_id
每次发送scroll请求时,都要再重新刷新这个scroll的开启时间,以防不小心超时导致数据取得不完整,如果没有数据了,就会回传空的hits,可以用这个判断是否遍历完成了数据
优缺点
优点
- 支持全量遍历(单次遍历的 size 值也不能超过 max_result_window 大小)
缺点
- 响应时间非实时。
- 保留上下文需要足够的堆内存空间。
适用场景
- 全量或数据量很大时遍历结果数据,而非分页查询。
- 官方文档强调:不再建议使用scroll API进行深度分页,如果要分页检索超过 Top 10,000+ 结果时,推荐使用:PIT + search_after。
scroll 分页原理
游标查询会取某个时间点的快照数据,查询初始化之后索引上的任何变化会被它忽略,它通过保存旧的数据文件来实现这个特性,结果就像保留初始化时的索引视图一样。
深度分页的代价根源是结果集全局排序,如果去掉全局排序的特性的话查询结果的成本就会很低, 游标查询用字段 _doc 来排序,这个指令让 Elasticsearch 仅仅从还有结果的分片返回下一批结果。
启用游标查询可以通过在查询的时候设置参数 scroll 的值为我们期望的游标查询的过期时间, 游标查询的过期时间会在每次做查询的时候刷新,所以这个时间只需要足够处理当前批的结果就可以了,而不是处理查询结果的所有文档的所需时间。
这个过期时间的参数很重要,因为保持这个游标查询窗口需要消耗资源,所以我们期望如果不再需要维护这种资源就该早点儿释放掉,设置这个超时能够让 Elasticsearch 在稍后空闲的时候自动释放这部分资源。
滚动游标原理
对一次查询生成一个游标 scroll_id , 后续的查询只需要根据这个游标scroll_id 去取数据,直到结果集中返回的 hits 字段为空,就表示遍历结束。
scroll_id 的生成可以理解为建立了一个临时的历史快照,或者可以理解为一个保存doc快照的临时的结果文件,快照文件形成之后,原doc的增删改查等操作不会影响到这个快照的结果。
Scroll 的理解
- 使用scroll就是一次把要用的数据都排完了,缓存起来
- 在遍历时,从这个快照里取数据,分批取出
- 因此,游标可以增加性能的原因,Scroll 使用from+size还好
- 是因为如果做深分页,from+size 每次搜索都必须重新排序,非常浪费资源,而且容易OOM
scroll的清理
srcoll_id 的存在会耗费大量的资源来保存一份当前查询结果集映像,并且会占用文件描述符
为了防止因打开太多scroll而导致的问题,不允许用户打开滚动超过某个限制,默认情况下,打开的滚动的最大数量为500,可以使用search.max_open_scroll_context群集设置更新此限制,虽然es 会有自动清理机制,但是,尽量保障所有文档获取完毕之后,手动清理掉 scroll_id
根据scroll_id清理
使用 es 提供的 CLEAR_API 来删除指定的 scroll_id
DELETE /_search/scroll/FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAxZvdlVSblJQdFFLaWx5RjJDaGpSakxnAAAAAAAALkAWMGY3M3liWXFRVE9jOTZPbU5fUFNFdxZOc0dSOFl5WVRPZTExdUNrZnJrRmp3AAAAAAAALyEWSk9zQ2VQR0xTR09TZ2RmcWdEa05NdxZIaFBUWWVlTFRpeS1IajI5cjBGWEh3AAAAAAAAABkWRHhTSEQ3R2ZRVC1rX2JURHdnU2d3Zw==
清理所有的scroll
根据ID清理会比较麻烦,我们完全可以全部清除掉
DELETE /_search/scroll/_all
search_after 查询
scroll 的方式,官方的建议不用于实时的请求(一般用于数据导出),因为每一个
scroll_id不仅会占用大量的资源,而且会生成历史快照,对于数据的变更不会反映到快照上。
search_after 查询本质:使用前一页中的一组排序值来检索匹配的下一页,search_after 分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。
但是需要注意,因为每一页的数据依赖于上一页最后一条数据,所以无法跳页请求,无法指定页数,只能实现“下一页”这种需求。
为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,其实使用业务层的 id 也可以。
前置条件:使用 search_after 要求后续的多个请求返回与第一次查询相同的排序结果序列,也就是说,即便在后续翻页的过程中,可能会有新数据写入等操作,但这些操作不会对原有结果集构成影响。
使用方式
search_after 分页查询可以简单概括为如下几个步骤
创建 PIT 视图
创建 PIT 视图,这是前置条件不能省
POST logstash-village-2022.08.22/_pit?keep_alive=5m
keep_alive=5m,类似scroll的参数,代表视图保留时间是 5 分钟,超过 5 分钟执行会报错
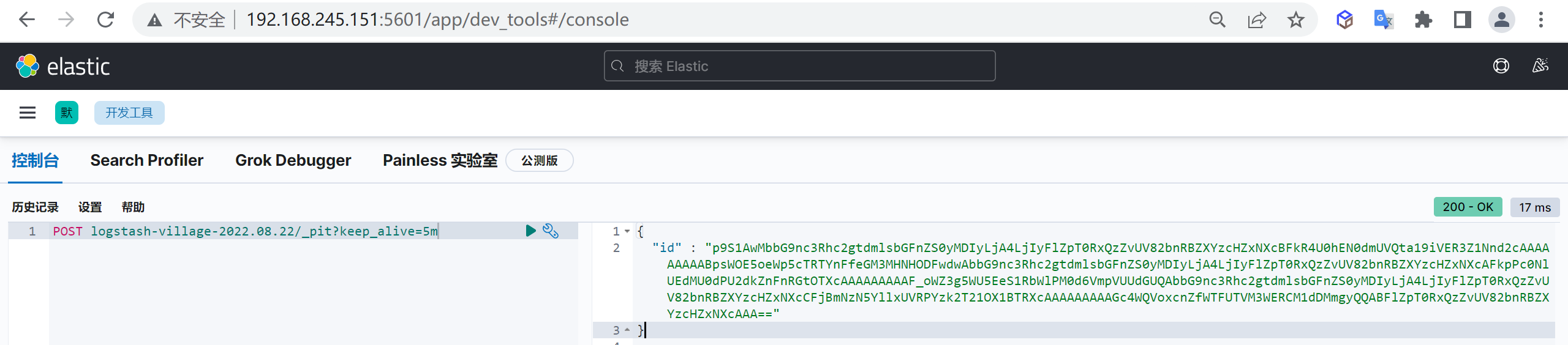
创建基础查询
创建基础查询语句,这里要设置翻页的条件
- 设置了PIT,检索时候就不需要再指定索引。
- id 是基于步骤1 返回的 id 值。
- 排序 sort 指的是:按照哪个关键字排序。
GET /_search
{
"size": 10,
"query": {
"match": {
"province": "河南省"
}
},
"pit": {
"id": "p9S1AwMbbG9nc3Rhc2gtdmlsbGFnZS0yMDIyLjA4LjIyFlZpT0RxQzZvUV82bnRBZXYzcHZxNXcBFkR4U0hEN0dmUVQta19iVER3Z1Nnd2cAAAAAAAAABswWOE5oeWp5cTRTYnFfeGM3MHNHODFwdwAbbG9nc3Rhc2gtdmlsbGFnZS0yMDIyLjA4LjIyFlZpT0RxQzZvUV82bnRBZXYzcHZxNXcAFkpPc0NlUEdMU0dPU2dkZnFnRGtOTXcAAAAAAAAAGHwWZ3g5WU5EeS1RbWlPM0d6VmpVUUdGUQAbbG9nc3Rhc2gtdmlsbGFnZS0yMDIyLjA4LjIyFlZpT0RxQzZvUV82bnRBZXYzcHZxNXcCFjBmNzN5YllxUVRPYzk2T21OX1BTRXcAAAAAAAAAGncWQVoxcnZfWTFUTVM3WERCM1dDMmgyQQABFlZpT0RxQzZvUV82bnRBZXYzcHZxNXcAAA==",
"keep_alive": "1m"
},
"sort": [
{
"greening": {
"order": "desc"
}
}
]
}在每个返回文档的最后,会有两个结果值,如下所示
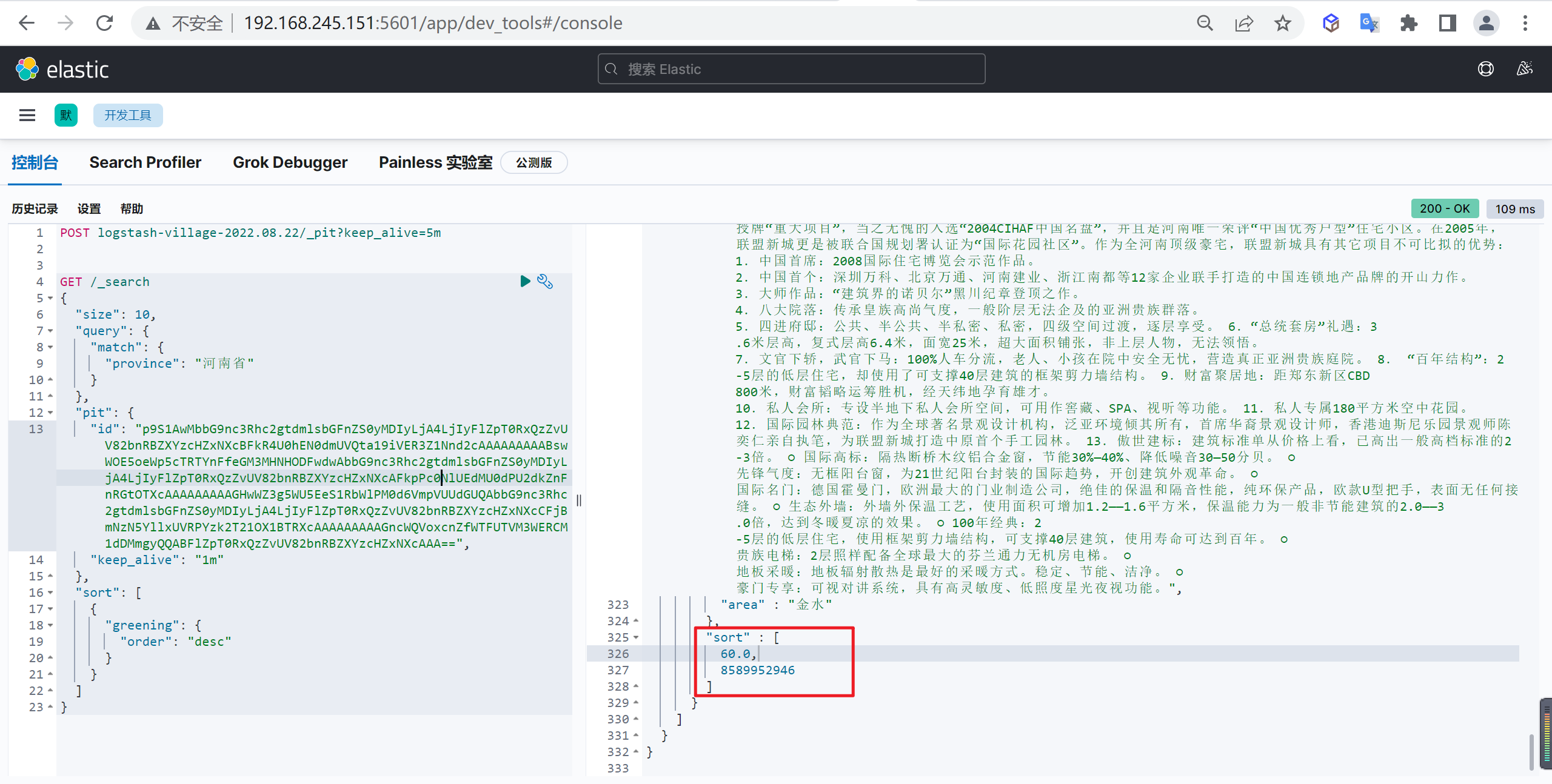
其中,
60就是我们指定的排序方式:基于{"greening": {"order": "desc" }}降序排列
官方文档把这种隐含的字段叫做:tiebreaker (决胜字段),tiebreaker 等价于_shard_doc。
tiebreaker 本质含义:每个文档的唯一值,确保分页不会丢失或者分页结果数据出现重复(相同页重复或跨页重复)。
后续翻页
后续翻页都需要借助 search_after 指定前一页的最后一个文档的 sort 字段值,search_after 查询仅支持向后翻页
GET /_search
{
"size": 10,
"query": {
"match": {
"province": "河南省"
}
},
"pit": {
"id": "p9S1AwMbbG9nc3Rhc2gtdmlsbGFnZS0yMDIyLjA4LjIyFlZpT0RxQzZvUV82bnRBZXYzcHZxNXcBFjBmNzN5YllxUVRPYzk2T21OX1BTRXcAAAAAAAAAG58WQVoxcnZfWTFUTVM3WERCM1dDMmgyQQAbbG9nc3Rhc2gtdmlsbGFnZS0yMDIyLjA4LjIyFlZpT0RxQzZvUV82bnRBZXYzcHZxNXcAFkR4U0hEN0dmUVQta19iVER3Z1Nnd2cAAAAAAAAABwoWOE5oeWp5cTRTYnFfeGM3MHNHODFwdwAbbG9nc3Rhc2gtdmlsbGFnZS0yMDIyLjA4LjIyFlZpT0RxQzZvUV82bnRBZXYzcHZxNXcCFkpPc0NlUEdMU0dPU2dkZnFnRGtOTXcAAAAAAAAAGTIWZ3g5WU5EeS1RbWlPM0d6VmpVUUdGUQABFlZpT0RxQzZvUV82bnRBZXYzcHZxNXcAAA==",
"keep_alive": "1m"
},
"sort": [
{
"greening": {
"order": "desc"
}
}
],
"search_after": [
60,
8589970292
]
}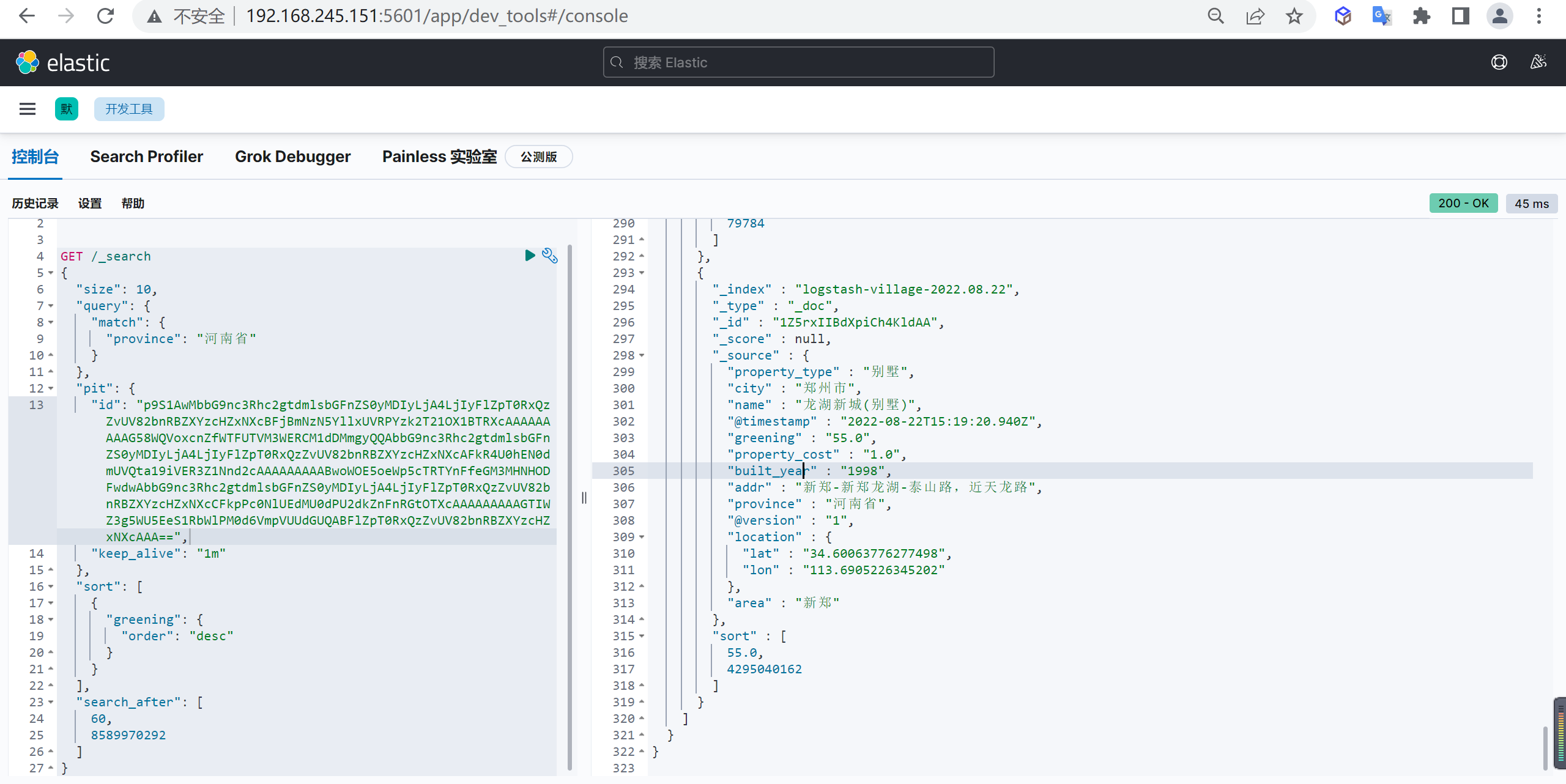
优缺点
优点
- 不严格受制于 max_result_window,可以无限制往后翻页(不严格含义:单次请求值不能超过 max_result_window;但总翻页结果集可以超过)
缺点
- 只支持向后翻页,不支持随机翻页。
适用场景
不支持随机翻页,更适合手机端应用的场景
分页原理
search_after 查询本质:使用前一页中的一组排序值来检索匹配的下一页
可以创建一个时间点 Point In Time(PIT)保障搜索过程中保留特定事件点的索引状态,Point In Time(PIT)是 Elasticsearch 7.10 版本之后才有的新特性,PIT的本质是存储索引数据状态的轻量级视图。
PIT视图
如下示例能很好的解读 PIT 视图的内涵。
# 创建 PIT
POST customer/_pit?keep_alive=1m
# 获取数据量 2
GET customer/_count
# 新增一条数据
POST customer/_doc/3
{
"user" : "王五",
"post_date" : "2022-08-15T14:12:12",
"message" : "王五插入一条数据"
}
# 数据总量为 3
POST customer/_count
# 查询PIT,数据依然是2,说明走的是之前时间点的视图的统计。
POST /_search
{
"track_total_hits": true,
"query": {
"match_all": {}
},
"pit": {
"id": "p9S1AwEIY3VzdG9tZXIWeU8zclhvM09UQzJ2dTZRaGlpZE5ndwAWSk9zQ2VQR0xTR09TZ2RmcWdEa05NdwAAAAAAAAAXVhZneDlZTkR5LVFtaU8zR3pWalVRR0ZRAAEWeU8zclhvM09UQzJ2dTZRaGlpZE5ndwAA"
}
}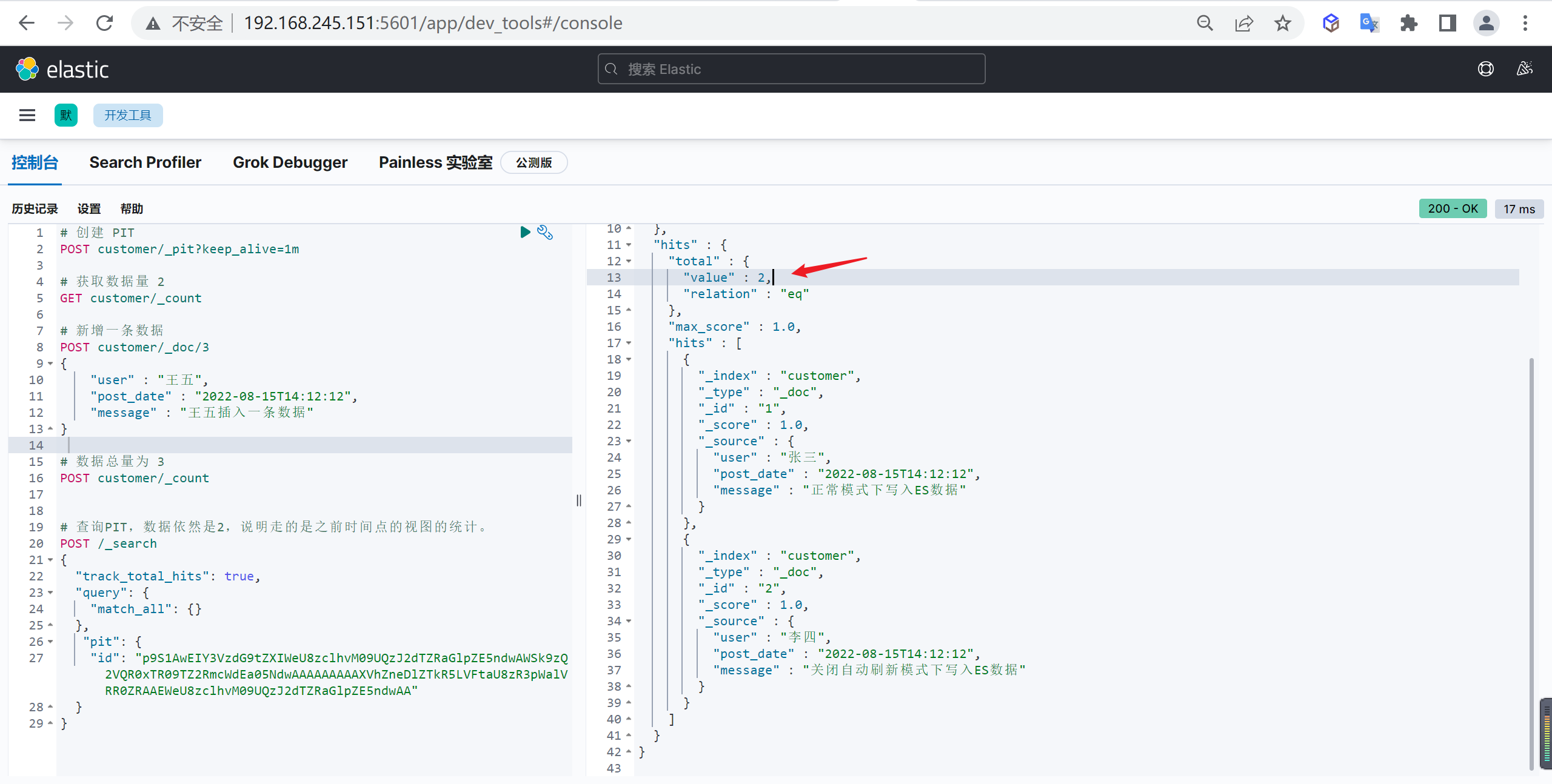
有了 PIT,search_after 的后续查询都是基于 PIT 视图进行,能有效保障数据的一致性
三种分页方式对比
性能对比
| 页方式 | 1~10 | 49000~49010 | 99000~99010 |
|---|---|---|---|
| form+size | 8ms | 30ms | 117ms |
| scroll | 7ms | 66ms | 36ms |
| search_after | 5ms | 8ms | 7ms |
优缺点对比
| 分页方式 | 性能 | 优点 | 缺点 | 场景 |
|---|---|---|---|---|
| from + size | 低 | 灵活性好,实现简单 | 深度分页问题 | 数据量比较小,能容忍深度分页问题 |
| scroll | 中 | 解决了深度分页问题 | 无法反应数据的实时性(快照版本) | 维护成本高,需要维护一个 scroll_id |
| search_after | 高 | 性能最好不存在深度分页问题能够反映数据的实时变更 | 实现复杂,需要有一个全局唯一的字段连续分页的实现会比较复杂,因为每一次查询都需要上次查询的结果 | 海量数据的分页 |
ElasticSearch 数据存储
数据写入
Elasticsearch采用多Shard方式,通过配置routing规则将数据分成多个数据子集,每个数据子集提供独立的索引和搜索功能,当写入文档的时候,根据routing规则,将文档发送给特定Shard中建立索引,这样就能实现分布式了,此外,Elasticsearch整体架构上采用了一主多副的方式:
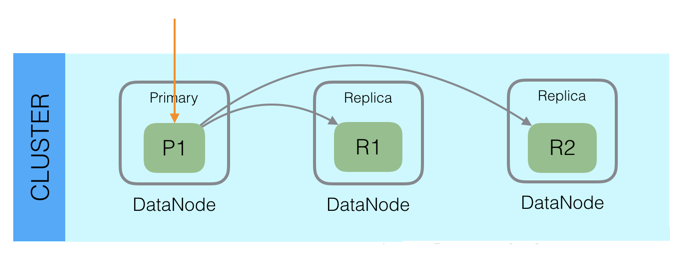
每个Index由多个Shard组成(默认是1个),每个Shard有一个主节点和多个副本节点,副本个数可配。
写入过程
但每次写入的时候,写入请求会先根据_routing规则选择发给哪个Shard,Index Request中可以设置使用哪个Filed的值作为路由参数,如果没有设置,则使用Mapping中的配置,如果mapping中也没有配置,则使用_id作为路由参数,然后通过_routing的Hash值选择出Shard(在OperationRouting类中),最后从集群的Meta中找出该Shard的Primary节点。
请求接着会发送给Primary Shard,在Primary Shard上执行成功后,再从Primary Shard上将请求同时发送给多个Replica Shard,请求在多个Replica Shard上执行成功并返回给Primary Shard后,写入请求执行成功,返回结果给客户端。
在写入时,我们可以在Request自己指定_routing,也可以在Mapping指定文档中的Field值作为_routing,如果没有指定_routing,则会把_id作为_routing进行计算。
由于写入时,具有相同_routing的文档一定会分配在同一个分片上,所以如果是自定义的_routing,在查询时,一定要指定_routing进行查询,否则是查询不到文档的,这并不是局限性,恰恰相反,指定_routing的查询,性能上会好很多,因为指定_routing意味着直接去存储数据的shard上搜索,而不会搜索所有shard。
写入原理
我们可以采用多个副本后,避免了单机或磁盘故障发生时,但是Elasticsearch里为了减少磁盘IO保证读写性能,一般是每隔一段时间(比如30分钟)才会把Lucene的Segment写入磁盘持久化,对于写入内存,但还未Flush到磁盘的Lucene数据,如果发生机器宕机或者掉电,那么内存中的数据也会丢失,这时候如何保证?ES这里采用了预写日志的机制,在ES中预写日志是translog
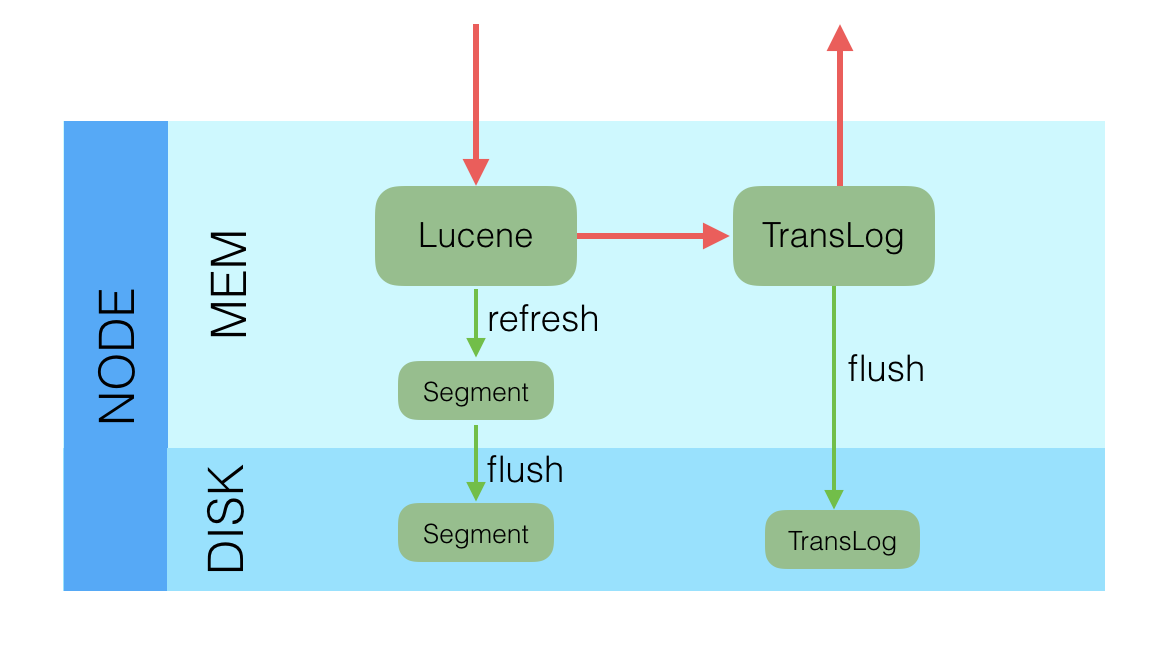
什么是translog
仔细分析下上面ES的refresh和flush,就会发现如果在数据还没有被flush之前,机器宕掉了,那上次flush之后到宕机前的数据就丢了
当ES异常恢复时会丢掉最后一次flush之后的数据(如果有的话),这对于绝大多数业务是不能接受的,所以ES引入了translog来解决这个问题,其实也不算什么新技术,就是类似于传统DB里面的预写日志(WAL),不过在ES里面叫事务日志(transaction log),简称translog。
这样ES的写入的时候,先在内存buffer中进行Lucene documents的写入,写入成功后再写translog,内存buffer中的Lucene documents经过refresh会形成file system cache中的segment,此时内容就可以被搜索到了,然后经过flush,持久化到磁盘上面。
写入过程
在每一个Shard中,写入流程分为两部分,先写入Lucene,再写入TransLog
写入请求到达Shard后,先写Lucene文件,创建好索引,此时索引还在内存里面,接着去写TransLog,写完TransLog后,刷新TransLog数据到磁盘上,写磁盘成功后,请求返回给用户,这里有几个关键点:
和数据库不同,数据库是先写redo log,然后再写内存,而Elasticsearch是先写内存,最后才写TransLog,一种可能的原因是Lucene的内存写入会有很复杂的逻辑,很容易失败,比如分词,字段长度超过限制等,比较重,为了避免TransLog中有大量无效记录,减少recover的复杂度和提高速度,所以就把写Lucene放在了最前面。
写Lucene内存后,并不是可被搜索的,需要通过Refresh把内存的对象转成完整的Segment后,然后再次reopen后才能被搜索,一般这个时间设置为1秒钟,导致写入Elasticsearch的文档,最快要1秒钟才可被从搜索到,所以Elasticsearch在搜索方面是NRT(Near Real Time)近实时的系统。
当Elasticsearch作为NoSQL数据库时,查询方式是GetById,这种查询可以直接从TransLog中查询,这时候就成了RT(Real Time)实时系统。
每隔一段比较长的时间,比如30分钟后,Lucene会把内存中生成的新Segment刷新到磁盘上,刷新后索引文件已经持久化了,历史的TransLog就没用了,会清空掉旧的TransLog。
Lucene缓存中的数据默认1秒之后才生成segment文件,即使是生成了segment文件,这个segment是写到页面缓存中的,并不是实时的写到磁盘,只有达到一定时间或者达到一定的量才会强制flush磁盘。
如果这期间机器宕掉,内存中的数据就丢了,如果发生这种情况,内存中的数据是可以从TransLog中进行恢复的,TransLog默认是每5秒都会刷新一次磁盘,但这依然不能保证数据安全,因为仍然有可能最多丢失TransLog中5秒的数据。
这里可以通过配置增加TransLog刷磁盘的频率来增加数据可靠性,最小可配置100ms,但不建议这么做,因为这会对性能有非常大的影响,一般情况下,Elasticsearch是通过副本机制来解决这一问题的。
写入过程分析
追加事务日志
当一个文档被索引,它被加入到内存缓存,同时加到事务日志,不断有新的文档被写入到内存,同时也都会记录到事务日志中,这时新数据还不能被检索和查询。

刷新缓存
当达到默认的刷新时间或内存中的数据达到一定量后,会触发一次 refresh:
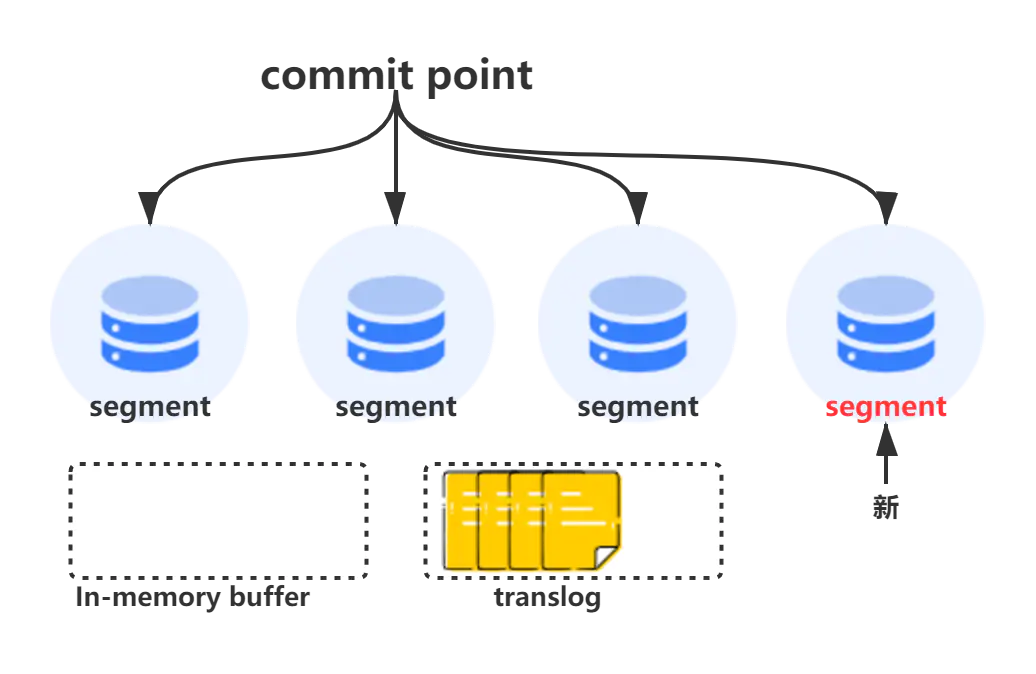
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行fsync操作。
- 这个段被打开,使其可被搜索。
- 内存缓冲区被清空。
继续追加事务日志
这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志。
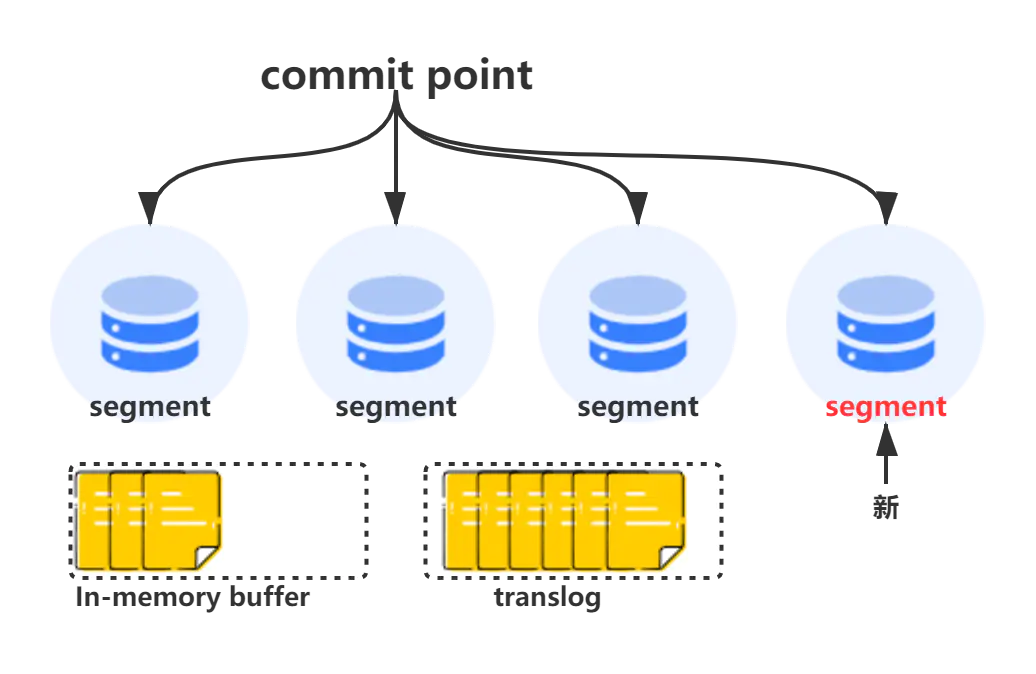
持久化
随着新文档索引不断被写入,当日志数据大小超过 512M 或者时间超过 30 分钟时,会进行一次全提交:
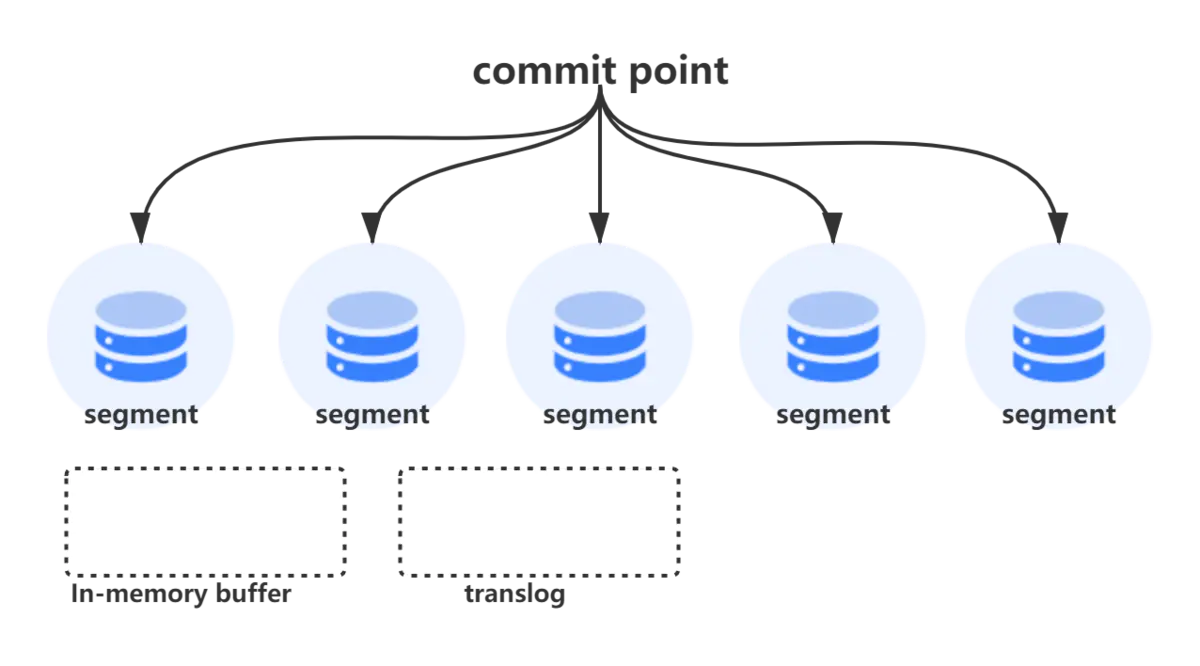
- 内存缓存区的所有文档会写入到新段中,同时清除缓存;
- 文件系统缓存通过
fsync操作flush到硬盘,生成提交点; - 事务日志文件被删除,创建一个空的新日志。
副本可靠性
即使主分片所在节点宕机,丢失了5秒数据,依然是可以通过副本来进行恢复的。
引入translog之后,解决了进程突然挂掉或者机器突然宕机导致还处于内存,没有被持久化到磁盘的数据丢失的问题,但数据仅落到磁盘还是无法完全保证数据的安全,比如磁盘损坏等
分布式领域解决这个问题最直观和最简单的方式就是采用副本机制,比如HDFS、Kafka等都是此类代表,ES也使用了副本的机制,一个索引由一个primary和n(n≥0)个replica组成,replica的个数支持可以通过接口动态调整,为了可靠,primary和replica的shard不能在同一台机器上面。
在数据写入的时候,数据会先写primary,写成功之后,同时分发给多个replica,待所有replica都返回成功之后,再返回给客户端,所以一个写请求的耗时可以粗略认为是写primary的时间+耗时最长的那个replica的时间。
读写一致性
数据写入
- ES会将文档发送给协调节点,根据document数据路由到指定的节点,该节点包含该
primary shard - 把文档存储写入到
primary shard,如果设置了index.write.wait_for_active_shards=1,那么写完主节点,直接返回客户端,如果index.write.wait_for_active_shards=all,那么必须要把所有的副本写入完成才返回客户端 - 如果
index.write.wait_for_active_shards=1,那么es会异步的把主分片的数据同步到副本分片上去。(在此期间,可能会出现读请求可能读取不到最新数据的情况)
数据读取
- 客户端发送请求发送到任意一个节点,该节点成为协调节点
- 协调节点根据请求的查询的条件找到文档对应的主分片和副本节点的地址
- 随机选择一个节点,一般是轮询,可能查询主节点,也可能查询的是副本节点,然后将数据返回给协调节点
- 协调节点将数据返回给客户端
- 由于可能存在primary shard的数据还没同步到 replica shard上的情况,所以客户端可能查询到旧的数据,我们可以做相应的调整,保证读取到最新的数据。
数据存储
分片是 Elasticsearch 最小的工作单元,一个分片其实就是一个lucene索引,众多的分片组合在一起是一个完整的elasticsearch索引
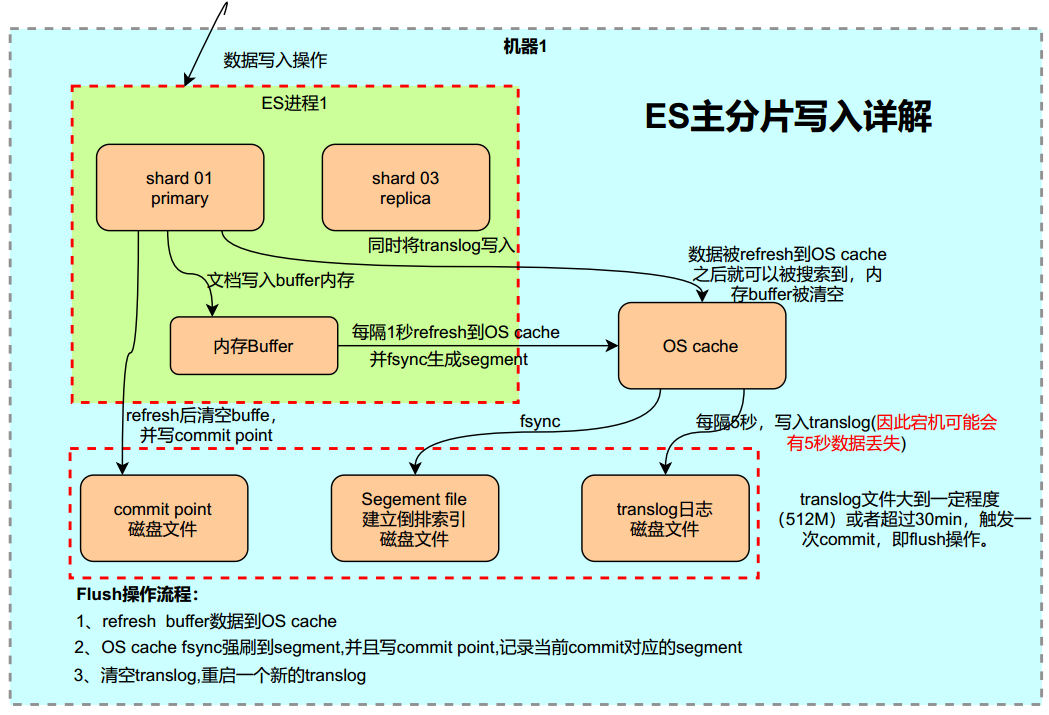
数据存储原理
倒排索引不可变
倒排索引被写入磁盘后是
不可改变的:它永远不会修改。
不可变优点
写入磁盘的倒排索引是不可变的,优势主要表现在
- 不需要锁,因为如果从来不需要更新一个索引,就不必担心多个程序同时尝试修改,也就不需要锁。
- 一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性,只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘,这提供了很大的性能提升。
- 写入单个大的倒排索引,可以压缩数据,只需要较少磁盘 IO 和缓存索引的内存即可。
不可变缺点
当然,不可变的索引有它的缺点:
- 当对旧数据进行删除时,旧数据不会马上被删除,而是在
.del文件中被标记为删除,而旧数据只能等到段更新时才能被移除,这样会造成大量的空间浪费。 - 若有一条数据频繁的更新,每次更新都是新增新的标记旧的,则会有大量的空间浪费。
- 每次新增数据时都需要新增一个段来存储数据,当段的数量太多时,对服务器的资源例如文件句柄的消耗会非常大。
- 在查询的结果中包含所有的结果集,需要排除被标记删除的旧数据,这增加了查询的负担。
段的引入
在全文检索的早些时候,会为整个文档集合建立一个大索引,并且写入磁盘,只有新的索引准备好了,它就会替代旧的索引,最近的修改才可以被检索,这无疑是低效的,因为上面种种原因,引入了段
- 新的文档首先写入内存区的索引缓存,这时不可检索。
- 时不时(默认 1s 一次),内存区的索引缓存被 refresh 到文件系统缓存(该过程比直接到磁盘代价低很多),成为一个新的段(segment)并被打开,这时可以被检索。
- 新的段提交,写入磁盘,提交后,新的段加入提交点,缓存被清除,等待接收新的文档。
什么是段
分片下的索引文件被拆分为多个子文件,每个子文件叫作段, 每一个段本身都是一个倒排索引,并且段具有不变性,一旦索引的数据被写入硬盘,就不可再修改。
段被写入到磁盘后会生成一个提交点,提交点是一个用来记录所有提交后段信息的文件,一个段一旦拥有了提交点,就说明这个段只有读的权限,失去了写的权限,相反当段在内存中时,就只有写的权限,而不具备读数据的权限,意味着不能被检索。
为什么段不可变
在 lucene 中,为了实现高索引速度,故使用了segment 分段架构存储
一批写入数据保存在一个段中,其中每个段是磁盘中的单个文件,由于两次写入之间的文件操作非常繁重,因此将一个段设为不可变的,以便所有后续写入都转到新的段。
段的合并
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增
什么是段合并
而段数目太多会带来较大的麻烦,每一个段都会消耗文件句柄、内存和 cpu 运行周期,更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
Elasticsearch 通过在后台进行段合并来解决这个问题,小的段被合并到大的段,然后这些大的段再被合并到更大的段。
段合并的时候会将那些旧的已删除文档从文件系统中清除,被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。
段合并流程
启动段合并不需要你做任何事,进行索引和搜索时会自动进行。
- 当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
- 合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中,这并不会中断索引和搜索。
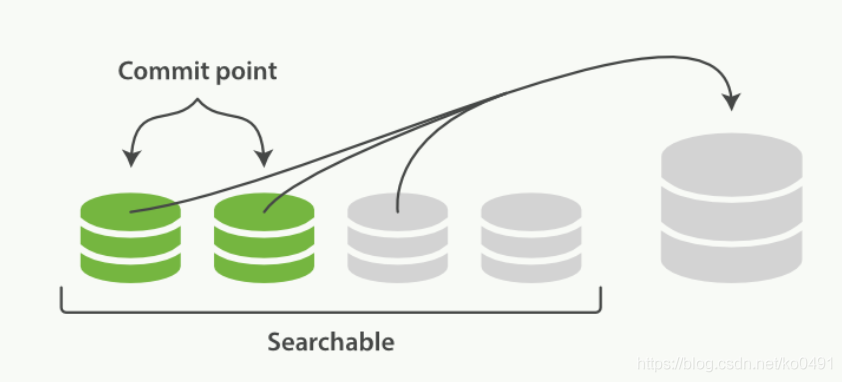
一旦合并结束,老的段被删除
- 新的段被刷新(flush)到了磁盘,写入一个包含新段且排除旧的和较小的段的新提交点。
- 新的段被打开用来搜索。
- 老的段被删除。
合并大的段需要消耗大量的 I/O 和 CPU 资源,如果任其发展会影响搜索性能,Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然 有足够的资源很好地执行。
默认情况下,归并线程的限速配置 indices.store.throttle.max_bytes_per_sec 是 20MB,对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。
索引更新
如何更新索引
因为索引的不可变性带来的好处,那如何在保持不可变同时更新倒排索引?
答案是,使用多个索引,不是重写整个倒排索引,而是增加额外的索引反映最近的变化,每个倒排索引都可以按顺序查询,从最老的开始,最后把结果聚合。
更新细节
索引文件分段存储并且不可修改,那么新增、更新和删除如何处理呢?
- 新增,新增很好处理,由于数据是新的,所以只需要对当前文档新增一个段就可以了。
- 删除,由于不可修改,所以对于删除操作,不会把文档从旧的段中移除,而是通过新增一个
.del文件(每一个提交点都有一个 .del 文件),包含了段上已经被删除的文档。当一个文档被删除,它实际上只是在.del文件中被标记为删除,依然可以匹配查询,但是最终返回之前会被从结果中删除。 - 更新,不能修改旧的段来进行反映文档的更新,其实更新相当于是删除和新增这两个动作组成,会将旧的文档在
.del文件中标记删除,然后文档的新版本被索引到一个新的段中,可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就会被移除。
如何查询
当一个查询触发时,所有已知的段按顺序被查询。
词项统计会对所有段的结果进行聚合,以保证每个词和每个文档的关联都被准确计算,这种方式可以用相对较低的成本将新文档添加到索引。
段是不可改变的,所以既不能从把文档从旧的段中移除,也不能修改旧的段来进行反映文档的更新。 取而代之的是,每个提交点会包含一个 .del 文件,文件中会列出这些被删除文档的段信息。
当一个文档被 “删除” 时,它实际上只是在 .del 文件中被标记删除,一个被标记删除的文档仍然可以被查询匹配到, 但它会在最终结果被返回前从结果集中移除。
文档更新也是类似的操作方式:当一个文档被更新时,旧版本文档被标记删除,文档的新版本被索引到一个新的段中,可能两个版本的文档都会被一个查询匹配到,但被删除的那个旧版本文档在结果集返回前就已经被移除。
近实时搜索原理
随着按段(per-segment)搜索的发展,一个新的文档从索引到可被搜索的延迟显著降低了
直接写入存在的问题
提交一个新的段到磁盘需要
fsync操作,确保段被物理地写入磁盘,即时电源失效也不会丢失数据
但是fsync是昂贵的,严重影响性能,当写数据量大的时候会造成 ES 停顿卡死,查询也无法做到快速响应,新文档在几分钟之内即可被检索,但这样还是不够快,磁盘在这里成为了瓶颈,提交(Commiting)一个新的段到磁盘需要一个fsync来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据, 但是 fsync 操作代价很大; 如果每次索引一个文档都去执行一次的话会造成很大的性能问题。
延时写策略
所以
fsync不能在每个文档被索引的时就触发,需要一种更轻量级的方式使新的文档可以被搜索,这意味移除fsync,为了提升写的性能,ES没有每新增一条数据就增加一个段到磁盘上,而是采用延迟写的策略。
每当有新增的数据时,就将其先写入到内存中,在内存和磁盘之间是文件系统缓存,当达到默认的时间(1秒钟)或者内存的数据达到一定量时,会触发一次刷新(Refresh),将内存中的数据生成到一个新的段上并缓存到文件缓存系统上,稍后再被刷新到磁盘中并生成提交点。
如何实现近实时搜索
这里的内存使用的是ES的JVM内存,而文件缓存系统使用的是操作系统文件缓冲区,也就是操作系统内存
新的数据会继续的被写入内存,但内存中的数据并不是以段的形式存储的,因此不能提供检索功能,由内存刷新到文件缓存系统的时候会生成了新的段,并将段打开以供搜索使用,而不需要等到被刷新到磁盘。
在 Elasticsearch 中,这种写入和打开一个新段的轻量的过程叫做 refresh (即内存刷新到文件缓存系统)默认情况下每个分片会每秒自动刷新一次,这就是为什么说 Elasticsearch 是近实时的搜索了:文档的改动不会立即被搜索,但是会在一秒内可见。
这些行为可能会对新用户造成困惑: 他们索引了一个文档然后尝试搜索它,但却没有搜到,这个问题的解决办法是用 refresh API 执行一次手动刷新: /users/_refresh。
近实时写入测试
准备工作
下面我们先创建一个索引
PUT customer?pretty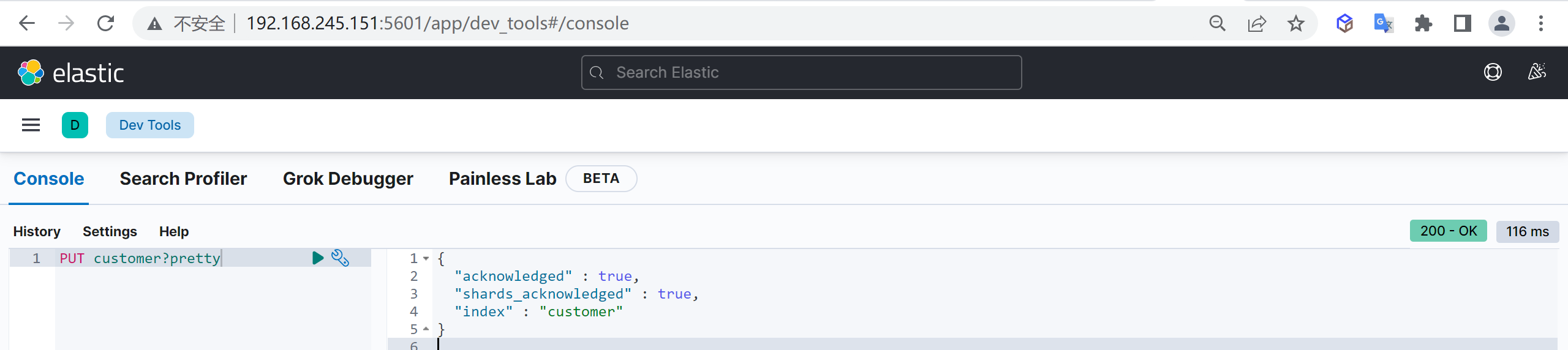
使用默认设置
写入数据
下面我们以正常的方式进行写入
POST customer/_doc/1
{
"user" : "张三",
"post_date" : "2022-08-15T14:12:12",
"message" : "正常模式下写入ES数据"
}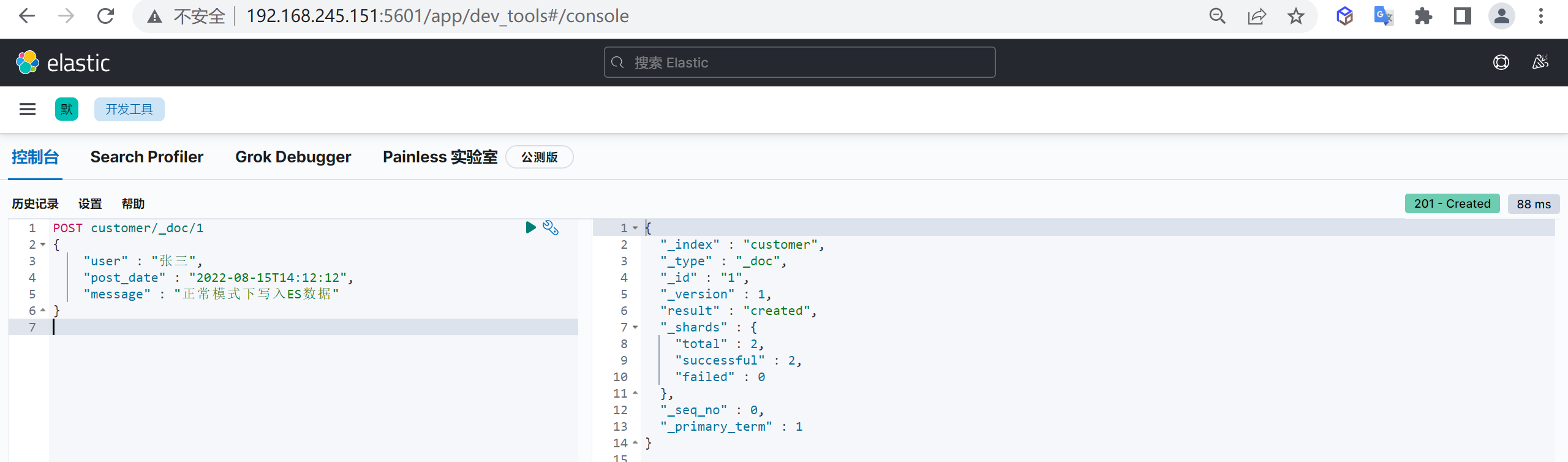
查询数据
接下来我们马上进行数据的查询
GET customer/_search
{
}我们发现数据马上就被查询出来了
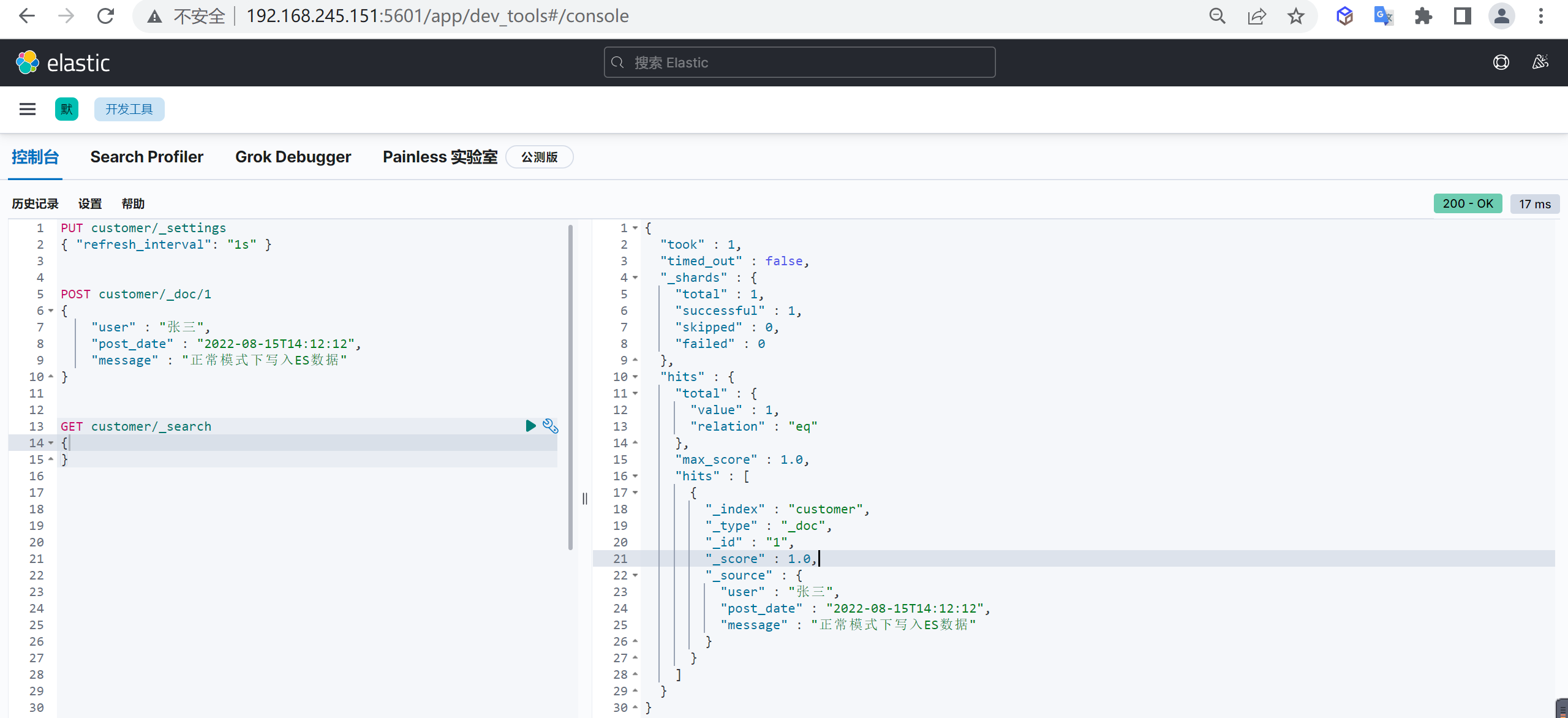
关闭自动刷新
下面我们将自动刷新给关闭掉在进行测试
关闭自动刷新
# 关闭自动刷新
PUT customer/_settings
{ "refresh_interval": -1 }下面我们已经关闭了自动刷新,这个时候数据不会被刷新进段中了

写入数据
下面我们我们在关闭自动刷新的情况下写入数据
post customer/_doc/2
{
"user" : "李四",
"post_date" : "2022-08-15T14:12:12",
"message" : "关闭自动刷新模式下写入ES数据"
}文档已经被创建成功了
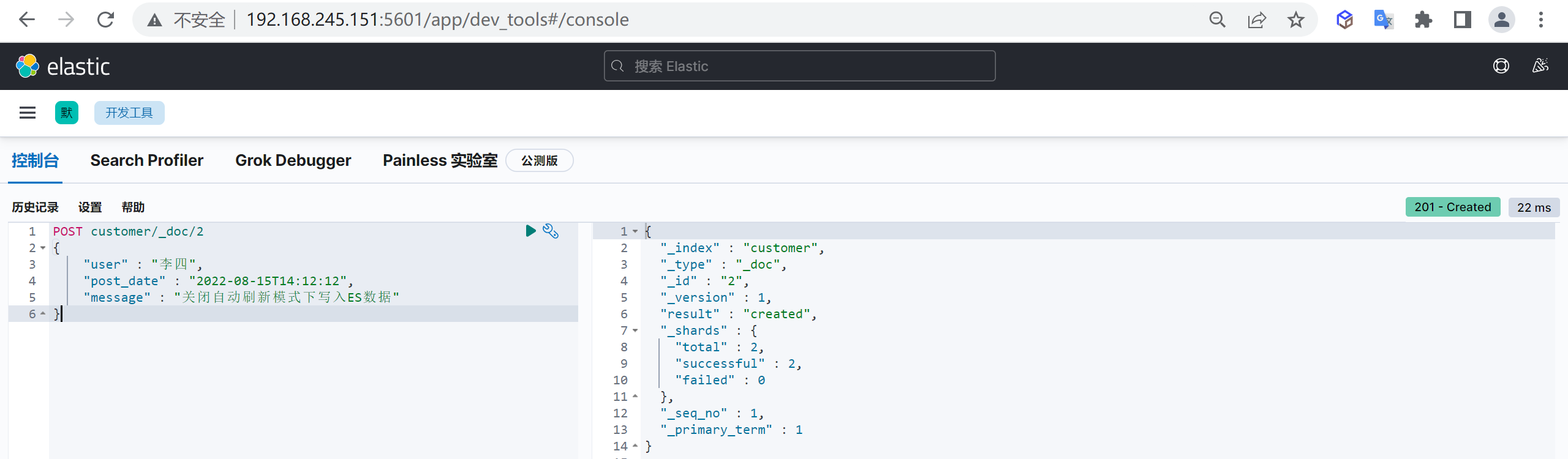
查询数据
接下来我们马上进行数据的查询
GET customer/_search
{
}我们发现数据还是只有张三而没有李四,说明数据还没有被刷新过来
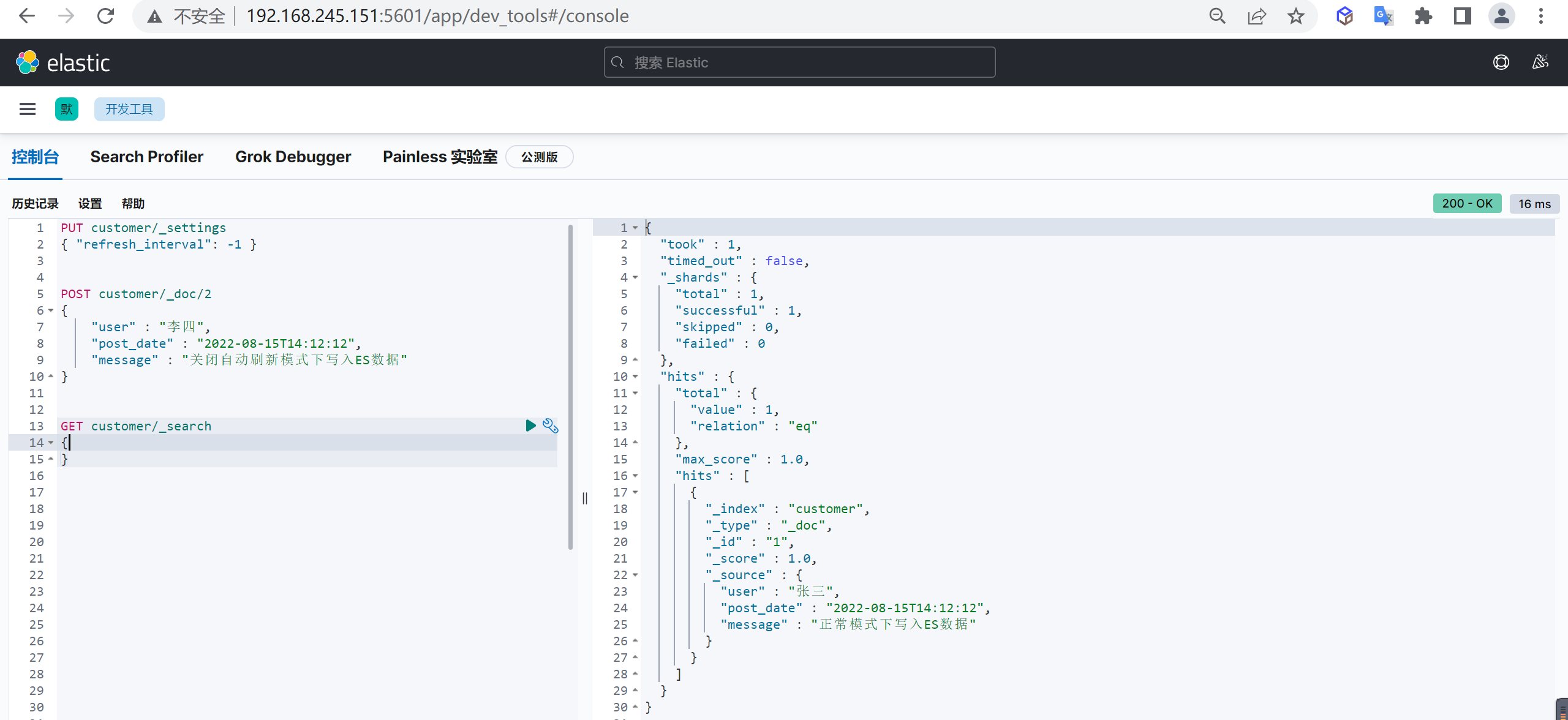
开启自动刷新
我们开启自动刷新后在进行查询
# 正常模式每一秒刷新一次
PUT customer/_settings
{ "refresh_interval": "1s" }
#接下来在进行正常的查询来查看效果
GET customer/_search
{
}我们发现李四的数据已经被查询出来了
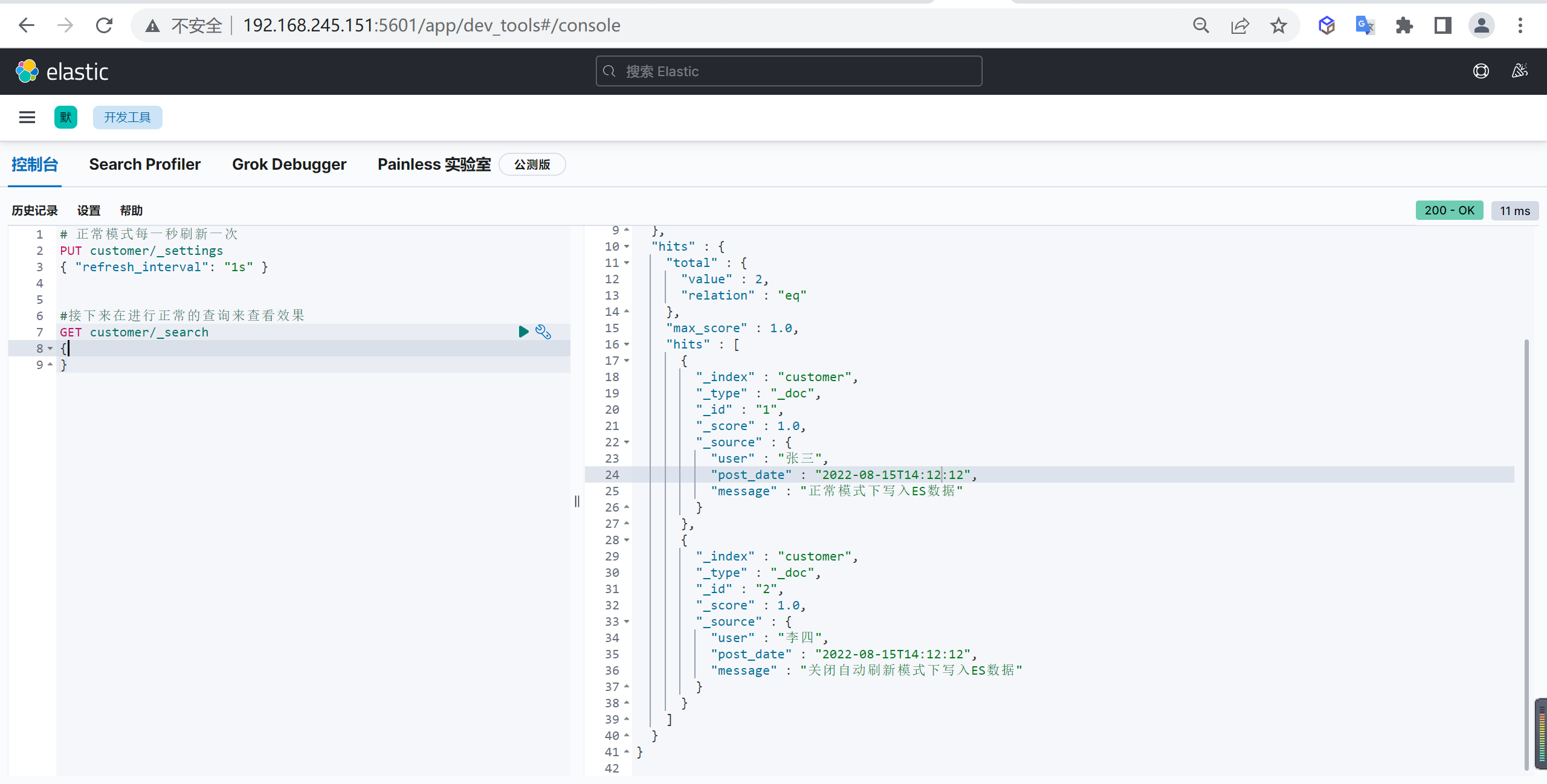
ES可靠性
相关概念
ES作为全文检索兼存储系统,数据可靠性至关重要,本文讨论ES是如何实现数据可靠性的,ES底层基于Lucene,所以有必要先搞清楚一些相关的概念。
refresh && flush && commit
Lucene中,有flush和commit的概念
所谓flush,就是定期将内存Buffer里面的数据刷新到Directory这样一个抽象的文件存储层,其实就是生成segment,需要注意的是,因为操作系统file cache的原因,这里的刷新未必会真的落盘,一般只是从内存buffer刷到了file cache而已,实质还是在内存中,所以是一个相对比较高效和轻量级的操作,flush方法的java doc是这样描述的:
Moves all in-memory segments to the Directory, but does not commit (fsync) them (call commit() for that).形成segment以后,数据就可以被搜索了,但因为Lucene flush一般比较频繁(ES里面执行频率默认是1秒),所以会产生很多小的segment文件,一方面太多的文件会占用太多的文件描述符;
另一方面,搜索时文件太多也会影响搜索效率,所以Lucene有专门的Merge线程定期将小的segment文件merge为大文件。
Lucene的commit上面的Java doc已经提到了,它会调用fsync,commit方法的java doc如下
Commits all pending changes (added and deleted documents, segment merges, added indexes, etc.) to the index, and syncs all referenced index files, such that a reader will see the changes and the index updates will survive an OS or machine crash or power loss.因为会调用fsync,所以commit之后,文件肯定会被持久化到磁盘上,所以这是一个重操作,一方面是磁盘的性能比较差,另一方面是commit的时候会执行更新索引等操作,commit一般是当我们认为系统到达一个稳定点的时候,commit一次,类似于流式系统里面的checkpoint,当系统出现故障的时候,Lucene会从最近的一次commit point进行恢复,而不是最近的一次flush。
总结一下,flush会生成segment,之后数据就能被搜索了,是一个轻量级操作,但此时并不保证数据被持久化了。commit是一个比较重的落盘操作,用于持久化,不能被频繁执行。
ES 概念
ES中有refresh和flush的概念,其实是和Lucene一一对应的,不过换了个名字,ES里面的refresh就是Lucene里面的flush;ES里面的flush就是Lucene里面的commit。所以,ES里面的refresh默认1秒执行一次,也就是数据写入ES之后最快1秒之后可以被搜索到,这也就是ES提供的近实时搜索NRT(Near Realtime)。而flush的执行时机有两个点:一个是ES会根据内存使用情况启发式的执行flush,另外一个时机是当translog达到512MB(默认值)时执行一次flush。网上很多文章(一般都比较早了)都提到每30分钟也会执行一次,但我在6.6版本的代码及文档里面没有找到这部分说明。
translog
仔细想一下上面介绍的Lucene的flush和commit,就会发现如果在数据还没有被commit之前,机器宕掉了,那上次commit之后到宕机前的数据就丢了。实际上,Lucene也是这么做的,异常恢复时会丢掉最后一次commit之后的数据(如果有的话)。这对于绝大多数业务是不能接受的,所以ES引入了translog来解决这个问题。其实也不算什么新技术,就是类似于传统DB里面的预写日志(WAL),不过在ES里面叫事务日志(transaction log),简称translog。
这样ES的写入的时候,先在内存buffer中进行Lucene documents的写入,写入成功后再写translog。内存buffer中的Lucene documents经过refresh会形成file system cache中的segment,此时,内容就可以被搜索到了。然后经过flush,持久化到磁盘上面。
重要问题
- 为了保证数据完全的可靠,一般的写入流程都是先写WAL,再写内存,但ES是先写内存buffer,然后再写translog。这个顺序目前没有找到官方的说明,网上大部分说的是写的过程比较复杂,容易出错,先写内存可以降低处理的复杂性。不过这个顺序个人认为对于用户而言其实不是很关键,因为不管先写谁,最终两者都写成功才会返回给客户端。
- translog的落盘(即图中的fsync过程)有两种策略,分别对应不同的可靠程度,第一种是每次请求(一个index、update、delete或者bulk操作)都会执行fsync,fsync成功后,才会给客户端返回成功,也就是请求同步刷盘,这种可靠性最高,只要返回成功,那数据一定已经落盘了,这也是默认的方式。第二种是异步的,按照定时达量的方式,默认每5秒或者512MB的时候就fsync一次。异步一般可以获得更高的吞吐量,但弊端是存在数据丢失的风险。
- ES的flush(或者Lucene的commit)也是落盘,为什么不直接用,而加一个translog?translog或者所有的WAL的一大特性就是他们都是追加写,这样大多数时候都可以实现顺序读写,读和写可以完全并发,所以性能一般都是非常好的。有一些测试表明,磁盘的顺序写甚至比内存的随机写更快,见The Pathologies of Big Data的Figure 3。
- translog不是全局的,而是每个shard(也就是Lucene的index)一个,且每个shard的所有translog中同一时刻只会有一个translog文件是可写的,其它都是只读的(如果有的话)。具体细节可查看
Translog类的Java doc说明。 - translog的老化机制在6.0之前是segment flush到磁盘后,就删掉了。6.0之后是按定时达量的策略进行删除,默认是512MB或者12小时。
副本
引入translog之后,解决了进程突然挂掉或者机器突然宕机导致还处于内存,没有被持久化到磁盘的数据丢失的问题,但数据仅落到磁盘还是无法完全保证数据的安全,比如磁盘损坏等。分布式领域解决这个问题最直观和最简单的方式就是采用副本机制,比如HDFS、Kafka等都是此类代表,ES也使用了副本的机制。一个索引由一个primary和n(n≥0)个replica组成,replica的个数支持可以通过接口动态调整。为了可靠,primary和replica的shard不能在同一台机器上面。
这里要注意区分一下replica和shard的关系:比如创建一个索引的时候指定了5个shard,那么此时primary分片就有5个shard,每个replica也会有5个shard。我们可以通过接口随意修改replica的个数,但不能修改每个primary/replica包含5个shard这个事实。 当然,shard的个数也可以通过shrink接口进行调整,但这是一个很重的操作,而且有诸多限制,比如shard个数只能减少,且新个数是原来的因子,比如原来是8个shard,那只能选择调整为4、2或1个;如果原来是5个,那就只能调整为1个了。所以实际中,shard的个数一般要预先计划好(经验值是保证一个shard的大小在30~50GB之间),而replica的个数可以根据实际情况后面再做调整。
在数据写入的时候,数据会先写primary,写成功之后,同时分发给多个replica,待所有replica都返回成功之后,再返回给客户端。所以一个写请求的耗时可以粗略认为是写primary的时间+耗时最长的那个replica的时间。
写入优化
总体来说,ES的写入能力不算太好,所以经常需要对写入性能做优化,除了保证良好的硬件配置外,还可以从ES自身进行机制进行优化,结合上面的介绍,可以很容易得出下面的一些优化手段:
- 如果对于搜索的实时性要求不高,可以适当增加refresh的时间,比如从默认的1秒改为30秒或者1min,甚至更长。如果是离线导入再搜索的场景,可以直接设置为”-1”,即关闭自动的refresh,等导入完成后,通过接口手动refresh。其提高性能的原理是增加refresh的时间可以减少大量小的segment文件,这样在可以提高flush的效率,减小merge的压力。
- 如果对于数据可靠性要求不是特别高,可以将translog的落盘机制由默认的请求同步落盘,改为定时达量的异步落盘,提高落盘的效率。
- 如果对于数据可靠性要求不是特别高,可以在写入高峰期先不设置副本,待过了高峰之后再通过接口增加副本。这个可以通过ES的ILM策略,实现自动化。
ElasticSearch 性能调优
概述
性能优化是个涉及面非常广的问题,不同的环境,不同的业务场景可能会存在不同的优化方案,本文只对一些相关的知识点做简单的总结,具体方案可以根据场景自行尝试。
配置文件调优
通过
elasticsearch.yml配置文件调优
内存锁定
允许 JVM 锁住内存,禁止操作系统交换出去
由于JVM发生swap交换会导致极大降低ES的性能,为了防止ES发生内存交换,我们可以通过锁定内存来实现,这将极大提高查询性能,但同时可能造成OOM,需要对应做好资源监控,必要的时候进行干预。
修改ES配置
修改ES的配置文件elasticsearch.yml,设置bootstrap.memory_lock为true
#集群名称
cluster.name: elastic
#当前该节点的名称
node.name: node-3
#是不是有资格竞选主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#给当前节点自定义属性(可以省略)
#node.attr.rack: r1
#数据存档位置
path.data: /usr/share/elasticsearch/data
#日志存放位置
path.logs: /usr/share/elasticsearch/log
#是否开启时锁定内存(默认为是)
#bootstrap.memory_lock: true
#设置网关地址,我是被这个坑死了,这个地址我原先填写了自己的实际物理IP地址,
#然后启动一直报无效的IP地址,无法注入9300端口,这里只需要填写0.0.0.0
network.host: 0.0.0.0
#设置映射端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写
#es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上
discovery.seed_hosts: ["node-1","node-2","node-3"]
#当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了,
#其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者,
#如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#在群集完全重新启动后阻止初始恢复,直到启动N个节点
#简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用,
gateway.recover_after_nodes: 2
#删除索引是是否需要显示其名称,默认为显示
#action.destructive_requires_name: true
# 允许内存锁定,提高ES性能
bootstrap.memory_lock: true修改JVM配置
修改jvm.options,通常设置-Xms和-Xmx的的值为“物理内存大小的一半和32G的较小值”
这是因为,es内核使用lucene,lucene本身是单独占用内存的,并且占用的还不少,官方建议设置es内存,大小为物理内存的一半,剩下的一半留给lucene
-Xms2g
-Xmx2g关闭操作系统的swap
临时关闭
sudo swapoff -a 永久关闭
注释掉或删除所有swap相关的内容
vi /etc/fstab
修改文件描述符
修改/etc/security/limits.conf,设置memlock为unlimited
elk hard memlock unlimited
elk soft memlock unlimited修改系统配置
设置虚拟内存
修改
/etc/systemd/system.conf,设置vm.max_map_count为一个较大的值
vm.max_map_count=10240000修改文件上限
修改
/etc/systemd/system.conf,设置DefaultLimitNOFILE,DefaultLimitNPROC,DefaultLimitMEMLOCK为一个较大值,或者不限定
DefaultLimitNOFILE=100000
DefaultLimitNPROC=100000
DefaultLimitMEMLOCK=infinity重启ES
服务发现优化
Elasticsearch 默认被配置为使用单播发现,以防止节点无意中加入集群
组播发现应该永远不被使用在生产环境了,否则你得到的结果就是一个节点意外的加入到了你的生产环境,仅仅是因为他们收到了一个错误的组播信号,ES是一个P2P类型的分布式系统,使用gossip协议,集群的任意请求都可以发送到集群的任一节点,然后es内部会找到需要转发的节点,并且与之进行通信,在es1.x的版本,es默认是开启组播,启动es之后,可以快速将局域网内集群名称,默认端口的相同实例加入到一个大的集群,后续再es2.x之后,都调整成了单播,避免安全问题和网络风暴;
单播discovery.zen.ping.unicast.hosts,建议写入集群内所有的节点及端口,如果新实例加入集群,新实例只需要写入当前集群的实例,即可自动加入到当前集群,之后再处理原实例的配置即可,新实例加入集群,不需要重启原有实例;
节点zen相关配置:discovery.zen.ping_timeout:判断master选举过程中,发现其他node存活的超时设置,主要影响选举的耗时,参数仅在加入或者选举 master 主节点的时候才起作用discovery.zen.join_timeout:节点确定加入到集群中,向主节点发送加入请求的超时时间,默认为3sdiscovery.zen.minimum_master_nodes:参与master选举的最小节点数,当集群能够被选为master的节点数量小于最小数量时,集群将无法正常选举。
故障检测( fault detection )
故障检测情况
以下两种情况下回进行故障检测
* 第一种是由master向集群的所有其他节点发起ping,验证节点是否处于活动状态
* 第二种是:集群每个节点向master发起ping,判断master是否存活,是否需要发起选举配置方式
故障检测需要配置以下设置使用
discovery.zen.fd.ping_interval:节点被ping的频率,默认为1s。discovery.zen.fd.ping_timeout等待ping响应的时间,默认为 30s,运行的集群中,master 检测所有节点,以及节点检测 master 是否正常。discovery.zen.fd.ping_retriesping失败/超时多少导致节点被视为失败,默认为3。
队列数量优化
不建议盲目加大es的队列数量,要根据实际情况来进行调整
如果是偶发的因为数据突增,导致队列阻塞,加大队列size可以使用内存来缓存数据,如果是持续性的数据阻塞在队列,加大队列size除了加大内存占用,并不能有效提高数据写入速率,反而可能加大es宕机时候,在内存中可能丢失的上数据量。
查看线程池情况
通过以下可以查看线程池的情况,哪些情况下,加大队列size呢?
GET /_cat/thread_pool
观察api中返回的queue和rejected,如果确实存在队列拒绝或者是持续的queue,可以酌情调整队列size。
内存使用
配置熔断限额
设置indices的内存熔断相关参数,根据实际情况进行调整,防止写入或查询压力过高导致OOM
indices.breaker.total.limit: 50%,集群级别的断路器,默认为jvm堆的70%indices.breaker.request.limit: 10%,单个request的断路器限制,默认为jvm堆的60%indices.breaker.fielddata.limit: 10%,fielddata breaker限制,默认为jvm堆的60%。
配置缓存
根据实际情况调整查询占用cache,避免查询cache占用过多的jvm内存,参数为静态的,需要在每个数据节点配置
indices.queries.cache.size: 5%,控制过滤器缓存的内存大小,默认为10%,接受百分比值,5%或者精确值,例如512mb。
创建分片优化
如果集群规模较大,可以阻止新建shard时扫描集群内全部shard的元数据,提升shard分配速度
cluster.routing.allocation.disk.include_relocations: false,默认为true
系统层面调优
jdk版本
选用当前版本ES推荐使用的ES,或者使用ES自带的JDK
jdk内存配置
首先,-Xms和-Xmx设置为相同的值,避免在运行过程中再进行内存分配,同时,如果系统内存小于64G,建议设置略小于机器内存的一半,剩余留给系统使用,同时,jvm heap建议不要超过32G(不同jdk版本具体的值会略有不同),否则jvm会因为内存指针压缩导致内存浪费
关闭交换分区
关闭交换分区,防止内存发生交换导致性能下降(部分情况下,宁死勿慢)
swapoff -a
文件句柄
Lucene 使用了 大量的 文件,同时,Elasticsearch 在节点和 HTTP 客户端之间进行通信也使用了大量的套接字,所有这一切都需要足够的文件描述符,默认情况下,linux默认运行单个进程打开1024个文件句柄,这显然是不够的,故需要加大文件句柄数 ulimit -n 65536
mmap
Elasticsearch 对各种文件混合使用了 NioFs( 注:非阻塞文件系统)和 MMapFs ( 注:内存映射文件系统)。
请确保你配置的最大映射数量,以便有足够的虚拟内存可用于 mmapped 文件。这可以暂时设置:sysctl -w vm.max_map_count=262144 或者你可以在 /etc/sysctl.conf 通过修改 vm.max_map_count 永久设置它。
磁盘
如果你正在使用 SSDs,确保你的系统 I/O 调度程序是配置正确的
当你向硬盘写数据,I/O 调度程序决定何时把数据实际发送到硬盘,大多数默认linux 发行版下的调度程序都叫做 cfq(完全公平队列),但它是为旋转介质优化的:机械硬盘的固有特性意味着它写入数据到基于物理布局的硬盘会更高效。
这对 SSD 来说是低效的,尽管这里没有涉及到机械硬盘,但是,deadline 或者 noop 应该被使用,deadline 调度程序基于写入等待时间进行优化, noop 只是一个简单的 FIFO 队列。
echo noop > /sys/block/sd/queue/scheduler磁盘挂载
mount -o noatime,data=writeback,barrier=0,nobh /dev/sd* /esdata*其中,noatime,禁止记录访问时间戳;data=writeback,不记录journal;barrier=0,因为关闭了journal,所以同步关闭barrier;nobh,关闭buffer_head,防止内核影响数据IO
磁盘其他注意事项
使用 RAID 0,条带化 RAID 会提高磁盘I/O,代价显然就是当一块硬盘故障时整个就故障了,不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能。
另外,使用多块硬盘,并允许 Elasticsearch 通过多个 path.data 目录配置把数据条带化分配到它们上面,不要使用远程挂载的存储,比如 NFS 或者 SMB/CIFS。这个引入的延迟对性能来说完全是背道而驰的。
使用方式调优
当elasticsearch本身的配置没有明显的问题之后,发现es使用还是非常慢,这个时候,就需要我们去定位es本身的问题了,首先祭出定位问题的第一个命令:
Index(写)调优
副本数置0
如果是集群首次灌入数据,可以将副本数设置为0,写入完毕再调整回去,这样副本分片只需要拷贝,节省了索引过程
PUT /my_temp_index/_settings
{
"number_of_replicas": 0
}自动生成doc ID
通过Elasticsearch写入流程可以看出,如果写入doc时如果外部指定了id,则Elasticsearch会先尝试读取原来doc的版本号,以判断是否需要更新,这会涉及一次读取磁盘的操作,通过自动生成doc ID可以避免这个环节
合理设置mappings
将不需要建立索引的字段index属性设置为not_analyzed或no。
- 对字段不分词,或者不索引,可以减少很多运算操作,降低CPU占用,尤其是binary类型,默认情况下占用CPU非常高,而这种类型进行分词通常没有什么意义。
- 减少字段内容长度,如果原始数据的大段内容无须全部建立 索引,则可以尽量减少不必要的内容。
- 使用不同的分析器(analyzer),不同的分析器在索引过程中 运算复杂度也有较大的差异。
调整_source字段
_source` 字段用于存储 doc 原始数据,对于部分不需要存储的字段,可以通过 includes excludes过滤,或者将`_source`禁用,一般用于索引和数据分离,这样可以降低 I/O 的压力,不过实际场景中大多不会禁用`_source对analyzed的字段禁用norms
Norms用于在搜索时计算doc的评分,如果不需要评分,则可以将其禁用
title": {
"type": "string",
"norms": {
"enabled": false
}调整索引的刷新间隔
该参数缺省是1s,强制ES每秒创建一个新segment,从而保证新写入的数据近实时的可见、可被搜索到,比如该参数被调整为30s,降低了刷新的次数,把刷新操作消耗的系统资源释放出来给index操作使用
PUT /my_index/_settings
{
"index" : {
"refresh_interval": "30s"
}
}这种方案以牺牲可见性的方式,提高了index操作的性能。
批处理
批处理把多个index操作请求合并到一个batch中去处理,和mysql的jdbc的bacth有类似之处
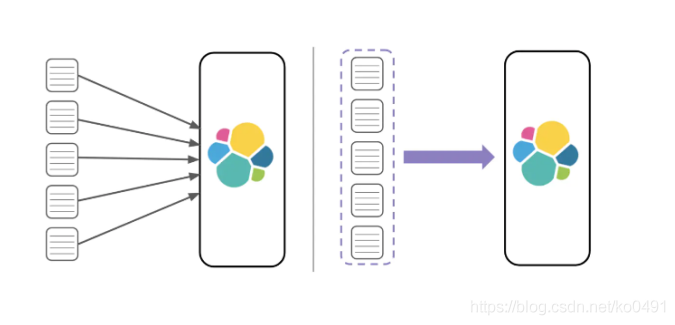
比如每批1000个documents是一个性能比较好的size,每批中多少document条数合适,受很多因素影响而不同,如单个document的大小等,ES官网建议通过在单个node、单个shard做性能基准测试来确定这个参数的最优值
Document的路由处理
当对一批中的documents进行index操作时,该批index操作所需的线程的个数由要写入的目的shard的个数决定
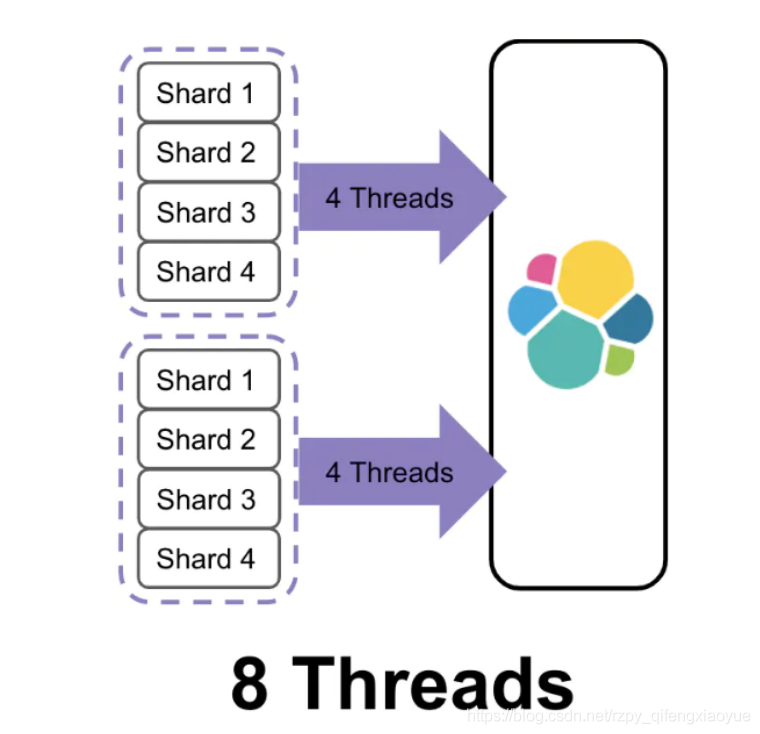
有2批documents写入ES, 每批都需要写入4个shard,所以总共需要8个线程,如果能减少shard的个数,那么耗费的线程个数也会减少,例如下图,两批中每批的shard个数都只有2个,总共线程消耗个数4个,减少一半。
默认的routing就是id,也可以在发送请求的时候,手动指定一个routing value,比如说put/index/doc/id?routing=user_id
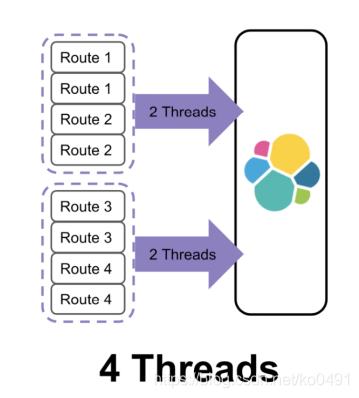
值得注意的是线程数虽然降低了,但是单批的处理耗时可能增加了。和提高刷新间隔方法类似,这有可能会延长数据不见的时间
Search(读)调优
在存储的Document条数超过10亿条后,我们如何进行搜索调优
数据分组
很多人拿ES用来存储日志,日志的索引管理方式一般基于日期的,基于天、周、月、年建索引,如下图,基于天建索引
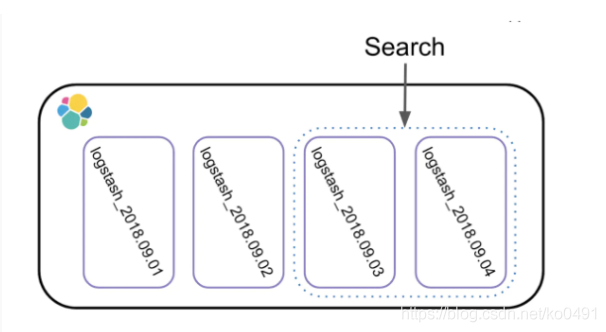
当搜索单天的数据,只需要查询一个索引的shards就可以,当需要查询多天的数据时,需要查询多个索引的shards,这种方案其实和数据库的分表、分库、分区查询方案相比,思路类似,小数据范围查询而不是大海捞针。
开始的方案是建一个index,当数据量增大的时候,就扩容增加index的shard的个数,当shards增大时,要搜索的shards个数也随之显著上升,基于数据分组的思路,可以基于client进行数据分组,每一个client只需依赖自己的index的数据shards进行搜索,而不是所有的数据shards,大大提高了搜索的性能,如下图:
使用Filter替代Query
在搜索时候使用Query,需要为Document的相关度打分,使用Filter,没有打分环节处理,做的事情更少,而且filter理论上更快一些。
如果搜索不需要打分,可以直接使用filter查询,如果部分搜索需要打分,建议使用’bool’查询,这种方式可以把打分的查询和不打分的查询组合在一起使用,如
GET /_search
{
"query": {
"bool": {
"must": {
"term": {
"user": "kimchy"
}
},
"filter": {
"term": {
"tag": "tech"
}
}
}
}
}ID字段定义为keyword
一般情况,如果ID字段不会被用作Range 类型搜索字段,都可以定义成keyword类型,这是因为keyword会被优化,以便进行terms查询,Integers等数字类的mapping类型,会被优化来进行range类型搜索,将integers改成keyword类型之后,搜索性能大约能提升30%
hot_threads
可以使用以下命令,抓取30s区间内的节点上占用资源的热线程,并通过排查占用资源最多的TOP线程来判断对应的资源消耗是否正常
GET /_nodes/hot_threads&interval=30s一般情况下,bulk,search类的线程占用资源都可能是业务造成的,但是如果是merge线程占用了大量的资源,就应该考虑是不是创建index或者刷磁盘间隔太小,批量写入size太小造成的。
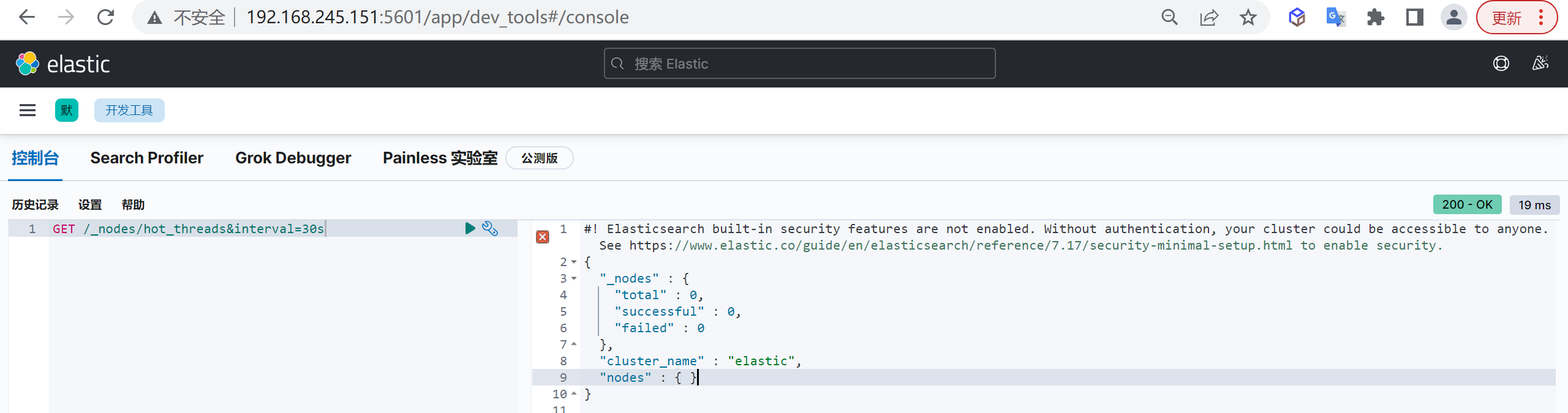
pending_tasks
有一些任务只能由主节点去处理,比如创建一个新的索引或者在集群中移动分片,由于一个集群中只能有一个主节点,所以只有这一master节点可以处理集群级别的元数据变动
在99.9999%的时间里,这不会有什么问题,元数据变动的队列基本上保持为零,在一些罕见的集群里,元数据变动的次数比主节点能处理的还快,这会导致等待中的操作会累积成队列,这个时候可以通过pending_tasks api分析当前什么操作阻塞了es的队列,比如,集群异常时,会有大量的shard在recovery,如果集群在大量创建新字段,会出现大量的put_mappings的操作,所以正常情况下,需要禁用动态mapping。
GET /_cluster/pending_tasks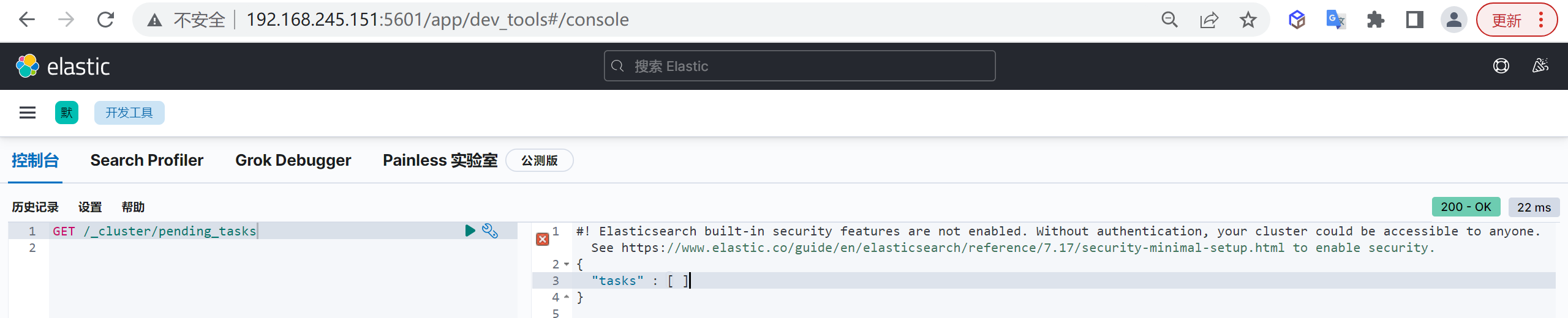
字段存储
当前es主要有doc_values,fielddata,storefield三种类型,大部分情况下,并不需要三种类型都存储,可根据实际场景进行调整:
当前用得最多的就是doc_values,列存储,对于不需要进行分词的字段,都可以开启doc_values来进行存储(且只保留keyword字段),节约内存,当然,开启doc_values会对查询性能有一定的影响,但是,这个性能损耗是比较小的,而且是值得的;
fielddata构建和管理 100% 在内存中,常驻于 JVM 内存堆,所以可用于快速查询,但是这也意味着它本质上是不可扩展的,有很多边缘情况下要提防,如果对于字段没有分析需求,可以关闭fielddata;
storefield主要用于_source字段,默认情况下,数据在写入es的时候,es会将doc数据存储为_source字段,查询时可以通过_source字段快速获取doc的原始结构,如果没有update,reindex等需求,可以将_source字段disable;
_all,ES在6.x以前的版本,默认将写入的字段拼接成一个大的字符串,并对该字段进行分词,用于支持整个doc的全文检索,在知道doc字段名称的情况下,建议关闭掉该字段,节约存储空间,也避免不带字段key的全文检索;
norms:搜索时进行评分,日志场景一般不需要评分,建议关闭;
事务日志
Elasticsearch 2.0之后为了保证不丢数据,每次 index、bulk、delete、update 完成的时候,一定会触发同步刷新 translog 到磁盘上,才给请求返回 200 OK
异步刷新
采用异步刷新,这个改变在提高数据安全性的同时当然也降低了一点性能,如果你不在意这点可能性,还是希望性能优先,可以在 index template 里设置如下参数
{
"index.translog.durability": "async"
}其他参数
index.translog.sync_interval
对于一些大容量的偶尔丢失几秒数据问题也并不严重的集群,使用异步的 fsync 还是比较有益的,比如,写入的数据被缓存到内存中,再每5秒执行一次 fsync ,默认为5s,小于的值100ms是不允许的。
index.translog.flush_threshold_size
translog存储尚未安全保存在Lucene中的所有操作,虽然这些操作可用于读取,但如果要关闭并且必须恢复,则需要重新编制索引,此设置控制这些操作的最大总大小,以防止恢复时间过长,达到设置的最大size后,将发生刷新,生成新的Lucene提交点,默认为512mb。
refresh_interval
执行刷新操作的频率,这会使索引的最近更改对搜索可见,默认为1s,可以设置-1为禁用刷新,对于写入速率要求较高的场景,可以适当的加大对应的时长,减小磁盘io和segment的生成;
禁止动态mapping
动态mapping的缺点
- 造成集群元数据一直变更,导致 不稳定;
- 可能造成数据类型与实际类型不一致;
- 对于一些异常字段或者是扫描类的字段,也会频繁的修改mapping,导致业务不可控。
映射配置
动态mapping配置的可选值及含义如下
- true:支持动态扩展,新增数据有新的字段属性时,自动添加对于的mapping,数据写入成功
- false:不支持动态扩展,新增数据有新的字段属性时,直接忽略,数据写入成功
- strict:不支持动态扩展,新增数据有新的字段时,报错,数据写入失败
批量写入
批量请求显然会大大提升写入速率,且这个速率是可以量化的,官方建议每次批量的数据物理字节数5-15MB是一个比较不错的起点,注意这里说的是物理字节数大小。
文档计数对批量大小来说不是一个好指标,比如说,如果你每次批量索引 1000 个文档,记住下面的事实:1000 个 1 KB 大小的文档加起来是 1 MB 大,1000 个 100 KB 大小的文档加起来是 100 MB 大。
这可是完完全全不一样的批量大小了,批量请求需要在协调节点上加载进内存,所以批量请求的物理大小比文档计数重要得多,从 5–15 MB 开始测试批量请求大小,缓慢增加这个数字,直到你看不到性能提升为止。
然后开始增加你的批量写入的并发度(多线程等等办法),用iostat 、 top 和 ps 等工具监控你的节点,观察资源什么时候达到瓶颈。如果你开始收到 EsRejectedExecutionException ,你的集群没办法再继续了:至少有一种资源到瓶颈了,或者减少并发数,或者提供更多的受限资源(比如从机械磁盘换成 SSD),或者添加更多节点。
索引和shard
es的索引,shard都会有对应的元数据,
因为es的元数据都是保存在master节点,且元数据的更新是要hold住集群向所有节点同步的,当es的新建字段或者新建索引的时候,都会要获取集群元数据,并对元数据进行变更及同步,此时会影响集群的响应,所以需要关注集群的index和shard数量,
使用建议
建议如下
- 使用shrink和rollover api,相对生成合适的数据shard数;
- 根据数据量级及对应的性能需求,选择创建index的名称,形如:按月生成索引:test-YYYYMM,按天生成索引:test-YYYYMMDD;
- 控制单个shard的size,正常情况下,日志场景,建议单个shard不大于50GB,线上业务场景,建议单个shard不超过20GB;
段合并
段合并的计算量庞大, 而且还要吃掉大量磁盘 I/O
合并在后台定期操作,因为他们可能要很长时间才能完成,尤其是比较大的段,这个通常来说都没问题,因为大规模段合并的概率是很小的。
如果发现merge占用了大量的资源,可以设置:index.merge.scheduler.max_thread_count: 1 特别是机械磁盘在并发 I/O 支持方面比较差,所以我们需要降低每个索引并发访问磁盘的线程数,这个设置允许 max_thread_count + 2 个线程同时进行磁盘操作,也就是设置为 1 允许三个线程,对于 SSD,你可以忽略这个设置,默认是 Math.min(3, Runtime.getRuntime().availableProcessors() / 2) ,对 SSD 来说运行的很好。
业务低峰期通过force_merge强制合并segment,降低segment的数量,减小内存消耗;关闭冷索引,业务需要的时候再进行开启,如果一直不使用的索引,可以定期删除,或者备份到hadoop集群;
自动生成_id
当写入端使用特定的id将数据写入es时,es会去检查对应的index下是否存在相同的id,这个操作会随着文档数量的增加而消耗越来越大,所以如果业务上没有强需求,建议使用es自动生成的id,加快写入速率。
routing
对于数据量较大的业务查询场景,es侧一般会创建多个shard,并将shard分配到集群中的多个实例来分摊压力,正常情况下,一个查询会遍历查询所有的shard,然后将查询到的结果进行merge之后,再返回给查询端。
此时,写入的时候设置routing,可以避免每次查询都遍历全量shard,而是查询的时候也指定对应的routingkey,这种情况下,es会只去查询对应的shard,可以大幅度降低合并数据和调度全量shard的开销。
使用alias
生产提供服务的索引,切记使用别名提供服务,而不是直接暴露索引名称,避免后续因为业务变更或者索引数据需要reindex等情况造成业务中断。
避免宽表
在索引中定义太多字段是一种可能导致映射爆炸的情况,这可能导致内存不足错误和难以恢复的情况,这个问题可能比预期更常见,index.mapping.total_fields.limit ,默认值是1000
避免稀疏索引
因为索引稀疏之后,对应的相邻文档id的delta值会很大,lucene基于文档id做delta编码压缩导致压缩率降低,从而导致索引文件增大,同时,es的keyword,数组类型采用doc_values结构,每个文档都会占用一定的空间,即使字段是空值,所以稀疏索引会造成磁盘size增大,导致查询和写入效率降低。
ElasticSearch 基础查询
概述
查询是 ElasticSearch 核心功能,也是最为丰富有趣的功能,接下来我们开始学习全文查询、词项查询、复合查询、嵌套查询、位置查询、特殊查询等查询功能
正排索引
在关系型数据库中用到的索引,就是“正排索引”,假如有一张博客表:
| id | 作者 | 标题 | 内容 |
|---|---|---|---|
| 1 | 张三 | 博客标题1 | 查询是 ElasticSearch 核心功能 |
| 2 | 李四 | 博客标题2 | 也是最为丰富有趣的功能 |
索引描述
针对这个表建立 id 和标题字段的索引(正排索引):
| 索引 | 内容 |
|---|---|
| 1 | 查询是 ElasticSearch 核心功能 |
| 2 | 也是最为丰富有趣的功能 |
| 博客标题1 | 查询是 ElasticSearch 核心功能 |
| 博客标题2 | 也是最为丰富有趣的功能 |
当我们通过 id 或者标题去查询文章内容时,就可以快速找到。
但如果我们通过文章内容的关键字去查询,就只能去内容中做字符匹配了,查询效率相当慢!为了提高查询效率,就要考虑使用倒排索引。
倒排索引
倒排索引就是以文章内容的关键字建立索引,通过索引找到文档id,进而找到整个文档:
| 索引 | 文档id=1 | 文档id=2 |
|---|---|---|
| 查询 | √ | |
| 是 | √ | √ |
| 丰富有趣 | √ | |
| 功能 | √ | √ |
组成部分
一般来说,倒排索引分为两个部分:
- 词项词典:记录所有的文档词项,以及词项与倒排列表的关联关系。
- 倒排列表:记录词项与文章内容的关联关系,由一系列倒排索引项组成,倒排索引项包括文档 id、词频(词项在文档中出现的次数,评分时使用)、位置(词项在文档中分词的位置)、偏移(记录词项开始和结束的位置)
查询过程
ElasticSearch 的查询分为两个过程
创建索引
当向索引中保存文档时,默认情况下,ElasticSearch 会保存两份内容,一份是 _source 中的数据,另一份则是通过分词、排序等一系列过程生成的倒排索引文件,倒排索引中保存了词项和文档之间的对应关系
查询
当 es 接收到用户的查询请求之后,就会去倒排索引中查询,通过的倒排索引中维护的倒排记录表找到关键词对应的文档集合,然后对文档进行评分、排序、高亮等处理,处理完成后返回文档。
导入数据
因为需要查询,我们先导入一些数据
创建索引
创建一个书籍管理的索引
PUT books
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"publish":{
"type": "text",
"analyzer": "ik_max_word"
},
"type":{
"type": "text",
"analyzer": "ik_max_word"
},
"author":{
"type": "keyword"
},
"info":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "double"
}
}
}
}导入脚本
执行命令导入数据脚本
curl -XPOST "http://192.168.245.151:9200/books/_bulk?pretty" -H "content-type:application/json" --data-binary @bookdata.json基本查询
简单查询
我们查询所有文档
get books/_search
{
"query": {
"match_all": {}
}
}
# 可以简写为以下形式
get books/_search
hits 中是查询结果,total 是符合查询条件的文档数,简单查询默认查询 10 条记录。
词项查询
词项查询即
term查询,根据分词查询,查询指定字段中包含给定单词的文档
term 查询不被解析,只有查询的词和文档中的词精确匹配,才会返回文档,应用场景如:人名、地名等等
查询 name 字段中包含“计算机”的文档
get books/_search
{
"query":{
"term": {
"name": "计算机"
}
}
}分页查询
查询默认返回前 10 条数据
ElasticSearch中也可以像关系型数据库一样,设置分页参数,size 设置查询多少条数据, from 设置查询开始的位置
get books/_search
{
"query": {
"term": {
"name": "计算机"
}
},
"size": 20,
"from": 10
}过滤返回字段
如果返回的字段比较多,又不需要这么多字段,可以通过
_source指定返回的字段
get books/_search
{
"query": {
"term": {
"name": "计算机"
}
},
"_source": [
"name",
"author"
],
"size": 20,
"from": 10
}过滤最低评分
有的文档得分特别低,说明这个文档和我们查询的关键字相关度很低,可以通过
min_score设置一个最低分,只有得分超过最低分的文档才会被返回
get books/_search
{
"query": {
"term": {
"name": "计算机"
}
},
"_source": [
"name",
"author"
],
"min_score": 2.75,
"size": 20,
"from": 10
}高亮显示
通过
highlight设置查询关键字高亮,这样可以更好的显示搜索的关键字
Highlight就是我们所谓的高亮,即允许对一个或者对个字段在搜索结果中高亮显示,比如字体加粗或者字体呈现和其他文本普通颜色等。
GET books/_search
{
"query": {
"term": {
"name": "计算机"
}
},
"_source": [
"name",
"author"
],
"min_score": 2.75,
"highlight": {
"fields": {
"name": {}
}
},
"size": 20,
"from": 10
}全文查询
match
match会对查询语句进行分词,分词后,如果查询语句中的任何一个词项被匹配,则文档就会被索引到。
不相关查询
查询两个不相关的关键字
GET books/_search
{
"query": {
"match": {
"name": "美术"
}
}
}
GET books/_search
{
"query": {
"term": {
"name": "计算机"
}
}
}
单独查询美术和计算机时,查询到符合条件的文档数分别是 9 和 46 条。
合并查询
我们在进行合并查询
GET books/_search
{
"query": {
"match": {
"name": "美术计算机"
}
}
}合并查询时会对美术计算机进行分词,分词之后再去查询,只要文档中包含任意一个分词,就回返回文档,最后查询到符合条件的文档树正好是55条。
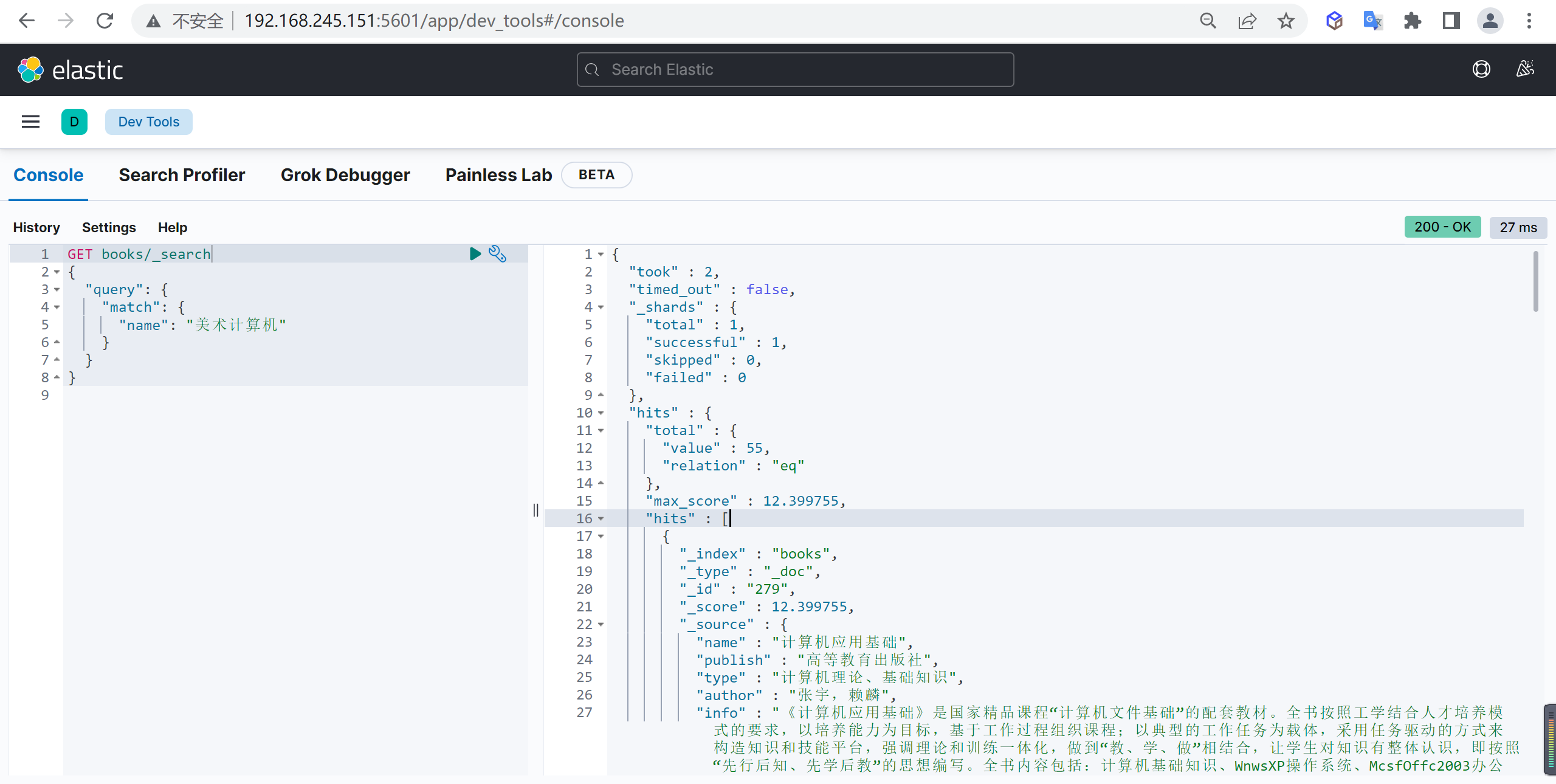
可以看到,分词后词项之间是 OR 的关系,如果想要修改,也可以通过
operator改为 AND
GET books/_search
{
"query": {
"match": {
"name": {
"query": "十一五计算机",
"operator": "and"
}
}
}
}match_phrase
match_phrase就是短语查询,也会对查询的关键字进行分词,但是它分词后有两个特点:
- 分词后的词项顺序必须和文档中词项的顺序一致
所有的词都必须出现在文档中
phrase match,就是要去将多个term作为一个短语,一起去搜索,只有包含这个短语的doc才会作为结果返回,match是只在包含其中任何一个分词就返回
什么是近似匹配
现假设有两个句子
1. 普通高等教育“十一五”国家级规划教材:大学计算机基础
2. 普通高等教育“十一五”国家级规划教材:计算机控制系统(第2版)(配光盘)
进行查询
"query": {
"match": {
"name": "十一五计算机"
}
}match query进行搜索,只能搜索到包含
十一五或计算机的document,包含十一五或计算机的doc都会被返回回来
增加需求
假如要增加如下需求
十一五计算机,就靠在一起,中间不能插入任何其他字符,就要搜索出来这种doc- 但是要求,
十一五和计算机两个单词靠的越近,doc的分数越高,排名越靠前 我们搜索时,文档中必须包含`十一五计算机这两个文档,且他们之间的距离不能超过5
要实现上述三个需求,用match做全文检索,是搞不定的,必须得用proximity match(近似匹配),proximity match分两种,短语匹配(phrase match)和近似匹配(proximity match)
DSL分析
- 检索词“十一五计算机”被分词为两个Token【十一五,Position=0】【计算机,Position=1】
倒排索引检索时,等价于sql:【where Token = 十一五 and 十一五_Position=0 and Token = 计算机 and 计算机_Position=1】;
如果我们不要求这两个单词相邻,希望放松一点条件,可以添加slop参数,slop代表两个token之间相隔的最多的距离(最多需要移动多少次才能相邻)
需求分析
这里直接使用前面十一五计算机短语,并不能查询到文档,因为分词之后,关键字之间还间隔这国家级规划教材:大学这些内容
这种情况可以使用 slop 参数来指定关键字之间的距离,注意这个距离,不是指关键字之间间隔的字数,而是指它们之间的 position 位置的间隔。
什么是 position
每份文档中的字段被分词器解析之后,解析出来的词项都包含一个 position 字段表示词项的位置,每份文档的 position 都从 0 开始,每个词项递增 1
分词测试
因为我们使用的分词器是
ik_max_word,这里我们就是用ik_max_word测试分词
GET books/_analyze
{
"text": "普通高等教育“十一五”国家级规划教材:大学计算机基础",
"analyzer": "ik_max_word"
}下面是分词的结果
{
"tokens" : [
...
{
"token" : "十一五",
"start_offset" : 7,
"end_offset" : 10,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "十一",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "五",
"start_offset" : 9,
"end_offset" : 10,
"type" : "CN_CHAR",
"position" : 6
},
...
{
"token" : "计算机",
"start_offset" : 21,
"end_offset" : 24,
"type" : "CN_WORD",
"position" : 13
}
]
}分词后 十一五 最后出现的 position = 6 ,而 计算机 第一次出现的 position = 13,中间间隔了 6 个位置,所以只需要设置
slop为 6 即可查询到文档
查询
GET books/_search
{
"query": {
"match_phrase": {
"name": {
"query": "十一五计算机",
"slop": 6
}
}
}
}match_phrase_prefix
类似于
match_phrase查询,只不过这里多了一个通配符,match_phrase_prefix将最后一个词项作为前缀去查询匹配,但是这种匹配方式效率较低,了解即可,不推荐使用
GET books/_search
{
"query": {
"match_phrase_prefix": {
"name": {
"query": "计",
"max_expansions": 1
}
}
}
} 这个查询过程,会自动进行词项匹配,会自动查找以 计 开始的词项,默认是 10 个,我们可以通过 max_expansions 控制值匹配的词项个数。例如以 计 开始的词项控制匹配个数为 1 、2 、3 时,匹配到的词项分别为 计分、计划、计算 。
注意
match_phrase_prefix` 是针对分片级别的查询,每个分片匹配的词项可能不一致。我们现在练习创建的索引分片数为 1 ,所以使用起来并不会有什么问题。但是如果分片数大于 1 时,查询结果就可能有问题。
以 match_phrase_prefix 为 1 ,分片数为 3 举例,可能会查询出 3 个匹配词项对应的文档:
| 分片数 | 匹配词项 | 文档数 |
|---|---|---|
| 分片1 | 计分 | 2 |
| 分片2 | 计划 | 1 |
| 分片3 | 计算 | 46 |
multi_match
multi_match查询提供了一个简便的方法用来对多个字段执行相同的查询
查询
同时查询
name以及info字段包含java的文档
GET books/_search
{
"query": {
"multi_match": {
"query": "java",
"fields": ["name","info"]
}
}
}参数
- query: 来自用户输入的查询短语
fields: 数组,默认支持最大长度1024,可以单独为任意字段设置相关度权重,支持通配符;fields可以为空,为空时会取mapping阶段配置的所有支持term查询的filed组合在一起进行查询
query_string
query_string 是 ES DSL 查询中最为强大的查询语句,支持非常复杂的语法,适合用来做自己的搜索引擎
基本查询
查询
name字段包含十一五和计算机的文档
GET books/_search
{
"query": {
"query_string": {
"default_field": "name",
"query": "(十一五) AND (计算机)"
}
}
}更多待补充
simple_query_string
这个是
query_string的升级,可以直接使用 +、|、- 代替 AND、OR、NOT 等
simple_query_string 使用 fields 来指定查询的字段,即使只指定一个字段,值也必须为数组类型
GET books/_search
{
"query": {
"simple_query_string": {
"fields": ["name"],
"query": "(十一五) + (计算机)"
}
}
}词项查询
词项查询,也就是
term查询,以及以term延伸的词项查询
我们已经多次涉及到这个技能点,但是没有细讲,今天我们就来从头理一下 term 查询
term
term不会对查询字符进行分词,直接拿查询字符去倒排索引中比对
基本查询
下面我们查询以下
计算机为关键字进行查询
GET books/_search
{
"query": {
"term": {
"name": "计算机"
}
}
}我们发现是可以查询出来数据的
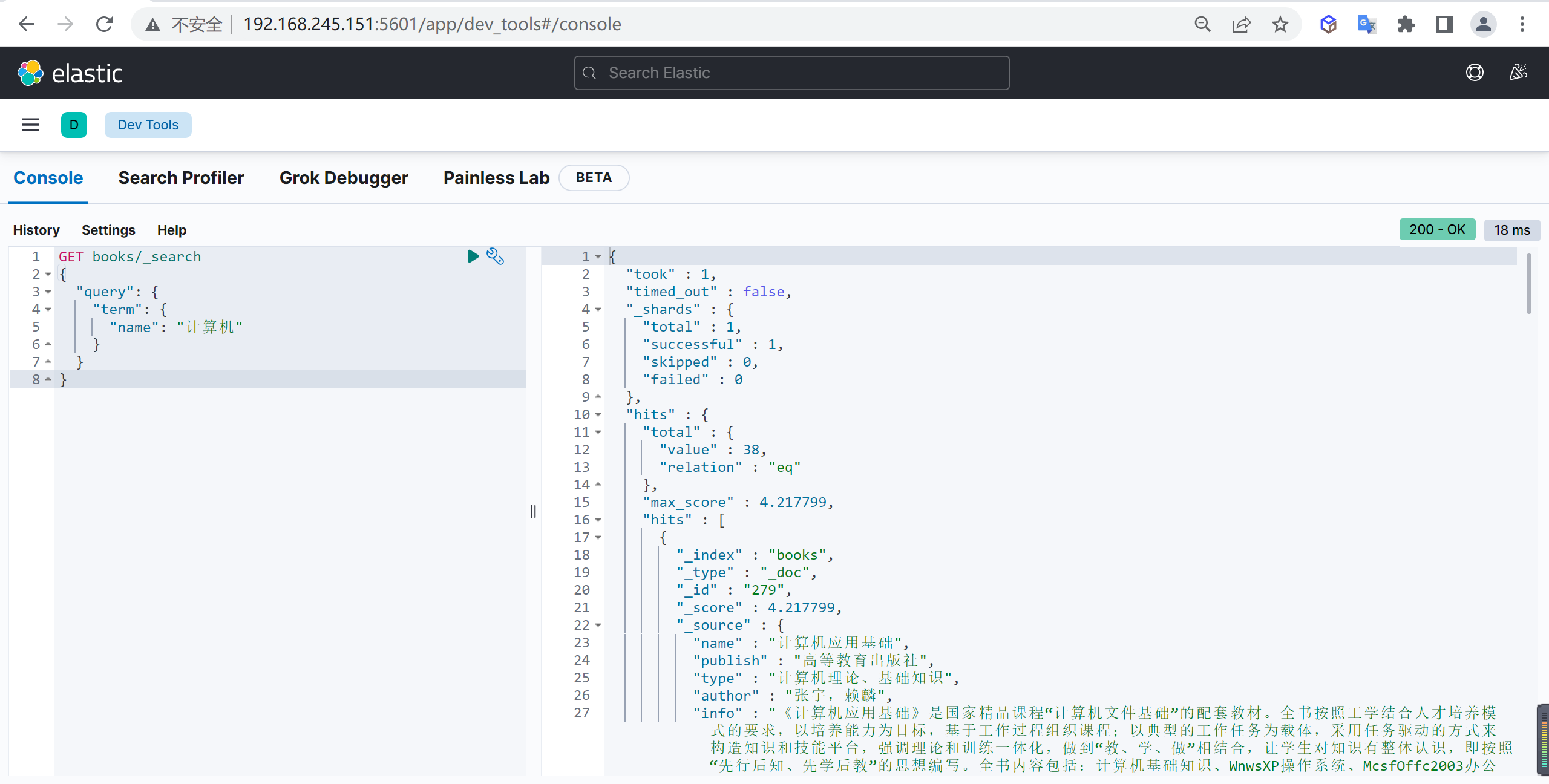
语句查询
下面我们找一个未分词的
计算机应用进行查询
GET books/_search
{
"query": {
"term": {
"name": "计算机应用"
}
}
}因为直接到倒排词库查询,所以是查询不出来结果的
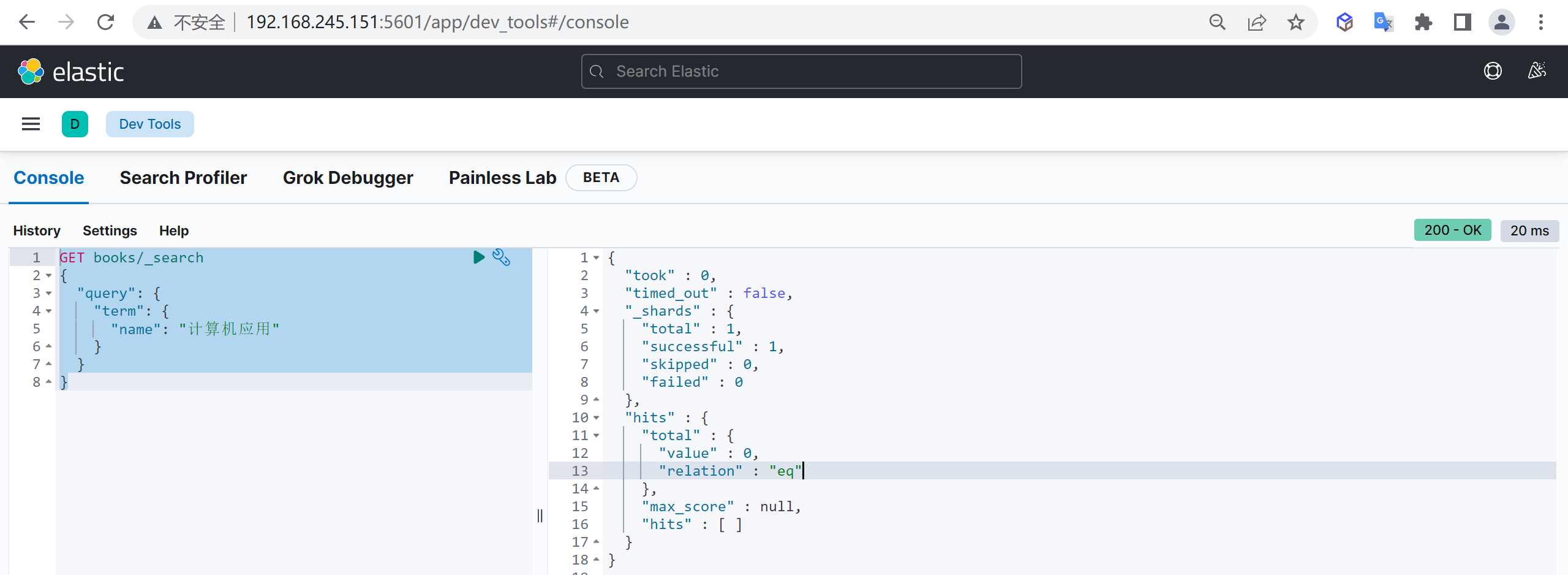
terms
使用多个关键字进行查询,参数为数组类型,关键字之间的关系为 OR 。
基本查询
只要
name任意包含下面的任意一个就可以查询出来
GET books/_search
{
"query": {
"terms": {
"name": ["计算机","应用","科学"]
}
}
}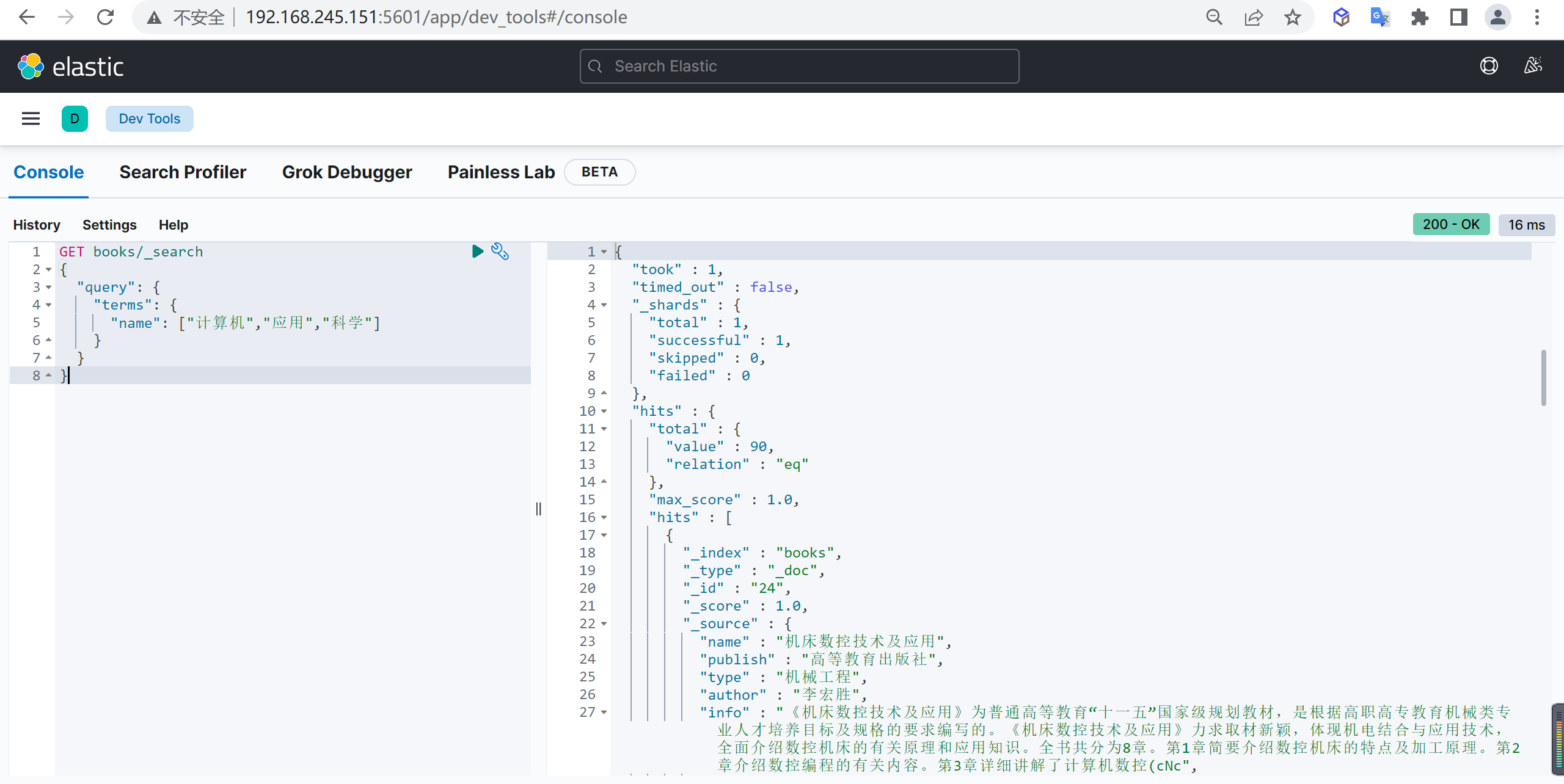
Terms lookup
terms中除了简单的多个关键字查询,还支持 Terms lookup 查询
先查询获取已知文档的字段值,然后再将这些值用作关键字查询其他文档,有点类似于关系型数据库中的子查询,支持跨字段或者跨索引。
参数介绍
首先介绍一下 Terms lookup 的参数:
| 字段 | 内容 |
|---|---|
| index | 必填,已知文档所在的索引。 |
| id | 必填,已知文档的ID。 |
| path | 必填,需要获取的文档字段值。 |
| routing | 选填,文档的路由值,如果在为文档建立索引时提供了自定义路由值,则此参数是必需的。 |
准备数据
新建索引,添加一个文档,name 字段包含三个作者的名字
PUT author/_doc/1
{
"name": ["吴尧", "朱家雄", "朱彦鹏,罗晓辉,周勇"]
}查询数据
使用 author 索引中 id 为 1 的 name 字段值作为查询关键字
GET books/_search
{
"query": {
"terms": {
"author": {
"index": "author",
"id": "1",
"path": "name"
}
}
}
}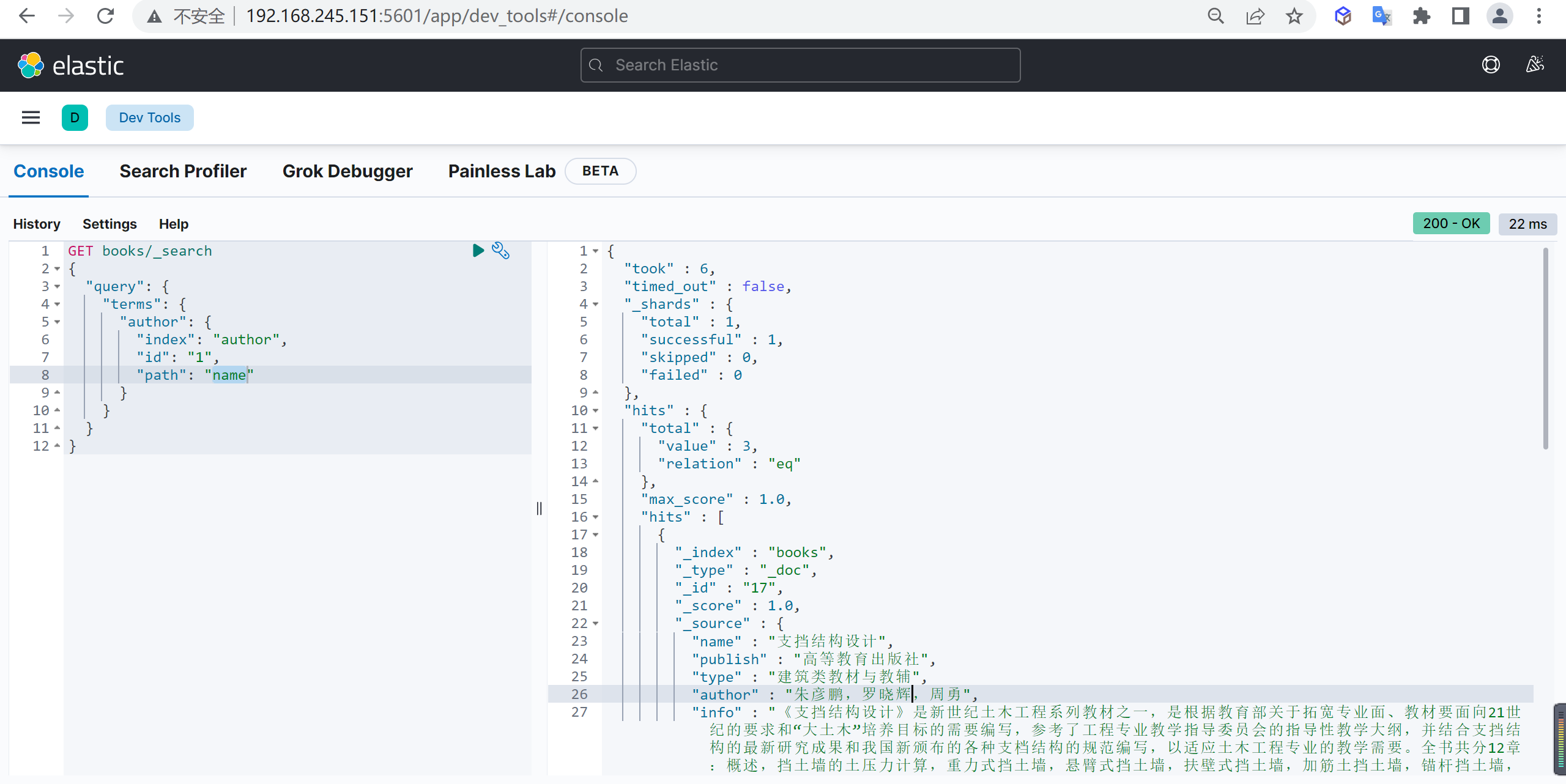
注意事项
默认情况下,Elasticsearch 将 terms 查询限制为最多65536个关键字,包括 Terms lookup 查询出来的关键字,可以通过 index.max_terms_count修改限制
range
range可以进行范围查询,按照日期范围、数字范围等查询。
参数介绍
range中的主要参数:
| 字段 | 内容 |
|---|---|
| gt | 大于 |
| gte | 大于或等于。 |
| lt | 小于。 |
| lte | 小于或等于。 |
| format | 日期格式,如果不指定将使用 mapping 中定义日期格式。 |
| relation | 指定范围查询如何匹配 range 字段的值,可选值为: - INTERSECTS (默认值):将文档的范围字段值与查询范围相交。 - CONTAINS:使用范围字段值完全包含查询范围的文档进行匹配。 - WITHIN:使用范围字段值完全在查询范围内的文档进行匹配。 |
基本查询
查询价格范围是10-20之间的书籍,并且对价格进行倒序排序
GET books/_search
{
"query": {
"range": {
"price": {
"gte": 10,
"lte": 20
}
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
],
"_source": [
"name",
"price"
]
}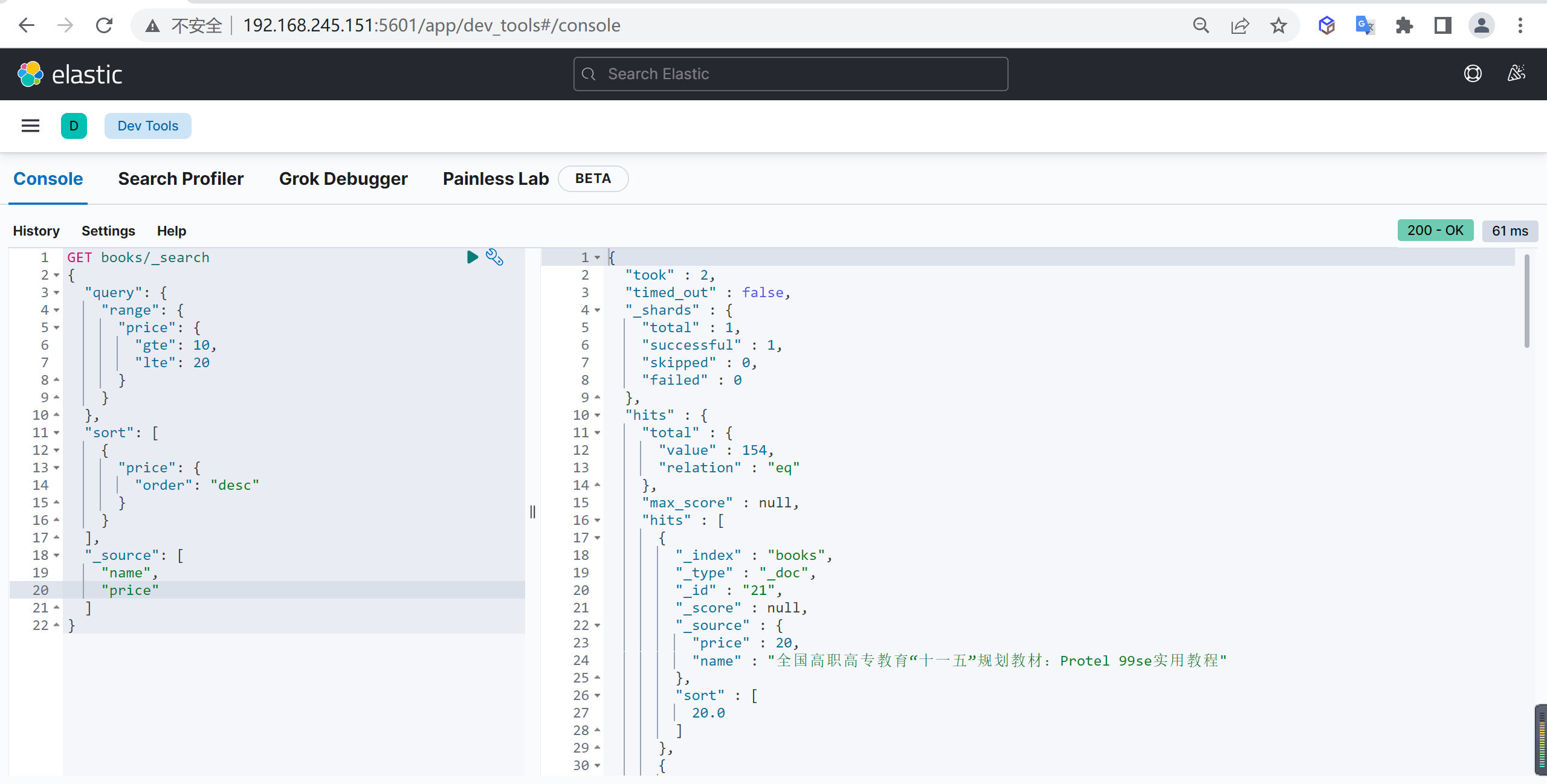
exists
exists可以判断字段是否为空,可以指定多个字段,只返回指定字段中至少有一个非空值的文档
基本查询
books 中不存在 amby 字段的书籍
GET books/_search
{
"query": {
"exists": {
"field": "amby"
}
}
}注意: 空字符串也是有值,null 才是空值。
prefix
prefix用于前缀查询,效率略低,除非必要,一般不推荐使用。
基本查询
查找书籍中以大学开头的文档
GET books/_search
{
"query": {
"prefix": {
"name": {
"value": "大学"
}
}
}
}
wildcard
wildcard` 即通配符查询,支持单字符 `?` 和多字符 `*
基本查询
查询所有姓张的作者的书
# 查询所有姓张的作者的书
GET books/_search
{
"query": {
"wildcard": {
"author": {
"value": "张*"
}
}
}
}
# 查询所有姓张并且名字只有两个字的作者的书
GET books/_search
{
"query": {
"wildcard": {
"author": {
"value": "张?"
}
}
}
}regexp
正则表达式查询
基本查询
查询所有姓张并且名字只有两个字的作者的书
GET books/_search
{
"query": {
"regexp": {
"author": "张."
}
}
}fuzzy
在实际搜索中,有时我们可能会打错字,从而导致搜索不到,在
match全文查询中,可以通过fuzziness属性实现模糊查询,而在词项查询中,就可以使用fuzzy查询与搜索关键字相似的文档。
什么是相似度
怎么样就算相似?以 LevenShtein 编辑距离为准,编辑距离是指将一个字符变为另一个字符所需要更改字符的次数,更改主要包括四种:
- 更改字符 ( javb >> java )
- 删除字符 ( javva >> java )
- 插入字符 ( jaa >> java )
- 转置字符 ( jaav >> java )
为了找到相似的词,模糊查询会在指定的编辑距离中创建搜索关键词的所有可能变化或者扩展的集合,然后进行搜索匹配。
基本查询
GET books/_search
{
"query": {
"fuzzy": {
"name": "javba"
}
}
}我们发现输入错误的字符可以搜索出来正确的文档
ids
根据ID进行查询
基本查询
查询ID是1、2、3的文档
GET books/_search
{
"query": {
"ids":{
"values": [1,2,3]
}
}
}复合查询
constant_score
当我们使用全文查询或词项查询时,ElasticSearch 默认会根据词频(TF)对查询结果进行评分,再根据评分排序后返回查询结果。
如果我们不关心检索词频(TF)对搜索结果排序的影响时,可以使用 constant_score 将查询语句或者过滤语句包裹起来。
基本查询
查询关键字是java的文档
GET books/_search
{
"query": {
"term": {
"name": "java"
}
}
}忽略评分
这样查询我们就可以忽略评分,忽略评分后默认显示评分是
1.0分,boost设置显示评分未1.5
GET books/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "java"
}
},
"boost": 1.5
}
}
}bool
bool底层使用的是 Lucene 的BooleanQuery,可以将任意多个简单查询组装在一起
关键参数
有四个关键字可供选择,四个关键字所描述的条件可以有一个或者多个
| 字段 | 内容 |
|---|---|
| must | 文档必须匹配 must 选项下的查询条件。 |
| should | 文档可以匹配 should 下的查询条件,也可以不匹配。 |
| must_not | 文档必须不满足 must_not 选项下的查询条件。 |
| filter | 类似于 must,但是 filter 不评分,只是过滤数据。 |
基本查询
查询 name 字段中必须包含 “计算”,同时书价不在 [0,30] 区间内,info 字段可以包含 “程序设计” 也可以不包含
GET books/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": "计算"
}
}
],
"must_not": [
{
"range": {
"price": {
"gte": 1,
"lte": 30
}
}
}
],
"should": [
{
"match": {
"info": "程序设计"
}
}
]
}
},
"sort": [
{
"price": {
"order": "asc"
}
}
],
"from": 0,
"size": 40
}minmum_should_match
bool查询还涉及到一个关键字minmum_should_match参数,在 ElasticSearch 官网上称作 “最小匹配度”
在之前学习的 match 或者这里的 should 查询中,都可以设置 minmum_should_match 参数
查询分析
查询 name 中包含 “程序设计” 关键字的文档
GET books/_search
{
"query": {
"match": {
"name": "程序设计"
}
}
}关键字分词
例如上面的查询,查询的时候首先会对查询的关键字进行分词
GET _analyze
{
"analyzer": "ik_max_word",
"text": "程序设计"
}分词的结果是:[“程序设计”,”程序”,”设计”],然后使用
should将分词后的每一个词项查询term子句组合构成一个bool查询,换句话说,上面的查询和下面的查询等价:
GET books/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"name": "程序设计"
}
},
{
"term": {
"name": "程序"
}
},
{
"term": {
"name": "设计"
}
}
]
}
}
} 在这两个查询语句中,都是文档只需要包含词项中的任意一项即可,文档就回被返回,在 match 查询中,可以通过 operator 参数设置文档必须匹配所有词项。
部分匹配
但如果只想匹配一部分词项,就要使用
minmum_should_match,指定至少匹配的词项,可以指定个数或者百分比,以下三个查询等价:
GET books/_search
{
"query": {
"match": {
"name": {
"query": "程序设计",
"operator": "and"
}
}
}
}
# 指定个数
GET books/_search
{
"query": {
"match": {
"name": {
"query": "程序设计",
"minimum_should_match": 3
}
}
}
}
# 指定百分比
GET books/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"name": "程序设计"
}
},
{
"term": {
"name": "程序"
}
},
{
"term": {
"name": "设计"
}
}
],
"minimum_should_match": "100%"
}
}
}dis_max
返回与一个或多个包装查询(称为查询子句或子句)匹配的文档
如果返回的文档与多个查询子句匹配,则该dis_max查询会为该文档分配来自所有匹配子句的最高相关性得分,再加上所有其他匹配子查询的平局打破增量
准备数据
为了更好的演示dis_max,我们加入一些数据
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"content":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
POST blog/_doc
{
"title":"如何通过Java代码调用Redis",
"content":"真实一偏很好的针对于Redis缓存的解决方案"
}
POST blog/_doc
{
"title":"初识 MongoDB",
"content":"简单介绍一下 MongoDB,以及如何通过 Java 调用 MongoDB,MongoDB 是一个不错 NoSQL 解决方案"
}基本查询
现在搜索 “Java解决方案” 关键字,但是不确定关键字是在 title 还是在 content,所以两者都搜索
GET blog/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "Java解决方案"
}
},
{
"match": {
"content": "Java解决方案"
}
}
]
}
}
}按照我们理解,第二篇文档中的content同时包含了 “Java” 和 “解决方案” ,应该评分更高,但是实际搜索并非这样,第一篇文档的评分反而比较高:
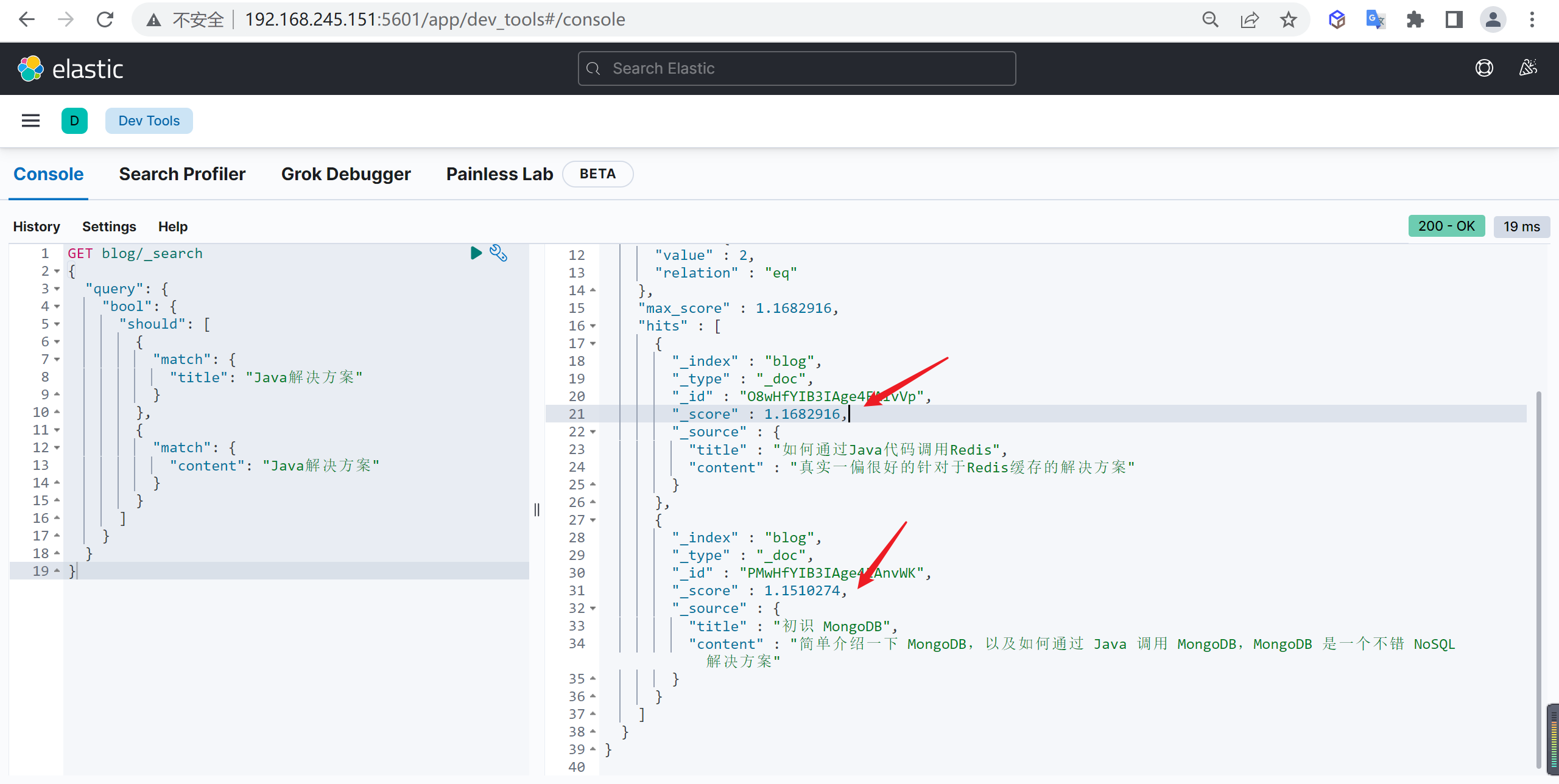
should评分策略
要理解为什么会这样,我们需要看一下
should查询的评分策略:
- 首先执行
should中的所有查询 - 对所有查询结果的评分求和
- 对求和结果
*有查询结果的子句数量 - 再将上一步结果
/所有查询子句数量
第一篇
- title 中 包含 Java,假设评分是 1.1
- content 中包含 解决方案,假设评分是 1.2
- 有查询结果的子句数量为 2
- 所有查询子句数量也是 2
- 最终结果:
(1.1 + 1.2)* 2 / 2 = 2.3
第二篇
- title 中 不包含查询关键字,没有得分
- content 中包含 Java 和 解决方案,假设评分时 2
- 有查询结果的子句数量为 1
- 所有查询子句数量也是 2
- 最终结果:
2 * 1 / 2 = 1
如何解决
在
should查询中,title 和 content 相当于是相互竞争的关系。
为了解决这一问题,就需要用到 dis_max (disjunction max query,分离最大化查询):匹配的文档依然返回,但是只将最佳匹配的子句评分作为查询的评分。
GET blog/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": "Java解决方案"
}
},
{
"match": {
"content": "Java解决方案"
}
}
]
}
}
}查询过程
第一篇
- title 中 包含 Java,假设评分是 1.1
- content 中包含 解决方案,假设评分是 1.2
- 最后取两个子句中的最高分作为文档的最后得分,即 1.2
第二篇
- title 中 不包含查询关键字,没有得分
- content 中包含 Java 和 解决方案,假设评分时 2
- 最后取两个子句中的最高分作为文档的最后得分,即 2
- 所以最后第二篇的得分高于第一篇,符合我们的需求。
其他参数
tie_breaker
在 dis_max 查询中,只考虑最佳匹配子句的评分,完全不考虑其他子句的评分。但是,有的时候,我们又不得不考虑一下其他 query 的分数,此时,可以通过 tie_breaker 参数来优化。
tie_breaker
参数取值范围:0 ~ 1,默认取值为 0,会将其他查询子句的评分,乘以 tie_breaker 参数,然后再和最佳匹配的子句进行综合计算
function_score
例如想要搜索附近的肯德基,搜索的关键字是肯德基,我希望能够将评分较高的肯德基餐厅优先展示出来。
但是默认的评分策略是没有办法考虑到餐厅评分的,他只是考虑相关性,这个时候可以通过 function_score query 来实现。
准备数据
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"votes":{
"type": "integer"
}
}
}
}
PUT blog/_doc/1
{
"title":"Java集合详解",
"votes":100
}
PUT blog/_doc/2
{
"title":"Java多线程详解,Java锁详解",
"votes":10
}基本查询
查询标题中包含 java 关键字的文档:
GET blog/_search
{
"query": {
"match": {
"title": "java"
}
}
}因为第二篇文档的 title 中有两个 java,所有得分会比较高
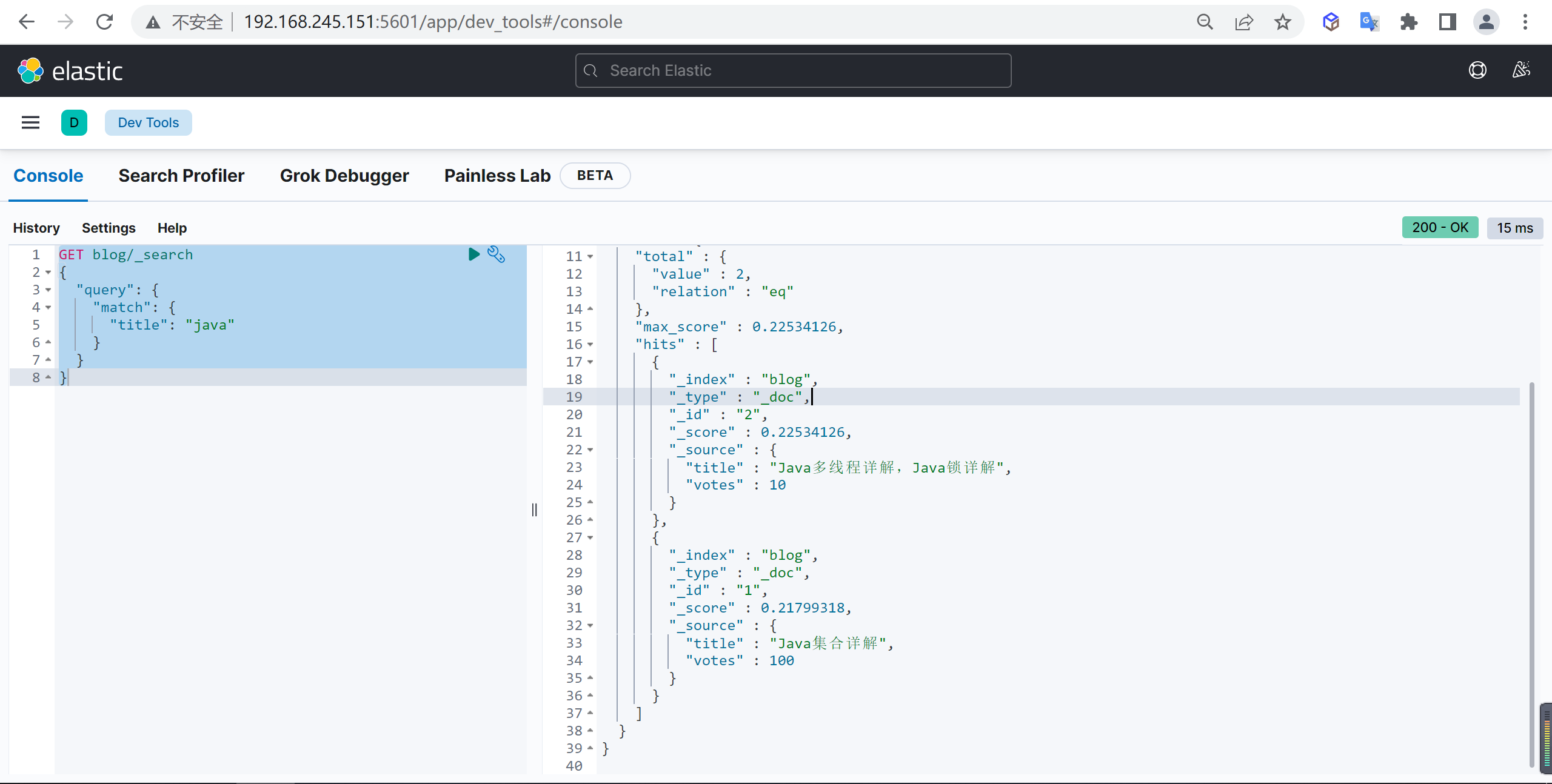
考虑votes评分
如果希望能够考虑 votes 字段,将 votes 高的文档优先展示,就可以通过
function_score来实现。
具体的思路,就是在旧的得分基础上,根据 votes 的数值进行综合运算,重新得出一个新的评分,具体的计算方式有以下几种:
weightrandom_scorescript_scorefield_value_factor
weight
weight可以对评分设置权重,在旧的评分基础上乘以weight,他其实无法解决我们上面所说的问题
基本查询
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"weight": 10
}
]
}
}
}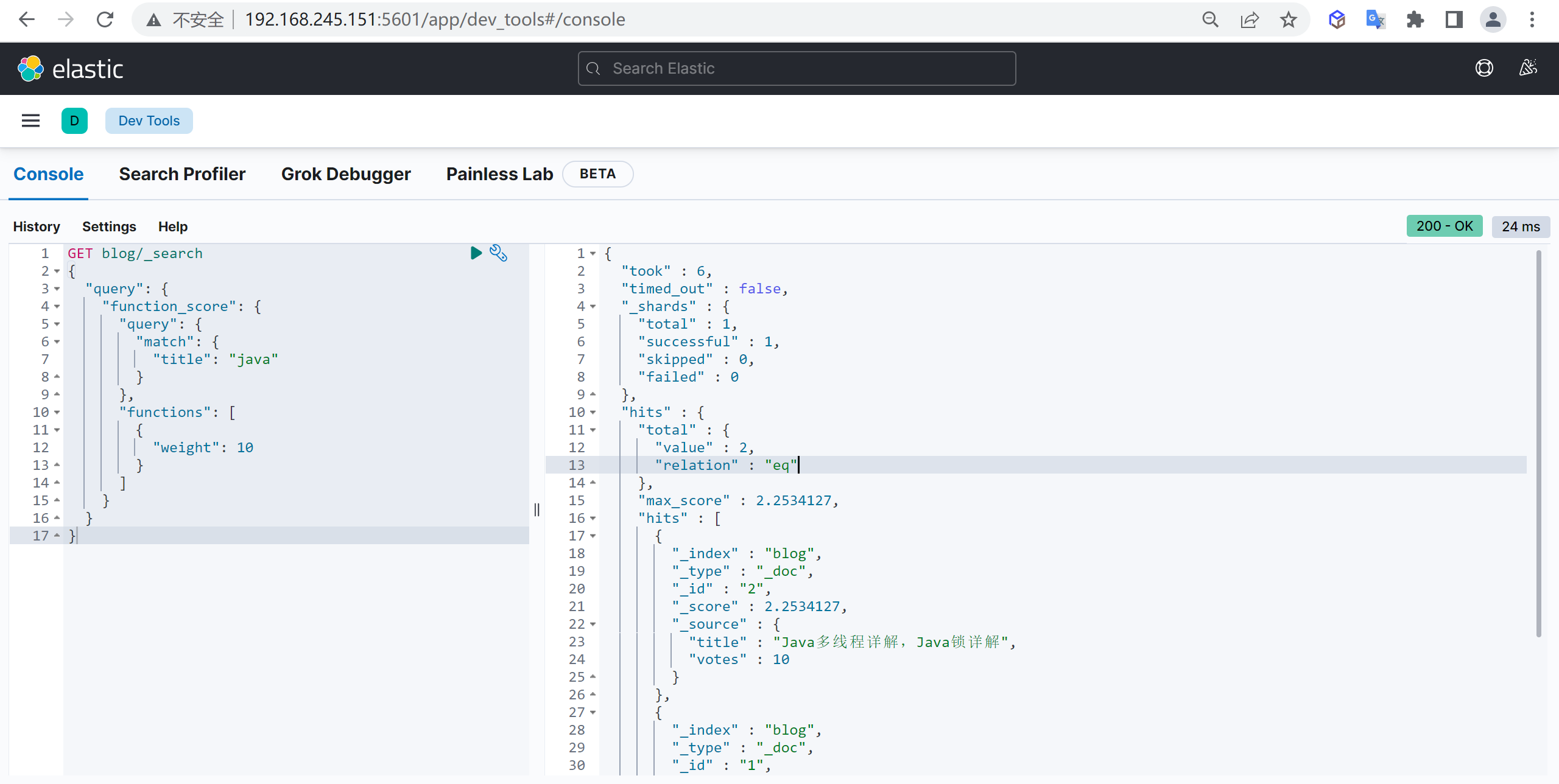
random_score
random_score会根据 uid 字段进行 hash 运算,生成随机分数,使用random_score时可以配置一个种子,如果不配置,默认使用当前时间
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"random_score": {}
}
]
}
}
}其他也无法解决问题,只是分值随机了
script_score
script_score是自定义评分脚本
基本查询
假设每个文档的最终得分是旧的分数加上 votes,查询方式如下
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"script_score": {
"script": {
"lang": "painless",
"source": "_score + doc['votes'].value"
}
}
}
]
}
}
}这种方式符合我们的预期
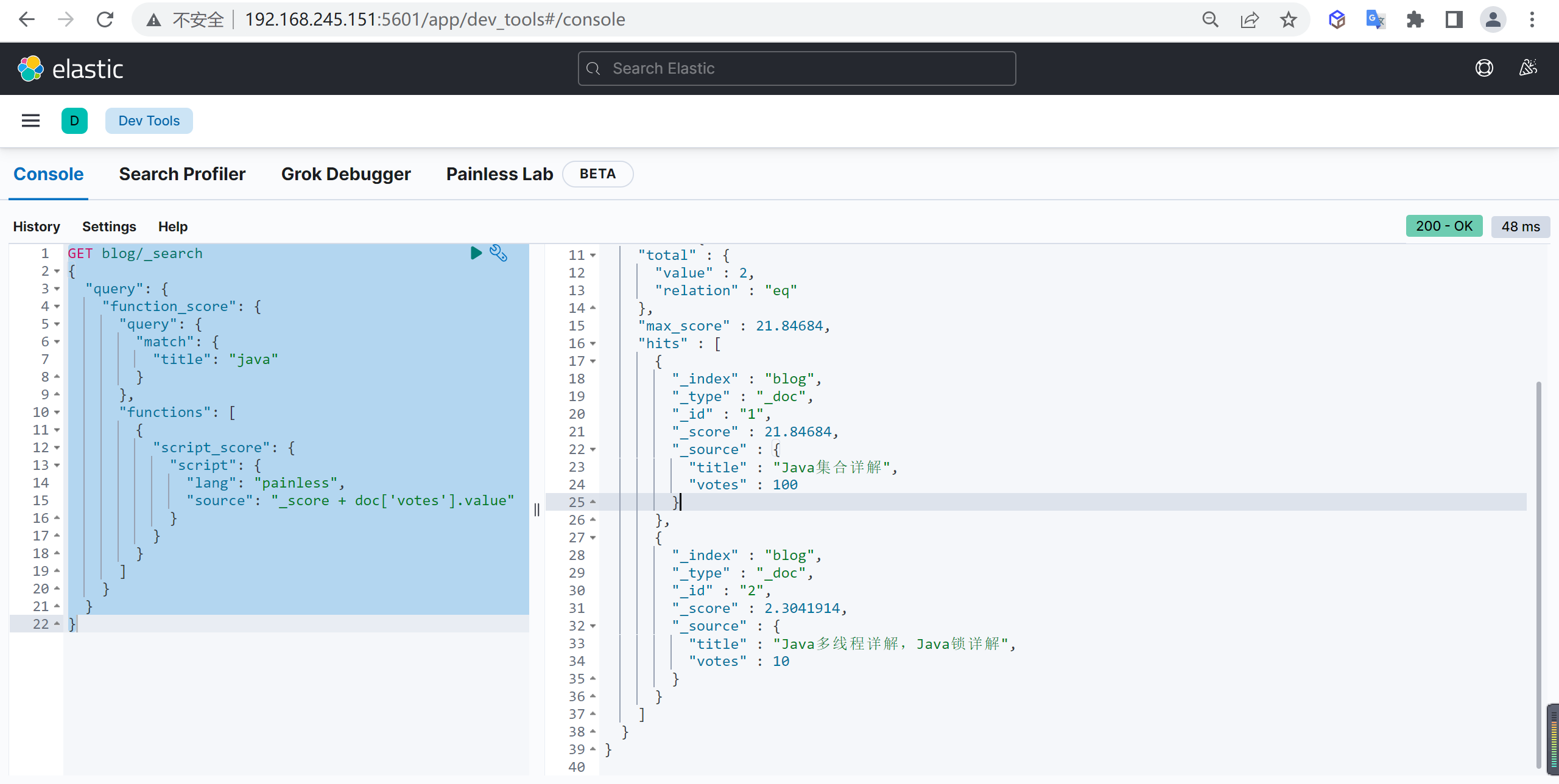
field_value_factor
field_value_factor类似于script_score,但是不用自己写脚本,而是使用影响因子和内置函数进行计算
参数说明
| 字段 | 内容 |
|---|---|
| field | 需要进行计算的文档字段。 |
| factor | 计算时与字段值相乘的影响因子,默认为 1。 |
| modifier | 可选择 ElasticSearch 内置函数,默认不使用 |
基本使用
下面演示一个稍复杂查询,将 votes 字段值乘以影响因子 1.6,结果再取平方根,最后忽略
query查询的分数sqrt(1.6 * doc['votes'].value):
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"field_value_factor": {
"field": "votes",
"factor": 1.6,
"modifier": "sqrt"
}
}
],
"boost_mode": "replace"
}
}
}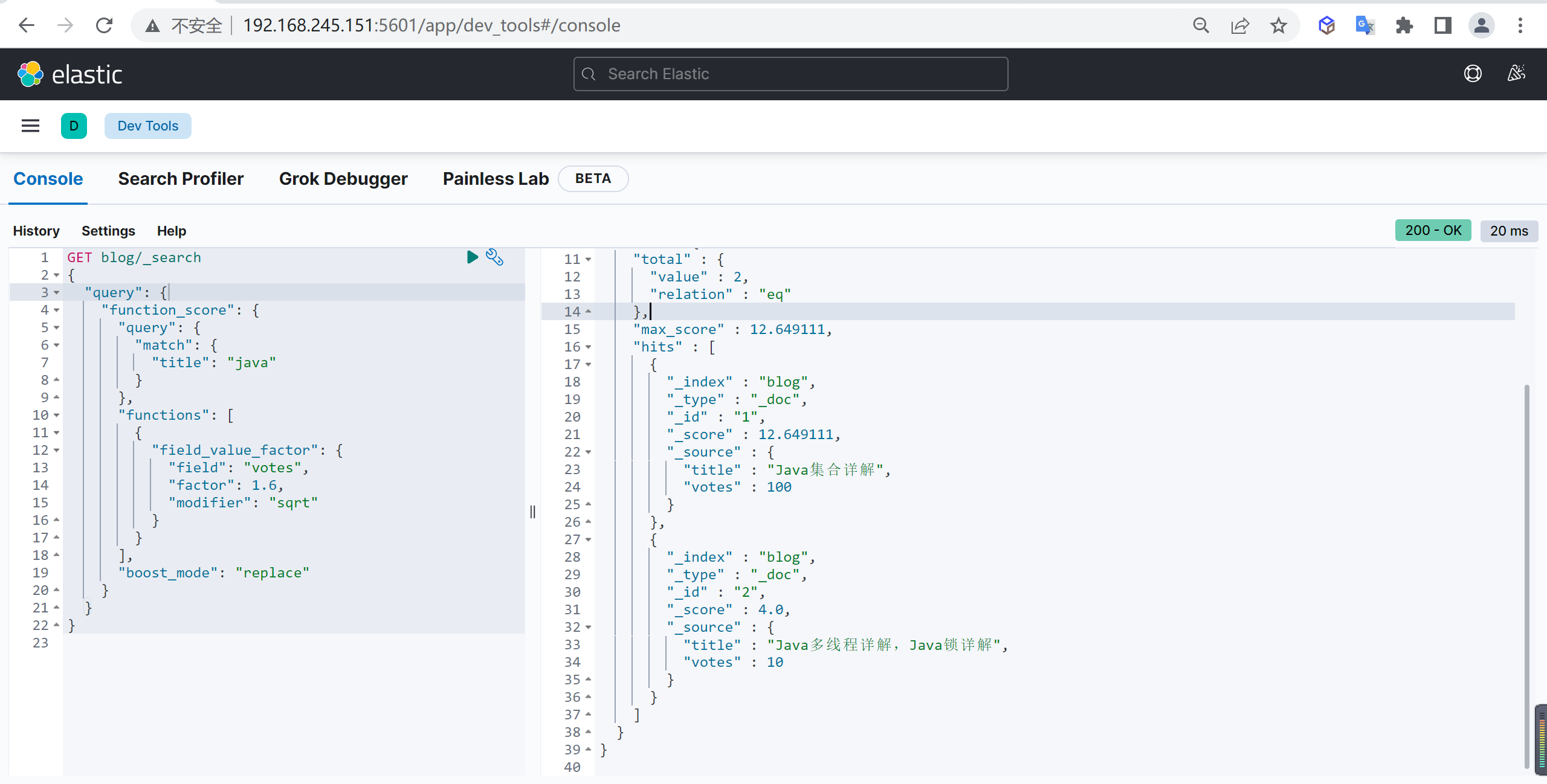
modifier参数
modifier其他的内置函数还有:
| 字段 | 内容 |
|---|---|
| none | 不进行任何计算 (默认) |
| log | 字段值取常用对数。如果字段值为0到1之间,将导致错误,可以考虑使用下面的 log1p 函数 |
| log1p | 字段值加1后,取常用对数 |
| log2p | 字段值加2后,取常用对数 |
| ln | 字段值取自然对数。如果字段值为0到1之间,将导致错误,可以考虑使用下面的 ln1p 函数 |
| ln1p | 字段值加1后,取自然对数 |
| ln2p | 字段值加2后,取自然对数 |
| square | 字段值的平方 |
| sqrt | 字段值求平方根 |
| reciprocal | 字段值取倒数 |
score_mode参数
score_mode参数表示functions模块中不同计算方法之间的得分计算方式
| 字段 | 内容 |
|---|---|
| multiply | 得分相乘 (默认) |
| sum | 得分相加 |
| avg | 得分取平均值 |
| first | 取第一个有效的方法得分 |
| max | 最大的得分 |
| min | 最小的得分 |
使用案例如下
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"field_value_factor": {
"field": "votes",
"factor": 1.6,
"modifier": "sqrt"
}
},
{
"script_score": {
"script": "_score + doc['votes'].value"
}
}
],
"boost_mode": "replace"
}
}
}
max_boost参数表示functions模块中得分上限
GET blog/_search
{
"query": {
"function_score": {
"query": {
"match": {
"title": "java"
}
},
"functions": [
{
"field_value_factor": {
"field": "votes",
"factor": 1.6,
"modifier": "sqrt"
}
}
],
"boost_mode": "replace",
"max_boost": 10
}
}
}boosting
可以对有些评分进行降低
参数
| 字段 | 内容 |
|---|---|
| positive | 得分不变 |
| nagetive | 降低得分 |
| nagetive_boost | 降低得分的权重,取值范围 [0 ~1] |
基本查询
下面进行以下正常的查询
GET books/_search
{
"query": {
"match": {
"name": "java"
}
}
}降低评分
使用 nagetive 和 nagetive_boost 降低字段值中包含 “2008” 的文档得分
GET books/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"name": "java"
}
},
"negative": {
"match": {
"name": "2008"
}
},
"negative_boost": 0.5
}
}
}地理位置查询
数据准备
地理位置查询需要准备一些位置信息,我们插入一些数据
创建索引
PUT geo
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"location":{
"type": "geo_point"
}
}
}
}插入数据
准备一个geo.json 文件,贴上如下文件内容,注意最后一行要留空
{"index":{"_index":"geo","_id":1}}
{"name":"西安","location":"34.288991865037524,108.9404296875"}
{"index":{"_index":"geo","_id":2}}
{"name":"北京","location":"39.926588421909436,116.43310546875"}
{"index":{"_index":"geo","_id":3}}
{"name":"上海","location":"31.240985378021307,121.53076171875"}
{"index":{"_index":"geo","_id":4}}
{"name":"天津","location":"39.13006024213511,117.20214843749999"}
{"index":{"_index":"geo","_id":5}}
{"name":"杭州","location":"30.259067203213018,120.21240234375001"}
{"index":{"_index":"geo","_id":6}}
{"name":"武汉","location":"30.581179257386985,114.3017578125"}
{"index":{"_index":"geo","_id":7}}
{"name":"合肥","location":"31.840232667909365,117.20214843749999"}
{"index":{"_index":"geo","_id":8}}
{"name":"重庆","location":"29.592565403314087,106.5673828125"}批量插入
执行下面的命令批量插入数据
curl -XPOST "http://192.168.245.151:9200/geo/_bulk?pretty" -H "content-type:application/json" --data-binary @geo.jsongeo_distance
给出一个中心点和距离,查询以该中心点为圆心,以距离为半径范围内的文档
基本查询
查询以圆心为中心,600KM范围内的文档
GET geo/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_distance": {
"distance": "600km",
"location": {
"lat": 34.288991865037524,
"lon": 108.9404296875
}
}
}
]
}
}
}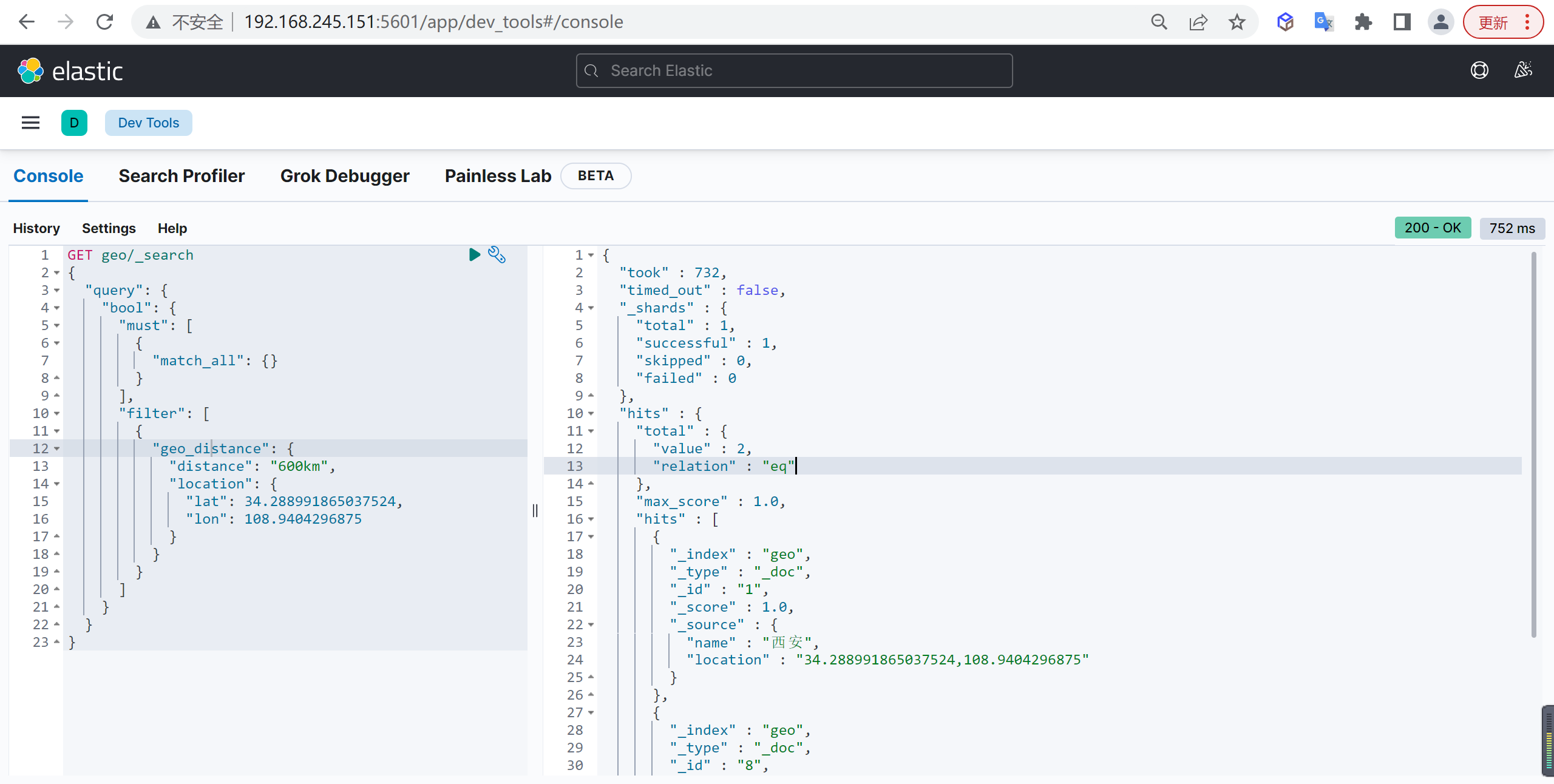
geo_bounding_box
geo_bounding分别制定左上和右下两个点,查询两个点组成的矩形内所有文档
基本查询
GET geo/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 32.0639555946604,
"lon": 118.78967285156249
},
"bottom_right": {
"lat": 29.98824461550903,
"lon": 122.20642089843749
}
}
}
}
]
}
}
}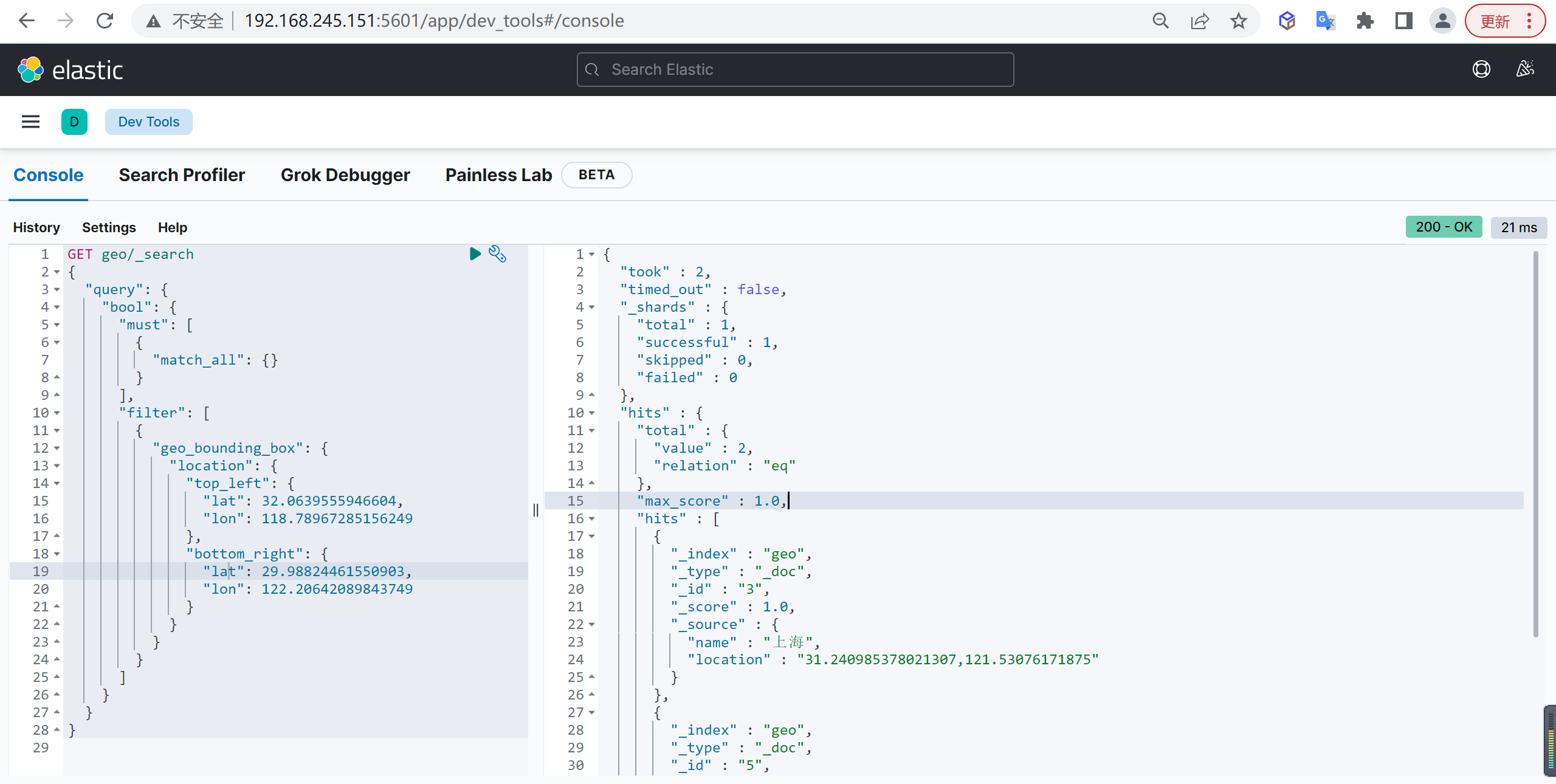
geo_polygon
geo_polygon最少制定三个点,查询组成的多边形范围内所有文档
基本查询
GET geo/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_polygon": {
"location": {
"points": [
{
"lat": 31.793755581217674,
"lon": 113.8238525390625
},
{
"lat": 30.007273923504556,
"lon":114.224853515625
},
{
"lat": 30.007273923504556,
"lon":114.8345947265625
}
]
}
}
}
]
}
}
}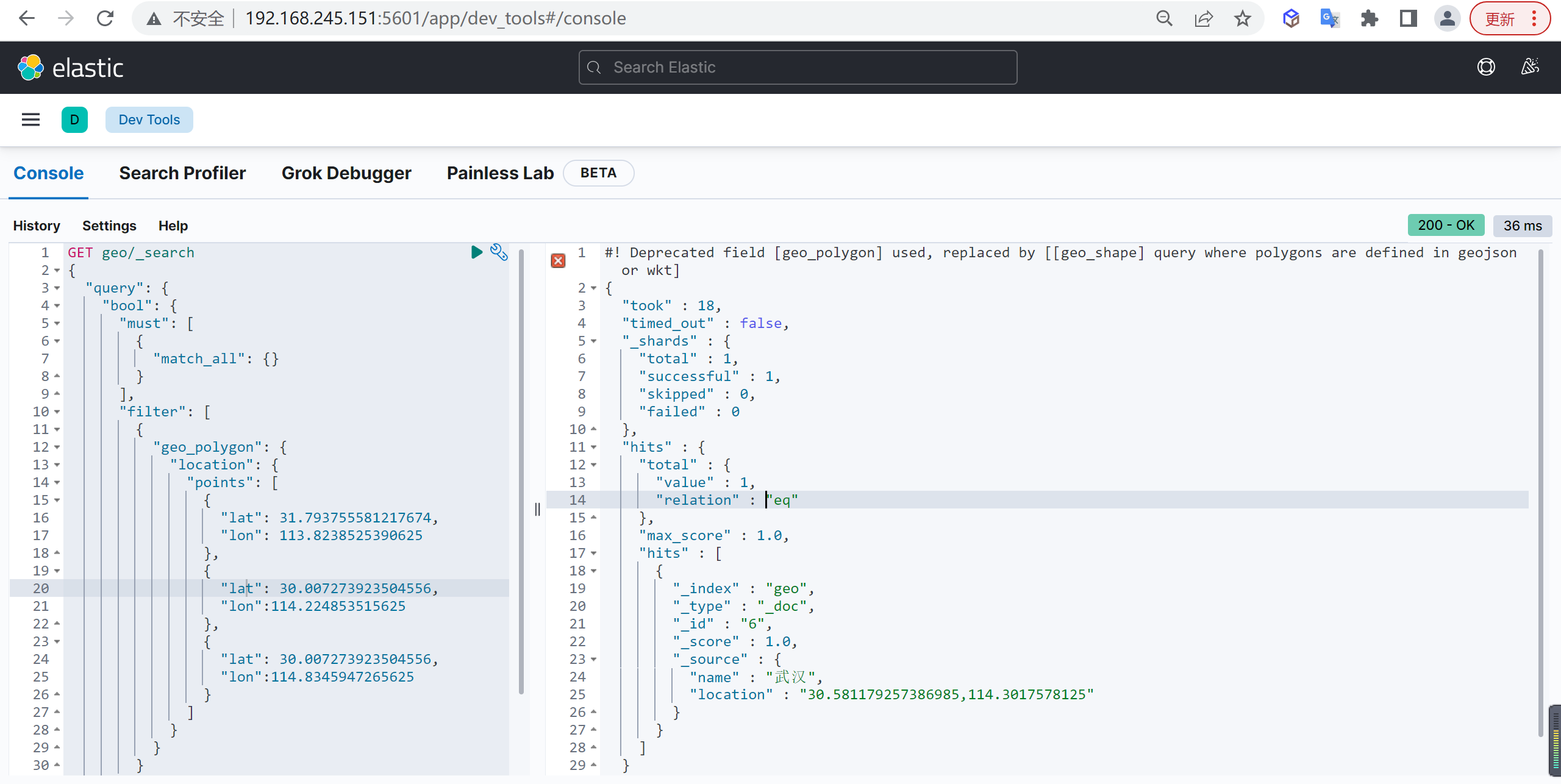
geo_shape
geo_shape用来查询图形,针对geo_shape字段类型,两个图形之间的关系有:相交、包含、不相交
准备数据
新建索引
PUT geo_shape
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"location": {
"type": "geo_shape"
}
}
}
}插入数据
添加一条线
PUT geo_shape/_doc/1
{
"name": "西安-郑州",
"location": {
"type": "linestring",
"coordinates": [
[108.9404296875, 34.279914398549934],
[113.66455078125, 34.768691457552706]
]
}
}基本查询
接下来查询某一个图形中是否包含该线:
GET geo_shape/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"geo_shape": {
"location": {
"shape": {
"type": "envelope",
"coordinates": [
[
106.5234375,
36.80928470205937
],
[
115.33447265625,
32.24997445586331
]
]
},
"relation": "within"
}
}
}
]
}
}
}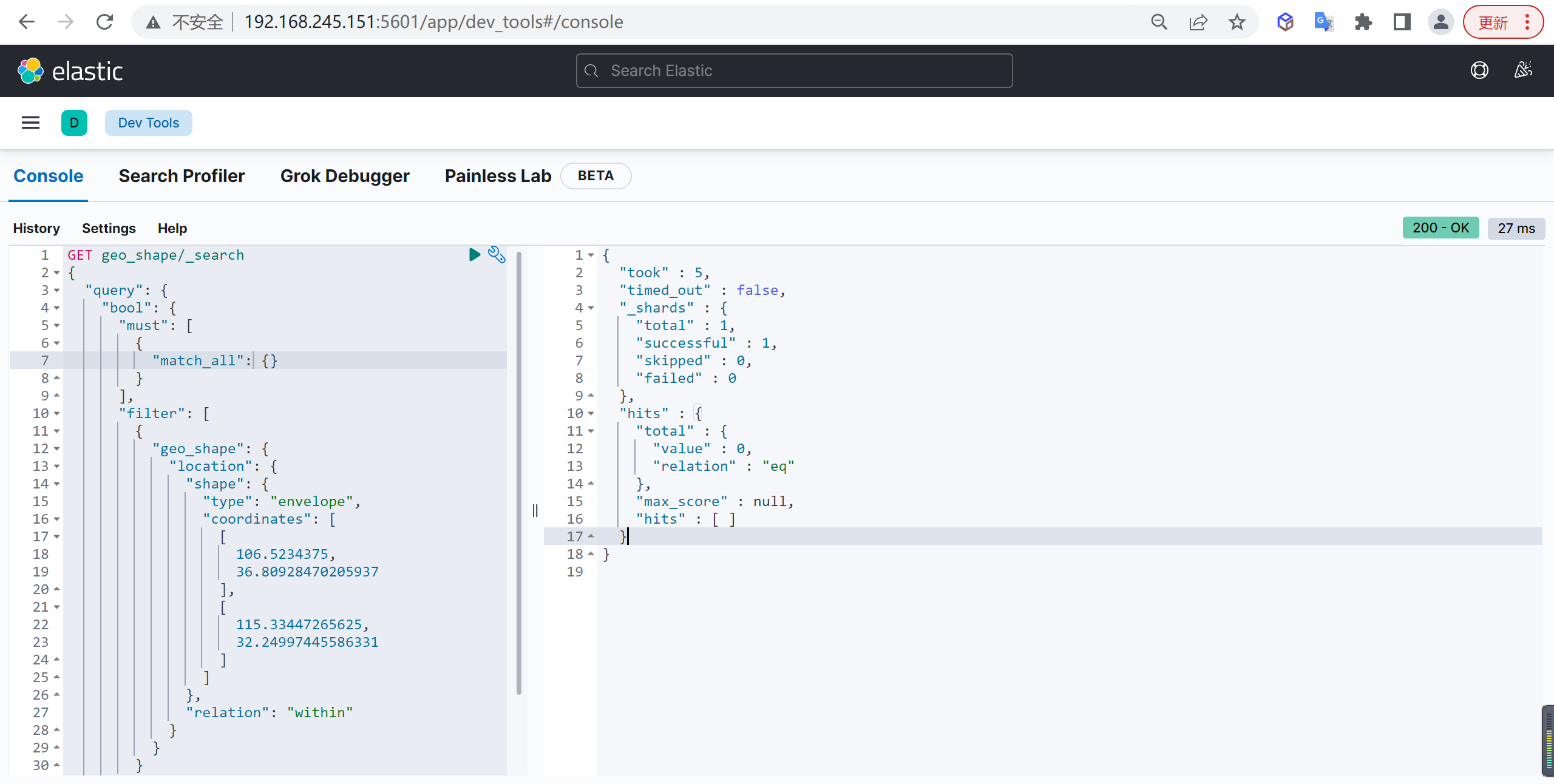
关键参数
relation属性表示两个图形的关系:
within包含intersects相交disjoint不相交
ElasticSearch 聚合查询
指标聚合
指标聚合比较简单,大多数都是对查询返回的数据进行简单的数值处理
Max
Max聚合可以统计最大值,类似 MySQL 数据库中的 max 函数
基本查询
例如查询价格最高的书籍
GET books/_search
{
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}聚合结果在最下面,我们发现数据最大的值是
269
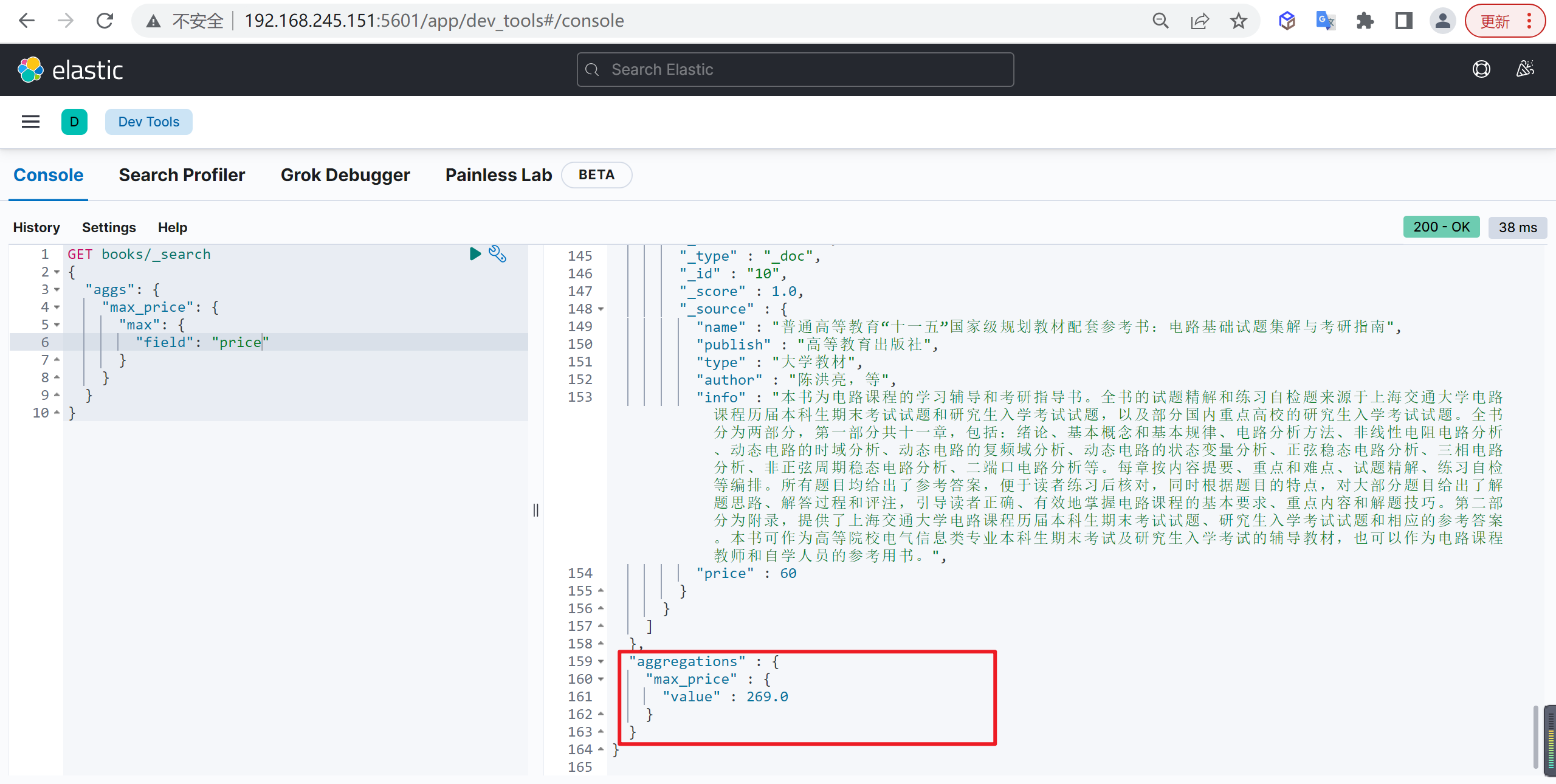
设置默认值
有些文档没有
price字段,还可以使用missing来设置默认值
插入文档
插入的字段没有
price
POST books/_doc
{
"name": "测试数据",
"publish" :"高等教育出版社",
"type" :"大学教材",
"author" :"大方哥",
"info": "高等教育出版社高等教育出版社高等教育出版社高等教育出版社高等教育出版社"
}基本查询
我们下面就进行查询,使用 missing 参数,设置 price 空字段值为 1000
GET books/_search
{
"aggs": {
"max_price": {
"max": {
"field": "price",
"missing": 1000
}
}
}
}忽略问题文档
有时候我们需要排除不存在
price字段的数据,我们可以使用script进行处理,
基本查询
可以先通过
doc['price'].size()!=0去判断文档是否有对应的属性
GET books/_search
{
"aggs": {
"max_price": {
"max": {
"script": {
"source": "if (doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}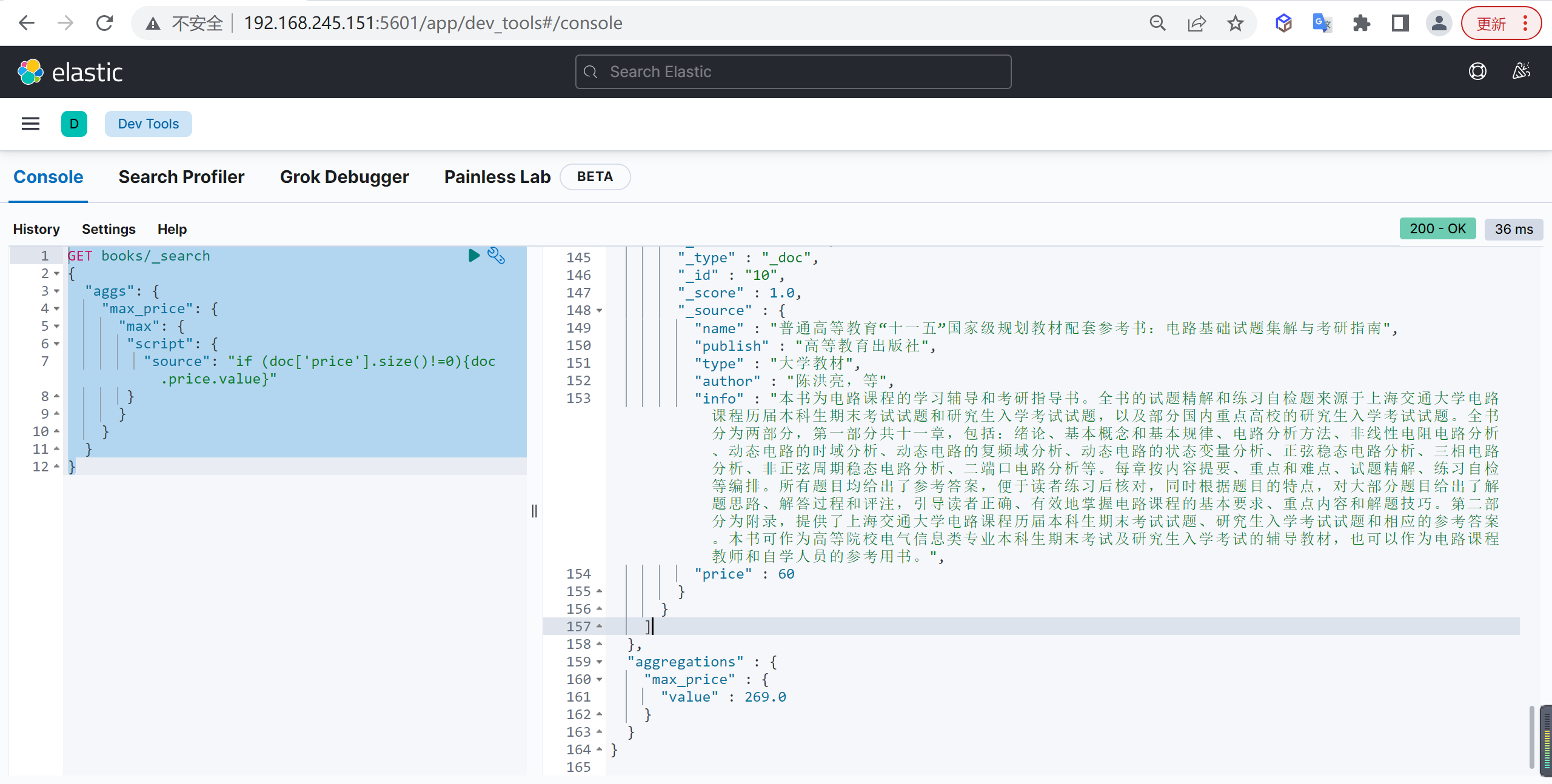
Min
统计最小值,用法和
Max基本一致:
基本查询
GET books/_search
{
"aggs": {
"min_price": {
"min": {
"field": "price",
"missing": 1000
}
}
}
}忽略问题文档
GET books/_search
{
"aggs": {
"min_price": {
"min": {
"script": {
"source": "if (doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}Avg
统计平均值
基本查询
我们统计数据价格的平均值
GET books/_search
{
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}书籍的平均价格是29.4元
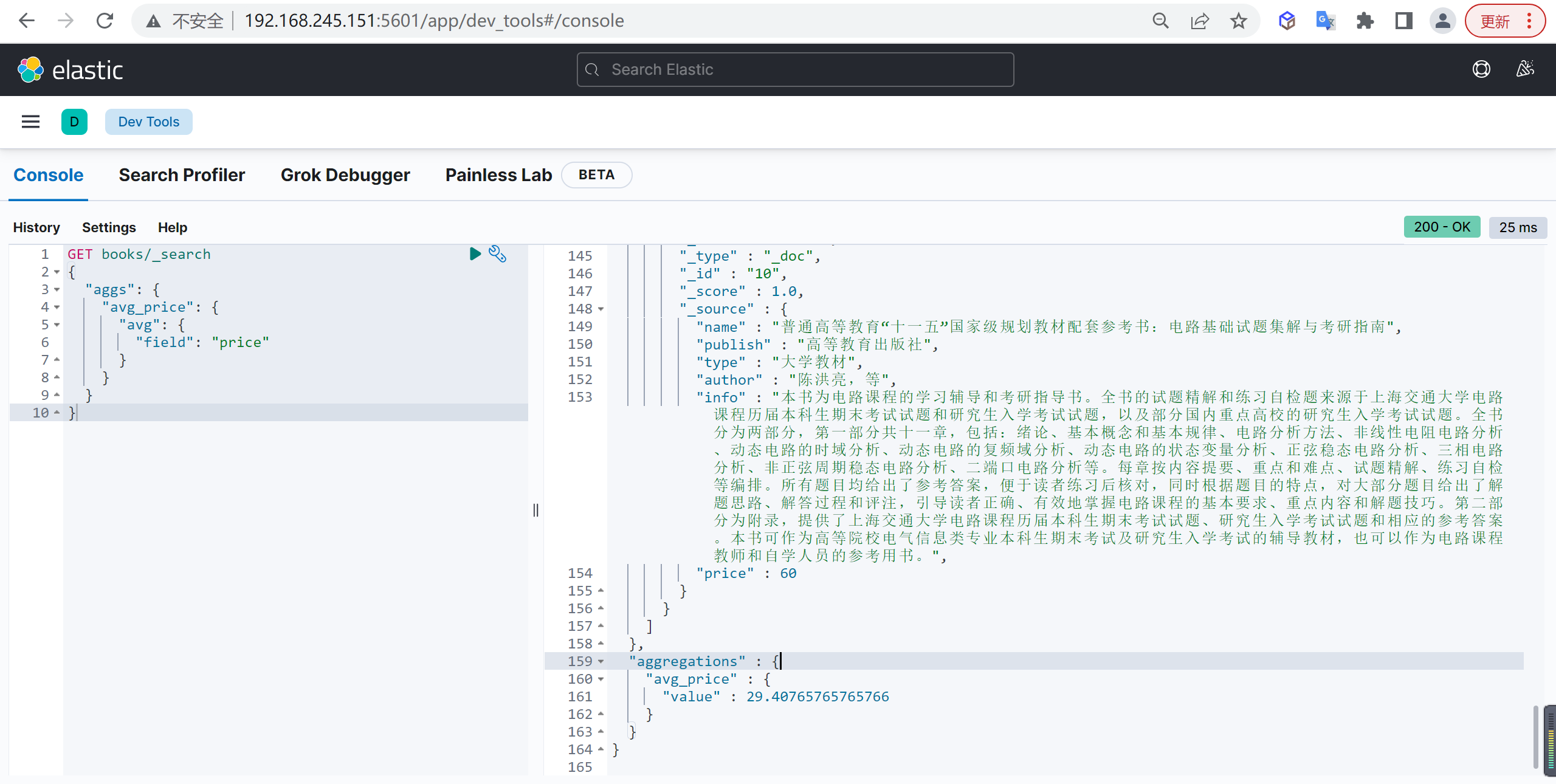
忽略问题文档
GET books/_search
{
"aggs": {
"avg_price": {
"avg": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}Sum
对字段求合
基本查询
GET books/_search
{
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
}
}
}忽略问题文档
GET books/_search
{
"aggs": {
"sum_price": {
"sum": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}Cardinality
Cardinality聚合用于基数统计,类似于 MySQL 中的 distinct count(0),去重后再计数。
注意事项
ElasticSearch 中
text字段类型是分析型,默认不允许进行聚合操作,如果有聚合操作的需求,可以考虑以下两种方式:
- 设置
text字段类型的 fielddata 属性为 true。 - 将字段类型或者字段的子域在设置成
keyword。
设置fielddata
设置
text字段类型的 fielddata 属性为 true
重置索引
因为 books 索引已经存在,我们要先删除,再新建索引设置 fielddata,导入数据后再进行
Cardinality统计
DELETE books
PUT books
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"publish":{
"type": "text",
"analyzer": "ik_max_word",
"fielddata": true
},
"type":{
"type": "text",
"analyzer": "ik_max_word"
},
"author":{
"type": "keyword"
},
"info":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "double"
}
}
}
}重新导入数据
到 bookdata.json 文件目录下,用 cmd 命令行工具,重新导入数据:
curl -XPOST "http://192.168.245.151:9200/books/_bulk?pretty" -H "content-type:application/json" --data-binary @bookdata.json基础查询
现在就可以使用
cardinality查询出版社的总数量
GET books/_search
{
"aggs": {
"publish_count": {
"cardinality": {
"field": "publish"
}
}
}
}查询出来的数据是43
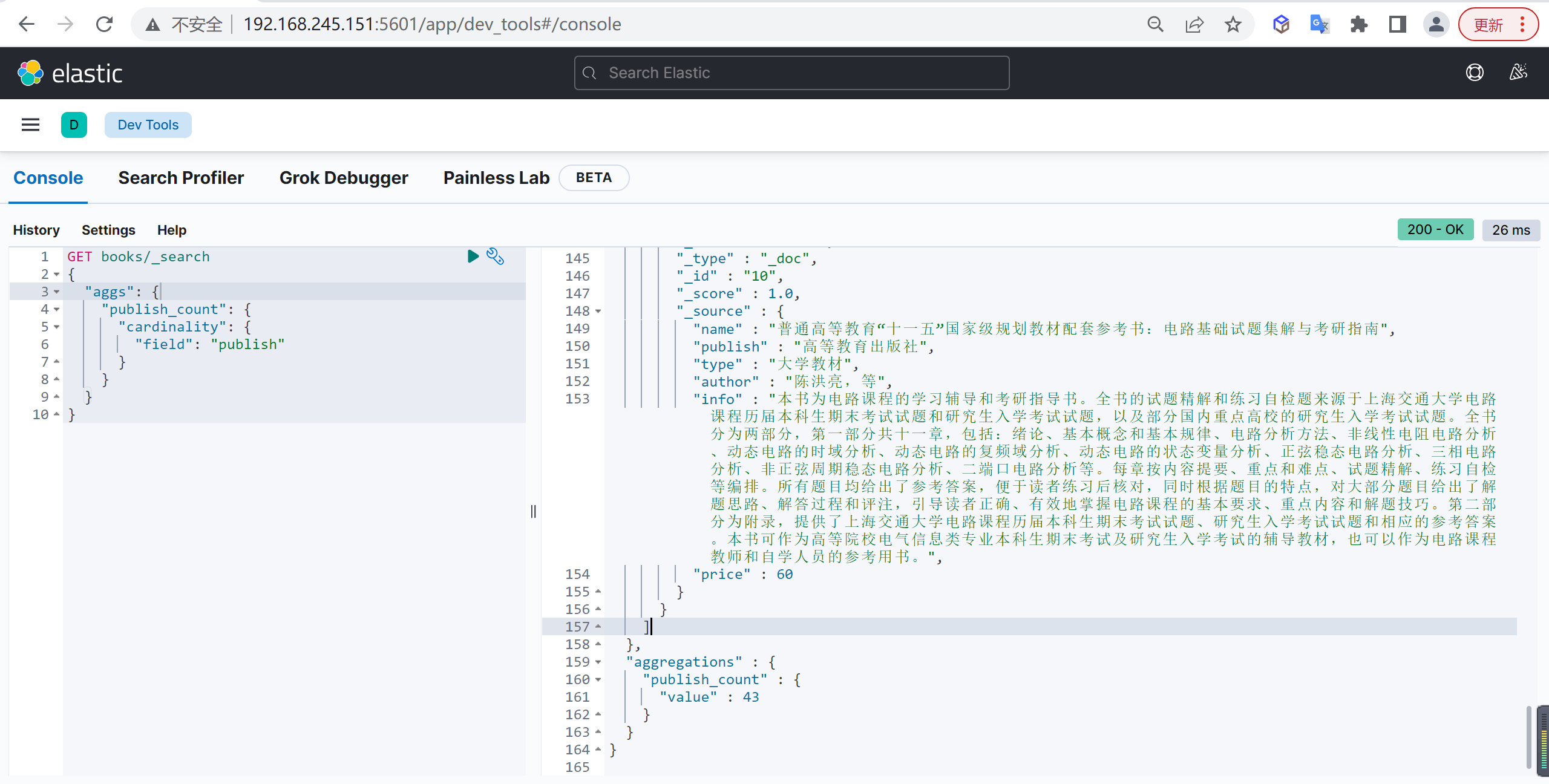
主要事项
这种方式虽然可以进行聚合操作,但是无法满足精准聚合,因为
text类型会进行分词。
而且 fielddata 是动态创建到内存中,如果文档很多时,可能有动态创建慢,占内存等问题,所以推荐使用下面第二种方式
设置keyword
将字段类型或者字段的子域设置成
keyword
重置索引
同样需要删除索引再新建,这次将 publish 字段子域设置成
keyword
DELETE books
PUT books
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"publish":{
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"size": {
"type": "keyword"
}
}
},
"type":{
"type": "text",
"analyzer": "ik_max_word"
},
"author":{
"type": "keyword"
},
"info":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "double"
}
}
}
}重新导入数据
到 bookdata.json 文件目录下,用 cmd 命令行工具,重新导入数据:
curl -XPOST "http://192.168.245.151:9200/books/_bulk?pretty" -H "content-type:application/json" --data-binary @bookdata.json基础查询
再次使用
cardinality查询出版社的总数量
GET books/_search
{
"aggs": {
"publish_count": {
"cardinality": {
"field": "publish"
}
}
}
}Stats
stats表示基本统计聚合,可以同时返回min、max、sum、count、avg结果
基本查询
GET books/_search
{
"aggs": {
"stats_agg": {
"stats": {
"field": "price"
}
}
}
}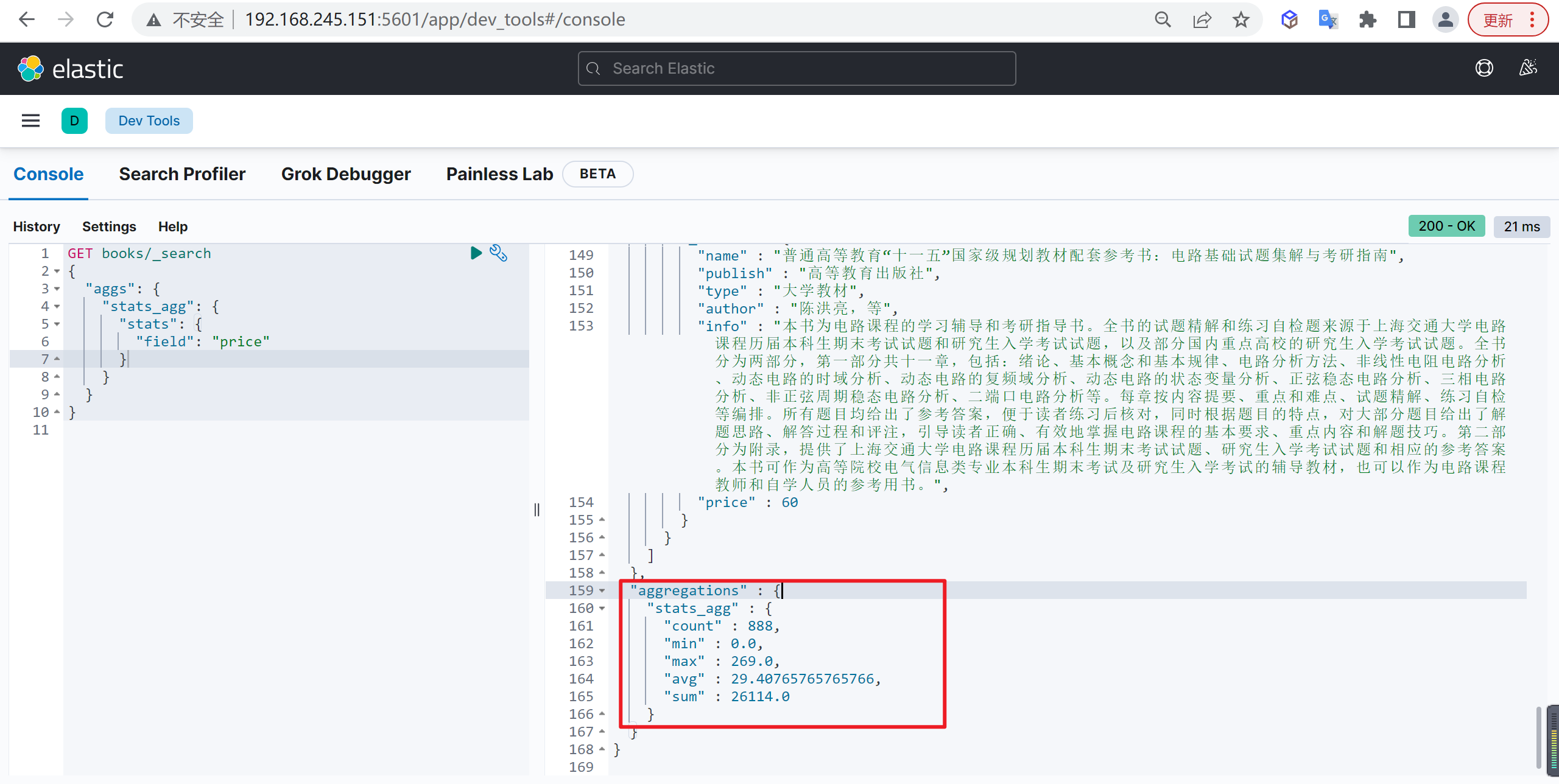
Extends Stats
Extends Stats表示高级统计聚合,比stats聚合返回更多的内容
基本查询
GET books/_search
{
"aggs": {
"extended_stats_agg": {
"extended_stats": {
"field": "price"
}
}
}
}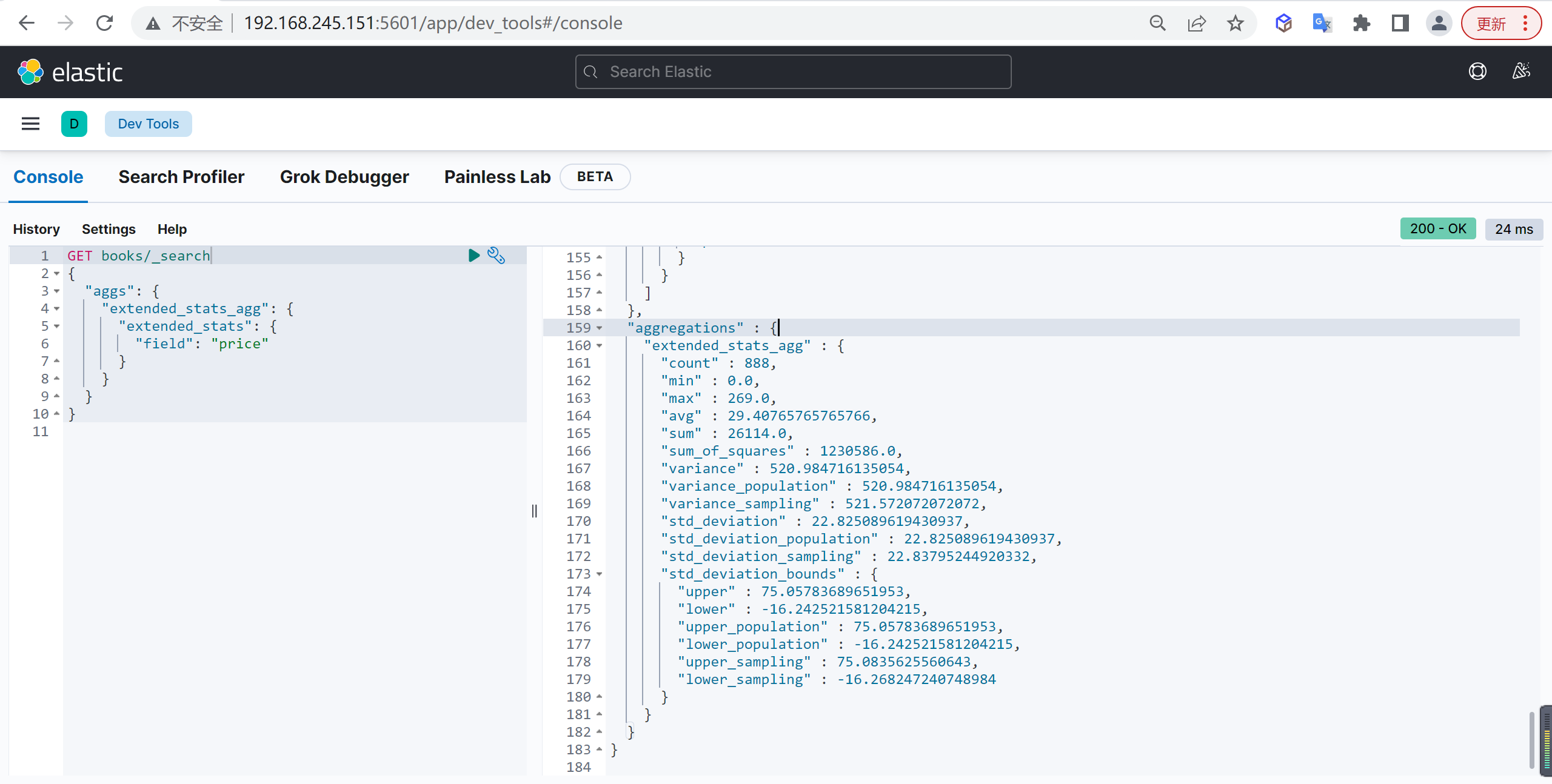
Percentiles
Percentiles是百分位数值统计,运用于统计学中:将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。
基本查询
文字解释看起来比较难理解,还是拿书籍价格举例,分别看一下 25%、50%、75%、100% 这四个百分位上的书籍价格:
GET books/_search
{
"aggs": {
"percentiles_agg": {
"percentiles": {
"field": "price",
"percents": [
1,
5,
10,
15,
25,
50,
75,
95,
100
]
}
}
}
}可以看到,中位数 50% 的书籍价格是 28 元,也就是说有一半的书籍价格比 28 元低,另一半比 28 元高,对应的 25%、75%、100% 也是类似。
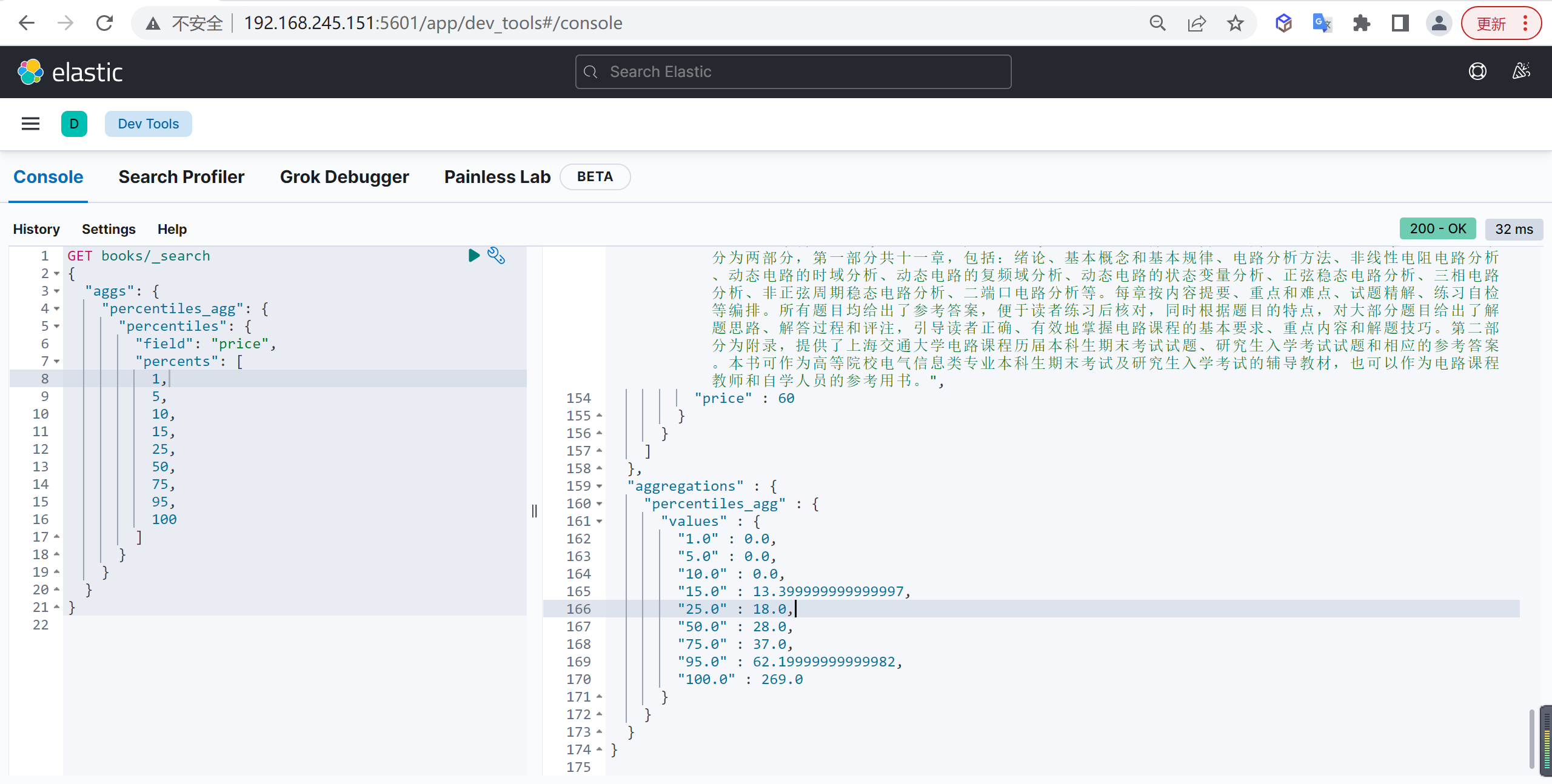
Value count
Value count可以按照字段统计文档数量,该字段值为空 null 的文档会被丢弃
基本查询
GET books/_search
{
"aggs": {
"count": {
"value_count": {
"field": "price"
}
}
}
}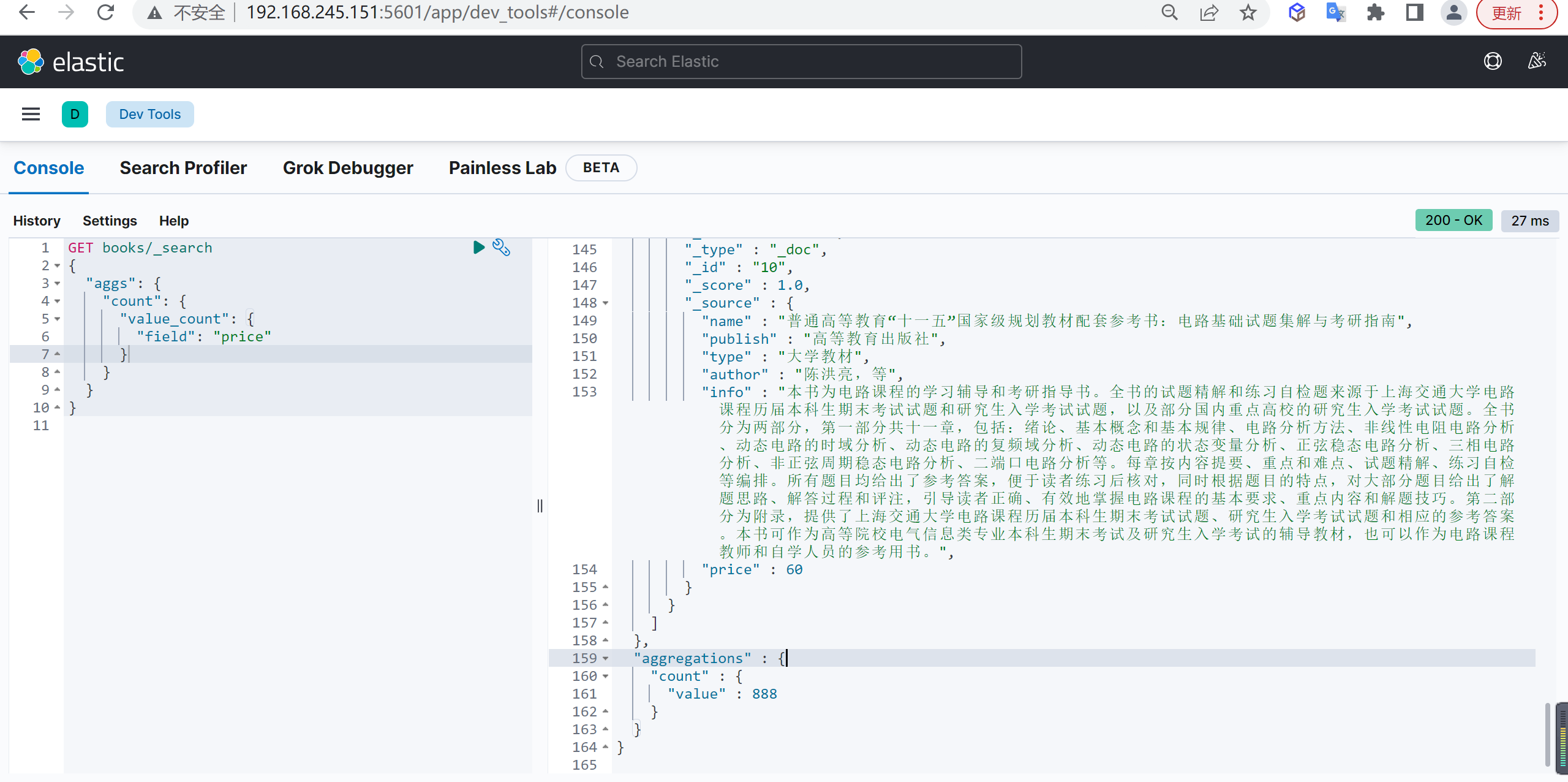
桶聚合
Terms
Terms用于分组聚合,例如,统计各个出版社出版的图书总数量
基本查询
统计各出版社图书总数量,并列出前五个
GET books/_search
{
"aggs": {
"bucket_terms": {
"terms": {
"field": "publish.size",
"size": 5
}
}
}
}
terms分组聚合不能作用于 text 类型,这里我们用的是 keyword 类型的子域 publish.size
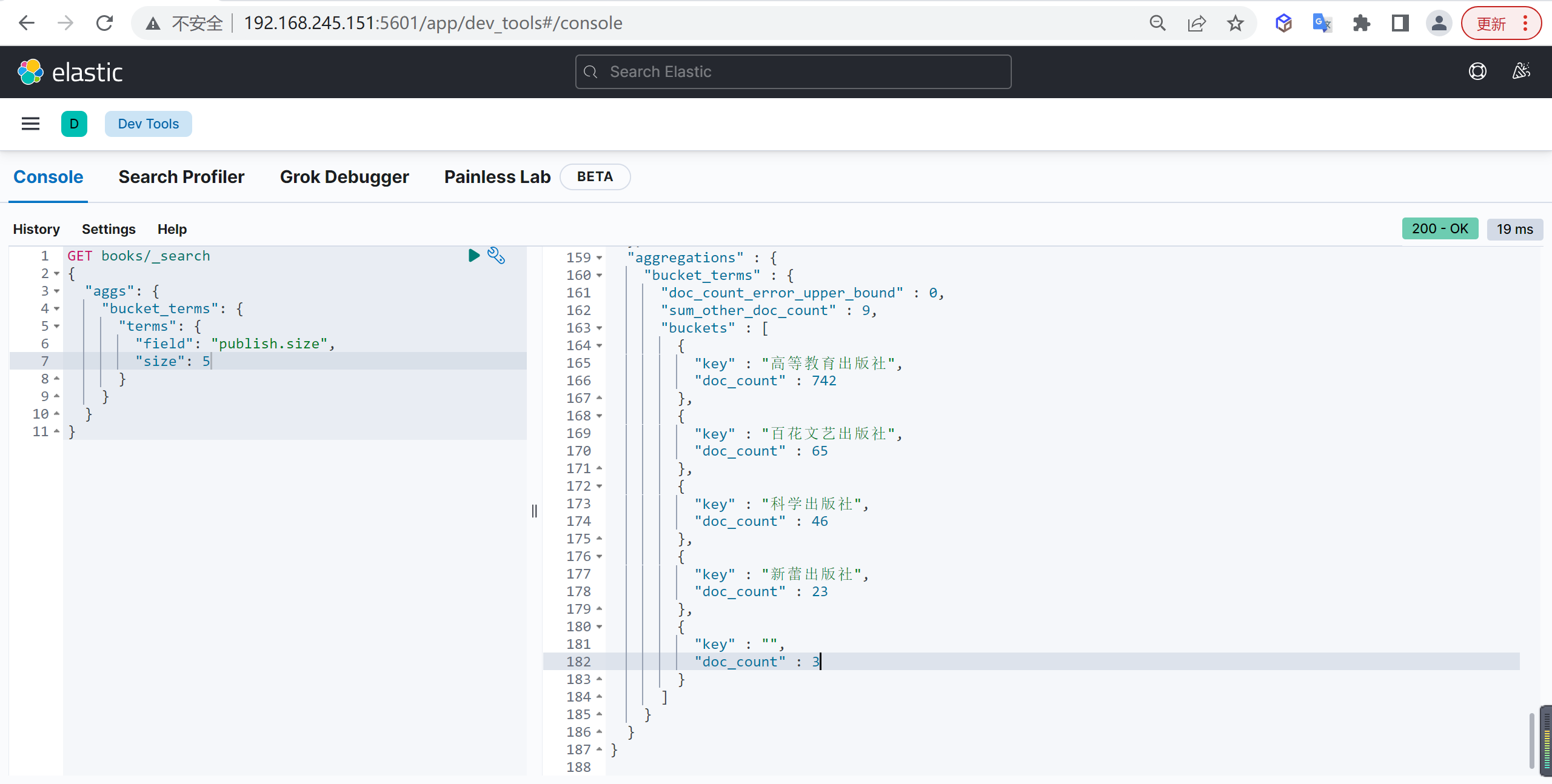
价格统计
在
terms分组聚合的基础上,还可以对每个桶进行指标聚合,统计不同出版社所出版的图书平均价格:
GET books/_search
{
"aggs": {
"bucket_terms": {
"terms": {
"field": "publish.size",
"size": 5
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}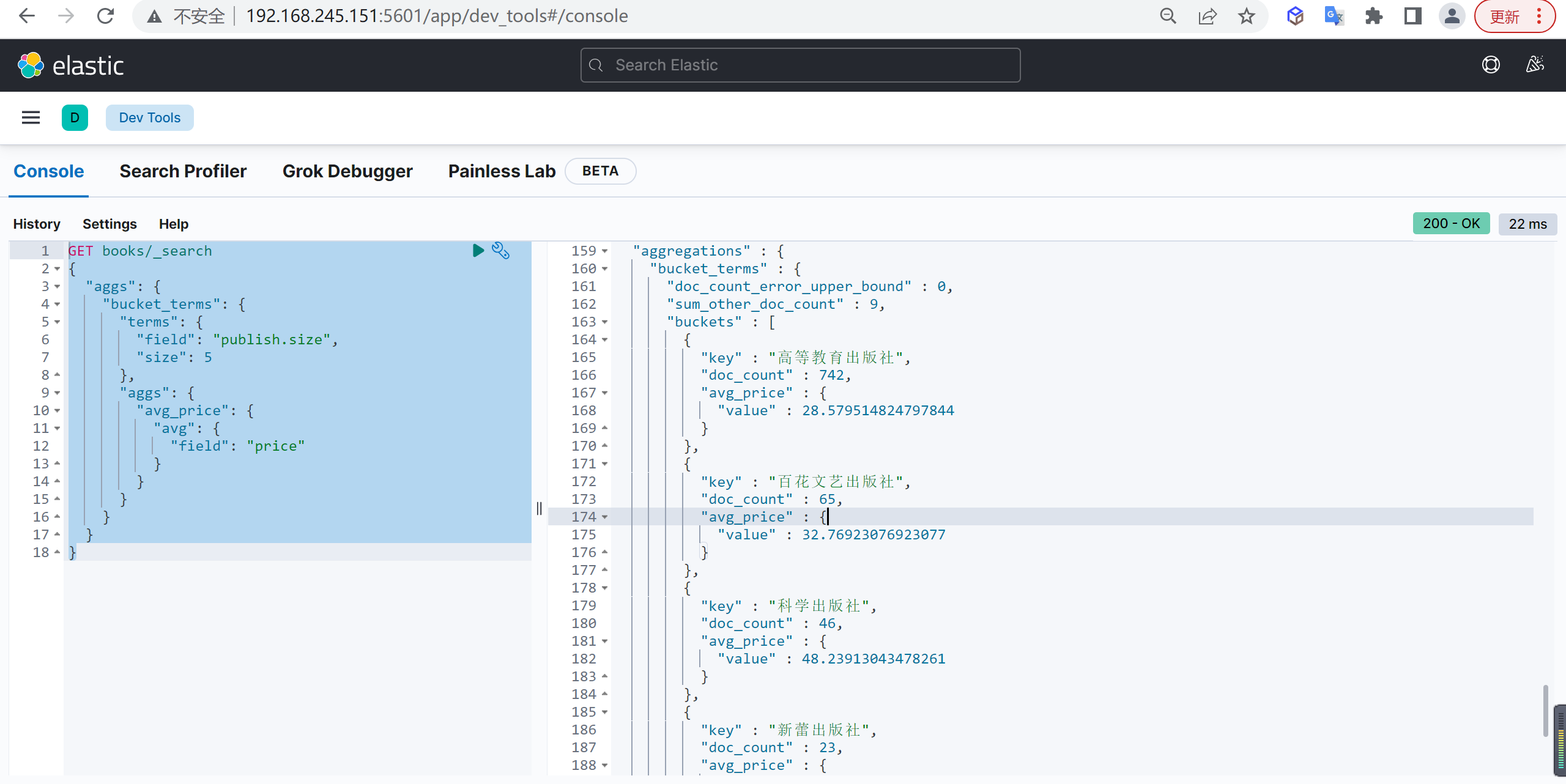
Filter
Filter是过滤器聚合,可以将符合过滤器中条件的文档分到一个桶中,然后可以求其平均值
基本查询
例如查询书名中包含 java 的图书的平均价格
GET books/_search
{
"aggs": {
"bucket_filter": {
"filter": {
"term": {
"name": "java"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}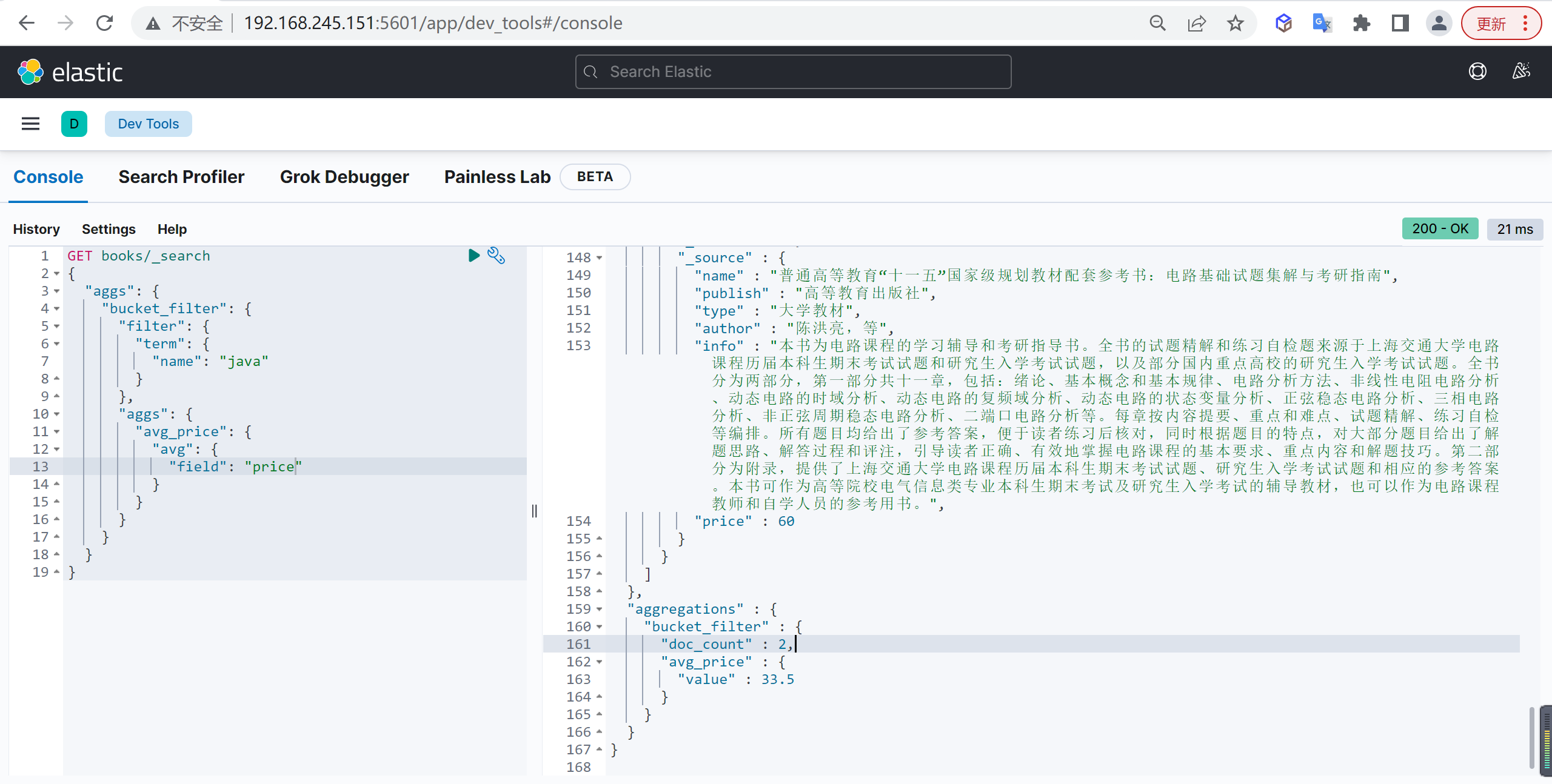
Filters
多过滤器聚合,过滤条件可以有多个
基本查询
例如查询书名中包含 java 或者 office 的图书的平均价格:
GET books/_search
{
"aggs": {
"bucket_filter": {
"filters": {
"filters": [
{
"term": {
"name": "java"
}
},
{
"term": {
"name": "office"
}
}
]
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}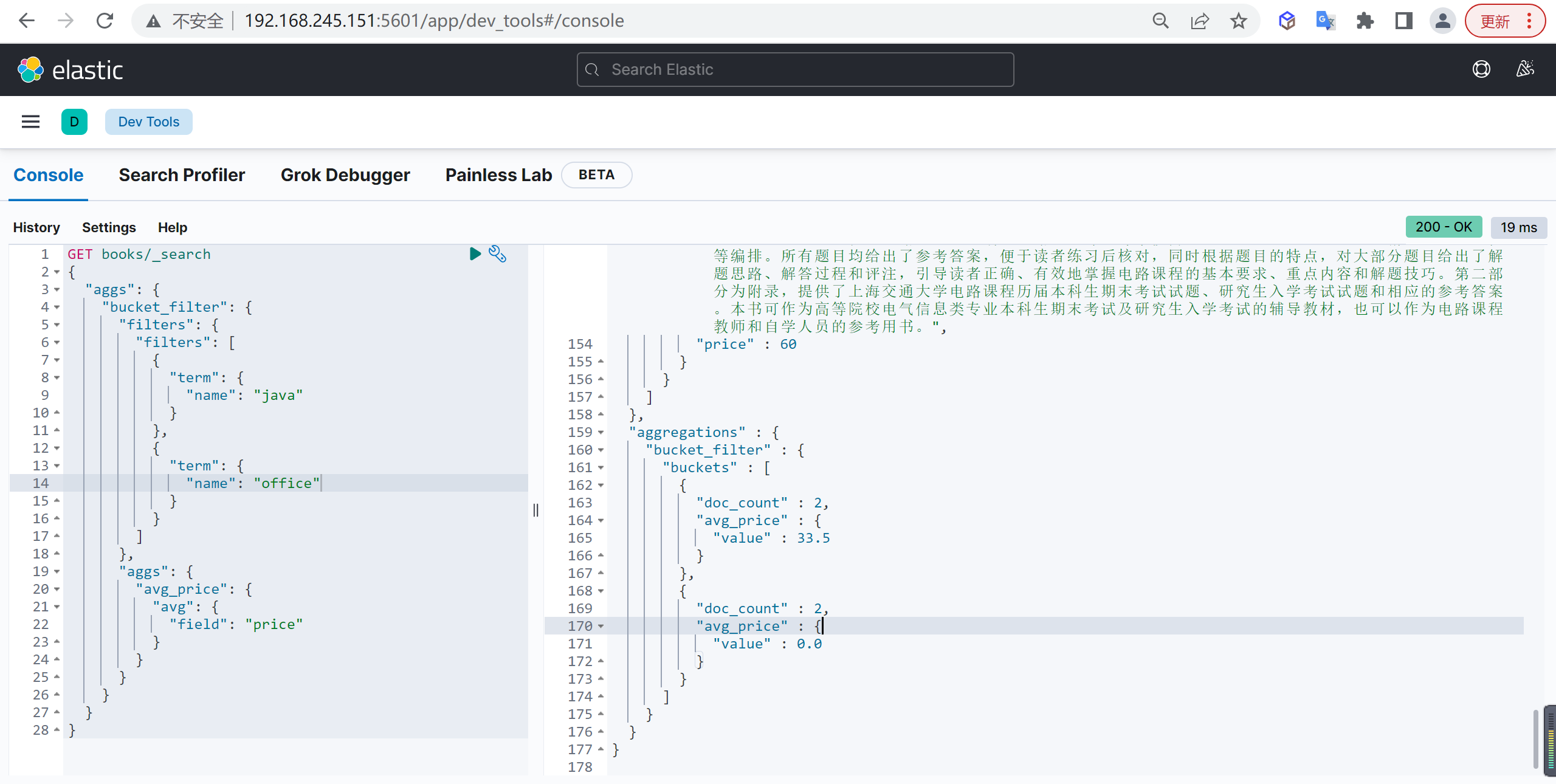
Range
按照范围聚合,在某一个范围内的文档数统计
基本查询
例如统计图书价格在 0-50、50-100、100-150、150以上的图书数量:
GET books/_search
{
"aggs": {
"bucket_range": {
"range": {
"field": "price",
"ranges": [
{
"to": 50
},
{
"from": 50,
"to": 100
},
{
"from": 100,
"to": 150
},
{
"from": 150
}
]
}
}
}
}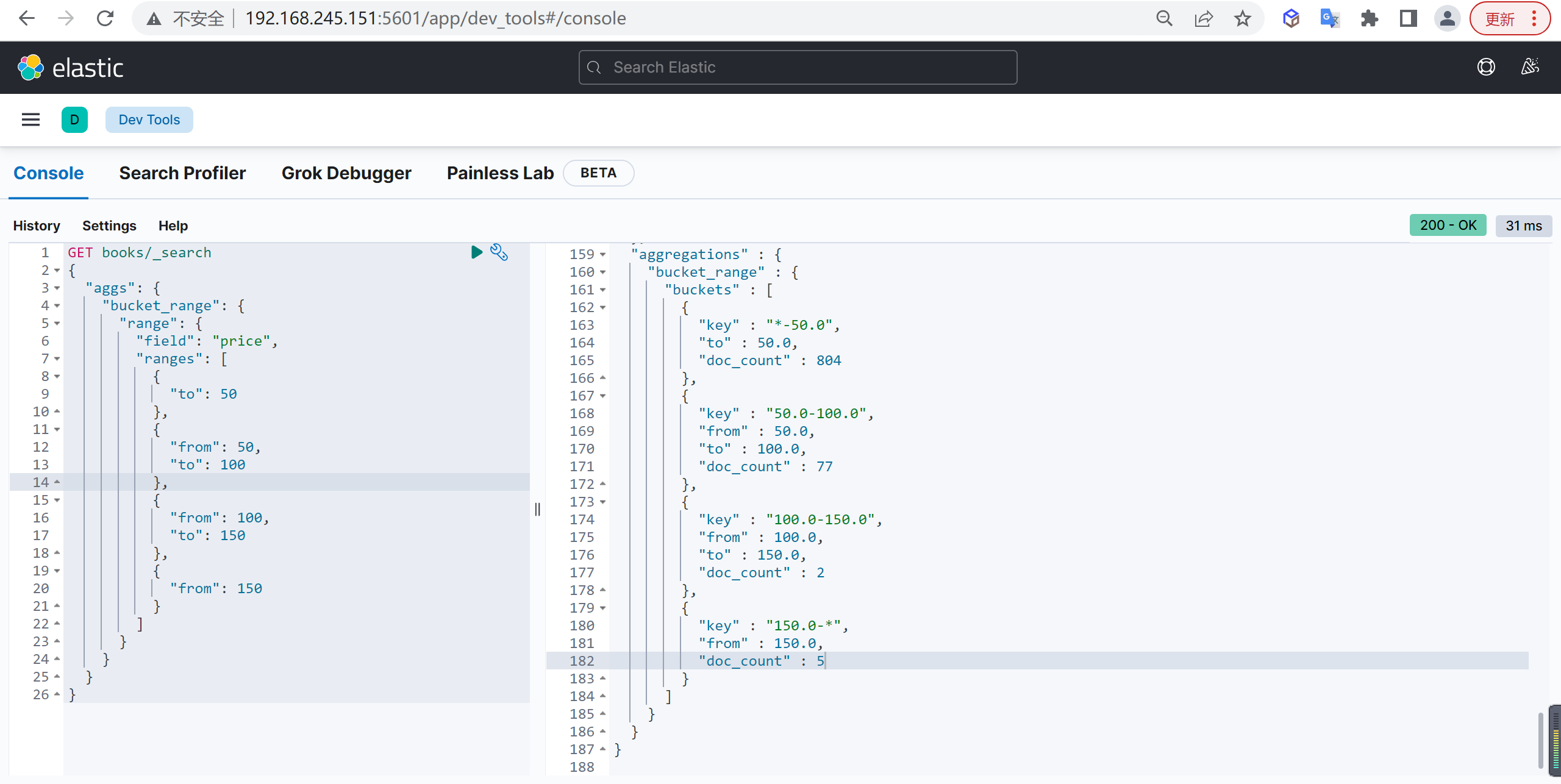
出版社统计
基于上面的架构聚集结果,在统计出来每一个分桶中出版社的数量
GET books/_search
{
"aggs": {
"bucket_range": {
"range": {
"field": "price",
"ranges": [
{
"to": 50
},
{
"from": 50,
"to": 100
},
{
"from": 100,
"to": 150
},
{
"from": 150
}
]
},
"aggs": {
"publish_size": {
"cardinality": {
"field": "publish.size"
}
}
}
}
}
}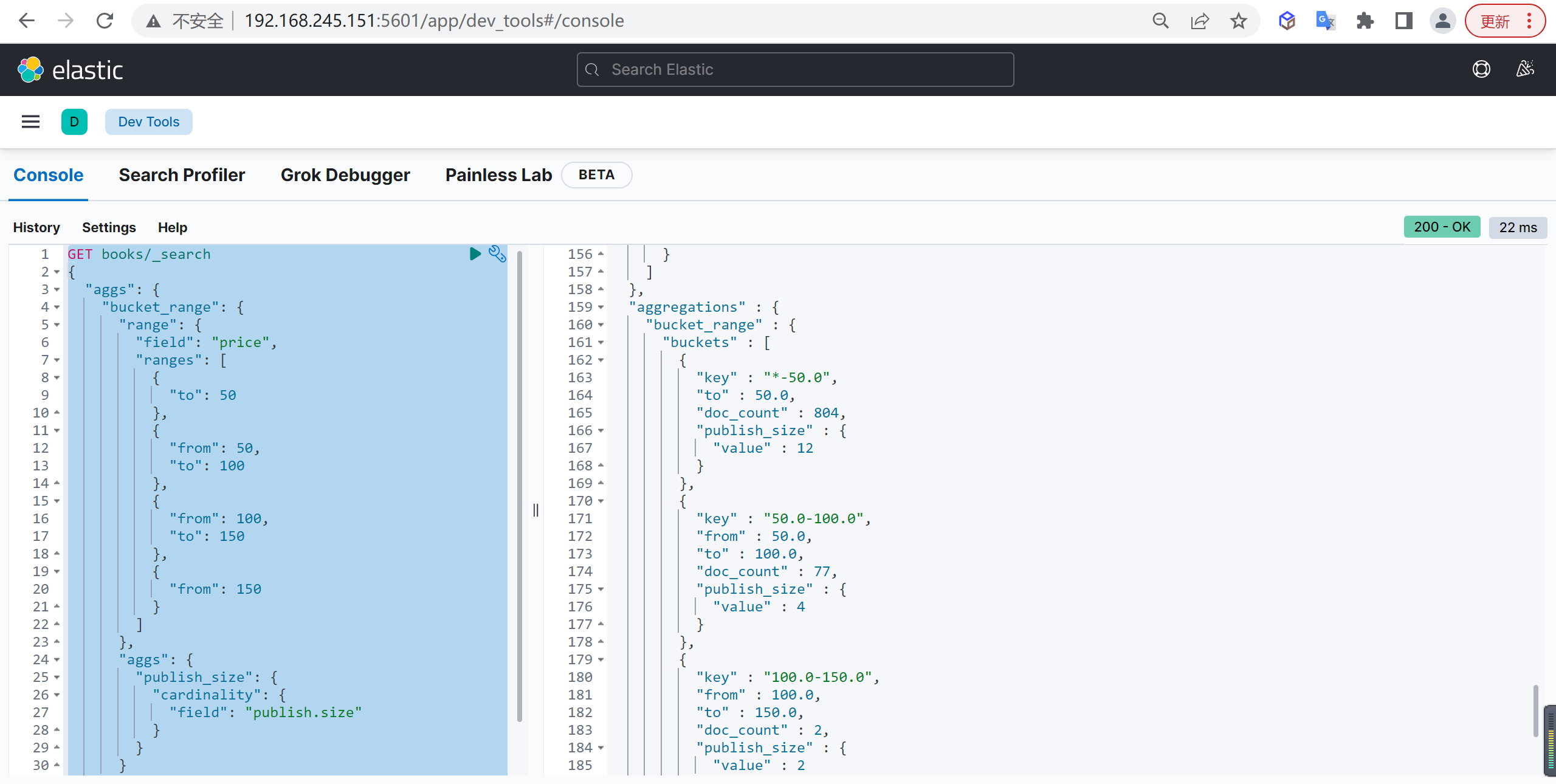
Date Range
ange聚合和Date Range聚合都可以可以统计日期,后者的优势在于可以使用日期表达式
插入数据
首先造一些测试数据:
PUT blog/_doc/1
{
"title":"java",
"date":"2018-12-30"
}
PUT blog/_doc/2
{
"title":"java",
"date":"2020-12-30"
}
PUT blog/_doc/3
{
"title":"java",
"date":"2022-10-30"
}基本查询
统计一年前到一年后的微博数量
GET blog/_search
{
"aggs": {
"bucket_date_range": {
"date_range": {
"field": "date",
"ranges": [
{
"from": "now-10M/M",
"to": "now+1y/y"
}
]
}
}
}
}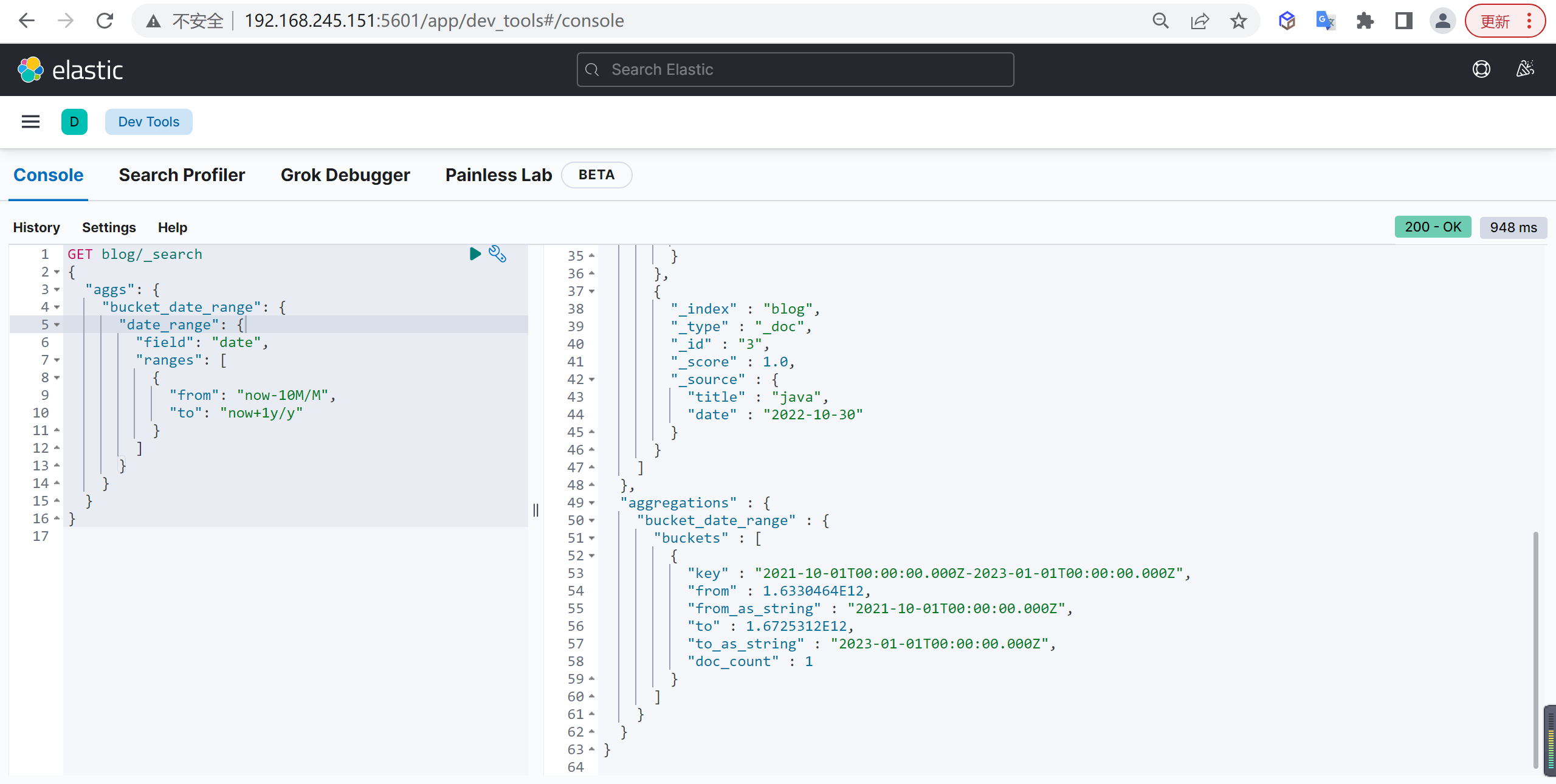
Date Histogram
时间直方图聚
基本查询
例如统计各个月份的博客数量
GET blog/_search
{
"aggs": {
"bucket_date_his": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
}
}
}
}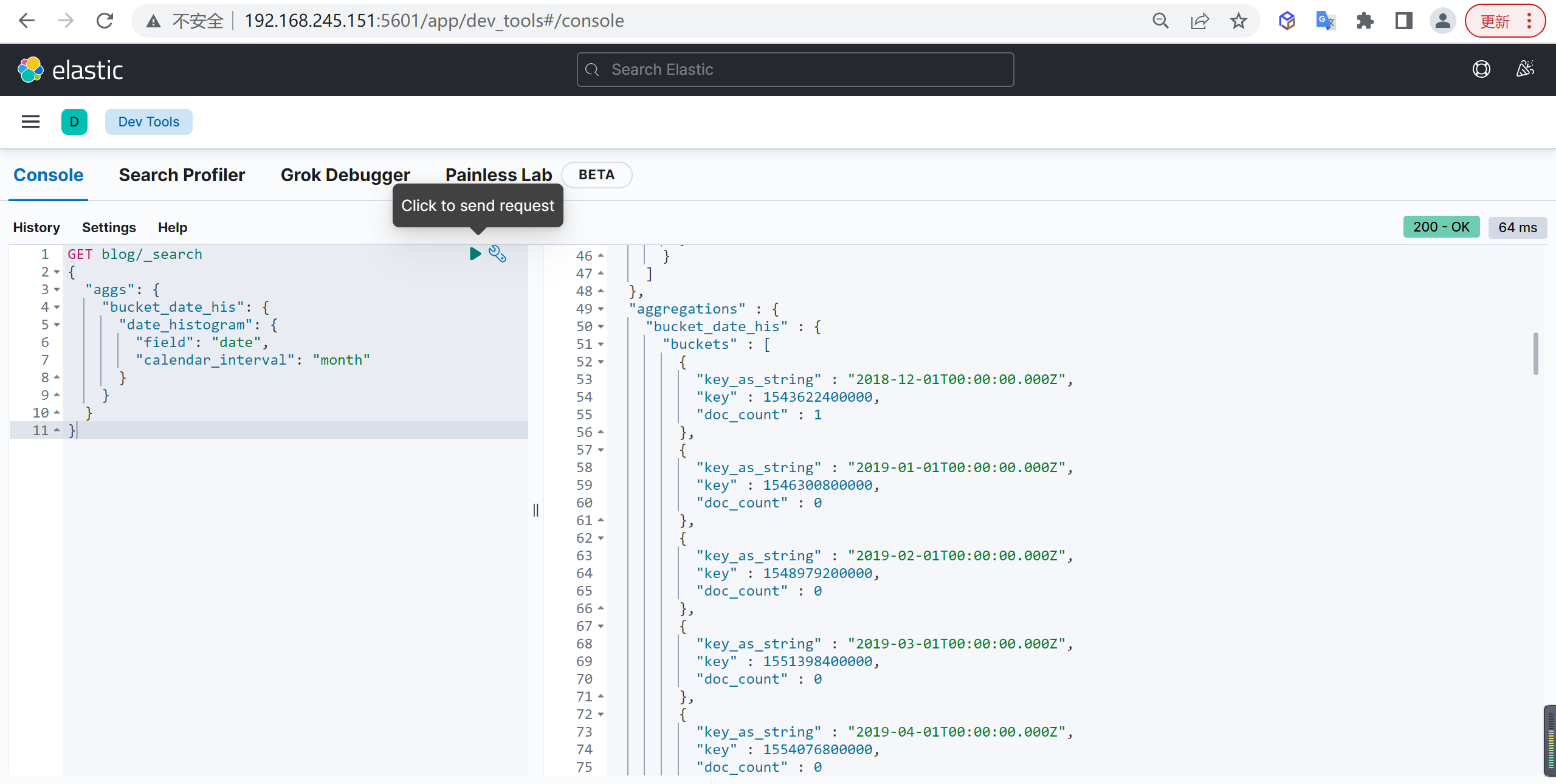
Missing
空值聚合
基本查询
统计所有没有 price 字段的文档:
GET books/_search
{
"aggs": {
"bucket_missing": {
"missing": {
"field": "price"
}
}
}
}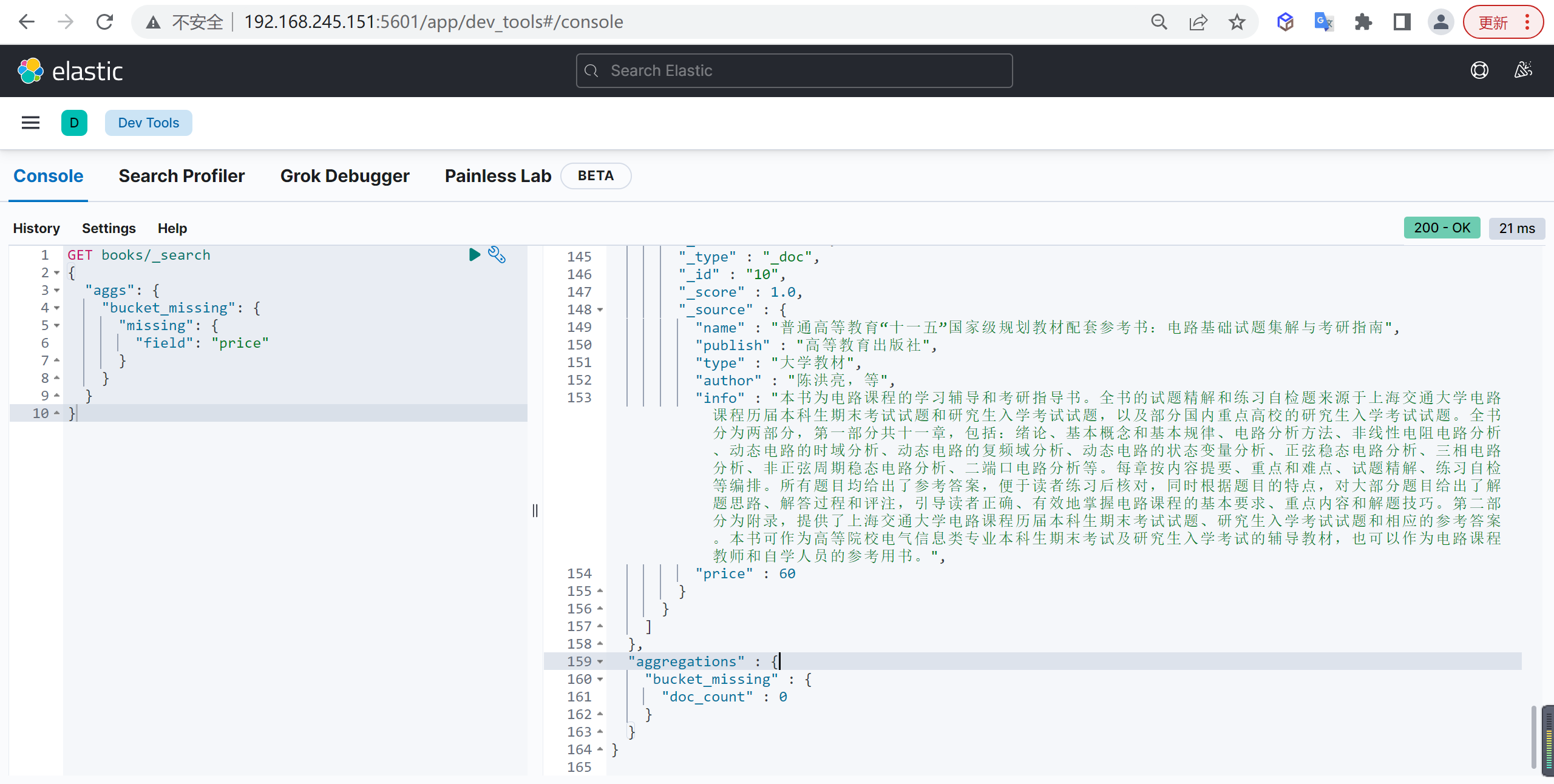
Children
可以根据父子文档关系进行分桶
基本查询
查询子类型为 student 的文档数量
GET stu_class/_search
{
"aggs": {
"bucket_children": {
"children": {
"type": "student"
}
}
}
}Geo Distance
对地理位置数据做统计
基本查询
例如分别统计 (34.288991865037524,108.9404296875) 坐标方圆 600KM 和 超过 600KM 的城市数量
GET geo/_search
{
"aggs": {
"bucket_geo": {
"geo_distance": {
"field": "location",
"origin": {
"lat": 34.288991865037524,
"lon": 108.9404296875
},
"unit": "km",
"ranges": [
{
"to": 600
},{
"from": 600
}
]
}
}
}
}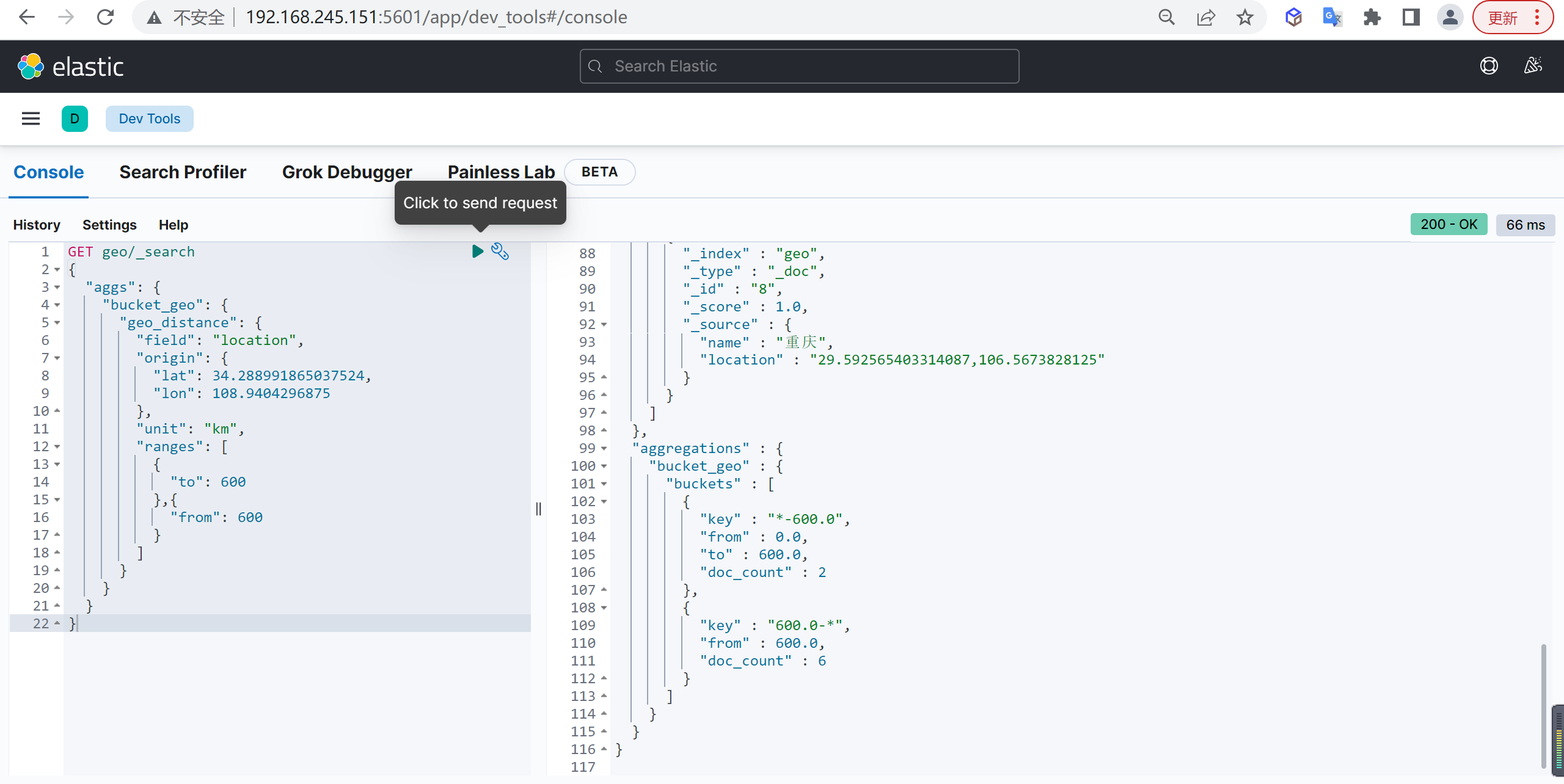
IP Range
IP 地址范围聚合
准备数据
之前的 blog 索引没有设置 ip 字段,删掉重新设置一下
重置索引
DELETE blog
PUT blog
{
"mappings": {
"properties": {
"ip": {
"type": "ip"
}
}
}
}插入数据
PUT blog/_doc/1
{
"title":"java",
"date":"2018-12-30",
"ip":"127.0.0.1"
}
PUT blog/_doc/2
{
"title":"java",
"date":"2020-12-30",
"ip":"127.0.0.5"
}
PUT blog/_doc/3
{
"title":"java",
"date":"2022-10-30",
"ip":"127.0.0.10"
}基本查询
例如查询指定 IP 地址的博客数量
GET blog/_search
{
"aggs": {
"bucket_ip_range": {
"ip_range": {
"field": "ip",
"ranges": [
{
"from": "127.0.0.5",
"to": "127.0.0.11"
}
]
}
}
}
}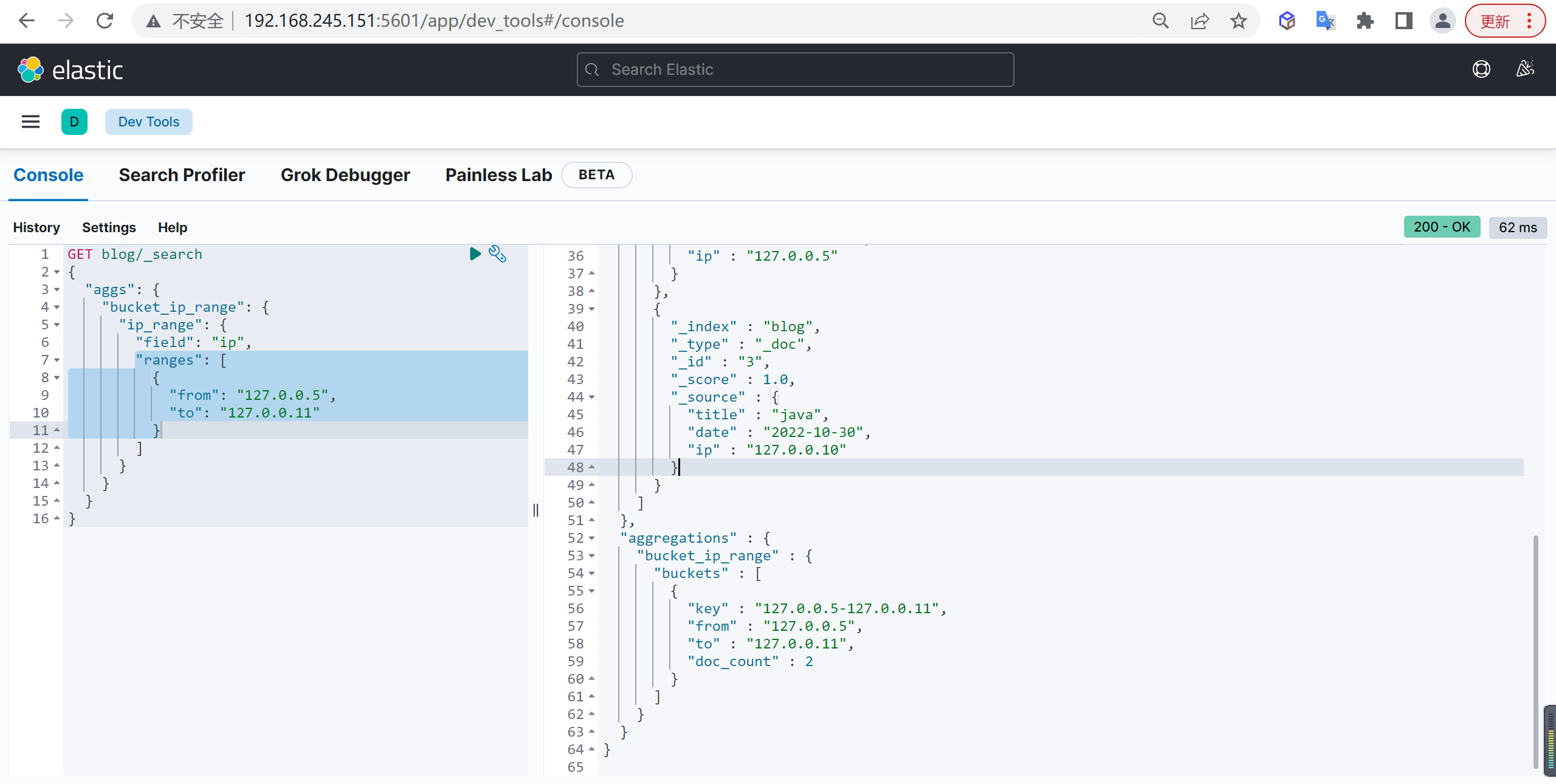
管道聚合
管道聚合相当于在之前聚合的基础上,进行再次聚合
Avg Bucket
计算聚合平均值
基本查询
统计每个出版社所出版图书的平均值,然后再统计所有出版社的平均值
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"avg_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}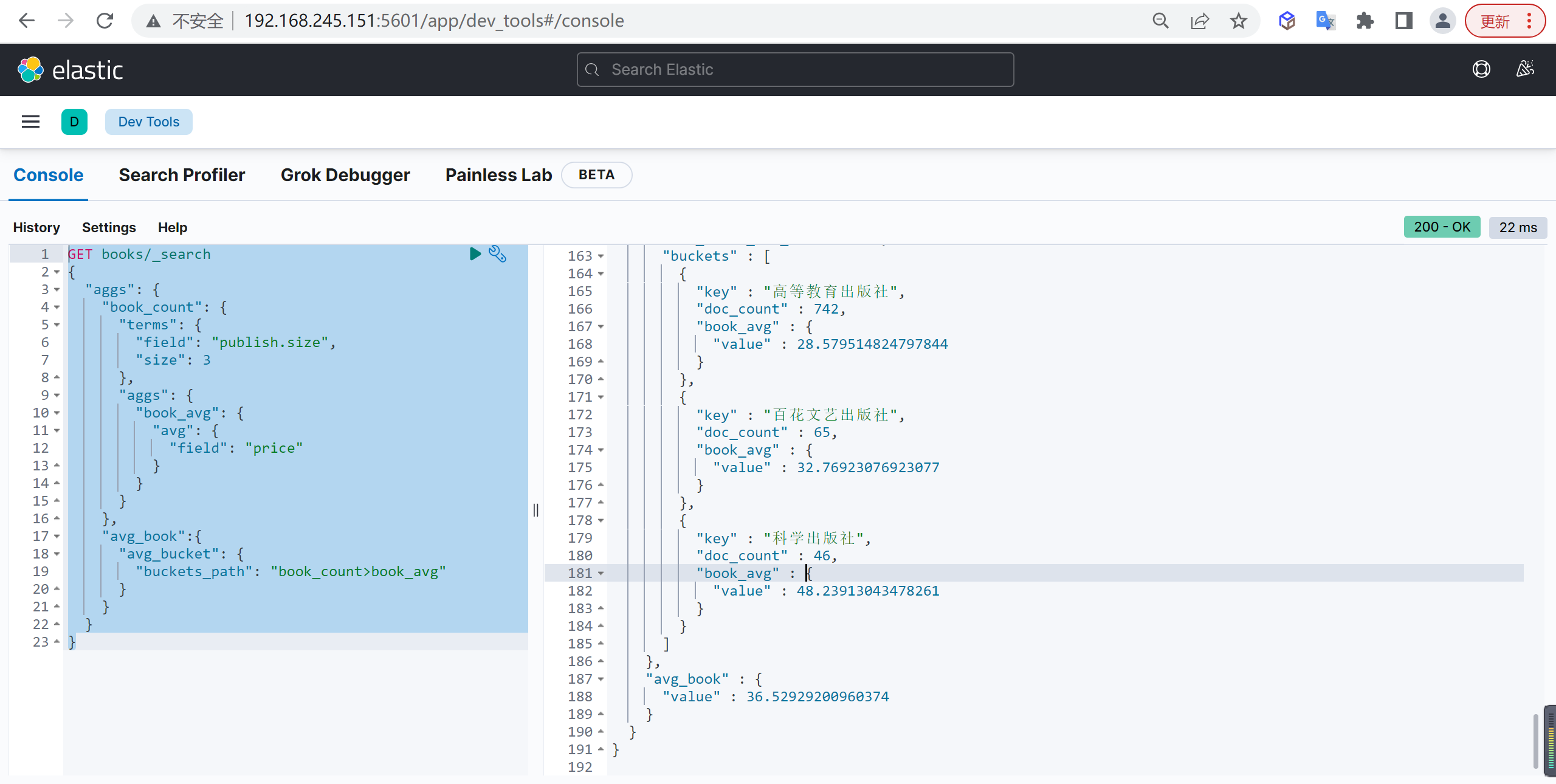
Max Bucket
计算聚合最大值
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值中的最大值
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"max_book":{
"max_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}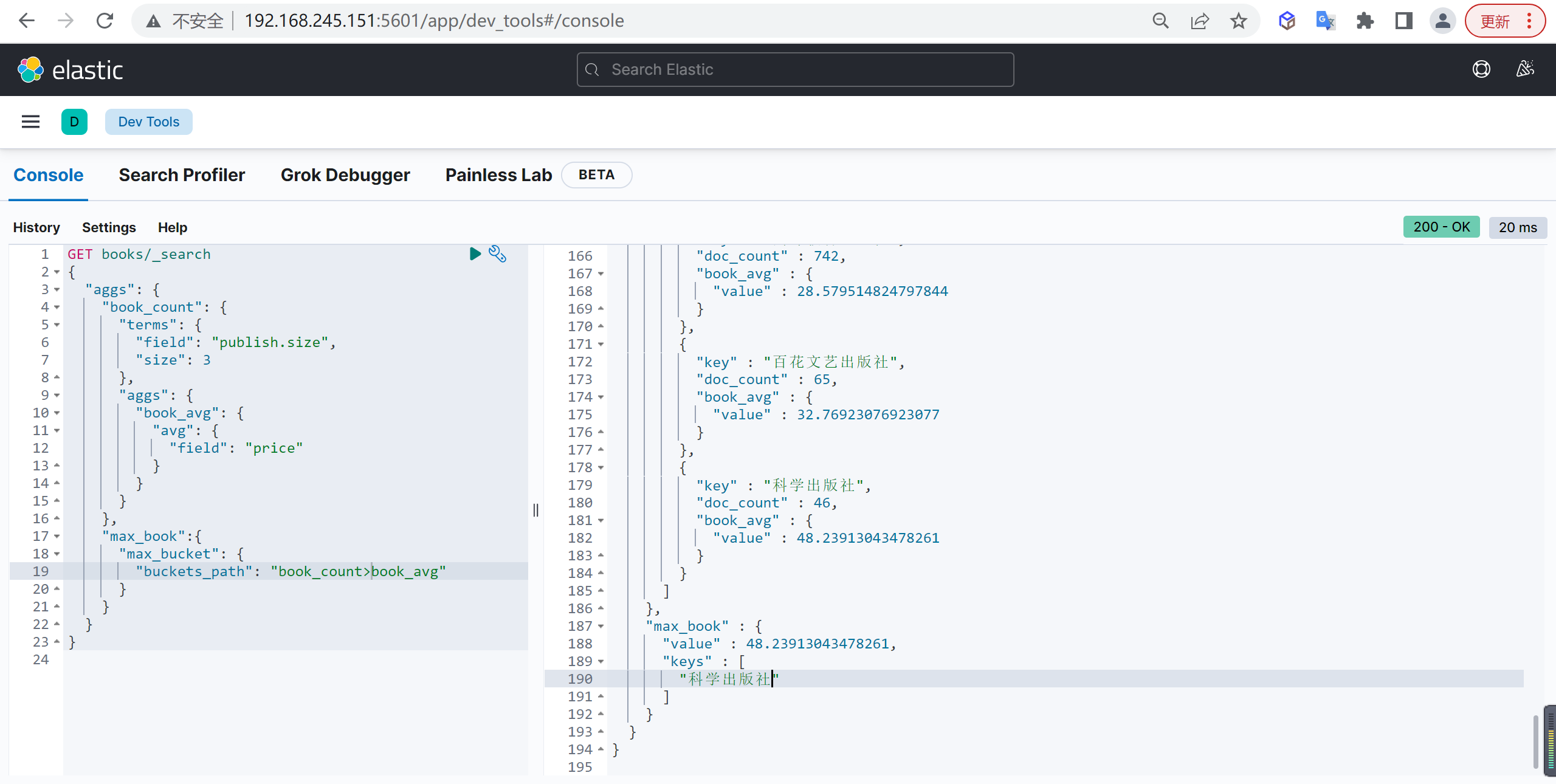
Min Bucket
计算聚合最小值
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值中的最小值:
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"min_book":{
"min_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
Sum Bucket
计算聚合累加
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值之和
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"sum_book":{
"sum_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}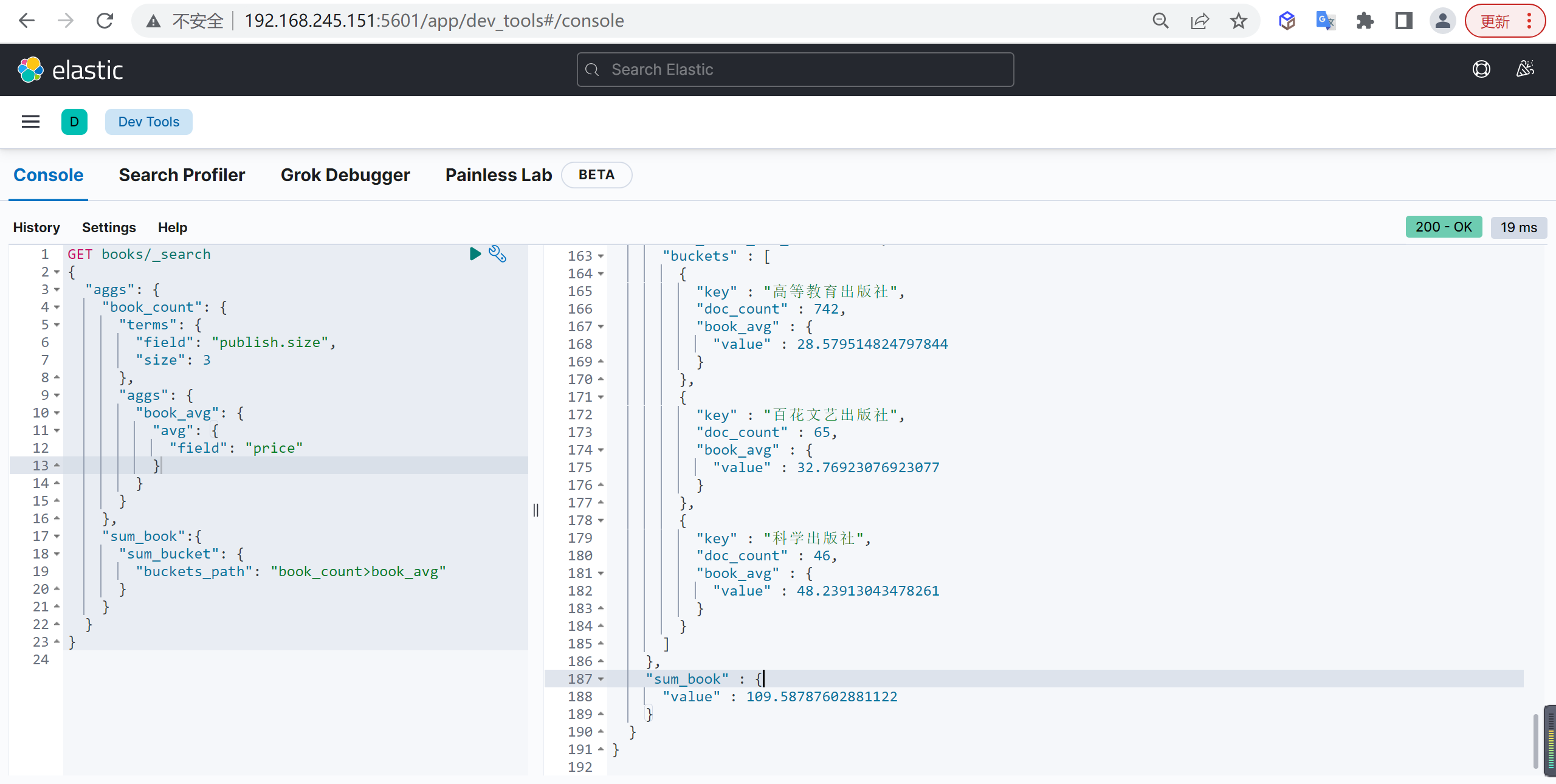
Stats Bucket
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值的各种数据:
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"stats_book":{
"stats_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}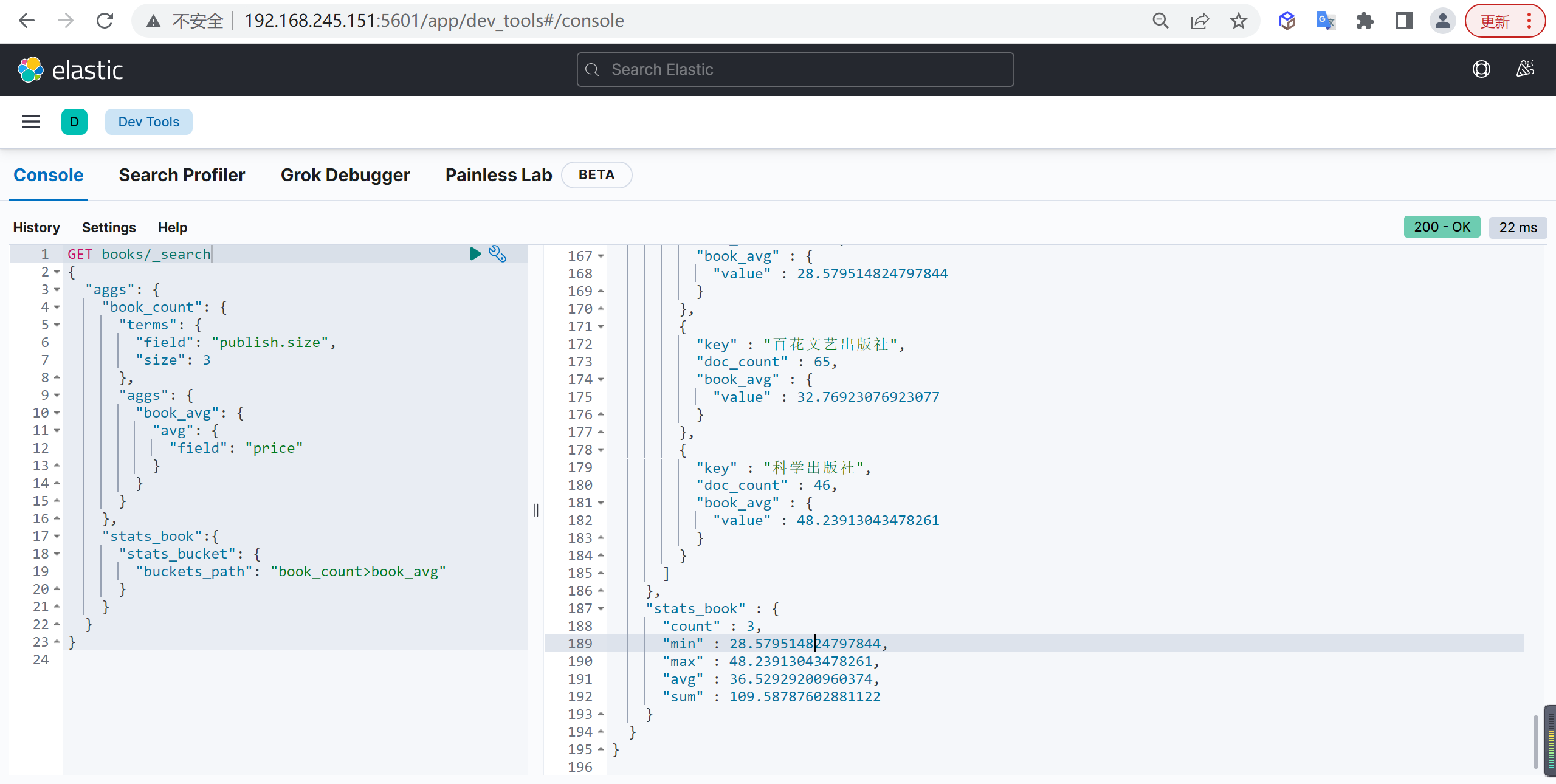
Extended Stats Bucket
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值的各种数据,比
Stats Bucket统计多了一些方差之类的数据:
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"extended_book":{
"extended_stats_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}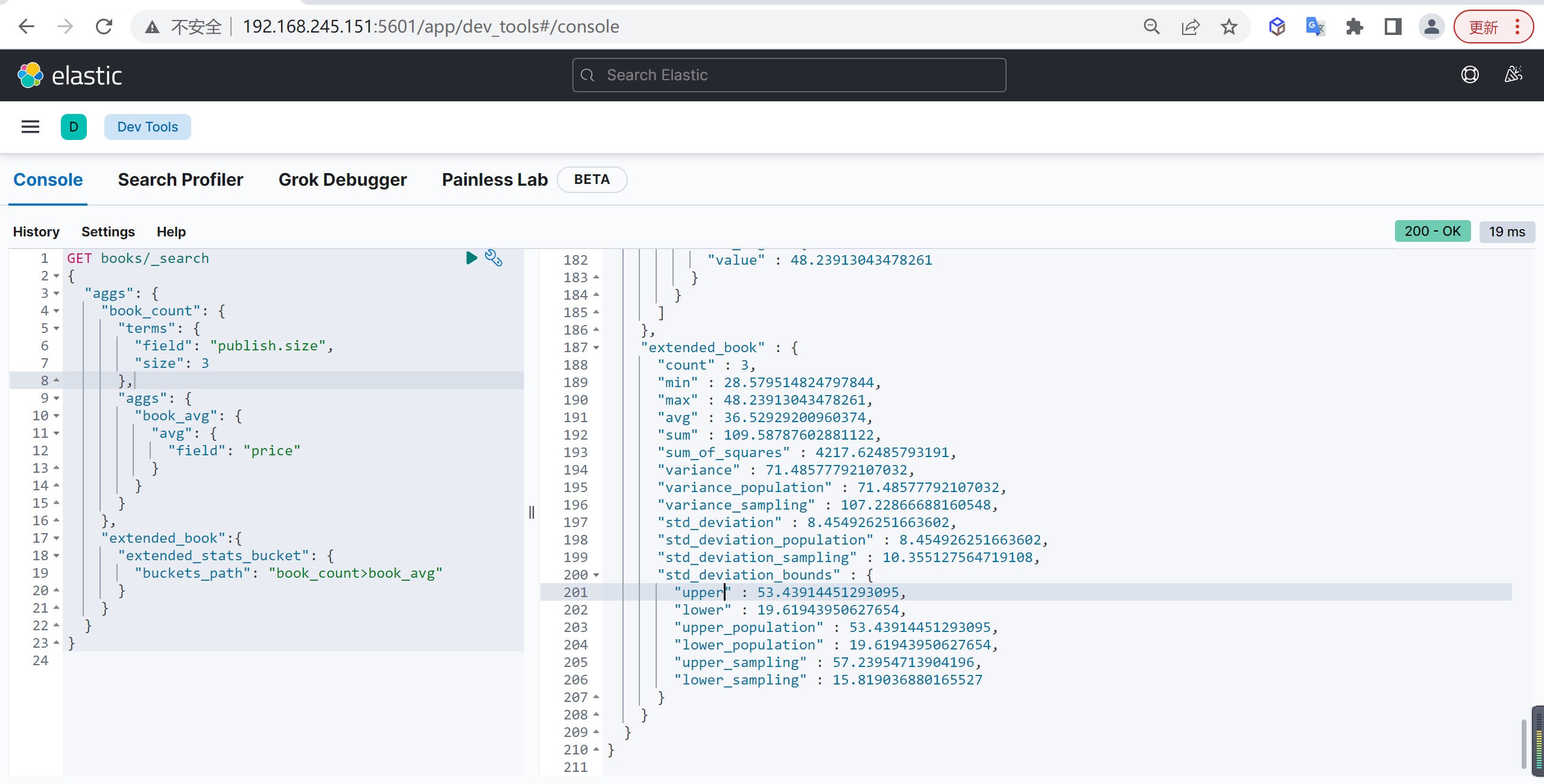
Percentiles Bucket
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值的百分位数据
GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"percentiles_book":{
"percentiles_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}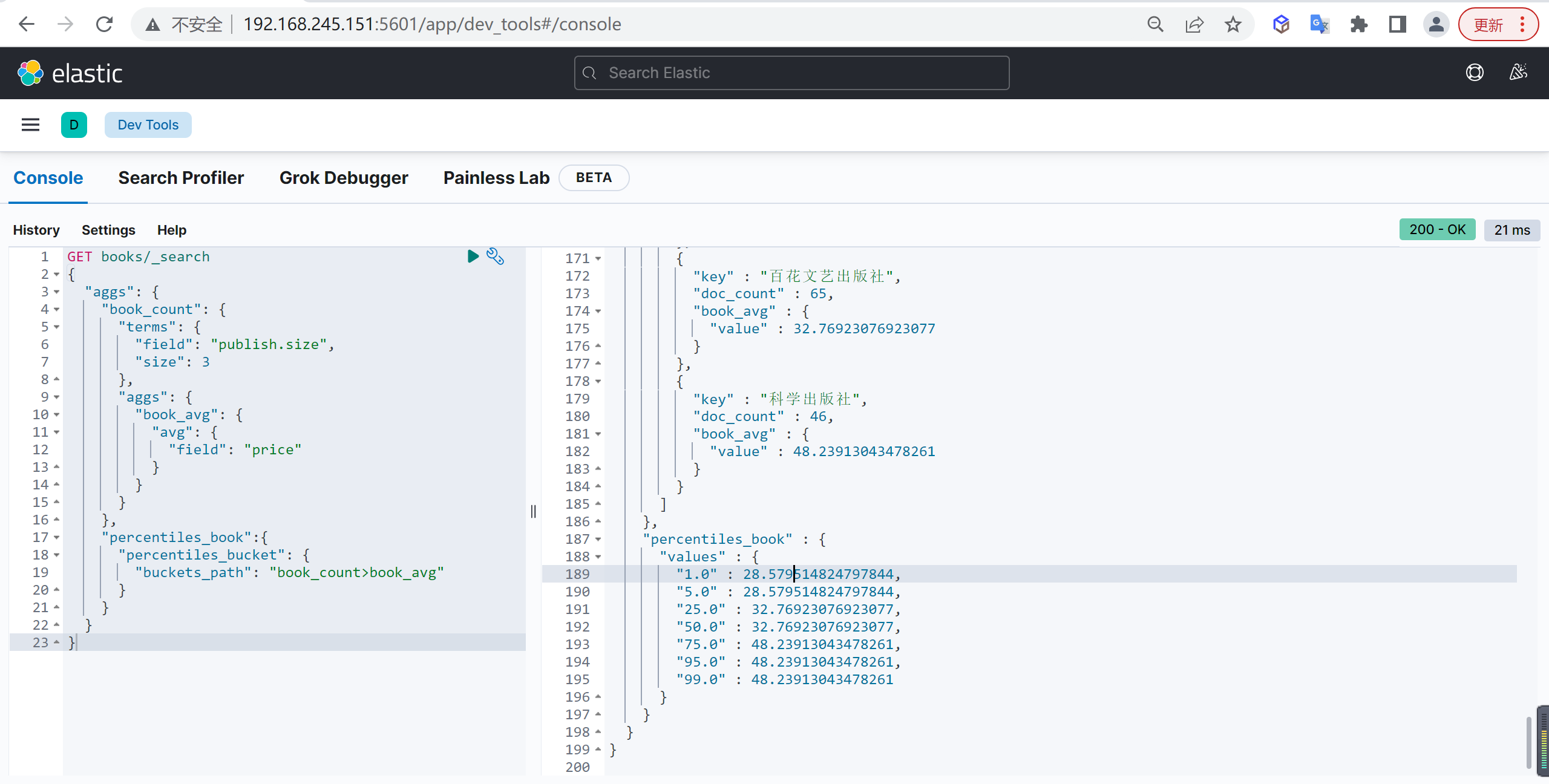
ElasticSearch 相关查询
相关性查询概述
相关性算分描述了一个文档和查询语句匹配的程度,es会对每个匹配查询条件的结果进行算分打分的本质是排序,将相关性高的文档排在最前面
在全文检索]中,检索结果与查询条件的相关性是一个极为重要的问题,优秀的全文检索引擎应该将那些与查询条件相关性高的文档排在最前面。想象一下,如果满足查询条件的文档成千上万,让用户在这些文档中再找出自己最满意的那一条,这无异于再做一次人工检索,用户一般很少会有耐心在检索结果中翻到第3页,所以处理好检索结果的相关性对于检索引擎来说至关重要。
Google公司就是因为发明了Page Rank算法,巧妙地解决了网页检索结果的相关性问题,才在众多搜索公司中迅速崛起。
相关性问题有两方面问题要解决,一是如何评价单个查询条件的相关性,二是如何将多个查询条件的相关性组合起来。
什么是相关性评分
全文检索与数据库查询的一个显著区别,就是它并不一定会根据查询条件做完全精确的匹配。
除了模糊查询以外,全文检索还会根据查询条件给文档的相关性打分并排序,将那些与查询条件相关性高的文档排在最前面,相关性( Relevance)或相似性(Similarity)是指两个事物间相互关联的程度,在检索领特指检索请求与检索结果之间的相关程度。
在 Elaticsearch返回的每条结果中都会包含一个_score字段,这个字段的值就是当前文档匹配检索请求的相关性评分,我们也可以称为相关度。
解决相关性问题的核心是计算相关度的算法和模型,相关度算法和模型是全文检索文章最重要的技术之一。相关度算法和相关度模型并非完全相同的概念,相关度模型可以认为是具有相同理论基础的算法集合,所以在实际应用时都是指定到具体的相关度算法,相关度模型则是从理论层面对相关度算法的归类。
相关度模型
Elasticsearch支持多种相关度算法,它们通过类型名称来标识,包括boolean、BM25、DFR等等很多,这些算法分别归属于几种不同的理论模型,它们是布尔模型、向量空间模型、概率模型、语言模型等。
布尔模型
布尔模型( Boolean Model)是最简单的相关度模型,最终的相关度只有1或0两种
如果检索中包含多个查询条件,则查询条件之间的相关度组合方式取决它们之间的逻辑运算符,即以逻辑运算中的与、或、非组合评分,文档的最终评分为1时会被添加到检索结果中,而评分为0时则不会出现在检索结果中,这与使用SQL语句查询数据库有些类似,完全根据查询条件决定结果,非此即彼,在Elasticearch支持的相关度算法中,boolean算法即采用布尔模型,有些地方也部分地采用了布尔模型。
向量空间模型
向量空间模型(Vector Space Mode)组合多个相关度时采用的是基于向量的算法
在向量空间模型中,多个查询条件的相关度以向量的形式表示,向量实际上就是包含多个数的一维数组,例如[1,2, 3,4, 5, 6]就是一个6维向量,其中每个数字都代表一个查询条件的相关度。
文档对于n个查询条件会形成一个n维的向量空间,如果定义1个查询条件最佳匹配的n维向量,那么与这个向量越接近则相关度越高,从向量的角度来看,就是两个向量之间的夹角越小相关度越高,所以n个相关度的组合就转换为向量之间夹角的计算。
简单理解,可以只考虑一个二维向量,也就是查询条件只有两个,这样就可以将两个相关度映射到二维坐标图的X轴和Y轴上,假设两个查询条件权重相同,那么最佳匹配值就可以设置为[1, 1],如果某文档匹配了第一个条件,部分地匹配了第二个条件,则该文档的向量值为[1, 0.2],将这两个向量绘制在二维坐标图中,就得到了它们的夹角。
对于多维向量来说,线性代数提供了余弦近似度算法,专门用于计算两个多维向量的夹角。
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性,0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为-1到1之间。
注意这上下界对任何维度的向量空间中都适用,而且余弦相似性最常用于高维正空间,例如在信息检索中,每个词项被赋予不同的维度,而一个维度由一个向量表示,其各个维度上的值对应于该词项在文档中出现的频率。余弦相似度因此可以给出两篇文档在其主题方面的相似度。
概率模型
概率模型是基于概率论构建的模型,BM25、DFR、DFI都属于概率模型中的一种实现算法,背后有着非常严谨的概率理论依据。
以其中最为流行的BM25为例,它背后的概率理论是贝叶斯定理,而这个定理在许多领城中都有广泛的应用,BM25法将检索出来的文档(D)分为相关文档(R)和不相关文档(NR)两类,使用P(R|D)代表文档属于相关文档的概率,而使用P(NR|D)表示文档属于不相关文档的概率,则当P(R|D)>P(NR|D)时认为这个文档与用户查询相关。根据贝叶斯公式将P(R|D)>P(NR|D)转换为对某个比值的计算。在此基础上再进行一此转换,就可以得到不同的相关度算法。
语言模型
语言模型最早并不是应用于全文检索领域,而是应用于语音识别、机器翻译、拼写检查等领域。
在全文检索中,语言模型为每个文档建立不同的计算模型,用以判断由文档生成某一查询条件的概率是多少,而这个概率的值就可以认为是相关度。可见,语言模型与其他检索模型正好相反,其他检索模型都是从查询条件查找满足条件的文档,而语言模型则是根据文档推断可能的查询条件。
相关度算法
下面我们看一下常见的几种相关度算法
TF/IDF
对于一篇几百字几千字的文章,如何生成足以准确表示该文章的特征向量呢?
就像论文一样,摘要、关键词毫无疑问就是全篇最核心的内容,因此,我们要设法提取一篇文档的关键词,并对每个关键词计算其对应的特征权值,从而形成特征向量,这里涉及一个非常简单但又相当强大的算法,即TF-IDF算法。
TF/IDF实际上两个影响相关度的因素,即TF和IDF,其中TF是词项频率简称词频,指一个词项在当前文档中出现的次数,而IDF则是逆向文档频率,指词项在所有文档中出现的次数。
Elasticsearch提供的几种算法中都或多或少有TF/IDF的思想,例如BM25算法虽然是通过概率论推导而来,但最终的计算公式与TF/IDF在本质上也是一致的。
词频 - TF
词频,英文缩写为TF,英文全写为Term Frequency,词频用于描述
检索词在一篇文档中出现的频率,即:检索词出现的次数除以文档的总字数。
衡量一条查询语句和结果文档相关性的简单方法:简单地将搜索语句中的每一个词的TF进行相加。
例如,我的苹果,即为:TF(我) + TF(的) + TF(苹果)。
停用词,英文名为Stop Word,例如我的苹果中的的在文档中可能出现很多次,但贡献的相关度却几乎没有用处,因此不应该考虑他们的词频。
逆文档频率 - IDF
相对于逆文档频率,我们先来说说文档频率。
文档频率,英文缩写为DF,英文全写为Document Frequency,用于检索词在所有文档中出现的频率。
苹果在相对较少的文档中出现我在相对较多的文档中出现的在大量的文档中出现
逆文档频率,英文全写为:Inverse Document Frequency,简单说也就是:
log(全部文档数 / 检索词出现过的文档总数)
TF-IDF
TF-IDF的本质就是将
TF求和变成了加权求和,TF(我)*IDF(我)+TF(的)*IDF(的)+TF(苹果)*IDF(苹果)
| 出现的文档数 | 总文档数 | IDF | |
|---|---|---|---|
| 我 | 5亿 | 10亿 | log(2) = 1 |
| 的 | 10亿 | 10亿 | log(1) = 0 |
| 苹果 | 200万 | 10亿 | log(500) = 8.96 |
可见,在使用TF/IDF计算评分时必须要用到词项在文档中出现的频率,即词频,默认情况下文档text类型字段在编入索引时都会记录词频,Elasticsearch中的classic算法实际上是使用Lucene的实用评分函数(Practical Scoring Function),这个评分函数结合了布尔模型、TF/IDF和向量空间模型来共同计算分值,该算法是早期Elasticsearch运算相关度的算法,现在已经改为BM25了。
BM25
BM25是Best Match25的简写,由于最早应用于一个名为Okapi的系统中,所以很多文献中也称之为 Okapi BM25
BM25算法被认为是当今最先进的相关度算法之一,Elasticsearch文档字段的默认相关度算法就是采用BM25,它属于概率模型,依据贝叶斯公式,经过一系列的严格推导以后,得出了一个关于IDF的公式
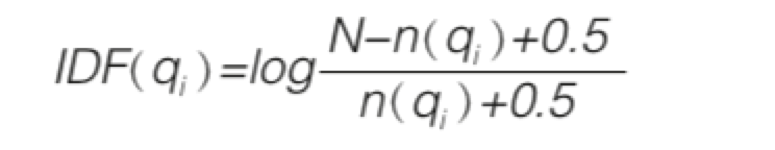
同时在这个基础上,最终的公式上加入了对TF、当前文档的长度、词频饱和度、长度归一化等因素的考虑:
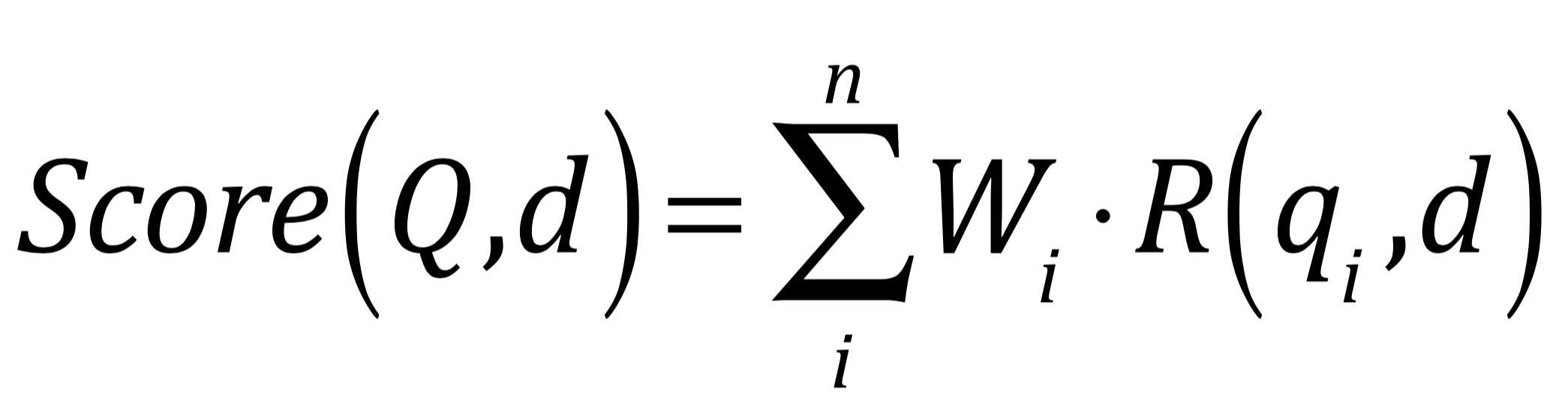
词频饱和度
所谓词频饱和度指的是当词频超过一定数量之后,它对相关度的影响将趋于饱和
换句话说,词频10次的相关度比词频1次的分值要大很多,但100次10次之间差距就不会那么明显了。在BM25算法中,控制词频饱和度的参数是k1,默认值为1.2,参数k1的值越小词频对相关度的影响就会越快趋于饱和,而值越大词频饱和度变化越慢。
举例来说,如果将k1设置为1,词频达到10时就会趋于饱和;而当k1设置为100时词频在100时才会趋于饱和,一般来说k1的取值范围为[1.2, 2.0]。
长度归一化
一般来说, 查询条件中的词项出现在较短的文本中,比出现在较长的文本中对结果的相关性影响更大。
举例来说,如果一篇文章的标题中包含elasticsearch,那么这篇文章是专门介绍elasticsearch的可能性比只在文章内容中出现elasticsearch的可能要高很多,但这种比较其实是建立在两个不同的字段上,而在实际检索时往往是针对相同的字段做比较。
比如在两篇文章的标题中都出现了elasticsearch,那么哪一篇文章的相关度更高呢?
BM25针对这种情况对文本长度做了所谓的归一化处理,即考虑当前文档字段的文本长度与所有文档的字段平均长度的比值,而这个比值就是长度归一化因素。
为了控制长度归一化对相关度的影响,在长度归一化中加了一个控制参数b,这个值的取值范围为[0.0, 1.0],取值0.0时会禁用归一化,而取值1.0则会完全启用归一化,默认值为0. 75。
和TF/IDF
下面我们看看BM25和TF/IDF的区别
- 从Elasticsearch5.0开始,默认算法由TF-IDF改为BM25
- 和经典的TF-IDF相比,当TF无限增加时,BM25计算的相关性分数会趋于一个固定数值。
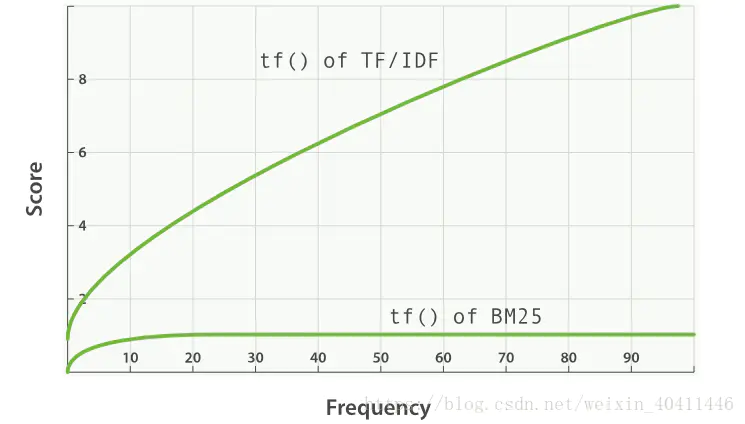
相关性查询
查看TF-IDF
在查询语句时,我们可通过explain查看TF-IDF
GET logstash-village/_search
{
"explain": true,
"query": {
"match": {
"addr": "龙苑小区"
}
}
}查询后可以看到TF-IDF的相关性评分
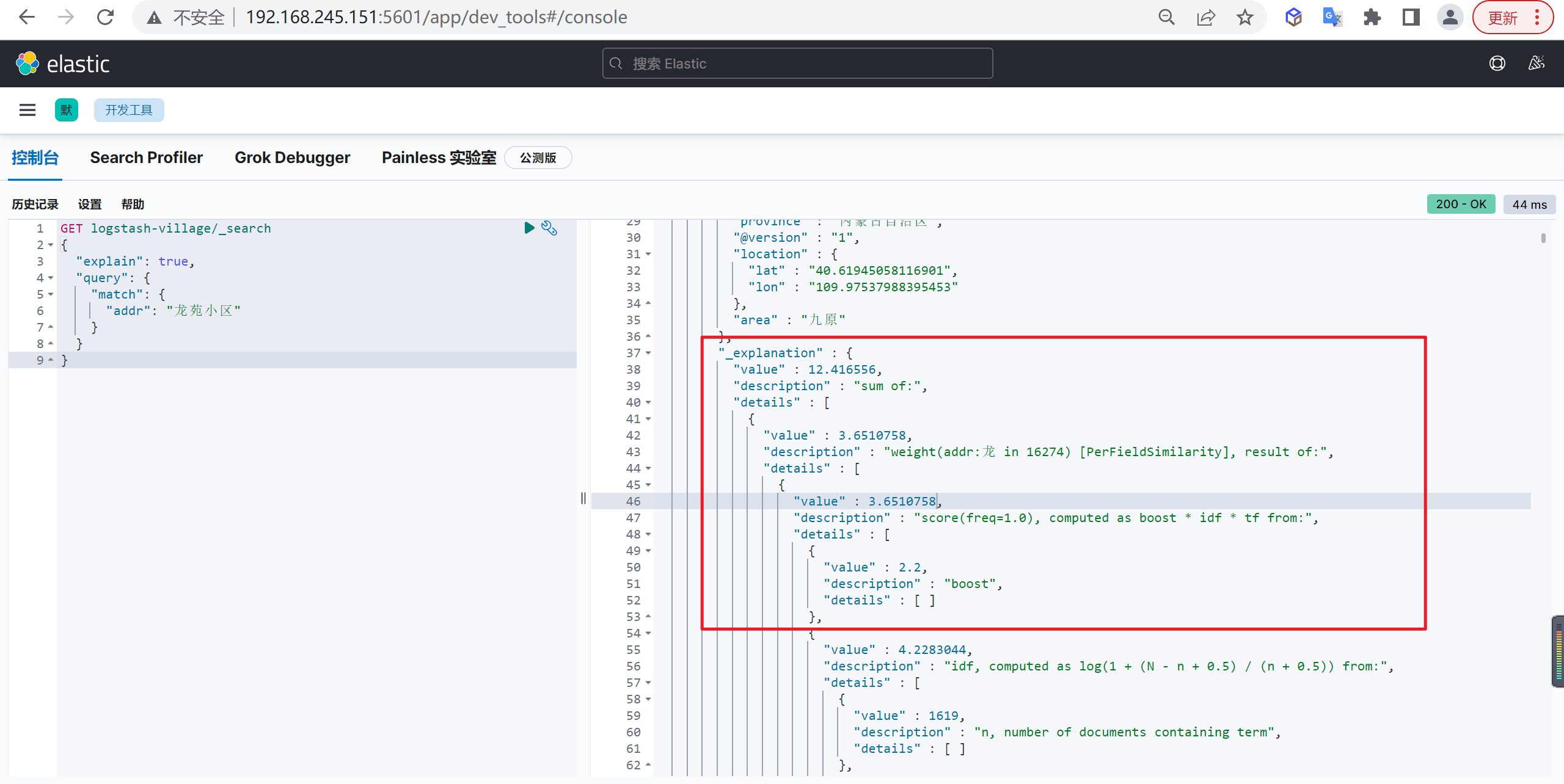
Boosting
Boosting是控制相关度的一种手段。
可选参数
返回匹配positive查询的文档,并降低匹配negative查询的文档相似度分
- 当boost > 1时,打分的权重相对性提升
- 当0 < boost <1时,打分的权重相对性降低
- 当boost <0时,贡献负分
这样就可以在不排除某些文档的前提下对文档进行查询,搜索结果中存在只不过相似度分数相比正常匹配的要低
应用场景
希望包含了某项内容的结果不是不出现,而是排序靠后
正常查询
GET logstash-village/_search
{
"query": {
"match": {
"addr": "龙苑小区"
}
}
}正常查询的时候我们发现内蒙古排在第一位
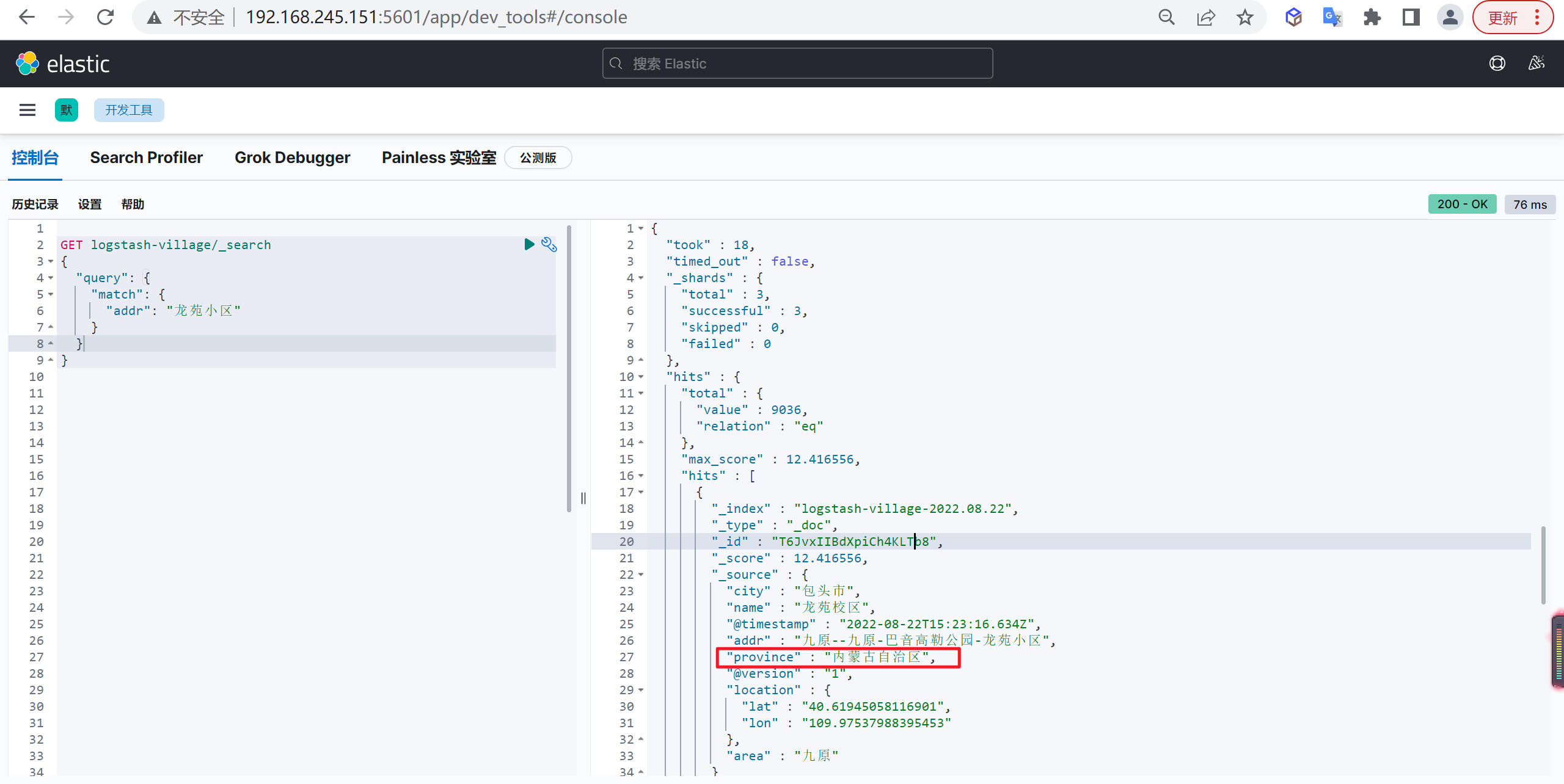
降低评分
我们不需要不太关注于内蒙古地区的数据,我们可以将内蒙古相关评分降低
GET logstash-village/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"addr": "龙苑小区"
}
},
"negative": {
"term": {
"province": "内蒙古自治区"
}
},
"negative_boost": 0.9
}
}
}我们设置
"negative_boost": 0.9,这样相关性评分就会降低,我们发现数据已经变了
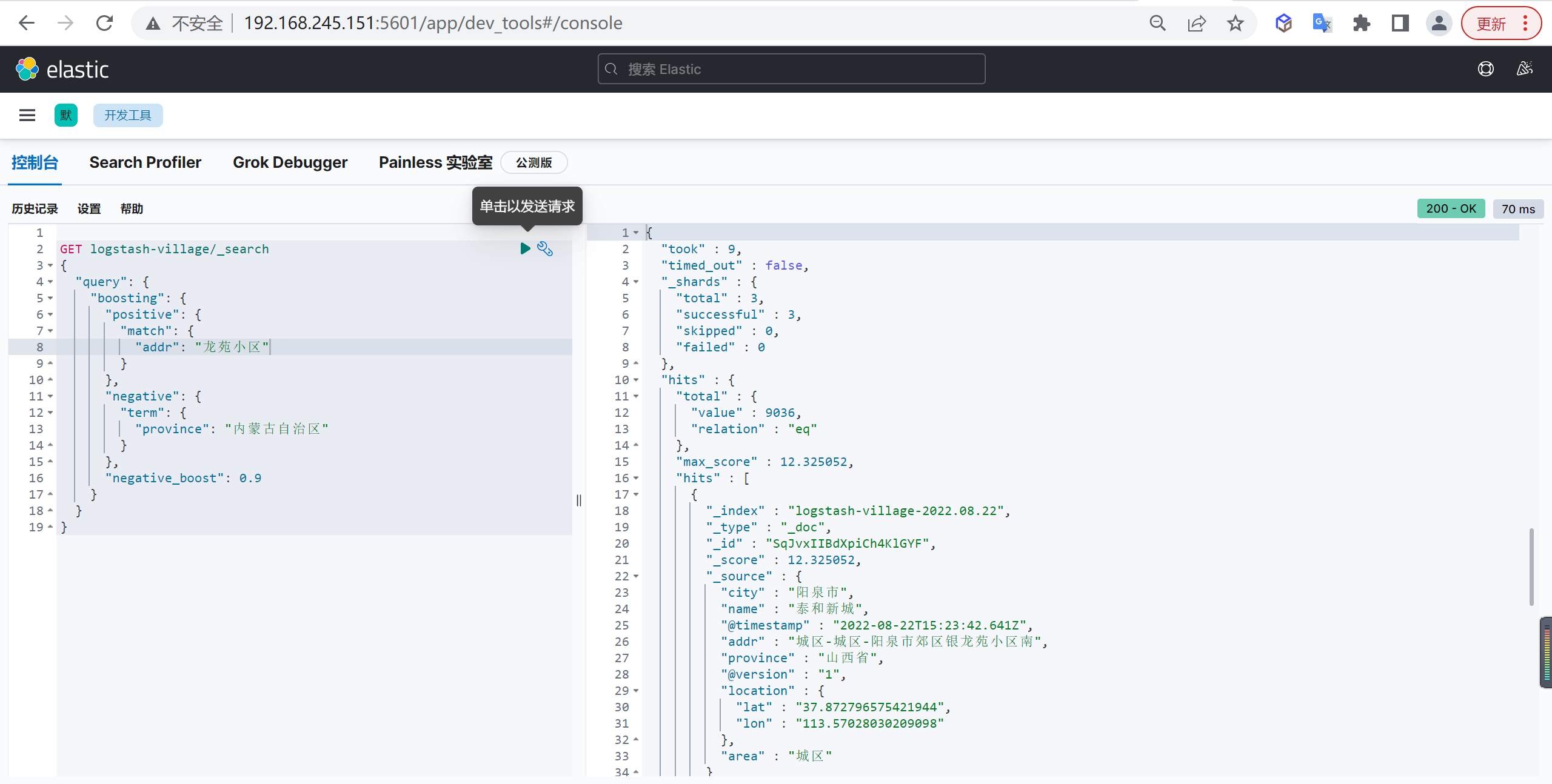
布尔查询
一个bool查询,是一个或者多个查询子句的组合,总共包括4种子句,其中2种会影响算分,2种不影响算分
相关查询
- must: 相当于
&&,必须匹配,贡献算分 - should: 相当于
||,选择性匹配,贡献算分 - must_not: 相当于
!,必须不能匹配,不贡献算分 - filter: 必须匹配,不贡献算法
查询方式
在Elasticsearch中,有Query和 Filter两种不同的查询方式
- Query : 相关性算分
- Filter : 不需要算分 ,可以利用Cache,获得更好的性能
相关性并不只是全文本检索的专利,也适用于yes | no 的子句,匹配的子句越多,相关性评分越高,如果多条查询子句被合并为一条复合查询语句,比如 bool查询,则每个查询子句计算得出的评分会被合并到总的相关性评分中
bool查询
子查询可以任意顺序出现,可以嵌套多个查询,如果你的bool查询中,没有must条件,should中必须至少满足一条查询
GET logstash-village/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"addr": "龙源小区"
}
},
{
"range": {
"greening": {
"gte": 30
}
}
}
],
"must_not": [
{
"term": {
"property_type": "公寓"
}
}
],
"should": [
{
"term": {
"province": "河南省"
}
},
{
"term": {
"province": "安徽省"
}
}
],
"filter": [
{
"range": {
"built_year": {
"gte": 2010,
"lte": 2020
}
}
}
]
}
}
}通过bool查询查询地址包含
龙苑小区,并且绿化率大于30%非公寓住宅,并且在省份在河南省或者安徽省,并且建造年份在2010-2020的小区住房
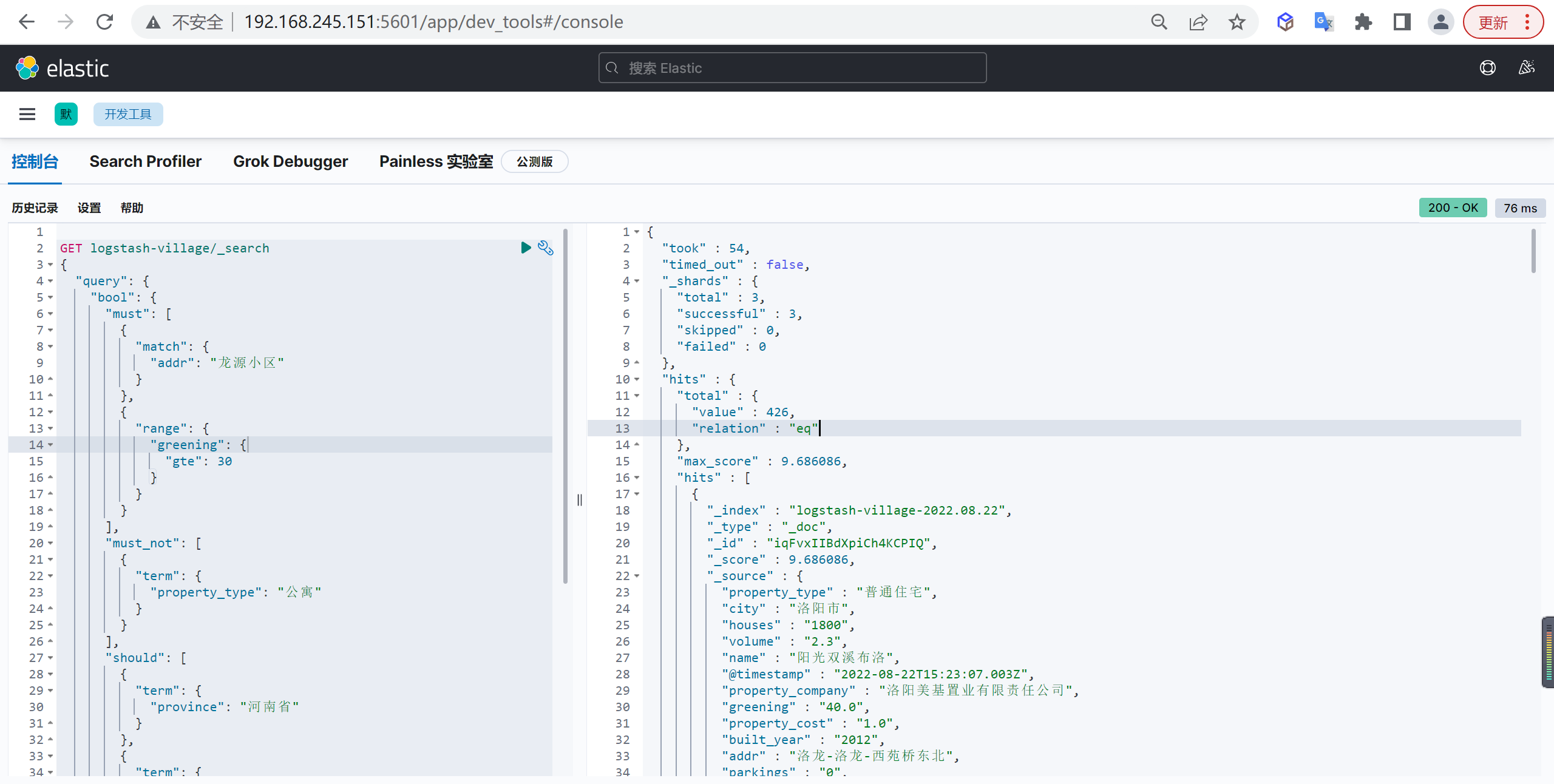
 微信
微信 支付宝
支付宝



