tomcat之servlet理解
Servlet 接口
为什么要有Servlet接口?
浏览器发给服务端的是一个 HTTP 格式的请求,HTTP 服务器收到这个请求后,需要调用服务端程序来处理,所谓的服务端程序就是你写的 Java 类,一般来说不同的请求需要由不同的 Java 类来处理。
那么问题来了,HTTP 服务器怎么知道要调用哪个 Java 类的哪个方法呢。最直接的做法是在 HTTP 服务器代码里写一大堆 if else 逻辑判断:如果是 A 请求就调 X 类的 M1 方法,如果是 B 请求就调 Y 类的 M2 方法。但这样做明显有问题,因为 HTTP 服务器的代码跟业务逻辑耦合在一起了,如果新加一个业务方法还要改 HTTP 服务器的代码。
那该怎么解决这个问题呢?我们知道,面向接口编程是解决耦合问题的法宝,于是有一伙人就定义了一个接口,各种业务类都必须实现这个接口,这个接口就叫 Servlet 接口,有时我们也把实现了 Servlet 接口的业务类叫作 Servlet。
但是这里还有一个问题,对于特定的请求,HTTP 服务器如何知道由哪个 Servlet 来处理呢?Servlet 又是由谁来实例化呢?显然 HTTP 服务器不适合做这个工作,否则又和业务类耦合了。
于是,还是那伙人又发明了 Servlet 容器,Servlet 容器用来加载和管理业务类。HTTP 服务器不直接跟业务类打交道,而是把请求交给 Servlet 容器去处理,Servlet 容器会将请求转发到具体的 Servlet,如果这个 Servlet 还没创建,就加载并实例化这个 Servlet,然后调用这个 Servlet 的接口方法。因此 Servlet 接口其实是Servlet 容器跟具体业务类之间的接口。
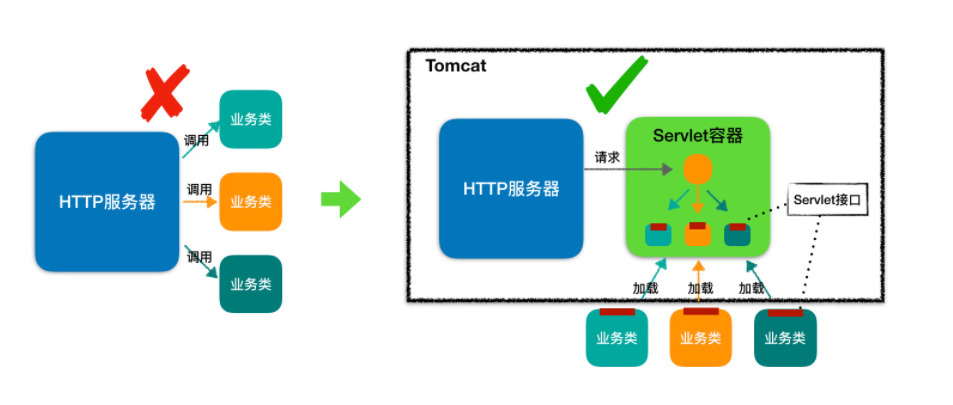
图的左边表示 HTTP 服务器直接调用具体业务类,它们是紧耦合的。再看图的右边,HTTP 服务器不直接调用业务类,而是把请求交给容器来处理,容器通过 Servlet 接口调用业务类。因此 Servlet 接口和 Servlet 容器的出现,达到了 HTTP 服务器与业务类解耦的目的。
图的左边表示 HTTP 服务器直接调用具体业务类,它们是紧耦合的。再看图的右边,HTTP 服务器不直接调用业务类,而是把请求交给容器来处理,容器通过 Servlet 接口调用业务类。因此 Servlet 接口和 Servlet 容器的出现,达到了 HTTP 服务器与业务类解耦的目的。
详解
Servlet 接口定义了下面五个方法:
public interface Servlet {
void init(ServletConfig config) throws ServletException;
ServletConfig getServletConfig();
void service(ServletRequest req, ServletResponse res)throws ServletException, IOException;
String getServletInfo();
void destroy();
}其中最重要是的 service 方法,具体业务类在这个方法里实现处理逻辑。这个方法有两个参数:ServletRequest 和 ServletResponse。ServletRequest 用来封装请求信息,ServletResponse 用来封装响应信息,因此本质上这两个类是对通信协议的封装。
比如 HTTP 协议中的请求和响应就是对应了 HttpServletRequest 和 HttpServletResponse 这两个类。你可以通过 HttpServletRequest 来获取所有请求相关的信息,包括请求路径、Cookie、HTTP 头、请求参数等。
我们还可以通过 HttpServletRequest 来创建和获取 Session。而 HttpServletResponse 是用来封装 HTTP 响应的。
你可以看到接口中还有两个跟生命周期有关的方法 init 和 destroy,这是一个比较贴心的设计,Servlet 容器在加载 Servlet 类的时候会调用 init 方法,在卸载的时候会调用 destroy 方法。我们可能会在 init 方法里初始化一些资源,并在 destroy 方法里释放这些资源,比如 Spring MVC 中的 DispatcherServlet,就是在 init 方法里创建了自己的 Spring 容器。
你还会注意到 ServletConfig 这个类,ServletConfig 的作用就是封装 Servlet 的初始化参数。你可以在 web.xml 给 Servlet 配置参数,并在程序里通过 getServletConfig 方法拿到这些参数。
我们知道,有接口一般就有抽象类,抽象类用来实现接口和封装通用的逻辑,因此 Servlet 规范提供了 GenericServlet 抽象类,我们可以通过扩展它来实现 Servlet。虽然 Servlet 规范并不在乎通信协议是什么,但是大多数的 Servlet 都是在 HTTP 环境中处理的,因此 Servet 规范还提供了 HttpServlet 来继承 GenericServlet,并且加入了 HTTP 特性。这样我们通过继承 HttpServlet 类来实现自己的 Servlet,只需要重写两个方法:doGet 和 doPost。
Servlet 容器
注意点:
Web 应用的目录格式是什么样的,以及我该怎样扩展和定制化 Servlet 容器的功能。
工作流程
当客户请求某个资源时,HTTP 服务器会用一个 ServletRequest 对象把客户的请求信息封装起来,然后调用 Servlet 容器的 service 方法,Servlet 容器拿到请求后,根据请求的 URL 和 Servlet 的映射关系,找到相应的 Servlet,如果 Servlet 还没有被加载,就用反射机制创建这个 Servlet,并调用 Servlet 的 init 方法来完成初始化,接着调用 Servlet 的 service 方法来处理请求,把 ServletResponse 对象返回给 HTTP 服务器,HTTP 服务器会把响应发送给客户端。同样我通过一张图来帮助你理解。
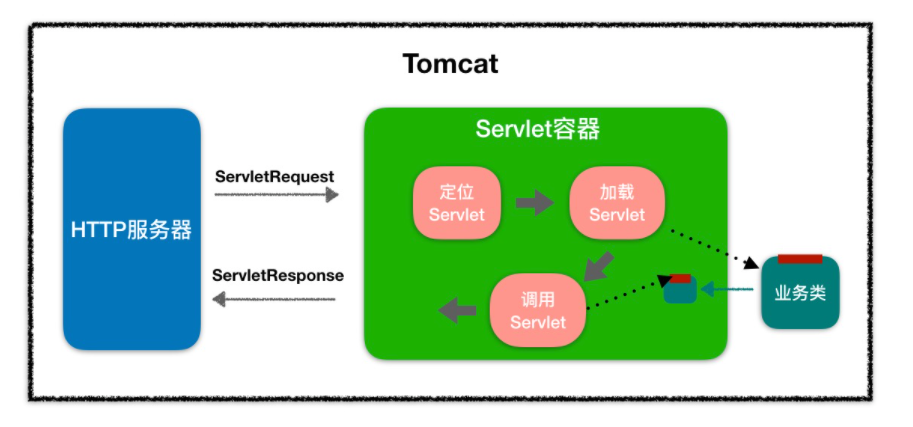
Web 应用
Servlet 容器会实例化和调用 Servlet,那 Servlet 是怎么注册到 Servlet 容器中的呢?一般来说,我们是以 Web 应用程序的方式来部署 Servlet 的,而根据 Servlet 规范,Web 应用程序有一定的目录结构,在这个目录下分别放置了 Servlet 的类文件、配置文件以及静态资源,Servlet 容器通过读取配置文件,就能找到并加载 Servlet。Web 应用的目录结构大概是下面这样的:
| - MyWebApp
| - WEB-INF/web.xml -- 配置文件,用来配置 Servlet 等
| - WEB-INF/lib/ -- 存放 Web 应用所需各种 JAR 包
| - WEB-INF/classes/ -- 存放你的应用类,比如 Servlet 类
| - META-INF/ -- 目录存放工程的一些信息Servlet 规范里定义了ServletContext这个接口来对应一个 Web 应用。Web 应用部署好后,Servlet 容器在启动时会加载 Web 应用,并为每个 Web 应用创建唯一的 ServletContext 对象。你可以把 ServletContext 看成是一个全局对象,一个 Web 应用可能有多个 Servlet,这些 Servlet 可以通过全局的 ServletContext 来共享数据,这些数据包括 Web 应用的初始化参数、Web 应用目录下的文件资源等。由于 ServletContext 持有所有 Servlet 实例,你还可以通过它来实现 Servlet 请求的转发。
扩展机制
Filter是过滤器,这个接口允许你对请求和响应做一些统一的定制化处理,比如你可以根据请求的频率来限制访问,或者根据国家地区的不同来修改响应内容。过滤器的工作原理是这样的:Web 应用部署完成后,Servlet 容器需要实例化 Filter 并把 Filter 链接成一个 FilterChain。当请求进来时,获取第一个 Filter 并调用 doFilter 方法,doFilter 方法负责调用这个 FilterChain 中的下一个 Filter。
Listener是监听器,这是另一种扩展机制。当 Web 应用在 Servlet 容器中运行时,Servlet 容器内部会不断的发生各种事件,如 Web 应用的启动和停止、用户请求到达等。 Servlet 容器提供了一些默认的监听器来监听这些事件,当事件发生时,Servlet 容器会负责调用监听器的方法。当然,你可以定义自己的监听器去监听你感兴趣的事件,将监听器配置在 web.xml 中。比如 Spring 就实现了自己的监听器,来监听 ServletContext 的启动事件,目的是当 Servlet 容器启动时,创建并初始化全局的 Spring 容器。
最后我给你总结一下 Filter 和 Listener 的本质区别:
- Filter 是干预过程的,它是过程的一部分,是基于过程行为的。
- Listener 是基于状态的,任何行为改变同一个状态,触发的事件是一致的。
servlet,spring,springMVC三个容器的关系图
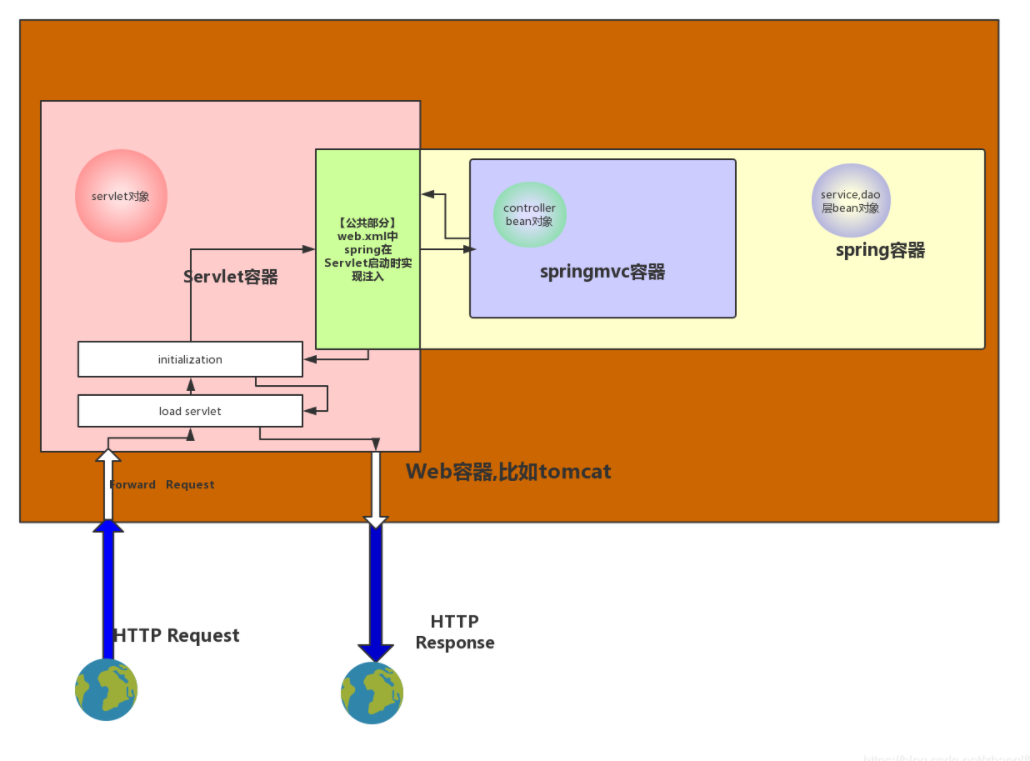
web容器中有servlet容器,spring项目部署后存在spring容器。其中spring控制service层和dao层的bean对象以及controller层bean对象。servlet容器控制servlet对象。项目启动是,首先 servlet初始化,初始化过程中通过web.xml中spring的配置加载spring配置,初始化spring容器。待容器加载完成。servlet初始化完成,则完成启动。springmvc是viewAndModie的请求传递和结果解析。本身并没有容器管理,都是交给spring管理。
HTTP请求到达web容器后,会到达Servlet容器,容器通过分发器分发到具体的spring的Controller层。执行业务操作后返回结果。
tomcat&Jetty在启动时给每个Web应用创建一个全局的上下文环境,这个上下文就是ServletContext,其为后面的Spring容器提供宿主环境。
tomcat&Jetty在启动过程中触发容器初始化事件,Spring的ContextLoaderListener会监听到这个事件,它的contextInitialized方法会被调用,在这个方法中,Spring会初始化全局的Spring根容器,这个就是Spring的IoC容器,IoC容器初始化完毕后,Spring将其存储到ServletContext中,便于以后来获取。
tomcat&Jetty在启动过程中还会扫描Servlet,一个Web应用中的Servlet可以有多个,以SpringMVC中的DispatcherServlet为例,这个Servlet实际上是一个标准的前端控制器,用以转发、匹配、处理每个Servlet请求。
Servlet一般会延迟加载,当第一个请求达到时,tomcat&Jetty发现DispatcherServlet还没有被实例化,就调用DispatcherServlet的init方法,DispatcherServlet在初始化的时候会建立自己的容器,叫做SpringMVC 容器,用来持有Spring MVC相关的Bean。同时,Spring MVC还会通过ServletContext拿到Spring根容器,并将Spring根容器设为SpringMVC容器的父容器,请注意,Spring MVC容器可以访问父容器中的Bean,但是父容器不能访问子容器的Bean, 也就是说Spring根容器不能访问SpringMVC容器里的Bean。说的通俗点就是,在Controller里可以访问Service对象,但是在Service里不可以访问Controller对象。
Servlet 管理
tomcat 是用 Wrapper 容器来管理 Servlet 的,那 Wrapper 容器具体长什么样子呢?我们先来看看它里面有哪些关键的成员变量:
protected volatile Servlet instance = null;毫无悬念,它拥有一个 Servlet 实例,并且 Wrapper 通过 loadServlet 方法来实例化 Servlet。为了方便你阅读,我简化了代码:
public synchronized Servlet loadServlet() throws ServletException {
Servlet servlet;
//1. 创建一个 Servlet 实例
servlet = (Servlet) instanceManager.newInstance(servletClass);
//2. 调用了 Servlet 的 init 方法,这是 Servlet 规范要求的
initServlet(servlet);
return servlet;
}其实 loadServlet 主要做了两件事:创建 Servlet 的实例,并且调用 Servlet 的 init 方法,因为这是 Servlet 规范要求的。
那接下来的问题是,什么时候会调到这个 loadServlet 方法呢?为了加快系统的启动速度,我们往往会采取资源延迟加载的策略,tomcat 也不例外,默认情况下 tomcat 在启动时不会加载你的 Servlet,除非你把 Servlet 的loadOnStartup参数设置为true。
这里还需要你注意的是,虽然 tomcat 在启动时不会创建 Servlet 实例,但是会创建 Wrapper 容器,就好比尽管枪里面还没有子弹,先把枪造出来。那子弹什么时候造呢?是真正需要开枪的时候,也就是说有请求来访问某个 Servlet 时,这个 Servlet 的实例才会被创建。
每个容器组件都有自己的 Pipeline,每个 Pipeline 中有一个 Valve 链,并且每个容器组件有一个 BasicValve(基础阀)。Wrapper 作为一个容器组件,它也有自己的 Pipeline 和 BasicValve,Wrapper 的 BasicValve 叫StandardWrapperValve。
你可以想到,当请求到来时,Context 容器的 BasicValve 会调用 Wrapper 容器中 Pipeline 中的第一个 Valve,然后会调用到 StandardWrapperValve。我们先来看看它的 invoke 方法是如何实现的,同样为了方便你阅读,我简化了代码:
public final void invoke(Request request, Response response) {
//1. 实例化 Servlet
servlet = wrapper.allocate();
//2. 给当前请求创建一个 Filter 链
ApplicationFilterChain filterChain =
ApplicationFilterFactory.createFilterChain(request, wrapper, servlet);
//3. 调用这个 Filter 链,Filter 链中的最后一个 Filter 会调用 Servlet
filterChain.doFilter(request.getRequest(), response.getResponse());
}StandardWrapperValve 的 invoke 方法比较复杂,去掉其他异常处理的一些细节,本质上就是三步:
- 第一步,创建 Servlet 实例;
- 第二步,给当前请求创建一个 Filter 链;
- 第三步,调用这个 Filter 链。
你可能会问,为什么需要给每个请求创建一个 Filter 链?这是因为每个请求的请求路径都不一样,而 Filter 都有相应的路径映射,因此不是所有的 Filter 都需要来处理当前的请求,我们需要根据请求的路径来选择特定的一些 Filter 来处理。
第二个问题是,为什么没有看到调到 Servlet 的 service 方法?这是因为 Filter 链的 doFilter 方法会负责调用 Servlet,具体来说就是 Filter 链中的最后一个 Filter 会负责调用 Servlet。
Filter 管理
我们知道,跟 Servlet 一样,Filter 也可以在web.xml文件里进行配置,不同的是,Filter 的作用域是整个 Web 应用,因此 Filter 的实例是在 Context 容器中进行管理的,Context 容器用 Map 集合来保存 Filter。
private Map<String, FilterDef> filterDefs = new HashMap<>();那上面提到的 Filter 链又是什么呢?Filter 链的存活期很短,它是跟每个请求对应的。一个新的请求来了,就动态创建一个 FIlter 链,请求处理完了,Filter 链也就被回收了。理解它的原理也非常关键,我们还是来看看源码:
public final class ApplicationFilterChain implements FilterChain {
//Filter 链中有 Filter 数组,这个好理解
private ApplicationFilterConfig[] filters = new ApplicationFilterConfig[0];
//Filter 链中的当前的调用位置
private int pos = 0;
// 总共有多少了 Filter
private int n = 0;
// 每个 Filter 链对应一个 Servlet,也就是它要调用的 Servlet
private Servlet servlet = null;
public void doFilter(ServletRequest req, ServletResponse res) {
internalDoFilter(request,response);
}
private void internalDoFilter(ServletRequest req,
ServletResponse res){
// 每个 Filter 链在内部维护了一个 Filter 数组
if (pos < n) {
ApplicationFilterConfig filterConfig = filters[pos++];
Filter filter = filterConfig.getFilter();
filter.doFilter(request, response, this);
return;
}
servlet.service(request, response);
}从 ApplicationFilterChain 的源码我们可以看到几个关键信息:
- Filter 链中除了有 Filter 对象的数组,还有一个整数变量 pos,这个变量用来记录当前被调用的 Filter 在数组中的位置。
- Filter 链中有个 Servlet 实例,这个好理解,因为上面提到了,每个 Filter 链最后都会调到一个 Servlet。
- Filter 链本身也实现了 doFilter 方法,直接调用了一个内部方法 internalDoFilter。
- internalDoFilter 方法的实现比较有意思,它做了一个判断,如果当前 Filter 的位置小于 Filter 数组的长度,也就是说 Filter 还没调完,就从 Filter 数组拿下一个 Filter,调用它的 doFilter 方法。否则,意味着所有 Filter 都调到了,就调用 Servlet 的 service 方法。
答案是Filter 本身的 doFilter 方法会调用 Filter 链的 doFilter 方法,我们还是来看看代码就明白了:
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain){
...
// 调用 Filter 的方法
chain.doFilter(request, response);
}注意 Filter 的 doFilter 方法有个关键参数 FilterChain,就是 Filter 链。并且每个 Filter 在实现 doFilter 时,必须要调用 Filter 链的 doFilter 方法,而 Filter 链中保存当前 FIlter 的位置,会调用下一个 FIlter 的 doFilter 方法,这样链式调用就完成了。
Listener 管理
我们接着聊 Servlet 规范里 Listener。跟 Filter 一样,Listener 也是一种扩展机制,你可以监听容器内部发生的事件,主要有两类事件:
- 第一类是生命状态的变化,比如 Context 容器启动和停止、Session 的创建和销毁。
- 第二类是属性的变化,比如 Context 容器某个属性值变了、Session 的某个属性值变了以及新的请求来了等。
我们可以在web.xml配置或者通过注解的方式来添加监听器,在监听器里实现我们的业务逻辑。对于 tomcat 来说,它需要读取配置文件,拿到监听器类的名字,实例化这些类,并且在合适的时机调用这些监听器的方法。
tomcat 是通过 Context 容器来管理这些监听器的。Context 容器将两类事件分开来管理,分别用不同的集合来存放不同类型事件的监听器:
// 监听属性值变化的监听器
private List<Object> applicationEventListenersList = new CopyOnWriteArrayList<>();
// 监听生命事件的监听器
private Object applicationLifecycleListenersObjects[] = new Object[0];剩下的事情就是触发监听器了,比如在 Context 容器的启动方法里,就触发了所有的 ServletContextListener:
//1. 拿到所有的生命周期监听器
Object instances[] = getApplicationLifecycleListeners();
for (int i = 0; i < instances.length; i++) {
//2. 判断 Listener 的类型是不是 ServletContextListener
if (!(instances[i] instanceof ServletContextListener))
continue;
//3. 触发 Listener 的方法
ServletContextListener lr = (ServletContextListener) instances[i];
lr.contextInitialized(event);
}需要注意的是,这里的 ServletContextListener 接口是一种留给用户的扩展机制,用户可以实现这个接口来定义自己的监听器,监听 Context 容器的启停事件。Spring 就是这么做的。ServletContextListener 跟 tomcat 自己的生命周期事件 LifecycleListener 是不同的。LifecycleListener 定义在生命周期管理组件中,由基类 LifeCycleBase 统一管理。
异步Servlet
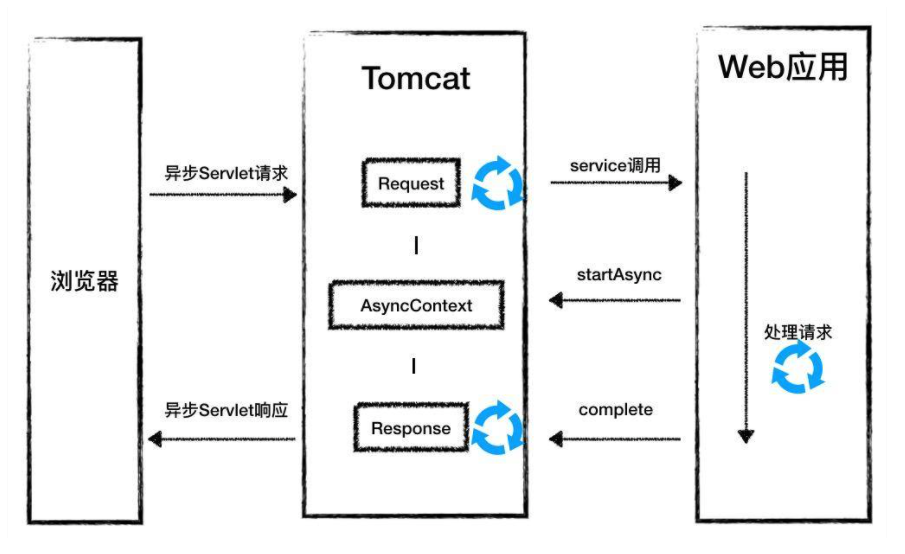
我们来思考这样一个问题,假如你的 Web 应用需要较长的时间来处理请求(比如数据库查询或者等待下游的服务调用返回),那么 tomcat 线程一直不回收,会占用系统资源,在极端情况下会导致“线程饥饿”,也就是说 tomcat 和 Jetty 没有更多的线程来处理新的请求。
那该如何解决这个问题呢?方案是 Servlet 3.0 中引入的异步 Servlet。主要是在 Web 应用里启动一个单独的线程来执行这些比较耗时的请求,而 tomcat 线程立即返回,不再等待 Web 应用将请求处理完,这样 tomcat 线程可以立即被回收到线程池,用来响应其他请求,降低了系统的资源消耗,同时还能提高系统的吞吐量。
例子
@WebServlet(urlPatterns = {"/async"}, asyncSupported = true)
public class AsyncServlet extends HttpServlet {
//Web 应用线程池,用来处理异步 Servlet
ExecutorService executor = Executors.newSingleThreadExecutor();
public void service(HttpServletRequest req, HttpServletResponse resp) {
//1. 调用 startAsync 或者异步上下文
final AsyncContext ctx = req.startAsync();
// 用线程池来执行耗时操作
executor.execute(new Runnable() {
@Override
public void run() {
// 在这里做耗时的操作
try {
ctx.getResponse().getWriter().println("Handling Async Servlet");
} catch (IOException e) {}
//3. 异步 Servlet 处理完了调用异步上下文的 complete 方法
ctx.complete();
}
});
}
}上面的代码有三个要点:
- 通过注解的方式来注册 Servlet,除了 @WebServlet 注解,还需要加上 asyncSupported=true 的属性,表明当前的 Servlet 是一个异步 Servlet。
- Web 应用程序需要调用 Request 对象的 startAsync 方法来拿到一个异步上下文 AsyncContext。这个上下文保存了请求和响应对象。
- Web 应用需要开启一个新线程来处理耗时的操作,处理完成后需要调用 AsyncContext 的 complete 方法。目的是告诉 tomcat,请求已经处理完成。
这里请你注意,虽然异步 Servlet 允许用更长的时间来处理请求,但是也有超时限制的,默认是 30 秒,如果 30 秒内请求还没处理完,tomcat 会触发超时机制,向浏览器返回超时错误,如果这个时候你的 Web 应用再调用ctx.complete方法,会得到一个 IllegalStateException 异常。
异步原理
startAsync 方法
startAsync 方法其实就是创建了一个异步上下文 AsyncContext 对象,AsyncContext 对象的作用是保存请求的中间信息。
这是因为 tomcat 的工作线程在Request.startAsync调用之后,就直接结束回到线程池中了,线程本身不会保存任何信息。也就是说一个请求到服务端,执行到一半,你的 Web 应用正在处理,这个时候 tomcat 的工作线程没了,这就需要有个缓存能够保存原始的 Request 和 Response 对象,而这个缓存就是 AsyncContext。
有了 AsyncContext,你的 Web 应用通过它拿到 request 和 response 对象,拿到 Request 对象后就可以读取请求信息,请求处理完了还需要通过 Response 对象将 HTTP 响应发送给浏览器。
除了创建 AsyncContext 对象,startAsync 还需要完成一个关键任务,那就是告诉 tomcat 当前的 Servlet 处理方法返回时,不要把响应发到浏览器,因为这个时候,响应还没生成呢;并且不能把 Request 对象和 Response 对象销毁,因为后面 Web 应用还要用呢。
在 tomcat 中,负责 flush 响应数据的是 CoyoteAdaptor,它还会销毁 Request 对象和 Response 对象,因此需要通过某种机制通知 CoyoteAdaptor,具体来说是通过下面这行代码:
this.request.getCoyoteRequest().action(ActionCode.ASYNC_START, this);你可以把它理解为一个 Callback,在这个 action 方法里设置了 Request 对象的状态,设置它为一个异步 Servlet 请求。
我们知道连接器是调用 CoyoteAdapter 的 service 方法来处理请求的,而 CoyoteAdapter 会调用容器的 service 方法,当容器的 service 方法返回时,CoyoteAdapter 判断当前的请求是不是异步 Servlet 请求,如果是,就不会销毁 Request 和 Response 对象,也不会把响应信息发到浏览器。你可以通过下面的代码理解一下,这是 CoyoteAdapter 的 service 方法,我对它进行了简化:
public void service(org.apache.coyote.Request req, org.apache.coyote.Response res) {
// 调用容器的 service 方法处理请求
connector.getService().getContainer().getPipeline().
getFirst().invoke(request, response);
// 如果是异步 Servlet 请求,仅仅设置一个标志,
// 否则说明是同步 Servlet 请求,就将响应数据刷到浏览器
if (request.isAsync()) {
async = true;
} else {
request.finishRequest();
response.finishResponse();
}
// 如果不是异步 Servlet 请求,就销毁 Request 对象和 Response 对象
if (!async) {
request.recycle();
response.recycle();
}
}接下来,当 CoyoteAdaptor 的 service 方法返回到 ProtocolHandler 组件时,ProtocolHandler 判断返回值,如果当前请求是一个异步 Servlet 请求,它会把当前 Socket 的协议处理者 Processor 缓存起来,将 SocketWrapper 对象和相应的 Processor 存到一个 Map 数据结构里。
private final Map<S,Processor> connections = new ConcurrentHashMap<>();之所以要缓存是因为这个请求接下来还要接着处理,还是由原来的 Processor 来处理,通过 SocketWrapper 就能从 Map 里找到相应的 Processor。
complete 方法
接着我们再来看关键的ctx.complete方法,当请求处理完成时,Web 应用调用这个方法。那么这个方法做了些什么事情呢?最重要的就是把响应数据发送到浏览器。
这件事情不能由 Web 应用线程来做,也就是说ctx.complete方法不能直接把响应数据发送到浏览器,因为这件事情应该由 tomcat 线程来做,但具体怎么做呢?
我们知道,连接器中的 Endpoint 组件检测到有请求数据达到时,会创建一个 SocketProcessor 对象交给线程池去处理,因此 Endpoint 的通信处理和具体请求处理在两个线程里运行。
在异步 Servlet 的场景里,Web 应用通过调用ctx.complete方法时,也可以生成一个新的 SocketProcessor 任务类,交给线程池处理。对于异步 Servlet 请求来说,相应的 Socket 和协议处理组件 Processor 都被缓存起来了,并且这些对象都可以通过 Request 对象拿到。
讲到这里,你可能已经猜到ctx.complete是如何实现的了:
public void complete() {
// 检查状态合法性,我们先忽略这句
check();
// 调用 Request 对象的 action 方法,其实就是通知连接器,这个异步请求处理完了
request.getCoyoteRequest().action(ActionCode.ASYNC_COMPLETE, null);
}我们可以看到 complete 方法调用了 Request 对象的 action 方法。而在 action 方法里,则是调用了 Processor 的 processSocketEvent 方法,并且传入了操作码 OPEN_READ。
case ASYNC_COMPLETE: {
clearDispatches();
if (asyncStateMachine.asyncComplete()) {
processSocketEvent(SocketEvent.OPEN_READ, true);
}
break;
}我们接着看 processSocketEvent 方法,它调用 SocketWrapper 的 processSocket 方法:
protected void processSocketEvent(SocketEvent event, boolean dispatch) {
SocketWrapperBase<?> socketWrapper = getSocketWrapper();
if (socketWrapper != null) {
socketWrapper.processSocket(event, dispatch);
}
}而 SocketWrapper 的 processSocket 方法会创建 SocketProcessor 任务类,并通过 tomcat 线程池来处理:
public boolean processSocket(SocketWrapperBase<S> socketWrapper,
SocketEvent event, boolean dispatch) {
if (socketWrapper == null) {
return false;
}
SocketProcessorBase<S> sc = processorCache.pop();
if (sc == null) {
sc = createSocketProcessor(socketWrapper, event);
} else {
sc.reset(socketWrapper, event);
}
// 线程池运行
Executor executor = getExecutor();
if (dispatch && executor != null) {
executor.execute(sc);
} else {
sc.run();
}
}请你注意 createSocketProcessor 函数的第二个参数是 SocketEvent,这里我们传入的是 OPEN_READ。通过这个参数,我们就能控制 SocketProcessor 的行为,因为我们不需要再把请求发送到容器进行处理,只需要向浏览器端发送数据,并且重新在这个 Socket 上监听新的请求就行了。
 微信
微信 支付宝
支付宝







