NIO
NIO简单介绍
前言
Java NIO有两种解释:
- 一种叫非阻塞IO(Non-blocking I/O)
- 另一种叫新的IO(New I/O)
其实两种概念也是相同的。
一、概述
Java NIO是从Java1.4版本开始引入的一个新的IO API,可以代替标准的IO API。
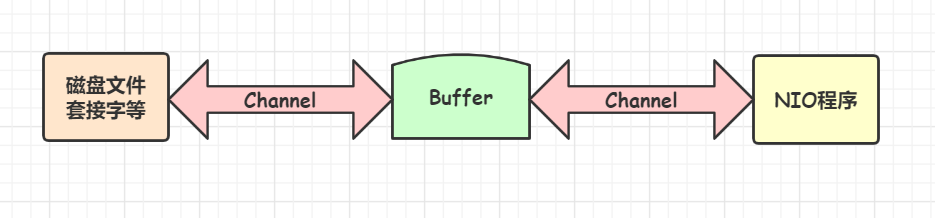
NIO与原来的IO有同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的,基于通道的IO操作。NIO将以更加高效的方式进行文件的读写操作。
NIO有三大核心部分
- Channel(通道)
- Buffer(缓冲区)
- Selector(选择器)
二、Java NIO与BIO的区别
- BIO以流的方式处理数据,而NIO以块的方式处理数据,块IO的效率比流IO高很多;
- BIO是阻塞的,NIO则是非阻塞的;
- BIO基于字节流和字符流进行操作,而NIO基于Channel(通道)和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(选择器)用于监听多个通道的事件(比如:连接请求,数据到达等),因此使用单个线程就可以监听多个客户端通道;
- BIO是单向的,如:InputStream, OutputStream;而NIO是双向的,既可以用来进行读操作,又可以用来进行写操作。
三、NIO三大核心原理
3.1 Buffer(缓冲区)
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存,这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存,相比较直接对数组的操作,Buffer API更加容易操作和管理。
3.2 Channel(通道)
Java NIO的通道类似流,但又有些不同: 既可以从通道中读取数据,又可以写数据到通道。但流的(input或output)读写通常是单向的。通道可以非阻塞读取和写入通道,也可以支持读取或写入缓冲区,同时支持异步地读写。
常见的 Channel 有
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
3.3 Selector(选择器)
Selector是一个Java NIO组件,可以能够检查一个或多个NIO通道,并确定哪些通道已经准备好进行读取或写入。一个单独的线程可以管理多个channel,从而管理多个网络连接。
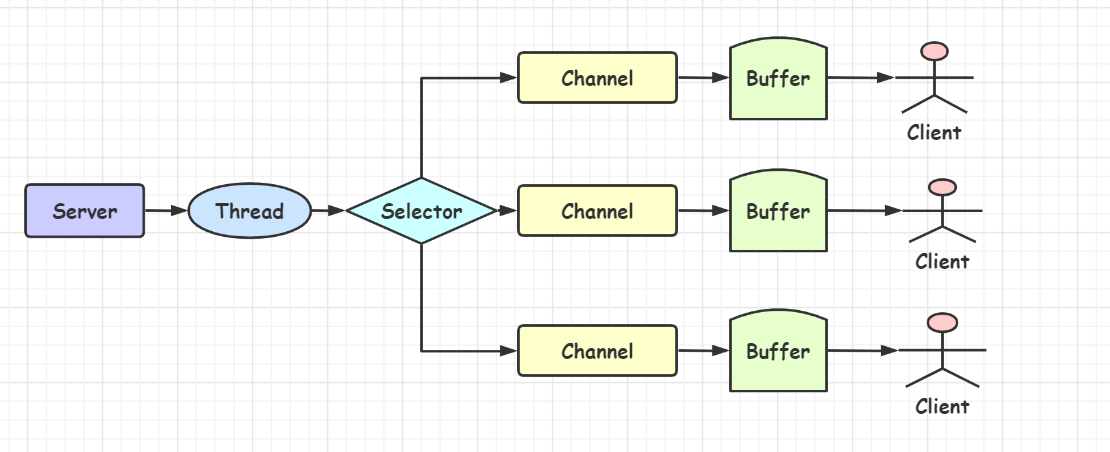
- 每个Channel都会对应一个Buffer
- 一个线程对应Selector,一个Selector对应多个Channel(连接)
- 程序切换到那个Channel是由事件决定的
- Selector会根据不同的事件,在各个通道上切换
- Buffer就是一个内存块,底层是一个数组
- 数据的读取写入是通过Buffer完成的,BIO中要么是输入流,或者是输出流,不能双向,但是NIO的Buffer时可以读也可以写
- Channel负责传输,Buffer负责存取数据
四、缓冲区Buffer
一个用于特定基本数据类型的容器。由 Java NIO包定义的,所有缓冲区都是Buffer抽象类的子类。Java NIO中的Buffer主要用于与NIO通道进行交互,数据是从通道读入缓冲区,从缓冲区写入通道中的
Buffer类及其子类
Buffer就像一个数组,可以保存多个相同类型的数据。根据数据类型不同,有以下Buffer常用子类:
- ByteBuffer
- MappedByteBuffer
- DirectByteBuffer
- HeapByteBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
- CharBuffer
上述Buffer类 他们都采用相似的方法进行管理数据,只是各自管理的数据类型不同而已。都是通过如下方法获取一个Buffer对象:
//创建一个容量为capacity的xxxBuffer对象
static xxxBuffer allocate(int capacity);
|
|
|
IntBuffer buffer = IntBuffer.allocate(10);Buffer中的重要概念
容量(capacity):创建后不能更改,且容量不能为负;
限制(limit):表示缓冲区中可以操作数据的大小。缓冲区的限制不能为负,并且不能大于其容量;
写入模式,限制等于buffer的容量。读取模式下,limit等于写入的数据量
位置(position):下一个要读取或写入的数据的索引。缓冲区的位置不能为负,并且不能大于其限制;
标记(mark)与重置(reset):标记是一个索引,通过Buffer中的mark()方法指定Buffer中一个特定的position,之后可以通过调用reset()方法恢复到这个position。
NIO之bytebuffer基本使用
前言
本篇将通过nio读取一个文本文件来演示bytebuffer的基本使用
一、准备
- 数据准备
创建data.txt文件,增加如下内容:
1234567890abcd- 创建Maven项目
- 安装lombok插件
二、ByteBuffer 使用分析
- 向 buffer 写入数据,例如调用 channel.read(buffer)
- 调用 flip() 切换至读模式
- 从 buffer 读取数据,例如调用 buffer.get()
- 调用 clear() 或 compact() 切换至写模式
- 重复 1~4 步骤
三、代码实现
- 引入pom依赖
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.39.Final</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.18</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
</dependencies>- 代码实现
import lombok.extern.slf4j.Slf4j;
import java.io.FileInputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* Created by lilinchao
* Date 2022/5/24
* Description ByteBuffer Demo
*/
@Slf4j
public class TestByteBuffer {
public static void main(String[] args){
/**
* FileChannel
* 方式1:输入输出流
* 方式2:RandomAccessFile
*/
try (FileChannel channel = new FileInputStream("datas/data.txt").getChannel()){
//准备缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
while (true){
//1.从 channel 读取数据,向buffer写入
int len = channel.read(buffer);
log.debug("读取到的字节数:{}",len);
if(len == -1){ //判断内容是否读取完
break;
}
//打印buffer中的内容
buffer.flip(); //2.切换至读模式
while (buffer.hasRemaining()){ //是否还有剩余未读数据
byte b = buffer.get(); //3.读取数据内容
log.debug("实际字节:{}",(char) b);
}
buffer.clear(); //4.切换到写模式
}
} catch (IOException e) {
e.printStackTrace();
}
}
}运行结果
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 读取到的字节数:10
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:1
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:2
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:3
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:4
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:5
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:6
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:7
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:8
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:9
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:0
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 读取到的字节数:4
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:a
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:b
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:c
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 实际字节:d
10:16:41 [DEBUG] [main] c.l.n.b.TestByteBuffer - 读取到的字节数:-1整体目录结构
NIO之bytebuffer内部结构和方法
一、bytebuffer内部结构
1.1 属性介绍
Bytebuffer有以下重要属性:
- capacity(容量):缓冲区的容量。通过构造函数赋予,一旦设置,无法更改。
- position(指针):读写指针,记录数据读写的位置,缓冲区的位置不能为负,并且不能大于limit。
- limit(读写限制):缓冲区的界限。位于limit 后的数据不可读写。缓冲区的限制不能为负,并且不能大于其容量。
1.2 结构
- 写模式
当缓冲区刚创建成功时
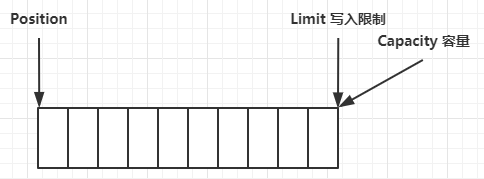
写模式下,position 是写入位置,limit 等于容量。
下图表示写入了 4 个字节后的状态:
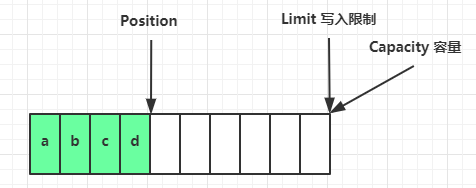
Position移动到第5个字节开始位置
- 读模式
flip动作发生后,position切换为读取位置,limit切换为读取限制
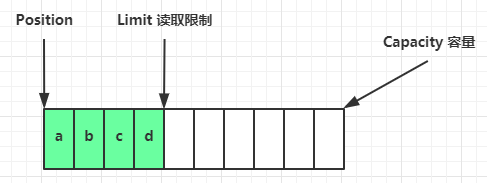
- position重新赋值到开始位置,因为读取数据从开始位置开始读取
- limit被赋值为position写入时的最后位置,作为数据读取的最终位置
读取4个字节后,状态如下图:
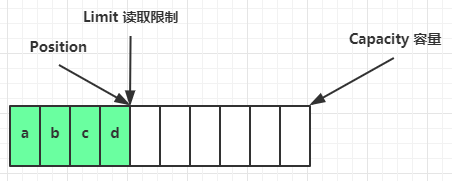
- 当position位置与limit位置相同时,数据读取结束。
- 数据未读取完重新切换到写模式时
compact 方法,是把未读完的部分向前压缩,然后切换至写模式
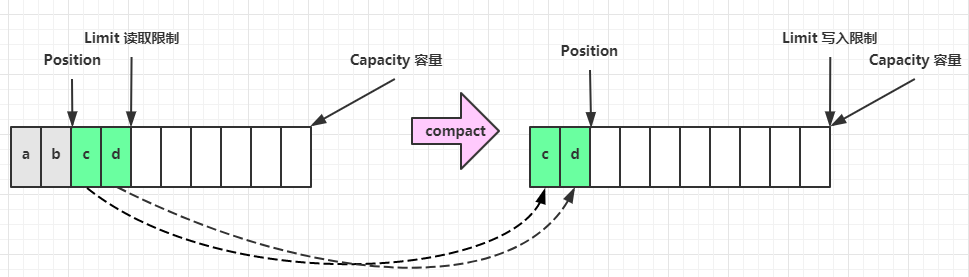
二、ByteBuffer常见方法
描述:可以将一个数据放入到缓冲区中。
进行该操作后,postition的值会+1,指向下一个可以放入的位置。capacity = limit ,为缓冲区容量的值。
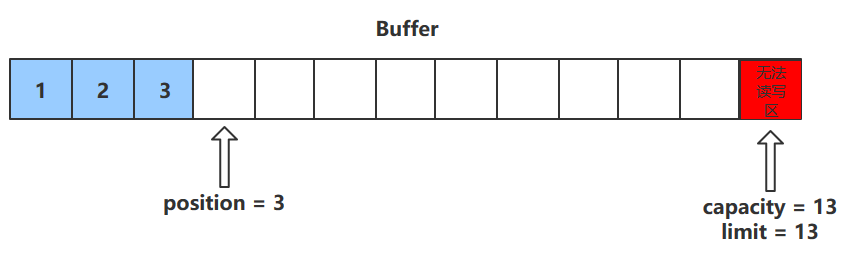
描述:用来切换对缓冲区的操作模式,由写->读 / 读->写
进行该操作后:
- 如果是写模式->读模式,position = 0 , limit 指向最后一个元素的下一个位置,capacity不变;
- 如果是读模式->写模式,则恢复为put()方法中的值。
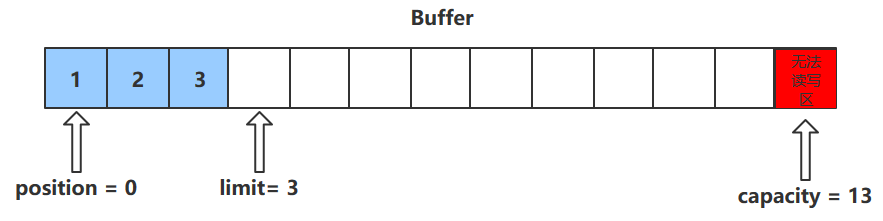
描述:该方法会读取缓冲区中的一个值
进行该操作后,position会+1,如果超过了limit则会抛出异常
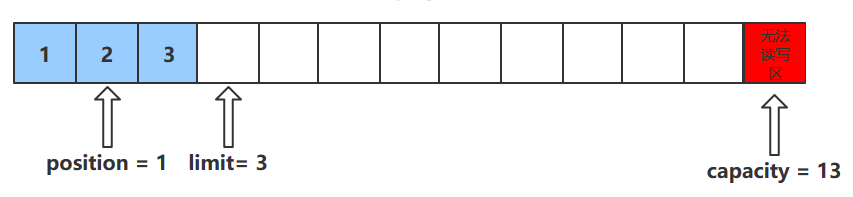
注意:get(i)方法不会改变position的值
描述:该方法只能在读模式下使用
rewind()方法后,会恢复position、limit和capacity的值,变为进行get()前的值
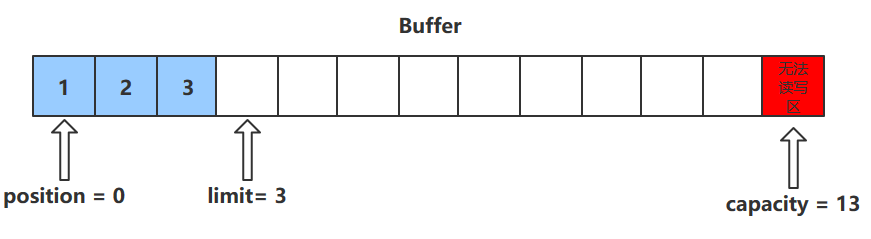
描述:会将缓冲区中的各个属性恢复为最初的状态,position = 0, capacity = limit
此时缓冲区的数据依然存在,处于“被遗忘”状态,下次进行写操作时会覆盖这些数据
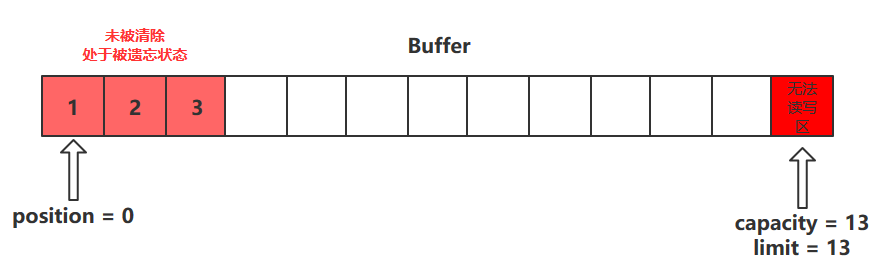
描述:mark 是在读取时,做一个标记,即使 position 改变,只要调用 reset 就能回到 mark 的位置
mark():将postion的值保存到mark属性中
reset():将position的值改为mark中保存的值
注意:rewind 和 flip 都会清除 mark 位置
描述:compact会把未读完的数据向前压缩,然后切换到写模式
数据前移后,原位置的值并未清零,写时会覆盖之前的值
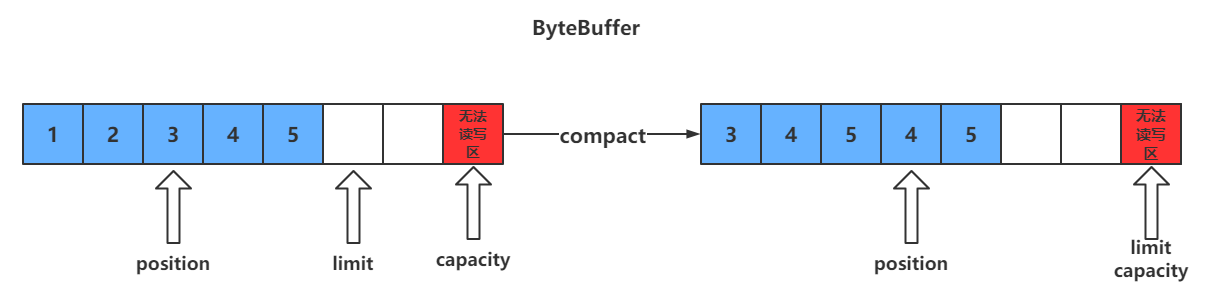
注意:此方法为ByteBuffer的方法,而不是Buffer的方法
clear()和compact()方法对比:
clear只是对position、limit、mark进行重置,而compact在对position进行设置,以及limit、mark进行重置的同时,还涉及到数据在内存中拷贝(会调用arraycopy)。所以compact比clear更耗性能。但compact能保存你未读取的数据,将新数据追加到为读取的数据之后;而clear则不行,若你调用了clear,则未读取的数据就无法再读取到了
需要根据情况来判断使用哪种方法进行模式切换
NIO之bytebuffer常见方法演示
1. 分配内存空间
可以使用allocate() 和 allocateDirect()方法为ByteBuffer分配空间,其他buffer类也有该方法
- allocate(): 使用的是java的堆内存,堆内字节缓冲区,读写效率低,会受到GC的影响
- allocateDirect():使用的是直接内存,直接内存字节缓冲区,读写效率高(零拷贝),不会受GC影响,因为是系统直接内存,所以分配内存要调用操作系统函数,所以分配内存的速度较慢,如果使用不当(资源没得到合理释放),会造成内存泄漏。
import java.nio.ByteBuffer;
/**
* Created by lilinchao
* Date 2022/5/25
* Description 分配空间
*/
public class ByteBufferAllocateDemo {
public static void main(String[] args) {
System.out.println(ByteBuffer.allocate(16).getClass());
System.out.println(ByteBuffer.allocateDirect(16).getClass());
}
}输出结果
class java.nio.HeapByteBuffer
class java.nio.DirectByteBuffer2. 向buffer写入数据
有两种办法
调用 channel 的 read 方法
int readBytes = channel.read(buf);调用 buffer 自己的 put 方法
buf.put((byte)127);
3. 从buffer读取数据
同样有两种办法
调用 channel 的 write 方法
int writeBytes = channel.write(buf);调用 buffer 自己的 get 方法
byte b = buf.get();
get 方法会让 position 读指针向后走,如果想重复读取数据
- 可以调用 rewind 方法将 position 重新置为 0
- 或者调用 get(int i) 方法获取索引 i 的内容,它不会移动读指针
读写示例
import java.nio.ByteBuffer;
import static com.lilinchao.nio.bytebuffer_2.ByteBufferUtil.debugAll;
/**
* Created by lilinchao
* Date 2022/5/25
* Description bytebuffer读写示例
*/
public class TestByteBufferReadWrite {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(10);
buffer.put((byte) 0x61); //a
debugAll(buffer);
buffer.put(new byte[]{0x62,0x63,0x64}); //b、c、d
debugAll(buffer);
//flip:切换对缓冲区的操作模式 写模式 --> 读模式
buffer.flip();
System.out.println(buffer.get());
//get(i):不会改变索引的位置
System.out.println(buffer.get(2));
debugAll(buffer);
//compact:会把未读完的数据向前压缩,然后切换到写模式
buffer.compact();
debugAll(buffer);
buffer.put(new byte[]{0x65,0x6f});
debugAll(buffer);
// rewind 从头开始读
buffer.flip();
System.out.println((char)buffer.get());
System.out.println((char)buffer.get());
buffer.rewind();
System.out.println((char)buffer.get());
}
}运行结果
+--------+-------------------- all ------------------------+----------------+
position: [1], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 00 00 00 00 00 00 00 00 00 |a......... |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [4], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 00 00 00 00 00 00 |abcd...... |
+--------+-------------------------------------------------+----------------+
97
99
+--------+-------------------- all ------------------------+----------------+
position: [1], limit: [4]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 62 63 64 00 00 00 00 00 00 |abcd...... |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [3], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 62 63 64 64 00 00 00 00 00 00 |bcdd...... |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 62 63 64 65 6f 00 00 00 00 00 |bcdeo..... |
+--------+-------------------------------------------------+----------------+
b
c
b4. mark 和 reset
mark 是在读取时,做一个标记,即使 position 改变,只要调用 reset 就能回到 mark 的位置
import java.nio.ByteBuffer;
/**
* Created by lilinchao
* Date 2022/5/25
* Description mark 和 reset方法
*/
public class TestByteBufferMarkAndReset {
public static void main(String[] args) {
ByteBuffer byteBuffer = ByteBuffer.allocate(10);
byteBuffer.put(new byte[]{'a', 'b', 'c', 'd'});
byteBuffer.flip();
System.out.println((char) byteBuffer.get()); // 读取 a
System.out.println((char) byteBuffer.get()); // 读取 b
byteBuffer.mark(); // 加标记 索引为2 的位置
System.out.println((char) byteBuffer.get()); // 读取 c
System.out.println((char) byteBuffer.get()); // 读取 d
byteBuffer.reset(); // 将position 重置到索引为2的位置
System.out.println((char) byteBuffer.get()); // 读取 c
System.out.println((char) byteBuffer.get()); // 读取 d
}
}运行结果
a
b
c
d
c
d5. 字符串与 ByteBuffer 互转
ByteBuffer buffer1 = StandardCharsets.UTF_8.encode("你好");
ByteBuffer buffer2 = Charset.forName("utf-8").encode("你好");
debug(buffer1);
debug(buffer2);
CharBuffer buffer3 = StandardCharsets.UTF_8.decode(buffer1);
System.out.println(buffer3.getClass());
System.out.println(buffer3.toString());输出结果
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| e4 bd a0 e5 a5 bd |...... |
+--------+-------------------------------------------------+----------------+
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| e4 bd a0 e5 a5 bd |...... |
+--------+-------------------------------------------------+----------------+
class java.nio.HeapCharBuffer
你好示例
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.charset.StandardCharsets;
import static com.lilinchao.nio.bytebuffer_2.ByteBufferUtil.debugAll;
/**
* Created by lilinchao
* Date 2022/5/25
* Description 字符串与 ByteBuffer 互转 Demo
*/
public class TestByteBufferString {
public static void main(String[] args) {
//1、字符串转为 ByteBuffer,还是写模式
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put("hello".getBytes());
debugAll(buffer);
// 2、Charset 字符集类,自动切换到读模式
ByteBuffer helloBuffer = StandardCharsets.UTF_8.encode("hello");
debugAll(helloBuffer);
// 3、wrap,自动切换到读模式
ByteBuffer buffer3 = ByteBuffer.wrap("hello".getBytes());
debugAll(buffer3);
// 4、转换为字符串
CharBuffer charBuffer = StandardCharsets.UTF_8.decode(helloBuffer);
System.out.println(charBuffer.toString());
// 不起作用
buffer.flip(); // 切换读模式,起作用
CharBuffer charBuffer1 = StandardCharsets.UTF_8.decode(buffer);
System.out.println(charBuffer1.toString());
}
}运行结果
+--------+-------------------- all ------------------------+----------------+
position: [5], limit: [16]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f 00 00 00 00 00 00 00 00 00 00 00 |hello...........|
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f |hello |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f |hello |
+--------+-------------------------------------------------+----------------+
hello
hello6. Scattering Reads(分散读)
分散读取集中写的方法不重要,重要的是思想,可以减少在ByteBuffer之间的拷贝,减少数据的复制次数,提高效率。
示例
- 创建一个文本文件words.txt
onetwothree- 分散读取示例代码
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import static com.lilinchao.nio.bytebuffer_2.ByteBufferUtil.debugAll;
/**
* Created by lilinchao
* Date 2022/5/25
* Description 分散读 Demo
*/
public class ScatteringReadsDemo {
public static void main(String[] args) {
try(FileChannel channel = new RandomAccessFile("datas/words.txt", "r").getChannel()) {
ByteBuffer b1 = ByteBuffer.allocate(3); // one
ByteBuffer b2 = ByteBuffer.allocate(3); // two
ByteBuffer b3 = ByteBuffer.allocate(5); // three
channel.read(new ByteBuffer[]{b1, b2, b3});
b1.flip();
b2.flip();
b3.flip();
debugAll(b1);
debugAll(b2);
debugAll(b3);
} catch (IOException e) {
e.printStackTrace();
}
}
}运行结果
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [3]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 6f 6e 65 |one |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [3]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 74 77 6f |two |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [5]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 74 68 72 65 65 |three |
+--------+-------------------------------------------------+----------------+7. Gathering Writes(集中写)
使用如下方式写入,可以将多个 buffer 的数据填充至 channel
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import static com.lilinchao.nio.bytebuffer_2.ByteBufferUtil.debugAll;
/**
* Created by lilinchao
* Date 2022/5/25
* Description 集中写Demo
*/
public class GatheringWritesDemo {
public static void main(String[] args) {
try (RandomAccessFile file = new RandomAccessFile("datas/words.txt", "rw")) {
FileChannel channel = file.getChannel();
ByteBuffer d = ByteBuffer.allocate(4);
ByteBuffer e = ByteBuffer.allocate(4);
channel.position(11);
d.put(new byte[]{'f', 'o', 'u', 'r'});
e.put(new byte[]{'f', 'i', 'v', 'e'});
d.flip();
e.flip();
debugAll(d);
debugAll(e);
channel.write(new ByteBuffer[]{d, e});
} catch (IOException e) {
e.printStackTrace();
}
}
}运行结果
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [4]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 66 6f 75 72 |four |
+--------+-------------------------------------------------+----------------+
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [4]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 66 69 76 65 |five |
+--------+-------------------------------------------------+----------------+最后:调试工具类
import io.netty.util.internal.StringUtil;
import java.nio.ByteBuffer;
import static io.netty.util.internal.MathUtil.isOutOfBounds;
import static io.netty.util.internal.StringUtil.NEWLINE;
/**
* @Author: lilinchao
* @Date: 2022/5/25
* @Description:调试工具类
*/
public class ByteBufferUtil {
private static final char[] BYTE2CHAR = new char[256];
private static final char[] HEXDUMP_TABLE = new char[256 * 4];
private static final String[] HEXPADDING = new String[16];
private static final String[] HEXDUMP_ROWPREFIXES = new String[65536 >>> 4];
private static final String[] BYTE2HEX = new String[256];
private static final String[] BYTEPADDING = new String[16];
static {
final char[] DIGITS = "0123456789abcdef".toCharArray();
for (int i = 0; i < 256; i++) {
HEXDUMP_TABLE[i << 1] = DIGITS[i >>> 4 & 0x0F];
HEXDUMP_TABLE[(i << 1) + 1] = DIGITS[i & 0x0F];
}
int i;
// Generate the lookup table for hex dump paddings
for (i = 0; i < HEXPADDING.length; i++) {
int padding = HEXPADDING.length - i;
StringBuilder buf = new StringBuilder(padding * 3);
for (int j = 0; j < padding; j++) {
buf.append(" ");
}
HEXPADDING[i] = buf.toString();
}
// Generate the lookup table for the start-offset header in each row (up to 64KiB).
for (i = 0; i < HEXDUMP_ROWPREFIXES.length; i++) {
StringBuilder buf = new StringBuilder(12);
buf.append(NEWLINE);
buf.append(Long.toHexString(i << 4 & 0xFFFFFFFFL | 0x100000000L));
buf.setCharAt(buf.length() - 9, '|');
buf.append('|');
HEXDUMP_ROWPREFIXES[i] = buf.toString();
}
// Generate the lookup table for byte-to-hex-dump conversion
for (i = 0; i < BYTE2HEX.length; i++) {
BYTE2HEX[i] = ' ' + StringUtil.byteToHexStringPadded(i);
}
// Generate the lookup table for byte dump paddings
for (i = 0; i < BYTEPADDING.length; i++) {
int padding = BYTEPADDING.length - i;
StringBuilder buf = new StringBuilder(padding);
for (int j = 0; j < padding; j++) {
buf.append(' ');
}
BYTEPADDING[i] = buf.toString();
}
// Generate the lookup table for byte-to-char conversion
for (i = 0; i < BYTE2CHAR.length; i++) {
if (i <= 0x1f || i >= 0x7f) {
BYTE2CHAR[i] = '.';
} else {
BYTE2CHAR[i] = (char) i;
}
}
}
/**
* 打印所有内容
* @param buffer
*/
public static void debugAll(ByteBuffer buffer) {
int oldlimit = buffer.limit();
buffer.limit(buffer.capacity());
StringBuilder origin = new StringBuilder(256);
appendPrettyHexDump(origin, buffer, 0, buffer.capacity());
System.out.println("+--------+-------------------- all ------------------------+----------------+");
System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), oldlimit);
System.out.println(origin);
buffer.limit(oldlimit);
}
/**
* 打印可读取内容
* @param buffer
*/
public static void debugRead(ByteBuffer buffer) {
StringBuilder builder = new StringBuilder(256);
appendPrettyHexDump(builder, buffer, buffer.position(), buffer.limit() - buffer.position());
System.out.println("+--------+-------------------- read -----------------------+----------------+");
System.out.printf("position: [%d], limit: [%d]\n", buffer.position(), buffer.limit());
System.out.println(builder);
}
private static void appendPrettyHexDump(StringBuilder dump, ByteBuffer buf, int offset, int length) {
if (isOutOfBounds(offset, length, buf.capacity())) {
throw new IndexOutOfBoundsException(
"expected: " + "0 <= offset(" + offset + ") <= offset + length(" + length
+ ") <= " + "buf.capacity(" + buf.capacity() + ')');
}
if (length == 0) {
return;
}
dump.append(
" +-------------------------------------------------+" +
NEWLINE + " | 0 1 2 3 4 5 6 7 8 9 a b c d e f |" +
NEWLINE + "+--------+-------------------------------------------------+----------------+");
final int startIndex = offset;
final int fullRows = length >>> 4;
final int remainder = length & 0xF;
// Dump the rows which have 16 bytes.
for (int row = 0; row < fullRows; row++) {
int rowStartIndex = (row << 4) + startIndex;
// Per-row prefix.
appendHexDumpRowPrefix(dump, row, rowStartIndex);
// Hex dump
int rowEndIndex = rowStartIndex + 16;
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);
}
dump.append(" |");
// ASCII dump
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);
}
dump.append('|');
}
// Dump the last row which has less than 16 bytes.
if (remainder != 0) {
int rowStartIndex = (fullRows << 4) + startIndex;
appendHexDumpRowPrefix(dump, fullRows, rowStartIndex);
// Hex dump
int rowEndIndex = rowStartIndex + remainder;
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2HEX[getUnsignedByte(buf, j)]);
}
dump.append(HEXPADDING[remainder]);
dump.append(" |");
// Ascii dump
for (int j = rowStartIndex; j < rowEndIndex; j++) {
dump.append(BYTE2CHAR[getUnsignedByte(buf, j)]);
}
dump.append(BYTEPADDING[remainder]);
dump.append('|');
}
dump.append(NEWLINE +
"+--------+-------------------------------------------------+----------------+");
}
private static void appendHexDumpRowPrefix(StringBuilder dump, int row, int rowStartIndex) {
if (row < HEXDUMP_ROWPREFIXES.length) {
dump.append(HEXDUMP_ROWPREFIXES[row]);
} else {
dump.append(NEWLINE);
dump.append(Long.toHexString(rowStartIndex & 0xFFFFFFFFL | 0x100000000L));
dump.setCharAt(dump.length() - 9, '|');
dump.append('|');
}
}
public static short getUnsignedByte(ByteBuffer buffer, int index) {
return (short) (buffer.get(index) & 0xFF);
}
}NIO之bytebuffer黏包和半包
一、示例
网络上有多条数据发送给服务端,数据之间使用 \n 进行分隔
但由于某种原因这些数据在接收时,被进行了重新组合,例如原始数据有3条为
- Hello,world\n
- I’m zhangsan\n
- How are you?\n
变成了下面的两个 byteBuffer (黏包,半包)
- Hello,world\nI’m zhangsan\nHo
- w are you?\n
分析
本来分别将上方三条数据发送给服务端,但是发送到服务的却是两条
- 第一条数据中的第二行和第三行中的Ho当作一条数据发送给了服务端,产生了黏包。
- 第二条数据,因为服务端并未接收到完整的第三条数据,所以产生了半包。
二、黏包和半包出现原因
- 黏包
发送方在发送数据时,并不是一条一条地发送数据,而是将数据整合在一起,当数据达到一定的数量后再一起发送。这就会导致多条信息被放在一个缓冲区中被一起发送出去
- 半包
接收方的缓冲区的大小是有限的,当接收方的缓冲区满了以后,就需要将信息截断,等缓冲区空了以后再继续放入数据。这就会发生一段完整的数据最后被截断的现象
三、代码示例
解决方案
- 通过get(index)方法遍历ByteBuffer,遇到分隔符时进行处理。注意:get(index)不会改变position的值
- 记录该段数据长度,以便于申请对应大小的缓冲区
- 将缓冲区的数据通过get()方法写入到target中
- 调用compact方法切换模式,因为缓冲区中可能还有未读的数据
import java.nio.ByteBuffer;
import static com.lilinchao.nio.bytebuffer_2.ByteBufferUtil.debugAll;
/**
* Created by lilinchao
* Date 2022/5/26
* Description 黏包和半包 Demo
*/
public class TestByteBufferExam {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(32);
// 模拟黏包
buffer.put("Hello,world\nI'm zhangsan\nHo".getBytes());
split(buffer);
//模拟半包
buffer.put("w are you?\nhaha!\n".getBytes());
split(buffer);
}
private static void split(ByteBuffer buffer){
//切换到读模式 才能从buffer中读取数据
buffer.flip();
int oldLimit = buffer.limit();
for (int i=0;i<oldLimit;i++){
// 遍历寻找分隔符
// get(i)不会移动position
if(buffer.get(i) == '\n'){
System.out.println(i);
// 缓冲区长度
int length = i+1-buffer.position();
ByteBuffer target = ByteBuffer.allocate(length);
// 0 ~ limit
buffer.limit(i + 1);
target.put(buffer); //从buffer 读,向 target 写
debugAll(target);
buffer.limit(oldLimit);
}
}
//切换到写模式,但是缓冲区可能未读完,这里需要使用compact
buffer.compact();
}
}运行结果
11
+--------+-------------------- all ------------------------+----------------+
position: [12], limit: [12]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 65 6c 6c 6f 2c 77 6f 72 6c 64 0a |Hello,world. |
+--------+-------------------------------------------------+----------------+
24
+--------+-------------------- all ------------------------+----------------+
position: [13], limit: [13]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 49 27 6d 20 7a 68 61 6e 67 73 61 6e 0a |I'm zhangsan. |
+--------+-------------------------------------------------+----------------+
12
+--------+-------------------- all ------------------------+----------------+
position: [13], limit: [13]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 6f 77 20 61 72 65 20 79 6f 75 3f 0a |How are you?. |
+--------+-------------------------------------------------+----------------+
18
+--------+-------------------- all ------------------------+----------------+
position: [6], limit: [6]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 61 68 61 21 0a |haha!. |
+--------+-------------------------------------------------+----------------+NIO之FileChannel介绍
一、概念
FileChannel是一个连接到文件的通道,使用FileChannel可以从文件读数据,也可以向文件中写入数据。Java NIO的FileChannel是标准 Java IO 读写文件的替代方案。
FileChannel的主要作用是读取、写入、映射、操作文件。
FileChannel 只能工作在阻塞模式下。
FileChannel 和 标准Java IO对比
| FileInputStream/FileOutputStream | FileChannel |
|---|---|
| 单向 | 双向 |
| 面向字节的读写 | 面向Buffer读写 |
| 不支持 | 支持内存文件映射 |
| 不支持 | 支持转入或转出其他通道 |
| 不支持 | 支持文件锁 |
| 不支持操作文件元信息 | 不支持操作文件元信息 |
FileChannel的优点
- 在文件中的特定位置读取和写入
- 将文件的一部分直接加载到内存中,这样可以更高效
- 可以以更快的速度将文件数据从一个通道传输到另一个通道
- 可以锁定文件的一部分以限制其他线程的访问
- 为避免数据丢失,可以强制将文件更新立即写入存储
二、FileChannel 类结构
package java.nio.channels;
publicabstractclass FileChannel
extends AbstractInterruptibleChannel
implements SeekableByteChannel, GatheringByteChannel, ScatteringByteChannel{
/**
* 初始化一个无参构造器.
*/
protected FileChannel() { }
//打开或创建一个文件,返回一个文件通道来访问文件
public static FileChannel open(Path path,
Set<? extends OpenOption> options,
FileAttribute<?>... attrs)
throws IOException
{
FileSystemProvider provider = path.getFileSystem().provider();
return provider.newFileChannel(path, options, attrs);
}
privatestaticfinal FileAttribute<?>[] NO_ATTRIBUTES = new FileAttribute[0];
//打开或创建一个文件,返回一个文件通道来访问文件
public static FileChannel open(Path path, OpenOption... options)
throws IOException
{
Set<OpenOption> set = new HashSet<OpenOption>(options.length);
Collections.addAll(set, options);
return open(path, set, NO_ATTRIBUTES);
}
//从这个通道读入一个字节序列到给定的缓冲区
public abstract int read(ByteBuffer dst) throws IOException;
//从这个通道读入指定开始位置和长度的字节序列到给定的缓冲区
public abstract long read(ByteBuffer[] dsts, int offset, int length) throws IOException;
/**
* 从这个通道读入一个字节序列到给定的缓冲区
*/
public final long read(ByteBuffer[] dsts) throws IOException {
return read(dsts, 0, dsts.length);
}
/**
* 从给定的缓冲区写入字节序列到这个通道
*/
public abstract int write(ByteBuffer src) throws IOException;
/**
* 从给定缓冲区的子序列向该信道写入字节序列
*/
public abstract long write(ByteBuffer[] srcs, int offset, int length)
throws IOException;
/**
* 从给定的缓冲区写入字节序列到这个通道
*/
public final long write(ByteBuffer[] srcs) throws IOException {
return write(srcs, 0, srcs.length);
}
/**
* 返回通道读写缓冲区中的开始位置
*/
public abstract long position() throws IOException;
/**
* 设置通道读写缓冲区中的开始位置
*/
public abstract FileChannel position(long newPosition) throws IOException;
/**
* 返回此通道文件的当前大小
*/
public abstract long size() throws IOException;
/**
* 通过指定的参数size来截取通道的大小
*/
public abstract FileChannel truncate(long size) throws IOException;
/**
* 强制将通道中的更新文件写入到存储设备(磁盘等)中
*/
public abstract void force(boolean metaData) throws IOException;
/**
* 将当前通道中的文件写入到可写字节通道中
* position就是开始写的位置,long就是写的长度
*/
public abstract long transferTo(long position, long count,WritableByteChannel target)throws IOException;
/**
* 将当前通道中的文件写入可读字节通道中
* position就是开始写的位置,long就是写的长度
*/
public abstract long transferFrom(ReadableByteChannel src,long position, long count) throws IOException;
/**
* 从通道中读取一系列字节到给定的缓冲区中
* 从指定的读取开始位置position处读取
*/
public abstract int read(ByteBuffer dst, long position) throws IOException;
/**
* 从给定的缓冲区写入字节序列到这个通道
* 从指定的读取开始位置position处开始写
*/
public abstract int write(ByteBuffer src, long position) throws IOException;
// -- Memory-mapped buffers --
/**
* 一个文件映射模式类型安全枚举
*/
publicstaticclass MapMode {
//只读映射模型
publicstaticfinal MapMode READ_ONLY
= new MapMode("READ_ONLY");
//读写映射模型
publicstaticfinal MapMode READ_WRITE
= new MapMode("READ_WRITE");
/**
* 私有模式(复制在写)映射
*/
publicstaticfinal MapMode PRIVATE
= new MapMode("PRIVATE");
privatefinal String name;
private MapMode(String name) {
this.name = name;
}
}
/**
* 将该通道文件的一个区域直接映射到内存中
*/
public abstract MappedByteBuffer map(MapMode mode,long position, long size) throws IOException;
/**
* 获取当前通道文件的给定区域上的锁
* 区域就是从position处开始,size长度
* shared为true代表获取共享锁,false代表获取独占锁
*/
public abstract FileLock lock(long position, long size, boolean shared) throws IOException;
/**
* 获取当前通道文件上的独占锁
*/
public final FileLock lock() throws IOException {
return lock(0L, Long.MAX_VALUE, false);
}
/**
* 尝试获取给定的通道文件区域上的锁
* 区域就是从position处开始,size长度
* shared为true代表获取共享锁,false代表获取独占锁
*/
public abstract FileLock tryLock(long position, long size, boolean shared)
throws IOException;
/**
* 尝试获取当前通道文件上的独占锁
*/
public final FileLock tryLock() throws IOException {
return tryLock(0L, Long.MAX_VALUE, false);
}
}三、FileChannel常用方法介绍
3.1 通道获取
FileChannel 可以通过 FileInputStream, FileOutputStream, RandomAccessFile 的对象中的 getChannel() 方法来获取,也可以通过静态方法 FileChannel.open(Path, OpenOption ...) 来打开。
通过静态静态方法 FileChannel.open() 打开的通道可以指定打开模式,模式通过 StandardOpenOption 枚举类型指定。
示例
FileChannel channell = FileChannel.open(
Paths.get("data","test","c.txt"), // 路径:data/test/c.txt
StandardOpenOption.CREATE,
StandardOpenOption.WRITE
);
FileChannel channel2 = FileChannel.open(
new File("a.txt").toPath(),
StandardOpenOption.CREATE_NEW,
StandardOpenOption.WRITE,StandardOpenOption.READ
);path获取
- Paths.get(String first, String… more):将传入的参数根据顺序进行统一拼接成为一个完整文件路径;
- new File(String pathname).toPath():传入一个路径参数;
StandardOpenOption 枚举类型
public enum StandardOpenOption implements OpenOption {
READ, // 读
WRITE, // 写
APPEND, // 在写模式下,进行追加写
TRUNCATE_EXISTING, // 如果文件已经存在,并且它被打开以进行WRITE访问,那么它的长度将被截断为0。如果文件仅以READ访问方式打开,则忽略此选项。
CREATE, // 如果文件不存在,请创建一个新文件。如果还设置了CREATE_NEW选项,则忽略此选项。与其他文件系统操作相比,检查文件是否存在以及创建文件(如果不存在)是原子性的。
CREATE_NEW, // 创建一个新文件,如果文件已经存在则失败。与其他文件系统操作相比,检查文件是否存在以及创建文件(如果不存在)是原子性的。
DELETE_ON_CLOSE, // 关闭时删除文件
SPARSE, // 稀疏文件。当与CREATE_NEW选项一起使用时,此选项将提示新文件将是稀疏的。当文件系统不支持创建稀疏文件时,该选项将被忽略。
SYNC, // 要求对文件内容或元数据的每次更新都以同步方式写入底层存储设备。
DSYNC; // 要求对文件内容的每次更新都以同步方式写入底层存储设备。
}从 FileInputStream 对象中获取的通道是以读的方式打开文件,从 FileOutpuStream 对象中获取的通道是以写的方式打开文件。
FileOutputStream ous = new FileOutputStream(new File("a.txt"));
FileChannel out = ous.getChannel(); // 获取一个只读通道
FileInputStream ins = new FileInputStream(new File("a.txt"));
FileChannel in = ins.getChannel(); // 获取一个只写通道从 RandomAccessFaile 中获取的通道取决于 RandomAccessFaile 对象是以什么方式创建的
RandomAccessFile file = new RandomAccessFile("a.txt", "rw");
FileChannel channel = file.getChannel(); // 获取一个可读写文件通道模式说明
- r:读模式
- w:写模式
- rw:读写模式
3.2 读取数据
读取数据的 read(ByteBuffer buf) 方法返回的值表示读取到的字节数,如果读到了文件末尾,返回值为 -1。读取数据时,position 会往后移动。
将数据读取到单个缓冲区
和一般通道的操作一样,数据也是需要读取到1个缓冲区中,然后从缓冲区取出数据。在调用 read 方法读取数据的时候,可以传入参数 position 和 length 来指定开始读取的位置和长度。
FileChannel channel = FileChannel.open(Paths.get("a.txt"), StandardOpenOption.READ);
ByteBuffer buf = ByteBuffer.allocate(5);
while(channel.read(buf)!=-1){
buf.flip();
System.out.print(new String(buf.array()));
buf.clear();
}
channel.close();读取到多个缓冲区
文件通道 FileChannel 实现了 ScatteringByteChannel 接口,可以将文件通道中的内容同时读取到多个 ByteBuffer 当中,这在处理包含若干长度固定数据块的文件时很有用。
ScatteringByteChannel channel = FileChannel.open(Paths.get("a.txt"), StandardOpenOption.READ);
ByteBuffer key = ByteBuffer.allocate(5), value=ByteBuffer.allocate(10);
ByteBuffer[] buffers = new ByteBuffer[]{key, value};
while(channel.read(buffers)!=-1){
key.flip();
value.flip();
System.out.println(new String(key.array()));
System.out.println(new String(value.array()));
key.clear();
value.clear();
}
channel.close();3.3 写入数据
从单个缓冲区写入
单个缓冲区操作也非常简单,它返回往通道中写入的字节数。
FileChannel channel = FileChannel.open(Paths.get("a.txt"), StandardOpenOption.WRITE);
ByteBuffer buf = ByteBuffer.allocate(5);
byte[] data = "Hello, Java NIO.".getBytes();
for (int i = 0; i < data.length; ) {
buf.put(data, i, Math.min(data.length - i, buf.limit() - buf.position()));
buf.flip();
i += channel.write(buf);
buf.compact();
}
channel.force(false);
channel.close();从多个缓冲区写入
FileChannel 实现了 GatherringByteChannel 接口,与 ScatteringByteChannel 相呼应。可以一次性将多个缓冲区的数据写入到通道中。
FileChannel channel = FileChannel.open(Paths.get("a.txt"), StandardOpenOption.WRITE);
ByteBuffer key = ByteBuffer.allocate(10), value = ByteBuffer.allocate(10);
byte[] data = "017 Robothy".getBytes();
key.put(data, 0, 3);
value.put(data, 4, data.length-4);
ByteBuffer[] buffers = new ByteBuffer[]{key, value};
key.flip();
value.flip();
channel.write(buffers);
channel.force(false); // 将数据刷出到磁盘
channel.close();RandomAccessFile、FileInputStream、FileOutputStream比较:
| 获取方式 | 是否有文件读写权限 |
|---|---|
| RandomAccessFile.getChannel | 可读,是否可写根据传入mode来判断 |
| FileInputStream.getChannel | 可读,不可写 |
| FileOutputStream.getChannel | 可写,不可读 |
3.4 数据刷出
为了减少访问磁盘的次数,通过文件通道对文件进行操作之后可能不会立即刷出到磁盘,此时如果系统崩溃,将导致数据的丢失。为了减少这种风险,在进行了重要数据的操作之后应该调用 force() 方法强制将数据刷出到磁盘。
无论是否对文件进行过修改操作,即使文件通道是以只读模式打开的,只要调用了 force(metaData) 方法,就会进行一次 I/O 操作。参数 metaData 指定是否将元数据(例如:访问时间)也刷出到磁盘。
channel.force(false); // 将数据刷出到磁盘,但不包括元数据3.5 关闭FileChannel
用完FileChannel后必须将其关闭。
channel.close();3.6 其他方法
描述:如果想在 FileChannel 的某一个指定位置读写数据,可以通过调用 FileChannel 的 position() 方法来获取当前的 position 值,也可以调用 FileChannel 的 position(long pos) 方法设置 position 的值。
long pos = channel.position();
channel.position(pos +123);注意
如果设置的 position 值超出了 File 文件的最后位置,在读取该 Channel 时就会返回 -1 ,即返回“读取到文件的末尾”的标识。
但此时若向 Channel 中写入数据,该 Channel 连接的 File 会被“扩张”到这个设置的 position 值的位置,然后将数据写入到这个 File 中,这会导致该 File 带有“空洞”,存储在磁盘上的这个物理文件就会不连续。
FileChannel 的 size() 方法会返回这个 FileChannel 连接的 File 文件的大小。
long fileSize = channel.size();可以调用 FileChannel.truncate() 方法截断一个 File。截断时需要指定一个长度。
channel.truncate(1024);本示例将文件长度截断为1024个字节。
- 如果给定大小小于该文件的当前大小,则截取该文件,丢弃文件末尾后面的所有字节。
- 如果给定大小大于或等于该文件的当前大小,则不修改文件。
无论是哪种情况,如果此通道的文件位置大于给定大小,则将位置设置为该大小。
transferTo 和 transferFrom方法
通道之间的数据传输:如果两个通道中有一个是 FileChannel,那你可以直接将数据从一个 channel 传输到另外一个 channel。
transferFrom():FileChannel 的 transferFrom()方法可以将数据从源通道传输到 FileChannel 中。
long transferFrom(ReadableByteChannel src,long position, long count)- src:源通道。
- position:文件中的位置,从此位置开始传输;必须为非负数。
- count: 要传输的最大字节数;必须为非负数。
如果源通道的剩余空间小于 count 个字节,则所传输的字节数要小于请求的字节数。
transferTo():将数据从 FileChannel 传输到其他的 channel 中。
long transferTo(long position, long count,WritableByteChannel target)- position:文件中的位置,从此位置开始传输,必须为非负数。
- count:要传输的最大字节数;必须为非负数。
- target:目标通道
示例
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.nio.channels.FileChannel;
/**
* Created by lilinchao
* Date 2022/5/27
* Description 对文件进行复制操作
*/
public class copyFileChannelDemo {
public static void main(String[] args) throws Exception {
//准备输入流(源文件)
FileInputStream fileInputStream = new FileInputStream("datas/data.txt");
//准备输出流(目标文件)
FileOutputStream fileOutputStream = new FileOutputStream("datas/data3.txt");
//根据流获取通道
FileChannel inputStreamChannel = fileInputStream.getChannel();
FileChannel outputStreamChannel = fileOutputStream.getChannel();
//指向复制方法
// outputStreamChannel.transferFrom(inputStreamChannel,0,inputStreamChannel.size());
inputStreamChannel.transferTo(0,inputStreamChannel.size(),outputStreamChannel);
//关闭资源
fileInputStream.close();
fileOutputStream.close();
}
}NIO之FileChannel练习
将数据写入指定文件
import lombok.extern.slf4j.Slf4j;
import java.io.File;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.StandardCharsets;
import java.nio.file.StandardOpenOption;
/**
* Created by lilinchao
* Date 2022/5/27
* Description channel Demo
*/
@Slf4j
public class channelDemo01 {
public static void main(String[] args) throws IOException {
// 获得一个根据指定文件路径的读写权限文件通道
FileChannel fileChannel = FileChannel.open(new File("datas/data.txt").toPath(), StandardOpenOption.WRITE,StandardOpenOption.READ);
//获得一段有指定内容的缓冲区
ByteBuffer source = ByteBuffer.wrap("helloWorld,Scala,Java".getBytes(StandardCharsets.UTF_8));
ByteBuffer target = ByteBuffer.allocate(50);
log.info("fileChannel.position():{}",fileChannel.position());
//将缓冲区中的内容写入文件通道
fileChannel.write(source);
//通道大小
log.info("fileChannel.position():{}", fileChannel.position());
//设置读写位置
fileChannel.position(0);
//将通道中的内容写到空缓冲区
fileChannel.read(target);
//转换缓冲区读写模式
target.flip();
log.info("target:{}", new String(target.array(), 0, target.limit()));
//关闭资源
fileChannel.close();
}
}数据读写
import lombok.extern.slf4j.Slf4j;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.StandardCharsets;
/**
* Created by lilinchao
* Date 2022/5/27
* Description 数据读写
*/
@Slf4j
public class channelDemo02 {
public static void main(String[] args) throws IOException {
//获取输出流
FileOutputStream outputStream = new FileOutputStream("datas/data.txt");
//根据输出流获得一个"写"权限的通道
FileChannel outChannel = outputStream.getChannel();
//获得一个有指定内容的缓冲区
ByteBuffer source = ByteBuffer.wrap("HelloWorld".getBytes(StandardCharsets.UTF_8));
//将缓冲区内容写入到通道
outChannel.write(source);
//获取输入流
FileInputStream fileInputStream = new FileInputStream("datas/data.txt");
//根据输入流获得一个"读"权限的通道
FileChannel inChannel = fileInputStream.getChannel();
//获得一个空内容的缓冲区
ByteBuffer target = ByteBuffer.allocate(50);
//将通道中的内容读到缓冲区
inChannel.read(target);
//转换缓冲区读写模式
target.flip();
//读出缓冲区中的内容
log.info("target:{}", new String(target.array(), 0, target.limit()));
//关闭资源
outChannel.close();
inChannel.close();
}
}超过 2g 大小的文件传输
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.channels.FileChannel;
/**
* Created by lilinchao
* Date 2022/5/27
* Description 超过 2g 大小的文件传输
*/
public class TestFileChannelTransferTo {
public static void main(String[] args) {
try (
FileChannel from = new FileInputStream("datas/data.txt").getChannel();
FileChannel to = new FileOutputStream("datas/to.txt").getChannel()
) {
// 效率高,底层会利用操作系统的零拷贝进行优化
long size = from.size();
// left 变量代表还剩余多少字节
for (long left = size; left > 0; ) {
System.out.println("position:" + (size - left) + " left:" + left);
left -= from.transferTo((size - left), left, to);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}FileChannel Demo 改变子缓冲区内容
import java.io.File;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.IntBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.StandardCharsets;
/**
* Created by lilinchao
* Date 2022/5/27
* Description FileChannel Demo
*/
public class TestFileChannelDemo {
public static void main(String[] args) throws Exception {
// testSlice();
// testFileChannel();
// testIntBuffer();
// writeFileChannel();
testFileChannelTransfer();
}
/**
* 切片:改变缓冲区的内容
*/
public static void testSlice() throws Exception {
//获取通道
RandomAccessFile accessFile = new RandomAccessFile(new File("datas/data.txt"),"rw");
FileChannel channel = accessFile.getChannel();
//缓冲区
ByteBuffer buffer = ByteBuffer.allocate(9);
//将数据读入缓冲区
channel.read(buffer);
buffer.position(3);
buffer.limit(7);
//用于创建一个新的字节缓冲区,其内容是给定缓冲区内容的共享子序列。
ByteBuffer slice = buffer.slice();
//改变子缓冲区内容
for (int i = 0;i<slice.capacity();i++){
byte b = slice.get(i);
b *=2;
slice.put(i,b);
}
buffer.position(0);
buffer.limit(buffer.capacity());
while (buffer.remaining() > 0){
System.out.println(buffer.get());
}
}
/**
* fileChannel读文件
*/
public static void testFileChannel() throws Exception {
RandomAccessFile accessFile = new RandomAccessFile(new File("datas/data.txt"),"rw");
FileChannel channel = accessFile.getChannel();
//缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
//将数据读入缓冲区
//返回的值表示读取到的字节数,如果读到了文件末尾,返回值为 -1
int read = channel.read(buffer);
while (read != -1){
System.out.println("file长度:"+read);
buffer.flip();
while (buffer.hasRemaining()){
System.out.println((char) buffer.get());
}
//切换到写模式,position=0,limit变为capacity
buffer.clear();
read = channel.read(buffer);
}
accessFile.close();
System.out.println("end");
}
/**
* intBuffer
*/
public static void testIntBuffer(){
//用于在现有缓冲区旁边分配一个新的int缓冲区
IntBuffer buffer = IntBuffer.allocate(1024);
buffer.put(new int[]{1,2,3});
buffer.flip();
while (buffer.hasRemaining()){
System.out.println(buffer.get());
}
}
/**
* fileChannel写文件
*/
public static void writeFileChannel() throws Exception {
RandomAccessFile rw = new RandomAccessFile("datas/data.txt","rw");
FileChannel channel = rw.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
buffer.put("欢迎来到李林超博客!!!".getBytes(StandardCharsets.UTF_8));
buffer.flip();
while (buffer.hasRemaining()){
channel.write(buffer);
}
channel.close();
}
//fileChannel通道之间传输
public static void testFileChannelTransfer() throws Exception {
RandomAccessFile accessFileA = new RandomAccessFile("datas/data.txt","rw");
FileChannel channelFrom = accessFileA.getChannel();
RandomAccessFile accessFileB = new RandomAccessFile("datas/dataB.txt","rw");
FileChannel channelTo = accessFileB.getChannel();
//from 的内容传输到 channelTo
channelTo.transferFrom(channelFrom,0,channelFrom.size());
accessFileA.close();
accessFileB.close();
}
}NIO之Path介绍
一、Path介绍
Path接口是java NIO2的一部分。首次在java 7中引入。Path接口在java.nio.file包下,所以全称是java.nio.file.Path。
java中的Path表示文件系统的路径。可以指向文件或文件夹。
Path同时也有相对路径和绝对路径之分:
- 绝对路径:表示从文件系统的根路径到文件或是文件夹的路径。
- 相对路径:表示从特定路径下访问指定文件或文件夹的路径。
二、Path方法介绍
2.1 创建Path实例
如果使用java.nio.file.Path实例,必须先创建它。通过Paths.get(String first, String… more)静态工厂方法创建。
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* Created by lilinchao
* Date 2022/5/29
* Description 1.0
*/
public class PathDemo {
public static void main(String[] args) {
//创建Path实例
Path path = Paths.get("D:\\path_test\\first_path.txt");
}
}2.2 创建绝对路径
以绝对路径文件作为参数调用Paths.get()工厂方法就是创建一个绝对Path实例。
// windows 系统
Path path = Paths.get("D:\\path_test\\first_path.txt");
// Unix系统
Path path = Paths.get("/home/path_test/first_path.txt");说明
参数
D:\\path_test\\first_path.txt是一个绝对路径。有两个
\字符的原因是第一个\是转义字符,表示紧跟着它的字符需要被转义。\\表示需要向字符串中写入一个\字符。在Unix系统(Linux,MacOS,FreeBSD等)中通过使用
/来表示路径
2.3 创建相对路径
相对路径指从一个已确定的路径开始到某一文件或文件夹的路径。将确定路径和相对路径拼接起来就是相对路径对应的绝对路径地址。
Paths类可以创建相对路径的实例,可以使用Paths.get(String basePath, String relativePath)方法来创建一个相对路径的实例
//创建一个指向d:\path_test\demo文件夹路径的实例
Path path = Paths.get("d:\\path_test", "demo");
// 创建一个指向d:\path_test\demo\first_path.txt文件路径的实例
Path path = Paths.get("d:\\path_test", "demo\\first_path.txt");通过上方的示例,第一感觉就是,将两个参数拼接起来以构成一个访问该文件的绝对路径。
这样理解也没有错,只是,参数的路径表达方式更加的灵活,可以跟上特殊符号.和..。
.代表当前目录
// 绝对路径就是该代码运行时的目录的绝对路径
Path currentDir = Paths.get(".");
System.out.println(currentDir.toAbsolutePath());运行结果
D:\Codes\idea\netty-demo\...代表父目录或者是上一级目录
// Path实例的绝对路径就是该代码运行时的父目录的绝对路径
Path parentDir = Paths.get("..");
System.out.println(parentDir.toAbsolutePath());运行结果
D:\Codes\idea\netty-demo\..- . 和 … 可以在Paths.get() 方法中结合使用
Path path1 = Paths.get("d:\\path_test", ".\\demo");
Path path2 = Paths.get("d:\\path_test\\demo", "..\\demo2");2.4 Path.normalize()方法
Path接口中的normalize()可以标准化一个路径。标准化意思是解析路径中的.和 .. 。
示例
String originalPath = "d:\\path_test\\demo\\..\\demo2";
Path path1 = Paths.get(originalPath);
System.out.println("path1 = " + path1);
Path path2 = path1.normalize();
System.out.println("path2 = " + path2);运行结果
path1 = d:\path_test\demo\..\demo2
path2 = d:\path_test\demo2我们可以看到规范化的路径没有包含demo..多余的部分,移除的部分对于绝对路径是无关紧要的。
NIO之Files介绍
一、概述
Files是Java1.7 在nio中新增的专门用于处理文件和目录的工具类。Files和Path配合可以很方便的完成对文件/目录的创建、读取、修改、删除等操作。
二、常用方法介绍
2.1 Files.exits()
boolean exists(Path path, LinkOption… options)
描述:方法检查一个路径是否存在于当前的文件系统中。
参数:
- Path :传入的文件路径。必须
- LinkOption:
exits()方法的选项数组。如LinkOption.NOFOLLOW_LINKS代表不允许跟随文件系统中的符号链接来确定路径是否存在。非必须
Path path = Paths.get("D:\\path_test\\demo");
boolean exists = Files.exists(path);
System.out.println(exists);2.2 Files.createDirectory()
createDirectory(Path dir, FileAttribute<?>… attrs)
描述:此方法使用给定的路径创建目录,如果创建目录成功,它将返回创建的目录的路径。
参数:
- Path :需要创建的文件路径。必须
- FileAttribute:是在创建不存在的目录时自动设置的可选参数,它返回创建的目录的路径。非必须
注意
- 如果目录已经存在,那么它会抛出nio.file.FileAlreadyExistsException。
- 不能一次创建多级目录,否则会抛异常 NoSuchFileException
Path path = Paths.get("D:\\path_test\\demo2");
Files.createDirectories(path);2.3 Files.createDirectories()
createDirectories(Path dir, FileAttribute<?>… attrs)
描述:此方法通过首先创建所有不存在的父目录来使用给定路径创建目录。如果由于目录已存在而无法创建该目录,则此方法不会引发异常。
该方法用来创建多级目录。
Path path = Paths.get("D:\\path_test\\demo3\\a\\b");
Files.createDirectories(path);2.4 Files.copy()
long copy(InputStream in, Path target, CopyOption… options)
描述:此方法将指定输入流中的所有字节复制到指定目标文件,并返回读取或写入的字节数作为长值。
- 将InputStream中的数据复制到目标文件
InputStream inputStream = new FileInputStream("D:\\path_test\\demo\\first_input.txt");
Path targetPath = Paths.get("D:\\path_test\\demo3\\first_copy2.txt");
long size = Files.copy(inputStream, targetPath, StandardCopyOption.REPLACE_EXISTING);
System.out.println(size);注意
- 默认情况,如果目标文件已经存在或是一个符号链接,则复制失败;
- 指定了REPLACE_EXISTING的情况,如果目标文件已经存在,那么只要它不是一个非空目录(例如它是一个空目录,或者是一个符号链接),它就会被替换。截止到JDK1.8,options只支持
REPLACE_EXISTING。
long copy(Path source, OutputStream out)
描述:此方法将指定源文件中的所有字节复制到给定的输出流,并返回读取或写入的字节数作为长值。
- 将本地文件中的内容复制到OutputStream
Path path = Paths.get("D:\\path_test\\demo\\first_copy.txt");
OutputStream outputStream = new FileOutputStream("D:\\path_test\\demo\\first_output.txt");
long size = Files.copy(path, outputStream);
System.out.println(size);注意
- 当发生异常的时候,由于输出了可能已经获取到了一部分内容,所以输出流此时的内容可能很奇怪,应该直接关闭。
- 如果输出流是Flushable的实现类的实例,在执行完方法以后应该调用flush方法以刷新缓存。
Path copy(Path source, Path target, CopyOption… options)
描述:此方法将给定的源文件复制到指定的目标文件,并返回目标文件的路径。
- 将文件first_copy.txt复制到文件first_copy2.txt
Path path = Paths.get("D:\\path_test\\demo3\\first_copy.txt");
Path targetPath = Paths.get("D:\\path_test\\demo3\\first_copy2.txt");
Path copy = Files.copy(path, targetPath);
System.out.println(copy);注意
- 在默认情况下,如果目标文件已经存在,或者是一个符号链接,那么复制失败;
options参数
| 参数 | 说明 |
|---|---|
| REPLACE_EXISTING | 如果目标文件已经存在,那么只要它不是一个非空目录,它就会被替换。 |
| COPY_ATTRIBUTES | 把source的文件属性复制给target,被复制的属性取决于平台和文件系统,但是至少在source和target都支持的情况下,会复制最新修改时间。 |
| NOFOLLOW_LINKS | 直接复制符号链接自身,而不是符号链接指向的目的地。可被复制的属性也会被复制,也就是说NOFOLLOW_LINKS的情况下配置COPY_ATTRIBUTES是没有意义的。 |
2.5 Files.move()
move(Path source, Path target, CopyOption… options)
描述:此方法将源文件移动或重命名为目标文件,并返回目标文件的路径。
Path sourcePath = Paths.get("D:\\path_test\\demo\\first_copy.txt");
Path targetPath = Paths.get("D:\\path_test\\demo3\\first_copy2.txt");
Path move = Files.move(sourcePath, targetPath, StandardCopyOption.REPLACE_EXISTING);
System.out.println(move);options参数
| 参数 | 说明 |
|---|---|
| REPLACE_EXISTING | 如果目标文件存在,则如果它不是非空目录,则替换它。 |
| ATOMIC_MOVE | 表示移动文件作为原子文件系统操作执行,所有其他选项都被忽略。 |
注意
- 如果目标文件存在但由于未指定REPLACE_EXISTING选项而无法替换,则此方法将引发FileAleadyExistsException。
- 如果指定了REPlACE_EXISTING选项,则此方法将引发DirectoryNotEmptyException但无法替换该文件,因为它是一个非空目录。
2.6 Files.delete()
void delete(Path path)
描述:删除一个文件或文件夹。
Path path = Paths.get("D:\\path_test\\demo");
//如果path指定到一个目录,并且目标不为空时会抛出异常
Files.delete(path);如果目标存在,并且是文件或者空的文件夹,就删除文件;如果目标不存在,或者目标是非空的文件夹,就会抛出异常。
2.7 Files.walkFileTree()
描述:Files.walkFileTree()方法可以递归遍历目录树。它使用一个Path和一个FileVisitor作为参数。
首先先展示一下FileVisitor接口
public interface FileVisitor {
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException;
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException;
public FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException;
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException;
}Files.walkFileTree()方法需要一个FileVisitor的实现类作为参数,实现FileVisitor接口就需要实现上述方法。
如果不想做特殊实现或者只想实现一部分,可以继承SimpleFileVisitor类,它其中有对FileVisitor的方法的默认实现。
示例
Files.walkFileTree(path, new FileVisitor<Path>() {
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
System.out.println("pre visit dir:" + dir);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println("visit file: " + file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) throws IOException {
System.out.println("visit file failed: " + file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
System.out.println("post visit directory: " + dir);
return FileVisitResult.CONTINUE;
}
});这些方法在遍历的不同时间被调用
preVisitDirectory()方法在访问任何目录前被调用。postVisitDirectory()方法在访问任何目录后被调用。visitFile()方法在访问任何文件时被调用。visitFileFailed()在访问任何文件失败时被调用。(比如没权限)
每个方法返回一个FileVisitResult枚举,这些返回指决定了遍历如何进行。
包括
| 参数 | 说明 |
|---|---|
| CONTINUE | 表示遍历将继续正常进行 |
| TERMINATE | 表示文件遍历将终止 |
| SKIP_SIBLINGS | 表示文件遍历将继续,但不在访问此文件/目录的同级文件/目录 |
| SKIP_SUBTREE | 表示文件遍历将继续,但不再访问此目录内的文件 |
NIO之Files Demo
一、遍历目录文件
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author lilinchao
* @date 2022/5/30
* @description 遍历目录,统计文件和文件夹个数
**/
public class FilesTraverseDirectoryDemo {
public static void main(String[] args) throws IOException {
Path path = Paths.get("D:\\Tools\\jdk1.8.0_201");
AtomicInteger dirCount = new AtomicInteger();
AtomicInteger fileCount = new AtomicInteger();
Files.walkFileTree(path,new SimpleFileVisitor<Path>(){
//preVisitDirectory()在访问任何目录前被调用
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
System.out.println(dir);
dirCount.incrementAndGet();
return super.preVisitDirectory(dir, attrs);
}
//visitFile()在访问任何文件时被调用
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println(file);
fileCount.incrementAndGet();
return super.visitFile(file, attrs);
}
});
System.out.println(dirCount);
System.out.println(fileCount);
}
}二、统计Jar的数目
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author lilinchao
* @date 2022/5/30
* @description 统计文件中Jar的个数
**/
public class FilesCountJarNumberDemo {
public static void main(String[] args) throws IOException {
Path path = Paths.get("D:\\Tools\\jdk1.8.0_201");
AtomicInteger fileCount = new AtomicInteger();
Files.walkFileTree(path,new SimpleFileVisitor<Path>(){
//visitFile()在访问任何文件时被调用
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
if(file.toFile().getName().endsWith(".jar")){
fileCount.incrementAndGet();
}
return super.visitFile(file, attrs);
}
});
System.out.println(fileCount);
}
}三、删除多级目录
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
/**
* @author lilinchao
* @date 2022/5/30
* @description 删除多级目录
**/
public class FilesDeleteDirectoryDemo {
public static void main(String[] args) throws IOException {
Path path = Paths.get("D:\\libs2");
Files.walkFileTree(path,new SimpleFileVisitor<Path>(){
//visitFile()在访问任何文件时被调用
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
Files.delete(file);
return super.visitFile(file, attrs);
}
//postVisitDirectory()在访问任何目录后被调用
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
Files.delete(dir);
return super.postVisitDirectory(dir, exc);
}
});
System.out.println("删除完毕!");
}
}四、拷贝多级目录
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
/**
* @author lilinchao
* @date 2022/5/30
* @description 拷贝多级目录
**/
public class FilesCopyDirectoryDemo {
public static void main(String[] args) throws IOException {
long start = System.currentTimeMillis();
String source = "D:\\libs";
String target = "D:\\libs_aaa";
Files.walk(Paths.get(source)).forEach(path -> {
try {
String targetName = path.toString().replace(source,target);
//是目录
if(Files.isDirectory(path)){
//createDirectory()方法利用Path创建一个新的目录
Files.createDirectory(Paths.get(targetName));
}else if(Files.isRegularFile(path)){ //是普通文件
//copy()方法将文件从一个path复制到另一个
Files.copy(path,Paths.get(targetName));
}
} catch (Exception e) {
e.printStackTrace();
}
});
long end = System.currentTimeMillis();
System.out.println(end - start);
}
}NIO之阻塞模式和非阻塞模式
前言
SocketChannel方法介绍
创建一个服务器对象
ServerSocketChannel.open()- 服务器对象需要绑定ip和端口,使用
bind(InetSocketAddress )方法,需要使用传入InetSocketAddress,只需传入一个端口号即可; - 服务器调用accept()方法获取客户端的连接请求;
- 通过接收到的客户端连接对象
read(buffer)方法获取客户端发送的消息。
- 服务器对象需要绑定ip和端口,使用
创建客户端
SocketChannel.open()- 客户端使用
connect(InetSocketAddress server)方法,连接对应的服务器; - 通过
write(buffer)方法发送消息到连接的服务器
- 客户端使用
一、阻塞模式
1.1 概念
- 阻塞模式下,相关方法都会导致线程暂停
- ServerSocketChannel.accept 会在没有连接建立时让线程暂停
- SocketChannel.read 会在没有数据可读时让线程暂停
- 阻塞的表现其实就是线程暂停了,暂停期间不会占用 cpu,但线程相当于闲置
- 单线程下,阻塞方法之间相互影响,几乎不能正常工作,需要多线程支持
- 但多线程下,有新的问题,体现在以下方面
- 32 位 jvm 一个线程 320k,64 位 jvm 一个线程 1024k,如果连接数过多,必然导致 OOM,并且线程太多,反而会因为频繁上下文切换导致性能降低
- 可以采用线程池技术来减少线程数和线程上下文切换,但治标不治本,如果有很多连接建立,但长时间 inactive,会阻塞线程池中所有线程,因此不适合长连接,只适合短连接
1.2 代码演示
- 服务端代码
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.ArrayList;
import java.util.List;
import static com.lilinchao.nio.util.ByteBufferUtil.debugRead;
/**
* @author lilinchao
* @date 2022/5/31
* @description 使用 nio 来理解阻塞模式, 单线程 服务端
**/
@Slf4j
public class ServerDemo {
public static void main(String[] args) throws IOException {
//创建ByteBuffer缓冲区
ByteBuffer buffer = ByteBuffer.allocate(16);
//1. 创建服务器
ServerSocketChannel ssc = ServerSocketChannel.open();
//2.绑定监听端口
ssc.bind(new InetSocketAddress(8080));
//3.连接集合
List<SocketChannel> channels = new ArrayList<>();
//循环接收客户端的连接
while (true){
//4. accept建立与客户端连接,SocketChannel 用来与客户端之间通信
log.debug("connecting...");
//阻塞方法,没有连接时,会阻塞线程
SocketChannel sc = ssc.accept();
log.debug("connected... {}",sc);
channels.add(sc);
// 循环遍历集合中的连接
for (SocketChannel channel : channels){
// 处理通道中的数据
// 当通道中没有数据可读时,会阻塞线程
log.debug("befor read... {}",channel);
channel.read(buffer);
//切换到读模式
buffer.flip();
debugRead(buffer);
//切换到写模式
buffer.clear();
log.debug("after read... {}",channel);
}
}
}
}- 客户端代码
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.SocketChannel;
/**
* @author lilinchao
* @date 2022/5/31
* @description 1.0
**/
public class ClientDemo {
public static void main(String[] args) throws IOException {
SocketChannel sc = SocketChannel.open();
sc.connect(new InetSocketAddress("localhost",8080));
System.out.println("waiting...");
}
}1.3 结果分析
1、启动服务端程序
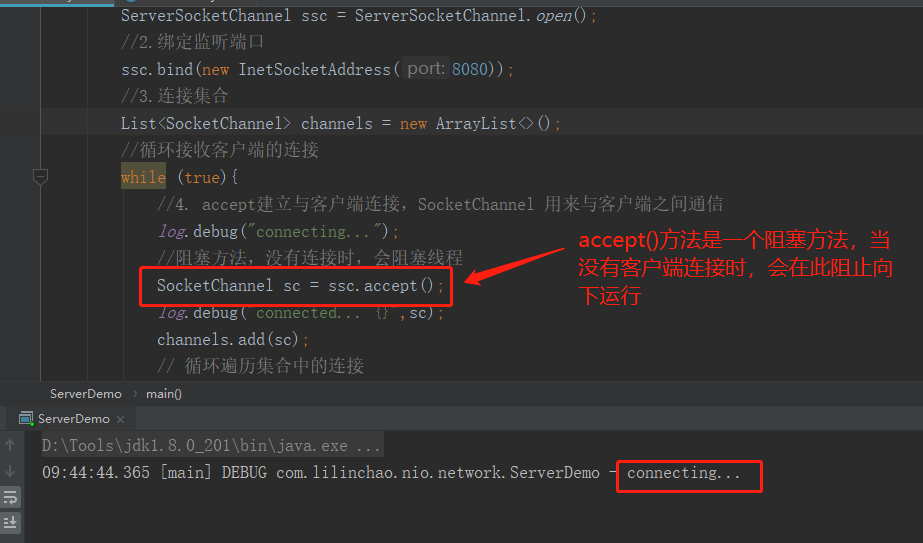
- 当刚启动服务端程序时,会在accept()方法产生阻塞,等待客户端的连接。
客户端-服务器建立连接前,服务器端因accept阻塞
2、通过Debug模式启动客户端
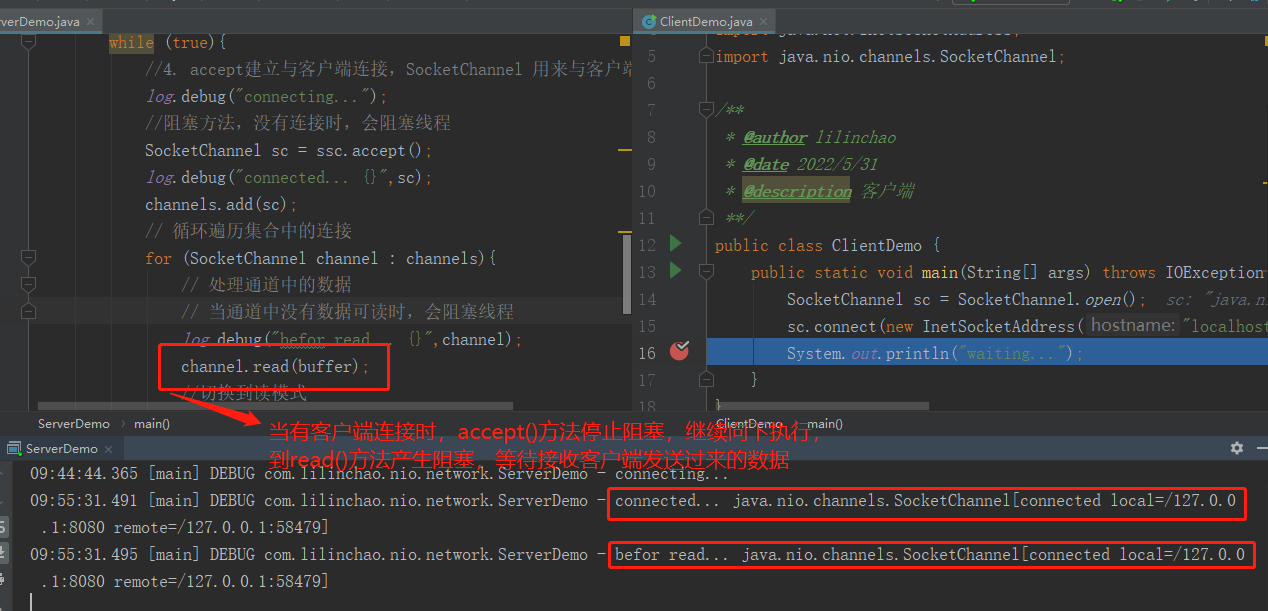
- 客户端在acccept()方法没有继续阻塞,向下运行;
- 在read()方法等待读入数据,当客户端没有向服务器端发送数据时,会在此产生阻塞;
客户端-服务器建立连接后,客户端发送消息前,服务器端因通道为空被阻塞
3、客户端向服务端发送数据
- 向服务端发送数据
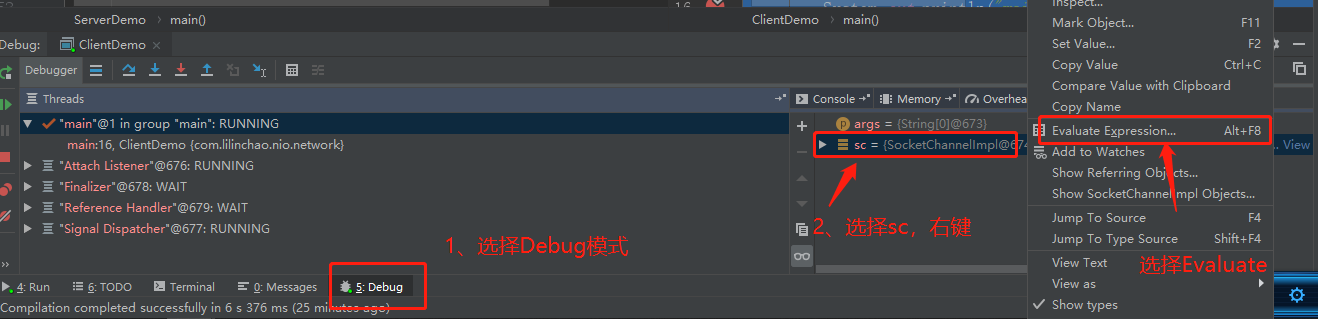
sc.write(Charset.defaultCharset().encode("hello!"));- 控制台打印结果
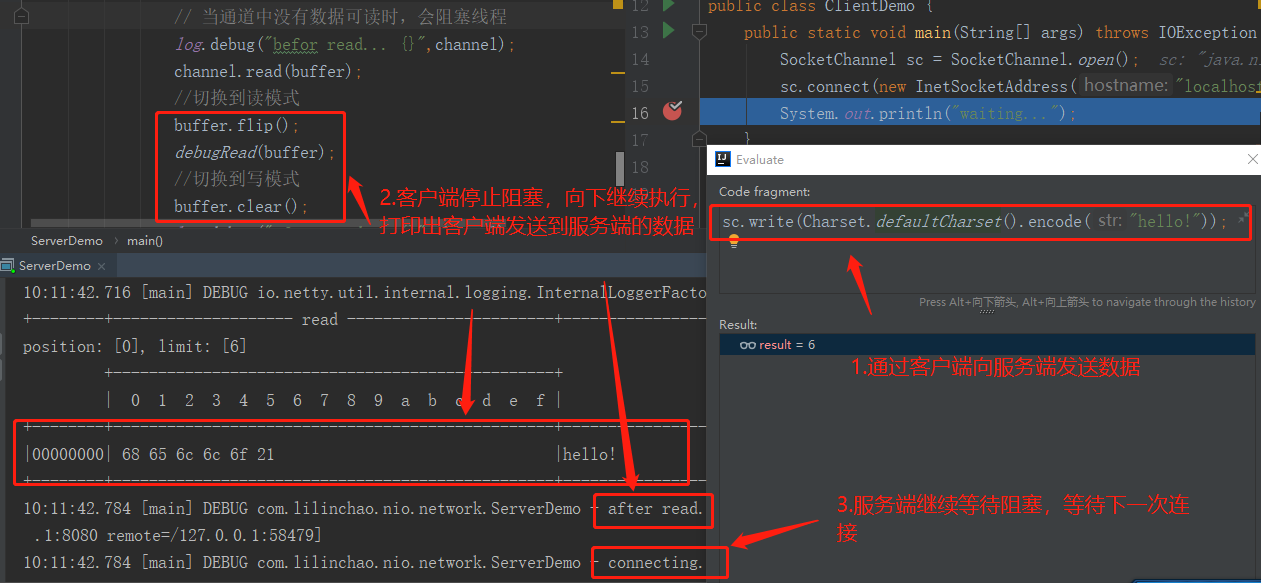
客户端发送数据后,服务器处理通道中的数据。再次进入循环时,再次被accept阻塞
4、之前的客户端再次发送消息
服务器端因为被accept阻塞,无法处理之前客户端发送到通道中的信息,影响了整个程序的正常执行。
二、非阻塞模式
2.1 概念
- 非阻塞模式下,相关方法都会不会让线程暂停
- 在 ServerSocketChannel.accept 在没有连接建立时,会返回 null,继续运行
- SocketChannel.read 在没有数据可读时,会返回 0,但线程不必阻塞,可以去执行其它 SocketChannel 的 read 或是去执行 ServerSocketChannel.accept
- 写数据时,线程只是等待数据写入 Channel 即可,无需等 Channel 通过网络把数据发送出去
- 但非阻塞模式下,即使没有连接建立,和可读数据,线程仍然在不断运行,白白浪费了 cpu
- 数据复制过程中,线程实际还是阻塞的(AIO 改进的地方)
2.2 代码演示
服务端代码
可以通过
ServerSocketChannel的configureBlocking(false)方法将获得连接设置为非阻塞的。此时若没有连接,accept会返回null
可以通过
SocketChannel的configureBlocking(false)方法将从通道中读取数据设置为非阻塞的。若此时通道中没有数据可读,read会返回-1
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.ArrayList;
import java.util.List;
import static com.lilinchao.nio.util.ByteBufferUtil.debugRead;
/**
* @author lilinchao
* @date 2022/5/31
* @description 使用 nio 来理解非阻塞模式 服务端
**/
@Slf4j
public class ServerDemo2 {
public static void main(String[] args) throws IOException {
//创建ByteBuffer缓冲区
ByteBuffer buffer = ByteBuffer.allocate(16);
//1. 创建服务器
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false); //非阻塞模式
//2.绑定监听端口
ssc.bind(new InetSocketAddress(8080));
//3.连接集合
List<SocketChannel> channels = new ArrayList<>();
//循环接收客户端的连接
while (true){
//4. accept建立与客户端连接,SocketChannel 用来与客户端之间通信
SocketChannel sc = ssc.accept(); //非阻塞,线程还会继续运行,如果没有连接建立,但sc是null
if(sc != null){
log.debug("connected... {}",sc);
sc.configureBlocking(false); //非阻塞模式
channels.add(sc);
}
// 循环遍历集合中的连接
for (SocketChannel channel : channels){
//5. 接收客户端发送的数据
int read = channel.read(buffer);
if(read > 0){
//切换到读模式
buffer.flip();
debugRead(buffer);
//切换到写模式
buffer.clear();
log.debug("after read... {}",channel);
}
}
}
}
}- 客户端代码不变
该方法虽然可以解决阻塞模式下的问题,但是因为设置为了非阻塞,会一直执行while(true)中的代码,CPU一直处于忙碌状态,会使得性能变低,所以实际情况中不使用这种方法处理请求。
NIO之选择器(Selector)
一、概述
Selector一般称为选择器,也可以翻译为多路复用器,是Java NIO核心组件之一,主要功能是用于检查一个或者多个NIO Channel(通道)的状态是否处于可读、可写。如此可以实现单线程管理多个Channel(通道),当然也可以管理多个网络连接。
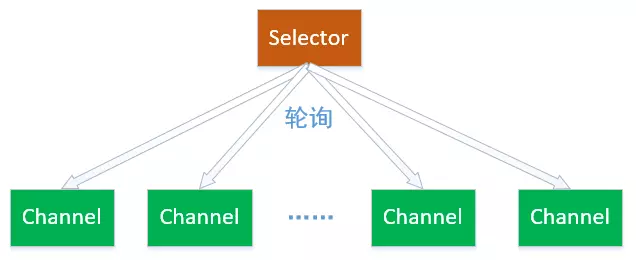
使用Selector的好处在于,可以使用更少的线程来处理更多的通道,相比使用更多的线程,避免了线程上下文切换带来的开销等。
二、Selector(选择器)方法
2.1 Selector的创建
通过调用静态工厂方法Selector.open()方法创建一个Selector对象。
Selector selector = Selector.open();open()方法实际上是向SPI发出请求,通过默认的SelectorProvider对象获取一个新的Selector实例。
2.2 注册Channel到Selector
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, Selectionkey.OP_READ);代码的第一行:让这个Channel(通道)是非阻塞的。
它是SelectableChannel抽象类里的方法,用于使通道处于阻塞模式或非阻塞模式,false表示非阻塞,true表示阻塞。
它的签名是:
abstract SelectableChannel configureBlocking(boolean block)要想Channel注册到Selector中,那么这个Channel必须是非阻塞的。
所以FileChannel不适合Selector,因为FileChannel不能切换为非阻塞模式,更准确的说是因为FileChannel没有继承SelectableChannel。但是SocketChannel可以正常使用。
代码的第二行:register()方法就是将通道注册到Selector中,并且让Selector监听感兴趣的事件(第二个参数)。
- 着重讲一下第二个参数,它是一个“interest集合”,意思是在通过Selector监听Channel对什么事件感兴趣。可以监听四种不同类型的事件:Connect、Accept、Read、Write。
| 参数 | 常量表示 | 说明 |
|---|---|---|
| Connect | SelectionKey.OP_CONNECT | 成功连接到另一个服务器称为“连接就绪” |
| Accept | SelectionKey.OP_ACCEPT | ServerSocketChannel准备好接收新进入的连接称为“接收就绪” |
| Read | SelectionKey.OP_READ | 有数据可读的通道称为“读就绪” |
| Write | SelectionKey.OP_WRITE | 等待写数据的通道称为“写就绪” |
如果对不止一种事件感兴趣,可以使用或( | )运算符来操作
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;2.3 SelectionKey
一个SelectionKey键表示了一个特定的通道对象和一个特定的选择器对象之间的注册关系。
key.attachment(); //返回SelectionKey的attachment,attachment可以在注册channel的时候指定。
key.channel(); // 返回该SelectionKey对应的channel。
key.selector(); // 返回该SelectionKey对应的Selector。
key.interestOps(); //返回代表需要Selector监控的IO操作的bit mask
key.readyOps(); // 返回一个bit mask,代表在相应channel上可以进行的IO操作。方法介绍
- key.interestOps()
描述:通过这个方法来判断Selector是否对Channel的某种事件感兴趣;
int interestSet = selectionKey.interestOps();
boolean isInterestedInAccept = (interestSet & SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT;
boolean isInterestedInConnect = interestSet & SelectionKey.OP_CONNECT;
boolean isInterestedInRead = interestSet & SelectionKey.OP_READ;
boolean isInterestedInWrite = interestSet & SelectionKey.OP_WRITE;- key.readyOps()
描述:readySet 集合时通道已经准备就绪的操作的集合。
Java中定义了以下几个方法来检查这些操作是否就绪:
//创建ready集合的方法
int readySet = selectionKey.readyOps();
//检查这些操作是否就绪的方法
selectionKey.isAcceptable();//等价selectionKey.readyOps()&SelectionKey.OP_ACCEPT
selectionKey.isConnectable();
selectionKey.isReadable();
selectionKey.isWritable();- key.attachment()
描述:可以将一个对象或者更多信息附着到SelectionKey上,这样就能方便的识别某个特定的通道。
例如,可以附加与通道一起使用的Buffer,或者包含聚集数据的某个对象。如:
key.attach(theObject);
Object attachedObj = key.attachment();还可以在register()方法使用的时候(即Selector注册Channel的时候)附加对象:
SelectionKey key = channel.register(selector, SelectionKey.OP_READ, theObject);- key.channel()和key.selector()
描述:取出SelectionKey关联的Channel和Selector
Channel channel = key.channel();
Selector selector = key.selector();三、Selector中的Channel
选择器维护注册过的通道,这种选择器与通道的注册关系被封装在SelectionKey中。
public abstract class Selector
{
...
public abstract Set keys();
public abstract Set selectedKeys();
public abstract int select() throws IOException;
public abstract int select(long timeout) throws IOException;
public abstract int selectNow() throws IOException;
public abstract void wakeup();
...
}Selector维护的三种类型SelectionKey集合
(1)已注册的键的集合(Registered key set)
所有与选择器关联的通道所生成的键的集合称为已注册键的集合。这个集合通过keys()方法返回,并且有可能是空的。
注意:并不是所有注册过的键都有效。同时已注册键的集合是不可以直接修改的,若这么做的话,将会抛出java.lang.UnsupportedOperationException 异常。
(2)已选择键的集合(Selected key set)
已注册键的集合的子集,这个集合的每个成员都是相关的通道被选择器判断为已经准备好的并且包含于键的interest集合中的操作。这个集合通过selectedKeys()方法返回(有可能是空的)。
注意:这些键可以直接从这个集合中移除,但是不能添加。若这么做的话将会抛出java.lang.UnsupportedOperationException异常。
(3)已取消键的集合(Cancelled key set)
已注册键的集合的子集,这个集合包含了cancel()方法被调用过的键(这个键已经被无效化),但他们还没有被注销。这个集合是选择器对象的私有成员,因而无法直接访问。
注意:当键被取消(可以通过isValid()方法来判断)时,它将被放在相关的选择器的已取消的键的集合里。注册不会立即被取消,但键会立即失效。当再次调用select()方法时(或者一个正在进行的select()调用结束时),已取消的键的集合中的被取消的键将会被清理掉,并且相应的注销也将会完成。通道会被注销,新的SelectionKey将被返回。当通道关闭时,所有相关的键会自动取消(一个通道可以被注册到多个选择器上)。当选择器关闭时,所有被注册到该选择器的通道都将被注销,并且相应的键将立即被无效化(取消),一旦键被无效化,调用它的与之相关的方法就将抛出CancelledKeyException 异常。
四、select()方法
在刚初始化的Selector对象中,上面讲述的三个集合都是空的。通过Selector的select()方法可以选择已经准备就绪的通道(这些通道包含你感兴趣的事件)。比如你对读就绪的通道感兴趣,那么select()方法就会返回读事件已经就绪的那些通道。
下面是Selector重载的几个select()方法:
- int select():阻塞到至少有一个通道在你注册的事件上就绪了;
- int select(long timeout):和select()一样,但最长阻塞时间为timeout毫秒;
- int selectNow():非阻塞,执行就绪检查过程,但不阻塞,如果当前没有通道就绪,立刻返回0;
select()方法返回的int值表示有多少通道已经就绪,是自上次调用select()方法后有多少通道变成就绪状态。
之前在调用select()时进入就绪的通道不会在本次调用中被计入,而在前一次select()调用进入就绪但现在已经不在就绪状态的通道也不会被计入。
例如:首次调用select()方法,如果有一个通道变成了就绪状态,返回了1,若再次调用select()方法,如果另一个通道就绪了,它会再次返回1。如果对第一个就绪的Channel没有做任何操作,现在就有两个就绪的通道,但在每次select()方法调用之间,只有一个通道就绪了。
一旦调用了select()方法,并且返回值不为0时,则可以通过调用Selector的selectedKeys()方法来访问已选择键的集合。如下:
Set selectedKeys = selector.selectedKeys();
Iterator keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
keyIterator.remove();
}请注意keyIterator.remove()每次迭代结束时的调用。在Selector删除SelectionKey作为自己选择的关键实例,当你完成处理后,你必须这样做。这样的话才能在通道下一次变为“就绪”时,Selector将再次将其添加到所选的键集合。
五、停止选择
选择器执行选择的过程,系统底层会一次询问每个通道是否就绪,这个过程可能会造成调用线程进入阻塞状态,那么我们有以下两种方式来唤醒在Select()方法中阻塞的线程。
(1)wakeup()方法:一个线程调用select()方法的那个对象上调用Selector.wakeup()方法。阻塞在select()方法上的线程会立马返回。如果有其它线程调用了wakeup()方法,但当前没有线程阻塞在select()方法上,下个调用select()方法的线程会立即“醒来(wake up)”。
(2)close()方法:该方法使得任何一个在选择操作中阻塞的线程都被唤醒,用完Selector后调用其close()方法会关闭该Selector,且使注册到该Selector上的所有SelectionKey实例无效。通道本身并不会关闭。
Selector处理accept和read事件
前言
- 多路复用
单线程可以配合 Selector 完成对多个 Channel 可读写事件的监控,这称之为多路复用
- 多路复用仅针对网络 IO、普通文件 IO 没法利用多路复用
- 如果不用 Selector 的非阻塞模式,线程大部分时间都在做无用功,而 Selector 能够保证
- 有可连接事件时才去连接
- 有可读事件才去读取
- 有可写事件才去写入
- 限于网络传输能力,Channel 未必时时可写,一旦 Channel 可写,会触发 Selector 的可写事件
一、处理accept事件
- 服务器端代码
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
/**
* @author lilinchao
* @date 2022/6/2
* @description Accept事件
**/
@Slf4j
public class AcceptServer {
public static void main(String[] args) throws IOException {
//1.创建Selector,可以管理多个channel
Selector selector = Selector.open();
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
//2.建立channel和selector之间的联系(注册)
//SelectionKey:事件发生后通过这个可以获取到相应事件,以及对应事件发生的channel
SelectionKey sscKey = ssc.register(selector, 0, null);
//表名这个key只关注accept事件
sscKey.interestOps(SelectionKey.OP_ACCEPT);
log.debug("register key:{}",sscKey);
ssc.bind(new InetSocketAddress(8080));
while (true){
//3. selector.select()方法,没有事件就阻塞,有事件发送就恢复运行继续向下处理
selector.select();
//4.处理事件,selectionKeys内部包含了所有发生的事件
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
while (iterator.hasNext()){
//注意,如果事件不调用accept进行处理,那么不会阻塞,因为事件没被处理,就不能阻塞
//也就是说事件要么处理要么取消,不能不管
SelectionKey key = iterator.next();
log.debug("key:{}",key);
//拿到触发事件的channel
ServerSocketChannel channel = (ServerSocketChannel)key.channel();
SocketChannel sc = channel.accept();
log.debug("{}",sc);
}
}
}
}- 客户端代码
import java.io.IOException;
import java.net.Socket;
/**
* @author lilinchao
* @date 2022/6/2
* @description 1.0
**/
public class AcceptClient {
public static void main(String[] args) {
try (Socket socket = new Socket("localhost", 8080)) {
System.out.println(socket);
socket.getOutputStream().write("world".getBytes());
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}
}- 运行
(1)启动服务端程序
(2)通过Debug模式启动客户端程序
(3)通过Debug模式再启动一个客户端程序
- 客户端启动项,选择【Edit Configurations】
- 选择【Allow parallel run】,再点击【OK】
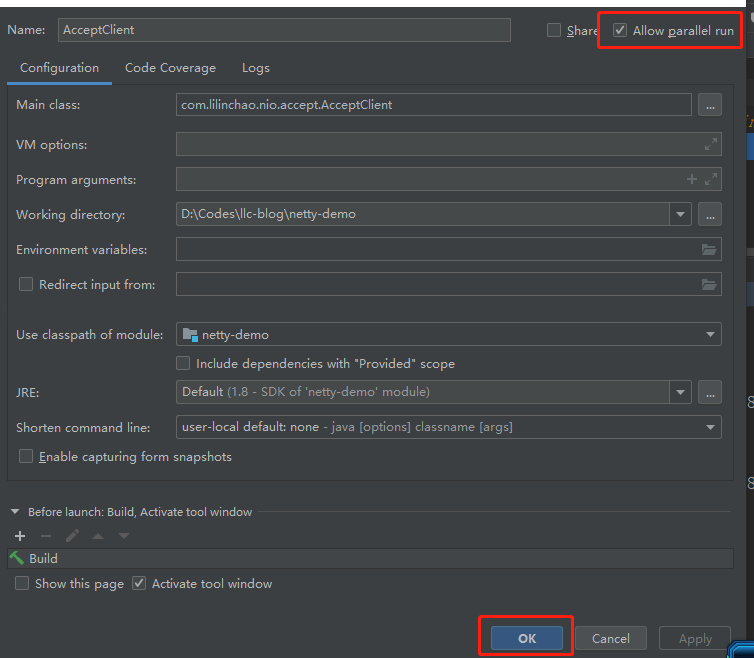
- 再通过Debug模式启动一个客户端
- 服务端程序输出结果
17:05:25.304 [main] DEBUG com.lilinchao.nio.accept.AcceptServer - register key:sun.nio.ch.SelectionKeyImpl@3b764bce
17:05:38.141 [main] DEBUG com.lilinchao.nio.accept.AcceptServer - key:sun.nio.ch.SelectionKeyImpl@3b764bce
17:05:38.142 [main] DEBUG com.lilinchao.nio.accept.AcceptServer - java.nio.channels.SocketChannel[connected local=/127.0.0.1:8080 remote=/127.0.0.1:51904]
17:05:55.911 [main] DEBUG com.lilinchao.nio.accept.AcceptServer - key:sun.nio.ch.SelectionKeyImpl@3b764bce
17:05:55.912 [main] DEBUG com.lilinchao.nio.accept.AcceptServer - java.nio.channels.SocketChannel[connected local=/127.0.0.1:8080 remote=/127.0.0.1:51919]从打印结果可以看出有两个客户端向服务端发送了连接请求。
问题:事件发生后能否不处理?
事件发生后,要么处理,要么取消(cancel),不能什么都不做,否则下次该事件仍会触发,这是因为 nio 底层使用的是水平触发
二、处理read事件
- 服务端代码
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import static com.lilinchao.nio.util.ByteBufferUtil.debugAll;
/**
* @author lilinchao
* @date 2022/6/2
* @description Read事件 服务端
**/
@Slf4j
public class ReadServer {
public static void main(String[] args) throws IOException {
//1.创建selector,管理多个channel
Selector selector = Selector.open();
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
//2. 建立channel和selector之间的联系(注册)
SelectionKey sscKey = ssc.register(selector, 0, null);
sscKey.interestOps(SelectionKey.OP_ACCEPT);
log.debug("register key:{}",sscKey);
ssc.bind(new InetSocketAddress(8080));
while (true){
//3. selector.select()方法,没有事件就阻塞,有了事件发送了就恢复运行继续向下处理
selector.select();
//4. 处理事件,selectionKeys拿到所有发生的可读可写的事件
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
//多个key的时候,accept和read方法都会触发事件,所以要区分事件类型
while (iterator.hasNext()){
SelectionKey key = iterator.next();
//处理key的时候要从selectKeys中删除,否则会报错
iterator.remove();
log.debug("key:{}",key);
//5.区分事件类型
if(key.isAcceptable()){
//拿到触发事件的channel
ServerSocketChannel channel = (ServerSocketChannel)key.channel();
SocketChannel sc = channel.accept();
//设置为非阻塞
sc.configureBlocking(false);
//scKey管sc的channel
SelectionKey scKey = sc.register(selector, 0, null);
//scKey关注读事件,也就是说客户端的通道关注可读事件
scKey.interestOps(SelectionKey.OP_READ);
log.debug("{}",sc);
}else if(key.isReadable()){
//客户端关闭之后也会引发read事件,这时需要从key中remove掉,否则拿不到channel,报错
try {
SocketChannel channel = (SocketChannel)key.channel();
ByteBuffer buffer1 = ByteBuffer.allocate(16);
//客户端正常断开,read返回值是-1
int read = channel.read(buffer1);
if(read == -1){
//正常断开
key.channel();
}
buffer1.flip();
debugAll(buffer1);
} catch (IOException e) {
e.printStackTrace();
key.cancel();//客户端断开,需要将key取消(从selector的key集合中真正删除)
}
}
}
}
}
}- 客户端代码
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.SocketAddress;
import java.nio.channels.SocketChannel;
/**
* @author lilinchao
* @date 2022/6/2
* @description Read事件 客户端
**/
public class ReadClient {
public static void main(String[] args) throws IOException {
SocketChannel sc = SocketChannel.open();
sc.connect(new InetSocketAddress("localhost", 8080));
SocketAddress localAddress = sc.getLocalAddress();
System.out.println("waiting...");
}
}- 运行
(1)启动服务端程序
(2)Debug启动客户端程序
- 选择【Evalute Expression】
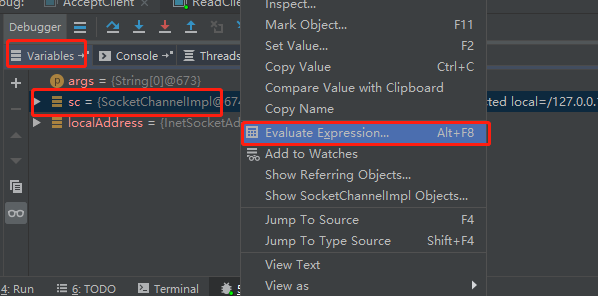
- 输入如下内容
sc.write(Charset.defaultCharset().encode("hello!"));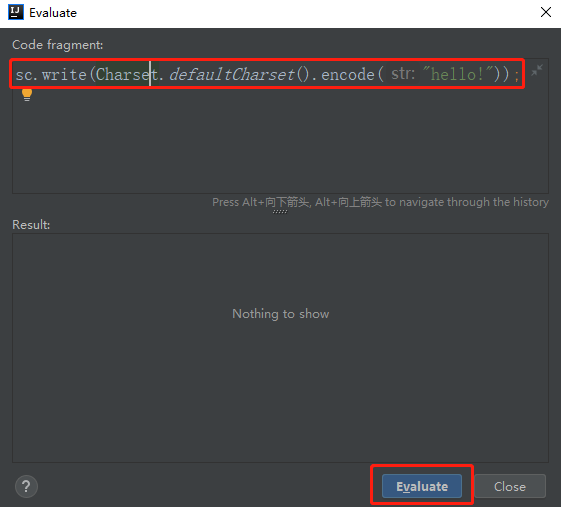
- 点击【Evaluate】提交
- 服务端输出结果
17:20:50.713 [main] DEBUG com.lilinchao.nio.read.ReadServer - register key:sun.nio.ch.SelectionKeyImpl@3b764bce
17:21:11.373 [main] DEBUG com.lilinchao.nio.read.ReadServer - key:sun.nio.ch.SelectionKeyImpl@3b764bce
17:21:11.374 [main] DEBUG com.lilinchao.nio.read.ReadServer - java.nio.channels.SocketChannel[connected local=/127.0.0.1:8080 remote=/127.0.0.1:52466]
17:23:48.603 [main] DEBUG com.lilinchao.nio.read.ReadServer - key:sun.nio.ch.SelectionKeyImpl@368102c8
17:23:48.653 [main] DEBUG io.netty.util.internal.logging.InternalLoggerFactory - Using SLF4J as the default logging framework
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [6]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 68 65 6c 6c 6f 21 00 00 00 00 00 00 00 00 00 00 |hello!..........|
+--------+-------------------------------------------------+----------------+服务端监听到客户端的连接,并读取打印客户端发送过来的数据。
问题:为何要 iter.remove()
因为 select 在事件发生后,就会将相关的 key 放入 selectedKeys 集合,但不会在处理完后从 selectedKeys 集合中移除,需要我们自己编码删除。例如
- 第一次触发了 ssckey 上的 accept 事件,没有移除 ssckey
- 第二次触发了 sckey 上的 read 事件,但这时 selectedKeys 中还有上次的 ssckey ,在处理时因为没有真正的 serverSocket 连上了,就会导致空指针异常
问题:cancel 的作用
cancel 会取消注册在 selector 上的 channel,并从 keys 集合中删除 key 后续不会再监听事件
NIO消息边界问题处理
一、消息边界问题的产生
1.1 服务端代码
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.nio.charset.Charset;
import java.util.Iterator;
/**
* Created by lilinchao
* Date 2022/6/3
* Description 消息边界问题 服务端
*/
@Slf4j
public class Server {
public static void main(String[] args) throws IOException {
//1.创建selector,管理多个channel
Selector selector = Selector.open();
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
//2. 建立channel和selector之间的联系(注册)
SelectionKey sscKey = ssc.register(selector, 0, null);
sscKey.interestOps(SelectionKey.OP_ACCEPT);
ssc.bind(new InetSocketAddress(8080));
while (true){
//3. selector.select()方法,没有事件就阻塞,有了事件发送了就恢复运行继续向下处理
selector.select();
//4. 处理事件,selectionKeys拿到所有发生的可读可写的事件
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
//多个key的时候,accept和read方法都会触发事件,所以要区分事件类型
while (iterator.hasNext()){
SelectionKey key = iterator.next();
//处理key的时候要从selectKeys中删除,否则会报错
iterator.remove();
//5.区分事件类型
if(key.isAcceptable()){
//拿到触发事件的channel
ServerSocketChannel channel = (ServerSocketChannel)key.channel();
SocketChannel sc = channel.accept();
//设置为非阻塞
sc.configureBlocking(false);
//scKey管sc的channel
SelectionKey scKey = sc.register(selector, 0, null);
//scKey关注读事件,也就是说客户端的通道关注可读事件
scKey.interestOps(SelectionKey.OP_READ);
}else if(key.isReadable()){
//客户端关闭之后也会引发read事件,这时需要从key中remove掉,否则拿不到channel,报错
try {
SocketChannel channel = (SocketChannel)key.channel();
//将缓冲区大小设置为4
ByteBuffer buffer1 = ByteBuffer.allocate(4);
//客户端正常断开,read返回值是-1
int read = channel.read(buffer1);
if(read == -1){
//正常断开
key.channel();
}
buffer1.flip();
System.out.println(Charset.defaultCharset().decode(buffer1));
} catch (IOException e) {
e.printStackTrace();
key.cancel();//客户端断开,需要将key取消(从selector的key集合中真正删除)
}
}
}
}
}
}1.2 客户端代码
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.SocketAddress;
import java.nio.channels.SocketChannel;
/**
* Created by lilinchao
* Date 2022/6/3
* Description 客户端
*/
public class Client {
public static void main(String[] args) throws IOException {
SocketChannel sc = SocketChannel.open();
sc.connect(new InetSocketAddress("localhost", 8080));
SocketAddress localAddress = sc.getLocalAddress();
System.out.println("waiting...");
}
}运行程序
(1)运行服务端代码
(2)通过Debug模式运行客户端代码
(3)通过客户端向服务端发送如下请求
sc.write(Charset.defaultCharset().encode("中国"));服务端输出结果
从输出结果可以看到,国字出现了乱码。
问题分析
因为在服务端代码中设置的接收客户端数据的缓冲区大小是4个字节,在UTF-8编码中,一个汉字占三个字节,也就是服务端在接收客户端发送到的消息时,只接收到了中字的三个字节和国字的第一个字节就进行了打印输出,导致国字出现了半包问题,产生了乱码。
二、消息边界问题分析
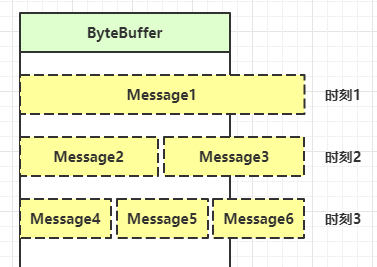
分析
- 时刻1:ByteBufeer较小,但是发送过来的消息比较大,一次处理不完;
- 时刻2:ByteBufeer较大,消息比较小。会出现半包现象
- 时刻3:ButeBuffer可以一次性接收客户端发送过来的多条消息。此时会出现黏包现象
解决思路
(1)固定消息长度,数据包大小一样,服务器按预定长度读取,当发送的数据较少时,需要将数据进行填充,直到长度与消息规定长度一致。缺点是浪费带宽
(2)按分隔符拆分,缺点是效率低,需要一个一个字符去匹配分隔符
(3)TLV 格式,即 Type 类型、Length 长度、Value 数据(也就是在消息开头用一些空间存放后面数据的长度),如HTTP请求头中的Content-Type与Content-Length。类型和长度已知的情况下,就可以方便获取消息大小,分配合适的 buffer,缺点是 buffer 需要提前分配,如果内容过大,则影响 server 吞吐量
三、解决消息边界问题
本示例将按照第二种方式,按分隔符拆分来解决消息边界问题。
3.1 附件与扩容
Channel的register方法还有第三个参数:附件,可以向其中放入一个Object类型的对象,该对象会与登记的Channel以及其对应的SelectionKey绑定,可以从SelectionKey获取到对应通道的附件
public final SelectionKey register(Selector sel, int ops, Object att)可通过SelectionKey的attachment()方法获得附件
ByteBuffer buffer = (ByteBuffer) key.attachment();需要在Accept事件发生后,将通道注册到Selector中时,对每个通道添加一个ByteBuffer附件,让每个通道发生读事件时都使用自己的通道,避免与其他通道发生冲突而导致问题
// 设置为非阻塞模式,同时将连接的通道也注册到选择器中,同时设置附件
socketChannel.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(16);
// 添加通道对应的Buffer附件
socketChannel.register(selector, SelectionKey.OP_READ, buffer);当Channel中的数据大于缓冲区时,需要对缓冲区进行扩容操作。此代码中的扩容的判定方法:Channel调用compact方法后,position与limit相等,说明缓冲区中的数据并未被读取(容量太小),此时创建新的缓冲区,其大小扩大为两倍。同时还要将旧缓冲区中的数据拷贝到新的缓冲区中,同时调用SelectionKey的attach方法将新的缓冲区作为新的附件放入SelectionKey中
// 如果缓冲区太小,就进行扩容
if (buffer.position() == buffer.limit()) {
ByteBuffer newBuffer = ByteBuffer.allocate(buffer.capacity()*2);
// 将旧buffer中的内容放入新的buffer中
newBuffer.put(buffer);
// 将新buffer作为附件放到key中
key.attach(newBuffer);
}3.2 完整代码
- 需求
将服务端缓冲区大小设置成16,客户端向服务端发送数据21个字节的数据
0123456789abcdef3333\n
\n为消息的分隔符,占一个字节大小
- 过程分析
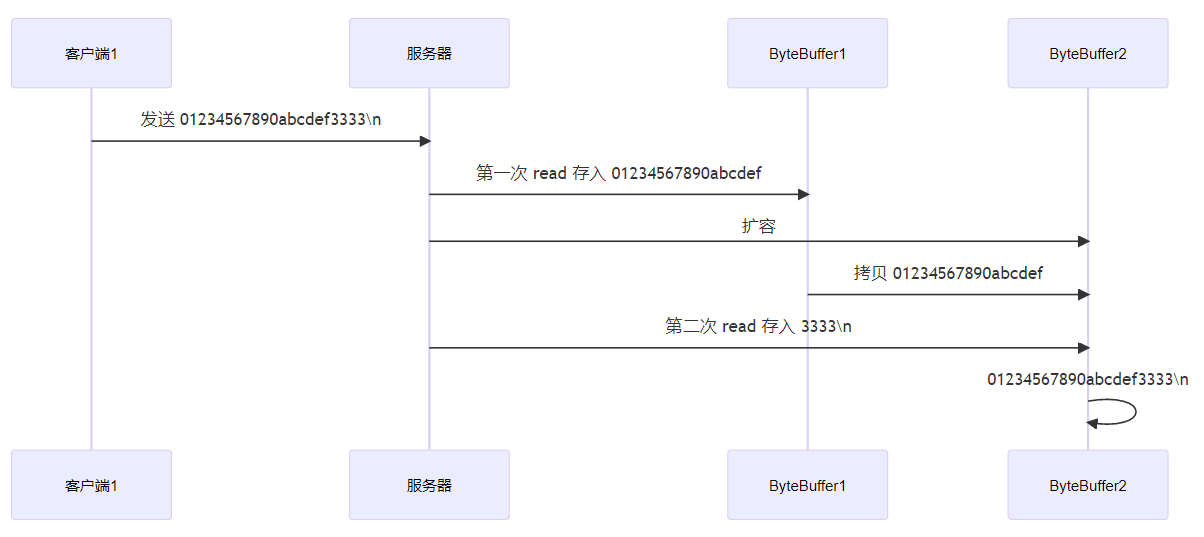
- 服务端代码
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import static com.lilinchao.nio.bytebuffer_2.ByteBufferUtil.debugAll;
/**
* Created by lilinchao
* Date 2022/6/3
* Description 服务端
*/
@Slf4j
public class MessageBorderServer {
public static void main(String[] args) throws IOException {
// 1. 创建 selector, 管理多个 channel
Selector selector = Selector.open();
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
// 2. 建立 selector 和 channel 的联系(注册)
// SelectionKey 就是将来事件发生后,通过它可以知道事件和哪个channel的事件
SelectionKey sscKey = ssc.register(selector, 0, null);
// key 只关注 accept 事件
sscKey.interestOps(SelectionKey.OP_ACCEPT);
log.debug("sscKey:{}", sscKey);
ssc.bind(new InetSocketAddress(8080));
while (true) {
// 3. select 方法, 没有事件发生,线程阻塞,有事件,线程才会恢复运行
// select 在事件未处理时,它不会阻塞, 事件发生后要么处理,要么取消,不能置之不理
selector.select();
// 4. 处理事件, selectedKeys 内部包含了所有发生的事件
Iterator<SelectionKey> iter = selector.selectedKeys().iterator(); // accept, read
while (iter.hasNext()) {
SelectionKey key = iter.next();
// 处理key 时,要从 selectedKeys 集合中删除,否则下次处理就会有问题
iter.remove();
log.debug("key: {}", key);
// 5. 区分事件类型
if (key.isAcceptable()) { // 如果是 accept
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
SocketChannel sc = channel.accept();
sc.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(16); // attachment
// 将一个 byteBuffer 作为附件关联到 selectionKey 上
SelectionKey scKey = sc.register(selector, 0, buffer);
scKey.interestOps(SelectionKey.OP_READ);
log.debug("{}", sc);
log.debug("scKey:{}", scKey);
} else if (key.isReadable()) { // 如果是 read
try {
SocketChannel channel = (SocketChannel) key.channel(); // 拿到触发事件的channel
// 获取 selectionKey 上关联的附件
ByteBuffer buffer = (ByteBuffer) key.attachment();
int read = channel.read(buffer); // 如果是正常断开,read 的方法的返回值是 -1
if(read == -1) {
key.cancel();
} else {
split(buffer);
// 需要扩容
if (buffer.position() == buffer.limit()) {
ByteBuffer newBuffer = ByteBuffer.allocate(buffer.capacity() * 2);
buffer.flip();
newBuffer.put(buffer); // 0123456789abcdef3333\n
key.attach(newBuffer);
}
}
} catch (IOException e) {
e.printStackTrace();
key.cancel(); // 因为客户端断开了,因此需要将 key 取消(从 selector 的 keys 集合中真正删除 key)
}
}
}
}
}
private static void split(ByteBuffer source) {
source.flip();
for (int i = 0; i < source.limit(); i++) {
// 找到一条完整消息
if (source.get(i) == '\n') {
int length = i + 1 - source.position();
// 把这条完整消息存入新的 ByteBuffer
ByteBuffer target = ByteBuffer.allocate(length);
// 从 source 读,向 target 写
for (int j = 0; j < length; j++) {
target.put(source.get());
}
debugAll(target);
}
}
source.compact(); // 0123456789abcdef position 16 limit 16
}
}- 客户端代码
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.SocketChannel;
import java.nio.charset.Charset;
/**
* Created by lilinchao
* Date 2022/6/3
* Description 1.0
*/
public class MessageBorderClient {
public static void main(String[] args) throws IOException {
SocketChannel sc = SocketChannel.open();
sc.connect(new InetSocketAddress("localhost", 8080));
sc.write(Charset.defaultCharset().encode("0123456789abcdef3333\n"));
System.in.read();
}
}- 输出结果
11:50:04 [DEBUG] [main] c.l.n.b.MessageBorderServer - sscKey:sun.nio.ch.SelectionKeyImpl@7dc36524
11:50:32 [DEBUG] [main] c.l.n.b.MessageBorderServer - key: sun.nio.ch.SelectionKeyImpl@7dc36524
11:50:32 [DEBUG] [main] c.l.n.b.MessageBorderServer - java.nio.channels.SocketChannel[connected local=/127.0.0.1:8080 remote=/127.0.0.1:51861]
11:50:32 [DEBUG] [main] c.l.n.b.MessageBorderServer - scKey:sun.nio.ch.SelectionKeyImpl@27f674d
11:50:32 [DEBUG] [main] c.l.n.b.MessageBorderServer - key: sun.nio.ch.SelectionKeyImpl@27f674d
11:50:32 [DEBUG] [main] c.l.n.b.MessageBorderServer - key: sun.nio.ch.SelectionKeyImpl@27f674d
+--------+-------------------- all ------------------------+----------------+
position: [21], limit: [21]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 30 31 32 33 34 35 36 37 38 39 61 62 63 64 65 66 |0123456789abcdef|
|00000010| 33 33 33 33 0a |3333. |
+--------+-------------------------------------------------+----------------+四、bytebuffer大小分配
- 每个 channel 都需要记录可能被切分的消息,因为 ByteBuffer 不能被多个 channel 共同使用,因此需要为每个 channel 维护一个独立的 ByteBuffer
- ByteBuffer 不能太大,比如一个 ByteBuffer 1Mb 的话,要支持百万连接就要 1Tb 内存,因此需要设计大小可变的 ByteBuffer
- 一种思路是首先分配一个较小的 buffer,例如 4k,如果发现数据不够,再分配 8k 的 buffer,将 4k buffer 内容拷贝至 8k buffer,优点是消息连续容易处理,缺点是数据拷贝耗费性能,参考实现 http://tutorials.jenkov.com/java-performance/resizable-array.html
- 另一种思路是用多个数组组成 buffer,一个数组不够,把多出来的内容写入新的数组,与前面的区别是消息存储不连续解析复杂,优点是避免了拷贝引起的性能损耗
NIO Selector之处理write事件
一次无法写完例子
- 非阻塞模式下,无法保证把 buffer 中所有数据都写入 channel,因此需要追踪 write 方法的返回值(代表实际写入字节数)
用 selector 监听所有 channel 的可写事件,每个 channel 都需要一个 key 来跟踪 buffer,但这样又会导致占用内存过多,就有两阶段策略
- 当消息处理器第一次写入消息时,才将 channel 注册到 selector 上
- selector 检查 channel 上的可写事件,如果所有的数据写完了,就取消 channel 的注册
- 如果不取消,会每次可写均会触发 write 事件
服务端代码
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.nio.charset.Charset;
import java.util.Iterator;
/**
* Created by lilinchao
* Date 2022/6/3
* Description 可写事件 服务端
*/
public class WriteServer {
public static void main(String[] args) throws IOException {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
ssc.bind(new InetSocketAddress(8080));
Selector selector = Selector.open();
ssc.register(selector, SelectionKey.OP_ACCEPT);
while (true){
selector.select();
Iterator<SelectionKey> iter = selector.selectedKeys().iterator();
while (iter.hasNext()){
SelectionKey key = iter.next();
iter.remove();
if(key.isAcceptable()){
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
SelectionKey sckey = sc.register(selector,SelectionKey.OP_READ);
//1.向客户端发送内容
StringBuilder sb = new StringBuilder();
for (int i=0;i<30000000;i++){
sb.append("a");
}
ByteBuffer buffer = Charset.defaultCharset().encode(sb.toString());
//2.write表示实际写了多少字节
int write = sc.write(buffer);
System.out.println("实际写入字节:" + write);
//3.如果有剩余未读字节,才需要关注写事件
if(buffer.hasRemaining()){
// read 1 write 4
//在原有关注事件的基础上,多关注一个写事件
sckey.interestOps(sckey.interestOps() + SelectionKey.OP_WRITE);
//把buffer作为附件加入sckey
sckey.attach(buffer);
}
}else if(key.isWritable()){
ByteBuffer buffer = (ByteBuffer) key.attachment();
SocketChannel sc = (SocketChannel) key.channel();
int write = sc.write(buffer);
System.out.println("实际写入字节:" + write);
if (!buffer.hasRemaining()) { // 写完了
key.interestOps(key.interestOps() - SelectionKey.OP_WRITE);
key.attach(null);
}
}
}
}
}
}- 客户端代码
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
/**
* Created by lilinchao
* Date 2022/6/3
* Description 客户端
*/
public class WriteClient {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
SocketChannel sc = SocketChannel.open();
sc.configureBlocking(false);
sc.register(selector, SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
sc.connect(new InetSocketAddress("localhost", 8080));
int count = 0;
while (true) {
selector.select();
Iterator<SelectionKey> iter = selector.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
if (key.isConnectable()) {
System.out.println(sc.finishConnect());
} else if (key.isReadable()) {
ByteBuffer buffer = ByteBuffer.allocate(1024 * 1024);
count += sc.read(buffer);
buffer.clear();
System.out.println(count);
}
}
}
}
}- 服务端运行结果
实际写入字节:5242840
实际写入字节:3014633
实际写入字节:4063201
实际写入字节:4718556
实际写入字节:2490349
实际写入字节:2621420
实际写入字节:2621420
实际写入字节:2621420
实际写入字节:2606161NIO之多线程优化
前言
之前说到的服务端程序都是在一个线程上进行的,这个线程不仅负责连接客户端发来的请求,同时还要处理读写事件,这样效率还是不够高。如今电脑都是多核处理器,这意味着可以同时进行多个线程,所以服务端应该充分利用这一点。
一、概述
服务端线程可以建立多个线程,将这些线程分成两组:
- 单线程配一个选择器(Boss),专门处理 accept 事件
- 创建 cpu 核心数的线程(Worker),每个线程配一个选择器,轮流处理 read 事件
关系图
说明
- Boss线程只负责Accept事件,Worker线程负责客户端与服务端之间的读写问题,他们都各自维护一个Selector负责监听通道的事件。
- 当Boss线程检测到有客户端的连接请求,就会把这个连接返回的
SocketChannel注册到某一个Worker线程上。 - 当有读写事件发生时,其中一个Worker线程就会检测到事件,就会在该线程中进行处理,这样的设计做到了功能在线程上的分离。
二、实现思路
创建一个负责处理Accept事件的Boss线程,与多个负责处理Read事件的Worker线程;
Boss线程执行的操作
接受并处理Accepet事件,当Accept事件发生后,调用Worker的register(SocketChannel socket)方法,让Worker去处理Read事件,其中需要根据标识index去判断将任务分配给哪个Worker
// 创建固定数量的Worker Worker[] workers = new Worker[Runtime.getRuntime().availableProcessors()]; // 用于负载均衡的原子整数 AtomicInteger index = new AtomicInteger(0); // 负载均衡,轮询分配Worker workers[index.getAndIncrement()% workers.length].register(socket);register(SocketChannel socket)方法会通过同步队列完成Boss线程与Worker线程之间的通信,让SocketChannel的注册任务被Worker线程执行。添加任务后需要调用selector.wakeup()来唤醒被阻塞的Selectorpublic void register(final SocketChannel socket) throws IOException { // 只启动一次 if (!started) { // 初始化操作 } // 向同步队列中添加SocketChannel的注册事件 // 在Worker线程中执行注册事件 queue.add(new Runnable() { @Override public void run() { try { socket.register(selector, SelectionKey.OP_READ); } catch (IOException e) { e.printStackTrace(); } } }); // 唤醒被阻塞的Selector selector.wakeup(); }
Worker线程执行的操作
- 从同步队列中获取注册任务,并处理Read事件
三、代码实现
- 服务端代码
import lombok.extern.slf4j.Slf4j;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Iterator;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.atomic.AtomicInteger;
import static com.lilinchao.nio.bytebuffer_2.ByteBufferUtil.debugAll;
/**
* Created by lilinchao
* Date 2022/6/4
* Description 多线程优化 -- 服务端
*/
@Slf4j
public class MultiThreadServer {
public static void main(String[] args) throws IOException {
Thread.currentThread().setName("boss");
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
// 负责轮询Accept事件的Selector
Selector boss = Selector.open();
SelectionKey bossKey = ssc.register(boss, 0, null);
bossKey.interestOps(SelectionKey.OP_ACCEPT);
ssc.bind(new InetSocketAddress(8080));
//创建固定数量的worker = core 数
Worker[] workers = new Worker[Runtime.getRuntime().availableProcessors()];
for (int i=0;i<workers.length;i++){
workers[i] = new Worker("worker-"+i);
}
// 用于负载均衡的原子整数
AtomicInteger index = new AtomicInteger();
while (true){
boss.select();
Iterator<SelectionKey> iterator = boss.selectedKeys().iterator();
while (iterator.hasNext()){
SelectionKey key = iterator.next();
iterator.remove();
if(key.isAcceptable()){
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
log.debug("connected:{}",sc.getRemoteAddress());
// 2. 关联 selector (静态内部类可以访问到selector)
log.debug("before register:{}",sc.getRemoteAddress());
// 负载均衡,轮询分配Worker
workers[index.getAndIncrement() % workers.length].register(sc);
log.debug("after register:{}",sc.getRemoteAddress());
}
}
}
}
static class Worker implements Runnable{
private Thread thread;
private Selector selector;
private String name;
private volatile boolean start = false; //还未初始化
/**
* 同步队列,用于Boss线程与Worker线程之间的通信
*/
private ConcurrentLinkedQueue<Runnable> queue = new ConcurrentLinkedQueue<>();
public Worker(String name) {
this.name = name;
}
//初始化线程和Selector
public void register(SocketChannel sc) throws IOException {
//只启动一次
if(!this.start){
this.thread = new Thread(this,name);
this.selector = Selector.open();
this.thread.start();
this.start = true;
}
//向队列添加任务,但这个任务并没有立刻执行
queue.add(() -> {
try {
sc.register(selector,SelectionKey.OP_READ,null);
} catch (ClosedChannelException e) {
e.printStackTrace();
}
});
selector.wakeup(); //唤醒select方法
}
@Override
public void run() {
while (true){
try {
selector.select(); //阻塞
// 通过同步队列获得任务并运行
Runnable task = queue.poll();
if(task != null){
task.run(); //获得任务,执行注册
}
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
while (iterator.hasNext()){
SelectionKey key = iterator.next();
iterator.remove();
// Worker只负责Read事件
if(key.isReadable()){
ByteBuffer buffer = ByteBuffer.allocate(16);
SocketChannel channel = (SocketChannel) key.channel();
log.debug("read...{}",channel.getRemoteAddress());
channel.read(buffer);
buffer.flip();
debugAll(buffer);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}- 客户端代码
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.SocketChannel;
import java.nio.charset.Charset;
/**
* Created by lilinchao
* Date 2022/6/3
* Description 客户端
*/
public class TestClient {
public static void main(String[] args) throws IOException {
SocketChannel sc = SocketChannel.open();
sc.connect(new InetSocketAddress("localhost", 8080));
sc.write(Charset.defaultCharset().encode("0123456789abcdef"));
System.in.read();
}
}- 运行结果
13:03:57 [DEBUG] [boss] c.l.n.t.MultiThreadServer - connected:/127.0.0.1:52622
13:03:57 [DEBUG] [boss] c.l.n.t.MultiThreadServer - before register:/127.0.0.1:52622
13:03:57 [DEBUG] [boss] c.l.n.t.MultiThreadServer - after register:/127.0.0.1:52622
13:03:57 [DEBUG] [worker-0] c.l.n.t.MultiThreadServer - read.../127.0.0.1:52622
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [16]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 30 31 32 33 34 35 36 37 38 39 61 62 63 64 65 66 |0123456789abcdef|
+--------+-------------------------------------------------+----------------+在运行时,可以同时运行多个客户端程序,查看服务端的输出效果。
问题:如何拿到 cpu 个数
Runtime.getRuntime().availableProcessors()如果工作在 docker 容器下,因为容器不是物理隔离的,会拿到物理 cpu 个数,而不是容器申请时的个数- 这个问题直到 jdk 10 才修复,使用 jvm 参数 UseContainerSupport 配置, 默认开启
NIO之IO模型
一、IO流程
就是对于 Linux 系统, I/O 操作不是一步完成的。此处的 I/O 操作是一个通用型的概念,对于 socket 通信,也可以看作一个 I/O 操作过程,只不过操作的是网络对象。
I/O 操作一般分为两个部分:
- 应用程序发起 I/O 操作请求,等待数据,或者将要操作的数据拷贝到系统内核中(比如 socket)。
- 系统内核进行 I/O 操作(一般是内核将数据拷贝到用户进程中)。
阻塞和非阻塞
首先明确一点:阻塞和非阻塞发生在请求处,关注的是程序在等待调用结果时的状态。
通过上面的概念可以很容易的理解以下结论:
- 阻塞调用是指调用结果返回之前,当前进程(线程)会被挂起。调用进程(线程)阻塞在 I/O 操作请求处,直到 I/O 操作请求完成,数据到来,最重要的是用户进程的函数在请求的过程中不会返回。
- 非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前进程(线程),进程(线程)可以去干别的事情。一般使用轮询的方式来查询 I/O 操作数据是否准确好了。
理解上面概念的一个要点是请求的结果是否立即返回,同时需要注意的是,结果立即返回,不代表 I/O 操作完成,阻塞和非阻塞只关注请求是否立即获得结果。
同步和异步
同样需要明确一点:同步和异步关注的是消息通信机制,具体来说就是调用者是否等待调用结果的返回,对于 I/O 操作而言,就是应用程序是否等待 I/O 操作完成。
注意:此处的 I/O 操作一般是指上文中 I/O 操作中的两部分的第二部分。
同步和异步其实就是指 I/O 操作的第二部分,也就是进行具体 I/O 操作过程中,用户进程是否等待 I/O 操作结果返回。
- 阻塞和非阻塞是指进程访问的数据如果尚未就绪,进程是否需要等待,简单说这相当于函数内部的实现区别,也就是未就绪时是直接返回还是等待就绪。
- 同步和异步是指访问数据的机制,同步一般指主动请求并等待 I/O 操作完毕的方式,当数据就绪后在读写的时候必须等待,异步则指主动请求数据后便可以继续处理其它任务,随后等待 I/O,操作完毕的通知,这可以使进程在数据读写时也不阻塞。
二、IO模型
2.1 阻塞IO
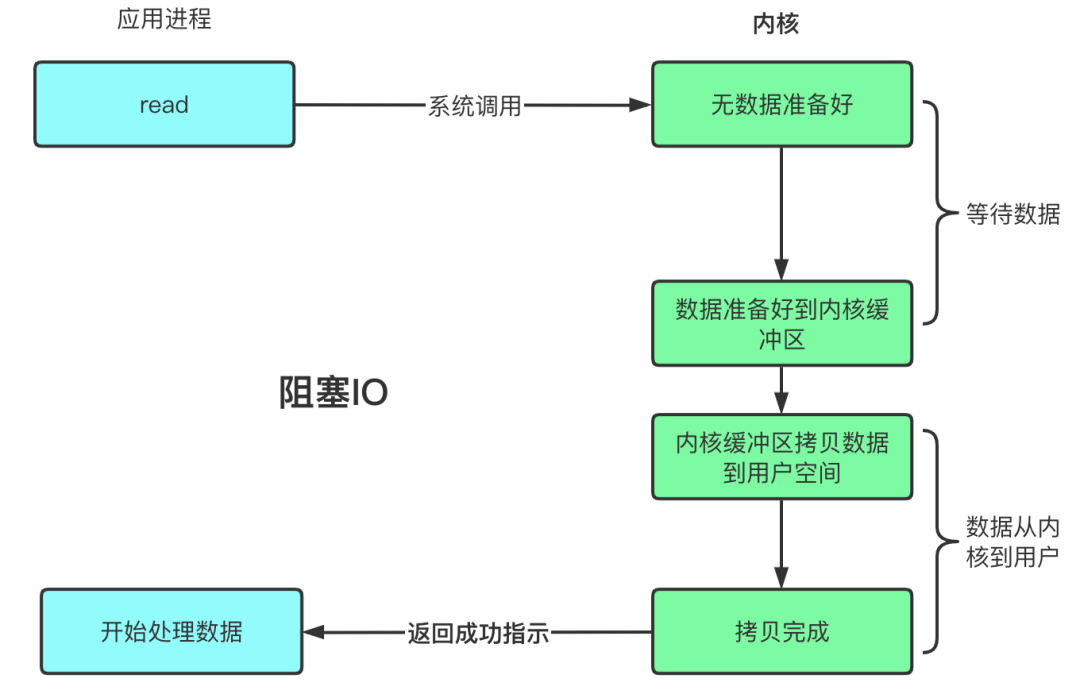
用户线程发起一次read,由用户空间切换到内核空间,但是可能数据还没发送过来,该read方法就会阻塞住,等到复制(网卡->内存)完数据后,再从内核切换到用户线程。这里的阻塞即用户线程被阻塞。
从上面可以看到线程在两个阶段发生了阻塞:
- CPU把数据从磁盘读到内核缓冲区。
- CPU把数据从内核缓冲区拷贝到用户缓冲区。
2.2 非阻塞IO
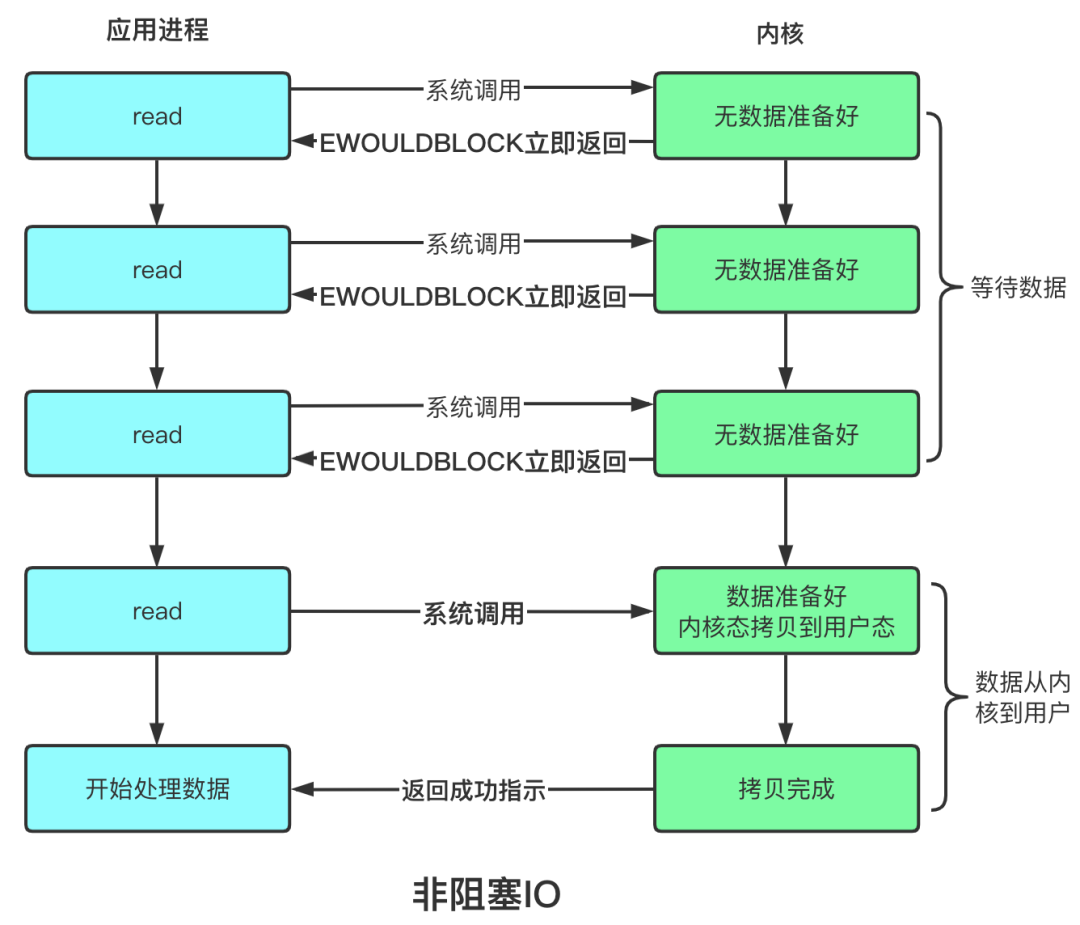
非阻塞IO发出read请求后发现数据没准备好,会继续往下执行,此时应用程序会不断轮询polling内核询问数据是否准备好,当数据没有准备好时,内核立即返回EWOULDBLOCK错误。直到数据被拷贝到应用程序缓冲区,read请求才获取到结果。
需要注意的是最后一次 read 调用获取数据的过程,是一个同步的过程,是需要等待的过程。
这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。
这种方法并没有特别好的地方,它会牵扯到多次用户空间到内核空间的转换,切换太频繁会影响性能。
2.3 IO多路复用
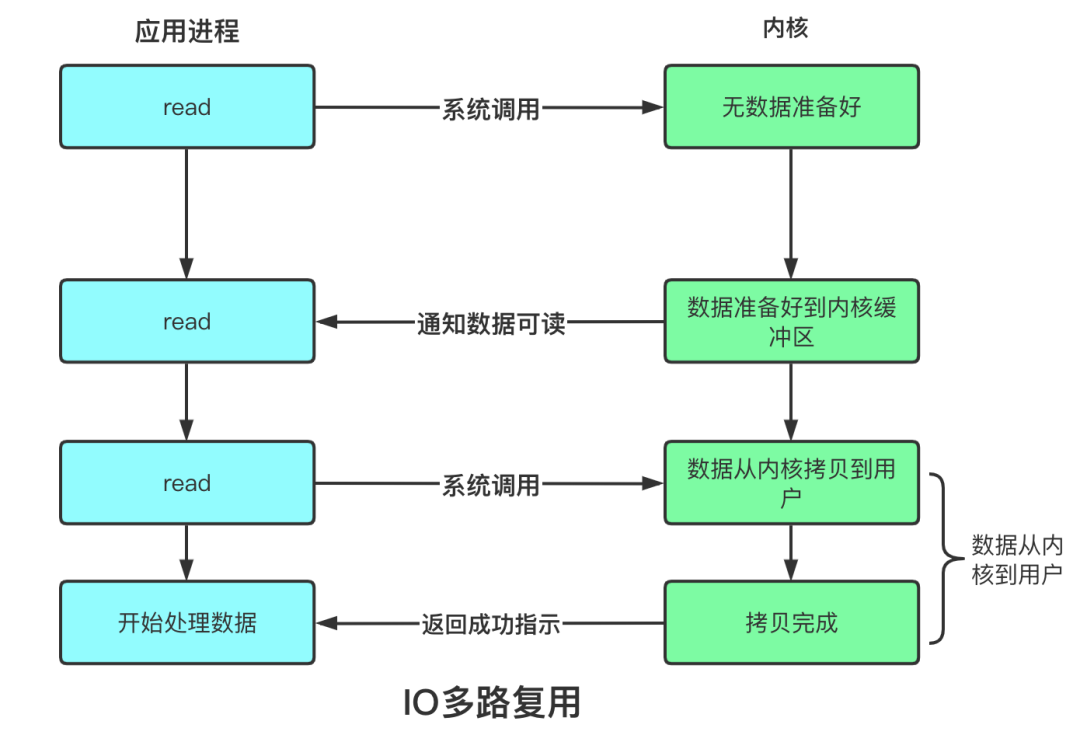
IO多路复用的原文叫 I/O multiplexing,这里的 multiplexing 指的其实是在单个线程通过记录跟踪每一个Sock(I/O流)的状态来同时管理多个I/O流。
目的是尽量多的提高服务器的吞吐能力。实现一个线程监控多个IO请求,哪个IO有请求就把数据从内核拷贝到进程缓冲区,拷贝期间是阻塞的。
多路复用与阻塞IO的区别
- 阻塞IO模式下,若线程因accept事件被阻塞,发生read事件后,仍需等待accept事件执行完成后,才能去处理read事件;
- 多路复用模式下,一个事件发生后,若另一个事件处于阻塞状态,不会影响该事件的执行。
2.4 异步IO
上面的提到过的操作都不是真正的异步,因为两个阶段总要等待会儿,而真正的异步 I/O 是内核数据准备好和数据从内核态拷贝到用户态这两个过程都不用等待。
很庆幸,Linux给我们准备了aio_read跟aio_write函数实现真实的异步,当用户发起aio_read请求后就会自动返回。内核会自动将数据从内核缓冲区拷贝到用户进程空间,应用进程啥都不用管。
三、同步和异步详解
3.1 同步
同步跟异步的区别在于数据从内核空间拷贝到用户空间是否由用户线程完成,这里又分为同步阻塞跟同步非阻塞两种。
- 同步阻塞:此时一个线程维护一个连接,该线程完成数据从读写到处理全部过程,数据读写时线程是被阻塞的。
- 同步非阻塞:非阻塞的意思是用户线程发出读请求后,读请求不会阻塞当前用户线程,不过用户线程还是要不断的去主动判断数据是否准备OK了。此时还是会阻塞等待内核复制数据到用户进程。他与同步BIO区别是使用一个连接全程等待
以同步非阻塞为例,如下可看到,在将数据从内核拷贝到用户空间这一过程,是由用户线程阻塞完成的。
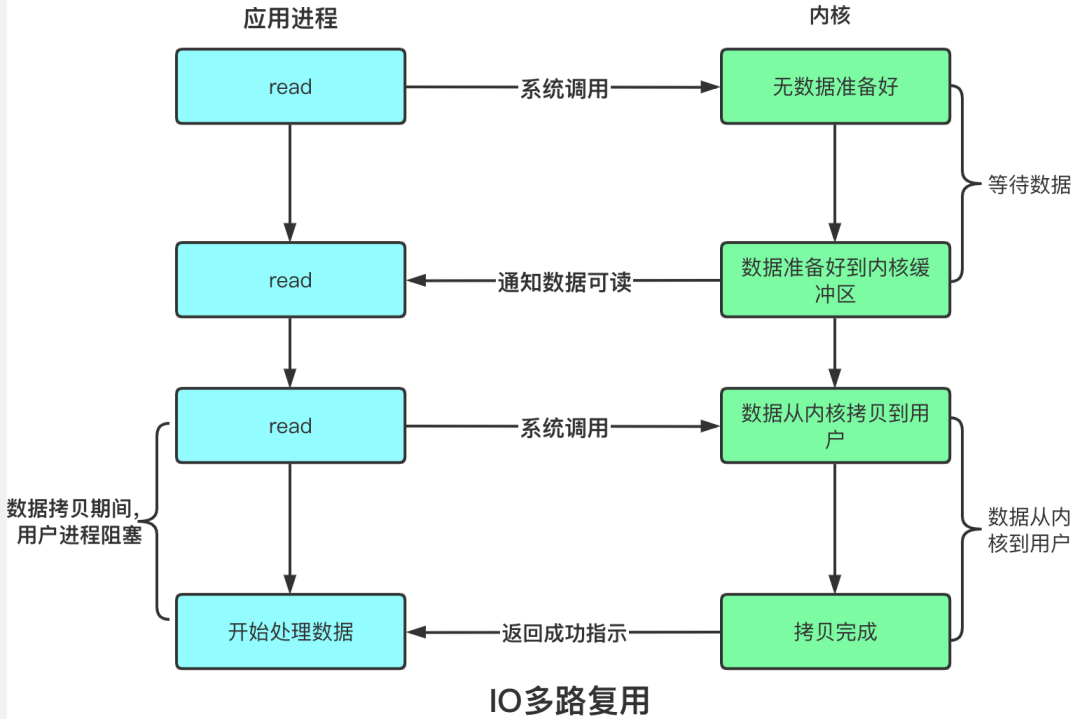
3.2 异步
对于异步来说,用户进行读或者写后,将立刻返回,由内核去完成数据读取以及拷贝工作,完成后通知用户,并执行回调函数(用户提供的callback),此时数据已从内核拷贝到用户空间,用户线程只需要对数据进行处理即可,不需要关注读写,用户不需要等待内核对数据的复制操作,用户在得到通知时数据已经被复制到用户空间。
以如下的真实异步非阻塞为例:
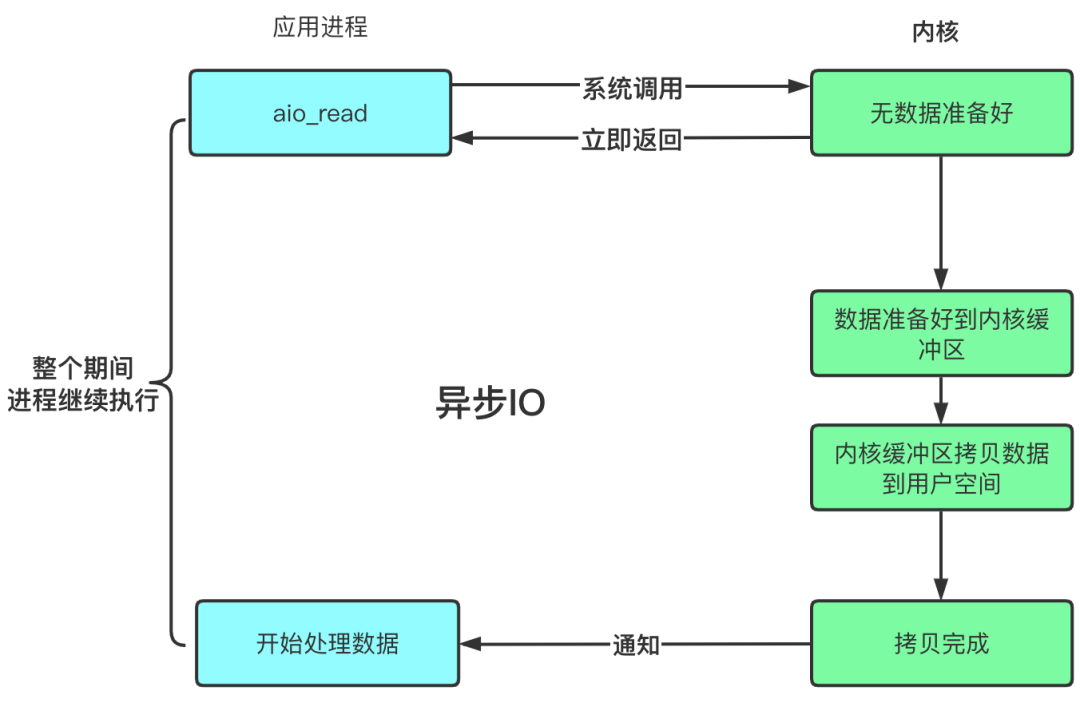
可发现,用户在调用之后会立即返回,由内核完成数据的拷贝工作,并通知用户线程,进行回调。
3.3 同步跟异步对比
同步关注的消息通信机制synchronous communication,在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由调用者主动等待这个调用的结果。
异步关注消息通信机制asynchronous communication,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
NIO之零拷贝
一、传统IO问题
传统的 IO 将一个文件通过 socket 写出
File f = new File("helloword/data.txt");
RandomAccessFile file = new RandomAccessFile(file, "r");
byte[] buf = new byte[(int)f.length()];
file.read(buf);
Socket socket = ...;
socket.getOutputStream().write(buf);内部工作流程是这样的:
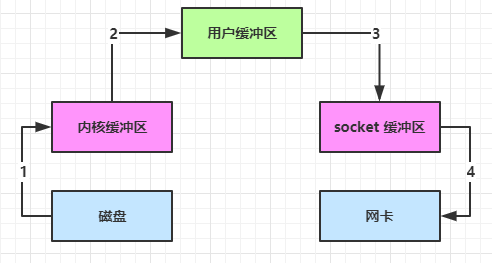
- java 本身并不具备 IO 读写能力,因此 read 方法调用后,要从 java 程序的用户态切换至内核态,去调用操作系统(Kernel)的读能力,将数据读入内核缓冲区。这期间用户线程阻塞,操作系统使用 DMA(Direct Memory Access)来实现文件读,其间也不会使用 cpu;
- 从内核态切换回用户态,将数据从内核缓冲区读入用户缓冲区(即 byte[] buf),这期间 cpu 会参与拷贝,无法利用 DMA;
- 调用 write 方法,这时将数据从用户缓冲区(byte[] buf)写入 socket 缓冲区,cpu 会参与拷贝;
- 接下来要向网卡写数据,这项能力 java 又不具备,因此又得从用户态切换至内核态,调用操作系统的写能力,使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu。
可以看到中间环节较多,java 的 IO 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的
- 用户态与内核态的切换发生了 3 次,这个操作比较重量级
- 数据拷贝了共 4 次
二、NIO 优化
2.1 优化一
通过 DirectByteBuf
- ByteBuffer.allocate(10) HeapByteBuffer 使用的还是 java 内存
- ByteBuffer.allocateDirect(10) DirectByteBuffer 使用的是操作系统内存
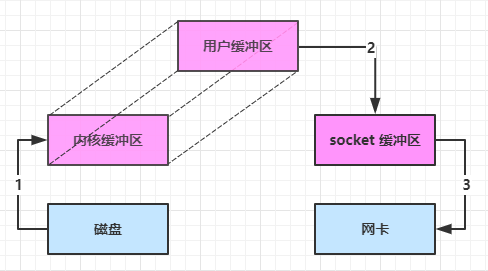
大部分步骤与优化前相同,不再赘述。唯有一点:java 可以使用 DirectByteBuf 将堆外内存映射到 jvm 内存中来直接访问使用
- 这块内存不受 jvm 垃圾回收的影响,因此内存地址固定,有助于 IO 读写
- java 中的 DirectByteBuf 对象仅维护了此内存的虚引用,内存回收分成两步
- DirectByteBuf 对象被垃圾回收,将虚引用加入引用队列
- 通过专门线程访问引用队列,根据虚引用释放堆外内存
- 减少了一次数据拷贝,用户态与内核态的切换次数没有减少
2.2 优化二
进一步优化(底层采用了 linux 2.1 后提供的 sendFile 方法),java 中对应着两个 channel 调用 transferTo/transferFrom 方法拷贝数据
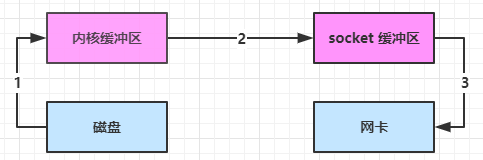
- java 调用 transferTo 方法后,要从 java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 cpu
- 数据从内核缓冲区传输到 socket 缓冲区,cpu 会参与拷贝
- 最后使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu
可以看到
- 只发生了一次用户态与内核态的切换
- 数据拷贝了 3 次
2.3 优化三
进一步优化(linux 2.4)
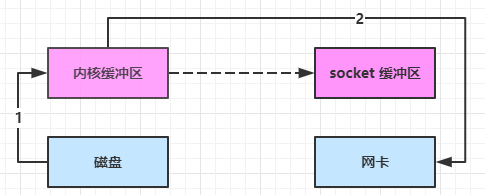
- java 调用 transferTo 方法后,要从 java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 cpu
- 只会将一些 offset 和 length 信息拷入 socket 缓冲区,几乎无消耗
- 使用 DMA 将 内核缓冲区的数据写入网卡,不会使用 cpu
整个过程仅只发生了一次用户态与内核态的切换,数据拷贝了 2 次。
总结
所谓的【零拷贝】,并不是真正无拷贝,而是在不会拷贝重复数据到 jvm 内存中,零拷贝的优点有
- 更少的用户态与内核态的切换
- 不利用 cpu 计算,减少 cpu 缓存伪共享
- 零拷贝适合小文件传输
 微信
微信 支付宝
支付宝






