JavaSE基础-2
异常
异常概述
引入异常
生活中的异常:
正常情况下,小王每日开车去上班,耗时大约30分钟
但是,异常情况迟早要发生!
面对异常该怎么办呢?生活中,我们会根据不同的异常进行相应的处理,而不会就此中断我们的生活
在使用计算机语言进行项目开发的过程中,即使程序员把代码写得 尽善尽美,在系统的运行过程中仍然会遇到一些问题,因为很多问题不是靠代码能够避免的,比如:客户输入数据的格式,读取文件是否存在,网络是否始终保持通畅等等。
- 异常 :指的是程序在执行过程中,出现的非正常的情况,如果不处理最终会导致JVM的非正常停止。
异常指的并不是语法错误,语法错了,编译不通过,不会产生字节码文件,根本不能运行.
异常也不是指逻辑代码错误而没有得到想要的结果,例如:求a与b的和,你写成了a-b 除数为0的情况
对于异常,一般有两种解决方法:一是遇到错误就终止程序的运行。另一种方法是由程序员在编写程序时,就考虑到错误的检测、错误消息的提示,以及错误的处理。
Java中是如何表示不同的异常情况,又是如何让程序员得知,并处理异常的呢?
Java中把不同的异常用不同的类表示,一旦发生某种异常,就通过创建该异常类型的对象,并且抛出,然后程序员可以catch到这个异常对象,并处理,如果无法catch到这个异常对象,那么这个异常对象将会导致程序终止。
异常体系
异常的根类是java.lang.Throwable,其下有两个子类:java.lang.Error与java.lang.Exception,平常所说的异常指java.lang.Exception。
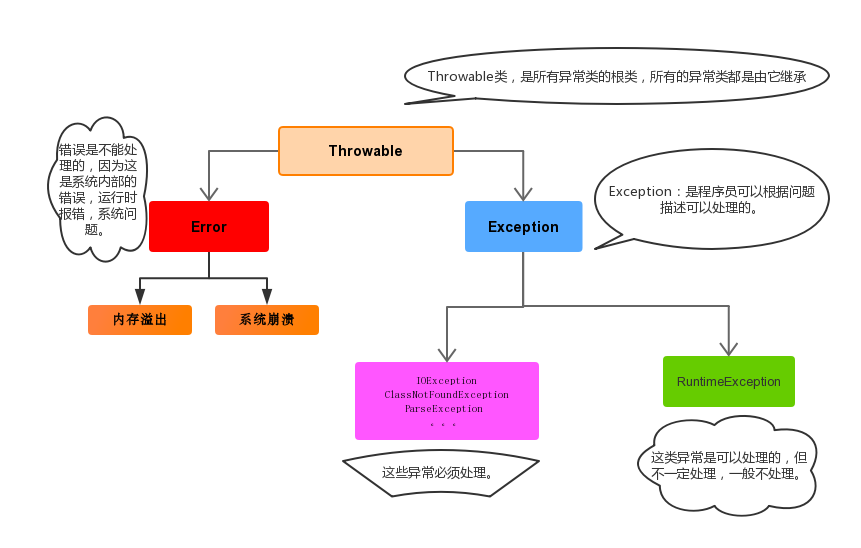
Throwable体系:
- Error:严重错误Error,无法通过处理的错误,只能事先避免,好比绝症。
- Exception:表示异常,其它因编程错误或偶然的外在因素导致的一般性问题,程序员可以通过代码的方式纠正,使程序继续运行,是必须要处理的。好比感冒、阑尾炎。
- 例如:空指针访问、试图读取不存在的文件、网络连接中断、数组角标越界
Throwable中的常用方法:
public void printStackTrace():打印异常的详细信息。包含了异常的类型,异常的原因,还包括异常出现的位置,在开发和调试阶段,都得使用printStackTrace。
public String getMessage():获取发生异常的原因。提示给用户的时候,就提示错误原因。
出现异常,不要紧张,把异常的简单类名,拷贝到API中去查。
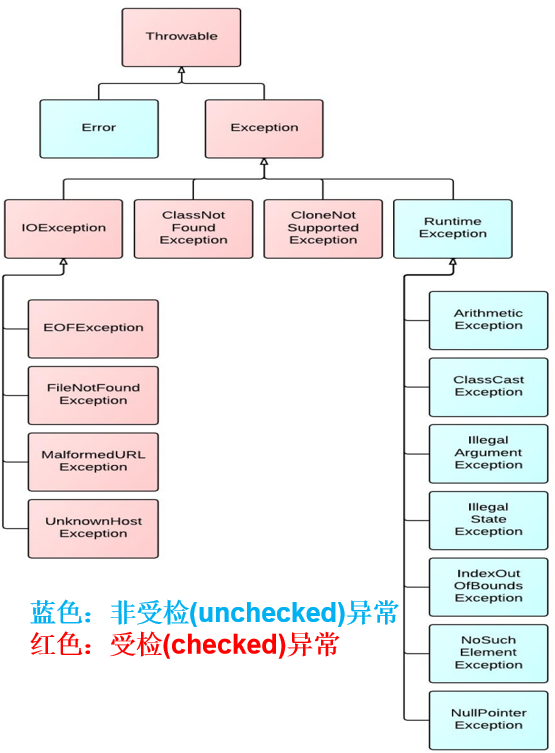
异常分类
我们平常说的异常就是指Exception,因为这类异常一旦出现,我们就要对代码进行更正,修复程序。
异常(Exception)的分类:根据在编译时期还是运行时期去检查异常?
- 编译时期异常:checked异常。在编译时期,就会检查,如果没有处理异常,则编译失败。(如文件找不到异常)
- 运行时期异常:runtime异常。在运行时期,检查异常.在编译时期,运行异常不会被编译器检测到(不报错)。(如数组索引越界异常,类型转换异常)。程序员应该积极避免其出现的异常,而不是使用try..catch处理,因为这类异常很普遍,若都使用try..catch或throws处理可能会对程序的可读性和运行效率产生影响。
演示常见的错误和异常
VirtualMachineError
最常见的就是:StackOverflowError、OutOfMemoryError
@Test
public void test01(){
//StackOverflowError
digui();
}
public void digui(){
digui();
}@Test
public void test02(){
//OutOfMemoryError
//方式一:
int[] arr = new int[Integer.MAX_VALUE];
}
@Test
public void test03(){
//OutOfMemoryError
//方式二:
StringBuilder s = new StringBuilder();
while(true){
s.append("atguigu");
}
}运行时异常
@Test
public void test01(){
//NullPointerException
int[][] arr = new int[3][];
System.out.println(arr[0].length);
}
@Test
public void test02(){
//ClassCastException
Person p = new Man();
Woman w = (Woman) p;
}
@Test
public void test03(){
//ArrayIndexOutOfBoundsException
int[] arr = new int[5];
for (int i = 1; i <= 5; i++) {
System.out.println(arr[i]);
}
}
@Test
public void test04(){
//InputMismatchException
Scanner input = new Scanner(System.in);
System.out.print("请输入一个整数:");
int num = input.nextInt();
}
@Test
public void test05(){
int a = 1;
int b = 0;
//ArithmeticException
System.out.println(a/b);
}编译时异常
@Test
public void test06() throws InterruptedException{
Thread.sleep(1000);//休眠1秒
}
@Test
public void test07() throws FileNotFoundException{
FileInputStream fis = new FileInputStream("Java学习秘籍.txt");
}
@Test
public void test08() throws SQLException{
Connection conn = DriverManager.getConnection("....");
}异常的抛出机制
先运行下面的程序,程序会产生一个数组索引越界异常ArrayIndexOfBoundsException。我们通过图解来解析下异常产生的过程。
工具类
public class ArrayTools {
// 对给定的数组通过给定的角标获取元素。
public static int getElement(int[] arr, int index) {
int element = arr[index];
return element;
}
}测试类
public class ExceptionDemo {
public static void main(String[] args) {
int[] arr = { 34, 12, 67 };
intnum = ArrayTools.getElement(arr, 4)
System.out.println("num=" + num);
System.out.println("over");
}
}上述程序执行过程图解:


异常的处理
Java异常处理的五个关键字:try、catch、finally、throw、throws
异常throw
Java程序的执行过程中如出现异常,会生成一个异常类对象,该异常对象将被提交给Java运行时系统,这个过程称为抛出(throw)异常。异常对象的生成有两种方式:
- 由虚拟机自动生成:程序运行过程中,虚拟机检测到程序发生了问题,如果在当前代码中没有找到相应的处理程序,就会在后台自动创建一个对应异常类的实例对象并抛出——自动抛出
- 由开发人员手动创建:Exception exception = new ClassCastException();——创建好的异常对象不抛出对程序没有任何影响,和创建一个普通对象一样,但是一旦throw抛出,就会对程序运行产生影响了。
下面我们说明手动抛出异常:
比如,在定义方法时,方法需要接受参数。那么,当调用方法使用接受到的参数时,首先需要先对参数数据进行合法的判断,数据若不合法,就应该告诉调用者,这时可以使用抛出异常的方式来告诉调用者。
在java中,提供了一个throw关键字,它用来抛出一个指定的异常对象。那么,抛出一个异常具体如何操作呢?
创建一个异常对象。封装一些提示信息(信息可以自己编写)。
需要将这个异常对象告知给调用者。怎么告知呢?怎么将这个异常对象传递到调用者处呢?通过关键字throw就可以完成。throw 异常对象。
throw用在方法内,用来抛出一个异常对象,将这个异常对象传递到调用者处,并结束当前方法的执行。
使用格式:
throw new 异常类名(参数);例如:
throw new NullPointerException("要访问的arr数组不存在");
throw new ArrayIndexOutOfBoundsException("该索引在数组中不存在,已超出范围");学习完抛出异常的格式后,我们通过下面程序演示下throw的使用。
public class ThrowDemo {
public static void main(String[] args) {
//创建一个数组
int[] arr = {2,4,52,2};
//根据索引找对应的元素
int index = 4;
int element = getElement(arr, index);
System.out.println(element);
System.out.println("over");
}
/*
* 根据 索引找到数组中对应的元素
*/
public static int getElement(int[] arr,int index){
if(arr == null){
/*
判断条件如果满足,当执行完throw抛出异常对象后,方法已经无法继续运算。
这时就会结束当前方法的执行,并将异常告知给调用者。这时就需要通过异常来解决。
*/
throw new NullPointerException("要访问的arr数组不存在");
}
//判断 索引是否越界
if(index<0 || index>arr.length-1){
/*
判断条件如果满足,当执行完throw抛出异常对象后,方法已经无法继续运算。
这时就会结束当前方法的执行,并将异常告知给调用者。这时就需要通过异常来解决。
*/
throw new ArrayIndexOutOfBoundsException("哥们,角标越界了~~~");
}
int element = arr[index];
return element;
}
}注意:如果产生了问题,我们就会throw将问题描述类即异常进行抛出,也就是将问题返回给该方法的调用者。
那么对于调用者来说,该怎么处理呢?一种是进行捕获处理,另一种就是继续讲问题声明出去,使用throws声明处理。
练习1
1、声明Husband类,包含姓名和妻子属性,属性私有化,提供一个Husband(String name)的构造器,重写toString方法,返回丈夫姓名和妻子的姓名
2、声明Wife类,包含姓名和丈夫属性,属性私有化,提供一个Wife(String name)的构造器,重写toString方法,返回妻子的姓名和丈夫的姓名
3、声明TestMarry类,在main中,创建Husband和Wife对象后直接打印妻子和丈夫对象,查看异常情况,看如何解决
练习2
1、声明银行账户类Account
(1)包含账号、余额属性,要求属性私有化,提供无参和有参构造,
(2)包含取款方法,当取款金额为负数时,抛出IllegalArgumentException,异常信息为“取款金额有误,不能为负数”,当取款金额超过余额时,抛出UnsupportedOperationException,异常信息为“取款金额不足,不支持当前取款操作”
(3)包含存款方法,当取款金额为负数时,抛出IllegalArgumentException,异常信息为“存款金额有误,不能为负数”
2、编写测试类,创建账号对象,并调用取款和存款方法,并传入非法参数,测试发生对应的异常。
声明异常throws
声明异常:将问题标识出来,报告给调用者。如果方法内通过throw抛出了编译时异常,而没有捕获处理(稍后讲解该方式),那么必须通过throws进行声明,让调用者去处理。
关键字throws运用于方法声明之上,用于表示当前方法不处理异常,而是提醒该方法的调用者来处理异常(抛出异常).
声明异常格式:
修饰符 返回值类型 方法名(参数) throws 异常类名1,异常类名2…{ } 声明异常的代码演示:
import java.io.File;
import java.io.FileNotFoundException;
public class TestException {
public static void main(String[] args) throws FileNotFoundException {
readFile("不敲代码学会Java秘籍.txt");
}
// 如果定义功能时有问题发生需要报告给调用者。可以通过在方法上使用throws关键字进行声明
public static void readFile(String filePath) throws FileNotFoundException{
File file = new File(filePath);
if(!file.exists()){
throw new FileNotFoundException(filePath+"文件不存在");
}
}
}throws用于进行异常类的声明,若该方法可能有多种异常情况产生,那么在throws后面可以写多个异常类,用逗号隔开。
import java.io.File;
import java.io.FileNotFoundException;
public class TestException {
public static void main(String[] args) throws FileNotFoundException,IllegalAccessException {
readFile("不敲代码学会Java秘籍.txt");
}
// 如果定义功能时有问题发生需要报告给调用者。可以通过在方法上使用throws关键字进行声明
public static void readFile(String filePath) throws FileNotFoundException,IllegalAccessException{
File file = new File(filePath);
if(!file.exists()){
throw new FileNotFoundException(filePath+"文件不存在");
}
if(!file.isFile()){
throw new IllegalAccessException(filePath + "不是文件,无法直接读取");
}
//...
}
}练习
1、声明银行账户类Account
(1)包含账号、余额属性,要求属性私有化,提供无参和有参构造,
(2)包含取款方法,当取款金额为负数时,抛出Exception,异常信息为“越取你余额越多,想得美”,当取款金额超过余额时,抛出Exception,异常信息为“取款金额不足,不支持当前取款操作”
(3)包含存款方法,当取款金额为负数时,抛出Exception,异常信息为“越存余额越少,你愿意吗?”
2、编写测试类,创建账号对象,并调用取款和存款方法,并传入非法参数,测试发生对应的异常。
捕获异常try…catch
如果异常出现的话,会立刻终止程序,所以我们得处理异常:
- 该方法不处理,而是声明抛出,由该方法的调用者来处理(throws)。
- 在方法中使用try-catch的语句块来处理异常。
try-catch的方式就是捕获异常。
*捕获异常:Java中对异常有针对性的语句进行捕获,可以对出现的异常进行指定方式的处理。
捕获异常语法如下:
try{
编写可能会出现异常的代码
}catch(异常类型1 e){
处理异常的代码
//记录日志/打印异常信息/继续抛出异常
}catch(异常类型2 e){
处理异常的代码
//记录日志/打印异常信息/继续抛出异常
}
....try:该代码块中编写可能产生异常的代码。
catch:用来进行某种异常的捕获,实现对捕获到的异常进行处理。
- 可以有多个catch块,按顺序匹配。
- 如果多个异常类型有包含关系,那么小上大下
演示如下:
public class TestException {
public static void main(String[] args) {
try {
readFile("不敲代码学会Java秘籍.txt");
} catch (FileNotFoundException e) {
// e.printStackTrace();
// System.out.println("好好敲代码,不要老是想获得什么秘籍");
System.out.println(e.getMessage());
} catch (IllegalAccessException e) {
e.printStackTrace();
}
System.out.println("继续学习吧...");
}
// 如果定义功能时有问题发生需要报告给调用者。可以通过在方法上使用throws关键字进行声明
public static void readFile(String filePath) throws FileNotFoundException, IllegalAccessException{
File file = new File(filePath);
if(!file.exists()){
throw new FileNotFoundException(filePath+"文件不存在");
}
if(!file.isFile()){
throw new IllegalAccessException(filePath + "不是文件,无法直接读取");
}
//...
}
}如何获取异常信息:
Throwable类中定义了一些查看方法:
public String getMessage():获取异常的描述信息,原因(提示给用户的时候,就提示错误原因。
public void printStackTrace():打印异常的跟踪栈信息并输出到控制台。
包含了异常的类型,异常的原因,还包括异常出现的位置,在开发和调试阶段,都得使用printStackTrace。
finally块
finally:有一些特定的代码无论异常是否发生,都需要执行。另外,因为异常会引发程序跳转,导致有些语句执行不到。而finally就是解决这个问题的,在finally代码块中存放的代码都是一定会被执行的。
什么时候的代码必须最终执行?
当我们在try语句块中打开了一些物理资源(磁盘文件/网络连接/数据库连接等),我们都得在使用完之后,最终关闭打开的资源。
finally的语法:
try{
}catch(...){
}finally{
无论try中是否发生异常,也无论catch是否捕获异常,也不管try和catch中是否有return语句,都一定会执行
}
或
try{
}finally{
无论try中是否发生异常,也不管try中是否有return语句,都一定会执行
} 注意:finally不能单独使用。
比如在我们之后学习的IO流中,当打开了一个关联文件的资源,最后程序不管结果如何,都需要把这个资源关闭掉。
finally代码参考如下:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class TestException {
public static void main(String[] args) {
readFile("不敲代码学会Java秘籍.txt");
System.out.println("继续学习吧...");
}
// 如果定义功能时有问题发生需要报告给调用者。可以通过在方法上使用throws关键字进行声明
public static void readFile(String filePath) {
File file = new File(filePath);
FileInputStream fis = null;
try {
if(!file.exists()){
throw new FileNotFoundException(filePath+"文件不存在");
}
if(!file.isFile()){
throw new IllegalAccessException(filePath + "不是文件,无法直接读取");
}
fis = new FileInputStream(file);
//...
} catch (Exception e) {
//抓取到的是编译期异常 抛出去的是运行期
throw new RuntimeException(e);
}finally{
System.out.println("无论如何,这里的代码一定会被执行");
try {
if(fis!=null){
fis.close();
}
} catch (IOException e) {
//抓取到的是编译期异常 抛出去的是运行期
throw new RuntimeException(e);
}
}
}
}当只有在try或者catch中调用退出JVM的相关方法,例如System.exit(0),此时finally才不会执行,否则finally永远会执行。

finally与return
形式一:从try回来
public class TestReturn {
public static void main(String[] args) {
int result = test("12");
System.out.println(result);
}
public static int test(String str){
try{
Integer.parseInt(str);
return 1;
}catch(NumberFormatException e){
return -1;
}finally{
System.out.println("test结束");
}
}
}形式二:从catch回来
public class TestReturn {
public static void main(String[] args) {
int result = test("a");
System.out.println(result);
}
public static int test(String str){
try{
Integer.parseInt(str);
return 1;
}catch(NumberFormatException e){
return -1;
}finally{
System.out.println("test结束");
}
}
}形式三:从finally回来
public class TestReturn {
public static void main(String[] args) {
int result = test("a");
System.out.println(result);
}
public static int test(String str){
try{
Integer.parseInt(str);
return 1;
}catch(NumberFormatException e){
return -1;
}finally{
System.out.println("test结束");
return 0;
}
}
}异常注意事项
多个异常使用捕获又该如何处理呢?
- 多个异常分别处理。
- 多个异常一次捕获,多次处理。(推荐)
- 多个异常一次捕获一次处理。
一般我们是使用一次捕获多次处理方式,格式如下:
try{
编写可能会出现异常的代码
}catch(异常类型A e){ 当try中出现A类型异常,就用该catch来捕获.
处理异常的代码
//记录日志/打印异常信息/继续抛出异常
}catch(异常类型B e){ 当try中出现B类型异常,就用该catch来捕获.
处理异常的代码
//记录日志/打印异常信息/继续抛出异常
}注意:这种异常处理方式,要求多个catch中的异常不能相同,并且若catch中的多个异常之间有子父类异常的关系,那么子类异常要求在上面的catch处理,父类异常在下面的catch处理。
运行时异常被抛出可以不处理。即不捕获也不声明抛出。
如果finally有return语句,永远返回finally中的结果,避免该情况.
如果父类抛出了多个异常,子类重写父类方法时,抛出和父类相同的异常或者是父类异常的子类或者不抛出异常。
父类方法没有抛出异常,子类重写父类该方法时也不可抛出异常。此时子类方法中产生了编译时异常,只能捕获处理,不能声明抛出
自定义异常
为什么需要自定义异常类:
我们说了Java中不同的异常类,分别表示着某一种具体的异常情况,那么在开发中总是有些异常情况是Java开发人员没有定义好的,此时我们根据自己业务的异常情况来定义异常类。例如年龄负数问题,考试成绩负数问题等等。那么能不能自己定义异常呢?可以
异常类如何定义:
- 自定义一个编译期异常: 自定义类 并继承于
java.lang.Exception。 - 自定义一个运行时期的异常类:自定义类 并继承于
java.lang.RuntimeException。
演示自定义异常:
要求:我们模拟注册操作,如果用户名已存在,则抛出异常并提示:亲,该用户名已经被注册。
首先定义一个登陆异常类RegisterException:
// 业务逻辑异常
public class RegisterException extends Exception {
/**
* 空参构造
*/
public RegisterException() {
}
/**
*
* @param message 表示异常提示
*/
public RegisterException(String message) {
super(message);
}
}模拟登陆操作,使用数组模拟数据库中存储的数据,并提供当前注册账号是否存在方法用于判断。
public class Demo {
// 模拟数据库中已存在账号
private static String[] names = {"bill","hill","jill"};
public static void main(String[] args) {
//调用方法
try{
// 可能出现异常的代码
checkUsername("nill");
System.out.println("注册成功");//如果没有异常就是注册成功
}catch(RegisterException e){
//处理异常
e.printStackTrace();
}
}
//判断当前注册账号是否存在
//因为是编译期异常,又想调用者去处理 所以声明该异常
public static boolean checkUsername(String uname) throws LoginException{
for (int i=0; i<names.length; i++) {
if(names[i].equals(uname)){//如果名字在这里面 就抛出登陆异常
throw new RegisterException("亲"+name+"已经被注册了!");
}
}
return true;
}
}结论:
- 从Exception类或者它的子类派生一个子类即可
- 习惯上,自定义异常类应该包含2个构造器:一个是无参构造,另一个是带有详细信息的构造器
- 自定义的异常只能通过throw抛出。
- 自定义异常最重要的是异常类的名字,当异常出现时,可以根据名字判断异常类型。
多线程
我们在之前,学习的程序在没有跳转语句的前提下,都是由上至下依次执行,那现在想要设计一个程序,边打游戏边听歌,怎么设计?
要解决上述问题,咱们得使用多进程或者多线程来解决.
相关概念
并发与并行(了解)
- 并行(parallel):指两个或多个事件在同一时刻发生(同时发生)。指在同一时刻,有多条指令在多个处理器上同时执行。
- 并发(concurrency):指两个或多个事件在同一个时间段内发生。指在同一个时刻只能有一条指令执行,但多个进程的指令被快速轮换执行,使得在宏观上具有多个进程同时执行的效果。
在操作系统中,安装了多个程序,并发指的是在一段时间内宏观上有多个程序同时运行,这在单 CPU 系统中,每一时刻只能有一个程序执行,即微观上这些程序是分时的交替运行,只不过是给人的感觉是同时运行,那是因为分时交替运行的时间是非常短的。
而在多个 CPU 系统中,则这些可以并发执行的程序便可以分配到多个处理器上(CPU),实现多任务并行执行,即利用每个处理器来处理一个可以并发执行的程序,这样多个程序便可以同时执行。目前电脑市场上说的多核 CPU,便是多核处理器,核越多,并行处理的程序越多,能大大的提高电脑运行的效率。
注意:单核处理器的计算机肯定是不能并行的处理多个任务的,只能是多个任务在单个CPU上并发运行。同理,线程也是一样的,从宏观角度上理解线程是并行运行的,但是从微观角度上分析却是串行运行的,即一个线程一个线程的去运行,当系统只有一个CPU时,线程会以某种顺序执行多个线程,我们把这种情况称之为线程调度。
单核CPU:只能并发
多核CPU:并行+并发
例子:
并行:多项工作一起执行,之后再汇总,例如:泡方便面,电水壶烧水,一边撕调料倒入桶中
并发:同一时刻多个线程在访问同一个资源,多个线程对一个点,例如:春运抢票、电商秒杀…
线程与进程
程序:为了完成某个任务和功能,选择一种编程语言编写的一组指令的集合。
软件:1个或多个应用程序+相关的素材和资源文件等构成一个软件系统。
进程:是指一个内存中运行的应用程序,每个进程都有一个独立的内存空间,进程也是程序的一次执行过程,是系统运行程序的基本单位;系统运行一个程序即是一个进程从创建、运行到消亡的过程。
线程:线程是进程中的一个执行单元,负责当前进程中程序的执行,一个进程中至少有一个线程。一个进程中是可以有多个线程的,这个应用程序也可以称之为多线程程序。
简而言之:一个软件中至少有一个应用程序,应用程序的一次运行就是一个进程,一个进程中至少有一个线程。
面试题:进程是操作系统调度和分配资源的最小单位,线程是CPU调度的最小单位。不同的进程之间是不共享内存的。进程之间的数据交换和通信的成本是很高。不同的线程是共享同一个进程的内存的。当然不同的线程也有自己独立的内存空间。对于方法区,堆中中的同一个对象的内存,线程之间是可以共享的,但是栈的局部变量永远是独立的。
例如:
每个应用程序的运行都是一个进程
我们可以再电脑底部任务栏,右键——->打开任务管理器,可以查看当前任务的进程:
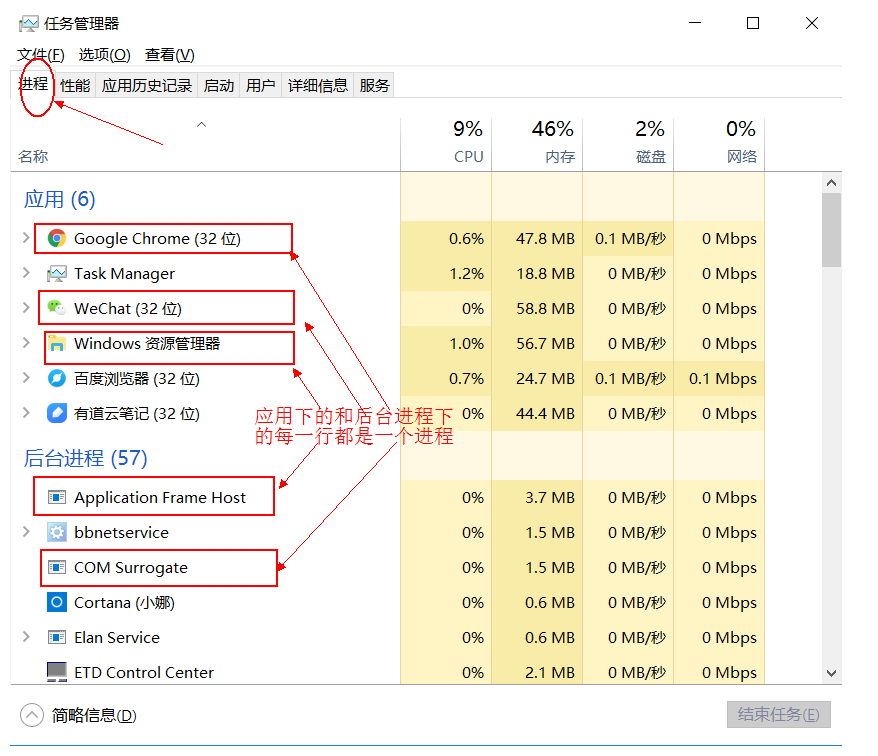
一个应用程序的多次运行,就是多个进程

一个进程中包含多个线程
线程调度
分时调度
所有线程轮流使用 CPU 的使用权,平均分配每个线程占用 CPU 的时间。
抢占式调度
优先让优先级高的线程使用 CPU,如果线程的优先级相同,那么会随机选择一个(线程随机性),Java使用的为抢占式调度。
抢占式调度详解
大部分操作系统都支持多进程并发运行,现在的操作系统几乎都支持同时运行多个程序。比如:现在我们上课一边使用编辑器,一边使用录屏软件,同时还开着画图板,dos窗口等软件。此时,这些程序是在同时运行,”感觉这些软件好像在同一时刻运行着“。
实际上,CPU(中央处理器)使用抢占式调度模式在多个线程间进行着高速的切换。对于CPU的一个核而言,某个时刻,只能执行一个线程,而 CPU的在多个线程间切换速度相对我们的感觉要快,看上去就是在同一时刻运行。
其实,多线程程序并不能提高程序的运行速度,但能够提高程序运行效率,让CPU的使用率更高。
另行创建和启动线程
当运行Java程序时,其实已经有一个线程了,那就是main线程。
那么如何创建和启动main线程以外的线程呢?
继承Thread类
Java使用java.lang.Thread类代表线程,所有的线程对象都必须是Thread类或其子类的实例。每个线程的作用是完成一定的任务,实际上就是执行一段程序流即一段顺序执行的代码。Java使用线程执行体来代表这段程序流。Java中通过继承Thread类来创建并启动多线程的步骤如下:
- 定义Thread类的子类,并重写该类的run()方法,该run()方法的方法体就代表了线程需要完成的任务,因此把run()方法称为线程执行体。
- 创建Thread子类的实例,即创建了线程对象
- 调用线程对象的start()方法来启动该线程
代码如下:
测试类:
public class Demo01 {
public static void main(String[] args) {
//创建自定义线程对象
MyThread mt = new MyThread("新的线程!");
//开启新线程
mt.start();
//在主方法中执行for循环
for (int i = 0; i < 10; i++) {
System.out.println("main线程!"+i);
}
}
}自定义线程类:
public class MyThread extends Thread {
//定义指定线程名称的构造方法
public MyThread(String name) {
//调用父类的String参数的构造方法,指定线程的名称
super(name);
}
/**
* 重写run方法,完成该线程执行的逻辑
*/
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(getName()+":正在执行!"+i);
}
}
}实现Runnable接口
Java有单继承的限制,当我们无法继承Thread类时,那么该如何做呢?在核心类库中提供了Runnable接口,我们可以实现Runnable接口,重写run()方法,然后再通过Thread类的对象代理启动和执行我们的线程体run()方法
步骤如下:
- 定义Runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
- 创建Runnable实现类的实例,并以此实例作为Thread的target来创建Thread对象,该Thread对象才是真正
的线程对象。 - 调用线程对象的start()方法来启动线程。
代码如下:
public class MyRunnable implements Runnable{
@Override
public void run() {
for (int i = 0; i < 20; i++) {
System.out.println(Thread.currentThread().getName()+" "+i);
}
}
}public class Demo {
public static void main(String[] args) {
//创建自定义类对象 线程任务对象
MyRunnable mr = new MyRunnable();
//创建线程对象
Thread t = new Thread(mr, "小强");
t.start();
for (int i = 0; i < 20; i++) {
System.out.println("旺财 " + i);
}
}
} 通过实现Runnable接口,使得该类有了多线程类的特征。run()方法是多线程程序的一个执行目标。所有的多线程
代码都在run方法里面。Thread类实际上也是实现了Runnable接口的类。
在启动的多线程的时候,需要先通过Thread类的构造方法Thread(Runnable target) 构造出对象,然后调用Thread对象的start()方法来运行多线程代码。
实际上所有的多线程代码都是通过运行Thread的start()方法来运行的。因此,不管是继承Thread类还是实现
Runnable接口来实现多线程,最终还是通过Thread的对象的API来控制线程的,熟悉Thread类的API是进行多线程编程的基础。
tips:Runnable对象仅仅作为Thread对象的target,Runnable实现类里包含的run()方法仅作为线程执行体。
而实际的线程对象依然是Thread实例,只是该Thread线程负责执行其target的run()方法。
使用匿名内部类对象来实现线程的创建和启动
new Thread("新的线程!"){
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(getName()+":正在执行!"+i);
}
}
}.start();new Thread(new Runnable(){
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName()+":" + i);
}
}
}).start();Thread类
构造方法
public Thread() :分配一个新的线程对象。
public Thread(String name) :分配一个指定名字的新的线程对象。
public Thread(Runnable target) :分配一个带有指定目标新的线程对象。
public Thread(Runnable target,String name) :分配一个带有指定目标新的线程对象并指定名字。
常用方法系列1
- public void run() :此线程要执行的任务在此处定义代码。
- public String getName() :获取当前线程名称。
- public static Thread currentThread() :返回对当前正在执行的线程对象的引用。
- public final boolean isAlive():测试线程是否处于活动状态。如果线程已经启动且尚未终止,则为活动状态。
- public final int getPriority() :返回线程优先级
public final void setPriority(int newPriority) :改变线程的优先级
- 每个线程都有一定的优先级,优先级高的线程将获得较多的执行机会。每个线程默认的优先级都与创建它的父线程具有相同的优先级。Thread类提供了setPriority(int newPriority)和getPriority()方法类设置和获取线程的优先级,其中setPriority方法需要一个整数,并且范围在[1,10]之间,通常推荐设置Thread类的三个优先级常量:
- MAX_PRIORITY(10):最高优先级
- MIN _PRIORITY (1):最低优先级
- NORM_PRIORITY (5):普通优先级,默认情况下main线程具有普通优先级。
public static void main(String[] args) {
Thread t = new Thread(){
public void run(){
System.out.println(getName() + "的优先级:" + getPriority());
}
};
t.setPriority(Thread.MAX_PRIORITY);
t.start();
System.out.println(Thread.currentThread().getName() +"的优先级:" + Thread.currentThread().getPriority());
}9.3.3 常用方法系列2
public void start() :导致此线程开始执行; Java虚拟机调用此线程的run方法。
public static void sleep(long millis) :使当前正在执行的线程以指定的毫秒数暂停(暂时停止执行)。
public static void yield():yield只是让当前线程暂停一下,让系统的线程调度器重新调度一次,希望优先级与当前线程相同或更高的其他线程能够获得执行机会,但是这个不能保证,完全有可能的情况是,当某个线程调用了yield方法暂停之后,线程调度器又将其调度出来重新执行。
void join() :等待该线程终止。
void join(long millis) :等待该线程终止的时间最长为 millis 毫秒。如果millis时间到,将不再等待。
void join(long millis, int nanos) :等待该线程终止的时间最长为 millis 毫秒 + nanos 纳秒。
public final void stop():强迫线程停止执行。 该方法具有固有的不安全性,已经标记为@Deprecated不建议再使用,那么我们就需要通过其他方式来停止线程了,其中一种方式是使用变量的值的变化来控制线程是否结束。
示例代码:倒计时
public static void main(String[] args) {
for (int i = 10; i>=0; i--) {
System.out.println(i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("新年快乐!");
}示例代码:强行加塞
主线程:打印[1,10],每隔10毫秒打印一个数字,
自定义线程类:不停的问是否结束,输入Y或N,
现在当主线程打印完5之后,就让自定义线程类加塞,直到自定义线程类结束,主线程再继续。
import java.util.Scanner;
public class TestJoin {
public static void main(String[] args) {
ChatThread t = new ChatThread();
t.start();
for (int i = 1; i <= 10; i++) {
System.out.println("main:" + i);
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
//当main打印到5之后,需要等join进来的线程停止后才会继续了。
if(i==5){
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
class ChatThread extends Thread{
public void run(){
Scanner input = new Scanner(System.in);
while(true){
System.out.println("是否结束?(Y、N)");
char confirm = input.next().charAt(0);
if(confirm == 'Y' || confirm == 'y'){
break;
}
}
input.close();
}
}9.3.4 volatile保证线程间的数据的可见性
public class TestVolatile {
private static boolean flag = true;//保证
public static void main(String[] args) {
//创建一个线程并启动
new Thread(new Runnable() {
@Override
public void run() {
while (flag) {
// System.out.println("=============");
}
}
}).start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = false;
}
}
volatile的作用是确保不会因编译器的优化而省略某些指令,volatile的变量是说这变量可能会被意想不到地改变,每次都小心地重新读取这个变量的值,而不是使用保存在寄存器里的备份,这样,编译器就不会去假设这个变量的值了。
9.3.5守护线程(了解)
有一种线程,它是在后台运行的,它的任务是为其他线程提供服务的,这种线程被称为“守护线程”。JVM的垃圾回收线程就是典型的守护线程。
守护线程有个特点,就是如果所有非守护线程都死亡,那么守护线程自动死亡。
调用setDaemon(true)方法可将指定线程设置为守护线程。必须在线程启动之前设置,否则会报IllegalThreadStateException异常。
调用isDaemon()可以判断线程是否是守护线程。
public class TestThread {
public static void main(String[] args) {
MyDaemon m = new MyDaemon();
m.setDaemon(true);
m.start();
for (int i = 1; i <= 100; i++) {
System.out.println("main:" + i);
}
}
}
class MyDaemon extends Thread {
public void run() {
while (true) {
System.out.println("我一直守护者你...");
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}线程安全
当我们使用多个线程访问同一资源(可以是同一个变量、同一个文件、同一条记录等)的时候,若多个线程只有读操作,那么不会发生线程安全问题,但是如果多个线程中对资源有读和写的操作,就容易出现线程安全问题。
我们通过一个案例,演示线程的安全问题:
电影院要卖票,我们模拟电影院的卖票过程。假设要播放的电影是 “葫芦娃大战奥特曼”,本次电影的座位共100个
(本场电影只能卖100张票)。
我们来模拟电影院的售票窗口,实现多个窗口同时卖 “葫芦娃大战奥特曼”这场电影票(多个窗口一起卖这100张票)
同一个资源问题
局部变量不能共享
示例代码:
package com.atguigu.safe;
public class SaleTicketDemo1 {
public static void main(String[] args) {
Window w1 = new Window();
Window w2 = new Window();
Window w3 = new Window();
w1.start();
w2.start();
w3.start();
}
}
class Window extends Thread{
public void run(){
int total = 100;
while(total>0) {
System.out.println(getName() + "卖出一张票,剩余:" + --total);
}
}
}结果:发现卖出300张票。
问题:局部变量是每次调用方法都是独立的,那么每个线程的run()的total是独立的,不是共享数据。
不同对象的实例变量不共享
package com.atguigu.safe;
public class SaleTicketDemo2 {
public static void main(String[] args) {
TicketSaleThread t1 = new TicketSaleThread();
TicketSaleThread t2 = new TicketSaleThread();
TicketSaleThread t3 = new TicketSaleThread();
t1.start();
t2.start();
t3.start();
}
}
class TicketSaleThread extends Thread{
private int total = 10;
public void run(){
while(total>0) {
System.out.println(getName() + "卖出一张票,剩余:" + --total);
}
}
}结果:发现卖出300张票。
问题:不同的实例对象的实例变量是独立的。
静态变量是共享的
示例代码:
package com.atguigu.safe;
public class SaleTicketDemo3 {
public static void main(String[] args) {
TicketThread t1 = new TicketThread();
TicketThread t2 = new TicketThread();
TicketThread t3 = new TicketThread();
t1.start();
t2.start();
t3.start();
}
}
class TicketThread extends Thread{
private static int total = 10;
public void run(){
while(total>0) {
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getName() + "卖出一张票,剩余:" + --total);
}
}
}结果:发现卖出近100张票。
问题(1):但是有重复票或负数票问题。
原因:线程安全问题
问题(2):如果要考虑有两场电影,各卖100张票等
原因:TicketThread类的静态变量,是所有TicketThread类的对象共享
同一个对象的实例变量共享
示例代码:多个Thread线程使用同一个Runnable对象
package com.atguigu.safe;
public class SaleTicketDemo3 {
public static void main(String[] args) {
TicketSaleRunnable tr = new TicketSaleRunnable();
Thread t1 = new Thread(tr,"窗口一");
Thread t2 = new Thread(tr,"窗口一");
Thread t3 = new Thread(tr,"窗口一");
t1.start();
t2.start();
t3.start();
}
}
class TicketSaleRunnable implements Runnable{
private int total = 10;
public void run(){
while(total>0) {
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "卖出一张票,剩余:" + --total);
}
}
}结果:发现卖出近100张票。
问题:但是有重复票或负数票问题。
原因:线程安全问题
抽取资源类,共享同一个资源对象
示例代码:
package com.atguigu.thread.resource;
public class SaleTicketDemo5 {
public static void main(String[] args) {
//2、创建资源对象
Ticket ticket = new Ticket();
//3、启动多个线程操作资源类的对象
Thread t1 = new Thread("窗口一"){
public void run(){
while(true){
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t2 = new Thread("窗口二"){
public void run(){
while(true){
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t3 = new Thread(new Runnable(){
public void run(){
while(true){
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
},"窗口三");
t1.start();
t2.start();
t3.start();
}
}
//1、编写资源类
class Ticket{
private int total = 10;
public void sale(){
if(total>0) {
System.out.println(Thread.currentThread().getName() + "卖出一张票,剩余:" + --total);
}else{
throw new RuntimeException("没有票了");
}
}
public int getTotal(){
return total;
}
}
发现程序出现了两个问题:
- 相同的票数,比如某张票被卖了两回。
- 不存在的票,比如0票与-1票,是不存在的。
这种问题,几个窗口(线程)票数不同步了,这种问题称为线程不安全。
尝试解决线程安全问题
要解决上述多线程并发访问一个资源的安全性问题:也就是解决重复票与不存在票问题,Java中提供了同步机制
(synchronized)来解决。
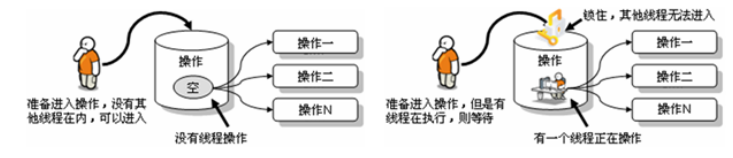
根据案例简述:
窗口1线程进入操作的时候,窗口2和窗口3线程只能在外等着,窗口1操作结束,窗口1和窗口2和窗口3才有机会进入代码去执行。也就是说在某个线程修改共享资源的时候,其他线程不能修改该资源,等待修改完毕同步之后,才能去抢夺CPU资源,完成对应的操作,保证了数据的同步性,解决了线程不安全的现象。
为了保证每个线程都能正常执行原子操作,Java引入了线程同步机制。注意:在任何时候,最多允许一个线程拥有同步锁,谁拿到锁就进入代码块,其他的线程只能在外等着(BLOCKED)。
同步方法:synchronized 关键字直接修饰方法,表示同一时刻只有一个线程能进入这个方法,其他线程在外面等着。
public synchronized void method(){
可能会产生线程安全问题的代码
}同步代码块:synchronized 关键字可以用于某个区块前面,表示只对这个区块的资源实行互斥访问。
格式:
synchronized(同步锁){
需要同步操作的代码
}锁对象选择
同步锁对象:
- 锁对象可以是任意类型。
- 多个线程对象 要使用同一把锁。
1、同步方法的锁对象问题
(1)静态方法:当前类的Class对象
(2)非静态方法:this
示例代码一:
package com.atguigu.thread2.safemethod;
public class SaleTicketSafeDemo1 {
public static void main(String[] args) {
// 2、创建资源对象
Ticket ticket = new Ticket();
// 3、启动多个线程操作资源类的对象
Thread t1 = new Thread("窗口一") {
public void run() {
while (true) {
try {
Thread.sleep(10);// 加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t2 = new Thread("窗口二") {
public void run() {
while (true) {
try {
Thread.sleep(10);// 加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t3 = new Thread(new Runnable() {
public void run() {
while (true) {
try {
Thread.sleep(10);// 加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
}, "窗口三");
t1.start();
t2.start();
t3.start();
}
}
// 1、编写资源类
class Ticket {
private int total = 10;
//非静态方法隐含的锁对象就是this
public synchronized void sale() {
if (total > 0) {
System.out.println(Thread.currentThread().getName() + "卖出一张票,剩余:" + --total);
} else {
throw new RuntimeException(Thread.currentThread().getName() + "发现没有票了");
}
}
public int getTotal() {
return total;
}
}
示例代码二:
package com.atguigu.thread2.safemethod;
public class SaleTicketSafeDemo2 {
public static void main(String[] args) {
TicketRunnable tr = new TicketRunnable();
Thread t1 = new Thread(tr,"窗口一");
Thread t2 = new Thread(tr,"窗口二");
Thread t3 = new Thread(tr,"窗口三");
t1.start();
t2.start();
t3.start();
}
}
class TicketRunnable implements Runnable {
private int ticket = 10;
@Override
public void run() {
while(ticket > 0){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
sellTicket();
}
}
//非静态方法隐含的锁对象就是this
public synchronized void sellTicket() {
if (ticket > 0) {
System.out.println(Thread.currentThread().getName() + "正在卖:" + ticket--);
}
}
}示例代码三:
package com.atguigu.thread2.safemethod;
public class SaleTicketSafeDemo3 {
public static void main(String[] args) {
TicketThread t1 = new TicketThread();
TicketThread t2 = new TicketThread();
TicketThread t3 = new TicketThread();
t1.start();
t2.start();
t3.start();
}
}
class TicketThread extends Thread {
private static int ticket = 100;
@Override
public void run() {
while (ticket>0) {
try {
Thread.sleep(100);
} catch(InterruptedException e) {
e.printStackTrace();
}
sellTicket();
}
}
//这里必须是静态方法,因为如果是非静态方法,隐含的锁对象是this,那么多个线程就不是同一个锁对象了
//而静态方法隐含的锁对象是当前类的Class对象
public synchronized static void sellTicket(){
if(ticket>0){//有票可以卖
System.out.println(Thread.currentThread().getName() + "正在卖:" + ticket--);
}
}
}2、同步代码块的锁对象
同步锁对象:
- 锁对象可以是任意类型。
- 多个线程对象 要使用同一把锁。
- 习惯上先考虑this,但是要注意是否同一个this
示例代码一:this对象
package com.atguigu.thread2.safeblock;
public class SaleTicketSafeDemo1 {
public static void main(String[] args) {
// 2、创建资源对象
Ticket ticket = new Ticket();
// 3、启动多个线程操作资源类的对象
Thread t1 = new Thread("窗口一") {
public void run() {
while (true) {
try {
Thread.sleep(10);// 加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t2 = new Thread("窗口二") {
public void run() {
while (true) {
try {
Thread.sleep(10);// 加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t3 = new Thread(new Runnable() {
public void run() {
while (true) {
try {
Thread.sleep(10);// 加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
}, "窗口三");
t1.start();
t2.start();
t3.start();
}
}
// 1、编写资源类
class Ticket {
private int total = 10;
public void sale() {
synchronized (this) {
if (total > 0) {
System.out.println(Thread.currentThread().getName() + "卖出一张票,剩余:" + --total);
} else {
throw new RuntimeException(Thread.currentThread().getName() + "发现没有票了");
}
}
}
public int getTotal() {
return total;
}
}
示例代码二:this对象
package com.atguigu.thread2.safeblock;
public class SaleTicketSafeDemo2 {
public static void main(String[] args) {
TicketRunnable tr = new TicketRunnable();
Thread t1 = new Thread(tr,"窗口一");
Thread t2 = new Thread(tr,"窗口二");
Thread t3 = new Thread(tr,"窗口三");
t1.start();
t2.start();
t3.start();
}
}
class TicketRunnable implements Runnable {
private int ticket = 10;
@Override
public void run() {
while(ticket > 0){
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (this) {
if (ticket > 0) {
System.out.println(Thread.currentThread().getName() + "正在卖:" + ticket--);
}
}
}
}
}示例代码三:其他对象
package com.atguigu.thread2.safeblock;
public class SaleTicketSafeDemo3 {
public static void main(String[] args) {
TicketThread t1 = new TicketThread();
TicketThread t2 = new TicketThread();
TicketThread t3 = new TicketThread();
t1.start();
t2.start();
t3.start();
}
}
class TicketThread extends Thread{
private static int total = 10;
private static final Object myLock = new Object();
public void run(){
while(total>0) {
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
} catch (InterruptedException e) {
e.printStackTrace();
}
// synchronized (this) {//此处不能选this对象作为锁,因为this对于上面的三个线程来说是不同的
// synchronized (TicketThread.class) {//可以,因为在JVM中TicketThread类的Class对象只有一个
// synchronized ("") {//可以,因为在JVM中""字符串对象只有一个
synchronized (myLock) {//可以,因为在JVM中myLock对象只有一个
if(total>0){
System.out.println(getName() + "卖出一张票,剩余:" + --total);
}
}
}
}
}锁的范围问题
锁的范围太小:不能解决安全问题
锁的范围太大:因为一旦某个线程抢到锁,其他线程就只能等待,所以范围太大,效率会降低,不能合理利用CPU资源。
示例代码一:锁范围太小
package com.atguigu.thread3.lockrange;
public class SaleTicketSafeDemo1 {
public static void main(String[] args) {
//2、创建资源对象
Ticket2 ticket = new Ticket2();
//3、启动多个线程操作资源类的对象
Thread t1 = new Thread("窗口一"){
public void run(){
while(true){
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t2 = new Thread("窗口二"){
public void run(){
while(true){
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t3 = new Thread(new Runnable(){
public void run(){
while(true){
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
},"窗口三");
t1.start();
t2.start();
t3.start();
}
}
//1、编写资源类
class Ticket2{
private int total = 10;
public void sale(){
if(total>0) {
//锁的范围太小
synchronized (this) {
System.out.println(Thread.currentThread().getName() + "卖出一张票,剩余:" + --total);
}
}else{
throw new RuntimeException(Thread.currentThread().getName() + "发现没有票了");
}
}
public int getTotal(){
return total;
}
}
示例代码二:锁范围太小
package com.atguigu.thread3.lockrange;
public class SaleTicketSafeDemo2 {
public static void main(String[] args) {
TicketRunnable tr = new TicketRunnable();
Thread t1 = new Thread(tr,"窗口一");
Thread t2 = new Thread(tr,"窗口二");
Thread t3 = new Thread(tr,"窗口三");
t1.start();
t2.start();
t3.start();
}
}
class TicketRunnable implements Runnable {
private int ticket = 10;
@Override
public void run() {
while(ticket > 0){
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (this) {
//if (ticket > 0) {//条件没有锁进去
System.out.println(Thread.currentThread().getName() + "正在卖:" + ticket--);
//}
}
}
}
}示例代码三:锁范围太大
package com.atguigu.thread3.lockrange;
public class SaleTicketSafeDemo3 {
public static void main(String[] args) {
TicketRunnableDemo tr = new TicketRunnableDemo();
Thread t1 = new Thread(tr,"窗口一");
Thread t2 = new Thread(tr,"窗口二");
Thread t3 = new Thread(tr,"窗口三");
t1.start();
t2.start();
t3.start();
}
}
class TicketRunnableDemo implements Runnable {
private int ticket = 10;
@Override
public synchronized void run() {
while(ticket > 0){
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "正在卖:" + ticket--);
}
}
}
示例代码四:锁范围太大
package com.atguigu.thread3.lockrange;
public class SaleTicketSafeDemo1 {
public static void main(String[] args) {
//2、创建资源对象
Ticket ticket = new Ticket();
//3、启动多个线程操作资源类的对象
Thread t1 = new Thread("窗口一"){
public void run(){
//问题:一旦某个线程占了ticket锁,就要等它把票全部卖完,才会释放锁了
synchronized (ticket) {
while(true){
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
}
};
Thread t2 = new Thread("窗口二"){
public void run(){
synchronized (ticket) {
while(true){
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
}
};
Thread t3 = new Thread(new Runnable(){
public void run(){
synchronized (ticket) {
while(true){
try {
Thread.sleep(10);//加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
}
},"窗口三");
t1.start();
t2.start();
t3.start();
}
}
//1、编写资源类
class Ticket{
private int total = 10;
public void sale(){
if(total>0) {
System.out.println(Thread.currentThread().getName() + "卖出一张票,剩余:" + --total);
}else{
throw new RuntimeException(Thread.currentThread().getName() + "发现没有票了");
}
}
public int getTotal(){
return total;
}
}如何编写多线程的程序呢?
原则:
- 线程操作资源类
- 高内聚低耦合
步骤:
- 编写资源类
- 考虑线程安全问题,在资源类中考虑使用同步代码块或同步方法
public class TestSynchronized {
public static void main(String[] args) {
// 2、创建资源对象
Ticket ticket = new Ticket();
// 3、启动多个线程操作资源类的对象
Thread t1 = new Thread("窗口一") {
public void run() {
while (true) {
try {
Thread.sleep(10);// 加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t2 = new Thread("窗口二") {
public void run() {
while (true) {
try {
Thread.sleep(10);// 加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
};
Thread t3 = new Thread(new Runnable() {
public void run() {
while (true) {
try {
Thread.sleep(10);// 加入这个,使得问题暴露的更明显
ticket.sale();
} catch (Exception e) {
e.printStackTrace();
break;
}
}
}
}, "窗口三");
t1.start();
t2.start();
t3.start();
}
}
// 1、编写资源类
class Ticket {
private int total = 10;
public synchronized void sale() {
if(total<=0){
throw new RuntimeException(Thread.currentThread().getName() + "发现没有票了");
}
System.out.println(Thread.currentThread().getName() + "卖出一张票,剩余:" + --total);
}
public int getTotal() {
return total;
}
}单例设计模式的线程安全问题
1、饿汉式没有线程安全问题
饿汉式:上来就创建对象
package com.atguigu.thread4;
public class OnlyOneDemo {
public static void main(String[] args) {
OnlyOne o1 = OnlyOne.INSTANCE;
OnlyOne o2 = OnlyOne.INSTANCE;
System.out.println(o1);
System.out.println(o2);
System.out.println(o1==o2);
}
}
class OnlyOne{
public static final OnlyOne INSTANCE = new OnlyOne();
private OnlyOne(){
}
}2、懒汉式线程安全问题
延迟创建对象
public class SingleTest {
@Test
public void test1() {
Single s1 = Single.getInstance();
Single s2 = Single.getInstance();
System.out.println(s1);
System.out.println(s2);
System.out.println(s1 == s2);
}
Single s1;
Single s2;
@Test
public void test2() throws InterruptedException {
new Thread(new Runnable() {
@Override
public void run() {
s1 = Single.getInstance();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
s2 = Single.getInstance();
}
}).start();
Thread.sleep(1000);
System.out.println(s1 + " : " + s2);
System.out.println(s1 == s2);
}
}等待唤醒机制
线程间通信
为什么要处理线程间通信:
多个线程在处理同一个资源,但是处理的动作(线程的任务)却不相同。而多个线程并发执行时, 在默认情况下CPU是随机切换线程的,当我们需要多个线程来共同完成一件任务,并且我们希望他们有规律的执行, 那么多线程之间需要一些通信机制,可以协调它们的工作,以此来帮我们达到多线程共同操作一份数据。
比如:线程A用来生成包子的,线程B用来吃包子的,包子可以理解为同一资源,线程A与线程B处理的动作,一个是生产,一个是消费,此时B线程必须等到A线程完成后才能执行,那么线程A与线程B之间就需要线程通信,即—— 等待唤醒机制。
等待唤醒机制
什么是等待唤醒机制
这是多个线程间的一种协作机制。谈到线程我们经常想到的是线程间的竞争(race),比如去争夺锁,但这并不是故事的全部,线程间也会有协作机制。
就是在一个线程满足某个条件时,就进入等待状态(wait()/wait(time)), 等待其他线程执行完他们的指定代码过后再将其唤醒(notify());或可以指定wait的时间,等时间到了自动唤醒;在有多个线程进行等待时,如果需要,可以使用 notifyAll()来唤醒所有的等待线程。wait/notify 就是线程间的一种协作机制。
- wait:线程不再活动,不再参与调度,进入 wait set 中,因此不会浪费 CPU 资源,也不会去竞争锁了,这时的线程状态即是 WAITING或TIMED_WAITING。它还要等着别的线程执行一个特别的动作,也即是“通知(notify)”或者等待时间到,在这个对象上等待的线程从wait set 中释放出来,重新进入到调度队列(ready queue)中
- notify:则选取所通知对象的 wait set 中的一个线程释放;
- notifyAll:则释放所通知对象的 wait set 上的全部线程。
注意:
被通知线程被唤醒后也不一定能立即恢复执行,因为它当初中断的地方是在同步块内,而此刻它已经不持有锁,所以她需要再次尝试去获取锁(很可能面临其它线程的竞争),成功后才能在当初调用 wait 方法之后的地方恢复执行。
总结如下:
- 如果能获取锁,线程就从 WAITING 状态变成 RUNNABLE(可运行) 状态;
- 否则,线程就从 WAITING 状态又变成 BLOCKED(等待锁) 状态
调用wait和notify方法需要注意的细节
- wait方法与notify方法必须要由同一个锁对象调用。因为:对应的锁对象可以通过notify唤醒使用同一个锁对象调用的wait方法后的线程。
- wait方法与notify方法是属于Object类的方法的。因为:锁对象可以是任意对象,而任意对象的所属类都是继承了Object类的。
- wait方法与notify方法必须要在同步代码块或者是同步函数中使用。因为:必须要通过锁对象调用这2个方法。
生产者与消费者问题
等待唤醒机制可以解决经典的“生产者与消费者”的问题。
生产者与消费者问题(英语:Producer-consumer problem),也称有限缓冲问题(英语:Bounded-buffer problem),是一个多线程同步问题的经典案例。该问题描述了两个(多个)共享固定大小缓冲区的线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。
生产者与消费者问题中其实隐含了两个问题:
- 线程安全问题:因为生产者与消费者共享数据缓冲区,不过这个问题可以使用同步解决。
- 线程的协调工作问题:
- 要解决该问题,就必须让生产者线程在缓冲区满时等待(wait),暂停进入阻塞状态,等到下次消费者消耗了缓冲区中的数据的时候,通知(notify)正在等待的线程恢复到就绪状态,重新开始往缓冲区添加数据。同样,也可以让消费者线程在缓冲区空时进入等待(wait),暂停进入阻塞状态,等到生产者往缓冲区添加数据之后,再通知(notify)正在等待的线程恢复到就绪状态。通过这样的通信机制来解决此类问题。
一个厨师一个服务员问题
案例:有家餐馆的取餐口比较小,只能放10份快餐,厨师做完快餐放在取餐口的工作台上,服务员从这个工作台取出快餐给顾客。现在有1个厨师和1个服务员。
package com.atguigu.thread5;
public class TestCommunicate {
public static void main(String[] args) {
// 1、创建资源类对象
Workbench workbench = new Workbench();
// 2、创建和启动厨师线程
new Thread("厨师") {
public void run() {
while (true) {
workbench.put();
}
}
}.start();
// 3、创建和启动服务员线程
new Thread("服务员") {
public void run() {
while (true) {
workbench.take();
}
}
}.start();
}
}
// 1、定义资源类
class Workbench {
private static final int MAX_VALUE = 10;
private int num;
public synchronized void put() {
if (num >= MAX_VALUE) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
num++;
System.out.println(Thread.currentThread().getName() + "制作了一份快餐,现在工作台上有:" + num + "份快餐");
this.notify();
}
public synchronized void take() {
if (num <= 0) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
num--;
System.out.println(Thread.currentThread().getName() + "取走了一份快餐,现在工作台上有:" + num + "份快餐");
this.notify();
}
}
多个厨师多个服务员问题
案例:有家餐馆的取餐口比较小,只能放10份快餐,厨师做完快餐放在取餐口的工作台上,服务员从这个工作台取出快餐给顾客。现在有多个厨师和多个服务员。
package com.atguigu.thread5;
public class TestCommunicate2 {
public static void main(String[] args) {
// 1、创建资源类对象
WindowBoard windowBoard = new WindowBoard();
// 2、创建和启动厨师线程
// 3、创建和启动服务员线程
Cook c1 = new Cook("张三",windowBoard);
Cook c2 = new Cook("李四",windowBoard);
Waiter w1 = new Waiter("小红",windowBoard);
Waiter w2 = new Waiter("小绿",windowBoard);
c1.start();
c2.start();
w1.start();
w2.start();
}
}
//1、定义资源类
class WindowBoard {
private static final int MAX_VALUE = 10;
private int num;
public synchronized void put() {
while (num >= MAX_VALUE) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
num++;
System.out.println(Thread.currentThread().getName() + "制作了一份快餐,现在工作台上有:" + num + "份快餐");
this.notifyAll();
}
public synchronized void take() {
while (num <= 0) {
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
num--;
System.out.println(Thread.currentThread().getName() + "取走了一份快餐,现在工作台上有:" + num + "份快餐");
this.notifyAll();
}
}
//2、定义厨师类
class Cook extends Thread{
private WindowBoard windowBoard;
public Cook(String name,WindowBoard windowBoard) {
super(name);
this.windowBoard = windowBoard;
}
public void run(){
while(true) {
windowBoard.put();
}
}
}
//3、定义服务员类
class Waiter extends Thread{
private WindowBoard windowBoard;
public Waiter(String name,WindowBoard windowBoard) {
super(name);
this.windowBoard = windowBoard;
}
public void run(){
while(true) {
windowBoard.take();
}
}
}
练习
1、要求两个线程,同时打印字母,每个线程都能连续打印3个字母。两个线程交替打印,一个线程打印字母的小写形式,一个线程打印字母的大写形式,但是字母是连续的。当字母循环到z之后,回到a。

package com.atguigu.thread7;
public class PrintLetterDemo {
public static void main(String[] args) {
// 2、创建资源对象
PrintLetter p = new PrintLetter();
// 3、创建两个线程打印
new Thread("小写字母") {
public void run() {
while (true) {
p.printLower();
try {
Thread.sleep(1000);// 控制节奏
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}.start();
new Thread("大写字母") {
public void run() {
while (true) {
p.printUpper();
try {
Thread.sleep(1000);// 控制节奏
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}.start();
}
}
// 1、定义资源类
class PrintLetter {
private char letter = 'a';
public synchronized void printLower() {
for (int i = 1; i <= 3; i++) {
System.out.println(Thread.currentThread().getName() + "->" + letter);
letter++;
if (letter > 'z') {
letter = 'a';
}
}
this.notify();
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public synchronized void printUpper() {
for (int i = 1; i <= 3; i++) {
System.out.println(Thread.currentThread().getName() + "->" + (char) (letter - 32));
letter++;
if (letter > 'z') {
letter = 'a';
}
}
this.notify();
try {
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}线程生命周期
观点1:5种状态
简单来说,线程的生命周期有五种状态:新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)、死亡(Dead)。CPU需要在多条线程之间切换,于是线程状态会多次在运行、阻塞、就绪之间切换。

新建
当一个Thread类或其子类的对象被声明并创建时,新生的线程对象处于新建状。此时它和其他Java对象一样,仅仅由JVM为其分配了内存,并初始化了实例变量的值。此时的线程对象并没有任何线程的动态特征,程序也不会执行它的线程体run()。
就绪
但是当线程对象调用了start()方法之后,就不一样了,线程就从新建状态转为就绪状态。JVM会为其创建方法调用栈和程序计数器,当然,处于这个状态中的线程并没有开始运行,只是表示已具备了运行的条件,随时可以被调度。至于什么时候被调度,取决于JVM里线程调度器的调度。
注意:
程序只能对新建状态的线程调用start(),并且只能调用一次,如果对非新建状态的线程,如已启动的线程或已死亡的线程调用start()都会报错IllegalThreadStateException异常。
运行
如果处于就绪状态的线程获得了CPU,开始执行run()方法的线程体代码,则该线程处于运行状态。如果计算机只有一个CPU,在任何时刻只有一个线程处于运行状态,如果计算机有多个处理器,将会有多个线程并行(Parallel)执行。
当然,美好的时光总是短暂的,而且CPU讲究雨露均沾。对于抢占式策略的系统而言,系统会给每个可执行的线程一个小时间段来处理任务,当该时间用完,系统会剥夺该线程所占用的资源,让其回到就绪状态等待下一次被调度。此时其他线程将获得执行机会,而在选择下一个线程时,系统会适当考虑线程的优先级。
阻塞
当在运行过程中的线程遇到如下情况时,线程会进入阻塞状态:
- 线程调用了sleep()方法,主动放弃所占用的CPU资源;
- 线程试图获取一个同步监视器,但该同步监视器正被其他线程持有;
- 线程执行过程中,同步监视器调用了wait(),让它等待某个通知(notify);
- 线程执行过程中,同步监视器调用了wait(time)
- 线程执行过程中,遇到了其他线程对象的加塞(join);
- 线程被调用suspend方法被挂起(已过时,因为容易发生死锁);
当前正在执行的线程被阻塞后,其他线程就有机会执行了。针对如上情况,当发生如下情况时会解除阻塞,让该线程重新进入就绪状态,等待线程调度器再次调度它:
- 线程的sleep()时间到;
- 线程成功获得了同步监视器;
- 线程等到了通知(notify);
- 线程wait的时间到了
- 加塞的线程结束了;
- 被挂起的线程又被调用了resume恢复方法(已过时,因为容易发生死锁);
5. 死亡
线程会以以下三种方式之一结束,结束后的线程就处于死亡状态:
- run()方法执行完成,线程正常结束
- 线程执行过程中抛出了一个未捕获的异常(Exception)或错误(Error)
- 直接调用该线程的stop()来结束该线程(已过时,因为容易发生死锁)
观点2:6种状态
在java.lang.Thread.State的枚举类中这样定义:
public enum State {
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;
}首先它没有区分:就绪和运行状态,因为对于Java对象来说,只能标记为可运行,至于什么时候运行,不是JVM来控制的了,是OS来进行调度的,而且时间非常短暂,因此对于Java对象的状态来说,无法区分。只能我们人为的进行想象和理解。
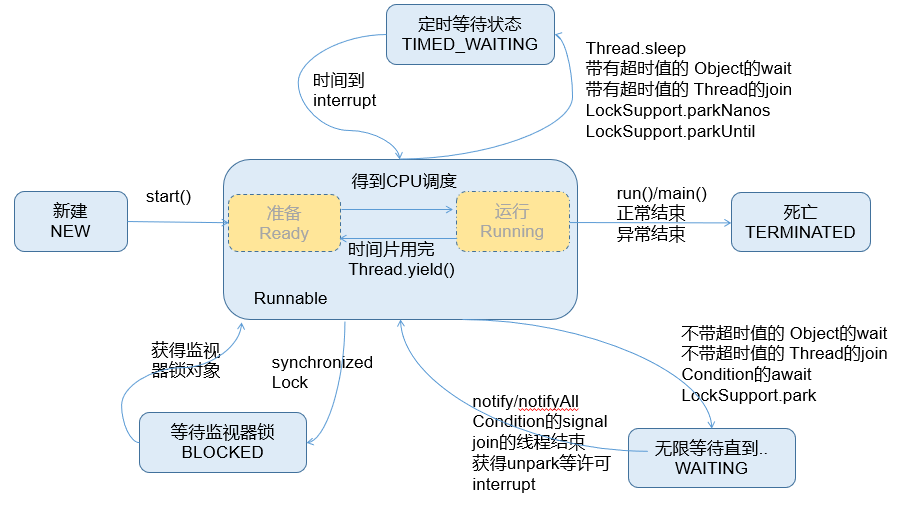
其次根据Thread.State的定义,阻塞状态是分为三种的:BLOCKED、WAITING、TIMED_WAITING。
- BLOCKED:是指互有竞争关系的几个线程,其中一个线程占有锁对象时,其他线程只能等待锁。只有获得锁对象的线程才能有执行机会。
- TIMED_WAITING:当前线程执行过程中遇到Thread类的sleep或join,Object类的wait,LockSupport类的park方法,并且在调用这些方法时,设置了时间,那么当前线程会进入TIMED_WAITING,直到时间到,或被中断。
- WAITING:当前线程执行过程中遇到遇到Object类的wait,Thread类的join,LockSupport类的park方法,并且在调用这些方法时,没有指定时间,那么当前线程会进入WAITING状态,直到被唤醒。
- 通过Object类的wait进入WAITING状态的要有Object的notify/notifyAll唤醒;
- 通过Condition的await进入WAITING状态的要有Conditon的signal方法唤醒;
- 通过LockSupport类的park方法进入WAITING状态的要有LockSupport类的unpark方法唤醒
- 通过Thread类的join进入WAITING状态,只有调用join方法的线程对象结束才能让当前线程恢复;
说明:当从WAITING或TIMED_WAITING恢复到Runnable状态时,如果发现当前线程没有得到监视器锁,那么会立刻转入BLOCKED状态。
释放锁操作与死锁
任何线程进入同步代码块、同步方法之前,必须先获得对同步监视器的锁定,那么何时会释放对同步监视器的锁定呢?
释放锁的操作
当前线程的同步方法、同步代码块执行结束。
当前线程在同步代码块、同步方法中出现了未处理的Error或Exception,导致当前线程异常结束。
当前线程在同步代码块、同步方法中执行了锁对象的wait()方法,当前线程被挂起,并释放锁。
不会释放锁的操作
线程执行同步代码块或同步方法时,程序调用Thread.sleep()、Thread.yield()方法暂停当前线程的执行。
线程执行同步代码块时,其他线程调用了该线程的suspend()方法将该该线程挂起,该线程不会释放锁(同步监视器)。应尽量避免使用suspend()和resume()这样的过时来控制线程。
死锁
不同的线程分别锁住对方需要的同步监视器对象不释放,都在等待对方先放弃时就形成了线程的死锁。一旦出现死锁,整个程序既不会发生异常,也不会给出任何提示,只是所有线程处于阻塞状态,无法继续。
public class TestDeadLock {
public static void main(String[] args) {
Object g = new Object();
Object m = new Object();
Owner s = new Owner(g,m);
Customer c = new Customer(g,m);
new Thread(s).start();
new Thread(c).start();
}
}
class Owner implements Runnable{
private Object goods;
private Object money;
public Owner(Object goods, Object money) {
super();
this.goods = goods;
this.money = money;
}
@Override
public void run() {
synchronized (goods) {
System.out.println("先给钱");
synchronized (money) {
System.out.println("发货");
}
}
}
}
class Customer implements Runnable{
private Object goods;
private Object money;
public Customer(Object goods, Object money) {
super();
this.goods = goods;
this.money = money;
}
@Override
public void run() {
synchronized (money) {
System.out.println("先发货");
synchronized (goods) {
System.out.println("再给钱");
}
}
}
}面试题:sleep()和wait()方法的区别
(1)sleep()不释放锁,wait()释放锁
(2)sleep()指定休眠的时间,wait()可以指定时间也可以无限等待直到notify或notifyAll
(3)sleep()在Thread类中声明的静态方法,wait方法在Object类中声明
因为我们调用wait()方法是由锁对象调用,而锁对象的类型是任意类型的对象。那么希望任意类型的对象都要有的方法,只能声明在Object类中。
基础API与常见算法
和数学相关的类
java.lang.Math
java.lang.Math 类包含用于执行基本数学运算的方法,如初等指数、对数、平方根和三角函数。类似这样的工具类,其所有方法均为静态方法,并且不会创建对象,调用起来非常简单。
public static double abs(double a):返回 double 值的绝对值。
double d1 = Math.abs(-5); //d1的值为5
double d2 = Math.abs(5); //d2的值为5public static double ceil(double a):返回大于等于参数的最小的整数。
double d1 = Math.ceil(3.3); //d1的值为 4.0
double d2 = Math.ceil(-3.3); //d2的值为 -3.0
double d3 = Math.ceil(5.1); //d3的值为 6.0public static double floor(double a):返回小于等于参数最大的整数。
double d1 = Math.floor(3.3); //d1的值为3.0
double d2 = Math.floor(-3.3); //d2的值为-4.0
double d3 = Math.floor(5.1); //d3的值为 5.0public static long round(double a):返回最接近参数的 long。(相当于四舍五入方法)
long d1 = Math.round(5.5); //d1的值为6.0
long d2 = Math.round(5.4); //d2的值为5.0- public static double pow(double a,double b):返回a的b幂次方法
- public static double sqrt(double a):返回a的平方根
- public static double random():返回[0,1)的随机值
- public static final double PI:返回圆周率
- public static double max(double x, double y):返回x,y中的最大值
- public static double min(double x, double y):返回x,y中的最小值
double result = Math.pow(2,31);
double sqrt = Math.sqrt(256);
double rand = Math.random();
double pi = Math.PI;练习
请使用Math 相关的API,计算在 -10.8 到5.9 之间,绝对值大于6 或者小于2.1 的整数有多少个?
public class MathTest {
public static void main(String[] args) {
// 定义最小值
double min = -10.8;
// 定义最大值
double max = 5.9;
// 定义变量计数
int count = 0;
// 范围内循环
for (double i = Math.ceil(min); i <= max; i++) {
// 获取绝对值并判断
if (Math.abs(i) > 6 || Math.abs(i) < 2.1) {
// 计数
count++;
}
}
System.out.println("个数为: " + count + " 个");
}
}java.math包
BigInteger
不可变的任意精度的整数。
- BigInteger(String val)
- BigInteger add(BigInteger val)
- BigInteger subtract(BigInteger val)
- BigInteger multiply(BigInteger val)
- BigInteger divide(BigInteger val)
- BigInteger remainder(BigInteger val)
- ….
@Test
public void test01(){
// long bigNum = 123456789123456789123456789L;
BigInteger b1 = new BigInteger("123456789123456789123456789");
BigInteger b2 = new BigInteger("78923456789123456789123456789");
// System.out.println("和:" + (b1+b2));//错误的,无法直接使用+进行求和
System.out.println("和:" + b1.add(b2));
System.out.println("减:" + b1.subtract(b2));
System.out.println("乘:" + b1.multiply(b2));
System.out.println("除:" + b2.divide(b1));
System.out.println("余:" + b2.remainder(b1));
}RoundingMode枚举类
CEILING :向正无限大方向舍入的舍入模式。
DOWN :向零方向舍入的舍入模式。
FLOOR:向负无限大方向舍入的舍入模式。
HALF_DOWN :向最接近数字方向舍入的舍入模式,如果与两个相邻数字的距离相等,则向下舍入。
HALF_EVEN:向最接近数字方向舍入的舍入模式,如果与两个相邻数字的距离相等,则向相邻的偶数舍入。
HALF_UP:向最接近数字方向舍入的舍入模式,如果与两个相邻数字的距离相等,则向上舍入。
UNNECESSARY:用于断言请求的操作具有精确结果的舍入模式,因此不需要舍入。
UP:远离零方向舍入的舍入模式。
BigDecimal
不可变的、任意精度的有符号十进制数。
- BigDecimal(String val)
- BigDecimal add(BigDecimal val)
- BigDecimal subtract(BigDecimal val)
- BigDecimal multiply(BigDecimal val)
- BigDecimal divide(BigDecimal val)
- BigDecimal divide(BigDecimal divisor, int roundingMode)
- BigDecimal divide(BigDecimal divisor, int scale, RoundingMode roundingMode)
- BigDecimal remainder(BigDecimal val)
- ….
@Test
public void test02(){
/*double big = 12.123456789123456789123456789;
System.out.println("big = " + big);*/
BigDecimal b1 = new BigDecimal("123.45678912345678912345678912345678");
BigDecimal b2 = new BigDecimal("7.8923456789123456789123456789998898888");
// System.out.println("和:" + (b1+b2));//错误的,无法直接使用+进行求和
System.out.println("和:" + b1.add(b2));
System.out.println("减:" + b1.subtract(b2));
System.out.println("乘:" + b1.multiply(b2));
System.out.println("除:" + b1.divide(b2,20,RoundingMode.UP));//divide(BigDecimal divisor, int scale, int roundingMode)
System.out.println("除:" + b1.divide(b2,20,RoundingMode.DOWN));//divide(BigDecimal divisor, int scale, int roundingMode)
System.out.println("余:" + b1.remainder(b2));
}java.util.Random
用于产生随机数
boolean nextBoolean():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 boolean 值。
void nextBytes(byte[] bytes):生成随机字节并将其置于用户提供的 byte 数组中。
double nextDouble():返回下一个伪随机数,它是取自此随机数生成器序列的、在 0.0 和 1.0 之间均匀分布的 double 值。
float nextFloat():返回下一个伪随机数,它是取自此随机数生成器序列的、在 0.0 和 1.0 之间均匀分布的 float 值。
double nextGaussian():返回下一个伪随机数,它是取自此随机数生成器序列的、呈高斯(“正态”)分布的 double 值,其平均值是 0.0,标准差是 1.0。
int nextInt():返回下一个伪随机数,它是此随机数生成器的序列中均匀分布的 int 值。
int nextInt(int n):返回一个伪随机数,它是取自此随机数生成器序列的、在 0(包括)和指定值(不包括)之间均匀分布的 int 值。
long nextLong():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 long 值。
@Test
public void test03(){
Random r = new Random();
System.out.println("随机整数:" + r.nextInt());
System.out.println("随机小数:" + r.nextDouble());
System.out.println("随机布尔值:" + r.nextBoolean());
}日期时间API
JDK1.8之前
java.util.Date
new Date():当前系统时间
long getTime():返回该日期时间对象距离1970-1-1 0.0.0 0毫秒之间的毫秒值
new Date(long 毫秒):把该毫秒值换算成日期时间对象
@Test
public void test5(){
long time = Long.MAX_VALUE;
Date d = new Date(time);
System.out.println(d);
}
@Test
public void test4(){
long time = 1559807047979L;
Date d = new Date(time);
System.out.println(d);
}
@Test
public void test3(){
Date d = new Date();
long time = d.getTime();
System.out.println(time);//1559807047979
}
@Test
public void test2(){
long time = System.currentTimeMillis();
System.out.println(time);//1559806982971
//当前系统时间距离1970-1-1 0:0:0 0毫秒的时间差,毫秒为单位
}
@Test
public void test1(){
Date d = new Date();
System.out.println(d);
}java.util.TimeZone
通常,使用 getDefault 获取 TimeZone,getDefault 基于程序运行所在的时区创建 TimeZone。
也可以用 getTimeZone 及时区 ID 获取 TimeZone 。例如美国太平洋时区的时区 ID 是 “America/Los_Angeles”。
@Test
public void test8(){
String[] all = TimeZone.getAvailableIDs();
for (int i = 0; i < all.length; i++) {
System.out.println(all[i]);
}
}
@Test
public void test7(){
TimeZone t = TimeZone.getTimeZone("America/Los_Angeles");
}常见时区ID:
Asia/Shanghai
UTC
America/New_Yorkjava.util.Calendar
Calendar 类是一个抽象类,它为特定瞬间与一组诸如 YEAR、MONTH、DAY_OF_MONTH、HOUR 等 日历字段之间的转换提供了一些方法,并为操作日历字段(例如获得下星期的日期)提供了一些方法。瞬间可用毫秒值来表示,它是距历元(即格林威治标准时间 1970 年 1 月 1 日的 00:00:00.000,格里高利历)的偏移量。与其他语言环境敏感类一样,Calendar 提供了一个类方法 getInstance,以获得此类型的一个通用的对象。
(1)getInstance():得到Calendar的对象
(2)get(常量)
@Test
public void test6(){
Calendar c = Calendar.getInstance();
System.out.println(c);
int year = c.get(Calendar.YEAR);
System.out.println(year);
int month = c.get(Calendar.MONTH)+1;
System.out.println(month);
//...
}
@Test
public void test7(){
TimeZone t = TimeZone.getTimeZone("America/Los_Angeles");
//getInstance(TimeZone zone)
Calendar c = Calendar.getInstance(t);
System.out.println(c);
}java.text.SimpleDateFormat
SimpleDateFormat用于日期时间的格式化。
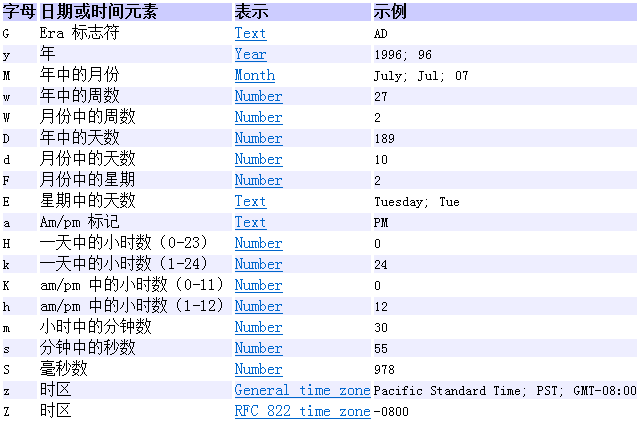
@Test
public void test10() throws ParseException{
String str = "2019年06月06日 16时03分14秒 545毫秒 星期四 +0800";
SimpleDateFormat sf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒 SSS毫秒 E Z");
Date d = sf.parse(str);
System.out.println(d);
}
@Test
public void test9(){
Date d = new Date();
SimpleDateFormat sf = new SimpleDateFormat("yyyy年MM月dd日 HH时mm分ss秒 SSS毫秒 E Z");
//把Date日期转成字符串,按照指定的格式转
String str = sf.format(d);
System.out.println(str);
}JDK1.8之后
Java1.0中包含了一个Date类,但是它的大多数方法已经在Java 1.1引入Calendar类之后被弃用了。而Calendar并不比Date好多少。它们面临的问题是:
- 可变性:象日期和时间这样的类对象应该是不可变的。Calendar类中可以使用三种方法更改日历字段:set()、add() 和 roll()。
- 偏移性:Date中的年份是从1900开始的,而月份都是从0开始的。
- 格式化:格式化只对Date有用,Calendar则不行。
- 此外,它们也不是线程安全的,不能处理闰秒等。
可以说,对日期和时间的操作一直是Java程序员最痛苦的地方之一。第三次引入的API是成功的,并且java 8中引入的java.time API 已经纠正了过去的缺陷,将来很长一段时间内它都会为我们服务。
Java 8 吸收了 Joda-Time 的精华,以一个新的开始为 Java 创建优秀的 API。
- java.time – 包含值对象的基础包
- java.time.chrono – 提供对不同的日历系统的访问。
- java.time.format – 格式化和解析时间和日期
- java.time.temporal – 包括底层框架和扩展特性
- java.time.zone – 包含时区支持的类
Java 8 吸收了 Joda-Time 的精华,以一个新的开始为 Java 创建优秀的 API。新的 java.time 中包含了所有关于时钟(Clock),本地日期(LocalDate)、本地时间(LocalTime)、本地日期时间(LocalDateTime)、时区(ZonedDateTime)和持续时间(Duration)的类。
本地日期时间:LocalDate、LocalTime、LocalDateTime
| 方法 | 描述 |
|---|---|
| now() / now(ZoneId zone) | 静态方法,根据当前时间创建对象/指定时区的对象 |
| of() | 静态方法,根据指定日期/时间创建对象 |
| getDayOfMonth()/getDayOfYear() | 获得月份天数(1-31) /获得年份天数(1-366) |
| getDayOfWeek() | 获得星期几(返回一个 DayOfWeek 枚举值) |
| getMonth() | 获得月份, 返回一个 Month 枚举值 |
| getMonthValue() / getYear() | 获得月份(1-12) /获得年份 |
| getHours()/getMinute()/getSecond() | 获得当前对象对应的小时、分钟、秒 |
| withDayOfMonth()/withDayOfYear()/withMonth()/withYear() | 将月份天数、年份天数、月份、年份修改为指定的值并返回新的对象 |
| with(TemporalAdjuster t) | 将当前日期时间设置为校对器指定的日期时间 |
| plusDays(), plusWeeks(), plusMonths(), plusYears(),plusHours() | 向当前对象添加几天、几周、几个月、几年、几小时 |
| minusMonths() / minusWeeks()/minusDays()/minusYears()/minusHours() | 从当前对象减去几月、几周、几天、几年、几小时 |
| plus(TemporalAmount t)/minus(TemporalAmount t) | 添加或减少一个 Duration 或 Period |
| isBefore()/isAfter() | 比较两个 LocalDate |
| isLeapYear() | 判断是否是闰年(在LocalDate类中声明) |
| format(DateTimeFormatter t) | 格式化本地日期、时间,返回一个字符串 |
| parse(Charsequence text) | 将指定格式的字符串解析为日期、时间 |
@Test
public void test7(){
LocalDate now = LocalDate.now();
LocalDate before = now.minusDays(100);
System.out.println(before);//2019-02-26
}
@Test
public void test06(){
LocalDate lai = LocalDate.of(2019, 5, 13);
LocalDate go = lai.plusDays(160);
System.out.println(go);//2019-10-20
}
@Test
public void test05(){
LocalDate lai = LocalDate.of(2019, 5, 13);
System.out.println(lai.getDayOfYear());
}
@Test
public void test04(){
LocalDate lai = LocalDate.of(2019, 5, 13);
System.out.println(lai);
}
@Test
public void test03(){
LocalDateTime now = LocalDateTime.now();
System.out.println(now);
}
@Test
public void test02(){
LocalTime now = LocalTime.now();
System.out.println(now);
}
@Test
public void test01(){
LocalDate now = LocalDate.now();
System.out.println(now);
}指定时区日期时间:ZonedDateTime
常见时区ID:
Asia/Shanghai
UTC
America/New_Yorkimport java.time.ZoneId;
import java.time.ZonedDateTime;
public class TestZonedDateTime {
public static void main(String[] args) {
ZonedDateTime t = ZonedDateTime.now();
System.out.println(t);
ZonedDateTime t1 = ZonedDateTime.now(ZoneId.of("America/New_York"));
System.out.println(t1);
}
}持续日期/时间:Period和Duration
Period:用于计算两个“日期”间隔
public static void main(String[] args) {
LocalDate t1 = LocalDate.now();
LocalDate t2 = LocalDate.of(2018, 12, 31);
Period between = Period.between(t1, t2);
System.out.println(between);
System.out.println("相差的年数:"+between.getYears());//1年
System.out.println("相差的月数:"+between.getMonths());//又7个月
System.out.println("相差的天数:"+between.getDays());//零25天
System.out.println("相差的总数:"+between.toTotalMonths());//总共19个月
}Duration:用于计算两个“时间”间隔
public static void main(String[] args) {
LocalDateTime t1 = LocalDateTime.now();
LocalDateTime t2 = LocalDateTime.of(2017, 8, 29, 0, 0, 0, 0);
Duration between = Duration.between(t1, t2);
System.out.println(between);
System.out.println("相差的总天数:"+between.toDays());
System.out.println("相差的总小时数:"+between.toHours());
System.out.println("相差的总分钟数:"+between.toMinutes());
System.out.println("相差的总秒数:"+between.getSeconds());
System.out.println("相差的总毫秒数:"+between.toMillis());
System.out.println("相差的总纳秒数:"+between.toNanos());
System.out.println("不够一秒的纳秒数:"+between.getNano());
}DateTimeFormatter:日期时间格式化
该类提供了三种格式化方法:
预定义的标准格式。如:ISO_DATE_TIME;ISO_DATE
本地化相关的格式。如:ofLocalizedDate(FormatStyle.MEDIUM)
自定义的格式。如:ofPattern(“yyyy-MM-dd hh:mm:ss”)
@Test
public void test10(){
LocalDateTime now = LocalDateTime.now();
// DateTimeFormatter df = DateTimeFormatter.ofLocalizedDateTime(FormatStyle.LONG);//2019年6月6日 下午04时40分03秒
DateTimeFormatter df = DateTimeFormatter.ofLocalizedDateTime(FormatStyle.SHORT);//19-6-6 下午4:40
String str = df.format(now);
System.out.println(str);
}
@Test
public void test9(){
LocalDateTime now = LocalDateTime.now();
DateTimeFormatter df = DateTimeFormatter.ISO_DATE_TIME;//2019-06-06T16:38:23.756
String str = df.format(now);
System.out.println(str);
}
@Test
public void test8(){
LocalDateTime now = LocalDateTime.now();
DateTimeFormatter df = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH时mm分ss秒 SSS毫秒 E 是这一年的D天");
String str = df.format(now);
System.out.println(str);
}系统相关类
java.lang.System类
系统类中很多好用的方法,其中几个如下:
static long currentTimeMillis() :返回当前系统时间距离1970-1-1 0:0:0的毫秒值
static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length):
从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。常用于数组的插入和删除
static void exit(int status) :退出当前系统
static void gc() :运行垃圾回收器。
static String getProperty(String key):获取某个系统属性
…
public class Test{
public static void main(String[] args){
long time = System.currentTimeMillis();
System.out.println("现在的系统时间距离1970年1月1日凌晨:" + time + "毫秒");
System.exit(0);
System.out.println("over");//不会执行
}
}java.lang.Runtime类
每个 Java 应用程序都有一个 Runtime 类实例,使应用程序能够与其运行的环境相连接。可以通过 getRuntime 方法获取当前运行时。 应用程序不能创建自己的 Runtime 类实例。
public static Runtime getRuntime(): 返回与当前 Java 应用程序相关的运行时对象。
public long totalMemory():返回 Java 虚拟机中的内存总量。此方法返回的值可能随时间的推移而变化,这取决于主机环境。
public long freeMemory():回 Java 虚拟机中的空闲内存量。调用 gc 方法可能导致 freeMemory 返回值的增加。
数组的算法升华
数组的算法升华
数组的反转
方法有两种:
1、借助一个新数组
2、首尾对应位置交换
第一种方式示例代码:
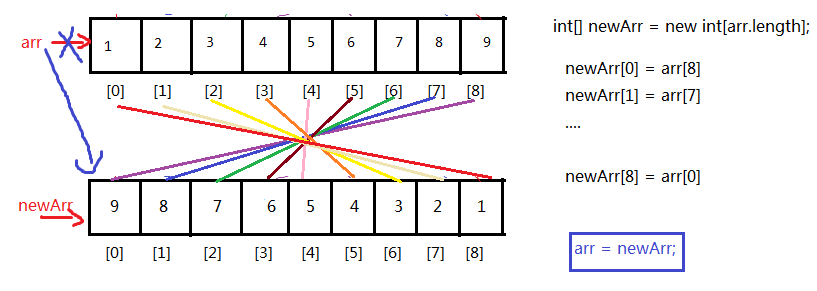
int[] arr = {1,2,3,4,5,6,7,8,9};
//(1)先创建一个新数组
int[] newArr = new int[arr.length];
//(2)复制元素
int len = arr.length;
for(int i=0; i<newArr.length; i++){
newArr[i] = arr[len -1 - i];
}
//(3)舍弃旧的,让arr指向新数组
arr = newArr;//这里把新数组的首地址赋值给了arr
//(4)遍历显示
for(int i=0; i<arr.length; i++){
System.out.println(arr[i]);
}
缺点:需要借助一个数组,浪费额外空间,原数组需要垃圾回收
第二种方式示例代码:
实现思想:数组对称位置的元素互换。
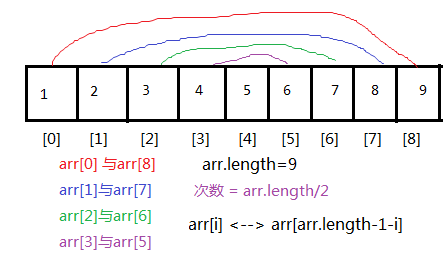
int[] arr = {1,2,3,4,5,6,7,8,9};
//(1)计算要交换的次数: 次数 = arr.length/2
//(2)首尾对称位置交换
for(int i=0; i<arr.length/2; i++){//循环的次数就是交换的次数
int temp = arr[i];
arr[i] = arr[arr.length-1-i];
arr[arr.length-1-i] = temp;
}
//(3)遍历显示
for(int i=0; i<arr.length; i++){
System.out.println(arr[i]);
}或

public static void main(String[] args){
int[] arr = {1,2,3,4,5,6,7,8,9};
//左右对称位置交换
for(int left=0,right=arr.length-1; left<right; left++,right--){
//首 与 尾交换
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
//(3)遍历显示
for(int i=0; i<arr.length; i++){
System.out.println(arr[i]);
}
}数组的扩容
示例:当原来的数组长度不够了需要扩容,例如需要新增位置来存储10
int[] arr = {1,2,3,4,5,6,7,8,9};
//如果要把arr数组扩容,增加1个位置
//(1)先创建一个新数组,它的长度 = 旧数组的长度+1,或者也可以扩大为原来数组长度的1.5倍,2倍等
int[] newArr = new int[arr.length + 1];
//(2)复制元素
//注意:i<arr.length 因位arr比newArr短,避免下标越界
for(int i=0; i<arr.length; i++){
newArr[i] = arr[i];
}
//(3)把新元素添加到newArr的最后
newArr[newArr.length-1] = 10;
//(4)如果下面继续使用arr,可以让arr指向新数组
arr = newArr;
//(4)遍历显示
for(int i=0; i<arr.length; i++){
System.out.println(arr[i]);
}(1)至于新数组的长度定义多少合适,看实际情况,如果新增的元素个数确定,那么可以增加指定长度,如果新增元素个数不确定,那么可以扩容为原来的1.5倍、2倍等
(2)数组扩容太多会造成浪费,太少会导致频繁扩容,效率低下
数组元素的插入
示例:在原数组的某个[index]插入一个元素
情形一:原数组未满
String[] arr = new String[5];
arr[0]="张三";
arr[1]="李四";
arr[2]="王五";
那么目前数组的长度是5,而数组的实际元素个数是3,如果此时需要在“张三”和“李四”之间插入一个“赵六”,即在[index=1]的位置插入“赵六”,需要怎么做呢?String[] arr = new String[5];
arr[0]="张三";
arr[1]="李四";
arr[2]="王五";
//(1)移动2个元素,需要移动的起始元素下标是[1],它需要移动到[2],一共一共2个
System.arraycopy(arr,1,arr,2,2);
//(2)插入新元素
arr[1]="赵六";
//(3)遍历显示
for(int i=0; i<arr.length; i++){
System.out.println(arr[i]);
}情形二:原数组已满
String[] arr = new String[3];
arr[0]="张三";
arr[1]="李四";
arr[2]="王五";
那么目前数组的长度是3,而数组的实际元素个数是3,如果此时需要在“张三”和“李四”之间插入一个“赵六”,即在[index=1]的位置插入“赵六”,需要怎么做呢?String[] arr = new String[3];
arr[0]="张三";
arr[1]="李四";
arr[2]="王五";
//(1)先扩容
String[] newArr = new String[4];
for(int i=0; i<arr.length; i++){
newArr[i] = arr[i];
}
arr=newArr;
//(2)移动2个元素,需要移动的起始元素下标是[1],它需要移动到[2],一共一共2个
System.arraycopy(arr,1,arr,2,2);
//(3)插入新元素
arr[1]="赵六";
//(4)遍历显示
for(int i=0; i<arr.length; i++){
System.out.println(arr[i]);
}数组元素的删除
示例:
String[] arr = new String[3];
arr[0]="张三";
arr[1]="李四";
arr[2]="王五";
现在需要删除“李四”,我们又不希望数组中间空着元素,该如何处理呢?String[] arr = new String[3];
arr[0]="张三";
arr[1]="李四";
arr[2]="王五";
//(1)移动元素,需要移动元素的起始下标[2],该元素需要移动到[1],一共需要移动1个元素
System.arraycopy(arr,2,arr,1,1);
//(2)因为数组元素整体往左移动,这里本质上是复制,原来最后一个元素需要置空
arr[2]=null;//使得垃圾回收尽快回收对应对象的内存数组的二分查找
二分查找:对折对折再对折
要求:要求数组元素必须支持比较大小,并且数组中的元素已经按大小排好序
示例:
class Exam2{
public static void main(String[] args){
int[] arr = {2,5,7,8,10,15,18,20,22,25,28};//数组是有序的
int value = 18;
int index = -1;
int left = 0;
int right = arr.length - 1;
int mid = (left + right)/2;
while(left<=right){
//找到结束
if(value == arr[mid]){
index = mid;
break;
}//没找到
else if(value > arr[mid]){//往右继续查找
//移动左边界,使得mid往右移动
left = mid + 1;
}else if(value < arr[mid]){//往左边继续查找
right = mid - 1;
}
mid = (left + right)/2;
}
if(index==-1){
System.out.println(value + "不存在");
}else{
System.out.println(value + "的下标是" + index);
}
}
}

数组的直接选择排序
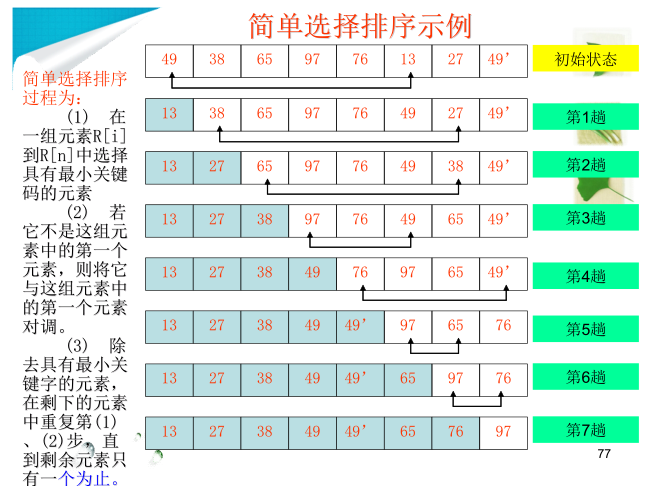
示例代码:简单的直接选择排序
int[] arr = {49,38,65,97,76,13,27,49};
for(int i=1; i<arr.length; i++){//外循环的次数 = 轮数 = 数组的长度-1
//(1)找出本轮未排序元素中的最值
/*
未排序元素:
第1轮:i=1,未排序,[0,7],本轮未排序元素第一个元素是[0]
第2轮:i=2,未排序,[1,7],本轮未排序元素第一个元素是[1]
...
第7轮:i=7,未排序,[6,7],本轮未排序元素第一个元素是[6]
每一轮未排序元素的起始下标:0,1,2,3,4,5,6,正好是i-1的
未排序的后面的元素依次:
第1轮:[1,7] j=1,2,3,4,5,6,7
第2轮:[2,4] j=2,3,4,5,6,7
。。。。
第7轮:[7] j=7
j的起点是i,终点都是7
*/
int max = arr[i-1];
int index = i-1;
for(int j=i; j<arr.length; j++){
if(arr[j] > max){
max = arr[j];
index = j;
}
}
//(2)如果这个最值没有在它应该在的位置,就与这个位置的元素交换
/*
第1轮,最大值应该在[0]
第2轮,最大值应该在[1]
....
第7轮,最大值应该在[6]
正好是i-1的值
*/
if(index != i-1){
//交换arr[i-1]与arr[index]
int temp = arr[i-1];
arr[i-1] = arr[index];
arr[index] = temp;
}
}
//显示结果
for(int i=0; i<arr.length; i++){
System.out.print(arr[i]);
}
数组工具类
java.util.Arrays数组工具类,提供了很多静态方法来对数组进行操作,而且如下每一个方法都有各种重载形式,以下只列出int[]类型的,其他类型的数组类推:
static int binarySearch(int[] a, int key) :要求数组有序,在数组中查找key是否存在,如果存在返回第一次找到的下标,不存在返回负数
static int[] copyOf(int[] original, int newLength) :根据original原数组复制一个长度为newLength的新数组,并返回新数组
static int[] copyOfRange(int[] original, int from, int to) :复制original原数组的[from,to)构成新数组,并返回新数组
static boolean equals(int[] a, int[] a2) :比较两个数组的长度、元素是否完全相同
static void fill(int[] a, int val) :用val填充整个a数组
- static void fill(int[] a, int fromIndex, int toIndex, int val):将a数组[fromIndex,toIndex)部分填充为val
- static void sort(int[] a) :将a数组按照从小到大进行排序
- static void sort(int[] a, int fromIndex, int toIndex) :将a数组的[fromIndex, toIndex)部分按照升序排列
- static String toString(int[] a) :把a数组的元素,拼接为一个字符串,形式为:[元素1,元素2,元素3。。。]
示例代码:
import java.util.Arrays;
import java.util.Random;
public class Test{
public static void main(String[] args){
int[] arr = new int[5];
// 打印数组,输出地址值
System.out.println(arr); // [I@2ac1fdc4
// 数组内容转为字符串
System.out.println("arr数组初始状态:"+ Arrays.toString(arr));
Arrays.fill(arr, 3);
System.out.println("arr数组现在状态:"+ Arrays.toString(arr));
Random rand = new Random();
for (int i = 0; i < arr.length; i++) {
arr[i] = rand.nextInt(100);//赋值为100以内的随机整数
}
System.out.println("arr数组现在状态:"+ Arrays.toString(arr));
int[] arr2 = Arrays.copyOf(arr, 10);
System.out.println("新数组:" + Arrays.toString(arr2));
System.out.println("两个数组的比较结果:" + Arrays.equals(arr, arr2));
Arrays.sort(arr);
System.out.println("arr数组现在状态:"+ Arrays.toString(arr));
}
}数组面试题
编程题1
找出数组中一个值,使其左侧值的加和等于右侧值的加和,
例如:[1,2,5,3,2,4,2],结果为:第4个值3
[9, 6, 8, 8, 7, 6, 9, 5, 2, 5],结果是没有
public static void main(String[] args) {
int[] arr = {1,2,5,3,2,4,2};
int index = leftSumEqualsRightSum(arr);
if(index!=-1) {
System.out.println(arr[index]);
}else {
System.out.println("没有");
}
}
public static int leftSumEqualsRightSum(int[] arr) {
for (int mid = 0; mid < arr.length; mid++) {
int leftSum = 0;
int rightSum = 0;
for (int i = 0; i <mid; i++) {
leftSum += arr[i];
}
for (int i = mid+1; i < arr.length; i++) {
rightSum += arr[i];
}
if(leftSum==rightSum) {
return mid;
}
}
return -1;
}编程题2
左奇右偶
- 10个整数的数组{26,67,49,38,52,66,7,71,56,87}。
- 元素重新排列,所有的奇数保存到数组左边,所有的偶数保存到数组右边。
代码实现,效果如图所示:
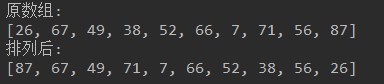
开发提示:
- 左边的偶数与右边的奇数换位置:
- 定义两个变量left和right,从左边开始查找偶数的位置,找到后用left记录,从右边开始找奇数的位置,找到后用right记录,如果left<right,那么就交换,然后在上一次的基础上继续查找,直到left与right擦肩。
//效率最高
public void order2(int[] arr){
for (int left = 0,right = arr.length-1; left < right; ){
//left代表左边需要交换的数的下标,偶数的下标
//如果arr[left]此时是奇数,说明此时left不是我们要找的下标,left++往后移动
while(arr[left]%2!=0){//当arr[left]是偶数时,结束while循环
left++;
}
//如果arr[right]此时是偶数,说明此时right不是我们要找的下标,right--往前移动
while(arr[right]%2==0){//当arr[right]是奇数时,结束while循环
right--;
}
if(left < right){
int temp = arr[left];
arr[left] = arr[right];
arr[right]= temp;
}
}
}public void order3(int[] arr){
int len = arr.length;
while (len>0) {
for (int j=0; j<len-1; j++){
//左边的元素是偶数,就和它相邻的元素交换
if (arr[j]%2==0) {
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
len--;
}
}public void order(int[] arr){
//从左边往右边找偶数,记录下标,evenIndex,这个是错误的数字的下标
//从右边往左边找奇数,记录下标,oddIndex,这个是错误的数字的下标
//交换arr[oddIndex]与arr[evenIndex],调整之后就可以了
int evenIndex = 0;
int oddIndex = arr.length-1;
while(evenIndex < oddIndex){
for (int i=0; i<arr.length; i++){
if(arr[i]%2==0){
evenIndex = i;
break;
}
}
for(int i=arr.length-1; i>=0; i--){
if(arr[i]%2!=0){
oddIndex = i;
break;
}
}
if(evenIndex < oddIndex) {
int temp = arr[evenIndex];
arr[evenIndex] = arr[oddIndex];
arr[oddIndex] = temp;
}
}
}编程题3
数组去重
- 10个整数{9,10,6,6,1,9,3,5,6,4},范围1-10,保存到数组中。
- 去除数组中重复的内容,只保留唯一的元素。
按步骤编写代码,效果如图所示:
开发提示:
- 定义一个变量count,初始化为数组的长度
- 遍历每一个元素,如果该元素与前面的某个元素相等,那么通过移动数组,把该元素覆盖掉,并修改count—。
- 最后创建一个新数组,长度为count,并从原数组把前count个元素复制过来
编程题4

import java.util.Arrays;
public class TestExer4 {
public static void main(String[] args) {
double[] arr = new double[10];
for (int i = 0; i < arr.length-1; i++) {
arr[i] = Math.random() * 100;//[0,100)之间的小数
}
arr[arr.length-1] = 0;
System.out.println("直线上每一个点距离下一个点的距离:"+Arrays.toString(arr));
double length = 150.5;
int count = 0;
double sum = 0;
for (int i = 0; i < arr.length; i++) {
sum += arr[i];
if(sum<=length) {
count++;
}else {
break;
}
}
System.out.println("长度为:" + length + "的绳子最多能覆盖" +count+"个点");
}
}编程题5

冒泡排序:
public static void bubbleSort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
for (int j = 0; j < arr.length-i; j++) {
if(arr[j] > arr[j+1]) {
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}直接选择排序:
public static void selectSort(int[] arr) {
for (int i = 0; i < arr.length-1; i++) {
int minIndex = i;
for (int j = i+1; j < arr.length; j++) {
if(arr[minIndex] > arr[j]) {
minIndex = j;
}
}
if(minIndex!=i) {
int temp = arr[minIndex];
arr[minIndex] = arr[i];
arr[i] = temp;
}
}
}附加
1、折半插入排序
例如:数组{12,2,6,1,5}
第一次:在[0,1)之间找插入2的位置==>left = [0] ==> {2,12,6,1,5}
第二次:在[0,2)之间找插入6的位置==>left = [1] ==> {2,6,12,1,5}
第三次:在[0,3)之间找插入1的位置==>left = [0] ==>{1,2,6,12,5}
第四次:在[0,4)之间找插入5的位置==>left = [2] ==>{1,2,5,6,12}
@Test
public void test(){
int[] arr = {12,2,6,1,5};
sort(arr);
System.out.println(Arrays.toString(arr));
}
public void sort(int[] arr){
for (int i=1; i<arr.length; i++){
//找到[0,i)之间插入arr[i]的位置
//使用二分查找法
int left = 0;
int right=i-1;
while (left<=right){
int mid = (left + right)/2;
if(arr[i]<=arr[mid]){
right = mid - 1;
}else{
left = mid + 1;
}
}
//在[0,i)插入arr[i]
if(left < i){
int temp = arr[i];
System.arraycopy(arr,left,arr,left+1,i-left);
arr[left] = temp;
}
}
}
快速排序
例如:数组{5, 2, 6, 12, 1,7,9}
@Test
public void test(){
int[] arr = {5, 2, 6, 12, 1,7,9};
sort(arr,0, arr.length-1);
System.out.println(Arrays.toString(arr));
}
//将[start+1,end]之间的元素分为两拨,左边的所有元素比arr[start]小,右边的所有元素比arr[start]大
public void sort(int[] arr,int start, int end){
if(start < end){
int left = start+1;
int right = end;
while(left<right){
//从左往右,从[start+1]开始找比arr[start]大的数arr[left],让它与arr[right]交换
//当arr[left]大于arr[start]就停止循环,因为此时找到了比arr[start]大的数arr[left]
while(arr[left]<=arr[start] && left<=end){
left++;
}
//从右往左,从[end]开始找比比arr[start]小的数arr[right],让它与arr[left]交换
//当arr[right]小于arr[start]就停止循环,因为此时找到了比arr[start]小的数arr[right]
while(arr[right]>=arr[start] && right>start){
right--;
}
if(left < right){
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
}
//经过上面的while,//如果right>start+1,那么说明在[start+1,end]之间的数分为两拨
//[start+1,right]之间的是比arr[start]小的数
//[right,end]之间的是比arr[start]大的数
//交换arr[start]与arr[right]
if(right > start + 1){
int temp = arr[start];
arr[start] = arr[right];
arr[right] = temp;
}
//此时[start,right-1]之间都是比arr[start]小的数据了,但是它们还未排序
//此时[right+1,end]之间都是比arr[start]大的数据了,但是它们还未排序
//所以需要分别对[start,right-1]、[right+1,end]之间元素重复上面的操作继续排序
sort(arr,start,right-1);
sort(arr,right+1,end);
}
}第1次调用sort(arr,0,6)
交换arr[left=2]与arr[right=4]:[5, 2, 1, 12, 6, 7, 9]
交换基准位置的元素与分界位置的元素:arr[start=0]与arr[right=2]:[1, 2, 5, 12, 6, 7, 9]
第2次调用sort(arr,0,1)
第3次调用sort(arr,0,0)
第4次调用sort(arr,2,1)
第5次调用sort(arr,3,6)
交换基准位置的元素与分界位置的元素:arr[start=3]与arr[right=6]:[1, 2, 5, 9, 6, 7, 12]
第6次调用sort(arr,3,5)
交换基准位置的元素与分界位置的元素:arr[start=3]与arr[right=5]:[1, 2, 5, 7, 6, 9, 12]
第7次调用sort(arr,3,4)
第8次调用sort(arr,3,3)
第9次调用sort(arr,5,4)
第10次调用sort(arr,6,5)
第11次调用sort(arr,7,6)

字符串
java.lang.String 类代表字符串。Java程序中所有的字符串文字(例如"abc" )都可以被看作是实现此类的实例。字符串是常量;它们的值在创建之后不能更改。字符串缓冲区支持可变的字符串。因为 String 对象是不可变的,所以可以共享。
String 类包括的方法可用于检查序列的单个字符、比较字符串、搜索字符串、提取子字符串、创建字符串副本并将所有字符全部转换为大写或小写。
Java 语言提供对字符串串联符号(”+”)以及将其他对象转换为字符串的特殊支持(toString()方法)。
字符串的特点
1、字符串String类型本身是final声明的,意味着我们不能继承String。
2、字符串的对象也是不可变对象,意味着一旦进行修改,就会产生新对象
我们修改了字符串后,如果想要获得新的内容,必须重新接受。
如果程序中涉及到大量的字符串的修改操作,那么此时的时空消耗比较高。可能需要考虑使用StringBuilder或StringBuffer的可变字符序列。
3、String对象内部是用字符数组进行保存的
JDK1.9之前有一个char[] value数组,JDK1.9之后byte[]数组
"abc" 等效于 char[] data={ 'a' , 'b' , 'c' }。
例如:
String str = "abc";
相当于:
char data[] = {'a', 'b', 'c'};
String str = new String(data);
// String底层是靠字符数组实现的。4、String类中这个char[] values数组也是final修饰的,意味着这个数组不可变,然后它是private修饰,外部不能直接操作它,String类型提供的所有的方法都是用新对象来表示修改后内容的,所以保证了String对象的不可变。
5、就因为字符串对象设计为不可变,那么所以字符串有常量池来保存很多常量对象
常量池在方法区。
如果细致的划分:
(1)JDK1.6及其之前:方法区
(2)JDK1.7:堆
(3)JDK1.8:元空间
String s1 = "abc";
String s2 = "abc";
System.out.println(s1 == s2);
// 内存中只有一个"abc"对象被创建,同时被s1和s2共享。构造字符串对象
使用构造方法
public String():初始化新创建的 String对象,以使其表示空字符序列。String(String original): 初始化一个新创建的String对象,使其表示一个与参数相同的字符序列;换句话说,新创建的字符串是该参数字符串的副本。public String(char[] value):通过当前参数中的字符数组来构造新的String。public String(char[] value,int offset, int count):通过字符数组的一部分来构造新的String。public String(byte[] bytes):通过使用平台的默认字符集解码当前参数中的字节数组来构造新的String。public String(byte[] bytes,String charsetName):通过使用指定的字符集解码当前参数中的字节数组来构造新的String。
构造举例,代码如下:
//字符串常量对象
String str = "hello";
// 无参构造
String str1 = new String();
//创建"hello"字符串常量的副本
String str2 = new String("hello");
//通过字符数组构造
char chars[] = {'a', 'b', 'c','d','e'};
String str3 = new String(chars);
String str4 = new String(chars,0,3);
// 通过字节数组构造
byte bytes[] = {97, 98, 99 };
String str5 = new String(bytes);
String str6 = new String(bytes,"GBK");使用静态方法
- static String copyValueOf(char[] data): 返回指定数组中表示该字符序列的 String
- static String copyValueOf(char[] data, int offset, int count):返回指定数组中表示该字符序列的 String
- static String valueOf(char[] data) : 返回指定数组中表示该字符序列的 String
- static String valueOf(char[] data, int offset, int count) : 返回指定数组中表示该字符序列的 String
- static String valueOf(xx value):xx支持各种数据类型,返回各种数据类型的value参数的字符串表示形式。
public static void main(String[] args) {
char[] data = {'h','e','l','l','o','j','a','v','a'};
String s1 = String.copyValueOf(data);
String s2 = String.copyValueOf(data,0,5);
int num = 123456;
String s3 = String.valueOf(num);
System.out.println(s1);
System.out.println(s2);
System.out.println(s3);
}使用””+
任意数据类型与”字符串”进行拼接,结果都是字符串
public static void main(String[] args) {
int num = 123456;
String s = num + "";
System.out.println(s);
Student stu = new Student();
String s2 = stu + "";//自动调用对象的toString(),然后与""进行拼接
System.out.println(s2);
}字符串的对象的个数
1、字符串常量对象
String str1 = "hello";//1个,在常量池中2、字符串的普通对象和常量对象一起
String str3 = new String("hello");
//str3首先指向堆中的一个字符串对象,然后堆中字符串的value数组指向常量池中常量对象的value数组字符串对象的内存分析
String s;
String s = null;
String s = "";
String s = new String();
String s = new String("");
String s = "abc";
String s = new String("abc");
char[] arr = {'a','b'};
String s = new String(arr);
char[] arr = {'a','b','c','d','e'};
String s = new String(arr,0,3);
字符串拼接问题
拼接结果的存储和比较问题
原则:
(1)常量+常量:结果是常量池
(2)常量与变量 或 变量与变量:结果是堆
(3)拼接后调用intern方法:结果在常量池
@Test
public void test06(){
String s1 = "hello";
String s2 = "world";
String s3 = "helloworld";
String s4 = (s1 + "world").intern();//把拼接的结果放到常量池中
String s5 = (s1 + s2).intern();
System.out.println(s3 == s4);//true
System.out.println(s3 == s5);//true
}
@Test
public void test05(){
final String s1 = "hello";
final String s2 = "world";
String s3 = "helloworld";
String s4 = s1 + "world";//s4字符串内容也helloworld,s1是常量,"world"常量,常量+ 常量 结果在常量池中
String s5 = s1 + s2;//s5字符串内容也helloworld,s1和s2都是常量,常量+ 常量 结果在常量池中
String s6 = "hello" + "world";//常量+ 常量 结果在常量池中,因为编译期间就可以确定结果
System.out.println(s3 == s4);//true
System.out.println(s3 == s5);//true
System.out.println(s3 == s6);//true
}
@Test
public void test04(){
String s1 = "hello";
String s2 = "world";
String s3 = "helloworld";
String s4 = s1 + "world";//s4字符串内容也helloworld,s1是变量,"world"常量,变量 + 常量的结果在堆中
String s5 = s1 + s2;//s5字符串内容也helloworld,s1和s2都是变量,变量 + 变量的结果在堆中
String s6 = "hello" + "world";//常量+ 常量 结果在常量池中,因为编译期间就可以确定结果
System.out.println(s3 == s4);//false
System.out.println(s3 == s5);//false
System.out.println(s3 == s6);//true
}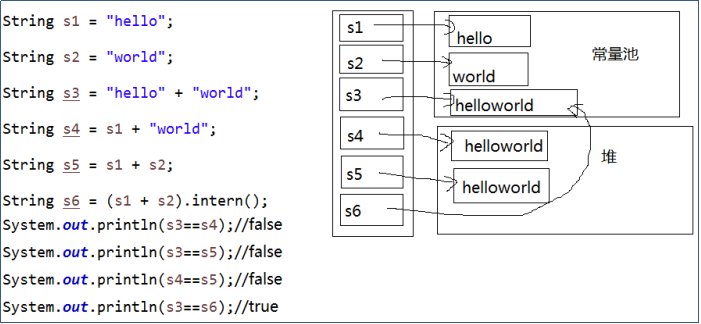

拼接效率问题
public class TestString {
public static void main(String[] args) {
String str = "0";
for (int i = 0; i <= 5; i++) {
str += i;
}
System.out.println(str);
}
}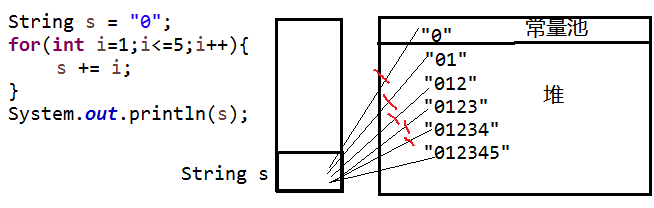
不过现在的JDK版本,都会使用可变字符序列对如上代码进行优化,我们反编译查看字节码:
javap -c TestString.class
两种拼接
public class TestString {
public static void main(String[] args) {
String str = "hello";
String str2 = "world";
String str3 ="helloworld";
String str4 = "hello".concat("world");
String str5 = "hello"+"world";
System.out.println(str3 == str4);//false
System.out.println(str3 == str5);//true
}
}concat方法拼接,哪怕是两个常量对象拼接,结果也是在堆。
字符串对象的比较
1、==:比较是对象的地址
只有两个字符串变量都是指向字符串的常量对象时,才会返回true
String str1 = "hello";
String str2 = "hello";
System.out.println(str1 == str2);//true
String str3 = new String("hello");
String str4 = new String("hello");
System.out.println(str1 == str4); //false
System.out.println(str3 == str4); //false2、equals:比较是对象的内容,因为String类型重写equals,区分大小写
只要两个字符串的字符内容相同,就会返回true
String str1 = "hello";
String str2 = "hello";
System.out.println(str1.equals(str2));//true
String str3 = new String("hello");
String str4 = new String("hello");
System.out.println(str1.equals(str3));//true
System.out.println(str3.equals(str4));//true3、equalsIgnoreCase:比较的是对象的内容,不区分大小写
String str1 = new String("hello");
String str2 = new String("HELLO");
System.out.println(str1.equalsIgnoreCase(strs)); //true4、compareTo:String类型重写了Comparable接口的抽象方法,自然排序,按照字符的Unicode编码值进行比较大小的,严格区分大小写
String str1 = "hello";
String str2 = "world";
str1.compareTo(str2) //小于0的值5、compareToIgnoreCase:不区分大小写,其他按照字符的Unicode编码值进行比较大小
String str1 = new String("hello");
String str2 = new String("HELLO");
str1.compareToIgnoreCase(str2) //等于0空字符的比较
1、哪些是空字符串
String str1 = "";
String str2 = new String();
String str3 = new String("");空字符串:长度为0
2、如何判断某个字符串是否是空字符串
if("".equals(str))
if(str!=null && str.isEmpty())
if(str!=null && str.equals(""))
if(str!=null && str.length()==0)字符串的常用方法
系列1
(1)boolean isEmpty():字符串是否为空
(2)int length():返回字符串的长度
(3)String concat(xx):拼接,等价于+
(4)boolean equals(Object obj):比较字符串是否相等,区分大小写
(5)boolean equalsIgnoreCase(Object obj):比较字符串是否相等,区分大小写
(6)int compareTo(String other):比较字符串大小,区分大小写,按照Unicode编码值比较大小
(7)int compareToIgnoreCase(String other):比较字符串大小,不区分大小写
(8)String toLowerCase():将字符串中大写字母转为小写
(9)String toUpperCase():将字符串中小写字母转为大写
(10)String trim():去掉字符串前后空白符
@Test
public void test01(){
//将用户输入的单词全部转为小写,如果用户没有输入单词,重新输入
Scanner input = new Scanner(System.in);
String word;
while(true){
System.out.print("请输入单词:");
word = input.nextLine();
if(word.trim().length()!=0){
word = word.toLowerCase();
break;
}
}
System.out.println(word);
}
@Test
public void test02(){
//随机生成验证码,验证码由0-9,A-Z,a-z的字符组成
char[] array = new char[26*2+10];
for (int i = 0; i < 10; i++) {
array[i] = (char)('0' + i);
}
for (int i = 10,j=0; i < 10+26; i++,j++) {
array[i] = (char)('A' + j);
}
for (int i = 10+26,j=0; i < array.length; i++,j++) {
array[i] = (char)('a' + j);
}
String code = "";
Random rand = new Random();
for (int i = 0; i < 4; i++) {
code += array[rand.nextInt(array.length)];
}
System.out.println("验证码:" + code);
//将用户输入的单词全部转为小写,如果用户没有输入单词,重新输入
Scanner input = new Scanner(System.in);
System.out.print("请输入验证码:");
String inputCode = input.nextLine();
if(!code.equalsIgnoreCase(inputCode)){
System.out.println("验证码输入不正确");
}
}系列2:查找
(11)boolean contains(xx):是否包含xx
(12)int indexOf(xx):从前往后找当前字符串中xx,即如果有返回第一次出现的下标,要是没有返回-1
(13)int lastIndexOf(xx):从后往前找当前字符串中xx,即如果有返回最后一次出现的下标,要是没有返回-1
@Test
public void test01(){
String str = "尚硅谷是一家靠谱的培训机构,尚硅谷可以说是IT培训的小清华,JavaEE是尚硅谷的当家学科,尚硅谷的大数据培训是行业独角兽。尚硅谷的前端和运维专业一样独领风骚。";
System.out.println("是否包含清华:" + str.contains("清华"));
System.out.println("培训出现的第一次下标:" + str.indexOf("培训"));
System.out.println("培训出现的最后一次下标:" + str.lastIndexOf("培训"));
}系列3:字符串截取
(14)String substring(int beginIndex) :返回一个新的字符串,它是此字符串的从beginIndex开始截取到最后的一个子字符串。
(15)String substring(int beginIndex, int endIndex) :返回一个新字符串,它是此字符串从beginIndex开始截取到endIndex(不包含)的一个子字符串。
@Test
public void test01(){
String str = "helloworldjavaatguigu";
String sub1 = str.substring(5);
String sub2 = str.substring(5,10);
System.out.println(sub1);
System.out.println(sub2);
}
@Test
public void test02(){
String fileName = "快速学习Java的秘诀.dat";
//截取文件名
System.out.println("文件名:" + fileName.substring(0,fileName.lastIndexOf(".")));
//截取后缀名
System.out.println("后缀名:" + fileName.substring(fileName.lastIndexOf(".")));
}系列4:和字符相关
(16)char charAt(index):返回[index]位置的字符
(17)char[] toCharArray(): 将此字符串转换为一个新的字符数组返回
(18)String(char[] value):返回指定数组中表示该字符序列的 String。
(19)String(char[] value, int offset, int count):返回指定数组中表示该字符序列的 String。
(20)static String copyValueOf(char[] data): 返回指定数组中表示该字符序列的 String
(21)static String copyValueOf(char[] data, int offset, int count):返回指定数组中表示该字符序列的 String
(22)static String valueOf(char[] data, int offset, int count) : 返回指定数组中表示该字符序列的 String
(23)static String valueOf(char[] data) :返回指定数组中表示该字符序列的 String
@Test
public void test01(){
//将字符串中的字符按照大小顺序排列
String str = "helloworldjavaatguigu";
char[] array = str.toCharArray();
Arrays.sort(array);
str = new String(array);
System.out.println(str);
}
@Test
public void test02(){
//将首字母转为大写
String str = "jack";
str = Character.toUpperCase(str.charAt(0))+str.substring(1);
System.out.println(str);
}系列5:编码与解码
(24)byte[] getBytes():编码,把字符串变为字节数组,按照平台默认的字符编码进行编码
byte[] getBytes(字符编码方式):按照指定的编码方式进行编码
(25)new String(byte[] ) 或 new String(byte[], int, int):解码,按照平台默认的字符编码进行解码
new String(byte[],字符编码方式 ) 或 new String(byte[], int, int,字符编码方式):解码,按照指定的编码方式进行解码
/*
* GBK,UTF-8,ISO8859-1所有的字符编码都向下兼容ASCII码
*/
public static void main(String[] args) throws Exception {
String str = "中国";
System.out.println(str.getBytes("ISO8859-1").length);// 2
// ISO8859-1把所有的字符都当做一个byte处理,处理不了多个字节
System.out.println(str.getBytes("GBK").length);// 4 每一个中文都是对应2个字节
System.out.println(str.getBytes("UTF-8").length);// 6 常规的中文都是3个字节
/*
* 不乱码:(1)保证编码与解码的字符集名称一样(2)不缺字节
*/
System.out.println(new String(str.getBytes("ISO8859-1"), "ISO8859-1"));// 乱码
System.out.println(new String(str.getBytes("GBK"), "GBK"));// 中国
System.out.println(new String(str.getBytes("UTF-8"), "UTF-8"));// 中国
}字符编码发展
ASCII码
计算机一开始发明的时候是用来解决数字计算的问题,后来人们发现,计算机还可以做更多的事,例如文本处理。但由于计算机只识“数”,因此人们必须告诉计算机哪个数字来代表哪个特定字符,例如65代表字母‘A’,66代表字母‘B’,以此类推。但是计算机之间字符-数字的对应关系必须得一致,否则就会造成同一段数字在不同计算机上显示出来的字符不一样。因此美国国家标准协会ANSI制定了一个标准,规定了常用字符的集合以及每个字符对应的编号,这就是ASCII字符集(Character Set),也称ASCII码。
那时候的字符编解码系统非常简单,就是简单的查表过程。其中:
- 0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符),如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)
- 32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
- 65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
OEM字符集的衍生
当计算机开始发展起来的时候,人们逐渐发现,ASCII字符集里那可怜的128个字符已经不能再满足他们的需求了。人们就在想,一个字节能够表示的数字(编号)有256个,而ASCII字符只用到了0x00~0x7F,也就是占用了前128个,后面128个数字不用白不用,因此很多人打起了后面这128个数字的主意。可是问题在于,很多人同时有这样的想法,但是大家对于0x80-0xFF这后面的128个数字分别对应什么样的字符,却有各自的想法。这就导致了当时销往世界各地的机器上出现了大量各式各样的OEM字符集。不同的OEM字符集导致人们无法跨机器交流各种文档。例如职员甲发了一封简历résumés给职员乙,结果职员乙看到的却是r?sum?s,因为é字符在职员甲机器上的OEM字符集中对应的字节是0x82,而在职员乙的机器上,由于使用的OEM字符集不同,对0x82字节解码后得到的字符却是?。
多字节字符集(MBCS)和中文字符集
上面我们提到的字符集都是基于单字节编码,也就是说,一个字节翻译成一个字符。这对于拉丁语系国家来说可能没有什么问题,因为他们通过扩展第8个比特,就可以得到256个字符了,足够用了。但是对于亚洲国家来说,256个字符是远远不够用的。因此这些国家的人为了用上电脑,又要保持和ASCII字符集的兼容,就发明了多字节编码方式,相应的字符集就称为多字节字符集(Muilti-Bytes Charecter Set)。例如中国使用的就是双字节字符集编码。
例如目前最常用的中文字符集GB2312,涵盖了所有简体字符以及一部分其他字符;GBK(K代表扩展的意思)则在GB2312的基础上加入了对繁体字符等其他非简体字符。这两个字符集的字符都是使用1-2个字节来表示。Windows系统采用936代码页来实现对GBK字符集的编解码。在解析字节流的时候,如果遇到字节的最高位是0的话,那么就使用936代码页中的第1张码表进行解码,这就和单字节字符集的编解码方式一致了。如果遇到字节的最高位是1的话,那么就表示需要两个字节值才能对应一个字符。

ANSI标准、国家标准、ISO标准
不同ASCII衍生字符集的出现,让文档交流变得非常困难,因此各种组织都陆续进行了标准化流程。例如美国ANSI组织制定了ANSI标准字符编码(注意,我们现在通常说到ANSI编码,通常指的是平台的默认编码,例如英文操作系统中是ISO-8859-1,中文系统是GBK),ISO组织制定的各种ISO标准字符编码,还有各国也会制定一些国家标准字符集,例如中国的GBK,GB2312和GB18030。
操作系统在发布的时候,通常会往机器里预装这些标准的字符集还有平台专用的字符集,这样只要你的文档是使用标准字符集编写的,通用性就比较高了。例如你用GB2312字符集编写的文档,在中国大陆内的任何机器上都能正确显示。同时,我们也可以在一台机器上阅读多个国家不同语言的文档了,前提是本机必须安装该文档使用的字符集。
Unicode的出现
虽然通过使用不同字符集,我们可以在一台机器上查阅不同语言的文档,但是我们仍然无法解决一个问题:如果一份文档中含有不同国家的不同语言的字符,那么无法在一份文档中显示所有字符。为了解决这个问题,我们需要一个全人类达成共识的巨大的字符集,这就是Unicode字符集。
Unicode字符集涵盖了目前人类使用的所有字符,并为每个字符进行统一编号,分配唯一的字符码(Code Point)。Unicode字符集将所有字符按照使用上的频繁度划分为17个层面(Plane),每个层面上有216=65536个字符码空间。其中第0个层面BMP,基本涵盖了当今世界用到的所有字符。其他的层面要么是用来表示一些远古时期的文字,要么是留作扩展。我们平常用到的Unicode字符,一般都是位于BMP层面上的。目前Unicode字符集中尚有大量字符空间未使用。
Unicode同样也不完美,这里就有三个的问题,一个是,我们已经知道,英文字母只用一个字节表示就够了,第二个问题是如何才能区别Unicode和ASCII?计算机怎么知道两个字节表示一个符号,而不是分别表示两个符号呢?第三个,如果和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,就少了很多值无法用于表示字符,不够表示所有字符。Unicode在很长一段时间内无法推广,直到互联网的出现,为解决Unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。UTF-8就是在互联网上使用最广的一种Unicode的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号。从unicode到uft-8并不是直接的对应,而是要过一些算法和规则来转换(即Uncidoe字符集≠UTF-8编码方式)。
并不是直接的对应,而是要过一些算法和规则来转换(即Uncidoe字符集≠UTF-8编码方式)。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
—————————————————————–
0000 0000-0000 007F | 0xxxxxxx(兼容原来的ASCII)
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx

因此,Unicode只是定义了一个庞大的、全球通用的字符集,并为每个字符规定了唯一确定的编号,具体存储成什么样的字节流,取决于字符编码方案。推荐的Unicode编码是UTF-16和UTF-8。
早期字符编码、字符集和代码页等概念都是表达同一个意思。例如GB2312字符集、GB2312编码,936代码页,实际上说的是同个东西。
但是对于Unicode则不同,Unicode字符集只是定义了字符的集合和唯一编号,Unicode编码,则是对UTF-8、UCS-2/UTF-16等具体编码方案的统称而已,并不是具体的编码方案。所以当需要用到字符编码的时候,你可以写gb2312,codepage936,utf-8,utf-16,但请不要写Unicode。
系列6:开头与结尾
(26)boolean startsWith(xx):是否以xx开头
(27)boolean endsWith(xx):是否以xx结尾
@Test
public void test2(){
String name = "张三";
System.out.println(name.startsWith("张"));
}
@Test
public void test(){
String file = "Hello.txt";
if(file.endsWith(".java")){
System.out.println("Java源文件");
}else if(file.endsWith(".class")){
System.out.println("Java字节码文件");
}else{
System.out.println("其他文件");
}
}系列7:替换
(29)String replace(xx,xx):不支持正则
(30)String replaceFirst(正则,value):替换第一个匹配部分
(31)String repalceAll(正则, value):替换所有匹配部分
@Test
public void test4(){
String str = "hello244world.java;887";
//把其中的非字母去掉
str = str.replaceAll("[^a-zA-Z]", "");
System.out.println(str);
}系列8:拆分
(32)String[] split(正则):按照某种规则进行拆分
@Test
public void test4(){
String str = "张三.23|李四.24|王五.25";
//|在正则中是有特殊意义,我这里要把它当做普通的|
String[] all = str.split("\\|");
//转成一个一个学生对象
Student[] students = new Student[all.length];
for (int i = 0; i < students.length; i++) {
//.在正则中是特殊意义,我这里想要表示普通的.
String[] strings = all[i].split("\\.");//张三, 23
String name = strings[0];
int age = Integer.parseInt(strings[1]);
students[i] = new Student(name,age);
}
for (int i = 0; i < students.length; i++) {
System.out.println(students[i]);
}
}
@Test
public void test3(){
String str = "1Hello2World3java4atguigu5";
str = str.replaceAll("^\\d|\\d$", "");
String[] all = str.split("\\d");
for (int i = 0; i < all.length; i++) {
System.out.println(all[i]);
}
}
@Test
public void test2(){
String str = "1Hello2World3java4atguigu";
str = str.replaceFirst("\\d", "");
System.out.println(str);
String[] all = str.split("\\d");
for (int i = 0; i < all.length; i++) {
System.out.println(all[i]);
}
}
@Test
public void test1(){
String str = "Hello World java atguigu";
String[] all = str.split(" ");
for (int i = 0; i < all.length; i++) {
System.out.println(all[i]);
}
}可变字符序列
String与可变字符序列的区别
因为String对象是不可变对象,虽然可以共享常量对象,但是对于频繁字符串的修改和拼接操作,效率极低。因此,JDK又在java.lang包提供了可变字符序列StringBuilder和StringBuffer类型。
StringBuffer:老的,线程安全的(因为它的方法有synchronized修饰)
StringBuilder:线程不安全的
StringBuilder、StringBuffer的API
常用的API,StringBuilder、StringBuffer的API是完全一致的
(1)StringBuffer append(xx):拼接,追加
(2)StringBuffer insert(int index, xx):在[index]位置插入xx
(3)StringBuffer delete(int start, int end):删除[start,end)之间字符
StringBuffer deleteCharAt(int index):删除[index]位置字符
(4)void setCharAt(int index, xx):替换[index]位置字符
(5)StringBuffer reverse():反转
(6)void setLength(int newLength) :设置当前字符序列长度为newLength
(7)StringBuffer replace(int start, int end, String str):替换[start,end)范围的字符序列为str
(8)int indexOf(String str):在当前字符序列中查询str的第一次出现下标
int indexOf(String str, int fromIndex):在当前字符序列[fromIndex,最后]中查询str的第一次出现下标
int lastIndexOf(String str):在当前字符序列中查询str的最后一次出现下标
int lastIndexOf(String str, int fromIndex):在当前字符序列[fromIndex,最后]中查询str的最后一次出现下标
(9)String substring(int start):截取当前字符序列[start,最后]
(10)String substring(int start, int end):截取当前字符序列[start,end)
(11)String toString():返回此序列中数据的字符串表示形式
@Test
public void test6(){
StringBuilder s = new StringBuilder("helloworld");
s.setLength(30);
System.out.println(s);
}
@Test
public void test5(){
StringBuilder s = new StringBuilder("helloworld");
s.setCharAt(2, 'a');
System.out.println(s);
}
@Test
public void test4(){
StringBuilder s = new StringBuilder("helloworld");
s.reverse();
System.out.println(s);
}
@Test
public void test3(){
StringBuilder s = new StringBuilder("helloworld");
s.delete(1, 3);
s.deleteCharAt(4);
System.out.println(s);
}
@Test
public void test2(){
StringBuilder s = new StringBuilder("helloworld");
s.insert(5, "java");
s.insert(5, "chailinyan");
System.out.println(s);
}
@Test
public void test1(){
StringBuilder s = new StringBuilder();
s.append("hello").append(true).append('a').append(12).append("atguigu");
System.out.println(s);
System.out.println(s.length());
}效率测试
/*
* Runtime:JVM运行时环境
* Runtime是一个单例的实现
*/
public class TestTime {
public static void main(String[] args) {
// testStringBuilder();
testStringBuffer();
// testString();
}
public static void testString(){
long start = System.currentTimeMillis();
String s = new String("0");
for(int i=1;i<=10000;i++){
s += i;
}
long end = System.currentTimeMillis();
System.out.println("String拼接+用时:"+(end-start));//444
long memory = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();
System.out.println("String拼接+memory占用内存: " + memory);//53185144字节
}
public static void testStringBuilder(){
long start = System.currentTimeMillis();
StringBuilder s = new StringBuilder("0");
for(int i=1;i<=10000;i++){
s.append(i);
}
long end = System.currentTimeMillis();
System.out.println("StringBuilder拼接+用时:"+(end-start));//4
long memory = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();
System.out.println("StringBuilder拼接+memory占用内存: " + memory);//1950488
}
public static void testStringBuffer(){
long start = System.currentTimeMillis();
StringBuffer s = new StringBuffer("0");
for(int i=1;i<=10000;i++){
s.append(i);
}
long end = System.currentTimeMillis();
System.out.println("StringBuffer拼接+用时:"+(end-start));//7
long memory = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();
System.out.println("StringBuffer拼接+memory占用内存: " + memory);//1950488
}
}字符串特点相关面试题
1、面试题:字符串的length和数组的length有什么不同?
字符串的length(),数组的length属性
字符串对象不可变
class TEXT{
public int num;
public String str;
public TEXT(int num, String str){
this.num = num;
this.str = str;
}
}
public class Class4 {
//tIn是传对象的地址,修改形参的属性,会影响实参
//intIn是传数据,基本数据类型的形参修改和实参无关
//Integer和String对象不可变
public static void f1(TEXT tIn, int intIn, Integer integerIn, String strIn){
tIn.num =200;
tIn.str = "bcd";//形参和实参指向的是同一个TEXT的对象,修改了属性,就相当于修改实参对象的属性
intIn = 200;//基本数据类型的形参是实参的“副本”,无论怎么修改和实参都没关系
integerIn = 200;//Integer对象和String对象一样都是不可变,一旦修改都是新对象,和实参无关
strIn = "bcd";
}
public static void main(String[] args) {
TEXT tIn = new TEXT(100, "abc");//tIn.num = 100, tIn.str="abc"
int intIn = 100;
Integer integerIn = 100;
String strIn = "abc";
f1(tIn,intIn,integerIn,strIn);
System.out.println(tIn.num + tIn.str + intIn + integerIn + strIn);
//200 + bcd + 100 + 100 + abc
}
}
字符串对象个数
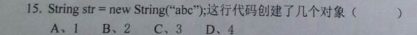

字符串对象比较



空字符串

字符串算法相关面试题
编程题
在字符串中找出连续最长数字串,返回这个串的长度,并打印这个最长数字串。
例如:abcd12345cd125se123456789,返回9,打印出123456789

public class TestExer1 {
public static void main(String[] args) {
String str = "abcd12345cd125se123456789";
//去掉最前和最后的字母
str = str.replaceAll("^[a-zA-Z]+", "");
//[a-zA-Z]:表示字母范围
//+:一次或多次
String[] strings = str.split("[a-zA-Z]+");
String max = "";
for (String string : strings) {
if(string.length() > max.length()) {
max = string;
}
}
System.out.println("最长的数字串:" + max + ",它的长度为:" + max.length());
}
}编程题
不能使用trim(),实现去除字符串两端的空格。
public static void main(String[] args) {
String str =" he llo ";
System.out.println(myTrim(str));
System.out.println(myTrim2(str));
System.out.println(myTrim3(str));
}
public static String myTrim3(String str){
//利用正则表达式
//^表示开头 \s表示 空白符 *表示0次或多次 |表示或者 $表示结尾
return str.replaceAll("(^\\s*)|(\\s*$)", "");
}
public static String myTrim2(String str){
while(str.startsWith(" ")){
str = str.replaceFirst(" ", "");
}
while(str.endsWith(" ")){
str = str.substring(0, str.length()-1);
}
return str;
}
public static String myTrim(String str){
char[] array = str.toCharArray();
int start =0;
for(int i=0;i<array.length;i++){
if(array[i] == ' '){
start++;
}else{
break;
}
}
int end = array.length-1;
for(int i=end;i>=0;i--){
if(array[i] == ' '){
end--;
}else{
break;
}
}
String result = str.substring(start,end+1);
return result;
}编程题
将字符串中指定部分进行反转。比如将“abcdefgho”反转为”abfedcgho”
public static void main(String[] args) {
String str ="abcdefgho";
System.out.println(str);
System.out.println(reverse(str,2,5));
}
//从第start个字符,到第end个字符
public static String reverse(String str,int start,int end){
char[] array = str.toCharArray();
for(int i = start,j=end;i< j;i++,j--){
char temp =array[i];
array[i]=array[j];
array[j]=temp;
}
String s = new String(array);
return s;
}
//从第start个字符,到第end个字符
public static String reverse(String str,int start,int end){
String left = str.substring(0,start);
String middle = str.substring(start,end+1);
String left = str.substring(end+1);
return left+new StringBuilder(middle).reverse()+right;
}编程题
获取一个字符串在另一个字符串中出现的次数。
比如:获取”ab”在 “abababkkcadkabkebfkabkskab”中出现的次数
public static void main(String[] args) {
String str1="ab";
String str2="abababkkcadkabkebfkabkskab";
System.out.println(count(str1,str2));
}
public static int count(String str1,String str2){
int count =0;
do{
int index = str2.indexOf(str1);
if(index !=-1){
count++;
str2 = str2.substring(index + str1.length());
}else{
break;
}
}while(true);
return count;
}编程题
获取两个字符串中最大相同子串。
比如:str1 = “abcwerthelloyuiodef“;str2 = “cvhellobnm”
提示:将短的那个串进行长度依次递减的子串与较长的串比较。
public static void main(String[] args) {
String str=findMaxSubString("abcwerthelloyuiodef","cvhellobnm");
System.out.println(str);
}
//提示:将短的那个串进行长度依次递减的子串与较长的串比较。
public static String findMaxSubString(String str1,String str2){
String result="";
String mixStr = str1.length()<str2.length()?str1:str2;
String maxStr = str1.length()>str2.length()?str1:str2;
//外循环控制从左到右的下标,内循环控制从右到左的下标
for(int i=0;i<mixStr.length();i++){
for(int j=mixStr.length();j>=i;j--){
String str=mixStr.substring(i, j);
if(maxStr.contains(str)){
//找出最大相同子串
if(result.length()<str.length()){
result = str;
}
}
}
}
return result;
}编程题
编写代码完成如下功能
public static String replace(String text, String target, String replace){
….
}
示例:replace(“aabbccbb”, “bb”, “dd”); 结果:aaddccdd
注意:不能使用String及StringBuffer等类的replace等现成的替换API方法。

public static void main(String[] args) {
System.out.println(replace("aabbcbcbb","bb","dd"));
}
public static String replace(String text, String target, String replace){
while(true) {
int index = text.indexOf(target);
if(index!=-1) {
text = text.substring(0,index) + replace + text.substring(index+target.length());
}else {
break;
}
}
return text;
}编程题
1个字符串中可能包含a-z中的多个字符,字符也可能重复,例如:String data = “aabcexmkduyruieiopxzkkkkasdfjxjdsds”;写一个程序,对于给定一个这样的字符串求出字符串出现次数最多的那个字母以及出现的次数(若次数最多的字母有多个,则全部求出)

public static void main(String[] args) {
String str = "aabbyolhljlhlxxmnbwyteuhfhjloiqqbhrg";
//统计每个字母的次数
int[] counts = new int[26];
char[] letters = str.toCharArray();
for (int i = 0; i < letters.length; i++) {
counts[letters[i]-97]++;
}
//找出最多次数值
int max = counts[0];
for (int i = 1; i < counts.length; i++) {
if(max < counts[i]) {
max = counts[i];
}
}
//找出所有最多次数字母
for (int i = 0; i < counts.length; i++) {
if(counts[i] == max) {
System.out.println((char)(i+97));
}
}
}如果学习完集合之后,该题还可以使用Map集合写出不同的答案
编程题
假设日期段用两个6位长度的正整数表示,例如:(201401,201406)用来表示2014年1月到2014年6月,求两个日期段的重叠月份数。例如:输入:时间段1:201401和201406,时间段2:201403和201409,输出:4
解释:重叠月份:3,4,5,6月共4个月
情形1:两个时间段都是同一年内的,实现代码如下:
public static void main(String[] args) {
String date1Start = "201401";
String date1End = "201406";
String date2Start = "201403";
String date2End = "201409";
int date1StartMonth = Integer.parseInt(date1Start.substring(4));
int date1EndMonth = Integer.parseInt(date1End.substring(4));
int date2StartMonth = Integer.parseInt(date2Start.substring(4));
int date2EndMonth = Integer.parseInt(date2End.substring(4));
int start = date1StartMonth >= date2StartMonth ? date1StartMonth : date2StartMonth;
int end = date1EndMonth <= date2EndMonth ? date1EndMonth : date2EndMonth;
System.out.println("重叠月份数:"+(end-start+1));
System.out.println("重叠的月份有:");
for (int i = start; i <= end; i++) {
System.out.println(i);
}
}情形2:两个时间段可能不在同一年内的,实现代码如下:
public static void main(String[] args) {
String date1Start = "201401";
String date1End = "201506";
String date2Start = "201403";
String date2End = "201505";
String date1 = handleDate(date1Start,date1End);
String date2 = handleDate(date2Start,date2End);
System.out.println(date1);
System.out.println(date2);
String sameDate = findMaxSubString(date1,date2);
System.out.println("重叠的月份数:" + sameDate.length()/6);
if (!"".equals(sameDate)) {
System.out.println("重叠的月份有:");
while (sameDate.length() > 0) {
String sameMonth = sameDate.substring(0, 6);
System.out.println(sameMonth);
sameDate = sameDate.substring(6);
}
}
}
public static String findMaxSubString(String str1,String str2){
String result="";
String mixStr = str1.length()<str2.length()?str1:str2;
String maxStr = str1.length()>str2.length()?str1:str2;
//外循环控制从左到右的下标,内循环控制从右到左的下标
for(int i=0;i<mixStr.length();i++){
for(int j=mixStr.length();j>=i;j--){
String str=mixStr.substring(i, j);
if(maxStr.contains(str)){
//找出最大相同子串
if(result.length()<str.length()){
result = str;
}
}
}
}
return result;
}
public static String handleDate(String dateStart, String dateEnd) {
int dateStartYear = Integer.parseInt(dateStart.substring(0,4));
int dateEndYear = Integer.parseInt(dateEnd.substring(0,4));
int dateStartMonth = Integer.parseInt(dateStart.substring(4));
int dateEndMonth = Integer.parseInt(dateEnd.substring(4));
String date = "";
if(dateStartYear == dateEndYear) {//一年之内
for (int i = dateStartMonth; i <=dateEndMonth; i++) {
if(i<10) {
date += dateStartYear+"0"+i;
}else {
date += dateStartYear+""+i;
}
}
}else {//跨年
for (int i = dateStartMonth; i <=12; i++) {//date1StartYear起始年
if(i<10) {
date += dateStartYear+"0"+i;
}else {
date += dateStartYear+""+i;
}
}
for (int i = dateStartYear+1; i < dateEndYear; i++) {//中间间隔年
for (int j = 1; j <= 12; j++) {
if(j<10) {
date += i+"0"+j;
}else {
date += i+""+j;
}
}
}
for (int i = 1; i <= dateEndMonth; i++) {//date1EndYear结束年
if(i<10) {
date += dateEndYear+"0"+i;
}else {
date += dateEndYear+""+i;
}
}
}
return date;
}
}集合
集合是java中提供的一种容器,可以用来存储多个数据。
集合和数组既然都是容器,它们有啥区别呢?
- 数组的长度是固定的。集合的长度是可变的。
- 数组中可以存储基本数据类型值,也可以存储对象,而集合中只能存储对象
集合主要分为两大系列:Collection和Map,Collection 表示一组对象,Map表示一组映射关系或键值对。
Collection
Collection 层次结构中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。JDK 不提供此接口的任何直接实现:它提供更具体的子接口(如 Set 和 List、Queue)实现。此接口通常用来传递 collection,并在需要最大普遍性的地方操作这些 collection。
Collection
1、添加元素
(1)add(E obj):添加元素对象到当前集合中
(2)addAll(Collection<? extends E> other):添加other集合中的所有元素对象到当前集合中,即this = this ∪ other
2、删除元素
(1) boolean remove(Object obj) :从当前集合中删除第一个找到的与obj对象equals返回true的元素。
(2)boolean removeAll(Collection<?> coll):从当前集合中删除所有与coll集合中相同的元素。即this = this - this ∩ coll
3、判断
(1)boolean isEmpty():判断当前集合是否为空集合。
(2)boolean contains(Object obj):判断当前集合中是否存在一个与obj对象equals返回true的元素。
(3)boolean containsAll(Collection<?> c):判断c集合中的元素是否在当前集合中都存在。即c集合是否是当前集合的“子集”。
4、获取元素个数
(1)int size():获取当前集合中实际存储的元素个数
5、交集
(1)boolean retainAll(Collection<?> coll):当前集合仅保留与c集合中的元素相同的元素,即当前集合中仅保留两个集合的交集,即this = this ∩ coll;
6、转为数组
(1)Object[] toArray():返回包含当前集合中所有元素的数组
方法演示:
import java.util.ArrayList;
import java.util.Collection;
public class Demo1Collection {
public static void main(String[] args) {
// 创建集合对象
// 使用多态形式
Collection<String> coll = new ArrayList<String>();
// 使用方法
// 添加功能 boolean add(String s)
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
System.out.println(coll);
// boolean contains(E e) 判断o是否在集合中存在
System.out.println("判断 扫地僧 是否在集合中"+coll.contains("扫地僧"));
//boolean remove(E e) 删除在集合中的o元素
System.out.println("删除石破天:"+coll.remove("石破天"));
System.out.println("操作之后集合中元素:"+coll);
// size() 集合中有几个元素
System.out.println("集合中有"+coll.size()+"个元素");
// Object[] toArray()转换成一个Object数组
Object[] objects = coll.toArray();
// 遍历数组
for (int i = 0; i < objects.length; i++) {
System.out.println(objects[i]);
}
// void clear() 清空集合
coll.clear();
System.out.println("集合中内容为:"+coll);
// boolean isEmpty() 判断是否为空
System.out.println(coll.isEmpty());
}
} @Test
public void test2(){
Collection coll = new ArrayList();
coll.add(1);
coll.add(2);
System.out.println("coll集合元素的个数:" + coll.size());
Collection other = new ArrayList();
other.add(1);
other.add(2);
other.add(3);
coll.addAll(other);
// coll.add(other);
System.out.println("coll集合元素的个数:" + coll.size());
}注意:coll.addAll(other);与coll.add(other);
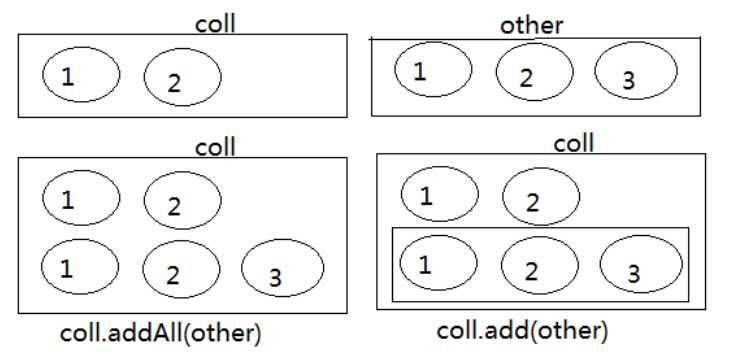
@Test
public void test5(){
Collection coll = new ArrayList();
coll.add(1);
coll.add(2);
coll.add(3);
coll.add(4);
coll.add(5);
System.out.println("coll集合元素的个数:" + coll.size());//5
Collection other = new ArrayList();
other.add(1);
other.add(2);
other.add(8);
coll.retainAll(other);//保留交集
System.out.println("coll集合元素的个数:" + coll.size());//2
}Iterator迭代器
Iterator接口
在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK专门提供了一个接口java.util.Iterator。Iterator接口也是Java集合中的一员,但它与Collection、Map接口有所不同,Collection接口与Map接口主要用于存储元素,而Iterator主要用于迭代访问(即遍历)Collection中的元素,因此Iterator对象也被称为迭代器。
想要遍历Collection集合,那么就要获取该集合迭代器完成迭代操作,下面介绍一下获取迭代器的方法:
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的。
下面介绍一下迭代的概念:
- 迭代:即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续在判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
Iterator接口的常用方法如下:
public E next():返回迭代的下一个元素。public boolean hasNext():如果仍有元素可以迭代,则返回 true。
接下来我们通过案例学习如何使用Iterator迭代集合中元素:
public class IteratorDemo {
public static void main(String[] args) {
// 使用多态方式 创建对象
Collection<String> coll = new ArrayList<String>();
// 添加元素到集合
coll.add("串串星人");
coll.add("吐槽星人");
coll.add("汪星人");
//遍历
//使用迭代器 遍历 每个集合对象都有自己的迭代器
Iterator<String> it = coll.iterator();
// 泛型指的是 迭代出 元素的数据类型
while(it.hasNext()){ //判断是否有迭代元素
String s = it.next();//获取迭代出的元素
System.out.println(s);
}
}
}tips::在进行集合元素取出时,如果集合中已经没有元素了,还继续使用迭代器的next方法,将会发生java.util.NoSuchElementException没有集合元素的错误。
迭代器的实现原理
我们在之前案例已经完成了Iterator遍历集合的整个过程。当遍历集合时,首先通过调用集合的iterator()方法获得迭代器对象,然后使用hashNext()方法判断集合中是否存在下一个元素,如果存在,则调用next()方法将元素取出,否则说明已到达了集合末尾,停止遍历元素。
Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素,为了让初学者能更好地理解迭代器的工作原理,接下来通过一个图例来演示Iterator对象迭代元素的过程:
在调用Iterator的next方法之前,迭代器的索引位于第一个元素之前,指向第一个元素,当第一次调用迭代器的next方法时,返回第一个元素,然后迭代器的索引会向后移动一位,指向第二个元素,当再次调用next方法时,返回第二个元素,然后迭代器的索引会再向后移动一位,指向第三个元素,依此类推,直到hasNext方法返回false,表示到达了集合的末尾,终止对元素的遍历。
使用Iterator迭代器删除元素
java.util.Iterator迭代器中有一个方法:
void remove() ;
那么,既然Collection已经有remove(xx)方法了,为什么Iterator迭代器还要提供删除方法呢?
因为Collection的remove方法,无法根据条件删除。
例如:要删除以下集合元素中的偶数
@Test
public void test02(){
Collection<Integer> coll = new ArrayList<>();
coll.add(1);
coll.add(2);
coll.add(3);
coll.add(4);
// coll.remove(?)//无法编写
Iterator<Integer> iterator = coll.iterator();
while(iterator.hasNext()){
Integer element = iterator.next();
if(element%2 == 0){
// coll.remove(element);//错误的
iterator.remove();
}
}
System.out.println(coll);
}注意:不要在使用Iterator迭代器进行迭代时,调用Collection的remove(xx)方法,否则会报异常java.util.ConcurrentModificationException,或出现不确定行为。
增强for
增强for循环(也称for each循环)是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的。
格式:
for(元素的数据类型 变量 : Collection集合or数组){
//写操作代码
}练习1:遍历数组
通常只进行遍历元素,不要在遍历的过程中对数组元素进行修改。
public class NBForDemo1 {
public static void main(String[] args) {
int[] arr = {3,5,6,87};
//使用增强for遍历数组
for(int a : arr){//a代表数组中的每个元素
System.out.println(a);
}
}
}练习2:遍历集合
通常只进行遍历元素,不要在遍历的过程中对集合元素进行增加、删除、替换操作。
public class NBFor {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<String>();
coll.add("小河神");
coll.add("老河神");
coll.add("神婆");
//使用增强for遍历
for(String s :coll){//接收变量s代表 代表被遍历到的集合元素
System.out.println(s);
}
}
}java.lang.Iterable接口
java.lang.Iterable接口,实现这个接口允许对象成为 “foreach” 语句的目标。
Java 5时Collection接口继承了java.lang.Iterable接口,因此Collection系列的集合就可以直接使用foreach循环遍历。
java.lang.Iterable接口的抽象方法:
- public Iterator iterator(): 获取对应的迭代器,用来遍历数组或集合中的元素的。
自定义某容器类型,实现java.lang.Iterable接口,发现就可以使用foreach进行迭代。
import java.util.Iterator;
public class TestMyArrayList {
public static void main(String[] args) {
MyArrayList<String> my = new MyArrayList<>();
for(String obj : my) {
System.out.println(obj);
}
}
}
class MyArrayList<T> implements Iterable<T>{
@Override
public Iterator<T> iterator() {
return null;
}
}foreach本质上就是使用Iterator迭代器进行遍历的。
我们在如下代码的for(Student student : coll)这行打断点,然后使用单步调试进入源码,发现foreach本质上是调用集合的iterator()方法,返回一个迭代器进行迭代的
import java.util.ArrayList;
import java.util.Collection;
public class TestForeach {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<>();
coll.add("陈琦");
coll.add("李晨");
coll.add("邓超");
coll.add("黄晓明");
//调用ArrayList里面的Iterator iterator()
for (String str : coll) {
System.out.println(str);
}
}
}
所以也不要在foreach遍历的过程使用Collection的remove()方法。否则,要么报异常java.util.ConcurrentModificationException,要么行为不确定。
Java中modCount的用法,快速失败(fail-fast)机制
当使用foreach或Iterator迭代器遍历集合时,同时调用迭代器自身以外的方法修改了集合的结构,例如调用集合的add和remove方法时,就会报ConcurrentModificationException。
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class TestForeach {
public static void main(String[] args) {
Collection<String> list = new ArrayList<>();
list.add("hello");
list.add("java");
list.add("atguigu");
list.add("world");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
list.remove(iterator.next());
}
}
}如果在Iterator、ListIterator迭代器创建后的任意时间从结构上修改了集合(通过迭代器自身的 remove 或 add 方法之外的任何其他方式),则迭代器将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就完全失败,而不是冒着在将来不确定的时间任意发生不确定行为的风险。
这样设计是因为,迭代器代表集合中某个元素的位置,内部会存储某些能够代表该位置的信息。当集合发生改变时,该信息的含义可能会发生变化,这时操作迭代器就可能会造成不可预料的事情。因此,果断抛异常阻止,是最好的方法。这就是Iterator迭代器的快速失败(fail-fast)机制。
注意,迭代器的快速失败行为不能得到保证,一般来说,存在不同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的方式是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测 bug。例如:
@Test
public void test02() {
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("java");
list.add("atguigu");
list.add("world");
//以下代码没有发生ConcurrentModificationException异常
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String str = iterator.next();
if("atguigu".equals(str)){
list.remove(str);
}
}
}那么如何实现快速失败(fail-fast)机制的呢?
- 在ArrayList等集合类中都有一个modCount变量。它用来记录集合的结构被修改的次数。
- 当我们给集合添加和删除操作时,会导致modCount++。
- 然后当我们用Iterator迭代器遍历集合时,创建集合迭代器的对象时,用一个变量记录当前集合的modCount。例如:
int expectedModCount = modCount;,并且在迭代器每次next()迭代元素时,都要检查expectedModCount != modCount,如果不相等了,那么说明你调用了Iterator迭代器以外的Collection的add,remove等方法,修改了集合的结构,使得modCount++,值变了,就会抛出ConcurrentModificationException。
下面以AbstractList
AbstractList
/**
* The number of times this list has been <i>structurally modified</i>.
* Structural modifications are those that change the size of the
* list, or otherwise perturb it in such a fashion that iterations in
* progress may yield incorrect results.
*
* <p>This field is used by the iterator and list iterator implementation
* returned by the {@code iterator} and {@code listIterator} methods.
* If the value of this field changes unexpectedly, the iterator (or list
* iterator) will throw a {@code ConcurrentModificationException} in
* response to the {@code next}, {@code remove}, {@code previous},
* {@code set} or {@code add} operations. This provides
* <i>fail-fast</i> behavior, rather than non-deterministic behavior in
* the face of concurrent modification during iteration.
*
* <p><b>Use of this field by subclasses is optional.</b> If a subclass
* wishes to provide fail-fast iterators (and list iterators), then it
* merely has to increment this field in its {@code add(int, E)} and
* {@code remove(int)} methods (and any other methods that it overrides
* that result in structural modifications to the list). A single call to
* {@code add(int, E)} or {@code remove(int)} must add no more than
* one to this field, or the iterators (and list iterators) will throw
* bogus {@code ConcurrentModificationExceptions}. If an implementation
* does not wish to provide fail-fast iterators, this field may be
* ignored.
*/
protected transient int modCount = 0;modCount是这个list被结构性修改的次数。结构性修改是指:改变list的size大小,或者,以其他方式改变他导致正在进行迭代时出现错误的结果。
这个字段用于迭代器和列表迭代器的实现类中,由迭代器和列表迭代器方法返回。如果这个值被意外改变,这个迭代器将会抛出 ConcurrentModificationException的异常来响应:next,remove,previous,set,add 这些操作。在迭代过程中,他提供了fail-fast行为而不是不确定行为来处理并发修改。
子类使用这个字段是可选的,如果子类希望提供fail-fast迭代器,它仅仅需要在add(int, E),remove(int)方法(或者它重写的其他任何会结构性修改这个列表的方法)中添加这个字段。调用一次add(int,E)或者remove(int)方法时必须且仅仅给这个字段加1,否则迭代器会抛出伪装的ConcurrentModificationExceptions错误。如果一个实现类不希望提供fail-fast迭代器,则可以忽略这个字段。
Arraylist的Itr迭代器:
private class Itr implements Iterator<E> {
int cursor;
int lastRet = -1;
int expectedModCount = modCount;//在创建迭代器时,expectedModCount初始化为当前集合的modCount的值
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();//校验expectedModCount与modCount是否相等
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
if (modCount != expectedModCount)//校验expectedModCount与modCount是否相等
throw new ConcurrentModificationException();//不相等,抛异常
}
}List集合
我们掌握了Collection接口的使用后,再来看看Collection接口中的子接口,他们都具备那些特性呢?
List接口介绍
java.util.List接口继承自Collection接口,是单列集合的一个重要分支,习惯性地会将实现了List接口的对象称为List集合。
List接口特点:
- List集合所有的元素是以一种线性方式进行存储的,例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)
- 它是一个元素存取有序的集合。即元素的存入顺序和取出顺序有保证。
- 它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
- 集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
List集合类中元素有序、且可重复。这就像银行门口客服,给每一个来办理业务的客户分配序号:第一个来的是“张三”,客服给他分配的是0;第二个来的是“李四”,客服给他分配的1;以此类推,最后一个序号应该是“总人数-1”。
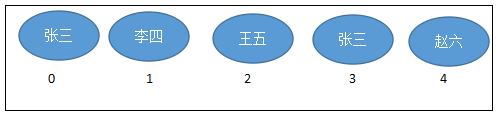
注意:
List集合关心元素是否有序,而不关心是否重复,请大家记住这个原则。例如“张三”可以领取两个号。
List接口中常用方法
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法,如下:
List除了从Collection集合继承的方法外,List 集合里添加了一些根据索引来操作集合元素的方法。
1、添加元素
- void add(int index, E ele)
- boolean addAll(int index, Collection<? extends E> eles)
2、获取元素
- E get(int index)
- List subList(int fromIndex, int toIndex)
3、获取元素索引
- int indexOf(Object obj)
- int lastIndexOf(Object obj)
4、删除和替换元素
- E remove(int index)
- E set(int index, E ele)
List集合特有的方法都是跟索引相关:
public class ListDemo {
public static void main(String[] args) {
// 创建List集合对象
List<String> list = new ArrayList<String>();
// 往 尾部添加 指定元素
list.add("图图");
list.add("小美");
list.add("不高兴");
System.out.println(list);
// add(int index,String s) 往指定位置添加
list.add(1,"没头脑");
System.out.println(list);
// String remove(int index) 删除指定位置元素 返回被删除元素
// 删除索引位置为2的元素
System.out.println("删除索引位置为2的元素");
System.out.println(list.remove(2));
System.out.println(list);
// String set(int index,String s)
// 在指定位置 进行 元素替代(改)
// 修改指定位置元素
list.set(0, "三毛");
System.out.println(list);
// String get(int index) 获取指定位置元素
// 跟size() 方法一起用 来 遍历的
for(int i = 0;i<list.size();i++){
System.out.println(list.get(i));
}
//还可以使用增强for
for (String string : list) {
System.out.println(string);
}
}
}在JavaSE中List名称的类型有两个,一个是java.util.List集合接口,一个是java.awt.List图形界面的组件,别导错包了。
List接口的实现类们
List接口的实现类有很多,常见的有:
ArrayList:动态数组
Vector:动态数组
LinkedList:双向链表
Stack:栈
它们的区别我们在数据结构部分再详细讲解
ListIterator
List 集合额外提供了一个 listIterator() 方法,该方法返回一个 ListIterator 对象, ListIterator 接口继承了 Iterator 接口,提供了专门操作 List 的方法:
- void add():通过迭代器添加元素到对应集合
- void set(Object obj):通过迭代器替换正迭代的元素
- void remove():通过迭代器删除刚迭代的元素
- boolean hasPrevious():如果以逆向遍历列表,往前是否还有元素。
- Object previous():返回列表中的前一个元素。
- int previousIndex():返回列表中的前一个元素的索引
- boolean hasNext()
- Object next()
- int nextIndex()
public static void main(String[] args) {
List<Student> c = new ArrayList<>();
c.add(new Student(1,"张三"));
c.add(new Student(2,"李四"));
c.add(new Student(3,"王五"));
c.add(new Student(4,"赵六"));
c.add(new Student(5,"钱七"));
//从指定位置往前遍历
ListIterator<Student> listIterator = c.listIterator(c.size());
while(listIterator.hasPrevious()){
Student previous = listIterator.previous();
System.out.println(previous);
}
}Set集合
Set接口是Collection的子接口,set接口没有提供额外的方法。但是比Collection接口更加严格了。
Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个 Set 集合中,则添加操作失败。
Set集合支持的遍历方式和Collection集合一样:foreach和Iterator。
Set的常用实现类有:HashSet、TreeSet、LinkedHashSet。
HashSet
HashSet 是 Set 接口的典型实现,大多数时候使用 Set 集合时都使用这个实现类。
java.util.HashSet底层的实现其实是一个java.util.HashMap支持,然后HashMap的底层物理实现是一个Hash表。(什么是哈希表,下一节在HashMap小节在细讲,这里先不展开)
HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取和查找性能。HashSet 集合判断两个元素相等的标准:两个对象通过 hashCode() 方法比较相等,并且两个对象的 equals() 方法返回值也相等。因此,存储到HashSet的元素要重写hashCode和equals方法。
示例代码:定义一个Employee类,该类包含属性:name, birthday,其中 birthday 为 MyDate类的对象;MyDate为自定义类型,包含年、月、日属性。要求 name和birthday一样的视为同一个员工。
public class Employee {
private String name;
private MyDate birthday;
public Employee(String name, MyDate birthday) {
super();
this.name = name;
this.birthday = birthday;
}
public Employee() {
super();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public MyDate getBirthday() {
return birthday;
}
public void setBirthday(MyDate birthday) {
this.birthday = birthday;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((birthday == null) ? 0 : birthday.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Employee other = (Employee) obj;
if (birthday == null) {
if (other.birthday != null)
return false;
} else if (!birthday.equals(other.birthday))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "姓名:" + name + ", 生日:" + birthday;
}
}public class MyDate {
private int year;
private int month;
private int day;
public MyDate(int year, int month, int day) {
super();
this.year = year;
this.month = month;
this.day = day;
}
public MyDate() {
super();
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public int getDay() {
return day;
}
public void setDay(int day) {
this.day = day;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + day;
result = prime * result + month;
result = prime * result + year;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
MyDate other = (MyDate) obj;
if (day != other.day)
return false;
if (month != other.month)
return false;
if (year != other.year)
return false;
return true;
}
@Override
public String toString() {
return year + "-" + month + "-" + day;
}
}import java.util.HashSet;
public class TestHashSet {
@SuppressWarnings("all")
public static void main(String[] args) {
HashSet<Employee> set = new HashSet<>();
set.add(new Employee("张三", new MyDate(1990,1,1)));
//重复元素无法添加,因为MyDate和Employee重写了hashCode和equals方法
set.add(new Employee("张三", new MyDate(1990,1,1)));
set.add(new Employee("李四", new MyDate(1992,2,2)));
for (Employee object : set) {
System.out.println(object);
}
}
}LinkedHashSet
LinkedHashSet是HashSet的子类,它在HashSet的基础上,在结点中增加两个属性before和after维护了结点的前后添加顺序。java.util.LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。LinkedHashSet插入性能略低于 HashSet,但在迭代访问 Set 里的全部元素时有很好的性能。
LinkedHashSet<String> set = new LinkedHashSet<>();
set.add("张三");
set.add("李四");
set.add("王五");
set.add("张三");
System.out.println("元素个数:" + set.size());
for (String name : set) {
System.out.println(name);
}运行结果:
元素个数:3
张三
李四
王五TreeSet
底层结构:里面维护了一个TreeMap,都是基于红黑树实现的!
特点:
1、不允许重复
2、实现排序
自然排序或定制排序
如何实现去重的?
如果使用的是自然排序,则通过调用实现的compareTo方法
如果使用的是定制排序,则通过调用比较器的compare方法如何排序?
方式一:自然排序
让待添加的元素类型实现Comparable接口,并重写compareTo方法
方式二:定制排序
创建Set对象时,指定Comparator比较器接口,并实现compare方法自然顺序
如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable 接口。实现 Comparable 的类必须实现 compareTo(Object obj) 方法,两个对象即通过 compareTo(Object obj) 方法的返回值来比较大小。对于 TreeSet 集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过 compareTo(Object obj) 方法比较返回值为0。
代码示例一:按照字符串Unicode编码值排序
@Test
public void test1(){
TreeSet<String> set = new TreeSet<>();
set.add("zhangsan"); //String它实现了java.lang.Comparable接口
set.add("lisi");
set.add("wangwu");
set.add("zhangsan");
System.out.println("元素个数:" + set.size());
for (String str : set) {
System.out.println(str);
}
}定制排序
如果放到TreeSet中的元素的自然排序(Comparable)规则不符合当前排序需求时,或者元素的类型没有实现Comparable接口。那么在创建TreeSet时,可以单独指定一个Comparator的对象。使用定制排序判断两个元素相等的标准是:通过Comparator比较两个元素返回了0。
代码示例:学生类型未实现Comparable接口,单独指定Comparator比较器,按照学生的学号排序
public class Student{
private int id;
private String name;
public Student(int id, String name) {
super();
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
//......这里省略了name属性的get/set
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + "]";
}
}@Test
public void test3(){
TreeSet<Student> set = new TreeSet(new Comparator<Student>(){
@Override
public int compare(Student o1, Student o2) {
return o1.getId() - o2.getId();
}
});
set.add(new Student(3,"张三"));
set.add(new Student(1,"李四"));
set.add(new Student(2,"王五"));
set.add(new Student(3,"张三风"));
System.out.println("元素个数:" + set.size());
for (Student stu : set) {
System.out.println(stu);
}
}Collection系列的集合框架图
Map
概述
现实生活中,我们常会看到这样的一种集合:IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种一一对应的关系,就叫做映射。Java提供了专门的集合类用来存放这种对象关系的对象,即java.util.Map<K,V>接口。
我们通过查看Map接口描述,发现Map<K,V>接口下的集合与Collection<E>接口下的集合,它们存储数据的形式不同。
Collection中的集合,元素是孤立存在的(理解为单身),向集合中存储元素采用一个个元素的方式存储。Map中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。Collection中的集合称为单列集合,Map中的集合称为双列集合。- 需要注意的是,
Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值(这个值可以是单个值,也可以是个数组或集合值)。
Map常用方法
1、添加操作
- V put(K key,V value)
- void putAll(Map<? extends K,? extends V> m)
2、删除
- void clear()
V remove(Object key)
3、元素查询的操作
V get(Object key)
- boolean containsKey(Object key)
- boolean containsValue(Object value)
boolean isEmpty()
4、元视图操作的方法:
Set
keySet() - Collection
values() Set
5、其他方法
int size()
public class MapDemo {
public static void main(String[] args) {
//创建 map对象
HashMap<String, String> map = new HashMap<String, String>();
//添加元素到集合
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("邓超", "孙俪");
System.out.println(map);
//String remove(String key)
System.out.println(map.remove("邓超"));
System.out.println(map);
// 想要查看 黄晓明的媳妇 是谁
System.out.println(map.get("黄晓明"));
System.out.println(map.get("邓超"));
}
}tips:
使用put方法时,若指定的键(key)在集合中没有,则没有这个键对应的值,返回null,并把指定的键值添加到集合中;
若指定的键(key)在集合中存在,则返回值为集合中键对应的值(该值为替换前的值),并把指定键所对应的值,替换成指定的新值。
Map集合的遍历
Collection集合的遍历:(1)foreach(2)通过Iterator对象遍历
Map的遍历,不能支持foreach,因为Map接口没有继承java.lang.Iterable
(1)分开遍历:
- 单独遍历所有key
- 单独遍历所有value
(2)成对遍历:
- 遍历的是映射关系Map.Entry类型的对象,Map.Entry是Map接口的内部接口。每一种Map内部有自己的Map.Entry的实现类。在Map中存储数据,实际上是将Key——>value的数据存储在Map.Entry接口的实例中,再在Map集合中插入Map.Entry的实例化对象,如图示:

public class TestMap {
public static void main(String[] args) {
HashMap<String,String> map = new HashMap<>();
map.put("许仙", "白娘子");
map.put("董永", "七仙女");
map.put("牛郎", "织女");
map.put("许仙", "小青");
System.out.println("所有的key:");
Set<String> keySet = map.keySet();
for (String key : keySet) {
System.out.println(key);
}
System.out.println("所有的value:");
Collection<String> values = map.values();
for (String value : values) {
System.out.println(value);
}
System.out.println("所有的映射关系");
Set<Map.Entry<String,String>> entrySet = map.entrySet();
for (Map.Entry<String,String> entry : entrySet) {
// System.out.println(entry);
System.out.println(entry.getKey()+"->"+entry.getValue());
}
}
}Map的实现类们
Map接口的常用实现类:HashMap、TreeMap、LinkedHashMap和Properties。其中HashMap是 Map 接口使用频率最高的实现类。
HashMap和Hashtable的区别与联系
- HashMap和Hashtable都是哈希表。
HashMap和Hashtable判断两个 key 相等的标准是:两个 key 的hashCode 值相等,并且 equals() 方法也返回 true。因此,为了成功地在哈希表中存储和获取对象,用作键的对象必须实现 hashCode 方法和 equals 方法。
Hashtable是线程安全的,任何非 null 对象都可以用作键或值。
HashMap是线程不安全的,并允许使用 null 值和 null 键。
示例代码:添加员工姓名为key,薪资为value
public static void main(String[] args) {
HashMap<String,Double> map = new HashMap<>();
map.put("张三", 10000.0);
//key相同,新的value会覆盖原来的value
//因为String重写了hashCode和equals方法
map.put("张三", 12000.0);
map.put("李四", 14000.0);
//HashMap支持key和value为null值
String name = null;
Double salary = null;
map.put(name, salary);
Set<Entry<String, Double>> entrySet = map.entrySet();
for (Entry<String, Double> entry : entrySet) {
System.out.println(entry);
}
}LinkedHashMap
LinkedHashMap 是 HashMap 的子类。此实现与 HashMap 的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序)。
示例代码:添加员工姓名为key,薪资为value
public static void main(String[] args) {
LinkedHashMap<String,Double> map = new LinkedHashMap<>();
map.put("张三", 10000.0);
//key相同,新的value会覆盖原来的value
//因为String重写了hashCode和equals方法
map.put("张三", 12000.0);
map.put("李四", 14000.0);
//HashMap支持key和value为null值
String name = null;
Double salary = null;
map.put(name, salary);
Set<Entry<String, Double>> entrySet = map.entrySet();
for (Entry<String, Double> entry : entrySet) {
System.out.println(entry);
}
}TreeMap
基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
代码示例:添加员工姓名为key,薪资为value
package com.atguigu.map;
import java.util.Comparator;
import java.util.Map.Entry;
import java.util.Set;
import java.util.TreeMap;
import org.junit.Test;
public class TestTreeMap {
@Test
public void test1() {
TreeMap<String,Integer> map = new TreeMap<>();
map.put("Jack", 11000);
map.put("Alice", 12000);
map.put("zhangsan", 13000);
map.put("baitao", 14000);
map.put("Lucy", 15000);
//String实现了Comparable接口,默认按照Unicode编码值排序
Set<Entry<String, Integer>> entrySet = map.entrySet();
for (Entry<String, Integer> entry : entrySet) {
System.out.println(entry);
}
}
@Test
public void test2() {
//指定定制比较器Comparator,按照Unicode编码值排序,但是忽略大小写
TreeMap<String,Integer> map = new TreeMap<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.compareToIgnoreCase(o2);
}
});
map.put("Jack", 11000);
map.put("Alice", 12000);
map.put("zhangsan", 13000);
map.put("baitao", 14000);
map.put("Lucy", 15000);
Set<Entry<String, Integer>> entrySet = map.entrySet();
for (Entry<String, Integer> entry : entrySet) {
System.out.println(entry);
}
}
}Properties
Properties 类是 Hashtable 的子类,Properties 可保存在流中或从流中加载。属性列表中每个键及其对应值都是一个字符串。
存取数据时,建议使用setProperty(String key,String value)方法和getProperty(String key)方法。
代码示例:
public static void main(String[] args) {
Properties properties = System.getProperties();
String p2 = properties.getProperty("file.encoding");//当前源文件字符编码
System.out.println(p2);
}Set集合与Map集合的关系
Set的内部实现其实是一个Map。即HashSet的内部实现是一个HashMap,TreeSet的内部实现是一个TreeMap,LinkedHashSet的内部实现是一个LinkedHashMap。
部分源代码摘要:
HashSet源码:
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
//这个构造器是给子类LinkedHashSet调用的
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}LinkedHashSet源码:
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);//调用HashSet的某个构造器
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);//调用HashSet的某个构造器
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);//调用HashSet的某个构造器
addAll(c);
}TreeSet源码:
public TreeSet() {
this(new TreeMap<E,Object>());
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}但是,咱们存到Set中只有一个元素,又是怎么变成(key,value)的呢?
以HashSet中的源码为例:
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}原来是,把添加到Set中的元素作为内部实现map的key,然后用一个常量对象PRESENT对象,作为value。
这是因为Set的元素不可重复和Map的key不可重复有相同特点。Map有一个方法keySet()可以返回所有key。
集合框架

Collections工具类
参考操作数组的工具类:Arrays。
Collections 是一个操作 Set、List 和 Map 等集合的工具类。Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法:
- public static
boolean addAll(Collection<? super T> c,T… elements)将所有指定元素添加到指定 collection 中。 - public static
int binarySearch(List<? extends Comparable<? super T>> list,T key)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且必须是可比较大小的,即支持自然排序的。而且集合也事先必须是有序的,否则结果不确定。 - public static
int binarySearch(List<? extends T> list,T key,Comparator<? super T> c)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且集合也事先必须是按照c比较器规则进行排序过的,否则结果不确定。 - public static
> T max(Collection<? extends T> coll)在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,而且支持自然排序 - public static
T max(Collection<? extends T> coll,Comparator<? super T> comp)在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,按照比较器comp找出最大者 - public static void reverse(List<?> list)反转指定列表List中元素的顺序。
- public static void shuffle(List<?> list) List 集合元素进行随机排序,类似洗牌
- public static
> void sort(List list)根据元素的自然顺序对指定 List 集合元素按升序排序 - public static
void sort(List list,Comparator<? super T> c)根据指定的 Comparator 产生的顺序对 List 集合元素进行排序 - public static void swap(List<?> list,int i,int j)将指定 list 集合中的 i 处元素和 j 处元素进行交换
- public static int frequency(Collection<?> c,Object o)返回指定集合中指定元素的出现次数
- public static
void copy(List<? super T> dest,List<? extends T> src)将src中的内容复制到dest中 - public static
boolean replaceAll(List list,T oldVal,T newVal):使用新值替换 List 对象的所有旧值 - Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题
- Collections类中提供了多个unmodifiableXxx()方法,该方法返回指定 Xxx的不可修改的视图。
泛型
泛型的概念
泛型的引入
例如:生产瓶子的厂家,一开始并不知道我们将来会用瓶子装什么,我们什么都可以装,但是有的时候,我们在使用时,想要限定某个瓶子只能用来装什么,这样我们不会装错,而用的时候也可以放心的使用,无需再三思量。我们生活中是在使用这个瓶子时在瓶子上“贴标签”,这样就轻松解决了问题。

还有,在Java中我们在声明方法时,当在完成方法功能时如果有未知的数据需要参与,这些未知的数据需要在调用方法时才能确定,那么我们把这样的数据通过形参表示。那么在方法体中,用这个形参名来代表那个未知的数据,而调用者在调用时,对应的传入值就可以了。
受以上两点启发,JDK1.5设计了泛型的概念。泛型即为“类型参数”,这个类型参数在声明它的类、接口或方法中,代表未知的通用的类型。例如:
java.lang.Comparable接口和java.util.Comparator接口,是用于对象比较大小的规范接口,这两个接口只是限定了当一个对象大于另一个对象时返回正整数,小于返回负整数,等于返回0。但是并不确定是什么类型的对象比较大小,之前的时候只能用Object类型表示,使用时既麻烦又不安全,因此JDK1.5就给它们增加了泛型。
public interface Comparable<T>{
int compareTo(T o) ;
}public interface Comparator<T>{
int compare(T o1, T o2) ;
}其中
泛型的好处
示例代码:
JavaBean:圆类型
class Circle{
private double radius;
public Circle(double radius) {
super();
this.radius = radius;
}
public double getRadius() {
return radius;
}
public void setRadius(double radius) {
this.radius = radius;
}
@Override
public String toString() {
return "Circle [radius=" + radius + "]";
}
}比较器
import java.util.Comparator;
public class CircleComparator implements Comparator{
@Override
public int compare(Object o1, Object o2) {
//强制类型转换
Circle c1 = (Circle) o1;
Circle c2 = (Circle) o2;
return Double.compare(c1.getRadius(), c2.getRadius());
}
}测试类
public class TestGeneric {
public static void main(String[] args) {
CircleComparator com = new CircleComparator();
System.out.println(com.compare(new Circle(1), new Circle(2)));
System.out.println(com.compare("圆1", "圆2"));//运行时异常:ClassCastException
}
}那么我们在使用如上面这样的接口时,如果没有泛型或不指定泛型,很麻烦,而且有安全隐患。
因为在设计(编译)Comparator接口时,不知道它会用于哪种类型的对象比较,因此只能将compare方法的形参设计为Object类型,而实际在compare方法中需要向下转型为Circle,才能调用Circle类的getRadius()获取半径值进行比较。
使用泛型:
比较器:
class CircleComparator implements Comparator<Circle>{
@Override
public int compare(Circle o1, Circle o2) {
//不再需要强制类型转换,代码更简洁
return Double.compare(o1.getRadius(), o2.getRadius());
}
}测试类
import java.util.Comparator;
public class TestGeneric {
public static void main(String[] args) {
CircleComparator com = new CircleComparator();
System.out.println(com.compare(new Circle(1), new Circle(2)));
// System.out.println(com.compare("圆1", "圆2"));//编译错误,因为"圆1", "圆2"不是Circle类型,是String类型,编译器提前报错,而不是冒着风险在运行时再报错
}
}如果有了泛型并使用泛型,那么既能保证安全,又能简化代码。
因为把不安全的因素在编译期间就排除了;既然通过了编译,那么类型一定是符合要求的,就避免了类型转换。
泛型的相关名词
<类型>这种语法形式就叫泛型。
其中:
是类型变量(Type Variables),而 是代表未知的数据类型,我们可以指定为 , , 等,那么<类型>的形式我们成为类型参数; - 类比方法的参数的概念,我们可以把
,称为类型形参,将 称为类型实参,有助于我们理解泛型;
- 类比方法的参数的概念,我们可以把
Comparator
这种就称为参数化类型(Parameterized Types)。
自从有了泛型之后,Java的数据类型就更丰富了:
Class:Class 类的实例表示正在运行的 Java 应用程序中的类和接口。枚举是一种类,注释是一种接口。每个数组属于被映射为 Class 对象的一个类,所有具有相同元素类型和维数的数组都共享该 Class 对象。基本的 Java 类型(boolean、byte、char、short、int、long、float 和 double)和关键字 void 也表示为 Class 对象。
- GenericArrayType:泛化的数组类型,即T[]
- ParameterizedType:参数化类型,例如:Comparator
,Comparator - TypeVariable:类型变量,例如:Comparator
中的T,Map - WildcardType:通配符类型,例如:Comparator<?>等
在哪里可以声明类型变量\
- 声明类或接口时,在类名或接口名后面声明类型变量,我们把这样的类或接口称为泛型类或泛型接口
【修饰符】 class 类名<类型变量列表> 【extends 父类】 【implements 父接口们】{
}
【修饰符】 interface 接口名<类型变量列表> 【implements 父接口们】{
}
例如:
public class ArrayList<E>
public interface Map<K,V>{
....
} - 声明方法时,在【修饰符】与返回值类型之间声明类型变量,我们把声明(是声明不是单纯的使用)了类型变量的方法称为泛型方法
【修饰符】 <类型变量列表> 返回值类型 方法名(【形参列表】)【throws 异常列表】{
//...
}
例如:java.util.Arrays类中的
public static <T> List<T> asList(T... a){
....
}参数类型:泛型类与泛型接口
当我们在声明类或接口时,类或接口中定义某个成员时,该成员有些类型是不确定的,而这个类型需要在使用这个类或接口时才可以确定,那么我们可以使用泛型。
声明泛型类与泛型接口
语法格式:
【修饰符】 class 类名<类型变量列表> 【extends 父类】 【implements 父接口们】{
}
【修饰符】 interface 接口名<类型变量列表> 【implements 父接口们】{
}注意:
- <类型变量列表>:可以是一个或多个类型变量,一般都是使用单个的大写字母表示。例如:
、 - <类型变量列表>中的类型变量不能用于静态成员上。
什么时候使用泛型类或泛型接口呢?
- 当某个类的非静态实例变量的类型不确定,需要在创建对象或子类继承时才能确定
- 当某个(些)类的非静态方法的形参类型不确定,需要在创建对象或子类继承时才能确定
示例代码:
例如:我们要声明一个学生类,该学生包含姓名、成绩,而此时学生的成绩类型不确定,为什么呢,因为,语文老师希望成绩是“优秀”、“良好”、“及格”、“不及格”,数学老师希望成绩是89.5, 65.0,英语老师希望成绩是’A’,’B’,’C’,’D’,’E’。那么我们在设计这个学生类时,就可以使用泛型。
public class Student<T>{
private String name;
private T score;
public Student() {
super();
}
public Student(String name, T score) {
super();
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public T getScore() {
return score;
}
public void setScore(T score) {
this.score = score;
}
@Override
public String toString() {
return "姓名:" + name + ", 成绩:" + score;
}
}使用泛型类与泛型接口
在使用这种参数化的类与接口时,我们需要指定泛型变量的实际类型参数:
(1)实际类型参数必须是引用数据类型,不能是基本数据类型
(2)在创建类的对象时指定类型变量对应的实际类型参数
public class TestGeneric{
public static void main(String[] args) {
//语文老师使用时:
Student<String> stu1 = new Student<String>("张三", "良好");
//数学老师使用时:
//Student<double> stu2 = new Student<double>("张三", 90.5);//错误,必须是引用数据类型
Student<Double> stu2 = new Student<Double>("张三", 90.5);
//英语老师使用时:
Student<Character> stu3 = new Student<Character>("张三", 'C');
//错误的指定
//Student<Object> stu = new Student<String>();//错误的
}
}JDK1.7支持简写形式:Student
stu1 = new Student<>(“张三”, “良好”); 指定泛型实参时,必须左右两边一致,不存在多态现象
(3)在继承泛型类或实现泛型接口时,指定类型变量对应的实际类型参数
class ChineseStudent extends Student<String>{
public ChineseStudent() {
super();
}
public ChineseStudent(String name, String score) {
super(name, score);
}
}public class TestGeneric{
public static void main(String[] args) {
//语文老师使用时:
ChineseStudent stu = new ChineseStudent("张三", "良好");
}
}
class Circle implements Comparable<Circle>{
private double radius;
public Circle(double radius) {
super();
this.radius = radius;
}
public double getRadius() {
return radius;
}
public void setRadius(double radius) {
this.radius = radius;
}
@Override
public String toString() {
return "Circle [radius=" + radius + "]";
}
@Override
public int compareTo(Circle c){
return Double.compare(radius,c.radius);
}
}类型变量的上限
当在声明类型变量时,如果不希望这个类型变量代表任意引用数据类型,而是某个系列的引用数据类型,那么可以设定类型变量的上限。
语法格式:
<类型变量 extends 上限>如果有多个上限
<类型变量 extends 上限1 & 上限2>如果多个上限中有类有接口,那么只能有一个类,而且必须写在最左边。接口的话,可以多个。
如果在声明<类型变量>时没有指定任何上限,默认上限是java.lang.Object。
例如:我们要声明一个两个数求和的工具类,要求两个加数必须是Number数字类型,并且实现Comparable接口。
class SumTools<T extends Number & Comparable<T>>{
private T a;
private T b;
public SumTools(T a, T b) {
super();
this.a = a;
this.b = b;
}
@SuppressWarnings("unchecked")
public T getSum(){
if(a instanceof BigInteger){
return (T) ((BigInteger) a).add((BigInteger)b);
}else if(a instanceof BigDecimal){
return (T) ((BigDecimal) a).add((BigDecimal)b);
}else if(a instanceof Integer){
return (T)(Integer.valueOf((Integer)a+(Integer)b));
}else if(a instanceof Long){
return (T)(Long.valueOf((Long)a+(Long)b));
}else if(a instanceof Float){
return (T)(Float.valueOf((Float)a+(Float)b));
}else if(a instanceof Double){
return (T)(Double.valueOf((Double)a+(Double)b));
}
throw new UnsupportedOperationException("不支持该操作");
}
}测试类
public static void main(String[] args) {
SumTools<Integer> s = new SumTools<Integer>(1,2);
Integer sum = s.getSum();
System.out.println(sum);
// SumTools<String> s = new SumTools<String>("1","2");//错误,因为String类型不是extends Number
}泛型擦除
当使用参数化类型的类或接口时,如果没有指定泛型,那么会怎么样呢?
会发生泛型擦除,自动按照最左边的第一个上限处理。如果没有指定上限,上限即为Object。
public static void main(String[] args) {
SumTools s = new SumTools(1,2);
Number sum = s.getSum();
System.out.println(sum);
}import java.util.Comparator;
public class CircleComparator implements Comparator{
@Override
public int compare(Object o1, Object o2) {
//强制类型转换
Circle c1 = (Circle) o1;
Circle c2 = (Circle) o2;
return Double.compare(c1.getRadius(), c2.getRadius());
}
}练习
练习1
1、声明一个坐标类Coordinate
2、在测试类中,创建两个不同的坐标类对象,
分别指定T类型为String和Double,并为x,y赋值,打印对象
public class TestExer1 {
public static void main(String[] args) {
Coordinate<String> c1 = new Coordinate<>("北纬38.6", "东经36.8");
System.out.println(c1);
// Coordinate<Double> c2 = new Coordinate<>(38.6, 38);//自动装箱与拆箱只能与对应的类型 38是int,自动装为Integer
Coordinate<Double> c2 = new Coordinate<>(38.6, 36.8);
System.out.println(c2);
}
}
class Coordinate<T>{
private T x;
private T y;
public Coordinate(T x, T y) {
super();
this.x = x;
this.y = y;
}
public Coordinate() {
super();
}
public T getX() {
return x;
}
public void setX(T x) {
this.x = x;
}
public T getY() {
return y;
}
public void setY(T y) {
this.y = y;
}
@Override
public String toString() {
return "Coordinate [x=" + x + ", y=" + y + "]";
}
}练习2
1、声明一个Person类,包含姓名和伴侣属性,其中姓名是String类型,而伴侣的类型不确定,
因为伴侣可以是Person,可以是Animal(例如:金刚),可以是Ghost鬼(例如:倩女幽魂),
可以是Demon妖(例如:白娘子),可以是Robot机器人(例如:剪刀手爱德华)。。。
2、在测试类中,创建Person对象,并为它指定伴侣,打印显示信息
public class TestExer3 {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static void main(String[] args) {
Person<Demon> xu = new Person<Demon>("许仙",new Demon("白娘子"));
System.out.println(xu);
Person<Person> xie = new Person<Person>("谢学建",new Person("徐余龙"));
Person fere = xie.getFere();
fere.setFere(xie);
System.out.println(xie);
System.out.println(fere);
}
}
class Demon{
private String name;
public Demon(String name) {
super();
this.name = name;
}
@Override
public String toString() {
return "Demon [name=" + name + "]";
}
}
class Person<T>{
private String name;
private T fere;
public Person(String name, T fere) {
super();
this.name = name;
this.fere = fere;
}
public Person(String name) {
super();
this.name = name;
}
public Person() {
super();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public T getFere() {
return fere;
}
public void setFere(T fere) {
this.fere = fere;
}
@SuppressWarnings("rawtypes")
@Override
public String toString() {
if(fere instanceof Person){
Person p = (Person) fere;
return "Person [name=" + name + ", fere=" + p.getName() + "]";
}
return "Person [name=" + name + ", fere=" + fere + "]";
}
}练习3
1、声明员工类型Employee,包含姓名(String),薪资(double),年龄(int)
2、员工类Employee实现java.lang.Comparable
3、在测试类中创建Employee数组,然后调用Arrays.sort(Object[] arr)方法进行排序,遍历显示员工信息
4、再次调用Arrays.sort(Object[] arr,Comparator
public class TestExer3 {
@Test
public void test01() {
Employee[] arr = new Employee[3];
arr[0] = new Employee("Irene", 18000, 18);
arr[1] = new Employee("Jack", 14000, 28);
arr[2] = new Employee("Alice", 14000, 24);
Arrays.sort(arr);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
@Test
public void test02() {
Employee[] arr = new Employee[3];
arr[0] = new Employee("Irene", 18000, 18);
arr[1] = new Employee("Jack", 14000, 28);
arr[2] = new Employee("Alice", 14000, 24);
//Arrays.sort(T[] arr,Comparator<T> c)
Arrays.sort(arr, new Comparator<Employee>() {
//按照年龄排序,年龄相同的安装姓名自然顺序比较大小
@Override
public int compare(Employee o1, Employee o2) {
if(o1.getAge() != o2.getAge()) {
return o1.getAge() - o2.getAge();
}
return o1.getName().compareTo(o2.getName());
}
});
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
class Employee implements Comparable<Employee>{
private String name;
private double salary;
private int age;
public Employee(String name, double salary, int age) {
super();
this.name = name;
this.salary = salary;
this.age = age;
}
public Employee() {
super();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Employee [name=" + name + ", salary=" + salary + ", age=" + age + "]";
}
//重写抽象方法,按照薪资比较大小,薪资相同的按照姓名的自然顺序比较大小。
@Override
public int compareTo(Employee o) {
if(this.salary != o.salary) {
return Double.compare(this.salary, o.salary);
}
return this.name.compareTo(o.name);//name是String类型,有compareTo方法
}
}泛型方法
前面介绍了在定义类、接口时可以声明<类型变量>,在该类的方法和属性定义、接口的方法定义中,这些<类型变量>可被当成普通类型来用。但是,在另外一些情况下,
(1)如果我们定义类、接口时没有使用<类型变量>,但是某个方法形参类型不确定时,可以单独这个方法定义<类型变量>;
(2)另外我们之前说类和接口上的类型形参是不能用于静态方法中,那么当某个静态方法的形参类型不确定时,可以单独定义<类型变量>。
那么,JDK1.5之后,还提供了泛型方法的支持。
语法格式:
【修饰符】 <类型变量列表> 返回值类型 方法名(【形参列表】)【throws 异常列表】{
//...
}- <类型变量列表>:可以是一个或多个类型变量,一般都是使用单个的大写字母表示。例如:
、 - <类型变量>同样也可以指定上限
示例代码:
我们编写一个数组工具类,包含可以给任意对象数组进行从小到大排序,要求数组元素类型必须实现Comparable接口
public class MyArrays{
public static <T extends Comparable<T>> void sort(T[] arr){
for (int i = 1; i < arr.length; i++) {
for (int j = 0; j < arr.length-i; j++) {
if(arr[j].compareTo(arr[j+1])>0){
T temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
}测试类
public class TestGeneric{
public static void main(String[] args) {
int[] arr = {3,2,5,1,4};
// MyArrays.sort(arr);//错误的,因为int[]不是对象数组
String[] strings = {"hello","java","chai"};
MyArrays.sort(strings);
System.out.println(Arrays.toString(strings));
Circle[] circles = {new Circle(2.0),new Circle(1.2),new Circle(3.0)};
MyArrays.sort(circles);
System.out.println(Arrays.toString(circles));
}
}类型通配符
当我们声明一个变量/形参时,这个变量/形参的类型是一个泛型类或泛型接口,例如:Comparator
例如:
这个学生类是一个参数化的泛型类,代码如下(详细请看$12.2.1中的示例说明):
public class Student<T>{
private String name;
private T score;
public Student() {
super();
}
public Student(String name, T score) {
super();
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public T getScore() {
return score;
}
public void setScore(T score) {
this.score = score;
}
@Override
public String toString() {
return "姓名:" + name + ", 成绩:" + score;
}
}<?>任意类型
例如:我们要声明一个学生管理类,这个管理类要包含一个方法,可以遍历学生数组。
学生管理类:
class StudentService {
public static void print(Student<?>[] arr) {
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}测试类
public class TestGeneric {
public static void main(String[] args) {
// 语文老师使用时:
Student<String> stu1 = new Student<String>("张三", "良好");
// 数学老师使用时:
// Student<double> stu2 = new Student<double>("张三", 90.5);//错误,必须是引用数据类型
Student<Double> stu2 = new Student<Double>("张三", 90.5);
// 英语老师使用时:
Student<Character> stu3 = new Student<Character>("张三", 'C');
Student<?>[] arr = new Student[3];
arr[0] = stu1;
arr[1] = stu2;
arr[2] = stu3;
StudentService.print(arr);
}
}<? extends 上限>
例如:我们要声明一个学生管理类,这个管理类要包含一个方法,找出学生数组中成绩最高的学生对象。
要求学生的成绩的类型必须可比较大小,实现Comparable接口。
学生管理类:
class StudentService {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static Student<? extends Comparable> max(Student<? extends Comparable>[] arr){
Student<? extends Comparable> max = arr[0];
for (int i = 0; i < arr.length; i++) {
if(arr[i].getScore().compareTo(max.getScore())>0){
max = arr[i];
}
}
return max;
}
}测试类
public class TestGeneric {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static void main(String[] args) {
Student<? extends Double>[] arr = new Student[3];
arr[0] = new Student<Double>("张三", 90.5);
arr[1] = new Student<Double>("李四", 80.5);
arr[2] = new Student<Double>("王五", 94.5);
Student<? extends Comparable> max = StudentService.max(arr);
System.out.println(max);
}
}<? super 下限>
现在要声明一个数组工具类,包含可以给任意对象数组进行从小到大排序,只要你指定定制比较器对象,而且这个定制比较器对象可以是当前数组元素类型自己或其父类的定制比较器对象
数组工具类:
class MyArrays{
public static <T> void sort(T[] arr, Comparator<? super T> c){
for (int i = 1; i < arr.length; i++) {
for (int j = 0; j < arr.length-i; j++) {
if(c.compare(arr[j], arr[j+1])>0){
T temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
}例如:有如下JavaBean
class Person{
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public Person() {
super();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "name=" + name + ", age=" + age;
}
}
class Student extends Person{
private int score;
public Student(String name, int age, int score) {
super(name, age);
this.score = score;
}
public Student() {
super();
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return super.toString() + ",score=" + score;
}
}测试类
public class TestGeneric {
public static void main(String[] args) {
Student[] all = new Student[3];
all[0] = new Student("张三", 23, 89);
all[1] = new Student("李四", 22, 99);
all[2] = new Student("王五", 25, 67);
MyArrays.sort(all, new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge() - o2.getAge();
}
});
System.out.println(Arrays.toString(all));
MyArrays.sort(all, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getScore() - o2.getScore();
}
});
System.out.println(Arrays.toString(all));
}
}
### 使用类型通配符来指定类型参数的问题
<?>:不可变,因为<?>类型不确定,编译时,任意类型都是错
<? extends 上限>:因为<? extends 上限>的?可能是上限或上限的子类,即类型不确定,编译按任意类型处理都是错。
<? super 下限>:可以将值修改为下限或下限子类的对象,因为<? super 下限>?代表是下限或下限的父类,那么设置为下限或下限子类的对象是安全的。
```java
public class TestGeneric {
public static void main(String[] args) {
Student<?> stu1 = new Student<>();
stu1.setScore(null);//除了null,无法设置为其他值
Student<? extends Number> stu2 = new Student<>();
stu2.setScore(null);//除了null,无法设置为其他值
Student<? super Number> stu3 = new Student<>();
stu3.setScore(56);//可以设置Number或其子类的对象
}
}
class Student<T>{
private String name;
private T score;
public Student() {
super();
}
public Student(String name, T score) {
super();
this.name = name;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public T getScore() {
return score;
}
public void setScore(T score) {
this.score = score;
}
@Override
public String toString() {
return "姓名:" + name + ", 成绩:" + score;
}
}
## 练习
在数组工具类中声明如下泛型方法:
(1)可以在任意类型的对象数组中,查找某个元素的下标,按照顺序查找,如果有重复的,就返回第一个找到的,如果没有返回-1
(2)可以在任意类型的对象数组中,查找最大值,要求元素必须实现Comparable接口
(3)可以在任意类型的对象数组中,查找最大值,按照指定定制比较器来比较元素大小
(4)可以给任意对象数组进行从小到大排序,要求数组元素类型必须实现Comparable接口
(5)可以给任意对象数组进行从小到大排序,只要你指定定制比较器对象,不要求数组元素实现Comparable接口
(6)可以将任意对象数组的元素拼接为一个字符串返回
```java
public class MyArrays {
//可以在任意类型的对象数组中,查找某个元素的下标,按照顺序查找,如果有重复的,就返回第一个找到的,如果没有返回-1
public static <T> int find(T[] arr, T value) {
for (int i = 0; i < arr.length; i++) {
if(arr[i].equals(value)) {//使用==比较太严格,使用equals方法,因为任意对象都有equals方法
return i;
}
}
return -1;
}
//可以在任意类型的对象数组中,查找最大值,要求元素必须实现Comparable接口
public static <T extends Comparable<? super T>> T max(T[] arr) {
T max = arr[0];
for (int i = 0; i < arr.length; i++) {
if(max.compareTo(arr[i])<0) {//if(max < arr[i]) {
max = arr[i];
}
}
return max;
}
//可以在任意类型的对象数组中,查找最大值,按照指定定制比较器来比较元素大小
public static <T> T max(T[] arr, Comparator<? super T> c) {
T max = arr[0];
for (int i = 0; i < arr.length; i++) {
if(c.compare(max, arr[i])<0) {//if(max < arr[i]) {
max = arr[i];
}
}
return max;
}
//可以给任意对象数组进行从小到大排序,要求数组元素类型必须实现Comparable接口
public static <T extends Comparable<? super T>> void sort(T[] arr) {
for (int i = 0; i < arr.length-1; i++) {
int minIndex = i;
for (int j = i+1; j < arr.length; j++) {
if(arr[minIndex].compareTo(arr[j])>0) {
minIndex = j;
}
}
if(minIndex!=i) {
T temp = arr[minIndex];
arr[minIndex] = arr[i];
arr[i] = temp;
}
}
}
//可以给任意对象数组进行从小到大排序,只要你指定定制比较器对象,不要求数组元素实现Comparable接口
public static <T> void sort(T[] arr, Comparator<? super T> c) {
for (int i = 0; i < arr.length-1; i++) {
int minIndex = i;
for (int j = i+1; j < arr.length; j++) {
if(c.compare(arr[minIndex],arr[j])>0) {
minIndex = j;
}
}
if(minIndex!=i) {
T temp = arr[minIndex];
arr[minIndex] = arr[i];
arr[i] = temp;
}
}
}
//可以将任意对象数组的元素拼接为一个字符串返回
public static <T> String toString(T[] arr) {
String str = "[";
for (int i = 0; i < arr.length; i++) {
if(i==0) {
str += arr[i];
}else {
str += "," + arr[i];
}
}
str += "]";
return str;
}
}数据结构与算法
数据结构
数据结构就是研究数据的逻辑结构和物理结构以及它们之间相互关系,并对这种结构定义相应的运算,而且确保经过这些运算后所得到的新结构仍然是原来的结构类型。
数据的逻辑结构指反映数据元素之间的逻辑关系,而与他们在计算机中的存储位置无关:
- 集合(数学中集合的概念):数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系;
- 线性结构:数据结构中的元素存在一对一的相互关系;
- 树形结构:数据结构中的元素存在一对多的相互关系;
- 图形结构:数据结构中的元素存在多对多的相互关系。
数据的物理结构/存储结构:是描述数据具体在内存中的存储(如:顺序结构、链式结构、索引结构、哈希结构)等,一种数据逻辑结构可表示成一种或多种物理存储结构。
数据结构和算法是一门完整并且复杂的课程,那么我们今天只是简单的讨论常见的几种数据结构,让我们对数据结构与算法有一个初步的了解。
动态数组
动态数组的特点
逻辑结构:线性的
物理结构:顺序结构
申请内存:一次申请一大段连续的空间,一旦申请到了,内存就固定了。
存储特点:所有数据存储在这个连续的空间中,数组中的每一个元素都是一个具体的数据(或对象),所有数据都紧密排布,不能有间隔。
例如:整型数组

例如:对象数组
动态数组的基本操作
与数据结构相关的数据操作:
- 插入
- 删除
- 修改
- 查找
- 遍历
public interface Container<E> extends Iterable<E>{
void add(E e);
void insert(int index,E value);
void delete(E e);
void delete(int index);
E update(int index, E value);
void update(E old, E value);
boolean contains(E e);
int indexOf(E e);
E get(int index);
Object[] getAll();
int size();
}动态数组实现
import java.util.Arrays;
import java.util.Iterator;
import java.util.NoSuchElementException;
public class MyArrayList<E> implements Container<E>{
private Object[] all;
private int total;
public MyArrayList(){
all = new Object[5];
}
@Override
public void add(E e) {
ensureCapacityEnough();
all[total++] = e;
}
private void ensureCapacityEnough() {
if(total >= all.length){
all = Arrays.copyOf(all, all.length*2);
}
}
@Override
public void insert(int index, E value) {
//是否需要扩容
ensureCapacityEnough();
addCheckIndex(index);
if(total-index>0) {
System.arraycopy(all, index, all, index+1, total-index);
}
all[index]=value;
total++;
}
private void addCheckIndex(int index) {
if(index<0 || index>total){
throw new IndexOutOfBoundsException(index+"越界");
}
}
@Override
public void delete(E e) {
int index = indexOf(e);
if(index==-1){
throw new NoSuchElementException(e+"不存在");
}
delete(index);
}
@Override
public void delete(int index) {
checkIndex(index);
if(total-index-1>0) {
System.arraycopy(all, index+1, all, index, total-index-1);
}
all[--total] = null;
}
private void checkIndex(int index) {
if(index<0 || index>total){
throw new IndexOutOfBoundsException(index+"越界");
}
}
@Override
public E update(int index, E value) {
checkIndex(index);
E oldValue = get(index);
all[index]=value;
return oldValue;
}
@Override
public void update(E old, E value) {
int index = indexOf(old);
if(index!=-1){
update(index, value);
}
}
@Override
public boolean contains(E e) {
return indexOf(e) != -1;
}
@Override
public int indexOf(E e) {
int index = -1;
if(e==null){
for (int i = 0; i < total; i++) {
if(e == all[i]){
index = i;
break;
}
}
}else{
for (int i = 0; i < total; i++) {
if(e.equals(all[i])){
index = i;
break;
}
}
}
return index;
}
@SuppressWarnings("unchecked")
@Override
public E get(int index) {
checkIndex(index);
return (E) all[index];
}
@Override
public Object[] getAll() {
return Arrays.copyOf(all, total);
}
@Override
public int size() {
return total;
}
@Override
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E>{
private int cursor;
@Override
public boolean hasNext() {
return cursor!=total;
}
@SuppressWarnings("unchecked")
@Override
public E next() {
return (E) all[cursor++];
}
@Override
public void remove() {
MyArrayList.this.delete(--cursor);
}
}
}动态数组测试
import java.util.Arrays;
import java.util.Iterator;
import org.junit.Test;
public class TestMyArrayList {
@Test
public void test01(){
MyArrayList<String> my = new MyArrayList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
System.out.println("元素个数:" + my.size());
Object[] all = my.getAll();
System.out.println(Arrays.toString(all));
my.insert(2, "尚硅谷");
System.out.println("元素个数:" + my.size());
all = my.getAll();
System.out.println(Arrays.toString(all));
}
@Test
public void test02(){
MyArrayList<String> my = new MyArrayList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
my.delete(1);
System.out.println("元素个数:" + my.size());
Object[] all = my.getAll();
System.out.println(Arrays.toString(all));
my.delete("atguigu");
System.out.println("元素个数:" + my.size());
all = my.getAll();
System.out.println(Arrays.toString(all));
}
@Test
public void test03(){
MyArrayList<String> my = new MyArrayList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
String update = my.update(3, "尚硅谷");
System.out.println("元素个数:" + my.size());
System.out.println("被替换的是:" + update);
Object[] all = my.getAll();
System.out.println(Arrays.toString(all));
my.update("java", "Java");
System.out.println("元素个数:" + my.size());
System.out.println("被替换的是:java");
all = my.getAll();
System.out.println(Arrays.toString(all));
}
@Test
public void test04(){
MyArrayList<String> my = new MyArrayList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
System.out.println(my.contains("java"));
System.out.println(my.indexOf("java"));
System.out.println(my.get(0));
}
@Test
public void test05(){
MyArrayList<String> my = new MyArrayList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
for (String string : my) {
System.out.println(string);
}
}
@Test
public void test06(){
MyArrayList<String> my = new MyArrayList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
Iterator<String> iterator = my.iterator();
while(iterator.hasNext()) {
String next = iterator.next();
if(next.length()>4) {
iterator.remove();
}
}
for (String string : my) {
System.out.println(string);
}
}
}Java核心类库中的动态数组
Java的List接口的实现类中有两个动态数组的实现:Vector和ArrayList。
ArrayList与Vector的区别?
它们的底层物理结构都是数组,我们称为动态数组。
- ArrayList是新版的动态数组,线程不安全,效率高,Vector是旧版的动态数组,线程安全,效率低。
- 动态数组的扩容机制不同,ArrayList扩容为原来的1.5倍,Vector扩容增加为原来的2倍。
- 数组的初始化容量,如果在构建ArrayList与Vector的集合对象时,没有显式指定初始化容量,那么Vector的内部数组的初始容量默认为10,而ArrayList在JDK1.6及之前的版本也是10,而JDK1.7之后的版本ArrayList初始化为长度为0的空数组,之后在添加第一个元素时,再创建长度为10的数组。
- Vector因为版本古老,支持Enumeration 迭代器。但是该迭代器不支持快速失败。而Iterator和ListIterator迭代器支持快速失败。如果在迭代器创建后的任意时间从结构上修改了向量(通过迭代器自身的 remove 或 add 方法之外的任何其他方式),则迭代器将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就完全失败,而不是冒着在将来不确定的时间任意发生不确定行为的风险。
源码分析
Vector源码分析
public Vector() {
this(10);//指定初始容量initialCapacity为10
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);//指定capacityIncrement增量为0
}
public Vector(int initialCapacity, int capacityIncrement增量为0) {
super();
//判断了形参初始容量initialCapacity的合法性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
//创建了一个Object[]类型的数组
this.elementData = new Object[initialCapacity];//默认是10
//增量,默认是0,如果是0,后面就按照2倍增加,如果不是0,后面就按照你指定的增量进行增量
this.capacityIncrement = capacityIncrement;
}//synchronized意味着线程安全的
public synchronized boolean add(E e) {
modCount++;
//看是否需要扩容
ensureCapacityHelper(elementCount + 1);
//把新的元素存入[elementCount],存入后,elementCount元素的个数增1
elementData[elementCount++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
//看是否超过了当前数组的容量
if (minCapacity - elementData.length > 0)
grow(minCapacity);//扩容
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;//获取目前数组的长度
//如果capacityIncrement增量是0,新容量 = oldCapacity的2倍
//如果capacityIncrement增量是不是0,新容量 = oldCapacity + capacityIncrement增量;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
//如果按照上面计算的新容量还不够,就按照你指定的需要的最小容量来扩容minCapacity
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//如果新容量超过了最大数组限制,那么单独处理
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//把旧数组中的数据复制到新数组中,新数组的长度为newCapacity
elementData = Arrays.copyOf(elementData, newCapacity);
}public boolean remove(Object o) {
return removeElement(o);
}
public synchronized boolean removeElement(Object obj) {
modCount++;
//查找obj在当前Vector中的下标
int i = indexOf(obj);
//如果i>=0,说明存在,删除[i]位置的元素
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
public int indexOf(Object o) {
return indexOf(o, 0);
}
public synchronized int indexOf(Object o, int index) {
if (o == null) {//要查找的元素是null值
for (int i = index ; i < elementCount ; i++)
if (elementData[i]==null)//如果是null值,用==null判断
return i;
} else {//要查找的元素是非null值
for (int i = index ; i < elementCount ; i++)
if (o.equals(elementData[i]))//如果是非null值,用equals判断
return i;
}
return -1;
}
public synchronized void removeElementAt(int index) {
modCount++;
//判断下标的合法性
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
//j是要移动的元素的个数
int j = elementCount - index - 1;
//如果需要移动元素,就调用System.arraycopy进行移动
if (j > 0) {
//把index+1位置以及后面的元素往前移动
//index+1的位置的元素移动到index位置,依次类推
//一共移动j个
System.arraycopy(elementData, index + 1, elementData, index, j);
}
//元素的总个数减少
elementCount--;
//将elementData[elementCount]这个位置置空,用来添加新元素,位置的元素等着被GC回收
elementData[elementCount] = null; /* to let gc do its work */
}ArrayList源码分析
JDK1.6:
public ArrayList() {
this(10);//指定初始容量为10
}
public ArrayList(int initialCapacity) {
super();
//检查初始容量的合法性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
//数组初始化为长度为initialCapacity的数组
this.elementData = new Object[initialCapacity];
}JDK1.7
private static final int DEFAULT_CAPACITY = 10;//默认初始容量10
private static final Object[] EMPTY_ELEMENTDATA = {};
public ArrayList() {
super();
this.elementData = EMPTY_ELEMENTDATA;//数组初始化为一个空数组
}
public boolean add(E e) {
//查看当前数组是否够多存一个元素
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == EMPTY_ELEMENTDATA) {//如果当前数组还是空数组
//minCapacity按照 默认初始容量和minCapacity中的的最大值处理
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//看是否需要扩容处理
ensureExplicitCapacity(minCapacity);
}
//...JDK1.8
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;//初始化为空数组
}
public boolean add(E e) {
//查看当前数组是否够多存一个元素
ensureCapacityInternal(size + 1); // Increments modCount!!
//存入新元素到[size]位置,然后size自增1
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
//如果当前数组还是空数组
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//那么minCapacity取DEFAULT_CAPACITY与minCapacity的最大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//查看是否需要扩容
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;//修改次数加1
// 如果需要的最小容量 比 当前数组的长度 大,即当前数组不够存,就扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;//当前数组容量
int newCapacity = oldCapacity + (oldCapacity >> 1);//新数组容量是旧数组容量的1.5倍
//看旧数组的1.5倍是否够
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//看旧数组的1.5倍是否超过最大数组限制
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//复制一个新数组
elementData = Arrays.copyOf(elementData, newCapacity);
}public boolean remove(Object o) {
//先找到o在当前ArrayList的数组中的下标
//分o是否为空两种情况讨论
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {//null值用==比较
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {//非null值用equals比较
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++;//修改次数加1
//需要移动的元素个数
int numMoved = size - index - 1;
//如果需要移动元素,就用System.arraycopy移动元素
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//将elementData[size-1]位置置空,让GC回收空间,元素个数减少
elementData[--size] = null; // clear to let GC do its work
} public E remove(int index) {
rangeCheck(index);//检验index是否合法
modCount++;//修改次数加1
//取出[index]位置的元素,[index]位置的元素就是要被删除的元素,用于最后返回被删除的元素
E oldValue = elementData(index);
//需要移动的元素个数
int numMoved = size - index - 1;
//如果需要移动元素,就用System.arraycopy移动元素
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//将elementData[size-1]位置置空,让GC回收空间,元素个数减少
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}public E set(int index, E element) {
rangeCheck(index);//检验index是否合法
//取出[index]位置的元素,[index]位置的元素就是要被替换的元素,用于最后返回被替换的元素
E oldValue = elementData(index);
//用element替换[index]位置的元素
elementData[index] = element;
return oldValue;
}
public E get(int index) {
rangeCheck(index);//检验index是否合法
return elementData(index);//返回[index]位置的元素
}public int indexOf(Object o) {
//分为o是否为空两种情况
if (o == null) {
//从前往后找
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
public int lastIndexOf(Object o) {
//分为o是否为空两种情况
if (o == null) {
//从后往前找
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}链式存储结构
逻辑结构:有线性的和非线性的
物理结构:不要求连续的存储空间
存储特点:数据必须封装到“结点”中,结点包含多个数据项,数据值只是其中的一个数据项,其他的数据项用来记录与之有关的结点的地址。
例如:以下列出几种常见的链式存储结构(当然远不止这些)
链表
单链表
单链表结点:
class Node{
Object data;
Node next;
public Node(Object data, Node next) {
this.data = data;
this.next = next;
}
}单链表:
public class OneWayLinkedList<E>{
private Node<E> head;//头结点
private int total;//记录实际元素个数
private static class Node<E>{
E data;
Node<E> next;
Node(E data, Node<E> next) {
this.data = data;
this.next = next;
}
}
}双链表
双链表结点:
class Node{
Node prev;
Object data;
Node next;
public Node(Node prev, Object data, Node next) {
this.prev = prev;
this.data = data;
this.next = next;
}
}双向链表:
public class LinkedList<E>{
private Node<E> first;//头结点
private Node<E> last;//尾结点
private int total;//记录实际元素个数
private static class Node<E>{
Node<E> prev;
E data;
Node<E> next;
Node(Node<E> prev, E data, Node<E> next) {
this.prev = prev;
this.data = data;
this.next = next;
}
}
}二叉树
二叉树实现基本结构
class Node{
Node parent;
Node left;
Object data;
Node right;
public Node(Node parent,Node left, Object data, Node right) {
this.parent = parent;
this.left = left;
this.data = data;
this.right = right;
}
}二叉树
public class BinaryTree<E>{
private Node<E> root;
private int total;
private static class Node<E>{
Node<E> parent;
Node<E> left;
E data;
Node<E> right;
public Node(Node<E> parent, Node<E> left, E data, Node<E> right) {
this.parent = parent;
this.left = left;
this.data = data;
this.right = right;
}
}
}二叉树分类
满二叉树: 除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。 第n层的结点数是2的n-1次方,2的n次方-1
完全二叉树: 叶结点只能出现在最底层的两层,且最底层叶结点均处于次底层叶结点的左侧。
平衡二叉树:平衡二叉树(Self-balancing binary search tree)又被称为AVL树(有别于AVL算法),且具有以下性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树, 但不要求非叶节点都有两个子结点 。平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等。 最小二叉平衡树的节点的公式如下 F(n)=F(n-1)+F(n-2)+1 这个类似于一个递归的数列,可以参考Fibonacci(斐波那契)数列,1是根节点,F(n-1)是左子树的节点数量,F(n-2)是右子树的节点数量。
例如:斐波那契数列(Fibonacci):1,1,2,3,5,8,13…..
规律:除了第一个和第二个数以外,后面的数等于前两个数之和,
f(0) =1,
f(1) = 1,
f(2) = f(0) + f(1) =2,
f(3) = f(1) + f(2) = 3,
f(4) = f(2) + f(3) = 5
…
f(n) = f(n-2) + f(n-1);
二叉树的遍历
- 前序遍历:中左右
- 中序遍历:左中右
- 后序遍历:左右中
前序遍历:ABDHIECFG
中序遍历:HDIBEAFCG
后序遍历:HIDEBFGCA
单链表
单链表的实现
逻辑结构:单向链表
物理结构:链式顺序结构
package com.atguigu.test06;
public class OneWayLinkedList<E>{
private Node<E> head;
private int total;
private static class Node<E>{
E data;
Node<E> next;
Node(E data, Node<E> next) {
this.data = data;
this.next = next;
}
}
public void add(E e) {
Node<E> newNode = new Node<>(e,null);
if(head==null){
head = newNode;
}else{
Node<E> node = head;
while(node.next!=null){
node = node.next;
}
node.next = newNode;
}
total++;
}
public void delete(E e) {
Node<E> node = head;
Node<E> find = null;
Node<E> last = null;
if(e==null){
while(node!=null){
if(node.data==null){
find = node;
break;
}
last = node;
node = node.next;
}
}else{
while(node!=null){
if(e.equals(node.data)){
find = node;
break;
}
last = node;
node = node.next;
}
}
if(find != null){
if(last==null){
head = find.next;
}else{
last.next = find.next;
}
total--;
}
}
public void update(E old, E value) {
Node<E> node = head;
Node<E> find = null;
if(old==null){
while(node!=null){
if(node.data==null){
find = node;
break;
}
node = node.next;
}
}else{
while(node!=null){
if(old.equals(node.data)){
find = node;
break;
}
node = node.next;
}
}
if(find != null){
find.data = value;
}
}
public boolean contains(E e) {
return indexOf(e) != -1;
}
public int indexOf(E e) {
int index = -1;
if(e==null){
int i=0;
for(Node<E> node = head; node!=null; node=node.next ){
if(node.data==e){
index=i;
break;
}
i++;
}
}else{
int i=0;
for(Node<E> node = head; node!=null; node=node.next ){
if(e.equals(node.data)){
index=i;
break;
}
i++;
}
}
return index;
}
public Object[] getAll() {
Object[] all = new Object[total];
Node<E> node = head;
for (int i = 0; i < all.length; i++,node = node.next) {
all[i] = node.data;
}
return all;
}
public int size() {
return total;
}
}单链表的测试
import java.util.Arrays;
import org.junit.Test;
public class TestOneWayLinkedList {
@Test
public void test01(){
OneWayLinkedList<String> my = new OneWayLinkedList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
System.out.println("元素个数:" + my.size());
Object[] all = my.getAll();
System.out.println(Arrays.toString(all));
}
@Test
public void test02(){
OneWayLinkedList<String> my = new OneWayLinkedList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
my.delete("hello");
System.out.println("元素个数:" + my.size());
Object[] all = my.getAll();
System.out.println(Arrays.toString(all));
my.delete("atguigu");
System.out.println("元素个数:" + my.size());
all = my.getAll();
System.out.println(Arrays.toString(all));
my.delete("data");
System.out.println("元素个数:" + my.size());
all = my.getAll();
System.out.println(Arrays.toString(all));
}
@Test
public void test03(){
OneWayLinkedList<String> my = new OneWayLinkedList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
my.update("java", "Java");
System.out.println("元素个数:" + my.size());
Object[] all = my.getAll();
System.out.println(Arrays.toString(all));
}
@Test
public void test04(){
OneWayLinkedList<String> my = new OneWayLinkedList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
System.out.println(my.contains("java"));
System.out.println(my.indexOf("java"));
}
@Test
public void test05(){
OneWayLinkedList<String> my = new OneWayLinkedList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
for (String string : my) {
System.out.println(string);
}
}
}双链表
Java中有双链表的实现:LinkedList,它是List接口的实现类。
LinkedList源码分析
int size = 0;
Node<E> first;//记录第一个结点的位置
Node<E> last;//记录最后一个结点的位置
private static class Node<E> {
E item;//元素数据
Node<E> next;//下一个结点
Node<E> prev;//前一个结点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}public boolean add(E e) {
linkLast(e);//默认把新元素链接到链表尾部
return true;
}
void linkLast(E e) {
final Node<E> l = last;//用l 记录原来的最后一个结点
//创建新结点
final Node<E> newNode = new Node<>(l, e, null);
//现在的新结点是最后一个结点了
last = newNode;
//如果l==null,说明原来的链表是空的
if (l == null)
//那么新结点同时也是第一个结点
first = newNode;
else
//否则把新结点链接到原来的最后一个结点的next中
l.next = newNode;
//元素个数增加
size++;
//修改次数增加
modCount++;
} public boolean remove(Object o) {
//分o是否为空两种情况
if (o == null) {
//找到o对应的结点x
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);//删除x结点
return true;
}
}
} else {
//找到o对应的结点x
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);//删除x结点
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {//x是要被删除的结点
// assert x != null;
final E element = x.item;//被删除结点的数据
final Node<E> next = x.next;//被删除结点的下一个结点
final Node<E> prev = x.prev;//被删除结点的上一个结点
//如果被删除结点的前面没有结点,说明被删除结点是第一个结点
if (prev == null) {
//那么被删除结点的下一个结点变为第一个结点
first = next;
} else {//被删除结点不是第一个结点
//被删除结点的上一个结点的next指向被删除结点的下一个结点
prev.next = next;
//断开被删除结点与上一个结点的链接
x.prev = null;//使得GC回收
}
//如果被删除结点的后面没有结点,说明被删除结点是最后一个结点
if (next == null) {
//那么被删除结点的上一个结点变为最后一个结点
last = prev;
} else {//被删除结点不是最后一个结点
//被删除结点的下一个结点的prev执行被删除结点的上一个结点
next.prev = prev;
//断开被删除结点与下一个结点的连接
x.next = null;//使得GC回收
}
//把被删除结点的数据也置空,使得GC回收
x.item = null;
//元素个数减少
size--;
//修改次数增加
modCount++;
//返回被删除结点的数据
return element;
}链表与动态数组的区别
动态数组底层的物理结构是数组,因此根据索引访问的效率非常高,但是根据索引的插入和删除效率不高,因为涉及到移动元素,而且添加操作时可能涉及到扩容问题,那么就会增加时空消耗。
链表底层的物理结构是链表,因此根据索引访问的效率不高,但是插入和删除的效率高,因为不需要移动元素,只需要修改前后元素的指向关系即可,而链表的添加不会涉及到扩容问题。
栈和队列
堆栈是一种先进后出(FILO:first in last out)或后进先出(LIFI:last in first out)的结构。
队列是一种(但并非一定)先进先出(FIFO)的结构。
Stack类
java.util.Stack
比Vector多了几个方法
- (1)peek:查看栈顶元素,不弹出
- (2)pop:弹出栈
- (3)push:压入栈 即添加到链表的头
@Test
public void test3(){
Stack<Integer> list = new Stack<>();
list.push(1);
list.push(2);
list.push(3);
System.out.println(list);
/*System.out.println(list.pop());
System.out.println(list.pop());
System.out.println(list.pop());
System.out.println(list.pop());//java.util.NoSuchElementException
*/
System.out.println(list.peek());
System.out.println(list.peek());
System.out.println(list.peek());
}Queue和Deque接口
Queue除了基本的 Collection操作外,队列还提供其他的插入、提取和检查操作。每个方法都存在两种形式:一种抛出异常(操作失败时),另一种返回一个特殊值(null 或 false,具体取决于操作)。Queue 实现通常不允许插入 元素,尽管某些实现(如 )并不禁止插入 。即使在允许 null 的实现中,也不应该将 插入到 中,因为 也用作 方法的一个特殊返回值,表明队列不包含元素。
| 抛出异常 | 返回特殊值 | |
|---|---|---|
| 插入 | add(e) | offer(e) |
| 移除 | remove() | poll() |
| 检查 | element() | peek() |
Deque,名称 deque 是“double ended queue(双端队列)”的缩写,通常读为“deck”。此接口定义在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)。
| 第一个元素(头部) | 最后一个元素(尾部) | |||
|---|---|---|---|---|
| 抛出异常 | 特殊值 | 抛出异常 | 特殊值 | |
| 插入 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 移除 | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 检查 | getFirst() | peekFirst() | getLast() | peekLast() |
此接口扩展了 Queue接口。在将双端队列用作队列时,将得到 FIFO(先进先出)行为。将元素添加到双端队列的末尾,从双端队列的开头移除元素。从 Queue 接口继承的方法完全等效于 Deque 方法,如下表所示:
Queue 方法 |
等效 Deque 方法 |
|---|---|
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
双端队列也可用作 LIFO(后进先出)堆栈。应优先使用此接口而不是遗留 Stack 类。在将双端队列用作堆栈时,元素被推入双端队列的开头并从双端队列开头弹出。堆栈方法完全等效于 Deque 方法,如下表所示:
| 堆栈方法 | 等效 Deque 方法 |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
结论:Deque接口的实现类既可以用作FILO堆栈使用,又可以用作FIFO队列使用。
Deque接口的实现类有ArrayDeque和LinkedList,它们一个底层是使用数组实现,一个使用双向链表实现。
哈希表
HashMap和Hashtable都是哈希表。
hashCode值
hash算法是一种可以从任何数据中提取出其“指纹”的数据摘要算法,它将任意大小的数据映射到一个固定大小的序列上,这个序列被称为hash code、数据摘要或者指纹。比较出名的hash算法有MD5、SHA。hash是具有唯一性且不可逆的,唯一性是指相同的“对象”产生的hash code永远是一样的。

哈希表的物理结构
HashMap和Hashtable是散列表,其中维护了一个长度为2的幂次方的Entry类型的数组table,数组的每一个元素被称为一个桶(bucket),你添加的映射关系(key,value)最终都被封装为一个Map.Entry类型的对象,放到了某个table[index]桶中。使用数组的目的是查询和添加的效率高,可以根据索引直接定位到某个table[index]。
数组元素类型:Map.Entry
JDK1.7:
映射关系被封装为HashMap.Entry类型,而这个类型实现了Map.Entry接口。
观察HashMap.Entry类型是个结点类型,即table[index]下的映射关系可能串起来一个链表。因此我们把table[index]称为“桶bucket”。
public class HashMap<K,V>{
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
//...省略
}
//...
}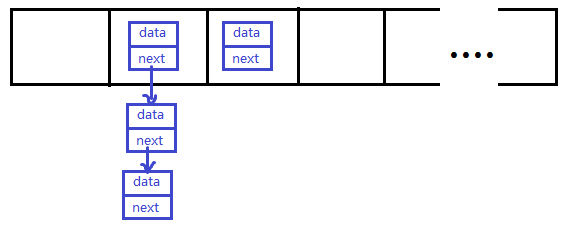
JDK1.8:
映射关系被封装为HashMap.Node类型或HashMap.TreeNode类型,它俩都直接或间接的实现了Map.Entry接口。
存储到table数组的可能是Node结点对象,也可能是TreeNode结点对象,它们也是Map.Entry接口的实现类。即table[index]下的映射关系可能串起来一个链表或一棵红黑树(自平衡的二叉树)。
public class HashMap<K,V>{
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//...省略
}
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev;
boolean red;//是红结点还是黑结点
//...省略
}
//....
}public class LinkedHashMap<K,V>{
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
//...
}
数组的长度始终是2的n次幂
table数组的默认初始化长度:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;如果你手动指定的table长度不是2的n次幂,会通过如下方法给你纠正为2的n次幂
JDK1.7:
HashMap处理容量方法:
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}Integer包装类:
public static int highestOneBit(int i) {
// HD, Figure 3-1
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}JDK1.8:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}如果数组不够了,扩容了怎么办?扩容了还是2的n次幂,因为每次数组扩容为原来的2倍
JDK1.7:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//扩容为原来的2倍
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}JDK1.8:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;//oldCap原来的容量
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}//newCap = oldCap << 1 新容量=旧容量扩容为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//......此处省略其他代码
}那么为什么要保持table数组一直是2的n次幂呢?
那么HashMap是如何决定某个映射关系存在哪个桶的呢?
因为hash值是一个整数,而数组的长度也是一个整数,有两种思路:
①hash 值 % table.length会得到一个[0,table.length-1]范围的值,正好是下标范围,但是用%运算,不能保证均匀存放,可能会导致某些table[index]桶中的元素太多,而另一些太少,因此不合适。
②hash 值 & (table.length-1),因为table.length是2的幂次方,因此table.length-1是一个二进制低位全是1的数,所以&操作完,也会得到一个[0,table.length-1]范围的值。

JDK1.7:
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1); //此处h就是hash
}JDK1.8:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // i = (n - 1) & hash
tab[i] = newNode(hash, key, value, null);
//....省略大量代码
}hash是hashCode的再运算
不管是JDK1.7还是JDK1.8中,都不是直接用key的hashCode值直接与table.length-1计算求下标的,而是先对key的hashCode值进行了一个运算,JDK1.7和JDK1.8关于hash()的实现代码不一样,但是不管怎么样都是为了提高hash code值与 (table.length-1)的按位与完的结果,尽量的均匀分布。
JDK1.7:
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}JDK1.8:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}虽然算法不同,但是思路都是将hashCode值的高位二进制与低位二进制值进行了异或,然高位二进制参与到index的计算中。
为什么要hashCode值的二进制的高位参与到index计算呢?
因为一个HashMap的table数组一般不会特别大,至少在不断扩容之前,那么table.length-1的大部分高位都是0,直接用hashCode和table.length-1进行&运算的话,就会导致总是只有最低的几位是有效的,那么就算你的hashCode()实现的再好也难以避免发生碰撞,这时让高位参与进来的意义就体现出来了。它对hashcode的低位添加了随机性并且混合了高位的部分特征,显著减少了碰撞冲突的发生。
解决[index]冲突问题
虽然从设计hashCode()到上面HashMap的hash()函数,都尽量减少冲突,但是仍然存在两个不同的对象返回的hashCode值相同,或者hashCode值就算不同,通过hash()函数计算后,得到的index也会存在大量的相同,因此key分布完全均匀的情况是不存在的。那么发生碰撞冲突时怎么办?
JDK1.8之间使用:数组+链表的结构。
JDK1.8之后使用:数组+链表/红黑树的结构。
即hash相同或hash&(table.lengt-1)的值相同,那么就存入同一个“桶”table[index]中,使用链表或红黑树连接起来。
为什么JDK1.8会出现红黑树和链表共存呢?
因为当冲突比较严重时,table[index]下面的链表就会很长,那么会导致查找效率大大降低,而如果此时选用二叉树可以大大提高查询效率。
但是二叉树的结构又过于复杂,如果结点个数比较少的时候,那么选择链表反而更简单。
所以会出现红黑树和链表共存。
什么时候树化?什么时候反树化?
static final int TREEIFY_THRESHOLD = 8;//树化阈值
static final int UNTREEIFY_THRESHOLD = 6;//反树化阈值
static final int MIN_TREEIFY_CAPACITY = 64;//最小树化容量当某table[index]下的链表的结点个数达到8,并且table.length>=64,那么如果新Entry对象还添加到该table[index]中,那么就会将table[index]的链表进行树化。
当某table[index]下的红黑树结点个数少于6个,此时,
- 如果继续删除table[index]下树结点,一直删除到2个以下时就会变回链表。
- 如果继续添加映射关系到当前map中,如果添加导致了map的table重新resize,那么只要table[index]下的树结点仍然<=6个,那么会变回链表
class MyKey{
int num;
public MyKey(int num) {
super();
this.num = num;
}
@Override
public int hashCode() {
if(num<=20){
return 1;
}else{
final int prime = 31;
int result = 1;
result = prime * result + num;
return result;
}
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
MyKey other = (MyKey) obj;
if (num != other.num)
return false;
return true;
}
}
public class TestHashMap {
@Test
public void test1(){
//这里为了演示的效果,我们造一个特殊的类,这个类的hashCode()方法返回固定值1
//因为这样就可以造成冲突问题,使得它们都存到table[1]中
HashMap<MyKey, String> map = new HashMap<>();
for (int i = 1; i <= 11; i++) {
map.put(new MyKey(i), "value"+i);//树化演示
}
}
@Test
public void test2(){
HashMap<MyKey, String> map = new HashMap<>();
for (int i = 1; i <= 11; i++) {
map.put(new MyKey(i), "value"+i);
}
for (int i = 1; i <=11; i++) {
map.remove(new MyKey(i));//反树化演示
}
}
@Test
public void test3(){
HashMap<MyKey, String> map = new HashMap<>();
for (int i = 1; i <= 11; i++) {
map.put(new MyKey(i), "value"+i);
}
for (int i = 1; i <=5; i++) {
map.remove(new MyKey(i));
}//table[1]下剩余6个结点
for (int i = 21; i <= 100; i++) {
map.put(new MyKey(i), "value"+i);//添加到扩容时,反树化
}
}JDK1.7的put方法源码分析
(1)几个关键的常量和变量值的作用:
初始化容量:
int DEFAULT_INITIAL_CAPACITY = 1 << 4;//16①默认负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;②阈值:扩容的临界值
int threshold;threshold = table.length * loadFactor;③负载因子
final float loadFactor;负载因子的值大小有什么关系?
如果太大,threshold就会很大,那么如果冲突比较严重的话,就会导致table[index]下面的结点个数很多,影响效率。
如果太小,threshold就会很小,那么数组扩容的频率就会提高,数组的使用率也会降低,那么会造成空间的浪费。
public HashMap() {
//DEFAULT_INITIAL_CAPACITY:默认初始容量16
//DEFAULT_LOAD_FACTOR:默认加载因子0.75
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
//校验initialCapacity合法性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
//校验initialCapacity合法性 initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//校验loadFactor合法性
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//加载因子,初始化为0.75
this.loadFactor = loadFactor;
// threshold 初始为初始容量
threshold = initialCapacity;
init();
}public V put(K key, V value) {
//如果table数组是空的,那么先创建数组
if (table == EMPTY_TABLE) {
//threshold一开始是初始容量的值
inflateTable(threshold);
}
//如果key是null,单独处理
if (key == null)
return putForNullKey(value);
//对key的hashCode进行干扰,算出一个hash值
int hash = hash(key);
//计算新的映射关系应该存到table[i]位置,
//i = hash & table.length-1,可以保证i在[0,table.length-1]范围内
int i = indexFor(hash, table.length);
//检查table[i]下面有没有key与我新的映射关系的key重复,如果重复替换value
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//添加新的映射关系
addEntry(hash, key, value, i);
return null;
}
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);//容量是等于toSize值的最接近的2的n次方
//计算阈值 = 容量 * 加载因子
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//创建Entry[]数组,长度为capacity
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
//如果key是null,直接存入[0]的位置
private V putForNullKey(V value) {
//判断是否有重复的key,如果有重复的,就替换value
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//把新的映射关系存入[0]的位置,而且key的hash值用0表示
addEntry(0, null, value, 0);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
//判断是否需要库容
//扩容:(1)size达到阈值(2)table[i]正好非空
if ((size >= threshold) && (null != table[bucketIndex])) {
//table扩容为原来的2倍,并且扩容后,会重新调整所有映射关系的存储位置
resize(2 * table.length);
//新的映射关系的hash和index也会重新计算
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//存入table中
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
//原来table[i]下面的映射关系作为新的映射关系next
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;//个数增加
}1、put(key,value)
(1)当第一次添加映射关系时,数组初始化为一个长度为16的HashMap$Entry的数组,这个HashMap$Entry类型是实现了java.util.Map.Entry接口
(2)特殊考虑:如果key为null,index直接是[0],hash也是0
(3)如果key不为null,在计算index之前,会对key的hashCode()值,做一个hash(key)再次哈希的运算,这样可以使得Entry对象更加散列的存储到table中
(4)计算index = table.length-1 & hash;
(5)如果table[index]下面,已经有映射关系的key与我要添加的新的映射关系的key相同了,会用新的value替换旧的value。
(6)如果没有相同的,会把新的映射关系添加到链表的头,原来table[index]下面的Entry对象连接到新的映射关系的next中。
(7)添加之前先判断if(size >= threshold && table[index]!=null)如果该条件为true,会扩容
if(size >= threshold && table[index]!=null){
①会扩容
②会重新计算key的hash
③会重新计算index
}(8)size++
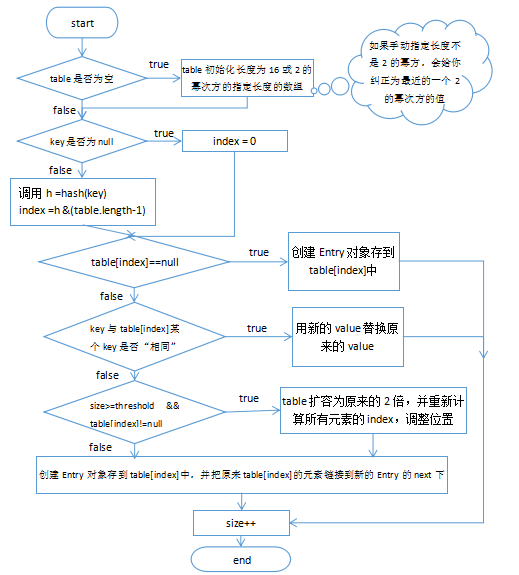
2、get(key)
(1)计算key的hash值,用这个方法hash(key)
(2)找index = table.length-1 & hash;
(3)如果table[index]不为空,那么就挨个比较哪个Entry的key与它相同,就返回它的value
3、remove(key)
(1)计算key的hash值,用这个方法hash(key)
(2)找index = table.length-1 & hash;
(3)如果table[index]不为空,那么就挨个比较哪个Entry的key与它相同,就删除它,把它前面的Entry的next的值修改为被删除Entry的next
JDK1.8的put方法源码分析
几个常量和变量:
(1)DEFAULT_INITIAL_CAPACITY:默认的初始容量 16
(2)MAXIMUM_CAPACITY:最大容量 1 << 30
(3)DEFAULT_LOAD_FACTOR:默认加载因子 0.75
(4)TREEIFY_THRESHOLD:默认树化阈值8,当链表的长度达到这个值后,要考虑树化
(5)UNTREEIFY_THRESHOLD:默认反树化阈值6,当树中的结点的个数达到这个阈值后,要考虑变为链表
(6)MIN_TREEIFY_CAPACITY:最小树化容量64
当单个的链表的结点个数达到8,并且table的长度达到64,才会树化。
当单个的链表的结点个数达到8,但是table的长度未达到64,会先扩容
(7)Node<K,V>[] table:数组
(8)size:记录有效映射关系的对数,也是Entry对象的个数
(9)int threshold:阈值,当size达到阈值时,考虑扩容
(10)double loadFactor:加载因子,影响扩容的频率public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
// all other fields defaulted,其他字段都是默认值
} public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//目的:干扰hashCode值
static final int hash(Object key) {
int h;
//如果key是null,hash是0
//如果key非null,用key的hashCode值 与 key的hashCode值高16进行异或
// 即就是用key的hashCode值高16位与低16位进行了异或的干扰运算
/*
index = hash & table.length-1
如果用key的原始的hashCode值 与 table.length-1 进行按位与,那么基本上高16没机会用上。
这样就会增加冲突的概率,为了降低冲突的概率,把高16位加入到hash信息中。
*/
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; //数组
Node<K,V> p; //一个结点
int n, i;//n是数组的长度 i是下标
//tab和table等价
//如果table是空的
if ((tab = table) == null || (n = tab.length) == 0){
n = (tab = resize()).length;
/*
tab = resize();
n = tab.length;*/
/*
如果table是空的,resize()完成了①创建了一个长度为16的数组②threshold = 12
n = 16
*/
}
//i = (n - 1) & hash ,下标 = 数组长度-1 & hash
//p = tab[i] 第1个结点
//if(p==null) 条件满足的话说明 table[i]还没有元素
if ((p = tab[i = (n - 1) & hash]) == null){
//把新的映射关系直接放入table[i]
tab[i] = newNode(hash, key, value, null);
//newNode()方法就创建了一个Node类型的新结点,新结点的next是null
}else {
Node<K,V> e;
K k;
//p是table[i]中第一个结点
//if(table[i]的第一个结点与新的映射关系的key重复)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))){
e = p;//用e记录这个table[i]的第一个结点
}else if (p instanceof TreeNode){//如果table[i]第一个结点是一个树结点
//单独处理树结点
//如果树结点中,有key重复的,就返回那个重复的结点用e接收,即e!=null
//如果树结点中,没有key重复的,就把新结点放到树中,并且返回null,即e=null
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
}else {
//table[i]的第一个结点不是树结点,也与新的映射关系的key不重复
//binCount记录了table[i]下面的结点的个数
for (int binCount = 0; ; ++binCount) {
//如果p的下一个结点是空的,说明当前的p是最后一个结点
if ((e = p.next) == null) {
//把新的结点连接到table[i]的最后
p.next = newNode(hash, key, value, null);
//如果binCount>=8-1,达到7个时
if (binCount >= TREEIFY_THRESHOLD - 1){ // -1 for 1st
//要么扩容,要么树化
treeifyBin(tab, hash);
}
break;
}
//如果key重复了,就跳出for循环,此时e结点记录的就是那个key重复的结点
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))){
break;
}
p = e;//下一次循环,e=p.next,就类似于e=e.next,往链表下移动
}
}
//如果这个e不是null,说明有key重复,就考虑替换原来的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null){
e.value = value;
}
afterNodeAccess(e);//什么也没干
return oldValue;
}
}
++modCount;
//元素个数增加
//size达到阈值
if (++size > threshold){
resize();//一旦扩容,重新调整所有映射关系的位置
}
afterNodeInsertion(evict);//什么也没干
return null;
}
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;//oldTab原来的table
//oldCap:原来数组的长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//oldThr:原来的阈值
int oldThr = threshold;//最开始threshold是0
//newCap,新容量
//newThr:新阈值
int newCap, newThr = 0;
if (oldCap > 0) {//说明原来不是空数组
if (oldCap >= MAXIMUM_CAPACITY) {//是否达到数组最大限制
threshold = Integer.MAX_VALUE;
return oldTab;
}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY){
//newCap = 旧的容量*2 ,新容量<最大数组容量限制
//新容量:32,64,...
//oldCap >= 初始容量16
//新阈值重新算 = 24,48 ....
newThr = oldThr << 1; // double threshold
}
}else if (oldThr > 0){ // initial capacity was placed in threshold
newCap = oldThr;
}else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;//新容量是默认初始化容量16
//新阈值= 默认的加载因子 * 默认的初始化容量 = 0.75*16 = 12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;//阈值赋值为新阈值12,24.。。。
//创建了一个新数组,长度为newCap,16,32,64.。。
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {//原来不是空数组
//把原来的table中映射关系,倒腾到新的table中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {//e是table下面的结点
oldTab[j] = null;//把旧的table[j]位置清空
if (e.next == null)//如果是最后一个结点
newTab[e.hash & (newCap - 1)] = e;//重新计算e的在新table中的存储位置,然后放入
else if (e instanceof TreeNode)//如果e是树结点
//把原来的树拆解,放到新的table
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
/*
把原来table[i]下面的整个链表,重新挪到了新的table中
*/
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
//创建一个新结点
return new Node<>(hash, key, value, next);
}
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index;
Node<K,V> e;
//MIN_TREEIFY_CAPACITY:最小树化容量64
//如果table是空的,或者 table的长度没有达到64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();//先扩容
else if ((e = tab[index = (n - 1) & hash]) != null) {
//用e记录table[index]的结点的地址
TreeNode<K,V> hd = null, tl = null;
/*
do...while,把table[index]链表的Node结点变为TreeNode类型的结点
*/
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;//hd记录根结点
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
//如果table[index]下面不是空
if ((tab[index] = hd) != null)
hd.treeify(tab);//将table[index]下面的链表进行树化
}
} 1、添加过程
A. 先计算key的hash值,如果key是null,hash值就是0,如果为null,使用(h = key.hashCode()) ^ (h >>> 16)得到hash值;
B. 如果table是空的,先初始化table数组;
C. 通过hash值计算存储的索引位置index = hash & (table.length-1)
D. 如果table[index]==null,那么直接创建一个Node结点存储到table[index]中即可
E. 如果table[index]!=null
a) 判断table[index]的根结点的key是否与新的key“相同”(hash值相同并且(满足key的地址相同或key的equals返回true)),如果是那么用e记录这个根结点
b) 如果table[index]的根结点的key与新的key“不相同”,而且table[index]是一个TreeNode结点,说明table[index]下是一棵红黑树,如果该树的某个结点的key与新的key“相同”(hash值相同并且(满足key的地址相同或key的equals返回true)),那么用e记录这个相同的结点,否则将(key,value)封装为一个TreeNode结点,连接到红黑树中
c) 如果table[index]的根结点的key与新的key“不相同”,并且table[index]不是一个TreeNode结点,说明table[index]下是一个链表,如果该链表中的某个结点的key与新的key“相同”,那么用e记录这个相同的结点,否则将新的映射关系封装为一个Node结点直接链接到链表尾部,并且判断table[index]下结点个数达到TREEIFY_THRESHOLD(8)个,如果table[index]下结点个数已经达到,那么再判断table.length是否达到MIN_TREEIFY_CAPACITY(64),如果没达到,那么先扩容,扩容会导致所有元素重新计算index,并调整位置,如果table[index]下结点个数已经达到TREEIFY_THRESHOLD(8)个并table.length也已经达到MIN_TREEIFY_CAPACITY(64),那么会将该链表转成一棵自平衡的红黑树。
F. 如果在table[index]下找到了新的key“相同”的结点,即e不为空,那么用新的value替换原来的value,并返回旧的value,结束put方法
G. 如果新增结点而不是替换,那么size++,并且还要重新判断size是否达到threshold阈值,如果达到,还要扩容。
if(size > threshold ){
①会扩容
②会重新计算key的hash
③会重新计算index
}
2、remove(key)
(1)计算key的hash值,用这个方法hash(key)
(2)找index = table.length-1 & hash;
(3)如果table[index]不为空,那么就挨个比较哪个Entry的key与它相同,就删除它,把它前面的Entry的next的值修改为被删除Entry的next
(4)如果table[index]下面原来是红黑树,结点删除后,个数小于等于6,会把红黑树变为链表
关于映射关系的key是否可以修改?
映射关系存储到HashMap中会存储key的hash值,这样就不用在每次查找时重新计算每一个Entry或Node(TreeNode)的hash值了,因此如果已经put到Map中的映射关系,再修改key的属性,而这个属性又参与hashcode值的计算,那么会导致匹配不上。
这个规则也同样适用于LinkedHashMap、HashSet、LinkedHashSet、Hashtable等所有散列存储结构的集合。
JDK1.7:
public class HashMap<K,V>{
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash; //记录Entry映射关系的key的hash(key.hashCode())值
//...省略
}
//...
}JDK1.8:
public class HashMap<K,V>{
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;//记录Node映射关系的key的hash(key.hashCode())值
final K key;
V value;
Node<K,V> next;
//...省略
}
//....
}示例代码:
import java.util.HashMap;
public class TestHashMap {
public static void main(String[] args) {
HashMap<ID,String> map = new HashMap<>();
ID i1 = new ID(1);
ID i2 = new ID(2);
ID i3 = new ID(3);
map.put(i1, "haha");
map.put(i2, "hehe");
map.put(i3, "xixi");
System.out.println(map.get(i1));//haha
i1.setId(10);
System.out.println(map.get(i1));//null
}
}
class ID{
private int id;
public ID(int id) {
super();
this.id = id;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + id;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
ID other = (ID) obj;
if (id != other.id)
return false;
return true;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
}所以实际开发中,经常选用String,Integer等作为key,因为它们都是不可变对象。
File类与IO流
java.io.File类
概述
File类是java.io包下代表与平台无关的文件和目录,也就是说如果希望在程序中操作文件和目录都可以通过File类来完成,File类能新建、删除、重命名文件和目录。
在API中File的解释是文件和目录路径名的抽象表示形式,即File类是文件或目录的路径,而不是文件本身,因此File类不能直接访问文件内容本身,如果需要访问文件内容本身,则需要使用输入/输出流。
File类代表磁盘或网络中某个文件或目录的路径名称,如:/atguigu/javase/io/佟刚.jpg
但不能直接通过File对象读取和写入数据,如果要操作数据,需要IO流。File对象好比是到水库的“路线地址”,要“存取”里面的水到你“家里”,需要“管道”。
构造方法
public File(String pathname):通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例。public File(String parent, String child):从父路径名字符串和子路径名字符串创建新的 File实例。public File(File parent, String child):从父抽象路径名和子路径名字符串创建新的 File实例。
- 构造举例,代码如下:
// 文件路径名
String pathname = "D:\\aaa.txt";
File file1 = new File(pathname);
// 文件路径名
String pathname2 = "D:\\aaa\\bbb.txt";
File file2 = new File(pathname2);
// 通过父路径和子路径字符串
String parent = "d:\\aaa";
String child = "bbb.txt";
File file3 = new File(parent, child);
// 通过父级File对象和子路径字符串
File parentDir = new File("d:\\aaa");
String child = "bbb.txt";
File file4 = new File(parentDir, child);小贴士:
- 一个File对象代表硬盘中实际存在的一个文件或者目录。
- 无论该路径下是否存在文件或者目录,都不影响File对象的创建。
常用方法(了解)
获取文件和目录基本信息的方法
public String getName():返回由此File表示的文件或目录的名称。public long length():返回由此File表示的文件的长度。public String getPath():将此File转换为路径名字符串。public long lastModified():返回File对象对应的文件或目录的最后修改时间(毫秒值)方法演示,代码如下:
import java.io.File;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
public class TestFile {
public static void main(String[] args) {
File f = new File("d:/aaa/bbb.txt");
System.out.println("文件构造路径:"+f.getPath());
System.out.println("文件名称:"+f.getName());
System.out.println("文件长度:"+f.length()+"字节");
System.out.println("文件最后修改时间:" + LocalDateTime.ofInstant(Instant.ofEpochMilli(f.lastModified()),ZoneId.of("Asia/Shanghai")));
File f2 = new File("d:/aaa");
System.out.println("目录构造路径:"+f2.getPath());
System.out.println("目录名称:"+f2.getName());
System.out.println("目录长度:"+f2.length()+"字节");
System.out.println("文件最后修改时间:" + LocalDateTime.ofInstant(Instant.ofEpochMilli(f.lastModified()),ZoneId.of("Asia/Shanghai")));
}
}
输出结果:
文件构造路径:d:\aaa\bbb.java
文件名称:bbb.java
文件长度:636字节
文件最后修改时间:2019-07-23T22:01:32.065
目录构造路径:d:\aaa
目录名称:aaa
目录长度:4096字节
文件最后修改时间:2019-07-23T22:01:32.065API中说明:length(),表示文件的长度。但是File对象表示目录,则返回值未指定。
各种路径问题
public String getPath():将此File转换为路径名字符串。public String getAbsolutePath():返回此File的绝对路径名字符串。String getCanonicalPath():返回此File对象所对应的规范路径名。
File类可以使用文件路径字符串来创建File实例,该文件路径字符串既可以是绝对路径,也可以是相对路径。
默认情况下,系统总是依据用户的工作路径来解释相对路径,这个路径由系统属性“user.dir”指定,通常也就是运行Java虚拟机时所作的路径。
- 绝对路径:从盘符开始的路径,这是一个完整的路径。
- 相对路径:相对于项目目录的路径,这是一个便捷的路径,开发中经常使用。
- 规范路径:所谓规范路径名,即对路径中的“..”等进行解析后的路径名
@Test
public void test1() throws IOException{
File f1 = new File("d:\\atguigu\\javase\\HelloIO.java");
System.out.println("文件/目录的名称:" + f1.getName());
System.out.println("文件/目录的构造路径名:" + f1.getPath());
System.out.println("文件/目录的绝对路径名:" + f1.getAbsolutePath());
System.out.println("文件/目录的规范路径名:" + f1.getCanonicalPath());
System.out.println("文件/目录的父目录名:" + f1.getParent());
}
@Test
public void test2() throws IOException{
File f2 = new File("HelloIO.java");
System.out.println("user.dir =" + System.getProperty("user.dir"));
System.out.println("文件/目录的名称:" + f2.getName());
System.out.println("文件/目录的构造路径名:" + f2.getPath());
System.out.println("文件/目录的绝对路径名:" + f2.getAbsolutePath());
System.out.println("文件/目录的规范路径名:" + f2.getCanonicalPath());
System.out.println("文件/目录的父目录名:" + f2.getParent());
}
@Test
public void test3() throws IOException{
File f3 = new File("../../HelloIO.java");
System.out.println("user.dir =" + System.getProperty("user.dir"));
System.out.println("文件/目录的名称:" + f3.getName());
System.out.println("文件/目录的构造路径名:" + f3.getPath());
System.out.println("文件/目录的绝对路径名:" + f3.getAbsolutePath());
System.out.println("文件/目录的规范路径名:" + f3.getCanonicalPath());
System.out.println("文件/目录的父目录名:" + f3.getParent());
}window的路径分隔符使用“\”,而Java程序中的“\”表示转义字符,所以在Windows中表示路径,需要用“\\”。或者直接使用“/”也可以,Java程序支持将“/”当成平台无关的路径分隔符。或者直接使用File.separator常量值表示。
把构造File对象指定的文件或目录的路径名,称为构造路径,它可以是绝对路径,也可以是相对路径
当构造路径是绝对路径时,那么getPath和getAbsolutePath结果一样
当构造路径是相对路径时,那么getAbsolutePath的路径 = user.dir的路径 + 构造路径
当路径中不包含”..”和”/开头”等形式的路径,那么规范路径和绝对路径一样,否则会将..等进行解析。路径中如果出现“..”表示上一级目录,路径名如果以“/”开头,表示从“根目录”下开始导航。
判断功能的方法
public boolean exists():此File表示的文件或目录是否实际存在。public boolean isDirectory():此File表示的是否为目录。public boolean isFile():此File表示的是否为文件。
方法演示,代码如下:
public class FileIs {
public static void main(String[] args) {
File f = new File("d:\\aaa\\bbb.java");
File f2 = new File("d:\\aaa");
// 判断是否存在
System.out.println("d:\\aaa\\bbb.java 是否存在:"+f.exists());
System.out.println("d:\\aaa 是否存在:"+f2.exists());
// 判断是文件还是目录
System.out.println("d:\\aaa 文件?:"+f2.isFile());
System.out.println("d:\\aaa 目录?:"+f2.isDirectory());
}
}
输出结果:
d:\aaa\bbb.java 是否存在:true
d:\aaa 是否存在:true
d:\aaa 文件?:false
d:\aaa 目录?:true如果文件或目录不存在,那么exists()、isFile()和isDirectory()都是返回true
创建删除功能的方法
public boolean createNewFile():当且仅当具有该名称的文件尚不存在时,创建一个新的空文件。public boolean delete():删除由此File表示的文件或目录。 只能删除空目录。public boolean mkdir():创建由此File表示的目录。public boolean mkdirs():创建由此File表示的目录,包括任何必需但不存在的父目录。
方法演示,代码如下:
public class FileCreateDelete {
public static void main(String[] args) throws IOException {
// 文件的创建
File f = new File("aaa.txt");
System.out.println("是否存在:"+f.exists()); // false
System.out.println("是否创建:"+f.createNewFile()); // true
System.out.println("是否存在:"+f.exists()); // true
// 目录的创建
File f2= new File("newDir");
System.out.println("是否存在:"+f2.exists());// false
System.out.println("是否创建:"+f2.mkdir()); // true
System.out.println("是否存在:"+f2.exists());// true
// 创建多级目录
File f3= new File("newDira\\newDirb");
System.out.println(f3.mkdir());// false
File f4= new File("newDira\\newDirb");
System.out.println(f4.mkdirs());// true
// 文件的删除
System.out.println(f.delete());// true
// 目录的删除
System.out.println(f2.delete());// true
System.out.println(f4.delete());// false
}
}API中说明:delete方法,如果此File表示目录,则目录必须为空才能删除。
递归实现多级目录操作(了解,有时间作为复习递归练习用)
public String[] list():返回一个String数组,表示该File目录中的所有子文件或目录。
public File[] listFiles():返回一个File数组,表示该File目录中的所有的子文件或目录。public File[] listFiles(FileFilter filter):返回所有满足指定过滤器的文件和目录。如果给定 filter 为 null,则接受所有路径名。否则,当且仅当在路径名上调用过滤器的 FileFilter.accept(java.io.File) 方法返回 true 时,该路径名才满足过滤器。如果当前File对象不表示一个目录,或者发生 I/O 错误,则返回 null。
递归打印多级目录
分析:多级目录的打印。遍历之前,无从知道到底有多少级目录,所以我们可以使用递归实现。
代码实现:
@Test
public void test3() {
File dir = new File("d:/atguigu");
listSubFiles(dir);
}
public void listSubFiles(File dir) {
if (dir != null && dir.isDirectory()) {
File[] listFiles = dir.listFiles();
if (listFiles != null) {
for (File sub : listFiles) {
listSubFiles(sub);//递归调用
}
}
}
System.out.println(dir);
}递归打印某目录下(包括子目录)中所有满足条件的文件
示例代码:列出”D:/atguigu”下所有”.java”文件
@Test
public void test5() {
File dir = new File("D:/atguigu");
listByFileFilter(dir);
}
public void listByFileFilter(File file) {
if (file != null && file.isDirectory()) {
File[] listFiles = file.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
return name.endsWith(".java") || new File(dir,name).isDirectory();
}
});
if (listFiles != null) {
for (File sub : listFiles) {
if(sub.isFile()){
System.out.println(sub);
}
listByFileFilter(sub);
}
}
}
}递归求目录总大小
@Test
public void test4() {
File dir = new File("D:/atguigu");
long length = getLength(dir);
System.out.println("大小:" + length);
}
public long getLength(File dir){
if (dir != null && dir.isDirectory()) {
File[] listFiles = dir.listFiles();
if(listFiles!=null){
long sum = 0;
for (File sub : listFiles) {
sum += getLength(sub);
}
return sum;
}
}else if(dir != null && dir.isFile()){
return dir.length();
}
return 0;
}递归删除非空目录
如果目录非空,连同目录下的文件和文件夹一起删除
@Test
public void test6() {
File dir = new File("D:/atguigu/javase");
forceDeleteDir(dir);
}
public void forceDeleteDir(File dir) {
if (dir != null && dir.isDirectory()) {
File[] listFiles = dir.listFiles();
if(listFiles!=null){
for (File sub : listFiles) {
forceDeleteDir(sub);
}
}
}
dir.delete();
}IO概述
什么是IO
生活中,你肯定经历过这样的场景。当你编辑一个文本文件,忘记了ctrl+s ,可能文件就白白编辑了。当你电脑上插入一个U盘,可以把一个视频,拷贝到你的电脑硬盘里。那么数据都是在哪些设备上的呢?键盘、内存、硬盘、外接设备等等。
我们把这种数据的传输,可以看做是一种数据的流动,按照流动的方向,以内存为基准,分为输入input 和输出output ,即流向内存是输入流,流出内存的输出流。
Java中I/O操作主要是指使用java.io包下的内容,进行输入、输出操作。输入也叫做读取数据,输出也叫做作写出数据。
IO的分类
根据数据的流向分为:输入流和输出流。
- 输入流 :把数据从
其他设备上读取到内存中的流。- 以InputStream,Reader结尾
- 输出流 :把数据从
内存中写出到其他设备上的流。- 以OutputStream、Writer结尾
根据数据的类型分为:字节流和字符流。
- 字节流 :以字节为单位,读写数据的流。
- 以InputStream和OutputStream结尾
- 字符流 :以字符为单位,读写数据的流。
- 以Reader和Writer结尾
根据IO流的角色不同分为:节点流和处理流。
节点流:可以从或向一个特定的地方(节点)读写数据。如FileReader.
处理流:是对一个已存在的流进行连接和封装,通过所封装的流的功能调用实现数据读写。如BufferedReader.处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
这种设计是装饰模式(Decorator Pattern)也称为包装模式(Wrapper Pattern),其使用一种对客户端透明的方式来动态地扩展对象的功能,它是通过继承扩展功能的替代方案之一。在现实生活中你也有很多装饰者的例子,例如:人需要各种各样的衣着,不管你穿着怎样,但是,对于你个人本质来说是不变的,充其量只是在外面加上了一些装饰,有,“遮羞的”、“保暖的”、“好看的”、“防雨的”….
常用的节点流:
- 文 件 FileInputStream FileOutputStrean FileReader FileWriter 文件进行处理的节点流。
- 字符串 StringReader StringWriter 对字符串进行处理的节点流。
- 数 组 ByteArrayInputStream ByteArrayOutputStream CharArrayReader CharArrayWriter 对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组)。
- 管 道 PipedInputStream、PipedOutputStream、PipedReader、PipedWriter对管道进行处理的节点流。
常用处理流:
缓冲流:BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter—-增加缓冲功能,避免频繁读写硬盘。
转换流:InputStreamReader、OutputStreamReader—-实现字节流和字符流之间的转换。
- 数据流:DataInputStream、DataOutputStream -提供读写Java基础数据类型功能
- 对象流:ObjectInputStream、ObjectOutputStream—提供直接读写Java对象功能
4大顶级抽象父类们
| 输入流 | 输出流 | |
|---|---|---|
| 字节流 | 字节输入流InputStream | 字节输出流OutputStream |
| 字符流 | 字符输入流Reader | 字符输出流Writer |
字节流
一切皆为字节
一切文件数据(文本、图片、视频等)在存储时,都是以二进制数字的形式保存,都一个一个的字节,那么传输时一样如此。所以,字节流可以传输任意文件数据。在操作流的时候,我们要时刻明确,无论使用什么样的流对象,底层传输的始终为二进制数据。
字节输出流【OutputStream】
java.io.OutputStream抽象类是表示字节输出流的所有类的超类,将指定的字节信息写出到目的地。它定义了字节输出流的基本共性功能方法。
public void close():关闭此输出流并释放与此流相关联的任何系统资源。public void flush():刷新此输出流并强制任何缓冲的输出字节被写出。public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。public void write(byte[] b, int off, int len):从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。public abstract void write(int b):将指定的字节输出流。
小贴士:
close方法,当完成流的操作时,必须调用此方法,释放系统资源。
FileOutputStream类
OutputStream有很多子类,我们从最简单的一个子类开始。
java.io.FileOutputStream类是文件输出流,用于将数据写出到文件。
构造方法
public FileOutputStream(File file):创建文件输出流以写入由指定的 File对象表示的文件。public FileOutputStream(String name): 创建文件输出流以指定的名称写入文件。
当你创建一个流对象时,必须传入一个文件路径。该路径下,如果没有这个文件,会创建该文件。如果有这个文件,会清空这个文件的数据。
- 构造举例,代码如下:
public class FileOutputStreamConstructor throws IOException {
public static void main(String[] args) {
// 使用File对象创建流对象
File file = new File("a.txt");
FileOutputStream fos = new FileOutputStream(file);
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("b.txt");
}
}写出字节数据
- 写出字节:
write(int b)方法,每次可以写出一个字节数据,代码使用演示:
public class FOSWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 写出数据
fos.write(97); // 写出第1个字节
fos.write(98); // 写出第2个字节
fos.write(99); // 写出第3个字节
// 关闭资源
fos.close();
}
}
输出结果:
abc小贴士:
- 虽然参数为int类型四个字节,但是只会保留一个字节的信息写出。
- 流操作完毕后,必须释放系统资源,调用close方法,千万记得。
- 写出字节数组:
write(byte[] b),每次可以写出数组中的数据,代码使用演示:
public class FOSWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 字符串转换为字节数组
byte[] b = "尚硅谷".getBytes();
// 写出字节数组数据
fos.write(b);
// 关闭资源
fos.close();
}
}
输出结果:
尚硅谷- 写出指定长度字节数组:
write(byte[] b, int off, int len),每次写出从off索引开始,len个字节,代码使用演示:
public class FOSWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 字符串转换为字节数组
byte[] b = "abcde".getBytes();
// 写出从索引2开始,2个字节。索引2是c,两个字节,也就是cd。
fos.write(b,2,2);
// 关闭资源
fos.close();
}
}
输出结果:
cd数据追加续写
经过以上的演示,每次程序运行,创建输出流对象,都会清空目标文件中的数据。如何保留目标文件中数据,还能继续添加新数据呢?
public FileOutputStream(File file, boolean append): 创建文件输出流以写入由指定的 File对象表示的文件。public FileOutputStream(String name, boolean append): 创建文件输出流以指定的名称写入文件。
这两个构造方法,参数中都需要传入一个boolean类型的值,true 表示追加数据,false 表示清空原有数据。这样创建的输出流对象,就可以指定是否追加续写了,代码使用演示:
public class FOSWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt",true);
// 字符串转换为字节数组
byte[] b = "abcde".getBytes();
// 写出从索引2开始,2个字节。索引2是c,两个字节,也就是cd。
fos.write(b);
// 关闭资源
fos.close();
}
}
文件操作前:cd
文件操作后:cdabcde写出换行
Windows系统里,换行符号是\r\n 。把
以指定是否追加续写了,代码使用演示:
public class FOSWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 定义字节数组
byte[] words = {97,98,99,100,101};
// 遍历数组
for (int i = 0; i < words.length; i++) {
// 写出一个字节
fos.write(words[i]);
// 写出一个换行, 换行符号转成数组写出
fos.write("\r\n".getBytes());
}
// 关闭资源
fos.close();
}
}
输出结果:
a
b
c
d
e
- 回车符
\r和换行符\n:
- 回车符:回到一行的开头(return)。
- 换行符:下一行(newline)。
- 系统中的换行:
- Windows系统里,每行结尾是
回车+换行,即\r\n;- Unix系统里,每行结尾只有
换行,即\n;- Mac系统里,每行结尾是
回车,即\r。从 Mac OS X开始与Linux统一。
字节输入流【InputStream】
java.io.InputStream抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
public void close():关闭此输入流并释放与此流相关联的任何系统资源。public abstract int read(): 从输入流读取数据的下一个字节。public int read(byte[] b): 从输入流中读取一些字节数,并将它们存储到字节数组 b中 。
小贴士:
close方法,当完成流的操作时,必须调用此方法,释放系统资源。
FileInputStream类
java.io.FileInputStream类是文件输入流,从文件中读取字节。
构造方法
FileInputStream(File file): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。FileInputStream(String name): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
当你创建一个流对象时,必须传入一个文件路径。该路径下,如果没有该文件,会抛出FileNotFoundException 。
- 构造举例,代码如下:
public class FileInputStreamConstructor throws IOException{
public static void main(String[] args) {
// 使用File对象创建流对象
File file = new File("a.txt");
FileInputStream fis = new FileInputStream(file);
// 使用文件名称创建流对象
FileInputStream fis = new FileInputStream("b.txt");
}
}读取字节数据
- 读取字节:
read方法,每次可以读取一个字节的数据,提升为int类型,读取到文件末尾,返回-1,代码使用演示:
public class FISRead {
public static void main(String[] args) throws IOException{
// 使用文件名称创建流对象
FileInputStream fis = new FileInputStream("read.txt");
// 读取数据,返回一个字节
int read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
read = fis.read();
System.out.println((char) read);
// 读取到末尾,返回-1
read = fis.read();
System.out.println( read);
// 关闭资源
fis.close();
}
}
输出结果:
a
b
c
d
e
-1循环改进读取方式,代码使用演示:
public class FISRead {
public static void main(String[] args) throws IOException{
// 使用文件名称创建流对象
FileInputStream fis = new FileInputStream("read.txt");
// 定义变量,保存数据
int b ;
// 循环读取
while ((b = fis.read())!=-1) {
System.out.println((char)b);
}
// 关闭资源
fis.close();
}
}
输出结果:
a
b
c
d
e小贴士:
- 虽然读取了一个字节,但是会自动提升为int类型。
- 流操作完毕后,必须释放系统资源,调用close方法,千万记得。
- 使用字节数组读取:
read(byte[] b),每次读取b的长度个字节到数组中,返回读取到的有效字节个数,读取到末尾时,返回-1,代码使用演示:
public class FISRead {
public static void main(String[] args) throws IOException{
// 使用文件名称创建流对象.
FileInputStream fis = new FileInputStream("read.txt"); // 文件中为abcde
// 定义变量,作为有效个数
int len ;
// 定义字节数组,作为装字节数据的容器
byte[] b = new byte[2];
// 循环读取
while (( len= fis.read(b))!=-1) {
// 每次读取后,把数组变成字符串打印
System.out.println(new String(b));
}
// 关闭资源
fis.close();
}
}
输出结果:
ab
cd
ed错误数据d,是由于最后一次读取时,只读取一个字节e,数组中,上次读取的数据没有被完全替换,所以要通过len ,获取有效的字节,代码使用演示:
public class FISRead {
public static void main(String[] args) throws IOException{
// 使用文件名称创建流对象.
FileInputStream fis = new FileInputStream("read.txt"); // 文件中为abcde
// 定义变量,作为有效个数
int len ;
// 定义字节数组,作为装字节数据的容器
byte[] b = new byte[2];
// 循环读取
while (( len= fis.read(b))!=-1) {
// 每次读取后,把数组的有效字节部分,变成字符串打印
System.out.println(new String(b,0,len));// len 每次读取的有效字节个数
}
// 关闭资源
fis.close();
}
}
输出结果:
ab
cd
e小贴士:
使用数组读取,每次读取多个字节,减少了系统间的IO操作次数,从而提高了读写的效率,建议开发中使用。
字节流练习:图片复制
复制图片文件,代码使用演示:
public class Copy {
public static void main(String[] args) throws IOException {
// 1.创建流对象
// 1.1 指定数据源
FileInputStream fis = new FileInputStream("D:\\test.jpg");
// 1.2 指定目的地
FileOutputStream fos = new FileOutputStream("test_copy.jpg");
// 2.读写数据
// 2.1 定义数组
byte[] b = new byte[1024];
// 2.2 定义长度
int len;
// 2.3 循环读取
while ((len = fis.read(b))!=-1) {
// 2.4 写出数据
fos.write(b, 0 , len);
}
// 3.关闭资源
fos.close();
fis.close();
}
}小贴士:
流的关闭原则:先开后关,后开先关。
字符流
当使用字节流读取文本文件时,可能会有一个小问题。就是遇到中文字符时,可能不会显示完整的字符,那是因为一个中文字符可能占用多个字节存储。所以Java提供一些字符流类,以字符为单位读写数据,专门用于处理文本文件。
字符输入流【Reader】
java.io.Reader抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
public void close():关闭此流并释放与此流相关联的任何系统资源。public int read(): 从输入流读取一个字符。public int read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组 cbuf中 。
FileReader类
java.io.FileReader类是读取字符文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
小贴士:
- 字符编码:字节与字符的对应规则。Windows系统的中文编码默认是GBK编码表。
eclipse中默认GBK,idea中默认UTF-8
- 字节缓冲区:一个字节数组,用来临时存储字节数据。
构造方法
FileReader(File file): 创建一个新的 FileReader ,给定要读取的File对象。FileReader(String fileName): 创建一个新的 FileReader ,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径。类似于FileInputStream 。
- 构造举例,代码如下:
public class FileReaderConstructor throws IOException{
public static void main(String[] args) {
// 使用File对象创建流对象
File file = new File("a.txt");
FileReader fr = new FileReader(file);
// 使用文件名称创建流对象
FileReader fr = new FileReader("b.txt");
}
}读取字符数据
- 读取字符:
read方法,每次可以读取一个字符的数据,提升为int类型,读取到文件末尾,返回-1,循环读取,代码使用演示:
public class FRRead {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileReader fr = new FileReader("read.txt");
// 定义变量,保存数据
int b ;
// 循环读取
while ((b = fr.read())!=-1) {
System.out.println((char)b);
}
// 关闭资源
fr.close();
}
}
输出结果:
尚
硅
谷小贴士:虽然读取了一个字符,但是会自动提升为int类型。
- 使用字符数组读取:
read(char[] cbuf),每次读取b的长度个字符到数组中,返回读取到的有效字符个数,读取到末尾时,返回-1,代码使用演示:
public class FRRead {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileReader fr = new FileReader("read.txt");
// 定义变量,保存有效字符个数
int len ;
// 定义字符数组,作为装字符数据的容器
char[] cbuf = new char[2];
// 循环读取
while ((len = fr.read(cbuf))!=-1) {
System.out.println(new String(cbuf));
}
// 关闭资源
fr.close();
}
}
输出结果:
尚硅
谷硅获取有效的字符改进,代码使用演示:
public class FISRead {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileReader fr = new FileReader("read.txt");
// 定义变量,保存有效字符个数
int len ;
// 定义字符数组,作为装字符数据的容器
char[] cbuf = new char[2];
// 循环读取
while ((len = fr.read(cbuf))!=-1) {
System.out.println(new String(cbuf,0,len));
}
// 关闭资源
fr.close();
}
}
输出结果:
尚硅
谷字符输出流【Writer】
java.io.Writer抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。它定义了字节输出流的基本共性功能方法。
void write(int c)写入单个字符。void write(char[] cbuf)写入字符数组。abstract void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。void write(String str)写入字符串。void write(String str, int off, int len)写入字符串的某一部分,off字符串的开始索引,len写的字符个数。void flush()刷新该流的缓冲。void close()关闭此流,但要先刷新它。
FileWriter类
java.io.FileWriter类是写出字符到文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
构造方法
FileWriter(File file): 创建一个新的 FileWriter,给定要读取的File对象。FileWriter(String fileName): 创建一个新的 FileWriter,给定要读取的文件的名称。
当你创建一个流对象时,必须传入一个文件路径,类似于FileOutputStream。
- 构造举例,代码如下:
public class FileWriterConstructor {
public static void main(String[] args) throws IOException {
// 使用File对象创建流对象
File file = new File("a.txt");
FileWriter fw = new FileWriter(file);
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("b.txt");
}
}基本写出数据
写出字符:write(int b) 方法,每次可以写出一个字符数据,代码使用演示:
public class FWWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 写出数据
fw.write(97); // 写出第1个字符
fw.write('b'); // 写出第2个字符
fw.write('C'); // 写出第3个字符
fw.write(30000); // 写出第4个字符,中文编码表中30000对应一个汉字。
/*
【注意】关闭资源时,与FileOutputStream不同。
如果不关闭,数据只是保存到缓冲区,并未保存到文件。
*/
// fw.close();
}
}
输出结果:
abC田小贴士:
- 虽然参数为int类型四个字节,但是只会保留一个字符的信息写出。
- 未调用close方法,数据只是保存到了缓冲区,并未写出到文件中。
关闭和刷新
因为内置缓冲区的原因,如果不关闭输出流,无法写出字符到文件中。但是关闭的流对象,是无法继续写出数据的。如果我们既想写出数据,又想继续使用流,就需要flush 方法了。
flush:刷新缓冲区,流对象可以继续使用。close:先刷新缓冲区,然后通知系统释放资源。流对象不可以再被使用了。
代码使用演示:
public class FWWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 写出数据,通过flush
fw.write('刷'); // 写出第1个字符
fw.flush();
fw.write('新'); // 继续写出第2个字符,写出成功
fw.flush();
// 写出数据,通过close
fw.write('关'); // 写出第1个字符
fw.close();
fw.write('闭'); // 继续写出第2个字符,【报错】java.io.IOException: Stream closed
fw.close();
}
}小贴士:即便是flush方法写出了数据,操作的最后还是要调用close方法,释放系统资源。
写出其他数据
- 写出字符数组 :
write(char[] cbuf)和write(char[] cbuf, int off, int len),每次可以写出字符数组中的数据,用法类似FileOutputStream,代码使用演示:
public class FWWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 字符串转换为字节数组
char[] chars = "尚硅谷".toCharArray();
// 写出字符数组
fw.write(chars); // 尚硅谷
// 写出从索引1开始,2个字节。索引1是'硅',两个字节,也就是'硅谷'。
fw.write(b,1,2); // 硅谷
// 关闭资源
fos.close();
}
}- 写出字符串:
write(String str)和write(String str, int off, int len),每次可以写出字符串中的数据,更为方便,代码使用演示:
public class FWWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 字符串
String msg = "尚硅谷";
// 写出字符数组
fw.write(msg); //尚硅谷
// 写出从索引1开始,2个字节。索引1是'硅',两个字节,也就是'硅谷'。
fw.write(msg,1,2); // 尚硅谷
// 关闭资源
fos.close();
}
}- 续写和换行:操作类似于FileOutputStream。
public class FWWrite {
public static void main(String[] args) throws IOException {
// 使用文件名称创建流对象,可以续写数据
FileWriter fw = new FileWriter("fw.txt",true);
// 写出字符串
fw.write("尚");
// 写出换行
fw.write("\r\n");
// 写出字符串
fw.write("硅谷");
// 关闭资源
fw.close();
}
}
输出结果:
尚
硅谷小贴士:字符流,只能操作文本文件,不能操作图片,视频等非文本文件。
当我们单纯读或者写文本文件时 使用字符流 其他情况使用字节流
缓冲流
缓冲流,也叫高效流,按照数据类型分类:
- 字节缓冲流:
BufferedInputStream,BufferedOutputStream - 字符缓冲流:
BufferedReader,BufferedWriter
缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。
字节缓冲流
构造方法
public BufferedInputStream(InputStream in):创建一个 新的缓冲输入流。public BufferedOutputStream(OutputStream out): 创建一个新的缓冲输出流。
构造举例,代码如下:
// 创建字节缓冲输入流
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("bis.txt"));
// 创建字节缓冲输出流
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("bos.txt"));效率测试
查询API,缓冲流读写方法与基本的流是一致的,我们通过复制大文件(375MB),测试它的效率。
- 基本流,代码如下:
public class BufferedDemo {
public static void main(String[] args) throws IOException {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
FileInputStream fis = new FileInputStream("jdk9.exe");
FileOutputStream fos = new FileOutputStream("copy.exe");
// 读写数据
int b;
while ((b = fis.read()) != -1) {
fos.write(b);
}
fos.close();
fis.close();
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("普通流复制时间:"+(end - start)+" 毫秒");
}
}
十几分钟过去了...- 缓冲流,代码如下:
public class BufferedDemo {
public static void main(String[] args) throws IOException {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("jdk9.exe"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.exe"));
// 读写数据
int b;
while ((b = bis.read()) != -1) {
bos.write(b);
}
bos.close();
bis.close();
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("缓冲流复制时间:"+(end - start)+" 毫秒");
}
}
缓冲流复制时间:8016 毫秒如何更快呢?
使用数组的方式,代码如下:
public class BufferedDemo {
public static void main(String[] args) throws IOException {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("jdk9.exe"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.exe"));
// 读写数据
int len;
byte[] bytes = new byte[8*1024];
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0 , len);
}
bos.close();
bis.close();
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("缓冲流使用数组复制时间:"+(end - start)+" 毫秒");
}
}
缓冲流使用数组复制时间:666 毫秒字符缓冲流
构造方法
public BufferedReader(Reader in):创建一个 新的缓冲输入流。public BufferedWriter(Writer out): 创建一个新的缓冲输出流。
构造举例,代码如下:
// 创建字符缓冲输入流
BufferedReader br = new BufferedReader(new FileReader("br.txt"));
// 创建字符缓冲输出流
BufferedWriter bw = new BufferedWriter(new FileWriter("bw.txt"));特有方法
字符缓冲流的基本方法与普通字符流调用方式一致,不再阐述,我们来看它们具备的特有方法。
- BufferedReader:
public String readLine(): 读一行文字。 - BufferedWriter:
public void newLine(): 写一行行分隔符,由系统属性定义符号。
readLine方法演示,代码如下:
public class BufferedReaderDemo {
public static void main(String[] args) throws IOException {
// 创建流对象
BufferedReader br = new BufferedReader(new FileReader("in.txt"));
// 定义字符串,保存读取的一行文字
String line = null;
// 循环读取,读取到最后返回null
while ((line = br.readLine())!=null) {
System.out.print(line);
System.out.println("------");
}
// 释放资源
br.close();
}
}newLine方法演示,代码如下:
public class BufferedWriterDemo throws IOException {
public static void main(String[] args) throws IOException {
// 创建流对象
BufferedWriter bw = new BufferedWriter(new FileWriter("out.txt"));
// 写出数据
bw.write("尚");
// 写出换行
bw.newLine();
bw.write("硅");
bw.newLine();
bw.write("谷");
bw.newLine();
// 释放资源
bw.close();
}
}
输出效果:
尚
硅
谷转换流
字符编码和字符集
字符编码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
编码:字符(能看懂的)—字节(看不懂的)
解码:字节(看不懂的)—>字符(能看懂的)
字符编码
Character Encoding: 就是一套自然语言的字符与二进制数之间的对应规则。编码表:生活中文字和计算机中二进制的对应规则
字符集
- 字符集
Charset:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。
可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
- ASCII字符集 :
- ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
- 基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。
- ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
- ISO-8859-1字符集:
- 拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
- ISO-8859-1使用单字节编码,兼容ASCII编码。
- GBxxx字符集:
- GB就是国标的意思,是为了显示中文而设计的一套字符集。
- GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符了。
- GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
- GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
- Unicode字符集 :
- Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。
- 它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。
- UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
- 128个US-ASCII字符,只需一个字节编码。
- 拉丁文等字符,需要二个字节编码。
- 大部分常用字(含中文),使用三个字节编码。
- 其他极少使用的Unicode辅助字符,使用四字节编码。
编码引出的问题
在Eclipse中,使用FileReader 读取项目中的文本文件。由于Eclipse的设置UTF-8编码但是,当读取Windows系统中创建的文本文件时,由于Windows系统的默认是GBK编码,就会出现乱码。
public class ReaderDemo {
public static void main(String[] args) throws IOException {
FileReader fileReader = new FileReader("E:\\File_GBK.txt");
int read;
while ((read = fileReader.read()) != -1) {
System.out.print((char)read);
}
fileReader.close();
}
}
输出结果:
���那么如何读取GBK编码的文件呢?
InputStreamReader类
转换流java.io.InputStreamReader,是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。InputStreamReader(InputStream in, String charsetName): 创建一个指定字符集的字符流。
构造举例,代码如下:
InputStreamReader isr = new InputStreamReader(new FileInputStream("in.txt"));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("in.txt") , "GBK");指定编码读取
public class ReaderDemo2 {
public static void main(String[] args) throws IOException {
// 定义文件路径,文件为gbk编码
String FileName = "E:\\file_gbk.txt";
// 创建流对象,默认UTF8编码
InputStreamReader isr = new InputStreamReader(new FileInputStream(FileName));
// 创建流对象,指定GBK编码
InputStreamReader isr2 = new InputStreamReader(new FileInputStream(FileName) , "GBK");
// 定义变量,保存字符
int read;
// 使用默认编码字符流读取,乱码
while ((read = isr.read()) != -1) {
System.out.print((char)read); // ��Һ�
}
isr.close();
// 使用指定编码字符流读取,正常解析
while ((read = isr2.read()) != -1) {
System.out.print((char)read);// 大家好
}
isr2.close();
}
}OutputStreamWriter类
转换流java.io.OutputStreamWriter ,是Writer的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。OutputStreamWriter(OutputStream in, String charsetName): 创建一个指定字符集的字符流。
构造举例,代码如下:
OutputStreamWriter isr = new OutputStreamWriter(new FileOutputStream("out.txt"));
OutputStreamWriter isr2 = new OutputStreamWriter(new FileOutputStream("out.txt") , "GBK");指定编码写出
public class OutputDemo {
public static void main(String[] args) throws IOException {
// 定义文件路径
String FileName = "E:\\out.txt";
// 创建流对象,默认UTF8编码
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(FileName));
// 写出数据
osw.write("你好"); // 保存为6个字节
osw.close();
// 定义文件路径
String FileName2 = "E:\\out2.txt";
// 创建流对象,指定GBK编码
OutputStreamWriter osw2 = new OutputStreamWriter(new FileOutputStream(FileName2),"GBK");
// 写出数据
osw2.write("你好");// 保存为4个字节
osw2.close();
}
}转换流理解图解
转换流是字节与字符间的桥梁!

练习:转换文件编码
将GBK编码的文本文件,转换为UTF-8编码的文本文件。
案例分析
- 指定GBK编码的转换流,读取文本文件。
- 使用UTF-8编码的转换流,写出文本文件。
案例实现
public class TransDemo {
public static void main(String[] args) {
// 1.定义文件路径
String srcFile = "file_gbk.txt";
String destFile = "file_utf8.txt";
// 2.创建流对象
// 2.1 转换输入流,指定GBK编码
InputStreamReader isr = new InputStreamReader(new FileInputStream(srcFile) , "GBK");
// 2.2 转换输出流,默认utf8编码
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(destFile));
// 3.读写数据
// 3.1 定义数组
char[] cbuf = new char[1024];
// 3.2 定义长度
int len;
// 3.3 循环读取
while ((len = isr.read(cbuf))!=-1) {
// 循环写出
osw.write(cbuf,0,len);
}
// 4.释放资源
osw.close();
isr.close();
}
}数据流
前面学习的IO流,在程序代码中,要么将数据直接按照字节处理,要么按照字符处理。那么,如果要在程序中直接处理Java的基础数据类型,怎么办呢?
String name = “巫师”;
int age = 300;
char gender = ‘男’;
int energy = 5000;
double price = 75.5;
boolean relive = true;完成这个需求,可以使用DataOutputStream进行写,随后用DataInputStream进行读取,而且顺序要一致。
示例代码:
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class TestData {
public void save() throws IOException{
String name = "巫师";
int age = 300;
char gender = '男';
int energy = 5000;
double price = 75.5;
boolean relive = true;
DataOutputStream dos = new DataOutputStream(new FileOutputStream("game.dat"));
dos.writeUTF(name);
dos.writeInt(age);
dos.writeChar(gender);
dos.writeInt(energy);
dos.writeDouble(price);
dos.writeBoolean(relive);
dos.close();
}
public void reload()throws IOException{
DataInputStream dis = new DataInputStream(new FileInputStream("game.dat"));
String name = dis.readUTF();
int age = dis.readInt();
char gender = dis.readChar();
int energy = dis.readInt();
double price = dis.readDouble();
boolean relive = dis.readBoolean();
System.out.println(name+"," + age + "," + gender + "," + energy + "," + price + "," + relive);
dis.close();
}
}序列化
概述
Java 提供了一种对象序列化的机制。用一个字节序列可以表示一个对象,该字节序列包含该对象的类型和对象中存储的属性等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。看图理解序列化:
ObjectOutputStream类
java.io.ObjectOutputStream 类,将Java对象的原始数据类型写出到文件,实现对象的持久存储。
构造方法
public ObjectOutputStream(OutputStream out): 创建一个指定OutputStream的ObjectOutputStream。
构造举例,代码如下:
FileOutputStream fileOut = new FileOutputStream("employee.txt");
ObjectOutputStream out = new ObjectOutputStream(fileOut);序列化操作
- 该类必须实现
java.io.Serializable接口,Serializable是一个标记接口,不实现此接口的类将不会使任何状态序列化或反序列化,会抛出NotSerializableException。- 如果对象的某个属性也是引用数据类型,那么如果该属性也要序列化的话,也要实现
Serializable接口
- 如果对象的某个属性也是引用数据类型,那么如果该属性也要序列化的话,也要实现
- 该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用
transient关键字修饰。 - 静态变量的值不会序列化
public class Employee implements java.io.Serializable {
public static String company = "尚硅谷";
public String name;
public String address;
public transient int age; // transient瞬态修饰成员,不会被序列化
public void addressCheck() {
System.out.println("Address check : " + name + " -- " + address);
}
}2.写出对象方法
public final void writeObject (Object obj): 将指定的对象写出。
public class SerializeDemo{
public static void main(String [] args) {
Employee e = new Employee();
e.name = "zhangsan";
e.address = "beiqinglu";
e.age = 20;
try {
// 创建序列化流对象
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("employee.txt"));
// 写出对象
out.writeObject(e);
// 释放资源
out.close();
fileOut.close();
System.out.println("Serialized data is saved"); // 姓名,地址被序列化,年龄没有被序列化。
} catch(IOException i) {
i.printStackTrace();
}
}
}
输出结果:
Serialized data is savedObjectInputStream类
ObjectInputStream反序列化流,将之前使用ObjectOutputStream序列化的原始数据恢复为对象。
构造方法
public ObjectInputStream(InputStream in): 创建一个指定InputStream的ObjectInputStream。
反序列化操作1
如果能找到一个对象的class文件,我们可以进行反序列化操作,调用ObjectInputStream读取对象的方法:
public final Object readObject (): 读取一个对象。
public class DeserializeDemo {
public static void main(String [] args) {
Employee e = null;
try {
// 创建反序列化流
FileInputStream fileIn = new FileInputStream("employee.txt");
ObjectInputStream in = new ObjectInputStream(fileIn);
// 读取一个对象
e = (Employee) in.readObject();
// 释放资源
in.close();
fileIn.close();
}catch(IOException i) {
// 捕获其他异常
i.printStackTrace();
return;
}catch(ClassNotFoundException c) {
// 捕获类找不到异常
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
// 无异常,直接打印输出
System.out.println("Name: " + e.name); // zhangsan
System.out.println("Address: " + e.address); // beiqinglu
System.out.println("age: " + e.age); // 0
}
}对于JVM可以反序列化对象,它必须是能够找到class文件的类。如果找不到该类的class文件,则抛出一个 ClassNotFoundException 异常。
反序列化操作2
另外,当JVM反序列化对象时,能找到class文件,但是class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个InvalidClassException异常。发生这个异常的原因如下:
- 该类的序列版本号与从流中读取的类描述符的版本号不匹配
- 该类包含未知数据类型
Serializable 接口给需要序列化的类,提供了一个序列版本号。serialVersionUID 该版本号的目的在于验证序列化的对象和对应类是否版本匹配。
public class Employee implements java.io.Serializable {
// 加入序列版本号
private static final long serialVersionUID = 1L;
public String name;
public String address;
// 添加新的属性 ,重新编译, 可以反序列化,该属性赋为默认值.
public int eid;
public void addressCheck() {
System.out.println("Address check : " + name + " -- " + address);
}
}练习:序列化集合
- 将存有多个自定义对象的集合序列化操作,保存到
list.txt文件中。 - 反序列化
list.txt,并遍历集合,打印对象信息。
案例分析
- 把若干学生对象 ,保存到集合中。
- 把集合序列化。
- 反序列化读取时,只需要读取一次,转换为集合类型。
- 遍历集合,可以打印所有的学生信息
案例实现
public class SerTest {
public static void main(String[] args) throws Exception {
// 创建 学生对象
Student student = new Student("老王", "laow");
Student student2 = new Student("老张", "laoz");
Student student3 = new Student("老李", "laol");
ArrayList<Student> arrayList = new ArrayList<>();
arrayList.add(student);
arrayList.add(student2);
arrayList.add(student3);
// 序列化操作
// serializ(arrayList);
// 反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("list.txt"));
// 读取对象,强转为ArrayList类型
ArrayList<Student> list = (ArrayList<Student>)ois.readObject();
for (int i = 0; i < list.size(); i++ ){
Student s = list.get(i);
System.out.println(s.getName()+"--"+ s.getPwd());
}
}
private static void serializ(ArrayList<Student> arrayList) throws Exception {
// 创建 序列化流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("list.txt"));
// 写出对象
oos.writeObject(arrayList);
// 释放资源
oos.close();
}
}java.io.Externalizable接口
除了Serializable接口之外,还可以实现java.io.Externalizable接口,但是要求重写:
void readExternal(ObjectInput in)
void writeExternal(ObjectOutput out)
关于哪些属性序列化和反序列化,由程序员自己定。虽然可以自己决定任意属性的输出和读取,但是还是建议不要输出静态的和transient属性。
学生类:
import java.io.Externalizable;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectOutput;
public class Student implements Externalizable{
private static String school = "atguigu";
private String name;
private transient int age;
private int score;
public Student(String name, int age, int score) {
super();
this.name = name;
this.age = age;
this.score = score;
}
public Student() {
super();
}
public static String getSchool() {
return school;
}
public static void setSchool(String school) {
Student.school = school;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "Student [name=" + name +",age =" +age + ", score=" + score +",schoool = " + school+ "]";
}
//一下两个方法不是程序员手动调用,而是在对象被序列化和反序列时,IO流自动调用
@Override
public void writeExternal(ObjectOutput out) throws IOException {
//在这个方法中,程序员自己定,哪些属性需要序列化,及其顺序
out.writeUTF(school);
out.writeUTF(name);
out.writeInt(score);
out.writeInt(age);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
//读取的顺序要与写的顺序一致
school = in.readUTF();
name = in.readUTF();
score = in.readInt();
age = in.readInt();
}
}测试类
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import org.junit.Test;
/*
* 类通过实现 java.io.Serializable 接口以启用其序列化功能。未实现此接口的类将无法使其任何状态序列化或反序列化。
* 序列化接口没有方法或字段,仅用于标识可序列化的语义。
*
* java.io.Externalizable 实例类的唯一特性是可以被写入序列化流中,该类负责保存和恢复实例内容。
* 则它要实现 Externalizable 接口的 writeExternal 和 readExternal 方法。
*
* void readExternal(ObjectInput in)
* void writeExternal(ObjectOutput out)
*
* 虽然可以自己决定任意属性的输出和读取,但是还是建议不要输出静态的和transient属性
*/
public class TestExternalizable {
@Test
public void in()throws IOException, ClassNotFoundException{
FileInputStream fis = new FileInputStream("stu.dat");
ObjectInputStream ois = new ObjectInputStream(fis);
Object obj = ois.readObject();
System.out.println(obj);
ois.close();
fis.close();
}
@Test
public void out()throws IOException{
Student student = new Student("张三", 23, 89);
Student.setSchool("尚硅谷");
FileOutputStream fos = new FileOutputStream("stu.dat");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(student);
oos.close();
fos.close();
}
}
重新认识PrintStream和Scanner、System.in和out
PrintStream类
平时我们在控制台打印输出,是调用print方法和println方法完成的,这两个方法都来自于java.io.PrintStream类,该类能够方便地打印各种数据类型的值,是一种便捷的输出方式。
构造方法
public PrintStream(String fileName): 使用指定的文件名创建一个新的打印流。
构造举例,代码如下:
PrintStream ps = new PrintStream("ps.txt");改变打印流向
System.out就是PrintStream类型的,只不过它的流向是系统规定的,打印在控制台上。不过,既然是流对象,我们就可以玩一个”小把戏”,改变它的流向。
public class PrintDemo {
public static void main(String[] args) throws IOException {
// 调用系统的打印流,控制台直接输出97
System.out.println(97);
// 创建打印流,指定文件的名称
PrintStream ps = new PrintStream("ps.txt");
// 设置系统的打印流流向,输出到ps.txt
System.setOut(ps);
// 调用系统的打印流,ps.txt中输出97
System.out.println(97);
}
}Scanner类
构造方法
- Scanner(File source) :构造一个新的 Scanner,它生成的值是从指定文件扫描的。
- Scanner(File source, String charsetName) :构造一个新的 Scanner,它生成的值是从指定文件扫描的。
- Scanner(InputStream source) :构造一个新的 Scanner,它生成的值是从指定的输入流扫描的。
- Scanner(InputStream source, String charsetName) :构造一个新的 Scanner,它生成的值是从指定的输入流扫描的。
常用方法:
- boolean hasNextXxx(): 如果通过使用nextXxx()方法,此扫描器输入信息中的下一个标记可以解释为默认基数中的一个 Xxx 值,则返回 true。
- Xxx nextXxx(): 将输入信息的下一个标记扫描为一个Xxx
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Scanner;
import org.junit.Test;
public class TestFile {
@Test
public void test1() throws IOException {
Scanner input = new Scanner(System.in);
ArrayList<String> list = new ArrayList<>();
while(true){
System.out.print("请输入一个单词:");
String str = input.nextLine();
if("stop".equals(str)){
break;
}
list.add(str);
}
System.out.println(list);
input.close();
}
@Test
public void test2() throws IOException {
Scanner input = new Scanner(new File("1.txt"));
while(input.hasNextLine()){
String str = input.nextLine();
System.out.println(str);
}
input.close();
}
@Test
public void test3() throws FileNotFoundException{
System.setIn(new FileInputStream("1.txt"));
Scanner input = new Scanner(System.in);
while(input.hasNextLine()){
String str = input.nextLine();
System.out.println(str);
}
input.close();
}
}JDK1.7之后引入新try..catch
语法格式:
try(需要关闭的资源对象的声明){
业务逻辑代码
}catch(异常类型 e){
处理异常代码
}catch(异常类型 e){
处理异常代码
}
....它没有finally,也不需要程序员去关闭资源对象,无论是否发生异常,都会关闭资源对象
示例代码:
@Test
public void test03() {
//从d:/1.txt(GBK)文件中,读取内容,写到项目根目录下1.txt(UTF-8)文件中
try(
FileInputStream fis = new FileInputStream("d:/1.txt");
InputStreamReader isr = new InputStreamReader(fis,"GBK");
BufferedReader br = new BufferedReader(isr);
FileOutputStream fos = new FileOutputStream("1.txt");
OutputStreamWriter osw = new OutputStreamWriter(fos,"UTF-8");
BufferedWriter bw = new BufferedWriter(osw);
){
String str;
while((str = br.readLine()) != null){
bw.write(str);
bw.newLine();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}网络编程
软件结构
- C/S结构 :全称为Client/Server结构,是指客户端和服务器结构。常见程序有QQ、红蜘蛛、飞秋等软件。
B/S结构 :全称为Browser/Server结构,是指浏览器和服务器结构。常见浏览器有IE、谷歌、火狐等。

两种架构各有优势,但是无论哪种架构,都离不开网络的支持。网络编程,就是在一定的协议下,实现两台计算机的通信的程序。
网络通信协议
TCP/IP协议参考模型
网络通信协议:通过计算机网络可以使多台计算机实现连接,位于同一个网络中的计算机在进行连接和通信时需要遵守一定的规则,这就好比在道路中行驶的汽车一定要遵守交通规则一样。在计算机网络中,这些连接和通信的规则被称为网络通信协议,它对数据的传输格式、传输速率、传输步骤等做了统一规定,通信双方必须同时遵守才能完成数据交换。
TCP/IP协议: 传输控制协议/因特网互联协议( Transmission Control Protocol/Internet Protocol),是Internet最基本、最广泛的协议。它定义了计算机如何连入因特网,以及数据如何在它们之间传输的标准。它的内部包含一系列的用于处理数据通信的协议,并采用了4层的分层模型,每一层都呼叫它的下一层所提供的协议来完成自己的需求。
上图中,OSI参考模型:模型过于理想化,未能在因特网上进行广泛推广。 TCP/IP参考模型(或TCP/IP协议):事实上的国际标准。
- TCP/IP协议中的四层分别是应用层、传输层、网络层和链路层,每层分别负责不同的通信功能。
链路层:链路层是用于定义物理传输通道,通常是对某些网络连接设备的驱动协议,例如针对光纤、网线提供的驱动。 - 网络层:网络层是整个TCP/IP协议的核心,它主要用于将传输的数据进行分组,将分组数据发送到目标计算机或者网络。而IP协议是一种非常重要的协议。IP(internet protocal)又称为互联网协议。IP的责任就是把数据从源传送到目的地。它在源地址和目的地址之间传送一种称之为数据包的东西,它还提供对数据大小的重新组装功能,以适应不同网络对包大小的要求。
- 传输层:主要使网络程序进行通信,在进行网络通信时,可以采用TCP协议,也可以采用UDP协议。TCP(Transmission Control Protocol)协议,即传输控制协议,是一种面向连接的、可靠的、基于字节流的传输层通信协议。UDP(User Datagram Protocol,用户数据报协议):是一个无连接的传输层协议、提供面向事务的简单不可靠的信息传送服务。
- 应用层:主要负责应用程序的协议,例如HTTP协议、FTP协议等。
而通常我们说的TCP/IP协议,其实是指TCP/IP协议族,因为该协议家族的两个最核心协议:TCP(传输控制协议)和IP(网际协议),为该家族中最早通过的标准,所以简称为TCP/IP协议。
TCP与UDP协议
通信的协议还是比较复杂的,java.net 包中包含的类和接口,它们提供低层次的通信细节。我们可以直接使用这些类和接口,来专注于网络程序开发,而不用考虑通信的细节。
java.net 包中提供了两种常见的网络协议的支持:
UDP:用户数据报协议(User Datagram Protocol)。
非面向连的,不可靠的:UDP是无连接通信协议,即在数据传输时,数据的发送端和接收端不建立逻辑连接。简单来说,当一台计算机向另外一台计算机发送数据时,发送端不会确认接收端是否存在,就会发出数据,同样接收端在收到数据时,也不会向发送端反馈是否收到数据。
由于使用UDP协议消耗资源小,通信效率高,所以通常都会用于音频、视频和普通数据的传输例如视频会议都使用UDP协议,因为这种情况即使偶尔丢失一两个数据包,也不会对接收结果产生太大影响。
但是在使用UDP协议传送数据时,由于UDP的面向无连接性,不能保证数据的完整性,因此在传输重要数据时不建议使用UDP协议。
大小限制的:数据被限制在64kb以内,超出这个范围就不能发送了。
数据报(Datagram):网络传输的基本单位
TCP:传输控制协议 (Transmission Control Protocol)。
面向连接的,可靠的:TCP协议是面向连接的通信协议,即传输数据之前,在发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输。是一种面向连接的、可靠的、基于字节流的传输层的通信协议,可以连续传输大量的数据。类似于打电话的效果。
这是因为它为当一台计算机需要与另一台远程计算机连接时,TCP协议会采用“三次握手”方式让它们建立一个连接,用于发送和接收数据的虚拟链路。数据传输完毕TCP协议会采用“四次挥手”方式断开连接。
TCP协议负责收集这些信息包,并将其按适当的次序放好传送,在接收端收到后再将其正确的还原。TCP协议保证了数据包在传送中准确无误。TCP协议使用重发机制,当一个通信实体发送一个消息给另一个通信实体后,需要收到另一个通信实体确认信息,如果没有收到另一个通信实体确认信息,则会再次重复刚才发送的消息。
三次握手:TCP协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可靠。
第一次握手,客户端向服务器端发出连接请求,等待服务器确认。
第二次握手,服务器端向客户端回送一个响应,通知客户端收到了连接请求。
第三次握手,客户端再次向服务器端发送确认信息,确认连接。
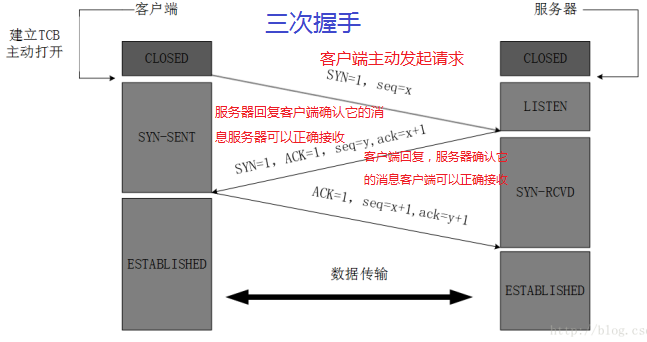
- 四次挥手:TCP协议中,在发送数据结束后,释放连接时需要经过四次挥手。
- 第一次挥手:客户端向服务器端提出结束连接,让服务器做最后的准备工作。此时,客户端处于半关闭状态,即表示不再向服务器发送数据了,但是还可以接受数据。
- 第二次挥手:服务器接收到客户端释放连接的请求后,会将最后的数据发给客户端。并告知上层的应用进程不再接收数据。
- 第三次挥手:服务器发送完数据后,会给客户端发送一个释放连接的报文。那么客户端接收后就知道可以正式释放连接了。
- 第四次挥手:客户端接收到服务器最后的释放连接报文后,要回复一个彻底断开的报文。这样服务器收到后才会彻底释放连接。这里客户端,发送完最后的报文后,会等待2MSL,因为有可能服务器没有收到最后的报文,那么服务器迟迟没收到,就会再次给客户端发送释放连接的报文,此时客户端在等待时间范围内接收到,会重新发送最后的报文,并重新计时。如果等待2MSL后,没有收到,那么彻底断开。
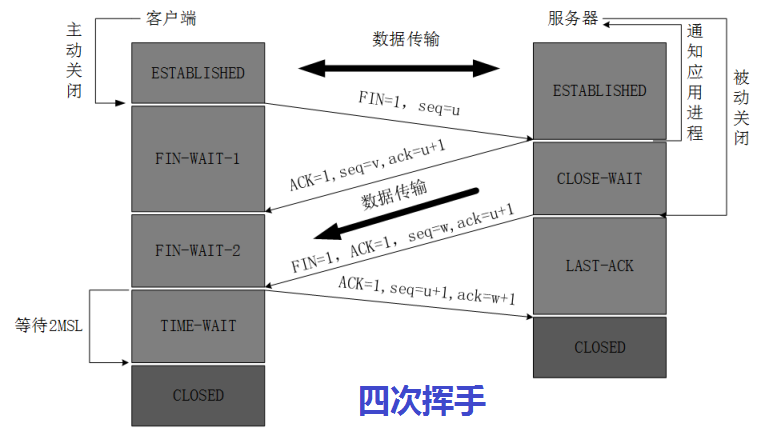
完成三次握手,连接建立后,客户端和服务器就可以开始进行数据传输了。由于这种面向连接的特性,TCP协议可以保证传输数据的安全,所以应用十分广泛,例如下载文件、浏览网页等。
网络编程三要素
协议
- 协议:计算机网络通信必须遵守的规则,已经介绍过了,不再赘述。
IP地址
IP地址:指互联网协议地址(Internet Protocol Address),俗称IP。IP地址用来给一个网络中的计算机设备做唯一的编号。假如我们把“个人电脑”比作“一台电话”的话,那么“IP地址”就相当于“电话号码”。
IP地址分类方式一:
IPv4:是一个32位的二进制数,通常被分为4个字节,表示成
a.b.c.d的形式,例如192.168.65.100。其中a、b、c、d都是0~255之间的十进制整数,那么最多可以表示42亿个。IPv6:由于互联网的蓬勃发展,IP地址的需求量愈来愈大,但是网络地址资源有限,使得IP的分配越发紧张。
为了扩大地址空间,拟通过IPv6重新定义地址空间,采用128位地址长度,每16个字节一组,分成8组十六进制数,表示成
ABCD:EF01:2345:6789:ABCD:EF01:2345:6789,号称可以为全世界的每一粒沙子编上一个网址,这样就解决了网络地址资源数量不够的问题。
IP地址分类方式二:
公网地址( 万维网使用)和 私有地址( 局域网使用)。192.168.开头的就是私有址址,范围即为192.168.0.0—192.168.255.255,专门为组织机构内部使用
常用命令:
- 查看本机IP地址,在控制台输入:
ipconfig- 检查网络是否连通,在控制台输入:
ping 空格 IP地址
ping 220.181.57.216特殊的IP地址:
- 本地回环地址(hostAddress):
127.0.0.1 - 主机名(hostName):
localhost
域名:
因为IP地址数字不便于记忆,因此出现了域名,域名容易记忆,当在连接网络时输入一个主机的域名后,域名服务器(DNS)负责将域名转化成IP地址,这样才能和主机建立连接。 ———- 域名解析
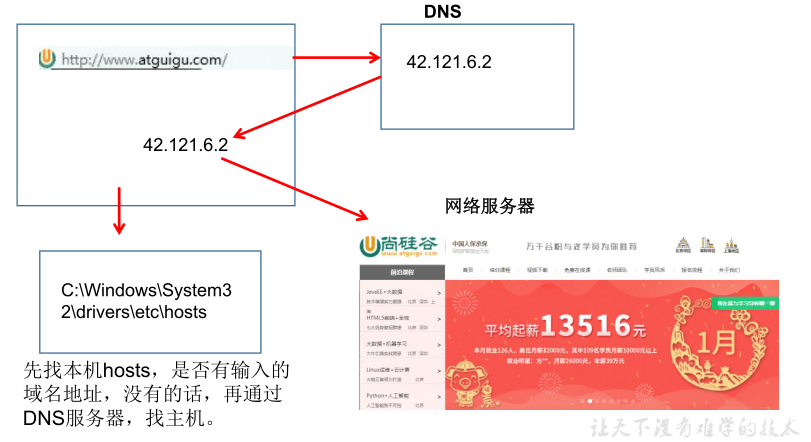
端口号
网络的通信,本质上是两个进程(应用程序)的通信。每台计算机都有很多的进程,那么在网络通信时,如何区分这些进程呢?
如果说IP地址可以唯一标识网络中的设备,那么端口号就可以唯一标识设备中的进程(应用程序)了。
- 端口号:用两个字节表示的整数,它的取值范围是0~65535。
- 公认端口:0~1023。被预先定义的服务通信占用,如:HTTP(80),FTP(21),Telnet(23)
- 注册端口:1024~49151。分配给用户进程或应用程序。如:Tomcat(8080),MySQL(3306),Oracle(1521)。
- 动态/ 私有端口:49152~65535。
如果端口号被另外一个服务或应用所占用,会导致当前程序启动失败。
利用协议+IP地址+端口号 三元组合,就可以标识网络中的进程了,那么进程间的通信就可以利用这个标识与其它进程进行交互。
InetAddress类
InetAddress类主要表示IP地址,两个子类:Inet4Address、Inet6Address。
Internet上的主机有两种方式表示地址:
- 域名(hostName):www.atguigu.com
- IP 地址(hostAddress):202.108.35.210
lInetAddress 类没有提供公共的构造器,而是提供 了 如下几个 静态方法来获取InetAddress 实例
- public static InetAddress getLocalHost()
- public static InetAddress getByName(String host)
- public static InetAddress getByAddress(byte[] addr)
InetAddress 提供了如下几个常用的方法
- public String getHostAddress() :返回 IP 地址字符串(以文本表现形式)。
- public String getHostName() :获取此 IP 地址的主机名
import java.net.InetAddress;
import java.net.UnknownHostException;
import org.junit.Test;
public class TestInetAddress {
@Test
public void test01() throws UnknownHostException{
InetAddress localHost = InetAddress.getLocalHost();
System.out.println(localHost);
}
@Test
public void test02()throws UnknownHostException{
InetAddress atguigu = InetAddress.getByName("www.atguigu.com");
System.out.println(atguigu);
}
@Test
public void test03()throws UnknownHostException{
// byte[] addr = {112,54,108,98};
byte[] addr = {(byte)192,(byte)168,24,56};
InetAddress atguigu = InetAddress.getByAddress(addr);
System.out.println(atguigu);
}
}
Socket
通信的两端都要有Socket(也可以叫“套接字”),是两台机器间通信的端点。网络通信其实就是Socket间的通信。Socket可以分为:
- 流套接字(stream socket):使用TCP提供可依赖的字节流服务
- ServerSocket:此类实现TCP服务器套接字。服务器套接字等待请求通过网络传入。
- Socket:此类实现客户端套接字(也可以就叫“套接字”)。套接字是两台机器间通信的端点。
- 数据报套接字(datagram socket):使用UDP提供“尽力而为”的数据报服务
- DatagramSocket:此类表示用来发送和接收UDP数据报包的套接字。
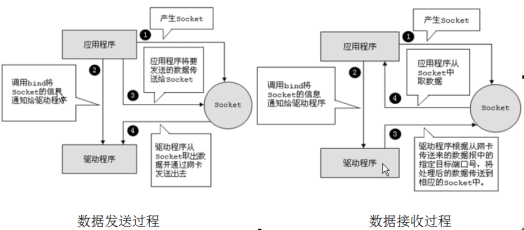
TCP网络编程
通信模型
Java语言的基于套接字TCP编程分为服务端编程和客户端编程,其通信模型如图所示:
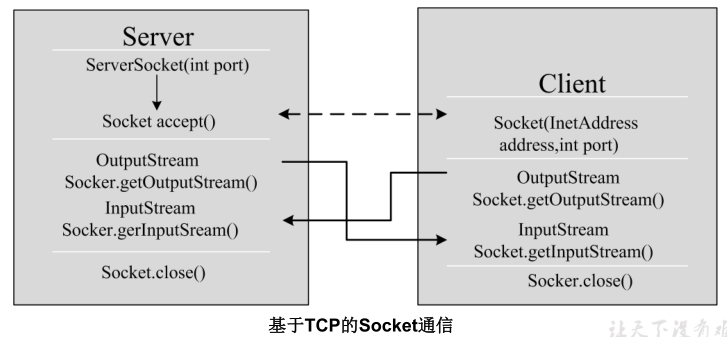
开发步骤
服务器端
服务器 程序的工作过程包含以下四个基本的 步骤:
- 调用 ServerSocket(int port) :创建一个服务器端套接字,并绑定到指定端口上。用于监听客户端的请求。
- 调用 accept() :监听连接请求,如果客户端请求连接,则接受连接,返回通信套接字对象。
- 调用 该Socket 类对象的 getOutputStream() 和 getInputStream () :获取输出流和输入流,开始网络数据的发送和接收。
- 关闭Socket 对象:客户端访问结束,关闭通信套接字。
客户端
客户端Socket 的工作过程包含以下四个基本的步骤 :
- 创建 Socket :根据指定服务端的 IP 地址或端口号构造 Socket 类对象。若服务器端响应,则建立客户端到服务器的通信线路。若连接失败,会出现异常。
- 打开连接到 Socket 的输入/ 出流: 使用 getInputStream()方法获得输入流,使用getOutputStream()方法获得输出流,进行数据传输
- 按照一定的协议对 Socket 进行读/ 写操作:通过输入流读取服务器放入线路的信息(但不能读取自己放入线路的信息),通过输出流将信息写入线路。
- 关闭 Socket :断开客户端到服务器的连接,释放线路
相关API
ServerSocket类的构造方法:
- ServerSocket(int port) :创建绑定到特定端口的服务器套接字。
ServerSocket类的常用方法:
- Socket accept():侦听并接受到此套接字的连接。
Socket类的常用构造方法:
- public Socket(InetAddress address,int port):创建一个流套接字并将其连接到指定 IP 地址的指定端口号。
- public Socket(String host,int port):创建一个流套接字并将其连接到指定主机上的指定端口号。
Socket类的常用方法:
- public InputStream getInputStream():返回此套接字的输入流,可以用于接收消息
- public OutputStream getOutputStream():返回此套接字的输出流,可以用于发送消息
- public InetAddress getInetAddress():此套接字连接到的远程 IP 地址;如果套接字是未连接的,则返回 null。
- public InetAddress getLocalAddress():获取套接字绑定的本地地址。
- public int getPort():此套接字连接到的远程端口号;如果尚未连接套接字,则返回 0。
- public int getLocalPort():返回此套接字绑定到的本地端口。如果尚未绑定套接字,则返回 -1。
- public void close():关闭此套接字。套接字被关闭后,便不可在以后的网络连接中使用(即无法重新连接或重新绑定)。需要创建新的套接字对象。 关闭此套接字也将会关闭该套接字的 InputStream 和 OutputStream。
- public void shutdownInput():如果在套接字上调用 shutdownInput() 后从套接字输入流读取内容,则流将返回 EOF(文件结束符)。 即不能在从此套接字的输入流中接收任何数据。
- public void shutdownOutput():禁用此套接字的输出流。对于 TCP 套接字,任何以前写入的数据都将被发送,并且后跟 TCP 的正常连接终止序列。 如果在套接字上调用 shutdownOutput() 后写入套接字输出流,则该流将抛出 IOException。 即不能通过此套接字的输出流发送任何数据。
注意:先后调用Socket的shutdownInput()和shutdownOutput()方法,仅仅关闭了输入流和输出流,并不等于调用Socket的close()方法。在通信结束后,仍然要调用Scoket的close()方法,因为只有该方法才会释放Socket占用的资源,比如占用的本地端口号等。
示例一:单个客户端与服务器单次通信
需求:客户端连接服务器,连接成功后给服务发送“lalala”,服务器收到消息后,给客户端返回“欢迎登录”,客户端接收消息后,断开连接
客户端示例代码
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
public class Client {
public static void main(String[] args) throws Exception {
// 1、准备Socket,连接服务器,需要指定服务器的IP地址和端口号
Socket socket = new Socket("127.0.0.1", 8888);
// 2、获取输出流,用来发送数据给服务器
OutputStream out = socket.getOutputStream();
// 发送数据
out.write("lalala".getBytes());
//会在流末尾写入一个“流的末尾”标记,对方才能读到-1,否则对方的读取方法会一致阻塞
socket.shutdownOutput();
//3、获取输入流,用来接收服务器发送给该客户端的数据
InputStream input = socket.getInputStream();
// 接收数据
byte[] data = new byte[1024];
StringBuilder s = new StringBuilder();
int len;
while ((len = input.read(data)) != -1) {
s.append(new String(data, 0, len));
}
System.out.println("服务器返回的消息是:" + s);
//4、关闭socket,不再与服务器通信,即断开与服务器的连接
//socket关闭,意味着InputStream和OutputStream也关闭了
socket.close();
}
}服务器端示例代码
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class Server {
public static void main(String[] args)throws Exception {
//1、准备一个ServerSocket对象,并绑定8888端口
ServerSocket server = new ServerSocket(8888);
System.out.println("等待连接....");
//2、在8888端口监听客户端的连接,该方法是个阻塞的方法,如果没有客户端连接,将一直等待
Socket socket = server.accept();
System.out.println("一个客户端连接成功!!");
//3、获取输入流,用来接收该客户端发送给服务器的数据
InputStream input = socket.getInputStream();
//接收数据
byte[] data = new byte[1024];
StringBuilder s = new StringBuilder();
int len;
while ((len = input.read(data)) != -1) {
s.append(new String(data, 0, len));
}
System.out.println("客户端发送的消息是:" + s);
//4、获取输出流,用来发送数据给该客户端
OutputStream out = socket.getOutputStream();
//发送数据
out.write("欢迎登录".getBytes());
out.flush();
//5、关闭socket,不再与该客户端通信
//socket关闭,意味着InputStream和OutputStream也关闭了
socket.close();
//6、如果不再接收任何客户端通信,可以关闭ServerSocket
server.close();
}
}示例二:多个客户端与服务器之间的多次通信
通常情况下,服务器不应该只接受一个客户端请求,而应该不断地接受来自客户端的所有请求,所以Java程序通常会通过循环,不断地调用ServerSocket的accept()方法。
如果服务器端要“同时”处理多个客户端的请求,因此服务器端需要为每一个客户端单独分配一个线程来处理,否则无法实现“同时”。
咱们之前学习IO流的时候,提到过装饰者设计模式,该设计使得不管底层IO流是怎样的节点流:文件流也好,网络Socket产生的流也好,程序都可以将其包装成处理流,甚至可以多层包装,从而提供更多方便的处理。
案例需求:多个客户端连接服务器,并进行多次通信
- 每一个客户端连接成功后,从键盘输入英文单词或中国成语,并发送给服务器
- 服务器收到客户端的消息后,把词语“反转”后返回给客户端
- 客户端接收服务器返回的“词语”,打印显示
- 当客户端输入“stop”时断开与服务器的连接
- 多个客户端可以同时给服务器发送“词语”,服务器可以“同时”处理多个客户端的请求

客户端示例代码
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.PrintStream;
import java.net.Socket;
import java.util.Scanner;
public class Client2 {
public static void main(String[] args) throws Exception {
// 1、准备Socket,连接服务器,需要指定服务器的IP地址和端口号
Socket socket = new Socket("127.0.0.1", 8888);
// 2、获取输出流,用来发送数据给服务器
OutputStream out = socket.getOutputStream();
PrintStream ps = new PrintStream(out);
// 3、获取输入流,用来接收服务器发送给该客户端的数据
InputStream input = socket.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(input));
Scanner scanner = new Scanner(System.in);
while(true){
System.out.println("输入发送给服务器的单词或成语:");
String message = scanner.nextLine();
if(message.equals("stop")){
socket.shutdownOutput();
break;
}
// 4、 发送数据
ps.println(message);
// 接收数据
String feedback = br.readLine();
System.out.println("从服务器收到的反馈是:" + feedback);
}
//5、关闭socket,断开与服务器的连接
scanner.close();
socket.close();
}
}
服务器端示例代码
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.net.ServerSocket;
import java.net.Socket;
public class Server2 {
public static void main(String[] args) throws IOException {
// 1、准备一个ServerSocket
ServerSocket server = new ServerSocket(8888);
System.out.println("等待连接...");
int count = 0;
while(true){
// 2、监听一个客户端的连接
Socket socket = server.accept();
System.out.println("第" + ++count + "个客户端"+socket.getInetAddress().getHostAddress()+"连接成功!!");
ClientHandlerThread ct = new ClientHandlerThread(socket);
ct.start();
}
//这里没有关闭server,永远监听
}
static class ClientHandlerThread extends Thread{
private Socket socket;
public ClientHandlerThread(Socket socket) {
super();
this.socket = socket;
}
public void run(){
try{
//(1)获取输入流,用来接收该客户端发送给服务器的数据
BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream()));
//(2)获取输出流,用来发送数据给该客户端
PrintStream ps = new PrintStream(socket.getOutputStream());
String str;
// (3)接收数据
while ((str = br.readLine()) != null) {
//(4)反转
StringBuilder word = new StringBuilder(str);
word.reverse();
//(5)返回给客户端
ps.println(word);
}
System.out.println(socket.getInetAddress().getHostAddress()+"正常退出");
}catch(Exception e){
System.out.println(socket.getInetAddress().getHostAddress()+"意外退出");
}finally{
try {
//(6)断开连接
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}UDP网络编程
UDP(User Datagram Protocol,用户数据报协议):是一个无连接的传输层协议、提供面向事务的简单不可靠的信息传送服务,类似于短信。
UDP协议是一种面向非连接的协议,面向非连接指的是在正式通信前不必与对方先建立连接,不管对方状态就直接发送,至于对方是否可以接收到这些数据内容,UDP协议无法控制,因此说,UDP协议是一种不可靠的协议。无连接的好处就是快,省内存空间和流量,因为维护连接需要创建大量的数据结构。UDP会尽最大努力交付数据,但不保证可靠交付,没有TCP的确认机制、重传机制,如果因为网络原因没有传送到对端,UDP也不会给应用层返回错误信息。
UDP协议是面向数据报文的信息传送服务。UDP在发送端没有缓冲区,对于应用层交付下来的报文在添加了首部之后就直接交付于ip层,不会进行合并,也不会进行拆分,而是一次交付一个完整的报文。比如我们要发送100个字节的报文,我们调用一次send()方法就会发送100字节,接收方也需要用receive()方法一次性接收100字节,不能使用循环每次获取10个字节,获取十次这样的做法。
UDP协议没有拥塞控制,所以当网络出现的拥塞不会导致主机发送数据的速率降低。虽然UDP的接收端有缓冲区,但是这个缓冲区只负责接收,并不会保证UDP报文的到达顺序是否和发送的顺序一致。因为网络传输的时候,由于网络拥塞的存在是很大的可能导致先发的报文比后发的报文晚到达。如果此时缓冲区满了,后面到达的报文将直接被丢弃。这个对实时应用来说很重要,比如:视频通话、直播等应用。
因此UDP适用于一次只传送少量数据、对可靠性要求不高的应用环境,数据报大小限制在64K以下。
相关API
基于UDP协议的网络编程仍然需要在通信实例的两端各建立一个Socket,但这两个Socket之间并没有虚拟链路,这两个Socket只是发送、接收数据报的对象,Java提供了DatagramSocket对象作为基于UDP协议的Socket,使用DatagramPacket代表DatagramSocket发送、接收的数据报。
DatagramSocket 类的常用方法:
- public DatagramSocket(int port)创建数据报套接字并将其绑定到本地主机上的指定端口。套接字将被绑定到通配符地址,IP 地址由内核来选择。
- public DatagramSocket(int port,InetAddress laddr)创建数据报套接字,将其绑定到指定的本地地址。本地端口必须在 0 到 65535 之间(包括两者)。如果 IP 地址为 0.0.0.0,套接字将被绑定到通配符地址,IP 地址由内核选择。
- public void close()关闭此数据报套接字。
- public void send(DatagramPacket p)从此套接字发送数据报包。DatagramPacket 包含的信息指示:将要发送的数据、其长度、远程主机的 IP 地址和远程主机的端口号。
- public void receive(DatagramPacket p)从此套接字接收数据报包。当此方法返回时,DatagramPacket 的缓冲区填充了接收的数据。数据报包也包含发送方的 IP 地址和发送方机器上的端口号。 此方法在接收到数据报前一直阻塞。数据报包对象的 length 字段包含所接收信息的长度。如果信息比包的长度长,该信息将被截短。
DatagramPacket类的常用方法:
- public DatagramPacket(byte[] buf,int length)构造 DatagramPacket,用来接收长度为 length 的数据包。 length 参数必须小于等于 buf.length。
- public DatagramPacket(byte[] buf,int length,InetAddress address,int port)构造数据报包,用来将长度为 length 的包发送到指定主机上的指定端口号。length 参数必须小于等于 buf.length。
- public int getLength()返回将要发送或接收到的数据的长度。
示例代码
发送端:
package com.atguigu.udp;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetAddress;
import java.util.ArrayList;
public class Send {
public static void main(String[] args)throws Exception {
// 1、建立发送端的DatagramSocket
DatagramSocket ds = new DatagramSocket();
//要发送的数据
ArrayList<String> all = new ArrayList<String>();
all.add("尚硅谷让天下没有难学的技术!");
all.add("学高端前沿的IT技术来尚硅谷!");
all.add("尚硅谷让你的梦想变得更具体!");
all.add("尚硅谷让你的努力更有价值!");
//接收方的IP地址
InetAddress ip = InetAddress.getByName("127.0.0.1");
//接收方的监听端口号
int port = 9999;
//发送多个数据报
for (int i = 0; i < all.size(); i++) {
// 2、建立数据包DatagramPacket
byte[] data = all.get(i).getBytes();
DatagramPacket dp = new DatagramPacket(data, data.length, ip, port);
// 3、调用Socket的发送方法
ds.send(dp);
}
// 4、关闭Socket
ds.close();
}
}接收端:
package com.atguigu.udp;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
public class Receive {
public static void main(String[] args) throws Exception {
// 1、建立接收端的DatagramSocket,需要指定本端的监听端口号
DatagramSocket ds = new DatagramSocket(9999);
//一直监听数据
while(true){
// 2、建立数据包DatagramPacket
byte[] buffer = new byte[1024*64];
DatagramPacket dp = new DatagramPacket(buffer , buffer.length);
// 3、调用Socket的接收方法
ds.receive(dp);
//4、拆封数据
String str = new String(buffer,0,dp.getLength());
System.out.println(str);
}
}
}反射(Reflect)
类加载
类在内存中的生命周期:加载—>使用—>卸载
类的加载过程
当程序主动使用某个类时,如果该类还未被加载到内存中,系统会通过加载、连接、初始化三个步骤来对该类进行初始化,如果没有意外,JVM将会连续完成这三个步骤,所以有时也把这三个步骤统称为类加载。
类的加载又分为三个阶段:
(1)加载:load
就是指将类型的clas字节码数据读入内存
(2)连接:link
①验证:校验合法性等
②准备:准备对应的内存(方法区),创建Class对象,为类变量赋默认值,为静态常量赋初始值。
③解析:把字节码中的符号引用替换为对应的直接地址引用
(3)初始化:initialize(类初始化)即执行
类初始化
1、哪些操作会导致类的初始化?
(1)运行主方法所在的类,要先完成类初始化,再执行main方法
(2)第一次使用某个类型就是在new它的对象,此时这个类没有初始化的话,先完成类初始化再做实例初始化
(3)调用某个类的静态成员(类变量和类方法),此时这个类没有初始化的话,先完成类初始化
(4)子类初始化时,发现它的父类还没有初始化的话,那么先初始化父类
(5)通过反射操作某个类时,如果这个类没有初始化,也会导致该类先初始化
类初始化执行的是
(),该方法由(1)类变量的显式赋值代码(2)静态代码块中的代码构成
class Father{
static{
System.out.println("main方法所在的类的父类(1)");//初始化子类时,会初始化父类
}
}
public class TestClinit1 extends Father{
static{
System.out.println("main方法所在的类(2)");//主方法所在的类会初始化
}
public static void main(String[] args) throws ClassNotFoundException {
new A();//第一次使用A就是创建它的对象,会初始化A类
B.test();//直接使用B类的静态成员会初始化B类
Class clazz = Class.forName("com.atguigu.test02.C");//通过反射操作C类,会初始化C类
}
}
class A{
static{
System.out.println("A类初始化");
}
}
class B{
static{
System.out.println("B类初始化");
}
public static void test(){
System.out.println("B类的静态方法");
}
}
class C{
static{
System.out.println("C类初始化");
}
}2、哪些使用类的操作,但是不会导致类的初始化?
(1)使用某个类的静态的常量(static final)
(2)通过子类调用父类的静态变量,静态方法,只会导致父类初始化,不会导致子类初始化,即只有声明静态成员的类才会初始化
(3)用某个类型声明数组并创建数组对象时,不会导致这个类初始化
public class TestClinit2 {
public static void main(String[] args) {
System.out.println(D.NUM);//D类不会初始化,因为NUM是final的
System.out.println(F.num);
F.test();//F类不会初始化,E类会初始化,因为num和test()是在E类中声明的
//G类不会初始化,此时还没有正式用的G类
G[] arr = new G[5];//没有创建G的对象,创建的是准备用来装G对象的数组对象
//G[]是一种新的类型,是数组类想,动态编译生成的一种新的类型
//G[].class
}
}
class D{
public static final int NUM = 10;
static{
System.out.println("D类的初始化");
}
}
class E{
static int num = 10;
static{
System.out.println("E父类的初始化");
}
public static void test(){
System.out.println("父类的静态方法");
}
}
class F extends E{
static{
System.out.println("F子类的初始化");
}
}
class G{
static{
System.out.println("G类的初始化");
}
}类加载器
很多开发人员都遇到过java.lang.ClassNotFoundException或java.lang.NoClassDefError,想要更好的解决这类问题,或者在一些特殊的应用场景,比如需要支持类的动态加载或需要对编译后的字节码文件进行加密解密操作,那么需要你自定义类加载器,因此了解类加载器及其类加载机制也就成了每一个Java开发人员的必备技能之一。
1、类加载器分为:
(1)引导类加载器(Bootstrap Classloader)又称为根类加载器
它负责加载jre/rt.jar核心库
它本身不是Java代码实现的,也不是ClassLoader的子类,获取它的对象时往往返回null
(2)扩展类加载器(Extension ClassLoader)
它负责加载jre/lib/ext扩展库
它是ClassLoader的子类
(3)应用程序类加载器(Application Classloader)
它负责加载项目的classpath路径下的类
它是ClassLoader的子类
(4)自定义类加载器
当你的程序需要加载“特定”目录下的类,可以自定义类加载器;
当你的程序的字节码文件需要加密时,那么往往会提供一个自定义类加载器对其进行解码
后面会见到的自定义类加载器:tomcat中
2、Java系统类加载器的双亲委托模式
简单描述:
下一级的类加载器,如果接到任务时,会先搜索是否加载过,如果没有,会先把任务往上传,如果都没有加载过,一直到根加载器,如果根加载器在它负责的路径下没有找到,会往回传,如果一路回传到最后一级都没有找到,那么会报ClassNotFoundException或NoClassDefError,如果在某一级找到了,就直接返回Class对象。
应用程序类加载器 把 扩展类加载器视为父加载器,
扩展类加载器 把 引导类加载器视为父加载器。
不是继承关系,是组合的方式实现的。
javalang.Class类
Java反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的反射机制。
要想解剖一个类,必须先要获取到该类的Class对象。而剖析一个类或用反射解决具体的问题就是使用相关API(1)java.lang.Class(2)java.lang.reflect.*。所以,Class对象是反射的根源。
哪些类型可以获取Class对象
所有Java类型
用代码示例
//(1)基本数据类型和void
例如:int.class
void.class
//(2)类和接口
例如:String.class
Comparable.class
//(3)枚举
例如:ElementType.class
//(4)注解
例如:Override.class
//(5)数组
例如:int[].class获取Class对象的四种方式
(1)类型名.class
要求编译期间已知类型
(2)对象.getClass()
获取对象的运行时类型
(3)Class.forName(类型全名称)
可以获取编译期间未知的类型
(4)ClassLoader的类加载器对象.loadClass(类型全名称)
可以用系统类加载对象或自定义加载器对象加载指定路径下的类型
public class TestClass {
@Test
public void test05() throws ClassNotFoundException{
Class c = TestClass.class;
ClassLoader loader = c.getClassLoader();
Class c2 = loader.loadClass("com.atguigu.test05.Employee");
Class c3 = Employee.class;
System.out.println(c2 == c3);
}
@Test
public void test03() throws ClassNotFoundException{
Class c2 = String.class;
Class c1 = "".getClass();
Class c3 = Class.forName("java.lang.String");
System.out.println(c1 == c2);
System.out.println(c1 == c3);
}
}查看某个类的类加载器对象
//获取应用程序类加载器对象
//获取扩展类加载器对象
//获取根加载器对象反射的应用
获取类型的详细信息
可以获取:包、修饰符、类型名、父类(包括泛型父类)、父接口(包括泛型父接口)、成员(属性、构造器、方法)、注解(类上的、方法上的、属性上的)
示例代码获取常规信息:
public class TestClassInfo {
public static void main(String[] args) throws NoSuchFieldException, SecurityException {
//1、先得到某个类型的Class对象
Class clazz = String.class;
//比喻clazz好比是镜子中的影子
//2、获取类信息
//(1)获取包对象,即所有java的包,都是Package的对象
Package pkg = clazz.getPackage();
System.out.println("包名:" + pkg.getName());
//(2)获取修饰符
//其实修饰符是Modifier,里面有很多常量值
/*
* 0x是十六进制
* PUBLIC = 0x00000001; 1 1
* PRIVATE = 0x00000002; 2 10
* PROTECTED = 0x00000004; 4 100
* STATIC = 0x00000008; 8 1000
* FINAL = 0x00000010; 16 10000
* ...
*
* 设计的理念,就是用二进制的某一位是1,来代表一种修饰符,整个二进制中只有一位是1,其余都是0
*
* mod = 17 0x00000011
* if ((mod & PUBLIC) != 0) 说明修饰符中有public
* if ((mod & FINAL) != 0) 说明修饰符中有final
*/
int mod = clazz.getModifiers();
System.out.println(Modifier.toString(mod));
//(3)类型名
String name = clazz.getName();
System.out.println(name);
//(4)父类,父类也有父类对应的Class对象
Class superclass = clazz.getSuperclass();
System.out.println(superclass);
//(5)父接口们
Class[] interfaces = clazz.getInterfaces();
for (Class class1 : interfaces) {
System.out.println(class1);
}
//(6)类的属性, 你声明的一个属性,它是Field的对象
/* Field clazz.getField(name) 根据属性名获取一个属性对象,但是只能得到公共的
Field[] clazz.getFields(); 获取所有公共的属性
Field clazz.getDeclaredField(name) 根据属性名获取一个属性对象,可以获取已声明的
Field[] clazz.getDeclaredFields() 获取所有已声明的属性
*/
Field valueField = clazz.getDeclaredField("value");
// System.out.println("valueField = " +valueField);
Field[] declaredFields = clazz.getDeclaredFields();
for (Field field : declaredFields) {
//修饰符、数据类型、属性名
int modifiers = field.getModifiers();
System.out.println("属性的修饰符:" + Modifier.toString(modifiers));
String name2 = field.getName();
System.out.println("属性名:" + name2);
Class<?> type = field.getType();
System.out.println("属性的数据类型:" + type);
}
System.out.println("-------------------------");
//(7)构造器们
Constructor[] constructors = clazz.getDeclaredConstructors();
for (Constructor constructor : constructors) {
//修饰符、构造器名称、构造器形参列表 、抛出异常列表
int modifiers = constructor.getModifiers();
System.out.println("构造器的修饰符:" + Modifier.toString(modifiers));
String name2 = constructor.getName();
System.out.println("构造器名:" + name2);
//形参列表
System.out.println("形参列表:");
Class[] parameterTypes = constructor.getParameterTypes();
for (Class parameterType : parameterTypes) {
System.out.println(parameterType);
}
//异常列表
System.out.println("异常列表:");
Class<?>[] exceptionTypes = constructor.getExceptionTypes();
for (Class<?> exceptionType : exceptionTypes) {
System.out.println(exceptionType);
}
}
System.out.println("=--------------------------------");
//(8)方法们
Method[] declaredMethods = clazz.getDeclaredMethods();
for (Method method : declaredMethods) {
//修饰符、返回值类型、方法名、形参列表 、异常列表
int modifiers = method.getModifiers();
System.out.println("方法的修饰符:" + Modifier.toString(modifiers));
Class<?> returnType = method.getReturnType();
System.out.println("返回值类型:" + returnType);
String name2 = method.getName();
System.out.println("方法名:" + name2);
//形参列表
System.out.println("形参列表:");
Class[] parameterTypes = method.getParameterTypes();
for (Class parameterType : parameterTypes) {
System.out.println(parameterType);
}
//异常列表
System.out.println("异常列表:");
Class<?>[] exceptionTypes = method.getExceptionTypes();
for (Class<?> exceptionType : exceptionTypes) {
System.out.println(exceptionType);
}
}
}
}创建任意引用类型的对象
两种方式:
1、直接通过Class对象来实例化(要求必须有无参构造)
2、通过获取构造器对象来进行实例化
方式一的步骤:
(1)获取该类型的Class对象(2)创建对象
@Test
public void test2()throws Exception{
Class<?> clazz = Class.forName("com.atguigu.test.Student");
//Caused by: java.lang.NoSuchMethodException: com.atguigu.test.Student.<init>()
//即说明Student没有无参构造,就没有无参实例初始化方法<init>
Object stu = clazz.newInstance();
System.out.println(stu);
}
@Test
public void test1() throws ClassNotFoundException, InstantiationException, IllegalAccessException{
// AtGuigu obj = new AtGuigu();//编译期间无法创建
Class<?> clazz = Class.forName("com.atguigu.test.AtGuigu");
//clazz代表com.atguigu.test.AtGuigu类型
//clazz.newInstance()创建的就是AtGuigu的对象
Object obj = clazz.newInstance();
System.out.println(obj);
}方式二的步骤:
(1)获取该类型的Class对象(2)获取构造器对象(3)创建对象
如果构造器的权限修饰符修饰的范围不可见,也可以调用setAccessible(true)
示例代码:
public class TestNewInstance {
@Test
public void test3()throws Exception{
//(1)获取Class对象
Class<?> clazz = Class.forName("com.atguigu.test.Student");
/*
* 获取Student类型中的有参构造
* 如果构造器有多个,我们通常是根据形参【类型】列表来获取指定的一个构造器的
* 例如:public Student(int id, String name)
*/
//(2)获取构造器对象
Constructor<?> constructor = clazz.getDeclaredConstructor(int.class,String.class);
//(3)创建实例对象
// T newInstance(Object... initargs) 这个Object...是在创建对象时,给有参构造的实参列表
Object obj = constructor.newInstance(2,"张三");
System.out.println(obj);
}
}操作任意类型的属性
(1)获取该类型的Class对象
Class clazz = Class.forName(“com.atguigu.bean.User”);
(2)获取属性对象
Field field = clazz.getDeclaredField(“username”);
(3)设置属性可访问
field.setAccessible(true);
(4)创建实例对象:如果操作的是非静态属性,需要创建实例对象
Object obj = clazz.newInstance();
(4)设置属性值
field.set(obj,”chai”);
(5)获取属性值
Object value = field.get(obj);
如果操作静态变量,那么实例对象可以省略,用null表示
示例代码:
public class TestField {
public static void main(String[] args)throws Exception {
//1、获取Student的Class对象
Class clazz = Class.forName("com.atguigu.test.Student");
//2、获取属性对象,例如:id属性
Field idField = clazz.getDeclaredField("id");
//3、如果id是私有的等在当前类中不可访问access的,我们需要做如下操作
idField.setAccessible(true);
//4、创建实例对象,即,创建Student对象
Object stu = clazz.newInstance();
//5、获取属性值
/*
* 以前:int 变量= 学生对象.getId()
* 现在:Object id属性对象.get(学生对象)
*/
Object value = idField.get(stu);
System.out.println("id = "+ value);
//6、设置属性值
/*
* 以前:学生对象.setId(值)
* 现在:id属性对象.set(学生对象,值)
*/
idField.set(stu, 2);
value = idField.get(stu);
System.out.println("id = "+ value);
}
}调用任意类型的方法
(1)获取该类型的Class对象
Class clazz = Class.forName(“com.atguigu.service.UserService”);
(2)获取方法对象
Method method = clazz.getDeclaredMethod(“login”,String.class,String.class);
(3)创建实例对象
Object obj = clazz.newInstance();
(4)调用方法
Object result = method.invoke(obj,”chai”,”123);
如果方法的权限修饰符修饰的范围不可见,也可以调用setAccessible(true)
如果方法是静态方法,实例对象也可以省略,用null代替
示例代码:
public class TestMethod {
@Test
public void test()throws Exception {
// 1、获取Student的Class对象
Class<?> clazz = Class.forName("com.atguigu.test.Student");
//2、获取方法对象
/*
* 在一个类中,唯一定位到一个方法,需要:(1)方法名(2)形参列表,因为方法可能重载
*
* 例如:void setName(String name)
*/
Method method = clazz.getDeclaredMethod("setName", String.class);
//3、创建实例对象
Object stu = clazz.newInstance();
//4、调用方法
/*
* 以前:学生对象.setName(值)
* 现在:方法对象.invoke(学生对象,值)
*/
method.invoke(stu, "张三");
System.out.println(stu);
}
}获取泛型父类信息
示例代码获取泛型父类信息:
/* Type:
* (1)Class
* (2)ParameterizedType
* 例如:Father<String,Integer>
* ArrayList<String>
* (3)TypeVariable
* 例如:T,U,E,K,V
* (4)WildcardType
* 例如:
* ArrayList<?>
* ArrayList<? super 下限>
* ArrayList<? extends 上限>
* (5)GenericArrayType
* 例如:T[]
*
*/
public class TestGeneric {
public static void main(String[] args) {
//需求:在运行时,获取Son类型的泛型父类的泛型实参<String,Integer>
//(1)还是先获取Class对象
Class clazz = Son.class;//四种形式任意一种都可以
//(2)获取泛型父类
// Class sc = clazz.getSuperclass();
// System.out.println(sc);
/*
* getSuperclass()只能得到父类名,无法得到父类的泛型实参列表
*/
Type type = clazz.getGenericSuperclass();
// Father<String,Integer>属于ParameterizedType
ParameterizedType pt = (ParameterizedType) type;
//(3)获取泛型父类的泛型实参列表
Type[] typeArray = pt.getActualTypeArguments();
for (Type type2 : typeArray) {
System.out.println(type2);
}
}
}
//泛型形参:<T,U>
class Father<T,U>{
}
//泛型实参:<String,Integer>
class Son extends Father<String,Integer>{
}读取注解信息
示例代码读取注解信息:
public class TestAnnotation {
public static void main(String[] args) {
//需求:可以获取MyClass类型上面配置的注解@MyAnnotation的value值
//读取注解
// (1)获取Class对象
Class<MyClass> clazz = MyClass.class;
//(2)获取注解对象
//获取指定注解对象
MyAnnotation my = clazz.getAnnotation(MyAnnotation.class);
//(3)获取配置参数值
String value = my.value();
System.out.println(value);
}
}
//声明
@Retention(RetentionPolicy.RUNTIME) //说明这个注解可以保留到运行时
@Target(ElementType.TYPE) //说明这个注解只能用在类型上面,包括类,接口,枚举等
@interface MyAnnotation{
//配置参数,如果只有一个配置参数,并且名称是value,在赋值时可以省略value=
String value();
}
//使用注解
@MyAnnotation("/login")
class MyClass{
}获取内部类或外部类信息
public Class<?>[] getClasses():返回所有公共内部类和内部接口。包括从超类继承的公共类和接口成员以及该类声明的公共类和接口成员。
public Class<?>[] getDeclaredClasses():返回 Class 对象的一个数组,这些对象反映声明为此 Class 对象所表示的类的成员的所有类和接口。包括该类所声明的公共、保护、默认(包)访问及私有类和接口,但不包括继承的类和接口。
public Class<?> getDeclaringClass():如果此 Class 对象所表示的类或接口是一个内部类或内部接口,则返回它的外部类或外部接口,否则返回null。
@Test
public void test5(){
Class<?> clazz = Map.class;
Class<?>[] inners = clazz.getDeclaredClasses();
for (Class<?> inner : inners) {
System.out.println(inner);
}
Class<?> ec = Map.Entry.class;
Class<?> outer = ec.getDeclaringClass();
System.out.println(outer);
}动态创建和操作任意类型的数组
在java.lang.reflect包下还提供了一个Array类,Array对象可以代表所有的数组。程序可以通过使用Array类来动态的创建数组,操作数组元素等。
Array类提供了如下几个方法:
public static Object newInstance(Class<?> componentType, int… dimensions):创建一个具有指定的组件类型和维度的新数组。
public static void setXxx(Object array,int index,xxx value):将array数组中[index]元素的值修改为value。此处的Xxx对应8种基本数据类型,如果该属性的类型是引用数据类型,则直接使用set(Object array,int index, Object value)方法。
public static xxx getXxx(Object array,int index,xxx value):将array数组中[index]元素的值返回。此处的Xxx对应8种基本数据类型,如果该属性的类型是引用数据类型,则直接使用get(Object array,int index)方法。
import java.lang.reflect.Array;
public class TestArray {
public static void main(String[] args) {
Object arr = Array.newInstance(String.class, 5);
Array.set(arr, 0, "尚硅谷");
Array.set(arr, 1, "佟刚");
System.out.println(Array.get(arr, 0));
System.out.println(Array.get(arr, 1));
System.out.println(Array.get(arr, 2));
}
} 微信
微信 支付宝
支付宝







