JAVA中的伪共享与缓存行
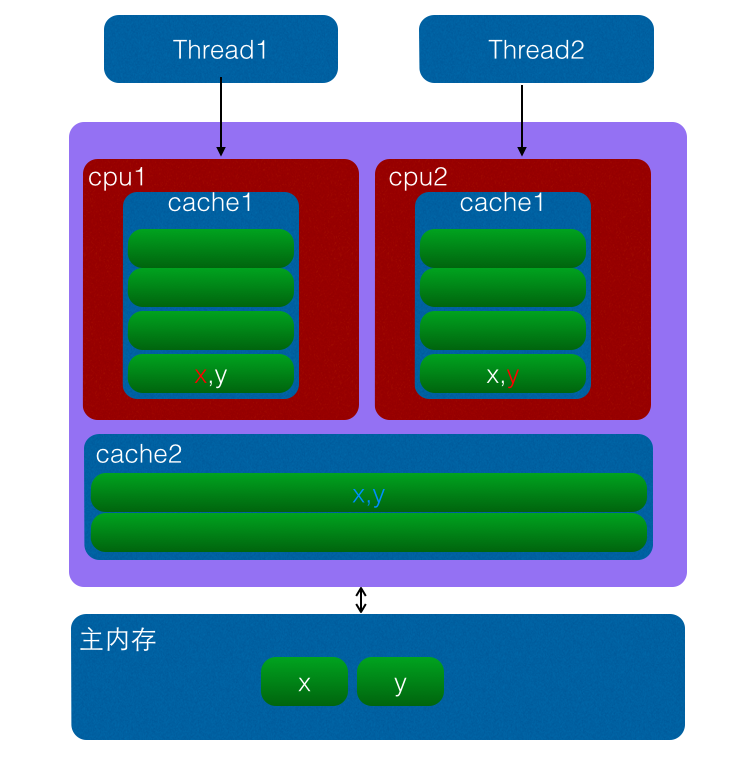
Java中的伪共享
解决伪共享最直接的方法就是填充(padding),例如下面的VolatileLong,一个long占8个字节,Java的对象头占用8个字节(32位系统)或者12字节(64位系统,默认开启对象头压缩,不开启占16字节)。一个缓存行64字节,那么我们可以填充6个long(6 * 8 = 48 个字节)。
现在,我们学习JVM对象的内存模型。所有的Java对象都有8字节的对象头,前四个字节用来保存对象的哈希码和锁的状态,前3个字节用来存储哈希码,最后一个字节用来存储锁状态,一旦对象上锁,这4个字节都会被拿出对象外,并用指针进行链接。剩下4个字节用来存储对象所属类的引用。对于数组来讲,还有一个保存数组大小的变量,为4字节。每一个对象的大小都会对齐到8字节的倍数,不够8字节部分需要填充。为了保证效率,Java编译器在编译Java对象的时候,通过字段类型对Java对象的字段进行排序,如下表所示。
| 顺序 | 类型 | 字节数量 |
|---|---|---|
| 1 | double | 8字节 |
| 2 | long | 8字节 |
| 3 | int | 4字节 |
| 4 | float | 4字节 |
| 5 | short | 2字节 |
| 6 | char | 2字节 |
| 7 | boolean | 1字节 |
| 8 | byte | 1字节 |
| 9 | 对象引用 | 4字节或者8字节 |
| 10 | 子类字段 | 重新排序 |
因此,我们可以在任何字段之间通过填充长整型的变量把热点变量隔离在不同的缓存行中,通过减少伪同步,在多核心CPU中能够极大的提高效率。
最简单的方式
/**
* 缓存行填充父类
*/
public class DataPadding {
//填充 6个long类型字段 8*4 = 48 个字节
private long p1, p2, p3, p4, p5, p6;
//需要操作的数据
private long data;
}因为JDK1.7以后就自动优化代码会删除无用的代码,在JDK1.7以后的版本这些不生效了。
继承的方式
/**
* 缓存行填充父类
*/
public class DataPadding {
//填充 6个long类型字段 8*4 = 48 个字节
private long p1, p2, p3, p4, p5, p6;
}继承缓存填充类
/**
* 继承DataPadding
*/
public class VolatileData extends DataPadding {
// 占用 8个字节 +48 + 对象头 = 64字节
private long data = 0;
public VolatileData() {
}
public VolatileData(long defValue) {
this.data = defValue;
}
public long accumulationAdd() {
//因为单线程操作不需要加锁
data++;
return data;
}
public long getValue() {
return data;
}
}这样在JDK1.8中是可以使用的
@Contended注解
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD, ElementType.TYPE})
public @interface Contended {
String value() default "";
}Contended注解可以用于类型上和属性上,加上这个注解之后虚拟机会自动进行填充,从而避免伪共享。这个注解在Java8 ConcurrentHashMap、ForkJoinPool和Thread等类中都有应用。我们来看一下Java8中ConcurrentHashMap中如何运用Contended这个注解来解决伪共享问题。以下说的ConcurrentHashMap都是Java8版本。
Contended可以用于类级别的修饰,同时也可以用于字段级别的修饰,当应用于字段级别时,被注释的字段将和其他字段隔离开来,会被加载在独立的缓存行上。在字段级别上,@Contended还支持一个“contention group”属性(Class-Level不支持),同一group的字段们在内存上将是连续(64字节范围内),但和其他他字段隔离开来。
在类上应用Contended:
@Contended
public static class ContendedTest2 {
private Object plainField1;
private Object plainField2;
private Object plainField3;
private Object plainField4;
}将使整个字段块的两端都被填充:(以下是使用 –XX:+PrintFieldLayout的输出)(翻译注:注意前面的@140表示字段在类中的地址偏移)
TestContended$ContendedTest2: field layout
Entire class is marked contended
@140 --- instance fields start ---
@140 "plainField1" Ljava.lang.Object;
@144 "plainField2" Ljava.lang.Object;
@148 "plainField3" Ljava.lang.Object;
@152 "plainField4" Ljava.lang.Object;
@288 --- instance fields end ---
@288 --- instance ends ---注意,我们使用了128 bytes的填充 – 2倍于大多数硬件缓存行的大小(cache line一般为64 bytes) – 来避免相邻扇区预取导致的伪共享冲突。
在字段上应用Contended:
public static class ContendedTest1 {
@Contended
private Object contendedField1;
private Object plainField1;
private Object plainField2;
private Object plainField3;
private Object plainField4;
}将导致该字段从连续的字段块中分离开来并高效的添加填充:
TestContended$ContendedTest1: field layout
@ 12 --- instance fields start ---
@ 12 "plainField1" Ljava.lang.Object;
@ 16 "plainField2" Ljava.lang.Object;
@ 20 "plainField3" Ljava.lang.Object;
@ 24 "plainField4" Ljava.lang.Object;
@156 "contendedField1" Ljava.lang.Object; (contended, group = 0)
@288 --- instance fields end ---
@288 --- instance ends ---注解多个字段使他们分别被填充:
public static class ContendedTest4 {
@Contended
private Object contendedField1;
@Contended
private Object contendedField2;
private Object plainField3;
private Object plainField4;
}被注解的2个字段都被独立地填充:
TestContended$ContendedTest4: field layout
@ 12 --- instance fields start ---
@ 12 "plainField3" Ljava.lang.Object;
@ 16 "plainField4" Ljava.lang.Object;
@148 "contendedField1" Ljava.lang.Object; (contended, group = 0)
@280 "contendedField2" Ljava.lang.Object; (contended, group = 0)
@416 --- instance fields end ---
@416 --- instance ends ---在有些cases中,你会想对字段进行分组,同一组的字段会和其他字段有访问冲突,但是和同一组的没有。例如,(同一个线程的)代码同时更新2个字段是很常见的情况。如果同时把2个字段都添加@Contended注解是足够的(翻译注:但是太足够了),但我们可以通过去掉他们之间的填充,来优化它们的内存空间占用。为了区分组,我们有一个参数“contention group”来描述:
public static class ContendedTest5 {
@Contended("updater1")
private Object contendedField1;
@Contended("updater1")
private Object contendedField2;
@Contended("updater2")
private Object contendedField3;
private Object plainField5;
private Object plainField6;
}内存布局是:
TestContended$ContendedTest5: field layout
@ 12 --- instance fields start ---
@ 12 "plainField5" Ljava.lang.Object;
@ 16 "plainField6" Ljava.lang.Object;
@148 "contendedField1" Ljava.lang.Object; (contended, group = 12)
@152 "contendedField2" Ljava.lang.Object; (contended, group = 12)
@284 "contendedField3" Ljava.lang.Object; (contended, group = 15)
@416 --- instance fields end ---
@416 --- instance ends ---注意c o n t e n d e d F i e l d 1 和 contendedField1 和contendedField1和contendedField2和其他字段之间有填充,但是它们之间是紧挨着的,类内偏移量为4 bytes,为一个对象的大小。
下面我们来做一个测试,看@Contended在字段级别,并且带分组的情况下,是否能解决伪缓存问题。
import sun.misc.Contended;
public class VolatileLong {
@Contended("group0")
public volatile long value1 = 0L;
@Contended("group0")
public volatile long value2 = 0L;
@Contended("group1")
public volatile long value3 = 0L;
@Contended("group1")
public volatile long value4 = 0L;
}我们用2个线程来修改字段
测试1:线程0修改value1和value2;线程1修改value3和value4;他们都在同一组中。
测试2:线程0修改value1和value3;线程1修改value2和value4;他们在不同组中。
测试1
public final class FalseSharing implements Runnable {
public final static long ITERATIONS = 500L * 1000L * 1000L;
private static Volatile Long volatileLong;
private String groupId;
public FalseSharing(String groupId) {
this.groupId = groupId;
}
public static void main(final String[] args) throws Exception {
// Thread.sleep(10000);
System.out.println("starting....");
volatileLong = new VolatileLong();
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException {
Thread t0 = new Thread(new FalseSharing("t0"));
Thread t1 = new Thread(new FalseSharing("t1"));
t0.start();
t1.start();
t0.join();
t1.join();
}
public void run() {
long i = ITERATIONS + 1;
if (groupId.equals("t0")) {
while (0 != --i) {
volatileLong.value1 = i;
volatileLong.value2 = i;
}
} else if (groupId.equals("t1")) {
while (0 != --i) {
volatileLong.value3 = i;
volatileLong.value4 = i;
}
}
}
}测试2:(基于以上代码修改下面的部分)
public void run() {
long i = ITERATIONS + 1;
if (groupId.equals("t0")) {
while (0 != --i) {
volatileLong.value1 = i;
volatileLong.value3 = i;
}
} else if (groupId.equals("t1")) {
while (0 != --i) {
volatileLong.value2 = i;
volatileLong.value4 = i;
}
}
}原作者的测试数据:
测试1:
starting....
duration = 16821484056测试2:
starting....
duration = 39191867777注意:在Java8中提供了@sun.misc.Contended来避免伪共享时,在运行时需要设置JVM启动参数-XX:-RestrictContended否则可能不生效。
缓存行填充的威力
/**
* 缓存行测试
*/
public class CacheLineTest {
/**
* 是否启用缓存行填充
*/
private final boolean isDataPadding = false;
/**
* 正常定义的变量
*/
private volatile long x = 0;
private volatile long y = 0;
private volatile long z = 0;
/**
* 通过缓存行填充的变量
*/
private volatile VolatileData volatileDataX = new VolatileData(0);
private volatile VolatileData volatileDataY = new VolatileData(0);
private volatile VolatileData volatileDataZ = new VolatileData(0);
/**
* 循环次数
*/
private final long size = 100000000;
/**
* 进行累加操作
*/
public void accumulationX() {
//计算耗时
long currentTime = System.currentTimeMillis();
long value = 0;
//循环累加
for (int i = 0; i < size; i++) {
//使用缓存行填充的方式
if (isDataPadding) {
value = volatileDataX.accumulationAdd();
} else {
//不使用缓存行填充的方式 因为时单线程操作不需要加锁
value = (++x);
}
}
//打印
System.out.println(value);
//打印耗时
System.out.println("耗时:" + (System.currentTimeMillis() - currentTime));
}
/**
* 进行累加操作
*/
public void accumulationY() {
long currentTime = System.currentTimeMillis();
long value = 0;
for (int i = 0; i < size; i++) {
if (isDataPadding) {
value = volatileDataY.accumulationAdd();
} else {
value = ++y;
}
}
System.out.println(value);
System.out.println("耗时:" + (System.currentTimeMillis() - currentTime));
}
/**
* 进行累加操作
*/
public void accumulationZ() {
long currentTime = System.currentTimeMillis();
long value = 0;
for (int i = 0; i < size; i++) {
if (isDataPadding) {
value = volatileDataZ.accumulationAdd();
} else {
value = ++z;
}
}
System.out.println(value);
System.out.println("耗时:" + (System.currentTimeMillis() - currentTime));
}
public static void main(String[] args) {
//创建对象
CacheLineTest cacheRowTest = new CacheLineTest();
//创建线程池
ExecutorService executorService = Executors.newFixedThreadPool(3);
//启动三个线程个调用他们各自的方法
executorService.execute(() -> cacheRowTest.accumulationX());
executorService.execute(() -> cacheRowTest.accumulationY());
executorService.execute(() -> cacheRowTest.accumulationZ());
executorService.shutdown();
}
}不使用缓存行填充测试
/**
* 是否启用缓存行填充
*/
private final boolean isDataPadding = false;输出
100000000
耗时:7960
100000000
耗时:7984
100000000
耗时:7989使用缓存行填充测试
/**
* 是否启用缓存行填充
*/
private final boolean isDataPadding = true;输出
100000000
耗时:176
100000000
耗时:178
100000000
耗时:182同样的结构他们之间差了 将近 50倍的速度差距
总结
当多个线程同时对共享的缓存行进行写操作的时候,因为缓存系统自身的缓存一致性原则,会引发伪共享问题,解决的常用办法是将共享变量根据缓存行大小进行补充对齐,使其加载到缓存时能够独享缓存行,避免与其他共享变量存储在同一个缓存行。
 微信
微信 支付宝
支付宝



