集成学习
集成学习算法简介
什么是集成学习
集成学习通过建立几个模型来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
复习:机器学习的两个核心任务
集成学习中boosting和Baggin
小结
- 什么是集成学习【了解】
- 通过建立几个模型来解决单一预测问题
- 机器学习两个核心任务【知道】
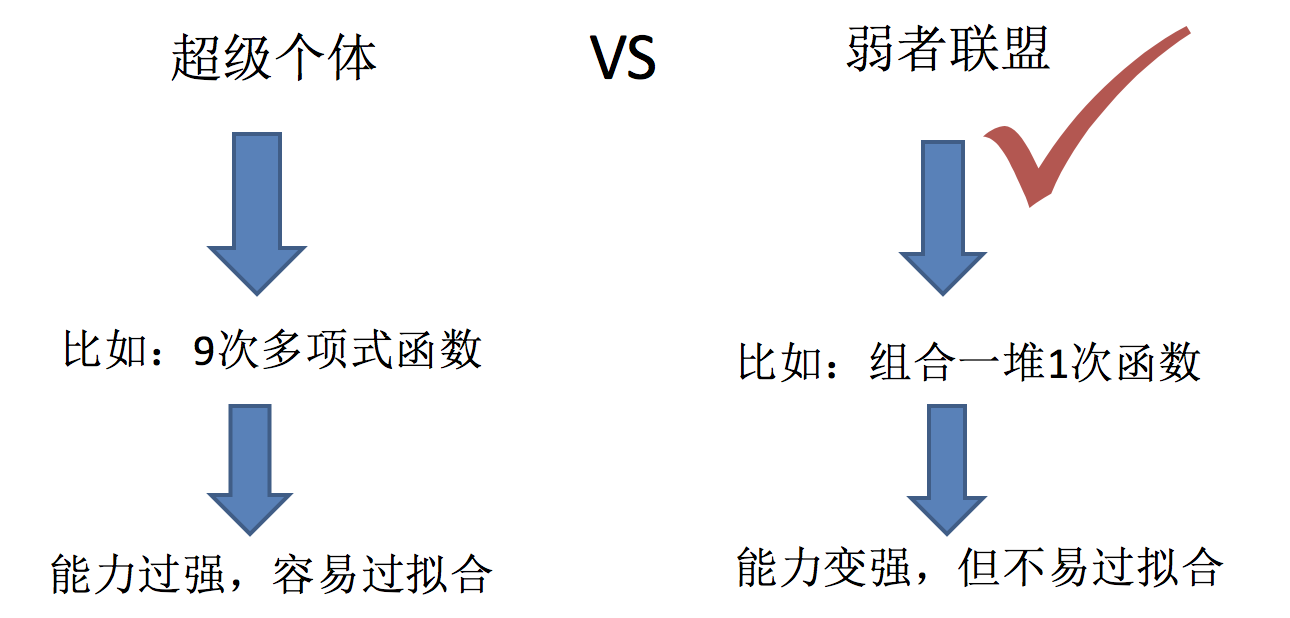
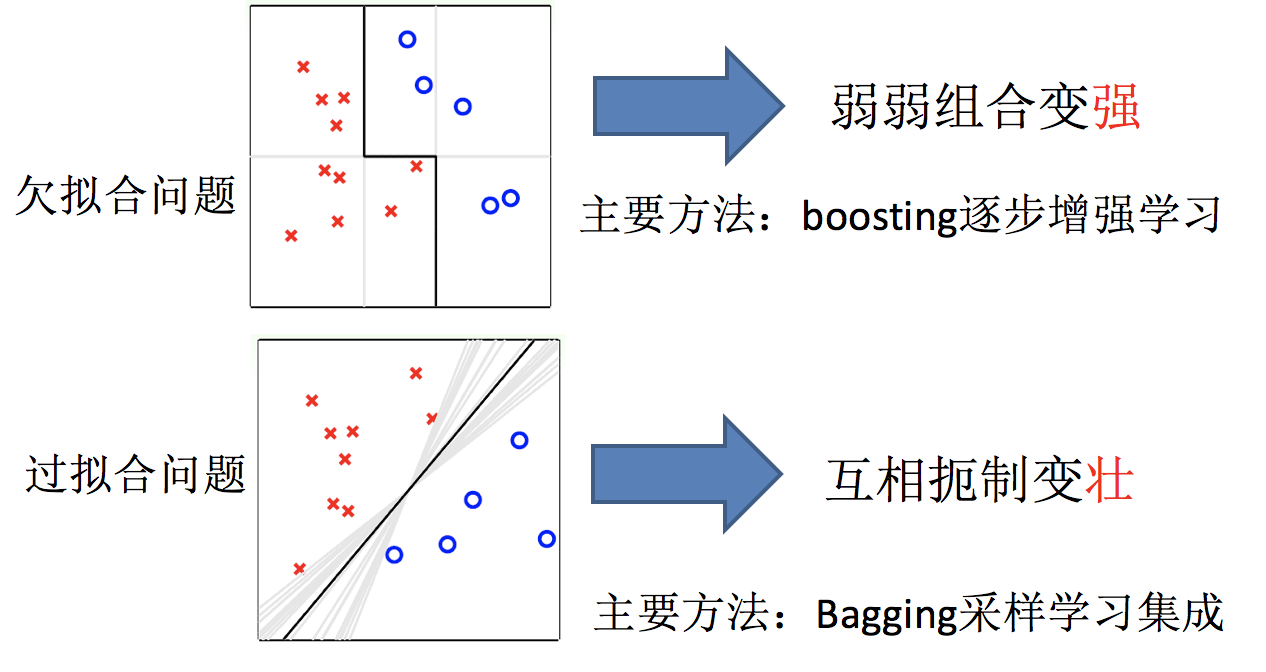
- 1.解决欠拟合问题
- 弱弱组合变强
- boosting
- 2.解决过拟合问题
- 互相遏制变壮
- Bagging
- 1.解决欠拟合问题
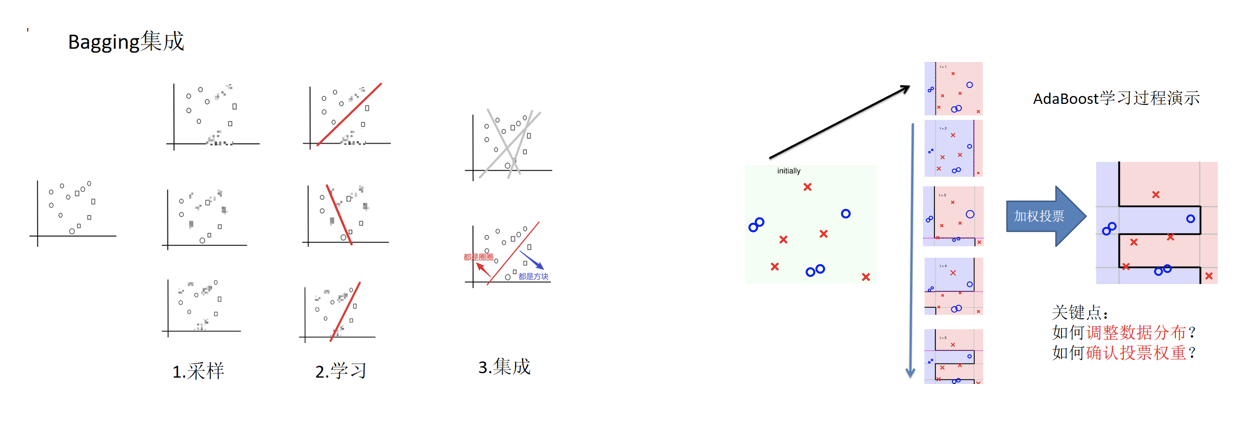
Bagging
Bagging集成原理
目标:把下面的圈和方块进行分类
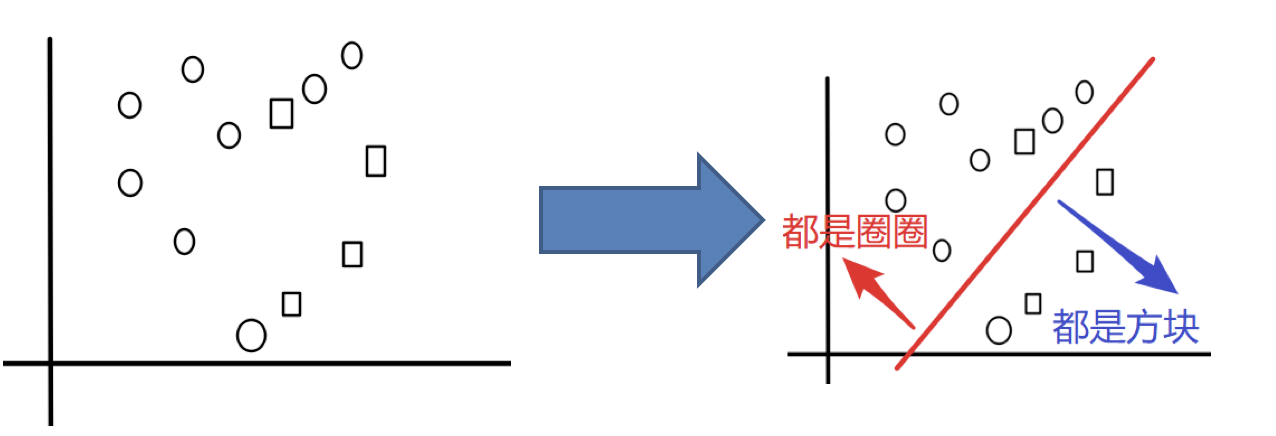
实现过程:
1.采样不同数据集
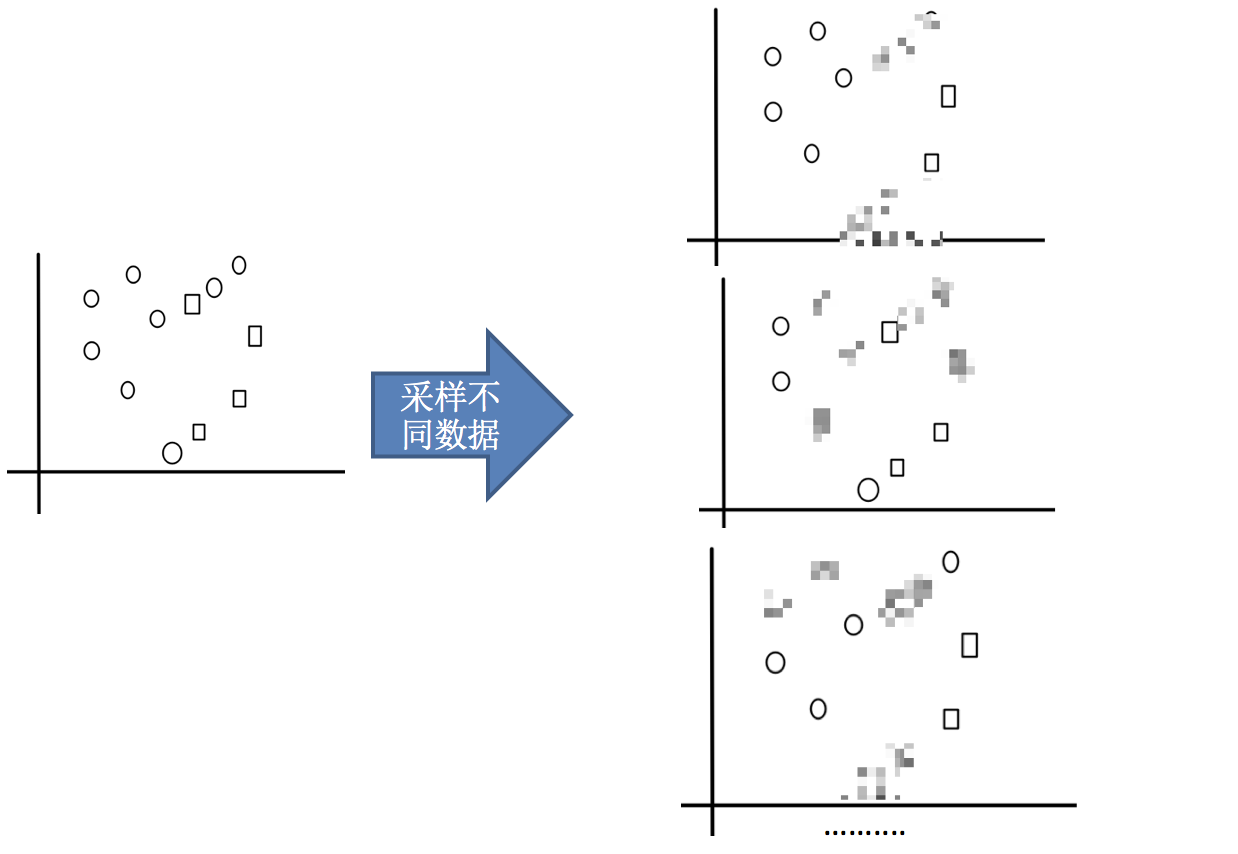
2.训练分类器
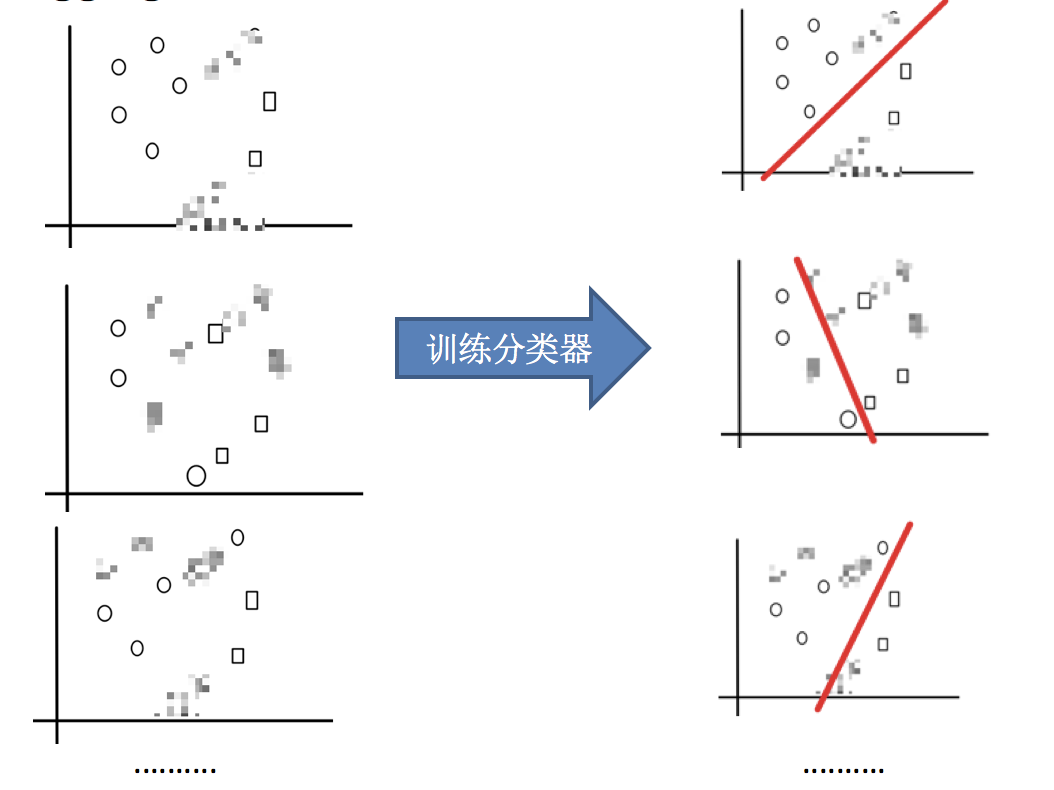
3.平权投票,获取最终结果
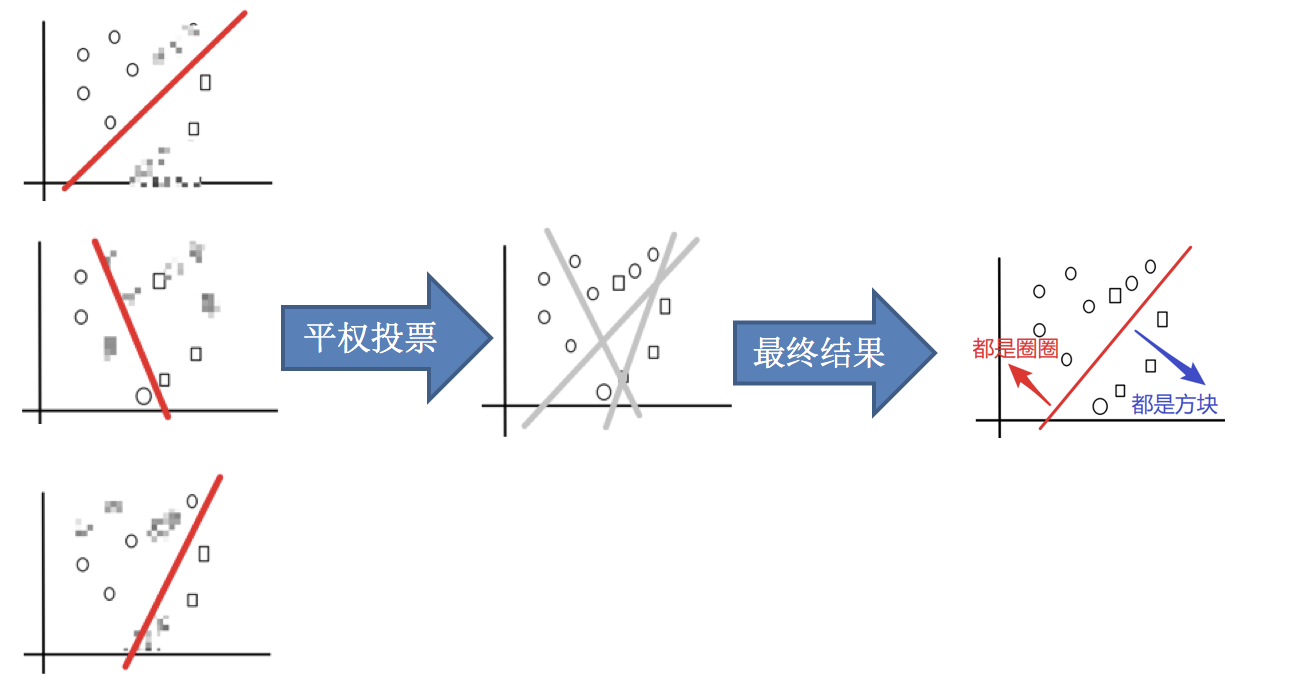
4.主要实现过程小结
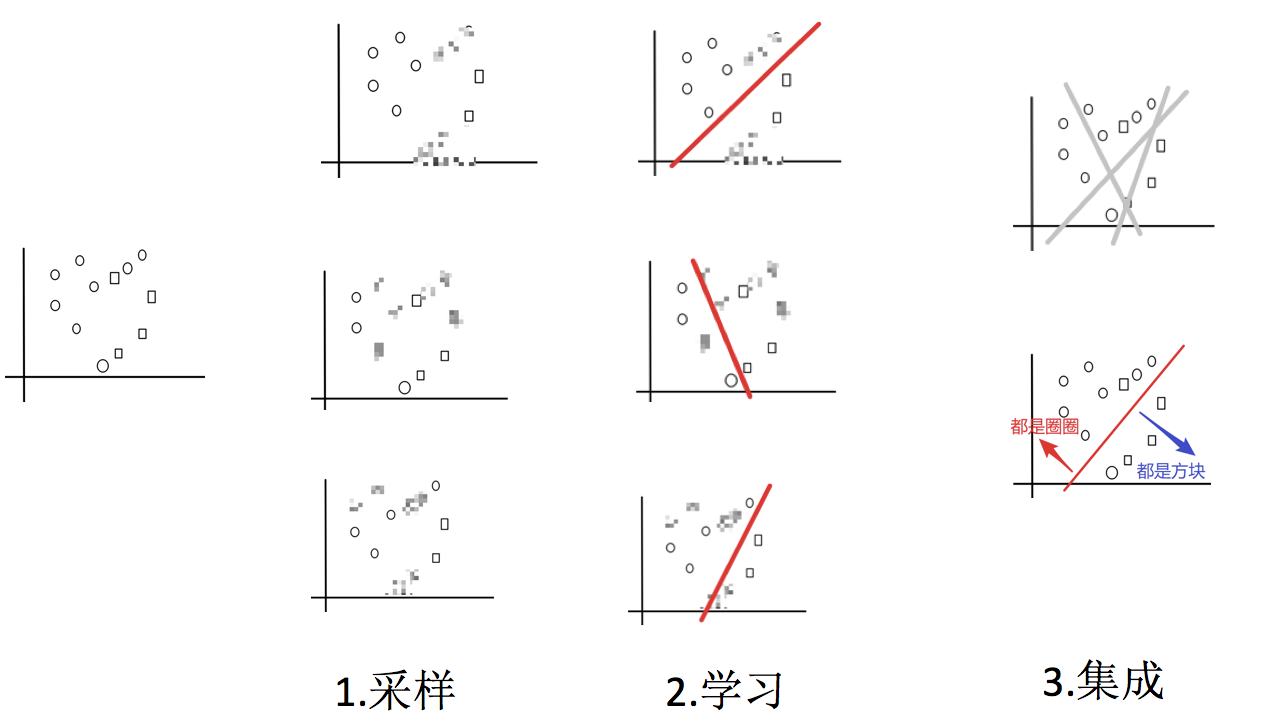
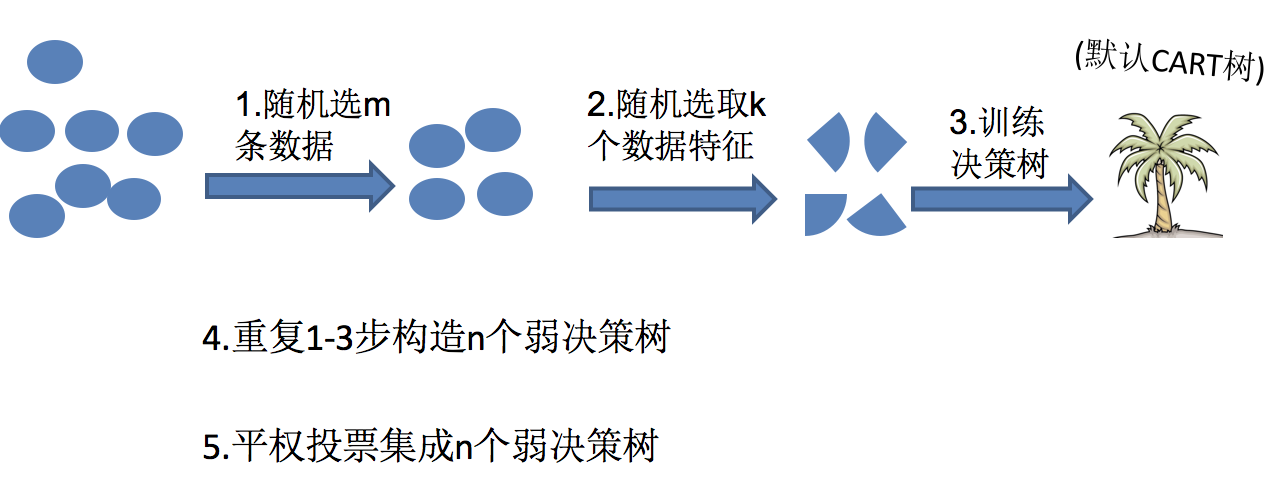
随机森林构造过程
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
随机森林 = Bagging + 决策树
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个树的结果是False, 那么最终投票结果就是True
随机森林够造过程中的关键步骤(用N来表示训练用例(样本)的个数,M表示特征数目):
1)一次随机选出一个样本,有放回的抽样,重复N次(有可能出现重复的样本)
2) 随机去选出m个特征, m <<M,建立决策树
思考
1.为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
2.为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
随机森林api介绍
- sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
- n_estimators:integer,optional(default = 10)森林里的树木数量120,200,300,500,800,1200
- Criterion:string,可选(default =“gini”)分割特征的测量方法
- max_depth:integer或None,可选(默认=无)树的最大深度 5,8,15,25,30
- max_features=”auto”,每个决策树的最大特征数量
- If “auto”, then
max_features=sqrt(n_features). - If “sqrt”, then
max_features=sqrt(n_features)(same as “auto”). - If “log2”, then
max_features=log2(n_features). - If None, then
max_features=n_features.
- If “auto”, then
- bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
- min_samples_split:节点划分最少样本数
- min_samples_leaf:叶子节点的最小样本数
- 超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
随机森林预测案例
- 实例化随机森林
# 随机森林去进行预测
rf = RandomForestClassifier()- 定义超参数的选择列表
param = {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5, 8, 15, 25, 30]}- 使用GridSearchCV进行网格搜索
# 超参数调优
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("随机森林预测的准确率为:", gc.score(x_test, y_test))注意
- 随机森林的建立过程
- 树的深度、树的个数等需要进行超参数调优
bagging集成优点
Bagging + 决策树/线性回归/逻辑回归/深度学习… = bagging集成学习方法
经过上面方式组成的集成学习方法:
- 均可在原有算法上提高约2%左右的泛化正确率
- 简单, 方便, 通用
小结
- bagging集成过程【知道】
- 1.采样 — 从所有样本里面,采样一部分
- 2.学习 — 训练弱学习器
- 3.集成 — 使用平权投票
- 随机森林介绍【知道】
- 随机森林定义
- 随机森林 = Bagging + 决策树
- 流程:
- 1.随机选取m条数据
- 2.随机选取k个特征
- 3.训练决策树
- 4.重复1-3
- 5.对上面的若决策树进行平权投票
- 注意:
- 1.随机选取样本,且是有放回的抽取
- 2.选取特征的时候吗,选择m<<M
- M是所有的特征数
- 包外估计
- 如果进行有放回的对数据集抽样,会发现,总是有一部分样本选不到;
- api
- sklearn.ensemble.RandomForestClassifier()
- 随机森林定义
- Bagging + 决策树/线性回归/逻辑回归/深度学习… = bagging集成学习方法【了解】
- bagging的优点【了解】
- 1.均可在原有算法上提高约2%左右的泛化正确率
- 2.简单, 方便, 通用
Boosting
boosting集成原理
什么是boosting

随着学习的积累从弱到强
简而言之:每新加入一个弱学习器,整体能力就会得到提升
代表算法:Adaboost,GBDT,XGBoost
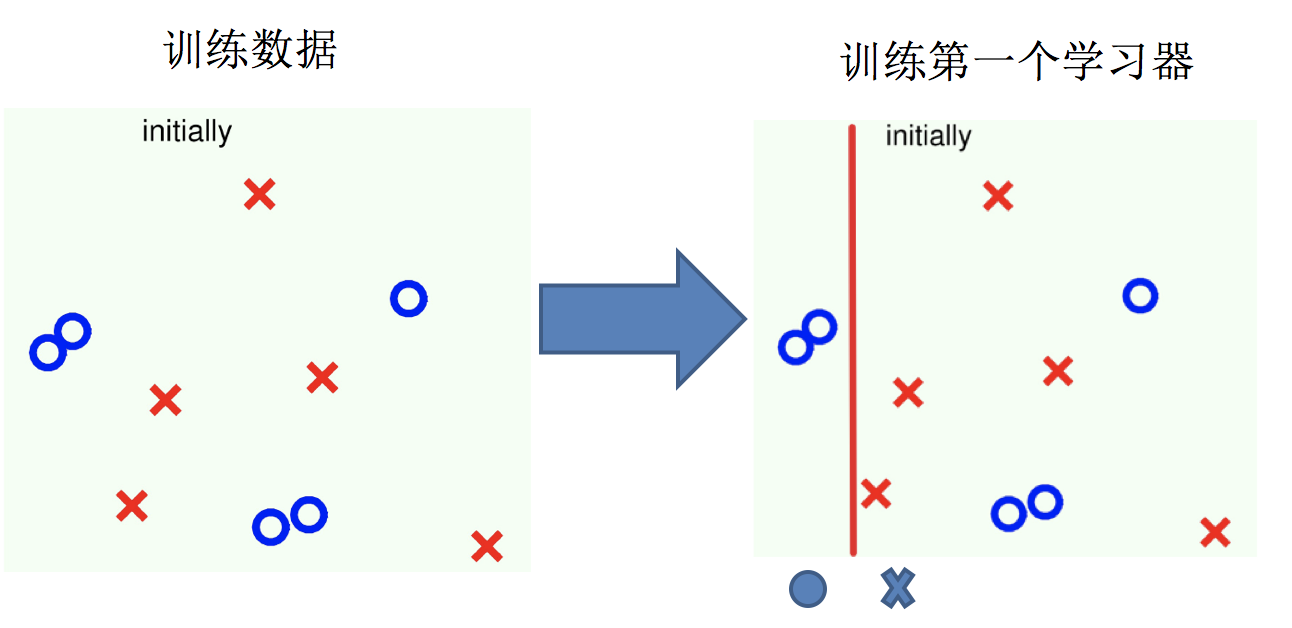
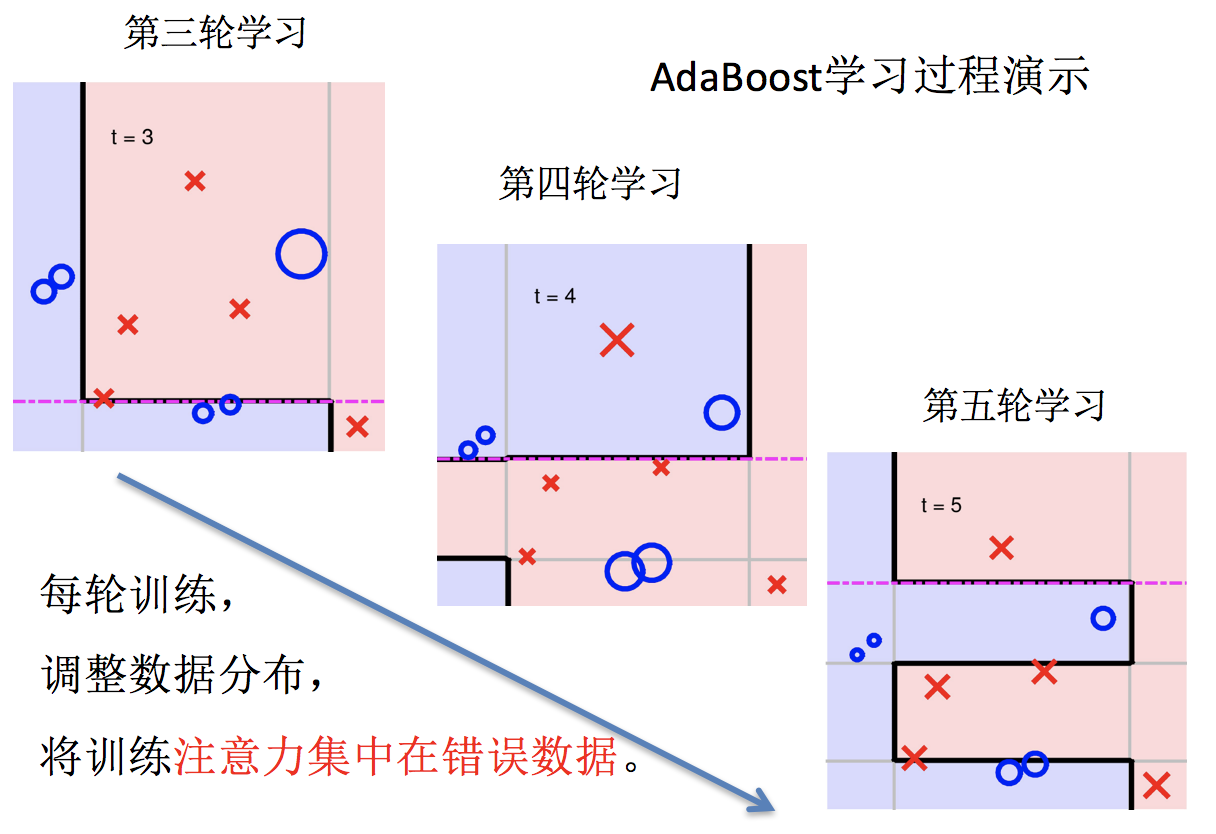
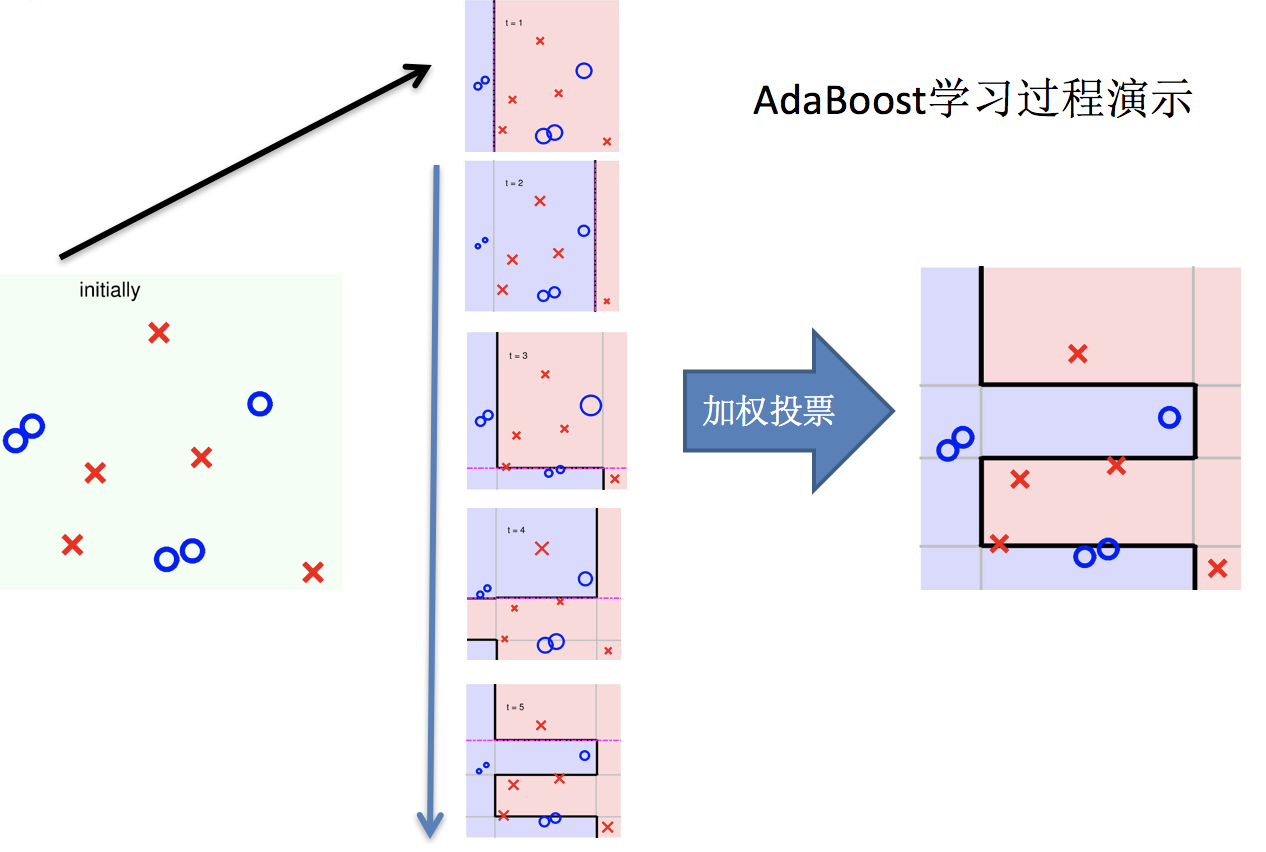
实现过程:
1.训练第一个学习器
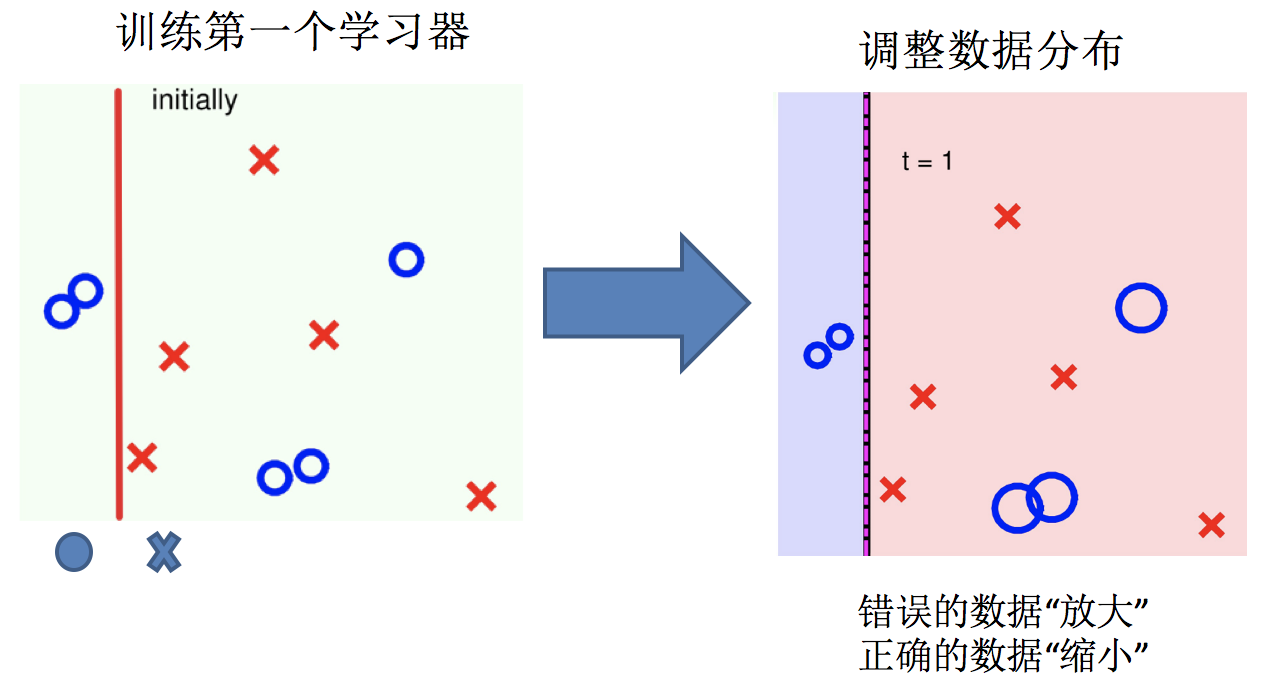
2.调整数据分布
3.训练第二个学习器
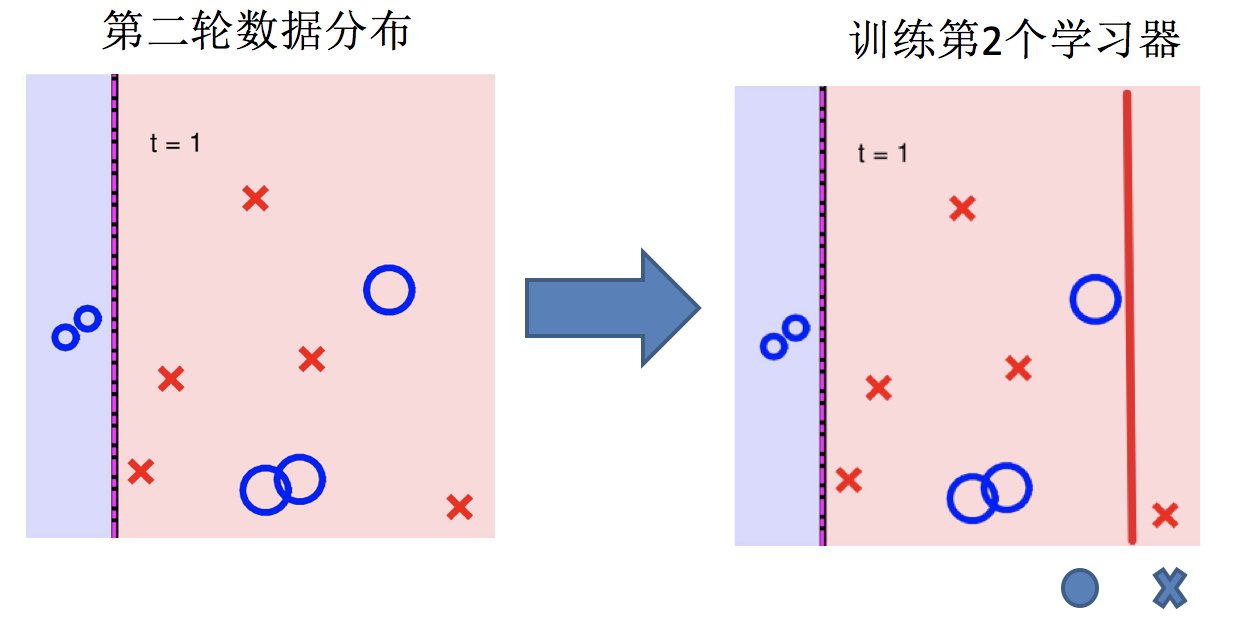
4.再次调整数据分布
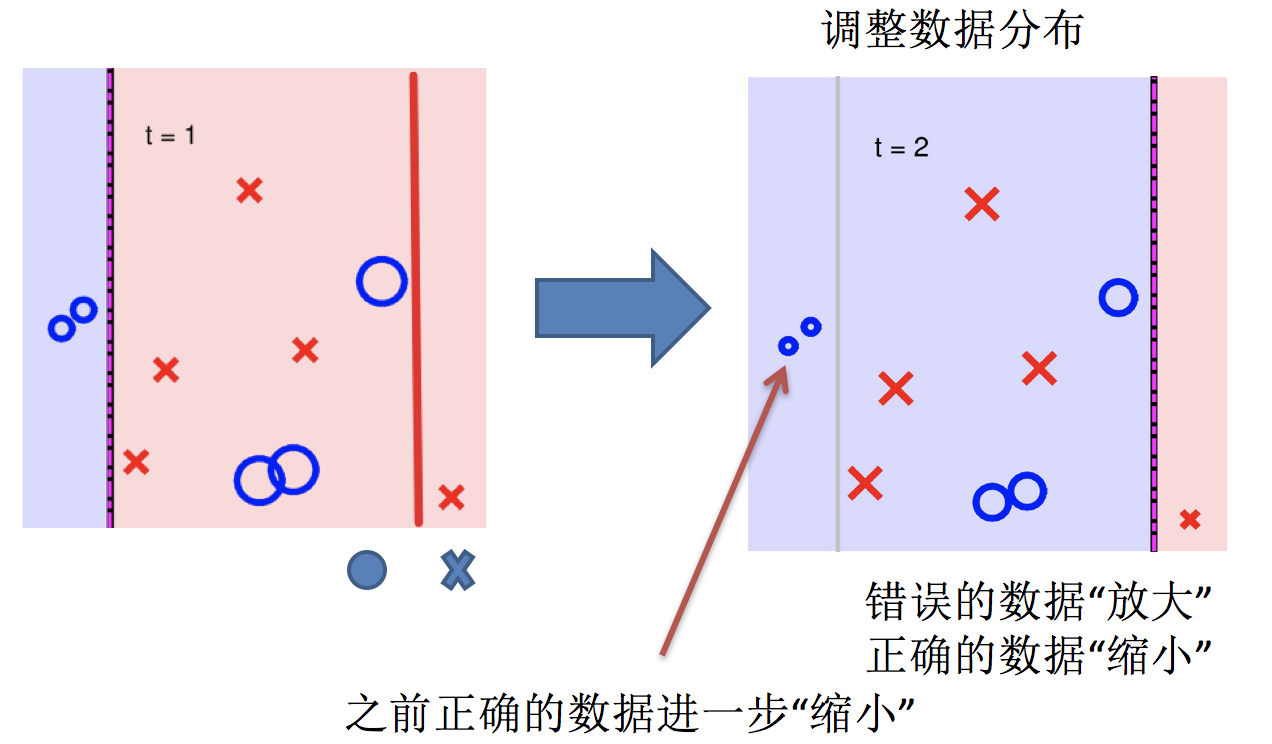
5.依次训练学习器,调整数据分布
6.整体过程实现
关键点:
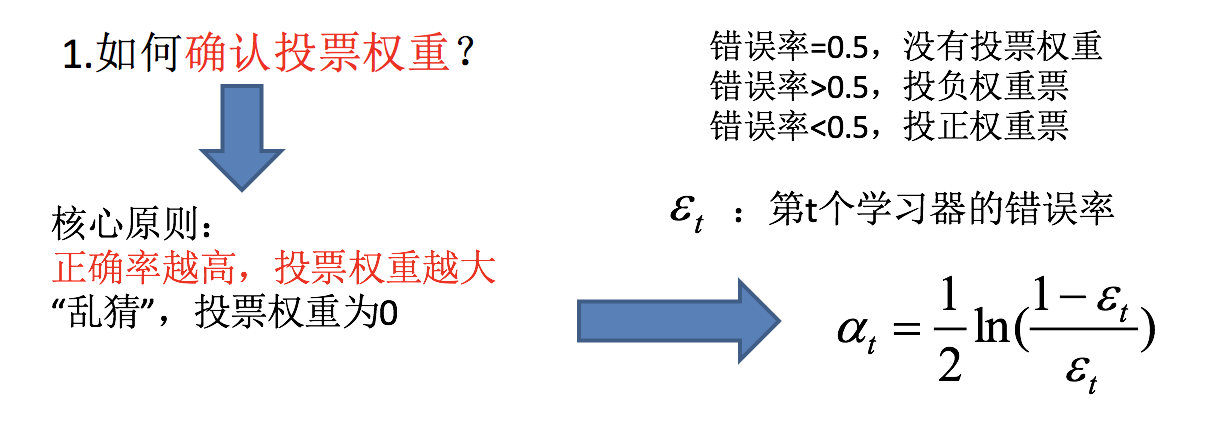
如何确认投票权重?
如何调整数据分布?

AdaBoost的构造过程小结

bagging集成与boosting集成的区别:
区别一:数据方面
Bagging:对数据进行采样训练;
Boosting:根据前一轮学习结果调整数据的重要性。
区别二:投票方面
Bagging:所有学习器平权投票;
Boosting:对学习器进行加权投票。
区别三:学习顺序
Bagging的学习是并行的,每个学习器没有依赖关系;
Boosting学习是串行,学习有先后顺序。
区别四:主要作用
Bagging主要用于提高泛化性能(解决过拟合,也可以说降低方差)
Boosting主要用于提高训练精度 (解决欠拟合,也可以说降低偏差)
api介绍
- from sklearn.ensemble import AdaBoostClassifier
GBDT(了解)
梯度提升决策树(GBDT Gradient Boosting Decision Tree) 是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就被认为是泛化能力(generalization)较强的算法。近些年更因为被用于搜索排序的机器学习模型而引起大家关注。
GBDT = 梯度下降 + Boosting + 决策树
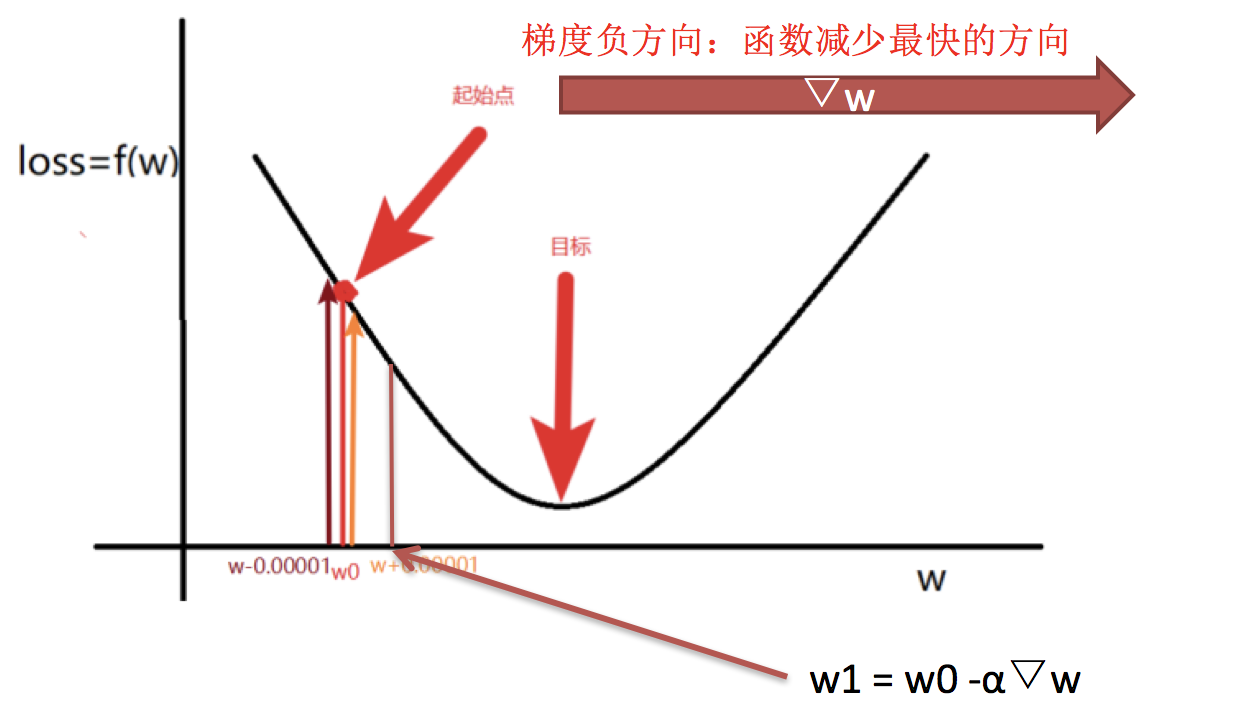
梯度的概念(复习)

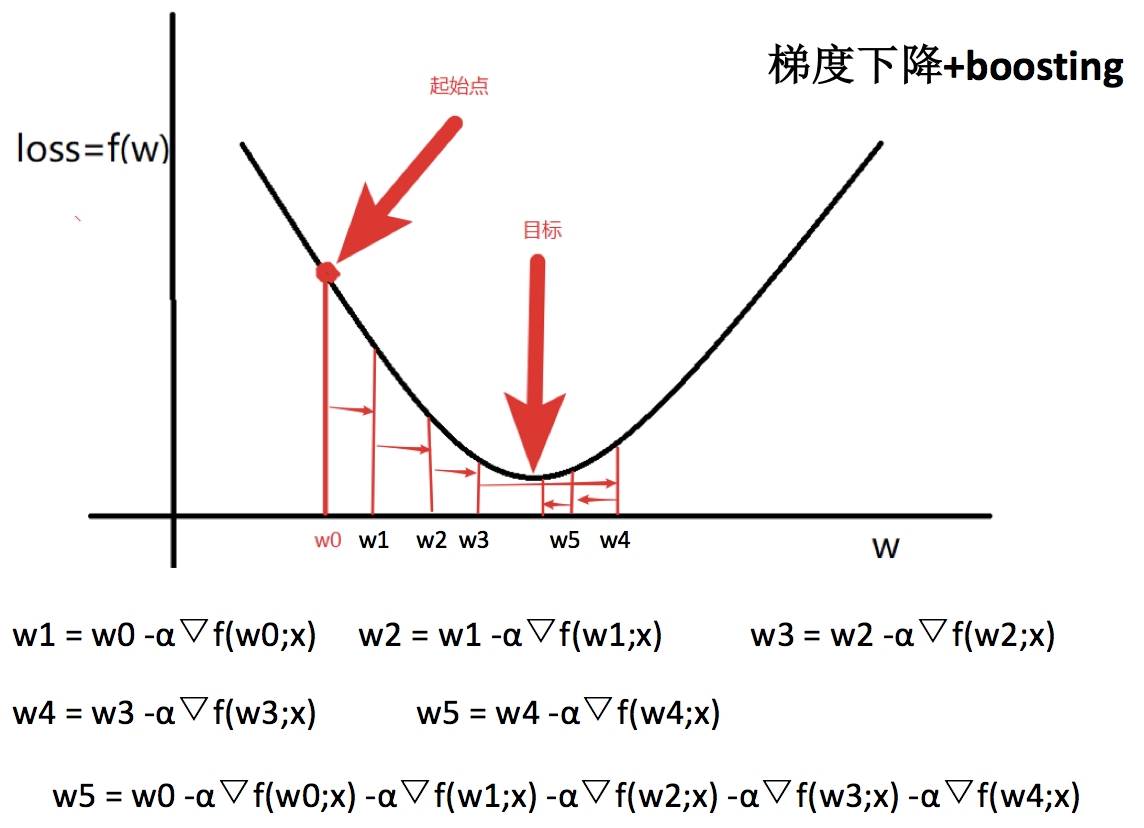
GBDT执行流程
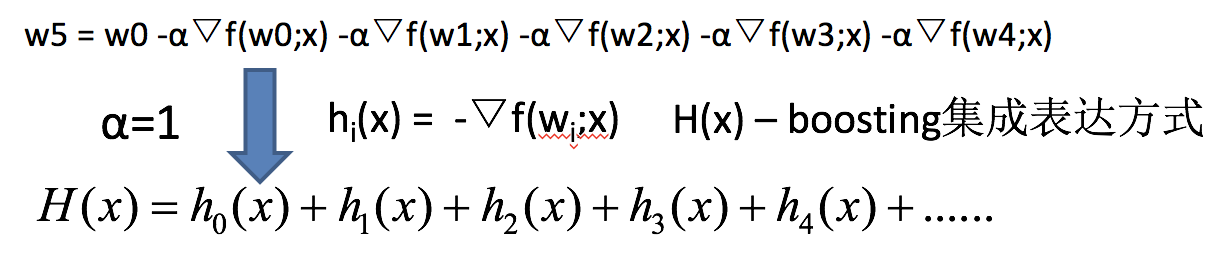
如果上式中的hi(x)=决策树模型,则上式就变为:
GBDT = 梯度下降 + Boosting + 决策树
案例
预测编号5的身高:
| 编号 | 年龄(岁) | 体重(KG) | 身高(M) |
|---|---|---|---|
| 1 | 5 | 20 | 1.1 |
| 2 | 7 | 30 | 1.3 |
| 3 | 21 | 70 | 1.7 |
| 4 | 30 | 60 | 1.8 |
| 5 | 25 | 65 | ? |
第一步:计算损失函数,并求出第一个预测值:
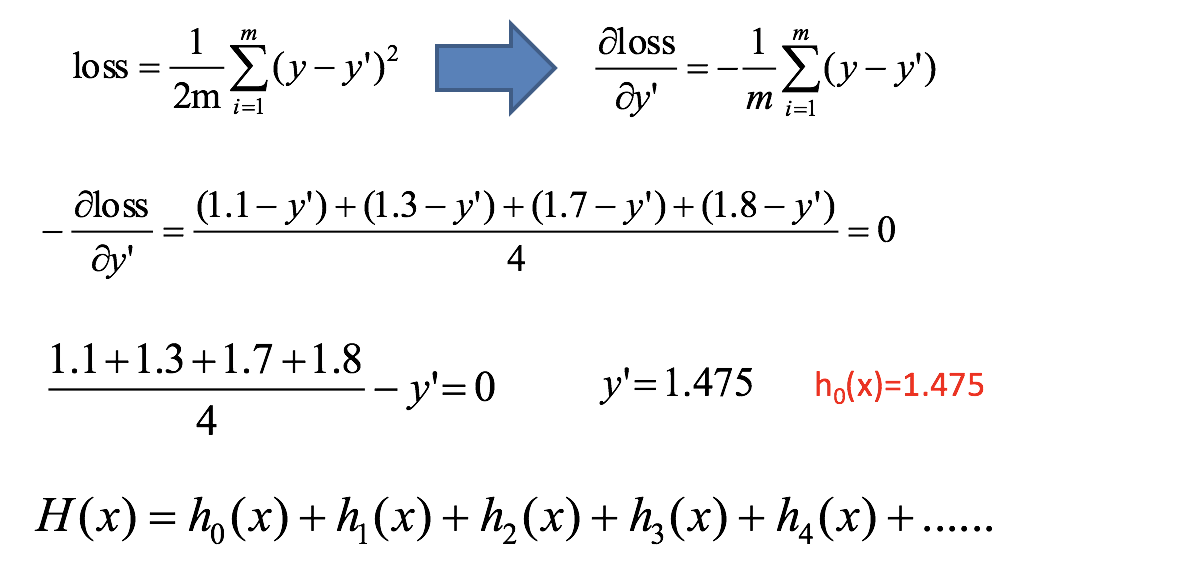
第二步:求解划分点
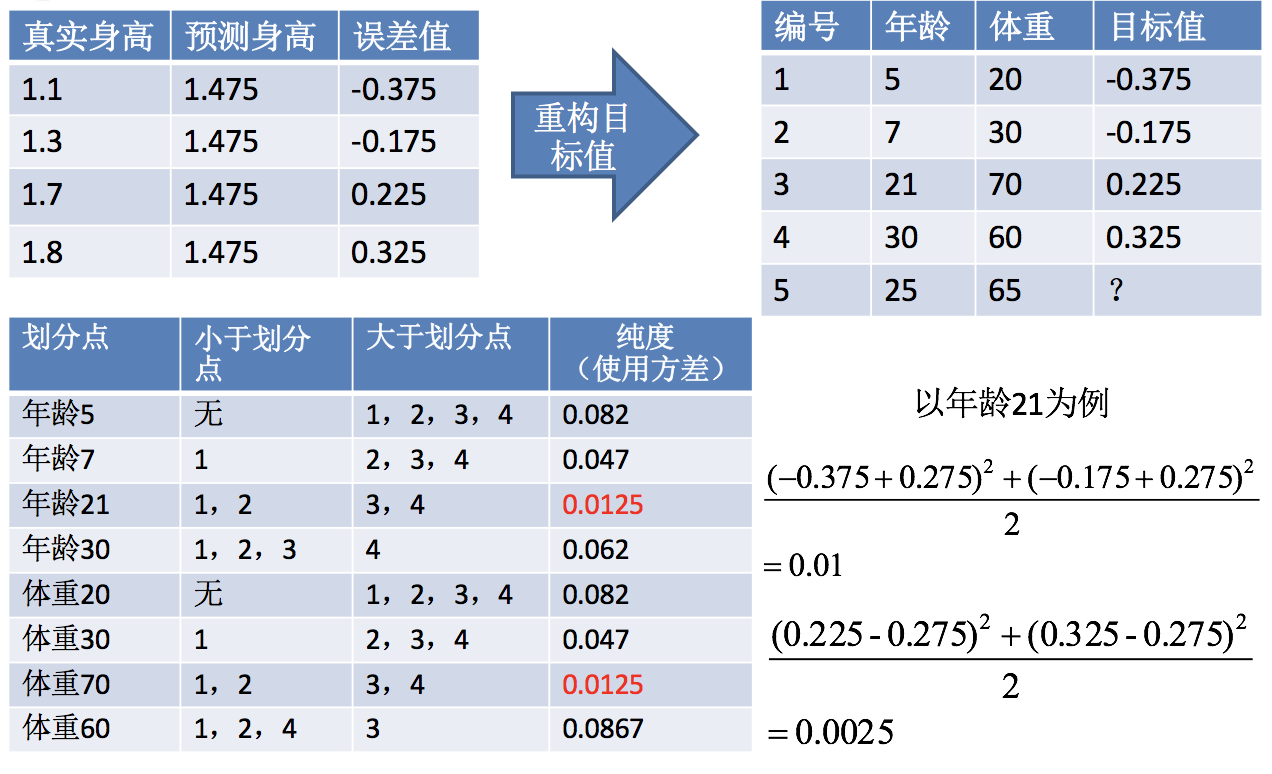
得出:年龄21为划分点的方差=0.01+0.0025=0.0125
第三步:通过调整后目标值,求解得出h1(x)
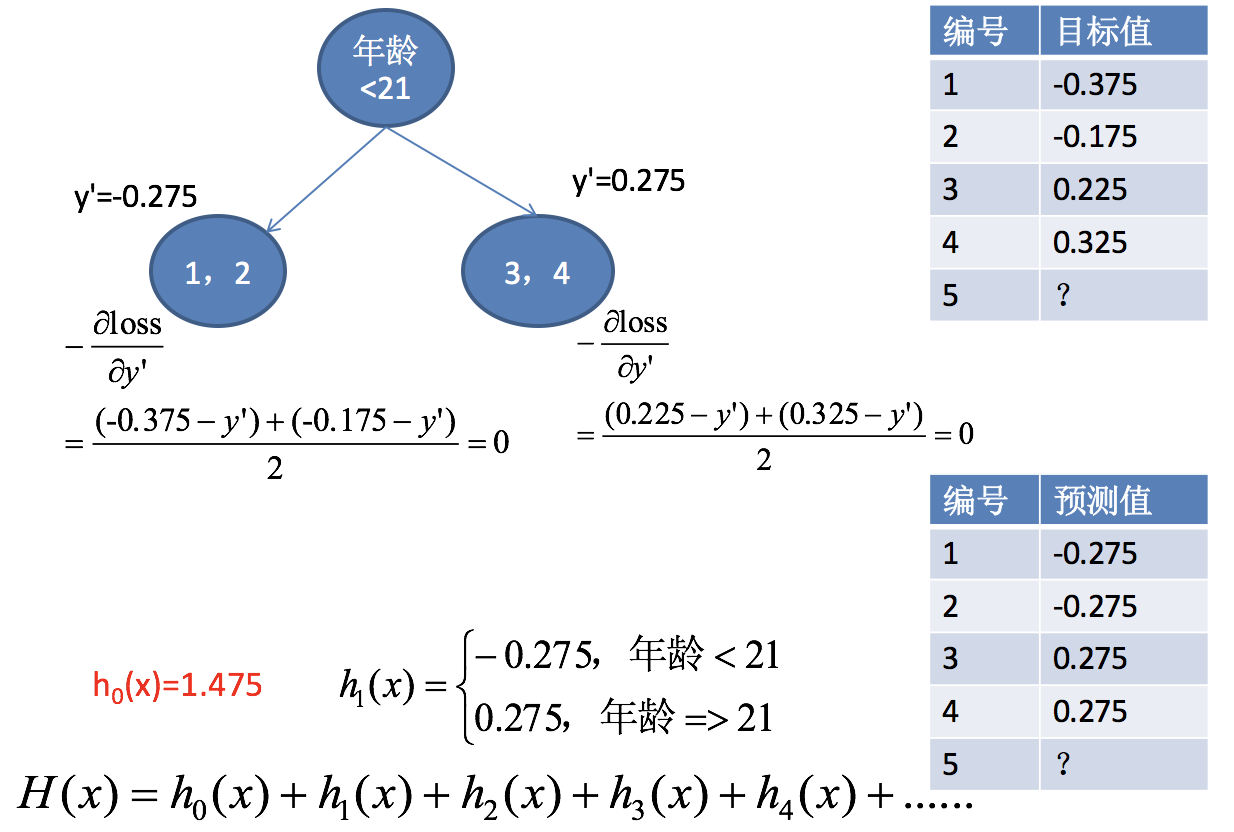
第四步:求解h2(x)

得出结果:

编号5身高 = 1.475 + 0.03 + 0.275 = 1.78
GBDT主要执行思想
1.使用梯度下降法优化代价函数;
2.使用一层决策树作为弱学习器,负梯度作为目标值;
3.利用boosting思想进行集成。
XGBoost【了解】
XGBoost= 二阶泰勒展开+boosting+决策树+正则化
- 面试题:了解XGBoost么,请详细说说它的原理
回答要点:二阶泰勒展开,boosting,决策树,正则化
Boosting:XGBoost使用Boosting提升思想对多个弱学习器进行迭代式学习
二阶泰勒展开:每一轮学习中,XGBoost对损失函数进行二阶泰勒展开,使用一阶和二阶梯度进行优化。
决策树:在每一轮学习中,XGBoost使用决策树算法作为弱学习进行优化。
正则化:在优化过程中XGBoost为防止过拟合,在损失函数中加入惩罚项,限制决策树的叶子节点个数以及决策树叶子节点的值。
什么是泰勒展开式【拓展】
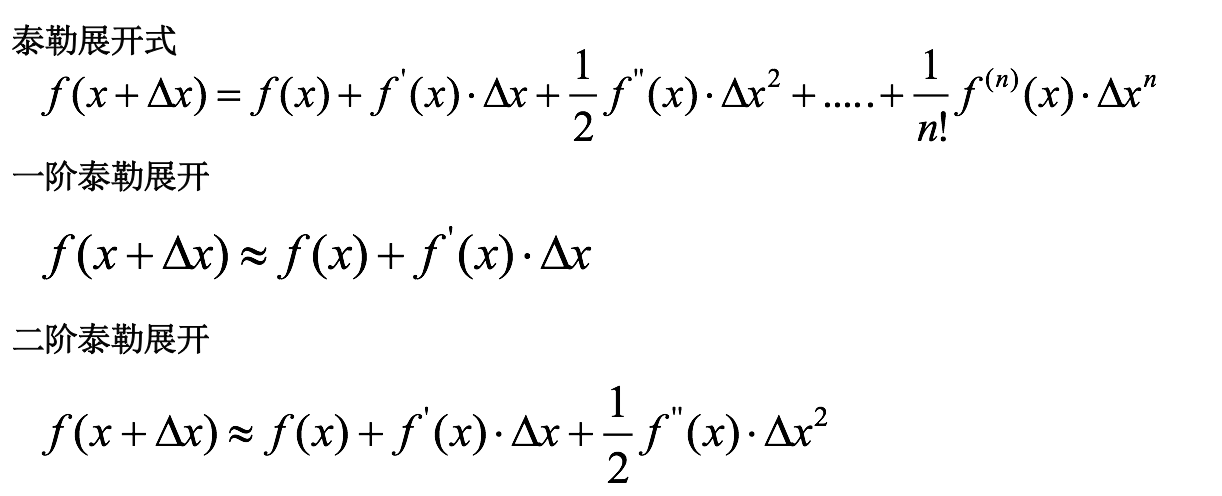
泰勒展开越多,计算结果越精确
 微信
微信 支付宝
支付宝







