Springboot整合JPA
JPA 简介
JPA 是什么
- Java Persistence API:用于对象持久化的 API
- Java EE 5.0 平台标准的 ORM 规范,使得应用程序以统一的方式访问持久层
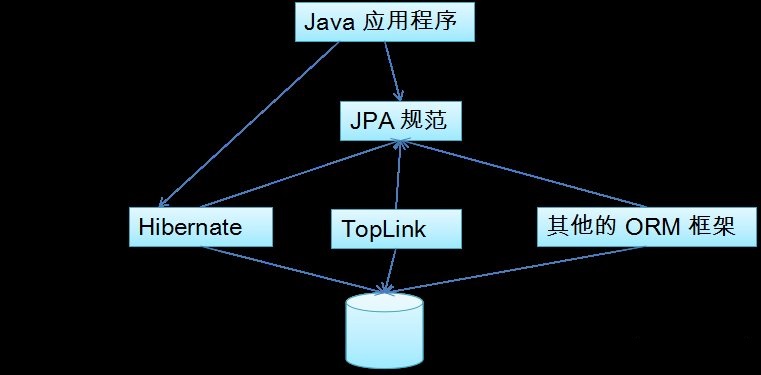
JPA 和 Hibernate 的关系
- JPA 是 Hibernate 的一个抽象(就像 JDBC 和 JDBC 驱动的关系);
- JPA 是规范:JPA 本质上就是一种 ORM 规范,不是 ORM 框架,这是因为 JPA 并未提供 ORM 实现,它只是制订了一些规范,提供了一些编程的 API 接口,但具体实现则由 ORM 厂商提供实现;
- Hibernate 是实现:Hibernate 除了作为 ORM 框架之外,它也是一种 JPA 实现。
从功能上来说, JPA 是 Hibernate 功能的一个子集。
JPA 的供应商
JPA 的目标之一是制定一个可以由很多供应商实现的 API,Hibernate 3.2+、TopLink 10.1+ 以及 OpenJPA 都提供了 JPA 的实现,Jpa 供应商有很多,常见的有如下四种:
- Hibernate:JPA 的始作俑者就是 Hibernate 的作者,Hibernate 从 3.2 开始兼容 JPA。
- OpenJPA:OpenJPA 是 Apache 组织提供的开源项目。
- TopLink:TopLink 以前需要收费,如今开源了。
- EclipseLink
JPA 的优势
- 标准化: 提供相同的 API,这保证了基于 JPA 开发的企业应用能够经过少量的修改就能够在不同的 JPA 框架下运行。
- 简单易用:集成方便,JPA 的主要目标之一就是提供更加简单的编程模型,在 JPA 框架下创建实体和创建 Java 类一样简单,只需要使用 javax.persistence.Entity 进行注解;JPA 的框架和接口也都非常简单。
- 可媲美JDBC的查询能力: JPA的查询语言是面向对象的,JPA 定义了独特的JPQL,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
- 支持面向对象的高级特性: JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,最大限度的使用面向对象的模型
JPA 包含的技术
- ORM 映射元数据:JPA 支持 XML 和 JDK 5.0 注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中。
- JPA 的 API:用来操作实体对象,执行CRUD操作,框架在后台完成所有的事情,开发者从繁琐的 JDBC 和 SQL 代码中解脱出来。
- 查询语言(JPQL):这是持久化操作中很重要的一个方面,通过面向对象而非面向数据库的查询语言查询数据,避免程序和具体的 SQL 紧密耦合。
Spring Data
Spring Data 是 Spring 的一个子项目。用于简化数据库访问,支持NoSQL 和 关系数据存储。其主要目标是使数据库的访问变得方便快捷。Spring Data 具有如下特点:
项目支持 NoSQL 存储
- MongoDB (文档数据库)
- Neo4j(图形数据库)
- Redis(键/值存储)
- Hbase(列族数据库)
支持的关系数据存储技术
- JDBC
- JPA
减少开发量
Spring Data Jpa 致力于减少数据访问层 (DAO) 的开发量. 开发者唯一要做的,就是声明持久层的接口,其他都交给 Spring Data JPA 来帮你完成
步骤
添加POM依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--querydsl依赖-->
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<scope>provided</scope>
</dependency>配置数据源
参看druid的数据源配置即可
添加实体,并添加注解
@Entity
@Table(name = "test")
public class TestEntity {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(nullable = false)
private String name;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Entity{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}添加持久层
继承自JpaRepository的持久层可以直接使用其定义好的CRUD操作,其实只有增删查操作,关于修改的操作还是需要自定义的。
@Repository
public interface TestRepository extends JpaRepository<TestEntity, Integer> {
//自定义repository。手写sql
@Query(value = "update TestEntity set name=?1 where id=?4", nativeQuery = true) //占位符传值形式
@Modifying
int updateById(String name, int id);
@Query("from TestEntity where name=:name")
//SPEL表达式
TestEntity findUser(@Param("name") String name);// 参数username 映射到数据库字段username
}添加Service层
@Service
public class TestServiceImpl implements TestService {
@Autowired
private TestRepository repository;
@Override
public List<TestEntity> queryAll() {
return repository.findAll();
}
}JPA高级功能
方法名匹配
在TestRepository中定义按照规则命名的方法,JPA可以将其自动转换为SQL,而免去手动编写的烦恼,比如定义如下方法:
User getTestByUseIdNo(String useIdNo);JPA会自动将其转换为如下的SQL:
select * from TEST where use_id_no = ?下面简单罗列方法命名规则:
| 关键字 | 例子 | sql |
|---|---|---|
| And | findByNameAndAge | …where x.name=?1 and x.age=?2 |
| Or | findByNameOrAge | …where x.name=?1 or x.age=?2 |
| Between | findByCreateTimeBetween | …where x.create_time between ?1 and ?2 |
| LessThan | findByAgeLessThan | …where x.age < ?1 |
| GreaterThan | findByAgeGreaterThan | …where x.age > ?1 |
| IsNull | findByAgeIsNull | …where x.age is null |
| IsNotNull,NotNull | findByAgeIsNotNull | …where x.age not null |
| Like | findByNameLike | …where x.name like ?1 |
| NotLike | findByNameNotLike | …where x.name not like ?1 |
| OrderBy | findByAgeOrderByNameDesc | …where x.age =?1 order by x.name desc |
| Not | findByNameNot | …where x.name <>?1 |
| In | findByAgeIn | …where x.age in ?1 |
| NotIn | findByAgeNotIn | …where x.age not in ?1 |
@Query注解
使用@Query注解在接口方法之上自定义执行SQL。
@Modifying
@Query(value = "update USER set USE_PHONE_NUM = :num WHERE USE_ID= :useId", nativeQuery = true)
void updateUsePhoneNum(@Param(value = "num") String num, @Param(value = "useId") int useId);上面的更新语句必须加上@Modifying注解,其实在JpaRepository中并未定义更新的方法,所有的更新操作均需要我们自己来定义,一般采用上面的方式来完成。
/**
* 表示一个查询方法是修改查询,这会改变执行的方式。只在@Query注解标注的方法或者派生的方法上添加这个注解,而不能
* 用于默认实现的方法,因为这个注解会修改执行方式,而默认的方法已经绑定了底层的APi。
*/
@Retention(RetentionPolicy.RUNTIME)
@Target({ ElementType.METHOD, ElementType.ANNOTATION_TYPE })
@Documented
public @interface Modifying {
boolean flushAutomatically() default false;
boolean clearAutomatically() default false;
}JPQL(SQL拼接)
使用JPQL需要在持久层接口的实现列中完成,即UserRepositoryImpl,这个类是UserRepository的实现类,我们在其中定义JPQL来完成复杂的SQL查询,包括动态查询,连表查询等高级功能。
QBE(QueryByExampleExecutor)
使用QBE来进行持久层开发,需要用到两个接口类,Example和ExampleMatcher,开发方式如下:
List users = repository.findAll(Example.of(user));或者配合ExampleMarcher使用:
ExampleMatcher matcher = ExampleMatcher.matching().withIgnoreCase();
List users = repository.findAll(Example.of(user, matcher));以上逻辑一般位于service之中。其中user模型中保存着查询的条件值,null的字段不是条件,只有设置了值的字段才是条件。ExampleMatcher是用来自定义字段匹配模式的。
处理枚举
使用Spring-Data-Jpa时,针对枚举的处理有两种方式,对应于EnumType枚举的两个值:
public enum EnumType {
/** Persist enumerated type property or field as an integer. */
ORDINAL,
/** Persist enumerated type property or field as a string. */
STRING
}其中ORDINAL表示的是默认的情况,这种情况下将会将枚举值在当前枚举定义的序号保存到数据库,这个需要是从0开始计算的,正对应枚举值定义的顺序。STRING表示将枚举的名称保存到数据库中。
前者用于保存序号,这对枚举的变更要求较多,我们不能随便删除枚举值,不能随意更改枚举值的位置,而且必须以0开头,而这一般又与我们定义的业务序号不一致,限制较多,一旦发生改变,极可能造成业务混乱;后者较为稳妥。
正常情况下,如果不在枚举字段上添加@Enumerated注解的话,默认就以ORDINAL模式存储,若要以STRING模式存储,请在枚举字段上添加如下注解:
@Enumerated(EnumType.STRING)
@Column(nullable=false) // 一般要加上非null约束
private UseState useState;分页功能
Spring-Data-Jpa中实现分页使用到了Pageable接口,这个接口将作为一个参数参与查询。
Pageable有一个抽象实现类AbstractPageRequest,是Pageable的抽象实现,而这个抽象类有两个实现子类:PageRequest和QPageRequest,前者现已弃用,现在我们使用QPageRequest来定义分页参数,其有三个构造器:
public QPageRequest(int page, int size) {
this(page, size, QSort.unsorted());
}
public QPageRequest(int page, int size, OrderSpecifier<?>... orderSpecifiers) {
this(page, size, new QSort(orderSpecifiers));
}
public QPageRequest(int page, int size, QSort sort) {
super(page, size);
this.sort = sort;
}在这里面我们可以看到一个QSort,这个QSort是专门用于与QPageRequest相配合使用的类,用于定义排序规则。默认情况下采用的是无排序的模式,即上面第一个构造器中的描述。
要构造一个QSort需要借助querydsl来完成,其中需要OrderSpecifier来完成。
这里有个简单的用老版本实现的分页查询:
public ResponseEntity<Page<User>> getUserPage(final int pageId) {
Sort sort = new Sort(new Sort.Order(Sort.Direction.DESC, "useId"));
Page<User> users = repository.findAll(new PageRequest(pageId,2, sort));
return new ResponseEntity<>(users, HttpStatus.OK);
} 微信
微信 支付宝
支付宝









