MyBatis-缓存模块
mybatis缓存
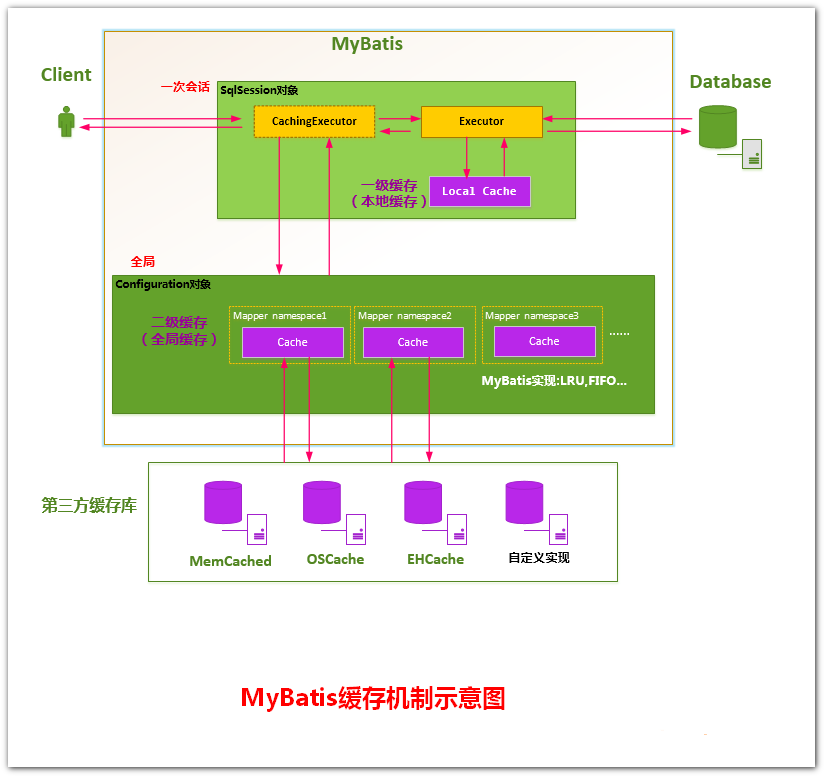
MyBatis作为一个强大的持久层框架,缓存是其必不可少的功能之一,MyBatis中的缓存是两层结构的,分为一级缓存,二级缓存,但本质上市相同的,它们使用的都是Cache接口的实现。
MyBatis缓存的实现是基于Map的,从缓存里面读写数据是缓存模块的核心基础功能
除核心功能之外,有很多额外的附加功能,如:防止缓存击穿,添加缓存情况策略(fifo、LRU),序列化功能,日志能力和定时清空能力等
附加功能可以以任意的组合附加到核心基础功能之上
装饰者模式
mybatis 缓存模块使用了装饰器模式
Mybatis缓存的核心模块就是在缓存中读写数据,但是除了在缓存中读写数据wait,还有其他的附加功能,这些附加功能可以任意的加在缓存这个核心功能上。
加载附加功能可以有很多种方法,动态代理或者继承都可以实现,但是附加功能存在多种组合,用这两种方法,会导致生成大量的子类,所以mybatis选择使用装饰器模式.(灵活性、扩展性)。
类结构
Mybatis 数据源的实现主要是在 cache包:

Cache 接口
一级缓存和二级缓存都是通过cache接口来实现的
Cache 接口是缓存模块的核心接口,定义了缓存的基本操作
/**
* 缓存核心接口
*/
public interface Cache {
/**
* 获取缓存ID
*/
String getId();
/**
* 设置缓存
*/
void putObject(Object key, Object value);
/**
* 根据Key获取缓存
*/
Object getObject(Object key);
/**
*
* 删除缓存
*/
Object removeObject(Object key);
/**
* 清空缓存
*/
void clear();
/**
* 获取缓存大小
*/
int getSize();
/**
* 获取读写锁
* @return A ReadWriteLock
*/
default ReadWriteLock getReadWriteLock() {
return null;
}
}缓存实现类PerpetualCache
在缓存模块使用了装饰器模式PerpetualCache在其中扮演ConcreteComponent 角色,使用 HashMap来实现 cache 的相关操作
/**
* 缓存的核心实现类
* 在装饰者模式中扮演了 ConcreteComponent(具体组件) 角色
* 使用HashMao实现了缓存
* @author Clinton Begin
*/
public class PerpetualCache implements Cache {
/**
* 缓存的ID
*/
private final String id;
/**
* 缓存的主体对象 hashMap
*/
private Map<Object, Object> cache = new HashMap<>();
/**
* 构造方法
* @param id
*/
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
/**
* 获取缓存的大小
* @return
*/
@Override
public int getSize() {
return cache.size();
}
/**
* 设置缓存
* @param key 缓存key
* @param value 缓存的Value
*/
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
/**
* 获取缓存
* @param key The key
* @return
*/
@Override
public Object getObject(Object key) {
return cache.get(key);
}
/**
* 删除缓存
* @param key The key
* @return
*/
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
/**
* 清空缓存
*/
@Override
public void clear() {
cache.clear();
}
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
return getId().hashCode();
}
}缓存项CacheKey
为什么需要一个复杂的对象表示缓存项的key?通常来说表示一个对象的key可以用一个String对象,为什么不可以吗?
在cache中唯一确定一个缓存项需要使用缓存项的key,Mybatis中因为涉及到动态SQL等多方面因素,其缓存项的key不等仅仅通过一个String表示,所以MyBatis 提供了CacheKey类来表示缓存项的key,在一个CacheKey对象中可以封装多个影响缓存项的因素。
怎么样的查询条件算和上一次查询是一样的查询,从而返回同样的结果回去?这个问题,得从CacheKey说起。
我们先看一下CacheKey的数据结构:
/**
* 缓存项cacheKey
*
* @author Clinton Begin
*/
public class CacheKey implements Cloneable, Serializable {
private static final long serialVersionUID = 1146682552656046210L;
//定义为Null的缓存key
public static final CacheKey NULL_CACHE_KEY = new NullCacheKey();
//默认的乘数
private static final int DEFAULT_MULTIPLYER = 37;
//默认的hashCode
private static final int DEFAULT_HASHCODE = 17;
//定义乘数变量
private final int multiplier;
//hashCode
private int hashcode;
//校验码
private long checksum;
//统计
private int count;
//更新列表
private List<Object> updateList;
/**
* 构造方法
*/
public CacheKey() {
//设置hashCode
this.hashcode = DEFAULT_HASHCODE;
//设置乘数
this.multiplier = DEFAULT_MULTIPLYER;
this.count = 0;
//更新列表 为空的list
this.updateList = new ArrayList<>();
}
/**
* 构造方法
*
* @param objects 需要缓存的数据
*/
public CacheKey(Object[] objects) {
//调用空的构造方法初始化缓存key
this();
//更新所有数据
updateAll(objects);
}
}equals方法
其中最重要的是第41行的updateList这个属性,为什么这么说,因为HashMap的Key是CacheKey,而HashMap的get方法是先判断hashCode,在hashCode冲突的情况下再进行equals判断,因此最终无论如何都会进行一次equals的判断。
/**
* 生成的equals方法
* <p>
* 如果是CacheKey
* 先比较CacheKey的hashCode
* 一样在比较 校验码
* 还一样比较更新次数
* 还是一样比较更新的每个值的hashCode
* 保证每一个比较的一致性
*
* @param object
* @return
*/
@Override
public boolean equals(Object object) {
if (this == object) {
return true;
}
if (!(object instanceof CacheKey)) {
return false;
}
final CacheKey cacheKey = (CacheKey) object;
//比较cachekey的hashCode
if (hashcode != cacheKey.hashcode) {
return false;
}
//比较校验码
if (checksum != cacheKey.checksum) {
return false;
}
//比较更新次数
if (count != cacheKey.count) {
return false;
}
//比较每个值的hashCode
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}进行equals的时候经过了几次比较
- 对象不为空
- 对象是CacheKey类型
- cacheKey的hashcode一致
- cacheKey的校验码checksum一致
- cacheKey的更新次数count一致
- updateList列表中每一个数据的hashCode一致
经过这样负责的比较,保证每一个cacheKey是完全一致才会计算equals一致。
更新方法update
如何生产hashcode
17是质子数中一个“不大不小”的存在,如果你使用的是一个如2的较小质数,
那么得出的乘积会在一个很小的范围,很容易造成哈希值的冲突。
而如果选择一个100以上的质数,得出的哈希值会超出int的最大范围,这两种都不合适。
而如果对超过 50,000 个英文单词(由两个不同版本的 Unix 字典合并而成)进行 hash code 运算,
并使用常数 31, 33, 37, 39 和 41 作为乘子(cachekey使用37),每个常数算出的哈希值冲突数都小于7个(国外大神做的测试),
那么这几个数就被作为生成hashCode值得备选乘数了
/**
* 更新数据
*
* @param object
*/
public void update(Object object) {
//获取hashCode 为null 则hashCode是1 否则是计算出来的hash值
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
//统计更新次数
count++;
//校验码更新
checksum += baseHashCode;
//计算对象初始的hashCode 防止hash冲突
baseHashCode *= count;
/**
* hashCode更新方法
* newHashCode = oldHashCode*乘数(31,33,37,39,41)中选择一个+ObjectHashCode
* 每次迭代乘以 乘数
*/
hashcode = multiplier * hashcode + baseHashCode;
//将缓存对象添加到更新列表
updateList.add(object);
}缓存增强
PerpetualCache是基类,其它实现的Cache的类都是对基类的扩
展,也就是装饰来包裹真实的对象。扩展了类的功能,也可以说是附加了一些方法。使得具有很好的灵活性
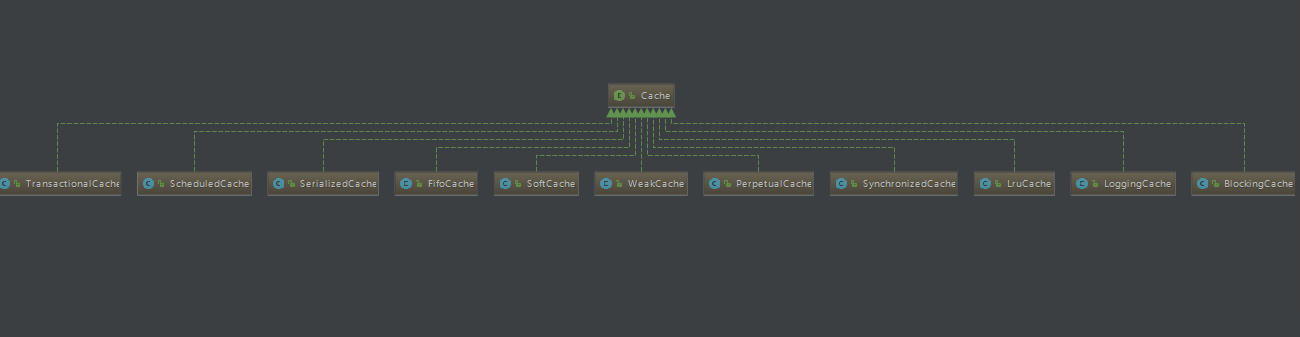
用于装饰PerpetualCache的标准装饰器共有8个(全部在 org.apache.ibatis.cache.decorators包中):
- BlockingCache:是阻塞版本的缓存装饰器,它保证只有一个线程到数据库中查找指定key对应的数据。
- FifoCache:先进先出算法,缓存回收策略
- LoggingCache:输出缓存命中的日志信息
- LruCache:最近最少使用算法,缓存回收策略
- ScheduledCache:调度缓存,负责定时清空缓存
- SerializedCache:缓存序列化和反序列化存储
- SoftCache:基于软引用实现的缓存管理策略
- SynchronizedCache:同步的缓存装饰器,用于防止多线程并发访问
- WeakCache:基于弱引用实现的缓存管理策略
- TransactionalCache:事务性的缓存
一级缓存和二级缓存
- 一级缓存,又叫本地缓存,是PerpetualCache类型的永久缓存,保存在执行器中(BaseExecutor),而执行器又在SqlSession(DefaultSqlSession)中,所以一级缓存的生命周期与SqlSession是相同的。
- 二级缓存,又叫自定义缓存,实现了Cache接口的类都可以作为二级缓存,所以可配置如encache等的第三方缓存。二级缓存以namespace名称空间为其唯一标识,被保存在Configuration核心配置对象中。
注意
二级缓存对象的默认类型为PerpetualCache,如果配置的缓存是默认类型,则mybatis
会根据配置自动追加一系列装饰器。
Cache对象之间的引用顺序
SynchronizedCache–>LoggingCache–>SerializedCache–>ScheduledCache–>LruCache–>PerpetualCache
 微信
微信 支付宝
支付宝








