ElasticSearch基础
1. Elasticsearch简介
Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储、检索数据。本身扩展性很好,可扩展到上百台服务器,处理PB级别的数据。ES使用Java开发并使用Lucene作为其核心来实现索引和搜索的功能,但是它通过简单的RestfulAPI和javaAPI来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Elasticsearch官网:https://www.elastic.co/cn/products/elasticsearch2. Elasticsearch的功能
- 分布式的搜索引擎
分布式:Elasticsearch自动将海量数据分散到多台服务器上去存储和检索搜索:百度、谷歌,站内搜索
- 全文检索
提供模糊搜索等自动度很高的查询方式,并进行相关性排名,高亮等功能
数据分析引擎(分组聚合)
电商网站,最近一周笔记本电脑这种商品销量排名top10的商家有哪些?新闻网站,最近1个月访问量排名top3的新闻板块是哪些
对海量数据进行近实时的处理
海量数据的处理:因为是分布式架构,Elasticsearch可以采用大量的服务器去存储和检索数据,自然而然就可以实现海量数据的处理
近实时:Elasticsearch可以实现秒级别的数据搜索和分析
3. Elasticsearch的特点
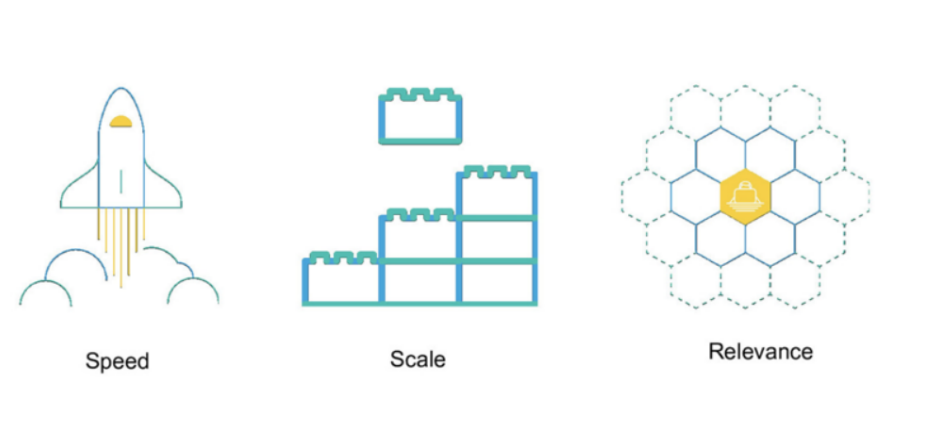
Elasticsearch的特点是它提供了一个极速的搜索体验。这源于它的高速(speed)。相比较其它 的一些大数据引擎,Elasticsearch可以实现秒级的搜索,速度非常有优势。Elasticsearch的 cluster是一种分布式的部署,极易扩展(scale )这样很容易使它处理PB级的数据库容量。最重要 的是Elasticsearch是它搜索的结果可以按照分数进行排序,它能提供我们最相关的搜索结果 (relevance) 。
- 安装方便:没有其他依赖,下载后安装非常方便;只用修改几个参数就可以搭建起来一个集群
- JSON:输入/输出格式为 JSON,意味着不需要定义 Schema,快捷方便
- RESTful:基本所有操作 ( 索引、查询、甚至是配置 ) 都可以通过 HTTP 接口进行
- 分布式:节点对外表现对等(每个节点都可以用来做入口) 加入节点自动负载均衡
- 多租户:可根据不同的用途分索引,可以同时操作多个索引
- 支持超大数据: 可以扩展到 PB 级的结构化和非结构化数据 海量数据的近实时处理
4. Elasticsearch企业使用场景
1.常见场景
- 搜索类场景
比如说电商网站、招聘网站、新闻资讯类网站、各种app内的搜索。 - 日志分析类场景
经典的ELK组合(Elasticsearch/Logstash/Kibana),可以完成日志收集,日志存储,日志分析查询界面基本功能,目前该方案的实现很普及,大部分企业日志分析系统使用了该方案。 - 数据预警平台及数据分析场景
例如电商价格预警,在支持的电商平台设置价格预警,当优惠的价格低于某个值时,触发通知消息,通知用户购买。
数据分析常见的比如分析电商平台销售量top 10的品牌,分析博客系统、头条网站top 10关注度、 评论数、访问量的内容等等。 - 商业BI(Business Intelligence)系统
比如大型零售超市,需要分析上一季度用户消费金额,年龄段,每天各时间段到店人数分布等信息,输出相应的报表数据,并预测下一季度的热卖商品,根据年龄段定向推荐适宜产品。 Elasticsearch执行数据分析和挖掘,Kibana做数据可视化。
2.常见案例
维基百科、百度百科:有全文检索、高亮、搜索推荐功能
stack overflflow:有全文检索,可以根据报错关键信息,去搜索解决方法。
github:从上千亿行代码中搜索你想要的关键代码和项目。
日志分析系统:各企业内部搭建的ELK平台。
5. 主流全文搜索方案对比
Lucene、Solr、Elasticsearch是目前主流的全文搜索方案,基于倒排索引机制完成快速全文搜索。

- Lucene
Lucene是Apache基金会维护的一套完全使用Java编写的信息搜索工具包(Jar包),它包含了索引结构、读写索引工具、相关性工具、排序等功能,因此在使用Lucene时仍需要我们自己进一步开发搜索引擎系统,例如数据获取、解析、分词等方面的东西。
注意:Lucene只是一个框架,我们需要在Java程序中集成它再使用。而且需要很多的学习才能明白它是如何运行的,熟练运用Lucene非常复杂。
- Solr
Solr是一个有HTTP接口的基于Lucene的查询服务器,是一个搜索引擎系统,封装了很多Lucene细节,Solr可以直接利用HTTP GET/POST请求去查询,维护修改索引。
- Elasticsearch
Elasticsearch也是一个建立在全文搜索引擎 Apache Lucene基础上的搜索引擎。采用的策略是分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
三者之间的区别和联系
Solr和Elasticsearch都是基于Lucene实现的。但Solr和Elasticsearch之间也是有区别的
1)Solr利用Zookpper进行分布式管理,而Elasticsearch自身带有分布式协调管理功能
2)Solr比Elasticsearch实现更加全面,Solr官方提供的功能更多,而Elasticsearch本身更注重于核心功能,高级功能多由第三方插件提供
3)Solr在传统的搜索应用中表现好于Elasticsearch,而Elasticsearch在实时搜索应用方面比Solr表现好
https://db-engines.com/en/ranking
6. Elasticsearch的版本
1.Elasticsearch版本介绍
Elasticsearch 主流版本为5.x , 6.x及7.x版本
7.x 更新的内容如下
1. 集群连接变化:TransportClient被废弃
以至于,es7的java代码,只能使用restclient。对于java编程,建议采用 High-level-rest-client 的方式操作ES集群。High-level REST client 已删除接受Header参数的API方
法,Cluster Health API默认为集群级别。 2. ES数据存储结构变化:简化了Type 默认使用_doc
es6时,官方就提到了es7会逐渐删除索引type,并且es6时已经规定每一个index只能有一个 type。在es7中使用默认的_doc作为type,官方说在8.x版本会彻底移除type。
api请求方式也发送变化,如获得某索引的某ID的文档:GET index/_doc/id其中index和id为具体的值- ES程序包默认打包jdk:以至于7.x版本的程序包大小突然增大了200MB+, 对比6.x发现,包大了 200MB+, 正是JDK的大小
- 默认配置变化:默认节点名称为主机名,默认分片数改为1,不再是5。
- Lucene升级为lucene 8 查询相关性速度优化:Weak-AND算法
es可以看过是分布式lucene,lucene的性能直接决定es的性能。lucene8在top k及其他查询上有很大的性能提升。weak-and算法 核心原理:取TOP N结果集,估算命中记录数。 TOP N的时候会跳过得分低于10000的文档来达到更快的性能。 - 间隔查询(Intervals queries): intervals query 允许用户精确控制查询词在文档中出现的先后关系,实现了对terms顺序、terms之间的距离以及它们之间的包含关系的灵活控制。
- 引入新的集群协调子系统 移除 minimum_master_nodes 参数,让 Elasticsearch 自己选择可以形成仲裁的节点。
- 7.0将不会再有OOM的情况,JVM引入了新的circuit breaker(熔断)机制,当查询或聚合的数据量超出单机处理的最大内存限制时会被截断。
设置indices.breaker.fifielddata.limit的默认值已从JVM堆大小的60%降低到40%。 - 分片搜索空闲时跳过refresh
以前版本的数据插入,每一秒都会有refresh动作,这使得es能成为一个近实时的搜索引擎。但是当没有查询需求的时候,该动作会使得es的资源得到较大的浪费。
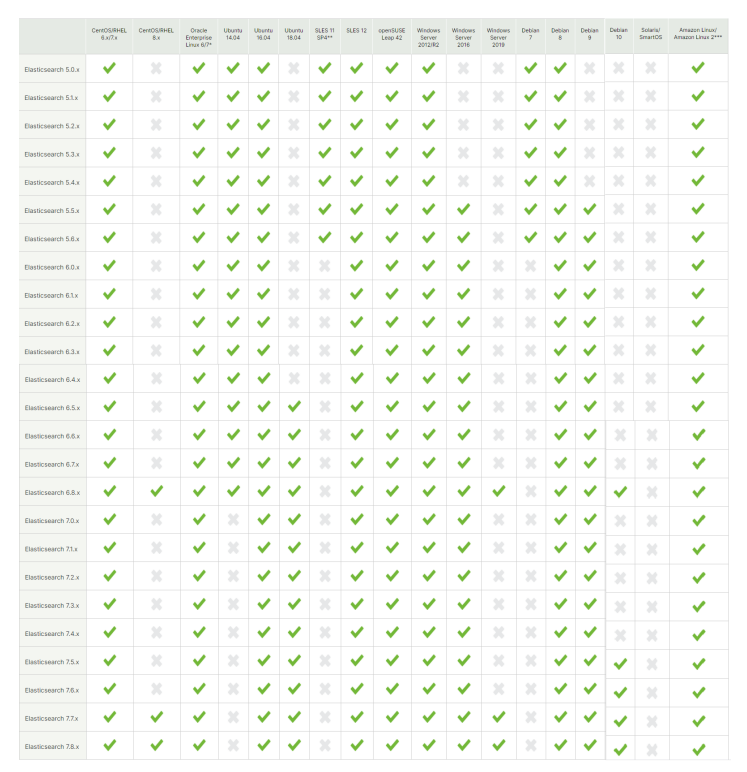
2.Elasticsearch与其他软件兼容
2.1Elasticsearch与操作系统
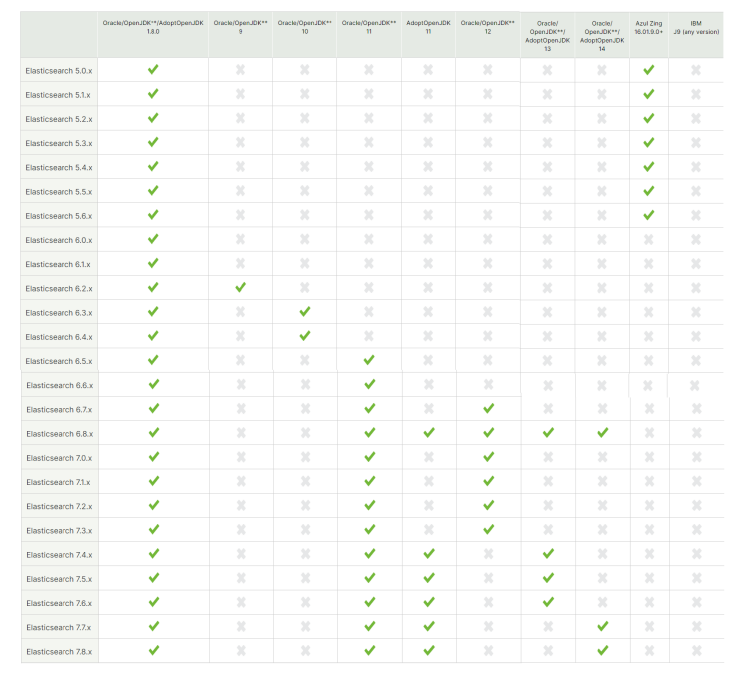
Elasticsearch and JVM
2. Elasticsearch Single-Node Mode部署
我们在虚拟机上部署Single-Node Mode Elasticsearch
下载Elasticsearch
地址: https://www.elastic.co/cn/downloads/elasticsearch 最新版本
下载: https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7.3..0 版本选择Linux版本下载:
开始安装JDK
1.解压三个tar.gz文件
tar -zxvf jdk-8u171-linux-x64.tar.gz
tar -zxvf elasticsearch-7.3.0-linux-x86_64.tar.gz2.移动文件到安装目录
mv /root/jdk1.8.0_171 /usr/java/
mv /root/elasticsearch-7.3.0 /usr/elasticsearch/3.配置jdk环境变量
vim /etc/profile在profifile结尾添加如下内容:
JAVA_HOME=/usr/java
JRE_HOME=/usr/java/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export JAVA_HOME JRE_HOME CLASS_PATH PATH让修改生效:
source /etc/profile检查jdk
java -versionjdk配置完成!
配置Elasticsearch
1.编辑vim /usr/elasticsearch/confifig/elasticsearch.yml,注意冒号后面有个空格。
vim /usr/elasticsearch/config/elasticsearch.yml单机安装请取消注释:node.name: node-1,否则无法正常启动。
修改网络和端口,取消注释master节点,单机只保留一个node
node.name: node-1
network.host: 192.168.211.136
#
# Set a custom port for HTTP:
#
http.port: 9200
cluster.initial_master_nodes: ["node-1"]2.按需修改
vim /usr/elasticsearch/confifig/jvm.options内存设置vim /usr/elasticsearch/config/jvm.options
根据实际情况修改占用内存,默认都是1G,单机1G内存,启动会占用700m+然后在安装kibana
后,基本上无法运行了,运行了一会就挂了报内存不足。 内存设置超出物理内存,也会无法启
动,启动报错。-Xms1g
-Xmx1g
3.添加es用户,es默认root用户无法启动,需要改为其他用户
useradd estest
修改密码
passwd estest改变es目录拥有者账号
chown -R estest /usr/elasticsearch/4.修改/etc/sysctl.conf
vim /etc/sysctl.conf末尾添加:
`vm.max_map_count=655360执行
sysctl -p让其生效
sysctl -p5.修改`/etc/security/limits.confvim /etc/security/limits.conf
末尾添加:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 40966.启动es
切换刚刚新建的用户
su estest启动命令
/usr/elasticsearch/bin/elasticsearch
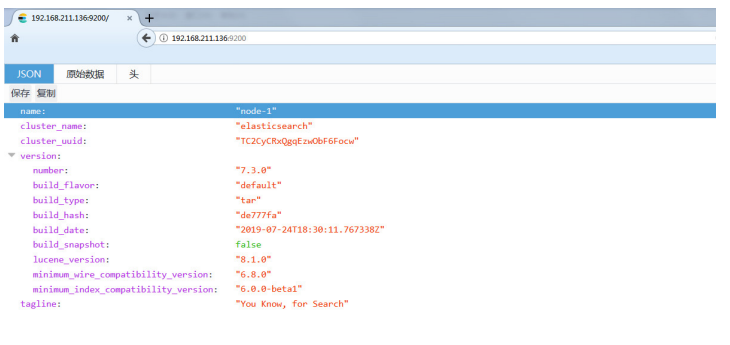
7.配置完成:浏览器访问测试。 ip:9200
 微信
微信 支付宝
支付宝









