计算机网络面试题
计算机网络概念
计算机网络:是一个将分散的、具有独立功能的计算机系统,通过通信设备与线路连接起来,由功能完善的软件实现资源共享和信息传递的系统。
这里需要注意的是,按分布范围,计算机网络里有局域网LAN和广域网WAN, 其中局域网的代表以太网,以及这两种网络最重要的区分点,局域网基于广播技术,广域网基于分组交换技术。
衡量计算机网络的性能的指标
速率
速率就是数据传输(数据是指0和1)的速率,比如你用迅雷下载,1兆每秒,来衡量目前数据传输的快慢。它是计算机网络中最重要的一个性能指标。
带宽
在计算机网络中,网络带宽是指在单位时间(一般指的是1秒钟)内能传输的数据量,比如说你家的电信网络是100兆比特,意思是,一秒内最大的传输速率是100兆比特。
吞吐量
吞吐量表示在单位时间内通过某个网络(或信道、接口)的数据量。
以上三点,我们举个案例
- 一条路每秒最多能过100辆车(宽带就相当于100辆/秒)。
- 而并不是每秒都会有100辆车过,假如第一秒有0辆,第二秒有10辆…,(但是最多不能超过100辆)。
- 所以有第1秒0辆/秒,第2秒10辆/秒,第3秒30辆/秒,这不能说带宽多少吧,于是就用吞吐量表示具体时间通过的量有多少(也有可能等于带宽的量)。
- 由此可知带宽是说的是最大值速率,吞吐量说的是某时刻速率。但吞吐量不能超过最大速率。
时延
时延是指数据(报文/分组/比特流)从网络(或链路)的一端传送到另一端所需的时间。单位是s。 时延分一下几种:
发送时延
就是说我跟你说话,从我开始说,到说话结束这段时间,就是发送时延。
传播时延
信道上第一个比特开始,到最后一个比特达到主机接口需要的时间就是传播时延。
排队时延
- 分组在经过网络传输时,要经过很多的
路由器。 - 但分组在进入路由器后要先在输入队列中
排队等待处理。 - 在路由器确定了转发接口后,还要在输出队列中排队等待转发,这就产生了
排队时延。 - 排队时延的长短往往却决于网络当时的通信量,当网络的通信量很大时会发生排队溢出,是
分组丢失。
处理时延
路由器或主机在收到数据包时,要花费一定时间进行处理,例如分析数据包的首部、进行首部差错检验,查找路由表为数据包选定准发接口,这就产生了处理时延。
往返时间(RTT)
在计算机网络中,往返时间也是一个重要的性能指标,它表示从发送方发送数据开始,到发送方收到来自接收方的确认(接受方收到数据后便立即发送确认)总共经历的时间
时延带宽积
是指传播时延乘以带宽
OSI参考模型
OSI参考模型是网络互连的七层框架。
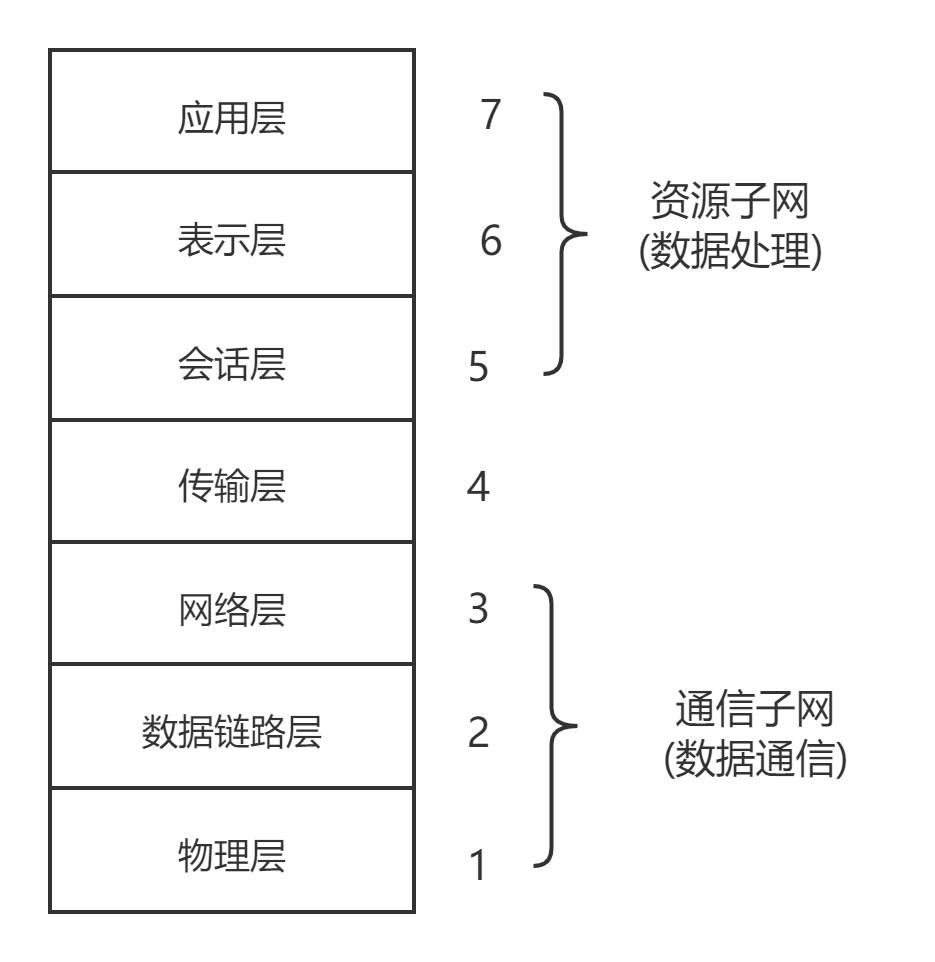
互联网的通信协议都对应了 7 层中的某一层,通过这一点,可以了解协议在整个网络模型中的作用,一般来说,各个分层的主要作用如下
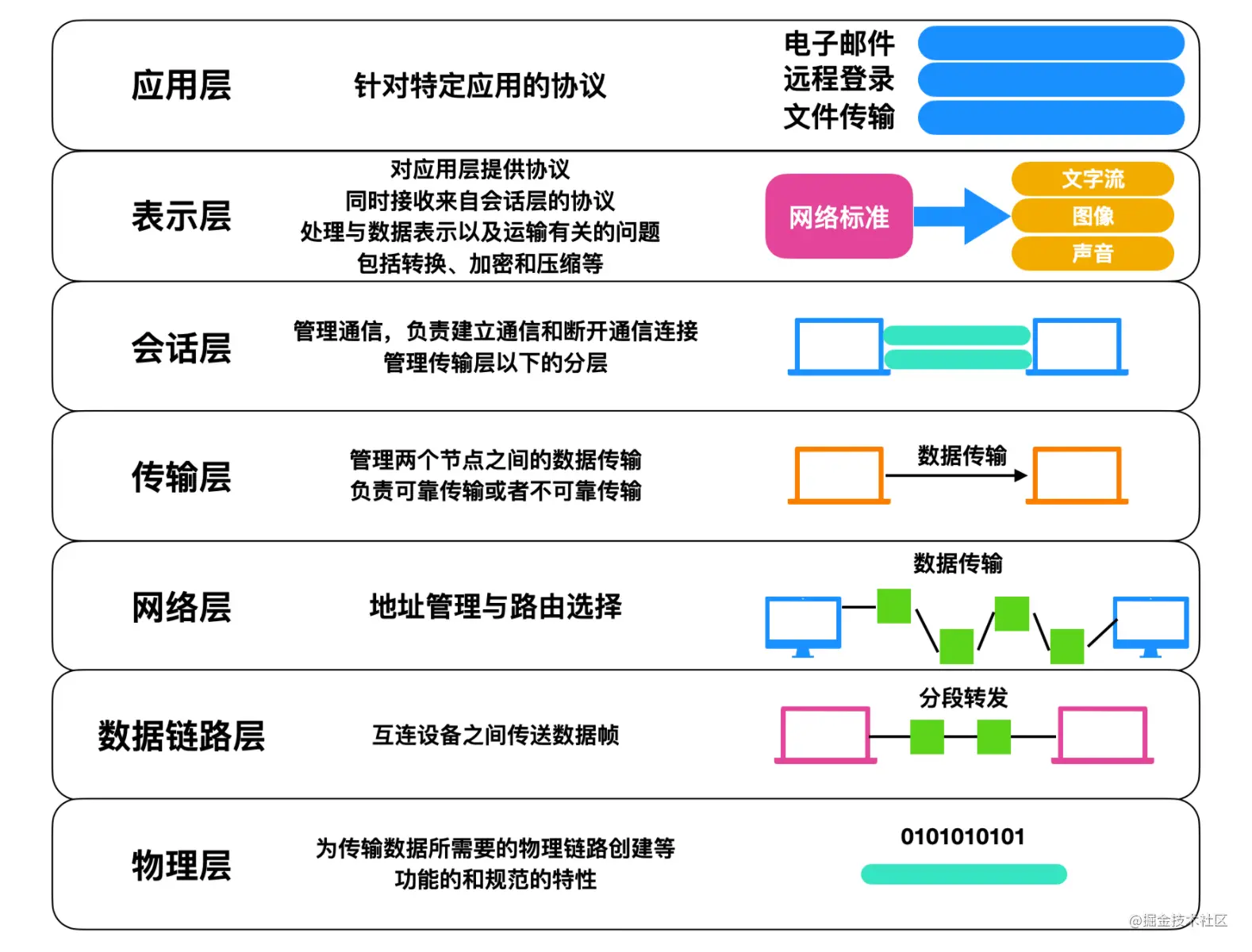
应用层:应用层是 OSI 标准模型的最顶层,是直接为应用进程提供服务的。其作用是在实现多个系统应用进程相互通信的同时,完成一系列业务处理所需的服务。包括文件传输、电子邮件远程登录和远端接口调用等协议。
表示层: 表示层向上对应用进程服务,向下接收会话层提供的服务,表示层位于 OSI 标准模型的第六层,表示层的主要作用就是将设备的固有数据格式转换为网络标准传输格式。
会话层:会话层位于 OSI 标准模型的第五层,它是建立在传输层之上,利用传输层提供的服务建立和维持会话。
传输层:传输层位于 OSI 标准模型的第四层,它在整个 OSI 标准模型中起到了至关重要的作用。传输层涉及到两个节点之间的数据传输,向上层提供可靠的数据传输服务。传输层的服务一般要经历传输连接建立阶段,数据传输阶段,传输连接释放阶段 3 个阶段才算完成一个完整的服务过程。
网络层:网络层位于 OSI 标准模型的第三层,它位于传输层和数据链路层的中间,将数据设法从源端经过若干个中间节点传送到另一端,从而向运输层提供最基本的端到端的数据传送服务。
数据链路层:数据链路层位于物理层和网络层中间,数据链路层定义了在单个链路上如何传输数据。
物理层:物理层是 OSI 标准模型中最低的一层,物理层是整个 OSI 协议的基础,就如同房屋的地基一样,物理层为设备之间的数据通信提供传输媒体及互连设备,为数据传输提供可靠的环境。
谈下你对五层网络协议体系结构的理解
- 1. 应用层
应用层(application-layer)的任务是通过应用进程间的交互来完成特定网络应用。应用层协议定义的是应用进程(进程:主机中正在运行的程序)间的通信和交互的规则。对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如域名系统 DNS,支持万维网应用的 HTTP 协议,支持电子邮件的 SMTP 协议等等。我们把应用层交互的数据单元称为报文。
- 2. 运输层
运输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务。应用进程利用该服务传送应用层报文。“通用的”是指并不针对某一个特定的网络应用,而是多种应用可以使用同一个运输层服务。
由于一台主机可同时运行多个线程,因此运输层有复用和分用的功能。所谓复用就是指多个应用层进程可同时使用下面运输层的服务,分用和复用相反,是运输层把收到的信息分别交付上面应用层中的相应进程。
- 3. 网络层
在计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP / IP 体系结构中,由于网络层使用 IP 协议,因此分组也叫 IP 数据报,简称数据报。
- 4. 数据链路层
数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。在两个相邻节点之间传送数据时,数据链路层将网络层交下来的 IP 数据报组装成帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如:同步信息,地址信息,差错控制等)。
在接收数据时,控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特结束。这样,数据链路层在收到一个帧后,就可从中提出数据部分,上交给网络层。控制信息还使接收端能够检测到所收到的帧中有无差错。如果发现差错,数据链路层就简单地丢弃这个出了差错的帧,以避免继续在网络中传送下去白白浪费网络资源。如果需要改正数据在链路层传输时出现差错(这就是说,数据链路层不仅要检错,而且还要纠错),那么就要采用可靠性传输协议来纠正出现的差错。这种方法会使链路层的协议复杂些。
- 5. 物理层
在物理层上所传送的数据单位是比特。物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
物理层有啥用
物理层更多的是规定一种标准,他并不管物理介质具体是什么,比如电线杆上是光纤还是双绞线,只要你能按物理层规定的标准传输数据就行。
那物理层到底有哪些主要任务呢?
- 比如说,规定了
电气特性,信号的电平用+10V - +15V表示二进制的0,用-10V - -15V表示二进制的1,只要条网线能表示这个特性,就不管你用什么材料了。 - 当然还有其它特性,我们不需要了解,
知道物理层是规定传输媒体接口的标准即可。
光纤宽带上网是以什么样的形式传输数据呢
首先计算机网卡传输出来的数据是电信号,光纤传输的是光脉冲信号,有光脉冲表示1,无光脉冲表示0。
而可见光的频率大约是10的8次方MHz,因此光纤通信系统的带宽远远大于其它各种传输媒体的带宽
所以我们计算机传输数据需要先把电信号转为光信号,然后光信号快到服务器的时候,再把光信号转为电信号。
物理层设备中继器
为什么需要中继器呢?
因为再线路上传输的信号功率会逐渐衰减,衰减到一定程度时将造成信号失真,因此会导致接收错误。中继器可以对信号进行再生和还原,增加信号的传输距离。
需要注意的是,中继器两端连接不同的网段,而不是子网。什么叫不同的网段呢,需要在网络层学习IP分类之后才能够理解这个概念,这里简单的理解为,不同的网段就是不同路由器连接的网络。
物理媒介
网络的传输是需要介质的。一个比特数据包从一个端系统开始传输,经过一系列的链路和路由器,从而到达另外一个端系统。这个比特会被转发了很多次,那么这个比特经过传输的过程所跨越的媒介就被称为物理媒介(phhysical medium),物理媒介有很多种,比如双绞铜线、同轴电缆、多模光纤榄、陆地无线电频谱和卫星无线电频谱。其实大致分为两种:引导性媒介和非引导性媒介。
双绞铜线
最便宜且最常用的引导性传输媒介就是双绞铜线,多年以来,它一直应用于电话网。从电话机到本地电话交换机的连线超过 99% 都是使用的双绞铜线,例如下面就是双绞铜线的实物图

双绞铜线由两根绝缘的铜线组成,每根大约 1cm 粗,以规则的螺旋形状排列,通常许多双绞线捆扎在一起形成电缆,并在双绞馅的外面套上保护层。一对电缆构成了一个通信链路。无屏蔽双绞线一般常用在局域网(LAN)中。
同轴电缆
与双绞线类似,同轴电缆也是由两个铜导体组成,下面是实物图

借助于这种结构以及特殊的绝缘体和保护层,同轴电缆能够达到较高的传输速率,同轴电缆普遍应用在在电缆电视系统中。同轴电缆常被用户引导型共享媒介。
光纤
光纤是一种细而柔软的、能够引导光脉冲的媒介,每个脉冲表示一个比特。一根光纤能够支持极高的比特率,高达数十甚至数百 Gbps。它们不受电磁干扰。光纤是一种引导型物理媒介,下面是光纤的实物图

一般长途电话网络全面使用光纤,光纤也广泛应用于因特网的主干。
陆地无线电信道
无线电信道承载电磁频谱中的信号。它不需要安装物理线路,并具有穿透墙壁、提供与移动用户的连接以及长距离承载信号的能力。
卫星无线电信道
一颗卫星电信道连接地球上的两个或多个微博发射器/接收器,它们称为地面站。通信中经常使用两类卫星:同步卫星和近地卫星。
数据链路层是干什么的?
我们用一个小故事来举例
网络层是个大Boss, 负责给数据链路层这个小秘书下达任务,让小秘把5份文件给B公司,小秘呢,就找送快递物理层去做这个事
但物理层是个傻子,他只知道拿起文件就飞奔到B公司,中间丢没丢东西也不清楚,所以数据链路层这个小秘书必须心里有底,一共送了5个文件,并且写到了快递外层。B公司小秘在拿到傻子送到的文件时,就要看看到底有没有文件丢了,如果丢了就要让傻子回去重新拿丢到的文件。
从这个故事中,我们可以总结下数据链路层主要功能
数据链路层的主要功能
(1) 封装成帧 数据链路层并不是无脑转发boss的信息,她要把文件编号封装一下。封装的网络数据包,在链路层就叫数据帧。
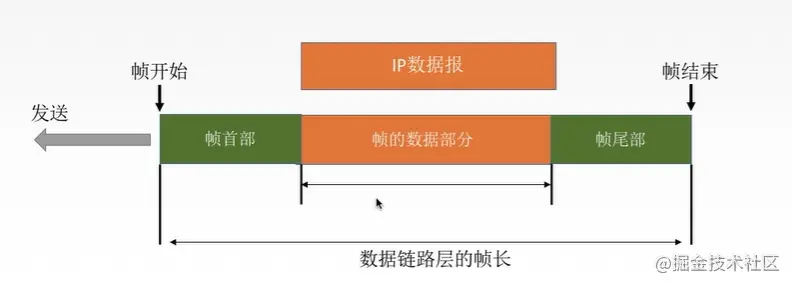
(2)透明传输
透明传输是指不管boss下达的任何信息,比如文件里有裁掉这个秘书的信息,秘书都要原原本本的传输。帧的数据部分可能有跟帧首部完全一样的字符,这时候就要采取一定的措施,让接受方不要被被误导,能让接收方知道哪些是帧的首部哪些是帧的数据。这个问题有没有类似js的转义字符的问题,比如字符串
(3)差错控制
差错控制是在文件送到B公司小秘书手里的时候,快递包上写着5个文件,秘书一看只有3个文件,就会让傻子重新发送有没有送到的文件。差错控制的方法有CRC循环冗余码,这个就不细讲了,我自己也不甚了解,只知道链路层的帧,会有一个FCS位留给这个码,用来判断一个帧是否出错。
(4)差错纠正
差错纠正是链路层知道1,2,3,4,5个文件,丢失的两个文件到底是哪两个,并且能通过重新发送没有的文件来纠正。
还有一些是故事里没有提到的数据链路层的功能,比如:
(5)流量控制 比如说发送方发送速度特别快,接收方接收速度特别慢,会造成传输出错。
这里需要注意的是,传输层TCP也有流量控制功能,区别在于TCP是端到端的流量控制,链路层是点到点(比如一个路由器到下一个路由器)
数据链路常用的协议
PPP 协议
PPP 协议是 Point to Point Protocol,即点对点协议,是一种链路层协议,是在为同等单元之间传输数据包而设计的。设计目的主要是用来通过拨号或专线方式建立点对点连接发送数据,使其成为各种主机、网桥和路由器之间简单连接的一种共通的解决方案。
帧中继
帧中继FR(Frame Relay)是八十年代初发展起来的一种数据通信技术,从X.25分组通信技术演变而来。
帧中继主要用于传递数据业务,它使用一组规程,将数据信息以帧的形式进行传送。帧中继使用逻辑连接,而不是物理连接。一个物理连接上可复用多个逻辑连接,即,可建立多条逻辑信道,能够实现带宽的复用和动态分配。
帧中继协议是对X.25协议的简化,处理效率高,网络吞吐量高,通信时延低。
CSMA/CD协议:载波侦听多路访问/碰撞检测
是对CSMA协议的改进方案,适用于总线型网络或者半双工网络环境
载波侦听:也就是发送前先侦听,每次发送数据之前都要先检查一下总线上是否有其他站点在发送数据,如果有
则暂时不要发送数据,等待信道变为空闲的时候再发送。
碰撞检测:就是一边发送一边侦听,适配器在发送数据的时候变检测信道上的信号电压的变化情况,用来判断自己在发送数据的时候其他站点是否也在发送数据。
CSMA/CD工作流程:先听后发,边听边发,冲突停发,随机重发
总线的传播时延对CSMA/CD的影响很大,CSMA/CD中的站不能同时发送和接收
所以CSMA/CD的以太网是不进行全双工通信,只能进行半双工通信
具体想了解更多的协议请访问:
https://www.cnnotes.com/drq1/p/9681226.html
https://note.51cto.com/cchome/528278
以太网的帧格式
以太网是一种局域网技术,其规定了访问控制方法、传输控制协议、网络拓扑结构、传输速率等,完成数据链路层和物理层的一些内容,它采用一种称作CSMA/CD的媒体接入方法,另外的一些局域网技术,比如无线局域网等。
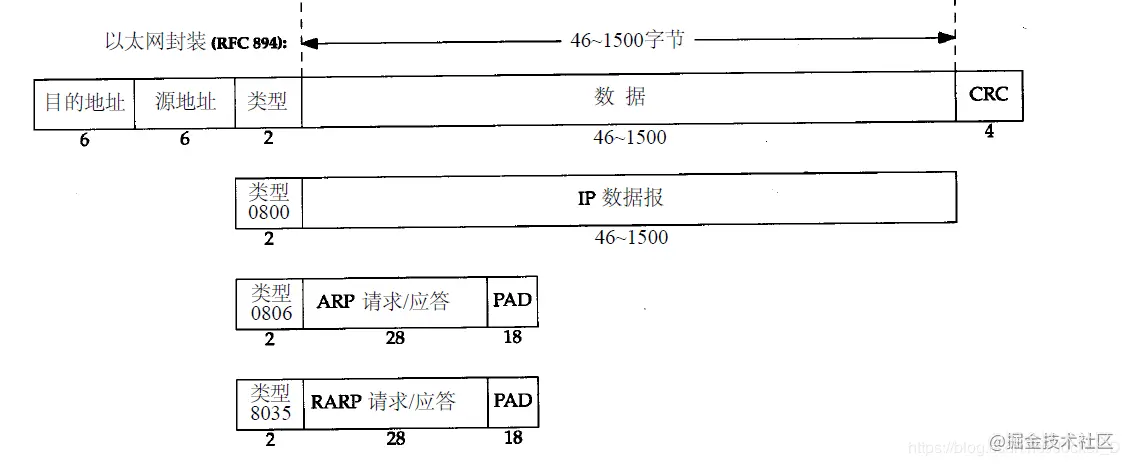
其中目的地址和源地址指的是MAC地址,即设备的物理地址。MAC地址用于标示网卡,每个网卡都具有唯一的MAC 地址
当在同一个局域网中,主机A需要给主机B发送消息时,主机A将以太网帧发出,此时局域网中所有主机均可收到这个桢,主机中的网卡接收到以太网桢后,会将目的MAC地址和自己的MAC地址进行比较,如果不相同就会丢弃,如果相同则会接收,此时则B主机就收到了A的消息。
其最后面是CRC循环冗余码,用于差错控制,即检验帧的正确性
在以太网协议中,目的地址分为三种单播地址、广播地址、多播地址,其中单播地址如上面A给B主机发送,其接收者为一个,并且其目的地址的最高字节的低位为0
以太网的特点
- 无连接。发送方和接收方不建立连接。
- 不可靠。接收方不向发送方进行确认,差错帧直接丢弃。
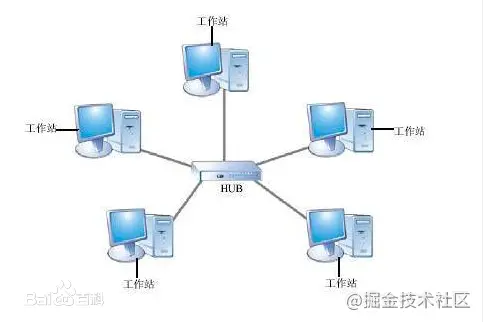
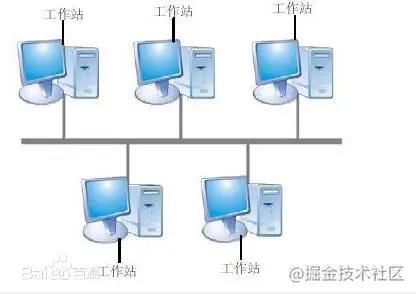
以太网的拓扑结构
跟以太网相关的拓扑结构有星型和总线型。
星型拓扑如下:
总线型拓扑如下:
互联网初期,以太网的总线型拓扑比较普遍。随着总线型以太网上的站点数目增多,可靠性也会随之下降,而随着大规模集成电路以及专门芯片的发展,使得星型以太网变得便宜又可靠。
需要注意的是,以太网虽然物理上是星型拓扑,但逻辑上是总线型。
链路层的设备
网桥
网桥根据MAC帧的目的地址进行转发和过滤。当网桥收到一个帧时,并不会向所有接口转发此帧,而是先检查此帧的目的MAC地址,然后再确定将该帧转发到哪一个口,或者是把它丢弃。
这里需要注意的是,网桥连接的是不同的网段,网段是什么呢,我这里简单介绍一下,具体要到讲IP地址的时候细说,同一网段指的是IP地址和子网掩码(讲ip地址的时候会细讲)相与得到相同的网络地址。
以太网交换机
谈到交换机,就不得不提两个概念,冲突域和广播域
- 冲突域: 是指同一时间
只能由一台设备发送信息的范围。 - 广播域:如果站点发出一个广播信号,
所有能接收到这个信号的设备范围称为广播域 - 也就是说,广播域可以
跨网段,而冲突域只是发生的同一个网段。
举个例子,公司里大家的电脑一般都是连接到交换机上,因为交换机可以隔离冲突域,冲突域的最大问题在于,同一时间只能有一台机器传输数据,公司那么多人,如果这样的话,传输数据速度太慢了。然后交换机再连接到路由器上,首先路由器能隔离广播域,其次不经过路由器,你的数据链路层上的包没办法进入到互联网里面去`,路由器是网络层的设备。
网络层概念
网络层主要任务是将分组(分组的概念是大多数计算机网络都不能连续地传送任意长的数据,所以实际上网络系统把数据分割成小块,然后逐块地发动,这种小块就称作分组)从一台主机移动到另一台主机,从而提供了主机到主机的通信服务和各种形式的进程到进程的通信。
网络传输方式
网络根据传输方式可以进行分类,一般分成两种 面向连接型和面向无连接型。
- 面向连接型中,在发送数据之前,需要在主机之间建立一条通信线路。
- 面向无连接型则不要求建立和断开连接,发送方可用于任何时候发送数据。接收端也不知道自己何时从哪里接收到数据。
分组交换
在互联网应用中,每个终端系统都可以彼此交换信息,这种信息也被称为 报文(Message),报文是一个集大成者,它可以包括你想要的任何东西,比如文字、数据、电子邮件、音频、视频等。为了从源目的地向端系统发送报文,需要把长报文切分为一个个小的数据块,这种数据块称为分组(Packets),也就是说,报文是由一个个小块的分组组成。在端系统和目的地之间,每个分组都要经过通信链路(communication links) 和分组交换机(switch packets) ,分组要在端系统之间交互需要经过一定的时间,如果两个端系统之间需要交互的分组为 L 比特,链路的传输速率问 R 比特/秒,那么传输时间就是 L / R秒。
一个端系统需要经过交换机给其他端系统发送分组,当分组到达交换机时,交换机就能够直接进行转发吗?不是的,交换机可没有这么无私,你想让我帮你转发分组?好,首先你需要先把整个分组数据都给我,我再考虑给你发送的问题,这就是存储转发传输
存储转发传输
存储转发传输指的就是交换机再转发分组的第一个比特前,必须要接受到整个分组,下面是一个存储转发传输的示意图,可以从图中窥出端倪
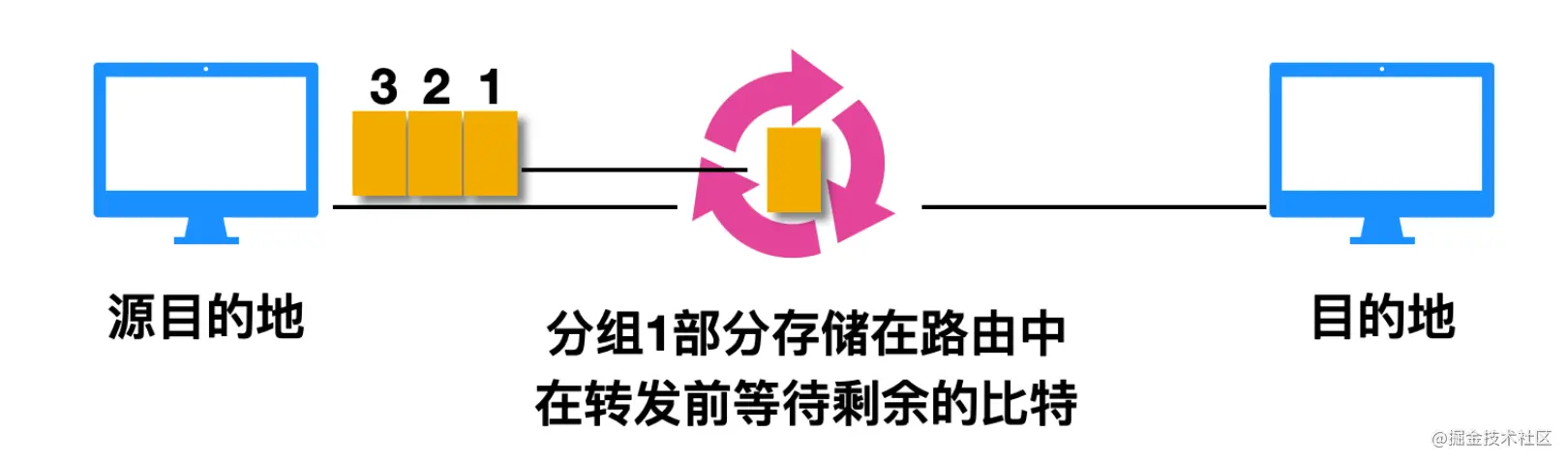
由图可以看出,分组 1、2、3 向交换器进行分组传输,并且交换机已经收到了分组1 发送的比特,此时交换机会直接进行转发吗?答案是不会的,交换机会把你的分组先缓存在本地。这就和考试作弊一样,一个学霸要经过学渣 A 给学渣 B 传答案,学渣 A 说,学渣 A 在收到答案后,它可能直接把卷子传过去吗?学渣A 说,等我先把答案抄完(保存功能)后再把卷子给你。
排队时延和分组丢失
什么?你认为交换机只能和一条通信链路进行相连?那你就大错特错了,这可是交换机啊,怎么可能只有一条通信链路呢?
所以我相信你一定能想到这个问题,多个端系统同时给交换器发送分组,一定存在顺序到达和排队的问题。事实上,对于每条相连的链路,该分组交换机会有一个输出缓存(output buffer) 和 输出队列(output queue) 与之对应,它用于存储路由器准备发往每条链路的分组。如果到达的分组发现路由器正在接收其他分组,那么新到达的分组就会在输出队列中进行排队,这种等待分组转发所耗费的时间也被称为 排队时延,上面提到分组交换器在转发分组时会进行等待,这种等待被称为 存储转发时延,所以我们现在了解到的有两种时延,但是其实是有四种时延。这些时延不是一成不变的,其变化程序取决于网络的拥塞程度。
因为队列是有容量限制的,当多条链路同时发送分组导致输出缓存无法接受超额的分组后,这些分组会丢失,这种情况被称为 丢包(packet loss),到达的分组或者已排队的分组将会被丢弃。
下图说明了一个简单的分组交换网络
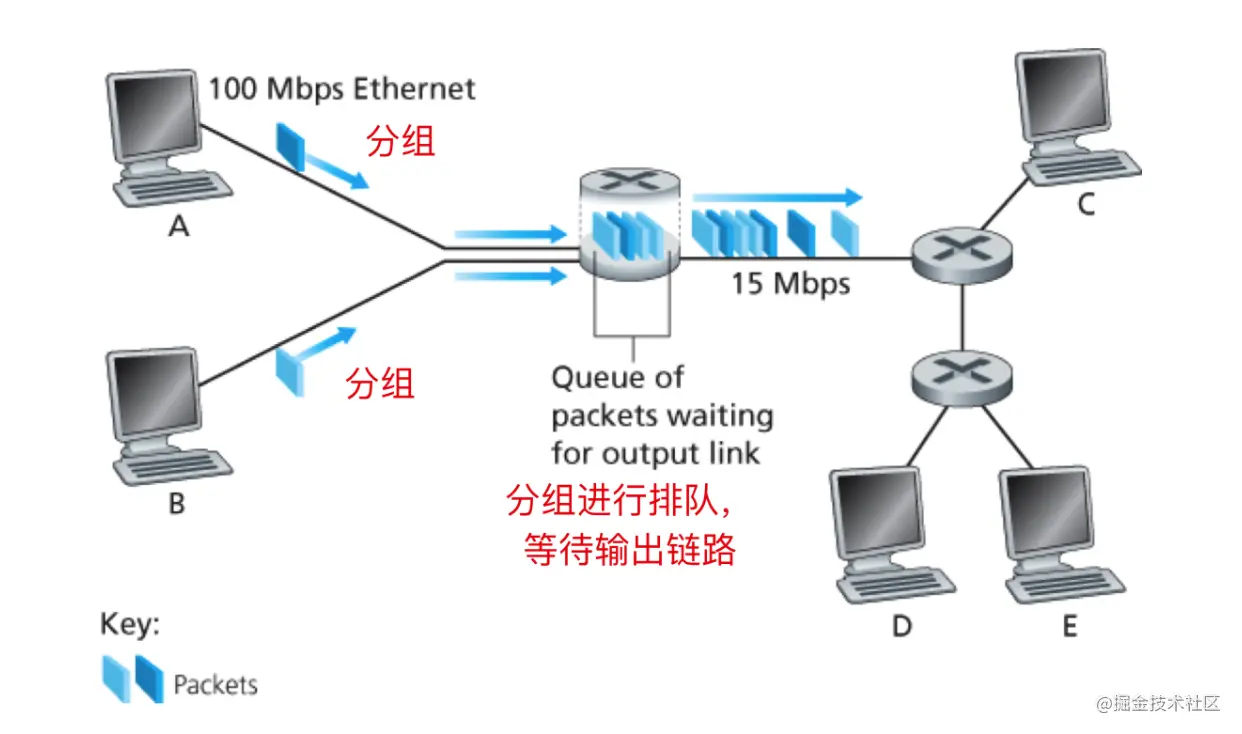
在上图中,分组由三位数据平板展示,平板的宽度表示着分组数据的大小。所有的分组都有相同的宽度,因此也就有相同的数据包大小。下面来一个情景模拟: 假定主机 A 和 主机 B 要向主机 E 发送分组,主机 A 和 B 首先通过100 Mbps以太网链路将其数据包发送到第一台路由器,然后路由器将这些数据包定向到15 Mbps 的链路。如果在较短的时间间隔内,数据包到达路由器的速率(转换为每秒比特数)超过15 Mbps,则在数据包在链路输出缓冲区中排队之前,路由器上会发生拥塞,然后再传输到链路上。例如,如果主机 A 和主机 B 背靠背同时发了5包数据,那么这些数据包中的大多数将花费一些时间在队列中等待。实际上,这种情况与许多普通情况完全相似,例如,当我们排队等候银行出纳员或在收费站前等候时。
转发表和路由器选择协议
我们刚刚讲过,路由器和多个通信线路进行相连,如果每条通信链路同时发送分组的话,可能会造成排队和丢包的情况,然后分组在队列中等待发送,现在我就有一个问题问你,队列中的分组发向哪里?这是由什么机制决定的?
换个角度想问题,路由的作用是什么?把不同端系统中的数据包进行存储和转发 。在因特网中,每个端系统都会有一个 IP 地址,当原主机发送一个分组时,在分组的首部都会加上原主机的 IP 地址。每一台路由器都会有一个 转发表(forwarding table),当一个分组到达路由器后,路由器会检查分组的目的地址的一部分,并用目的地址搜索转发表,以找出适当的传送链路,然后映射成为输出链路进行转发。
那么问题来了,路由器内部是怎样设置转发表的呢?详细的我们后面会讲到,这里只是说个大概,路由器内部也是具有路由选择协议的,用于自动设置转发表。
电路交换
在计算机网络中,另一种通过网络链路和路由进行数据传输的另外一种方式就是 电路交换(circuit switching)。电路交换在资源预留上与分组交换不同,什么意思呢?就是分组交换不会预留每次端系统之间交互分组的缓存和链路传输速率,所以每次都会进行排队传输;而电路交换会预留这些信息。一个简单的例子帮助你理解:这就好比有两家餐馆,餐馆 A 需要预定而餐馆 B 不需要预定,对于可以预定的餐馆 A,我们必须先提前与其进行联系,但是当我们到达目的地时,我们能够立刻入座并选菜。而对于不需要预定的那家餐馆来说,你可能不需要提前联系,但是你必须承受到达目的地后需要排队的风险。
下面显示了一个电路交换网络
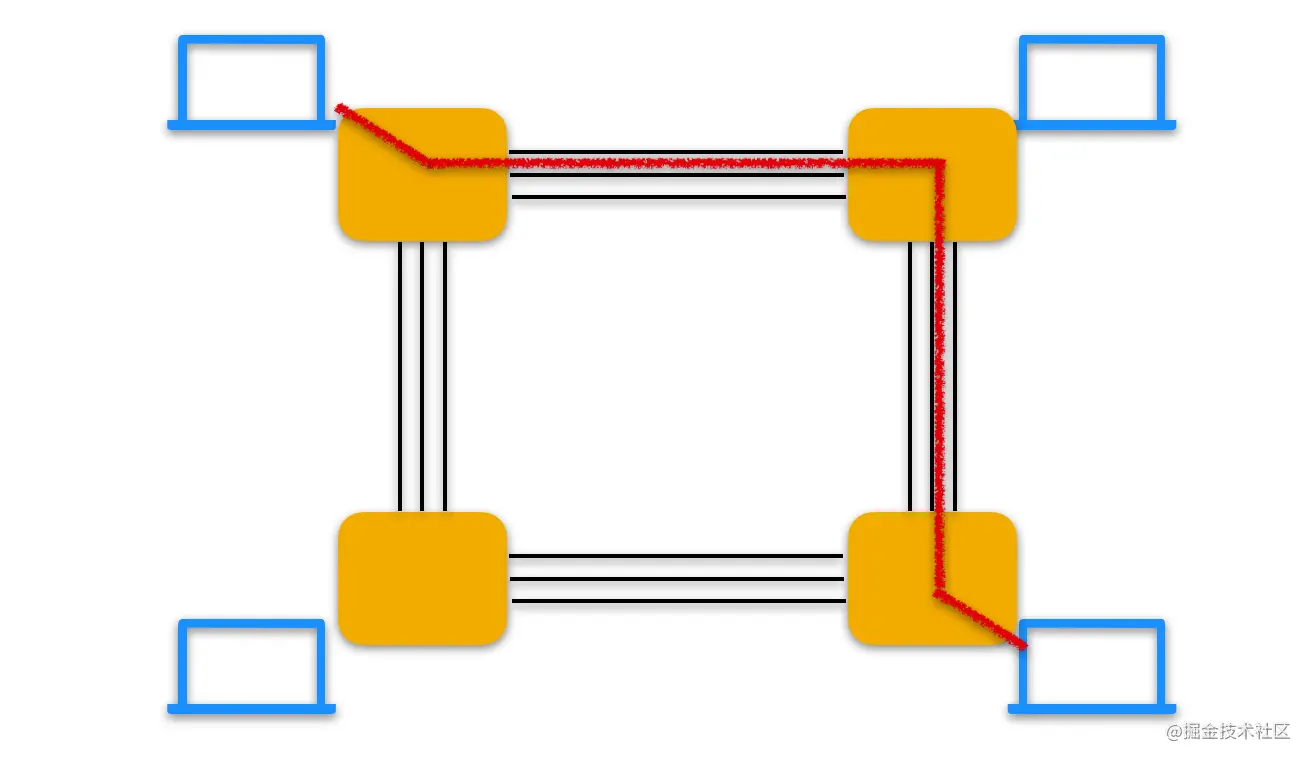
在这个网络中,4条链路用于4台电路交换机。这些链路中的每一条都有4条电路,因此每条链路能支持4条并行的链接。每台主机都与一台交换机直接相连,当两台主机需要通信时,该网络在两台主机之间创建一条专用的 端到端的链接(end-to-end connection)。
报文交换
报文交换(英文:message switching),又称存储转发交换,是数据交换的三种方式之一,报文整个地发送,一次一跳。报文交换是分组交换的前身,是由莱昂纳多·克莱洛克于1961年提出的。
报文交换的主要特点是:存储接收到的报文,判断其目标地址以选择路由,最后,在下一跳路由空闲时,将数据转发给下一跳路由。报文交换系统现今都由分组交换或电路交换网络所承载。
报文交换是以报文为数据交换的单位,报文携带有目标地址、源地址等信息,在交换结点采用存储转发的传输方式,因而有以下优缺点:
优点
①报文交换不需要为通信双方预先建立一条专用的通信线路,不存在连接建立时延,用户可随时发送报文。
②由于采用存储转发的传输方式,使之具有下列优点:a.在报文交换中便于设置代码检验和数据重发设施,加之交换结点还具有路径选择,就可以做到某条传输路径发生故障时,重新选择另一条路径传输数据,提高了传输的可靠性;b.在存储转发中容易实现代码转换和速率匹配,甚至收发双方可以不同时处于可用状态。这样就便于类型、规格和速度不同的计算机之间进行通信;c.提供多目标服务,即一个报文可以同时发送到多个目的地址,这在电路交换中是很难实现的;d.允许建立数据传输的优先级,使优先级高的报文优先转换。
③通信双方不是固定占有一条通信线路,而是在不同的时间一段一段地部分占有这条物理通路,因而大大提高了通信线路的利用率。
缺点
①由于数据进入交换结点后要经历存储、转发这一过程,从而引起转发时延(包括接收报文、检验正确性、排队、发送时间等),而且网络的通信量愈大,造成的时延就愈大,因此报文交换的实时性差,不适合传送实时或交互式业务的数据。
②报文交换只适用于数字信号。
③由于报文长度没有限制,而每个中间结点都要完整地接收传来的整个报文,当输出线路不空闲时,还可能要存储几个完整报文等待转发,要求网络中每个结点有较大的缓冲区。为了降低成本,减少结点的缓冲存储器的容量,有时要把等待转发的报文存在磁盘上,进一步增加了传送时延。
分组交换和电路交换的对比
分组交换的支持者经常说分组交换不适合实时服务,因为它的端到端时延时不可预测的。而分组交换的支持者却认为分组交换提供了比电路交换更好的带宽共享;它比电路交换更加简单、更有效,实现成本更低。但是现在的趋势更多的是朝着分组交换的方向发展。
分组交换网的时延、丢包和吞吐量
因特网可以看成是一种基础设施,该基础设施为运行在端系统上的分布式应用提供服务。我们希望在计算机网络中任意两个端系统之间传递数据都不会造成数据丢失,然而这是一个极高的目标,实践中难以达到。所以,在实践中必须要限制端系统之间的 吞吐量 用来控制数据丢失。如果在端系统之间引入时延,也不能保证不会丢失分组问题。所以我们从时延、丢包和吞吐量三个层面来看一下计算机网络。
分组交换中的时延
计算机网络中的分组从一台主机(源)出发,经过一系列路由器传输,在另一个端系统中结束它的历程。在这整个传输历程中,分组会涉及到四种最主要的时延:节点处理时延(nodal processing delay)、排队时延(queuing delay)、传输时延(total nodal delay)和传播时延(propagation delay)。这四种时延加起来就是 节点总时延(total nodal delay)。
如果用 dproc dqueue dtrans dpop 分别表示处理时延、排队时延、传输时延和传播时延,则节点的总时延由以下公式决定: dnodal = dproc + dqueue + dtrans + dpop。
具体看上文讲述的时延类型。
在这四种时延中,人们最感兴趣的时延或许就是排队时延了 dqueue。与其他三种时延(dproc、dtrans、dpop)不同的是,排队时延对不同的分组可能是不同的。例如,如果10个分组同时到达某个队列,第一个到达队列的分组没有排队时延,而最后到达的分组却要经受最大的排队时延(需要等待其他九个时延被传输)。
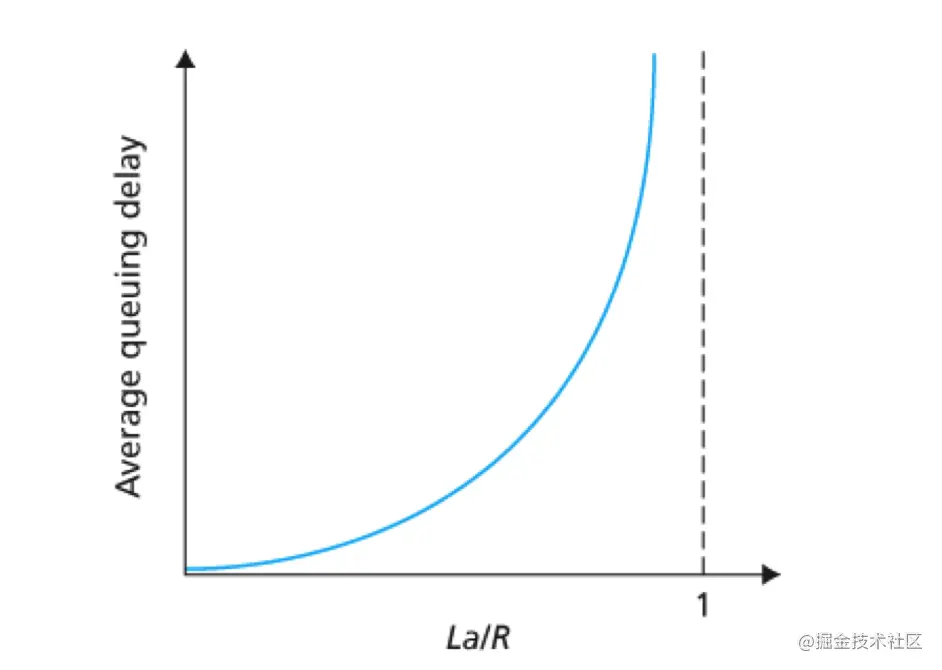
那么如何描述排队时延呢?或许可以从三个方面来考虑:流量到达队列的速率、链路的传输速率和到达流量的性质。即流量是周期性到达还是突发性到达,如果用 a 表示分组到达队列的平均速率( a 的单位是分组/秒,即 pkt/s)前面说过 R 表示的是传输速率,所以能够从队列中推出比特的速率(以 bps 即 b/s 位单位)。假设所有的分组都是由 L 比特组成的,那么比特到达队列的平均速率是 La bps。那么比率 La/R 被称为流量强度(traffic intensity),如果 La/R > 1,则比特到达队列的平均速率超过从队列传输出去的速率,这种情况下队列趋向于无限增加。所以,设计系统时流量强度不能大于1。
现在考虑 La / R <= 1 时的情况。流量到达的性质将影响排队时延。如果流量是周期性到达的,即每 L / R 秒到达一个分组,则每个分组将到达一个空队列中,不会有排队时延。如果流量是 突发性 到达的,则可能会有很大的平均排队时延。一般可以用下面这幅图表示平均排队时延与流量强度的关系
丢包
我们在上述的讨论过程中描绘了一个公式那就是 La/R 不能大于1,如果 La/R 大于1,那么到达的排队将会无穷大,而且路由器中的排队队列所容纳的分组是有限的,所以等到路由器队列堆满后,新到达的分组就无法被容纳,导致路由器 丢弃(drop) 该分组,即分组会 丢失(lost)。
计算机网络中的吞吐量
除了丢包和时延外,衡量计算机另一个至关重要的性能测度是端到端的吞吐量。假如从主机 A 向主机 B 传送一个大文件,那么在任何时刻主机 B 接收到该文件的速率就是 瞬时吞吐量(instantaneous throughput)。如果该文件由 F 比特组成,主机 B 接收到所有 F 比特用去 T 秒,则文件的传送平均吞吐量(average throughput) 是 F / T bps。
单播、广播、多播和任播
在网络通信中,可以根据目标地址的数量对通信进行分类,可以分为 单播、广播、多播和任播
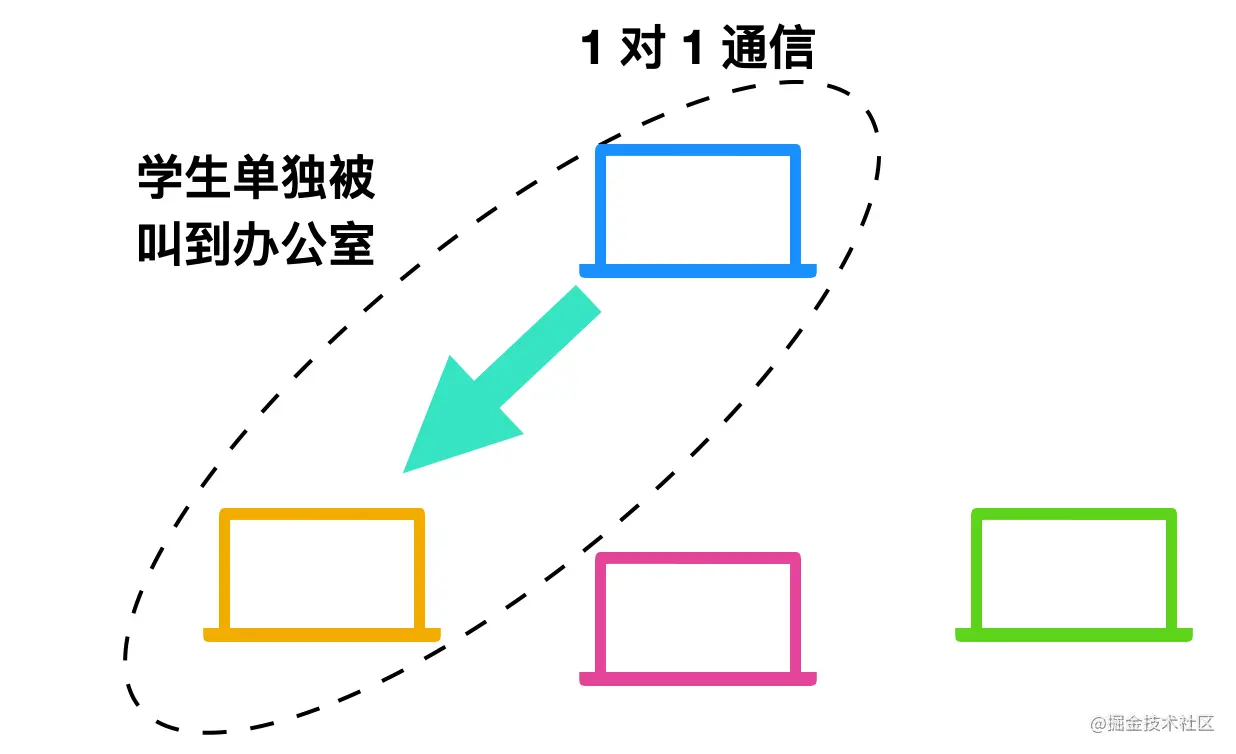
单播(Unicast)
单播最大的特点就是 1 对 1,早期的固定电话就是单播的一个例子,单播示意图如下
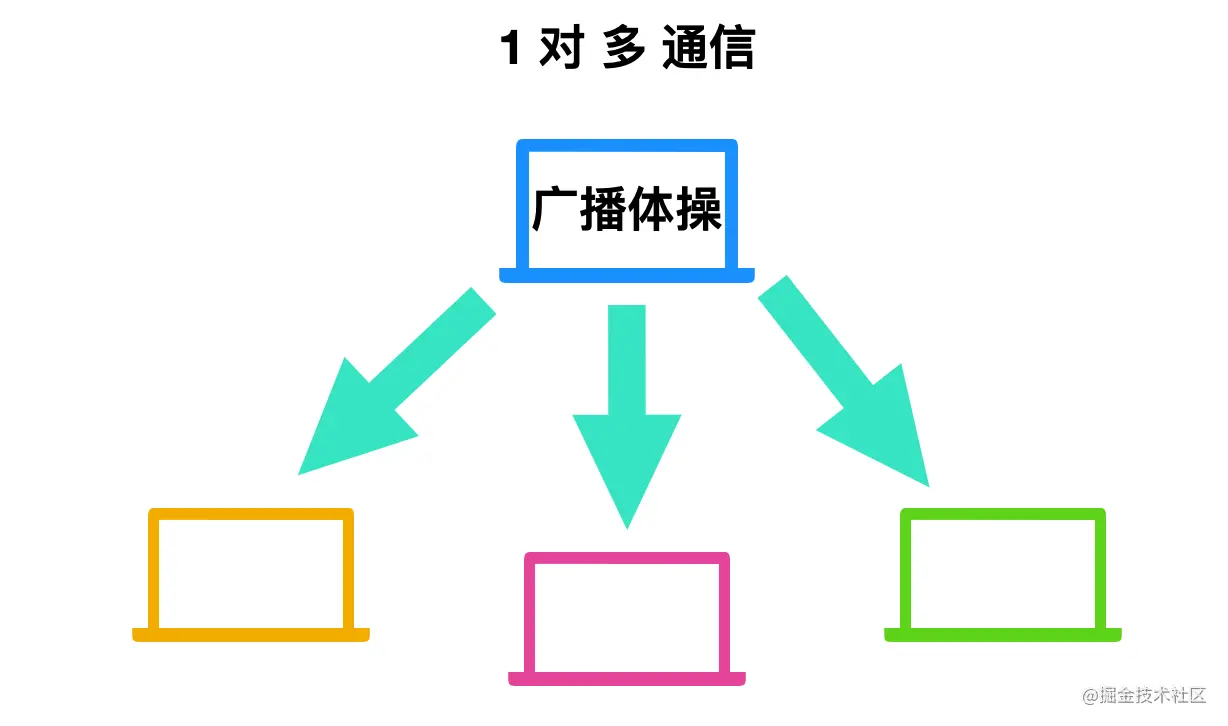
广播(Broadcast)
我们一般小时候经常会跳广播体操,这就是广播的一个事例,主机和与他连接的所有端系统相连,主机将信号发送给所有的端系统。
多播(Multicast)
多播与广播很类似,也是将消息发送给多个接收主机,不同之处在于多播需要限定在某一组主机作为接收端。
任播(Anycast)
任播是在特定的多台主机中选出一个接收端的通信方式。虽然和多播很相似,但是行为与多播不同,任播是从许多目标机群中选出一台最符合网络条件的主机作为目标主机发送消息。然后被选中的特定主机将返回一个单播信号,然后再与目标主机进行通信。
数据报
数据报是通过网络传输的数据的基本单元,包含一个报头(header)和数据本身。说白了,就是带地址的数据,比如你的写了一句微信”你好”,这串文字本上加上源地址,目的地址,就是数据报。
数据报格式
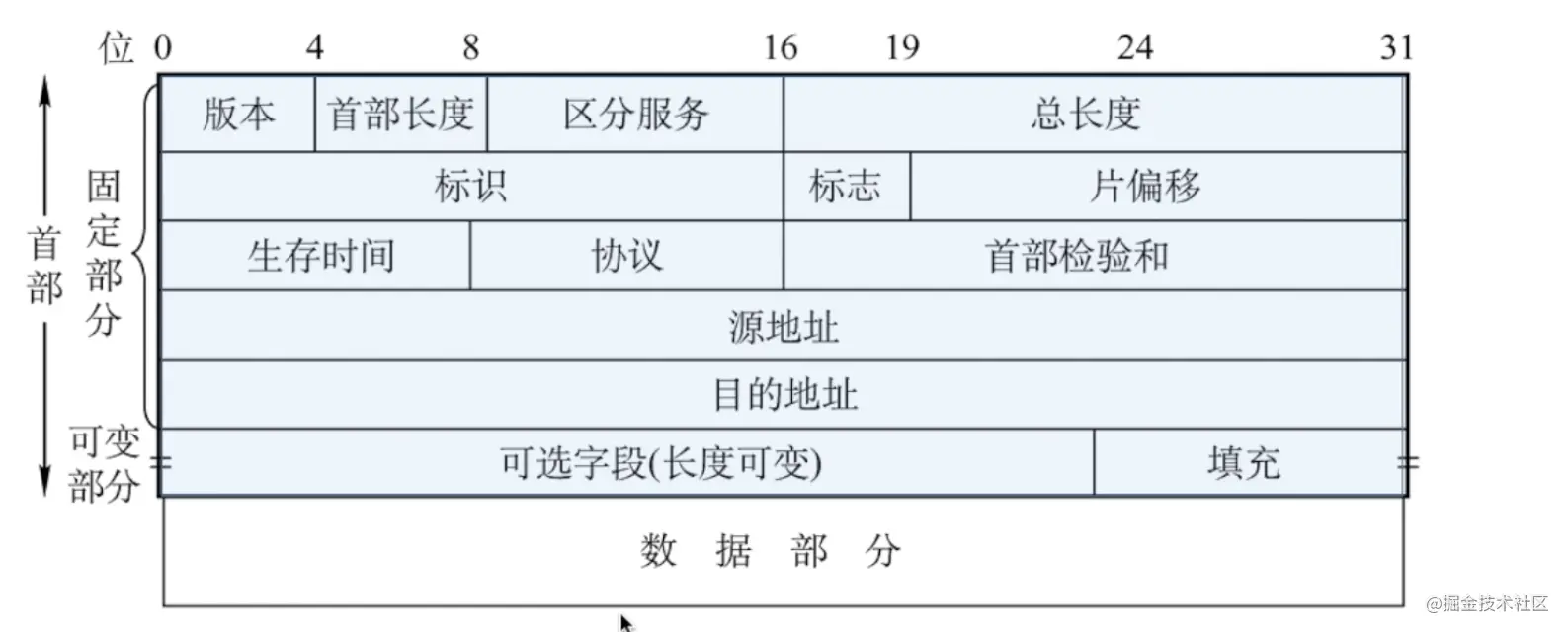
- 首部的固定部分是
20字节,共20 * 8 = 160比特(1字节=8比特) 0 - 4比特是版本号,版本有ipv4/ipv6- 首部长度,
单位是4B,最小为5, 为什么是5呢?因为首部至少20字节,所以4* 5就是20字节
区分服务不用看。
- 总长度是,
首部+数据 - 生存时间是
TTL,它告诉网络,数据包在网络中的时间是否太长而应被丢弃。每经过一个路由器减一,变成0就丢弃 - 协议是指数据部分用的什么协议,我们只需要知道
TCP协议用6表示,UDP协议用17表示即可。 首部校验和占16位。这个字段只检验数据报的首部,但不包括数据部分。- 目的地址和源地址都是
IP地址,目的地址是通过DNS查询得来的。
IP分片
链路层数据帧封装的数据大小是有限制的,以太网的MTU(MTU是指一种通信协议的某一层上面所能通过的最大数据包大小)是1500字节。
接下来我们就看看在ip数据包上,哪些字段标识了分片的数据呢?

- 标识是在
同一数据的分片时相同。 - 标志占3位,但只有两位有意义,第一个位叫
MF,MF=1即表示后面“还有分片”的数据报。MF=0表示这已是若干数据报片中的最后一个。 - 标志字段中间的一位记为
DF(Don’t Fragment),意思是“不能分片”。只有当DF=0时才允许分片。 - 片偏移,较长的分组在分片后,某片在原分组中的相对位置。
ip地址分类
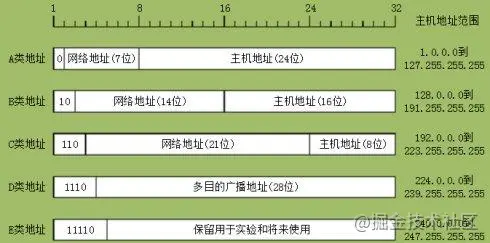
- A类:
1.0.0.0~126.255.255.255 - B类:
128.0.0.0~191.255.255.255 - C类:
192.0.0.0~223.255.255.255 - D类:
224.0.0.0~239.255.255.255 - E类:
240.0.0.0~254.255.255.255 - 其中
127.0.0.0~127.255.255.255用于环回测试,D类地址用于组播,E类地址用于科研
这里需要注意的是,你发没发现,为什么我们前端启动webpack测试环境的时候,一般地址都是192.168..(* 是指0-255的数字); 在公司和家里都是这个网段,不是很奇怪吗,你家里的网段怎么和公司一样呢?
其实是因为有一部分叫私有IP地址,是不能拿到网络上跟别的计算机通信的。只能是局域网自己内部用。比如说有:
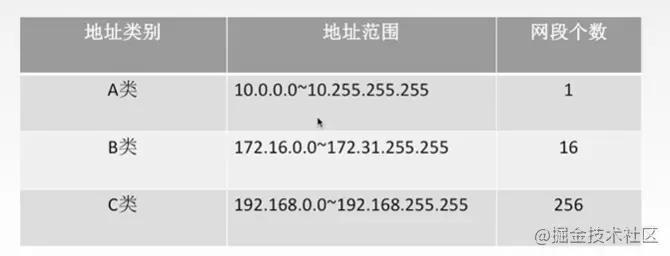
可以看到,C类私有地址就是192.168网段,每个局域网都可以有这些私有IP。
还有一些特殊地址,需要了解
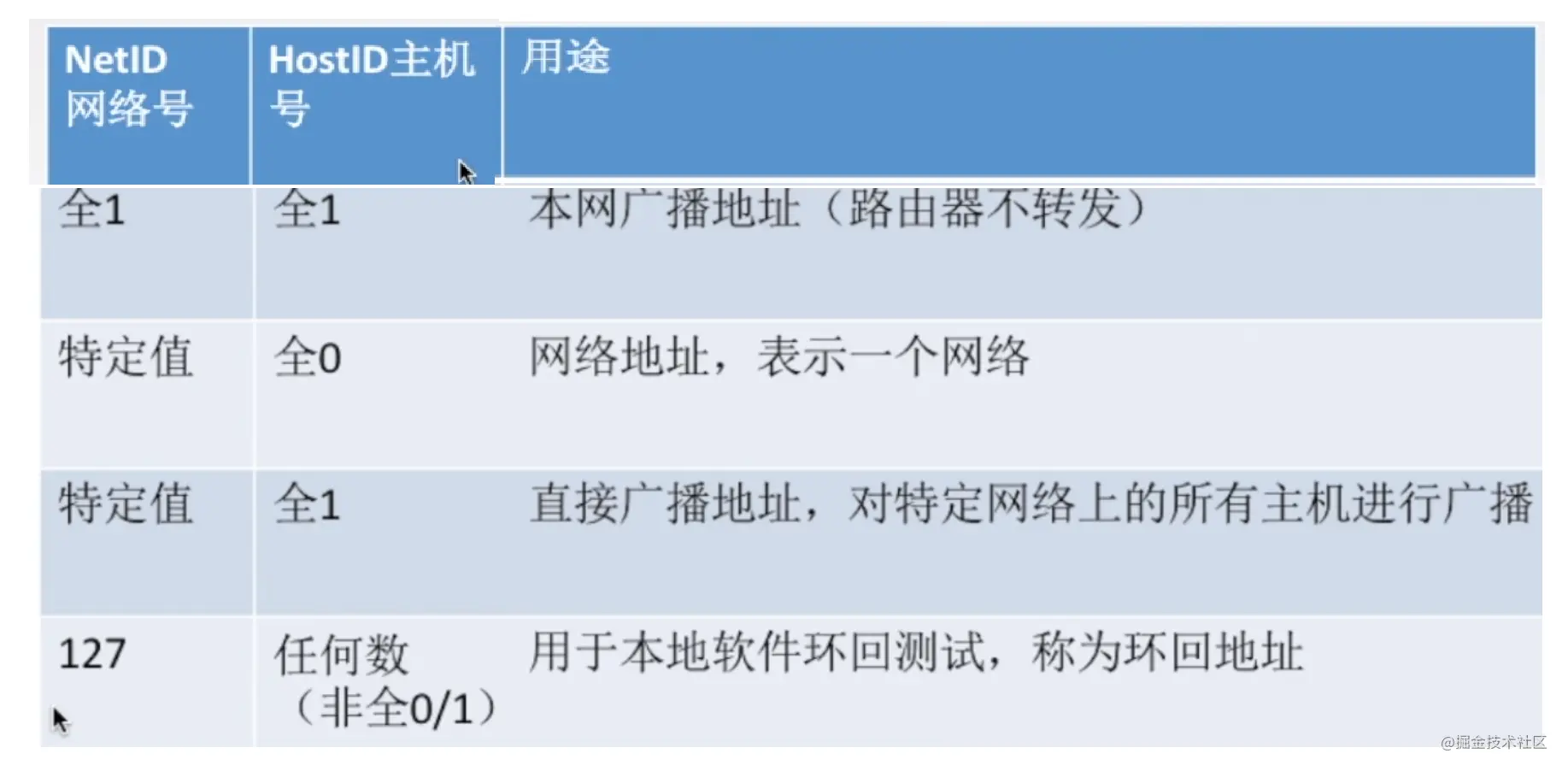
注意,这里的全1是指,ipv4地址由4个字节组成,每一个字节是8位,8位全一就是十进制的255, 即255.255.255.255。
- 第一行,全一,代表是
255.255.255.255,在本网络的目的地址写这个的话,就会内网广播 - 第二行,网络号特定值,主机号是全0,比如,
192.169.10.1,这是c类网络,所以网络号是192.169.10,主机号是1,当主机号全0时,就是0,表示192.169.10.0这个网段 - 第三行,还是
192.169.10.1这个c类地址,主机号都是1,也就是8个1,代表255,所以192.169.10.255表示本网段的广播地址 - 第四行,大家最熟悉不过了,
127作为网络号,主机号非全0或1,比如说127.0.0.1代表本机,称为环回地址。
网络地址转换
在ip地址分类里面,我们知道私有ip地址是不能跟外网交互的,在小公司大多数计算机的地址都是192.168网段,都是私有ip地址,它是怎么跟外网交互数据的呢,这里就引出来一个知识点叫网络地址转换NAT。
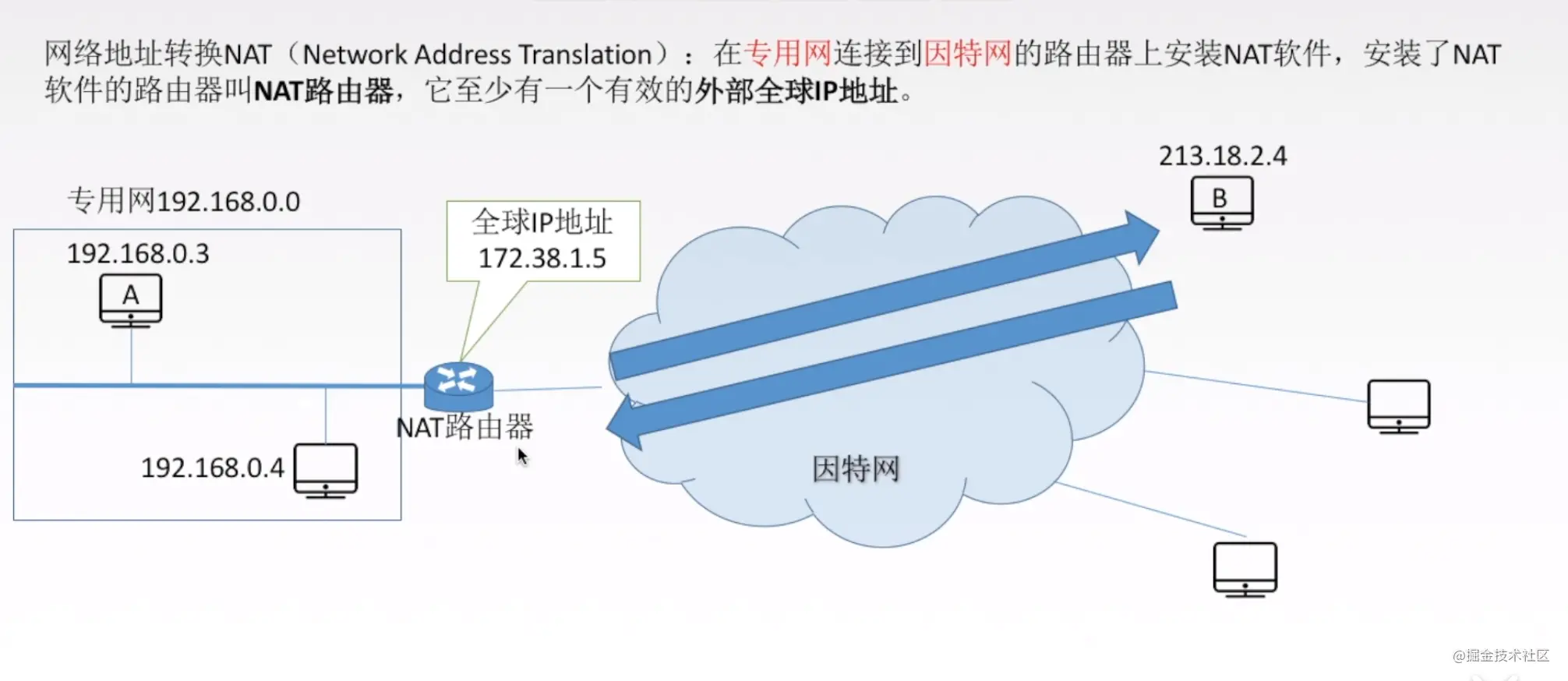
如上图所示,192.168.0.3,192.168.0.4都是私有网段上的,它们无法跟外网通信,这个时候由于路由器安装了NAT软件,就可以将自己的ip地址,即路由器的ip地址172.38.1.5作为内网的代理,去访问外网,外网返回来的数据,经过路由转换,转换成内网的192.168网段的私有地址。
静态NAT
将内部本地地址与内部全局地址进行一对一的明确转换。这种方法主要用在内部网络中有对外提供服务的服务器,如WEB、MAIL服务器时。该方法的缺点是需要独占宝贵的合法IP地址。即,如果某个合法IP地址已经被NAT静态地址转换定义,即使该地址当前没有被使用,也不能被用作其它的地址转换。
动态NAT
动态地址转换也是将内部本地地址与内部全局地址进行一对一的转换。但是,是从内部全局地址池中动态地选择一个未使用的地址对内部本地地址进行转换。该地址是由未被使用的地址组成的地址池中在定义时排在最前面的一个。当数据传输完毕后,路由器将把使用完的内部全局地址放回到地址池中,以供其它内部本地地址进行转换。但是在该地址被使用时,不能用该地址再进行一次转换。
端口复用
复用地址转换也称为端口地址转换(Port Address Translation,PAT),首先是一种动态地址转换。路由器将通过记录地址、应用程序端口等唯一标识一个转换。通过这种转换,可以使多个内部本地地址同时与同一个内部全局地址进行转换并对外部网络进行访问。对于只申请到少量IP地址甚至只有一个合法IP地址,却经常有很多用户同时要求上网的情况,这种转换方式非常有用
•理想状况下,一个单一的IP地址可以使用的端口数为4000个
子网划分和子网掩码
首先要明白,为什么要划分子网?
首先大家要知道:
总体来说,划分子网不但没有增加可用IP地址,而且减少了可用IP地址,因为每个子网中的全0网络地址和全1广播地址均不能作为主机ip来使用。
为什么划分子网:
- 例如,一个A类网络可以容纳16777214台主机。
- 但是在实际运用中,不可能把一个A类网络只用于一个子网,因为那样管理起来很不方便,也会出现广播风暴等种种问题,所以需要根据实际需求把它划分为若干个较小的子网。一个B类网络可以容纳65534台主机,往往也是需要划分子网的。
- 即便一个小型企业内部,为了部门之间的职能的需要,配置那些电脑可以互相访问,哪些不能互相访问,就需要通过划分子网的方法来实现。
接下来,我们看看子网划分
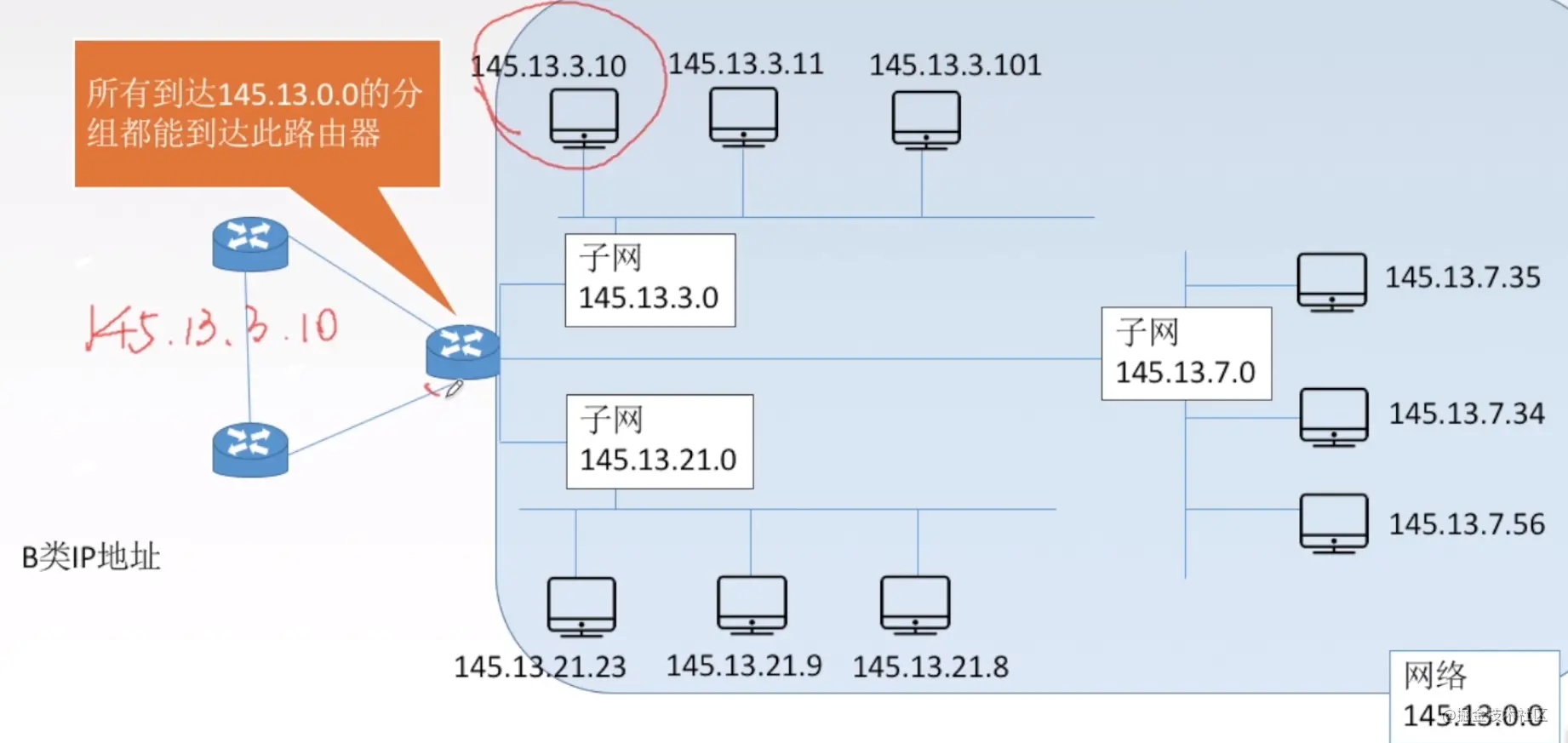
145.13.0.0这个网段划分了三个子网,其中一个是145.13.3.0,一个是145.13.21.0,问题来了,如果一个网络包来了,网络包要交给的ip地址是145.13.3.10,我们怎么知道给哪个子网呢?
方法是将目的包的ip地址,跟子网的子网掩码相与预算(二进制与预算规则是,1跟1得1,其它为0),也就是目的地址145.13.3.10跟子网145.13.3.0的子网掩码255.255.255.0的与预算,得到的结果是145.13.3.0,所以发送到的子网就是145.13.3.0。
如何划分超网?
构造超网(无分类编址 CIDR):CIDR 消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,把 32 位的 IP 地址划分为两个部分。
例如:128.14.35.7/20 是某个 CIDR 地址块中的一个地址,其前 20 位是网络前缀(用下划线表示的部分),后面的 12 位为主机号
ARP协议
为什么需要ARP协议呢?
我们简单回顾一下以太网的帧的格式
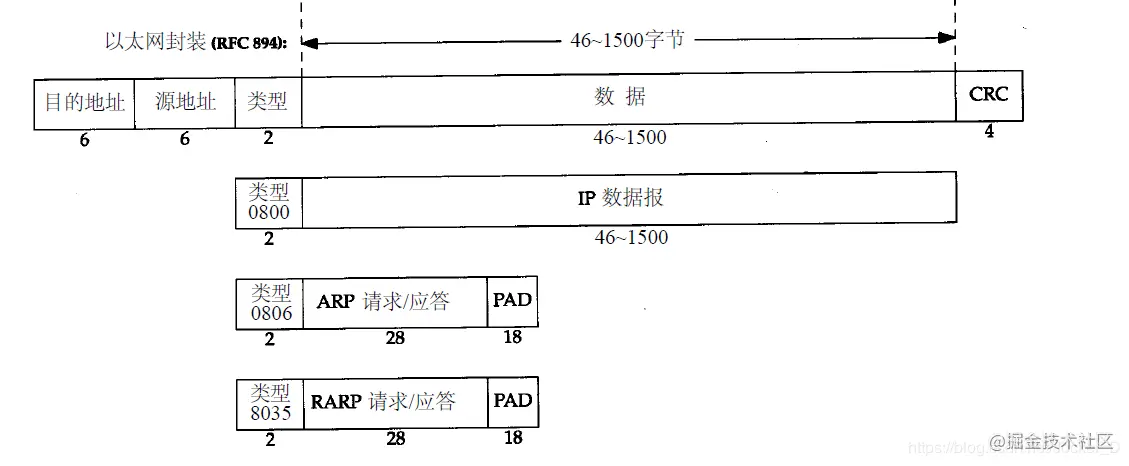
上图有一个源地址和目的地址,这两个地址都是指的mac地址,mac地址是什么呢?简单说来就是两台相邻的路由器A和B,A怎么把数据传给B呢,它总要知道B的物理地址吧,物理地址就像门牌号一样,我要知道你住在哪里,才能把数据送过去吧?
首先你肯定知道自己的mac地址是多少,因为在网卡上有,问题在于,别人的mac地址是多少?ARP协议就是来帮你找mac地址的。
接着我们说一下
ARP协议的过程(比较官方的介绍,看不懂可以略过):

每台主机都会在自己的ARP缓冲区中建立一个 ARP列表,以表示IP地址和MAC地址的映射关系
当源主机需要将一个数据包要发送到目的主机时,会首先检查自己 ARP列表中是否存在该IP地址对应的MAC地址
如果有,就直接将数据包发送到这个MAC地址;如果没有,就向本地网段发起一个ARP请求的广播包,查询此目的主机对应的MAC地址
此ARP请求数据包里包括源主机的IP地址、硬件地址、以及目的主机的IP地址。网络中所有的主机收到这个ARP请求后,会检查数据包中的目的IP是否和自己的IP地址一致
如果不相同就忽略此数据包;如果相同,该主机首先将发送端的MAC地址和IP地址添加到自己的ARP列表中
如果ARP表中已经存在该IP的信息,则将其覆盖,然后给源主机发送一个 ARP响应数据包,告诉对方自己是它需要查找的MAC地址
源主机收到这个ARP响应数据包后,将得到的目的主机的IP地址和MAC地址添加到自己的ARP列表中,并利用此信息开始数据的传输
如果源主机一直没有收到ARP响应数据包,表示ARP查询失败
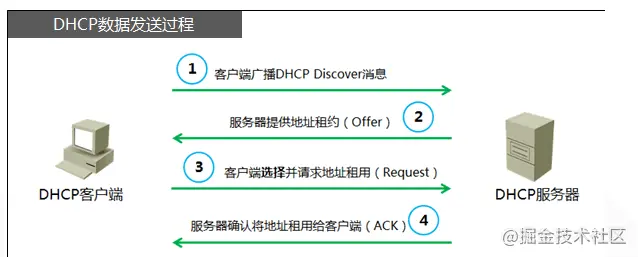
DHCP协议
DHCP(动态主机配置协议)是一个局域网的网络协议。指的是由服务器控制一段lP地址范围,客户机登录服务器时就可以自动获得服务器分配的lP地址和子网掩码。说白了,当你接入局域网的时候,自动由这个dhcp服务器给你分配ip,windows用户可能知道网卡配置里面,由自动获取ip的功能,如果路由器提供DHCP服务,你就会自动获取随机分配的ip。
路由器里可以开启这个服务。
大致工作过程(了解即可)
ICMP协议
ICMP协议是一个网络层协议。 为什么我们需要ICMP协议呢?
一个新搭建好的网络,往往需要先进行一个简单的测试,来验证网络是否畅通;但是IP协议并不提供可靠传输。如果丢包了,IP协议并不能通知传输层是否丢包以及丢包的原因。
所以我们就需要一种协议来完成这样的功能–ICMP协议。
ICMP协议的功能主要有:
- 确认IP包是否成功到达目标地址
- 通知在发送过程中IP包被丢弃的原因
我们举一个例子:
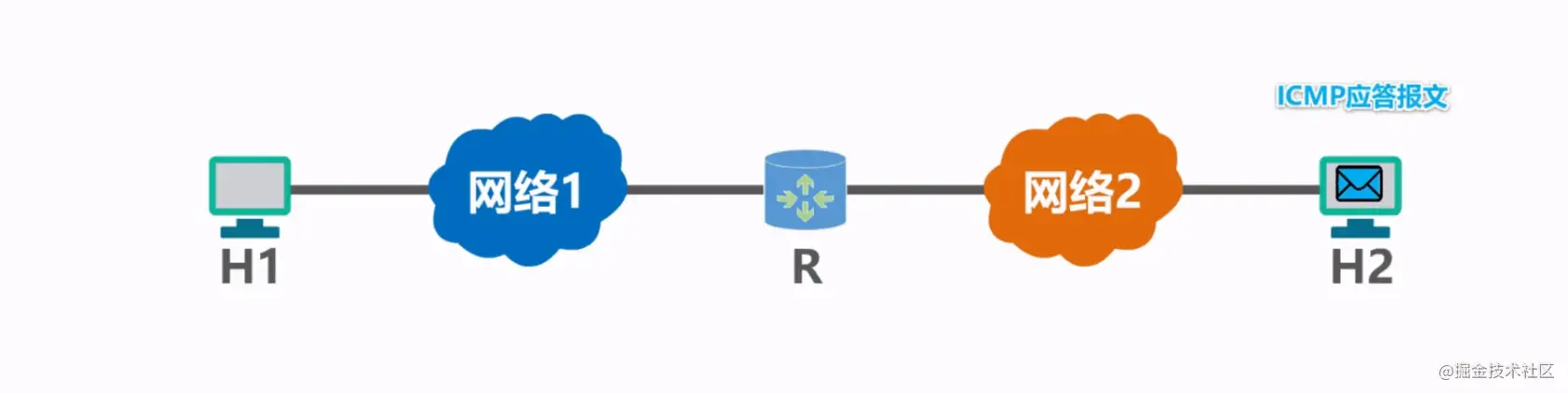
主机H2收到主机H1的一个UDP包,结果H2发现这个包里的端口没有被监听,这时候就回复给H2一个ICMP应答报文,意思是这个UDP数据包,无法交给应用进程,只能丢弃了。
以下是4种常见的ICMP差错报告报文

我们常用的ping命令借助ICMP协议,探测主机是否能找到目的主机。
简述一下 ping 的原理?
一般在网络不通的时候,大家会用 ping 测一下网络是否通畅。
ping 是基于 ICMP 协议工作的。ICMP 全称 Internet Control Message Protocol ,就是互联网控制报文协议。这里的关键词是“控制”,那具体是怎么控制的呢? 网络包在异常负责的网络环境中传输时,会遇到各种问题,当遇到问题时,要传出消息,报告情况,这样才能调整传输策略。
ICMP 报文是封装在 IP 包里面的。因为传输指令的时候,肯定需要源地址和目标地址。如下图:
什么是 Traceroute ?
Traceroute 是构建在 ICMP 协议之上的应用。
Traceroute ,是用来侦测主机到目的主机之间所经路由情况的重要工具,也是最便利的工具。
前面说到,尽管 ping 工具也可以进行侦测,但是,因为 IP 头的限制,ping 不能完全的记录下所经过的路由器。所以Traceroute 正好就填补了这个缺憾。
Traceroute 的原理是非常非常的有意思。
- 它受到目的主机的 IP 后,首先给目的主机发送一个 TTL=1(还记得 TTL 是什么吗?)的 UDP(后面就知道 UDP是什么了)数据包,而经过的第一个路由器收到这个数据包以后,就自动把 TTL 减1,而 TTL 变为 0 以后,路由器就把这个包给抛弃了,并同时产生 一个主机不可达的 ICMP 数据报给主机。
- 主机收到这个数据报以后再发一个 TTL=2 的 UDP 数据报给目的主机,然后刺激第二个路由器给主机发 ICMP 数据 报。如此往复直到到达目的主机。
这样,traceroute 就拿到了所有的路由器 IP 。从而避开了 IP 头只能记录有限路由 IP 的问题。
有人要问,我怎么知道 UDP 到没到达目的主机呢?
这就涉及一个技巧的问题,TCP 和 UDP 协议有一个端口号定义,而普通的网络程序只监控少数的几个号码较小的端口,比如说 80、23 等等。而 traceroute 发送的是端口号 >30000(真变态) 的 UDP 包,所以到达目的主机的时候,目的主机只能发送一个端口不可达的 ICMP 数据报给主机。主机接到这个报告以后就知道,目标主机到了。
😈 很多情况下,在我们 ping 不通目标地址时,会尝试使用 traceroute 命令,看看是否在中间哪个 IP 无法访问。
RIP协议
RIP(Routing Information Protocol,路由信息协议)是使用最久的协议之一。RIP是一种分布式的基于距离向量的路由选择协议,RIP协议是施乐公司20世纪80年代推出的,主要适用于小规模的网络环境。RIP协议主要用于一个AS(自治系统)内的路由信息的传递,每30s发送一次路由信息更新。
基本思想:
(1)、以跳数为代价单位;
(2)、每个路由器周期性的与相邻路由器交换若干
(3)相邻路由器得到路由信息后,按照距离矢量算法(最短路径原则,实现最佳性),建立或更新路由表。
OSPF
OSPF(Open Shortest Path First开放式最短路径优先)是一个内部网关协议(Interior Gateway Protocol,简称IGP),用于在单一自治系统(autonomous system,AS)内决策路由。是对链路状态路由协议的一种实现,隶属内部网关协议(IGP),故运作于自治系统内部。著名的迪克斯彻(Dijkstra)算法被用来计算最短路径树。OSPF支持负载均衡和基于服务类型的选路,也支持多种路由形式,如特定主机路由和子网路由等。
BGP
边界网关协议BGP(Border Gateway Protocol)是一种实现自治系统AS(Autonomous System)之间的路由可达,并选择最佳路由的距离矢量路由协议。
MP-BGP是对BGP-4进行了扩展,来达到在不同网络中应用的目的,BGP-4原有的消息机制和路由机制并没有改变。MP-BGP在IPv6单播网络上的应用称为BGP4+,在IPv4组播网络上的应用称为MBGP(Multicast BGP)。
详细请访问
网络设备路由器简介
路由器是一种具有多个输入端口和多个输出端口的专用计算机,其任务是转发和分组。
如下图所示,分别由转发和分组功能的说明。
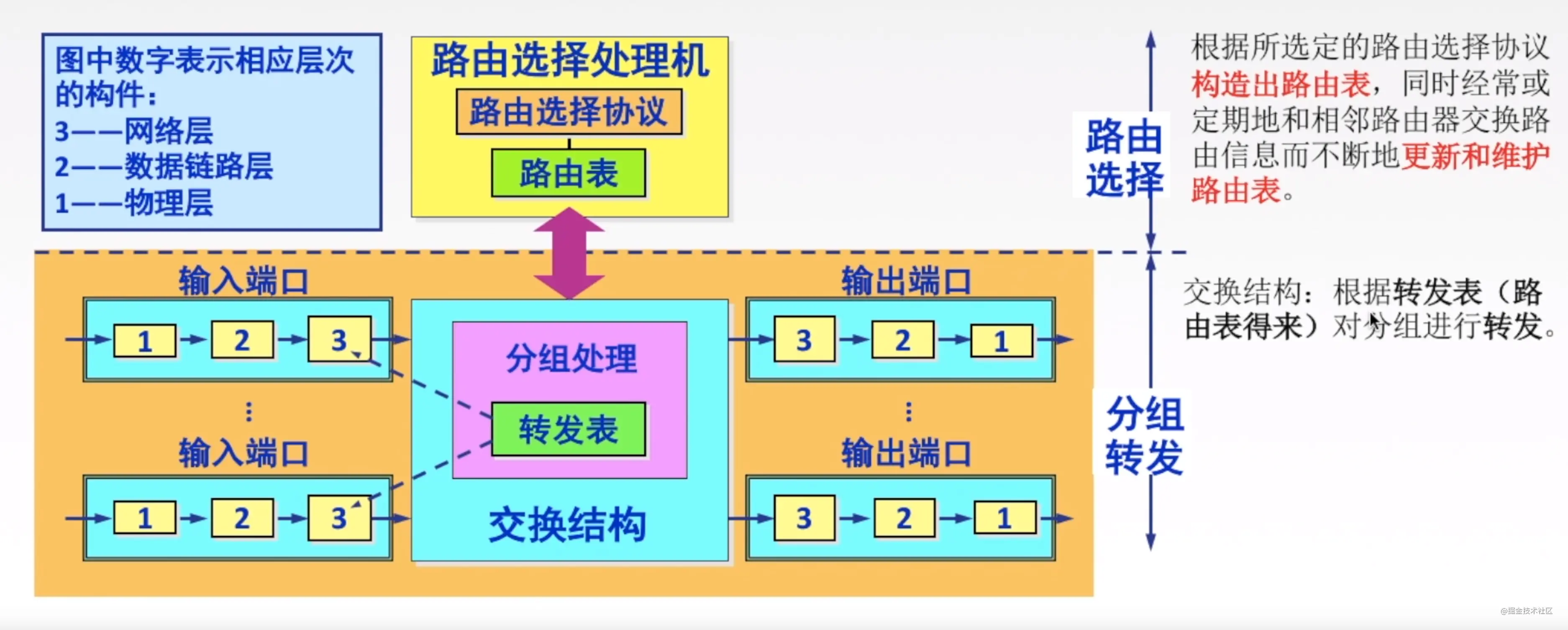
接着,我们看一下路由器输入端口做了哪些事情
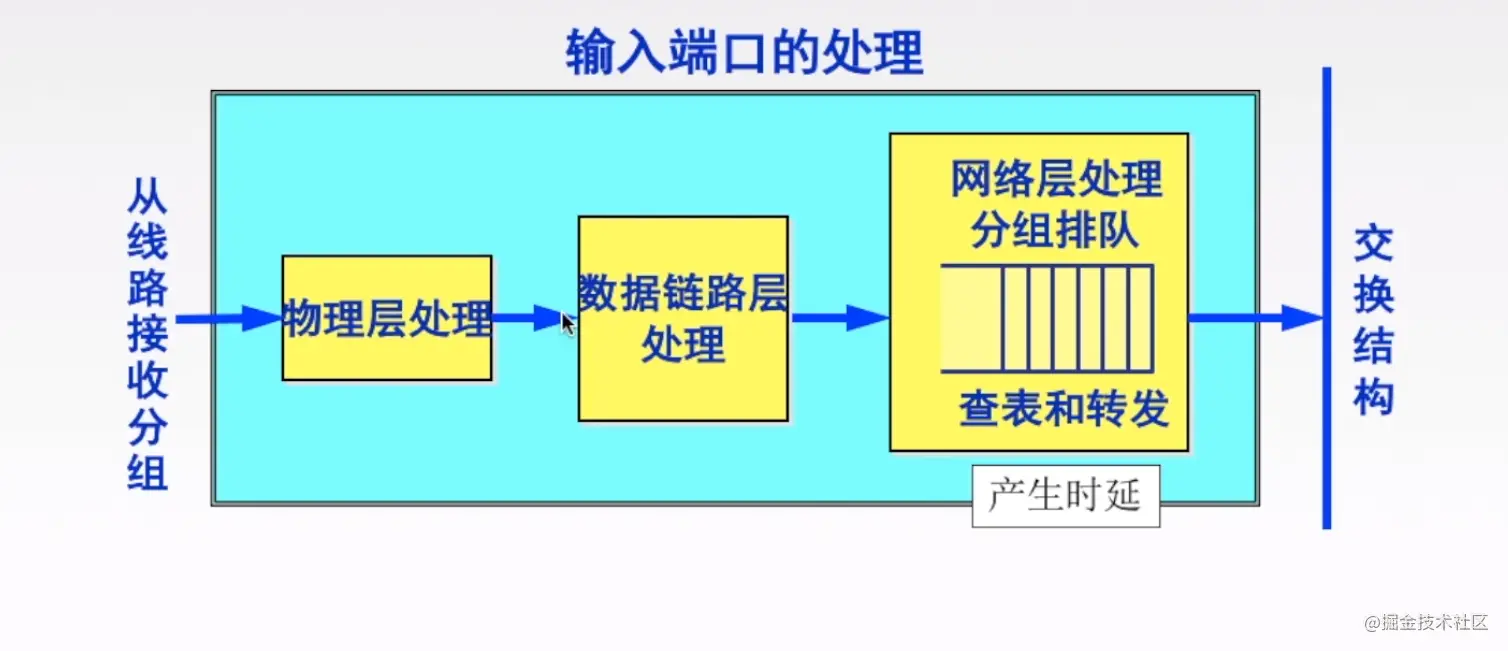
首先,物理层是傻瓜层,传输比特流,我们把物理层的比特流还原成数据链路层的数据帧,然后把数据链路层的数据报脱去,成为网络层数据包,交给路由器。这时候就要判断一下这个数据包是什么类型的了。
如果它是路由器之间,交换路由信息的分组,就会把这个数据包交付给如上上图所示的,路由选择处理机,进行处理和计算。如果是数据分组,就会放到一个队列里面,排队等候,然后选择一个合适的输出端口输出。
最后我们看一下路由器输出端口做了哪些事情
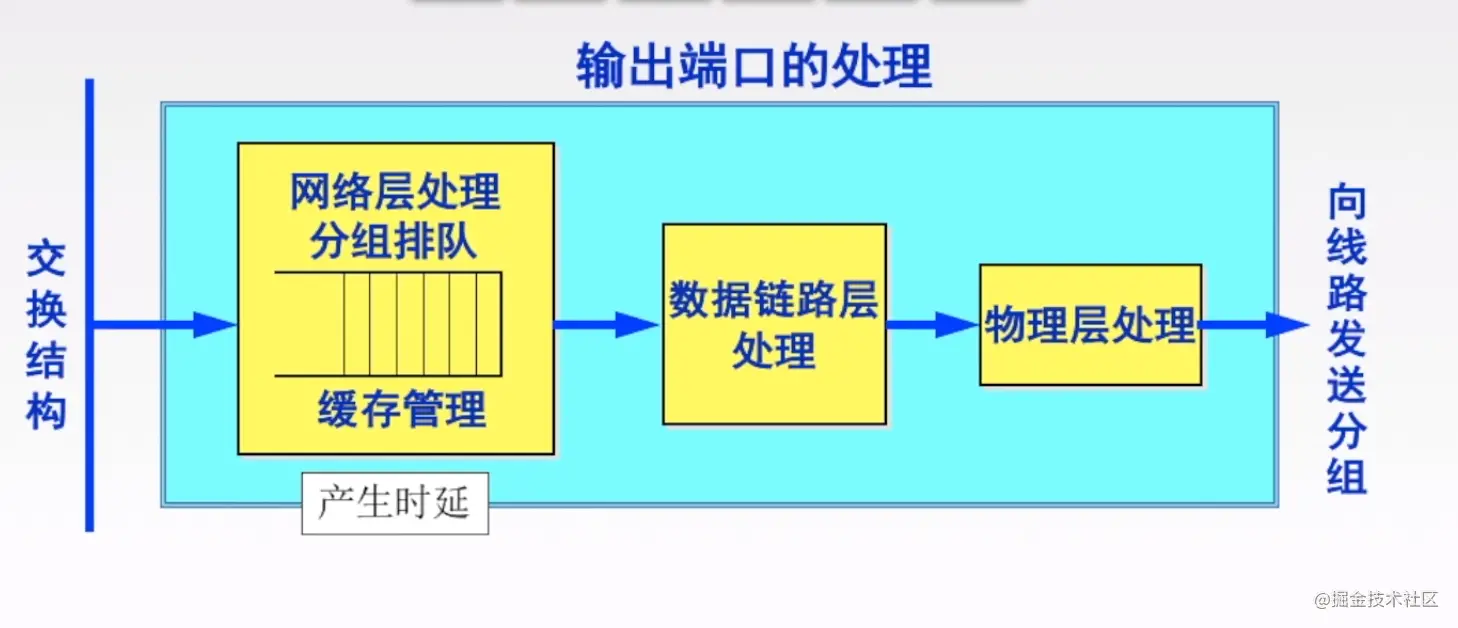
从上图可以看到,输出端口是做的输入端口的逆过程,将网络层的数据包转换为链路层的数据帧,最后转为物理层的比特流。
输入和输出端口需要注意的是,它们都有一个缓冲队列,比如输入数据的速度太快,输出数据速度慢,为了平衡输入输出速度,就用缓冲队列把数据缓冲下来,一个一个慢慢的处理,但缓冲队列也有限度,超出这个限度,缓冲队列容纳不下,包就会被丢到。
UDP 的主要特点是什么?
UDP是无连接的,减少开销和发送数据之前的时间延迟。大家都知道TCP的三次握手和四次分手,这个是需要时间花销的,但是UDP没有这部分花销。
UDP使用最大努力交付,即不保证可靠交付。那谁来保证可靠的交付呢?是由UDP的上一层协议,应用层来保证。
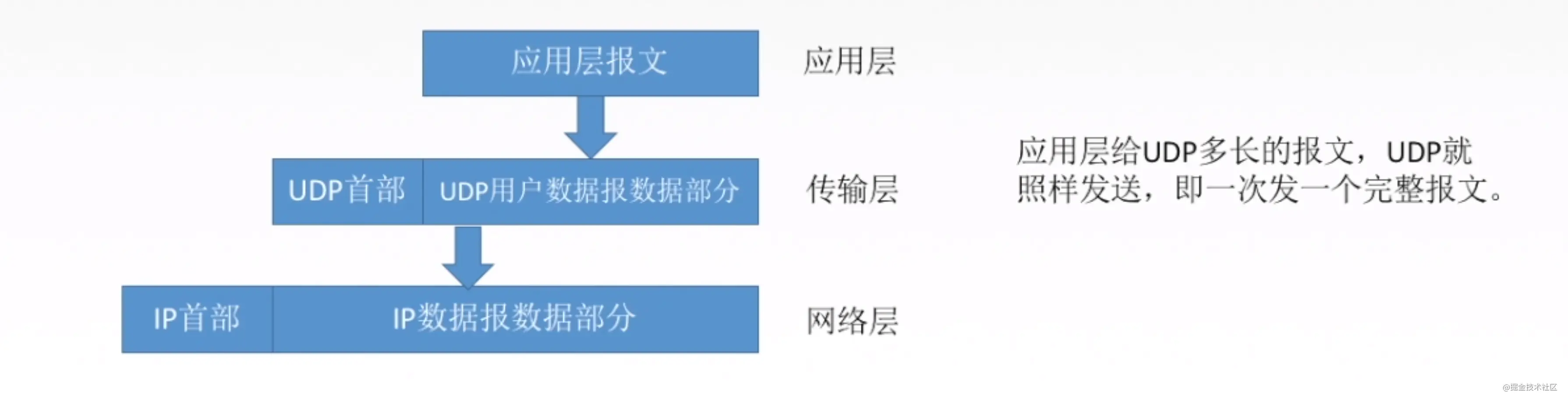
UDP是面向报文的,适合一次性传输少量数据的网络应用。什么意思呢,如下图,UDP这层,把应用层的全部内容作为自己的数据报部分,在IP层也只是加了一个IP首部,我们知道,在以太网,链路层上的数据如果超过1500字节,就会分片,所以网络层发现上面传输层给了太大的数据就会分片,加上UDP是不可靠的协议,这就加大了UDP的不可靠性,容易丢失,所以UDP适合数据量少的。
UDP没有拥塞控制,适合很多实时应用。也就是说如果网络堵塞,UDP不管那么多,照样按照自己的速率发数据,那有些人就会说,这协议是不是有点坑B,路都堵上了,还发死劲发数据呢,但是反过来看,这也是UDP的优点,它允许丢包,如果你的网络情况还不错,UDP就非常适合实时应用,比如视频会议。
UDP首部较小,只有8字节,而TCP由20字节。这也是减少网络传输开销的一方面。
UDP首部
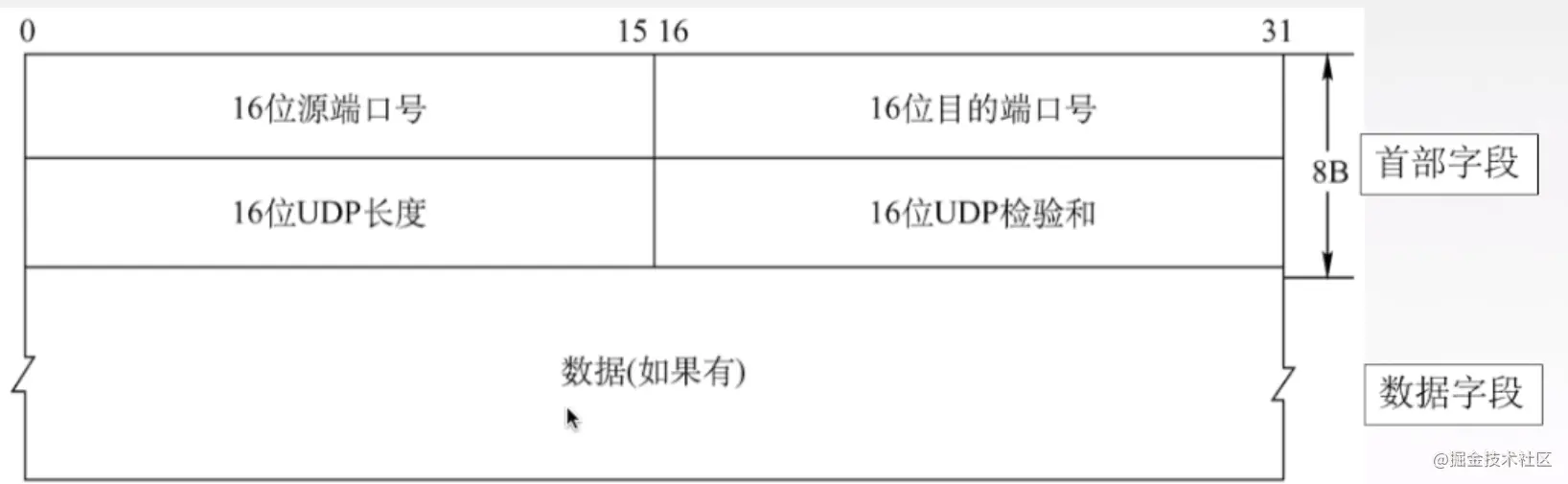
16位端口号占了2B,也就是16位,说明端口号的范围是0 - 65535。源端口号可以没有,因为不希望收到对方的回应,可以写全0,目的端口是一定要有的。
16位UDP长度是指首部+数据的长度,比如数据2B,首部固定是8B,那么UDP长度就是2+8 = 10B
16位UDP校验和,是用来校验首部和数据有错误,如果有错就丢弃掉。比如说目的主机找不到对应的端口号,就会给发送方返回一个ICMP,‘端口不可达’的差错报文。
TCP的主要特点是什么?
TCP是面向连接的传输层协议。比如说TCP的三次握手,四次分手,针对的都是连接。
每一条TCP连接只能有两个端点,每一条TCP连接是点对点的。也就是说TCP是不同计算机之间的进程的通信。
TCP提供可靠交付的服务,无差错,不丢失,不重复,按序到达。总结一下就是,可靠有序,不丢不重。
TCP提供全双工通信。全双工指的是连接双方可以同时收发数据。在收发两端都有发送缓存和接收缓存,发送缓存就是一个准备发送的队列,接收缓存是一个准备接收的队列。
TCP面向字节流。如下图,我们解释一下什么是面向字节流:
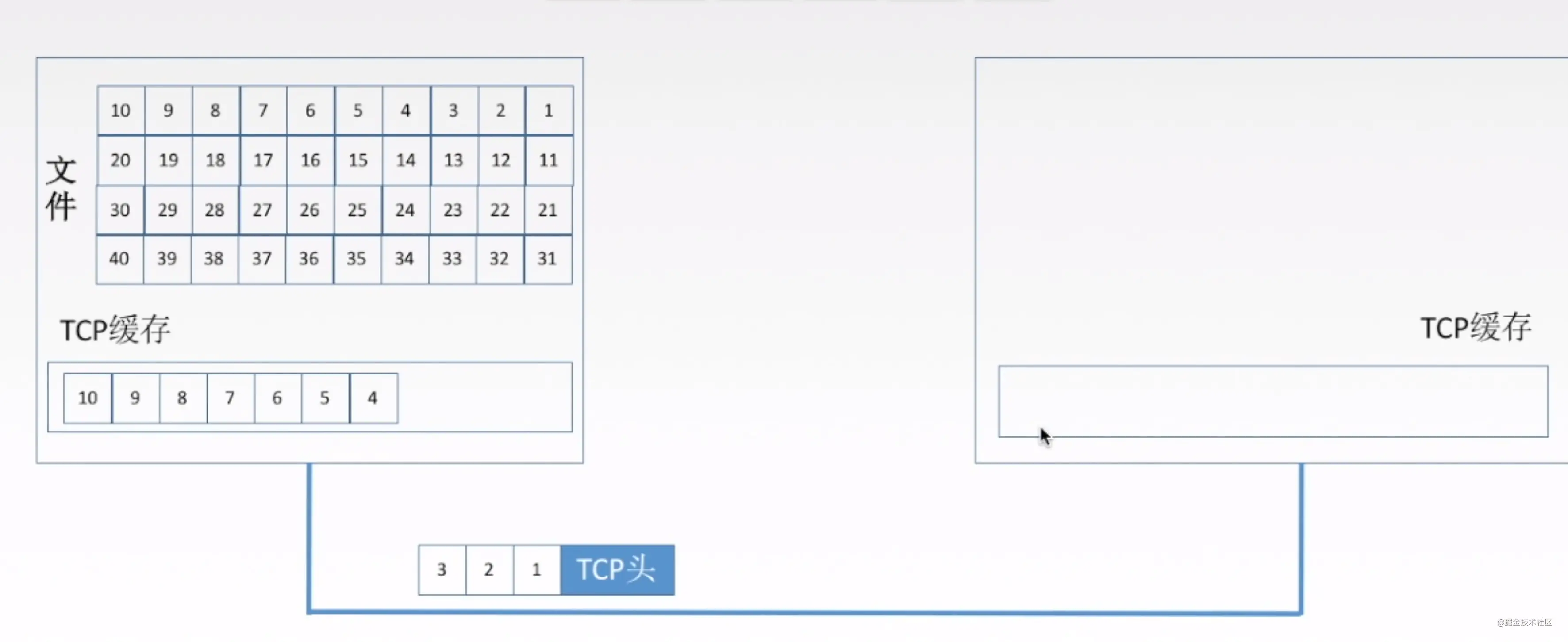
图中的1,2,3,4…..数据块,每一个表示一个字节。tcp将应用层的数据变为了这样的字节进行发送,比如玩过node同学,知道一个buffer,buffer就是字节流。
TCP报文的首部格式
如下图所示,我们看一下比较重要的一些首部字段,这里我们介绍固定的20字节的TCP首部
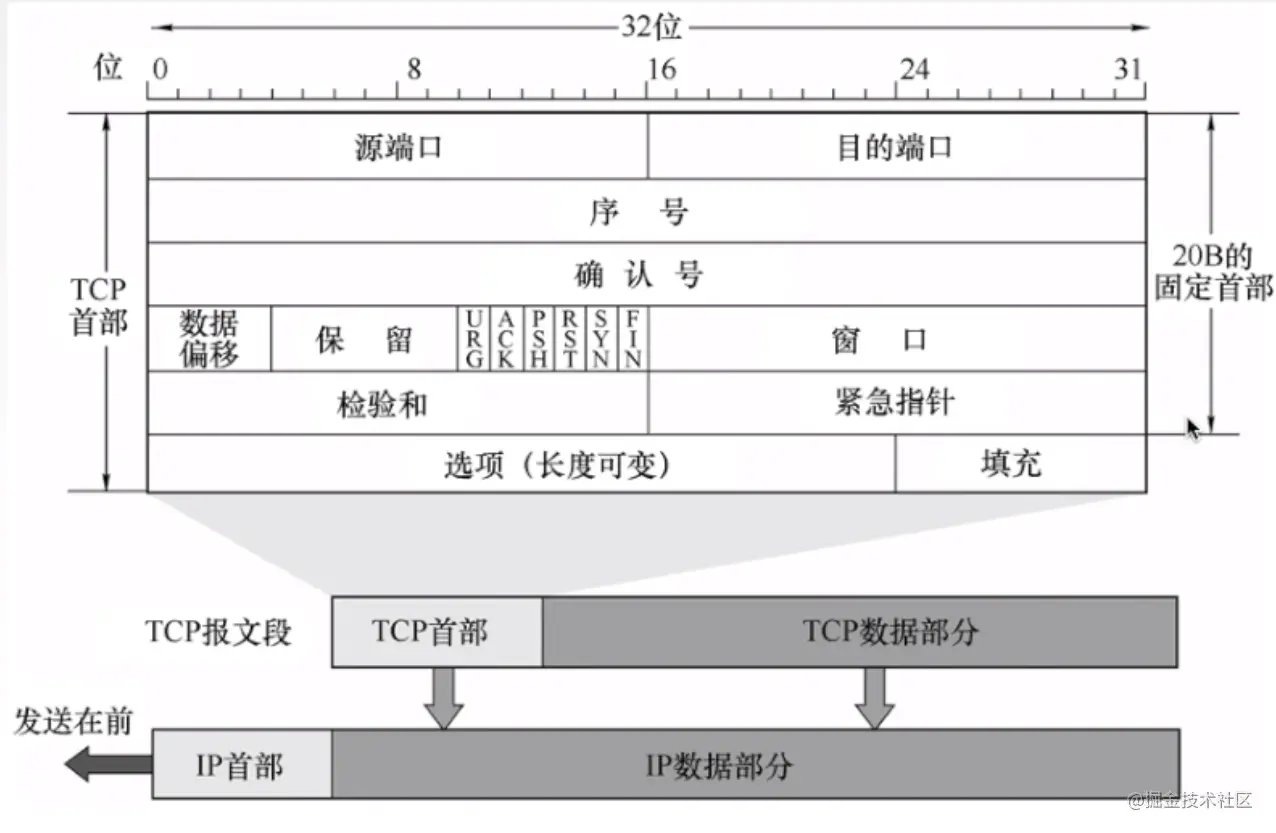
源端口和目的端口分别是指发送方应用程序的端口和目的方应用程序的端口号。
序号是指在一个TCP连接中传送的字节流中的每一个字节都按顺序编号,本字段表示本报文段所发送数据的第一个字节的序号。
确认号是指期望收到对方下一个报文段的第一个数据字节的序号。若确认好位n,则证明到需要N-1为止所有的数据都已经正确收到。如下图,我们举例说明一下

接收方收到了1,2,3个字节组成的数据包,然后接收方就会发送一个确认报文给发送方,其中确认报文的确认号就应该是4,因为1,2,3这三个字节的组成的数据包已经收到了。
- 数据偏移指的是TCP报文段的数据起始处举例TCP报文段的起始处有多远。
- 6个控制位介绍如下
| 控制位 | 作用 |
|---|---|
| ACK | 置1时表示确认号合法,为0的时候表示数据段不包含确认信息,确认号被忽略 |
| PSH | 置1时请求的数据段在接收方得到后就可直接送到应用程序,而不必等到缓冲区满时才传送 |
| RST | 置1时重建连接。如果接收到RST位时候,通常发生了某些错 |
| SYN | 置1时用来发起一个连接 |
| FIN | 置1时表示发端完成发送任务。用来释放连接,表明发送方已经没有数据发送了 |
| URG | 紧急指针,告诉接收TCP模块紧要指针域指着紧要数据 |
TCP 和 UDP 的区别?
TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的运输服务(TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。
UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如:QQ 语音、 QQ 视频 、直播等等。
TCP 和 UDP 分别对应的常见应用层协议有哪些?
FTP:定义了文件传输协议,使用 21 端口。常说某某计算机开了 FTP 服务便是启动了文件传输服务。下载文件,上传主页,都要用到 FTP 服务。
Telnet:它是一种用于远程登陆的端口,用户可以以自己的身份远程连接到计算机上,通过这种端口可以提供一种基于 DOS 模式下的通信服务。如以前的 BBS 是-纯字符界面的,支持 BBS 的服务器将 23 端口打开,对外提供服务。
SMTP:定义了简单邮件传送协议,现在很多邮件服务器都用的是这个协议,用于发送邮件。如常见的免费邮件服务中用的就是这个邮件服务端口,所以在电子邮件设置-中常看到有这么 SMTP 端口设置这个栏,服务器开放的是 25 号端口。
POP3:它是和 SMTP 对应,POP3 用于接收邮件。通常情况下,POP3 协议所用的是 110 端口。也是说,只要你有相应的使用 POP3 协议的程序(例如 Fo-xmail 或 Outlook),就可以不以 Web 方式登陆进邮箱界面,直接用邮件程序就可以收到邮件(如是163 邮箱就没有必要先进入网易网站,再进入自己的邮-箱来收信)。
HTTP:从 Web 服务器传输超文本到本地浏览器的传送协议。
DNS:用于域名解析服务,将域名地址转换为 IP 地址。DNS 用的是 53 号端口。
SNMP:简单网络管理协议,使用 161 号端口,是用来管理网络设备的。由于网络设备很多,无连接的服务就体现出其优势。
TFTP(Trival File Transfer Protocal):简单文件传输协议,该协议在熟知端口 69 上使用 UDP 服务。
TCP建立连接
TCP 建立连接的过程叫做握手,握手需要在客户和服务器之间交换三个 TCP 报文段。
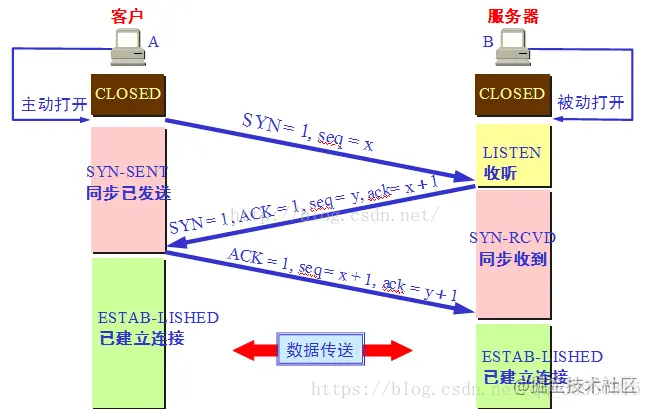
最初客户端和服务端都处于 CLOSED(关闭) 状态。本例中 A(Client) 主动打开连接,B(Server) 被动打开连接。
一开始,B 的 TCP 服务器进程首先创建传输控制块TCB,准备接受客户端进程的连接请求。然后服务端进程就处于 LISTEN(监听) 状态,等待客户端的连接请求。如有,立即作出响应。
第一次握手:A 的 TCP 客户端进程也是首先创建传输控制块 TCB。然后,在打算建立 TCP 连接时,向 B 发出连接请求报文段,这时首部中的同步位 SYN=1,同时选择一个初始序号 seq = x。TCP 规定,SYN 报文段(即 SYN = 1 的报文段)不能携带数据,但要消耗掉一个序号。这时,TCP 客户进程进入 SYN-SENT(同步已发送)状态。
第二次握手:B 收到连接请求报文后,如果同意建立连接,则向 A 发送确认。在确认报文段中应把 SYN 位和 ACK 位都置 1,确认号是 ack = x + 1,同时也为自己选择一个初始序号 seq = y。请注意,这个报文段也不能携带数据,但同样要消耗掉一个序号。这时 TCP 服务端进程进入 SYN-RCVD(同步收到)状态。
第三次握手:TCP 客户进程收到 B 的确认后,还要向 B 给出确认。确认报文段的 ACK 置 1,确认号 ack = y + 1,而自己的序号 seq = x + 1。这时 ACK 报文段可以携带数据。但如果不携带数据则不消耗序号,这种情况下,下一个数据报文段的序号仍是 seq = x + 1。这时,TCP 连接已经建立,A 进入 ESTABLISHED(已建立连接)状态。
为什么两次握手不可以呢?
为了防止已经失效的连接请求报文段突然又传送到了 B,因而产生错误。比如下面这种情况:A 发出的第一个连接请求报文段并没有丢失,而是在网路结点长时间滞留了,以致于延误到连接释放以后的某个时间段才到达 B。本来这是一个早已失效的报文段。但是 B 收到此失效的链接请求报文段后,就误认为 A 又发出一次新的连接请求。于是就向 A 发出确认报文段,同意建立连接。
对于上面这种情况,如果不进行第三次握手,B 发出确认后就认为新的运输连接已经建立了,并一直等待 A 发来数据。B 的许多资源就这样白白浪费了。
如果采用了三次握手,由于 A 实际上并没有发出建立连接请求,所以不会理睬 B 的确认,也不会向 B 发送数据。B 由于收不到确认,就知道 A 并没有要求建立连接。
为什么不需要四次握手?
有人可能会说 A 发出第三次握手的信息后在没有接收到 B 的请求就已经进入了连接状态,那如果 A 的这个确认包丢失或者滞留了怎么办?
我们需要明白一点,完全可靠的通信协议是不存在的。在经过三次握手之后,客户端和服务端已经可以确认之前的通信状况,都收到了确认信息。所以即便再增加握手次数也不能保证后面的通信完全可靠,所以是没有必要的。
Server 端收到 Client 端的 SYN 后,为什么还要传回 SYN?
接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
SYN 是 TCP / IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误])消息响应。这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
传了 SYN,为什么还要传 ACK?
双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方到接收方的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
TCP释放连接
据传输结束后,通信的双方都可以释放连接。现在 A 和 B 都处于 ESTABLISHED 状态。
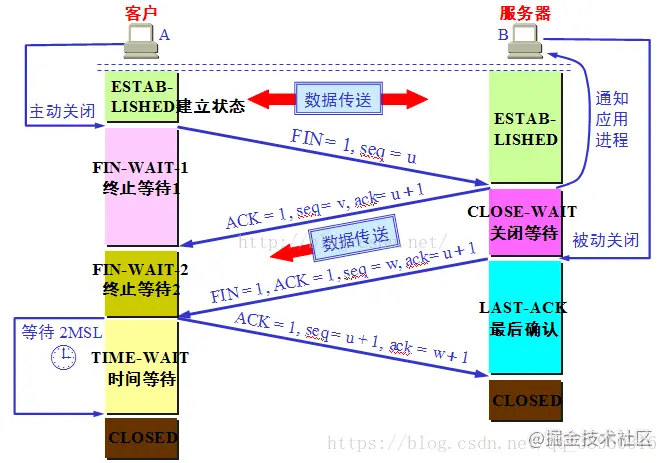
第一次挥手:A 的应用进程先向其 TCP 发出连接释放报文段,并停止再发送数据,主动关闭 TCP 连接。A 把连接释放报文段首部的终止控制位 FIN 置 1,其序号 seq = u(等于前面已传送过的数据的最后一个字节的序号加 1),这时 A 进入 FIN-WAIT-1(终止等待1)状态,等待 B 的确认。请注意:TCP 规定,FIN 报文段即使不携带数据,也将消耗掉一个序号。
第二次挥手:B 收到连接释放报文段后立即发出确认,确认号是 ack = u + 1,而这个报文段自己的序号是 v(等于 B 前面已经传送过的数据的最后一个字节的序号加1),然后 B 就进入 CLOSE-WAIT(关闭等待)状态。TCP 服务端进程这时应通知高层应用进程,因而从 A 到 B 这个方向的连接就释放了,这时的 TCP 连接处于半关闭(half-close)状态,即 A 已经没有数据要发送了,但 B 若发送数据,A 仍要接收。也就是说,从 B 到 A 这个方向的连接并未关闭,这个状态可能会持续一段时间。A 收到来自 B 的确认后,就进入 FIN-WAIT-2(终止等待2)状态,等待 B 发出的连接释放报文段。
第三次挥手:若 B 已经没有要向 A 发送的数据,其应用进程就通知 TCP 释放连接。这时 B 发出的连接释放报文段必须使 FIN = 1。假定 B 的序号为 w(在半关闭状态,B 可能又发送了一些数据)。B 还必须重复上次已发送过的确认号 ack = u + 1。这时 B 就进入 LAST-ACK(最后确认)状态,等待 A 的确认。
第四次挥手:A 在收到 B 的连接释放报文后,必须对此发出确认。在确认报文段中把 ACK 置 1,确认号 ack = w + 1,而自己的序号 seq = u + 1(前面发送的 FIN 报文段要消耗一个序号)。然后进入 TIME-WAIT(时间等待) 状态。请注意,现在 TCP 连接还没有释放掉。必须经过时间等待计时器设置的时间 2MSL(MSL:最长报文段寿命)后,A 才能进入到 CLOSED 状态,然后撤销传输控制块,结束这次 TCP 连接。当然如果 B 一收到 A 的确认就进入 CLOSED 状态,然后撤销传输控制块。所以在释放连接时,B 结束 TCP 连接的时间要早于 A。
CLOSE-WAIT和TIME-WAIT存在的意义?
- Close-wait存在的意义: 就是服务端还有数据要发送,这个时间内就是服务端发送完最后的数据
- Time-wait存在的意义:
- 第一,这里同样是要考虑丢包的问题,如果第四次挥手的报文丢失,服务端没收到确认ack报文就会重发第三次挥手的报文,这样报文一去一回最长时间就是2MSL,所以需要等这么长时间来确认服务端确实已经收到了
- 第二,防止类似与“三次握手”中提到了的“已经失效的连接请求报文段”出现在本连接中。客户端发送完最后一个确认报文后,在这个2MSL时间中,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样新的连接中不会出现旧连接的请求报文。
为什么 TIME-WAIT 状态必须等待 2MSL 的时间呢?
为了保证 A 发送的最后一个 ACK 报文段能够到达 B。这个 ACK 报文段有可能丢失,因而使处在 LAST-ACK 状态的 B 收不到对已发送的 FIN + ACK 报文段的确认。B 会超时重传这个 FIN+ACK 报文段,而 A 就能在 2MSL 时间内(超时 + 1MSL 传输)收到这个重传的 FIN+ACK 报文段。接着 A 重传一次确认,重新启动 2MSL 计时器。最后,A 和 B 都正常进入到 CLOSED 状态。如果 A 在 TIME-WAIT 状态不等待一段时间,而是在发送完 ACK 报文段后立即释放连接,那么就无法收到 B 重传的 FIN + ACK 报文段,因而也不会再发送一次确认报文段,这样,B 就无法按照正常步骤进入 CLOSED 状态。
防止已失效的连接请求报文段出现在本连接中。A 在发送完最后一个 ACK 报文段后,再经过时间 2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样就可以使下一个连接中不会出现这种旧的连接请求报文段。
为什么第二次跟第三次不能合并, 第二次和第三次之间的等待是什么?
当服务器执行第二次挥手之后, 此时证明客户端不会再向服务端请求任何数据, 但是服务端可能还正在给客户端发送数据(可能是客户端上一次请求的资源还没有发送完毕),所以此时服务端会等待把之前未传输完的数据传输完毕之后再发送关闭请求。
保活计时器的作用?
除时间等待计时器外,TCP 还有一个保活计时器(keepalive timer)。设想这样的场景:客户已主动与服务器建立了 TCP 连接。但后来客户端的主机突然发生故障。显然,服务器以后就不能再收到客户端发来的数据。因此,应当有措施使服务器不要再白白等待下去。这就需要使用保活计时器了。
服务器每收到一次客户的数据,就重新设置保活计时器,时间的设置通常是两个小时。若两个小时都没有收到客户端的数据,服务端就发送一个探测报文段,以后则每隔 75 秒钟发送一次。若连续发送 10个 探测报文段后仍然无客户端的响应,服务端就认为客户端出了故障,接着就关闭这个连接。
TCP 协议是如何保证可靠传输的?
数据包校验:目的是检测数据在传输过程中的任何变化,若校验出包有错,则丢弃报文段并且不给出响应,这时 TCP 发送数据端超时后会重发数据;
对失序数据包重排序:既然 TCP 报文段作为 IP 数据报来传输,而 IP 数据报的到达可能会失序,因此 TCP 报文段的到达也可能会失序。TCP 将对失序数据进行重新排序,然后才交给应用层;
丢弃重复数据:对于重复数据,能够丢弃重复数据;
应答机制:当 TCP 收到发自 TCP 连接另一端的数据,它将发送一个确认。这个确认不是立即发送,通常将推迟几分之一秒;
超时重发:当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段;
流量控制:TCP 连接的每一方都有固定大小的缓冲空间。TCP 的接收端只允许另一端发送接收端缓冲区所能接纳的数据,这可以防止较快主机致使较慢主机的缓冲区溢出,这就是流量控制。TCP 使用的流量控制协议是可变大小的滑动窗口协议。
谈谈你对停止等待协议的理解?
停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组;在停止等待协议中,若接收方收到重复分组,就丢弃该分组,但同时还要发送确认。主要包括以下几种情况:无差错情况、出现差错情况(超时重传)、确认丢失和确认迟到、确认丢失和确认迟到。
谈谈你对 ARQ 协议的理解?
自动重传请求 ARQ 协议
停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求 ARQ。
连续 ARQ 协议
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
谈谈你对滑动窗口的了解?
TCP 利用滑动窗口实现流量控制的机制。滑动窗口(Sliding window)是一种流量控制技术。早期的网络通信中,通信双方不会考虑网络的拥挤情况直接发送数据。由于大家不知道网络拥塞状况,同时发送数据,导致中间节点阻塞掉包,谁也发不了数据,所以就有了滑动窗口机制来解决此问题。
TCP 中采用滑动窗口来进行传输控制,滑动窗口的大小意味着接收方还有多大的缓冲区可以用于接收数据。发送方可以通过滑动窗口的大小来确定应该发送多少字节的数据。当滑动窗口为 0 时,发送方一般不能再发送数据报,但有两种情况除外,一种情况是可以发送紧急数据,例如,允许用户终止在远端机上的运行进程。另一种情况是发送方可以发送一个 1 字节的数据报来通知接收方重新声明它希望接收的下一字节及发送方的滑动窗口大小。
谈下你对流量控制的理解?
TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
谈下你对 TCP 拥塞控制的理解?使用了哪些算法?
拥塞控制和流量控制不同,前者是一个全局性的过程,而后者指点对点通信量的控制。在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。
拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致于过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
为了进行拥塞控制,TCP 发送方要维持一个拥塞窗口(cwnd) 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。
TCP 的拥塞控制采用了四种算法,即:慢开始、拥塞避免、快重传和快恢复。在网络层也可以使路由器采用适当的分组丢弃策略(如:主动队列管理 AQM),以减少网络拥塞的发生。
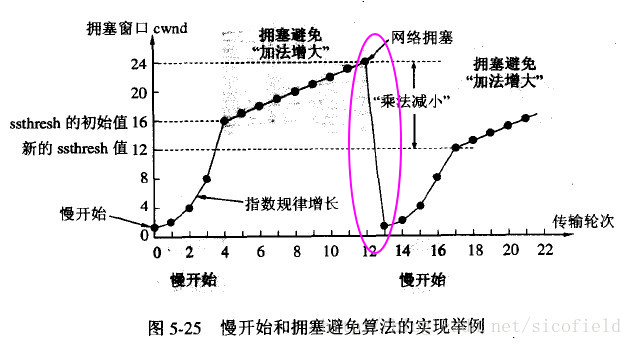
慢开始
慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd 初始值为 1,每经过一个传播轮次,cwnd 加倍。
拥塞避免
拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢增大,即每经过一个往返时间 RTT 就把发送方的 cwnd 加 1。
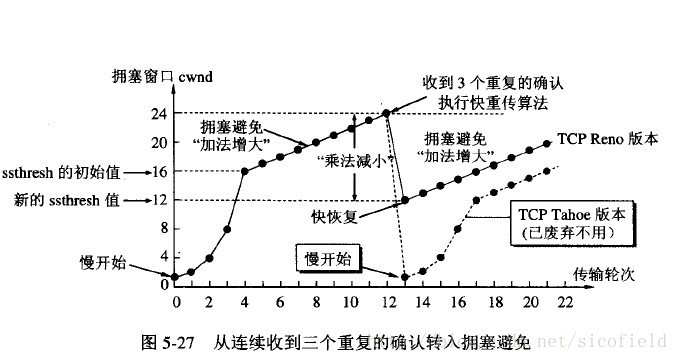
快重传与快恢复
TCP/IP 中,快速重传和快恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。
没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。
有了 FRR,就不会因为重传时要求的暂停被耽误。当有单独的数据包丢失时,快速重传和快恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
快重传
快重传,要求接收方在收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方),而不要等到自己发送数据时捎带确认。
快重传算法规定,发送方只要一连收到三个重复确认,就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期。

快恢复
快重传配合使用的还有快恢复算法,当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把 ssthresh 门限减半。
但是接下去并不执行慢开始算法:因为如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。
所以此时不执行慢开始算法,而是将 cwnd 设置为 ssthresh 的大小,然后执行拥塞避免算法。
什么是粘包?
在进行 Java NIO 学习时,可能会发现:如果客户端连续不断的向服务端发送数据包时,服务端接收的数据会出现两个数据包粘在一起的情况。
TCP 是基于字节流的,虽然应用层和 TCP 传输层之间的数据交互是大小不等的数据块,但是 TCP 把这些数据块仅仅看成一连串无结构的字节流,没有边界;
从 TCP 的帧结构也可以看出,在 TCP 的首部没有表示数据长度的字段。
基于上面两点,在使用 TCP 传输数据时,才有粘包或者拆包现象发生的可能。一个数据包中包含了发送端发送的两个数据包的信息,这种现象即为粘包。
接收端收到了两个数据包,但是这两个数据包要么是不完整的,要么就是多出来一块,这种情况即发生了拆包和粘包。拆包和粘包的问题导致接收端在处理的时候会非常困难,因为无法区分一个完整的数据包。
TCP 黏包是怎么产生的?
发送方产生粘包
采用 TCP 协议传输数据的客户端与服务器经常是保持一个长连接的状态(一次连接发一次数据不存在粘包),双方在连接不断开的情况下,可以一直传输数据。但当发送的数据包过于的小时,那么 TCP 协议默认的会启用 Nagle 算法,将这些较小的数据包进行合并发送(缓冲区数据发送是一个堆压的过程);这个合并过程就是在发送缓冲区中进行的,也就是说数据发送出来它已经是粘包的状态了。
接收方产生粘包
接收方采用 TCP 协议接收数据时的过程是这样的:数据到接收方,从网络模型的下方传递至传输层,传输层的 TCP 协议处理是将其放置接收缓冲区,然后由应用层来主动获取(C 语言用 recv、read 等函数);这时会出现一个问题,就是我们在程序中调用的读取数据函数不能及时的把缓冲区中的数据拿出来,而下一个数据又到来并有一部分放入的缓冲区末尾,等我们读取数据时就是一个粘包。(放数据的速度 > 应用层拿数据速度)
怎么解决拆包和粘包?
分包机制一般有两个通用的解决方法:
特殊字符控制;
在包头首都添加数据包的长度。
如果使用 netty 的话,就有专门的编码器和解码器解决拆包和粘包问题了。
tips:UDP 没有粘包问题,但是有丢包和乱序。不完整的包是不会有的,收到的都是完全正确的包。传送的数据单位协议是 UDP 报文或用户数据报,发送的时候既不合并,也不拆分。
应用层有啥用?
应用层对应用程序的通信提供服务。
- 区分是发送报文还是接收报文
- 定义报文类型的语法,比如某字段的意思,例如http中content-type字段是什么意思。
- 最后就是进程如何,什么时候把传输层的数据交给应用层。
一些比较重要的应用层协议如下图:

应用层常见的模型
第一种是客户端/服务器模型,也就是C/S架构。比如电子邮件、web都是。
第二种是P2P模型,每个主机既可以提供服务,也可以请求服务。比如迅雷下载也是使用P2P技术的。

短链接和长链接
而TCP连接有两种工作方式:短连接方式(Short-Live Connection)和长连接方式(Long-Live Connection)。
- 短连接方式:
- 当客户端有请求时,会建立一个TCP连接,接收到服务器响应后,就断开连接。下次有请求时,再建立连接,收到响应后,再断开。如此循环。这种方式主要有两个缺点:
- 建立TCP连接需要3次“握手”,拆除TCP连接需要4次“挥手”,这就需要7个数据包。如果请求和响应各占1个数据包,那么一次短连接的交互过程,有效的传输仅占2/9,这个利用率太低了。
- 主动断开TCP连接的一端,TCP状态机会进入TIME_WAIT状态。如果频繁地使用短连接方式,就有可能使客户端的机器产生大量的处于TIME_WAIT状态TCP连接。
- 长连接方式:
- 客户端和服务器建立TCP连接后,会一直使用这条连接进行数据交互,直到没有数据传输或异常断开。在空闲期间,通常会使用
`心跳数据包(Keep-Alive)保持链路不断开。目前长连接方式应用范围比较广泛。
比较http 0.9和http 1.0
- http0.9只是一个简单的协议,只有一个GET方法,没有首部,目标用来获取HTML。
- HTTP1.0协议大量内容:首部,响应码,重定向,错误,条件请求,内容编码等。
http0.9流程:
客户端,构建请求,通过DNS查询IP地址,三次握手建立TCP连接,客户端发起请求,服务器响应,四次挥手,断开TCP连接。(一个来回:服务器收到请求信息,读取对应的文件如HTML,并将数据返回给客户端)
http1.0流程:
客户端,构建请求,通过DNS查询IP地址,三次握手建立TCP连接,客户端发起请求,服务器响应,四次挥手,断开TCP连接。(多个来回:HTTP1.0引入请求投和响应头,由于出现了如Js,css等多种形式的文本,http0.9以满足不了需求,so,引入了content-encoding,content-type等字段)
因为不足缺陷,就有了http1.1。
关于http1.1以及http2
http1.1中浏览器再也不用为每个请求重新发起TCP连接了,增加内容有:缓存相关首部的扩展,OPTIONS方法,Upgrade首部,Range请求,压缩和传输编码,管道化等。但还是满足不了现在的web发展需求,so,就有了http.2版本。
http2解决了(管道化特性可以让客户端一次发送所有的请求,但是有些问题阻碍了管道化的发展,即是某个请求花了很长时间,那么队头阻塞会影响其他请求。)http中的队头阻塞问题。
使用http2会比http1.1在使用TCP时,用户体验的感知多数延迟的效果有了量化的改善,以及提升了TCP连接的利用率(并行的实现机制不依赖与服务器建立多个连接)
所以需要学习http2,了解更过的内容来掌握计算机网咯。
对于http2,你可以来运行一个http2的服务器,获取并安装一个http2的web服务器,下载并安装一张TLS证书,让浏览器和服务器通过http2来连接。(从数字证书认证机构申请一张证书)。
了解http2的协议,先让我们了解一下web页面的请求,就是用户在浏览器中呈现的效果,发生了些什么呢?
资源获取的步骤:
把待请求URL放入队列,判断URL是否已在请求队列,否的话就结束,是的话就判断请求域名是否DNS缓存中,没有的话就解析域名,有的话就到指定域名的TCP连接是否开启,没有的话就开启TCP连接,进行HTTPS请求,初始化并完成TLS协议握手,向页面对应的URL发送请求。
接收响应以及页面渲染步骤:
接收请求,判断是否HTML页面,是就解析HTML,对页面引用资源排优先级,添加引用资源到请求队列。(如果页面上的关键资源已经接收到,就开始渲染页面),判断是否有还要继续接收资源,继续解析渲染,直到结束。
HTTP的几种请求方法用途
第一种GET方法:发送一个请求来获取服务器上的某一些资源。
第二种POST方法:向URL指定的资源提交数据或附加新的数据。
第三种PUT方法:跟POST方法一样,可以向服务器提交数据,但是它们之间也所有不同,PUT指定了资源在服务器的位置,而POST没有哦。
第四种HEAD方法:指请求页面的首部。
第五种DELETE方法:删除服务器上的某资源。
第六种OPTIONS方法:它用于获取当前URL所支持的方法,如果请求成功,在Allow的头包含类似GET,POST等的信息。
第七种TRACE方法:用于激发一个远程的,应用层的请求消息回路。
第八种CONNECT方法:把请求连接转换到TCP/TP通道。
浏览器输入URL并回车的过程以及相关协议,DNS查询过程。
过程
1、DNS域名解析,得到IP地址
DNS解析流程:
参考:https://note.csdn.net/yanshuanche3765/article/details/82589210
(1)1. 浏览器先检查自身缓存中有没有被解析过的这个域名对应的ip地址,(如果有,解析结束。同时域名被缓存的时间也可通过TTL属性来设置。)
(2)在主机查询操作系统DNS缓存,也就是hosts文件里配置的。
(3)如果浏览器和系统缓存都没有,系统的 gethostname 函数就会像本地 DNS 服务器发送请求。而网络服务一般都会先经过路由器以及网络服务商(电信),所以会先查询路由器缓存,然后再查询 ISP 的 DNS 缓存。
(4)如果至此还没有命中域名,才会真正的请求本地域名服务器(LDNS)来解析这个域名,这台服务器一般在你的城市的某个角落,距离你不会很远,并且这台服务器的性能都很好,一般都会缓存域名解析结果,大约80%的域名解析到这里就完成了。
(5)如果LDNS仍然没有命中,本地的DNS服务器向根域名服务器发送查询请求,根域名服务器返回该域名的顶级级域名服务器。依次类推:根域名服务器-顶级域名服务器-主域名服务器
2、解析出IP地址后,根据IP地址和默认端口80和服务器建立连接,发送http请求
3、服务器对浏览器的请求作出响应,并把对应的html文本发送给浏览器
4、释放TCP连接(四次挥手断开连接)
6、浏览器解析该HTML文本并显示内容
用到的协议
- TCP:与服务器建立TCP连接
- IP: 建立TCP协议时,需要发送数据,发送数据在网络层使用IP协议
- OPSF: IP数据包在路由器之间,路由选择使用OPSF协议
- ARP: 路由器在与服务器通信时,需要将ip地址转换为MAC地址,需要使用ARP协议
- HTTP:在TCP建立完成后,使用HTTP协议访问网页
谈下你对 HTTP 长连接和短连接的理解?分别应用于哪些场景?
在 HTTP/1.0 中默认使用短连接。也就是说,客户端和服务器每进行一次 HTTP 操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个 HTML 或其他类型的 Web 页中包含有其他的 Web 资源(如:JavaScript 文件、图像文件、CSS 文件等),每遇到这样一个 Web 资源,浏览器就会重新建立一个 HTTP 会话。
而从 HTTP/1.1 起,默认使用长连接,用以保持连接特性。使用长连接的 HTTP 协议,会在响应头加入这行代码
Connection:keep-alive在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。
Keep-Alive 不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如:Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
你对 HTTP 状态码有了解吗?
- 1XX 信息
- 100 Continue :表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
- 2XX 成功
200 OK
204 No Content :请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
206 Partial Content :表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
- 3XX 重定向
301 Moved Permanently :永久性重定向;
302 Found :临时性重定向;
303 See Other :和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
304 Not Modified :如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
307 Temporary Redirect :临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
- 4XX 客户端错误
400 Bad Request :请求报文中存在语法错误。
401 Unauthorized :该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
403 Forbidden :请求被拒绝。
404 Not Found
- 5XX 服务器错误
500 Internal Server Error :服务器正在执行请求时发生错误;
503 Service Unavailable :服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
HTTP 状态码 301 和 302 代表的是什么?有什么区别?
301,302 都是 HTTP 状态的编码,都代表着某个 URL 发生了转移。
- 区别:
301 redirect: 301 代表永久性转移(Permanently Moved)
302 redirect: 302 代表暂时性转移(Temporarily Moved)
说下 GET 和 POST 的区别?
GET 和 POST 本质都是 HTTP 请求,只不过对它们的作用做了界定和适配,并且让他们适应各自的场景。
本质区别:GET 只是一次 HTTP请求,POST 先发请求头再发请求体,实际上是两次请求。
从功能上讲,GET 一般用来从服务器上获取资源,POST 一般用来更新服务器上的资源;
从 REST 服务角度上说,GET 是幂等的,即读取同一个资源,总是得到相同的数据,而 POST 不是幂等的,因为每次请求对资源的改变并不是相同的;进一步地,GET 不会改变服务器上的资源,而 POST 会对服务器资源进行改变;
从请求参数形式上看,GET 请求的数据会附在 URL 之后,即将请求数据放置在 HTTP 报文的 请求头 中,以 ? 分割 URL 和传输数据,参数之间以 & 相连。特别地,如果数据是英文字母/数字,原样发送;否则,会将其编码为 application/x-www-form-urlencoded MIME 字符串(如果是空格,转换为+,如果是中文/其他字符,则直接把字符串用 BASE64 加密,得出如:%E4%BD%A0%E5%A5%BD,其中 %XX 中的 XX 为该符号以 16 进制表示的 ASCII);而 POST 请求会把提交的数据则放置在是 HTTP 请求报文的 请求体 中;
就安全性而言,POST 的安全性要比 GET 的安全性高,因为 GET 请求提交的数据将明文出现在 URL 上,而且 POST 请求参数则被包装到请求体中,相对更安全;
从请求的大小看,GET 请求的长度受限于浏览器或服务器对 URL 长度的限制,允许发送的数据量比较小,而 POST 请求则是没有大小限制的。
谈谈你对域名缓存的了解?
为了提高 DNS 查询效率,并减轻服务器的负荷和减少因特网上的 DNS 查询报文数量,在域名服务器中广泛使用了高速缓存,用来存放最近查询过的域名以及从何处获得域名映射信息的记录。
由于名字到地址的绑定并不经常改变,为保持高速缓存中的内容正确,域名服务器应为每项内容设置计时器并处理超过合理时间的项(例如:每个项目两天)。当域名服务器已从缓存中删去某项信息后又被请求查询该项信息,就必须重新到授权管理该项的域名服务器绑定信息。当权限服务器回答一个查询请求时,在响应中都指明绑定有效存在的时间值。增加此时间值可减少网络开销,而减少此时间值可提高域名解析的正确性。
不仅在本地域名服务器中需要高速缓存,在主机中也需要。许多主机在启动时从本地服务器下载名字和地址的全部数据库,维护存放自己最近使用的域名的高速缓存,并且只在从缓存中找不到名字时才使用域名服务器。维护本地域名服务器数据库的主机应当定期地检查域名服务器以获取新的映射信息,而且主机必须从缓存中删除无效的项。由于域名改动并不频繁,大多数网点不需花精力就能维护数据库的一致性。
HTTP 和 HTTPS 的区别?
开销:HTTPS 协议需要到 CA 申请证书,一般免费证书很少,需要交费;
资源消耗:HTTP 是超文本传输协议,信息是明文传输,HTTPS 则是具有安全性的 ssl 加密传输协议,需要消耗更多的 CPU 和内存资源;
端口不同:HTTP 和 HTTPS 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443;
安全性:HTTP 的连接很简单,是无状态的;HTTPS 协议是由 TSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 HTTP 协议安全。
HTTPS 的优缺点?
- 优点:
使用 HTTPS 协议可认证用户和服务器,确保数据发送到正确的客户机和服务器;
HTTPS 协议是由 SSL + HTTP 协议构建的可进行加密传输、身份认证的网络协议,要比 HTTP 协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性;
HTTPS 是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
- 缺点:
HTTPS 协议握手阶段比较费时,会使页面的加载时间延长近 50%,增加 10% 到 20% 的耗电;
HTTPS 连接缓存不如 HTTP 高效,会增加数据开销和功耗,甚至已有的安全措施也会因此而受到影响;
SSL 证书需要钱,功能越强大的证书费用越高,个人网站、小网站没有必要一般不会用;
SSL 证书通常需要绑定 IP,不能在同一 IP 上绑定多个域名,IPv4 资源不可能支撑这个消耗;
HTTPS 协议的加密范围也比较有限,在黑客攻击、拒绝服务攻击、服务器劫持等方面几乎起不到什么作用。最关键的,SSL 证书的信用链体系并不安全,特别是在某些国家可以控制 CA 根证书的情况下,中间人攻击一样可行。
web性能优化技术(减少客户端网络延迟和优化页面渲染性能来提升web性能)
优化技术:
- DNS查询优化
- 客户端缓存
- 优化TCP连接
- 避免重定向
- 网络边缘的缓存
- 条件缓存
- 压缩和代码极简化
- 图片优化
如何进行网站性能优化
内容方面,减少Http请求(合并文件,css精灵,inline Image),减少DNS查询(DNS缓存,将资源分布到合适的数量的主机名),减少DOM元素的数量。
Cookie方面,可以减少Cookie的大小。
css方面,将样式表放到页面顶部;不使用css表达式;使用<link>不使用@import;可将css从外部引入;压缩css。
JavaScript方面,将脚本放到页面底部;将JavaScript从外部引入;压缩JavaScript,删除不需要的脚本,减少DOM的访问。
图片方面,可优化css精灵,不要再HTML中拉伸图片,优化图片(压缩)。
http-数据压缩
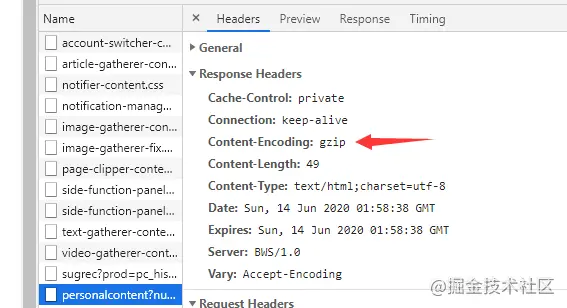
数据压缩,在浏览器中发送请求时会带着Content-Encoding: gzip,里面时浏览器支持的压缩格式列表,有多种如,gzip,deflate,br等。这样服务器就可以从中选择一个压缩算法,放进Content-Encoding响应头里,再把原数据压缩后发给浏览器。
http-分块传输
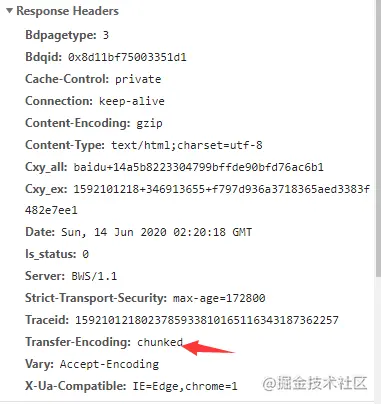
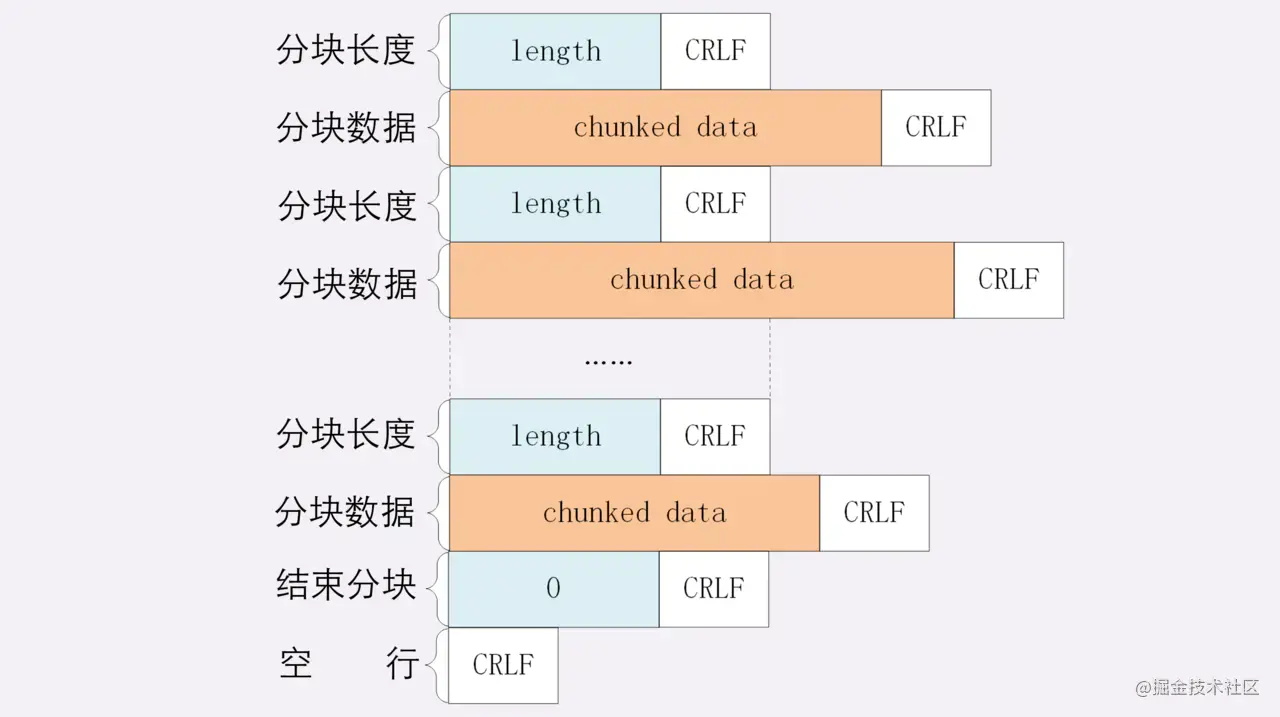
分块传输,就是将传输的文件分解成多个小块,然后分发给浏览器,浏览器收到后再重新组装复原。
每个分块包含两个部分,分块长度和分块数据(长度头和数据块),长度头以CRLF结尾的一行明文,数据块紧跟在长度头后面,也是用CRLF结尾,最后用一个长度为0的块表示结束。
在响应报文里用头字段Transfer-Encoding:chunked表示报文里的body部分不是一次性发送过来的,而是分成了许多块逐个发送的。
在Transfer-Encoding:chunked和Content-Length中,这两个字段是互斥的。
一个响应报文的传输长度要么已知,要么长度未知(chunked)。
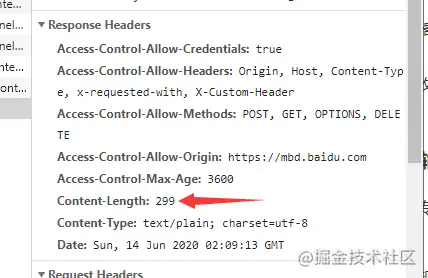
Content-Length: 299
http-范围请求
断点续传
要实现该功能需要制定下载的实体范围,这种制定范围发送请求叫做范围请求。
Accept-Ranges:服务器使用http响应头Accept-Ranges标识自身支持范围请求,字段的具体值用于定义范围请求的单位。
语法
Accept-Ranges: bytes,范围请求的单位是 bytes (字节)
Accept-Ranges: none,不支持任何范围请求单位范围请求时用于不需要全部数据,只需要其中的部分请求时,可以使用范围请求,允许客户端在请求头里使用专用字段来表示只获取文件的一部分。
Range的格式,请求头Range是HTTP范围请求的专用字段,格式是“bytes=x-y”,以字节为单位的数据范围。
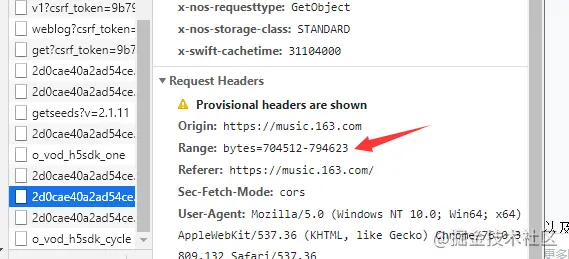
- “0-”表示从文档起点开始到文档结束的整个文件。
- “100-”表示从第100个字节开始到文档末尾。
- “-10”表示从文档末尾倒数的第10个字节开始。
示例:
执行范围时会使用头部字段 Range 来指定资源 byte 的范围。
Range格式:
5001-10000字节
Range : byte = 5001-10000
5000之后的
Range : byte = 5001-
0-3000字节,5001-10000字节
Range : byte=-3000,5001-10000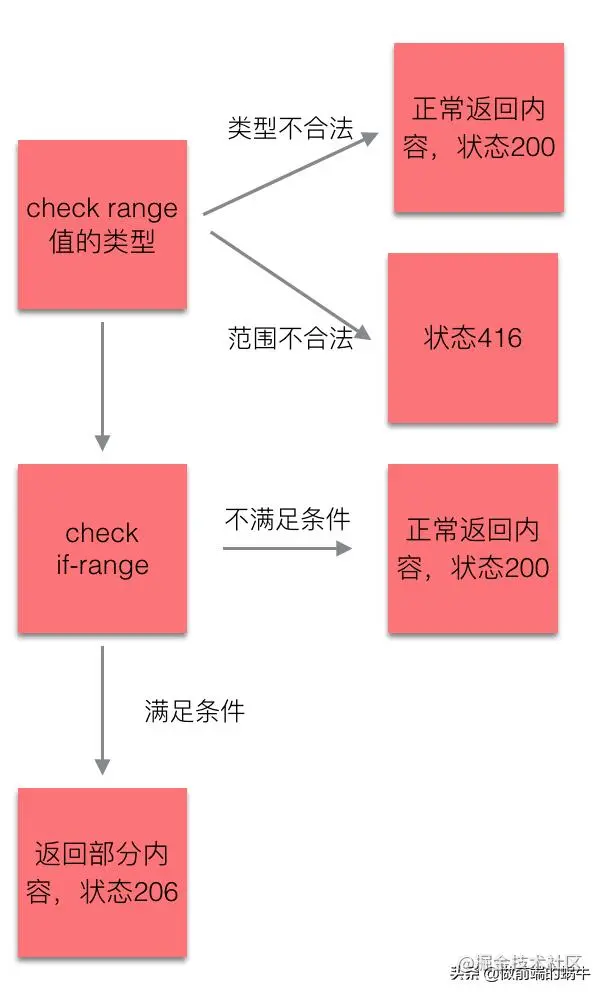
上图表示服务器收到Range字段后,检测范围合法性,范围越界,就会返回状态码416,如你的文件只有1000个字节,但请求范围在20000-3000,就会导致这个状态码的出现。
如果成功读取文件,范围正确,返回状态码“206”。服务器要添加一个响应头字段Content-Range,告诉片段的实际偏移量和资源的总大小。
最后是发送数据,直接把片段用TCP发给客户端,一个范围请求就算是处理完了。
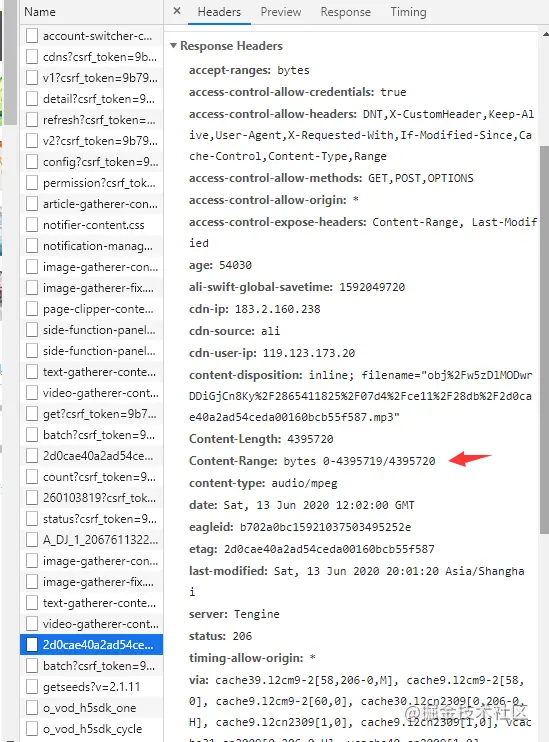
格式是“bytes x-y/length”,与Range头区别在没有“=”
Content-Range: bytes 0-4395719/4395720
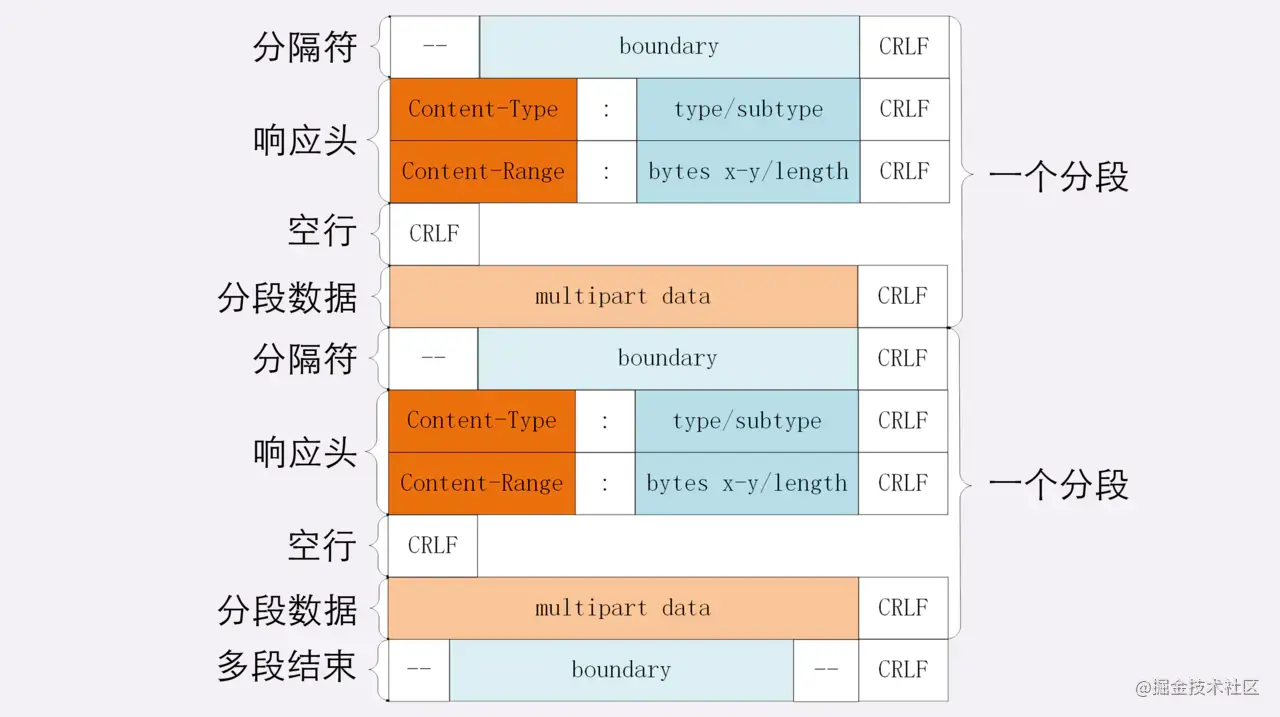
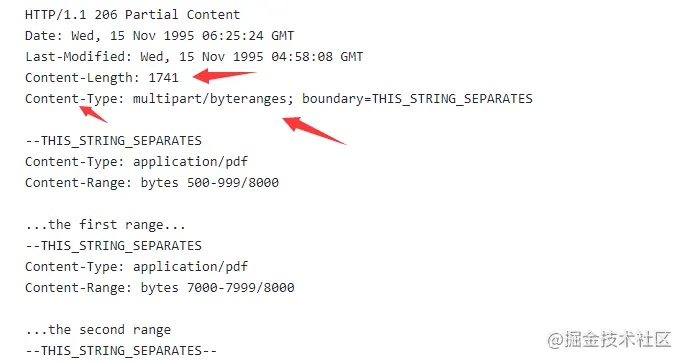
http-多段数据
多段数据,就是在Range头里使用多个“x-y”,一次性获取多个片段数据。使用一种特殊的MIME类型:“multipart/byteranges”,用来表示响应报文包含了多个范围时使用。多重范围请求 响应会在头部 Content-Type 表明 multipart-byteranges。
多段数据图:分隔标记boundary来区分不同的分段
说一说cookies,sessionStorage 和 localStorage 的区别?
- cookie是网站用来标识用户身份而存储在用户本地终端上的数据
- cookie数据始终在同源的http请求中携带,即使是不需要的情况,so,会在浏览器和服务器间来回传递
- sessionStorage和localStorage不会自动把数据发送给服务器,仅仅在本地保存
存储的大小
cookie的数据大小不能超过4k;sessionStorage和localStorage虽然也有存储大小的限制,但比cookie大得多,可以达到5M或者更大。
有限期时间
- localStorage存储持久数据,浏览器关闭后数据不会丢失,除了主动删除数据
- sessionStorage数据在当前浏览器窗口关闭后自动删除
- 设置得cookie过期时间之前都有效,就算窗口或者是浏览器关闭
为什么说利用多个域名来存储网站资源会更有效?
因为CDN缓存更方便;突破浏览器并发限制;节约cookie带宽;节约主域名得连接数,优化页面响应速度;防止不必要得安全性问题。
http2.0的内容
http2是超文本传输协议的第二版,相比http1协议的文本传输格式,http2是以二进制的格式进行数据传输的,具有更小的传输体积以及负载。
http2.0分层,分帧层(http2多路复用能力的核心部分),数据或http层(包含传统上被认为是 HTTP 及其关联数据的部分)。
HTTP2.0:
- 多路复用机制,引入了二进制的分帧层机制来实现多路复用。(分帧层是基于帧的二进制协议。这方便了机器解析。请求和响应交织在一起。)
- 可以设置请求的优先级(客户端的分帧层对分割块标上请求的优先级)。
- 头部压缩 请求头压缩,增加传输效率。
HTTP/2较HTTP/1.1优化亮点
- 多路复用的流
- 头部压缩
- 资源优先级和依赖设置
- 服务器推送
- 流量控制
- 重置消息
多路复用的实现:
在单个域名下仍可以建立一个TCP管道,使用一个TCP长连接,下载整个资源页面,只需要一次慢启动,并且避免了竞态,浏览器发起请求,分帧层会对每个请求进行分割,将同一个请求的分割块打上相同的id编号,然后通过协议栈将所有的分割体发送给服务器,然后通过服务器的分帧层根据id编号进行请求组装,服务器的分帧层将回应数据分割按同一个回应体进行ID分割回应给客户端,客户端拼装回应。
对于http2中的帧(frame),http1不是基于帧(frame)的,是文本分隔的。
GET/HTTP/1.1 <crlf>
这样,对于http1的请求或者是响应可能有的问题:
- 一次只能处理一个请求或者是响应,完成之前是不能停止解析的。
- 无法预判解析需要多少内层。
HTTP/1 的请求和响应报文,是由起始行、首部和正文组成,换行符分隔;HTTP/2是将请求和响应数据分割成更小的帧,采用二进制编码,易于解析的。
参考图片:
帧结构总结 所有的帧都包含一个9 byte的帧头 + 可边长的正文不同。根据帧的类型不同,正文部分的结构也不一样。
帧头:
http2-幕后
http2作为一个二进制协议,拥有包含轻量型,安全和快速在内的所有优势,保留了原始的http协议语义,对于http2更改了在系统之间传输数据的方式。
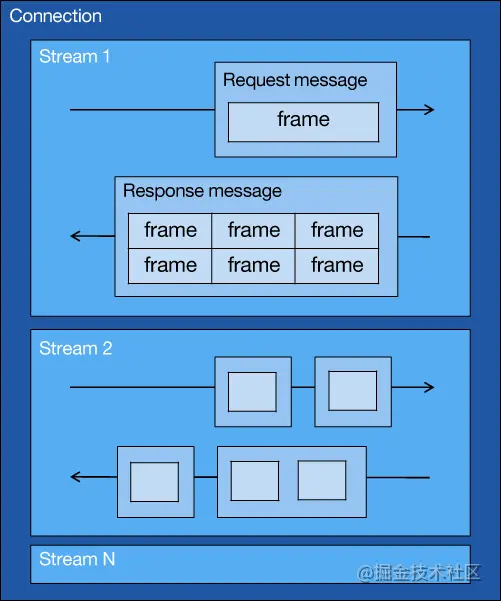
二进制分帧层(binary framing layer),所有通信都在单个TCP连接上执行,该连接在整个对话期间一直处于打开状态,主要是二进制协议将通信分解为帧的方式,这些帧交织在客户端与服务器之间的双向逻辑流中。
HTTP/2 连接的拓扑结构(展示了一个用于建立多个流的连接)
在流 1 中,发送了一条请求消息,并返回了相应的响应消息。
HTTP/2 帧结构

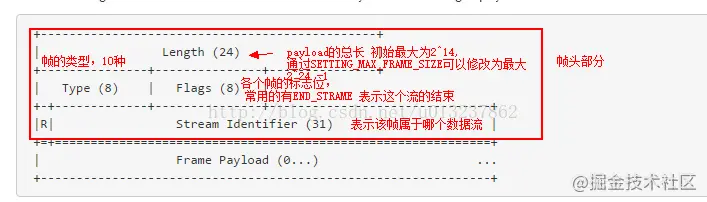
前9个字节对于每个帧是一致的。解析时只需要读取这些字节,就可以准确地知道在整个帧中期望的字节数。
帧首部字段表格:
| 名称 | 长度 | 描述 |
|---|---|---|
| length | 3字节 | 表示帧负载的长度 |
| type | 1字节 | 当前帧类型 |
| Flags | 1字节 | 具体帧类型的标识 |
| R | 1位 | 保留位,不要设置,否则会带来严重后果 |
| Stream Identifier | 31位 | 每个流的唯一ID |
| Frame Payload | 长度可变 | 真实的帧内容,长度是在length字段中设置的 |
备注:流Id是用来标识帧所属的流。流看作在连接上的一系列帧,它们构成了单独的 HTTP 请求和响应。
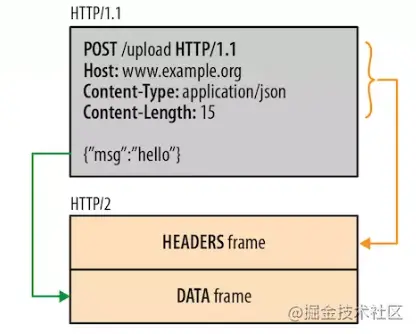
对于http1 的请求和响应都分成消息首部和消息体两部分;http2 从上面一张图可以知道,http2的请求和响应分成HEADERS 帧和 DATA 帧。
比较一下:
http2的一个重要特性是基于流的流量控制。提供了客户端调整传输速度的能力。其中WINDOW_UPDATE 帧用来指示流量控制信息。
有了多路复用,客户端可以一次发出多有资源的请求,不用像http1那样,发出对新对象请求之前,需要等待前一个响应完成。所以浏览器失去了在Http1中的默认资源请求优先级策略。
浏览器生成http请求消息
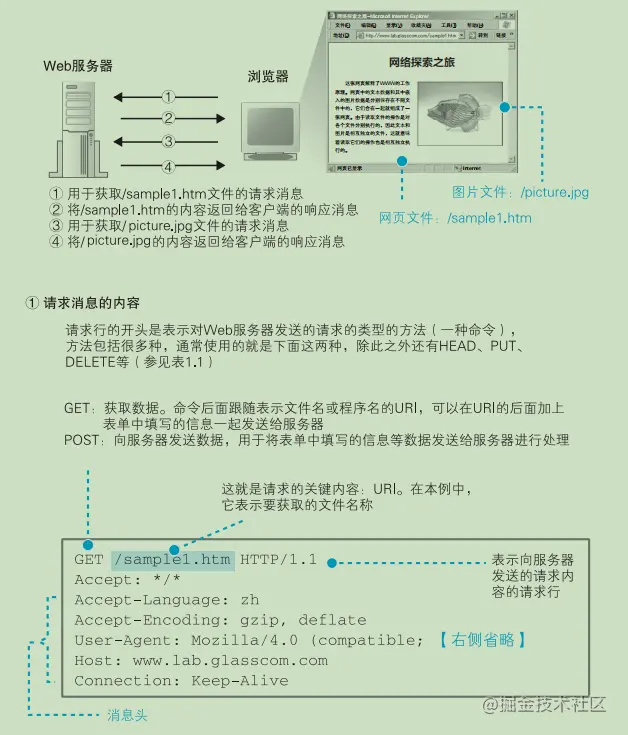
http的头字段
| 头字段类型 | 含义 |
|---|---|
| Date | 表示请求和响应生成的日期 |
| Pragma | 表示数据是否允许缓存的通信选项 |
| Cache-Control | 控制缓存的相关信息 |
| Connection | 设置发送响应之后TCP连接是否继续保持的通信选项 |
| Transfer-Encoding | 表示消息主体的编码格式 |
| Via | 记录途中经过的代理和网关 |
| Authorization | 身份认证数据 |
| From | 请求发送者的邮件地址 |
| Referer | 当通过点击超级链接进入下一个页面时,在这里会记录下上一个页面的URI |
| User-Agent | 客户端软件的名称和版本号等相关信息 |
| Accept | 客户端可支持的数据类型,以MIME类型来表示 |
| Accept-Charset | 客户端可支持的字符集 |
| Accept-Language | 客户端可支持的语言 |
| Host | 接收请求的服务器ip地址和端口号 |
| Range | 当需要只获取部分数据而不是全部数据时,可通过这个字段指定要获取的数据范围 |
| Location | 表示信息的准确位置 |
| Server | 服务器程序的名称和版本号等相关信息 |
| Allow | 表示指定的URI支持 |
| Content-Encoding | 当消息体经过压缩等编码处理时,表示其编码格式 |
| Content-Length | 表示消息体的长度 |
| Content-Type | 表示消息体的数据类型,以MIME规格定义的数据类型来表示 |
| Expires | 表示消息体的有效期 |
| Last-Modified | 数据的最后更新日期 |
| Content-Language | 表示消息体的语言 |
| Content-Location | 表示消息体在服务器上的位置 |
| Content-Range | 当仅请求部分数据时,表示消息体包含的数据范围 |
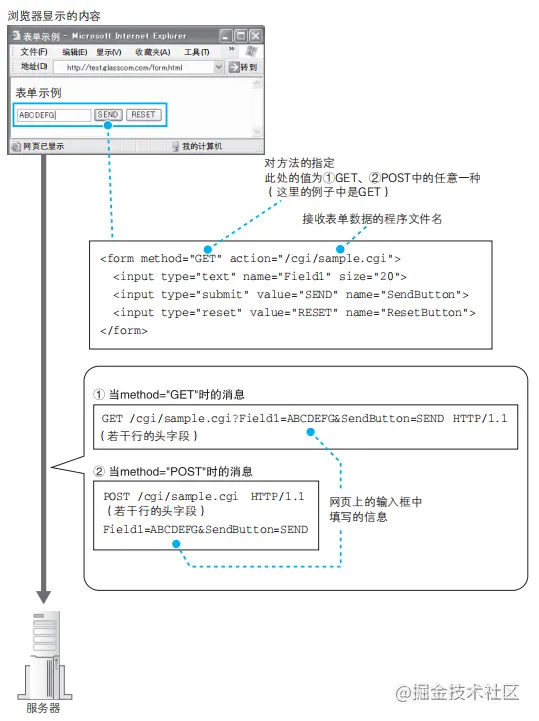
HTTP消息示例:
- HTTP,超文本传送协议。
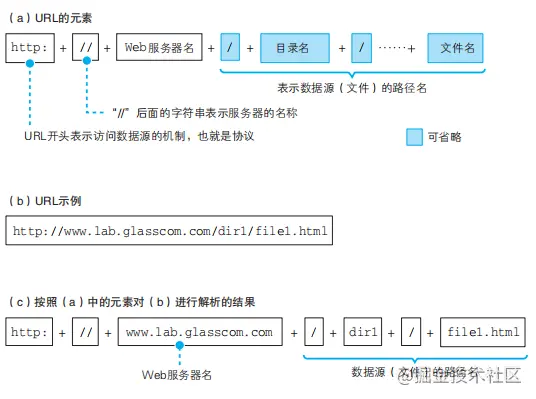
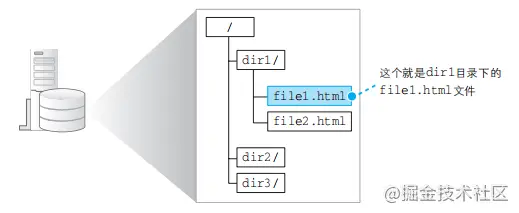
- 协议,通信操作的规则定义称为协议。
- URI,统一资源标识符。
- 1 条请求消息中只能写 1 个 URI。如果需要获取多个文件,必须 对每个文件单独发送 1 条请求。

IP 的基本思路
Ip地址的表示方法

IP地址的结构-子网掩码表示网络号与主机号之间的边界。

解析器的调用方法

DNS服务器的基本工作
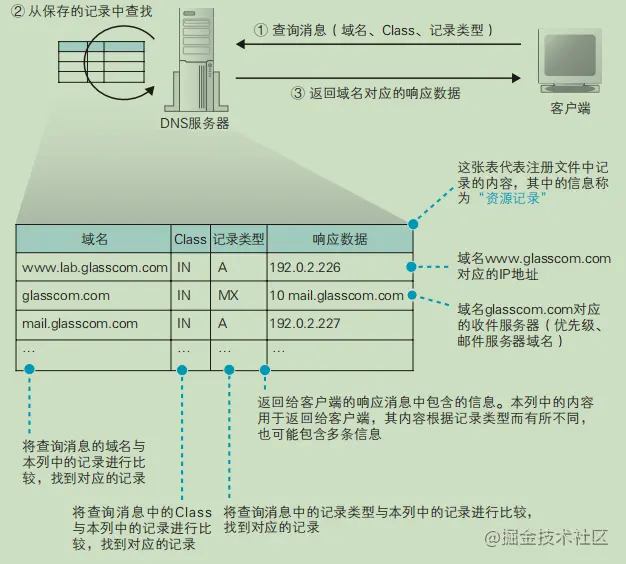
DNS 服务器之间的查询操作
数据通过类似管道的结构来流动
了解一下http-http3.0
在http2.0中,TCP管道传输途中也会导致丢包问题,造成队头阻塞(在http2.0中的TCP建立连接三次握手,和HTTPS的TSL连接也会耗费较多时间)
其实多路复用技术可以只通过一个TCP连接就可以传输所有的请求数据。
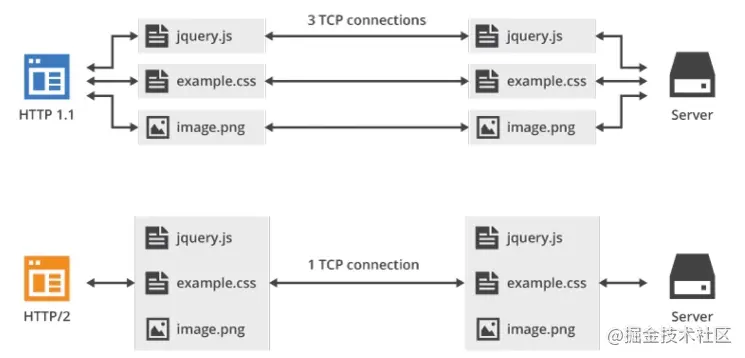
http3中弄了一个基于UDP协议的QUIC协议,QUIC虽说基于UDP,但是在基础上添加了很多功能。QUIC(快速UDP网络连接)是一种实验性的网络传输协议,由Google开发,该协议旨在使网页传输更快。
对于在http中的缺点就是延迟,浏览器的阻塞,在对同一域名,同时只能连接4个,超过了浏览器的最大连接限数时,后面的请求就会被阻塞;DNS的查询就是将域名解析为IP,来向目标服务器的IP建立连接,其中通过DNS缓存可以达到减少时间的作用;建立连接,HTTP是基于tcp协议的,三次握手,每次连接都无法复用,so,会每次请求都要三次握手和慢启动,都会影响导致延迟。(慢启动对大量小文件请求影响较大)
http处于计算机网络中的应用层,建立在TCP协议之上。(掌握了解tcp建立连接的3次握手和断开连接的4次挥手和每次建立连接带来的RTT延迟时间)。
相对于HTTP1.0使用了header里的if-modified-since,expires来做缓存判断,在HTTP1.1中引入了entity tag,if-unmodified-since,if-match,if-none-match等更多可供选择的缓存头来控制缓存策略。
http1.0传输数据时,每次都要重新建立连接,增加延迟,http1.1加入了keep-alive可以复用部分连接,但在域名分片等情况下仍要连接夺冠时连接,耗费资源,以及给服务器带来性能压力。
http1.1尝试使用pipeling来解决问题,就是浏览器可以一次性发出多个请求,在同一个域名下,同一条TCP连接,但对于pipeling要求返回是按照顺序的,即(如果前面有个请求很耗时的话,后面的请求即使服务器已经处理完,任会等待前面的请求处理完才开始按序返回。)
在http1.x中,Header携带内容过大,增加了传输的成本,在传输的内容都是明文,在一定程度上无法保证其数据的安全性。(在http1.x问题的出现,有了SPDY协议,用于解决http/1.1效率不高的问题,降低延迟,压缩Header等)
HTTP2主要解决用户和网站只用一个连接(同域名下所有通信都只用单个连接完成,单个连接可以承载任意数量的双向数据流,数据流是以消息的形式发送,消息由一个或多个帧组成)。
so,http采用二进制格式传输数据,不像http1.x的文本格式。(二进制:http2将请求和响应数据分割成帧,并且它们采用二进制的编码),对于HTTP2的概念:(流,消息,帧)
- 流,它是连接中的一个虚拟信道;
- 消息,它是HTTP消息,请求,以及响应;
- 帧,它是HTTP2.0通信的最小单位。
多个帧可以乱序发送,可根据帧首部的标识流进行重新组装。
对于http2,同一域名下只需要使用一个TCP连接,那么当出现丢包时,会导致整个TCP都要开始等待重传。对于http1.1来说,可以开启多个TCP连接,出现这种情况指挥影响一个连接(或者部分),其余的TCP连接正常传输。
HTTP/2 对首部采取了压缩策略,为了减少资源消耗并提升性能。(因为在http1中,在header携带cookie下,可能每次都要重复传输数据)
so,有了QUIC协议,整合了TCP,TLS,和HTTP/2的优点,并加以优化。那么QUIC是啥,它是用来替代TCP,SSL/TLS的传输层协议,在传输层之上还有应用层。
注意,它是一个基于UDP协议的QUIC协议,使用在http3上。
QUIC 新功能
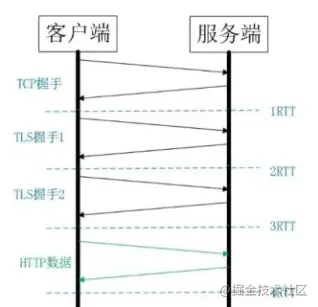
HTTPS 的一次完全握手的连接过程
QUIC可以解决传输单个数据流可以保证有序的交付,并且不会影响其他的数据流。(解决http2问题)
表示在QUIC连接中,一个连接上的多个stream,如其中stream1,stream2,stream3,stream4,其中stream2丢失(quic packet),其余UDP到达,应用层直接读取。—- 无需等待,不存在TCP队头阻塞,丢失的包需要重新传即可。
补充:
- TCP是基于IP和端口去识别连接的;
- QUIC是通过ID的方式去识别连接的
对于QUIC的包都是经过认证的,除了个别,so,这样,通过加密认证的报文,就可以降低安全风险。
HTTP2-TLS,TCP,IP
小结QUIC特点:(基于UDP)—- http3-QUIC,UDP,IP
- 多路数据流
- TLS
- 有序交付
- 快速握手
- 可靠性
了解一下DNS
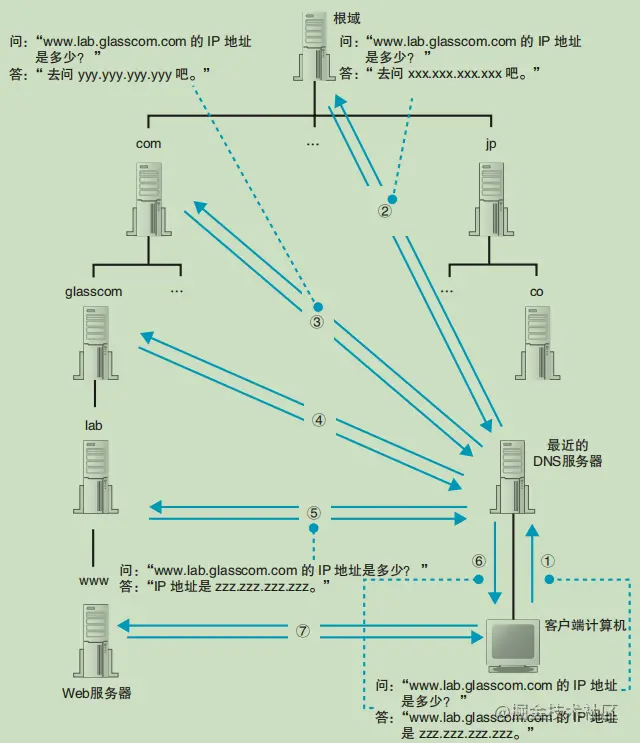
DNS是域名解析系统,它的作用非常简单,就是根据域名查出对应的IP地址。
- 从根域名服务器查到顶级域名服务器的NS记录和A记录,IP地址
- 从顶级域名服务器查到次级域名服务器的NS记录和A记录,IP地址
- 从次级域名服务器查出主机名的IP地址

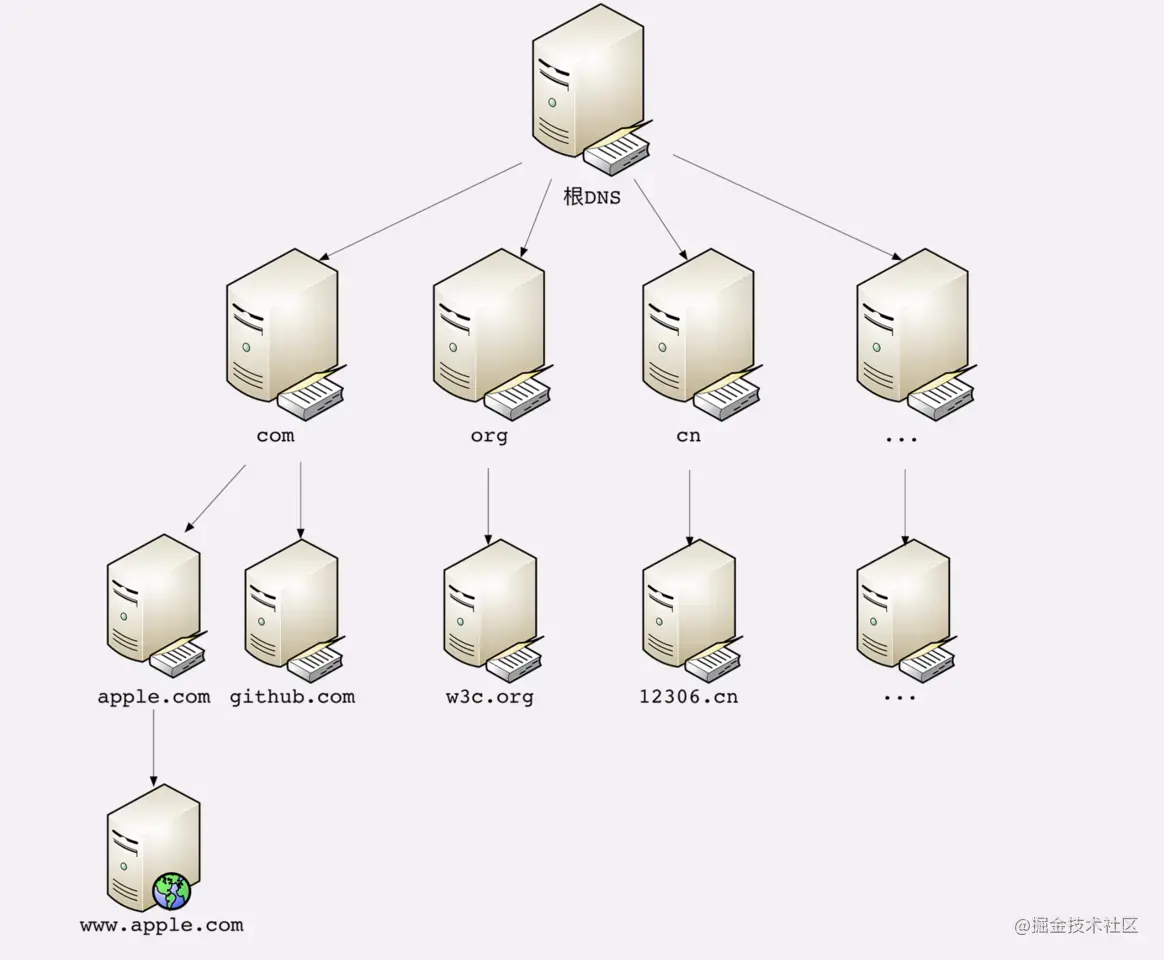
URI统一资源标识符
统一资源标识符是一个用于标识某一互联网资源名称的字符串。该标识允许用户对网络中的资源通过特定的协议进行交互操作。URI常见形式为统一资源定位符(URL),URN为统一资源名称。用于在特定的命令空间资源的标识,以补充网址。

HTTPS 的工作过程?
客户端发送自己支持的加密规则给服务器,代表告诉服务器要进行连接了;
服务器从中选出一套加密算法和 hash 算法以及自己的身份信息(地址等)以证书的形式发送给浏览器,证书中包含服务器信息,加密公钥,证书的办法机构;
客户端收到网站的证书之后要做下面的事情:
- 3.1 验证证书的合法性;
- 3.2 果验证通过证书,浏览器会生成一串随机数,并用证书中的公钥进行加密;
- 3.3 用约定好的 hash 算法计算握手消息,然后用生成的密钥进行加密,然后一起发送给服务器。
- 服务器接收到客户端传送来的信息,要做下面的事情:
- 4.1 用私钥解析出密码,用密码解析握手消息,验证 hash 值是否和浏览器发来的一致;
- 4.2 使用密钥加密消息;
- 如果计算法 hash 值一致,握手成功。
什么是单向认证、双向认证?
单向认证,指的是只有一个对象校验对端的证书合法性。
通常都是 Client 来校验服务器的合法性。那么 Client 需要一个
ca.crt,服务器需要server.crt和server.key。双向认证,指的是相互校验,Server 需要校验每个 Client ,Client 也需要校验服务器。
- Server 需要
server.key、server.crt、ca.crt。 - Client 需要
client.key、client.crt、ca.crt。
- Server 需要
🦅 1)单向认证的过程?
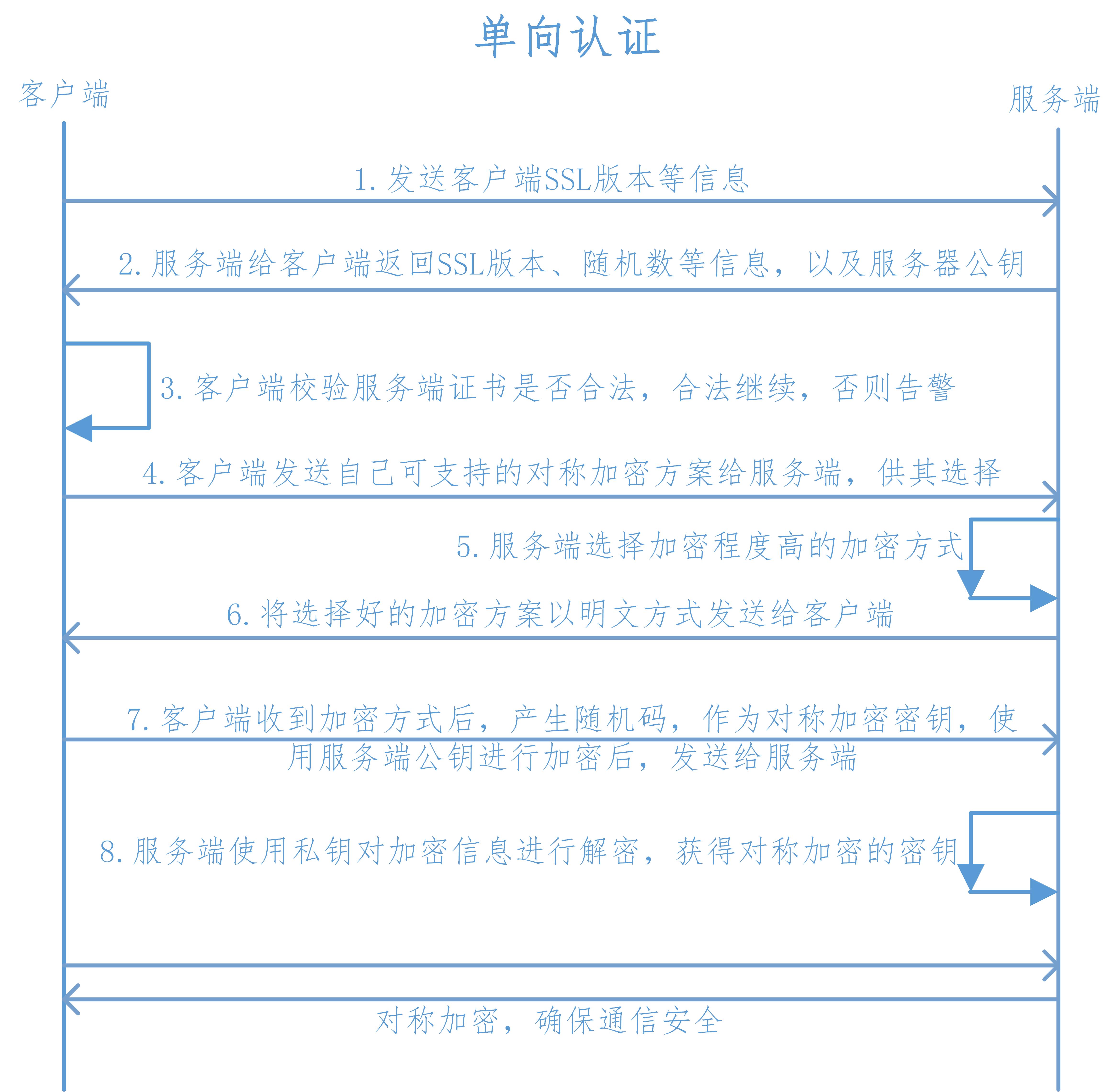
1、客户端向服务端发送 SSL 协议版本号、加密算法种类、随机数等信息。
2、服务端给客户端返回 SSL 协议版本号、加密算法种类、随机数等信息,同时也返回服务器端的证书,即公钥证书。
3、客户端使用服务端返回的信息验证服务器的合法性,包括:
证书是否过期。
发型服务器证书的 CA 是否可靠。
返回的公钥是否能正确解开返回证书中的数字签名。
服务器证书上的域名是否和服务器的实际域名相匹配
验证通过后,将继续进行通信;否则,终止通信。
- 4、客户端向服务端发送自己所能支持的对称加密方案,供服务器端进行选择。 - 5、服务器端在客户端提供的加密方案中选择加密程度最高的加密方式。
6、服务器将选择好的加密方案通过明文方式返回给客户端。
7、客户端接收到服务端返回的加密方式后,使用该加密方式生成产生随机码,用作通信过程中对称加密的密钥,使用服务端返回的公钥进行加密,将加密后的随机码发送至服务器。
8、服务器收到客户端返回的加密信息后,使用自己的私钥进行解密,获取对称加密密钥。
在接下来的会话中,服务器和客户端将会使用该密码进行对称加密,保证通信过程中信息的安全。
🦅 2)双向认证的过程?
双向认证和单向认证原理基本差不多,只是除了客户端需要认证服务端以外,增加了服务端对客户端的认证,具体过程如下:
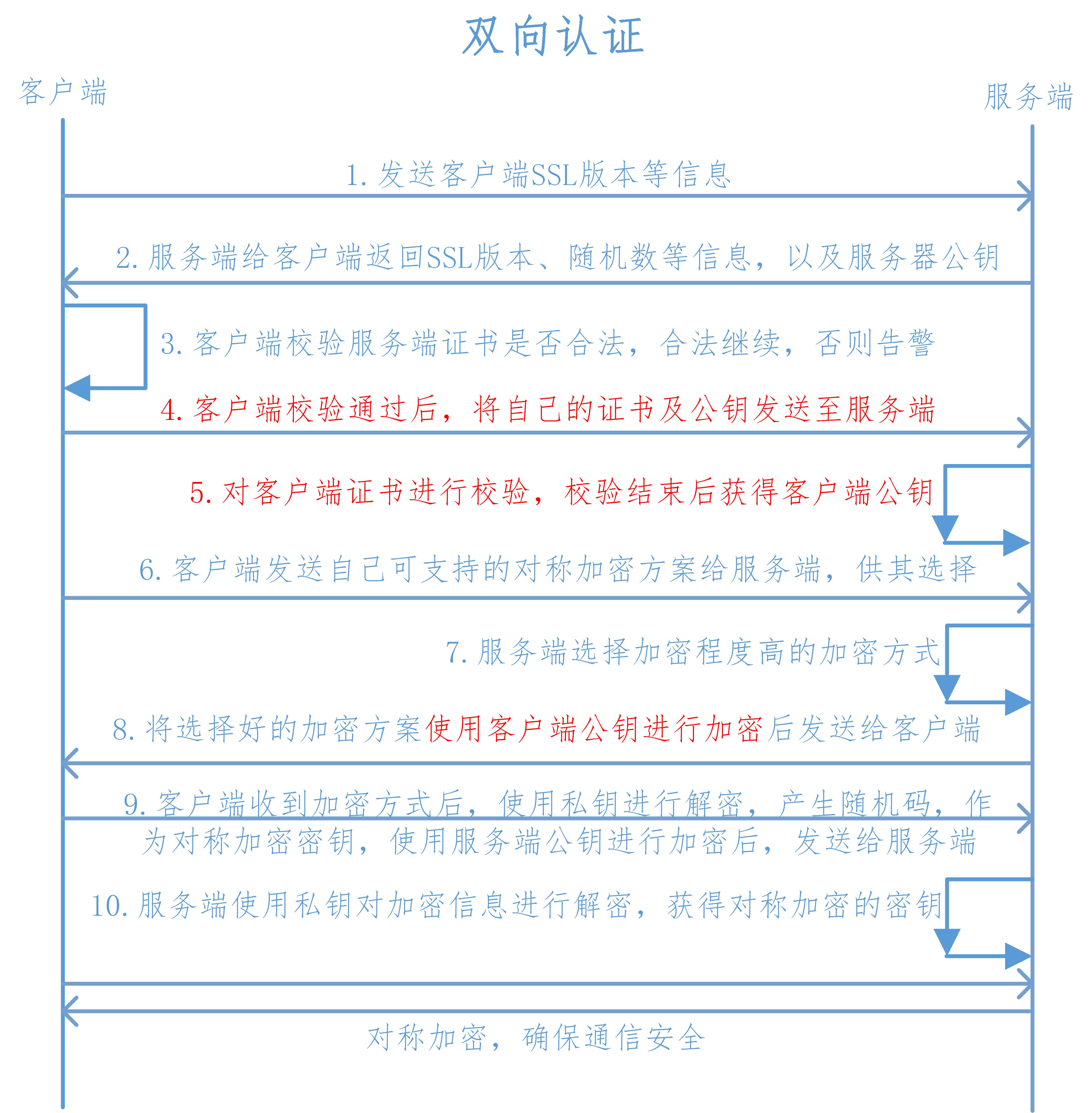
1、客户端向服务端发送 SSL 协议版本号、加密算法种类、随机数等信息。
2、服务端给客户端返回 SSL 协议版本号、加密算法种类、随机数等信息,同时也返回服务器端的证书,即公钥证书。
3、客户端使用服务端返回的信息验证服务器的合法性,包括:
证书是否过期。
发型服务器证书的 CA 是否可靠。
返回的公钥是否能正确解开返回证书中的数字签名。
服务器证书上的域名是否和服务器的实际域名相匹配
验证通过后,将继续进行通信;否则,终止通信。
【新增】4、服务端要求客户端发送客户端的证书,客户端会将自己的证书发送至服务端。
【新增】5、验证客户端的证书,通过验证后,会获得客户端的公钥。
6、客户端向服务端发送自己所能支持的对称加密方案,供服务器端进行选择。
7、服务器端在客户端提供的加密方案中选择加密程度最高的加密方式。
8、服务器将选择好的加密方案通过明文方式返回给客户端。
9、客户端接收到服务端返回的加密方式后,使用该加密方式生成产生随机码,用作通信过程中对称加密的密钥,使用服务端返回的公钥进行加密,将加密后的随机码发送至服务器。
10、服务器收到客户端返回的加密信息后,使用自己的私钥进行解密,获取对称加密密钥。
在接下来的会话中,服务器和客户端将会使用该密码进行对称加密,保证通信过程中信息的安全。
🦅 如何选择单向认证还是双向认证
一般一个站点很多用户访问就用单向认证。
企业接口对接就用双向认证。
如果想要提高 APP 的安全级别,也可以考虑双向认证。因为,APP 天然方便放入客户端证书,从而提高安全级别。
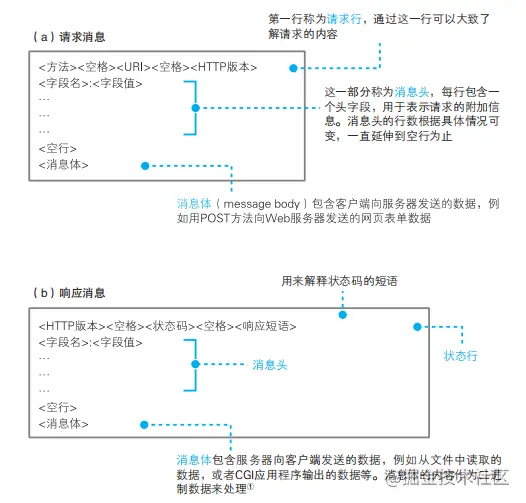
说说HTTP报文的组成部分
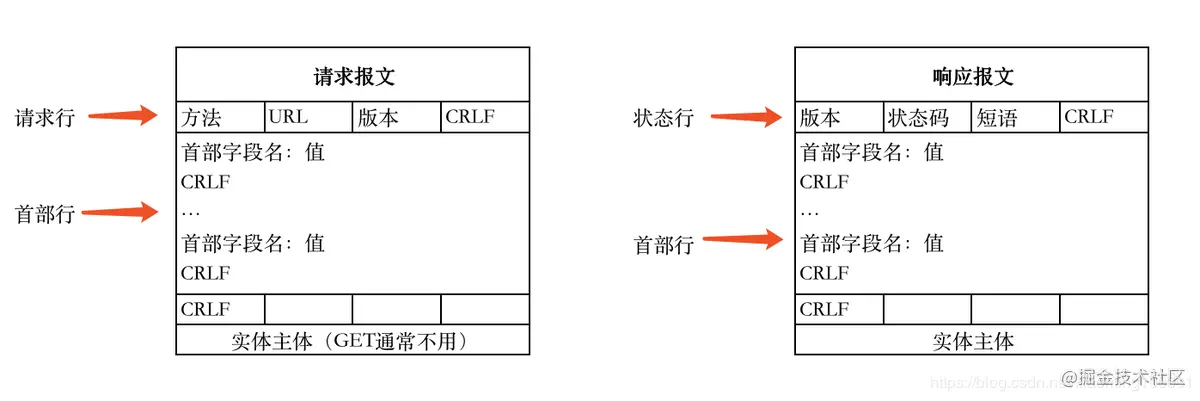
HTTP报文的组成部分包含:请求报文和响应报文
请求报文: 有请求行,请求头, 空行,请求体
响应报文: 有状态行,响应头,空行,响应体
请求报文包含:
1.请求方法,2.请求URL,3.HTTP协议以及版本,4.报文头,5.报文体
- 请求行,有请求方法,请求URL,http协议以及版本;
- 请求头,一堆键值对
- 空行,当服务器在解析请求头的时候,遇到了空行,表明后面的内容是请求体
- 请求体,请求数据
响应报文包含:
1.报文协议以及版本,2,状态码以及状态描述,3,响应头,4,响应体
- 状态行:http协议和版本,状态码以及状态描述
- 响应头
- 空行
- 响应体
对HTTP代理的理解
代理服务器功能:1,负载均衡,2,保障安全(利用心跳机制监控服务器,一旦发现故障机就将其踢出集群。),3,缓存代理。
理解代理缓存:
- 由一个代理服务器下载的页面存储;
- 一个代理服务器为多个用户提供一条通道;
- 缓冲的代理允许一个代理服务器减少对同一个网站的同样页面的请求次数
- 一旦代理服务器的一个用户请求了某个页面,代理服务器就保存该页面以服务于它的其他用户的同样的请求
- 代理缓存,这种处理减少了用户等待页面显示的时间
缓存的作用:
代理服务器或客户端本地磁盘内保存的资源副本,利用缓存可减少对源服务器的访问,可以节省通信流量和通信时间。
示例:
Cache-Control: max-age=300;表示时间间隔,再次请求的时间间隔300s内,就在缓存中获取,否则就在服务器中
Cache-Control:
- public 表示响应可被任何中间节点缓存
- private 表示中间节点不允许缓存
- no-cache 表示不使用Cache-Control的缓存控制方式做前置验证
- no-store 表示真正的不缓存任何东西
- max-age 表示当前资源的有效时间
强缓存:浏览器直接从本地存储中获取数据,不与服务器进行交互
协商缓存:浏览器发送请求到服务器,浏览器判断是否可使用本地缓存
学习了解强缓存👍:
强缓存主要学习expires和cache-control
cache-control该字段:max-age,s-maxage,public,private,no-cache,no-store。
cache-control: public, max-age=3600, s-maxage=3600
- 表示资源过了多少秒之后变为无效
- s-maxage 的优先级高于 max-age
- 在代理服务器中,只有 s-maxage 起作用
public 和 private
- public 表示该资源可以被所有客户端和代理服务器缓存
- private 表示该资源仅能客户端缓存
当浏览器去请求某个文件的时候,服务端就在response header里做了缓存的配置:
表现为:respone header 的cache-control

学习了解✍协商缓存:
response header里面的设置
etag: 'xxxx-xxx
last-modified: xx, 24 Dec xxx xxx:xx:xx GMT


HTTP特点以及缺点
特点是:
- 灵活可扩展
- 可靠传输
- 无状态等
缺点是:
- 无状态
- 明文传输
重定向和转发区别
1、重定向是两次请求,转发是一次请求。因此转发的速度要快于重定向
重定向过程:第一次,客户端request一个网址,服务器响应,并response回来,告诉浏览器,你应该去别一个网址。
2、重定向之后地址栏上的地址会发生变化,变化成第二次请求的地址,转发之后地址栏上的地址不会变化,还是第一次请求的地址
3、转发是服务器行为,重定向是客户端行为。
4、重定向时的网址可以是任何网址,转发的网址必须是本站点的网址
Session、Cookie和Token的区别
HTTP协议本身是无状态的。什么是无状态呢,即服务器无法判断用户身份。
什么是cookie
cookie是由Web服务器保存在用户浏览器上的小文件(key-value格式),包含用户相关的信息。客户端向服务器发起请求,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个Cookie。客户端浏览器会把Cookie保存起来。当浏览器再请求该网站时,浏览器把请求的网址连同该Cookie一同提交给服务器。服务器检查该Cookie,以此来辨认用户身份。
什么是session
session是依赖Cookie实现的。session是服务器端对象
session 是浏览器和服务器会话过程中,服务器分配的一块储存空间。服务器默认为浏览器在cookie中设置 sessionid,浏览器在向服务器请求过程中传输 cookie 包含 sessionid ,服务器根据 sessionid 获取出会话中存储的信息,然后确定会话的身份信息。
cookie与session区别
存储位置与安全性:cookie数据存放在客户端上,安全性较差,session数据放在服务器上,安全性相对更高;
存储空间:单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie,session无此限制
占用服务器资源:session一定时间内保存在服务器上,当访问增多,占用服务器性能,考虑到服务器性能方面,应当使用cookie。
什么是Token
- Token的引入:Token是在客户端频繁向服务端请求数据,服务端频繁的去数据库查询用户名和密码并进行对比,判断用户名和密码正确与否,并作出相应提示,在这样的背景下,Token便应运而生。
- Token的定义:Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。
- 使用Token的目的:Token的目的是为了减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。
- Token 是在服务端产生的。如果前端使用用户名/密码向服务端请求认证,服务端认证成功,那么在服务端会返回 Token 给前端。前端可以在每次请求的时候带上 Token 证明自己的合法地位
- Token常用JWT实现,原来需要客户端需要请求服务端验证session合法性,现在只需要通过算法检验Token是否合法,减少了查数据库或者访问服务器比对用户密码,用户身份的消耗。也就是通过算法和密钥代替了访问数据库或服务器比对的过程
session与token区别
- session机制存在服务器压力增大,CSRF跨站伪造请求攻击,扩展性不强等问题;
- session存储在服务器端,token存储在客户端
- token提供认证和授权功能,作为身份认证,token安全性比session好;
- session这种会话存储方式方式只适用于客户端代码和服务端代码运行在同一台服务器上,token适用于项目级的前后端分离(前后端代码运行在不同的服务器下)
https的对称加密,非对称加密,混合加密,CA认证
HTTPS ,超文本传输安全协议,目标是安全的HTTP通道,应用是安全数据传输。HTTP协议虽然使用广,但是存在不小的安全缺陷,主要是数据的明文传送和消息完整性检测的缺乏。
HTTPS协议是由HTTP加上TLS/SSL协议构建的可进行加密传输,身份认证的网络协议。
通过, 数字证书,加密算法,非对称密钥 等技术完成互联网数据传输加密,实现互联网传输安全保护。
HTTPS主要特性:
- 数据保密性
- 数据完整性
- 身份校验安全性
客户端和服务器端在传输数据之前,会通过基于证书对双方进行身份认证。客户端发起SSL握手消息给服务端要求连接,服务端将证书发送给客户端。客户端检查服务器端证书,确认是否由自己信任的证书签发机构签发,如果不是,将是否继续通讯的决定权交给用户选择,如果检查无误或者用户选择继续,则客户端认可服务端的身份。
服务端要求客户端发送证书,并检查是否通过验证,失败则关闭连接,认证成功,从客户端证书中获得客户端的公钥。
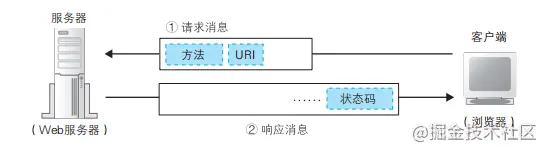
HTTP原理
客户端的浏览器首先要通过网络与服务器建立连接,该连接时通过TCP来完成的,一般TCP连接的端口号是80,建立连接后,客户端发送一个请求给服务器端;服务器端接收到请求后,给予相应的响应信息。
HTTPS原理
客户端将它所支持的算法列表和一个用作产生密钥的随机数发送给服务器,服务器从算法列表中选择一种加密算法,并将它和一份包含服务器公用密钥的证书发送给客户端,该证书还包含了用于认证目的的服务器标识,服务器同时还提供了一个用作产生密钥的随机数。
客户端对服务器的证书进行验证,并抽取服务器的公用密钥,再产生一个称作pre_master_secret的随机密码串,并使用服务器的公用密钥对其进行加密,并将加密后的信息发送给服务器。
客户端与服务器端根据pre_master_secret以及客户端与服务器的随机数独立计算出加密和MAC密钥。
混合加密
在传输数据中使用对称加密,但对称加密的密钥采用非对称加密来传输,混合加密比较安全,但无法知道数据是否被篡改
CA认证
CA认证, 即是电子认证服务,指电子签名相关各方提供真实性,可靠性验证的活动。

特性:参阅百度百科—简介,点击进入

HTTPS安全加密通道原理分析
什么是HTTPS协议,由于HTTP天生“明文”的特点,整个传输过程完全透明,任何人都能够在链路中截获,修改或者伪造请求、响应报文,数据不具有可信性。
使用HTTPS时,所有的HTTP请求和响应发送到网络前,都要进行加密。
https = http + ssl/tls 对称加密:加密 解密使用同一密钥 非对称加密:公钥-随意分发,私钥-服务器自己保持 公钥加密的数据,只能通过私钥解密 私钥加密的数据,只能公钥能解密
加密算法:
对称密钥加密算法,编,解码使用相同密钥的算法
非对称密钥加密算法,一个公钥,一个私钥,两个密钥是不同的,公钥可以公开给如何人使用,私钥是严格保密的。
加密通道的建立:
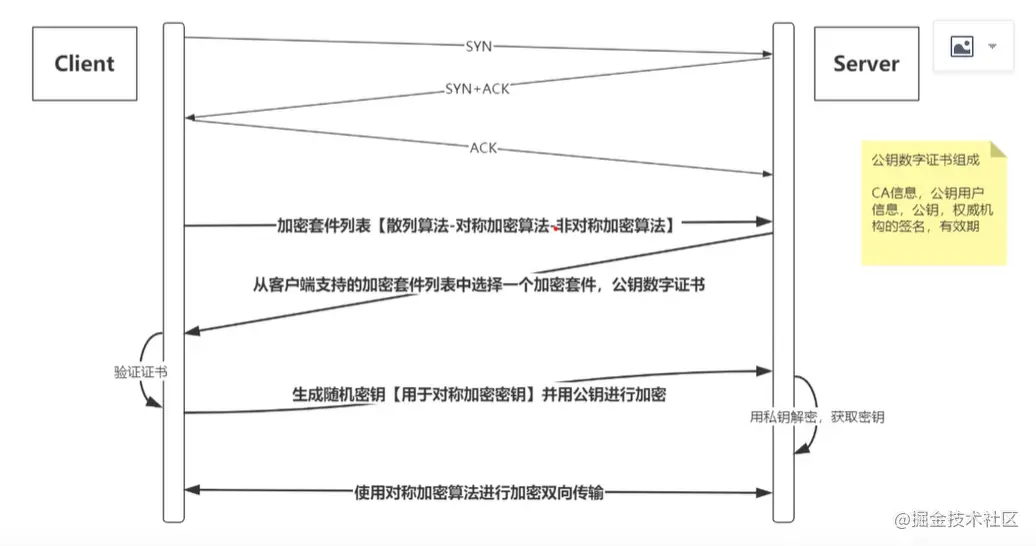
如何申请:
- 生成自己的公钥和私钥,服务器自己保留私钥
- 向CA机构提交公钥,公司,域名信息等待认证
- CA机构通过线上,线下多种途径验证你提交信息的真实性,合法性
- 信息审核通过,CA机构则会向你签发认证的数字证书,包含了公钥,组织信息,CA信息,有效时间,证书序列号,同时生成了一个签名
- 签名步骤:hash(用于申请证书所提交的明文信息)= 信息摘要
- CA再使用CA机构的私钥对信息摘要进行加密,密文就是证书的数字签名

HTTPS 握手会影响性能么?
TCP 有三次握手,再加上 HTTPS 的四次握手,影响肯定有,但是可以接受。
- 首先,HTTPS 肯定会更慢一点,时间主要花费在两组 SSL 之间的耗时和证书的读取验证上,对称算法的加解密时间几乎可以忽略不计。
- 而且如果不是首次握手,后续的请求并不需要完整的握手过程。客户端可以把上次的加密情况直接发送给服务器从而快速恢复,具体细节可以参考 《图解 SSL/TLS 协议》 。
- 除此以外,SSL 握手的时间并不是只能用来传递加密信息,还可以承担起客户端和服务器沟通 HTTP2 兼容情况的任务。因此从 HTTPS 切换到 HTTP2.0 不会有任何性能上的开销,反倒是得益于 HTTP2.0 的多路复用等技术,后续可以节约大量时间。
- 如果把 HTTPS2.0 当做目标,那么 HTTPS 的性能损耗就更小了,远远比不上它带来的安全性提升。
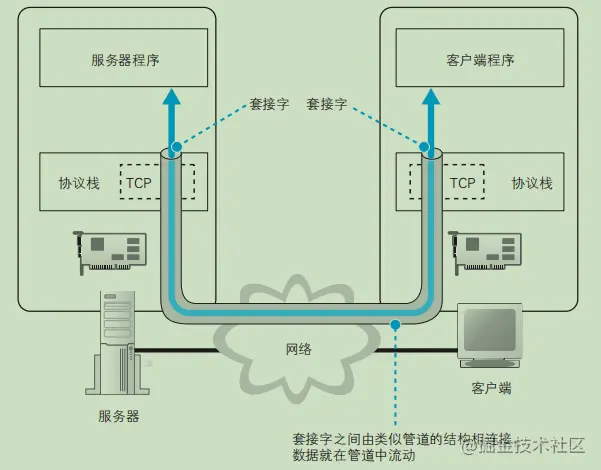
HTTP、TCP、Socket 的关系是什么?
- HTTP 本身就是一个协议,是从 Web 服务器传输超文本到本地浏览器的传送协议。
- Socket 是 TCP/IP 网络的 API ,其实就是一个门面模式,它把复杂的 TCP/IP 协议族隐藏在 Socket 接口后面。对用户来说,一组简单的接口就是全部,让 Socket 去组织数据,以符合指定的协议。
综上所述:
- 需要 IP 协议来连接网络
- TCP 是一种允许我们安全传输数据的机制,使用 TCP 协议来传输数据的 HTTP 是 Web 服务器和客户端使用的特殊协议。
- HTTP 基于 TCP 协议,所以可以使用 Socket 去建立一个 TCP 连接。
什么是数字签名?
为了避免数据在传输过程中被替换,比如黑客修改了你的报文内容,但是你并不知道,所以我们让发送端做一个数字签名,把数据的摘要消息进行一个加密,比如 MD5,得到一个签名,和数据一起发送。然后接收端把数据摘要进行 MD5 加密,如果和签名一样,则说明数据确实是真的。
什么是数字证书?
对称加密中,双方使用公钥进行解密。虽然数字签名可以保证数据不被替换,但是数据是由公钥加密的,如果公钥也被替换,则仍然可以伪造数据,因为用户不知道对方提供的公钥其实是假的。所以为了保证发送方的公钥是真的,CA 证书机构会负责颁发一个证书,里面的公钥保证是真的,用户请求服务器时,服务器将证书发给用户,这个证书是经由系统内置证书的备案的。
什么是对称加密和非对称加密?
对称密钥加密是指加密和解密使用同一个密钥的方式,这种方式存在的最大问题就是密钥发送问题,即如何安全地将密钥发给对方。
非对称加密指使用一对非对称密钥,即:公钥和私钥,公钥可以随意发布,但私钥只有自己知道。发送密文的一方使用对方的公钥进行加密处理,对方接收到加密信息后,使用自己的私钥进行解密。
由于非对称加密的方式不需要发送用来解密的私钥,所以可以保证安全性。但是和对称加密比起来,它非常的慢,所以我们还是要用对称加密来传送消息,但对称加密所使用的密钥我们可以通过非对称加密的方式发送出去。
OPTION是干啥的?举个用到OPTION的例子?
旨在发送一种探测请求,以确定针对某个目标地址的请求必须具有怎么样的约束,然后根据约束发送真正的请求。
比如针对跨域资源的预检,就是采用 HTTP 的 OPTIONS 方法先发送的。用来处理跨域请求
FTP协议
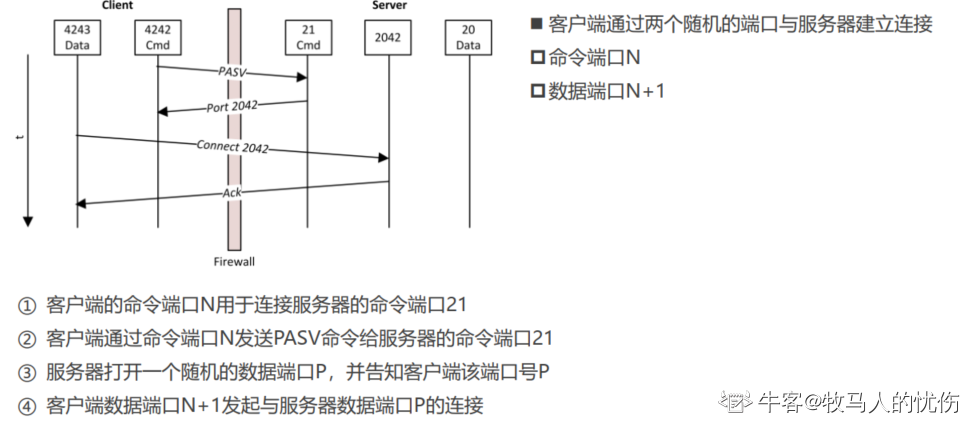
FTP(File Transport Protocol),译为:文件传输协议, RFC 959定义了此规范,是基于TCP的应用层协议
在RFC 1738中有定义, FTP的URL格式为: ftp://[user[:password]@]host[:port]/url-path
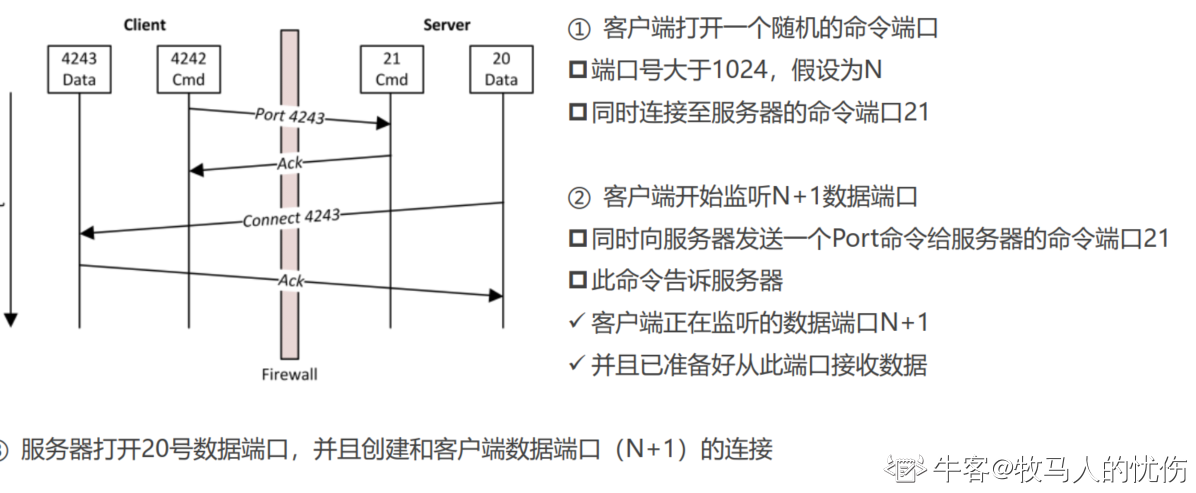
FTP有2种连接模式:主动(Active)和被动(Passive)
不管是哪种模式,都需要客户端和服务器建立2个连接
① 控制连接:用于传输状态信息(命令, cmd)
② 数据连接:用于传输文件和目录信息(data)
1.主动模式
2.被动模式
WebSocket
HTML5开始提供的一种浏览器与服务器进行全双工通讯的网络技术,属于应用层协议。它基于TCP传输协议,并复用HTTP的握手通道。
对大部分web开发者来说,上面这段描述有点枯燥,其实只要记住几点:
- WebSocket可以在浏览器里使用
- 支持双向通信
- 使用很简单
1、有哪些优点
说到优点,这里的对比参照物是HTTP协议,概括地说就是:支持双向通信,更灵活,更高效,可扩展性更好。
- 支持双向通信,实时性更强。
- 更好的二进制支持。
- 较少的控制开销。连接创建后,ws客户端、服务端进行数据交换时,协议控制的数据包头部较小。在不包含头部的情况下,服务端到客户端的包头只有2~10字节(取决于数据包长度),客户端到服务端的的话,需要加上额外的4字节的掩码。而HTTP协议每次通信都需要携带完整的头部。
- 支持扩展。ws协议定义了扩展,用户可以扩展协议,或者实现自定义的子协议。(比如支持自定义压缩算法等)
WebSocket连接保持+心跳
WebSocket为了保持客户端、服务端的实时双向通信,需要确保客户端、服务端之间的TCP通道保持连接没有断开。然而,对于长时间没有数据往来的连接,如果依旧长时间保持着,可能会浪费包括的连接资源。
但不排除有些场景,客户端、服务端虽然长时间没有数据往来,但仍需要保持连接。这个时候,可以采用心跳来实现。
- 发送方->接收方:ping
- 接收方->发送方:pong
ping、pong的操作,对应的是WebSocket的两个控制帧,opcode分别是0x9、0xA。
举例,WebSocket服务端向客户端发送ping,只需要如下代码(采用ws模块)
ws.ping('', false, true);跨站脚本攻击(XSS)
XSS :Cross Site Scripting,为不和层叠样式表(Cascading Style Sheets, CSS) 的缩写混淆,故将跨站脚本攻击缩写为XSS。 恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中 Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。 在一开始的时候,这种攻击的演示案例是跨域的,所以叫”跨站脚本”。 但是发展到今天,由于JavaScript的强大功能基于网站前端应用的复杂化,是否 跨域已经不再重要。但是由于历史原因,XSS这个名字一直保留下来。 XSS长期以来被列为客户端Web安全中的头号大敌。因为XSS破坏力强大,且产 生的场景复杂,难以一次性解决。 现在业内达成的共识是:针对各种不同场景产生的XSS,需要区分情景对待。 攻击原理: XSS的原理是WEB应用程序混淆了用户提交的数据和JS脚本的代码边界,导致 浏览器把用户的输入当成了JS代码来执行。
存储型XSS
存储型XSS,也就是持久型XSS。攻击者上传的包含恶意JS脚本的信息被 Web应用程序保存到数据库中,Web应用程序在生成新的页面的时候如果包含 了该恶意JS脚本,这样会导致所有访问该网页的浏览器解析执行该恶意脚本。这 种攻击类型一般常见在博客、论坛等网站中。
存储型是最危险的一种跨站脚本,比反射性XSS和Dom型XSS都更有隐蔽 性。 因为它不需要用户手动触发,任何允许用户存储数据的web程序都可能存 在存储型XSS漏洞。 若某个页面遭受存储型XSS攻击,所有访问该页面的用户会被XSS攻击。
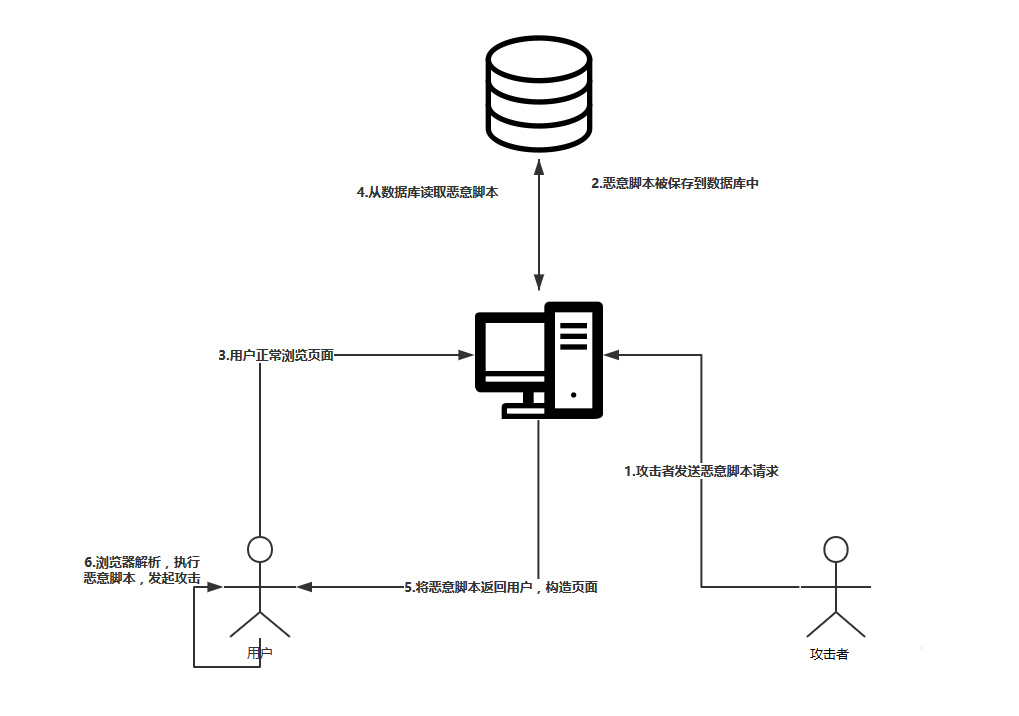
攻击步骤:
攻击者把恶意代码提交到目标网站的数据库中
用户打开目标网站,网站服务端把恶意代码从数据库中取出,拼接在HTML上返回给用户
用户浏览器接收到响应解析执行,混在其中的恶意代码也被执行
恶意代码窃取用户敏感数据发送给攻击者,或者冒充用户的行为,调用目标网站接口执行攻击者指定的操作
存储型 XSS(又被称为持久性XSS)攻击常见于带有用户保存数据的网站功能,如论坛发帖、商品评论、用户私信、留言等功能。
反射型XSS
反射型XSS,又称非持久型XSS,恶意代码并没有保存在目标网站,而是通过引诱用户点击一个恶意链接来实施攻击。这类恶意链接有哪些特征呢?
主要有:
- 恶意脚本附加到 url 中,只有点击此链接才会引起攻击
- 不具备持久性,即只要不通过这个特定 url 访问,就不会有问题
- xss漏洞一般发生于与用户交互的地方
DOM型XSS
DOM(Document Object Model),DOM型XSS其实是一种特殊类型的反射型XSS(不存储),它是基于DOM文档对象模型的一种漏洞,而且不需要与服务器进行交互(不处理)。
客户端的脚本程序可以通过DOM来动态修改页面内容,从客户端获取DOM中的数据并在本地执行。基于这个特性,就可以利用JS脚本来实现XSS漏洞的利用。
XSS漏洞预防策略
XSS攻击能够实现的主要原因:对用户的输入进行了原样的输出。
输入环节:
页面限制输入长度、特殊字符限制,后端代码限制输入长度、处理特殊字符Filter过滤器统一处理(自定义处理规则、使用apache commons text、使用owasp AntiSamy)开发人员来说,在后台执行用户录入数据长度的判断,特殊字符的专业通常会定义在流量官网部分。
Cookie防护:
通过植入的JS脚本获得用户的cookie,获得用户权限。
cookie设置httponly,一般servlet容器默认httpOnly true
在流量网关中统一做处理:*
resp.setHeader("SET-COOKIE", "JSESSIONID=" +
request.getSession().getId()+ "; HttpOnly")X-Frame-Options 响应头 (是否允许frame、iframe等标记):
iframe允许加载外部的网页,也可以自己作为外部网页被加载,同时是可以被隐藏。
是否允许用户去使用iframe,指定iframe加载的网页地址。
DENY 不允许、SAMEORIGIN 可在相同域名页面的 iframe 中展示、ALLOWFROM uri 可在指定页的 frame 中展示。
add_header X-Frame-Options SAMEORIGIN; //在nginx的http或server节点中配置
也可通过filter设置 resp.setHeader(“x-frame-options”,”SAMEORIGIN”);
输出环节:
OWASP ESAPI for Java显示时对字符进行转义处理,各种模板都有相关语法,注意标签的正确使
用。通常情况下前端框架或者对应的模板引擎都将转义设置为默认。
内容安全策略
内容安全策略 (CSP :Content-Security-Policy )是一个额外的安全层,用于检测并削弱某些特定类型的攻击,包括跨站脚本 (XSS) 和数据注入攻击等。
核心思想:网站通过发送一个 CSP 头部,来告诉浏览器什么是被授权执行的与什么是需要被禁止的,被誉为专门为解决XSS攻击而生的神器。
XSS 攻击利用了浏览器对于从服务器所获取的内容的信任。恶意脚本在受害者的浏览器中得以运行,因为浏览器信任其内容来源,即使有的时候这些脚本并非来自于它本该来的地方。
CSP通过指定有效域——即浏览器认可的可执行脚本的有效来源——使服务器
管理者有能力减少或消除XSS攻击所依赖的载体。一个CSP兼容的浏览器将会仅执行从白名单域获取到的脚本文件,忽略所有的其他脚本 (包括内联脚本和HTML的事件处理属性)。
跨站点请求伪造(CSRF)
CSRF攻击的全称是跨站请求伪造( cross site request forgery ):是一种对网站的恶意利用,尽管听起来跟XSS跨站脚本攻击有点相似,但事实上CSRF与XSS差别很大,XSS利用的是站点内的信任用户,而CSRF则是通过伪装来自受信任用户的请求来利用受信任的网站。
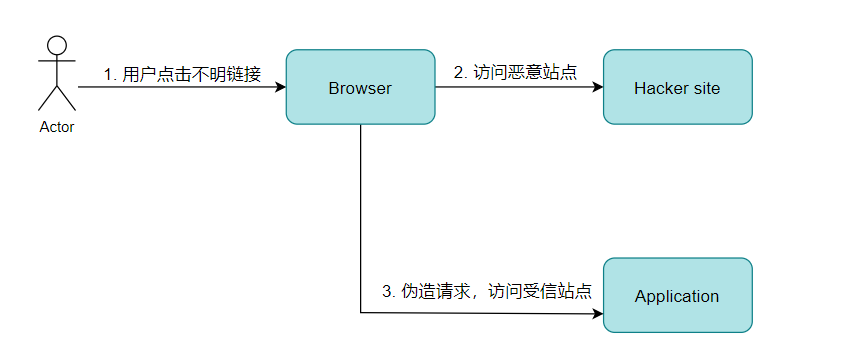
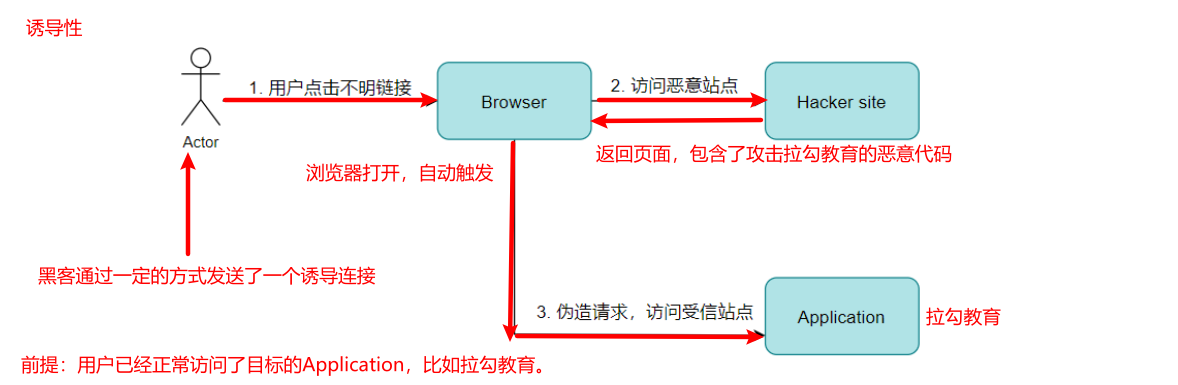
简单理解:一种可以被攻击者用来通过用户浏览器冒充用户身份向服务器发送
伪造请求并被目标服务器成功执行的漏洞被称之为CSRF漏洞。
特点:
- 用户浏览器:表示的受信任的用户
- 冒充身份:恶意程序冒充受信任用户(浏览器)身份
- 伪造请求:借助于受信任用户浏览器发起的访问
点击劫持
点击劫持(Click Jacking),也被称为UI覆盖攻击。
1 黑客创建一个网页利用iframe包含目标网站;隐藏目标中的网站,是用户无法察觉到目标网站的存在;
诱使用户点击图中特定的按钮。特定的按钮为位置和原网页中关键按钮位置一致
2 用户在不知情的情况下点击按钮,被引诱执行了危险操作
URL跳转漏洞
URL跳转漏洞(URL重定向漏洞),跳转漏洞一般用于钓鱼攻击。https://link.zhihu.com/?target=https://edu.lagou.com/
原理:
URL跳转漏洞本质上是利用Web应用中带有重定向功能的业务,将用户从一个网站重定向到另一个网站。其最简单的利用方式为诱导用户访问http://www.aaa.com?returnUrl=http://www.evil.com,借助www.aaa.com让用户访问www.evil.com,这种漏洞被利用了对用户和公司都是一种损失。
会话(Session)劫持
会话劫持(Session hijacking)就是一种通过窃取用户SessionID后,使用该SessionID登录进目标账户的攻击方法,此时攻击者实际上是使用了目标账户的有效Session。如果SessionID是保存在Cookie中的,则这种攻击可以称为Cookie劫持。
攻击步骤:
1、 目标用户需要先登录站点;
2、 登录成功后,该用户会得到站点提供的一个会话标识SessionID;
3、 攻击者通过某种攻击手段捕获Session ID;
4、 攻击者通过捕获到的Session ID访问站点即可获得目标用户合法会话。
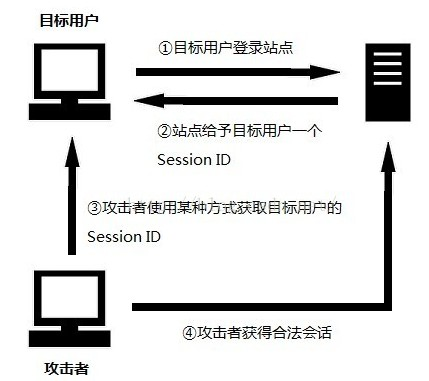
攻击者获取SessionID的方式有多种:
1、 暴力破解:尝试各种Session ID,直到破解为止;
2、 预测:如果Session ID使用非随机的方式产生,那么就有可能计算出来;
3、 窃取:使用网络嗅探、本地木马窃取、XSS攻击等方法获得。
会话固定(Session fixation)
会话固定(Session fixation)是一种诱骗受害者使用攻击者指定的会话标识(SessionID)的攻击手段。这是攻击者获取合法会话标识的最简单的方法。让合法用户使用黑客预先设置的sessionID进行登录,从而是Web不再进行生成新的sessionID,从而导致黑客设置的sessionId变成了合法桥梁。会话固定也可以看成是会话劫持的一种类型,原因是会话固定的攻击的主要目的同样是获得目标用户的合法会话,不过会话固定还可以是强迫受害者使用攻击者设定的一个有效会话,以此来获得用户的敏感信息。什么是Session Fixation呢?举一个形象的例子,假设A有一辆汽车,A把汽车卖给了B,但是A并没有把所有的车钥匙交给B,还自己藏下了一把。这时候如果B没
有给车换锁的话,A仍然是可以用藏下的钥匙使用汽车的。这个没有换“锁”而导致的安全问题,就是Session Fixation问題。
攻击步骤:
1、 攻击者通过某种手段重置目标用户的SessionID,然后监听用户会话状态;
2、 目标用户携带攻击者设定的Session ID登录站点;
3、 攻击者通过Session ID获得合法会话
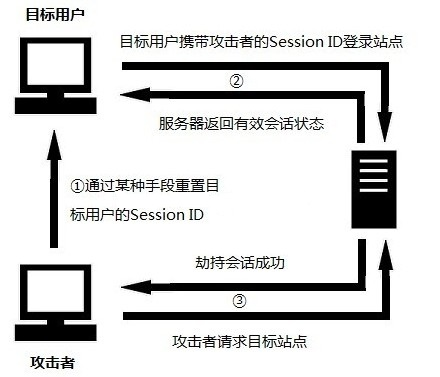
攻击者如何才能让目标用户使用这个SessionID呢?如果SessionID保存在Cookie中,比较难做到这一点。但若是SessionID保存在URL中,则攻击者只需要诱使目标用户打开这个URL即可。
Session保持攻击
一般来说,Session是有生命周期的,当用户长时间未活动后,或者用户点击退出后,服务器将销毁Session。Session如果一直未能失效,会导致什么问题呢?前面的章节提到session劫持攻击,是攻击者窃取了用户的SessionID,从而能够登录进用户的账户。
但如果攻击者能一直持有一个有效的Session(比如间隔性地刷新页面’以告诉服务器这个用户仍然在活动),而服务器对于活动的Session也一直不销毁的话,攻击者就能通过此有效Session—直使用用户的账户,成为一个永久的‘后门。但是Cookie有失效时间,Session也可能会过期,攻击者能永久地持有这个Session吗?一般的应用都会给session设置一个失效时间,当到达失效时间后,Session将被销毁。但有一些系统,出于用户体验的考虑,只要这个用户还“活着”,就不会让这个用户的Session失效。从而攻击者可以通过不停地发起访问请求,让Session一直“活”下去。
SQL盲注
所谓“盲注 ”,就是在服务器没有错误回显时完成的注入攻击。服务器没有错误回显,对于攻击者来说缺少了非常重要的“调试信息”,所以攻击者必须找到一个方法来验证注入的SQL语句是否得到执行。
最常见的盲注验证方法是,构造简单的条件语句,根据返回页面是否发生变化,来判断SQL语句是否得到执行。比如在DVWA靶机平台,输入1’ and 1=1#显示存在,输入1’ and 1=2# 显示不存在,由此可立即判断漏洞存在。
DDOS攻击
DDOS又称为分布式拒绝服务,全称是Distributed Denial of Service。DDOS本是利用合理的请求造成资源过载,导致服务不可用。
比如一个停车场总共有100个车位,当100个车位都停满车后,再有车想要停进来,就必须等已有的车先出去才行。如果已有的车一直不出去,那么停车场的入口就会排起长队,停车场的负荷过载,不能正常工作了,这种情况就是“拒绝服务”。我们的系统就好比是停车场,系统中的资源就是车位。资源是有限的,而服务必须一直提供下去。如果资源都已经被占用了,那么服务也将过载,导致系统停止新的响应。
分布式拒绝服务攻击,将正常请求放大了若干倍,通过若干个网络节点同时发起攻击,以达成规模效应。这些网络节点往往是黑客们所控制的“肉鸡”,数量达到一定规模后,就形成了一个“僵尸网络”。大型的僵尸网络,甚至达到了数万、数十万台的规模。如此规模的僵尸网络发起的DDOS攻击,几乎是不可阻挡的。
常见的DDOS攻击有SYN flood、UDP flood、ICMP flood等。其中SYN flood是一种最为经典的DDOS攻击,其发现于1996年,但至今仍然保持着非常强大的生命力。SYN flood如此猖獗是因为它利用了TCP协议设计中的缺陷,而TCP/IP协议是整个互联网的基础,牵一发而动全身,如今想要修复这样的缺陷几乎成为不可能的事情。
CDN工作原理
随着时代的发展,网民数量增多,访问路径过长,所以当用户与网站之间的链路被突发的大流量数据拥塞时,不同地区的用户访问网站的响应速度存在差异,为了提高用户访问的响应速度、优化现有Internet中信息的流动,需要在用户和服务器间加入中间层CDN。
CDN将内容推送到网络边缘,大量的用户访问被分散在网络边缘,不再构成网站出口、互联互通点的资源挤占,也不再需要跨越长距离IP路由,即减少了源服务器的资源占用,企业大大提升了用户访问的响应时间,从而使用户能以最快的速度,从最接近用户的地方获得所需的信息,彻底解决网络拥塞,提高响应速度。
CDN(Content Delivery Network),即内容分发网络。其目的是通过在现有的Internet中增加一层新的CACHE(缓存)层,将网站的内容发布到最接近用户的网络”边缘“的节点,使用户可以就近取得所需的内容,提高用户访问网站的响应速度。从技术上全面解决由于网络带宽小、用户访问量大、网点分布不均等原因,提高用户访问网站的响应速度。
通过CDN获取缓存内容的过程
CDN将我们对源站的请求导向了距离用户较近的最优缓存节点,而非源站。
下图所示是通过CDN进行请求响应的过程图。通过图中可以看出:
在DNS解析域名时新增了一个 全局负载均衡系统(GSLB) ,GSLB的主要功能是根据用户的本地DNS(通常距离用户的物理位置较近)的IP地址判断用户的位置,筛选出距离用户较近的 本地负载均衡系统(SLB) ,并将该SLB的IP地址作为结果返回给本地DNS。
SLB主要负责判断 缓存服务器集群 中是否包含用户请求的资源数据,如果缓存服务器中存在请求的资源,则根据缓存服务器集群中节点的健康程度、负载量、连接数等因素筛选出最优的缓存节点,并将HTTP请求重定向到最优的缓存节点上。
GSLB :Global Server Load Balancing,全局负载均衡服务器。
SLB(Server load balancing):负载均衡服务器是对集群内物理主机的负载均衡,而GSLB是对物理集群的负载均衡。
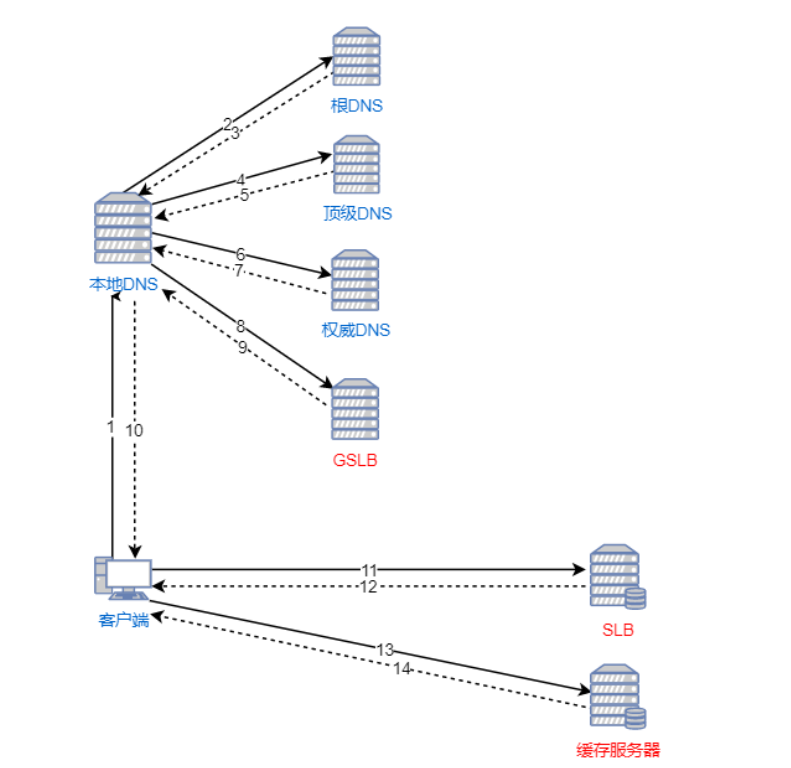
为了更清晰地说明CDN的工作原理,下面以客户端发起对”www.edu.lagou.com/index.html”的HTTP请求为例进行说明:
- 用户发起对”www.edu.lagou.com/index.html”的HTTP请求,首先需要通过本地DNS通过”迭代解析”的方式获取域名”edu.lagou.com”的IP地址;
- 如果本地DNS的缓存中没有该域名的记录,则向 根DNS 发送DNS查询报文;
- 根DNS 发现域名的前缀为”com”,则给出负责解析 com 的 顶级DNS 的IP地址;
- 本地DNS向 顶级DNS 发送DNS查询报文;
- 顶级DNS 发现域名的前缀为”lagou.com”,在本地记录中查找负责该前缀的权威DNS 的IP地址并进行回复;
- 本地DNS向 权威DNS 发送DNS查询报文;
- 权威DNS查找到一条NAME字段为”edu.lagou.com”的 CNAME记录 (由服务提供者配置,阿里云、网宿科技),该记录的Value字段为”edu.lagou.cdn.com”;并且还找到另一条NAME字段为”edu.lagou.cdn.com”的A记录(域名—>IP),该记录的Value字段为GSLB的IP地址;
本地DNS向GSLB发送DNS查询报文;
GSLB根据 本地DNS 的IP地址判断用户的大致位置为北京,筛选出位于海淀区且综合考量最优的SLB的IP地址填入DNS回应报文,作为DNS查询的最终结果;
- 本地DNS回复客户端的DNS请求,将上一步的IP地址作为最终结果回复给客户端;
- 客户端根据IP地址向SLB发送HTTP请求:”www.edu.lagou.com/index.html”;
- SLB综合考虑缓存服务器集群中各个节点的资源限制条件、健康度、负载情
况等因素,筛选出最优的缓存节点后回应客户端的HTTP请求(状态码为302,重定向地址为最优缓存节点的IP地址); - 客户端接收到SLB的HTTP回复后,重定向到该缓存节点上;
- 缓存节点判断请求的资源是否存在、过期,将缓存的资源直接回复给客户
端,否则到源站进行数据更新再回复。
Reactor和Proactor区别
1.Reactor被动的等待指示事件的到来并做出反应;它有一个等待的过程,做什么都要先注册到监听事件集合中等待socket可读时再进行操作;。
2.Proactor直接调用异步读写操作,调用完后放到到用户线程指定的缓存区,接着通知用户线程直接使用即可。
3.Proactor是真正意义上的用于异步IO,但是依赖操作系统对异步的支持。而Reactor用于同步IO
通俗语言:
reactor:能收数据了你跟我说一声。
proactor: 这有十个字节数据,收好了跟我说一声。
select、poll、epoll的区别?
select, poll, epoll 都是I/O多路复用的具体的实现,之所以有这三个存在,其实是他们出现是有先后顺序的。
select
- 它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
- 单个进程可监视的fd_set(监听的端口个数)数量被限制:32位机默认是1024个,64位机默认是2048。
poll
poll本质上和select没有区别,采用链表的方式替换原有fd_set数据结构,而使其没有连接数的限制。
epoll
- epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
- 效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数。即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。
- epoll通过内核和用户空间共享一块内存来实现的。select和poll都是内核需要将消息传递到用户空间,都需要内核拷贝动作
- epoll有EPOLLLT和EPOLLET两种触发模式。(暂时不去记,有个印象,大致是什么样就可以)
参考:
https://juejin.cn/post/6939691851746279437#heading-23
 微信
微信 支付宝
支付宝







