Redis事件驱动框架和执行模型模块
Redisserver启动后会做哪些操作
main函数是Redis整个运行程序的入口,并且Redis实例在运行时,也会从这个main函数开始执行。同时,由于Redis是典型的Client-Server架构,一旦Redis实例开始运行,Redis server也就会启动,而main函数其实也会负责Redis server的启动运行。
Redis运行的基本控制逻辑是在server.c文件中完成的,而main函数就是在server.c中。
介绍下Redis server是如何在main函数中启动并完成初始化的。Redis针对以下三个问题的实现思路:
- Redis server启动后具体会做哪些初始化操作?
- Redis server初始化时有哪些关键配置项?
- Redis server如何开始处理客户端请求?
main函数:Redis server的入口
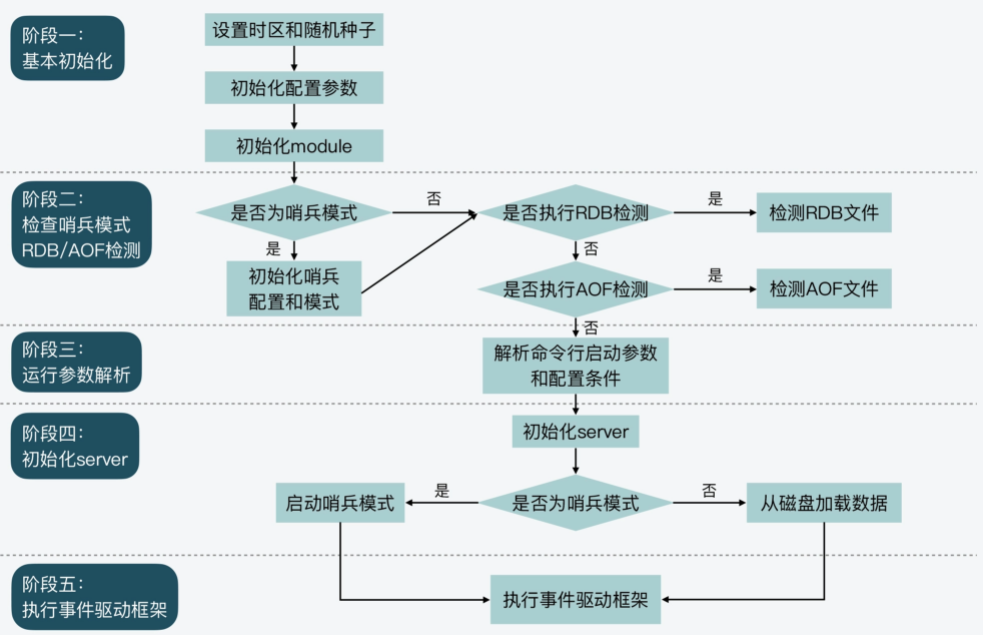
阶段一:基本初始化
在这个阶段,main函数主要是完成一些基本的初始化工作,包括设置server运行的时区、设置哈希函数的随机种子等。这部分工作的主要调用函数如下所示:
//设置时区
setlocale(LC_COLLATE,"");
tzset();
...
//设置随机种子
char hashseed[16];
getRandomHexChars(hashseed,sizeof(hashseed));
dictSetHashFunctionSeed((uint8_t*)hashseed);这里,你需要注意的是,在main函数的开始部分,有一段宏定义覆盖的代码。这部分代码的作用是,如果定义了REDIS_TEST宏定义,并且Redis server启动时的参数符合测试参数,那么main函数就会执行相应的测试程序。
这段宏定义的代码如以下所示,其中的示例代码就是调用ziplist的测试函数ziplistTest:
#ifdef REDIS_TEST
//如果启动参数有test和ziplist,那么就调用ziplistTest函数进行ziplist的测试
if (argc == 3 && !strcasecmp(argv[1], "test")) {
if (!strcasecmp(argv[2], "ziplist")) {
return ziplistTest(argc, argv);
}
...
}
#endif阶段二:检查哨兵模式,并检查是否要执行RDB检测或AOF检测
Redis server启动后,可能是以哨兵模式运行的,而哨兵模式运行的server在参数初始化、参数设置,以及server启动过程中要执行的操作等方面,与普通模式server有所差别。所以,main函数在执行过程中需要根据Redis配置的参数,检查是否设置了哨兵模式。
如果有设置哨兵模式的话,main函数会调用initSentinelConfig函数,对哨兵模式的参数进行初始化设置,以及调用initSentinel函数,初始化设置哨兵模式运行的server。
下面的代码展示了main函数中对哨兵模式的检查,以及对哨兵模式的初始化,你可以看下:
...
//判断server是否设置为哨兵模式
if (server.sentinel_mode) {
initSentinelConfig(); //初始化哨兵的配置
initSentinel(); //初始化哨兵模式
}
...除了检查哨兵模式以外,main函数还会检查是否要执行RDB检测或AOF检查,这对应了实际运行的程序是redis-check-rdb或redis-check-aof。在这种情况下,main函数会调用redis_check_rdb_main函数或redis_check_aof_main函数,检测RDB文件或AOF文件。你可以看看下面的代码,其中就展示了main函数对这部分内容的检查和调用:
...
//如果运行的是redis-check-rdb程序,调用redis_check_rdb_main函数检测RDB文件
if (strstr(argv[0],"redis-check-rdb") != NULL)
redis_check_rdb_main(argc,argv,NULL);
//如果运行的是redis-check-aof程序,调用redis_check_aof_main函数检测AOF文件
else if (strstr(argv[0],"redis-check-aof") != NULL)
redis_check_aof_main(argc,argv);
...阶段三:运行参数解析
在这一阶段,main函数会对命令行传入的参数进行解析,并且调用loadServerConfig函数,对命令行参数和配置文件中的参数进行合并处理,然后为Redis各功能模块的关键参数设置合适的取值,以便server能高效地运行。
阶段四:初始化server
在完成对运行参数的解析和设置后,main函数会调用initServer函数,对server运行时的各种资源进行初始化工作。这主要包括了server资源管理所需的数据结构初始化、键值对数据库初始化、server网络框架初始化等。
而在调用完initServer后,main函数还会再次判断当前server是否为哨兵模式。如果是哨兵模式,main函数会调用sentinelIsRunning函数,设置启动哨兵模式。否则的话,main函数会调用loadDataFromDisk函数,从磁盘上加载AOF或者是RDB文件,以便恢复之前的数据。
阶段五:执行事件驱动框架
为了能高效处理高并发的客户端连接请求,Redis采用了事件驱动框架,来并发处理不同客户端的连接和读写请求。所以,main函数执行到最后时,会调用aeMain函数进入事件驱动框架,开始循环处理各种触发的事件。
思维导图
Redis运行参数解析与设置
我们知道,Redis提供了丰富的功能,既支持多种键值对数据类型的读写访问,还支持数据持久化保存、主从复制、切片集群等。而这些功能的高效运行,其实都离不开相关功能模块的关键参数配置。
举例来说,Redis为了节省内存,设计了内存紧凑型的数据结构来保存Hash、Sorted Set等键值对类型。但是在使用了内存紧凑型的数据结构之后,如果往数据结构存入的元素个数过多或元素过大的话,键值对的访问性能反而会受到影响。因此,为了平衡内存使用量和系统访问性能,我们就可以通过参数,来设置和调节内存紧凑型数据结构的使用条件。
掌握这些关键参数的设置,可以帮助我们提升Redis实例的运行效率。
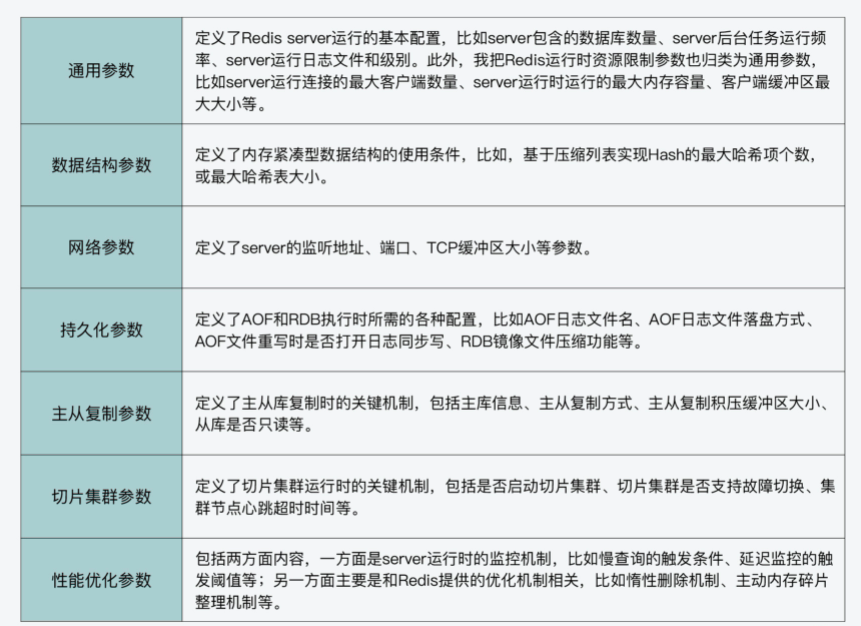
Redis的主要参数类型
首先,Redis运行所需的各种参数,都统一定义在了server.h文件的redisServer结构体中。根据参数作用的范围,我把各种参数划分为了七大类型,包括通用参数、数据结构参数、网络参数、持久化参数、主从复制参数、切片集群参数、性能优化参数。具体你可以参考下面表格中的内容。
Redis参数的设置方法
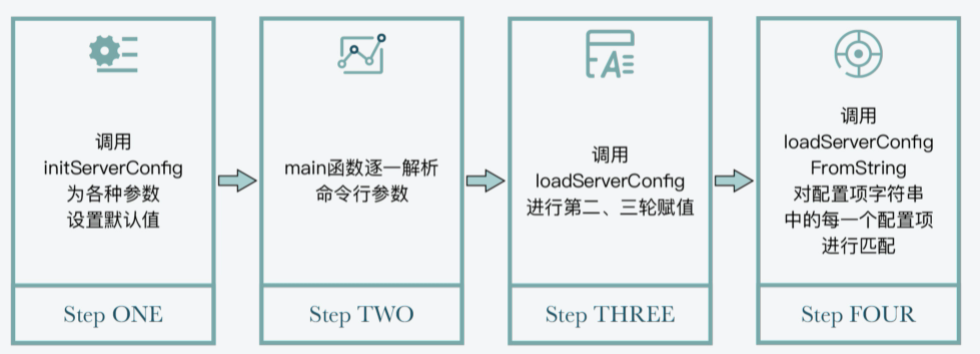
Redis对运行参数的设置实际上会经过三轮赋值,分别是默认配置值、命令行启动参数,以及配置文件配置值。
首先,Redis在main函数中会先调用initServerConfig函数,为各种参数设置默认值。参数的默认值统一定义在server.h文件中,都是以CONFIG_DEFAULT开头的宏定义变量。下面的代码显示的是部分参数的默认值,你可以看下。
#define CONFIG_DEFAULT_HZ 10 //server后台任务的默认运行频率
#define CONFIG_MIN_HZ 1 // server后台任务的最小运行频率
#define CONFIG_MAX_HZ 500 // server后台任务的最大运行频率
#define CONFIG_DEFAULT_SERVER_PORT 6379 //server监听的默认TCP端口
#define CONFIG_DEFAULT_CLIENT_TIMEOUT 0 //客户端超时时间,默认为0,表示没有超时限制在server.h中提供的默认参数值,一般都是典型的配置值。因此,如果你在部署使用Redis实例的过程中,对Redis的工作原理不是很了解,就可以使用代码中提供的默认配置。
当然,如果你对Redis各功能模块的工作机制比较熟悉的话,也可以自行设置运行参数。你可以在启动Redis程序时,在命令行上设置运行参数的值。比如,如果你想将Redis server监听端口从默认的6379修改为7379,就可以在命令行上设置port参数为7379,如下所示:
./redis-server --port 7379这里,你需要注意的是,Redis的命令行参数设置需要使用两个减号“–”来表示相应的参数名,否则的话,Redis就无法识别所设置的运行参数。
Redis在使用initServerConfig函数对参数设置默认配置值后,接下来,main函数就会对Redis程序启动时的命令行参数进行逐一解析。
main函数会把解析后的参数及参数值保存成字符串,接着,main函数会调用loadServerConfig函数进行第二和第三轮的赋值。以下代码显示了main函数对命令行参数的解析,以及调用loadServerConfig函数的过程,你可以看下。
int main(int argc, char **argv) {
…
//保存命令行参数
for (j = 0; j < argc; j++) server.exec_argv[j] = zstrdup(argv[j]);
…
if (argc >= 2) {
…
//对每个运行时参数进行解析
while(j != argc) {
…
}
…
//
loadServerConfig(configfile,options);
}这里你要知道的是,loadServerConfig函数是在config.c文件中实现的,该函数是以Redis配置文件和命令行参数的解析字符串为参数,将配置文件中的所有配置项读取出来,形成字符串。紧接着,loadServerConfig函数会把解析后的命令行参数,追加到配置文件形成的配置项字符串。
这样一来,配置项字符串就同时包含了配置文件中设置的参数,以及命令行设置的参数。
最后,loadServerConfig函数会进一步调用loadServerConfigFromString函数,对配置项字符串中的每一个配置项进行匹配。一旦匹配成功,loadServerConfigFromString函数就会按照配置项的值设置server的参数。
以下代码显示了loadServerConfigFromString函数的部分内容。这部分代码是使用了条件分支,来依次比较配置项是否是“timeout”和“tcp-keepalive”,如果匹配上了,就将server参数设置为配置项的值。
同时,代码还会检查配置项的值是否合理,比如是否小于0。如果参数值不合理,程序在运行时就会报错。另外对于其他的配置项,loadServerConfigFromString函数还会继续使用elseif分支进行判断。
loadServerConfigFromString(char *config) {
…
//参数名匹配,检查参数是否为“timeout“
if (!strcasecmp(argv[0],"timeout") && argc == 2) {
//设置server的maxidletime参数
server.maxidletime = atoi(argv[1]);
//检查参数值是否小于0,小于0则报错
if (server.maxidletime < 0) {
err = "Invalid timeout value"; goto loaderr;
}
}
//参数名匹配,检查参数是否为“tcp-keepalive“
else if (!strcasecmp(argv[0],"tcp-keepalive") && argc == 2) {
//设置server的tcpkeepalive参数
server.tcpkeepalive = atoi(argv[1]);
//检查参数值是否小于0,小于0则报错
if (server.tcpkeepalive < 0) {
err = "Invalid tcp-keepalive value"; goto loaderr;
}
}
…
}好了,到这里,你应该就了解了Redis server运行参数配置的步骤,我也画了一张图,以便你更直观地理解这个过程。
initServer:初始化Redis server
Redis server的初始化操作,主要可以分成三个步骤。
- 第一步,Redis server运行时需要对多种资源进行管理。
比如说,和server连接的客户端、从库等,Redis用作缓存时的替换候选集,以及server运行时的状态信息,这些资源的管理信息都会在initServer函数中进行初始化。
我给你举个例子,initServer函数会创建链表来分别维护客户端和从库,并调用evictionPoolAlloc函数(在evict.c中)采样生成用于淘汰的候选key集合。同时,initServer函数还会调用resetServerStats函数(在server.c中)重置server运行状态信息。
- 第二步,在完成资源管理信息的初始化后,initServer函数会对Redis数据库进行初始化。
因为一个Redis实例可以同时运行多个数据库,所以initServer函数会使用一个循环,依次为每个数据库创建相应的数据结构。
这个代码逻辑是实现在initServer函数中,它会为每个数据库执行初始化操作,包括创建全局哈希表,为过期key、被BLPOP阻塞的key、将被PUSH的key和被监听的key创建相应的信息表。
for (j = 0; j < server.dbnum; j++) {
//创建全局哈希表
server.db[j].dict = dictCreate(&dbDictType,NULL);
//创建过期key的信息表
server.db[j].expires = dictCreate(&keyptrDictType,NULL);
//为被BLPOP阻塞的key创建信息表
server.db[j].blocking_keys = dictCreate(&keylistDictType,NULL);
//为将执行PUSH的阻塞key创建信息表
server.db[j].ready_keys = dictCreate(&objectKeyPointerValueDictType,NULL);
//为被MULTI/WATCH操作监听的key创建信息表
server.db[j].watched_keys = dictCreate(&keylistDictType,NULL);
…
}- 第三步,initServer函数会为运行的Redis server创建事件驱动框架,并开始启动端口监听,用于接收外部请求。
注意,为了高效处理高并发的外部请求,initServer在创建的事件框架中,针对每个监听IP上可能发生的客户端连接,都创建了监听事件,用来监听客户端连接请求。同时,initServer为监听事件设置了相应的处理函数acceptTcpHandler。
这样一来,只要有客户端连接到server监听的IP和端口,事件驱动框架就会检测到有连接事件发生,然后调用acceptTcpHandler函数来处理具体的连接。你可以参考以下代码中展示的处理逻辑:
//创建事件循环框架
server.el = aeCreateEventLoop(server.maxclients+CONFIG_FDSET_INCR);
…
//开始监听设置的网络端口
if (server.port != 0 &&
listenToPort(server.port,server.ipfd,&server.ipfd_count) == C_ERR)
exit(1);
…
//为server后台任务创建定时事件
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) {
serverPanic("Can't create event loop timers.");
exit(1);
}
…
//为每一个监听的IP设置连接事件的处理函数acceptTcpHandler
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{ … }
}那么到这里,Redis server在完成运行参数设置和初始化后,就可以开始处理客户端请求了。为了能持续地处理并发的客户端请求,server在main函数的最后,会进入事件驱动循环机制。
执行事件驱动框架
事件驱动框架是Redis server运行的核心。该框架一旦启动后,就会一直循环执行,每次循环会处理一批触发的网络读写事件。
其实,进入事件驱动框架开始执行并不复杂,main函数直接调用事件框架的主体函数aeMain(在ae.c文件中)后,就进入事件处理循环了。
当然,在进入事件驱动循环前,main函数会分别调用aeSetBeforeSleepProc和aeSetAfterSleepProc两个函数,来设置每次进入事件循环前server需要执行的操作,以及每次事件循环结束后server需要执行的操作。下面代码显示了这部分的执行逻辑,你可以看下。
int main(int argc, char **argv) {
aeSetBeforeSleepProc(server.el,beforeSleep);
aeSetAfterSleepProc(server.el,afterSleep);
aeMain(server.el);
aeDeleteEventLoop(server.el);
}Redis事件驱动框架(上):何时使用select、poll、epoll
通常系统实现网络通信的基本方法是使用Socket编程模型,包括创建Socket、监听端口、处理连接请求和读写请求。但是,由于基本的Socket编程模型一次只能处理一个客户端连接上的请求,所以当要处理高并发请求时,一种方案就是使用多线程,让每个线程负责处理一个客户端的请求。
而Redis负责客户端请求解析和处理的线程只有一个,那么如果直接采用基本Socket模型,就会影响Redis支持高并发的客户端访问。
因此,为了实现高并发的网络通信,我们常用的Linux操作系统,就提供了select、poll和epoll三种编程模型,而在Linux上运行的Redis,通常就会采用其中的epoll模型来进行网络通信。
为什么Redis不使用基本的Socket编程模型?
使用Socket模型实现网络通信时,需要经过创建Socket、监听端口、处理连接和读写请求等多个步骤。
首先,当我们需要让服务器端和客户端进行通信时,可以在服务器端通过以下三步,来创建监听客户端连接的监听套接字(Listening Socket):
- 调用socket函数,创建一个套接字。我们通常把这个套接字称为主动套接字(Active Socket);
- 调用bind函数,将主动套接字和当前服务器的IP和监听端口进行绑定;
- 调用listen函数,将主动套接字转换为监听套接字,开始监听客户端的连接。

在完成上述三步之后,服务器端就可以接收客户端的连接请求了。为了能及时地收到客户端的连接请求,我们可以运行一个循环流程,在该流程中调用accept函数,用于接收客户端连接请求。
这里你需要注意的是,accept函数是阻塞函数,也就是说,如果此时一直没有客户端连接请求,那么,服务器端的执行流程会一直阻塞在accept函数。一旦有客户端连接请求到达,accept将不再阻塞,而是处理连接请求,和客户端建立连接,并返回已连接套接字(Connected Socket)。
最后,服务器端可以通过调用recv或send函数,在刚才返回的已连接套接字上,接收并处理读写请求,或是将数据发送给客户端。
下面的代码展示了这一过程,你可以看下。
listenSocket = socket(); //调用socket系统调用创建一个主动套接字
bind(listenSocket); //绑定地址和端口
listen(listenSocket); //将默认的主动套接字转换为服务器使用的被动套接字,也就是监听套接字
while (1) { //循环监听是否有客户端连接请求到来
connSocket = accept(listenSocket); //接受客户端连接
recv(connsocket); //从客户端读取数据,只能同时处理一个客户端
send(connsocket); //给客户端返回数据,只能同时处理一个客户端
}不过,从上述代码中,你可能会发现,虽然它能够实现服务器端和客户端之间的通信,但是程序每调用一次accept函数,只能处理一个客户端连接。因此,如果想要处理多个并发客户端的请求,我们就需要使用多线程的方法,来处理通过accept函数建立的多个客户端连接上的请求。
使用这种方法后,我们需要在accept函数返回已连接套接字后,创建一个线程,并将已连接套接字传递给创建的线程,由该线程负责这个连接套接字上后续的数据读写。同时,服务器端的执行流程会再次调用accept函数,等待下一个客户端连接。
以下给出的示例代码,就展示了使用多线程来提升服务器端的并发客户端处理能力:
listenSocket = socket(); //调用socket系统调用创建一个主动套接字
bind(listenSocket); //绑定地址和端口
listen(listenSocket); //将默认的主动套接字转换为服务器使用的被动套接字,即监听套接字
while (1) { //循环监听是否有客户端连接到来
connSocket = accept(listenSocket); //接受客户端连接,返回已连接套接字
pthread_create(processData, connSocket); //创建新线程对已连接套接字进行处理
}
//处理已连接套接字上的读写请求
processData(connSocket){
recv(connsocket); //从客户端读取数据,只能同时处理一个客户端
send(connsocket); //给客户端返回数据,只能同时处理一个客户端
}不过,虽然这种方法能提升服务器端的并发处理能力,遗憾的是,Redis的主执行流程是由一个线程在执行,无法使用多线程的方式来提升并发处理能力。所以,该方法对Redis并不起作用。
那么,还有没有什么其他方法,能帮助Redis提升并发客户端的处理能力呢?
这就要用到操作系统提供的IO多路复用功能了。在基本的Socket编程模型中,accept函数只能在一个监听套接字上监听客户端的连接,recv函数也只能在一个已连接套接字上,等待客户端发送的请求。
而IO多路复用机制,可以让程序通过调用多路复用函数,同时监听多个套接字上的请求。这里既可以包括监听套接字上的连接请求,也可以包括已连接套接字上的读写请求。这样当有一个或多个套接字上有请求时,多路复用函数就会返回。此时,程序就可以处理这些就绪套接字上的请求,比如读取就绪的已连接套接字上的请求内容。
使用select和poll机制实现IO多路复用
首先,我们来了解下select机制的编程模型。
不过在具体学习之前,我们需要知道,对于一种IO多路复用机制来说,我们需要掌握哪些要点,这样可以帮助我们快速抓住不同机制的联系与区别。其实,当我们学习IO多路复用机制时,我们需要能回答以下问题:
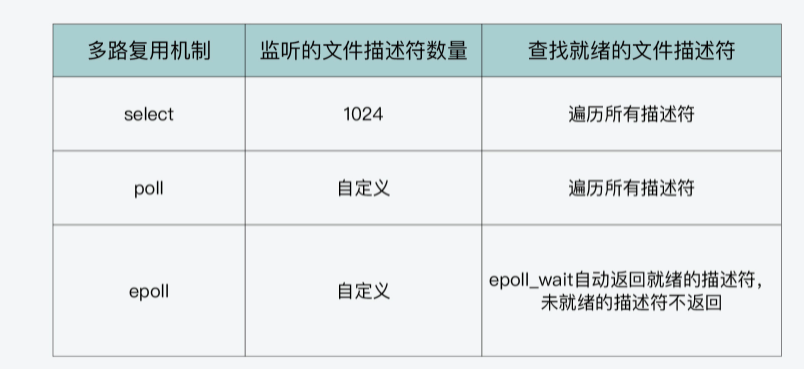
- 第一,多路复用机制会监听套接字上的哪些事件?
- 第二,多路复用机制可以监听多少个套接字?
- 第三,当有套接字就绪时,多路复用机制要如何找到就绪的套接字?
select机制与使用
select机制中的一个重要函数就是select函数。对于select函数来说,它的参数包括监听的文件描述符数量__nfds、被监听描述符的三个集合*__readfds、*__writefds和*__exceptfds,以及监听时阻塞等待的超时时长*__timeout。下面的代码显示了select函数的原型,你可以看下。
int select (int __nfds, fd_set *__readfds, fd_set *__writefds, fd_set *__exceptfds, struct timeval *__timeout)这里你需要注意的是,Linux针对每一个套接字都会有一个文件描述符,也就是一个非负整数,用来唯一标识该套接字。所以,在多路复用机制的函数中,Linux通常会用文件描述符作为参数。有了文件描述符,函数也就能找到对应的套接字,进而进行监听、读写等操作。
所以,select函数的参数__readfds、__writefds和__exceptfds表示的是,被监听描述符的集合,其实就是被监听套接字的集合。
这就和我刚才提出的第一个问题相关,也就是多路复用机制会监听哪些事件。select函数使用三个集合,表示监听的三类事件,分别是读数据事件(对应__readfds集合)、写数据事件(对应__writefds集合)和异常事件(对应__exceptfds集合)。
我们进一步可以看到,参数readfds、writefds和exceptfds的类型是fd_set结构体,它主要定义部分如下所示。其中,`fd_mask`类型是long int类型的别名,FD_SETSIZE和NFDBITS这两个宏定义的大小默认为1024和32。
typedef struct {
…
__fd_mask __fds_bits[__FD_SETSIZE / __NFDBITS];
…
} fd_set所以,fd_set结构体的定义,其实就是一个long int类型的数组,该数组中一共有32个元素(1024/32=32),每个元素是32位(long int类型的大小),而每一位可以用来表示一个文件描述符的状态。
好了,了解了fd_set结构体的定义,我们就可以回答刚才提出的第二个问题了。select函数对每一个描述符集合,都可以监听1024个描述符。
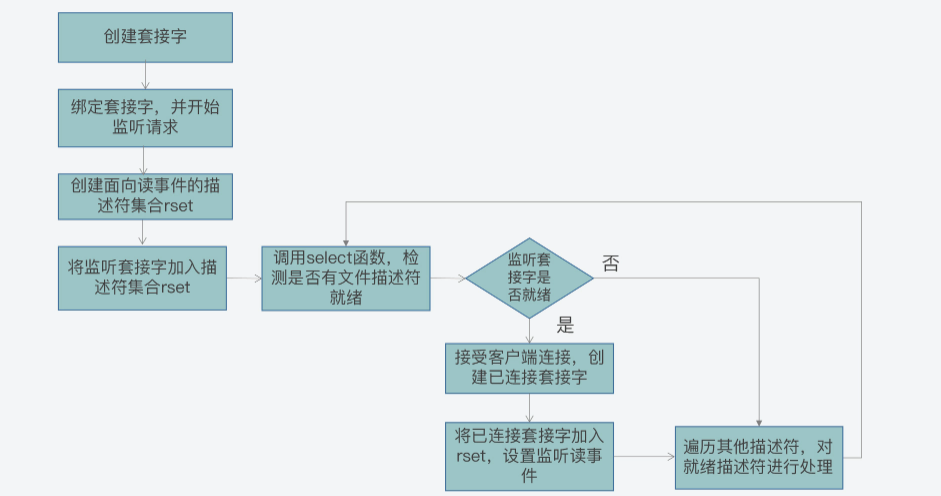
接下来,我们再来了解下如何使用select机制来实现网络通信。
首先,我们在调用select函数前,可以先创建好传递给select函数的描述符集合,然后再创建监听套接字。而为了让创建的监听套接字能被select函数监控,我们需要把这个套接字的描述符加入到创建好的描述符集合中。
然后,我们就可以调用select函数,并把创建好的描述符集合作为参数传递给select函数。程序在调用select函数后,会发生阻塞。而当select函数检测到有描述符就绪后,就会结束阻塞,并返回就绪的文件描述符个数。
那么此时,我们就可以在描述符集合中查找哪些描述符就绪了。然后,我们对已就绪描述符对应的套接字进行处理。比如,如果是__readfds集合中有描述符就绪,这就表明这些就绪描述符对应的套接字上,有读事件发生,此时,我们就在该套接字上读取数据。
而因为select函数一次可以监听1024个文件描述符的状态,所以select函数在返回时,也可能会一次返回多个就绪的文件描述符。这样一来,我们就可以使用一个循环流程,依次对就绪描述符对应的套接字进行读写或异常处理操作。
我也画了张图,展示了使用select函数进行网络通信的基本流程,你可以看下。
下面的代码展示的是使用select函数,进行并发客户端处理的关键步骤和主要函数调用:
int sock_fd,conn_fd; //监听套接字和已连接套接字的变量
sock_fd = socket() //创建套接字
bind(sock_fd) //绑定套接字
listen(sock_fd) //在套接字上进行监听,将套接字转为监听套接字
fd_set rset; //被监听的描述符集合,关注描述符上的读事件
int max_fd = sock_fd
//初始化rset数组,使用FD_ZERO宏设置每个元素为0
FD_ZERO(&rset);
//使用FD_SET宏设置rset数组中位置为sock_fd的文件描述符为1,表示需要监听该文件描述符
FD_SET(sock_fd,&rset);
//设置超时时间
struct timeval timeout;
timeout.tv_sec = 3;
timeout.tv_usec = 0;
while(1) {
//调用select函数,检测rset数组保存的文件描述符是否已有读事件就绪,返回就绪的文件描述符个数
n = select(max_fd+1, &rset, NULL, NULL, &timeout);
//调用FD_ISSET宏,在rset数组中检测sock_fd对应的文件描述符是否就绪
if (FD_ISSET(sock_fd, &rset)) {
//如果sock_fd已经就绪,表明已有客户端连接;调用accept函数建立连接
conn_fd = accept();
//设置rset数组中位置为conn_fd的文件描述符为1,表示需要监听该文件描述符
FD_SET(conn_fd, &rset);
}
//依次检查已连接套接字的文件描述符
for (i = 0; i < maxfd; i++) {
//调用FD_ISSET宏,在rset数组中检测文件描述符是否就绪
if (FD_ISSET(i, &rset)) {
//有数据可读,进行读数据处理
}
}
}不过从刚才的介绍中,你或许会发现select函数存在两个设计上的不足:
- 首先,select函数对单个进程能监听的文件描述符数量是有限制的,它能监听的文件描述符个数由__FD_SETSIZE决定,默认值是1024。
- 其次,当select函数返回后,我们需要遍历描述符集合,才能找到具体是哪些描述符就绪了。这个遍历过程会产生一定开销,从而降低程序的性能。
所以,为了解决select函数受限于1024个文件描述符的不足,poll函数对此做了改进。
poll机制与使用
poll机制的主要函数是poll函数,我们先来看下它的原型定义,如下所示:
int poll (struct pollfd *__fds, nfds_t __nfds, int __timeout);其中,参数fds是pollfd结构体数组,参数nfds表示的是fds数组的元素个数,而timeout表示poll函数阻塞的超时时间。
pollfd结构体里包含了要监听的描述符,以及该描述符上要监听的事件类型。这个我们可以从pollfd结构体的定义中看出来,如下所示。pollfd结构体中包含了三个成员变量fd、events和revents,分别表示要监听的文件描述符、要监听的事件类型和实际发生的事件类型。
struct pollfd {
int fd; //进行监听的文件描述符
short int events; //要监听的事件类型
short int revents; //实际发生的事件类型
};pollfd结构体中要监听和实际发生的事件类型,是通过以下三个宏定义来表示的,分别是POLLRDNORM、POLLWRNORM和POLLERR,它们分别表示可读、可写和错误事件。
#define POLLRDNORM 0x040 //可读事件
#define POLLWRNORM 0x100 //可写事件
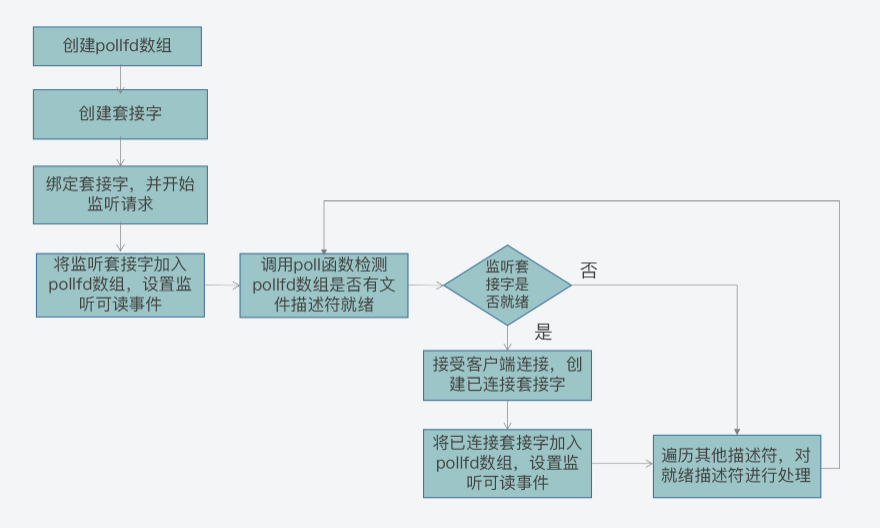
#define POLLERR 0x008 //错误事件好了,了解了poll函数的参数后,我们来看下如何使用poll函数完成网络通信。这个流程主要可以分成三步:
- 第一步,创建pollfd数组和监听套接字,并进行绑定;
- 第二步,将监听套接字加入pollfd数组,并设置其监听读事件,也就是客户端的连接请求;
- 第三步,循环调用poll函数,检测pollfd数组中是否有就绪的文件描述符。
而在第三步的循环过程中,其处理逻辑又分成了两种情况:
- 如果是连接套接字就绪,这表明是有客户端连接,我们可以调用accept接受连接,并创建已连接套接字,并将其加入pollfd数组,并监听读事件;
- 如果是已连接套接字就绪,这表明客户端有读写请求,我们可以调用recv/send函数处理读写请求。
我画了下面这张图,展示了使用poll函数的流程,你可以学习掌握下。
int sock_fd,conn_fd; //监听套接字和已连接套接字的变量
sock_fd = socket() //创建套接字
bind(sock_fd) //绑定套接字
listen(sock_fd) //在套接字上进行监听,将套接字转为监听套接字
//poll函数可以监听的文件描述符数量,可以大于1024
#define MAX_OPEN = 2048
//pollfd结构体数组,对应文件描述符
struct pollfd client[MAX_OPEN];
//将创建的监听套接字加入pollfd数组,并监听其可读事件
client[0].fd = sock_fd;
client[0].events = POLLRDNORM;
maxfd = 0;
//初始化client数组其他元素为-1
for (i = 1; i < MAX_OPEN; i++)
client[i].fd = -1;
while(1) {
//调用poll函数,检测client数组里的文件描述符是否有就绪的,返回就绪的文件描述符个数
n = poll(client, maxfd+1, &timeout);
//如果监听套件字的文件描述符有可读事件,则进行处理
if (client[0].revents & POLLRDNORM) {
//有客户端连接;调用accept函数建立连接
conn_fd = accept();
//保存已建立连接套接字
for (i = 1; i < MAX_OPEN; i++){
if (client[i].fd < 0) {
client[i].fd = conn_fd; //将已建立连接的文件描述符保存到client数组
client[i].events = POLLRDNORM; //设置该文件描述符监听可读事件
break;
}
}
maxfd = i;
}
//依次检查已连接套接字的文件描述符
for (i = 1; i < MAX_OPEN; i++) {
if (client[i].revents & (POLLRDNORM | POLLERR)) {
//有数据可读或发生错误,进行读数据处理或错误处理
}
}
}其实,和select函数相比,poll函数的改进之处主要就在于,它允许一次监听超过1024个文件描述符。但是当调用了poll函数后,我们仍然需要遍历每个文件描述符,检测该描述符是否就绪,然后再进行处理。
那么,有没有办法可以避免遍历每个描述符呢?这就是我接下来向你介绍的epoll机制。
使用epoll机制实现IO多路复用
首先,epoll机制是使用epoll_event结构体,来记录待监听的文件描述符及其监听的事件类型的,这和poll机制中使用pollfd结构体比较类似。
那么,对于epoll_event结构体来说,其中包含了epoll_data_t联合体变量,以及整数类型的events变量。epoll_data_t联合体中有记录文件描述符的成员变量fd,而events变量会取值使用不同的宏定义值,来表示epoll_data_t变量中的文件描述符所关注的事件类型,比如一些常见的事件类型包括以下这几种。
- EPOLLIN:读事件,表示文件描述符对应套接字有数据可读。
- EPOLLOUT:写事件,表示文件描述符对应套接字有数据要写。
- EPOLLERR:错误事件,表示文件描述符对于套接字出错。
下面的代码展示了epoll_event结构体以及epoll_data联合体的定义,你可以看下。
typedef union epoll_data
{
...
int fd; //记录文件描述符
...
} epoll_data_t;
struct epoll_event
{
uint32_t events; //epoll监听的事件类型
epoll_data_t data; //应用程序数据
};好了,现在我们知道,在使用select或poll函数的时候,创建好文件描述符集合或pollfd数组后,就可以往数组中添加我们需要监听的文件描述符。
但是对于epoll机制来说,我们则需要先调用epoll_create函数,创建一个epoll实例。这个epoll实例内部维护了两个结构,分别是记录要监听的文件描述符和已经就绪的文件描述符,而对于已经就绪的文件描述符来说,它们会被返回给用户程序进行处理。
所以,我们在使用epoll机制时,就不用像使用select和poll一样,遍历查询哪些文件描述符已经就绪了。这样一来, epoll的效率就比select和poll有了更高的提升。
在创建了epoll实例后,我们需要再使用epoll_ctl函数,给被监听的文件描述符添加监听事件类型,以及使用epoll_wait函数获取就绪的文件描述符。
我画了一张图,展示了使用epoll进行网络通信的流程,你可以看下。

下面的代码展示了使用epoll函数的流程,你也可以看下。
int sock_fd,conn_fd; //监听套接字和已连接套接字的变量
sock_fd = socket() //创建套接字
bind(sock_fd) //绑定套接字
listen(sock_fd) //在套接字上进行监听,将套接字转为监听套接字
epfd = epoll_create(EPOLL_SIZE); //创建epoll实例,
//创建epoll_event结构体数组,保存套接字对应文件描述符和监听事件类型
ep_events = (epoll_event*)malloc(sizeof(epoll_event) * EPOLL_SIZE);
//创建epoll_event变量
struct epoll_event ee
//监听读事件
ee.events = EPOLLIN;
//监听的文件描述符是刚创建的监听套接字
ee.data.fd = sock_fd;
//将监听套接字加入到监听列表中
epoll_ctl(epfd, EPOLL_CTL_ADD, sock_fd, &ee);
while (1) {
//等待返回已经就绪的描述符
n = epoll_wait(epfd, ep_events, EPOLL_SIZE, -1);
//遍历所有就绪的描述符
for (int i = 0; i < n; i++) {
//如果是监听套接字描述符就绪,表明有一个新客户端连接到来
if (ep_events[i].data.fd == sock_fd) {
conn_fd = accept(sock_fd); //调用accept()建立连接
ee.events = EPOLLIN;
ee.data.fd = conn_fd;
//添加对新创建的已连接套接字描述符的监听,监听后续在已连接套接字上的读事件
epoll_ctl(epfd, EPOLL_CTL_ADD, conn_fd, &ee);
} else { //如果是已连接套接字描述符就绪,则可以读数据
...//读取数据并处理
}
}
}好了,到这里,你就了解了epoll函数的使用方法了。实际上,也正是因为epoll能自定义监听的描述符数量,以及可以直接返回就绪的描述符,Redis在设计和实现网络通信框架时,就基于epoll机制中的epoll_create、epoll_ctl和epoll_wait等函数和读写事件,进行了封装开发,实现了用于网络通信的事件驱动框架,从而使得Redis虽然是单线程运行,但是仍然能高效应对高并发的客户端访问。
Redis事件驱动框架(中):Redis实现了Reactor模型吗?
Reactor模型的工作机制
好,首先,我们来看看什么是Reactor模型。
实际上,Reactor模型就是网络服务器端用来处理高并发网络IO请求的一种编程模型。我把这个模型的特征用两个“三”来总结,也就是:
- 三类处理事件,即连接事件、写事件、读事件;
- 三个关键角色,即reactor、acceptor、handler。
事件类型与关键角色
我们先来看看这三类事件和Reactor模型的关系。
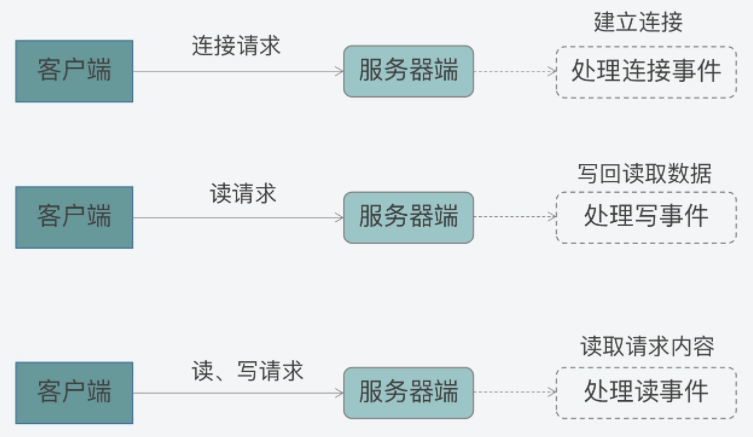
其实,Reactor模型处理的是客户端和服务器端的交互过程,而这三类事件正好对应了客户端和服务器端交互过程中,不同类请求在服务器端引发的待处理事件:
- 当一个客户端要和服务器端进行交互时,客户端会向服务器端发送连接请求,以建立连接,这就对应了服务器端的一个连接事件。
- 一旦连接建立后,客户端会给服务器端发送读请求,以便读取数据。服务器端在处理读请求时,需要向客户端写回数据,这对应了服务器端的写事件。
- 无论客户端给服务器端发送读或写请求,服务器端都需要从客户端读取请求内容,所以在这里,读或写请求的读取就对应了服务器端的读事件。
如下所示的图例中,就展示了客户端和服务器端在交互过程中,不同类请求和Reactor模型事件的对应关系,你可以看下。
这其实就是模型中三个关键角色的作用了:
首先,连接事件由acceptor来处理,负责接收连接;acceptor在接收连接后,会创建handler,用于网络连接上对后续读写事件的处理;
其次,读写事件由handler处理;
最后,在高并发场景中,连接事件、读写事件会同时发生,所以,我们需要有一个角色专门监听和分配事件,这就是reactor角色。当有连接请求时,reactor将产生的连接事件交由acceptor处理;当有读写请求时,reactor将读写事件交由handler处理。
下图就展示了这三个角色之间的关系,以及它们和事件的关系,你可以看下。
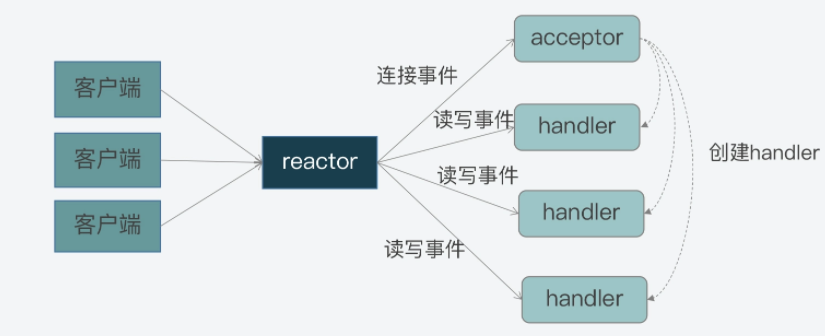
事实上,这三个角色都是Reactor模型中要实现的功能的抽象。当我们遵循Reactor模型开发服务器端的网络框架时,就需要在编程的时候,在代码功能模块中实现reactor、acceptor和handler的逻辑。
事件驱动框架
所谓的事件驱动框架,就是在实现Reactor模型时,需要实现的代码整体控制逻辑。简单来说,事件驱动框架包括了两部分:一是事件初始化;二是事件捕获、分发和处理主循环。
事件初始化是在服务器程序启动时就执行的,它的作用主要是创建需要监听的事件类型,以及该类事件对应的handler。而一旦服务器完成初始化后,事件初始化也就相应完成了,服务器程序就需要进入到事件捕获、分发和处理的主循环中。
在开发代码时,我们通常会用一个while循环来作为这个主循环。然后在这个主循环中,我们需要捕获发生的事件、判断事件类型,并根据事件类型,调用在初始化时创建好的事件handler来实际处理事件。
比如说,当有连接事件发生时,服务器程序需要调用acceptor处理函数,创建和客户端的连接。而当有读事件发生时,就表明有读或写请求发送到了服务器端,服务器程序就要调用具体的请求处理函数,从客户端连接中读取请求内容,进而就完成了读事件的处理。这里你可以参考下面给出的图例,其中显示了事件驱动框架的基本执行过程:
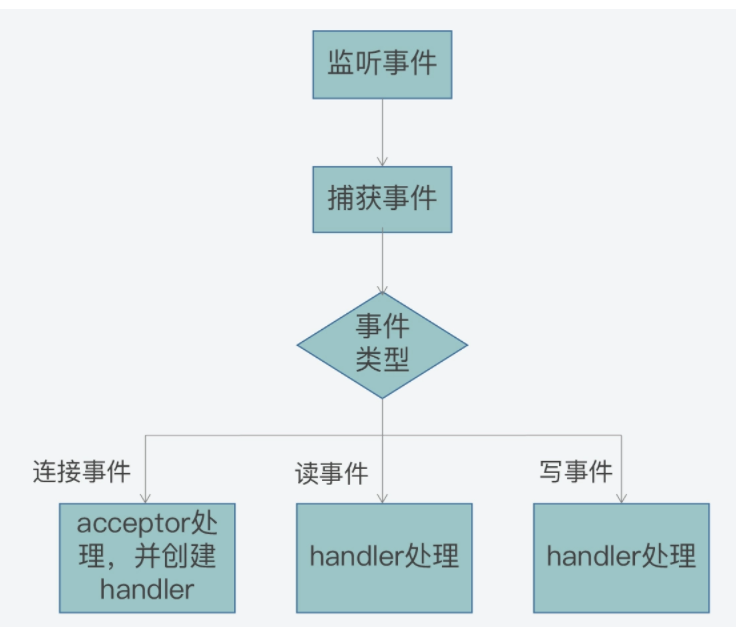
那么到这里,你应该就已经了解了Reactor模型的基本工作机制:客户端的不同类请求会在服务器端触发连接、读、写三类事件,这三类事件的监听、分发和处理又是由reactor、acceptor、handler三类角色来完成的,然后这三类角色会通过事件驱动框架来实现交互和事件处理。
Redis对Reactor模型的实现
首先我们要知道的是,Redis的网络框架实现了Reactor模型,并且自行开发实现了一个事件驱动框架。这个框架对应的Redis代码实现文件是ae.c,对应的头文件是ae.h。
前面我们已经知道,事件驱动框架的实现离不开事件的定义,以及事件注册、捕获、分发和处理等一系列操作。当然,对于整个框架来说,还需要能一直运行,持续地响应发生的事件。
那么由此,我们从ae.h头文件中就可以看到,Redis为了实现事件驱动框架,相应地定义了事件的数据结构、框架主循环函数、事件捕获分发函数、事件和handler注册函数。
事件的数据结构定义:以aeFileEvent为例
首先,我们要明确一点,就是在Redis事件驱动框架的实现当中,事件的数据结构是关联事件类型和事件处理函数的关键要素。而Redis的事件驱动框架定义了两类事件:IO事件和时间事件,分别对应了客户端发送的网络请求和Redis自身的周期性操作。
这也就是说,不同类型事件的数据结构定义是不一样的。IO事件aeFileEvent为例,给你介绍下它的数据结构定义。
aeFileEvent是一个结构体,它定义了4个成员变量mask、rfileProce、wfileProce和clientData,如下所示:
typedef struct aeFileEvent {
int mask; /* one of AE_(READABLE|WRITABLE|BARRIER) */
aeFileProc *rfileProc;
aeFileProc *wfileProc;
void *clientData;
} aeFileEvent;- mask是用来表示事件类型的掩码。对于网络通信的事件来说,主要有AE_READABLE、AE_WRITABLE和AE_BARRIER三种类型事件。框架在分发事件时,依赖的就是结构体中的事件类型;
- rfileProc和wfileProce分别是指向AE_READABLE和AE_WRITABLE这两类事件的处理函数,也就是Reactor模型中的handler。框架在分发事件后,就需要调用结构体中定义的函数进行事件处理;
- 最后一个成员变量clientData是用来指向客户端私有数据的指针。
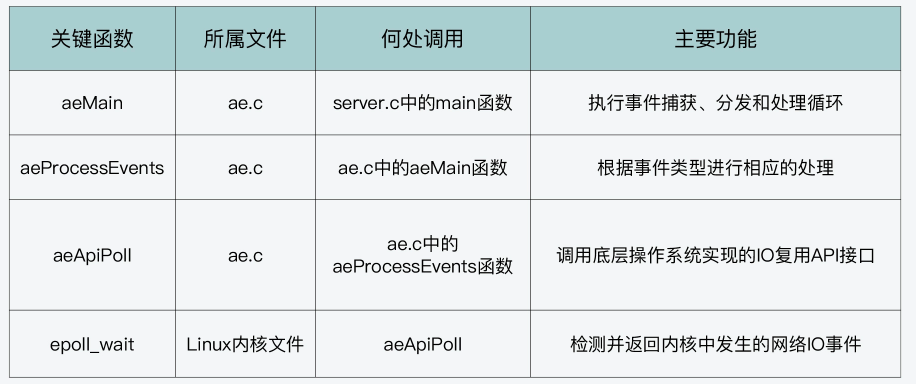
除了事件的数据结构以外,前面我还提到Redis在ae.h文件中,定义了支撑框架运行的主要函数,包括框架主循环的aeMain函数、负责事件捕获与分发的aeProcessEvents函数,以及负责事件和handler注册的aeCreateFileEvent函数,它们的原型定义如下:
oid aeMain(aeEventLoop *eventLoop);
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask, aeFileProc *proc, void *clientData);
int aeProcessEvents(aeEventLoop *eventLoop, int flags);主循环:aeMain函数
我们先来看下aeMain函数。
aeMain函数的逻辑很简单,就是用一个循环不停地判断事件循环的停止标记。如果事件循环的停止标记被设置为true,那么针对事件捕获、分发和处理的整个主循环就停止了;否则,主循环会一直执行。aeMain函数的主体代码如下所示:
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
…
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}那么这里你可能要问了,aeMain函数是在哪里被调用的呢?
按照事件驱动框架的编程规范来说,框架主循环是在服务器程序初始化完成后,就会开始执行。因此,如果我们把目光转向Redis服务器初始化的函数,就会发现服务器程序的main函数在完成Redis server的初始化后,会调用aeMain函数开始执行事件驱动框架。
不过,既然aeMain函数包含了事件框架的主循环,那么在主循环中,事件又是如何被捕获、分发和处理呢?这就是由aeProcessEvents函数来完成的了。
事件捕获与分发:aeProcessEvents函数
aeProcessEvents函数实现的主要功能,包括捕获事件、判断事件类型和调用具体的事件处理函数,从而实现事件的处理。
从aeProcessEvents函数的主体结构中,我们可以看到主要有三个if条件分支,如下所示:
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
int processed = 0, numevents;
/* 若没有事件处理,则立刻返回*/
if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS)) return 0;
/*如果有IO事件发生,或者紧急的时间事件发生,则开始处理*/
if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
…
}
/* 检查是否有时间事件,若有,则调用processTimeEvents函数处理 */
if (flags & AE_TIME_EVENTS)
processed += processTimeEvents(eventLoop);
/* 返回已经处理的文件或时间*/
return processed;
}这三个分支分别对应了以下三种情况:
- 情况一:既没有时间事件,也没有网络事件;
- 情况二:有IO事件或者有需要紧急处理的时间事件;
- 情况三:只有普通的时间事件。
那么对于第一种情况来说,因为没有任何事件需要处理,aeProcessEvents函数就会直接返回到aeMain的主循环,开始下一轮的循环;而对于第三种情况来说,该情况发生时只有普通时间事件发生,所以aeMain函数会调用专门处理时间事件的函数processTimeEvents,对时间事件进行处理。
现在,我们再来看看第二种情况。
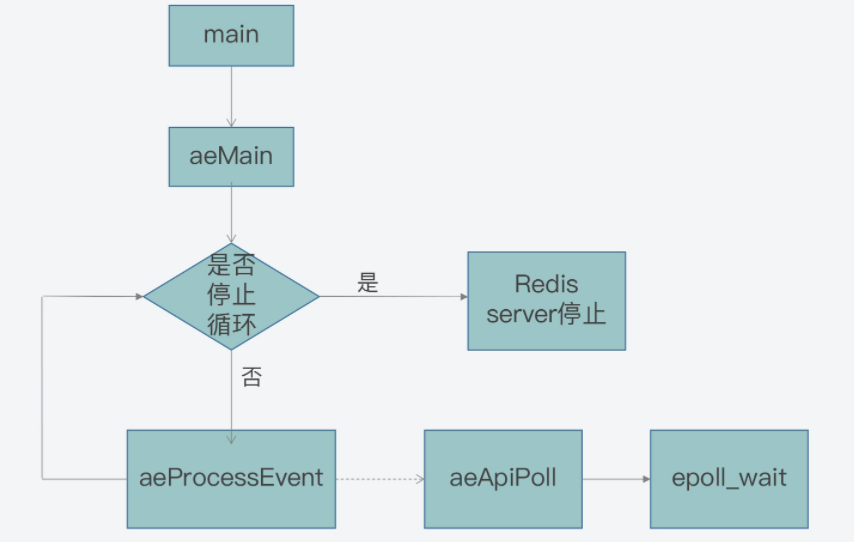
首先,当该情况发生时,Redis需要捕获发生的网络事件,并进行相应的处理。那么从Redis源码中我们可以分析得到,在这种情况下,aeApiPoll函数会被调用,用来捕获事件,如下所示:
int aeProcessEvents(aeEventLoop *eventLoop, int flags){
...
if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
...
//调用aeApiPoll函数捕获事件
numevents = aeApiPoll(eventLoop, tvp);
...
}
...
」那么,aeApiPoll是如何捕获事件呢?
实际上,Redis是依赖于操作系统底层提供的 IO多路复用机制,来实现事件捕获,检查是否有新的连接、读写事件发生。为了适配不同的操作系统,Redis对不同操作系统实现的网络IO多路复用函数,都进行了统一的封装,封装后的代码分别通过以下四个文件中实现:
- ae_epoll.c,对应Linux上的IO复用函数epoll;
- ae_evport.c,对应Solaris上的IO复用函数evport;
- ae_kqueue.c,对应macOS或FreeBSD上的IO复用函数kqueue;
- ae_select.c,对应Linux(或Windows)的IO复用函数select。
这样,在有了这些封装代码后,Redis在不同的操作系统上调用IO多路复用API时,就可以通过统一的接口来进行调用了。
首先,Linux上提供了epoll_wait API,用于检测内核中发生的网络IO事件。在ae_epoll.c文件中,aeApiPoll函数就是封装了对epoll_wait的调用。
这个封装程序如下所示,其中你可以看到,在aeApiPoll函数中直接调用了epoll_wait函数,并将epoll返回的事件信息保存起来的逻辑:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
…
//调用epoll_wait获取监听到的事件
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
if (retval > 0) {
int j;
//获得监听到的事件数量
numevents = retval;
//针对每一个事件,进行处理
for (j = 0; j < numevents; j++) {
#保存事件信息
}
}
return numevents;
}为了让你更加清晰地理解,事件驱动框架是如何实现最终对epoll_wait的调用,这里我也放了一张示意图,你可以看看整个调用链是如何工作和实现的。
那么,事件具体是由哪个函数来处理的呢?这就和框架中的aeCreateFileEvents函数有关了。
事件注册:aeCreateFileEvent函数
我们知道,当Redis启动后,服务器程序的main函数会调用initSever函数来进行初始化,而在初始化的过程中,aeCreateFileEvent就会被initServer函数调用,用于注册要监听的事件,以及相应的事件处理函数。
具体来说,在initServer函数的执行过程中,initServer函数会根据启用的IP端口个数,为每个IP端口上的网络事件,调用aeCreateFileEvent,创建对AE_READABLE事件的监听,并且注册AE_READABLE事件的处理handler,也就是acceptTcpHandler函数。这一过程如下图所示:

所以这里我们可以看到,AE_READABLE事件就是客户端的网络连接事件,而对应的处理函数就是接收TCP连接请求。下面的示例代码中,显示了initServer中调用aeCreateFileEvent的部分片段,你可以看下:
void initServer(void) {
…
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic("Unrecoverable error creating server.ipfd file event.");
}
}
…
}那么,aeCreateFileEvent如何实现事件和处理函数的注册呢?这就和刚才我介绍的Redis对底层IO多路复用函数封装有关了,下面我仍然以Linux系统为例,来给你说明一下。
首先,Linux提供了epoll_ctl API,用于增加新的观察事件。而Redis在此基础上,封装了aeApiAddEvent函数,对epoll_ctl进行调用。
所以这样一来,aeCreateFileEvent就会调用aeApiAddEvent,然后aeApiAddEvent再通过调用epoll_ctl,来注册希望监听的事件和相应的处理函数。等到aeProceeEvents函数捕获到实际事件时,它就会调用注册的函数对事件进行处理了。
小总结
Redis基于Reactor模型,实现了高性能的网络框架,通过事件驱动框架,Redis可以使用一个循环来不断捕获、分发和处理客户端产生的网络连接、数据读写事件。
Redis事件驱动框架的主要函数和功能、它们所属的C文件,以及这些函数本身是在Redis代码结构中的哪里被调用。
Redis事件驱动框架(下):Redis有哪些事件?
aeEventLoop结构体与初始化
首先,我们来看下Redis事件驱动框架循环流程对应的数据结构aeEventLoop。这个结构体是在事件驱动框架代码ae.h中定义的,记录了框架循环运行过程中的信息,其中,就包含了记录两类事件的变量,分别是:
- aeFileEvent类型的指针*events,表示IO事件。之所以类型名称为aeFileEvent,是因为所有的IO事件都会用文件描述符进行标识;
- aeTimeEvent类型的指针*timeEventHead,表示时间事件,即按一定时间周期触发的事件。
此外,aeEventLoop结构体中还有一个aeFiredEvent类型的指针*fired,这个并不是一类专门的事件类型,它只是用来记录已触发事件对应的文件描述符信息。
下面的代码显示了Redis中事件循环的结构体定义,你可以看下。
typedef struct aeEventLoop {
…
aeFileEvent *events; //IO事件数组
aeFiredEvent *fired; //已触发事件数组
aeTimeEvent *timeEventHead; //记录时间事件的链表头
…
void *apidata; //和API调用接口相关的数据
aeBeforeSleepProc *beforesleep; //进入事件循环流程前执行的函数
aeBeforeSleepProc *aftersleep; //退出事件循环流程后执行的函数
} aeEventLoop;了解了aeEventLoop结构体后,我们再来看下,这个结构体是如何初始化的,这其中就包括了IO事件数组和时间事件链表的初始化。
aeCreateEventLoop函数的初始化操作
因为Redis server在完成初始化后,就要开始运行事件驱动框架的循环流程,所以,aeEventLoop结构体在server.c的initServer函数中,就通过调用aeCreateEventLoop函数进行初始化了。这个函数的参数只有一个,是setsize。
下面的代码展示了initServer函数中对aeCreateEventLoop函数的调用。
initServer() {
…
//调用aeCreateEventLoop函数创建aeEventLoop结构体,并赋值给server结构的el变量
server.el = aeCreateEventLoop(server.maxclients+CONFIG_FDSET_INCR);
…
}从这里我们可以看到参数setsize的大小,其实是由server结构的maxclients变量和宏定义CONFIG_FDSET_INCR共同决定的。其中,maxclients变量的值大小,可以在Redis的配置文件redis.conf中进行定义,默认值是1000。而宏定义CONFIG_FDSET_INCR的大小,等于宏定义CONFIG_MIN_RESERVED_FDS的值再加上96,如下所示,这里的两个宏定义都是在server.h文件中定义的。
好了,到这里,你可能有疑问了:aeCreateEventLoop函数的参数setsize,设置为最大客户端数量加上一个宏定义值,可是这个参数有什么用呢?这就和aeCreateEventLoop函数具体执行的初始化操作有关了。
接下来,我们就来看下aeCreateEventLoop函数执行的操作,大致可以分成以下三个步骤。
第一步,aeCreateEventLoop函数会创建一个aeEventLoop结构体类型的变量eventLoop。然后,该函数会给eventLoop的成员变量分配内存空间,比如,按照传入的参数setsize,给IO事件数组和已触发事件数组分配相应的内存空间。此外,该函数还会给eventLoop的成员变量赋初始值。
第二步,aeCreateEventLoop函数会调用aeApiCreate函数。aeApiCreate函数封装了操作系统提供的IO多路复用函数,假设Redis运行在Linux操作系统上,并且IO多路复用机制是epoll,那么此时,aeApiCreate函数就会调用epoll_create创建epoll实例,同时会创建epoll_event结构的数组,数组大小等于参数setsize。
这里你需要注意,aeApiCreate函数是把创建的epoll实例描述符和epoll_event数组,保存在了aeApiState结构体类型的变量state,如下所示:
typedef struct aeApiState { //aeApiState结构体定义
int epfd; //epoll实例的描述符
struct epoll_event *events; //epoll_event结构体数组,记录监听事件
} aeApiState;
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
...
//将epoll_event数组保存在aeApiState结构体变量state中
state->events = zmalloc(sizeof(struct epoll_event)*eventLoop->setsize);
...
//将epoll实例描述符保存在aeApiState结构体变量state中
state->epfd = epoll_create(1024); 紧接着,aeApiCreate函数把state变量赋值给eventLoop中的apidata。这样一来,eventLoop结构体中就有了epoll实例和epoll_event数组的信息,这样就可以用来基于epoll创建和处理事件了。
eventLoop->apidata = state;第三步,aeCreateEventLoop函数会把所有网络IO事件对应文件描述符的掩码,初始化为AE_NONE,表示暂时不对任何事件进行监听。
我把aeCreateEventLoop函数的主要部分代码放在这里,你可以看下。
aeEventLoop *aeCreateEventLoop(int setsize) {
aeEventLoop *eventLoop;
int i;
//给eventLoop变量分配内存空间
if ((eventLoop = zmalloc(sizeof(*eventLoop))) == NULL) goto err;
//给IO事件、已触发事件分配内存空间
eventLoop->events = zmalloc(sizeof(aeFileEvent)*setsize);
eventLoop->fired = zmalloc(sizeof(aeFiredEvent)*setsize);
…
eventLoop->setsize = setsize;
eventLoop->lastTime = time(NULL);
//设置时间事件的链表头为NULL
eventLoop->timeEventHead = NULL;
…
//调用aeApiCreate函数,去实际调用操作系统提供的IO多路复用函数
if (aeApiCreate(eventLoop) == -1) goto err;
//将所有网络IO事件对应文件描述符的掩码设置为AE_NONE
for (i = 0; i < setsize; i++)
eventLoop->events[i].mask = AE_NONE;
return eventLoop;
//初始化失败后的处理逻辑,
err:
…好,那么从aeCreateEventLoop函数的执行流程中,我们其实可以看到以下两个关键点:
- 事件驱动框架监听的IO事件数组大小就等于参数setsize,这样决定了和Redis server连接的客户端数量。所以,当你遇到客户端连接Redis时报错“max number of clients reached”,你就可以去redis.conf文件修改maxclients配置项,以扩充框架能监听的客户端数量。
- 当使用Linux系统的epoll机制时,框架循环流程初始化操作,会通过aeApiCreate函数创建epoll_event结构数组,并调用epoll_create函数创建epoll实例,这都是使用epoll机制的准备工作要求。
IO事件处理
事实上,Redis的IO事件主要包括三类,分别是可读事件、可写事件和屏障事件。
其中,可读事件和可写事件其实比较好理解,也就是对应于Redis实例,我们可以从客户端读取数据或是向客户端写入数据。而屏障事件的主要作用是用来反转事件的处理顺序。比如在默认情况下,Redis会先给客户端返回结果,但是如果面临需要把数据尽快写入磁盘的情况,Redis就会用到屏障事件,把写数据和回复客户端的顺序做下调整,先把数据落盘,再给客户端回复。
在Redis源码中,IO事件的数据结构是aeFileEvent结构体,IO事件的创建是通过aeCreateFileEvent函数来完成的。下面的代码展示了aeFileEvent结构体的定义,你可以再回顾下:
typedef struct aeFileEvent {
int mask; //掩码标记,包括可读事件、可写事件和屏障事件
aeFileProc *rfileProc; //处理可读事件的回调函数
aeFileProc *wfileProc; //处理可写事件的回调函数
void *clientData; //私有数据
} aeFileEvent;而对于aeCreateFileEvent函数来说,在上节课我们已经了解了它是通过aeApiAddEvent函数来完成事件注册的。那么接下来,我们再从代码级别看下它是如何执行的,这可以帮助我们更加透彻地理解,事件驱动框架对IO事件监听是如何基于epoll机制对应封装的。
IO事件创建
首先,我们来看aeCreateFileEvent函数的原型定义,如下所示:
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask, aeFileProc *proc, void *clientData)这个函数的参数有5个,分别是循环流程结构体eventLoop、IO事件对应的文件描述符fd、事件类型掩码mask、事件处理回调函数`proc,以及事件私有数据*clientData`。
因为循环流程结构体*eventLoop中有IO事件数组,这个数组的元素是aeFileEvent类型,所以,每个数组元素都对应记录了一个文件描述符(比如一个套接字)相关联的监听事件类型和回调函数。
aeCreateFileEvent函数会先根据传入的文件描述符fd,在eventLoop的IO事件数组中,获取该描述符关联的IO事件指针变量*fe,如下所示:
aeFileEvent *fe = &eventLoop->events[fd];紧接着,aeCreateFileEvent函数会调用aeApiAddEvent函数,添加要监听的事件:
if (aeApiAddEvent(eventLoop, fd, mask) == -1)
return AE_ERR;aeApiAddEvent函数实际上会调用操作系统提供的IO多路复用函数,来完成事件的添加。我们还是假设Redis实例运行在使用epoll机制的Linux上,那么aeApiAddEvent函数就会调用epoll_ctl函数,添加要监听的事件。epoll_ctl函数,这个函数会接收4个参数,分别是:
- epoll实例;
- 要执行的操作类型(是添加还是修改);
- 要监听的文件描述符;
- epoll_event类型变量。
那么,这个调用过程是如何准备epoll_ctl函数需要的参数,从而完成执行的呢?
首先,epoll实例是我刚才给你介绍的aeCreateEventLoop函数,它是通过调用aeApiCreate函数来创建的,保存在了eventLoop结构体的apidata变量中,类型是aeApiState。所以,aeApiAddEvent函数会先获取该变量,如下所示:
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
//从eventLoop结构体中获取aeApiState变量,里面保存了epoll实例
aeApiState *state = eventLoop->apidata;
...
}其次,对于要执行的操作类型的设置,aeApiAddEvent函数会根据传入的文件描述符fd,在eventLoop结构体中IO事件数组中查找该fd。因为IO事件数组的每个元素,都对应了一个文件描述符,而该数组初始化时,每个元素的值都设置为了AE_NONE。
所以,如果要监听的文件描述符fd在数组中的类型不是AE_NONE,则表明该描述符已做过设置,那么操作类型就是修改操作,对应epoll机制中的宏定义EPOLL_CTL_MOD。否则,操作类型就是添加操作,对应epoll机制中的宏定义EPOLL_CTL_ADD。这部分代码如下所示:
//如果文件描述符fd对应的IO事件已存在,则操作类型为修改,否则为添加
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;第三,epoll_ctl函数需要的监听文件描述符,就是aeApiAddEvent函数接收到的参数fd。
最后,epoll_ctl函数还需要一个epoll_event类型变量,因此aeApiAddEvent函数在调用epoll_ctl函数前,会新创建epoll_event类型变量ee。然后,aeApiAddEvent函数会设置变量ee中的监听事件类型和监听文件描述符。
aeApiAddEvent函数的参数mask,表示的是要监听的事件类型掩码。所以,aeApiAddEvent函数会根据掩码值是可读(AE_READABLE)或可写(AE_WRITABLE)事件,来设置ee监听的事件类型是EPOLLIN还是EPOLLOUT。这样一来,Redis事件驱动框架中的读写事件就能够和epoll机制中的读写事件对应上来。下面的代码展示了这部分逻辑,你可以看下。
…
struct epoll_event ee = {0}; //创建epoll_event类型变量
…
//将可读或可写IO事件类型转换为epoll监听的类型EPOLLIN或EPOLLOUT
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd; //将要监听的文件描述符赋值给ee好了,到这里,aeApiAddEvent函数就准备好了epoll实例、操作类型、监听文件描述符以及epoll_event类型变量,然后,它就会调用epoll_ctl开始实际创建监听事件了,如下所示:
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
...
//调用epoll_ctl实际创建监听事件
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;
return 0;
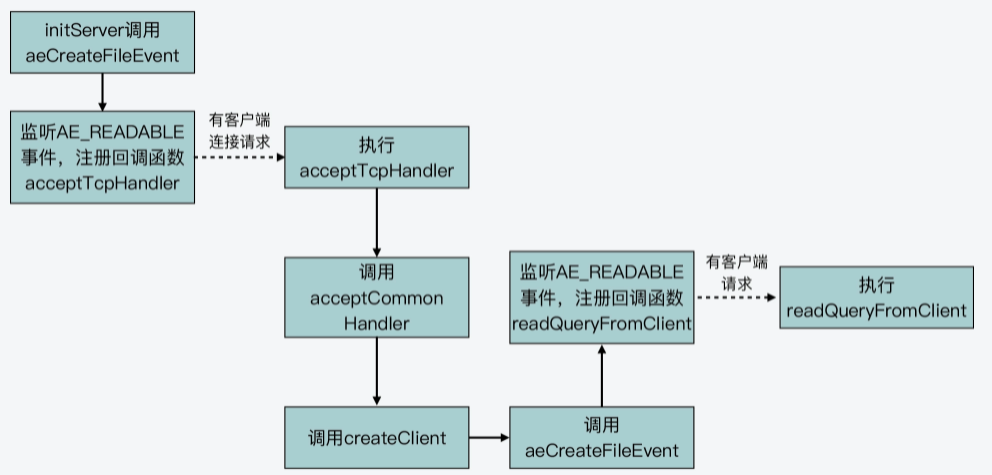
}了解了这些代码后,我们可以学习到事件驱动框架是如何基于epoll,封装实现了IO事件的创建。那么,在Redis server启动运行后,最开始监听的IO事件是可读事件,对应于客户端的连接请求。具体是initServer函数调用了aeCreateFileEvent函数,创建可读事件,并设置回调函数为acceptTcpHandler,用来处理客户端连接。
读事件处理
当Redis server接收到客户端的连接请求时,就会使用注册好的acceptTcpHandler函数进行处理。
acceptTcpHandler函数是在networking.c文件中,它会接受客户端连接,并创建已连接套接字cfd。然后,acceptCommonHandler函数(在networking.c文件中)会被调用,同时,刚刚创建的已连接套接字cfd会作为参数,传递给acceptCommonHandler函数。
acceptCommonHandler函数会调用createClient函数(在networking.c文件中)创建客户端。而在createClient函数中,我们就会看到,aeCreateFileEvent函数被再次调用了。
此时,aeCreateFileEvent函数会针对已连接套接字上,创建监听事件,类型为AE_READABLE,回调函数是readQueryFromClient(在networking.c文件中)。
好了,到这里,事件驱动框架就增加了对一个客户端已连接套接字的监听。一旦客户端有请求发送到server,框架就会回调readQueryFromClient函数处理请求。这样一来,客户端请求就能通过事件驱动框架进行处理了。
下面代码展示了createClient函数调用aeCreateFileEvent的过程,你可以看下。
client *createClient(int fd) {
…
if (fd != -1) {
…
//调用aeCreateFileEvent,监听读事件,对应客户端读写请求,使用readQueryFromclient回调函数处理
if (aeCreateFileEvent(server.el,fd,AE_READABLE,
readQueryFromClient, c) == AE_ERR)
{
close(fd);
zfree(c);
return NULL;
} }
…
}为了便于你掌握从监听客户端连接请求到监听客户端常规读写请求的事件创建过程,我画了下面这张图,你可以看下。
写事件处理
Redis实例在收到客户端请求后,会在处理客户端命令后,将要返回的数据写入客户端输出缓冲区。下图就展示了这个过程的函数调用逻辑:
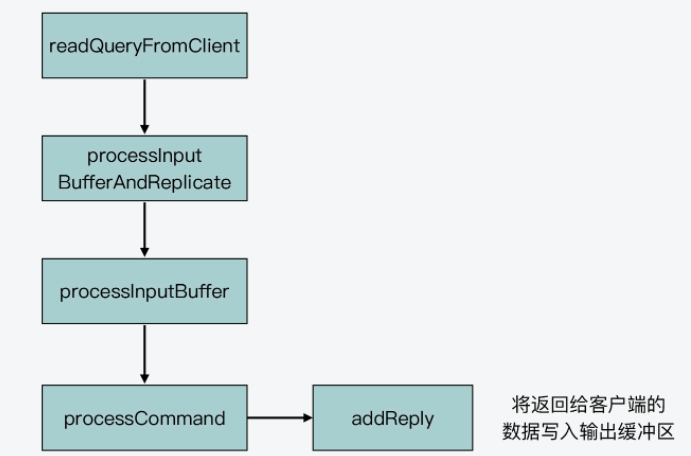
而在Redis事件驱动框架每次循环进入事件处理函数前,也就是在框架主函数aeMain中调用aeProcessEvents,来处理监听到的已触发事件或是到时的时间事件之前,都会调用server.c文件中的beforeSleep函数,进行一些任务处理,这其中就包括了调用handleClientsWithPendingWrites函数,它会将Redis sever客户端缓冲区中的数据写回客户端。
下面给出的代码是事件驱动框架的主函数aeMain。在该函数每次调用aeProcessEvents函数前,就会调用beforeSleep函数,你可以看下。
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
//如果beforeSleep函数不为空,则调用beforeSleep函数
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
//调用完beforeSleep函数,再处理事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}这里你要知道,beforeSleep函数调用的handleClientsWithPendingWrites函数,会遍历每一个待写回数据的客户端,然后调用writeToClient函数,将客户端输出缓冲区中的数据写回。下面这张图展示了这个流程,你可以看下。
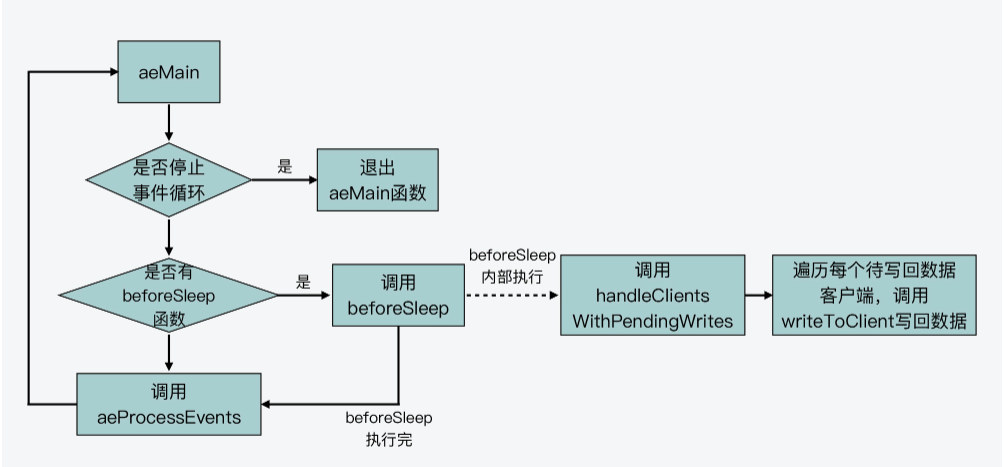
不过,如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites函数就会调用aeCreateFileEvent函数,创建可写事件,并设置回调函数sendReplyToClient。sendReplyToClient函数里面会调用writeToClient函数写回数据。
下面的代码展示了handleClientsWithPendingWrite函数的基本流程,你可以看下。
int handleClientsWithPendingWrites(void) {
listIter li;
listNode *ln;
…
//获取待写回的客户端列表
listRewind(server.clients_pending_write,&li);
//遍历每一个待写回的客户端
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
…
//调用writeToClient将当前客户端的输出缓冲区数据写回
if (writeToClient(c->fd,c,0) == C_ERR) continue;
//如果还有待写回数据
if (clientHasPendingReplies(c)) {
int ae_flags = AE_WRITABLE;
//创建可写事件的监听,以及设置回调函数
if (aeCreateFileEvent(server.el, c->fd, ae_flags,
sendReplyToClient, c) == AE_ERR)
{
…
}
} }
}好了,我们刚才了解的是读写事件对应的回调处理函数。实际上,为了能及时处理这些事件,Redis事件驱动框架的aeMain函数还会循环调用aeProcessEvents函数,来检测已触发的事件,并调用相应的回调函数进行处理。
从aeProcessEvents函数的代码中,我们可以看到该函数会调用aeApiPoll函数,查询监听的文件描述符中,有哪些已经就绪。一旦有描述符就绪,aeProcessEvents函数就会根据事件的可读或可写类型,调用相应的回调函数进行处理。aeProcessEvents函数调用的基本流程如下所示:
int aeProcessEvents(aeEventLoop *eventLoop, int flags){
…
//调用aeApiPoll获取就绪的描述符
numevents = aeApiPoll(eventLoop, tvp);
…
for (j = 0; j < numevents; j++) {
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
…
//如果触发的是可读事件,调用事件注册时设置的读事件回调处理函数
if (!invert && fe->mask & mask & AE_READABLE) {
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
//如果触发的是可写事件,调用事件注册时设置的写事件回调处理函数
if (fe->mask & mask & AE_WRITABLE) {
if (!fired || fe->wfileProc != fe->rfileProc) {
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
}
…
} }
…
}到这里,我们就了解了IO事件的创建函数aeCreateFileEvent,以及在处理客户端请求时对应的读写事件和它们的处理函数。
时间事件处理
其实,相比于IO事件有可读、可写、屏障类型,以及不同类型IO事件有不同回调函数来说,时间事件的处理就比较简单了。下面,我们就来分别学习下它的定义、创建、回调函数和触发处理。
时间事件定义
首先,我们来看下时间事件的结构体定义,代码如下所示:
typedef struct aeTimeEvent {
long long id; //时间事件ID
long when_sec; //事件到达的秒级时间戳
long when_ms; //事件到达的毫秒级时间戳
aeTimeProc *timeProc; //时间事件触发后的处理函数
aeEventFinalizerProc *finalizerProc; //事件结束后的处理函数
void *clientData; //事件相关的私有数据
struct aeTimeEvent *prev; //时间事件链表的前向指针
struct aeTimeEvent *next; //时间事件链表的后向指针
} aeTimeEvent;时间事件结构体中主要的变量,包括以秒记录和以毫秒记录的时间事件触发时的时间戳when_sec和when_ms,以及时间事件触发后的处理函数*timeProc。另外,在时间事件的结构体中,还包含了前向和后向指针*prev和*next,这表明时间事件是以链表的形式组织起来的。
在了解了时间事件结构体的定义以后,我们接着来看下,时间事件是如何创建的。
时间事件创建
与IO事件创建使用aeCreateFileEvent函数类似,时间事件的创建函数是aeCreateTimeEvent函数。这个函数的原型定义如下所示:
long long aeCreateTimeEvent(aeEventLoop *eventLoop, long long milliseconds, aeTimeProc *proc, void *clientData, aeEventFinalizerProc *finalizerProc)在它的参数中,有两个需要我们重点了解下,以便于我们理解时间事件的处理。一个是milliseconds,这是所创建时间事件的触发时间距离当前时间的时长,是用毫秒表示的。另一个是*proc,这是所创建时间事件触发后的回调函数。
aeCreateTimeEvent函数的执行逻辑不复杂,主要就是创建一个时间事件的变量te,对它进行初始化,并把它插入到框架循环流程结构体eventLoop中的时间事件链表中。在这个过程中,aeCreateTimeEvent函数会调用aeAddMillisecondsToNow函数,根据传入的milliseconds参数,计算所创建时间事件具体的触发时间戳,并赋值给te。
实际上,Redis server在初始化时,除了创建监听的IO事件外,也会调用aeCreateTimeEvent函数创建时间事件。下面代码显示了initServer函数对aeCreateTimeEvent函数的调用:
initServer() {
…
//创建时间事件
if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR){
… //报错信息
}
}从代码中,我们可以看到,时间事件触发后的回调函数是serverCron。
时间事件回调函数
serverCron函数是在server.c文件中实现的。一方面,它会顺序调用一些函数,来实现时间事件被触发后,执行一些后台任务。比如,serverCron函数会检查是否有进程结束信号,若有就执行server关闭操作。serverCron会调用databaseCron函数,处理过期key或进行rehash等。你可以参考下面给出的代码:
...
// 如果收到进程结束信号,则执行server关闭操作
if (server.shutdown_asap) {
if (prepareForShutdown(SHUTDOWN_NOFLAGS) == C_OK) exit(0);
...
}
...
// 执行客户端的异步操作
clientCron();
// 执行数据库的后台操作
databaseCron();
...另一方面,serverCron函数还会以不同的频率周期性执行一些任务,这是通过执行宏run_with_period来实现的。
run_with_period宏定义如下,该宏定义会根据Redis实例配置文件redis.conf中定义的hz值,来判断参数ms表示的时间戳是否到达。一旦到达,serverCron就可以执行相应的任务了。
#define run_with_period(_ms_) if ((_ms_ <= 1000/server.hz) || !(server.cronloops%((_ms_)/(1000/server.hz))))比如,serverCron函数中会以1秒1次的频率,检查AOF文件是否有写错误。如果有的话,serverCron就会调用flushAppendOnlyFile函数,再次刷回AOF文件的缓存数据。下面的代码展示了这一周期性任务:
serverCron() {
…
//每1秒执行1次,检查AOF是否有写错误
run_with_period(1000) {
if (server.aof_last_write_status == C_ERR)
flushAppendOnlyFile(0);
}
…
}如果你想了解更多的周期性任务,可以再详细阅读下serverCron函数中,以run_with_period宏定义包含的代码块。
时间事件的触发处理
其实,时间事件的检测触发比较简单,事件驱动框架的aeMain函数会循环调用aeProcessEvents函数,来处理各种事件。而aeProcessEvents函数在执行流程的最后,会调用processTimeEvents函数处理相应到时的任务。
aeProcessEvents(){
…
//检测时间事件是否触发
if (flags & AE_TIME_EVENTS)
processed += processTimeEvents(eventLoop);
…
}那么,具体到proecessTimeEvent函数来说,它的基本流程就是从时间事件链表上逐一取出每一个事件,然后根据当前时间判断该事件的触发时间戳是否已满足。如果已满足,那么就调用该事件对应的回调函数进行处理。这样一来,周期性任务就能在不断循环执行的aeProcessEvents函数中,得到执行了。
下面的代码显示了processTimeEvents函数的基本流程,你可以再看下。
static int processTimeEvents(aeEventLoop *eventLoop) {
...
te = eventLoop->timeEventHead; //从时间事件链表中取出事件
while(te) {
...
aeGetTime(&now_sec, &now_ms); //获取当前时间
if (now_sec > te->when_sec || (now_sec == te->when_sec && now_ms >= te->when_ms)) //如果当前时间已经满足当前事件的触发时间戳
{
...
retval = te->timeProc(eventLoop, id, te->clientData); //调用注册的回调函数处理
...
}
te = te->next; //获取下一个时间事件
...
}小结
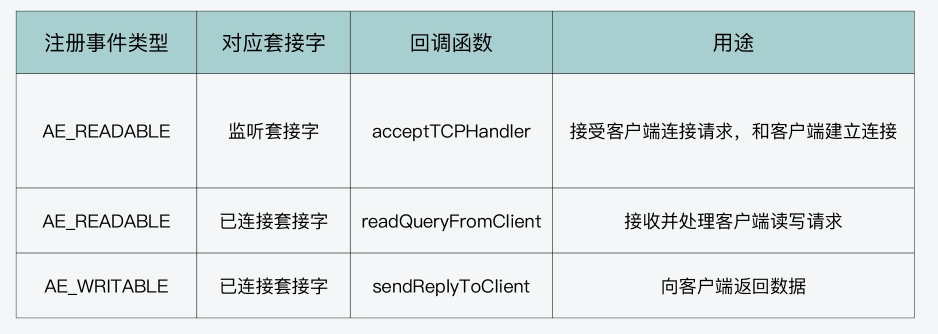
Redis事件驱动框架中的两类事件:IO事件和时间事件。
当Redis server创建Socket后,就会注册可读事件,并使用acceptTCPHandler回调函数处理客户端的连接请求。
当server和客户端完成连接建立后,server会在已连接套接字上监听可读事件,并使用readQueryFromClient函数处理客户端读写请求。这里,你需要再注意下,无论客户端发送的请求是读或写操作,对于server来说,都是要读取客户端的请求并解析处理。所以,server在客户端的已连接套接字上注册的是可读事件。
而当实例需要向客户端写回数据时,实例会在事件驱动框架中注册可写事件,并使用sendReplyToClient作为回调函数,将缓冲区中数据写回客户端。
Redis真的是单线程吗?
Redis的执行模型
所谓的执行模型,就是指Redis运行时使用的进程、子进程和线程的个数,以及它们各自负责的工作任务。
从shell命令执行到Redis进程创建
我们在启动Redis实例时,可以在shell命令行环境中,执行redis-server这个可执行文件,如下所示:
./redis-server /etc/redis/redis.confshell运行这个命令后,它实际会调用fork系统调用函数,来新建一个进程。因为shell本身是一个进程,所以,这个通过fork新创建的进程就被称为是shell进程的子进程,而shell进程被称为父进程。
紧接着,shell进程会调用execve系统调用函数,将子进程执行的主体替换成Redis的可执行文件。而Redis可执行文件的入口函数就是main函数,这样一来,子进程就会开始执行Redis server的main函数了。
下面的代码显示了execve系统调用函数原型。其中,filename是要运行的程序的文件名,argv[]和envp[]分别是要运行程序的参数和环境变量。
int execve(const char *filename, char *const argv[], char *const envp[]))下图显示了从shell执行命令到创建Redis进程的过程,你可以看下。

当我们用刚才介绍的shell命令运行Redis server后,我们会看到Redis server启动后的日志输出会打印到终端屏幕上,如下所示:
37807:M 19 Aug 2021 07:29:36.372 # Server initialized
37807:M 19 Aug 2021 07:29:36.372 * DB loaded from disk: 0.000 seconds
37807:M 19 Aug 2021 07:29:36.372 * Ready to accept connections这是因为shell进程调用fork函数创建的子进程,会从父进程中继承一些属性,比如父进程打开的文件描述符。对于shell进程来说,它打开的文件描述符包括0和1,这两个描述符分别代表了标准输入和标准输出。而execve函数只是把子进程的执行内容替换成Redis可执行文件,子进程从shell父进程继承到的标准输入和标准输出保持不变。
而一旦Redis进程创建开始运行后,它就会从main函数开始执行。
main函数调用initServerConfig函数初始化Redis server的运行参数,调用loadServerConfig函数解析配置文件参数。当main函数调用这些函数时,这些函数仍然是由原来的进程执行的。所以,在这种情况下,Redis仍然是单个进程在运行。
不过,在main函数完成参数解析后,会根据两个配置参数daemonize和supervised,来设置变量background的值。它们的含义分别是:
- 参数daemonize表示,是否要设置Redis以守护进程方式运行;
- 参数supervised表示,是否使用upstart或是systemd这两种守护进程的管理程序来管理Redis。
那么,我们来进一步了解下守护进程。守护进程是在系统后台运行的进程,独立于shell终端,不再需要用户在shell中进行输入了。一般来说,守护进程用于执行周期性任务或是等待相应事件发生再进行处理。Redis server本身就是在启动后,等待客户端输入,再进行处理。所以对于Redis这类服务器程序来说,我们通常会让它以守护进程方式运行。
好了,如果设置了Redis以守护进程方式执行,那么守护进程具体是怎么创建的呢?这就和main函数调用的daemonize函数相关了。daemonize函数就是用来将Redis进程转换为守护进程来运行。
下面的代码显示了main函数根据变量background值,来判断是否执行daemonize函数的逻辑,你可以看下。
//如果配置参数daemonize为1,supervised值为0,那么设置background值为1,否则,设置其为0。
int main(int argc, char **argv) {
…
int background = server.daemonize && !server.supervised;
//如果background值为1,调用daemonize函数。
if (background) daemonize();
…
}也就是说,如果background的值为1,就表示Redis被设置为以守护进程方式运行,因此main函数就会调用daemonize函数。
那么,接下来,我们就来学习下daemonize函数是如何将Redis转为守护进程运行的。
从daemonize函数的执行学习守护进程的创建
我们首先来看daemonize函数的部分执行内容,如下所示。我们可以看到,daemonize函数调用了fork函数,并根据fork函数返回值有不同的分支代码。
void daemonize(void) {
…
if (fork() != 0) exit(0); //fork成功执行或失败,则父进程退出
setsid(); //创建新的session
…
}从刚才的介绍中,我们已经知道,当我们在一个程序的函数中调用fork函数时,fork函数会创建一个子进程。而原本这个程序对应的进程,就称为这个子进程的父进程。那么,fork函数执行后的不同分支和父、子进程是什么关系呢?这就和fork函数的使用有关了。
实际上,fork函数的使用是比较有意思的,我们可以根据fork函数的不同返回值,来编写相应的分支代码,这些分支代码就对应了父进程和子进程各自要执行的逻辑。
为了便于你理解,我给你举个例子。我写了一段示例代码,这段代码的main函数会调用fork函数,并进一步根据fork函数的返回值是小于0、等于0,还是大于0,来执行不同的分支。注意,fork函数的不同返回值,其实代表了不同的含义,具体来说:
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
printf("hello main\n");
int rv = fork(); //fork函数的返回值
//返回值小于0,表示fork执行错误
if (rv < 0) {
fprintf(stderr, "fork failed\n");
}
//返回值等于0,对应子进程执行
else if (rv == 0) {
printf("I am child process %d\n", getpid());
}
//返回值大于0,对应父进程执行
else {
printf("I am parent process of (%d), %d\n", rv, getpid());
}
return 0;
}在这段代码中,我根据fork函数的返回值,分别写了三个分支代码,其中返回值等于0对应的代码分支,是子进程执行的代码。子进程会打印字符串“I am child process”,并打印子进程的进程号。而返回值大于0对应的代码分支,是父进程的代码。父进程会打印字符串“I am parent process of”,并打印它所创建的子进程进程号和它自身的进程号。
那么,如果你把这段代码编译后执行,你可以看到类似如下的结果,父进程打印了它的进程号62794,而子进程则打印了它的进程号62795。这表明刚才示例代码中的不同分支的确是由父、子进程来执行的。这也就是说,我们可以在fork函数执行后,使用不同分支,让父、子进程执行不同内容。
hello main
I am parent process of (62795), 62794
I am child process 62795好了,了解了fork函数创建子进程的知识后,我们再来看下刚才介绍的daemonize函数。
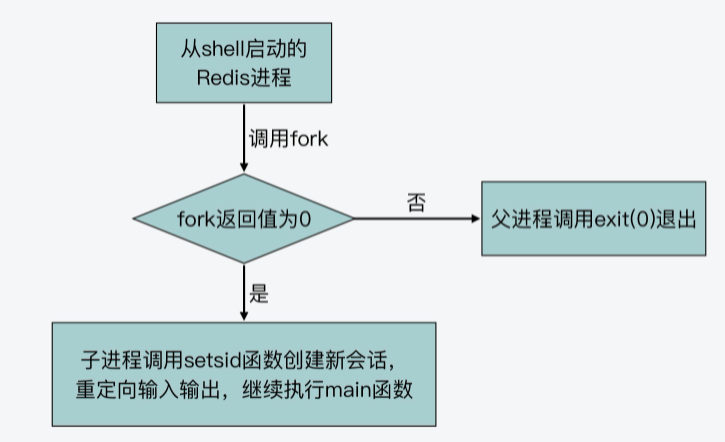
现在我们已经知道,daemonize函数调用fork函数后,可以根据fork函数返回值设置不同代码分支,对应父、子进程执行内容。其实,daemonize函数也的确设置了两个代码分支。
- 分支一
这个分支对应fork函数返回值不为0,表示fork函数成功执行后的父进程执行逻辑或是fork函数执行失败的执行逻辑。此时,父进程会调用exit(0)函数退出。也就是说,如果fork函数成功执行,父进程就退出了。当然,如果fork函数执行失败了,那么子进程也没有能成功创建,父进程也就退出执行了。你可以看下下面的代码,展示了这个分支。
void daemonize(void) {
…
if (fork() != 0) exit(0); //fork成功执行或失败,则父进程退出
…
}- 分支二
这个分支对应fork函数返回值为0,为子进程的执行逻辑。子进程首先会调用setsid函数,创建一个新的会话。
然后,子进程会用open函数打开/dev/null设备,并把它的标准输入、标准输出和标准错误输出,重新定向到/dev/null设备。因为守护进程是在后台运行,它的输入输出是独立于shell终端的。所以,为了让Redis能以守护进程方式运行,这几步操作的目的就是把当前子进程的输入、输出由原来的shell终端,转向/dev/null设备,这样一来,就不再依赖于shell终端了,满足了守护进程的要求。
我把daemonize函数的代码放在这里,你可以看下。
void daemonize(void) {
…
setsid(); //为子进程创建新的session
//将子进程的标准输入、标准输出、标准错误输出重定向到/dev/null中
if ((fd = open("/dev/null", O_RDWR, 0)) != -1) {
dup2(fd, STDIN_FILENO);
dup2(fd, STDOUT_FILENO);
dup2(fd, STDERR_FILENO);
if (fd > STDERR_FILENO) close(fd);
}
}好了,到这里,我们就了解了,Redis的main函数会根据配置参数daemonize和supervised,来判断是否以守护进程方式运行Redis。
那么,一旦Redis要以守护进程方式运行,main函数会调用daemonize函数。daemonize函数会进一步调用fork函数创建子进程,并根据返回值,分别执行父进程和子进程的代码分支。其中,父进程会退出。而子进程会代替原来的父进程,继续执行main函数的代码。
下面的图展示了daemonize函数调用fork函数后的两个分支的执行逻辑,你可以再回顾下。
事实上,Redis server启动后无论是否以守护进程形式运行,都还是一个进程在运行。对于一个进程来说,如果该进程启动后没有创建新的线程,那么这个进程的工作任务默认就是由一个线程来执行的,而这个线程我一般也称它为主线程。
对于Redis来说,它的主要工作,包括接收客户端请求、解析请求和进行数据读写等操作,都没有创建新线程来执行,所以,Redis主要工作的确是由单线程来执行的,这也是我们常说Redis是单线程程序的原因。因为Redis主要工作都是IO读写操作,所以,我也会把这个单线程称为主IO线程。
但其实,Redis 在3.0版本后,除了主IO线程外,的确还会启动一些后台线程来处理部分任务,从而避免这些任务对主IO线程的影响。那么,这些后台线程是在哪里启动的,又是如何执行的呢?
这就和Redis的bio.c文件相关了。接下来,我们就来从这个文件中学习下Redis的后台线程。
从bio.c文件学习Redis的后台线程
我们先来看下main函数在初始化过程最后调用的InitServerLast函数。InitServerLast函数的作用是进一步调用bioInit函数,来创建后台线程,让Redis把部分任务交给后台线程处理。这个过程如下所示。
void InitServerLast() {
bioInit();
…
}bioInit函数是在bio.c文件中实现的,它的主要作用调用pthread_create函数创建多个后台线程。不过在具体了解bioInit函数之前,我们先来看下bio.c文件中定义的主要数组,这也是在bioInit函数中要进行初始化的。
bio.c文件针对要创建的线程,定义了pthread_t类型的数组bio_threads,用来保存创建的线程描述符。此外,bio.c文件还创建了一个保存互斥锁的数组bio_mutex,以及两个保存条件变量的数组bio_newjob_cond和bio_step_cond。以下代码展示了这些数组的创建逻辑,你可以看下。
// 保存线程描述符的数组
static pthread_t bio_threads[BIO_NUM_OPS];
// 保存互斥锁的数组
static pthread_mutex_t bio_mutex[BIO_NUM_OPS];
// 保存条件变量的两个数组
static pthread_cond_t bio_newjob_cond[BIO_NUM_OPS];
static pthread_cond_t bio_step_cond[BIO_NUM_OPS];从中你可以注意到,这些数组的大小都是宏定义BIO_NUM_OPS,这个宏定义是在bio.h文件中定义的,默认值为3。
同时在bio.h文件中,你还可以看到另外三个宏定义,分别是BIO_CLOSE_FILE、BIO_AOF_FSYNC和BIO_LAZY_FREE。它们的代码如下所示:
#define BIO_CLOSE_FILE 0 /* Deferred close(2) syscall. */
#define BIO_AOF_FSYNC 1 /* Deferred AOF fsync. */
#define BIO_LAZY_FREE 2 /* Deferred objects freeing. */
#define BIO_NUM_OPS 3其中,BIO_NUM_OPS表示的是Redis后台任务的类型有三种。而BIO_CLOSE_FILE、BIO_AOF_FSYNC和BIO_LAZY_FREE,它们分别表示三种后台任务的操作码,这些操作码可以用来标识不同的任务。
- BIO_CLOSE_FILE:文件关闭后台任务。
- BIO_AOF_FSYNC:AOF日志同步写回后台任务。
- BIO_LAZY_FREE:惰性删除后台任务。
实际上,bio.c文件创建的线程数组、互斥锁数组和条件变量数组,大小都是包含三个元素,也正是对应了这三种任务。
bioInit函数:初始化数组
接下来,我们再来了解下bio.c文件中的初始化和线程创建函数bioInit。我刚才也给你介绍过这个函数,它是main函数执行完server初始化后,通过InitServerLast函数调用的。也就是说,Redis在完成server初始化后,就会创建线程来执行后台任务。
所以从这里来看,Redis在运行时其实已经不止是单个线程(也就是主IO线程)在运行了,还会有后台线程在运行。如果你以后遇到Redis是否是单线程的问题时,你就可以给出准确答案了。
bioInit函数首先会初始化互斥锁数组和条件变量数组。然后,该函数会调用listCreate函数,给bio_jobs这个数组的每个元素创建一个列表,同时给bio_pending数组的每个元素赋值为0。这部分代码如下所示:
for (j = 0; j < BIO_NUM_OPS; j++) {
pthread_mutex_init(&bio_mutex[j],NULL);
pthread_cond_init(&bio_newjob_cond[j],NULL);
pthread_cond_init(&bio_step_cond[j],NULL);
bio_jobs[j] = listCreate();
bio_pending[j] = 0;
}那么,要想了解给bio_jobs数组和bio_pending数组元素赋值的作用,我们就需要先搞清楚这两个数组的含义:
- bio_jobs数组的元素是bio_jobs结构体类型,用来表示后台任务。该结构体的成员变量包括了后台任务的创建时间time,以及任务的参数。为该数组的每个元素创建一个列表,其实就是为每个后台线程创建一个要处理的任务列表。
- bio_pending数组的元素类型是unsigned long long,用来表示每种任务中,处于等待状态的任务个数。将该数组每个元素初始化为0,其实就是表示初始时,每种任务都没有待处理的具体任务。
下面的代码展示了bio_job结构体,以及bio_jobs和bio_pending这两个数组的定义,你也可以看下。
struct bio_job {
time_t time; //任务创建时间
void *arg1, *arg2, *arg3; //任务参数
};
//以后台线程方式运行的任务列表
static list *bio_jobs[BIO_NUM_OPS];
//被阻塞的后台任务数组
static unsigned long long bio_pending[BIO_NUM_OPS];好了,到这里,你就了解了bioInit函数执行时,会把线程互斥锁、条件变量对应数组初始化为NULL,同时会给每个后台线程创建一个任务列表(对应bio_jobs数组的元素),以及会设置每种任务的待处理个数为0(对应bio_pending数组的元素)。
bioInit函数:设置线程属性并创建线程
在完成了初始化之后,接下来,bioInit函数会先通过pthread_attr_t类型的变量,给线程设置属性。然后,bioInit函数会调用前面我提到的pthread_create函数来创建线程。
不过,为了能更好地理解bioInit函数设置线程属性和创建线程的过程,我们需要先对pthread_create函数本身有所了解,该函数的原型如下所示:
int pthread_create(pthread_t *tidp, const pthread_attr_t *attr,
( void *)(*start_routine)( void *), void *arg);可以看到,pthread_create函数一共有4个参数,分别是:
- *tidp,指向线程数据结构pthread_t的指针;
- *attr,指向线程属性结构pthread_attr_t的指针;
- *start_routine,线程所要运行的函数的起始地址,也是指向函数的指针;
- *arg,传给运行函数的参数。
了解了pthread_create函数之后,我们来看下bioInit函数的具体操作。
首先,bioInit函数会调用pthread_attr_init函数,初始化线程属性变量attr,然后调用pthread_attr_getstacksize函数,获取线程的栈大小这一属性的当前值,并根据当前栈大小和REDIS_THREAD_STACK_SIZE宏定义的大小(默认值为4MB),来计算最终的栈大小属性值。紧接着,bioInit函数会调用pthread_attr_setstacksize函数,来设置栈大小这一属性值。
下面的代码展示了线程属性的获取、计算和设置逻辑,你可以看下。
pthread_attr_init(&attr);
pthread_attr_getstacksize(&attr,&stacksize);
if (!stacksize) stacksize = 1; /针对Solaris系统做处理
while (stacksize < REDIS_THREAD_STACK_SIZE) stacksize *= 2;
pthread_attr_setstacksize(&attr, stacksize);在完成线程属性的设置后,接下来,bioInit函数会通过一个for循环,来依次为每种后台任务创建一个线程。循环的次数是由BIO_NUM_OPS宏定义决定的,也就是3次。相应的,bioInit函数就会调用3次pthread_create函数,并创建3个线程。bioInit函数让这3个线程执行的函数都是bioProcessBackgroundJobs。
不过这里要注意一点,就是在这三次线程的创建过程中,传给这个函数的参数分别是0、1、2。这个创建过程如下所示:
for (j = 0; j < BIO_NUM_OPS; j++) {
void *arg = (void*)(unsigned long) j;
if (pthread_create(&thread,&attr,bioProcessBackgroundJobs,arg) != 0) {
… //报错信息
}
bio_threads[j] = thread;
}你看了这个代码,可能会有一个小疑问:为什么创建的3个线程,它们所运行的bioProcessBackgroundJobs函数接收的参数分别是0、1、2呢?
这就和bioProcessBackgroundJobs函数的实现有关了,我们来具体看下。
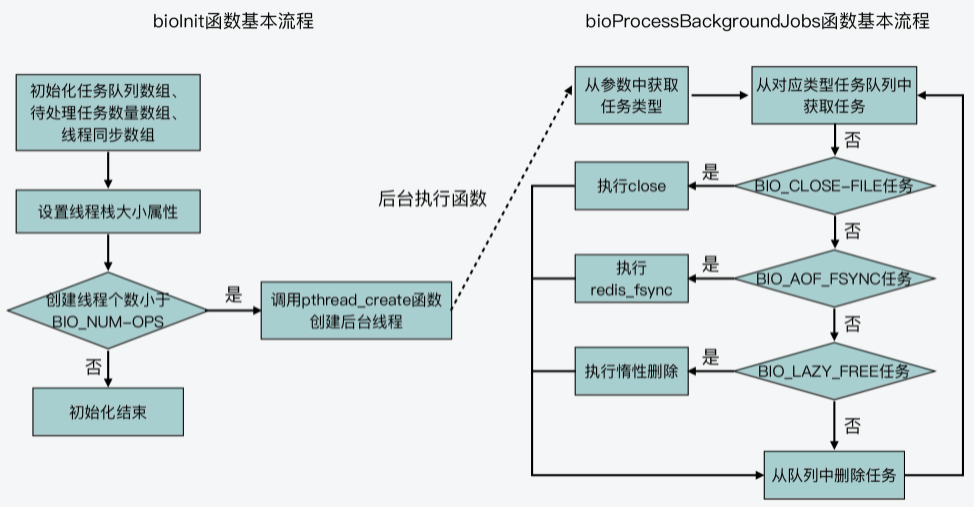
bioProcessBackgroundJobs函数:处理后台任务
首先,bioProcessBackgroundJobs函数会把接收到的参数arg,转成unsigned long类型,并赋值给type变量,如下所示:
void *bioProcessBackgroundJobs(void *arg) {
…
unsigned long type = (unsigned long) arg;
…
}而type变量表示的就是后台任务的操作码。这也是我刚才给你介绍的三种后台任务类型BIO_CLOSE_FILE、BIO_AOF_FSYNC和BIO_LAZY_FREE对应的操作码,它们的取值分别为0、1、2。
bioProcessBackgroundJobs函数的主要执行逻辑是一个while(1)的循环。在这个循环中,bioProcessBackgroundJobs函数会从bio_jobs这个数组中取出相应任务,并根据任务类型,调用具体的函数来执行。
我刚才已经介绍过,bio_jobs数组的每一个元素是一个队列。而因为bio_jobs数组的元素个数,等于后台任务的类型个数(也就是BIO_NUM_OPS),所以,bio_jobs数组的每个元素,实际上是对应了某一种后台任务的任务队列。
在了解了这一点后,我们就容易理解bioProcessBackgroundJobs函数中的while循环了。因为传给bioProcessBackgroundJobs函数的参数,分别是0、1、2,对应了三种任务类型,所以在这个循环中,bioProcessBackgroundJobs函数会一直不停地从某一种任务队列中,取出一个任务来执行。
同时,bioProcessBackgroundJobs函数会根据传入的任务操作类型调用相应函数,具体来说:
- 任务类型是BIO_CLOSE_FILE,则调用close函数;
- 任务类型是BIO_AOF_FSYNC,则调用redis_fsync函数;
- 任务类型是BIO_LAZY_FREE,则再根据参数个数等情况,分别调用lazyfreeFreeObjectFromBioThread、lazyfreeFreeDatabaseFromBioThread和lazyfreeFreeSlotsMapFromBioThread这三个函数。
最后,当某个任务执行完成后,bioProcessBackgroundJobs函数会从任务队列中,把这个任务对应的数据结构删除。我把这部分代码放在这里,你可以看下。
while(1) {
listNode *ln;
…
//从类型为type的任务队列中获取第一个任务
ln = listFirst(bio_jobs[type]);
job = ln->value;
…
//判断当前处理的后台任务类型是哪一种
if (type == BIO_CLOSE_FILE) {
close((long)job->arg1); //如果是关闭文件任务,那就调用close函数
} else if (type == BIO_AOF_FSYNC) {
redis_fsync((long)job->arg1); //如果是AOF同步写任务,那就调用redis_fsync函数
} else if (type == BIO_LAZY_FREE) {
//如果是惰性删除任务,那根据任务的参数分别调用不同的惰性删除函数执行
if (job->arg1)
lazyfreeFreeObjectFromBioThread(job->arg1);
else if (job->arg2 && job->arg3)
lazyfreeFreeDatabaseFromBioThread(job->arg2,job->arg3);
else if (job->arg3)
lazyfreeFreeSlotsMapFromBioThread(job->arg3);
} else {
serverPanic("Wrong job type in bioProcessBackgroundJobs().");
}
…
//任务执行完成后,调用listDelNode在任务队列中删除该任务
listDelNode(bio_jobs[type],ln);
//将对应的等待任务个数减一。
bio_pending[type]--;
…
}所以说,bioInit函数其实就是创建了3个线程,每个线程不停地去查看任务队列中是否有任务,如果有任务,就调用具体函数执行。
你可以再参考回顾下图所展示的bioInit函数和bioProcessBackgroundJobs函数的基本处理流程。
不过接下来你或许还会疑惑:既然bioProcessBackgroundJobs函数是负责执行任务的,那么哪个函数负责生成任务呢?
这就是下面,我要给你介绍的后台任务创建函数bioCreateBackgroundJob。
bioCreateBackgroundJob函数:创建后台任务
bioCreateBackgroundJob函数的原型如下,它会接收4个参数,其中,参数type表示该后台任务的类型,剩下来的3个参数,则对应了后台任务函数的参数,如下所示:
void bioCreateBackgroundJob(int type, void *arg1, void *arg2, void *arg3)bioCreateBackgroundJob函数在执行时,会先创建bio_job,这是后台任务对应的数据结构。然后,后台任务数据结构中的参数,会被设置为bioCreateBackgroundJob函数传入的参数arg1、arg2和arg3。
最后,bioCreateBackgroundJob函数调用listAddNodeTail函数,将刚才创建的任务加入到对应的bio_jobs队列中,同时,将bio_pending数组的对应值加1,表示有个任务在等待执行。
{
//创建新的任务
struct bio_job *job = zmalloc(sizeof(*job));
//设置任务数据结构中的参数
job->time = time(NULL);
job->arg1 = arg1;
job->arg2 = arg2;
job->arg3 = arg3;
pthread_mutex_lock(&bio_mutex[type]);
listAddNodeTail(bio_jobs[type],job); //将任务加到bio_jobs数组的对应任务列表中
bio_pending[type]++; //将对应任务列表上等待处理的任务个数加1
pthread_cond_signal(&bio_newjob_cond[type]);
pthread_mutex_unlock(&bio_mutex[type]);
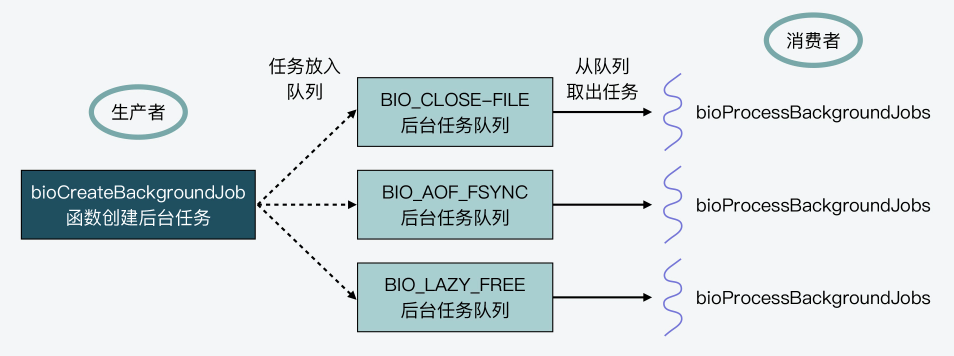
}好了,这样一来,当Redis进程想要启动一个后台任务时,只要调用bioCreateBackgroundJob函数,并设置好该任务对应的类型和参数即可。然后,bioCreateBackgroundJob函数就会把创建好的任务数据结构,放到后台任务对应的队列中。另一方面,bioInit函数在Redis server启动时,创建的线程会不断地轮询后台任务队列,一旦发现有任务可以执行,就会将该任务取出并执行。
其实,这种设计方式是典型的生产者-消费者模型。bioCreateBackgroundJob函数是生产者,负责往每种任务队列中加入要执行的后台任务,而bioProcessBackgroundJobs函数是消费者,负责从每种任务队列中取出任务来执行。然后Redis创建的后台线程,会调用bioProcessBackgroundJobs函数,从而实现一直循环检查任务队列。
下图展示的就是bioCreateBackgroundJob和bioProcessBackgroundJobs两者间的生产者-消费者模型,你可以看下。
好了,到这里,我们就学习了Redis后台线程的创建和运行机制。简单来说,主要是以下三个关键点:
- Redis是先通过bioInit函数初始化和创建后台线程;
- 后台线程运行的是bioProcessBackgroundJobs函数,这个函数会轮询任务队列,并根据要处理的任务类型,调用相应函数进行处理;
- 后台线程要处理的任务是由bioCreateBackgroundJob函数来创建的,这些任务创建后会被放到任务队列中,等待bioProcessBackgroundJobs函数处理。
Redis6.0多IO线程的效率提高了吗?
我们知道Redis server启动后的进程会以单线程的方式,执行客户端请求解析和处理工作。但是,Redis server也会通过bioInit函数启动三个后台线程,来处理后台任务。也就是说,Redis不再让主线程执行一些耗时操作,比如同步写、删除等,而是交给后台线程异步完成,从而避免了对主线程的阻塞。
实际上,在2020年5月推出的Redis 6.0版本中,Redis在执行模型中还进一步使用了多线程来处理IO任务,这样设计的目的,就是为了充分利用当前服务器的多核特性,使用多核运行多线程,让多线程帮助加速数据读取、命令解析以及数据写回的速度,提升Redis整体性能。
多IO线程的初始化
Redis 5.0中的三个后台线程,是server在初始化过程的最后,调用InitSeverLast函数,而InitServerLast函数再进一步调用bioInit函数来完成的。如果我们在Redis 6.0中查看InitServerLast函数,会发现和Redis 5.0相比,该函数在调完bioInit函数后,又调用了initThreadedIO函数。而initThreadedIO函数正是用来初始化多IO线程的,这部分的代码调用如下所示:
void InitServerLast() {
bioInit();
initThreadedIO(); //调用initThreadedIO函数初始化IO线程
set_jemalloc_bg_thread(server.jemalloc_bg_thread);
server.initial_memory_usage = zmalloc_used_memory();
}所以下面,我们就来看下initThreadedIO函数的主要执行流程,这个函数是在networking.c文件中实现的。
首先,initThreadedIO函数会设置IO线程的激活标志。这个激活标志保存在redisServer结构体类型的全局变量server当中,对应redisServer结构体的成员变量io_threads_active。initThreadedIO函数会把io_threads_active初始化为0,表示IO线程还没有被激活。这部分代码如下所示:
void initThreadedIO(void) {
server.io_threads_active = 0;
…
}这里,你要注意一下,刚才提到的全局变量server是Redis server运行时,用来保存各种全局信息的结构体变量。
紧接着,initThreadedIO函数会对设置的IO线程数量进行判断。这个数量就是保存在全局变量server的成员变量io_threads_num中的。那么在这里,IO线程的数量判断会有三种结果。
第一种,如果IO线程数量为1,就表示只有1个主IO线程,initThreadedIO函数就直接返回了。此时,Redis server的IO线程和Redis 6.0之前的版本是相同的。
if (server.io_threads_num == 1) return;第二种,如果IO线程数量大于宏定义IO_THREADS_MAX_NUM(默认值为128),那么initThreadedIO函数会报错,并退出整个程序。
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
… //报错日志记录
exit(1); //退出程序
}第三种,如果IO线程数量大于1,并且小于宏定义IO_THREADS_MAX_NUM,那么,initThreadedIO函数会执行一个循环流程,该流程的循环次数就是设置的IO线程数量。
如此一来,在该循环流程中,initThreadedIO函数就会给以下四个数组进行初始化操作。
- io_threads_list数组:保存了每个IO线程要处理的客户端,将数组每个元素初始化为一个List类型的列表;
- io_threads_pending数组:保存等待每个IO线程处理的客户端个数;
- io_threads_mutex数组:保存线程互斥锁;
- io_threads数组:保存每个IO线程的描述符。
这四个数组的定义都在networking.c文件中,如下所示:
pthread_t io_threads[IO_THREADS_MAX_NUM]; //记录线程描述符的数组
pthread_mutex_t io_threads_mutex[IO_THREADS_MAX_NUM]; //记录线程互斥锁的数组
_Atomic unsigned long io_threads_pending[IO_THREADS_MAX_NUM]; //记录线程待处理的客户端个数
list *io_threads_list[IO_THREADS_MAX_NUM]; //记录线程对应处理的客户端然后,在对这些数组进行初始化的同时,initThreadedIO函数还会根据IO线程数量,调用pthread_create函数创建相应数量的线程。
pthread_create函数的参数包括创建线程要运行的函数和函数参数(tidp、attr、start_routine、arg)。
所以,对于initThreadedIO函数来说,它创建的线程要运行的函数是IOThreadMain,参数是当前创建线程的编号。不过要注意的是,这个编号是从1开始的,编号为0的线程其实是运行Redis server主流程的主IO线程。
以下代码就展示了initThreadedIO函数对数组的初始化,以及创建IO线程的过程,你可以看下。
for (int i = 0; i < server.io_threads_num; i++) {
io_threads_list[i] = listCreate();
if (i == 0) continue; //编号为0的线程是主IO线程
pthread_t tid;
pthread_mutex_init(&io_threads_mutex[i],NULL); //初始化io_threads_mutex数组
io_threads_pending[i] = 0; //初始化io_threads_pending数组
pthread_mutex_lock(&io_threads_mutex[i]);
//调用pthread_create函数创建IO线程,线程运行函数为IOThreadMain
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
… //出错处理
}
io_threads[i] = tid; //初始化io_threads数组,设置值为线程标识
}IO线程的运行函数IOThreadMain
IOThreadMain函数也是在networking.c文件中定义的,它的主要执行逻辑是一个while(1)循环。在这个循环中,IOThreadMain函数会把io_threads_list数组中,每个IO线程对应的列表读取出来。
就像我在前面给你介绍的一样,io_threads_list数组中会针对每个IO线程,使用一个列表记录该线程要处理的客户端。所以,IOThreadMain函数就会从每个IO线程对应的列表中,进一步取出要处理的客户端,然后判断线程要执行的操作标记。这个操作标记是用变量io_threads_op表示的,它有两种取值。
- io_threads_op的值为宏定义IO_THREADS_OP_WRITE:这表明该IO线程要做的是写操作,线程会调用writeToClient函数将数据写回客户端。
- io_threads_op的值为宏定义IO_THREADS_OP_READ:这表明该IO线程要做的是读操作,线程会调用readQueryFromClient函数从客户端读取数据。
这部分的代码逻辑你可以看看下面的代码。
void *IOThreadMain(void *myid) {
…
while(1) {
listIter li;
listNode *ln;
//获取IO线程要处理的客户端列表
listRewind(io_threads_list[id],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln); //从客户端列表中获取一个客户端
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c,0); //如果线程操作是写操作,则调用writeToClient将数据写回客户端
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn); //如果线程操作是读操作,则调用readQueryFromClient从客户端读取数据
} else {
serverPanic("io_threads_op value is unknown");
}
}
listEmpty(io_threads_list[id]); //处理完所有客户端后,清空该线程的客户端列表
io_threads_pending[id] = 0; //将该线程的待处理任务数量设置为0
}
}我也画了下面这张图,展示了IOThreadMain函数的基本流程,你可以看下。
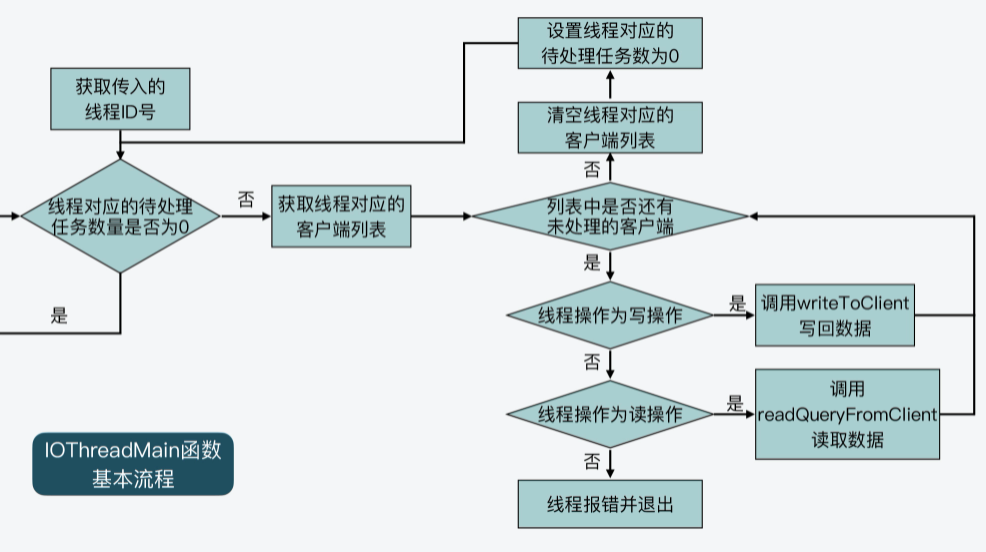
好了,到这里你应该就了解了,每一个IO线程运行时,都会不断检查是否有等待它处理的客户端。如果有,就根据操作类型,从客户端读取数据或是将数据写回客户端。你可以看到,这些操作都是Redis要和客户端完成的IO操作,所以,这也是为什么我们把这些线程称为IO线程的原因。
那么,你看到这里,可能也会产生一些疑问,IO线程要处理的客户端是如何添加到io_threads_list数组中的呢?
这就要说到Redis server对应的全局变量server了。server变量中有两个List类型的成员变量:clients_pending_write和clients_pending_read,它们分别记录了待写回数据的客户端和待读取数据的客户端,如下所示:
struct redisServer {
...
list *clients_pending_write; //待写回数据的客户端
list *clients_pending_read; //待读取数据的客户端
...
}你要知道,Redis server在接收到客户端请求和给客户端返回数据的过程中,会根据一定条件,推迟客户端的读写操作,并分别把待读写的客户端保存到这两个列表中。然后,Redis server在每次进入事件循环前,会再把列表中的客户端添加到io_threads_list数组中,交给IO线程进行处理。
所以接下来,我们就先来看下,Redis是如何推迟客户端的读写操作,并把这些客户端添加到clients_pending_write和clients_pending_read这两个列表中的。
如何推迟客户端读操作?
Redis server在和一个客户端建立连接后,就会开始监听这个客户端上的可读事件,而处理可读事件的回调函数是readQueryFromClient。
那么这里,我们再来看下Redis 6.0版本中的readQueryFromClient函数。这个函数一开始会先从传入参数conn中获取客户端c,紧接着就调用postponeClientRead函数,来判断是否推迟从客户端读取数据。这部分的执行逻辑如下所示:
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn); //从连接数据结构中获取客户
...
if (postponeClientRead(c)) return; //判断是否推迟从客户端读取数据
...
}现在,我们就来看下postponeClientRead函数的执行逻辑。这个函数会根据四个条件判断能否推迟从客户端读取数据。
条件一:全局变量server的io_threads_active值为1
这表示多IO线程已经激活。我刚才说过,这个变量值在initThreadedIO函数中是会被初始化为0的,也就是说,多IO线程初始化后,默认还没有激活(我一会儿还会给你介绍这个变量值何时被设置为1)。
条件二:全局变量server的io_threads_do_read值为1
这表示多IO线程可以用于处理延后执行的客户端读操作。这个变量值是在Redis配置文件redis.conf中,通过配置项io-threads-do-reads设置的,默认值为no,也就是说,多IO线程机制默认并不会用于客户端读操作。所以,如果你想用多IO线程处理客户端读操作,就需要把io-threads-do-reads配置项设为yes。
条件三:ProcessingEventsWhileBlocked变量值为0
这表示processEventsWhileBlokced函数没有在执行。ProcessingEventsWhileBlocked是一个全局变量,它会在processEventsWhileBlokced函数执行时被设置为1,在processEventsWhileBlokced函数执行完成时被设置为0。
而processEventsWhileBlokced函数是在networking.c文件中实现的。当Redis在读取RDB文件或是AOF文件时,这个函数会被调用,用来处理事件驱动框架捕获到的事件。这样就避免了因读取RDB或AOF文件造成Redis阻塞,而无法及时处理事件的情况。所以,当processEventsWhileBlokced函数执行处理客户端可读事件时,这些客户端读操作是不会被推迟执行的。
条件四:客户端现有标识不能有CLIENT_MASTER、CLIENT_SLAVE和CLIENT_PENDING_READ
其中,CLIENT_MASTER和CLIENT_SLAVE标识分别表示客户端是用于主从复制的客户端,也就是说,这些客户端不会推迟读操作。CLIENT_PENDING_READ本身就表示一个客户端已经被设置为推迟读操作了,所以,对于已带有CLIENT_PENDING_READ标识的客户端,postponeClientRead函数就不会再推迟它的读操作了。
总之,只有前面这四个条件都满足了,postponeClientRead函数才会推迟当前客户端的读操作。具体来说,postponeClientRead函数会给该客户端设置CLIENT_PENDING_REA标识,并调用listAddNodeHead函数,把这个客户端添加到全局变量server的clients_pending_read列表中。
我把postponeClientRead函数的代码放在这里,你可以看下。
int postponeClientRead(client *c) {
//判断IO线程是否激活,
if (server.io_threads_active && server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ)))
{
c->flags |= CLIENT_PENDING_READ; //给客户端的flag添加CLIENT_PENDING_READ标记,表示推迟该客户端的读操作
listAddNodeHead(server.clients_pending_read,c); //将客户端添加到clients_pending_read列表中
return 1;
} else {
return 0;
}
}好,现在你已经知道,Redis是在客户端读事件回调函数readQueryFromClient中,通过调用postponeClientRead函数来判断和推迟客户端读操作。下面,我再带你来看下Redis是如何推迟客户端写操作的。
如何推迟客户端写操作?
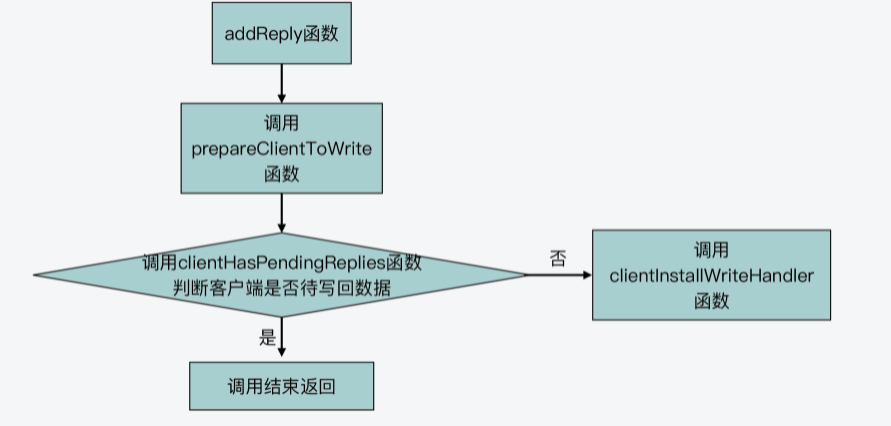
Redis在执行了客户端命令,要给客户端返回结果时,会调用addReply函数将待返回结果写入客户端输出缓冲区。
而在addReply函数的一开始,该函数会调用prepareClientToWrite函数,来判断是否推迟执行客户端写操作。下面代码展示了addReply函数对prepareClientToWrite函数的调用,你可以看下。
void addReply(client *c, robj *obj) {
if (prepareClientToWrite(c) != C_OK) return;
...
}所以这里,我们继续来看下prepareClientToWrite函数。这个函数会根据客户端设置的标识进行一系列的判断。其中,该函数会调用clientHasPendingReplies函数,判断当前客户端是否还有留存在输出缓冲区中的数据等待写回。
如果没有的话,那么,prepareClientToWrite就会调用clientInstallWriteHandler函数,再进一步判断能否推迟该客户端写操作。下面的代码展示了这一调用过程,你可以看下。
int prepareClientToWrite(client *c) {
...
//如果当前客户端没有待写回数据,调用clientInstallWriteHandler函数
if (!clientHasPendingReplies(c)) clientInstallWriteHandler(c);
return C_OK;
}那么这样一来,我们其实就知道了,能否推迟客户端写操作,最终是由clientInstallWriteHandler函数来决定的,这个函数会判断两个条件。
- 条件一:客户端没有设置过CLIENT_PENDING_WRITE标识,即没有被推迟过执行写操作。
- 条件二:客户端所在实例没有进行主从复制,或者客户端所在实例是主从复制中的从节点,但全量复制的RDB文件已经传输完成,客户端可以接收请求。
一旦这两个条件都满足了,clientInstallWriteHandler函数就会把客户端标识设置为CLIENT_PENDING_WRITE,表示推迟该客户端的写操作。同时,clientInstallWriteHandler函数会把这个客户端添加到全局变量server的待写回客户端列表中,也就是clients_pending_write列表中。
void clientInstallWriteHandler(client *c) {
//如果客户端没有设置过CLIENT_PENDING_WRITE标识,并且客户端没有在进行主从复制,或者客户端是主从复制中的从节点,已经能接收请求
if (!(c->flags & CLIENT_PENDING_WRITE) &&
(c->replstate == REPL_STATE_NONE ||
(c->replstate == SLAVE_STATE_ONLINE && !c->repl_put_online_on_ack)))
{
//将客户端的标识设置为待写回,即CLIENT_PENDING_WRITE
c->flags |= CLIENT_PENDING_WRITE;
listAddNodeHead(server.clients_pending_write,c); //将可获得加入clients_pending_write列表
}
}为了便于你更好地理解,我画了一张图,展示了Redis推迟客户端写操作的函数调用关系,你可以再回顾下。
不过,当Redis使用clients_pending_read和clients_pending_write两个列表,保存了推迟执行的客户端后,这些客户端又是如何分配给多IO线程执行的呢?这就和下面两个函数相关了。
- handleClientsWithPendingReadsUsingThreads函数:该函数主要负责将clients_pending_read列表中的客户端分配给IO线程进行处理。
- handleClientsWithPendingWritesUsingThreads函数:该函数主要负责将clients_pending_write列表中的客户端分配给IO线程进行处理。
所以接下来,我们就来看下这两个函数的具体操作。
如何把待读客户端分配给IO线程执行?
首先,我们来了解handleClientsWithPendingReadsUsingThreads函数。这个函数是在beforeSleep函数中调用的。
在Redis 6.0版本的代码中,事件驱动框架同样是调用aeMain函数来执行事件循环流程,该循环流程会调用aeProcessEvents函数处理各种事件。而在aeProcessEvents函数实际调用aeApiPoll函数捕获IO事件之前,beforeSleep函数会被调用。
这个过程如下图所示,你可以看下。
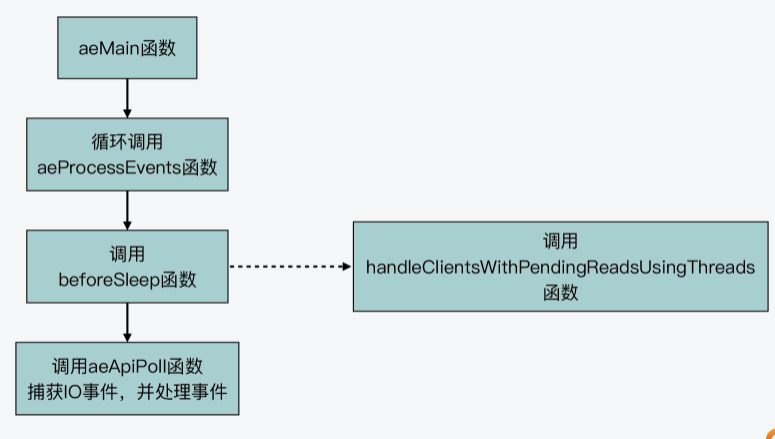
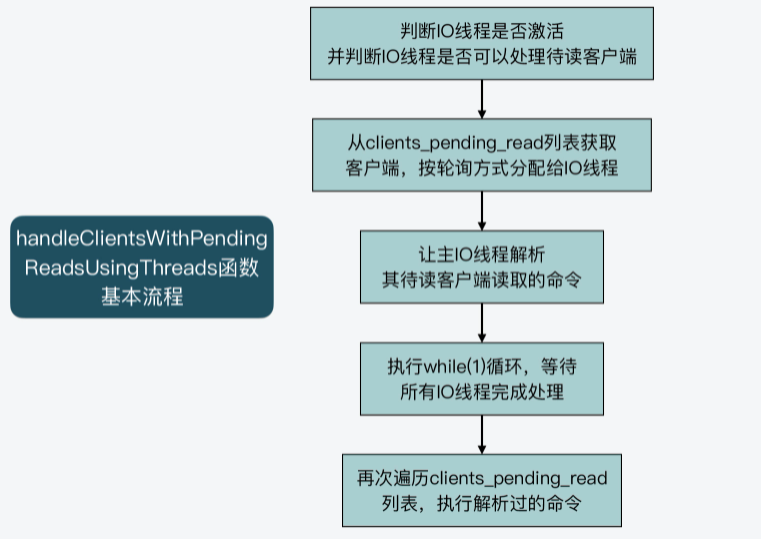
handleClientsWithPendingReadsUsingThreads函数的主要执行逻辑可以分成四步。
第一步,该函数会先根据全局变量server的io_threads_active成员变量,判定IO线程是否激活,并且根据server的io_threads_do_reads成员变量,判定用户是否设置了Redis可以用IO线程处理待读客户端。只有在IO线程激活,并且IO线程可以用于处理待读客户端时,handleClientsWithPendingReadsUsingThreads函数才会继续执行,否则该函数就直接结束返回了。这一步的判断逻辑如以下代码所示:
if (!server.io_threads_active || !server.io_threads_do_reads)
return 0;第二步,handleClientsWithPendingReadsUsingThreads函数会获取clients_pending_read列表的长度,这代表了要处理的待读客户端个数。然后,该函数会从clients_pending_read列表中逐一取出待处理的客户端,并用客户端在列表中的序号,对IO线程数量进行取模运算。
这样一来,我们就可以根据取模得到的余数,把该客户端分配给对应的IO线程进行处理。紧接着,handleClientsWithPendingReadsUsingThreads函数会调用listAddNodeTail函数,把分配好的客户端添加到io_threads_list列表的相应元素中。我刚才给你介绍过,io_threads_list数组的每个元素是一个列表,对应保存了每个IO线程要处理的客户端。
假设IO线程数量设置为3,clients_pending_read列表中一共有5个待读客户端,它们在列表中的序号分别是0,1,2,3和4。在这一步中,0号到4号客户端对线程数量3取模的结果分别是0,1,2,0,1,这也对应了即将处理这些客户端的IO线程编号。这也就是说,0号客户端由0号线程处理,1号客户端有1号线程处理,以此类推。你可以看到,这个分配方式其实就是把待处理客户端,以轮询方式逐一分配给各个IO线程。
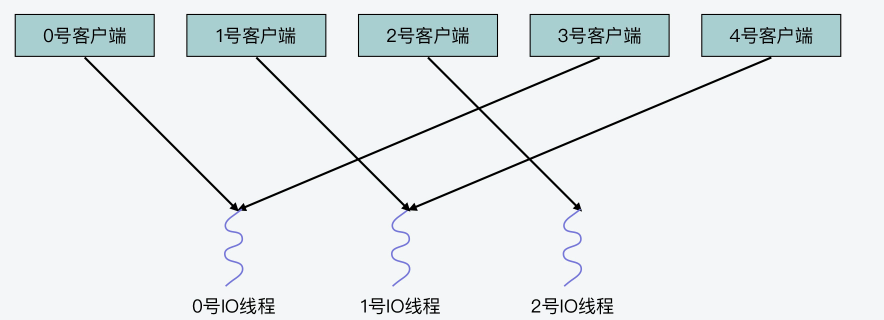
以下代码展示的就是以轮询方式将客户端分配给IO线程的执行逻辑:
int processed = listLength(server.clients_pending_read);
listRewind(server.clients_pending_read,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}这样,当handleClientsWithPendingReadsUsingThreads函数完成客户端的IO线程分配之后,它会将IO线程的操作标识设置为读操作,也就是IO_THREADS_OP_READ。然后,它会遍历io_threads_list数组中的每个元素列表长度,等待每个线程处理的客户端数量,赋值给 io_threads_pending数组。这一过程如下所示:
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}第三步,handleClientsWithPendingReadsUsingThreads函数会将io_threads_list数组0号列表(也就是io_threads_list[0]元素)中的待读客户端逐一取出来,并调用readQueryFromClient函数进行处理。
其实,handleClientsWithPendingReadsUsingThreads函数本身就是由IO主线程执行的,而io_threads_list数组对应的0号线程正是IO主线程,所以,这里就是让主IO线程来处理它的待读客户端。
listRewind(io_threads_list[0],&li); //获取0号列表中的所有客户端
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]); //处理完后,清空0号列表紧接着,handleClientsWithPendingReadsUsingThreads函数会执行一个while(1)循环,等待所有IO线程完成待读客户端的处理,如下所示:
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}第四步,handleClientsWithPendingReadsUsingThreads函数会再次遍历一遍clients_pending_read列表,依次取出其中的客户端。紧接着,它会判断客户端的标识中是否有CLIENT_PENDING_COMMAND。如果有CLIENT_PENDING_COMMAND标识,表明该客户端中的命令已经被某一个IO线程解析过,已经可以被执行了。
此时,handleClientsWithPendingReadsUsingThreads函数会调用processCommandAndResetClient函数执行命令。最后,它会直接调用processInputBuffer函数解析客户端中所有命令并执行。
这部分的代码逻辑如下所示,你可以看下。
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
...
//如果命令已经解析过,则执行该命令
if (c->flags & CLIENT_PENDING_COMMAND) {
c->flags &= ~CLIENT_PENDING_COMMAND;
if (processCommandAndResetClient(c) == C_ERR) {
continue;
}
}
//解析并执行所有命令
processInputBuffer(c);
}好了,到这里,你就了解了clients_pending_read列表中的待读客户端,是如何经过以上四个步骤来分配给IO线程进行处理的。下图展示了这个主要过程,你可以再回顾下。
那么,接下来,我们再来看下待写客户端的分配和处理。
如何把待写客户端分配给IO线程执行?
和待读客户端的分配处理类似,待写客户端分配处理是由handleClientsWithPendingWritesUsingThreads函数来完成的。该函数也是在beforeSleep函数中被调用的。
handleClientsWithPendingWritesUsingThreads函数的主要流程同样也可以分成4步,其中,第2、3和4步的执行逻辑,和handleClientsWithPendingReadsUsingThreads函数类似。
简单来说,在第2步,handleClientsWithPendingWritesUsingThreads函数会把待写客户端,按照轮询方式分配给IO线程,添加到io_threads_list数组各元素中。
然后,在第3步,handleClientsWithPendingWritesUsingThreads函数会让主IO线程处理其待写客户端,并执行while(1)循环等待所有IO线程完成处理。
在第4步,handleClientsWithPendingWritesUsingThreads函数会再次检查clients_pending_write列表中,是否还有待写的客户端。如果有的话,并且这些客户端还有留存在缓冲区中的数据,那么,handleClientsWithPendingWritesUsingThreads函数就会调用connSetWriteHandler函数注册可写事件,而这个可写事件对应的回调函数是sendReplyToClient函数。
等到事件循环流程再次执行时,刚才handleClientsWithPendingWritesUsingThreads函数注册的可写事件就会被处理,紧接着sendReplyToClient函数会执行,它会直接调用writeToClient函数,把客户端缓冲区中的数据写回。
这里,你需要注意的是,connSetWriteHandler函数最终会映射为connSocketSetWriteHandler函数,而connSocketSetWriteHandler函数是在connection.c文件中实现的。connSocketSetWriteHandler函数会调用aeCreateFileEvent函数创建AE_WRITABLE事件,这就是刚才介绍的可写事件的注册。
不过,和handleClientsWithPendingReadsUsingThreads函数不同的是在第1步,handleClientsWithPendingWritesUsingThreads函数,会判断IO线程数量是否为1,或者待写客户端数量是否小于IO线程数量的2倍。
如果这两个条件中有一个条件成立,那么handleClientsWithPendingWritesUsingThreads函数就不会用多线程来处理客户端了,而是会调用handleClientsWithPendingWrites函数由主IO线程直接处理待写客户端。这样做的目的,主要是为了在待写客户端数量不多时,避免采用多线程,从而节省CPU开销。
这一步的条件判断逻辑如下所示。其中,stopThreadedIOIfNeeded函数主要是用来判断待写客户端数量,是否不足为IO线程数量的2倍。
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}另外,handleClientsWithPendingWritesUsingThreads函数在第1步中,还会判断IO线程是否已激活。如果没有激活,它就会调用startThreadedIO函数,把全局变量server的io_threads_active成员变量值设置为1,表示IO线程已激活。这步判断操作如下所示:
if (!server.io_threads_active) startThreadedIO();总之你要知道的就是,Redis是通过handleClientsWithPendingWritesUsingThreads函数,把待写客户端按轮询方式分配给各个IO线程,并由它们来负责写回数据的。
从代码实现看分布式锁的原子性保证
分布式锁的实现方法
首先,对于分布式锁的加锁操作来说,我们可以使用Redis的SET命令。Redis SET命令提供了NX和EX选项,这两个选项的含义分别是:
- NX,表示当操作的key不存在时,Redis会直接创建;当操作的key已经存在了,则返回NULL值,Redis对key不做任何修改。
- EX,表示设置key的过期时间。
因此,我们可以让客户端发送以下命令来进行加锁。其中,lockKey是锁的名称,uid是客户端可以用来唯一标记自己的ID,expireTime是这个key所代表的锁的过期时间,当这个过期时间到了之后,这个key会被删除,相当于锁被释放了,这样就避免了锁一直无法释放的问题。
SET lockKey uid EX expireTime NX而如果还没有客户端创建过锁,那么,假设客户端A发送了这个SET命令给Redis,如下所示:
SET stockLock 1033 EX 30 NX这样,Redis就会创建对应的key为stockLock,而键值对的value就是这个客户端的ID 1033。此时,假设有另一个客户端B也发送了SET命令,如下所示,表示要把key为stockLock的键值对值,改为客户端B的ID 2033,也就是要加锁。
SET stockLock 2033 EX 30 NX由于使用了NX选项,如果stockLock的key已经存在了,客户端B就无法对其进行修改了,也就无法获得锁了,这样就实现了加锁的效果。
而对于解锁来说,我们可以使用如下的Lua脚本来完成,而Lua脚本会以EVAL命令的形式在Redis server中执行。客户端会使用GET命令读取锁对应key的value,并判断value是否等于客户端自身的ID。如果等于,就表明当前客户端正拿着锁,此时可以执行DEL命令删除key,也就是释放锁;如果value不等于客户端自身ID,那么该脚本会直接返回。
if redis.call("get",lockKey) == uid then
return redis.call("del",lockKey)
else
return 0
end这样一来,客户端就不会误删除别的客户端获得的锁了,从而保证了锁的安全性。
好,现在我们就了解了分布式锁的实现命令。那么在这里,我们需要搞明白的问题就是:无论是加锁的SET命令,还是解锁的Lua脚本和EVAL命令,在有IO多路复用时,会被同时执行吗?或者当我们使用了多IO线程后,会被多个线程同时执行吗?
这就和Redis中命令的执行过程有关了。下面,我们就来了解下,一条命令在Redis是如何完成执行的。
一条命令的处理过程
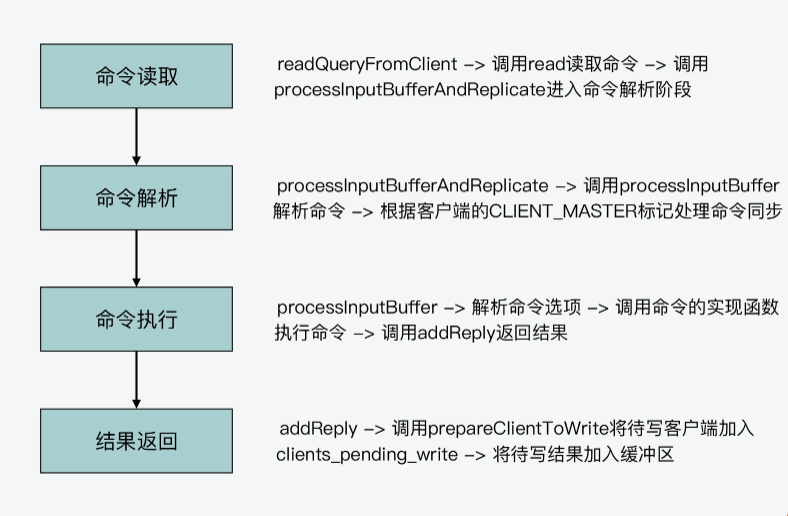
现在我们知道,Redis server一旦和一个客户端建立连接后,就会在事件驱动框架中注册可读事件,这就对应了客户端的命令请求。而对于整个命令处理的过程来说,我认为主要可以分成四个阶段,它们分别对应了Redis源码中的不同函数。这里,我把它们对应的入口函数,也就是它们是从哪个函数开始进行执行的,罗列如下:
- 命令读取,对应readQueryFromClient函数;
- 命令解析,对应processInputBufferAndReplicate函数;
- 命令执行,对应processCommand函数;
- 结果返回,对应addReply函数;
那么下面,我们就来分别看下这四个入口函数的基本流程,以及为了完成命令执行,它们内部的主要调用关系都是怎样的。
命令读取阶段:readQueryFromClient函数
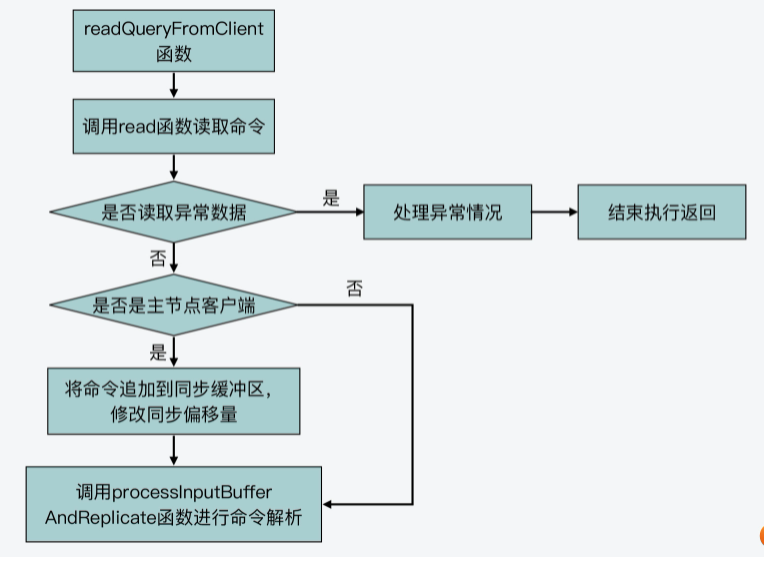
首先,我们来了解下readQueryFromClient函数的基本流程。
readQueryFromClient函数会从客户端连接的socket中,读取最大为readlen长度的数据,readlen值大小是宏定义PROTO_IOBUF_LEN。该宏定义是在server.h文件中定义的,默认值为16KB。
紧接着,readQueryFromClient函数会根据读取数据的情况,进行一些异常处理,比如数据读取失败或是客户端连接关闭等。此外,如果当前客户端是主从复制中的主节点,readQueryFromClient函数还会把读取的数据,追加到用于主从节点命令同步的缓冲区中。
最后,readQueryFromClient函数会调用processInputBufferAndReplicate函数,这就进入到了命令处理的下一个阶段,也就是命令解析阶段。
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
...
readlen = PROTO_IOBUF_LEN; //从客户端socket中读取的数据长度,默认为16KB
...
c->querybuf = sdsMakeRoomFor(c->querybuf, readlen); //给缓冲区分配空间
nread = read(fd, c->querybuf+qblen, readlen); //调用read从描述符为fd的客户端socket中读取数据
...
processInputBufferAndReplicate(c); //调用processInputBufferAndReplicate进一步处理读取内容
} 我在下面画了张图,展示了readQueryFromClient函数的基本流程,你可以看下。
命令解析阶段:processInputBufferAndReplicate函数
processInputBufferAndReplicate函数(在networking.c文件中)会根据当前客户端是否有CLIENT_MASTER标记,来执行两个分支。
- 分支一
这个分支对应了客户端没有CLIENT_MASTER标记,也就是说当前客户端不属于主从复制中的主节点。那么,processInputBufferAndReplicate函数会直接调用processInputBuffer(在networking.c文件中)函数,对客户端输入缓冲区中的命令和参数进行解析。所以在这里,实际执行命令解析的函数就是processInputBuffer函数。我们一会儿来具体看下这个函数。
- 分支二
这个分支对应了客户端有CLIENT_MASTER标记,也就是说当前客户端属于主从复制中的主节点。那么,processInputBufferAndReplicate函数除了调用processInputBuffer函数,解析客户端命令以外,它还会调用replicationFeedSlavesFromMasterStream函数(在replication.c文件中),将主节点接收到的命令同步给从节点。
下图就展示了processInputBufferAndReplicate函数的基本执行逻辑,你可以看下。
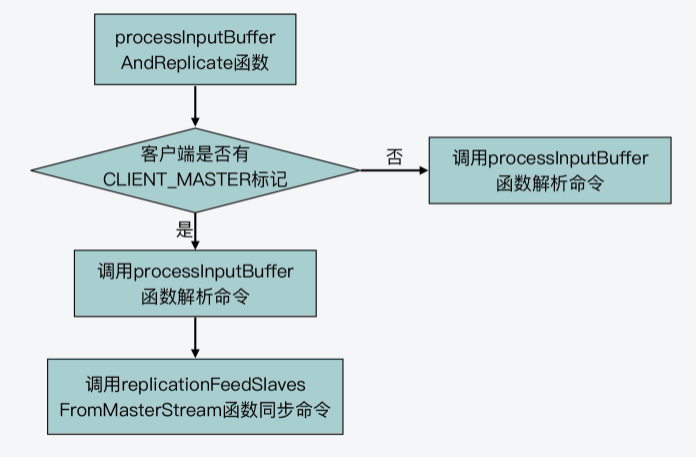
好了,我们刚才了解了,命令解析实际是在processInputBuffer函数中执行的,所以下面,我们还需要清楚这个函数的基本流程是什么样的。
首先,processInputBuffer函数会执行一个while循环,不断地从客户端的输入缓冲区中读取数据。然后,它会判断读取到的命令格式,是否以“*”开头。
如果命令是以“*”开头,那就表明这个命令是PROTO_REQ_MULTIBULK类型的命令请求,也就是符合RESP协议(Redis客户端与服务器端的标准通信协议)的请求。那么,processInputBuffer函数就会进一步调用processMultibulkBuffer(在networking.c文件中)函数,来解析读取到的命令。
而如果命令不是以“”开头,那则表明这个命令是PROTO_REQ_INLINE类型的命令请求,并不是RESP协议请求。这类命令也被称为*管道命令,命令和命令之间是使用换行符“\r\n”分隔开来的。比如,我们使用Telnet发送给Redis的命令,就是属于PROTO_REQ_INLINE类型的命令。在这种情况下,processInputBuffer函数会调用processInlineBuffer(在networking.c文件中)函数,来实际解析命令。
这样,等命令解析完成后,processInputBuffer函数就会调用processCommand函数,开始进入命令处理的第三个阶段,也就是命令执行阶段。
下面的代码展示了processInputBuffer函数解析命令时的主要流程,你可以看下。
void processInputBuffer(client *c) {
while(c->qb_pos < sdslen(c->querybuf)) {
...
if (!c->reqtype) {
//根据客户端输入缓冲区的命令开头字符判断命令类型
if (c->querybuf[c->qb_pos] == '*') {
c->reqtype = PROTO_REQ_MULTIBULK; //符合RESP协议的命令
} else {
c->reqtype = PROTO_REQ_INLINE; //管道类型命令
}
}
if (c->reqtype == PROTO_REQ_INLINE) {
if (processInlineBuffer(c) != C_OK) break; //对于管道类型命令,调用processInlineBuffer函数解析
} else if (c->reqtype == PROTO_REQ_MULTIBULK) {
if (processMultibulkBuffer(c) != C_OK) break; //对于RESP协议命令,调用processMultibulkBuffer函数解析
}
...
if (c->argc == 0) {
resetClient(c);
} else {
//调用processCommand函数,开始执行命令
if (processCommand(c) == C_OK) {
... }
... }
}
...
}下图展示了processInputBuffer函数的基本执行流程,你可以再回顾下。
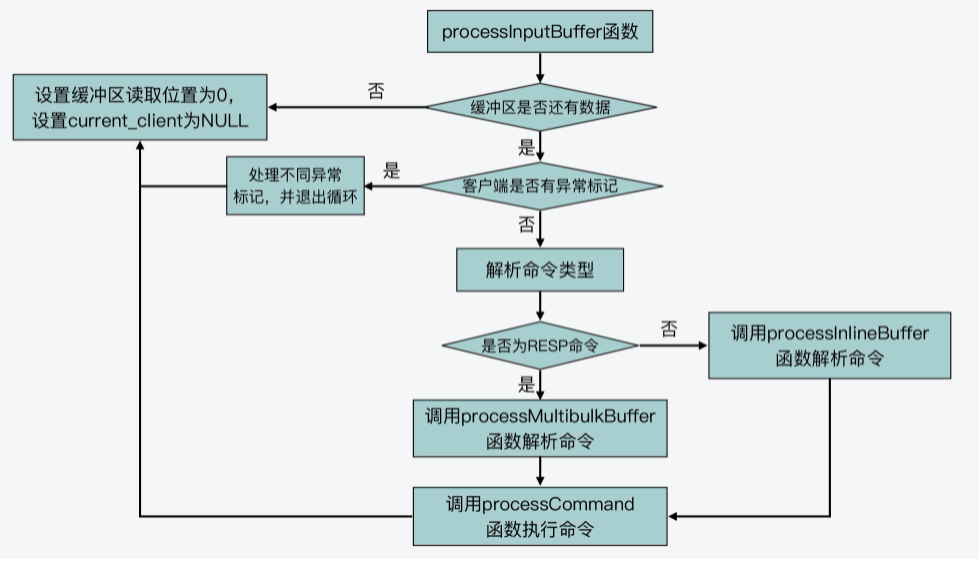
好,那么下面,我们接着来看第三个阶段,也就是命令执行阶段的processCommand函数的基本处理流程。
命令执行阶段:processCommand函数
首先,我们要知道,processCommand函数是在server.c文件中实现的。它在实际执行命令前的主要逻辑可以分成三步:
- 第一步,processCommand函数会调用moduleCallCommandFilters函数(在module.c文件),将Redis命令替换成module中想要替换的命令。
- 第二步,processCommand函数会判断当前命令是否为quit命令,并进行相应处理。
- 第三步,processCommand函数会调用lookupCommand函数,在全局变量server的commands成员变量中查找相关的命令。
这里,你需要注意下,全局变量server的commands成员变量是一个哈希表,它的定义是在server.h文件中的redisServer结构体里面,如下所示:
struct redisServer {
...
dict *commands;
...
}另外,commands成员变量的初始化是在initServerConfig函数中,通过调用dictCreate函数完成哈希表创建,再通过调用populateCommandTable函数,将Redis提供的命令名称和对应的实现函数,插入到哈希表中的。
void initServerConfig(void) {
...
server.commands = dictCreate(&commandTableDictType,NULL);
...
populateCommandTable();
...
}而这其中的populateCommandTable函数,实际上是使用到了redisCommand结构体数组redisCommandTable。
redisCommandTable数组是在server.c文件中定义的,它的每一个元素是一个redisCommand结构体类型的记录,对应了Redis实现的一条命令。也就是说,redisCommand结构体中就记录了当前命令所对应的实现函数是什么。
比如,以下代码展示了GET和SET这两条命令的信息,它们各自的实现函数分别是getCommand和setCommand。当然,如果你想进一步了解redisCommand结构体,也可以去看下它的定义,在server.h文件当中。
struct redisCommand redisCommandTable[] = {
...
{"get",getCommand,2,"rF",0,NULL,1,1,1,0,0},
{"set",setCommand,-3,"wm",0,NULL,1,1,1,0,0},
...
}好了,到这里,你就了解了lookupCommand函数会根据解析的命令名称,在commands对应的哈希表中查找相应的命令。
那么,一旦查到对应命令后,processCommand函数就会进行多种检查,比如命令的参数是否有效、发送命令的用户是否进行过验证、当前内存的使用情况,等等。这部分的处理逻辑比较多,你可以进一步阅读processCommand函数来了解下。
这样,等到processCommand函数对命令做完各种检查后,它就开始执行命令了。它会判断当前客户端是否有CLIENT_MULTI标记,如果有的话,就表明要处理的是Redis事务的相关命令,所以它会按照事务的要求,调用queueMultiCommand函数将命令入队保存,等待后续一起处理。
而如果没有,processCommand函数就会调用call函数来实际执行命令了。以下代码展示了这部分的逻辑,你可以看下。
//如果客户端有CLIENT_MULTI标记,并且当前不是exec、discard、multi和watch命令
if (c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand && c->cmd->proc != discardCommand &&
c->cmd->proc != multiCommand && c->cmd->proc != watchCommand)
{
queueMultiCommand(c); //将命令入队保存,等待后续一起处理
addReply(c,shared.queued);
} else {
call(c,CMD_CALL_FULL); //调用call函数执行命令
...
}这里你要知道,call函数是在server.c文件中实现的,它执行命令是通过调用命令本身,即redisCommand结构体中定义的函数指针来完成的。而就像我刚才所说的,每个redisCommand结构体中都定义了它对应的实现函数,在redisCommandTable数组中能查找到。
因为分布式锁的加锁操作就是使用SET命令来实现的,所以这里,我就以SET命令为例来介绍下它的实际执行过程。
SET命令对应的实现函数是setCommand,这是在t_string.c文件中定义的。setCommand函数首先会对命令参数进行判断,比如参数是否带有NX、EX、XX、PX等这类命令选项,如果有的话,setCommand函数就会记录下这些标记。
然后,setCommand函数会调用setGenericCommand函数,这个函数也是在t_string.c文件中实现的。setGenericCommand函数会根据刚才setCommand函数记录的命令参数的标记,来进行相应处理。比如,如果命令参数中有NX选项,那么,setGenericCommand函数会调用lookupKeyWrite函数(在db.c文件中),查找要执行SET命令的key是否已经存在。
如果这个key已经存在了,那么setGenericCommand函数就会调用addReply函数,返回NULL空值,而这也正是符合分布式锁的语义的。
下面的代码就展示了这个执行逻辑,你可以看下。
//如果有NX选项,那么查找key是否已经存在
if ((flags & OBJ_SET_NX && lookupKeyWrite(c->db,key) != NULL) ||
(flags & OBJ_SET_XX && lookupKeyWrite(c->db,key) == NULL))
{
addReply(c, abort_reply ? abort_reply : shared.nullbulk); //如果已经存在,则返回空值
return;
}好,那么如果SET命令可以正常执行的话,也就是说命令带有NX选项但是key并不存在,或者带有XX选项但是key已经存在,这样setGenericCommand函数就会调用setKey函数(在db.c文件中)来完成键值对的实际插入,如下所示:
setKey(c->db,key,val);然后,如果命令设置了过期时间,setGenericCommand函数还会调用setExpire函数设置过期时间。最后,setGenericCommand函数会调用addReply函数,将结果返回给客户端,如下所示:
addReply(c, ok_reply ? ok_reply : shared.ok);好了,到这里,SET命令的执行就结束了,你也可以再看下下面的基本流程图。
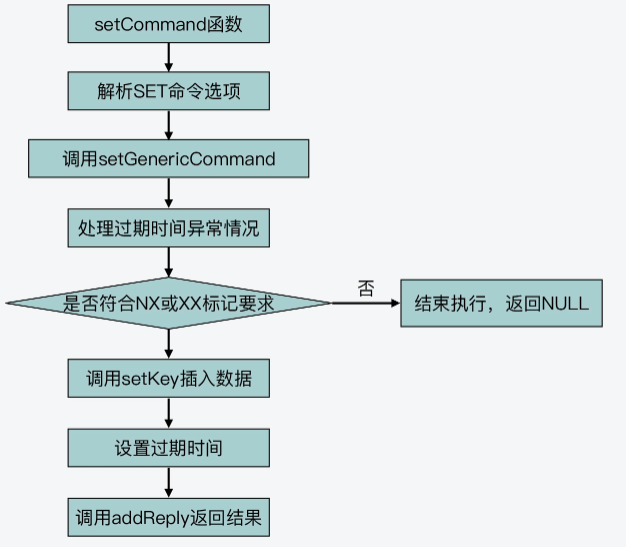
而且你也可以看到,无论是在命令执行的过程中,发现不符合命令的执行条件,或是命令能成功执行,addReply函数都会被调用,用来返回结果。所以,这就进入到我所说的命令处理过程的最后一个阶段:结果返回阶段。
结果返回阶段:addReply函数
addReply函数是在networking.c文件中定义的。它的执行逻辑比较简单,主要是调用prepareClientToWrite函数,并在prepareClientToWrite函数中调用clientInstallWriteHandler函数,将待写回客户端加入到全局变量server的clients_pending_write列表中。
然后,addReply函数会调用_addReplyToBuffer等函数(在networking.c中),将要返回的结果添加到客户端的输出缓冲区中。
好,现在你就了解一条命令是如何从读取,经过解析、执行等步骤,最终将结果返回给客户端的了。下图展示了这个过程以及涉及的主要函数,你可以再回顾下。
不过除此之外,你还需要注意一点,就是如果在前面的命令处理过程中,都是由IO主线程处理的,那么命令执行的原子性肯定能得到保证,分布式锁的原子性也就相应能得到保证了。
但是,如果这个处理过程配合上了我们前面介绍的IO多路复用机制和多IO线程机制,那么,这两个机制是在这个过程的什么阶段发挥作用的呢,以及会不会影响命令执行的原子性呢?
所以接下来,我们就来看下它们各自对原子性保证的影响。
IO多路复用对命令原子性保证的影响
首先你要知道,IO多路复用机制是在readQueryFromClient函数执行前发挥作用的。它实际是在事件驱动框架中调用aeApiPoll函数,获取一批已经就绪的socket描述符。然后执行一个循环,针对每个就绪描述符上的读事件,触发执行readQueryFromClient函数。
这样一来,即使IO多路复用机制同时获取了多个就绪socket描述符,在实际处理时,Redis的主线程仍然是针对每个事件逐一调用回调函数进行处理的。而且对于写事件来说,IO多路复用机制也是针对每个事件逐一处理的。
下面的代码展示了IO多路复用机制通过aeApiPoll函数获取一批事件,然后逐一处理的逻辑,你可以再看下。
numevents = aeApiPoll(eventLoop, tvp);
for (j = 0; j < numevents; j++) {
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
if (!invert && fe->mask & mask & AE_READABLE) {
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}所以这也就是说,即使使用了IO多路复用机制,命令的整个处理过程仍然可以由IO主线程来完成,也仍然可以保证命令执行的原子性。下图就展示了IO多路复用机制和命令处理过程的关系,你可以看下。
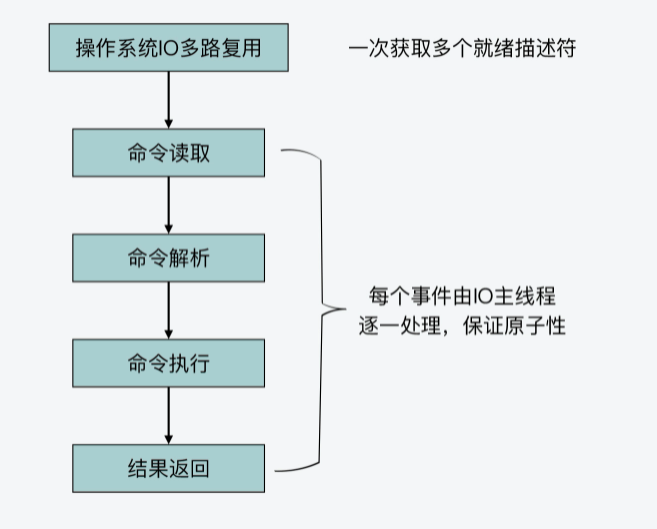
接下来,我们再来看下多IO线程对命令原子性保证的影响。
多IO线程对命令原子性保证的影响
我们知道,多IO线程可以执行读操作或是写操作。那么,对于读操作来说,readQueryFromClient函数会在执行过程中,调用postponeClient将待读客户端加入clients_pending_read等待列表。
然后,待读客户端会被分配给多IO线程执行,每个IO线程执行的函数就是readQueryFromClient函数,readQueryFromClient函数会读取命令,并进一步调用processInputBuffer函数解析命令,这个基本过程和Redis 6.0前的代码是一样的。
不过,相比于Redis 6.0前的代码,在Redis 6.0版本中,processInputBuffer函数中新增加了一个判断条件,也就是当客户端标识中有CLIENT_PENDING_READ的话,那么在解析完命令后,processInputBuffer函数只会把客户端标识改为CLIENT_PENDING_COMMAND,就退出命令解析的循环流程了。
此时,processInputBuffer函数只是解析了第一个命令,也并不会实际调用processCommand函数来执行命令,如下所示:
void processInputBuffer(client *c) {
/* Keep processing while there is something in the input buffer */
while(c->qb_pos < sdslen(c->querybuf)) {
...
if (c->argc == 0) {
resetClient(c);
} else {
//如果客户端有CLIENT_PENDING_READ标识,将其改为CLIENT_PENDING_COMMAND,就退出循环,并不调用processCommandAndResetClient函数执行命令
if (c->flags & CLIENT_PENDING_READ) {
c->flags |= CLIENT_PENDING_COMMAND;
break;
}
if (processCommandAndResetClient(c) == C_ERR) {
return;
}
}
}
}这样,等到所有的IO线程都解析完了第一个命令后,IO主线程中执行的handleClientsWithPendingReadsUsingThreads函数,会再调用processCommandAndResetClient函数执行命令,以及调用processInputBuffer函数解析剩余命令。
所以现在,你就可以知道,即使使用了多IO线程,其实命令执行这一阶段也是由主IO线程来完成的,所有命令执行的原子性仍然可以得到保证,也就是说分布式锁的原子性也仍然可以得到保证。
我们再来看下写回数据的流程。
在这个阶段,addReply函数是将客户端写回操作推迟执行的,而此时Redis命令已经完成执行了,所以,即使有多个IO线程在同时将客户端数据写回,也只是把结果返回给客户端,并不影响命令在Redis server中的执行结果。也就是说,即使使用了多IO线程写回,Redis同样可以保证命令执行的原子性。
下图展示了使用多IO线程机制后,命令处理过程各个阶段是由什么线程执行的,你可以再看下。
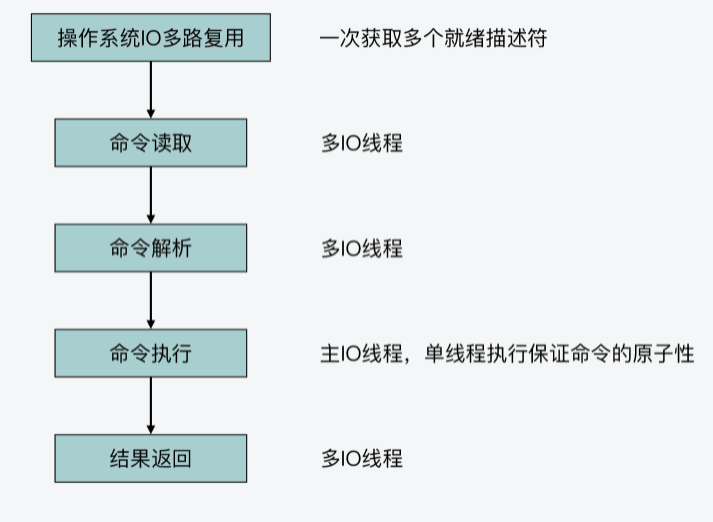
 微信
微信 支付宝
支付宝





