Java性能调优实战
为什么要做性能调优?
好的系统性能调优不仅仅可以提高系统的性能,还能为公司节省资源。这也是我们做性能调优的最直接的目的。
什么时候开始介入调优?
其实,在项目开发的初期,我们没有必要过于在意性能优化,这样反而会让我们疲于性能优化,不仅不会给系统性能带来提升,还会影响到开发进度,甚至获得相反的效果,给系统带来新的问题。
我们只需要在代码层面保证有效的编码,比如,减少磁盘 I/O 操作、降低竞争锁的使用以及使用高效的算法等等。遇到比较复杂的业务,我们可以充分利用设计模式来优化业务代码。例如,设计商品价格的时候,往往会有很多折扣活动、红包活动,我们可以用装饰模式去设计这个业务。
在系统编码完成之后,我们就可以对系统进行性能测试了。这时候,产品经理一般会提供线上预期数据,我们在提供的参考平台上进行压测,通过性能分析、统计工具来统计各项性能指标,看是否在预期范围之内。
在项目成功上线后,我们还需要根据线上的实际情况,依照日志监控以及性能统计日志,来观测系统性能问题,一旦发现问题,就要对日志进行分析并及时修复问题。
有哪些参考因素可以体现系统的性能?
CPU:有的应用需要大量计算,他们会长时间、不间断地占用 CPU 资源,导致其他资源无法争夺到 CPU 而响应缓慢,从而带来系统性能问题。例如,代码递归导致的无限循环,正则表达式引起的回溯,JVM 频繁的 FULL GC,以及多线程编程造成的大量上下文切换等,这些都有可能导致 CPU 资源繁忙。
内存:Java 程序一般通过 JVM 对内存进行分配管理,主要是用 JVM 中的堆内存来存储 Java 创建的对象。系统堆内存的读写速度非常快,所以基本不存在读写性能瓶颈。但是由于内存成本要比磁盘高,相比磁盘,内存的存储空间又非常有限。所以当内存空间被占满,对象无法回收时,就会导致内存溢出、内存泄露等问题。
磁盘 I/O:磁盘相比内存来说,存储空间要大很多,但磁盘 I/O 读写的速度要比内存慢,虽然目前引入的 SSD 固态硬盘已经有所优化,但仍然无法与内存的读写速度相提并论。
网络:网络对于系统性能来说,也起着至关重要的作用。如果你购买过云服务,一定经历过,选择网络带宽大小这一环节。带宽过低的话,对于传输数据比较大,或者是并发量比较大的系统,网络就很容易成为性能瓶颈。
异常:Java 应用中,抛出异常需要构建异常栈,对异常进行捕获和处理,这个过程非常消耗系统性能。如果在高并发的情况下引发异常,持续地进行异常处理,那么系统的性能就会明显地受到影响。
数据库:大部分系统都会用到数据库,而数据库的操作往往是涉及到磁盘 I/O 的读写。大量的数据库读写操作,会导致磁盘 I/O 性能瓶颈,进而导致数据库操作的延迟性。对于有大量数据库读写操作的系统来说,数据库的性能优化是整个系统的核心。
锁竞争:在并发编程中,我们经常会需要多个线程,共享读写操作同一个资源,这个时候为了保持数据的原子性(即保证这个共享资源在一个线程写的时候,不被另一个线程修改),我们就会用到锁。锁的使用可能会带来上下文切换,从而给系统带来性能开销。JDK1.6 之后,Java 为了降低锁竞争带来的上下文切换,对 JVM 内部锁已经做了多次优化,例如,新增了偏向锁、自旋锁、轻量级锁、锁粗化、锁消除等。而如何合理地使用锁资源,优化锁资源,就需要你了解更多的操作系统知识、Java 多线程编程基础,积累项目经验,并结合实际场景去处理相关问题。
响应时间
响应时间是衡量系统性能的重要指标之一,响应时间越短,性能越好,一般一个接口的响应时间是在毫秒级。在系统中,我们可以把响应时间自下而上细分为以下几种:
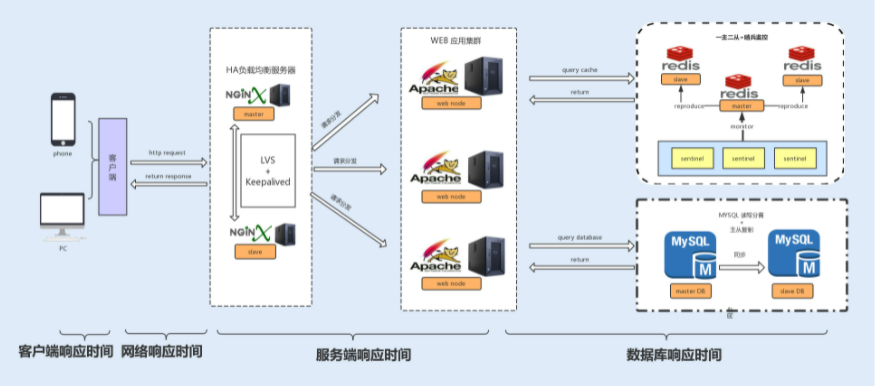
- 数据库响应时间:数据库操作所消耗的时间,往往是整个请求链中最耗时的;
- 服务端响应时间:服务端包括 Nginx 分发的请求所消耗的时间以及服务端程序执行所消耗的时间;
- 网络响应时间:这是网络传输时,网络硬件需要对传输的请求进行解析等操作所消耗的时间;
- 客户端响应时间:对于普通的 Web、App 客户端来说,消耗时间是可以忽略不计的,但如果你的客户端嵌入了大量的逻辑处理,消耗的时间就有可能变长,从而成为系统的瓶颈。
吞吐量
在测试中,我们往往会比较注重系统接口的 TPS(每秒事务处理量),因为 TPS 体现了接口的性能,TPS 越大,性能越好。在系统中,我们也可以把吞吐量自下而上地分为两种:磁盘吞吐量和网络吞吐量。
我们先来看磁盘吞吐量,磁盘性能有两个关键衡量指标。
一种是 IOPS(Input/Output Per Second),即每秒的输入输出量(或读写次数),这种是指单位时间内系统能处理的 I/O 请求数量,I/O 请求通常为读或写数据操作请求,关注的是随机读写性能。适应于随机读写频繁的应用,如小文件存储(图片)、OLTP 数据库、邮件服务器。
另一种是数据吞吐量,这种是指单位时间内可以成功传输的数据量。对于大量顺序读写频繁的应用,传输大量连续数据,例如,电视台的视频编辑、视频点播 VOD(Video On Demand),数据吞吐量则是关键衡量指标。
接下来看网络吞吐量,这个是指网络传输时没有帧丢失的情况下,设备能够接受的最大数据速率。网络吞吐量不仅仅跟带宽有关系,还跟 CPU 的处理能力、网卡、防火墙、外部接口以及 I/O 等紧密关联。而吞吐量的大小主要由网卡的处理能力、内部程序算法以及带宽大小决定。
计算机资源分配使用率
通常由 CPU 占用率、内存使用率、磁盘 I/O、网络 I/O 来表示资源使用率。这几个参数好比一个木桶,如果其中任何一块木板出现短板,任何一项分配不合理,对整个系统性能的影响都是毁灭性的。
负载承受能力
当系统压力上升时,你可以观察,系统响应时间的上升曲线是否平缓。这项指标能直观地反馈给你,系统所能承受的负载压力极限。例如,当你对系统进行压测时,系统的响应时间会随着系统并发数的增加而延长,直到系统无法处理这么多请求,抛出大量错误时,就到了极限。
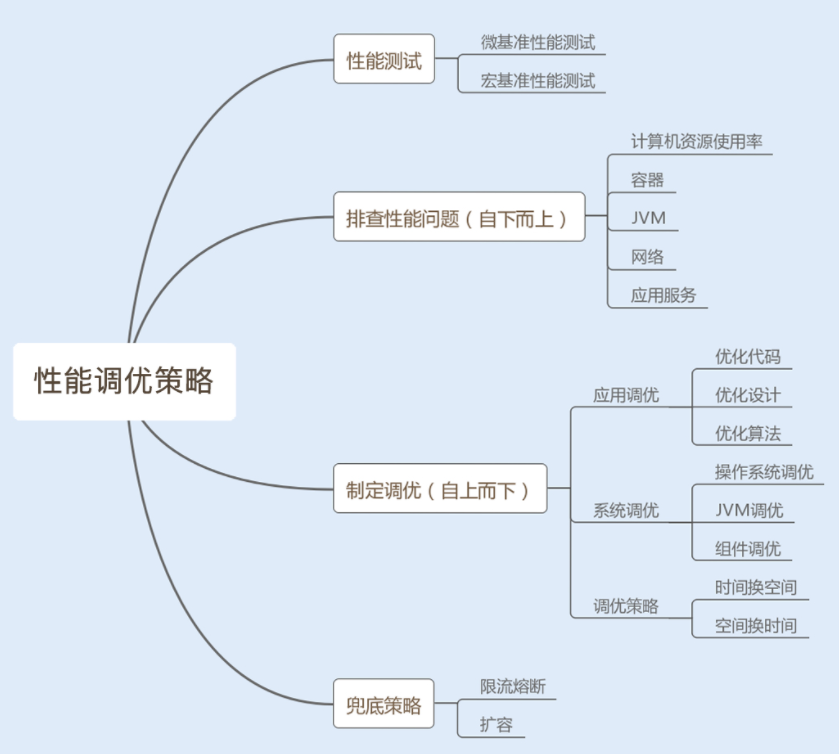
性能测试攻略
1. 微基准性能测试
微基准性能测试可以精准定位到某个模块或者某个方法的性能问题,特别适合做一个功能模块或者一个方法在不同实现方式下的性能对比。例如,对比一个方法使用同步实现和非同步实现的性能。
2. 宏基准性能测试
宏基准性能测试是一个综合测试,需要考虑到测试环境、测试场景和测试目标。
首先看测试环境,我们需要模拟线上的真实环境。
然后看测试场景。我们需要确定在测试某个接口时,是否有其他业务接口同时也在平行运行,造成干扰。如果有,请重视,因为你一旦忽视了这种干扰,测试结果就会出现偏差。
最后看测试目标。我们的性能测试是要有目标的,这里可以通过吞吐量以及响应时间来衡量系统是否达标。不达标,就进行优化;达标,就继续加大测试的并发数,探底接口的 TPS(最大每秒事务处理量),这样做,可以深入了解到接口的性能。除了测试接口的吞吐量和响应时间以外,我们还需要循环测试可能导致性能问题的接口,观察各个服务器的 CPU、内存以及 I/O 使用率的变化。
我们在做性能测试时,还要注意一些问题
热身问题
随着代码被执行的次数增多,当虚拟机发现某个方法或代码块运行得特别频繁时,就会把这些代码认定为热点代码(Hot Spot Code)。为了提高热点代码的执行效率,在运行时,虚拟机将会通过即时编译器(JIT compiler,just-in-time compiler)把这些代码编译成与本地平台相关的机器码,并进行各层次的优化,然后存储在内存中,之后每次运行代码时,直接从内存中获取即可。
性能测试结果不稳定
我们在做性能测试时发现,每次测试处理的数据集都是一样的,但测试结果却有差异。这是因为测试时,伴随着很多不稳定因素,比如机器其他进程的影响、网络波动以及每个阶段 JVM 垃圾回收的不同等等。
我们可以通过多次测试,将测试结果求平均,或者统计一个曲线图,只要保证我们的平均值是在合理范围之内,而且波动不是很大,这种情况下,性能测试就是通过的。
多 JVM 情况下的影响
如果我们的服务器有多个 Java 应用服务,部署在不同的 Tomcat 下,这就意味着我们的服务器会有多个 JVM。任意一个 JVM 都拥有整个系统的资源使用权。如果一台机器上只部署单独的一个 JVM,在做性能测试时,测试结果很好,或者你调优的效果很好,但在一台机器多个 JVM 的情况下就不一定了。所以我们应该尽量避免线上环境中一台机器部署多个 JVM 的情况。
合理分析结果,制定调优策略
我们在完成性能测试之后,需要输出一份性能测试报告,帮我们分析系统性能测试的情况。其中测试结果需要包含测试接口的平均、最大和最小吞吐量,响应时间,服务器的 CPU、内存、I/O、网络 IO 使用率,JVM 的 GC 频率等。
通过观察这些调优标准,可以发现性能瓶颈,我们再通过自下而上的方式分析查找问题。首先从操作系统层面,查看系统的 CPU、内存、I/O、网络的使用率是否存在异常,再通过命令查找异常日志,最后通过分析日志,找到导致瓶颈的原因;还可以从 Java 应用的 JVM 层面,查看 JVM 的垃圾回收频率以及内存分配情况是否存在异常,分析日志,找到导致瓶颈的原因。
如果系统和 JVM 层面都没有出现异常情况,我们可以查看应用服务业务层是否存在性能瓶颈,例如 Java 编程的问题、读写数据瓶颈等等。
分析查找问题是一个复杂而又细致的过程,某个性能问题可能是一个原因导致的,也可能是几个原因共同导致的结果。我们分析查找问题可以采用自下而上的方式,而我们解决系统性能问题,则可以采用自上而下的方式逐级优化。
1. 优化代码
应用层的问题代码往往会因为耗尽系统资源而暴露出来。例如,我们某段代码导致内存溢出,往往是将 JVM 中的内存用完了,这个时候系统的内存资源消耗殆尽了,同时也会引发 JVM 频繁地发生垃圾回收,导致 CPU 100% 以上居高不下,这个时候又消耗了系统的 CPU 资源。
还有一些是非问题代码导致的性能问题,这种往往是比较难发现的,需要依靠我们的经验来优化。例如,我们经常使用的 LinkedList 集合,如果使用 for 循环遍历该容器,将大大降低读的效率,但这种效率的降低很难导致系统性能参数异常。
这时有经验的同学,就会改用 Iterator (迭代器)迭代循环该集合,这是因为 LinkedList 是链表实现的,如果使用 for 循环获取元素,在每次循环获取元素时,都会去遍历一次 List,这样会降低读的效率。
2. 优化设计
面向对象有很多设计模式,可以帮助我们优化业务层以及中间件层的代码设计。优化后,不仅可以精简代码,还能提高整体性能。例如,单例模式在频繁调用创建对象的场景中,可以共享一个创建对象,这样可以减少频繁地创建和销毁对象所带来的性能消耗。
3. 优化算法
好的算法可以帮助我们大大地提升系统性能。例如,在不同的场景中,使用合适的查找算法可以降低时间复杂度。
4. 时间换空间
有时候系统对查询时的速度并没有很高的要求,反而对存储空间要求苛刻,这个时候我们可以考虑用时间来换取空间。
5. 空间换时间
这种方法是使用存储空间来提升访问速度。现在很多系统都是使用的 MySQL 数据库,较为常见的分表分库是典型的使用空间换时间的案例。
因为 MySQL 单表在存储千万数据以上时,读写性能会明显下降,这个时候我们需要将表数据通过某个字段 Hash 值或者其他方式分拆,系统查询数据时,会根据条件的 Hash 值判断找到对应的表,因为表数据量减小了,查询性能也就提升了。
6. 参数调优
以上都是业务层代码的优化,除此之外,JVM、Web 容器以及操作系统的优化也是非常关键的。
根据自己的业务场景,合理地设置 JVM 的内存空间以及垃圾回收算法可以提升系统性能。例如,如果我们业务中会创建大量的大对象,我们可以通过设置,将这些大对象直接放进老年代。这样可以减少年轻代频繁发生小的垃圾回收(Minor GC),减少 CPU 占用时间,提升系统性能。
Web 容器线程池的设置以及 Linux 操作系统的内核参数设置不合理也有可能导致系统性能瓶颈,根据自己的业务场景优化这两部分,可以提升系统性能。
兜底策略,确保系统稳定性
上边讲到的所有的性能调优策略,都是提高系统性能的手段,但在互联网飞速发展的时代,产品的用户量是瞬息万变的,无论我们的系统优化得有多好,还是会存在承受极限,所以为了保证系统的稳定性,我们还需要采用一些兜底策略。
什么是兜底策略?
第一,限流,对系统的入口设置最大访问限制。这里可以参考性能测试中探底接口的 TPS 。同时采取熔断措施,友好地返回没有成功的请求。
第二,实现智能化横向扩容。智能化横向扩容可以保证当访问量超过某一个阈值时,系统可以根据需求自动横向新增服务。
第三,提前扩容。这种方法通常应用于高并发系统,例如,瞬时抢购业务系统。这是因为横向扩容无法满足大量发生在瞬间的请求,即使成功了,抢购也结束了。
String 对象是如何实现的?
在 Java 语言中,Sun 公司的工程师们对 String 对象做了大量的优化,来节约内存空间,提升 String 对象在系统中的性能。
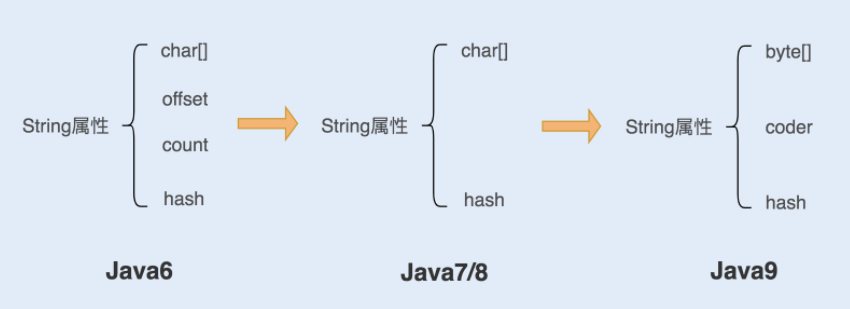
1. 在 Java6 以及之前的版本中,String 对象是对 char 数组进行了封装实现的对象,主要有四个成员变量:char 数组、偏移量 offset、字符数量 count、哈希值 hash。
String 对象是通过 offset 和 count 两个属性来定位 char[] 数组,获取字符串。这么做可以高效、快速地共享数组对象,同时节省内存空间,但这种方式很有可能会导致内存泄漏。
2. 从 Java7 版本开始到 Java8 版本,Java 对 String 类做了一些改变。String 类中不再有 offset 和 count 两个变量了。这样的好处是 String 对象占用的内存稍微少了些,同时,String.substring 方法也不再共享 char[],从而解决了使用该方法可能导致的内存泄漏问题。
3. 从 Java9 版本开始,工程师将 char[] 字段改为了 byte[] 字段,又维护了一个新的属性 coder,它是一个编码格式的标识。
工程师为什么这样修改呢?
我们知道一个 char 字符占 16 位,2 个字节。这个情况下,存储单字节编码内的字符(占一个字节的字符)就显得非常浪费。JDK1.9 的 String 类为了节约内存空间,于是使用了占 8 位,1 个字节的 byte 数组来存放字符串。
而新属性 coder 的作用是,在计算字符串长度或者使用 indexOf()函数时,我们需要根据这个字段,判断如何计算字符串长度。coder 属性默认有 0 和 1 两个值,0 代表 Latin-1(单字节编码),1 代表 UTF-16。如果 String 判断字符串只包含了 Latin-1,则 coder 属性值为 0,反之则为 1。
String 对象的不可变性
了解了 String 对象的实现后,你有没有发现在实现代码中 String 类被 final 关键字修饰了,而且变量 char 数组也被 final 修饰了。
我们知道类被 final 修饰代表该类不可继承,而 char[] 被 final+private 修饰,代表了 String 对象不可被更改。Java 实现的这个特性叫作 String 对象的不可变性,即 String 对象一旦创建成功,就不能再对它进行改变。
Java 这样做的好处在哪里呢?
第一,保证 String 对象的安全性。假设 String 对象是可变的,那么 String 对象将可能被恶意修改。
第二,保证 hash 属性值不会频繁变更,确保了唯一性,使得类似 HashMap 容器才能实现相应的 key-value 缓存功能。
第三,可以实现字符串常量池。在 Java 中,通常有两种创建字符串对象的方式,一种是通过字符串常量的方式创建,如 String str=“abc”;另一种是字符串变量通过 new 形式的创建,如 String str = new String(“abc”)。
当代码中使用第一种方式创建字符串对象时,JVM 首先会检查该对象是否在字符串常量池中,如果在,就返回该对象引用,否则新的字符串将在常量池中被创建。这种方式可以减少同一个值的字符串对象的重复创建,节约内存。
String str = new String(“abc”) 这种方式,首先在编译类文件时,”abc”常量字符串将会放入到常量结构中,在类加载时,“abc”将会在常量池中创建;其次,在调用 new 时,JVM 命令将会调用 String 的构造函数,同时引用常量池中的”abc” 字符串,在堆内存中创建一个 String 对象;最后,str 将引用 String 对象。
这里附上一个你可能会想到的经典反例。
平常编程时,对一个 String 对象 str 赋值“hello”,然后又让 str 值为“world”,这个时候 str 的值变成了“world”。那么 str 值确实改变了,为什么我还说 String 对象不可变呢?
首先,我来解释下什么是对象和对象引用。Java 初学者往往对此存在误区,特别是一些从 PHP 转 Java 的同学。在 Java 中要比较两个对象是否相等,往往是用 ==,而要判断两个对象的值是否相等,则需要用 equals 方法来判断。
这是因为 str 只是 String 对象的引用,并不是对象本身。对象在内存中是一块内存地址,str 则是一个指向该内存地址的引用。所以在刚刚我们说的这个例子中,第一次赋值的时候,创建了一个“hello”对象,str 引用指向“hello”地址;第二次赋值的时候,又重新创建了一个对象“world”,str 引用指向了“world”,但“hello”对象依然存在于内存中。
也就是说 str 并不是对象,而只是一个对象引用。真正的对象依然还在内存中,没有被改变。
String 对象的优化
1. 如何构建超大字符串?
编程过程中,字符串的拼接很常见。前面我讲过 String 对象是不可变的,如果我们使用 String 对象相加,拼接我们想要的字符串,是不是就会产生多个对象呢?例如以下代码:
String str= "ab" + "cd" + "ef";分析代码可知:首先会生成 ab 对象,再生成 abcd 对象,最后生成 abcdef 对象,从理论上来说,这段代码是低效的。
但实际运行中,我们发现只有一个对象生成,这是为什么呢?难道我们的理论判断错了?我们再来看编译后的代码,你会发现编译器自动优化了这行代码,如下:
String str= "abcdef";上面我介绍的是字符串常量的累计,我们再来看看字符串变量的累计又是怎样的呢?
String str = "abcdef";
for(int i=0; i<1000; i++) {
str = str + i;
}上面的代码编译后,你可以看到编译器同样对这段代码进行了优化。不难发现,Java 在进行字符串的拼接时,偏向使用 StringBuilder,这样可以提高程序的效率。
String str = "abcdef";
for(int i=0; i<1000; i++) {
str = (new StringBuilder(String.valueOf(str))).append(i).toString();
}综上已知:即使使用 + 号作为字符串的拼接,也一样可以被编译器优化成 StringBuilder 的方式。但再细致些,你会发现在编译器优化的代码中,每次循环都会生成一个新的 StringBuilder 实例,同样也会降低系统的性能。
所以平时做字符串拼接的时候,我建议你还是要显示地使用 String Builder 来提升系统性能。
如果在多线程编程中,String 对象的拼接涉及到线程安全,你可以使用 StringBuffer。但是要注意,由于 StringBuffer 是线程安全的,涉及到锁竞争,所以从性能上来说,要比 StringBuilder 差一些。
2. 如何使用 String.intern 节省内存?
讲完了构建字符串,我们再来讨论下 String 对象的存储问题。先看一个案例。
Twitter 每次发布消息状态的时候,都会产生一个地址信息,以当时 Twitter 用户的规模预估,服务器需要 32G 的内存来存储地址信息。
public class Location {
private String city;
private String region;
private String countryCode;
private double longitude;
private double latitude;
} 考虑到其中有很多用户在地址信息上是有重合的,比如,国家、省份、城市等,这时就可以将这部分信息单独列出一个类,以减少重复,代码如下:
public class SharedLocation {
private String city;
private String region;
private String countryCode;
}
public class Location {
private SharedLocation sharedLocation;
double longitude;
double latitude;
}通过优化,数据存储大小减到了 20G 左右。但对于内存存储这个数据来说,依然很大,怎么办呢?
这个案例来自一位 Twitter 工程师在 QCon 全球软件开发大会上的演讲,他们想到的解决方法,就是使用 String.intern 来节省内存空间,从而优化 String 对象的存储。
具体做法就是,在每次赋值的时候使用 String 的 intern 方法,如果常量池中有相同值,就会重复使用该对象,返回对象引用,这样一开始的对象就可以被回收掉。这种方式可以使重复性非常高的地址信息存储大小从 20G 降到几百兆。
SharedLocation sharedLocation = new SharedLocation();
sharedLocation.setCity(messageInfo.getCity().intern()); sharedLocation.setCountryCode(messageInfo.getRegion().intern());
sharedLocation.setRegion(messageInfo.getCountryCode().intern());
Location location = new Location();
location.set(sharedLocation);
location.set(messageInfo.getLongitude());
location.set(messageInfo.getLatitude());3. 如何使用字符串的分割方法?
Split() 方法使用了正则表达式实现了其强大的分割功能,而正则表达式的性能是非常不稳定的,使用不恰当会引起回溯问题,很可能导致 CPU 居高不下。
所以我们应该慎重使用 Split() 方法,我们可以用 String.indexOf() 方法代替 Split() 方法完成字符串的分割。如果实在无法满足需求,你就在使用 Split() 方法时,对回溯问题加以重视就可以了。
什么是正则表达式?
很基础,这里带你简单回顾一下。
正则表达式是计算机科学的一个概念,很多语言都实现了它。正则表达式使用一些特定的元字符来检索、匹配以及替换符合规则的字符串。
构造正则表达式语法的元字符,由普通字符、标准字符、限定字符(量词)、定位字符(边界字符)组成。详情可见下图:

正则表达式引擎
正则表达式是一个用正则符号写出的公式,程序对这个公式进行语法分析,建立一个语法分析树,再根据这个分析树结合正则表达式的引擎生成执行程序(这个执行程序我们把它称作状态机,也叫状态自动机),用于字符匹配。
而这里的正则表达式引擎就是一套核心算法,用于建立状态机。
目前实现正则表达式引擎的方式有两种:DFA 自动机(Deterministic Final Automata 确定有限状态自动机)和 NFA 自动机(Non deterministic Finite Automaton 非确定有限状态自动机)。
对比来看,构造 DFA 自动机的代价远大于 NFA 自动机,但 DFA 自动机的执行效率高于 NFA 自动机。
假设一个字符串的长度是 n,如果用 DFA 自动机作为正则表达式引擎,则匹配的时间复杂度为 O(n);如果用 NFA 自动机作为正则表达式引擎,由于 NFA 自动机在匹配过程中存在大量的分支和回溯,假设 NFA 的状态数为 s,则该匹配算法的时间复杂度为 O(ns)。
NFA 自动机的优势是支持更多功能。例如,捕获 group、环视、占有优先量词等高级功能。这些功能都是基于子表达式独立进行匹配,因此在编程语言里,使用的正则表达式库都是基于 NFA 实现的。
那么 NFA 自动机到底是怎么进行匹配的呢?我以下面的字符和表达式来举例说明。
text=“aabcab”
regex=“bc”NFA 自动机会读取正则表达式的每一个字符,拿去和目标字符串匹配,匹配成功就换正则表达式的下一个字符,反之就继续和目标字符串的下一个字符进行匹配。分解一下过程。
首先,读取正则表达式的第一个匹配符和字符串的第一个字符进行比较,b 对 a,不匹配;继续换字符串的下一个字符,也是 a,不匹配;继续换下一个,是 b,匹配。
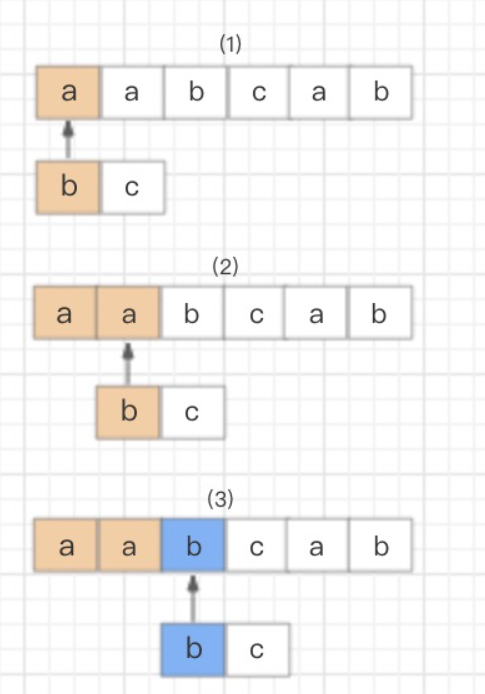
然后,同理,读取正则表达式的第二个匹配符和字符串的第四个字符进行比较,c 对 c,匹配;继续读取正则表达式的下一个字符,然而后面已经没有可匹配的字符了,结束。
这就是 NFA 自动机的匹配过程,虽然在实际应用中,碰到的正则表达式都要比这复杂,但匹配方法是一样的。
NFA 自动机的回溯
用 NFA 自动机实现的比较复杂的正则表达式,在匹配过程中经常会引起回溯问题。大量的回溯会长时间地占用 CPU,从而带来系统性能开销。我来举例说明。
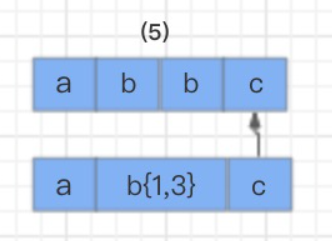
text=“abbc”
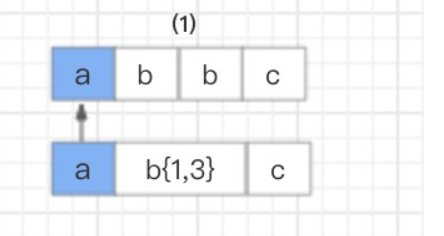
regex=“ab{1,3}c”这个例子,匹配目的比较简单。匹配以 a 开头,以 c 结尾,中间有 1-3 个 b 字符的字符串。NFA 自动机对其解析的过程是这样的:
首先,读取正则表达式第一个匹配符 a 和字符串第一个字符 a 进行比较,a 对 a,匹配。
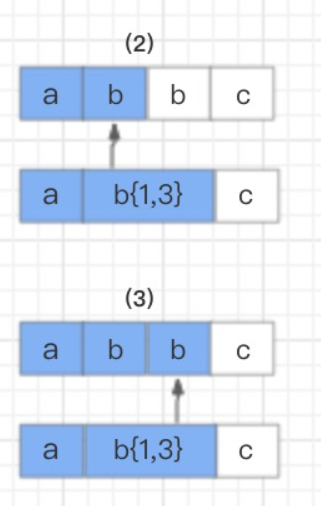
然后,读取正则表达式第二个匹配符 b{1,3} 和字符串的第二个字符 b 进行比较,匹配。但因为 b{1,3} 表示 1-3 个 b 字符串,NFA 自动机又具有贪婪特性,所以此时不会继续读取正则表达式的下一个匹配符,而是依旧使用 b{1,3} 和字符串的第三个字符 b 进行比较,结果还是匹配。
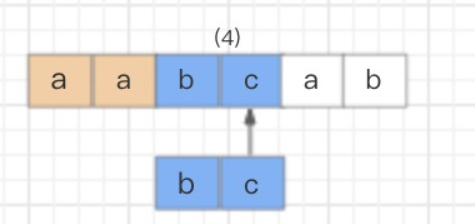
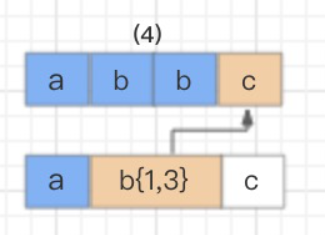
接着继续使用 b{1,3} 和字符串的第四个字符 c 进行比较,发现不匹配了,此时就会发生回溯,已经读取的字符串第四个字符 c 将被吐出去,指针回到第三个字符 b 的位置。
那么发生回溯以后,匹配过程怎么继续呢?程序会读取正则表达式的下一个匹配符 c,和字符串中的第四个字符 c 进行比较,结果匹配,结束。
如何避免回溯问题?
既然回溯会给系统带来性能开销,那我们如何应对呢?如果你有仔细看上面那个案例的话,你会发现 NFA 自动机的贪婪特性就是导火索,这和正则表达式的匹配模式息息相关,一起来了解一下。
1. 贪婪模式(Greedy)
顾名思义,就是在数量匹配中,如果单独使用 +、 ? 、* 或{min,max} 等量词,正则表达式会匹配尽可能多的内容。
例如,上边那个例子:
text=“abbc”
regex=“ab{1,3}c”
就是在贪婪模式下,NFA 自动机读取了最大的匹配范围,即匹配 3 个 b 字符。匹配发生了一次失败,就引起了一次回溯。如果匹配结果是“abbbc”,就会匹配成功。
text=“abbbc”
regex=“ab{1,3}c”
2. 懒惰模式(Reluctant)
在该模式下,正则表达式会尽可能少地重复匹配字符。如果匹配成功,它会继续匹配剩余的字符串。
例如,在上面例子的字符后面加一个“?”,就可以开启懒惰模式。
text=“abc”
regex=“ab{1,3}?c”
匹配结果是“abc”,该模式下 NFA 自动机首先选择最小的匹配范围,即匹配 1 个 b 字符,因此就避免了回溯问题。
3. 独占模式(Possessive)
同贪婪模式一样,独占模式一样会最大限度地匹配更多内容;不同的是,在独占模式下,匹配失败就会结束匹配,不会发生回溯问题。
还是上边的例子,在字符后面加一个“+”,就可以开启独占模式。
text=“abbc”
regex=“ab{1,3}+bc”结果是不匹配,结束匹配,不会发生回溯问题。讲到这里,你应该非常清楚了,避免回溯的方法就是:使用懒惰模式和独占模式。
还有开头那道“一个 split() 方法为什么会影响到 TPS”的存疑,你应该也清楚了吧?
我使用了 split() 方法提取域名,并检查请求参数是否符合规定。split() 在匹配分组时遇到特殊字符产生了大量回溯,我当时是在正则表达式后加了一个需要匹配的字符和“+”,解决了这个问题。
\\?(([A-Za-z0-9-~_=%]++\\&{0,1})+)正则表达式的优化
正则表达式带来的性能问题,给我敲了个警钟,在这里我也希望分享给你一些心得。任何一个细节问题,都有可能导致性能问题,而这背后折射出来的是我们对这项技术的了解不够透彻。所以我鼓励你学习性能调优,要掌握方法论,学会透过现象看本质。下面我就总结几种正则表达式的优化方法给你。
1. 少用贪婪模式,多用独占模式
贪婪模式会引起回溯问题,我们可以使用独占模式来避免回溯。前面详解过了,这里我就不再解释了。
2. 减少分支选择
分支选择类型“(X|Y|Z)”的正则表达式会降低性能,我们在开发的时候要尽量减少使用。如果一定要用,我们可以通过以下几种方式来优化:
首先,我们需要考虑选择的顺序,将比较常用的选择项放在前面,使它们可以较快地被匹配;
其次,我们可以尝试提取共用模式,例如,将“(abcd|abef)”替换为“ab(cd|ef)”,后者匹配速度较快,因为 NFA 自动机会尝试匹配 ab,如果没有找到,就不会再尝试任何选项;
最后,如果是简单的分支选择类型,我们可以用三次 index 代替“(X|Y|Z)”,如果测试的话,你就会发现三次 index 的效率要比“(X|Y|Z)”高出一些。
3. 减少捕获嵌套
在讲这个方法之前,我先简单介绍下什么是捕获组和非捕获组。
捕获组是指把正则表达式中,子表达式匹配的内容保存到以数字编号或显式命名的数组中,方便后面引用。一般一个 () 就是一个捕获组,捕获组可以进行嵌套。
非捕获组则是指参与匹配却不进行分组编号的捕获组,其表达式一般由(?:exp)组成。
在正则表达式中,每个捕获组都有一个编号,编号 0 代表整个匹配到的内容。我们可以看下面的例子:
public class RegexTest {
public static void main(String[] args) {
String text = "<input high=\\\"20\\\" weight=\\\"70\\\">test</input>";
String regex = "(<input.*?>)(.*?)(</input>)";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
System.out.println(matcher.group(2));
System.out.println(matcher.group(3));
}
}
}运行结果:
<input high=\"20\" weight=\"70\">test</input>
<input high=\"20\" weight=\"70\">
test
</input>如果你并不需要获取某一个分组内的文本,那么就使用非捕获分组。例如,使用“(?:X)”代替“(X)”,我们再看下面的例子:
public class RegexTest {
public static void main(String[] args) {
String text = "<input high=\\\"20\\\" weight=\\\"70\\\">test</input>";
String regex = "(?:<input.*?>)(.*?)(?:</input>)";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
// System.out.println(matcher.group(2));
// System.out.println(matcher.group(3));
}
}
}运行结果:
<input high=\"20\" weight=\"70\">test</input>
test综上可知:减少不需要获取的分组,可以提高正则表达式的性能。
初识 List 接口
在学习 List 集合类之前,我们先来通过这张图,看下 List 集合类的接口和类的实现关系:
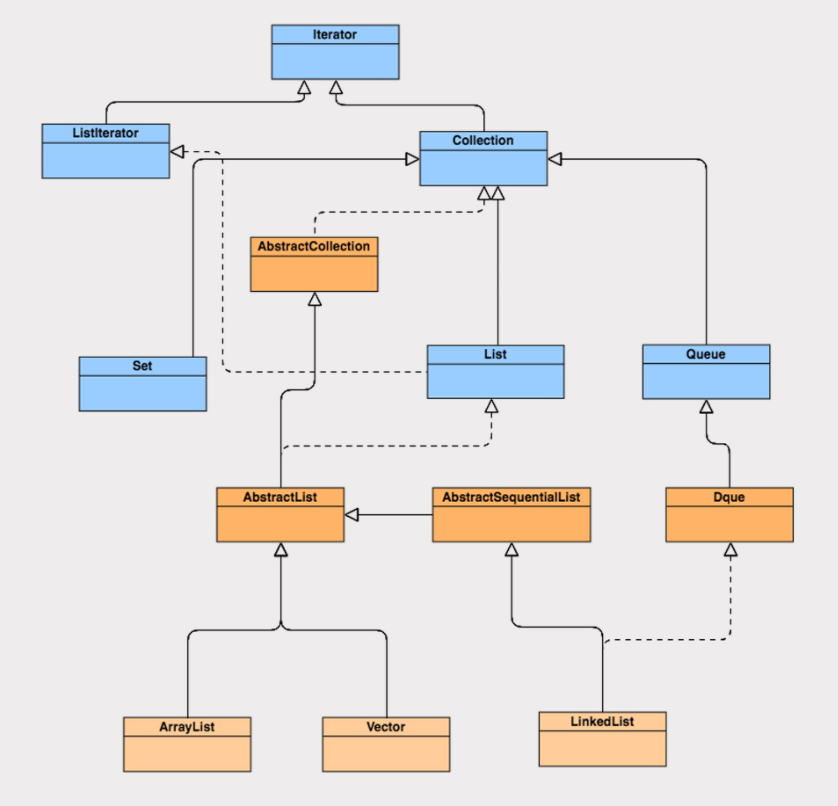
我们可以看到 ArrayList、Vector、LinkedList 集合类继承了 AbstractList 抽象类,而 AbstractList 实现了 List 接口,同时也继承了 AbstractCollection 抽象类。ArrayList、Vector、LinkedList 又根据自我定位,分别实现了各自的功能。
ArrayList 和 Vector 使用了数组实现,这两者的实现原理差不多,LinkedList 使用了双向链表实现。基础
我们可以看到 ArrayList、Vector、LinkedList 集合类继承了 AbstractList 抽象类,而 AbstractList 实现了 List 接口,同时也继承了 AbstractCollection 抽象类。ArrayList、Vector、LinkedList 又根据自我定位,分别实现了各自的功能。
ArrayList 和 Vector 使用了数组实现,这两者的实现原理差不多,LinkedList 使用了双向链表实现。
1.ArrayList 实现类
ArrayList 实现了 List 接口,继承了 AbstractList 抽象类,底层是数组实现的,并且实现了自增扩容数组大小。
ArrayList 还实现了 Cloneable 接口和 Serializable 接口,所以他可以实现克隆和序列化。
ArrayList 还实现了 RandomAccess 接口。你可能对这个接口比较陌生,不知道具体的用处。通过代码我们可以发现,这个接口其实是一个空接口,什么也没有实现,那 ArrayList 为什么要去实现它呢?
其实 RandomAccess 接口是一个标志接口,他标志着“只要实现该接口的 List 类,都能实现快速随机访问”。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable2.ArrayList 属性
ArrayList 属性主要由数组长度 size、对象数组 elementData、初始化容量 default_capacity 等组成, 其中初始化容量默认大小为 10。
// 默认初始化容量
private static final int DEFAULT_CAPACITY = 10;
// 对象数组
transient Object[] elementData;
// 数组长度
private int size;从 ArrayList 属性来看,它没有被任何的多线程关键字修饰,但 elementData 被关键字 transient 修饰了。
这还得从“ArrayList 是基于数组实现“开始说起,由于 ArrayList 的数组是基于动态扩增的,所以并不是所有被分配的内存空间都存储了数据。
如果采用外部序列化法实现数组的序列化,会序列化整个数组。ArrayList 为了避免这些没有存储数据的内存空间被序列化,内部提供了两个私有方法 writeObject 以及 readObject 来自我完成序列化与反序列化,从而在序列化与反序列化数组时节省了空间和时间。
因此使用 transient 修饰数组,是防止对象数组被其他外部方法序列化。
3.ArrayList 构造函数
ArrayList 类实现了三个构造函数,第一个是创建 ArrayList 对象时,传入一个初始化值;第二个是默认创建一个空数组对象;第三个是传入一个集合类型进行初始化。
当 ArrayList 新增元素时,如果所存储的元素已经超过其已有大小,它会计算元素大小后再进行动态扩容,数组的扩容会导致整个数组进行一次内存复制。因此,我们在初始化 ArrayList 时,可以通过第一个构造函数合理指定数组初始大小,这样有助于减少数组的扩容次数,从而提高系统性能。
public ArrayList(int initialCapacity) {
// 初始化容量不为零时,将根据初始化值创建数组大小
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {// 初始化容量为零时,使用默认的空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
// 初始化默认为空数组
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}4.ArrayList 新增元素
ArrayList 新增元素的方法有两种,一种是直接将元素加到数组的末尾,另外一种是添加元素到任意位置。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}两个方法的相同之处是在添加元素之前,都会先确认容量大小,如果容量够大,就不用进行扩容;如果容量不够大,就会按照原来数组的 1.5 倍大小进行扩容,在扩容之后需要将数组复制到新分配的内存地址。
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}当然,两个方法也有不同之处,添加元素到任意位置,会导致在该位置后的所有元素都需要重新排列,而将元素添加到数组的末尾,在没有发生扩容的前提下,是不会有元素复制排序过程的。
5.ArrayList 删除元素
ArrayList 的删除方法和添加任意位置元素的方法是有些相同的。ArrayList 在每一次有效的删除元素操作之后,都要进行数组的重组,并且删除的元素位置越靠前,数组重组的开销就越大。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}6.ArrayList 遍历元素
由于 ArrayList 是基于数组实现的,所以在获取元素的时候是非常快捷的。
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}LinkedList 是如何实现的?
虽然 LinkedList 与 ArrayList 都是 List 类型的集合,但 LinkedList 的实现原理却和 ArrayList 大相径庭,使用场景也不太一样。
LinkedList 是基于双向链表数据结构实现的,LinkedList 定义了一个 Node 结构,Node 结构中包含了 3 个部分:元素内容 item、前指针 prev 以及后指针 next,代码如下。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}总结一下,LinkedList 就是由 Node 结构对象连接而成的一个双向链表。在 JDK1.7 之前,LinkedList 中只包含了一个 Entry 结构的 header 属性,并在初始化的时候默认创建一个空的 Entry,用来做 header,前后指针指向自己,形成一个循环双向链表。
在 JDK1.7 之后,LinkedList 做了很大的改动,对链表进行了优化。链表的 Entry 结构换成了 Node,内部组成基本没有改变,但 LinkedList 里面的 header 属性去掉了,新增了一个 Node 结构的 first 属性和一个 Node 结构的 last 属性。这样做有以下几点好处:
- first/last 属性能更清晰地表达链表的链头和链尾概念;
- first/last 方式可以在初始化 LinkedList 的时候节省 new 一个 Entry;
- first/last 方式最重要的性能优化是链头和链尾的插入删除操作更加快捷了。
1.LinkedList 实现类
LinkedList 类实现了 List 接口、Deque 接口,同时继承了 AbstractSequentialList 抽象类,LinkedList 既实现了 List 类型又有 Queue 类型的特点;LinkedList 也实现了 Cloneable 和 Serializable 接口,同 ArrayList 一样,可以实现克隆和序列化。
由于 LinkedList 存储数据的内存地址是不连续的,而是通过指针来定位不连续地址,因此,LinkedList 不支持随机快速访问,LinkedList 也就不能实现 RandomAccess 接口。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable2.LinkedList 属性
我们前面讲到了 LinkedList 的两个重要属性 first/last 属性,其实还有一个 size 属性。我们可以看到这三个属性都被 transient 修饰了,原因很简单,我们在序列化的时候不会只对头尾进行序列化,所以 LinkedList 也是自行实现 readObject 和 writeObject 进行序列化与反序列化。
transient int size = 0;
transient Node<E> first;
transient Node<E> last;3.LinkedList 新增元素
LinkedList 添加元素的实现很简洁,但添加的方式却有很多种。默认的 add (Ee) 方法是将添加的元素加到队尾,首先是将 last 元素置换到临时变量中,生成一个新的 Node 节点对象,然后将 last 引用指向新节点对象,之前的 last 对象的前指针指向新节点对象。
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}LinkedList 也有添加元素到任意位置的方法,如果我们是将元素添加到任意两个元素的中间位置,添加元素操作只会改变前后元素的前后指针,指针将会指向添加的新元素,所以相比 ArrayList 的添加操作来说,LinkedList 的性能优势明显。
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}4.LinkedList 删除元素
在 LinkedList 删除元素的操作中,我们首先要通过循环找到要删除的元素,如果要删除的位置处于 List 的前半段,就从前往后找;若其位置处于后半段,就从后往前找。
这样做的话,无论要删除较为靠前或较为靠后的元素都是非常高效的,但如果 List 拥有大量元素,移除的元素又在 List 的中间段,那效率相对来说会很低。
5.LinkedList 遍历元素
LinkedList 的获取元素操作实现跟 LinkedList 的删除元素操作基本类似,通过分前后半段来循环查找到对应的元素。但是通过这种方式来查询元素是非常低效的,特别是在 for 循环遍历的情况下,每一次循环都会去遍历半个 List。
所以在 LinkedList 循环遍历时,我们可以使用 iterator 方式迭代循环,直接拿到我们的元素,而不需要通过循环查找 List。
1.ArrayList 和 LinkedList 新增元素操作测试
- 从集合头部位置新增元素
- 从集合中间位置新增元素
- 从集合尾部位置新增元素
测试结果 (花费时间):
- ArrayList>LinkedList
- ArrayList<LinkedList
- ArrayList<LinkedList
通过这组测试,我们可以知道 LinkedList 添加元素的效率未必要高于 ArrayList。
由于 ArrayList 是数组实现的,而数组是一块连续的内存空间,在添加元素到数组头部的时候,需要对头部以后的数据进行复制重排,所以效率很低;而 LinkedList 是基于链表实现,在添加元素的时候,首先会通过循环查找到添加元素的位置,如果要添加的位置处于 List 的前半段,就从前往后找;若其位置处于后半段,就从后往前找。因此 LinkedList 添加元素到头部是非常高效的。
同上可知,ArrayList 在添加元素到数组中间时,同样有部分数据需要复制重排,效率也不是很高;LinkedList 将元素添加到中间位置,是添加元素最低效率的,因为靠近中间位置,在添加元素之前的循环查找是遍历元素最多的操作。
而在添加元素到尾部的操作中,我们发现,在没有扩容的情况下,ArrayList 的效率要高于 LinkedList。这是因为 ArrayList 在添加元素到尾部的时候,不需要复制重排数据,效率非常高。而 LinkedList 虽然也不用循环查找元素,但 LinkedList 中多了 new 对象以及变换指针指向对象的过程,所以效率要低于 ArrayList。
ArrayList 和 LinkedList 删除元素操作测试
- 从集合头部位置删除元素
- 从集合中间位置删除元素
- 从集合尾部位置删除元素
测试结果 (花费时间):
- ArrayList>LinkedList
- ArrayList<LinkedList
- ArrayList<LinkedList
ArrayList 和 LinkedList 删除元素操作测试的结果和添加元素操作测试的结果很接近,这是一样的原理,我在这里就不重复讲解了。
3.ArrayList 和 LinkedList 遍历元素操作测试
- for(;;) 循环
- 迭代器迭代循环
测试结果 (花费时间):
- ArrayList<LinkedList
- ArrayList≈LinkedList
我们可以看到,LinkedList 的 for 循环性能是最差的,而 ArrayList 的 for 循环性能是最好的。
这是因为 LinkedList 基于链表实现的,在使用 for 循环的时候,每一次 for 循环都会去遍历半个 List,所以严重影响了遍历的效率;ArrayList 则是基于数组实现的,并且实现了 RandomAccess 接口标志,意味着 ArrayList 可以实现快速随机访问,所以 for 循环效率非常高。
LinkedList 的迭代循环遍历和 ArrayList 的迭代循环遍历性能相当,也不会太差,所以在遍历 LinkedList 时,我们要切忌使用 for 循环遍历。
什么是 Stream?
现在很多大数据量系统中都存在分表分库的情况。
例如,电商系统中的订单表,常常使用用户 ID 的 Hash 值来实现分表分库,这样是为了减少单个表的数据量,优化用户查询订单的速度。
但在后台管理员审核订单时,他们需要将各个数据源的数据查询到应用层之后进行合并操作。
例如,当我们需要查询出过滤条件下的所有订单,并按照订单的某个条件进行排序,单个数据源查询出来的数据是可以按照某个条件进行排序的,但多个数据源查询出来已经排序好的数据,并不代表合并后是正确的排序,所以我们需要在应用层对合并数据集合重新进行排序。
在 Java8 之前,我们通常是通过 for 循环或者 Iterator 迭代来重新排序合并数据,又或者通过重新定义 Collections.sorts 的 Comparator 方法来实现,这两种方式对于大数据量系统来说,效率并不是很理想。
Java8 中添加了一个新的接口类 Stream,他和我们之前接触的字节流概念不太一样,Java8 集合中的 Stream 相当于高级版的 Iterator,他可以通过 Lambda 表达式对集合进行各种非常便利、高效的聚合操作(Aggregate Operation),或者大批量数据操作 (Bulk Data Operation)。
Stream 的聚合操作与数据库 SQL 的聚合操作 sorted、filter、map 等类似。我们在应用层就可以高效地实现类似数据库 SQL 的聚合操作了,而在数据操作方面,Stream 不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据,提高数据的处理效率。
接下来我们就用一个简单的例子来体验下 Stream 的简洁与强大。
这个 Demo 的需求是过滤分组一所中学里身高在 160cm 以上的男女同学,我们先用传统的迭代方式来实现,代码如下:
Map<String, List<Student>> stuMap = new HashMap<String, List<Student>>();
for (Student stu: studentsList) {
if (stu.getHeight() > 160) { // 如果身高大于 160
if (stuMap.get(stu.getSex()) == null) { // 该性别还没分类
List<Student> list = new ArrayList<Student>(); // 新建该性别学生的列表
list.add(stu);// 将学生放进去列表
stuMap.put(stu.getSex(), list);// 将列表放到 map 中
} else { // 该性别分类已存在
stuMap.get(stu.getSex()).add(stu);// 该性别分类已存在,则直接放进去即可
}
}
}我们再使用 Java8 中的 Stream API 进行实现:
- 串行实现
Map<String, List<Student>> stuMap = stuList.stream().filter((Student s) -> s.getHeight() > 160) .collect(Collectors.groupingBy(Student ::getSex)); - 并行实现
Map<String, List<Student>> stuMap = stuList.parallelStream().filter((Student s) -> s.getHeight() > 160) .collect(Collectors.groupingBy(Student ::getSex)); Stream 如何优化遍历?
上面我们初步了解了 Java8 中的 Stream API,那 Stream 是如何做到优化迭代的呢?并行又是如何实现的?下面我们就透过 Stream 源码剖析 Stream 的实现原理。
1.Stream 操作分类
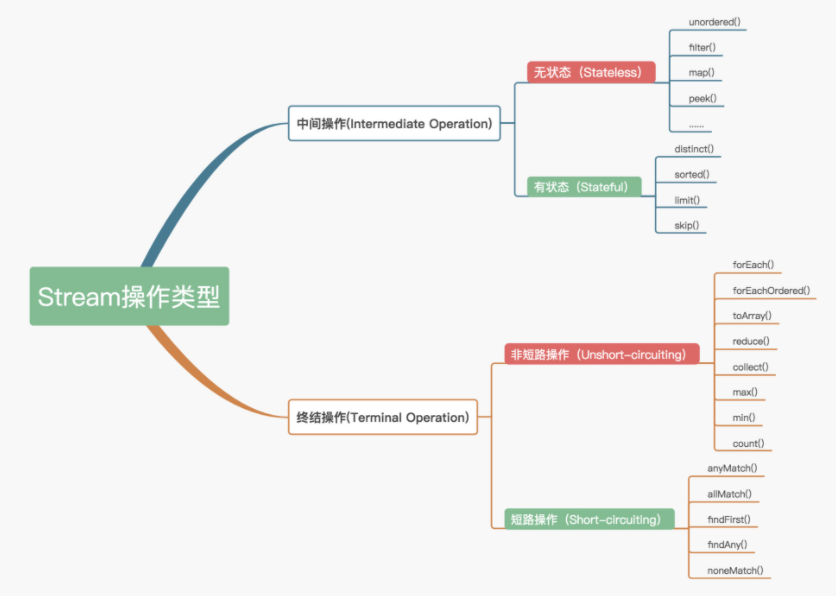
在了解 Stream 的实现原理之前,我们先来了解下 Stream 的操作分类,因为他的操作分类其实是实现高效迭代大数据集合的重要原因之一。为什么这样说,分析完你就清楚了。
官方将 Stream 中的操作分为两大类:中间操作(Intermediate operations)和终结操作(Terminal operations)。中间操作只对操作进行了记录,即只会返回一个流,不会进行计算操作,而终结操作是实现了计算操作。
中间操作又可以分为无状态(Stateless)与有状态(Stateful)操作,前者是指元素的处理不受之前元素的影响,后者是指该操作只有拿到所有元素之后才能继续下去。
终结操作又可以分为短路(Short-circuiting)与非短路(Unshort-circuiting)操作,前者是指遇到某些符合条件的元素就可以得到最终结果,后者是指必须处理完所有元素才能得到最终结果。操作分类详情如下图所示:
我们通常还会将中间操作称为懒操作,也正是由这种懒操作结合终结操作、数据源构成的处理管道(Pipeline),实现了 Stream 的高效。
2.Stream 源码实现
在了解 Stream 如何工作之前,我们先来了解下 Stream 包是由哪些主要结构类组合而成的,各个类的职责是什么。参照下图:
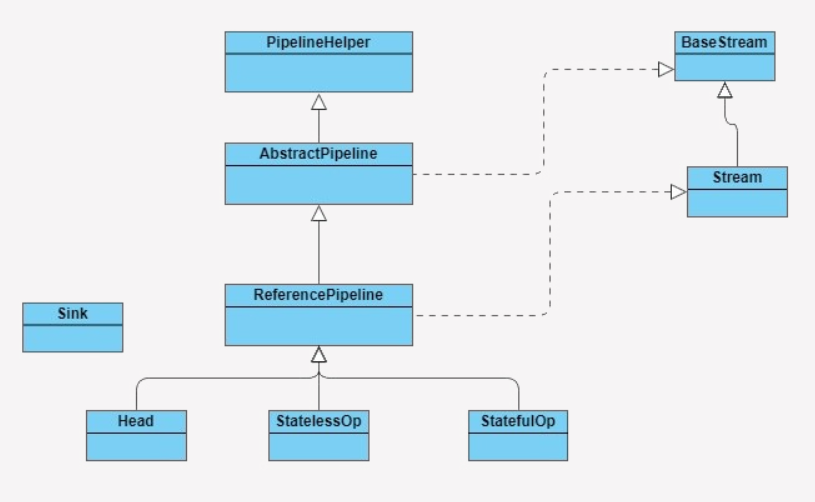
BaseStream 和 Stream 为最顶端的接口类。BaseStream 主要定义了流的基本接口方法,例如,spliterator、isParallel 等;Stream 则定义了一些流的常用操作方法,例如,map、filter 等。
ReferencePipeline 是一个结构类,他通过定义内部类组装了各种操作流。他定义了 Head、StatelessOp、StatefulOp 三个内部类,实现了 BaseStream 与 Stream 的接口方法。
Sink 接口是定义每个 Stream 操作之间关系的协议,他包含 begin()、end()、cancellationRequested()、accpt() 四个方法。ReferencePipeline 最终会将整个 Stream 流操作组装成一个调用链,而这条调用链上的各个 Stream 操作的上下关系就是通过 Sink 接口协议来定义实现的。
3.Stream 操作叠加
我们知道,一个 Stream 的各个操作是由处理管道组装,并统一完成数据处理的。在 JDK 中每次的中断操作会以使用阶段(Stage)命名。
管道结构通常是由 ReferencePipeline 类实现的,前面讲解 Stream 包结构时,我提到过 ReferencePipeline 包含了 Head、StatelessOp、StatefulOp 三种内部类。
Head 类主要用来定义数据源操作,在我们初次调用 names.stream() 方法时,会初次加载 Head 对象,此时为加载数据源操作;接着加载的是中间操作,分别为无状态中间操作 StatelessOp 对象和有状态操作 StatefulOp 对象,此时的 Stage 并没有执行,而是通过 AbstractPipeline 生成了一个中间操作 Stage 链表;当我们调用终结操作时,会生成一个最终的 Stage,通过这个 Stage 触发之前的中间操作,从最后一个 Stage 开始,递归产生一个 Sink 链。如下图所示:

下面我们再通过一个例子来感受下 Stream 的操作分类是如何实现高效迭代大数据集合的。
List<String> names = Arrays.asList(" 张三 ", " 李四 ", " 王老五 ", " 李三 ", " 刘老四 ", " 王小二 ", " 张四 ", " 张五六七 ");
String maxLenStartWithZ = names.stream()
.filter(name -> name.startsWith(" 张 "))
.mapToInt(String::length)
.max()
.toString();这个例子的需求是查找出一个长度最长,并且以张为姓氏的名字。从代码角度来看,你可能会认为是这样的操作流程:首先遍历一次集合,得到以“张”开头的所有名字;然后遍历一次 filter 得到的集合,将名字转换成数字长度;最后再从长度集合中找到最长的那个名字并且返回。
这里我要很明确地告诉你,实际情况并非如此。我们来逐步分析下这个方法里所有的操作是如何执行的。
首先 ,因为 names 是 ArrayList 集合,所以 names.stream() 方法将会调用集合类基础接口 Collection 的 Stream 方法:
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}然后,Stream 方法就会调用 StreamSupport 类的 Stream 方法,方法中初始化了一个 ReferencePipeline 的 Head 内部类对象:
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}再调用 filter 和 map 方法,这两个方法都是无状态的中间操作,所以执行 filter 和 map 操作时,并没有进行任何的操作,而是分别创建了一个 Stage 来标识用户的每一次操作。
而通常情况下 Stream 的操作又需要一个回调函数,所以一个完整的 Stage 是由数据来源、操作、回调函数组成的三元组来表示。如下图所示,分别是 ReferencePipeline 的 filter 方法和 map 方法:
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}new StatelessOp 将会调用父类 AbstractPipeline 的构造函数,这个构造函数将前后的 Stage 联系起来,生成一个 Stage 链表:
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;// 将当前的 stage 的 next 指针指向之前的 stage
this.previousStage = previousStage;// 赋值当前 stage 当全局变量 previousStage
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}因为在创建每一个 Stage 时,都会包含一个 opWrapSink() 方法,该方法会把一个操作的具体实现封装在 Sink 类中,Sink 采用(处理 -> 转发)的模式来叠加操作。
当执行 max 方法时,会调用 ReferencePipeline 的 max 方法,此时由于 max 方法是终结操作,所以会创建一个 TerminalOp 操作,同时创建一个 ReducingSink,并且将操作封装在 Sink 类中。
@Override
public final Optional<P_OUT> max(Comparator<? super P_OUT> comparator) {
return reduce(BinaryOperator.maxBy(comparator));
}最后,调用 AbstractPipeline 的 wrapSink 方法,该方法会调用 opWrapSink 生成一个 Sink 链表,Sink 链表中的每一个 Sink 都封装了一个操作的具体实现。
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}当 Sink 链表生成完成后,Stream 开始执行,通过 spliterator 迭代集合,执行 Sink 链表中的具体操作。
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}Java8 中的 Spliterator 的 forEachRemaining 会迭代集合,每迭代一次,都会执行一次 filter 操作,如果 filter 操作通过,就会触发 map 操作,然后将结果放入到临时数组 object 中,再进行下一次的迭代。完成中间操作后,就会触发终结操作 max。
4.Stream 并行处理
Stream 处理数据的方式有两种,串行处理和并行处理。要实现并行处理,我们只需要在例子的代码中新增一个 Parallel() 方法,代码如下所示:
List<String> names = Arrays.asList(" 张三 ", " 李四 ", " 王老五 ", " 李三 ", " 刘老四 ", " 王小二 ", " 张四 ", " 张五六七 ");
String maxLenStartWithZ = names.stream()
.parallel()
.filter(name -> name.startsWith(" 张 "))
.mapToInt(String::length)
.max()
.toString();Stream 的并行处理在执行终结操作之前,跟串行处理的实现是一样的。而在调用终结方法之后,实现的方式就有点不太一样,会调用 TerminalOp 的 evaluateParallel 方法进行并行处理。
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}这里的并行处理指的是,Stream 结合了 ForkJoin 框架,对 Stream 处理进行了分片,Splititerator 中的 estimateSize 方法会估算出分片的数据量。
通过预估的数据量获取最小处理单元的阀值,如果当前分片大小大于最小处理单元的阀值,就继续切分集合。每个分片将会生成一个 Sink 链表,当所有的分片操作完成后,ForkJoin 框架将会合并分片任何结果集。
合理使用 Stream
看到这里,你应该对 Stream API 是如何优化集合遍历有个清晰的认知了。Stream API 用起来简洁,还能并行处理,那是不是使用 Stream API,系统性能就更好呢?通过一组测试,我们一探究竟。
我们将对常规的迭代、Stream 串行迭代以及 Stream 并行迭代进行性能测试对比,迭代循环中,我们将对数据进行过滤、分组等操作。分别进行以下几组测试:
- 多核 CPU 服务器配置环境下,对比长度 100 的 int 数组的性能;
- 多核 CPU 服务器配置环境下,对比长度 1.00E+8 的 int 数组的性能;
- 多核 CPU 服务器配置环境下,对比长度 1.00E+8 对象数组过滤分组的性能;
单核 CPU 服务器配置环境下,对比长度 1.00E+8 对象数组过滤分组的性能。
常规的迭代 <Stream 并行迭代 <Stream 串行迭代
- Stream 并行迭代 < 常规的迭代 <Stream 串行迭代
- Stream 并行迭代 < 常规的迭代 <Stream 串行迭代
- 常规的迭代 <Stream 串行迭代 <Stream 并行迭代
通过以上测试结果,我们可以看到:在循环迭代次数较少的情况下,常规的迭代方式性能反而更好;在单核 CPU 服务器配置环境中,也是常规迭代方式更有优势;而在大数据循环迭代中,如果服务器是多核 CPU 的情况下,Stream 的并行迭代优势明显。所以我们在平时处理大数据的集合时,应该尽量考虑将应用部署在多核 CPU 环境下,并且使用 Stream 的并行迭代方式进行处理。
用事实说话,我们看到其实使用 Stream 未必可以使系统性能更佳,还是要结合应用场景进行选择,也就是合理地使用 Stream。
常用的性能测试工具
常用的性能测试工具有很多,在这里我将列举几个比较实用的。
对于开发人员来说,首选是一些开源免费的性能(压力)测试软件,例如 ab(ApacheBench)、JMeter 等;对于专业的测试团队来说,付费版的 LoadRunner 是首选。当然,也有很多公司是自行开发了一套量身定做的性能测试软件,优点是定制化强,缺点则是通用性差。
接下来,我会为你重点介绍 ab 和 JMeter 两款测试工具的特点以及常规的使用方法。
1.ab
ab 测试工具是 Apache 提供的一款测试工具,具有简单易上手的特点,在测试 Web 服务时非常实用。
ab 可以在 Windows 系统中使用,也可以在 Linux 系统中使用。这里我说下在 Linux 系统中的安装方法,非常简单,只需要在 Linux 系统中输入 yum-y install httpd-tools 命令,就可以了。
安装成功后,输入 ab 命令,可以看到以下提示:
ab 工具用来测试 post get 接口请求非常便捷,可以通过参数指定请求数、并发数、请求参数等。例如,一个测试并发用户数为 10、请求数量为 100 的的 post 请求输入如下:
ab -n 100 -c 10 -p 'post.txt' -T 'application/x-www-form-urlencoded' 'http://test.api.com/test/register'post.txt 为存放 post 参数的文档,存储格式如下:
usernanme=test&password=test&sex=1附上几个常用参数的含义:
- -n:总请求次数(最小默认为 1);
- -c:并发次数(最小默认为 1 且不能大于总请求次数,例如:10 个请求,10 个并发,实际就是 1 人请求 1 次);
- -p:post 参数文档路径(-p 和 -T 参数要配合使用);
- -T:header 头内容类型(此处切记是大写英文字母 T)。
当我们测试一个 get 请求接口时,可以直接在链接的后面带上请求的参数:
ab -c 10 -n 100 http://www.test.api.com/test/login?userName=test&password=test输出结果如下:
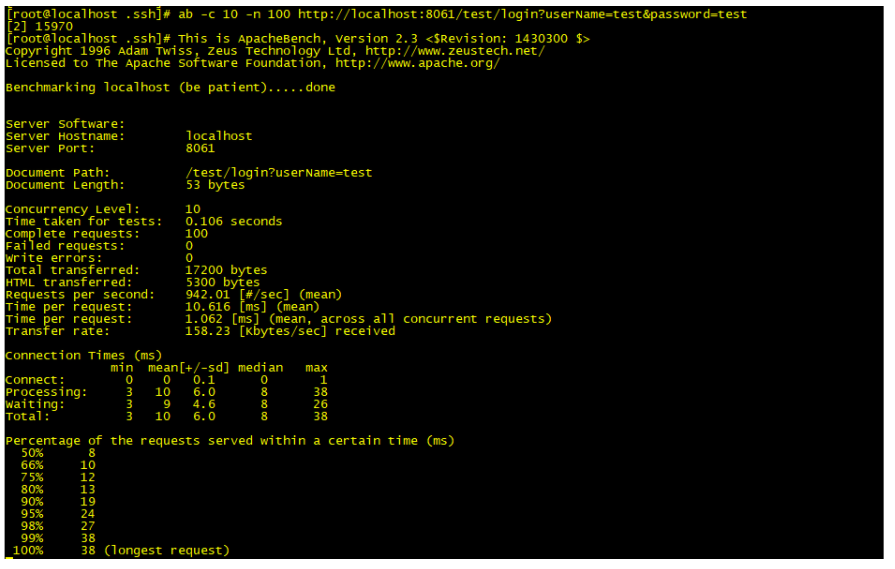
以上输出中,有几项性能指标可以提供给你参考使用:
- Requests per second:吞吐率,指某个并发用户数下单位时间内处理的请求数;
- Time per request:上面的是用户平均请求等待时间,指处理完成所有请求数所花费的时间 /(总请求数 / 并发用户数);
- Time per request:下面的是服务器平均请求处理时间,指处理完成所有请求数所花费的时间 / 总请求数;
- Percentage of the requests served within a certain time:每秒请求时间分布情况,指在整个请求中,每个请求的时间长度的分布情况,例如有 50% 的请求响应在 8ms 内,66% 的请求响应在 10ms 内,说明有 16% 的请求在 8ms~10ms 之间。
2.JMeter
JMeter 是 Apache 提供的一款功能性比较全的性能测试工具,同样可以在 Windows 和 Linux 环境下安装使用。
JMeter 在 Windows 环境下使用了图形界面,可以通过图形界面来编写测试用例,具有易学和易操作的特点。
JMeter 不仅可以实现简单的并发性能测试,还可以实现复杂的宏基准测试。我们可以通过录制脚本的方式,在 JMeter 实现整个业务流程的测试。JMeter 也支持通过 csv 文件导入参数变量,实现用多样化的参数测试系统性能。
Windows 下的 JMeter 安装非常简单,在官网下载安装包,解压后即可使用。如果你需要打开图形化界面,那就进入到 bin 目录下,找到 jmeter.bat 文件,双击运行该文件就可以了。
2.JMeter
JMeter 是 Apache 提供的一款功能性比较全的性能测试工具,同样可以在 Windows 和 Linux 环境下安装使用。
JMeter 在 Windows 环境下使用了图形界面,可以通过图形界面来编写测试用例,具有易学和易操作的特点。
JMeter 不仅可以实现简单的并发性能测试,还可以实现复杂的宏基准测试。我们可以通过录制脚本的方式,在 JMeter 实现整个业务流程的测试。JMeter 也支持通过 csv 文件导入参数变量,实现用多样化的参数测试系统性能。
Windows 下的 JMeter 安装非常简单,在官网下载安装包,解压后即可使用。如果你需要打开图形化界面,那就进入到 bin 目录下,找到 jmeter.bat 文件,双击运行该文件就可以了。
首先我们安装一个录制测试脚本的插件,叫做 BlazeMeter 插件。你可以在 Chrome 应用商店中找到它,然后点击安装, 如图所示:
然后使用谷歌账号登录这款插件,如果不登录,我们将无法生成 JMeter 文件,安装以及登录成功后的界面如下图所示:
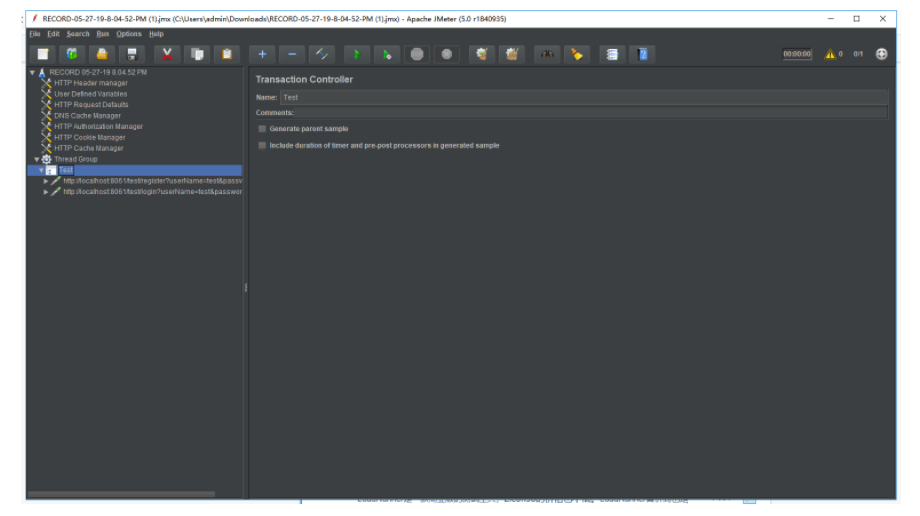
最后点击开始,就可以录制脚本了。录制成功后,点击保存为 JMX 文件,我们就可以通过 JMeter 打开这个文件,看到录制的脚本了,如下图所示:
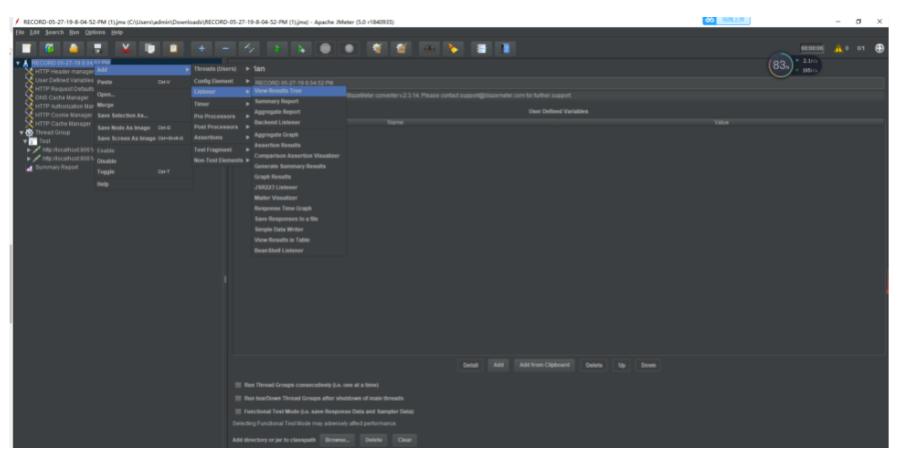
这个时候,我们还需要创建一个查看结果树,用来可视化查看运行的性能结果集合:
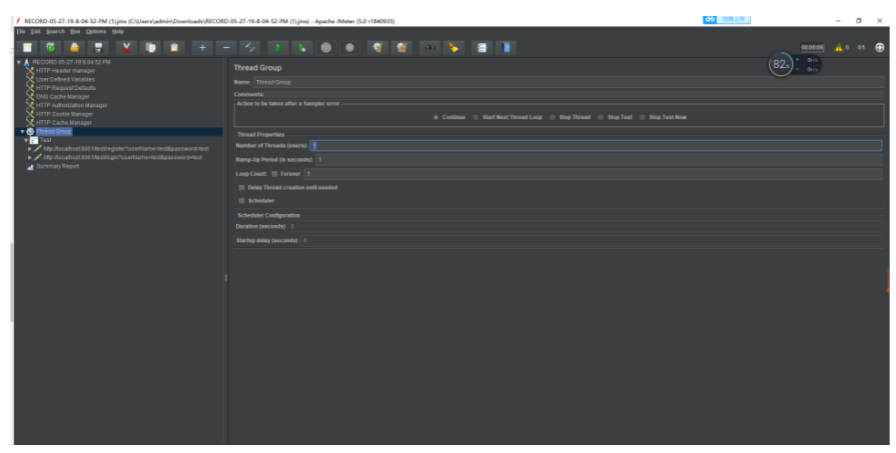
设置好结果树之后,我们可以对线程组的并发用户数以及循环调用次数进行设置:
设置成功之后,点击运行,我们可以看到运行的结果:
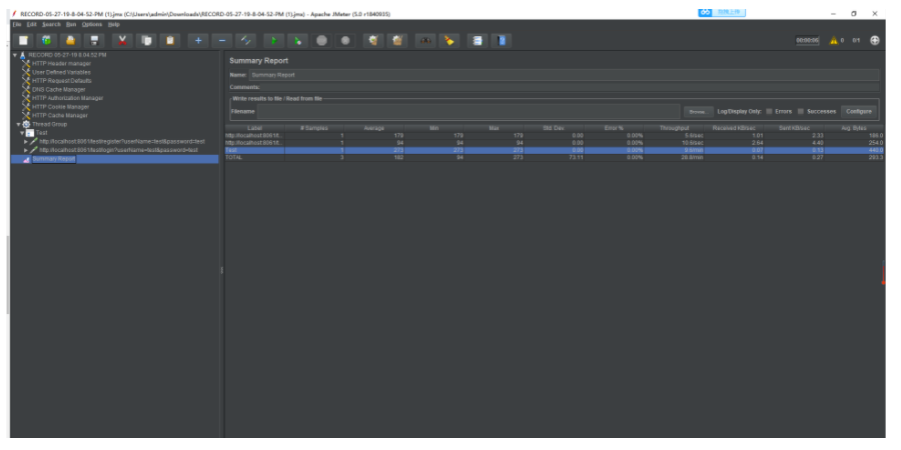
JMeter 的测试结果与 ab 的测试结果的指标参数差不多,这里我就不再重复讲解了。
3.LoadRunner
LoadRunner 是一款商业版的测试工具,并且 License 的售价不低。
作为一款专业的性能测试工具,LoadRunner 在性能压测时,表现得非常稳定和高效。相比 JMeter,LoadRunner 可以模拟出不同的内网 IP 地址,通过分配不同的 IP 地址给测试的用户,模拟真实环境下的用户。这里我就不展开详述了。
HashMap 的实现结构
了解完数据结构后,我们再来看下 HashMap 的实现结构。作为最常用的 Map 类,它是基于哈希表实现的,继承了 AbstractMap 并且实现了 Map 接口。
哈希表将键的 Hash 值映射到内存地址,即根据键获取对应的值,并将其存储到内存地址。也就是说 HashMap 是根据键的 Hash 值来决定对应值的存储位置。通过这种索引方式,HashMap 获取数据的速度会非常快。
例如,存储键值对(x,“aa”)时,哈希表会通过哈希函数 f(x) 得到”aa”的实现存储位置。
但也会有新的问题。如果再来一个 (y,“bb”),哈希函数 f(y) 的哈希值跟之前 f(x) 是一样的,这样两个对象的存储地址就冲突了,这种现象就被称为哈希冲突。那么哈希表是怎么解决的呢?方式有很多,比如,开放定址法、再哈希函数法和链地址法。
开放定址法很简单,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把 key 存放到冲突位置的空位置上去。这种方法存在着很多缺点,例如,查找、扩容等,所以我不建议你作为解决哈希冲突的首选。
再哈希法顾名思义就是在同义词产生地址冲突时再计算另一个哈希函数地址,直到冲突不再发生,这种方法不易产生“聚集”,但却增加了计算时间。如果我们不考虑添加元素的时间成本,且对查询元素的要求极高,就可以考虑使用这种算法设计。
HashMap 则是综合考虑了所有因素,采用链地址法解决哈希冲突问题。这种方法是采用了数组(哈希表)+ 链表的数据结构,当发生哈希冲突时,就用一个链表结构存储相同 Hash 值的数据。
HashMap 的重要属性
从 HashMap 的源码中,我们可以发现,HashMap 是由一个 Node 数组构成,每个 Node 包含了一个 key-value 键值对。
transient Node<K,V>[] table;Node 类作为 HashMap 中的一个内部类,除了 key、value 两个属性外,还定义了一个 next 指针。当有哈希冲突时,HashMap 会用之前数组当中相同哈希值对应存储的 Node 对象,通过指针指向新增的相同哈希值的 Node 对象的引用。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}HashMap 还有两个重要的属性:加载因子(loadFactor)和边界值(threshold)。在初始化 HashMap 时,就会涉及到这两个关键初始化参数。
int threshold;
final float loadFactor;LoadFactor 属性是用来间接设置 Entry 数组(哈希表)的内存空间大小,在初始 HashMap 不设置参数的情况下,默认 LoadFactor 值为 0.75。为什么是 0.75 这个值呢?
这是因为对于使用链表法的哈希表来说,查找一个元素的平均时间是 O(1+n),这里的 n 指的是遍历链表的长度,因此加载因子越大,对空间的利用就越充分,这就意味着链表的长度越长,查找效率也就越低。如果设置的加载因子太小,那么哈希表的数据将过于稀疏,对空间造成严重浪费。
Entry 数组的 Threshold 是通过初始容量和 LoadFactor 计算所得,在初始 HashMap 不设置参数的情况下,默认边界值为 12。如果我们在初始化时,设置的初始化容量较小,HashMap 中 Node 的数量超过边界值,HashMap 就会调用 resize() 方法重新分配 table 数组。这将会导致 HashMap 的数组复制,迁移到另一块内存中去,从而影响 HashMap 的效率。
HashMap 添加元素优化
初始化完成后,HashMap 就可以使用 put() 方法添加键值对了。从下面源码可以看出,当程序将一个 key-value 对添加到 HashMap 中,程序首先会根据该 key 的 hashCode() 返回值,再通过 hash() 方法计算出 hash 值,再通过 putVal 方法中的 (n - 1) & hash 决定该 Node 的存储位置。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
} static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 通过 putVal 方法中的 (n - 1) & hash 决定该 Node 的存储位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);我们先来了解下 hash() 方法中的算法。如果我们没有使用 hash() 方法计算 hashCode,而是直接使用对象的 hashCode 值,会出现什么问题呢?
假设要添加两个对象 a 和 b,如果数组长度是 16,这时对象 a 和 b 通过公式 (n - 1) & hash 运算,也就是 (16-1)&a.hashCode 和 (16-1)&b.hashCode,15 的二进制为 0000000000000000000000000001111,假设对象 A 的 hashCode 为 1000010001110001000001111000000,对象 B 的 hashCode 为 0111011100111000101000010100000,你会发现上述与运算结果都是 0。这样的哈希结果就太让人失望了,很明显不是一个好的哈希算法。
但如果我们将 hashCode 值右移 16 位(h >>> 16 代表无符号右移 16 位),也就是取 int 类型的一半,刚好可以将该二进制数对半切开,并且使用位异或运算(如果两个数对应的位置相反,则结果为 1,反之为 0),这样的话,就能避免上面的情况发生。这就是 hash() 方法的具体实现方式。简而言之,就是尽量打乱 hashCode 真正参与运算的低 16 位。
我再来解释下 (n - 1) & hash 是怎么设计的,这里的 n 代表哈希表的长度,哈希表习惯将长度设置为 2 的 n 次方,这样恰好可以保证 (n - 1) & hash 的计算得到的索引值总是位于 table 数组的索引之内。例如:hash=15,n=16 时,结果为 15;hash=17,n=16 时,结果为 1。
在获得 Node 的存储位置后,如果判断 Node 不在哈希表中,就新增一个 Node,并添加到哈希表中,整个流程我将用一张图来说明:
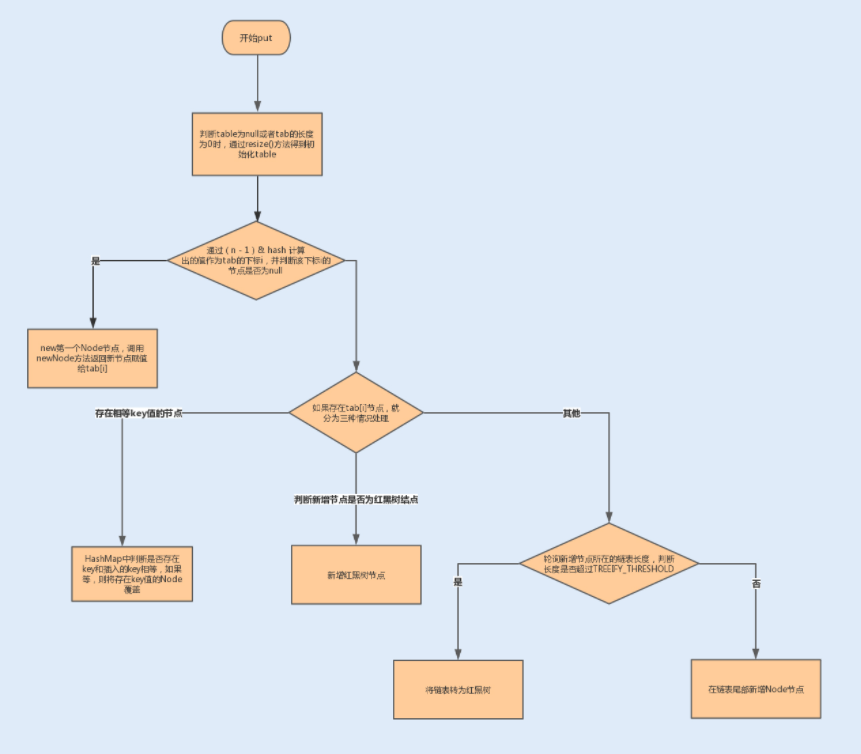
从图中我们可以看出:在 JDK1.8 中,HashMap 引入了红黑树数据结构来提升链表的查询效率。
这是因为链表的长度超过 8 后,红黑树的查询效率要比链表高,所以当链表超过 8 时,HashMap 就会将链表转换为红黑树,这里值得注意的一点是,这时的新增由于存在左旋、右旋效率会降低。讲到这里,我前面我提到的“因链表过长而导致的查询时间复杂度高”的问题,也就迎刃而解了。
以下就是 put 的实现源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//1、判断当 table 为 null 或者 tab 的长度为 0 时,即 table 尚未初始化,此时通过 resize() 方法得到初始化的 table
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
//1.1、此处通过(n - 1) & hash 计算出的值作为 tab 的下标 i,并另 p 表示 tab[i],也就是该链表第一个节点的位置。并判断 p 是否为 null
tab[i] = newNode(hash, key, value, null);
//1.1.1、当 p 为 null 时,表明 tab[i] 上没有任何元素,那么接下来就 new 第一个 Node 节点,调用 newNode 方法返回新节点赋值给 tab[i]
else {
//2.1 下面进入 p 不为 null 的情况,有三种情况:p 为链表节点;p 为红黑树节点;p 是链表节点但长度为临界长度 TREEIFY_THRESHOLD,再插入任何元素就要变成红黑树了。
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//2.1.1HashMap 中判断 key 相同的条件是 key 的 hash 相同,并且符合 equals 方法。这里判断了 p.key 是否和插入的 key 相等,如果相等,则将 p 的引用赋给 e
e = p;
else if (p instanceof TreeNode)
//2.1.2 现在开始了第一种情况,p 是红黑树节点,那么肯定插入后仍然是红黑树节点,所以我们直接强制转型 p 后调用 TreeNode.putTreeVal 方法,返回的引用赋给 e
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//2.1.3 接下里就是 p 为链表节点的情形,也就是上述说的另外两类情况:插入后还是链表 / 插入后转红黑树。另外,上行转型代码也说明了 TreeNode 是 Node 的一个子类
for (int binCount = 0; ; ++binCount) {
// 我们需要一个计数器来计算当前链表的元素个数,并遍历链表,binCount 就是这个计数器
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
// 插入成功后,要判断是否需要转换为红黑树,因为插入后链表长度加 1,而 binCount 并不包含新节点,所以判断时要将临界阈值减 1
treeifyBin(tab, hash);
// 当新长度满足转换条件时,调用 treeifyBin 方法,将该链表转换为红黑树
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}HashMap 获取元素优化
当 HashMap 中只存在数组,而数组中没有 Node 链表时,是 HashMap 查询数据性能最好的时候。一旦发生大量的哈希冲突,就会产生 Node 链表,这个时候每次查询元素都可能遍历 Node 链表,从而降低查询数据的性能。
特别是在链表长度过长的情况下,性能将明显降低,红黑树的使用很好地解决了这个问题,使得查询的平均复杂度降低到了 O(log(n)),链表越长,使用黑红树替换后的查询效率提升就越明显。
我们在编码中也可以优化 HashMap 的性能,例如,重新 key 值的 hashCode() 方法,降低哈希冲突,从而减少链表的产生,高效利用哈希表,达到提高性能的效果。
HashMap 扩容优化
HashMap 也是数组类型的数据结构,所以一样存在扩容的情况。
在 JDK1.7 中,HashMap 整个扩容过程就是分别取出数组元素,一般该元素是最后一个放入链表中的元素,然后遍历以该元素为头的单向链表元素,依据每个被遍历元素的 hash 值计算其在新数组中的下标,然后进行交换。这样的扩容方式会将原来哈希冲突的单向链表尾部变成扩容后单向链表的头部。
而在 JDK 1.8 中,HashMap 对扩容操作做了优化。由于扩容数组的长度是 2 倍关系,所以对于假设初始 tableSize = 4 要扩容到 8 来说就是 0100 到 1000 的变化(左移一位就是 2 倍),在扩容中只用判断原来的 hash 值和左移动的一位(newtable 的值)按位与操作是 0 或 1 就行,0 的话索引不变,1 的话索引变成原索引加上扩容前数组。
之所以能通过这种“与运算“来重新分配索引,是因为 hash 值本来就是随机的,而 hash 按位与上 newTable 得到的 0(扩容前的索引位置)和 1(扩容前索引位置加上扩容前数组长度的数值索引处)就是随机的,所以扩容的过程就能把之前哈希冲突的元素再随机分布到不同的索引中去。
什么是 I/O
I/O 是机器获取和交换信息的主要渠道,而流是完成 I/O 操作的主要方式。
在计算机中,流是一种信息的转换。流是有序的,因此相对于某一机器或者应用程序而言,我们通常把机器或者应用程序接收外界的信息称为输入流(InputStream),从机器或者应用程序向外输出的信息称为输出流(OutputStream),合称为输入 / 输出流(I/O Streams)。
机器间或程序间在进行信息交换或者数据交换时,总是先将对象或数据转换为某种形式的流,再通过流的传输,到达指定机器或程序后,再将流转换为对象数据。因此,流就可以被看作是一种数据的载体,通过它可以实现数据交换和传输。
Java 的 I/O 操作类在包 java.io 下,其中 InputStream、OutputStream 以及 Reader、Writer 类是 I/O 包中的 4 个基本类,它们分别处理字节流和字符流。如下图所示:
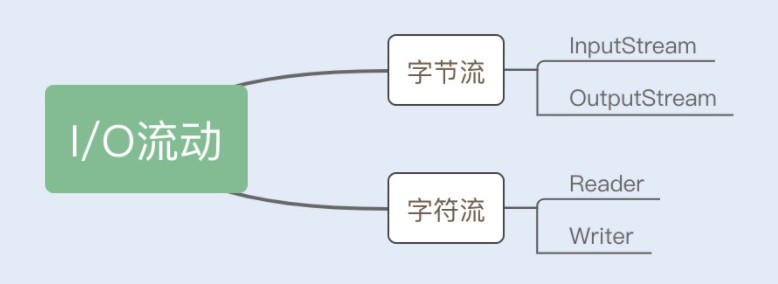
“不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?”
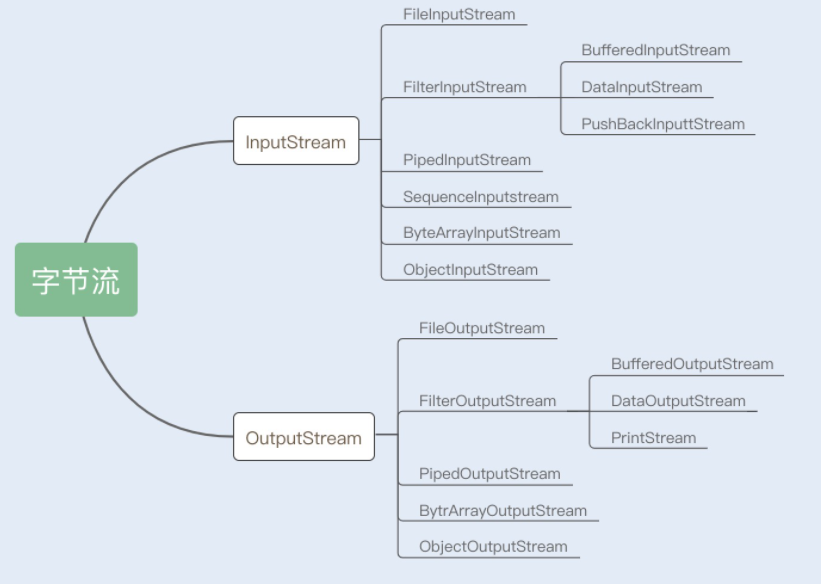
1. 字节流
InputStream/OutputStream 是字节流的抽象类,这两个抽象类又派生出了若干子类,不同的子类分别处理不同的操作类型。如果是文件的读写操作,就使用 FileInputStream/FileOutputStream;如果是数组的读写操作,就使用 ByteArrayInputStream/ByteArrayOutputStream;如果是普通字符串的读写操作,就使用 BufferedInputStream/BufferedOutputStream。具体内容如下图所示:
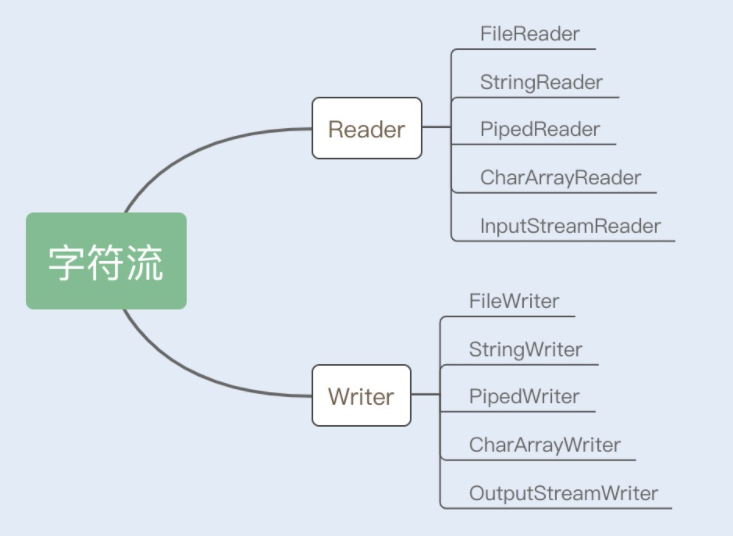
2. 字符流
Reader/Writer 是字符流的抽象类,这两个抽象类也派生出了若干子类,不同的子类分别处理不同的操作类型,具体内容如下图所示:
传统 I/O 的性能问题
我们知道,I/O 操作分为磁盘 I/O 操作和网络 I/O 操作。前者是从磁盘中读取数据源输入到内存中,之后将读取的信息持久化输出在物理磁盘上;后者是从网络中读取信息输入到内存,最终将信息输出到网络中。
1. 多次内存复制
在传统 I/O 中,我们可以通过 InputStream 从源数据中读取数据流输入到缓冲区里,通过 OutputStream 将数据输出到外部设备(包括磁盘、网络)。你可以先看下输入操作在操作系统中的具体流程,如下图所示:
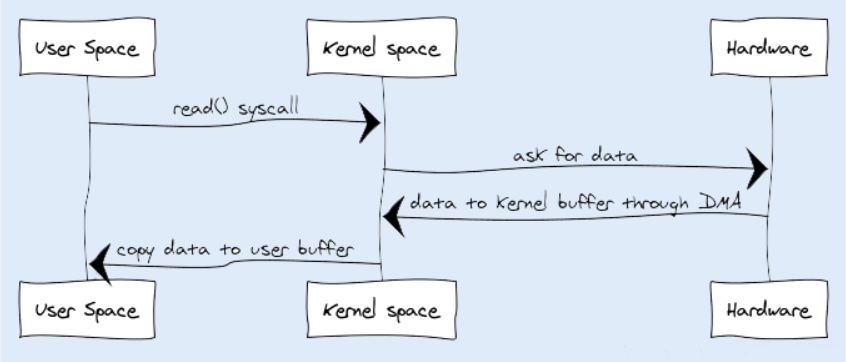
- JVM 会发出 read() 系统调用,并通过 read 系统调用向内核发起读请求;
- 内核向硬件发送读指令,并等待读就绪;
- 内核把将要读取的数据复制到指向的内核缓存中;
- 操作系统内核将数据复制到用户空间缓冲区,然后 read 系统调用返回。
在这个过程中,数据先从外部设备复制到内核空间,再从内核空间复制到用户空间,这就发生了两次内存复制操作。这种操作会导致不必要的数据拷贝和上下文切换,从而降低 I/O 的性能。
2. 阻塞
在传统 I/O 中,InputStream 的 read() 是一个 while 循环操作,它会一直等待数据读取,直到数据就绪才会返回。这就意味着如果没有数据就绪,这个读取操作将会一直被挂起,用户线程将会处于阻塞状态。
在少量连接请求的情况下,使用这种方式没有问题,响应速度也很高。但在发生大量连接请求时,就需要创建大量监听线程,这时如果线程没有数据就绪就会被挂起,然后进入阻塞状态。一旦发生线程阻塞,这些线程将会不断地抢夺 CPU 资源,从而导致大量的 CPU 上下文切换,增加系统的性能开销。
如何优化 I/O 操作
面对以上两个性能问题,不仅编程语言对此做了优化,各个操作系统也进一步优化了 I/O。JDK1.4 发布了 java.nio 包(new I/O 的缩写),NIO 的发布优化了内存复制以及阻塞导致的严重性能问题。JDK1.7 又发布了 NIO2,提出了从操作系统层面实现的异步 I/O。下面我们就来了解下具体的优化实现。
1. 使用缓冲区优化读写流操作
在传统 I/O 中,提供了基于流的 I/O 实现,即 InputStream 和 OutputStream,这种基于流的实现以字节为单位处理数据。
NIO 与传统 I/O 不同,它是基于块(Block)的,它以块为基本单位处理数据。在 NIO 中,最为重要的两个组件是缓冲区(Buffer)和通道(Channel)。Buffer 是一块连续的内存块,是 NIO 读写数据的中转地。Channel 表示缓冲数据的源头或者目的地,它用于读取缓冲或者写入数据,是访问缓冲的接口。
传统 I/O 和 NIO 的最大区别就是传统 I/O 是面向流,NIO 是面向 Buffer。Buffer 可以将文件一次性读入内存再做后续处理,而传统的方式是边读文件边处理数据。虽然传统 I/O 后面也使用了缓冲块,例如 BufferedInputStream,但仍然不能和 NIO 相媲美。使用 NIO 替代传统 I/O 操作,可以提升系统的整体性能,效果立竿见影。
2. 使用 DirectBuffer 减少内存复制
NIO 的 Buffer 除了做了缓冲块优化之外,还提供了一个可以直接访问物理内存的类 DirectBuffer。普通的 Buffer 分配的是 JVM 堆内存,而 DirectBuffer 是直接分配物理内存。
我们知道数据要输出到外部设备,必须先从用户空间复制到内核空间,再复制到输出设备,而 DirectBuffer 则是直接将步骤简化为从内核空间复制到外部设备,减少了数据拷贝。
这里拓展一点,由于 DirectBuffer 申请的是非 JVM 的物理内存,所以创建和销毁的代价很高。DirectBuffer 申请的内存并不是直接由 JVM 负责垃圾回收,但在 DirectBuffer 包装类被回收时,会通过 Java Reference 机制来释放该内存块。
3. 避免阻塞,优化 I/O 操作
NIO 很多人也称之为 Non-block I/O,即非阻塞 I/O,因为这样叫,更能体现它的特点。为什么这么说呢?
传统的 I/O 即使使用了缓冲块,依然存在阻塞问题。由于线程池线程数量有限,一旦发生大量并发请求,超过最大数量的线程就只能等待,直到线程池中有空闲的线程可以被复用。而对 Socket 的输入流进行读取时,读取流会一直阻塞,直到发生以下三种情况的任意一种才会解除阻塞:
- 有数据可读;
- 连接释放;
- 空指针或 I/O 异常。
阻塞问题,就是传统 I/O 最大的弊端。NIO 发布后,通道和多路复用器这两个基本组件实现了 NIO 的非阻塞,下面我们就一起来了解下这两个组件的优化原理。
通道(Channel)
前面我们讨论过,传统 I/O 的数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
最开始,在应用程序调用操作系统 I/O 接口时,是由 CPU 完成分配,这种方式最大的问题是“发生大量 I/O 请求时,非常消耗 CPU“;之后,操作系统引入了 DMA(直接存储器存储),内核空间与磁盘之间的存取完全由 DMA 负责,但这种方式依然需要向 CPU 申请权限,且需要借助 DMA 总线来完成数据的复制操作,如果 DMA 总线过多,就会造成总线冲突。
通道的出现解决了以上问题,Channel 有自己的处理器,可以完成内核空间和磁盘之间的 I/O 操作。在 NIO 中,我们读取和写入数据都要通过 Channel,由于 Channel 是双向的,所以读、写可以同时进行。
多路复用器(Selector)
Selector 是 Java NIO 编程的基础。用于检查一个或多个 NIO Channel 的状态是否处于可读、可写。
Selector 是基于事件驱动实现的,我们可以在 Selector 中注册 accpet、read 监听事件,Selector 会不断轮询注册在其上的 Channel,如果某个 Channel 上面发生监听事件,这个 Channel 就处于就绪状态,然后进行 I/O 操作。
一个线程使用一个 Selector,通过轮询的方式,可以监听多个 Channel 上的事件。我们可以在注册 Channel 时设置该通道为非阻塞,当 Channel 上没有 I/O 操作时,该线程就不会一直等待了,而是会不断轮询所有 Channel,从而避免发生阻塞。
目前操作系统的 I/O 多路复用机制都使用了 epoll,相比传统的 select 机制,epoll 没有最大连接句柄 1024 的限制。所以 Selector 在理论上可以轮询成千上万的客户端。
下面我用一个生活化的场景来举例,看完你就更清楚 Channel 和 Selector 在非阻塞 I/O 中承担什么角色,发挥什么作用了。
我们可以把监听多个 I/O 连接请求比作一个火车站的进站口。以前检票只能让搭乘就近一趟发车的旅客提前进站,而且只有一个检票员,这时如果有其他车次的旅客要进站,就只能在站口排队。这就相当于最早没有实现线程池的 I/O 操作。
后来火车站升级了,多了几个检票入口,允许不同车次的旅客从各自对应的检票入口进站。这就相当于用多线程创建了多个监听线程,同时监听各个客户端的 I/O 请求。
最后火车站进行了升级改造,可以容纳更多旅客了,每个车次载客更多了,而且车次也安排合理,乘客不再扎堆排队,可以从一个大的统一的检票口进站了,这一个检票口可以同时检票多个车次。这个大的检票口就相当于 Selector,车次就相当于 Channel,旅客就相当于 I/O 流。
Java 序列化
在说缺陷之前,你先得知道什么是 Java 序列化以及它的实现原理。
Java 提供了一种序列化机制,这种机制能够将一个对象序列化为二进制形式(字节数组),用于写入磁盘或输出到网络,同时也能从网络或磁盘中读取字节数组,反序列化成对象,在程序中使用。
JDK 提供的两个输入、输出流对象 ObjectInputStream 和 ObjectOutputStream,它们只能对实现了 Serializable 接口的类的对象进行反序列化和序列化。
ObjectOutputStream 的默认序列化方式,仅对对象的非 transient 的实例变量进行序列化,而不会序列化对象的 transient 的实例变量,也不会序列化静态变量。
在实现了 Serializable 接口的类的对象中,会生成一个 serialVersionUID 的版本号,这个版本号有什么用呢?它会在反序列化过程中来验证序列化对象是否加载了反序列化的类,如果是具有相同类名的不同版本号的类,在反序列化中是无法获取对象的。
具体实现序列化的是 writeObject 和 readObject,通常这两个方法是默认的,当然我们也可以在实现 Serializable 接口的类中对其进行重写,定制一套属于自己的序列化与反序列化机制。
另外,Java 序列化的类中还定义了两个重写方法:writeReplace() 和 readResolve(),前者是用来在序列化之前替换序列化对象的,后者是用来在反序列化之后对返回对象进行处理的。
Java 序列化的缺陷
如果你用过一些 RPC 通信框架,你就会发现这些框架很少使用 JDK 提供的序列化。其实不用和不好用多半是挂钩的,下面我们就一起来看看 JDK 默认的序列化到底存在着哪些缺陷。
1. 无法跨语言
现在的系统设计越来越多元化,很多系统都使用了多种语言来编写应用程序。比如,我们公司开发的一些大型游戏就使用了多种语言,C++ 写游戏服务,Java/Go 写周边服务,Python 写一些监控应用。
而 Java 序列化目前只适用基于 Java 语言实现的框架,其它语言大部分都没有使用 Java 的序列化框架,也没有实现 Java 序列化这套协议。因此,如果是两个基于不同语言编写的应用程序相互通信,则无法实现两个应用服务之间传输对象的序列化与反序列化。
2. 易被攻击
Java 官网安全编码指导方针中说明:“对不信任数据的反序列化,从本质上来说是危险的,应该予以避免”。可见 Java 序列化是不安全的。
我们知道对象是通过在 ObjectInputStream 上调用 readObject() 方法进行反序列化的,这个方法其实是一个神奇的构造器,它可以将类路径上几乎所有实现了 Serializable 接口的对象都实例化。
这也就意味着,在反序列化字节流的过程中,该方法可以执行任意类型的代码,这是非常危险的。
对于需要长时间进行反序列化的对象,不需要执行任何代码,也可以发起一次攻击。攻击者可以创建循环对象链,然后将序列化后的对象传输到程序中反序列化,这种情况会导致 hashCode 方法被调用次数呈次方爆发式增长, 从而引发栈溢出异常。
3. 序列化后的流太大
序列化后的二进制流大小能体现序列化的性能。序列化后的二进制数组越大,占用的存储空间就越多,存储硬件的成本就越高。如果我们是进行网络传输,则占用的带宽就更多,这时就会影响到系统的吞吐量。
Java 序列化中使用了 ObjectOutputStream 来实现对象转二进制编码,那么这种序列化机制实现的二进制编码完成的二进制数组大小,相比于 NIO 中的 ByteBuffer 实现的二进制编码完成的数组大小,有没有区别呢?
User user = new User();
user.setUserName("test");
user.setPassword("test");
ByteArrayOutputStream os =new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(os);
out.writeObject(user);
byte[] testByte = os.toByteArray();
System.out.print("ObjectOutputStream 字节编码长度:" + testByte.length + "\n");ByteBuffer byteBuffer = ByteBuffer.allocate( 2048);
byte[] userName = user.getUserName().getBytes();
byte[] password = user.getPassword().getBytes();
byteBuffer.putInt(userName.length);
byteBuffer.put(userName);
byteBuffer.putInt(password.length);
byteBuffer.put(password);
byteBuffer.flip();
byte[] bytes = new byte[byteBuffer.remaining()];
System.out.print("ByteBuffer 字节编码长度:" + bytes.length+ "\n");运行结果:
ObjectOutputStream 字节编码长度:99
ByteBuffer 字节编码长度:16这里我们可以清楚地看到:Java 序列化实现的二进制编码完成的二进制数组大小,比 ByteBuffer 实现的二进制编码完成的二进制数组大小要大上几倍。因此,Java 序列后的流会变大,最终会影响到系统的吞吐量。
4. 序列化性能太差
序列化的速度也是体现序列化性能的重要指标,如果序列化的速度慢,就会影响网络通信的效率,从而增加系统的响应时间。我们再来通过上面这个例子,来对比下 Java 序列化与 NIO 中的 ByteBuffer 编码的性能:
User user = new User();
user.setUserName("test");
user.setPassword("test");
long startTime = System.currentTimeMillis();
for(int i=0; i<1000; i++) {
ByteArrayOutputStream os =new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(os);
out.writeObject(user);
out.flush();
out.close();
byte[] testByte = os.toByteArray();
os.close();
}
long endTime = System.currentTimeMillis();
System.out.print("ObjectOutputStream 序列化时间:" + (endTime - startTime) + "\n");long startTime1 = System.currentTimeMillis();
for(int i=0; i<1000; i++) {
ByteBuffer byteBuffer = ByteBuffer.allocate( 2048);
byte[] userName = user.getUserName().getBytes();
byte[] password = user.getPassword().getBytes();
byteBuffer.putInt(userName.length);
byteBuffer.put(userName);
byteBuffer.putInt(password.length);
byteBuffer.put(password);
byteBuffer.flip();
byte[] bytes = new byte[byteBuffer.remaining()];
}
long endTime1 = System.currentTimeMillis();
System.out.print("ByteBuffer 序列化时间:" + (endTime1 - startTime1)+ "\n");运行结果:
ObjectOutputStream 序列化时间:29
ByteBuffer 序列化时间:6通过以上案例,我们可以清楚地看到:Java 序列化中的编码耗时要比 ByteBuffer 长很多。
使用 Protobuf 序列化替换 Java 序列化
目前业内优秀的序列化框架有很多,而且大部分都避免了 Java 默认序列化的一些缺陷。例如,最近几年比较流行的 FastJson、Kryo、Protobuf、Hessian 等。我们完全可以找一种替换掉 Java 序列化,这里我推荐使用 Protobuf 序列化框架。
Protobuf 是由 Google 推出且支持多语言的序列化框架,目前在主流网站上的序列化框架性能对比测试报告中,Protobuf 无论是编解码耗时,还是二进制流压缩大小,都名列前茅。
Protobuf 以一个 .proto 后缀的文件为基础,这个文件描述了字段以及字段类型,通过工具可以生成不同语言的数据结构文件。在序列化该数据对象的时候,Protobuf 通过.proto 文件描述来生成 Protocol Buffers 格式的编码。
这里拓展一点,我来讲下什么是 Protocol Buffers 存储格式以及它的实现原理。
Protocol Buffers 是一种轻便高效的结构化数据存储格式。它使用 T-L-V(标识 - 长度 - 字段值)的数据格式来存储数据,T 代表字段的正数序列 (tag),Protocol Buffers 将对象中的每个字段和正数序列对应起来,对应关系的信息是由生成的代码来保证的。在序列化的时候用整数值来代替字段名称,于是传输流量就可以大幅缩减;L 代表 Value 的字节长度,一般也只占一个字节;V 则代表字段值经过编码后的值。这种数据格式不需要分隔符,也不需要空格,同时减少了冗余字段名。
Protobuf 定义了一套自己的编码方式,几乎可以映射 Java/Python 等语言的所有基础数据类型。不同的编码方式对应不同的数据类型,还能采用不同的存储格式。如下图所示:
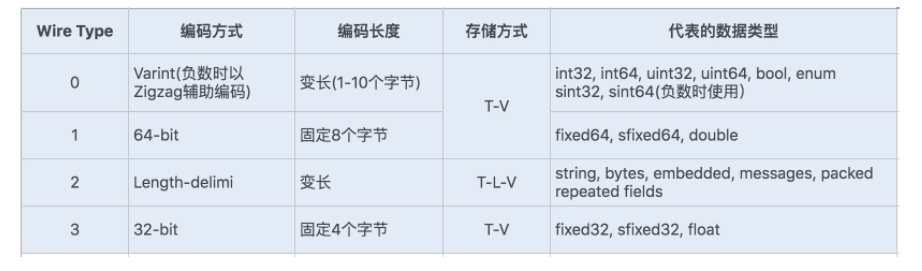
对于存储 Varint 编码数据,由于数据占用的存储空间是固定的,就不需要存储字节长度 Length,所以实际上 Protocol Buffers 的存储方式是 T - V,这样就又减少了一个字节的存储空间。
Protobuf 定义的 Varint 编码方式是一种变长的编码方式,每个数据类型一个字节的最后一位是一个标志位 (msb),用 0 和 1 来表示,0 表示当前字节已经是最后一个字节,1 表示这个数字后面还有一个字节。
对于 int32 类型数字,一般需要 4 个字节表示,若采用 Varint 编码方式,对于很小的 int32 类型数字,就可以用 1 个字节来表示。对于大部分整数类型数据来说,一般都是小于 256,所以这种操作可以起到很好地压缩数据的效果。
我们知道 int32 代表正负数,所以一般最后一位是用来表示正负值,现在 Varint 编码方式将最后一位用作了标志位,那还如何去表示正负整数呢?如果使用 int32/int64 表示负数就需要多个字节来表示,在 Varint 编码类型中,通过 Zigzag 编码进行转换,将负数转换成无符号数,再采用 sint32/sint64 来表示负数,这样就可以大大地减少编码后的字节数。
Protobuf 的这种数据存储格式,不仅压缩存储数据的效果好, 在编码和解码的性能方面也很高效。Protobuf 的编码和解码过程结合.proto 文件格式,加上 Protocol Buffer 独特的编码格式,只需要简单的数据运算以及位移等操作就可以完成编码与解码。可以说 Protobuf 的整体性能非常优秀。
RPC 通信是大型服务框架的核心
我们经常讨论微服务,首要应该了解的就是微服务的核心到底是什么,这样我们在做技术选型时,才能更准确地把握需求。
就我个人理解,我认为微服务的核心是远程通信和服务治理。远程通信提供了服务之间通信的桥梁,服务治理则提供了服务的后勤保障。所以,我们在做技术选型时,更多要考虑的是这两个核心的需求。
我们知道服务的拆分增加了通信的成本,特别是在一些抢购或者促销的业务场景中,如果服务之间存在方法调用,比如,抢购成功之后需要调用订单系统、支付系统、券包系统等,这种远程通信就很容易成为系统的瓶颈。所以,在满足一定的服务治理需求的前提下,对远程通信的性能需求就是技术选型的主要影响因素。
目前,很多微服务框架中的服务通信是基于 RPC 通信实现的,在没有进行组件扩展的前提下,SpringCloud 是基于 Feign 组件实现的 RPC 通信(基于 Http+Json 序列化实现),Dubbo 是基于 SPI 扩展了很多 RPC 通信框架,包括 RMI、Dubbo、Hessian 等 RPC 通信框架(默认是 Dubbo+Hessian 序列化)。不同的业务场景下,RPC 通信的选择和优化标准也不同。
例如,开头我提到的我们部门在选择微服务框架时,选择了 Dubbo。当时的选择标准就是 RPC 通信可以支持抢购类的高并发,在这个业务场景中,请求的特点是瞬时高峰、请求量大和传入、传出参数数据包较小。而 Dubbo 中的 Dubbo 协议就很好地支持了这个请求。
以下是基于 Dubbo:2.6.4 版本进行的简单的性能测试。分别测试 Dubbo+Protobuf 序列化以及 Http+Json 序列化的通信性能(这里主要模拟单一 TCP 长连接 +Protobuf 序列化和短连接的 Http+Json 序列化的性能对比)。为了验证在数据量不同的情况下二者的性能表现,我分别准备了小对象和大对象的性能压测,通过这样的方式我们也可以间接地了解下二者在 RPC 通信方面的水平。
无论从响应时间还是吞吐量上来看,单一 TCP 长连接 +Protobuf 序列化实现的 RPC 通信框架都有着非常明显的优势。
无论从响应时间还是吞吐量上来看,单一 TCP 长连接 +Protobuf 序列化实现的 RPC 通信框架都有着非常明显的优势。
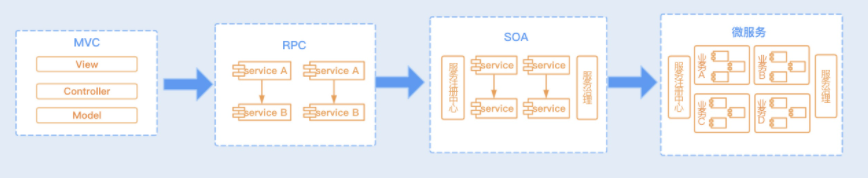
无论是微服务、SOA、还是 RPC 架构,它们都是分布式服务架构,都需要实现服务之间的互相通信,我们通常把这种通信统称为 RPC 通信。
RPC(Remote Process Call),即远程服务调用,是通过网络请求远程计算机程序服务的通信技术。RPC 框架封装好了底层网络通信、序列化等技术,我们只需要在项目中引入各个服务的接口包,就可以实现在代码中调用 RPC 服务同调用本地方法一样。正因为这种方便、透明的远程调用,RPC 被广泛应用于当下企业级以及互联网项目中,是实现分布式系统的核心。
RMI(Remote Method Invocation)是 JDK 中最先实现了 RPC 通信的框架之一,RMI 的实现对建立分布式 Java 应用程序至关重要,是 Java 体系非常重要的底层技术,很多开源的 RPC 通信框架也是基于 RMI 实现原理设计出来的,包括 Dubbo 框架中也接入了 RMI 框架。接下来我们就一起了解下 RMI 的实现原理,看看它存在哪些性能瓶颈有待优化。
RMI:JDK 自带的 RPC 通信框架
目前 RMI 已经很成熟地应用在了 EJB 以及 Spring 框架中,是纯 Java 网络分布式应用系统的核心解决方案。RMI 实现了一台虚拟机应用对远程方法的调用可以同对本地方法的调用一样,RMI 帮我们封装好了其中关于远程通信的内容。
RMI 的实现原理
RMI 远程代理对象是 RMI 中最核心的组件,除了对象本身所在的虚拟机,其它虚拟机也可以调用此对象的方法。而且这些虚拟机可以不在同一个主机上,通过远程代理对象,远程应用可以用网络协议与服务进行通信。
我们可以通过一张图来详细地了解下整个 RMI 的通信过程:
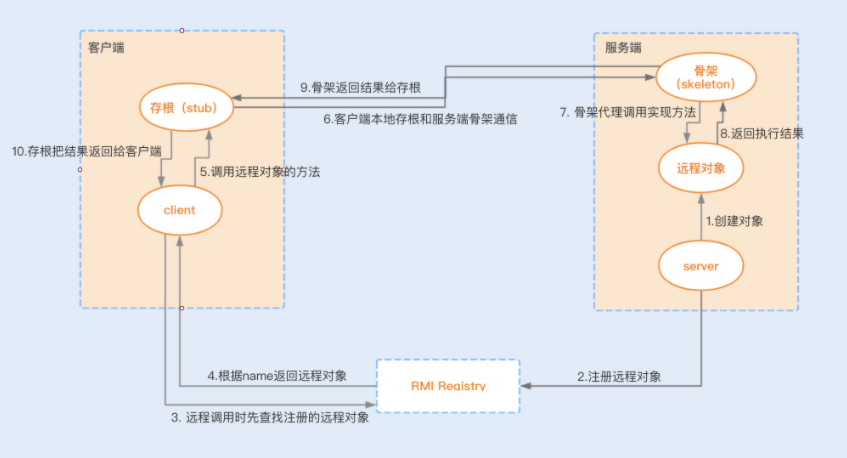
RMI 在高并发场景下的性能瓶颈
- Java 默认序列化
RMI 的序列化采用的是 Java 默认的序列化方式。
- TCP 短连接
由于 RMI 是基于 TCP 短连接实现,在高并发情况下,大量请求会带来大量连接的创建和销毁,这对于系统来说无疑是非常消耗性能的。
- 阻塞式网络 I/O
如果在 Socket 编程中使用传统的 I/O 模型,在高并发场景下基于短连接实现的网络通信就很容易产生 I/O 阻塞,性能将会大打折扣。
一个高并发场景下的 RPC 通信优化路径
1. 选择合适的通信协议
要实现不同机器间的网络通信,我们先要了解计算机系统网络通信的基本原理。网络通信是两台设备之间实现数据流交换的过程,是基于网络传输协议和传输数据的编解码来实现的。其中网络传输协议有 TCP、UDP 协议,这两个协议都是基于 Socket 编程接口之上,为某类应用场景而扩展出的传输协议。通过以下两张图,我们可以大概了解到基于 TCP 和 UDP 协议实现的 Socket 网络通信是怎样的一个流程。
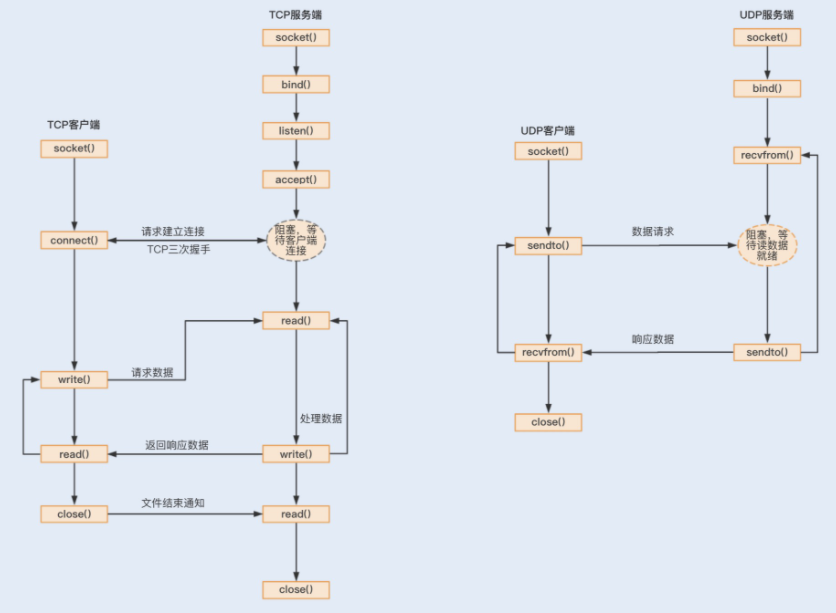
基于 TCP 协议实现的 Socket 通信是有连接的,而传输数据是要通过三次握手来实现数据传输的可靠性,且传输数据是没有边界的,采用的是字节流模式。
基于 UDP 协议实现的 Socket 通信,客户端不需要建立连接,只需要创建一个套接字发送数据报给服务端,这样就不能保证数据报一定会达到服务端,所以在传输数据方面,基于 UDP 协议实现的 Socket 通信具有不可靠性。UDP 发送的数据采用的是数据报模式,每个 UDP 的数据报都有一个长度,该长度将与数据一起发送到服务端。
通过对比,我们可以得出优化方法:为了保证数据传输的可靠性,通常情况下我们会采用 TCP 协议。如果在局域网且对数据传输的可靠性没有要求的情况下,我们也可以考虑使用 UDP 协议,毕竟这种协议的效率要比 TCP 协议高。
2. 使用单一长连接
服务之间的通信不同于客户端与服务端之间的通信。客户端与服务端由于客户端数量多,基于短连接实现请求可以避免长时间地占用连接,导致系统资源浪费。
但服务之间的通信,连接的消费端不会像客户端那么多,但消费端向服务端请求的数量却一样多,我们基于长连接实现,就可以省去大量的 TCP 建立和关闭连接的操作,从而减少系统的性能消耗,节省时间。
3. 优化 Socket 通信
建立两台机器的网络通信,我们一般使用 Java 的 Socket 编程实现一个 TCP 连接。传统的 Socket 通信主要存在 I/O 阻塞、线程模型缺陷以及内存拷贝等问题。
实现非阻塞 I/O:多路复用器 Selector 实现了非阻塞 I/O 通信。
高效的 Reactor 线程模型:Netty 使用了主从 Reactor 多线程模型,服务端接收客户端请求连接是用了一个主线程,这个主线程用于客户端的连接请求操作,一旦连接建立成功,将会监听 I/O 事件,监听到事件后会创建一个链路请求。
链路请求将会注册到负责 I/O 操作的 I/O 工作线程上,由 I/O 工作线程负责后续的 I/O 操作。利用这种线程模型,可以解决在高负载、高并发的情况下,由于单个 NIO 线程无法监听海量客户端和满足大量 I/O 操作造成的问题。
串行设计:服务端在接收消息之后,存在着编码、解码、读取和发送等链路操作。如果这些操作都是基于并行去实现,无疑会导致严重的锁竞争,进而导致系统的性能下降。为了提升性能,Netty 采用了串行无锁化完成链路操作,Netty 提供了 Pipeline 实现链路的各个操作在运行期间不进行线程切换。
零拷贝:一个数据从内存发送到网络中,存在着两次拷贝动作,先是从用户空间拷贝到内核空间,再是从内核空间拷贝到网络 I/O 中。而 NIO 提供的 ByteBuffer 可以使用 Direct Buffers 模式,直接开辟一个非堆物理内存,不需要进行字节缓冲区的二次拷贝,可以直接将数据写入到内核空间。
除了以上这些优化,我们还可以针对套接字编程提供的一些 TCP 参数配置项,提高网络吞吐量,Netty 可以基于 ChannelOption 来设置这些参数。
TCP_NODELAY:TCP_NODELAY 选项是用来控制是否开启 Nagle 算法。Nagle 算法通过缓存的方式将小的数据包组成一个大的数据包,从而避免大量的小数据包发送阻塞网络,提高网络传输的效率。我们可以关闭该算法,优化对于时延敏感的应用场景。
SO_RCVBUF 和 SO_SNDBUF:可以根据场景调整套接字发送缓冲区和接收缓冲区的大小。
SO_BACKLOG:backlog 参数指定了客户端连接请求缓冲队列的大小。服务端处理客户端连接请求是按顺序处理的,所以同一时间只能处理一个客户端连接,当有多个客户端进来的时候,服务端就会将不能处理的客户端连接请求放在队列中等待处理。
SO_KEEPALIVE:当设置该选项以后,连接会检查长时间没有发送数据的客户端的连接状态,检测到客户端断开连接后,服务端将回收该连接。我们可以将该时间设置得短一些,来提高回收连接的效率。
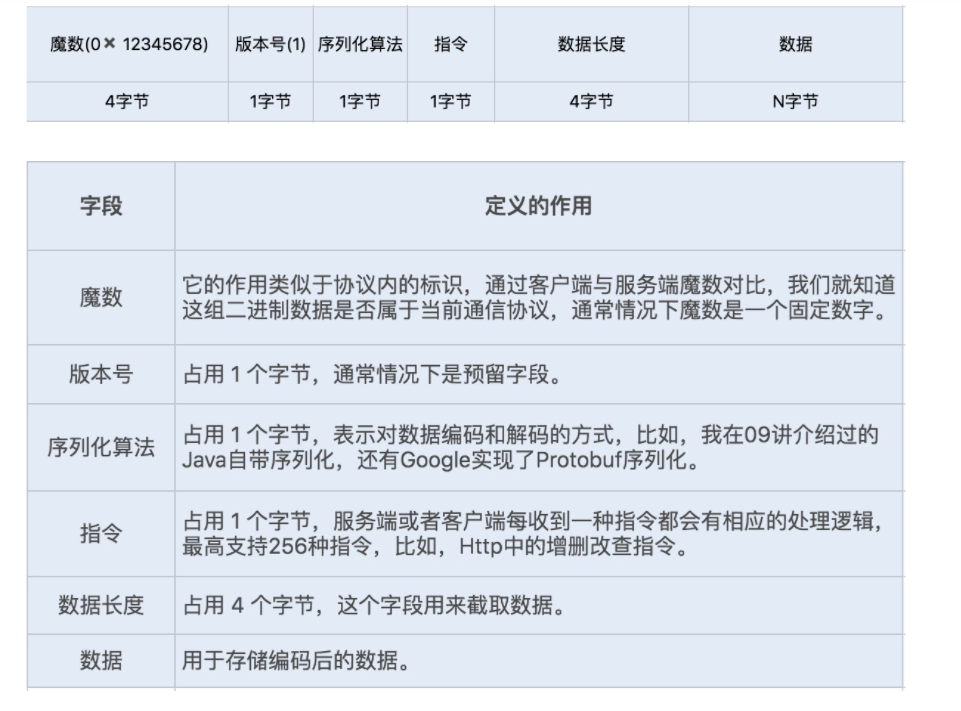
4. 量身定做报文格式
接下来就是实现报文,我们需要设计一套报文,用于描述具体的校验、操作、传输数据等内容。为了提高传输的效率,我们可以根据自己的业务和架构来考虑设计,尽量实现报体小、满足功能、易解析等特性。我们可以参考下面的数据格式:
5. 编码、解码
对于实现一个好的网络通信协议来说,兼容优秀的序列化框架是非常重要的。如果只是单纯的数据对象传输,我们可以选择性能相对较好的 Protobuf 序列化,有利于提高网络通信的性能。
6. 调整 Linux 的 TCP 参数设置选项
如果 RPC 是基于 TCP 短连接实现的,我们可以通过修改 Linux TCP 配置项来优化网络通信。开始 TCP 配置项的优化之前,我们先来了解下建立 TCP 连接的三次握手和关闭 TCP 连接的四次握手,这样有助后面内容的理解。
- 三次握手
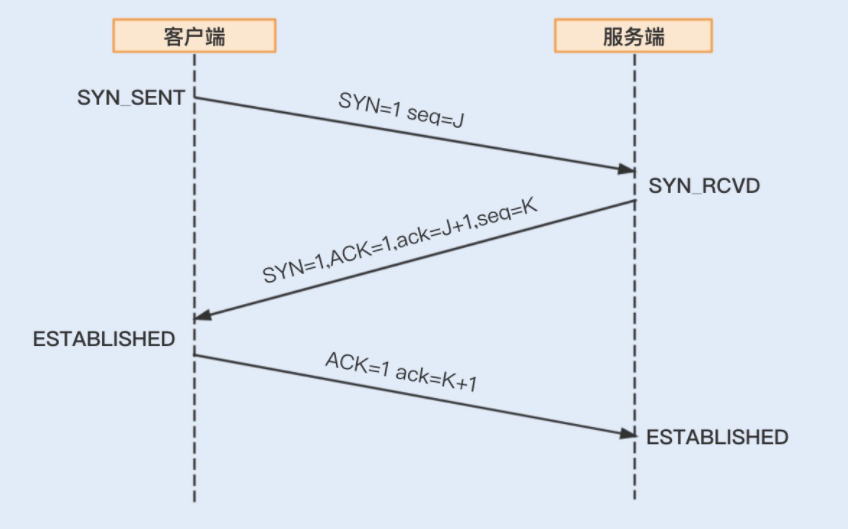
- 四次握手
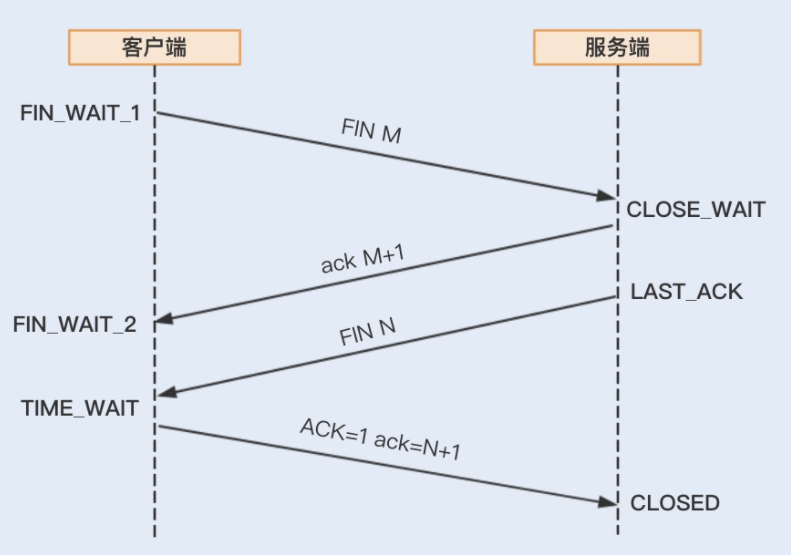
我们可以通过 sysctl -a | grep net.xxx 命令运行查看 Linux 系统默认的的 TCP 参数设置,如果需要修改某项配置,可以通过编辑 vim/etc/sysctl.conf,加入需要修改的配置项, 并通过 sysctl -p 命令运行生效修改后的配置项设置。通常我们会通过修改以下几个配置项来提高网络吞吐量和降低延时。
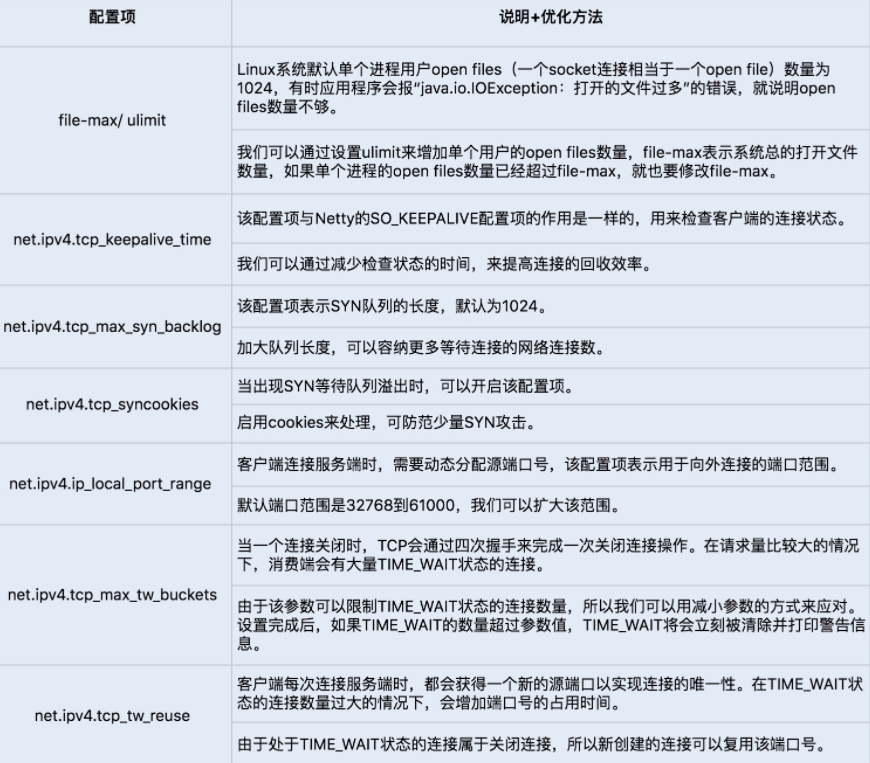
网络 I/O 模型优化
网络通信中,最底层的就是内核中的网络 I/O 模型了。随着技术的发展,操作系统内核的网络模型衍生出了五种 I/O 模型,《UNIX 网络编程》一书将这五种 I/O 模型分为阻塞式 I/O、非阻塞式 I/O、I/O 复用、信号驱动式 I/O 和异步 I/O。每一种 I/O 模型的出现,都是基于前一种 I/O 模型的优化升级。
最开始的阻塞式 I/O,它在每一个连接创建时,都需要一个用户线程来处理,并且在 I/O 操作没有就绪或结束时,线程会被挂起,进入阻塞等待状态,阻塞式 I/O 就成为了导致性能瓶颈的根本原因。
那阻塞到底发生在套接字(socket)通信的哪些环节呢?
在《Unix 网络编程》中,套接字通信可以分为流式套接字(TCP)和数据报套接字(UDP)。其中 TCP 连接是我们最常用的,一起来了解下 TCP 服务端的工作流程(由于 TCP 的数据传输比较复杂,存在拆包和装包的可能,这里我只假设一次最简单的 TCP 数据传输):
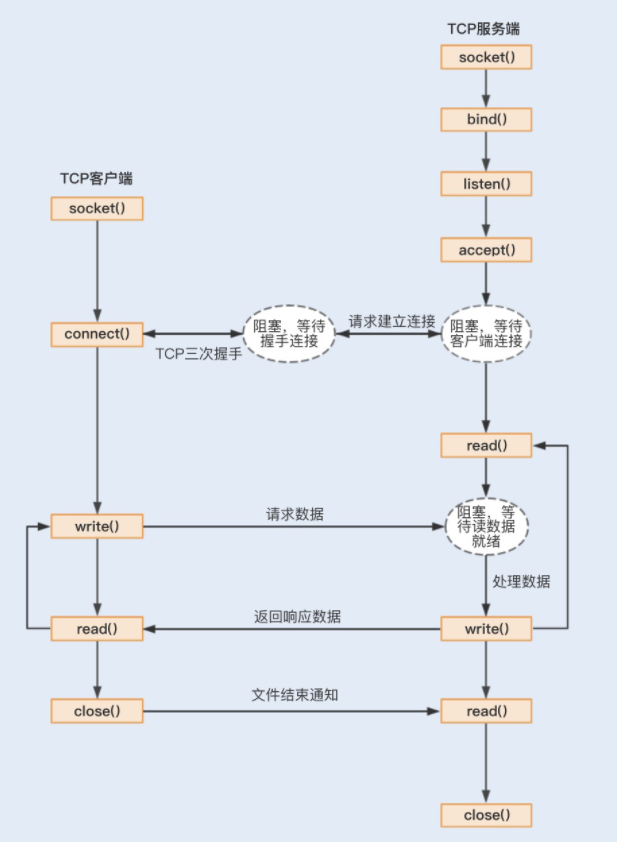
- 首先,应用程序通过系统调用 socket 创建一个套接字,它是系统分配给应用程序的一个文件描述符;
- 其次,应用程序会通过系统调用 bind,绑定地址和端口号,给套接字命名一个名称;
- 然后,系统会调用 listen 创建一个队列用于存放客户端进来的连接;
- 最后,应用服务会通过系统调用 accept 来监听客户端的连接请求。
当有一个客户端连接到服务端之后,服务端就会调用 fork 创建一个子进程,通过系统调用 read 监听客户端发来的消息,再通过 write 向客户端返回信息。
1. 阻塞式 I/O
在整个 socket 通信工作流程中,socket 的默认状态是阻塞的。也就是说,当发出一个不能立即完成的套接字调用时,其进程将被阻塞,被系统挂起,进入睡眠状态,一直等待相应的操作响应。从上图中,我们可以发现,可能存在的阻塞主要包括以下三种。
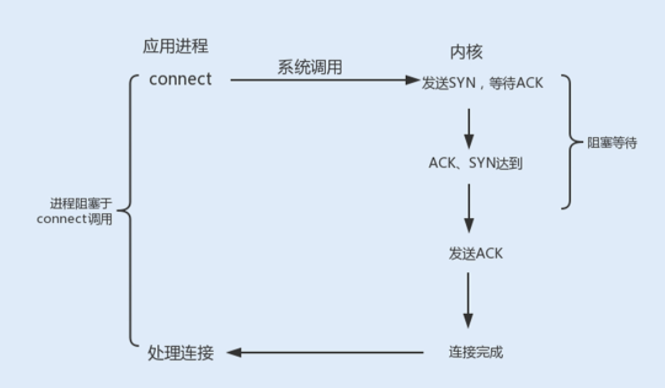
connect 阻塞:当客户端发起 TCP 连接请求,通过系统调用 connect 函数,TCP 连接的建立需要完成三次握手过程,客户端需要等待服务端发送回来的 ACK 以及 SYN 信号,同样服务端也需要阻塞等待客户端确认连接的 ACK 信号,这就意味着 TCP 的每个 connect 都会阻塞等待,直到确认连接。
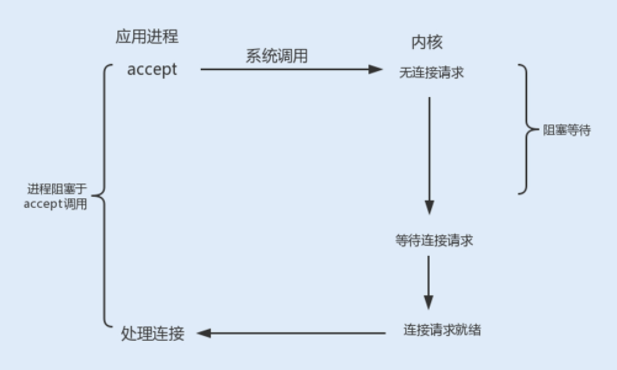
accept 阻塞:一个阻塞的 socket 通信的服务端接收外来连接,会调用 accept 函数,如果没有新的连接到达,调用进程将被挂起,进入阻塞状态。
read、write 阻塞:当一个 socket 连接创建成功之后,服务端用 fork 函数创建一个子进程, 调用 read 函数等待客户端的数据写入,如果没有数据写入,调用子进程将被挂起,进入阻塞状态。
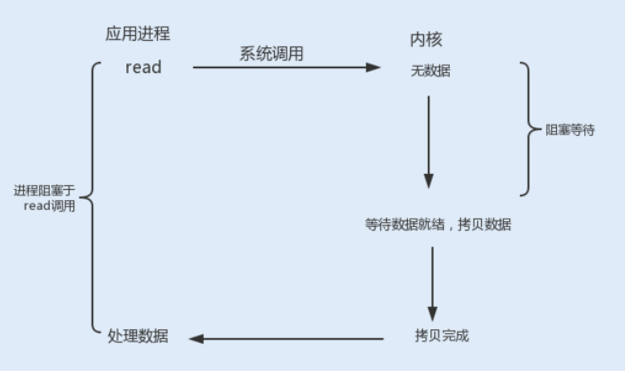
2. 非阻塞式 I/O
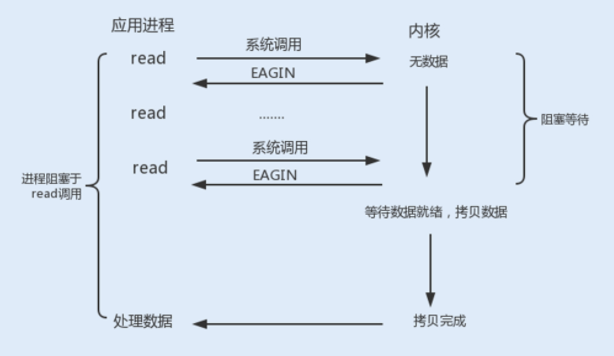
使用 fcntl 可以把以上三种操作都设置为非阻塞操作。如果没有数据返回,就会直接返回一个 EWOULDBLOCK 或 EAGAIN 错误,此时进程就不会一直被阻塞。
当我们把以上操作设置为了非阻塞状态,我们需要设置一个线程对该操作进行轮询检查,这也是最传统的非阻塞 I/O 模型。
3. I/O 复用
如果使用用户线程轮询查看一个 I/O 操作的状态,在大量请求的情况下,这对于 CPU 的使用率无疑是种灾难。 那么除了这种方式,还有其它方式可以实现非阻塞 I/O 套接字吗?
Linux 提供了 I/O 复用函数 select/poll/epoll,进程将一个或多个读操作通过系统调用函数,阻塞在函数操作上。这样,系统内核就可以帮我们侦测多个读操作是否处于就绪状态。
select() 函数:它的用途是,在超时时间内,监听用户感兴趣的文件描述符上的可读可写和异常事件的发生。Linux 操作系统的内核将所有外部设备都看做一个文件来操作,对一个文件的读写操作会调用内核提供的系统命令,返回一个文件描述符(fd)。
int select(int maxfdp1,fd_set *readset,fd_set *writeset,fd_set *exceptset,const struct timeval *timeout)查看以上代码,select() 函数监视的文件描述符分 3 类,分别是 writefds(写文件描述符)、readfds(读文件描述符)以及 exceptfds(异常事件文件描述符)。
调用后 select() 函数会阻塞,直到有描述符就绪或者超时,函数返回。当 select 函数返回后,可以通过函数 FD_ISSET 遍历 fdset,来找到就绪的描述符。fd_set 可以理解为一个集合,这个集合中存放的是文件描述符,可通过以下四个宏进行设置:
void FD_ZERO(fd_set *fdset); // 清空集合
void FD_SET(int fd, fd_set *fdset); // 将一个给定的文件描述符加入集合之中
void FD_CLR(int fd, fd_set *fdset); // 将一个给定的文件描述符从集合中删除
int FD_ISSET(int fd, fd_set *fdset); // 检查集合中指定的文件描述符是否可以读写 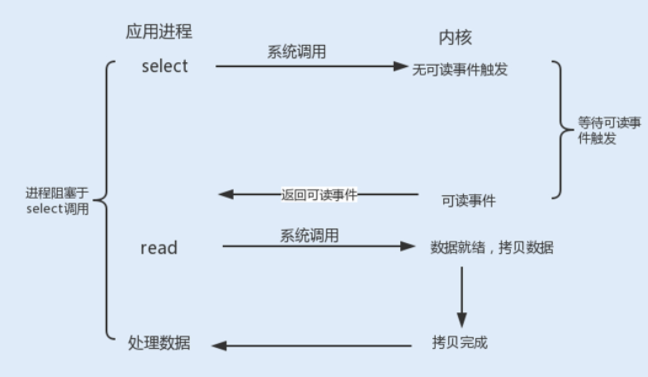
poll() 函数:在每次调用 select() 函数之前,系统需要把一个 fd 从用户态拷贝到内核态,这样就给系统带来了一定的性能开销。再有单个进程监视的 fd 数量默认是 1024,我们可以通过修改宏定义甚至重新编译内核的方式打破这一限制。但由于 fd_set 是基于数组实现的,在新增和删除 fd 时,数量过大会导致效率降低。
poll() 的机制与 select() 类似,二者在本质上差别不大。poll() 管理多个描述符也是通过轮询,根据描述符的状态进行处理,但 poll() 没有最大文件描述符数量的限制。
poll() 和 select() 存在一个相同的缺点,那就是包含大量文件描述符的数组被整体复制到用户态和内核的地址空间之间,而无论这些文件描述符是否就绪,他们的开销都会随着文件描述符数量的增加而线性增大。
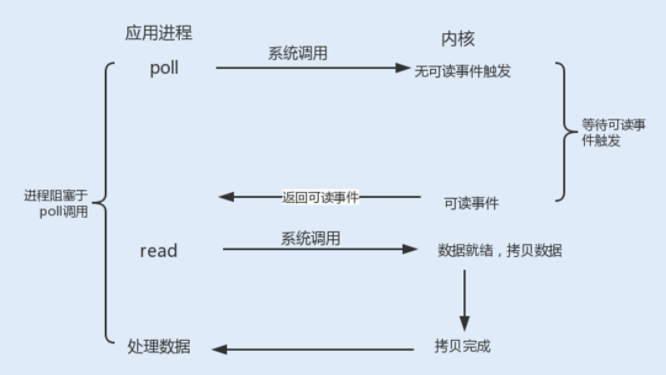
epoll() 函数:select/poll 是顺序扫描 fd 是否就绪,而且支持的 fd 数量不宜过大,因此它的使用受到了一些制约。
Linux 在 2.6 内核版本中提供了一个 epoll 调用,epoll 使用事件驱动的方式代替轮询扫描 fd。epoll 事先通过 epoll_ctl() 来注册一个文件描述符,将文件描述符存放到内核的一个事件表中,这个事件表是基于红黑树实现的,所以在大量 I/O 请求的场景下,插入和删除的性能比 select/poll 的数组 fd_set 要好,因此 epoll 的性能更胜一筹,而且不会受到 fd 数量的限制。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event event)通过以上代码,我们可以看到:epoll_ctl() 函数中的 epfd 是由 epoll_create() 函数生成的一个 epoll 专用文件描述符。op 代表操作事件类型,fd 表示关联文件描述符,event 表示指定监听的事件类型。
一旦某个文件描述符就绪时,内核会采用类似 callback 的回调机制,迅速激活这个文件描述符,当进程调用 epoll_wait() 时便得到通知,之后进程将完成相关 I/O 操作。
int epoll_wait(int epfd, struct epoll_event events,int maxevents,int timeout)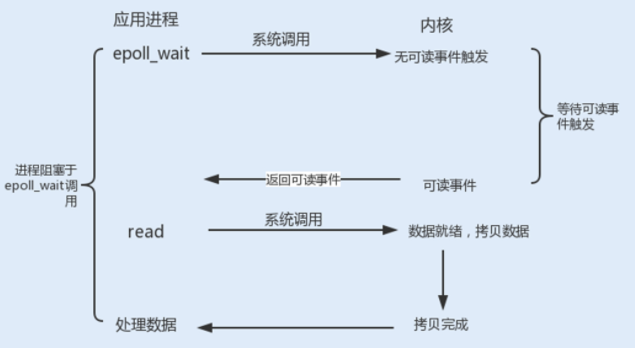
4. 信号驱动式 I/O
信号驱动式 I/O 类似观察者模式,内核就是一个观察者,信号回调则是通知。用户进程发起一个 I/O 请求操作,会通过系统调用 sigaction 函数,给对应的套接字注册一个信号回调,此时不阻塞用户进程,进程会继续工作。当内核数据就绪时,内核就为该进程生成一个 SIGIO 信号,通过信号回调通知进程进行相关 I/O 操作。
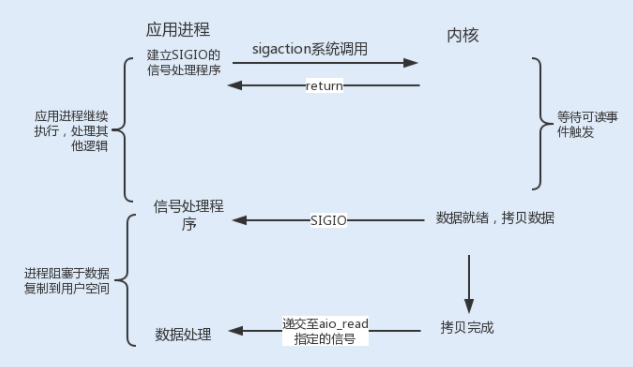
信号驱动式 I/O 相比于前三种 I/O 模式,实现了在等待数据就绪时,进程不被阻塞,主循环可以继续工作,所以性能更佳。
而由于 TCP 来说,信号驱动式 I/O 几乎没有被使用,这是因为 SIGIO 信号是一种 Unix 信号,信号没有附加信息,如果一个信号源有多种产生信号的原因,信号接收者就无法确定究竟发生了什么。而 TCP socket 生产的信号事件有七种之多,这样应用程序收到 SIGIO,根本无从区分处理。
5. 异步 I/O
信号驱动式 I/O 虽然在等待数据就绪时,没有阻塞进程,但在被通知后进行的 I/O 操作还是阻塞的,进程会等待数据从内核空间复制到用户空间中。而异步 I/O 则是实现了真正的非阻塞 I/O。
当用户进程发起一个 I/O 请求操作,系统会告知内核启动某个操作,并让内核在整个操作完成后通知进程。这个操作包括等待数据就绪和数据从内核复制到用户空间。由于程序的代码复杂度高,调试难度大,且支持异步 I/O 的操作系统比较少见(目前 Linux 暂不支持,而 Windows 已经实现了异步 I/O),所以在实际生产环境中很少用到异步 I/O 模型。
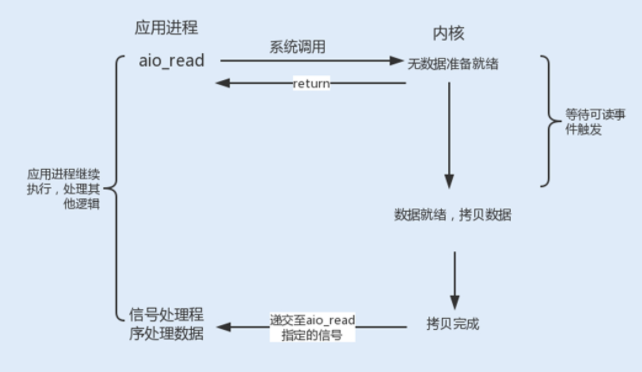
NIO 使用 I/O 复用器 Selector 实现非阻塞 I/O,Selector 就是使用了这五种类型中的 I/O 复用模型。Java 中的 Selector 其实就是 select/poll/epoll 的外包类。
我们在上面的 TCP 通信流程中讲到,Socket 通信中的 conect、accept、read 以及 write 为阻塞操作,在 Selector 中分别对应 SelectionKey 的四个监听事件 OP_ACCEPT、OP_CONNECT、OP_READ 以及 OP_WRITE。

在 NIO 服务端通信编程中,首先会创建一个 Channel,用于监听客户端连接;接着,创建多路复用器 Selector,并将 Channel 注册到 Selector,程序会通过 Selector 来轮询注册在其上的 Channel,当发现一个或多个 Channel 处于就绪状态时,返回就绪的监听事件,最后程序匹配到监听事件,进行相关的 I/O 操作。
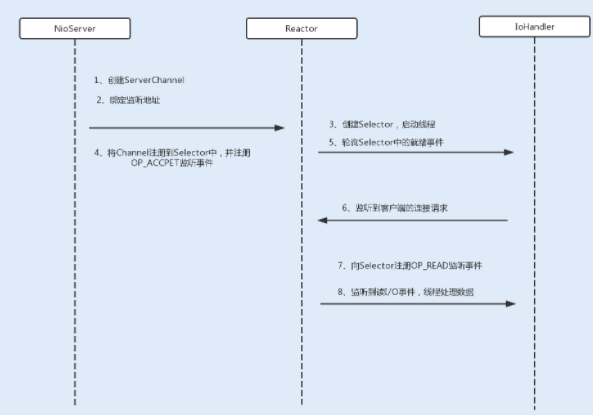
在创建 Selector 时,程序会根据操作系统版本选择使用哪种 I/O 复用函数。在 JDK1.5 版本中,如果程序运行在 Linux 操作系统,且内核版本在 2.6 以上,NIO 中会选择 epoll 来替代传统的 select/poll,这也极大地提升了 NIO 通信的性能。
由于信号驱动式 I/O 对 TCP 通信的不支持,以及异步 I/O 在 Linux 操作系统内核中的应用还不大成熟,大部分框架都还是基于 I/O 复用模型实现的网络通信。
零拷贝
在 I/O 复用模型中,执行读写 I/O 操作依然是阻塞的,在执行读写 I/O 操作时,存在着多次内存拷贝和上下文切换,给系统增加了性能开销。
零拷贝是一种避免多次内存复制的技术,用来优化读写 I/O 操作。
在网络编程中,通常由 read、write 来完成一次 I/O 读写操作。每一次 I/O 读写操作都需要完成四次内存拷贝,路径是 I/O 设备 -> 内核空间 -> 用户空间 -> 内核空间 -> 其它 I/O 设备。
Linux 内核中的 mmap 函数可以代替 read、write 的 I/O 读写操作,实现用户空间和内核空间共享一个缓存数据。mmap 将用户空间的一块地址和内核空间的一块地址同时映射到相同的一块物理内存地址,不管是用户空间还是内核空间都是虚拟地址,最终要通过地址映射映射到物理内存地址。这种方式避免了内核空间与用户空间的数据交换。I/O 复用中的 epoll 函数中就是使用了 mmap 减少了内存拷贝。
在 Java 的 NIO 编程中,则是使用到了 Direct Buffer 来实现内存的零拷贝。Java 直接在 JVM 内存空间之外开辟了一个物理内存空间,这样内核和用户进程都能共享一份缓存数据。
线程模型优化
除了内核对网络 I/O 模型的优化,NIO 在用户层也做了优化升级。NIO 是基于事件驱动模型来实现的 I/O 操作。Reactor 模型是同步 I/O 事件处理的一种常见模型,其核心思想是将 I/O 事件注册到多路复用器上,一旦有 I/O 事件触发,多路复用器就会将事件分发到事件处理器中,执行就绪的 I/O 事件操作。该模型有以下三个主要组件:
- 事件接收器 Acceptor:主要负责接收请求连接;
- 事件分离器 Reactor:接收请求后,会将建立的连接注册到分离器中,依赖于循环监听多路复用器 Selector,一旦监听到事件,就会将事件 dispatch 到事件处理器;
- 事件处理器 Handlers:事件处理器主要是完成相关的事件处理,比如读写 I/O 操作。
1. 单线程 Reactor 线程模型
最开始 NIO 是基于单线程实现的,所有的 I/O 操作都是在一个 NIO 线程上完成。由于 NIO 是非阻塞 I/O,理论上一个线程可以完成所有的 I/O 操作。
但 NIO 其实还不算真正地实现了非阻塞 I/O 操作,因为读写 I/O 操作时用户进程还是处于阻塞状态,这种方式在高负载、高并发的场景下会存在性能瓶颈,一个 NIO 线程如果同时处理上万连接的 I/O 操作,系统是无法支撑这种量级的请求的。

2. 多线程 Reactor 线程模型
为了解决这种单线程的 NIO 在高负载、高并发场景下的性能瓶颈,后来使用了线程池。
在 Tomcat 和 Netty 中都使用了一个 Acceptor 线程来监听连接请求事件,当连接成功之后,会将建立的连接注册到多路复用器中,一旦监听到事件,将交给 Worker 线程池来负责处理。大多数情况下,这种线程模型可以满足性能要求,但如果连接的客户端再上一个量级,一个 Acceptor 线程可能会存在性能瓶颈。
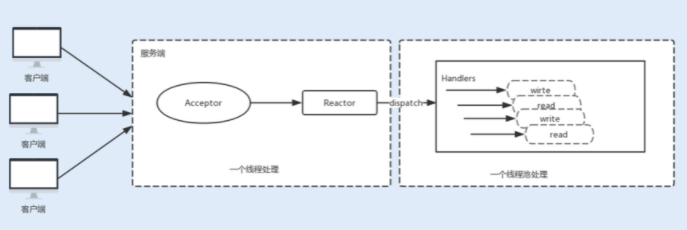
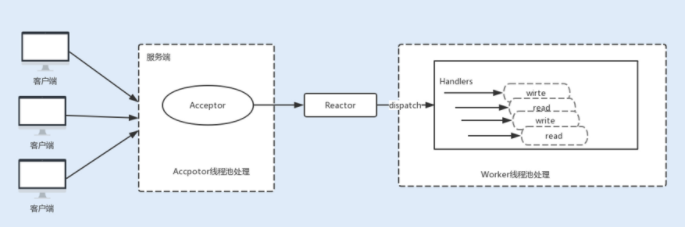
3. 主从 Reactor 线程模型
现在主流通信框架中的 NIO 通信框架都是基于主从 Reactor 线程模型来实现的。在这个模型中,Acceptor 不再是一个单独的 NIO 线程,而是一个线程池。Acceptor 接收到客户端的 TCP 连接请求,建立连接之后,后续的 I/O 操作将交给 Worker I/O 线程。
基于线程模型的 Tomcat 参数调优
Tomcat 中,BIO、NIO 是基于主从 Reactor 线程模型实现的。
在 BIO 中,Tomcat 中的 Acceptor 只负责监听新的连接,一旦连接建立监听到 I/O 操作,将会交给 Worker 线程中,Worker 线程专门负责 I/O 读写操作。
在 NIO 中,Tomcat 新增了一个 Poller 线程池,Acceptor 监听到连接后,不是直接使用 Worker 中的线程处理请求,而是先将请求发送给了 Poller 缓冲队列。在 Poller 中,维护了一个 Selector 对象,当 Poller 从队列中取出连接后,注册到该 Selector 中;然后通过遍历 Selector,找出其中就绪的 I/O 操作,并使用 Worker 中的线程处理相应的请求。
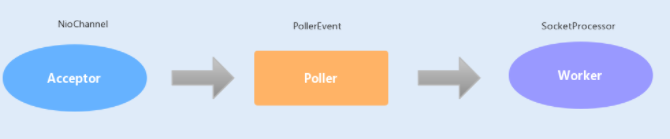
你可以通过以下几个参数来设置 Acceptor 线程池和 Worker 线程池的配置项。
acceptorThreadCount:该参数代表 Acceptor 的线程数量,在请求客户端的数据量非常巨大的情况下,可以适当地调大该线程数量来提高处理请求连接的能力,默认值为 1。
maxThreads:专门处理 I/O 操作的 Worker 线程数量,默认是 200,可以根据实际的环境来调整该参数,但不一定越大越好。
acceptCount:Tomcat 的 Acceptor 线程是负责从 accept 队列中取出该 connection,然后交给工作线程去执行相关操作,这里的 acceptCount 指的是 accept 队列的大小。
当 Http 关闭 keep alive,在并发量比较大时,可以适当地调大这个值。而在 Http 开启 keep alive 时,因为 Worker 线程数量有限,Worker 线程就可能因长时间被占用,而连接在 accept 队列中等待超时。如果 accept 队列过大,就容易浪费连接。
maxConnections:表示有多少个 socket 连接到 Tomcat 上。在 BIO 模式中,一个线程只能处理一个连接,一般 maxConnections 与 maxThreads 的值大小相同;在 NIO 模式中,一个线程同时处理多个连接,maxConnections 应该设置得比 maxThreads 要大的多,默认是 10000。
 微信
微信 支付宝
支付宝



