MapReduce高阶编程
MapReduce Counter计数器
计数器概述
在执行MapReduce程序的时候,控制台输出信息中通常有下面所示片段内容:
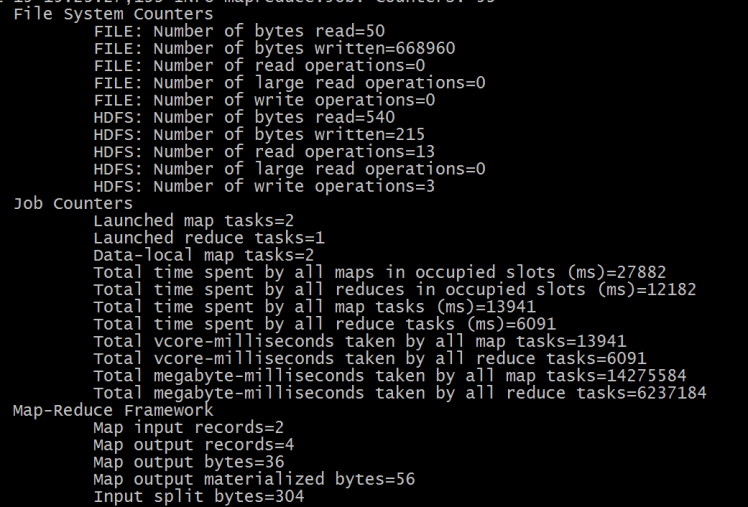
可以发现,输出信息中的核心词是counters,中文叫做计数器。在进行MapReduce运算过程中,许多时候,用户希望了解程序的运行情况。Hadoop内置的计数器功能收集作业的主要统计信息,可以帮助用户理解程序的运行情况,辅助用户诊断故障。
这些记录了该程序运行过程的的一些信息的计数,如Map input records=2,表示Map有2条记录。可以看出来这些内置计数器可以被分为若干个组,即对于大多数的计数器来说,Hadoop使用的组件分为若干类。
MapReduce内置计数器
Hadoop为每个MapReduce作业维护一些内置的计数器,这些计数器报告各种指标,例如和MapReduce程序执行中每个阶段输入输出的数据量相关的计数器,可以帮助用户进行判断程序逻辑是否生效、正确。
Hadoop内置计数器根据功能进行分组。每个组包括若干个不同的计数器,分别是:MapReduce任务计数器(Map-Reduce Framework)、文件系统计数器(File System Counters)、作业计数器(Job Counters)、输入文件任务计数器(File Input Format Counters)、输出文件计数器(File Output Format Counters)。
需要注意的是,内置的计数器都是MapReduce程序中全局的计数器,跟MapReduce分布式运算没有关系,不是所谓的每个局部的统计信息。
Map-Reduce Framework Counters
| 计数器名称 | 说明 |
|---|---|
| MAP_INPUT_RECORDS | 所有mapper已处理的输入记录数 |
| MAP_OUTPUT_RECORDS | 所有mapper产生的输出记录数 |
| MAP_OUTPUT_BYTES | 所有mapper产生的未经压缩的输出数据的字节数 |
| MAP_OUTPUT_MATERIALIZED_BYTES | mapper输出后确实写到磁盘上字节数 |
| COMBINE_INPUT_RECORDS | 所有combiner(如果有)已处理的输入记录数 |
| COMBINE_OUTPUT_RECORDS | 所有combiner(如果有)已产生的输出记录数 |
| REDUCE_INPUT_GROUPS | 所有reducer已处理分组的个数 |
| REDUCE_INPUT_RECORDS | 所有reducer已经处理的输入记录的个数。每当某个reducer的迭代器读一个值时,该计数器的值增加 |
| REDUCE_OUTPUT_RECORDS | 所有reducer输出记录数 |
| REDUCE_SHUFFLE_BYTES | Shuffle时复制到reducer的字节数 |
| SPILLED_RECORDS | 所有map和reduce任务溢出到磁盘的记录数 |
| CPU_MILLISECONDS | 一个任务的总CPU时间,以毫秒为单位,可由/proc/cpuinfo获取 |
| PHYSICAL_MEMORY_BYTES | 一个任务所用的物理内存,以字节数为单位,可由/proc/meminfo获取 |
| VIRTUAL_MEMORY_BYTES | 一个任务所用虚拟内存的字节数,由/proc/meminfo获取 |
File System Counters Counters
文件系统的计数器会针对不同的文件系统使用情况进行统计,比如HDFS、本地文件系统:
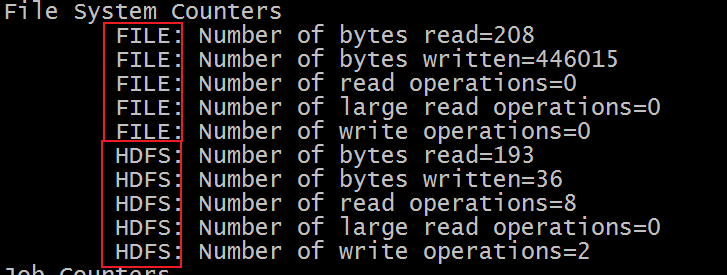
| 计数器名称 | 说明 |
|---|---|
| BYTES_READ | 程序从文件系统中读取的字节数 |
| BYTES_WRITTEN | 程序往文件系统中写入的字节数 |
| READ_OPS | 文件系统中进行的读操作的数量(例如,open操作,filestatus操作) |
| LARGE_READ_OPS | 文件系统中进行的大规模读操作的数量 |
| WRITE_OPS | 文件系统中进行的写操作的数量(例如,create操作,append操作) |
Job Counters
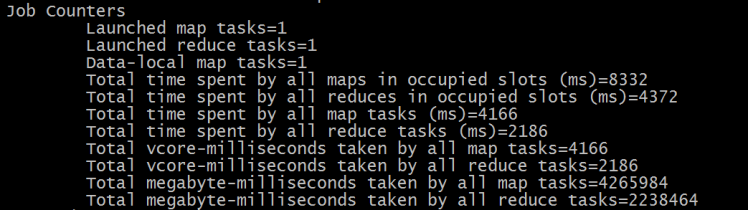
| 计数器名称 | 说明 |
|---|---|
| Launched map tasks | 启动的map任务数,包括以“推测执行”方式启动的任务 |
| Launched reduce tasks | 启动的reduce任务数,包括以“推测执行”方式启动的任务 |
| Data-local map tasks | 与输人数据在同一节点上的map任务数 |
| Total time spent by all maps in occupied slots (ms) | 所有map任务在占用的插槽中花费的总时间(毫秒) |
| Total time spent by all reduces in occupied slots (ms) | 所有reduce任务在占用的插槽中花费的总时间(毫秒) |
| Total time spent by all map tasks (ms) | 所有map task花费的时间 |
| Total time spent by all reduce tasks (ms) | 所有reduce task花费的时间 |
File Input|Output Format Counters

| 计数器名称 | 说明 |
|---|---|
| 读取的字节数(BYTES_READ) | 由map任务通过FilelnputFormat读取的字节数 |
| 写的字节数(BYTES_WRITTEN) | 由map任务(针对仅含map的作业)或者reduce任务通过FileOutputFormat写的字节数 |
MapReduce自定义计数器
虽然Hadoop内置的计数器比较全面,给作业运行过程的监控带了方便,但是对于一些业务中的特定要求(统计过程中对某种情况发生进行计数统计)MapReduce还是提供了用户编写自定义计数器的方法。最重要的是,计数器是全局的统计,避免了用户自己维护全局变量的不利性。
自定义计数器的使用分为两步:
首先通过context.getCounter方法获取一个全局计数器,创建的时候需要指定计数器所属的组名和计数器的名字:

然后在程序中需要使用计数器的地方,调用counter提供的方法即可,比如+1操作:
这样在执行程序的时候,在控制台输出的信息上就有自定义计数器组和计数器统计信息
案例:MapReduce自定义计数器使用
需求
针对一批文件进行词频统计,不知何种原因,在任意文件的任意地方都有可能插入单词”apple”,现要求使用计数器统计出数据中apple出现的次数,便于用户执行程序时判断。
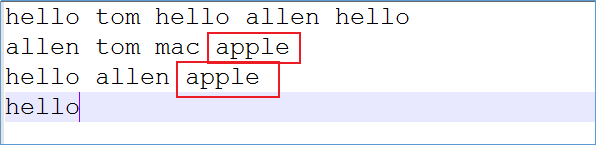
代码实现
Mapper类
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//从程序上下文对象获取一个全局计数器:用于统计apple出现的个数
//需要指定计数器组 和计数器的名字
Counter counter = context.getCounter("itcast_counters", "apple Counter");
String[] words = value.toString().split("\\s+");
for (String word : words) {
//判断读取内容是否为apple 如果是 计数器加1
if("apple".equals(word)){
counter.increment(1);
}
context.write(new Text(word),new LongWritable(1));
}
}
}Reducer类
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count +=value.get();
}
context.write(key,new LongWritable(count));
}
}运行主类
public class WordCountDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// 创建作业实例
Job job = Job.getInstance(getConf(), WordCountDriver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(this.getClass());
// 设置作业mapper reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交作业并等待执行完成
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
//配置文件对象
Configuration conf = new Configuration();
//使用工具类ToolRunner提交程序
int status = ToolRunner.run(conf, new WordCountDriver(), args);
//退出客户端程序 客户端退出状态码和MapReduce程序执行结果绑定
System.exit(status);
}
}执行结果
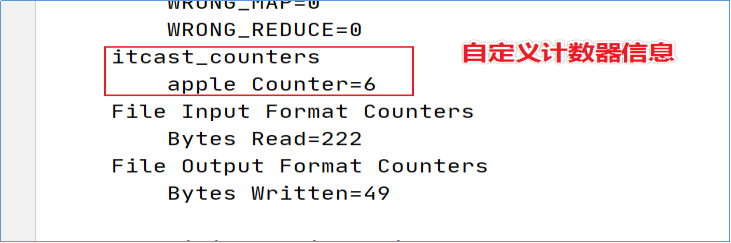
MapReduce DB操作
背景知识
通常组织会使用关系型数据来存储业务相关的数据,但随着数据的规模越来越大,尤其是像MySQL这种,在单表超过5千万条记录时,尽管对表使用了特定的存储引擎和索引优化,但依然不可避免的存在性能下降问题。
此时,我们可以通过使用MapReduce从MySQL中定期迁移使用频率较低的历史数据到HDFS中,一方面可以降低对MySQL的存储和计算负载,另一方面,通过分布式计算引擎可以更加高效的处理过去的历史数据。
对于MapReduce框架来说,使用inputform进行数据读取操作,读取的数据首先由mapper处理,然后交给reducer处理,最终使用outputformat进行数据的输出操作。默认情况下,输入输出的组件实现都是针对文本数据处理的,分别是TextInputFormat、TextOutputFormat。
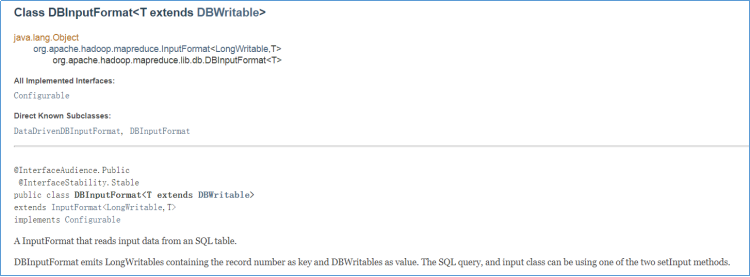
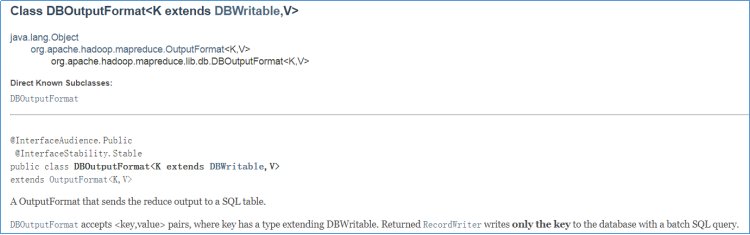
为了方便 MapReduce 直接访问关系型数据库(Mysql,Oracle),Hadoop提供了DBInputFormat和DBOutputFormat两个类。其中DBInputFormat负责从数据库中读取数据,而DBOutputFormat负责把数据最终写入数据库中。
读取数据库操作
需求
在mysql中itcast_shop数据库下创建表itheima_goods并加载数据到表中。要求使用MapReduce程序将表中的数据导出存放在指定的文件下。
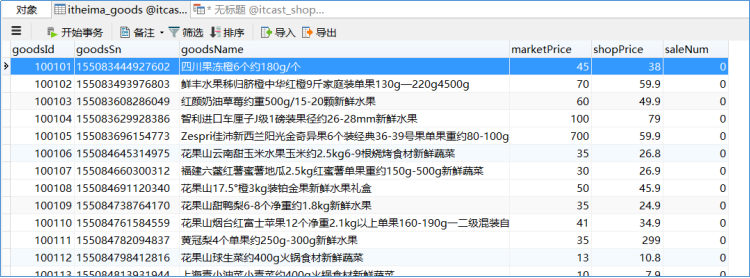
因为涉及到java操作mysql,因此需要在pom依赖中额外添加mysql-jdbc驱动。
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.32</version>
</dependency>DBInputFormat类
InputFormat类用于从SQL表读取数据。DBInputFormat底层一行一行读取表中的数据,返回
此外还需要使用setInput方法设置SQL查询的语句相关信息。

代码实现
第1步:编写GoodsBean类
定义GoodsBean的实体类,用于封装查询返回的结果(如果要查询表的所有字段,那么属性就跟表的字段一一对应即可)。并且需要实现序列化机制Writable。
此外,从数据库读取/写入数据库的对象应实现DBWritable。 DBWritable与Writable相似,区别在于write(PreparedStatement)方法采用PreparedStatement,而readFields(ResultSet)采用ResultSet。
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/**
* @description:
*/
public class GoodsBean implements Writable, DBWritable {
private long goodsId;//商品ID
private String goodsSn;//商品编号
private String goodsName;//商品名称
private double marketPrice;//市场价
private double shopPrice;//门店价
private long saleNum;//总销售量
/**
* 无参构造方法
*/
public GoodsBean() {
}
/**
* 有参构造方法
*/
public GoodsBean(long goodsId, String goodsSn, String goodsName, double marketPrice, double shopPrice, long saleNum) {
this.goodsId = goodsId;
this.goodsSn = goodsSn;
this.goodsName = goodsName;
this.marketPrice = marketPrice;
this.shopPrice = shopPrice;
this.saleNum = saleNum;
}
/**
* set方法 用于对象赋值
*/
public void set(long goodsId, String goodsSn, String goodsName, double marketPrice, double shopPrice, long saleNum) {
this.goodsId = goodsId;
this.goodsSn = goodsSn;
this.goodsName = goodsName;
this.marketPrice = marketPrice;
this.shopPrice = shopPrice;
this.saleNum = saleNum;
}
//此处省略setter getter方法
/**
* 序列化方法
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(goodsId);
out.writeUTF(goodsSn);
out.writeUTF(goodsName);
out.writeDouble(marketPrice);
out.writeDouble(shopPrice);
out.writeLong(saleNum);
}
/**
* 反序列化方法
*/
@Override
public void readFields(DataInput in) throws IOException {
this.goodsId = in.readLong();
this.goodsSn = in.readUTF();
this.goodsName = in.readUTF();
this.marketPrice = in.readDouble();
this.shopPrice = in.readDouble();
this.saleNum = in.readLong();
}
/**
* 在PreparedStatement中设置对象的字段。写数据库
*/
@Override
public void write(PreparedStatement ps) throws SQLException {
ps.setLong(1,goodsId);
ps.setString(2,goodsSn);
ps.setString(3,goodsName);
ps.setDouble(4,marketPrice);
ps.setDouble(5,shopPrice);
ps.setLong(6,saleNum);
}
/**
* 从ResultSet中读取对象的字段。 读数据库
*/
@Override
public void readFields(ResultSet rs) throws SQLException {
this.goodsId = rs.getLong(1);
this.goodsSn = rs.getString(2);
this.goodsName = rs.getString(3);
this.marketPrice = rs.getDouble(4);
this.shopPrice = rs.getDouble(5);
this.saleNum = rs.getLong(6);
}
@Override
public String toString() {
return goodsId+"\t"+goodsSn+"\t"+goodsName+"\t"+marketPrice+"\t"+shopPrice+"\t"+saleNum;
}
}第2步:编写Mapper类
package cn.itcast.hadoop.mapreduce.db.read;
import cn.itcast.hadoop.mapreduce.db.GoodsBean;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @description:
*/
public class ReadDBMapper extends Mapper<LongWritable, GoodsBean,LongWritable, Text> {
LongWritable outputKey = new LongWritable();
Text outputValue = new Text();
@Override
protected void map(LongWritable key, GoodsBean value, Context context) throws IOException, InterruptedException {
outputKey.set(key.get());
outputValue.set(value.toString());
context.write(outputKey,outputValue);
}
}第3步:创建程序驱动类
package cn.itcast.hadoop.mapreduce.db.read;
import cn.itcast.hadoop.mapreduce.db.GoodsBean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @description:
*/
public class ReadDBApp extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
//配置当前作业需要使用的JDBC信息
DBConfiguration.configureDB(
conf,
"com.mysql.jdbc.Driver",
"jdbc:mysql://192.168.227.151:3306/itcast_shop",
"root",
"hadoop"
);
// 创建作业实例
Job job = Job.getInstance(conf, ReadDBApp.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(ReadDBApp.class);
//设置inputformat类
job.setInputFormatClass(DBInputFormat.class);
FileOutputFormat.setOutputPath(job,new Path("d:\\dbout"));
job.setMapperClass(ReadDBMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);
//配置当前作业要查询的SQL语句和接收查询结果的JavaBean
DBInputFormat.setInput(
job,
GoodsBean.class,
"SELECT goodsId,goodsSn,goodsName,marketPrice,shopPrice,saleNum from itheima_goods",
"SELECT count(goodsId) from itheima_goods"
);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ReadDBApp(), args);
System.exit(status);
}
}提交运行
直接在驱动类中右键运行main方法,使用MapReduce的本地模式执行。也可以将程序使用maven插件打包成jar包,提交到yarn上进行分布式运行。
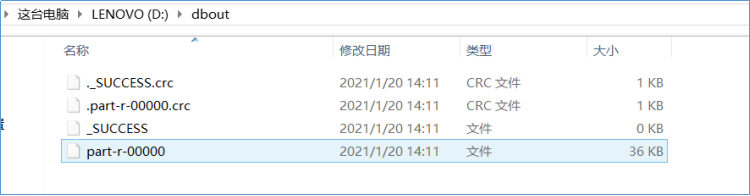
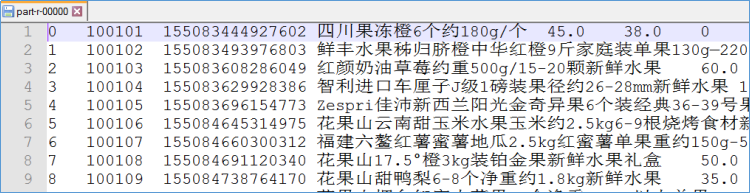
输出到数据库操作
需求
有一份结构化的数据文件,数据内容对应着mysql中一张表的内容,要求使用MapReduce程序将文件的内容读取写入到mysql中。
就以上例的输出文件作为结构化文件,下面在mysql中创建对应的表结构。

CREATE TABLE `itheima_goods_mr_write` (
`goodsId` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '商品id',
`goodsSn` varchar(20) NOT NULL COMMENT '商品编号',
`goodsName` varchar(200) NOT NULL COMMENT '商品名称',
`marketPrice` decimal(11,2) NOT NULL DEFAULT '0.00' COMMENT '市场价',
`shopPrice` decimal(11,2) NOT NULL DEFAULT '0.00' COMMENT '门店价',
`saleNum` int(11) NOT NULL DEFAULT '0' COMMENT '总销售量',
PRIMARY KEY (`goodsId`)
) ENGINE=InnoDB AUTO_INCREMENT=115909 DEFAULT CHARSET=utf8;DBOutputFormat类
OutputFormat,它将reduce输出发送到SQL表。DBOutputFormat接受<key,value>键值对,其中key必须具有扩展DBWritable的类型。
此外还需要使用setOutput方法设置SQL插入语句相关信息,比如表、字段等。

代码实现
第1步:编写GoodsBean类
定义GoodsBean的实体类,用于封装插入表中的数据(对象属性跟表的字段一一对应即可)。并且需要实现序列化机制Writable。
此外,从数据库读取/写入数据库的对象应实现DBWritable。 DBWritable与Writable相似,区别在于write(PreparedStatement)方法采用PreparedStatement,而readFields(ResultSet)采用ResultSet。
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/**
* @description:
*/
public class GoodsBean implements Writable, DBWritable {
private long goodsId;//商品ID
private String goodsSn;//商品编号
private String goodsName;//商品名称
private double marketPrice;//市场价
private double shopPrice;//门店价
private long saleNum;//总销售量
/**
* 无参构造方法
*/
public GoodsBean() {
}
/**
* 有参构造方法
*/
public GoodsBean(long goodsId, String goodsSn, String goodsName, double marketPrice, double shopPrice, long saleNum) {
this.goodsId = goodsId;
this.goodsSn = goodsSn;
this.goodsName = goodsName;
this.marketPrice = marketPrice;
this.shopPrice = shopPrice;
this.saleNum = saleNum;
}
/**
* set方法 用于对象赋值
*/
public void set(long goodsId, String goodsSn, String goodsName, double marketPrice, double shopPrice, long saleNum) {
this.goodsId = goodsId;
this.goodsSn = goodsSn;
this.goodsName = goodsName;
this.marketPrice = marketPrice;
this.shopPrice = shopPrice;
this.saleNum = saleNum;
}
//此处省略setter getter方法
/**
* 序列化方法
*/
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(goodsId);
out.writeUTF(goodsSn);
out.writeUTF(goodsName);
out.writeDouble(marketPrice);
out.writeDouble(shopPrice);
out.writeLong(saleNum);
}
/**
* 反序列化方法
*/
@Override
public void readFields(DataInput in) throws IOException {
this.goodsId = in.readLong();
this.goodsSn = in.readUTF();
this.goodsName = in.readUTF();
this.marketPrice = in.readDouble();
this.shopPrice = in.readDouble();
this.saleNum = in.readLong();
}
/**
* 在PreparedStatement中设置对象的字段。写数据库
*/
@Override
public void write(PreparedStatement ps) throws SQLException {
ps.setLong(1,goodsId);
ps.setString(2,goodsSn);
ps.setString(3,goodsName);
ps.setDouble(4,marketPrice);
ps.setDouble(5,shopPrice);
ps.setLong(6,saleNum);
}
/**
* 从ResultSet中读取对象的字段。 读数据库
*/
@Override
public void readFields(ResultSet rs) throws SQLException {
this.goodsId = rs.getLong(1);
this.goodsSn = rs.getString(2);
this.goodsName = rs.getString(3);
this.marketPrice = rs.getDouble(4);
this.shopPrice = rs.getDouble(5);
this.saleNum = rs.getLong(6);
}
@Override
public String toString() {
return goodsId+"\t"+goodsSn+"\t"+goodsName+"\t"+marketPrice+"\t"+shopPrice+"\t"+saleNum;
}
}第2步:编写Mapper类
import cn.itcast.hadoop.mapreduce.db.GoodsBean;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @description:
*/
public class WriteDBMapper extends Mapper<LongWritable, Text, NullWritable, GoodsBean> {
NullWritable outputKey = NullWritable.get();
GoodsBean outputValue = new GoodsBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//插入数据库成功的计数器
final Counter sc = context.getCounter("mr_sql_counters", "SUCCESS");
//插入数据库失败的计数器
final Counter fc = context.getCounter("mr_sql_counters", "FAILED");
//解析输入数据
String[] fields = value.toString().split("\\s+");
//判断输入的数据字段是否有缺少 如果不满足需求 则为非法数据
if (fields.length > 6){
outputValue.set(
Long.parseLong(fields[1]),
fields[2],
fields[3],
Double.parseDouble(fields[4]),
Double.parseDouble(fields[5]),
Long.parseLong(fields[6])
);
context.write(outputKey,outputValue);
//合法数据 计数器+1
sc.increment(1);
}else{
//非法数据 计数器+1
fc.increment(1);
}
}
}第3步:编写Reducer类
import cn.itcast.hadoop.mapreduce.db.GoodsBean;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @description: 在使用DBOutputFormat时,要求程序最终输出的key必须是继承自DBWritable的类型 value则没有具体要求
*/
public class WriteDBReducer extends Reducer<NullWritable, GoodsBean,GoodsBean,NullWritable> {
@Override
protected void reduce(NullWritable key, Iterable<GoodsBean> values, Context context) throws IOException, InterruptedException {
for (GoodsBean value : values) {
context.write(value,key);
}
}
}第4步:创建程序驱动类
package cn.itcast.hadoop.mapreduce.db.write;
import cn.itcast.hadoop.mapreduce.db.GoodsBean;
import cn.itcast.hadoop.mapreduce.db.read.ReadDBMapper;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @description:
*/
public class WriteDBApp extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
//配置当前作业需要使用的JDBC信息
DBConfiguration.configureDB(
conf,
"com.mysql.jdbc.Driver",
"jdbc:mysql://192.168.227.151:3306/itcast_shop?useUnicode=true&characterEncoding=utf8",
"root",
"hadoop"
);
// 创建作业实例
Job job = Job.getInstance(conf, WriteDBApp.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(WriteDBApp.class);
//设置mapper相关信息
job.setMapperClass(WriteDBMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(GoodsBean.class);
//设置reducer相关信息
job.setReducerClass(WriteDBReducer.class);
job.setOutputKeyClass(GoodsBean.class);
job.setOutputValueClass(NullWritable.class);
//设置输入的文件的路径
FileInputFormat.setInputPaths(job,new Path("D:\\datasets\\dboutput"));
//设置输出的format类型
job.setOutputFormatClass(DBOutputFormat.class);
//配置当前作业输出到数据库的表、字段信息
DBOutputFormat.setOutput(
job,
"itheima_goods_mr_write",
"goodsId", "goodsSn", "goodsName", "marketPrice", "shopPrice","saleNum");
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new WriteDBApp(), args);
System.exit(status);
}
}提交运行
直接在驱动类中右键运行main方法,使用MapReduce的本地模式执行。也可以将程序使用maven插件打包成jar包,提交到yarn上进行分布式运行。
MapReduce实现Join关联操作
背景知识
在实际的数据库应用中,我们经常需要从多个数据表中读取数据,这时我们就可以使用SQL语句中的连接(JOIN),在两个或多个数据表中查询数据。
在使用MapReduce框架进行数据处理的过程中,也会涉及到从多个数据集读取数据,进行join关联的操作,只不过此时需要使用java代码并且根据MapReduce的编程规范进行业务的实现。
但是由于MapReduce的分布式设计理念的特殊性,因此对于MapReduce实现join操作具备了一定的特殊性。特殊主要体现在:究竟在MapReduce中的什么阶段进行数据集的关联操作,是mapper阶段还是reducer阶段,之间的区别又是什么?
整个MapReduce的join分为两类:map side join、reduce side join。
reduce side join
概述
reduce side join,顾名思义,在reduce阶段执行join关联操作。这也是最容易想到和实现的join方式。因为通过shuffle过程就可以将相关的数据分到相同的分组中,这将为后面的join操作提供了便捷。
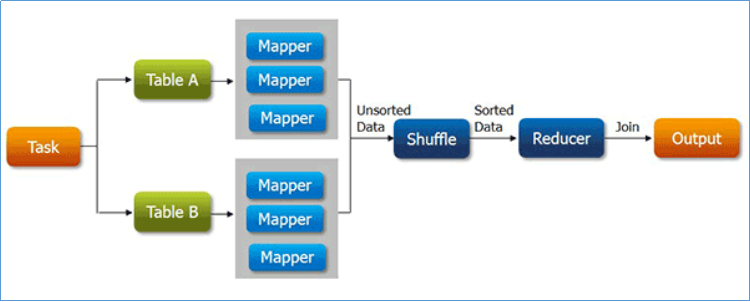
基本上,reduce side join大致步骤如下:
mapper分别读取不同的数据集;
mapper的输出中,通常以join的字段作为输出的key;
不同数据集的数据经过shuffle,key一样的会被分到同一分组处理;
在reduce中根据业务需求把数据进行关联整合汇总,最终输出。
弊端
reduce端join最大的问题是整个join的工作是在reduce阶段完成的,但是通常情况下MapReduce中reduce的并行度是极小的(默认是1个),这就使得所有的数据都挤压到reduce阶段处理,压力颇大。虽然可以设置reduce的并行度,但是又会导致最终结果被分散到多个不同文件中。
并且在数据从mapper到reducer的过程中,shuffle阶段十分繁琐,数据集大时成本极高。
MapReduce 分布式缓存
DistributedCache是hadoop框架提供的一种机制,可以将job指定的文件,在job执行前,先行分发到task执行的机器上,并有相关机制对cache文件进行管理。
DistributedCache能够缓存应用程序所需的文件 (包括文本,档案文件,jar文件等)。
Map-Redcue框架在作业所有任务执行之前会把必要的文件拷贝到slave节点上。 它运行高效是因为每个作业的文件只拷贝一次并且为那些没有文档的slave节点缓存文档。
使用方式
添加缓存文件
可以使用MapReduce的API添加需要缓存的文件。
//添加归档文件到分布式缓存中
job.addCacheArchive(URI uri);
//添加普通文件到分布式缓存中
job.addCacheFile(URI uri);注意:需要分发的文件,必须提前放到hdfs上.默认的路径前缀是hdfs://。
程序中读取缓存文件
在Mapper类或者Reducer类的setup方法中,用输入流获取分布式缓存中的文件。
protected void setup(Context context) throw IOException,InterruptedException{
FileReader reader = new FileReader("myfile");
BufferReader br = new BufferedReader(reader);
......
}map side join
概述
map side join,其精髓就是在map阶段执行join关联操作,并且程序也没有了reduce阶段,避免了shuffle时候的繁琐。实现的关键是使用MapReduce的分布式缓存。
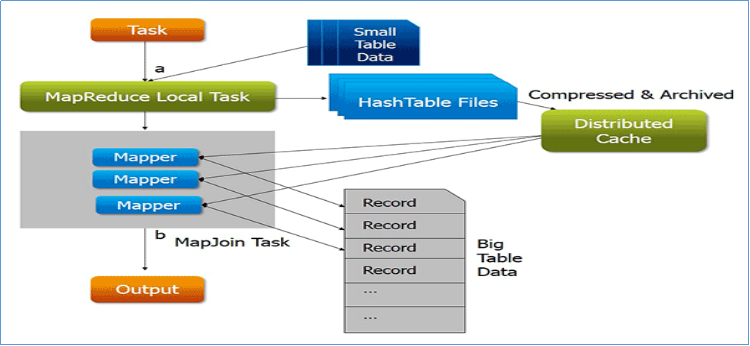
尤其是涉及到一大一小数据集的处理场景时,map端的join将会发挥出得天独厚的优势。
map side join的大致思路如下:
1、 首先分析join处理的数据集,使用分布式缓存技术将小的数据集进行分布式缓存
2、 MapReduce框架在执行的时候会自动将缓存的数据分发到各个maptask运行的机器上
3、 程序只运行mapper,在mapper初始化的时候从分布式缓存中读取小数据集数据,然后和自己读取的大数据集进行join关联,输出最终的结果。
4、 整个join的过程没有shuffle,没有reducer。
优势
map端join最大的优势减少shuffle时候的数据传输成本。并且mapper的并行度可以根据输入数据量自动调整,充分发挥分布式计算的优势。
MapReduce join案例:订单商品处理
需求背景
有两份结构化的数据文件:itheima_goods(商品信息表)、itheima_order_goods(订单信息表),具体字段内容如下。
要求使用MapReduce统计出每笔订单中对应的具体的商品名称信息。比如107860商品对应着:AMAZFIT黑色硅胶腕带。
itheima_goods

字段:goodsId(商品id)、goodsSn(商品编号)、goodsName(商品名称)
itheima_order_goods

字段: orderId(订单ID)、goodsId(商品ID)、payPrice(实际支付价格)
Reduce Side实现
思路分析
使用mapper处理订单数据和商品数据,输出的时候以goodsId商品编号作为key。相同goodsId的商品和订单会到同一个reduce的同一个分组,在分组中进行订单和商品信息的关联合并。在MapReduce程序中可以通过context获取到当前处理的切片所属的文件名称。根据文件名来判断当前处理的是订单数据还是商品数据,以此来进行不同逻辑的输出。
join处理完之后,最后可以再通过MapReduce程序排序功能,将属于同一笔订单的所有商品信息汇聚在一起。
代码实现
第1步:mapper类
package cn.itcast.hadoop.mapreduce.join.reduceside;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* @description:
*/
public class ReduceJoinMapper extends Mapper<LongWritable, Text,Text,Text> {
Text outKey = new Text();
Text outValue = new Text();
StringBuilder sb = new StringBuilder();
String filename =null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//获取当前处理的切片所属的文件名字
FileSplit inputSplit = (FileSplit) context.getInputSplit();
filename = inputSplit.getPath().getName();
System.out.println("当前正在处理的文件是:"+filename);
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//设置字符串长度,此处用于清空数据
sb.setLength(0);
//切割处理输入数据
String[] fields = value.toString().split("\\|");
//判断处理的是哪个文件
if(filename.contains("itheima_goods.txt")){//处理的是商品数据
// 100101|155083444927602|四川果冻橙6个约180g (商品id、商品编号、商品名称)
outKey.set(fields[0]);
StringBuilder append = sb.append(fields[1]).append("\t").append(fields[2]);
outValue.set(sb.insert(0, "goods#").toString());
System.out.println(outKey+"---->"+outValue);
context.write(outKey,outValue);
}else{//处理的是订单数据
// 2|113561|11192 (订单编号、商品id、实际支付价格)
outKey.set(fields[1]);
StringBuilder append = sb.append(fields[0]).append("\t").append(fields[2]);
outValue.set(sb.insert(0, "order#").toString());
System.out.println(outKey+"---->"+outValue);
context.write(outKey,outValue);
}
}
}第2步:reduce类
package cn.itcast.hadoop.mapreduce.join.reduceside;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* @description:
*/
public class ReduceJoinReducer extends Reducer<Text,Text,Text,Text> {
//用来存放 商品编号、商品名称
List<String> goodsList = new ArrayList<>();
//用来存放 订单编号、实际支付价格
List<String> orderList = new ArrayList<>();
Text outValue = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//遍历values
for (Text value : values) {
//将结果添加到对应的list中
if(value.toString().startsWith("goods#")){
String s = value.toString().split("#")[1];
goodsList.add(s);
}
if(value.toString().startsWith("order#")){
String s = value.toString().split("#")[1];
orderList.add(s);
}
}
//获取2个集合的长度
int goodsSize = goodsList.size();
int orderSize = orderList.size();
for (int i = 0; i < orderSize; i++) {
for (int j = 0; j < goodsSize; j++) {
outValue.set(orderList.get(i)+"\t"+goodsList.get(j));
//最终输出:商品id、订单编号、实际支付价格、商品编号、商品名称
context.write(key,outValue);
}
}
orderList.clear();
goodsList.clear();
}
}第3步:运行的主类
package cn.itcast.hadoop.mapreduce.join.reduceside;
import cn.itcast.hadoop.mapreduce.wordcount.WordCountMapper;
import cn.itcast.hadoop.mapreduce.wordcount.WordCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @description:
*/
public class ReduceJoinDriver extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
// 创建作业实例
Job job = Job.getInstance(getConf(), ReduceJoinDriver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(ReduceJoinDriver.class);
// 设置作业mapper reducer类
job.setMapperClass(ReduceJoinMapper.class);
job.setReducerClass(ReduceJoinReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path("D:\\datasets\\mr_join\\input"));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path("D:\\datasets\\mr_join\\rjout"));
// 提交作业并等待执行完成
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
//配置文件对象
Configuration conf = new Configuration();
//使用工具类ToolRunner提交程序
int status = ToolRunner.run(conf, new ReduceJoinDriver(), args);
//退出客户端程序 客户端退出状态码和MapReduce程序执行结果绑定
System.exit(status);
}
}第4步:结果排序
package cn.itcast.hadoop.mapreduce.join.reduceside;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @description:
*/
public class ReduceJoinSortApp {
public static class ReduceJoinMapper extends Mapper<LongWritable, Text,Text,Text>{
Text outKey = new Text();
Text outvalue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
outKey.set(fields[1]);
outvalue.set(fields[1]+"\t"+fields[0]+"\t"+fields[3]+"\t"+fields[4]+"\t"+fields[2]);
context.write(outKey,outvalue);
}
}
public static class ReduceJoinReducer extends Reducer<Text,Text,Text, NullWritable>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value : values) {
context.write(value,NullWritable.get());
}
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, ReduceJoinSortApp.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(ReduceJoinSortApp.class);
// 设置作业mapper reducer类
job.setMapperClass(ReduceJoinMapper.class);
job.setReducerClass(ReduceJoinReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path("D:\\datasets\\mr_join\\rjout"));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path("D:\\datasets\\mr_join\\rjresult"));
// 提交作业并等待执行完成
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 :1);
}
}提交运行
直接在驱动类中右键运行main方法,使用MapReduce的本地模式执行。也可以将程序使用maven插件打包成jar包,提交到yarn上进行分布式运行。
1) reduce join的结果
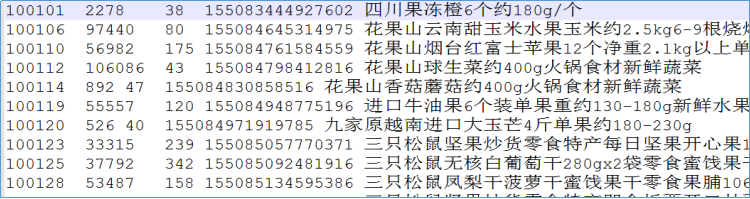
可以发现属于同一笔订单的商品信息被打散了。
2) 重新排序之后的结果

Map Side实现
思路分析
Map-side Join是指在Mapper任务中加载特定数据集,此案例中把商品数据进行分布式缓存,使用Mapper读取订单数据和缓存的商品数据进行连接。
通常为了方便使用,会在mapper的初始化方法setup中读取分布式缓存文件加载的程序的内存中,便于后续mapper处理数据。
因为在mapper阶段已经完成了数据的关联操作,因此程序不需要进行reduce。需要在job中将reducetask的个数设置为0,也就是mapper的输出就是程序最终的输出。
代码实现
第1步:mapper类
package cn.itcast.hadoop.mapreduce.join.mapside;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
/**
* @description:
*/
public class MapJoinMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
//创建集合 用于缓存商品数据itheima_goods.txt
Map<String, String> goodsMap = new HashMap<String,String>();
Text k = new Text();
/**
* 在程序的初始化方法中 从分布式缓存中加载缓存文件 写入goodsMap集合中
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//读取缓存文件 千万别写成/itheima_goods.txt否则会提示找不到该文件 字符缓冲输入流
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("itheima_goods.txt")));
String line = null;
while((line=br.readLine())!=null){
//一行数据格式为: 100101|155083444927602|四川果冻橙6个约180g(商品id,商品编号,商品名称)
String[] fields = line.split("\\|");
goodsMap.put(fields[0], fields[1]+"\t"+fields[2]);
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//一行订单数据 格式为: 1|107860|7191 (订单编号,商品id,实际支付价格)
String[] fields = value.toString().split("\\|");
//根据订单数据中商品id在缓存中找出来对应商品信息(商品名称),进行串接
String goodsInfo = goodsMap.get(fields[1]);
k.set(value.toString()+"\t"+goodsInfo);
context.write(k, NullWritable.get());
}
}第2步:程序运行主类
package cn.itcast.hadoop.mapreduce.join.mapside;
import cn.itcast.hadoop.mapreduce.join.reduceside.ReduceJoinSortApp;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
/**
* @description:
*/
public class MapJoinDriver {
public static void main(String[] args) throws Exception, InterruptedException {
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, MapJoinDriver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(MapJoinDriver.class);
// 设置作业mapper
job.setMapperClass(MapJoinMapper.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//设置作业最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//todo 添加分布式缓存文件
job.addCacheFile(new URI("/data/join/cache/itheima_goods.txt"));
//不需要reduce,那么也就没有了shuffle过程
job.setNumReduceTasks(0);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path("/data/join/input"));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path("/data/join/mrresult"));
// 提交作业并等待执行完成
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 :1);
}
}提交运行
分布式缓存的使用必须使用MapReduce的yarn模式运行。
1) 在工程的pom.xml文件中指定程序运行的主类全路径;
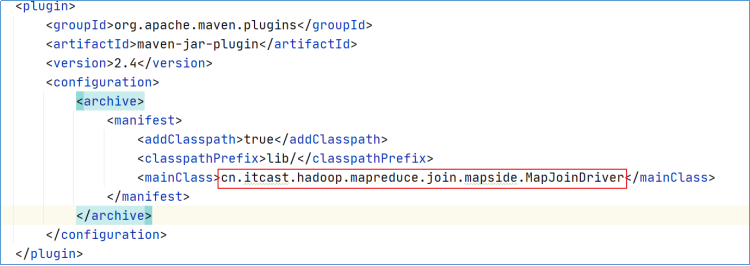
2) 执行mvn package命令生成jar包;
3) 将jar包上传到hadoop集群(任意节点上);
4) 执行命令(任意节点上):hadoop jar xxxx.jar。注意保证yarn集群提前启动成功。
查看输出结果

_SUCCESS文件表示作业执行成功
part-m-00000文件表示作业的输出内容 m表示这个结果文件是由mapper直接输出的。
MapReduce工作流
使用Hadoop里面的MapReduce来处理海量数据是非常简单方便的,但有时候我们的应用程序,往往需要多个MR作业,来计算结果,比如说一个最简单的使用MR提取海量搜索日志的TopN的问题,注意,这里面,其实涉及了两个MR作业,第一个是词频统计,第两个是排序求TopN,这显然是需要两个MapReduce作业来完成的。其他的还有,比如一些数据挖掘类的作业,常常需要迭代组合好几个作业才能完成,这类作业类似于DAG类的任务,各个作业之间是具有先后,或相互依赖的关系,比如说,这一个作业的输入,依赖上一个作业的输出等等。
在Hadoop里实际上提供了,JobControl类,来组合一个具有依赖关系的作业,在新版的API里,又新增了ControlledJob类,细化了任务的分配,通过这两个类,我们就可以轻松的完成类似DAG作业的模式,这样我们就可以通过一个提交来完成原来需要提交2次的任务,大大简化了任务的繁琐度。具有依赖式的作业提交后,hadoop会根据依赖的关系,先后执行的job任务,每个任务的运行都是独立的。
需求分析
针对MapReduce reduce join方式处理订单和商品数据之间的关联,需要进行两步程序处理,首先把两个数据集进行join操作,然后针对join的结果进行排序,保证同一笔订单的商品数据聚集在一起。
两个程序带有依赖关系,可以使用工作流进行任务的设定,依赖的绑定,一起提交执行。
代码实现
第1步:reduce join、result sort程序
程序详解知识点5《join案例:订单商品处理》
第2步:编写作业流程控制类
该驱动类主要负责建立reduce join与result sort两个ControlledJob,最终通过JobControl实现。
package cn.itcast.hadoop.mapreduce.jobcontrol;
import cn.itcast.hadoop.mapreduce.join.reduceside.ReduceJoinDriver;
import cn.itcast.hadoop.mapreduce.join.reduceside.ReduceJoinMapper;
import cn.itcast.hadoop.mapreduce.join.reduceside.ReduceJoinReducer;
import cn.itcast.hadoop.mapreduce.join.reduceside.ReduceJoinSortApp;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob;
import org.apache.hadoop.mapreduce.lib.jobcontrol.JobControl;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @description:
*/
public class MrJobFlow {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//第一个作业的配置
Job job1 = Job.getInstance(conf, ReduceJoinDriver.class.getSimpleName());
job1.setJarByClass(ReduceJoinDriver.class);
job1.setMapperClass(ReduceJoinMapper.class);
job1.setReducerClass(ReduceJoinReducer.class);
job1.setMapOutputKeyClass(Text.class);
job1.setMapOutputValueClass(Text.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job1, new Path("D:\\datasets\\mr_join\\input"));
FileOutputFormat.setOutputPath(job1, new Path("D:\\datasets\\mr_join\\rjout"));
//将普通作业包装成受控作业
ControlledJob ctrljob1 = new ControlledJob(conf);
ctrljob1.setJob(job1);
//第二个作业的配置
Job job2 = Job.getInstance(conf, ReduceJoinSortApp.class.getSimpleName());
job2.setJarByClass(ReduceJoinSortApp.class);
job2.setMapperClass(ReduceJoinSortApp.ReduceJoinMapper.class);
job2.setReducerClass(ReduceJoinSortApp.ReduceJoinReducer.class);
job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(Text.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job2, new Path("D:\\datasets\\mr_join\\rjout"));
FileOutputFormat.setOutputPath(job2, new Path("D:\\datasets\\mr_join\\rjresult"));
//将普通作业包装成受控作业
ControlledJob ctrljob2 = new ControlledJob(conf);
ctrljob2.setJob(job2);
//设置依赖job的依赖关系
ctrljob2.addDependingJob(ctrljob1);
// 主控制容器,控制上面的总的两个子作业
JobControl jobCtrl = new JobControl("myctrl");
// 添加到总的JobControl里,进行控制
jobCtrl.addJob(ctrljob1);
jobCtrl.addJob(ctrljob2);
// 在线程启动,记住一定要有这个
Thread t = new Thread(jobCtrl);
t.start();
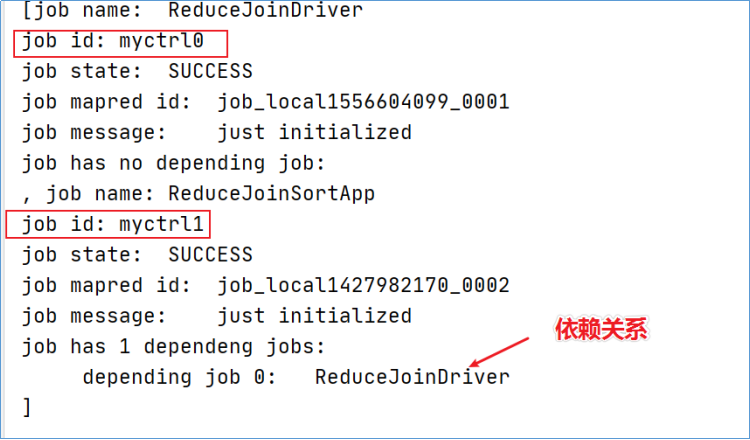
while(true) {
if (jobCtrl.allFinished()) {// 如果作业成功完成,就打印成功作业的信息
System.out.println(jobCtrl.getSuccessfulJobList());
jobCtrl.stop();
break;
}
}
}
}提交运行
直接在驱动类中右键运行main方法,使用MapReduce的本地模式执行。也可以将程序使用maven插件打包成jar包,提交到yarn上进行分布式运行。
 微信
微信 支付宝
支付宝








