HDFS数据安全与隐私保护
HDFS数据安全与隐私保护
Trash垃圾回收
背景
回收站(垃圾桶)是微软Windows操作系统里的一个系统文件夹,主要用来存放用户临时删除的文档资料,存放在回收站的文件可以恢复。
回收站的功能给了我们一剂“后悔药”。回收站保存了删除的文件、文件夹、图片、快捷方式等。这些项目将一直保留在回收站中,直到您清空回收站。我们许多误删除的文件就是从它里面找到的。

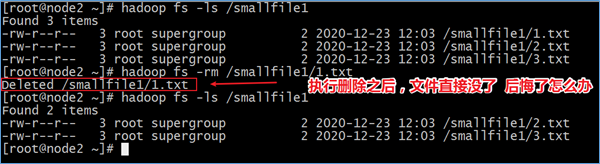
HDFS本身也是一个文件系统,那么就会涉及到文件数据的删除操作。默认情况下,HDFS中是没有回收站垃圾桶概念的,删除操作的数据将会被直接删除,没有后悔药。
功能概述
Trash机制,叫做回收站或者垃圾桶。Trash就像Windows操作系统中的回收站一样。它的目的是防止你无意中删除某些东西。默认情况下是不开启的。
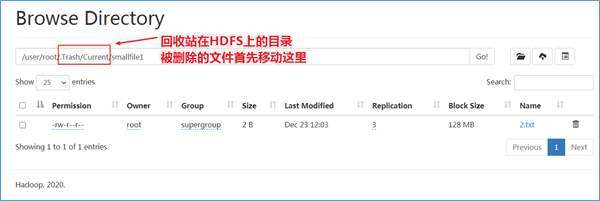
启用Trash功能后,从HDFS中删除某些内容时,文件或目录不会立即被清除,它们将被移动到回收站Current目录中(/user/${username}/.Trash/current)。
.Trash中的文件在用户可配置的时间延迟后被永久删除。也可以简单地将回收站里的文件移动到.Trash目录之外的位置来恢复回收站中的文件和目录。
Trash Checkpoint
检查点仅仅是用户回收站下的一个目录,用于存储在创建检查点之前删除的所有文件或目录。如果你想查看回收站目录,可以在/user/${username}/.Trash/{timestamp_of_checkpoint_creation}处看到:
最近删除的文件被移动到回收站Current目录,并且在可配置的时间间隔内,HDFS会为在Current回收站目录下的文件创建检查点/user/${username}/.Trash/<日期>,并在过期时删除旧的检查点。

功能开启
关闭HDFS集群
在node1节点上,执行一键关闭HDFS集群命令:stop-dfs.sh。
修改core-site.xml文件
在node1节点上修改core-site.xml文件,添加下面两个属性:
vim /export/server/hadoop-3.1.4/etc/hadoop/core-site.xml
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>0</value>
</property>fs.trash.interval:分钟数,当超过这个分钟数后检查点会被删除。如果为零,Trash回收站功能将被禁用。
fs.trash.checkpoint.interval:检查点创建的时间间隔(单位为分钟)。其值应该小于或等于fs.trash.interval。如果为零,则将该值设置为fs.trash.interval的值。每次运行检查点时,它都会从当前版本中创建一个新的检查点,并删除在数分钟之前创建的检查点。
同步集群配置文件
scp -r /export/server/hadoop-3.1.4/etc/hadoop/core-site.xml node2:/export/server/hadoop-3.1.4/etc/hadoop/
scp -r /export/server/hadoop-3.1.4/etc/hadoop/core-site.xml node3:/export/server/hadoop-3.1.4/etc/hadoop/启动HDFS集群
在node1节点上,执行一键启动HDFS集群命令:start-dfs.sh。
功能使用
删除文件到Trash
开启Trash功能后,正常执行删除操作,文件实际并不会被直接删除,而是被移动到了垃圾回收站。

当然也可以去Trash回收站下面查看一下:
删除文件跳过Trash
有的时候,我们希望直接把文件删除,不需要再经过Trash回收站了,可以在执行删除操作的时候添加一个参数:-skipTrash.
hadoop fs -rm -skipTrash /smallfile1/3.txt

清空Trash
除了fs.trash.interval参数控制到期自动删除之外,用户还可以通过命令手动清空回收站,释放HDFS磁盘存储空间。
首先想到的是删除整个回收站目录,将会清空回收站,这是一个选择。此外。HDFS提供了一个命令行工具来完成这个工作:
hadoop fs -expunge
该命令立即从文件系统中删除过期的检查点。
Snapshot快照
快照介绍和作用
HDFS snapshot是HDFS整个文件系统,或者某个目录在某个时刻的镜像。该镜像并不会随着源目录的改变而进行动态的更新。可以将快照理解为拍照片时的那一瞬间的投影,过了那个时间之后,又会有新的一个投影。
HDFS快照的核心功能包括:数据恢复、数据备份、数据测试。
数据恢复
可以通过滚动的方式来对重要的目录进行创建snapshot的操作,这样在系统中就存在针对某个目录的多个快照版本。当用户误删除掉某个文件时,可以通过最新的snapshot来进行相关的恢复操作。
数据备份
可以使用snapshot来进行整个集群,或者某些目录、文件的备份。管理员以某个时刻的snapshot作为备份的起始结点,然后通过比较不同备份之间差异性,来进行增量备份。
数据测试
在某些重要数据上进行测试或者实验,可能会直接将原始的数据破坏掉。可以临时的为用户针对要操作的数据来创建一个snapshot,然后让用户在对应的snapshot上进行相关的实验和测试,从而避免对原始数据的破坏。
HDFS快照的实现
在了解HDFS快照功能如何实现之前,首先有一个根本的原则需要记住:快照不是数据的简单拷贝,快照只做差异的记录。这一原则在其他很多系统的快照概念中都是适用的,比如磁盘快照,也是不保存真实数据的。因为不保存实际的数据,所以快照的生成往往非常迅速。
在HDFS中,如果在其中一个目录比如/A下创建一个快照,则快照文件中将会存在与/A目录下完全一致的子目录文件结构以及相应的属性信息,通过命令也能看到快照里面具体的文件内容。但是这并不意味着快照已经对此数据进行完全的拷贝 。这里遵循一个原则:对于大多不变的数据,你所看到的数据其实是当前物理路径所指的内容,而发生变更的inode数据才会被快照额外拷贝,也就是所说的差异拷贝。
inode译成中文就是索引节点,它用来存放文件及目录的基本信息,包含时间、名称、拥有者、所在组等信息。
HDFS快照不会复制datanode中的块,只记录了块列表和文件大小。
HDFS快照不会对常规HDFS操作产生不利影响,修改记录按逆时针顺序进行,因此可以直接访问当前数据。通过从当前数据中减去修改来计算快照数据。
快照的命令
快照功能启停命令
[root@node1 ~]# hdfs dfsadmin
Usage: hdfs dfsadmin
Note: Administrative commands can only be run as the HDFS superuser.
[-allowSnapshot <snapshotDir>]
[-disallowSnapshot <snapshotDir>]HDFS中可以针对整个文件系统或者文件系统中某个目录创建快照,但是创建快照的前提是相应的目录开启快照的功能。
如果针对没有启动快照功能的目录创建快照则会报错:

启用快照功能:
hdfs dfsadmin -allowSnapshot /allenwoon
禁用快照功能:
hdfs dfsadmin -disallowSnapshot /allenwoon
快照操作相关命令
[root@node1 ~]# hdfs dfs
Usage: hadoop fs [generic options]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[root@node1 ~]# hdfs lsSnapshottableDir
[root@node1 ~]# hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot>快照相关的操作命令有:createSnapshot创建快照、deleteSnapshot删除快照、renameSnapshot重命名快照、lsSnapshottableDir列出可以快照目录列表、snapshotDiff获取快照差异报告。
案例:快照的使用
1、开启指定目录的快照
hdfs dfsadmin -allowSnapshot /allenwoon

2、对指定目录创建快照
hdfs dfs -createSnapshot /allenwoon //系统自动生成快照名称
hdfs dfs -createSnapshot /allenwoon mysnap1 //指定名称创建快照
通过web浏览器访问快照
http://node1:9870/explorer.html#/allenwoon/.snapshot

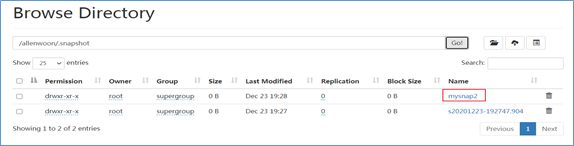
4、重命名快照
hdfs dfs -renameSnapshot /allenwoon mysnap1 mysnap2
5、列出当前用户所有可以快照的目录
hdfs lsSnapshottableDir

6、比较两个快照不同之处
[root@node1 ~]# echo 222 > 2.txt
[root@node1 ~]# hadoop fs -appendToFile 2.txt /allenwoon/1.txt
[root@node1 ~]# hadoop fs -cat /allenwoon/1.txt
1
222
[root@node1 ~]# hdfs dfs -createSnapshot /allenwoon mysnap3
Created snapshot /allenwoon/.snapshot/mysnap3
[root@node1 ~]# hadoop fs -put zookeeper.out /allenwoon
[root@node1 ~]# hdfs dfs -createSnapshot /allenwoon mysnap4
Created snapshot /allenwoon/.snapshot/mysnap4hdfs snapshotDiff /allenwoon mysnap2 mysnap3
hdfs snapshotDiff /allenwoon mysnap2 mysnap4
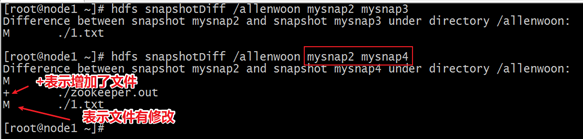
+ The file/directory has been created.
- The file/directory has been deleted.
M The file/directory has been modified.
R The file/directory has been renamed.
7、删除快照
hdfs dfs -deleteSnapshot /allenwoon mysnap4
8、删除有快照的目录
hadoop fs -rm -r /allenwoon

拥有快照的目录不允许被删除,某种程度上也保护了文件安全。
HDFS权限管理
总览概述
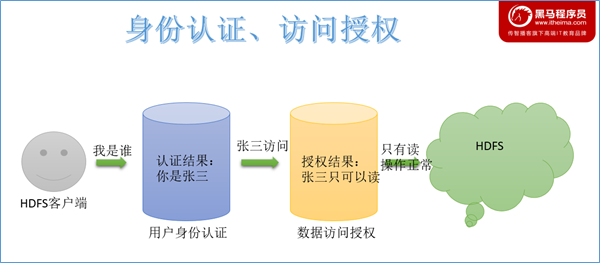
作为分布式文件系统,HDFS也集成了一套兼容POSIX的权限管理系统。客户端在进行每次文件操时,系统会从用户身份认证和数据访问授权两个环节进行验证: 客户端的操作请求会首先通过本地的用户身份验证机制来获得“凭证”(类似于身份证书),然后系统根据此“凭证”分辨出合法的用户名,再据此查看该用户所访问的数据是否已经授权。一旦这个流程中的某个环节出现异常,客户端的操作请求便会失败。
总览概述
作为分布式文件系统,HDFS也集成了一套兼容POSIX的权限管理系统。客户端在进行每次文件操时,系统会从用户身份认证和数据访问授权两个环节进行验证: 客户端的操作请求会首先通过本地的用户身份验证机制来获得“凭证”(类似于身份证书),然后系统根据此“凭证”分辨出合法的用户名,再据此查看该用户所访问的数据是否已经授权。一旦这个流程中的某个环节出现异常,客户端的操作请求便会失败。
UGO权限管理
介绍
HDFS的文件权限与Linux/Unix系统的UGO模型类型类似,可以简单描述为:每个文件和目录都与一个所有者和一个组相关联。该文件或目录对作为所有者(USER)的用户,作为该组成员的其他用户(GROUP)以及对所有其他用户(OTHER)具有单独的权限。
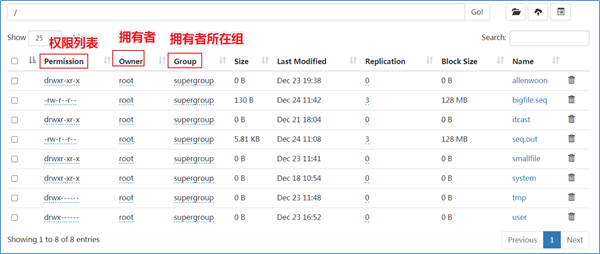
在HDFS中,对于文件,需要r权限才能读取文件,而w权限才能写入或追加到文件。没有x可执行文件的概念。
对于目录,需要r权限才能列出目录的内容,需要w权限才能创建或删除文件或目录,并且需要x权限才能访问目录的子级。
umask权限掩码
Linux中umask可用来设定权限掩码。权限掩码是由3个八进制的数字所组成,将现有的存取权限减掉权限掩码后,即可产生建立文件时预设的权限。
与Linux/Unix系统类似,HDFS也提供了umask掩码,用于设置在HDFS中默认新建的文件和目录权限位。默认umask值有属性fs.permissions.umask-mode指定,默认值022。
创建文件和目录时使用的umask,默认的权限就是:777-022=755。也就是drwxr-xr-x。
UGO权限相关命令
hadoop fs -chmod 750 /user/itcast/foo//变更目录或文件的权限位
hadoop fs -chown :portal /user/itcast/foo //变更目录或文件的属主或用户组
hadoop fs -chgrp itcast _group1 /user/itcast/foo//变更用户组
需要注意的是,使用这个命令的用户必须是超级用户,或者是该文件的属主,同时也是该用户组的成员。
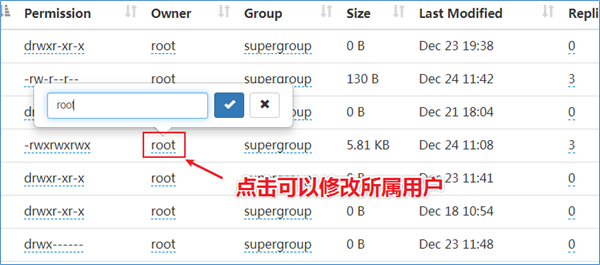
Web页面修改UGO权限
Hadoop3.0之后,支持在HDFS Web页面上使用鼠标修改。
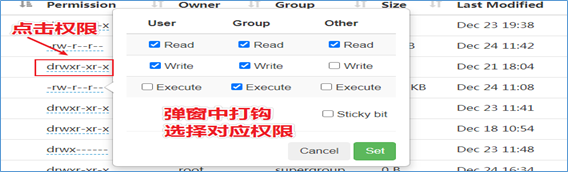
粘滞位(Sticky bit)用法在目录上设置,如此以来,只有目录内文件的所有者或者root才可以删除或移动该文件。如果不为目录设置粘滞位,任何具有该目录写和执行权限的用户都可以删除和移动其中的文件。实际应用中,粘滞位一般用于/tmp目录,以防止普通用户删除或移动其他用户的文件。
用户身份认证
用户身份认证独立于HDFS之外,也就说HDFS并不负责用户身份合法性检查,但HDFS会通过相关接口来获取相关的用户身份,然后用于后续的权限管理。用户是否合法,完全取决于集群使用认证体系。目前社区支持两种身份认证,即简单认证(Simple)和Kerberos。模式由hadoop.security.authentication属性指定,默认simple。
Simple认证
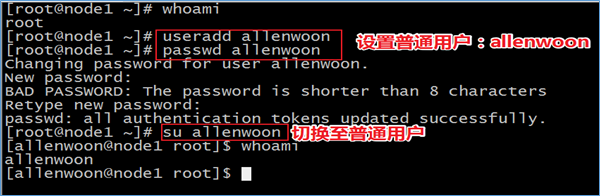
基于客户端所在的Linux/Unix系统的登录用户名来进行认证。只要用户能正常登录就认证成功。客户端与NameNode交互时,会将用户的登录账号(通过类似whoami的命令来获取)作为合法用户名传递至Namenode。 这意味着使用不同的账号登录到同一个客户端,会产生不同的用户名,故在多租户条件这种认证会导致权限混淆;同时恶意用户也可以伪造其他人的用户名非法获得相应的权限,对数据安全造成极大的隐患。线上生产环境一般不会使用。simple认证时,HDFS想法是:防止好人误做坏事,不防止坏人做坏事。

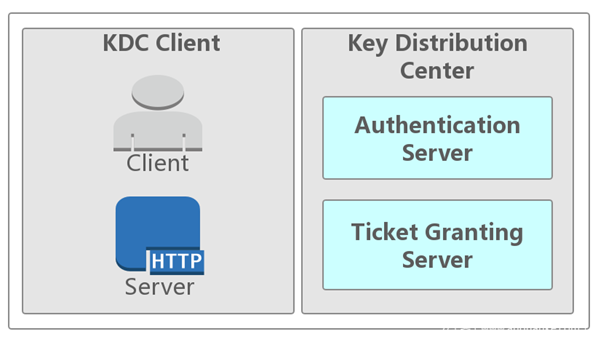
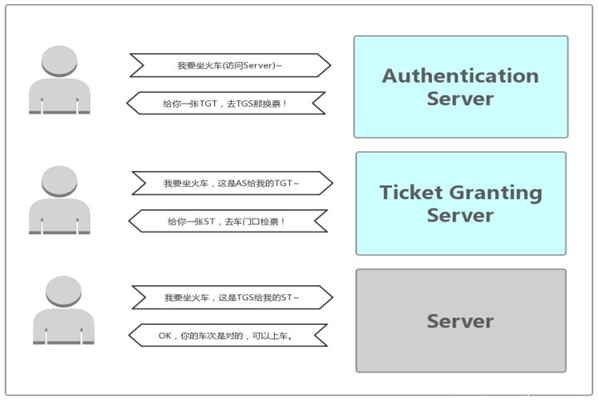
Kerberos认证(了解)
在神话里,Kerberos是Cerberus的希腊语,是一只守护地狱入口的三头巨犬,它确保没有人能在进入地狱后离开。
从技术角度来说,Kerberos是麻省理工学院(MIT)开发的一种网络身份认证协议。它旨在通过使用密钥加密技术为客户端/服务器应用程序提供强身份验证。

Group Mapping组映射
在用户身份验证成功之后,接下来会检查该用户所拥有的权限。HDFS的文件权限也是采用UGO模型,分成用户、组和其他权限。但与 Linux/Unix 系统不同,HDFS的用户和组都是使用字符串存储的,在 Linux/Unix上通用的UID和GID是无法在HDFS使用的。
此外,HDFS的组需要通过外部的用户组关联(Group Mapping)服务来获取。用户到组的映射可以使用系统自带的方案(使用NameNode服务器上的用户组系统),也可以通过其他实现类似功能的插件(LDAP、Ranger等)方式来代替。在拿到用户名后,NameNode会通过用户组关联服务获取该用户所对应的用户组列表,并用于后期的用户组权限校验。下面是两种主要的实现方式 。
基于Linux/Unix系统的用户和用户组
Linux/Unix系统上的用户和用户组信息存储在/etc/passwd和/etc/group文件中。默认情况下,HDFS会通过调用外部的 Shell 命令来获取用户的所有用户组列表。 此方案的优点在于组映射服务十分稳定,不易受外部服务的影响。但是用户和用户组管理涉及到root权限等,同时会在服务器上生成大量的用户组,后续管理,特别是自动化运维方面会有较大影响。

基于使用LDAP协议的数据库
OpenLDAP是一个开源LDAP的数据库,通过phpLDAPadmin等管理工具或相关接口可以方便地添加用户和修改用户组。HDFS 可以使用 LdapGroupsMappings 来使用 LDAP 服务。通过配置LDAP的相关属性,可以通过接口来直接获取到某个用户所有的用户组列表(memberOf)。 使用LDAP的不足在于需要保障LDAP服务的可用性和性能,关于LDAP的管理和使用将会后续再作介绍。 不同的LDAP有不同的实现,需要使用不同类型的LDAP Schema来构建,譬如示例中使用的是Person和GroupOfNames类型而不是PosixAccount和PosixGroup类型 以下是开启LDAP关联的配置文件:
<property>
<name>hadoop.security.group.mapping</name>
<value>org.apache.hadoop.security.LdapGroupsMapping</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.bind.user</name>
<value>cn=Manager,dc=hadoop,dc=apache,dc=org</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.bind.password</name>
<value>hadoop</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.url</name>
<value>ldap://localhost:389/dc=hadoop,dc=apache,dc=org</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.url</name>
<value>ldap://localhost:389/dc=hadoop,dc=apache,dc=org</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.base</name>
<value></value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.filter.user</name>
<value>(&(|(objectclass=person)(objectclass=applicationProcess))(cn={0}))</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.filter.group</name>
<value>(objectclass=groupOfNames)</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.attr.member</name>
<value>member</value>
</property>
<property>
<name>hadoop.security.group.mapping.ldap.search.attr.group.name</name>
<value>cn</value>
</property>ACL权限管理
背景和介绍
在UGO权限中,用户对文件只有三种身份,就是属主(user)、属组(group)和其他人(other):每种用户身份拥有读(read)、写(write)和执行(execute)三种权限。但是在实际工作中,使用UGO来控制权限可以满足大部分场景下的数据安全性要求,但是对于一些复杂的权限需求则无能为力。
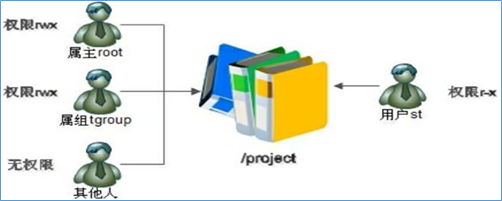
文件系统根目录中有一个 /project 目录,这是班级的项目目录。班级中的每个学员都可以访问和修改这个目录,老师也需要对这个目录拥有访问和修改权限,其他班级的学员当然不能访问这个目录。需要怎么规划这个目录的权限呢?应该这样:老师使用 root 用户,作为这个目录的属主,权限为 rwx;班级所有的学员都加入 tgroup 组,使 tgroup 组作为 /project目录的属组,权限是 rwx;其他人的权限设定为 0。这样这个目录的权限就可以符合我们的项目开发要求了。
有一天,班里来了一位试听的学员 st,她必须能够访问/project 目录,所以必须对这个目录拥有 r 和 x 权限;但是她又没有学习过以前的课程,所以不能赋予她 w 权限,怕她改错了目录中的内容,所以学员 st 的权限就是 r-x。可是如何分配她的身份呢?变为属主?当然不行,要不 root 该放哪里?加入 tgroup 组?也不行,因为 tgroup 组的权限是 rwx,而我们要求学员 st 的权限是 r-x。如果把其他人的权限改为 r-x 呢?这样一来,其他班级的所有学员都可以访问 /project 目录了。
当出现这种情况时,普通权限中的三种身份就不够用了。ACL 权限就是为了解决这个问题的。在使用 ACL 权限给用户 st 陚予权限时,st 既不是 /project 目录的属主,也不是属组,仅仅赋予用户 st 针对此目录的 r-x 权限。
ACL是Access Control List(访问控制列表)的缩写,ACL提供了一种方法,可以为特定的用户或组设置不同的权限,而不仅仅是文件的所有者和文件的组。
ACL Shell命令
hadoop fs -getfacl [-R] <path>
显示文件和目录的访问控制列表(ACL)。如果目录具有默认ACL,则getfacl还将显示默认ACL。
hadoop fs [generic options] -setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]
设置文件和目录的访问控制列表(ACL)。
hadoop fs -ls <args>
ls的输出将在带有ACL的任何文件或目录的权限字符串后附加一个’+’字符。
ACL操作实战
Root用户创建文件夹: hadoop fs -mkdir /itheima
此时使用普通用户allenwoon去操作/itheima 发现没有w权限
[allenwoon@node1 ~]$ echo 1 >> 1.txt
[allenwoon@node1 ~]$ hadoop fs -put 1.txt /itheima
put: Permission denied: user=allenwoon, access=WRITE, inode="/itheima":root:supergroup:drwxr-xr-x接下来使用ACL给allenwoon用户单独添加rwx权限
hadoop fs -setfacl -m user:allenwoon:rwx /itheima
setfacl: The ACL operation has been rejected. Support for ACLs has been disabled by setting dfs.namenode.acls.enabled to false.发现报错 原因是ACl功能默认是关闭的。
在hdfs-site.xml中设置dfs.namenode.acls.enabled=true 开启ACL 重启HDFS集群
再次设置ACl权限hadoop fs -setfacl -m user:allenwoon:rwx /itheima
设置成功之后查看ACL权限hadoop fs -getfacl /itheima
[root@node1 ~]# hadoop fs -getfacl /itheima
# file: /itheima
# owner: root
# group: supergroup
user::rwx
user:allenwoon:rwx 发现allenwoon权限配置成功
group::r-x
mask::rwx
other::r-x再使用普通用户allenwoon去操作,发现可以成功了
如果切换其他普通用户 发现还是无法操作
[itcast@node2 ~]$ echo 2 >> 2.txt
[itcast@node2 ~]$ hadoop fs -put 2.txt /itheima
put: Permission denied: user=itcast, access=WRITE, inode="/itheima":root:supergroup:drwxrwxr-x
----------------------------------------ACL其他操作命令
1、带有ACL的任何文件或目录的权限字符串后附加一个’+’字符
[root@node1 ~]# hadoop fs -ls /
Found 5 items
drwxr-xr-x - root supergroup 0 2021-01-06 20:59 /data
drwxr-xr-x - root supergroup 0 2020-12-31 11:59 /itcast
drwxrwxr-x+ - root supergroup 0 2021-01-07 19:38 /itheima
drwx------ - root supergroup 0 2020-12-31 11:56 /tmp
drwxr-xr-x - root supergroup 0 2020-12-31 11:56 /user2、删除指定的ACL条目hadoop fs -setfacl -x user:allenwoon /itheima
3、删除基本ACL条目以外的所有条目。保留用户,组和其他条目以与权限位兼容。hadoop fs -setfacl -b /itheima
4、设置默认的ACl权限,以后在该目录中新建文件或者子目录时,新建的文件/目录的ACL权限都是之前设置的default ACLs
[root@node1 ~]# hadoop fs -setfacl -m default:user:allenwoon:rwx /itheima
[root@node1 ~]# hadoop fs -getfacl /itheima
# file: /itheima
# owner: root
# group: supergroup
user::rwx
group::r-x
other::r-x
default:user::rwx
default:user:allenwoon:rwx
default:group::r-x
default:mask::rwx
default:other::r-x5、删除默认ACL权限
hadoop fs -setfacl -k /itheima
6、—set: 完全替换ACL,丢弃所有现有条目。 acl_spec必须包含用户,组和其他条目,以便与权限位兼容。
hadoop fs -setfacl --set user::rw-,user:hadoop:rw-,group::r--,other::r-- /file
HDFS Proxy user代理用户
介绍
Proxy user描述的是超级用户如何代表另一个用户提交作业或访问HDFS。
比如:用户名为“super”的超级用户希望代表用户joe提交作业并访问hdfs。因为超级用户具有kerberos凭证,但joe用户没有任何凭证。这些任务需要以用户joe的身份运行,而对namenode的任何文件访问都必须以用户joe的身份进行。要求用户joe可以在通过super的kerberos凭据进行身份验证的连接上连接到namenode。换句话说,super正在冒充用户joe。
使用示例
...
//为joe创建ugi。登录用户为“超级”。
UserGroupInformation ugi =
UserGroupInformation.createProxyUser(“ joe”,UserGroupInformation.getLoginUser());
ugi.doAs(new PrivilegedExceptionAction <Void>(){
public Void run()引发异常{
//提交工作
JobClient jc = new JobClient(conf);
jc.submitJob(conf);
//或访问hdfs
FileSystem fs = FileSystem.get(conf);
fs.mkdir(someFilePath);
}
}在此示例中,super的凭据用于登录,并为joe创建了代理用户ugi对象。在此代理用户ugi对象的doAs方法内执行操作。
配置参数
可以通过在core-site.xml中使用下面属性来配置代理用户:
hadoop.proxyuser.$superuser.hosts
hadoop.proxyuser.$superuser.groups
hadoop.proxyuser.$superuser.users
例如:名为super的超级用户只能从host1和host2连接来模拟属于group1和group2的用户。
<property>
<name>hadoop.proxyuser.super.hosts</name>
<value>host1,host2</value>
</property>
<property>
<name>hadoop.proxyuser.super.groups</name>
<value>group1,group2</value>
</property>如果不存在这些配置,则将无法进行模拟并且连接将失败。
还有更加宽松的配置,通配符*可用于允许来自任何主机或任何用户的模拟。例如,通过在core-site.xml中进行如下指定,从任何主机访问的名为oozie的用户都可以假冒属于任何组的任何用户。
<property>
<name>hadoop.proxyuser.oozie.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.oozie.groups</name>
<value>*</value>
</property>注意事项
如果集群以安全模式运行,则超级用户必须具有kerberos凭据才能模拟其他用户。
它不能为此功能使用委托令牌。如果超级用户将自己的委派令牌添加到代理用户ugi,那将是错误的,因为它将允许代理用户使用超级用户的特权连接到服务。
但是,如果超级用户确实希望将委派令牌授予joe,则它必须首先模拟joe并获得joe的委派令牌,与上面的代码示例相同,然后将其添加到joe的ugi中。这样,委派令牌将拥有者为joe。
HDFS Transparent Encryption透明加密
HDFS明文存储弊端
HDFS中的数据会以block的形式保存在各台数据节点的本地磁盘中,但这些block都是明文的,如果在操作系统下,直接访问block所在的目录,通过Linux的cat命令是可以直接查看里面的内容的,而且是明文。
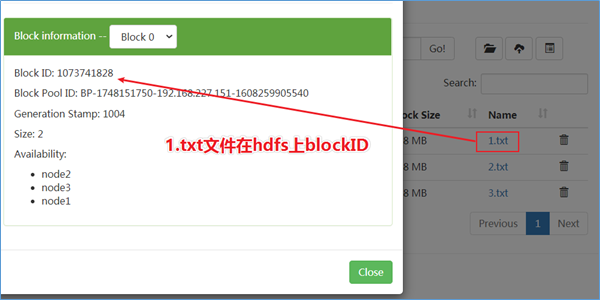
下面我们直接去DataNode本地存储block的目录,直接查看block内容:
/export/data/hadoop-3.1.4/dfs/data/current/BP-1748151750-192.168.227.151-1608259905540/current/finalized/subdir0/subdir0/

背景和应用
常见的加密层级
- 应用层加密
这是最安全也是最灵活的方式。加密内容最终由应用程序来控制,并且可以精确的反映用户的需求。但是,编写应用程序来实现加密一般都比较困难。
- 数据库层加密
类似于应用程序加密。大多数数据库厂商都提供某种形式的加密,但是可能会有性能问题,另外比如说索引没办法加密。
- 文件系统层加密
这种方式对性能影响不大,而且对应用程序是透明的,一般也比较容易实施。但是应用程序细粒度的要求策略,可能无法完全满足。
- 磁盘层加密
易于部署和高性能,但是相当不灵活,只能防止用户从物理层面盗窃数据。
HDFS的透明加密属于数据库层和文件系统层的加密。拥有不错的性能,且对于现有的应用程序是透明的。HDFS加密可以防止在文件系统或之下的攻击,也叫操作系统级别的攻击(OS-level attacks)。操作系统和磁盘只能与加密的数据进行交互,因为数据已经被HDFS加密了。
应用场景
数据加密对于全球许多政府,金融和监管机构都是强制性的,以满足隐私和其他安全要求。例如,卡支付行业已采用“支付卡行业数据安全标准”(PCI DSS)来提高信息安全性。其他示例包括美国政府的《联邦信息安全管理法案》(FISMA)和《健康保险可移植性和责任法案》(HIPAA)提出的要求。加密存储在HDFS中的数据可以帮助您的组织遵守此类规定。
透明加密介绍
HDFS透明加密(Transparent Encryption)支持端到端的透明加密,启用以后,对于一些需要加密的HDFS目录里的文件可以实现透明的加密和解密,而不需要修改用户的业务代码。端到端是指加密和解密只能通过客户端。对于加密区域里的文件,HDFS保存的即是加密后的文件,文件加密的秘钥也是加密的。让非法用户即使从操作系统层面拷走文件,也是密文,没法查看。

HDFS透明加密具有以下功能特点:
- 只有HDFS客户端可以加密或解密数据。
- 密钥管理在HDFS外部。HDFS无法访问未加密的数据或加密密钥。HDFS的管理和密钥的管理是独立的职责,由不同的用户角色(HDFS管理员,密钥管理员)承担,从而确保没有单个用户可以不受限制地访问数据和密钥。
- 操作系统和HDFS仅使用加密的HDFS数据进行交互,从而减轻了操作系统和文件系统级别的威胁。
- HDFS使用高级加密标准计数器模式(AES-CTR)加密算法。AES-CTR支持128位加密密钥(默认),或者在安装Java Cryptography Extension(JCE)无限强度JCE时支持256位加密密钥。
透明加密关键概念和架构
加密区域和密钥
HDFS的透明加密有一个新的概念,加密区域(the encryption zone)。加密区域是一个特殊的目录,写入文件的时候会被透明加密,读取文件的时候又会被透明解密。
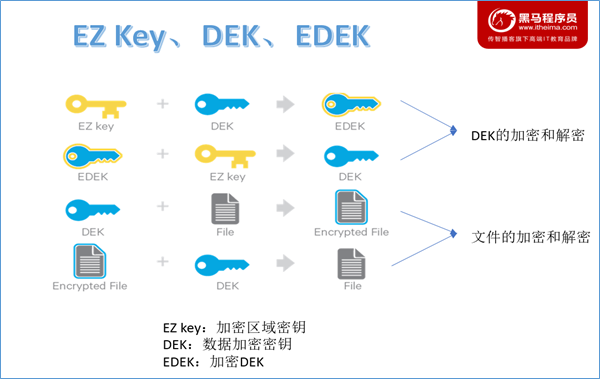
当加密区域被创建时,都会有一个加密区域秘钥(EZ密钥,encryption zone key)与之对应,EZ密钥存储在HDFS外部的备份密钥库中。加密区域里的每个文件都有其自己加密密钥,叫做数据加密秘钥(DEK,data encryption key)。DEK会使用其各自的加密区域的EZ密钥进行加密,以形成加密数据加密密钥(EDEK)HDFS不会直接处理DEK,HDFS只会处理EDEK。客户端会解密EDEK,然后用后续的DEK来读取和写入数据。
关于EZ密钥、DEK、EDEK三者关系如下所示:
Keystore和Hadoop KMS
存储密钥(key)的叫做密钥库(keystore),将HDFS与外部企业级密钥库(keystore)集成是部署透明加密的第一步。这是因为密钥(key)管理员和HDFS管理员之间的职责分离是此功能的非常重要的方面。但是,大多数密钥库都不是为Hadoop工作负载所见的加密/解密请求速率而设计的。
为此,Hadoop进行了一项新服务的开发,该服务称为Hadoop密钥管理服务器(Key Management Server,简写KMS),该服务用作HDFS客户端与密钥库之间的代理。密钥库和Hadoop KMS相互之间以及与HDFS客户端之间都必须使用Hadoop的KeyProvider API进行交互。
KMS主要有以下几个职责:
1.提供访问保存的加密区域秘钥(EZ key)
2.生成EDEK,EDEK存储在NameNode上
3.为HDFS客户端解密EDEK
访问加密区域内的文件
写入加密文件过程
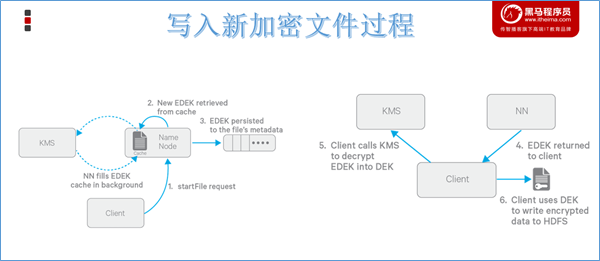
前提:创建HDFS加密区时会创建一个HDFS加密区(目录),同时会在KMS服务里创建一个key及其EZ Key,及两者之间的关联。
1.Client向NN请求在HDFS某个加密区新建文件;
2.NN向KMS请求此文件的EDEK,KMS用对应的EZ key生成一个新的EDEK发送给NN;
3.这个EDEK会被NN写入到文件的metadata中;
4.NN发送EDEK给Client;
5.Client发送EDEK给KMS请求解密,KMS用对应的EZ key将EDEK解密为DEK发送给Client;
6.Client用DEK加密文件内容发送给datanode进行存储。
DEK是加解密一个文件的密匙,而KMS里存储的EZ key是用来加解密所有文件的密匙(DEK)的密匙。所以,EZ Key是更为重要的数据,只在KMS内部使用(DEK的加解密只在KMS内存进行),不会被传递到外面使用,而HDFS服务端只能接触到EDEK,所以HDFS服务端也不能解密加密区文件。
读取解密文件过程
读流程与写流程类型,区别就是NN直接读取加密文件元数据里的EDEK返回给客户端,客户端一样把EDEK发送给KMS获取DEK。再对加密内容解密读取。
EDEK的加密和解密完全在KMS上进行。更重要的是,请求创建或解密EDEK的客户端永远不会处理EZ密钥。仅KMS可以根据要求使用EZ密钥创建和解密EDEK。
KMS配置
关闭HDFS集群
在node1上执行stop-dfs.sh。
key密钥生成
[root@node1 ~]# keytool -genkey -alias 'itcast'
Enter keystore password:
Re-enter new password:
What is your first and last name?
[Unknown]:
What is the name of your organizational unit?
[Unknown]:
What is the name of your organization?
[Unknown]:
What is the name of your City or Locality?
[Unknown]:
What is the name of your State or Province?
[Unknown]:
What is the two-letter country code for this unit?
[Unknown]:
Is CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown correct?
[no]: yes
Enter key password for <itcast>
(RETURN if same as keystore password):
Re-enter new password: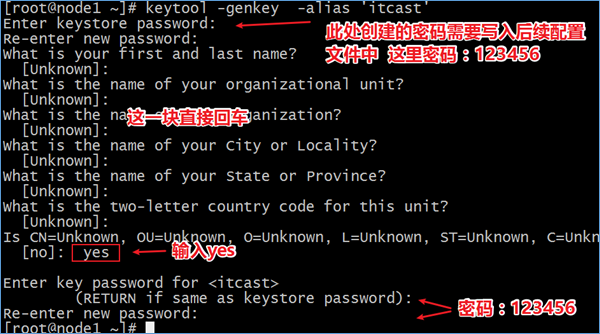
配置kms-site.xml
配置文件路径:/export/server/hadoop-3.1.4/etc/hadoop/kms-site.xml
<configuration>
<property>
<name>hadoop.kms.key.provider.uri</name>
<value>jceks://file@/${user.home}/kms.jks</value>
</property>
<property>
<name>hadoop.security.keystore.java-keystore-provider.password-file</name>
<value>kms.keystore.password</value>
</property>
<property>
<name>dfs.encryption.key.provider.uri</name>
<value>kms://http@node1:16000/kms</value>
</property>
<property>
<name>hadoop.kms.authentication.type</name>
<value>simple</value>
</property>
</configuration>密码文件通过类路径在Hadoop的配置目录中查找。
kms-env.sh
export KMS_HOME=/export/server/hadoop-3.1.4
export KMS_LOG=${KMS_HOME}/logs/kms
export KMS_HTTP_PORT=16000
export KMS_ADMIN_PORT=16001修改core|hdfs-site.xml
core-site.xml
<property>
<name>hadoop.security.key.provider.path</name>
<value>kms://http@node1:16000/kms</value>
</property>hdfs-site.xml
<property>
<name>dfs.encryption.key.provider.uri</name>
<value>kms://http@node1:16000/kms</value>
</property>同步配置文件
cd /export/server/hadoop-3.1.4/etc/hadoop/
scp core-site.xml hdfs-site.xml node2.itcast.cn:/export/server/hadoop-3.1.4/etc/hadoop/
scp core-site.xml hdfs-site.xml node3.itcast.cn:/export/server/hadoop-3.1.4/etc/hadoop/
scp kms-site.xml node2.itcast.cn:/export/server/hadoop-3.1.4/etc/hadoop/
scp kms-site.xml node3.itcast.cn:/export/server/hadoop-3.1.4/etc/hadoop/
scp kms-env.sh node2.itcast.cn:/export/server/hadoop-3.1.4/etc/hadoop/
scp kms-env.sh node3.itcast.cn:/export/server/hadoop-3.1.4/etc/hadoop/服务启动
KMS服务启动
hadoop --daemon start kms
HDFS集群启动
start-dfs.sh
透明加密使用
创建key
切换成普通用户allenwoon操作
su allenwoon
hadoop key create itcast
hadoop key list -metadata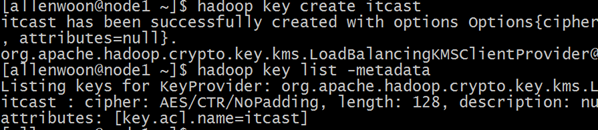
创建加密区
使用root超级用户操作
#作为超级用户,创建一个新的空目录,并将其设置为加密区域
hadoop fs -mkdir /zone
hdfs crypto -createZone -keyName itcast -path /zone
#将其chown给普通用户
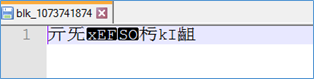
hadoop fs -chown allenwoon:allenwoon /zone测试加密效果
以普通用户操作
#以普通用户的身份放入文件,然后读出来
echo helloitcast >> helloWorld
hadoop fs -put helloWorld /zone
hadoop fs -cat /zone /helloWorld
#作为普通用户,从文件获取加密信息
hdfs crypto -getFileEncryptionInfo -path /zone/helloWorld 
直接下载文件的block 发现是无法读取数据的。
 微信
微信 支付宝
支付宝








