HDFS核心源码分析
HDFS核心源码分析
Hadoop源码编译
为什么要编译源码
Native Library本地库
Native Library,一般译为本地库或原生库,是由C/C++编写的动态库(*.so),并通过JNI(Java Native Interface)机制为java层提供接口。应用一般会出于性能、安全等角度考虑将相关逻辑用C/C++实现并编译为库的形式提供接口,供上层或其他模块调用。
Hadoop是使用Java语言开发的,但是有一些需求和操作并不适合使用java,所以就引入了本地库(Native Library) 的概念。说白了,就是Hadoop的某些功能,必须通过JNT来协调Java类文件和Native代码生成的库文件一起才能工作。系统要运行Native代码,首先要将Native编译成目标CPU架构的动态库文件
不同的处理器架构,需要编译出相应平台的动态库文件(Linux下对应[.so]文件,windows下对应[.dll]文件),才能被正确的执行。
Hadoop本地库主要组件有:
- 压缩编解码器(bzip2,lz4,snappy,zlib)。
- HDFS的本地IO实用程序,用于HDFS短路本地读取和集中式缓存管理。
- CRC32校验和实现。
源码修改
Hadoop属于Apache开源软件,如果用户在使用中发觉某些组件或者功能不能满足于自己的企业需求,可以基于开源协议对Hadoop源码进行修改,改成符合自己性能要求。此时也是需要重新编译源码然后部署安装。
如何编译源码
在Hadoop的源码包根目录下有一个文件:BUILDING.txt。里面描述了在不同平台下对Hadoop进行源码编译的要求和步骤。
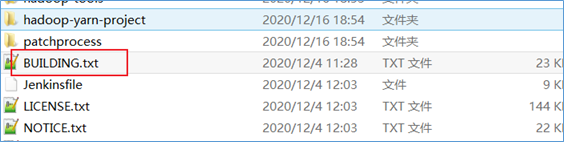
比如,在Linux/Unix平台如何编译,描述如下:
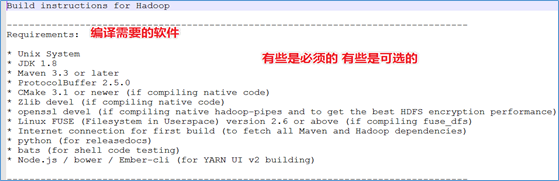

Linux平台编译
编译环境
安装编译相关的依赖
1、yum install gcc gcc-c++
#下面这个命令不需要执行 手动安装cmake
2、yum install make cmake #(这里cmake版本推荐为3.6版本以上,版本低源码无法编译!可手动安装)
3、yum install autoconf automake libtool curl
4、yum install lzo-devel zlib-devel openssl openssl-devel ncurses-devel
5、yum install snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop libXtst
手动安装cmake
#yum卸载已安装cmake 版本低
yum erase cmake
#解压
tar zxvf cmake-3.13.5.tar.gz
#编译安装
cd /export/server/cmake-3.13.5
./configure
make && make install
#验证
[root@node4 ~]# cmake -version
cmake version 3.13.5
#如果没有正确显示版本 请断开SSH连接 重写登录手动安装snappy
#卸载已经安装的
cd /usr/local/lib
rm -rf libsnappy*
#上传解压
tar zxvf snappy-1.1.3.tar.gz
#编译安装
cd /export/server/snappy-1.1.3
./configure
make && make install
#验证是否安装
[root@node4 snappy-1.1.3]# ls -lh /usr/local/lib |grep snappy
-rw-r--r-- 1 root root 511K Nov 4 17:13 libsnappy.a
-rwxr-xr-x 1 root root 955 Nov 4 17:13 libsnappy.la
lrwxrwxrwx 1 root root 18 Nov 4 17:13 libsnappy.so -> libsnappy.so.1.3.0
lrwxrwxrwx 1 root root 18 Nov 4 17:13 libsnappy.so.1 -> libsnappy.so.1.3.0
-rwxr-xr-x 1 root root 253K Nov 4 17:13 libsnappy.so.1.3.0安装配置JDK 1.8
#解压安装包
tar zxvf jdk-8u65-linux-x64.tar.gz
#配置环境变量
vim /etc/profile
export JAVA_HOME=/export/server/jdk1.8.0_65
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
#验证是否安装成功
java -version
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
You have new mail in /var/spool/mail/root安装maven
#解压安装包
tar zxvf apache-maven-3.5.4-bin.tar.gz
#配置环境变量
vim /etc/profile
export MAVEN_HOME=/export/server/apache-maven-3.5.4
export MAVEN_OPTS="-Xms4096m -Xmx4096m"
export PATH=:$MAVEN_HOME/bin:$PATH
source /etc/profile
#验证是否安装成功
[root@node4 ~]# mvn -v
Apache Maven 3.5.4
#添加maven 阿里云仓库地址 加快国内编译速度
vim /export/server/apache-maven-3.5.4/conf/settings.xml
<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>安装ProtocolBuffer 2.5.0
#解压
tar zxvf protobuf-2.5.0.tar.gz
#编译安装
cd /export/server/protobuf-2.5.0
./configure
make && make install
#验证是否安装成功
[root@node4 protobuf-2.5.0]# protoc --version
libprotoc 2.5.0编译Hadoop
#上传解压源码包
tar zxvf hadoop-3.1.4-src.tar.gz
#编译
cd /export/server/hadoop-3.1.4-src
mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib
#参数说明:
Pdist,native :把重新编译生成的hadoop动态库;
DskipTests :跳过测试
Dtar :最后把文件以tar打包
Dbundle.snappy :添加snappy压缩支持【默认官网下载的是不支持的】
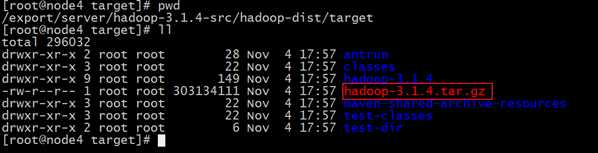
Dsnappy.lib=/usr/local/lib :指snappy在编译机器上安装后的库路径编译后安装包路径
/export/server/hadoop-3.1.4-src/hadoop-dist/target
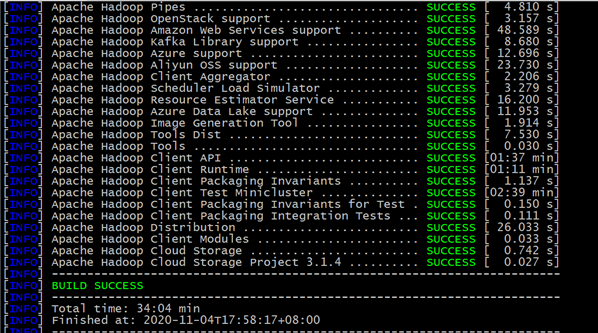
编译过程截图
编程成功:
编译成功之后安装包:
Windows平台编译
编译指南
在Hadoop的源码包根目录下有一个文件:BUILDING.txt。找到如何在windows平台进行编译的部分。
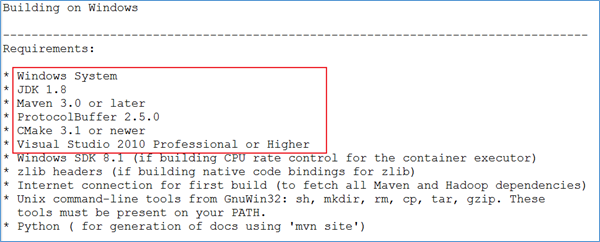
编译环境
安装windows10
在windows上编译Hadoop,需要在一台独立的windows 10虚拟机中编译,所以先把windows10装好。
安装maven
本次编译环境Maven仓库位置为: C:\opt\apache-maven-3.6.1。
配置Maven本地仓库,注意:本地仓库尽量短,否则编译时候会报:命令太长
<localRepository>C:\m2</localRepository>
修改settings中的源,改成国内阿里源会快很多。
<mirror>
<id>central</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central/</url>
</mirror>安装protobuf
解压资料包中的protobuf-2.5.0.zip
解压资料包中的protoc-2.5.0-win32.zip,并将解压后的protoc.exe移动到protobuf-2.5.0\src目录中
进入到解压后的 protobuf-2.5.0/java 目录,按住shift + 点击鼠标右键,选择打开 power shell
输入 mvn test,执行测试(需要等待一会,mvn会下载相关的依赖包)
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 02:02 min
[INFO] Finished at: 2020-09-28T16:07:53+08:00
[INFO] Final Memory: 36M/921M
[INFO] ------------------------------------------------------------------------ 5.再执行 mvn install
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 56.838 s
[INFO] Finished at: 2020-09-28T16:12:28+08:00
[INFO] Final Memory: 42M/990M
[INFO] ------------------------------------------------------------------------ 6.设置系统环境变量
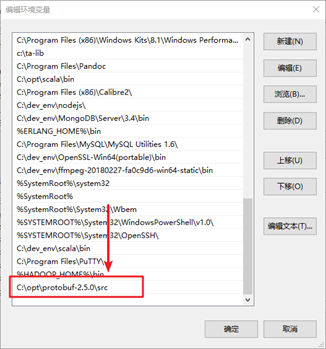
7.重启cmd命令行,查看protobuf版本号
C:\opt\protobuf-2.5.0\src>protoc --version
libprotoc 2.5.0安装cmake
解压到没有中文的目录
设置cmake的环境变量
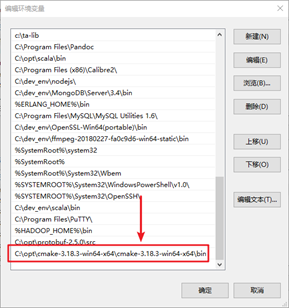
4.重启cmd查看cmake版本
C:\Users\China>cmake -version
cmake version 3.18.3
CMake suite maintained and supported by Kitware (kitware.com/cmake).安装VS 2010
解压资料包中的cn_visual_studio_2010_professional_x86_dvd_532145.iso
解压后双击autorun.exe

3.选择以下自定义安装组件,只保留Visual C++,其他的组件取消勾选
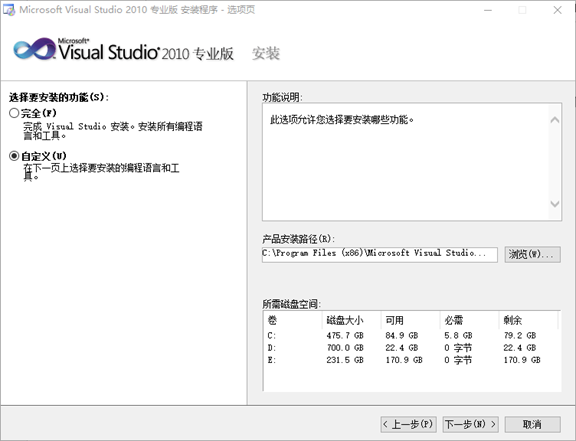
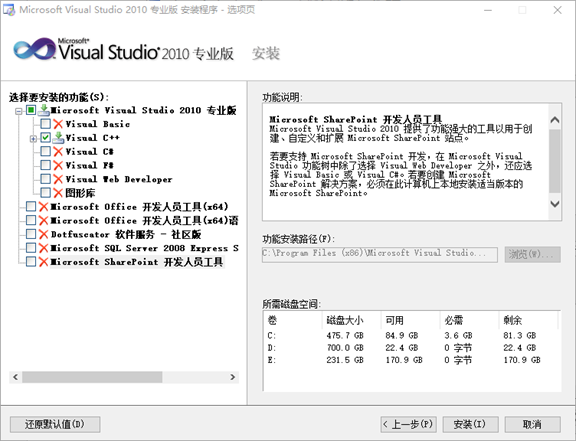
- 点击安装。

安装windows8.1 SDK
双击安装windows_8.1_sdksetup.exe
安装zlib
将zip包解压到编译的目录中
3.打开开始菜单,找到Visual Studio命令提示,并以管理员省份运行
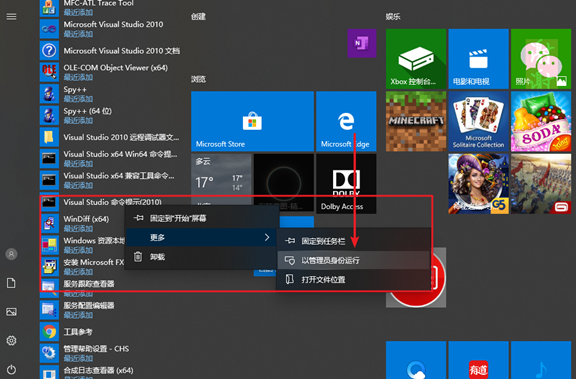
4.进入到zlib目录
Setting environment for using Microsoft Visual Studio 2010 x86 tools.
C:\WINDOWS\system32>cd C:\opt\zlib1211\zlib-1.2.11 5.执行以下命令编译
nmake -f win32/Makefile.msc 6.设置ZLIB环境变量
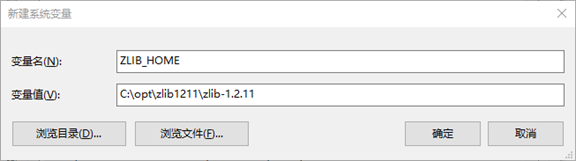
安装cygwin
配置好环境变量
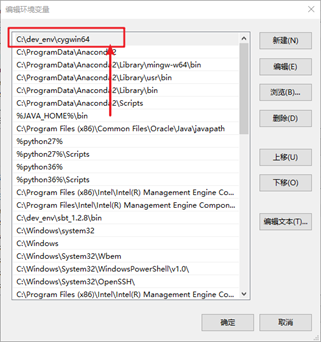
配置cygwin目录权限:
修改etc中的fstab,添加上noacl
none /cygdrive cygdrive binary,posix=0,user,noacl 0 0
目录权限问题是我把hadoop-src放在了C盘根目录下,而它要对此做权限管理,就会有问题
而如果放在用户文件夹,文件名的路径就太长了。
编译hadoop
设置环境变量
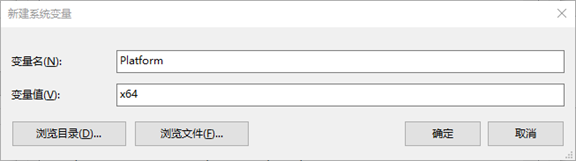
解压hadoop源码
修改pom.xml
将C:\hadoop-3.1.4-src\hadoop-hdfs-project\hadoop-hdfs-native-client的pom.xml中的142、147行failonerror修改为false
<exec executable="cmake" dir="${project.build.directory}/native"
failonerror="false">
<arg line="${basedir}/src/ -DGENERATED_JAVAH=${project.build.directory}/native/javah -DJVM_ARCH_DATA_MODEL=${sun.arch.data.model} -DREQUIRE_FUSE=${require.fuse} -A '${env.PLATFORM}'"/>
</exec>
<exec executable="msbuild" dir="${project.build.directory}/native"
failonerror="false">
<arg line="ALL_BUILD.vcxproj /nologo /p:Configuration=RelWithDebInfo /p:LinkIncremental=false"/>
</exec>编译
进入到源码目录
cd C:\opt\hadoop-3.1.4-src
开始编译
mvn clean package -Pdist,native-win -DskipTests -Dtar -Dmaven.javadoc.skip=true
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] Apache Hadoop Main ................................. SUCCESS [ 2.490 s]
[INFO] Apache Hadoop Build Tools .......................... SUCCESS [ 8.349 s]
[INFO] Apache Hadoop Project POM .......................... SUCCESS [ 2.282 s]
[INFO] Apache Hadoop Annotations .......................... SUCCESS [ 1.670 s]
[INFO] Apache Hadoop Assemblies ........................... SUCCESS [ 0.485 s]
[INFO] Apache Hadoop Project Dist POM ..................... SUCCESS [ 3.752 s]
[INFO] Apache Hadoop Maven Plugins ........................ SUCCESS [ 4.576 s]
[INFO] Apache Hadoop MiniKDC .............................. SUCCESS [ 1.241 s]
[INFO] Apache Hadoop Auth ................................. SUCCESS [ 6.226 s]
[INFO] Apache Hadoop Auth Examples ........................ SUCCESS [ 2.902 s]
[INFO] Apache Hadoop Common ............................... SUCCESS [01:14 min]
[INFO] Apache Hadoop NFS .................................. SUCCESS [ 3.664 s]
[INFO] Apache Hadoop KMS .................................. SUCCESS [ 4.815 s]
[INFO] Apache Hadoop Common Project ....................... SUCCESS [ 0.223 s]
[INFO] Apache Hadoop HDFS Client .......................... SUCCESS [ 34.704 s]
[INFO] Apache Hadoop HDFS ................................. SUCCESS [ 40.664 s]
[INFO] Apache Hadoop HDFS Native Client ................... SUCCESS [ 10.422 s]
[INFO] Apache Hadoop HttpFS ............................... SUCCESS [ 5.015 s]
[INFO] Apache Hadoop HDFS-NFS ............................. SUCCESS [ 1.685 s]
[INFO] Apache Hadoop HDFS-RBF ............................. SUCCESS [ 9.885 s]
[INFO] Apache Hadoop HDFS Project ......................... SUCCESS [ 0.156 s]
[INFO] Apache Hadoop YARN ................................. SUCCESS [ 0.125 s]
[INFO] Apache Hadoop YARN API ............................. SUCCESS [ 23.505 s]
[INFO] Apache Hadoop YARN Common .......................... SUCCESS [ 27.800 s]
[INFO] Apache Hadoop YARN Registry ........................ SUCCESS [ 5.649 s]
[INFO] Apache Hadoop YARN Server .......................... SUCCESS [ 0.110 s]
[INFO] Apache Hadoop YARN Server Common ................... SUCCESS [ 13.748 s]
[INFO] Apache Hadoop YARN NodeManager ..................... SUCCESS [ 19.686 s]
[INFO] Apache Hadoop YARN Web Proxy ....................... SUCCESS [ 2.984 s]
[INFO] Apache Hadoop YARN ApplicationHistoryService ....... SUCCESS [ 6.587 s]
[INFO] Apache Hadoop YARN Timeline Service ................ SUCCESS [ 4.163 s]
[INFO] Apache Hadoop YARN ResourceManager ................. SUCCESS [ 28.876 s]
[INFO] Apache Hadoop YARN Server Tests .................... SUCCESS [ 4.538 s]
[INFO] Apache Hadoop YARN Client .......................... SUCCESS [ 6.306 s]
[INFO] Apache Hadoop YARN SharedCacheManager .............. SUCCESS [ 2.906 s]
[INFO] Apache Hadoop YARN Timeline Plugin Storage ......... SUCCESS [ 3.675 s]
[INFO] Apache Hadoop YARN TimelineService HBase Backend ... SUCCESS [ 0.095 s]
[INFO] Apache Hadoop YARN TimelineService HBase Common .... SUCCESS [ 5.343 s]
[INFO] Apache Hadoop YARN TimelineService HBase Client .... SUCCESS [ 5.268 s]
[INFO] Apache Hadoop YARN TimelineService HBase Servers ... SUCCESS [ 0.125 s]
[INFO] Apache Hadoop YARN TimelineService HBase Server 1.2 SUCCESS [ 4.823 s]
[INFO] Apache Hadoop YARN TimelineService HBase tests ..... SUCCESS [ 6.625 s]
[INFO] Apache Hadoop YARN Router .......................... SUCCESS [ 3.860 s]
[INFO] Apache Hadoop YARN Applications .................... SUCCESS [ 0.125 s]
[INFO] Apache Hadoop YARN DistributedShell ................ SUCCESS [ 3.062 s]
[INFO] Apache Hadoop YARN Unmanaged Am Launcher ........... SUCCESS [ 1.882 s]
[INFO] Apache Hadoop MapReduce Client ..................... SUCCESS [ 0.422 s]
[INFO] Apache Hadoop MapReduce Core ....................... SUCCESS [ 14.190 s]
[INFO] Apache Hadoop MapReduce Common ..................... SUCCESS [ 7.164 s]
[INFO] Apache Hadoop MapReduce Shuffle .................... SUCCESS [ 4.968 s]
[INFO] Apache Hadoop MapReduce App ........................ SUCCESS [ 8.347 s]
[INFO] Apache Hadoop MapReduce HistoryServer .............. SUCCESS [ 4.659 s]
[INFO] Apache Hadoop MapReduce JobClient .................. SUCCESS [ 10.167 s]
[INFO] Apache Hadoop Mini-Cluster ......................... SUCCESS [ 2.329 s]
[INFO] Apache Hadoop YARN Services ........................ SUCCESS [ 0.125 s]
[INFO] Apache Hadoop YARN Services Core ................... SUCCESS [ 7.997 s]
[INFO] Apache Hadoop YARN Services API .................... SUCCESS [ 3.672 s]
[INFO] Apache Hadoop YARN Site ............................ SUCCESS [ 0.124 s]
[INFO] Apache Hadoop YARN UI .............................. SUCCESS [ 0.110 s]
[INFO] Apache Hadoop YARN Project ......................... SUCCESS [ 48.122 s]
[INFO] Apache Hadoop MapReduce HistoryServer Plugins ...... SUCCESS [ 1.815 s]
[INFO] Apache Hadoop MapReduce NativeTask ................. SUCCESS [ 3.190 s]
[INFO] Apache Hadoop MapReduce Uploader ................... SUCCESS [ 1.891 s]
[INFO] Apache Hadoop MapReduce Examples ................... SUCCESS [ 3.143 s]
[INFO] Apache Hadoop MapReduce ............................ SUCCESS [ 10.552 s]
[INFO] Apache Hadoop MapReduce Streaming .................. SUCCESS [ 2.927 s]
[INFO] Apache Hadoop Distributed Copy ..................... SUCCESS [ 4.068 s]
[INFO] Apache Hadoop Archives ............................. SUCCESS [ 1.554 s]
[INFO] Apache Hadoop Archive Logs ......................... SUCCESS [ 1.796 s]
[INFO] Apache Hadoop Rumen ................................ SUCCESS [ 3.285 s]
[INFO] Apache Hadoop Gridmix .............................. SUCCESS [ 3.093 s]
[INFO] Apache Hadoop Data Join ............................ SUCCESS [ 1.629 s]
[INFO] Apache Hadoop Extras ............................... SUCCESS [ 1.625 s]
[INFO] Apache Hadoop Pipes ................................ SUCCESS [ 0.109 s]
[INFO] Apache Hadoop OpenStack support .................... SUCCESS [ 2.391 s]
[INFO] Apache Hadoop Amazon Web Services support .......... SUCCESS [ 43.346 s]
[INFO] Apache Hadoop Kafka Library support ................ SUCCESS [ 2.066 s]
[INFO] Apache Hadoop Azure support ........................ SUCCESS [ 4.817 s]
[INFO] Apache Hadoop Aliyun OSS support ................... SUCCESS [ 2.067 s]
[INFO] Apache Hadoop Client Aggregator .................... SUCCESS [ 6.846 s]
[INFO] Apache Hadoop Scheduler Load Simulator ............. SUCCESS [ 5.208 s]
[INFO] Apache Hadoop Resource Estimator Service ........... SUCCESS [ 5.033 s]
[INFO] Apache Hadoop Azure Data Lake support .............. SUCCESS [ 2.068 s]
[INFO] Apache Hadoop Image Generation Tool ................ SUCCESS [ 2.421 s]
[INFO] Apache Hadoop Tools Dist ........................... SUCCESS [ 15.208 s]
[INFO] Apache Hadoop Tools ................................ SUCCESS [ 0.094 s]
[INFO] Apache Hadoop Client API ........................... SUCCESS [01:03 min]
[INFO] Apache Hadoop Client Runtime ....................... SUCCESS [ 53.722 s]
[INFO] Apache Hadoop Client Packaging Invariants .......... SUCCESS [ 0.499 s]
[INFO] Apache Hadoop Client Test Minicluster .............. SUCCESS [01:43 min]
[INFO] Apache Hadoop Client Packaging Invariants for Test . SUCCESS [ 0.376 s]
[INFO] Apache Hadoop Client Packaging Integration Tests ... SUCCESS [ 0.377 s]
[INFO] Apache Hadoop Distribution ......................... SUCCESS [17:00 min]
[INFO] Apache Hadoop Client Modules ....................... SUCCESS [ 0.124 s]
[INFO] Apache Hadoop Cloud Storage ........................ SUCCESS [ 2.110 s]
[INFO] Apache Hadoop Cloud Storage Project ................ SUCCESS [ 0.125 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 31:38 min
[INFO] Finished at: 2020-10-09T01:02:15+08:00
[INFO] Final Memory: 327M/1222M
[INFO] ------------------------------------------------------------------------HDFS源码结构分析
IDEA导入HDFS源码工程
解压Hadoop源码在Windows某个目录下(该目录最好没有中文没有空格)。
打开IDEA,选择Open or Import
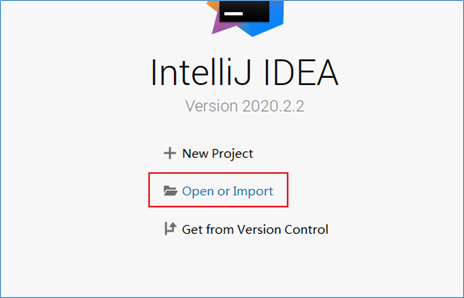
选择HDFS工程打开
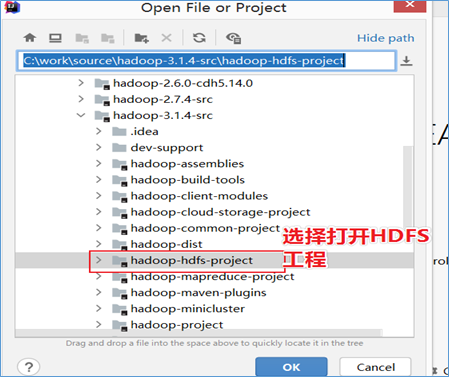
初次导入IDEA会自动根据POM依赖下载插件和依赖,此时静静等待即可。确保下载完成。

HDFS工程结构
hadoop-hdfs-project工程目录结构如下:
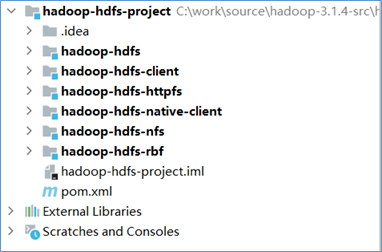
hadoop-hdfs
在hadoop-hdfs模块中,主要实现了网络、传输协议、JN、安全、server服务等相关功能。是hdfs的核心模块。并且提供了hdfs web UI页面功能的支撑。
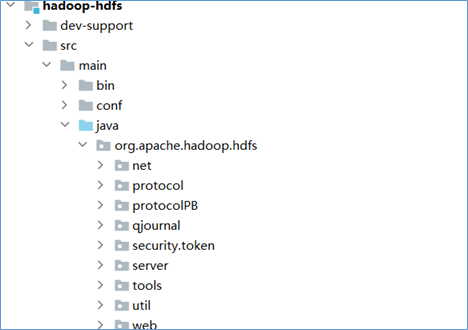
hadoop-hdfs-client
在hadoop-hdfs-client模块中,主要定义实现了和hdfs 客户端相关的功能逻辑。
hadoop-hdfs-httpfs
hadoop-hdfs-httpfs模块主要实现了通过HTTP协议操作访问hdfs文件系统的相关功能。HttpFS是一种服务器,它提供到HDFS的REST HTTP网关,具有完整的文件系统读写功能。
HttpFS可用于在运行不同Hadoop版本的群集之间传输数据(克服RPC版本问题),例如使用Hadoop DistCP。
hadoop-hdfs-native-client
hadoop-hdfs-native-client模块定义了hdfs访问本地库的相关功能和逻辑。该模块主要是使用C语言进行编写,用于和本地库进行交互操作。
hadoop-hdfs-nfs
hadoop-hdfs-nfs模块是Hadoop HDFS的NFS实现。
hadoop-hdfs-rbf
hadoop-hdfs-rbf模块是hadoop3.0之后的一个新的模块。主要实现了RBF功能。RBF是Router-based Federation简称,翻译中文叫做:基于路由的Federation方案。
简单来说就是:HDFS将路由信息放在了服务端来处理,而不是在客户端。以此完全做到对于客户端的透明。
HDFS核心源码解析
HDFS客户端核心类
Configuration
源码注释中对于Configuration类是这么描述的:

Configuration提供对配置参数的访问,通常称之为配置文件类。主要用于加载或者设定程序运行时相关的参数属性。
Configuration加载默认配置
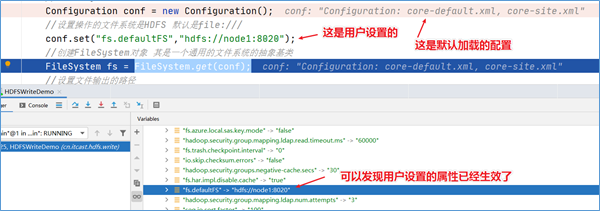
在程序中打上断点,看一下新建Configuration对象的时候加载了什么:
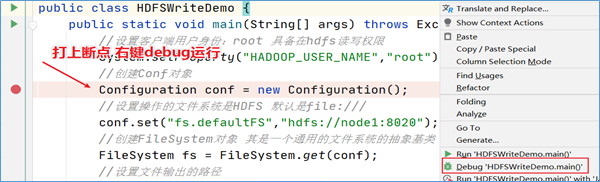
按下F7进入方法内部,再一次次按下F8,执行过程中可以发现,首先加载了静态方法和静态代码块,其中在静态代码块中显示默认加载了两个配置文件:
core-default.xml以及core-site.xml

Configuration加载用户设置
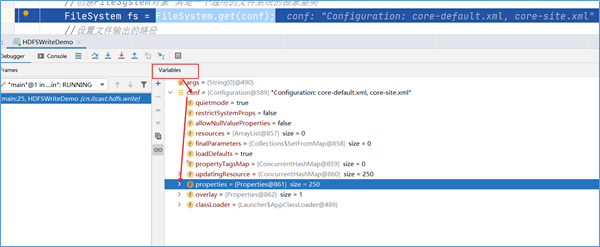
按下shift+F8,跳出Configuration类的创建,按F8执行下一步,当到达FileSystem.get(conf)这一行代码的时候,可以发现用户通过conf.set设置的属性也会被加载。
FileSystem
源码注释中对于FileSystem类是这么描述的:
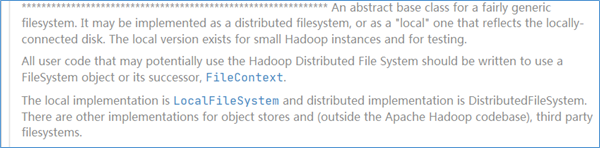
简单翻译下:FileSystem类是一个通用的文件系统的抽象基类。具体来说它可以实现为一个分布式的文件系统,也可以实现为一个本地文件系统。所有的可能会使用到HDFS的用户代码在进行编写时都应该使用FileSystem对象。
代表本地文件系统的实现是LocalFileSystem,代表分布式文件系统的实现是DistributedFileSystem。当然针对其他hadoop支持的文件系统也有不同的具体实现。
因此HDFS客户端在进行读写操作之前,需要创建FileSystem对象的实例。
获取FileSystem实例
将断点达到如下的位置,debug运行程序:
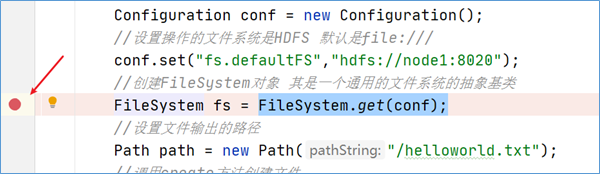
经过方法的层层调用,最终找到了FileSystem对象是通过调用getInternal方法得到的。
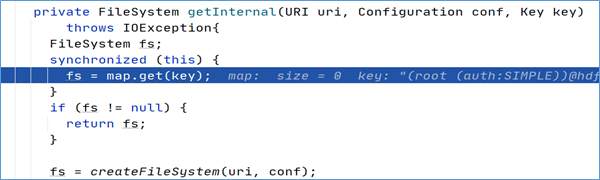
首先在getInternal方法中调用了createFileSystem方法,进去该方法:
原来,FileSystem实例是通过反射的方式获得的,具体实现是通过调用反射工具类ReflectionUtils的newInstance方法并将class对象以及Configuration对象作为参数传入最终得到了FileSystem实例。

HDFS通信协议
概述
HDFS作为一个分布式文件系统,它的某些流程是非常复杂的(例如读、写文件等典型流程),常常涉及数据节点、名字节点和客户端三者之间的配合、相互调用才能实现。为了降低节点间代码的耦合性,提高单个节点代码的内聚性, HDFS将这些节点间的调用抽象成不同的接口。
HDFS节点间的接口主要有两种类型:
Hadoop RPC接口:基于Hadoop RPC框架实现的接口;
流式接口:基于TCP或者HTTP实现的接口;
Hadoop RPC接口
RPC介绍
RPC 全称 Remote Procedure Call——远程过程调用。就是为了解决远程调用服务的一种技术,使得调用者像调用本地服务一样方便透明。
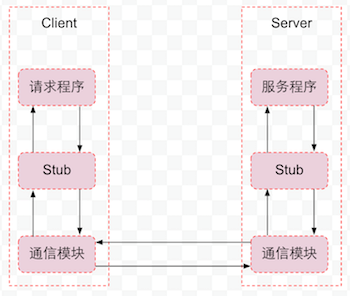
通信模块:传输RPC请求和响应的网络通信模块,可以基于TCP协议,也可以基于UDP协议,可以是同步,也可以是异步的。
客户端Stub程序:服务器和客户端都包括Stub程序。在客户端,Stub程序表现的就像本地程序一样,但底层却会将调用请求和参数序列化并通过通信模块发送给服务器。之后Stub程序等待服务器的响应信息,将响应信息反序列化并返回给请求程序。
服务器端Stub程序:在服务器端,Stub程序会将远程客户端发送的调用请求和参数反序列化,根据调用信息触发对应的服务程序,然后将服务程序返回的响应信息序列化并发回客户端。
请求程序:请求程序会像调用本地方法一样调用客户端Stub程序,然后接收Stub程序返回的响应信息。
服务程序:服务器会接收来自Stub程序的调用请求,执行对应的逻辑并返回执行结果。
Hadoop RPC调用使得HDFS进程能够像本地调用一样调用另一个进程中的方法,并且可以传递Java基本类型或者自定义类作为参数,同时接收返回值。如果远程进程在调用过程中出现异常,本地进程也会收到对应的异常。目前Hadoop RPC调用是基于Protobuf实现的。
Hadoop RPC接口主要定义在org.apache.hadoop.hdfs.protocol包和org.apache.hadoop.hdfs.server.protocol包中,核心的接口有:
ClientProtocol、ClientDatanodeProtocol、DatanodeProtocol。
ClientProtocol
ClientProtocol定义了客户端与名字节点间的接口,这个接口定义的方法非常多,客户端对文件系统的所有操作都需要通过这个接口,同时客户端读、写文件等操作也需要先通过这个接口与Namenode协商之后,再进行数据块的读出和写入操作。
ClientProtocol定义了所有由客户端发起的、由Namenode响应的操作。这个接口非常大,有80多个方法,核心的是:HDFS文件读相关的操作、HDFS文件写以及追加写的相关操作。
- 读数据相关的方法
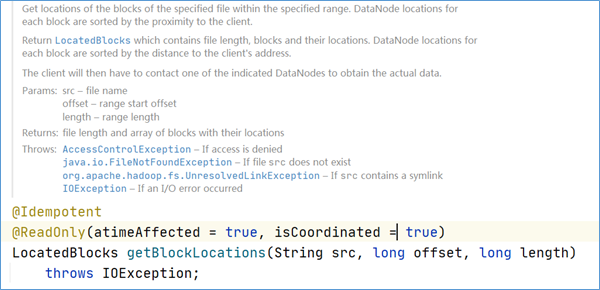
ClientProtocol中与客户端读取文件相关的方法主要有两个: getBlockLocations()和reportBadBlocks().
客户端会调用ClientProtocol.getBlockLocations)方法获取HDFS文件指定范围内所有数据块的位置信息。这个方法的参数是HDFS文件的文件名以及读取范围,返回值是文件指定范围内所有数据块的文件名以及它们的位置信息,使用LocatedBlocks对象封装。每个数据块的位置信息指的是存储这个数据块副本的所有Datanode的信息,这些Datanode会以与当前客户端的距离远近排序。客户端读取数据时,会首先调用getBlockLocations()方法获取HDFS文件的所有数据块的位置信息,然后客户端会根据这些位置信息从数据节点读取数据块。
客户端会调用ClientProtocol.reportBadBlocks()方法向Namenode汇报错误的数据块。当客户端从数据节点读取数据块且发现数据块的校验和并不正确时,就会调用这个方法向Namenode汇报这个错误的数据块信息。

- 写、追加数据相关方法
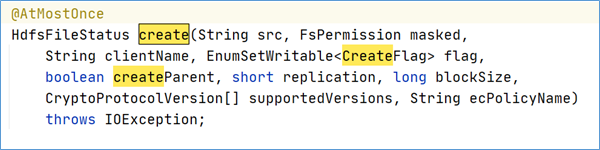
在HDFS客户端操作中最重要的一部分就是写入一个新的HDFS文件,或者打开一个已有的HDFS文件并执行追加写操作。ClientProtocol中定义了8个方法支持HDFS文件的写操作: create()、 append()、 addBlock()、 complete(), abandonBlockO),getAddtionnalDatanodes()、updateBlockForPipeline()和updatePipeline()。
create()方法用于在HDFS的文件系统目录树中创建一个新的空文件,创建的路径由src参数指定。这个空文件创建后对于其他的客户端是“可读”的,但是这些客户端不能删除、重命名或者移动这个文件,直到这个文件被关闭或者租约过期。客户端写一个新的文件时,会首先调用create方法在文件系统目录树中创建一个空文件,然后调用addBlock方法获取存储文件数据的数据块的位置信息,最后客户端就可以根据位置信息建立数据流管道,向数据节点写入数据了。
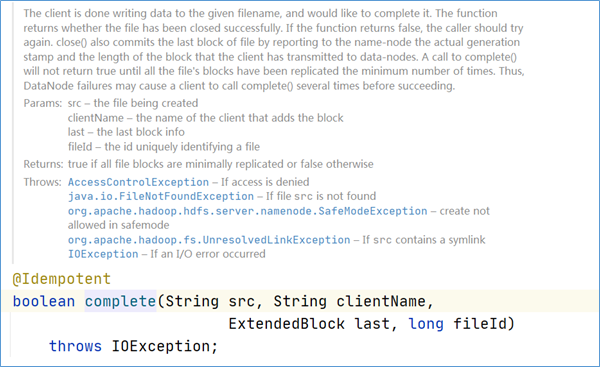
当客户端完成了整个文件的写入操作后,会调用complete()方法通知Namenode。这个操作会提交新写入HDFS文件的所有数据块,当这些数据块的副本数量满足系统配置的最小副本系数(默认值为1),也就是该文件的所有数据块至少有一个有效副本时, complete()方法会返回true,这时Namenode中文件的状态也会从构建中状态转换为正常状态;否则, complete会返回false,客户端就需要重复调用complete操作,直至该方法返回true
ClientDatanodeProtocol
客户端与数据节点间的接口。ClientDatanodeProtocol中定义的方法主要是用于客户端获取数据节点信息时调用,而真正的数据读写交互则是通过流式接口进行的。
ClientDatanodeProtocol中定义的接口可以分为两部分:一部分是支持HDFS文件读取操作的,例如getReplicaVisibleLength()以及getBlockLocalPathInfo);另一部分是支持DFSAdmin中与数据节点管理相关的命令。我们重点关注第一部分。
- getReplicaVisibleLength
客户端会调用getReplicaVisibleLength()方法从数据节点获取某个数据块副本真实的数据长度。当客户端读取一个HDFS文件时,需要获取这个文件对应的所有数据块的长度,用于建立数据块的输入流,然后读取数据。但是Namenode元数据中文件的最后一个数据块长度与Datanode实际存储的可能不一致,所以客户端在创建输入流时就需要调用getReplicaVisibleLength()方法从Datanode获取这个数据块的真实长度。

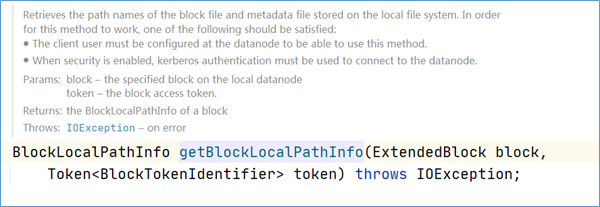
- getBlockLocalPathInfo
HDFS对于本地读取,也就是Client和保存该数据块的Datanode在同一台物理机器上时,是有很多优化的。Client会调用ClientProtocol.getBlockLocalPathInfo)方法获取指定数据块文件以及数据块校验文件在当前节点上的本地路径,然后利用这个本地路径执行本地读取操作,而不是通过流式接口执行远程读取,这样也就大大优化了读取的性能。
DatanodeProtocol
数据节点通过这个接口与名字节点通信,同时名字节点会通过这个接口中方法的返回值向数据节点下发指令。注意,这是名字节点与数据节点通信的唯一方式。这个接口非常重要,数据节点会通过这个接口向名字节点注册、汇报数据块的全量以及增量的存储情况。同时,名字节点也会通过这个接口中方法的返回值,将名字节点指令带回该数据块,根据这些指令,数据节点会执行数据块的复制、删除以及恢复操作。
可以将DatanodeProtocol定义的方法分为三种类型: Datanode启动相关、心跳相关以及数据块读写相关。
基于TCP/HTTP流式接口
HDFS除了定义RPC调用接口外,还定义了流式接口,流式接口是HDFS中基于TCP或者HTTP实现的接口。在HDFS中,流式接口包括了基于TCP的DataTransferProtocol接口,以及HA架构中Active Namenode和Standby Namenode之间的HTTP接口。
DataTransferProtocol
DataTransferProtocol是用来描述写入或者读出Datanode上数据的基于TCP的流式接口,HDFS客户端与数据节点以及数据节点与数据节点之间的数据块传输就是基于DataTransferProtocol接口实现的。HDFS没有采用Hadoop RPC来实现HDFS文件的读写功能,是因为Hadoop RPC框架的效率目前还不足以支撑超大文件的读写,而使用基于TCP的流式接口有利于批量处理数据,同时提高了数据的吞吐量。
DataTransferProtocol中最重要的方法就是readBlock()和writeBlock()。
readBlock:从当前Datanode读取指定的数据块。
writeBlock:将指定数据块写入数据流管道(pipeLine)中。
DataTransferProtocol接口调用并没有使用Hadoop RPC框架提供的功能,而是定义了用于发送DataTransferProtocol请求的Sender类,以及用于响应DataTransferProtocol请求的Receiver类。
Sender类和Receiver类都实现了DataTransferProtocol接口。。我们假设DFSClient发起了一个DataTransferProtocol.readBlock()操作,那么DFSClient会调用Sender将这个请求序列化,并传输给远端的Receiver。远端的Receiver接收到这个请求后,会反序列化请求,然后调用代码 执行读取操作。

数据写入流程分析
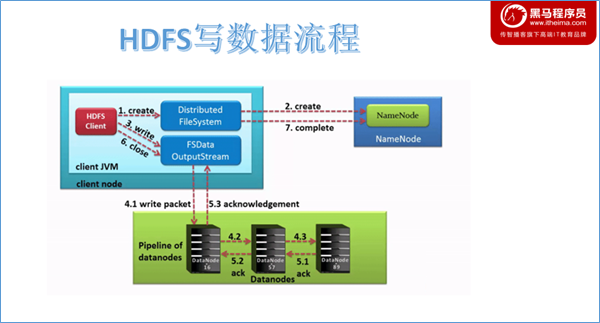
写入流程图
写入数据代码
package cn.itcast.hdfs.write;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.FileInputStream;
/**
* @description:
* @author: Allen Woon
* @time: 2020/12/26 17:36
*/
public class HDFSWriteDemo {
public static void main(String[] args) throws Exception{
//设置客户端用户身份:root 具备在hdfs读写权限
System.setProperty("HADOOP_USER_NAME","root");
//创建Conf对象
Configuration conf = new Configuration();
//设置操作的文件系统是HDFS 默认是file:///
conf.set("fs.defaultFS","hdfs://node1:8020");
//创建FileSystem对象 其是一个通用的文件系统的抽象基类
FileSystem fs = FileSystem.get(conf);
//设置文件输出的路径
Path path = new Path("/helloworld.txt");
//调用create方法创建文件
FSDataOutputStream out = fs.create(path);
//创建本地文件输入流
FileInputStream in = new FileInputStream("D:\\datasets\\hdfs\\helloworld.txt");
//IO工具类实现流对拷贝
IOUtils.copy(in,out);
//关闭连接
fs.close();
}
}写入数据流程梳理
客户端请求NameNode创建
HDFS客户端通过对DistributedFileSystem对象调用create()请求创建文件。DistributedFileSystem为客户端返回FSDataOutputStream输出流对象。通过源码注释可以发现FSDataOutputStream是一个包装类,所包装的是DFSOutputStream。
可以通过create方法调用不断跟下去,可以发现最终的调用也验证了上述结论,返回的是DFSOutputStream 。
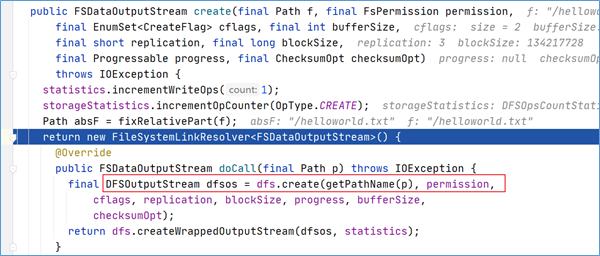
点击进入代码DFSOutputStream dfsos = dfs.create可以发现,DFSOutputStream这个类是从DFSClient类的create方法中返回过来的。
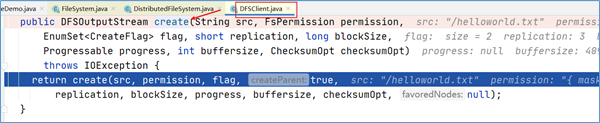
在DFSOutputStream dfsos = dfs.create打上断点,dubug。进来之后点进去发现,DFSClient类中的DFSOutputStream实例对象是通过调用DFSOutputStream类的newStreamForCreate方法产生的。
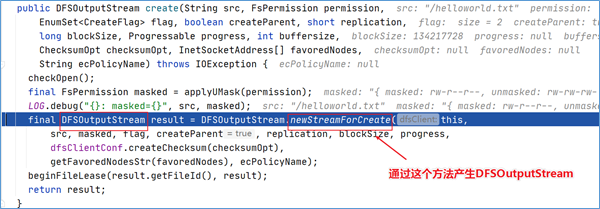
点击进入这个方法,找到了客户端请求NameNode新建元数据的关键代码。
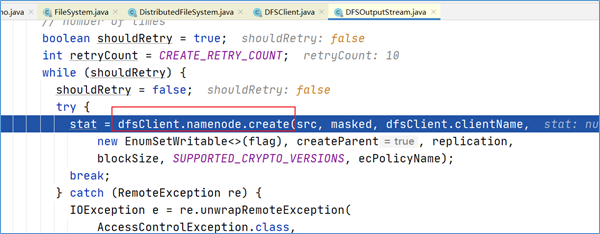
NameNode执行请求检查
DistributedFileSystem对namenode进行RPC调用,请求上传文件。namenode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,namenode就会为创建新文件记录一条记录。否则,文件创建失败并向客户端抛出一个IOException。
DataStreamer类
在之前的newStreamForCreate方法中,我们发现了最终返回的是out对象,并且在返回之前,调用了out对象的start方法。
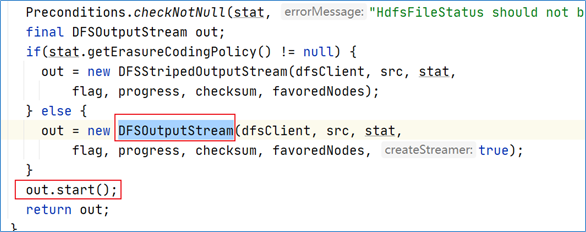
点进start方法,发现调用的是DataStreamer对象的start方法。

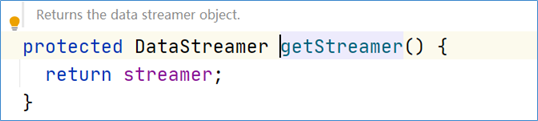
DataStreamer类是DFSOutputSteam的一个内部类,在这个类中,有一个方法叫做run方法,数据写入的关键代码就在这个run方法中实现。
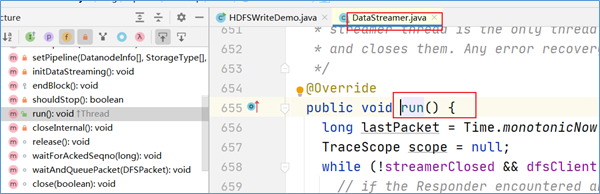
DataStreamer写数据
在客户端写入数据时,DFSOutputStream将它分成一个个数据包(packet 默认64kb),并写入一个称之为数据队列(data queue)的内部队列。DataStreamer请求NameNode挑选出适合存储数据副本的一组DataNode。这一组DataNode采用pipeline机制做数据的发送。默认是3副本存储。
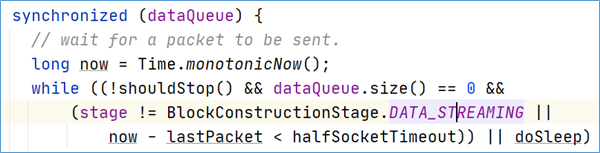
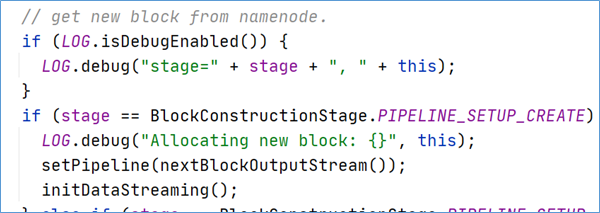
DataStreamer将数据包流式传输到pipeline的第一个datanode,该DataNode存储数据包并将它发送到pipeline的第二个DataNode。同样,第二个DataNode存储数据包并且发送给第三个(也是最后一个)DataNode。
DFSOutputStream也维护着一个内部数据包队列来等待DataNode的收到确认回执,称之为确认队列(ack queue),收到pipeline中所有DataNode确认信息后,该数据包才会从确认队列删除。
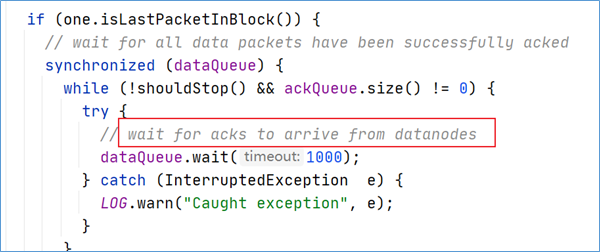
客户端完成数据写入后,将在流上调用close()方法关闭。该操作将剩余的所有数据包写入DataNode pipeline,并在联系到NameNode告知其文件写入完成之前,等待确认。
因为namenode已经知道文件由哪些块组成(DataStream请求分配数据块),因此它仅需等待最小复制块即可成功返回。数据块最小复制是由参数dfs.namenode.replication.min指定,默认是1.
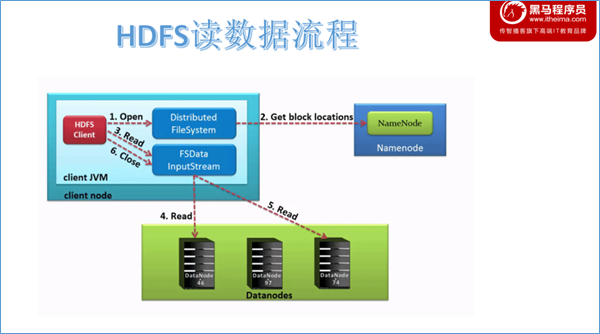
数据读取流程分析
读取流程图
读取数据代码
package cn.itcast.hdfs.read;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.FileInputStream;
import java.io.FileOutputStream;
/**
* @author: Allen Woon
* @time: 2020/12/26 17:48
*/
public class HDFSReadDemo {
public static void main(String[] args) throws Exception{
//设置客户端用户身份:root 具备在hdfs读写权限
System.setProperty("HADOOP_USER_NAME","root");
//创建Conf对象
Configuration conf = new Configuration();
//设置操作的文件系统是HDFS 默认是file:///
conf.set("fs.defaultFS","hdfs://node1:8020");
//创建FileSystem对象 其是一个通用的文件系统的抽象基类
FileSystem fs = FileSystem.get(conf);
//调用open方法读取文件
FSDataInputStream in = fs.open(new Path("/helloworld.txt"));
//创建本地文件输出流
FileOutputStream out = new FileOutputStream("D:\\helloworld.txt");
//IO工具类实现流对拷贝
IOUtils.copy(in,out);
//关闭连接
fs.close();
}
}读取数据流程梳理
客户端请求NameNode打开open
客户端通过调用DistributedFileSystem对象上的open()来打开希望读取的文件。DistributedFileSystem为客户端返回FSDataInputStream输入流对象。通过源码注释可以发现FSDataInputStream是一个包装类,所包装的是DFSInputStream。
可以通过open方法调用不断跟下去,可以发现最终的调用也验证了上述结论,返回的是DFSInputStream。
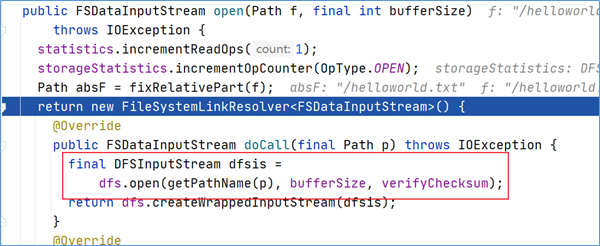
点击进入代码DFSInputStream dfsis =dfs.open可以发现,DFSInputStream这个类是从DFSClient类的open方法中返回过来的。该输入流从namenode获取block的位置信息。
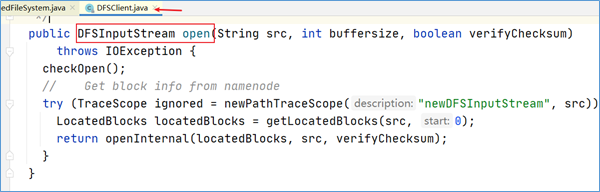
getLocatedBlocks
在上述open方法中,有一个核心方法调用叫做getLocatedBlocks,见名知意,该方法是用于获取块位置信息的。
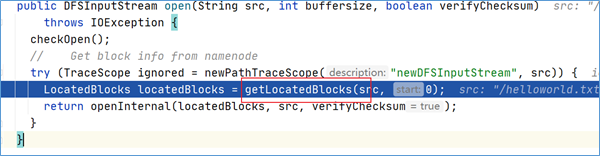
点击方法进去之后发现,最终调用的是callGetBlockLocations:
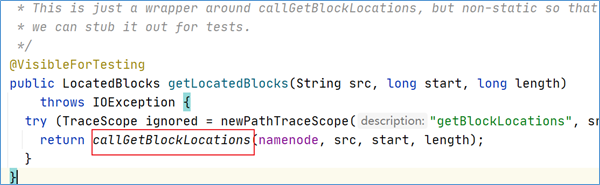
继续点下去,发现最终调用的是getBlockLocations方法。
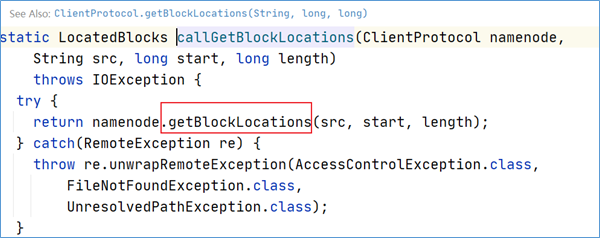
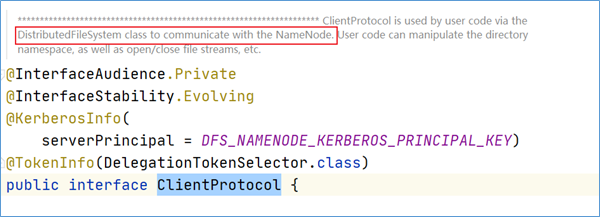
通过源码可以发现,getBlockLocations方法是位于ClientProtocol这个接口中。在ClientProtocol的注释上可以得出信息,这是客户端和namenode进行通信的。
NameNode返回块信息
DistributedFileSystem使用RPC调用namenode来确定文件中前几个块的块位置。对于每个块,namenode返回具有该块副本的datanode的地址,并且datanode根据块与客户端的距离进行排序。注意此距离指的是网络拓扑中的距离。比如客户端的本身就是一个DataNode,那么从本地读取数据明显比跨网络读取数据效率要高。
之前的getBlockLocations方法在源码注释上也描述了这段逻辑。
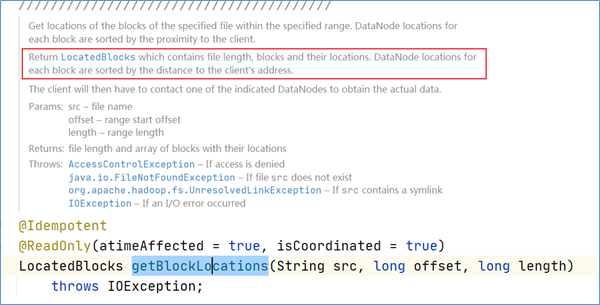
大致意思如下:获取指定范围内指定文件的块位置。 每个块的DataNode位置按与客户端的接近程度进行排序。返回LocatedBlocks,其中包含文件长度,块及其位置。 每个块的DataNode位置按到客户端地址的距离排序。然后,客户端将必须联系指示的DataNode之一以获得实际数据。
客户端读数据
DFSClient在获取到block的位置信息之后,继续调用openInternal方法。
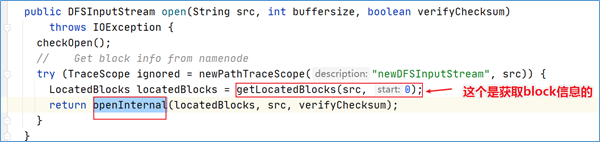
点击进入该方法可以发现,分了两种不同的输入流。这取决于文件的存储策略是否采用EC纠删码。如果未使用EC编码策略存储,那么直接创建DFSInputStream。
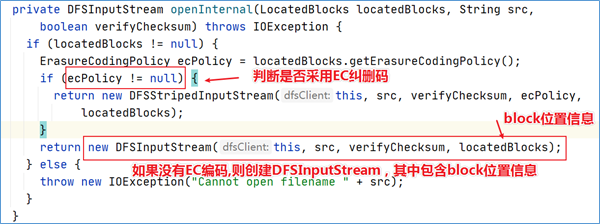
最终将block位置信息保存到DFSInputStream输入流对象中的成员变量中返回给客户端。
客户端在DFSInputStream流上调用read()方法。然后DFSInputStream连接到文件中第一个块的最近的DataNode节点。通过对数据流反复调用read()方法,将数据从DataNode传输到客户端。当该块快要读取结束时,DFSInputStream将关闭与该DataNode的连接,然后寻找下一个块的最佳datanode。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。
客户端从流中读取数据时,也会根据需要询问NameNode来检索下一批数据块的DataNode位置信息。一旦客户端完成读取,就对FSDataInputStream调用close()方法。
如果DFSInputStream与DataNode通信时遇到错误,它将尝试该块的下一个最接近的DataNode读取数据。并将记住发生故障的DataNode,保证以后不会反复读取该DataNode后续的块。此外,DFSInputStream也会通过校验和(checksum)确认从DataNode发来的数据是否完整。如果发现有损坏的块,DFSInputStream会尝试从其他DataNode读取该块的副本,也会将被损坏的块报告给namenode 。
 微信
微信 支付宝
支付宝








