HDFS入门与应用开发
企业存储系统
随着这两年产业互联网的推动和发展,越来越多的企业开始进行数字化转型,将传统的业务流程进行数字化改造。在进行数字化的过程中,需要数据来支撑企业的业务流程重塑,并以客户、产品为核心,以数据来支撑精细化运营。而数据分散在不同的系统中,要更充分的利用数据,需要将企业的大量数据集中存储,并进行业务化处理。此时,我们要想办法来解决大规模数据存储的问题。不管是使用哪种存储技术,都需要有存储硬件的支持。
硬盘

硬盘是计算机的主要存储硬件,可以用来存储大量数据。目前(2020年),市面上比较流行的硬盘多数是TB级的。
SATA硬盘
SATA即Serial ATA(串行ATA),是由Intel、IBM、Maxtor和Seagate等公司提出的硬盘接口规范。采用的是串行连接方式,很多时候会把SATA接口的硬盘称之为串口硬盘。

上图为希捷2TB高速机械硬盘,SATA接口,拥有256M的磁盘缓存,转速7200rpm,每秒可达90-190MB的速度。
SATA SSD固态硬盘

采用固态电子存储芯片阵列制作的硬盘,是以闪存作为永久性存储器的存储设备。固态硬盘的读取速度可以在500Mb/s左右。
RAID磁盘阵列
单个硬盘的存储能力是有限的,如果要存储更多的数据,可以通过某种技术,将若干个硬盘连接在一起,提供能耗的存储能力。我们在服务器上插更多的磁盘来提高存储容量,而服务器上的插槽是有限的,我们无法无限地增加硬盘。所以,我们可以买RAID磁盘阵列来解决数据存储速度、容错问题。

RAID可以将多块独立的硬盘组织在一起,可以将多块硬盘连接在一起,并在性能上、容错上会有一定地提升。
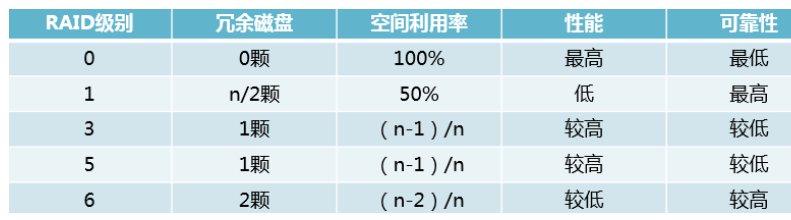
RAID有哪几种?有什么区别?
一共有0~6一共7种,这其中RAID 0、RAID1、RAID 5和RAID6比较常用。
RAID 0:如果你有n块磁盘,原来只能同时写一块磁盘,写满了再下一块,做了RAID 0之后,n块可以同时写,速度提升很快,但由于没有备份,可靠性很差。n最少为2。
RAID 1:正因为RAID 0太不可靠,所以衍生出了RAID 1。如果你有n块磁盘,把其中n/2块磁盘作为镜像磁盘,在往其中一块磁盘写入数据时,也同时往另一块写数据。坏了其中一块时,镜像磁盘自动顶上,可靠性最佳,但空间利用率太低。n最少为2。
RAID 3:为了说明白RAID 5,先说RAID 3.RAID 3是若你有n块盘,其中1块盘作为校验盘,剩余n-1块盘相当于作RAID 0同时读写,当其中一块盘坏掉时,可以通过校验码还原出坏掉盘的原始数据。这个校验方式比较特别,奇偶检验,1 XOR 0 XOR 1=0,0 XOR 1 XOR 0=1,最后的数据时校验数据,当中间缺了一个数据时,可以通过其他盘的数据和校验数据推算出来。但是这有个问题,由于n-1块盘做了RAID 0,每一次读写都要牵动所有盘来为它服务,而且万一校验盘坏掉就完蛋了。最多允许坏一块盘。n最少为3.
RAID 5:在RAID 3的基础上有所区别,同样是相当于是1块盘的大小作为校验盘,n-1块盘的大小作为数据盘,但校验码分布在各个磁盘中,不是单独的一块磁盘,也就是分布式校验盘,这样做好处多多。最多坏一块盘。n最少为3.
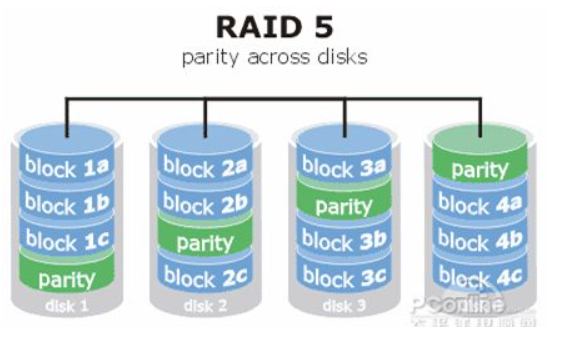
RAID 6:在RAID 5的基础上,又增加了一种校验码,和解方程似的,一种校验码一个方程,最多有两个未知数,也就是最多坏两块盘。
总体来说,
存储架构
DAS存储架构
DAS存储架构也称为直连式存储(Direct-Attached Storage),很多中小型的企业,存储系统会直接和服务器进行连接。因为DAS是通过服务器直接连接存储的,比较依赖操作系统来进行IO操作。


NAS网络接入存储
NAS也称为网络接入存储(Network-Attached Storage),是通过将各种存储设备通过网络地方式连接在一起,因为NAS存储是通过网络连接的,所以并不依赖某一种类的操作系统,所以不管是Windows、MacOS、Linux、Unix都是可以使用NAS的。

文件系统
介绍
- 计算机的文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易。
- 文件系统使用文件和树形目录的抽象逻辑概念代替了硬盘和光盘等物理设备使用数据块的概念,用户使用文件系统来保存数据不必关心数据实际保存在硬盘(或者光盘)的地址为多少的数据块上,只需要记住这个文件的所属目录和文件名。
- 在写入新数据之前,用户不必关心硬盘上的那个块地址没有被使用,硬盘上的存储空间管理(分配和释放)功能由文件系统自动完成,用户只需要记住数据被写入到了哪个文件中。
- 文件系统通常使用硬盘和光盘这样的存储设备,并维护文件在设备中的物理位置。但是,实际上文件系统也可能仅仅是一种访问资料的界面而已,实际的数据是通过网络协议(如NFS、SMB、9P等)提供的或者内存上,甚至可能根本没有对应的文件(如proc文件系统)。
- 严格地说,文件系统是一套实现了数据的存储、分级组织、访问和获取等操作的抽象数据类型(Abstract data type)。
重要概念
- 文件系统是一种用于向用户提供底层数据访问的机制。它将设备中的空间划分为特定大小的块(或者称为簇),一般每块512字节。数据存储在这些块中,大小被修正为占用整数个块。由文件系统软件来负责将这些块组织为文件和目录,并记录哪些块被分配给了哪个文件,以及哪些块没有被使用。
- 不过,文件系统并不一定只在特定存储设备上出现。它是数据的组织者和提供者,至于它的底层,可以是磁盘,也可以是其它动态生成数据的设备(比如网络设备)。
文件名
- 在文件系统中,文件名是用于定位存储位置。
- 大多数的文件系统对文件名的长度有限制。在一些文件系统中,文件名是大小写不敏感(如“AAA”和“aaa”指的是同一个文件);在另一些文件系统中则大小写敏感。
- 大多现今的文件系统允许文件名包含非常多的Unicode字符集的字符。然而在大多数文件系统的界面中,会限制某些特殊字符出现在文件名中。(文件系统可能会用这些特殊字符来表示一个设备、设备类型、目录前缀、或文件类型),为方便起见,一般不建议在文件名中包含特殊字符。
元数据
- 其它文件保存信息常常伴随着文件自身保存在文件系统中。
- 文件长度可能是分配给这个文件的区块数,也可能是这个文件实际的字节数。文件最后修改时间也许记录在文件的时间戳中。有的文件系统还保存文件的创建时间,最后访问时间及属性修改时间。(不过大多数早期的文件系统不记录文件的时间信息)其它信息还包括文件设备类型(如:区块数,字符集,套接口,子目录等等),文件所有者的ID,组ID,还有访问权限(如:只读,可执行等等)。
[root@node2 ~]# ll
total 32
-rw-------. 1 root root 2117 Apr 8 2020 anaconda-ks.cfg
drwxr-xr-x. 2 root root 6 Aug 30 09:33 Desktop
drwxr-xr-x. 2 root root 6 Aug 30 09:33 Documents
drwxr-xr-x. 2 root root 6 Aug 30 09:33 Downloads
-rw-r--r--. 1 root root 2165 Apr 8 2020 initial-setup-ks.cfg
drwxr-xr-x. 2 root root 6 Aug 30 09:33 Music
drwxr-xr-x. 2 root root 6 Aug 30 09:33 Pictures
-rw-r--r--. 1 root root 3158 Oct 10 22:53 profile
drwxr-xr-x. 2 root root 6 Aug 30 09:33 Public
drwxr-xr-x. 2 root root 6 Aug 30 09:33 Templates
drwxr-xr-x. 2 root root 6 Aug 30 09:33 Videos
-rw-r--r--. 1 root root 18234 Oct 10 18:04 zookeeper.out文件系统分类
磁盘文件系统
磁盘文件系统是一种设计用来利用数据存储设备来保存计算机文件的文件系统,最常用的数据存储设备是磁盘驱动器,可以直接或者间接地连接到计算机上。例如:FAT、exFAT、NTFS、HFS、HFS+、ext2、ext3、ext4、ODS-5、btrfs、XFS、UFS、ZFS。

Windows支持的文件系统
| Windows | FAT12/FAT16 | FAT32/VFAT | FAT64/exFAT | NTFS |
|---|---|---|---|---|
| Windows 3.x或更早 (MS-DOS 6.22) (PC-DOS 7.0) | 可读/可写 | 不支持 | 不支持 | 不支持 |
| Windows 95 | 可读/可写 | 不支持 | 不支持 | 不支持 |
| Windows 95(OSR2以后) Windows 98(含SE) ME | 可读/可写 | 可读/可写 | 不支持 | 不支持 |
| Windows NT | 可读/可写 | 不支持 | 不支持 | 可读/可写 |
| 2000 Windows XP Windows Vista Server 2003 Server 2008 (R2) Windows 7 Windows 8 Server 2012 (R2) Windows 8.1 Windows 10 | 可读/可写 | 可读/可写 | 可读/可写 | 可读/可写 |
| Windows XP Windows Vista Server 2003 Server 2008 (R2) Windows 7 Windows 8 Server 2012 (R2) Windows 8.1 | 可读/可写 | 可读/可写 | 可读/可写 | 可读/可写 |

Linux支持的文件系统
随着Linux的不断发展,它所支持的文件系统也在迅速扩充,Linux系统核心可以支持十多种文件系统类型:Btrfs、JFS、ReiserFS、exFAT、ext、ext2、ext3、ext4、XFS、ISO 9660、Minix、MSDOS、UMSDOS、VFAT、NTFS(Linux Kernel内置的NTFS驱动程序,写入功能不稳定)、HPFS、NFS、SMB、SysV、PROC**等。
注意:部分Linux发行版的Kernel默认不编译Kernel内置的NTFS文件系统支持,常见的在Linux下读写NTFS的解决方法是安装NTFS-3G或ufsd等NTFS驱动程序。部分Linux发行版对NTFS的支持度并不高。

UNIX及BSD操作系统下的文件系统
柏克莱加州大学开发早期的伯克利快速文件系统(Berkeley Fast File System),再由各UNIX厂商开发不同的文件系统,包括IRIX上的XFS、IBM AIX的JFS、HP HP-UNIX的VxFS及Solaris的ZFS。

macOS(Mac OS X)的文件系统
从1998年到2016年间使用HFS+,再早采用HFS。从2016年发布的macOS Sierra起,使用苹果文件系统(APFS)。
光盘
ISO 9660和UDF被用于CD、DVD与蓝光光盘。
网络文件系统
网络文件系统(NFS,Network File System)是一种将远程主机上的分区(目录)经网络挂载到本地系统的一种机制。
面临海量数据存储的问题
成本高
传统存储硬件通用性差,设备投资加上后期维护、升级扩容的成本非常高。

性能低
单节点I/O性能瓶颈无法逾越,容量和性能都不易扩展,难以支撑海量数据的高并发高吞吐场景。
可扩展性差
无法实现快速部署和弹性扩展。
支持大数据分析、AI
传统存储与Spark等大数据分析平台对接是否有难度,一套存储能否满足企业数据存储、管理和挖掘的需求。
场景案例:如何模拟实现分布式存储?
如何解决海量数据存的下问题
传统存储方式
应对文件存储服务,传统做法是在服务器上部署文件服务比如FTP。但是随着数据变多,会遇到存储瓶颈。此时,本能的操作反应是:内存不够加内存,磁盘不够加磁盘—单机纵向扩展。但是单机能够扩展的内存磁盘是有上限的,不能无限制下去。
分布式存储方式
纵向扩展有上限,自然想到横向扩展。所谓横向指的是采用多台机器存储,一台不够就多台一起存储,不够就加机器。
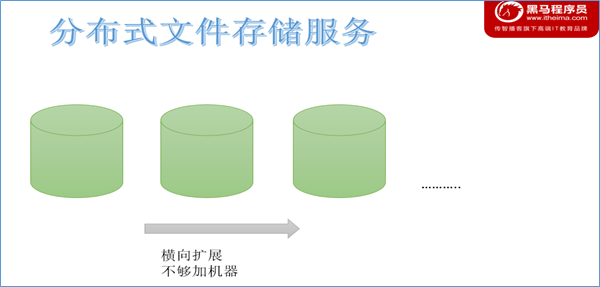
理论上,可以横向无限制下去。因此海量数据如何存储的下的问题解决方式就是采用多台机器存储—即分布式存储。
如何解决数据查询便捷问题
当文件被分布式存储在多台机器之后,后续获取文件的时候如何能快速找到文件位于哪台机器上呢。一台一台查询过来也不靠谱。因此可以借助于元数据记录来解决这个问题。把文件和其存储的机器的位置信息记录下来,类似于图书馆查阅图书系统,这样就可以快速定位文件存储在哪一台机器上了。

如何解决大文件传输效率慢问题
大数据使用场景下,GB、TP级别的大文件是常见的。当单个文件过大的时候,如何提高传输效率?通常的做法是分块存储:把大文件拆分成若干个小块(block 简写blk),分别存储在不同机器上,并行操作提高效率。
此外分块存储还可以解决数据存储负载均衡问题。此时元数据记录信息也应该更加详细:文件分了几块,分别位于哪些机器上。

如何解决数据丢失问题
机器、磁盘等硬件出现故障是难以避免的事情,如何保证数据存储的安全性。如果某台机器故障,数据块丢失,对于文件来说整体就是不完整的。冗余存储是个不错的选择。采用副本机制。副本越多,数据越安全,当然冗余也会越多。通过“不要把鸡蛋放在一个篮子里”的思想,可以把数据丢失的风险分散到各个机器上。
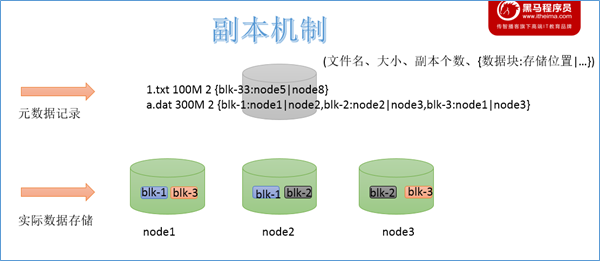
如何解决用户查询视角统一问题
随着存储的进行,数据文件越来越多,与之对应元数据信息也越来越多,如何让用户视觉层面感觉不到元数据的凌乱,同时也与传统的文件系统操作体验保持一致?传统的文件系统拥有所谓的目录树结构,带有层次感的namespace(命名空间),因此可以把分布式文件系统的元数据记录这一块也抽象成统一的目录树结构。

小结
通过上述场景式分析,可以得出要想实现一个分布式文件系统,是需要多方面综合考虑的。通常来说一个分布式文件系统需要具备:分布式特性、分块存储、副本机制、元数据记录、抽象目录树、统一namespace命名空间。
分布式文件HDFS
HDFS简介
- HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目,它的设计初衷是为了能够支持高吞吐和超大文件读写操作。
- HDFS是一种能够在普通硬件上运行的分布式文件系统,它是高度容错的,适应于具有大数据集的应用程序,它非常适于存储大型数据 (比如 TB 和 PB)。
- HDFS使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统
HDFS发展历史
- Doug Cutting 在做 Lucene 的时候, 需要编写一个爬虫服务, 这个爬虫写的并不顺利, 遇到 了一些问题, 诸如: 如何存储大规模的数据, 如何保证集群的可伸缩性, 如何动态容错等
- 2013年的时候, Google 发布了三篇论文, 被称作为三驾马车, 其中有一篇叫做 GFS
- GFS是描述了 Google 内部的一个叫做 GFS 的分布式大规模文件系统, 具有强大的可伸缩性和容错
- Doug Cutting后来根据 GFS 的论文, 创造了一个新的文件系统, 叫做 HDFS
HDFS设计目标
- HDFS集群由很多的服务器组成,而每一个机器都与可能会出现故障。HDFS为了能够进行故障检测、快速恢复等。
- HDFS主要适合去做批量数据出来,相对于数据请求时的反应时间,HDFS更倾向于保障吞吐量。
- 典型的HDFS中的文件大小是GB到TB,HDFS比较适合存储大文件。
- HDFS很多时候是以: Write-One-Read-Many来应用的,一旦在HDFS创建一个文件,写入完后就不需要修改了
HDFS应用场景
适合的应用场景
- 存储非常大的文件:这里非常大指的是几百M、G、或者TB级别,需要高吞吐量,对延时没有要求。
- 基于流的数据访问方式: 即一次写入、多次读取,数据集经常从数据源生成或者拷贝一次,然后在其上做很多分析工作 ,且不支持文件的随机修改。
- 正因为如此,HDFS适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用,因为,修改不方便,延迟大,网络开销大,成本太高。
- 运行于商业硬件上: Hadoop不需要特别贵的机器,可运行于普通廉价机器,可以处节约成本
- 需要高容错性
- 为数据存储提供所需的扩展能力
不适合的应用场景
- 低延时的数据访问 对延时要求在毫秒级别的应用,不适合采用HDFS。HDFS是为高吞吐数据传输设计的,因此可能牺牲延时
- 大量小文件的元数据保存在NameNode的内存中, 整个文件系统的文件数量会受限于NameNode的内存大小。 经验而言,一个文件/目录/文件块一般占有150字节的元数据内存空间。如果有100万个文件,每个文件占用1个文件块,则需要大约300M的内存。因此十亿级别的文件数量在现有商用机器上难以支持
- 多方读写,需要任意的文件修改 HDFS采用追加(append-only)的方式写入数据。不支持文件任意offset的修改,HDFS适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用,因为,修改不方便,延迟大,网络开销大,成本太高。
HDFS重要特性
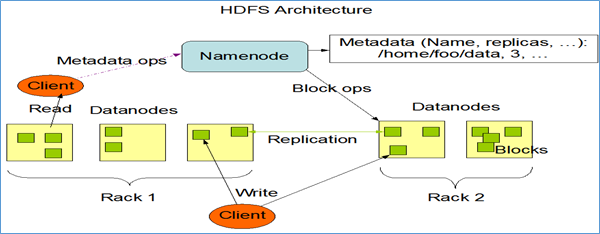
主从架构
HDFS采用master/slave架构。一般一个HDFS集群是有一个Namenode和一定数目的Datanode组成。Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。

分块机制
HDFS中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,参数位于hdfs-default.xml中:dfs.blocksize。默认大小是128M(134217728)。
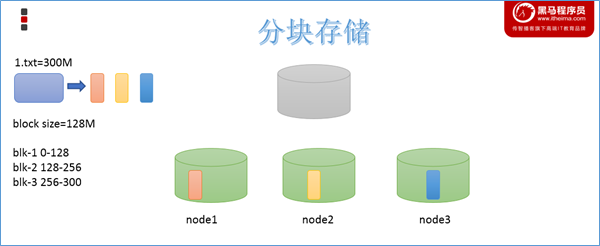
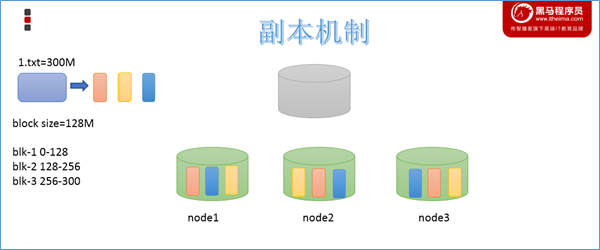
副本机制
为了容错,文件的所有block都会有副本。每个文件的block大小(dfs.blocksize)和副本系数(dfs.replication)都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
默认dfs.replication的值是3,也就是会额外再复制2份,连同本身总共3份副本。
Namespace
HDFS支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode负责维护文件系统的namespace名称空间,任何对文件系统名称空间或属性的修改都将被Namenode记录下来。
HDFS会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
元数据管理
在HDFS中,Namenode管理的元数据具有两种类型:
文件自身属性信息
文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
文件块位置映射信息
记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
数据块存储
文件的各个block的具体存储管理由DataNode节点承担。每一个block都可以在多个DataNode上存储。
微博HDFS案例

背景
微博有大量的用户数据,为了分析微博用户的行为。我们可以将微博的数据上传到HDFS,然后供其他大规模文本、情感分析程序来处理。
HDFS目录规划
当前我们的HDFS集群中应该是空空如也。因为我们并没有做任何的文件操作。为了方便我们将来管理文件系统,我们也对HDFS需要有一个目录规划,就像Linux一样。
目录规划:
| 目录 | 说明 |
|---|---|
| /source | 用于存储原始采集数据 |
| /common | 用于存储公共数据集,例如:IP库、省份信息、经纬度等 |
| /workspace | 工作空间,存储各团队计算出来的结果数据 |
| /tmp | 存储临时数据,每周清理一次 |
| /warehouse | 存储hive数据仓库中的数据 |
HDFS操作 - shell客户端
HDFS是存取数据的分布式文件系统,那么对HDFS的操作,就是文件系统的基本操作,比如文件的创建、修改、删除、修改权限等,文件夹的创建、删除、重命名等。对HDFS的操作命令类似于Linux的shell对文件的操作,如ls、mkdir、rm等。
语法格式
Hadoop提供了文件系统的shell命令行客户端,使用方法如下:
Usage: hdfs [SHELL_OPTIONS] COMMAND [GENERIC_OPTIONS] [COMMAND_OPTIONS]
选项:
| COMMAND_OPTIONS | Description |
|---|---|
| SHELL_OPTIONS | 常见的shell选项,例如:操作文件系统、管理hdfs集群.. |
| GENERIC_OPTIONS | 多个命令支持的公共选项 |
| COMMAND COMMAND_OPTIONS | 用户命令、或者是管理命令 |
示例:
# 查看HDFS中/parent/child目录下的文件或者文件夹
hdfs dfs -ls /parent/child - 所有HDFS命令都可以通过bin/hdfs脚本执行。
- 还有一个hadoop命令也可以执行文件系统操作,还可以用来提交作业,此处我们均使用hdfs,为了更好地区分和对hdfs更好的支持。
说明
- 文件系统shell包括与Hadoop分布式文件系统(HDFS)以及Hadoop支持的其他文件系统(如本地FS,HFTP FS,S3 FS等)直接交互的各种类似shell的命令。
- 所有FS shell命令都将路径URI作为参数。URI格式为
scheme://authority/path。对于HDFS,该scheme是hdfs,对于本地FS,该scheme是file。scheme和authority是可选的。如果未指定,则使用配置中指定的默认方案。 - 命令示例如下:
# 查看指定目录下的文件
hdfs dfs -ls hdfs://namenode:host/parent/child
# hdfs-site.xml中的fs.defaultFS中有配置
hdfs dfs -ls /parent/child shell命令选项
[root@node1 bin]# hdfs dfs -usage
Usage: hdfs dfs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]需求:创建目录规划
mkdir命令
格式 : hdfs dfs [-p] -mkdir <paths>
作用 : 以<paths>中的URI作为参数,创建目录。使用-p参数可以递归创建目录
hdfs dfs -mkdir /dir1
hdfs dfs -mkdir /dir2
hdfs dfs -p -mkdir /aaa/bbb/ccc创建目录规划
[root@node1 ~]# hdfs dfs -mkdir /common
[root@node1 ~]# hdfs dfs -mkdir /workspace
[root@node1 ~]# hdfs dfs -mkdir /tmp/
[root@node1 ~]# hdfs dfs -mkdir /warehouse
[root@node1 ~]# hdfs dfs -mkdir /source在WebUI中查看目录

我们发现,对应的目录都已经创建好了。
需求:使用命令查看HDFS中的目录
ls命令
格式: hdfs dfs -ls URI
作用:类似于Linux的ls命令,显示文件列表
hdfs dfs -ls /
选项
-R:表示递归展示目录下的内容
查看HDFS根目录下的所有内容
[root@node1 ~]# hdfs dfs -ls /
Found 7 items
drwxr-xr-x - root supergroup 0 2020-10-15 22:29 /common
drwxr-xr-x - root supergroup 0 2020-10-15 22:29 /source
drwxr-xr-x - root supergroup 0 2020-10-15 22:29 /tmp
drwxr-xr-x - root supergroup 0 2020-10-15 22:29 /warehouse
drwxr-xr-x - root supergroup 0 2020-10-15 22:29 /workspace需求:上传蔡徐坤微博评论数据到HDFS


在资料/数据集文件夹中,有一个caixukun.csv数据集。里面包含了大量蔡徐坤微博相关的评论数据集,我们需要将这些数据集上传到HDFS中。此处,我们需要将这些原始数据集上传到以下目录:
/source/weibo/star/comment_log/20190810_node1.itcast.cn/
命名方式:/source/{产品线}/{业务线}/{日志名称}/{日期}_{上报日志的机器}。
操作步骤:
先将目录创建出来。
再使用put命令将数据上传到该目录中。
put命令
-put参数可以将单个的源文件src或者多个源文件src从本地文件系统拷贝到目标文件系统中(<dst>对应的路径)。也可以从标准输入中读取输入,写入目标文件系统中。
语法格式:
hdfs dfs -put <localsrc > ... <dst>
上传微博评论数据
- 创建对应的文件夹。
hdfs dfs -mkdir -p /source/weibo/star/comment_log/20190810_node1.itcast.cn/
- 上传文件到文件夹中。
- 先将数据集上传到Linux
[root@node1 ~]# rz
rz waiting to receive.
?a? zmodem ′??. °′ Ctrl+C ??.
Transferring caixukun.csv...
100% 31496 KB 7874 KB/s 00:00:04 0 ′?- 再使用put命令上传到HDFS中
hdfs dfs -put caixukun.csv /source/weibo/star/comment_log/20190810_node1.itcast.cn
3.查看创建的目录和文件。
[root@node1 ~]# hdfs dfs -ls -h -R /source
drwxr-xr-x - root supergroup 0 2020-10-15 22:48 /source/weibo
drwxr-xr-x - root supergroup 0 2020-10-15 22:48 /source/weibo/star
drwxr-xr-x - root supergroup 0 2020-10-15 22:48 /source/weibo/star/comment_log
drwxr-xr-x - root supergroup 0 2020-10-15 22:51 /source/weibo/star/comment_log/20190810_node1.itcast.cn
-rw-r--r-- 3 root supergroup 30.8 M 2020-10-15 22:51 /source/weibo/star/comment_log/20190810_node1.itcast.cn/caixukun.csv需求:要求上传后把Linux本地文件自动删除
数据一旦上传到HDFS中后,就会一直保存下来,为了节省空间,可以把Linux本地的文件删除了。我们只需要执行 rm -f caixukun.csv即可。但我们想将来让HDFS上传后就自动删除该文件,我们可以使用moveFromLocal命令。
为了测试,我们要执行以下操作。
删除之前上传的文件。
重新使用moveFromLocal上传。
rm 命令
删除参数指定的文件和目录,参数可以有多个,删除目录需要加-r参数如果指定-skipTrash选项,那么在回收站可用的情况下,该选项将跳过回收站而直接删除文件;否则,在回收站可用时,在HDFS Shell 中执行此命令,会将文件暂时放到回收站中。
hdfs dfs -rm [-r] [-skipTrash] URI [URI…]
删除HDFS上的文件
hdfs dfs -rm /source/weibo/star/comment_log/20190810_node1.itcast.cn/caixukun.csv
moveFromLocal 命令
和put参数类似,但是源文件localsrc拷贝之后自身被删除
语法格式:
hdfs dfs -moveFromLocal <localsrc> <dst>
上传数据文件并自动删除本地
[root@node1 ~]# hdfs dfs -moveFromLocal caixukun.csv /source/weibo/star/comment_log/20190810_node1.itcast.cn/
[root@node1 ~]# ll
total 0
[root@node1 ~]# hdfs dfs -ls -h -R /source
drwxr-xr-x - root supergroup 0 2020-10-15 22:48 /source/weibo
drwxr-xr-x - root supergroup 0 2020-10-15 22:48 /source/weibo/star
drwxr-xr-x - root supergroup 0 2020-10-15 22:48 /source/weibo/star/comment_log
drwxr-xr-x - root supergroup 0 2020-10-15 23:04 /source/weibo/star/comment_log/20190810_node1.itcast.cn
-rw-r--r-- 3 root supergroup 30.8 M 2020-10-15 23:04 /source/weibo/star/comment_log/20190810_node1.itcast.cn/caixukun.csv需求:查看HDFS文件内容
要查看HDFS上的内容,有一种办法,我们可以先从HDFS将文件下载到Linux,然后我们用less命令、或者cat命令就可以查看了。
所以,操作步骤如下:
使用get命令,从HDFS下载文件到Linux
使用less命令,在Linux上查看下载的文件
-get
将文件拷贝到本地文件系统,可以通过指定-ignorecrc选项拷贝CRC校验失败的文件。-crc选项表示获取文件以及CRC校验文件。
语法格式:
hdfs dfs -get [-ignorecrc ] [-crc] <src> <localdst>
下载并查看
[root@node1 ~]# hdfs dfs -get /source/weibo/star/comment_log/20190810_node1.itcast.cn/caixukun.csv
[root@node1 ~]# ll
total 31500
-rw-r--r-- 1 root root 32252088 Oct 15 23:11 caixukun.csv
[root@node1 ~]# less caixukun.csv需求:直接查看HDFS中的文件内容
上面这种方法稍微有点麻烦,每次查看都得先下载,然后再查看。在HDFS中,可以使用-cat命令直接查看。
cat 命令
将参数所指示的文件内容输出到控制台。
语法格式:
hdfs dfs -cat URI [uri ...]
查看微博评论数据文件
hdfs dfs -cat /source/weibo/star/comment_log/20190810_node1.itcast.cn/caixukun.csv
我们发现,这个命令确实可以查看数据文件。但我们知道,HDFS上存储的都是很大的数据文件,这样查看一次要拉取这么大的数据输出到控制台,这是很耗时的。在生产环境中,我们要慎用。我们可以使用 head 命令,一次只查看下前1 KB的数据,它的性能更好、速度更快。或者使用 tail 命令,
head 命令
显示要输出的文件的开头的1KB数据。
语法格式:
hdfs dfs -head URI
tail 命令
显示文件结尾的1kb数据。
语法格式:
hdfs dfs -tail [-f] URI
与Linux中一样,-f选项表示数据只要有变化也会输出到控制台。
快速查看HDFS文件内容
[root@node1 ~]# hdfs dfs -head /source/weibo/star/comment_log/20190810_node1.itcast.cn/caixukun.csv
attitudes_count,comments_count,reposts_count,mid,raw_text,source,user.description,user.follow_count,user.followers_count,user.gender,user.id,user.mbrank,user.mbtype,user.profile_url,user.profile_image_url,user.screen_name,user.statuses_count,user.urank,user.verified,user.verified_reason
0,0,0,4348037901878739,也许可有可无是我的存在//@葵的妈奎的妹坤的妻:[抱抱][抱抱][抱抱][抱抱]哥哥,好想你呀@蔡徐坤,Android,,0,1,m,6974721802,0,0,https://m.weibo.cn/u/6974721802?uid=6974721802,https://tvax3.sinaimg.cn/default/images/default_avatar_male_180.gif,用户6974721802,88,4,False,
0,0,0,4348037901708511,我讨厌你中间加什么字最甜?我讨厌没你...蔡徐坤//@蔡徐坤我老公鸭://@AK47-KAKAKA:#东方风云榜让世界看见蔡徐坤#??| #蔡徐坤的未完成#,Android,,0,1,m,7011557609,0,0,https://m.weibo.cn/u/7011557609?uid=7011557609,https://tvax1.sinaimg.cn/crop.0.7.100.100.180/007EvMqRly8g0jwyht72ij302s037gls.jpg,用户7011557609,34,3,False,
0,0,0,4348037901
[root@node1 ~]# hdfs dfs -tail /source/weibo/star/comment_log/20190810_node1.itcast.cn/caixukun.csv
is wait wait wait,三星android智能手机,,0,1,m,7012474822,0,0,https://m.weibo.cn/u/7012474822?uid=7012474822,https://tvax2.sinaimg.cn/crop.0.0.640.640.180/007EzD2Cly8g0kfgdi3o9j30hs0hsq3t.jpg,专业护坤HDy295,58,3,False,
0,0,0,4348675595735533,"dei tuoi gioielli l’Orrore non è il meno attraente,",魅蓝 metal,,0,1,m,7012393763,0,0,https://m.weibo.cn/u/7012393763?uid=7012393763,https://tvax1.sinaimg.cn/crop.0.0.640.640.180/007EzhXdly8g0kb3negv1j30hs0hsgms.jpg,专业护菜X8F284,84,2,False,
0,0,0,4348677269012416,"del giorno, delle strade",前后2000万 OPPO R11,,0,1,m,7011819449,0,0,https://m.weibo.cn/u/7011819449?uid=7011819449,https://tvax3.sinaimg.cn/crop.0.0.640.640.180/007EwSy5ly8g0kb463rggj30hs0hswff.jpg,葵花宝典ot4840,84,3,False,
0,0,0,4348677256325540,"Verso di te, candela, la falena abbagliata",小米手机,,0,1,m,7011819506,0,0,https://m.weibo.cn/u/7011819506?uid=7011819506,https://tvax3.sinaimg.cn/crop.0.0.640.640.180/007EwSz0ly8g0kb43nxmbj30hs0hsdgm.jpg,陪坤左右XPj463,84,3,False,我们发现,现在很快就查看到了文件内容。
需求:拷贝一份数据到20190811目录
假设现在需要开始分析20190811这一天的用户行为信息。但分析的同时,我们需要也一并把上一天的数据加载进来。所以,此处我们需要将20190810这一天的数据,拷贝到20190811这一天的数据。
我们首先需要把 20190811 这一天的目录创建出来,然后可以开始拷贝了。
cp拷贝命令
将文件拷贝到目标路径中。如果<dest>为目录的话,可以将多个文件拷贝到该目录下。
语法格式:
hdfs dfs -cp URI [URI ...] <dest>
命令行选项:
- -f 选项将覆盖目标,如果它已经存在
- -p 选项将保留文件属性(时间戳、所有权、许可、ACL、XAttr)。
执行拷贝数据到新目录
# 创建目录
hdfs dfs -mkdir -p /source/weibo/star/comment_log/20190811_node1.itcast.cn/
# 拷贝文件
hdfs dfs -cp /source/weibo/star/comment_log/20190810_node1.itcast.cn/caixukun.csv /source/weibo/star/comment_log/20190811_node1.itcast.cn/需求:追加数据到HDFS数据文件
在数据集中有一个caixukun_new.csv数据集,是20190811这一天重新生成的数据。我们需要将这个文件上传到HDFS中。有两种做法:
直接将新文件上传到HDFS中20190811文件夹中。
将新文件追加到之前的数据文件caixukun.csv中。
这里,我们更倾向于使用第二种方案。HDFS设计的初衷就是存储超大型的文件,文件数量越少,也可以减小HDFS中的NameNode压力。
appendToFile 命令
追加一个或者多个文件到hdfs指定文件中.也可以从命令行读取输入
语法格式:
hdfs dfs -appendToFile <localsrc> ... <dst>
追加文件到HDFS已有文件中
# 1. 上传新的数据文件到Linux中
[root@node1 ~]# rz
rz waiting to receive.
?a? zmodem ′??. °′ Ctrl+C ??.
Transferring caixukun_new.csv...
100% 2755 KB 2755 KB/s 00:00:01 0 ′?
# 2. 查看HDFS现有文件大小
[root@node1 ~]# hdfs dfs -ls -h /source/weibo/star/comment_log/20190811_node1.itcast.cn/
Found 1 items
-rw-r--r-- 3 root supergroup 30.8 M 2020-10-15 23:28 /source/weibo/star/comment_log/20190811_node1.itcast.cn/caixukun.csv
# 3. 追加到HDFS现有文件
hdfs dfs -appendToFile caixukun_new.csv /source/weibo/star/comment_log/20190811_node1.itcast.cn/caixukun.csv
# 4. 再次查看HDFS文件大小
[root@node1 ~]# hdfs dfs -ls -h /source/weibo/star/comment_log/20190811_node1.itcast.cn/
Found 1 items
-rw-r--r-- 3 root supergroup 33.4 M 2020-10-15 23:44 /source/weibo/star/comment_log/20190811_node1.itcast.cn/caixukun.csv需求:查看当前HDFS磁盘空间
每一天微博都会产生很多的数据,我们非常有必要定期检查HDFS的整体磁盘空间,如果发现磁盘空间已经到达某个阈值,就需要新增新的DataNode节点了。
df 命令
df命令用来查看HDFS空闲的空间。
hdfs dfs -df [-h] URI [URI ...]
查看HDFS磁盘使用情况
[root@node1 ~]# hdfs dfs -df -h /
Filesystem Size Used Available Use%
hdfs://node1.itcast.cn:9820 346.6 G 2.1 G 236.7 G 1%需求:查看微博数据占用的空间
我们想知道当前微博数据占用了多少空间。可以使用du命令。
du 命令
显示目录中所有文件大小,当只指定一个文件时,显示此文件的大小。
语法格式:
hdfs dfs -du [-s] [-h] [-v] [-x] URI [URI ...]
命令选项:
- -s:表示显示文件长度的汇总摘要,而不是单个文件的摘要。
- -h:选项将以“人类可读”的方式格式化文件大小。
- -v:选项将列名显示为标题行。
- -x:选项将从结果计算中排除快照。
查看微博数据占用空间大小
[root@node1 ~]# hdfs dfs -du -s -h -v /source/weibo/
SIZE DISK_SPACE_CONSUMED_WITH_ALL_REPLICAS FULL_PATH_NAME
64.2 M 192.6 M /source/weibo需求:将20190810的数据移动到tmp目录
经分析程序检测,20190810这一天的数据里面存在大量垃圾数据,项目组决定,先将这些垃圾数据处理了,再放回到20190810目录中。首先需要将数据移动到tmp目录中,进行处理。
mv 命令
将hdfs上的文件从原路径移动到目标路径(移动之后文件删除),该命令不能跨文件系统。
hdfs dfs -mv URL <dest>
移动到tmp目录
[root@node1 ~]# hdfs dfs -mv /source/weibo/star/comment_log/20190810_node1.itcast.cn/caixukun.csv /tmp/caixukun_dirtydata.csv
[root@node1 ~]# hdfs dfs -ls /tmp/
Found 1 items
-rw-r--r-- 3 root supergroup 32252088 2020-10-15 23:04 /tmp/caixukun_dirtydata.csv需求:减少副本数提升存储资源利用率
HDFS中默认每个block会保存三个副本,同样一份数据需要存3份。假设,此处我们需要将 /source/weibo/start/comment_log/20190811_node1.itcast.cn 因为已经过去了很久,我们对该目录下的文件容错要求较低、而且数据使用频率也较低,所以,我们可以将它的副本数调整为2,此时我们需要使用setrep命令。
setrep 命令
hdfs dfs -setrep [-R] [-w] <numReplicas> <path>
更改文件的副本因子。 如果path是目录,则该命令以递归方式更改以path为根的目录树下所有文件的复制因子。
参数:
- -w:标志请求命令等待复制完成。 这可能会花费很长时间。
- -R:标志是为了向后兼容。 没有作用。
设置/source/weibo/star/comment_log/副本数
[root@node1 ~]# hdfs dfs -setrep -w 2 /source/weibo/star/comment_log
Replication 2 set: /source/weibo/star/comment_log/20190811_node1.itcast.cn/caixukun.csv
Waiting for /source/weibo/star/comment_log/20190811_node1.itcast.cn/caixukun.csv ...
WARNING: the waiting time may be long for DECREASING the number of replications.
. done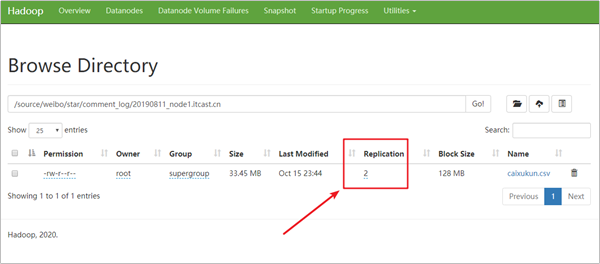
更多shell操作
| 命令 | 说明 | |
|---|---|---|
| checksum | 返回文件的校验和信息。 | |
| [root@node1 ~]# hdfs dfs -checksum /source/weibo/star/comment_log/20190811_node1.itcast.cn/caixukun.csv /source/weibo/star/comment_log/20190811_node1.itcast.cn/caixukun.csv MD5-of-0MD5-of-512CRC32C 000002000000000000000000d79e10d1da5484d351f7c9776849c3bb | ||
| copyFromLocal | 与put命令类似,将本地文件拷贝到HDFS。但put命令可以传多个文件、或者是标准输入(-) | |
| [root@node1 ~]# hdfs dfs -copyFromLocal caixukun_new.csv /tmp [root@node1 ~]# hdfs dfs -ls /tmp Found 3 items -rw-r—r— 3 root supergroup 32252088 2020-10-15 23:04 /tmp/caixukun_dirtydata.csv -rw-r—r— 3 root supergroup 2821683 2020-10-16 09:24 /tmp/caixukun_new.csv -rw-r—r— 3 root supergroup 24 2020-10-16 09:21 /tmp/test | ||
| copyToLocal | 与get命令类似,但只拷贝到一个本地文件 | |
| [root@node1 ~]# hdfs dfs -copyToLocal /tmp/test [root@node1 ~]# ll total 34260 -rw-r—r— 1 root root 32252088 Oct 15 23:11 caixukun.csv -rw-r—r— 1 root root 2821683 Oct 15 23:29 caixukun_new.csv -rw-r—r— 1 root root 24 Oct 16 09:28 test | ||
| count | 计算与指定文件模式匹配的路径下的目录,文件和字节数。 获取配额和使用情况。 具有-count的输出列是:DIR_COUNT,FILE_COUNT,CONTENT_SIZE,PATHNAME | |
| [root@node1 ~]# hdfs dfs -count -q -v -h /source QUOTA REM_QUOTA SPACE_QUOTA REM_SPACE_QUOTA DIR_COUNT FILE_COUNT CONTENT_SIZE PATHNAME none inf none inf 6 1 33.4 M /source | ||
| find | 查找与指定表达式匹配的所有文件,并对它们应用选定的操作。 如果未指定路径,则默认为当前工作目录。 如果未指定表达式,则默认为-print。 | |
| [root@node1 ~]# hdfs dfs -find / -name “caixukun*“ -print /source/weibo/star/comment_log/20190811_node1.itcast.cn/caixukun.csv /tmp/caixukun_dirtydata.csv /tmp/caixukun_new.csv | ||
| getfattr | 显示文件或目录的扩展属性名称和值。 | |
| setfattr | 设置文件或目录的扩展属性名称和值。 | |
| getmerge | 下载多个HDFS上的文件并合并为1个文件 | |
| stat | 以指定格式打印有关<path>上文件/目录的统计信息。 hdfs dfs -stat “type:%F perm:%a %u:%g size:%b mtime:%y atime:%x name:%n” / |
|
| test | 测试,判断是否存在、是否是文件夹、是否是文件、是有有读权限、写权限等 | |
| text | 获取源文件并以文本格式输出文件。 允许的格式是zip和TextRecordInputStream。 | |
| touch | 在HDFS上创建一个新的文件,并可以指定访问时间、修改时间、 | |
| touchz | 创建一个空文件。 如果文件存在,则返回错误。 | |
| truncate | 将与指定文件截断为指定长度。 [root@node1 ~]# hdfs dfs -truncate -w 10485760 /tmp/caixukun_dirtydata.csv Waiting for /tmp/caixukun_dirtydata.csv … Truncated /tmp/caixukun_dirtydata.csv to length: 10485760 | |
| usage | 返回某个命令的帮助 [root@node1 ~]# hdfs dfs -usage rm Usage: hadoop fs [generic options] -rm [-f] [-r\ | -R] [-skipTrash] [-safely] <src> … |
详细用法请参考官方文档:
https://hadoop.apache.org/docs/r3.1.4/hadoop-project-dist/hadoop-common/FileSystemShell.html
舆情数据上报

网络舆情监控系统利用互联网信息采集、智能信息处理技术(文本挖掘技术)和全文检索技术,对境内外网络中的新闻网页、论坛、博客、新闻评论,贴吧等网络资源进行精确采集、定向采集和智能分析,提供舆情信息检索、热点信息的发现、热点跟踪定位、敏感信息监控、辅助决策支持、舆情实时预警、舆情监管、统计分析等多层次、多维度的舆情信息的服务,实现用户的网络舆情监测和定向追踪等信息需求,形成简报、报告、图表等分析结果,从而帮助政府、企业及时掌握舆情动向,准确捕捉预警信息,对有较大影响的重要事件快速发现、快速处理,从正面引导舆论和宣传,构建积极向上的主流舆论,并为政府、企业决策提供信息依据。实现对舆情分析提出的目标。

接下来,我们会通过HDFS的Java API来实现该定时上报程序。
HDFS操作 - Java客户端
介绍
HDFS在生产应用中主要是客户端的开发,其核心步骤是从HDFS提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件。
配置Windows下Hadoop环境
问题
在windows上做HDFS客户端应用开发,需要设置Hadoop环境,而且要求是windows平台编译的Hadoop,不然会报以下的错误:
缺少winutils.exe
Could not locate executable null \bin\winutils.exe in the hadoop binaries
缺少hadoop.dll
Unable to load native-hadoop library for your platform… using builtin-Java classes where applicable
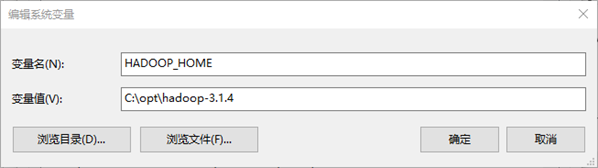
搭建步骤
将已经编译好的Windows版本Hadoop解压到到一个没有中文没有空格的路径下面
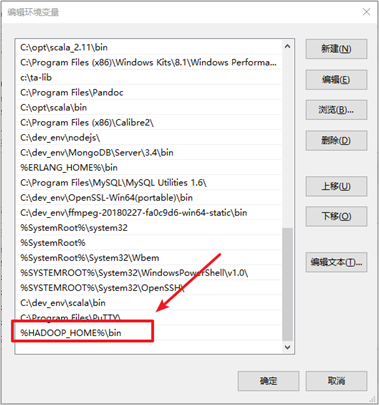
在windows上面配置hadoop的环境变量: HADOOP_HOME,并将%HADOOP_HOME%\bin添加到path中
配置HADOOP_HOME
配置PATH目录
3.把hadoop3.1.4文件夹中bin目录下的hadoop.dll文件放到系统盘: C:\Windows\System32 目录。
创建项目
在IDEA中创建项目:

导入Maven依赖
<repositories>
<repository>
<id>cental</id>
<url>http://maven.aliyun.com/nexus/content/groups/public//</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
<updatePolicy>always</updatePolicy>
<checksumPolicy>fail</checksumPolicy>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<!-- Google Options -->
<dependency>
<groupId>com.github.pcj</groupId>
<artifactId>google-options</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<configuration>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>jar-with-dependencies</shadedClassifierName>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.itcast.sentiment_upload.Entrance</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>从虚拟机下载Hadoop配置文件
cd /export/server/hadoop-3.1.4/etc/hadoop
sz core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml
到windows的下载目录找到这4个文件,并放入到IDEA项目的resources文件夹中。
并将资料中的log4j.properties复制到resources目录中。
创建代码包结构
在test/java目录中创建包:cn.itcast.sentiment_upload
| 包名 | 说明 |
|---|---|
| cn.itcast.sentiment_upload.arg | 处理命令行参数 |
| cn.itcast.sentiment_upload.dfs | 存放操作HDFS的工具类 |
| cn.itcast.sentiment_upload.task | 处理文件上传任务 |
关联Hadoop源代码
点击IDEA中的【Navigate】菜单,再点击【Class…】菜单
输入【FileSystem】搜索
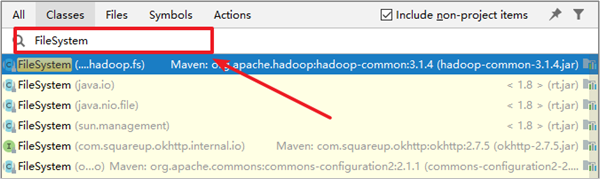
3.点击【Choose Sources…】
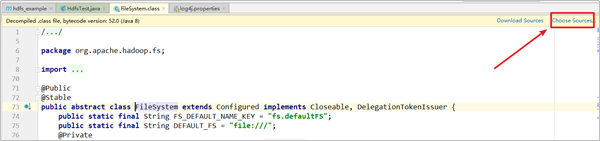
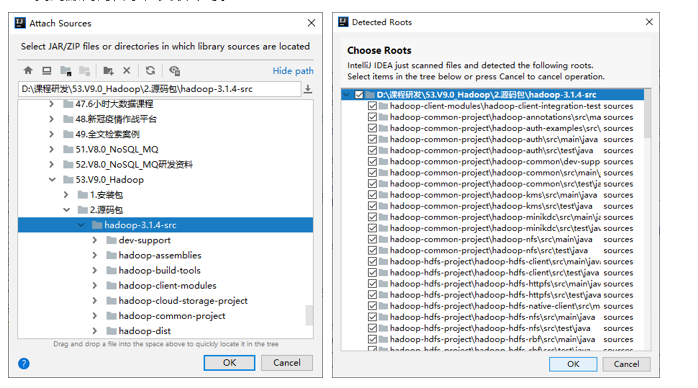
4.找到源代码目录,关联即可。
Log4j
Log4j介绍
简介
- 每个大型应用程序都包含其自己的日志记录或跟踪API。在1996年初,SEMPER项目决定编写自己。这是。经过多次改进和大量工作之后,API演变成了log4j,这是Java的流行日志记录库。该软件包是根据Apache Software License(Apache软件许可)分发的,而且,log4j已移植到C,C ++,C#,Perl,Python,Ruby和Eiffel语言。
- 将日志记录插入代码是调试的低成本技术方法,也可能是唯一的方法,因为调试器并不总是可用的。对于多线程应用程序和整个分布式应用程序通常是这种情况。
- 经验表明,日志记录是开发周期的重要组成部分。它具有几个优点
- 它提供有关应用程序运行的精确上下文。一旦插入到代码中,就无需人工干预即可生成日志输出。
- 日志输出可以保存在永久性介质中,以便以后进行研究。除了在开发周期中使用它外,足够丰富的日志记录包也可以视为审核工具。
- 在《The Practice of Programming》书中作者写到:
作为个人选择,我们倾向于不使用调试器而不只是获得堆栈跟踪或一个或两个变量的值。 原因之一是很容易在复杂的数据结构和控制流的细节上迷失方向。 我们发现,单步执行程序的效率不如认真思考,并在关键位置添加输出语句和自检代码。点击结束语句所花费的时间比查看明智放置的打印输出所花费的时间更长。 即使单步进入代码的关键部分,决定打印语句的位置所需的时间也更少,即使假设我们知道该位置。 更重要的是,调试语句保留在程序中,调试会话是暂时的。
官网
Log4j 2.x:https://logging.apache.org/log4j/2.x/(新版本)
Log4j 1.2:http://logging.apache.org/log4j/1.2/ (旧版本,很多大数据框架还在使用1.x版本)
(2015年8月5日,日志记录服务项目管理委员会宣布Log4j 1.x使用寿命到期。建议Log4j 1的用户升级到Apache Log4j 2)
Log4j三大组件
Log4j具有三个主要组件:
- Logger
- Appender
- Layout
这三种类型的组件协同工作,使开发人员能够根据消息类型和级别记录消息,并在运行时控制如何格式化这些消息以及在何处报告它们。
与一般System.out.println相比,任何日志记录API的第一个也是最重要的优势在于它能够禁用某些日志语句,同时允许其他日志不受阻碍地进行打印。
Logger组件
分层命名
Logger是有名称的组件。记录器名称区分大小写,并且遵循分层命名规则:
如果一个Logger的名称后跟一个点,则该Logger是另一个Logger的祖先,该后跟点的名称是该子Logger名称的前缀。 如果Logger与Logger之间没有祖先,则称该Logger为子Logger的父项。
例如,名为“ com.foo”的记录器是名为“ com.foo.Bar”的记录器的父级。 同样,“ java”是“ java.util”的父级,也是“ java.util.Vector”的祖先。大多数开发人员都熟悉这种命名方案。
Root Logger
Root Logger位于记录器层次结构的顶部, Root Logger是一直存在的。
Appender和Layout
- Log4j允许记录请求打印到多个目标。用log4j来说,输出目标称为appender。当前,存在用于控制台、文件、GUI组件、远程套接字服务器、JMS、NT事件记录器和远程UNIX Syslog 守护程序的附加程序。
- 一个Logger可以附加多个Appender
- 通常,开发人员不仅希望自定义输出目标,还希望自定义输出格式。通过Layout与Appender相关联来实现的。Layout负责根据用户的需求格式化日志记录请求,而Appender负责将格式化后的输出发送到其目的地。
- 配置示例
log4j.rootLogger = debug,stdout,R
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
#模式输出呼叫者的文件名和行号。
log4j.appender.stdout.layout.ConversionPattern =%5p [%t] (%F:%L) -%m%n
log4j.appender.R = org.apache.log4j.RollingFileAppender
log4j.appender.R.File = example.log
log4j.appender.R.MaxFileSize = 100KB
#保留一个备份文件
log4j.appender.R.MaxBackupIndex = 1
log4j.appender.R.layout = org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern =%p%t%c-%m%n日志的使用方式
调用LogManager.getLogger,然后调用info、debug输出录制
日志的级别
TRACE
与DEBUG相比,TRACE级别指定的信息事件更详细
DEBUG
DEBUG级别指定对调试应用程序最有用的细粒度信息事件。
INFO
INFO级别指定信息性消息,以粗粒度级别突出显示应用程序的进度。
WARN
WARN级别表示潜在的有害情况。
ERROR
ERROR级别指定错误事件,这些错误事件可能仍允许应用程序继续运行。
FATAL
FATAL级别指定非常严重的错误事件,可能会导致应用程序中止。
其他层次的Logger会自动从RootLogger或者它的父级继承日志级别
在程序中使用Log4j
为了方便将来排错,引入Log4j来作为日志输出。因为HDFS中的依赖自动包含了Log4j,我们可以直接添加一个log4j的配置文件直接使用日志功能
// 创建一个Logger
protected static final Logger Logger = LogManager.getLogger(Entrance.class);
实现HDFS操作类
创建接口以及实现类
在cn.itcast.sentiment_upload.dfs创建一个HDFSMgr接口,该类定义了操作HDFS的相关方法。
在cn.itcast.sentiment_upload.dfs创建一个实现HDFSMgr的实现类HDFSMgrImpl。
HDFS操作接口
HFDS操作接口包含了以下操作需要我们实现:
读取某个目录下的所有文件
上传文件到指定位置
从HDFS上下载文件到本地
创建目录
关闭操作HDFS的FileSystem
参考代码:
/**
* HFDS操作接口
*/
public interface HDFSMgr {
/**
* 读取某个目录下的所有文件
*
* @param recursion 是否递归读取
*/
List<String> ls(String path, boolean recursion);
/**
* 上传文件到指定位置
* @param src 原始文件
* @param dest 目标位置
*/
void put(String src, String dest);
/**
* 从HDFS上下载文件到本地
* @param src HDFS上的路径
* @param destLocal 本地位置
*/
void get(String src, String destLocal);
/**
* 创建目录
* @param path 目标路径
*/
void mkdir(String path);
/**
* 关闭操作HDFS的FileSystem
*/
void close();
}HDFS API介绍
涉及的主要类
在Java中操作HDFS,主要涉及以下Class:
- Configuration:该类的对象封转了客户端或者服务器的配置
- FileSystem:该类的对象是一个文件系统对象,可以用该对象的一些方法来对文件进行操作,通过FileSystem的静态方法get获得该对象。
FileSystem fs = FileSystem.get(conf);
- get方法从conf中的一个参数 fs.defaultFS的配置值判断具体是什么类型的文件系统。如果我们的代码中没有指定fs.defaultFS,并且工程classpath下也没有给定相应的配置,conf中的默认值就来自于hadoop的jar包中的core-default.xml,默认值为: file:///,则获取的将不是一个DistributedFileSystem的实例,而是一个本地文件系统的客户端对象。
Java API官方文档:
https://hadoop.apache.org/docs/r3.1.4/api/index.html
获取FileSystem方式
第一种方式
@Test
public void getFileSystem1() throws IOException {
Configuration configuration = new Configuration();
//指定我们使用的文件系统类型:
configuration.set("fs.defaultFS", "hdfs://node1:8020/");
//获取指定的文件系统
FileSystem fileSystem = FileSystem.get(configuration);
System.out.println(fileSystem.toString());
}第二种方式
@Test
public void getFileSystem2() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node1:8020"), new Configuration());
System.out.println("fileSystem:"+fileSystem);
}API: 读取某个目录下的所有文件
初始化实现类
实现步骤:
创建用于输出日志的Logger
加载配置文件
使用FileSystem.get(configuration)获取FileSystem对象,后续我们将使用它来操作HDFS。
/**
* Returns the configured FileSystem implementation.
* @param conf the configuration to use
*/
public static FileSystem get(Configuration conf) throws IOException {
return get(getDefaultUri(conf), conf);
}参考代码:
public class HDFSMgrImpl implements HDFSMgr {
protected static Logger Logger = LogManager.getLogger(HDFSMgrImpl.class.getName());
private Configuration configuration;
private FileSystem fileSystem;
public HDFSMgrImpl() {
try {
configuration = new Configuration();
fileSystem = FileSystem.get(configuration);
} catch (IOException e) {
Logger.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}
……
}编写实现
实现步骤:
- 使用FileSystem.listFiles来遍历读取HDFS路径
/**
* List the statuses and block locations of the files in the given path.
* Does not guarantee to return the iterator that traverses statuses
* of the files in a sorted order.(不保证文件的顺序)
*
* <pre>
* If the path is a directory,
* if recursive is false, returns files in the directory;
* if recursive is true, return files in the subtree rooted at the path.
* If the path is a file, return the file's status and block locations.
* </pre>
* @param f is the path
* @param recursive if the subdirectories need to be traversed recursively
*
* @return an iterator that traverses statuses of the files
*/
public RemoteIterator<LocatedFileStatus> listFiles(
final Path f, final boolean recursive)2.遍历所有的文件,将文件的路径添加到一个ArrayList,并返回
参考代码:
@Override
public List<String> ls(String path, boolean recursion) {
try {
// 指定遍历某个HDFS路径
RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(new Path(path), recursion);
ArrayList<String> fileList = new ArrayList<>();
while(iterator.hasNext()) {
LocatedFileStatus fileStatus = iterator.next();
// 获取文件的路径
fileList.add(fileStatus.getPath().toString());
}
return fileList;
} catch (IOException e) {
Logger.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}文件权限问题
我们发现程序在运行时,打印了一些异常:
org.apache.hadoop.security.AccessControlException: Permission denied: user=China, access=READ_EXECUTE, inode="/mr-history":root:supergroup:drwxrwx---异常信息为:user=China针对/mr-history没有权限。
我们可以配置IDEA运行配置选项,添加一个环境变量HADOOP_USER_NAME为root即可。
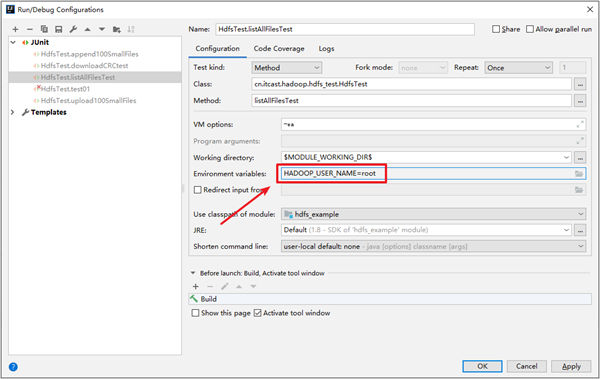
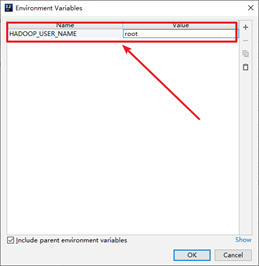
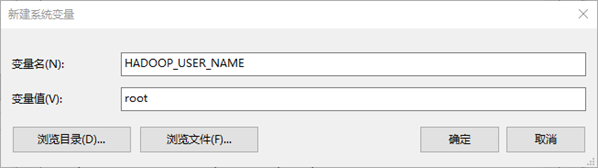
或者直接设置系统的环境变量,添加HADOOP_USER_NAME为root,后续我们开发将无需再配置用户名了。
API:实现关闭文件系统
调用FileSystem的close方法关闭文件系统,一旦关闭FileSystem实例将无法再使用了。
/**
* Close this FileSystem instance.
* Will release any held locks(释放所有的锁), delete all files queued for deletion
* through calls to {@link #deleteOnExit(Path)}, and remove this FS instance
* from the cache, if cached.
*
* After this operation, the outcome of any method call on this FileSystem
* instance, or any input/output stream created by it is <i>undefined</i>.
* @throws IOException IO failure
*/
@Override
public void close()参考代码:
/**
* 关闭文件系统
*/
@Override
public void close() {
try {
fileSystem.close();
} catch (IOException e) {
Logger.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}API:上传文件
使用copyFromLocalFile将文件上传到HDFS中。
/**
* The src file is on the local disk. Add it to the filesystem at
* the given dst name.
* delSrc indicates if the source should be removed
* @param delSrc whether to delete the src
* @param overwrite whether to overwrite an existing file
* @param src path
* @param dst path
* @throws IOException IO failure
*/
public void copyFromLocalFile(boolean delSrc, boolean overwrite,
Path src, Path dst)参考代码:
/**
* 上传文件到HDFS
*/
@Override
public void put(String src, String dest) {
try {
fileSystem.copyFromLocalFile(false, true, new Path(src), new Path(dest));
} catch (IOException e) {
Logger.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}API:从HDFS下载文件
使用copyToLocalFile从远程的文件系统下载到本地。
/**
* Copy it a file from the remote filesystem to the local one.
* @param src path src file in the remote filesystem
* @param dst path local destination
* @throws IOException IO failure
*/
public void copyToLocalFile(Path src, Path dst)参考代码:
@Override
public void get(String src, String destLocal) {
try {
fileSystem.copyToLocalFile(new Path(src), new Path(destLocal));
} catch (IOException e) {
Logger.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}API:创建文件夹
先判断路径是否存在,如果已经存在,直接返回
如果目录不存在,则使用mkdirs创建目录
/**
* Call {@link #mkdirs(Path, FsPermission)} with default permission.
* @param f path
* @return true if the directory was created
* @throws IOException IO failure
*/
public boolean mkdirs(Path f) throws IOException {
return mkdirs(f, FsPermission.getDirDefault());
}
/**
* Make the given file and all non-existent parents into
* directories. Has roughly the semantics of Unix @{code mkdir -p}.
* Existence of the directory hierarchy is not an error.
* @param f path to create
* @param permission to apply to f
* @throws IOException IO failure
*/
public abstract boolean mkdirs(Path f, FsPermission permission
) throws IOException;参考代码:
/**
* 创建文件夹
*/
@Override
public void mkdir(String path) {
try {
// 判断文件夹是否存在
if (fileSystem.exists(new Path(path))) {
return;
}
// 在HDFS中创建目录
fileSystem.mkdirs(new Path(path));
} catch (IOException e) {
Logger.error(e.getMessage(), e);
throw new RuntimeException(e);
}
}实现思路分析
使用Google Option解析命令行参数。
读取要采集的数据目录,生成上传任务,上传任务包含一个任务文件,该文件包含了要上传哪些文件到HDFS上。
执行任务,读取要上传的任务文件,挨个将任务文件中的文件上传到HDFS。上传中、上传完毕需要给任务文件添加特别的标识。
Google option命令行参数解析
为了实现程序的灵活性,可以手动指定从哪儿采集数据、以及配置上报到HDFS上什么样的位置。因为要从命令行中接收参数,此处使用Google-option来进行解析。以下是Google-option的github地址:https://github.com/pcj/google-options。
Google-option介绍
Google-option这是Bazel Project中的命令行参数解析器。 com.google.devtools.common.options程序包已拆分为一个单独的jar,用于通用实用程序。
Bazel:是Google开源的构建工具,它的速度非常快,是Maven的5倍以上。采用了Cache和增量构建。修改一行代码,Bazel只需要0.5s,但Maven需要重新构建一次。Bazel可以比较容易扩展至其他语言,原生支持Java、C++,现在还支持Rust、Go、Scala等
安装Google Option
<dependency>
<groupId>com.github.pcj</groupId>
<artifactId>google-options</artifactId>
<version>1.0.0</version>
</dependency>使用方式
- 创建一个类用于定义所有的命令行选项,这个类需要从OptionBase继承
package example;
import com.google.devtools.common.options.Option;
import com.google.devtools.common.options.OptionsBase;
import java.util.List;
/**
* Command-line options definition for example server.
*/
public class ServerOptions extends OptionsBase {
@Option(
name = "help",
abbrev = 'h',
help = "Prints usage info.",
defaultValue = "true"
)
public boolean help;
@Option(
name = "host",
abbrev = 'o',
help = "The server host.",
category = "startup",
defaultValue = ""
)
public String host;
@Option(
name = "port",
abbrev = 'p',
help = "The server port.",
category = "startup",
defaultValue = "8080"
)
public int port;
@Option(
name = "dir",
abbrev = 'd',
help = "Name of directory to serve static files.",
category = "startup",
allowMultiple = true,
defaultValue = ""
)
public List<String> dirs;
}2.解析这些参数并使用它们
package example;
import com.google.devtools.common.options.OptionsParser;
import java.util.Collections;
public class Server {
public static void main(String[] args) {
OptionsParser parser = OptionsParser.newOptionsParser(ServerOptions.class);
parser.parseAndExitUponError(args);
ServerOptions options = parser.getOptions(ServerOptions.class);
if (options.host.isEmpty() || options.port < 0 || options.dirs.isEmpty()) {
printUsage(parser);
return;
}
System.out.format("Starting server at %s:%d...\n", options.host, options.port);
for (String dirname : options.dirs) {
System.out.format("\\--> Serving static files at <%s>\n", dirname);
}
}
private static void printUsage(OptionsParser parser) {
System.out.println("Usage: java -jar server.jar OPTIONS");
System.out.println(parser.describeOptions(Collections.<String, String>emptyMap(),
OptionsParser.HelpVerbosity.LONG));
}
}开发舆情上报程序参数解析
使用GoogleOption创建参数实体类
在cn.itcast.sentiment_upload.arg包下创建一个SentimentOptions类,并从OptionsBase继承
定义以下几个参数
(1) 帮助,可以显示命令的帮助信息 help h 默认参数
(2) 要采集数据的位置 source s
(3) 生成待上传的临时目录 temp_dir t “/tmp/sentiment”
(4) 生成要上传到的HDFS路径 output o
参考代码:
import com.google.devtools.common.options.Option;
import com.google.devtools.common.options.OptionsBase;
/**
* 参数实体类
* (1) 帮助,可以显示命令的帮助信息 help h 默认参数
* (2) 要采集数据的位置 source s
* (3) 生成待上传的临时目录 temp_dir t "/tmp/sentiment"
* (4) 生成要上传到的HDFS路径 output o
*/
public class SentimentOptions extends OptionsBase {
@Option(
name = "help",
abbrev = 'h',
help = "打印帮助信息",
defaultValue = "true"
)
public boolean help;
@Option(
name = "source",
abbrev = 's',
help = "要采集数据的位置",
defaultValue = ""
)
public String sourceDir;
@Option(
name = "pending_dir",
abbrev = 'p',
help = "生成待上传的待上传目录",
defaultValue = "/tmp/pending/sentiment"
)
public String pendingDir;
@Option(
name = "output",
abbrev = 'o',
help = "生成要上传到的HDFS路径",
defaultValue = ""
)
public String output;
}在main方法中解析参数
/**
* 应用程序入口
*/
public class Entrance {
// 创建一个Logger
protected static final Logger Logger = LogManager.getLogger(Entrance.class.getName());
public static void main(String[] args) {
// 解析命令行参数
OptionsParser parser = OptionsParser.newOptionsParser(SentimentOptions.class);
parser.parseAndExitUponError(args);
SentimentOptions options = parser.getOptions(SentimentOptions.class);
// 判断参数如果为空,则打印帮助信息
if (options.sourceDir.isEmpty() || options.output .isEmpty()) {
printUsage(parser);
return;
}
}
private static void printUsage(OptionsParser parser) {
System.out.println("Usage: java -jar sentiment.jar OPTIONS");
System.out.println(parser.describeOptions(Collections.<String, String>emptyMap(),
OptionsParser.HelpVerbosity.LONG));
}
}实现生成数据采集任务
在cn.itcast.sentiment_upload.task包下创建TaskMgr源文件。先实现生成数据上报任务。
实现步骤:
判断原始数据目录是否存在
读取原始数据目录下的所有文件
判断待上传目录是否存在,不存在则创建一个
创建任务目录(目录名称:task年月日时分秒任务状态)
遍历待上传的文件,在待上传目录生成一个willDoing文件
将待移动的文件添加到willDoing文件中
参考代码:
public class TaskMgr {
protected static Logger Logger = LogManager.getLogger(TaskMgr.class.getName());
private HDFSMgr hdfsUtil;
public TaskMgr() {
hdfsUtil = new HDFSMgrImpl();
}
/**
* 2. 生成待上传目录
* 2.1 读取原始数据目录下的所有文件
* 2.2 判断文件格式是否匹配 weibo_data_*
* 2.3 创建一个任务目录,目录名为task_年月日时分秒
* 2.4 在待上传目录生成一个willDoing文件(文件名:willDoing_日期时间)
* 2.5 将文件移动到待上传的临时目录(文件名_日期时间.扩展名)
* 2.6 将待移动的文件添加到willDoing文件中
*/
public void genTask(SentimentOptions options) {
// 判断原始数据目录是否存在
File sourceDir = new File(options.sourceDir);
if(!sourceDir.exists()) {
String errorMsg = String.format("%s 要采集的原始数据目录不存在.", options.sourceDir);
Logger.error(errorMsg);
throw new RuntimeException(errorMsg);
}
// 读取原始数据目录下的所有文件
File[] allSourceDataFile = sourceDir.listFiles(f -> {
// 判断文件格式是否以 weibo_data_ 开头
String fileName = f.getName();
if (fileName.startsWith("weibo_data_")) {
return true;
}
return false;
});
// 判断待上传目录是否存在,不存在则创建一个
File tempDir = new File(options.pendingDir);
if(!tempDir.exists()) {
try {
FileUtils.forceMkdirParent(tempDir);
} catch (IOException e) {
Logger.error(e.getMessage(), e);
throw new RuntimeException(e.getMessage());
}
}
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmss");
StringBuilder stringBuilder = new StringBuilder();
// 创建任务目录(目录名称:task_年月日时分秒_任务状态
File taskDir = null;
// 判断数据文件是否为空
if(allSourceDataFile != null && allSourceDataFile.length > 0) {
taskDir = new File(tempDir, String.format("task_%s", sdf.format(new Date())));
taskDir.mkdir();
}
else {
return;
}
// 遍历待上传的文件
// 在待上传目录生成一个willDoing文件
for (File dataFile : allSourceDataFile) {
try {
File destFile = new File(taskDir, dataFile.getName());
FileUtils.moveFile(dataFile, destFile);
// 将文件的绝对路径保存下来
stringBuilder.append(destFile.getAbsoluteFile() + "\n");
} catch (IOException e) {
Logger.error(e.getMessage(), e);
}
}
// 将待移动的文件添加到willDoing文件中
try {
String taskName = String.format("willDoing_%s", sdf.format(new Date()));
FileUtils.writeStringToFile(new File(tempDir, taskName)
, stringBuilder.toString()
, "utf-8");
} catch (IOException e) {
Logger.error(e.getMessage(), e);
}
}
}实现执行数据上报任务
实现步骤:
读取待上传目录的willDoing任务文件,注意过滤COPY和DONE后的任务文件夹
遍历读取任务文件,开始上传
a) 将任务文件修改为_COPY,表示正在处理中
b) 获取任务的日期
c) 判断HDFS目标上传目录是否存在,不存在则创建
d) 读取任务文件
e) 按照换行符切分
f) 上传每一个文件,调用HDFSUtils进行数据文件上传
g) 上传成功后,将
_COPY后缀修改为_DONE
参考代码:
public void work(SentimentOptions options) {
// 3. 处理任务
// 3.1 读取待上传目录的willDoing任务文件,注意过滤COPY和DONE后的任务文件夹
File pendingDir = new File(options.pendingDir);
File[] pendingTaskDir = pendingDir.listFiles(f -> {
String taskName = f.getName();
// 文件是以willDoing开头的
if(!taskName.startsWith("willDoing")) return false;
if (taskName.endsWith(COPY_STATUS) || taskName.endsWith(DONE_STATUS)) {
return false;
} else {
return true;
}
});
// 3.2 遍历读取任务文件,开始上传
for (File pendingTask : pendingTaskDir) {
try {
// 将任务文件修改为_COPY,表示正在处理中
File copyTaskFile = new File(pendingTask.getAbsolutePath() + "_" + COPY_STATUS);
FileUtils.moveFile(pendingTask, copyTaskFile);
// 获取任务的日期
String taskDate = pendingTask.getName().split("_")[1];
String dataPathInHDFS = options.output + String.format("/%s", taskDate);
// 判断HDFS目标上传目录是否存在,不存在则创建
hdfsUtil.mkdir(dataPathInHDFS);
// 读取任务文件
String tasks = FileUtils.readFileToString(copyTaskFile, "utf-8");
// 按照换行符切分
String[] taskArray = tasks.split("\n");
// 上传每一个文件
for (String task : taskArray) {
// 调用HDFSUtils进行数据文件上传
hdfsUtil.put(task, dataPathInHDFS);
}
// 上传成功后,将_COPY后缀修改为_DONE
File doneTaskFile = new File(pendingTask.getAbsolutePath() + "_" + DONE_STATUS);
FileUtils.moveFile(copyTaskFile, doneTaskFile);
} catch (IOException e) {
Logger.error(e.getMessage(), e);
}
}
}项目打包
项目使用shade插件打包
shade插件可以将所有的jar打到一个jar包中。
需要导入以下依赖:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<configuration>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>jar-with-dependencies</shadedClassifierName>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.itcast.sentiment_upload.Entrance</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>执行打包,并创建一个目录,使用以下shell脚本来驱动jar包执行。
#!/bin/bash
export SENTIMENT_HOME=/root/sentiment_upload
export JAVA_HOME=/export/server/jdk1.8.0_241
export JAVA_CMD="${JAVA_HOME}/bin/java"
export JAVA_OPS="-jar ${SENTIMENT_HOME}/sentiment_upload-1.0-SNAPSHOT-jar-with-dependencies.jar"
SOURCE_DIR=$1
PENDING_DIR=$2
OUTPUT_DIR=$3
if [ ! $SOURCE_DIR ] || [ ! $OUTPUT_DIR ]; then
${JAVA_CMD} ${JAVA_OPS} -h
exit;
fi
if [ ! $PENDING_DIR ] ; then
${JAVA_CMD} ${JAVA_OPS} -s $SOURCE_DIR -o $OUTPUT_DIR
exit;
fi
${JAVA_CMD} ${JAVA_OPS} -s $SOURCE_DIR -p ${PENDING_DIR} -o $OUTPUT_DIR注意事项:
# 注意Jar包中有一个service目录,里面有org.apache.hadoop.filesystem,里面要有对HDFS的支持
# 需要添加以下支持
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
windows测试
java -jar sentiment_upload-1.0-SNAPSHOT-jar-with-dependencies.jar cn.itcast.sentiment_upload.Entrance -s D:\课程研发\53.V9.0_Hadoop\2.HDFS应用\3.代码\sentiment_upload\data\source -p D:\课程研发\53.V9.0_Hadoop\2.HDFS应用\3.代码\sentiment_upload\data\pending -o /source/sentiment/weibo/Linux测试
./sentiment_upload.sh --source /root/sentiment_upload/source --output /source/sentiment/weibo --pending_dir /root/sentiment_upload/pending扩展:LibHDFS客户端
概述
- Libhdfs是用于Hadoop的分布式文件系统(HDFS)的基于JNI的C API。
- 它为HDFSAPI的一个子集提供了C API,以操作HDFS文件和文件系统。
- Libhdfs是Hadoop发行版的一部分,并在
$Hadoop_HDFS_HOME/lib/本地/libhdfs.so - Libhdfs与Windows兼容,可以通过运行
MVN编译在Hadoop-HDFS-project/Hadoop-HDFS源树的目录。`
API
- Libhdfs API是Hadoop文件系统API.
- Libhdfs的头文件详细描述了每个api,并在$Hadoop_hdfs_home/include/hdfs.h.
示例程序
#include "hdfs.h"
int main(int argc, char **argv) {
hdfsFS fs = hdfsConnect("default", 0);
const char* writePath = "/tmp/testfile.txt";
hdfsFile writeFile = hdfsOpenFile(fs, writePath, O_WRONLY |O_CREAT, 0, 0, 0);
if(!writeFile) {
fprintf(stderr, "Failed to open %s for writing!\n", writePath);
exit(-1);
}
char* buffer = "Hello, World!";
tSize num_written_bytes = hdfsWrite(fs, writeFile, (void*)buffer, strlen(buffer)+1);
if (hdfsFlush(fs, writeFile)) {
fprintf(stderr, "Failed to 'flush' %s\n", writePath);
exit(-1);
}
hdfsCloseFile(fs, writeFile);
}链接库
请参阅cmake文件测试libhdfs_ops.c在libhdfs源目录中(Hadoop-hdfs-project/hadoop-hdfs/src/CMakeLists``线程.txt)或类似于:GCC以上_sample.c-i$Hadoop_HDFS_HOME/包括-L$Hadoop_HDFS_HOME/lib/本机-lhdfs-o以上样本
线程安全
Libdhfs是线程安全的。
- 并发和Hadoop FS“句柄”
- HadoopFS实现包括一个FS句柄缓存,该缓存基于NameNode的URI以及用户连接进行缓存。所以,所有调用HdfsConnect将返回相同的句柄,但调用HdfsConnectAsUser不同的用户将返回不同的句柄。但是,由于HDFS客户端句柄是完全线程安全的,这对并发性没有影响。
- 并发和libhdfs/jni
- 对JNI的libhdfs调用应该总是创建线程本地存储,因此(理论上),libhdfs应该与对HadoopFS的底层调用一样是线程安全的
 微信
微信 支付宝
支付宝








