HDFS数据存储与数据管理
HDFS数据存储与数据管理
HDFS REST HTTP API
我们之前所学习的HDFS shell客户端和Java客户端,都客户端上安装了HDFS客户端。之前我们在windows上也配置了HDFS的windows版本客户端,否则,我们将无法操作HDFS。而且,客户端的版本如果不匹配,有可能会导致无法操作。
如果我们想要在没有安装HDFS客户端的机器上操作该如何呢?譬如以下场景:
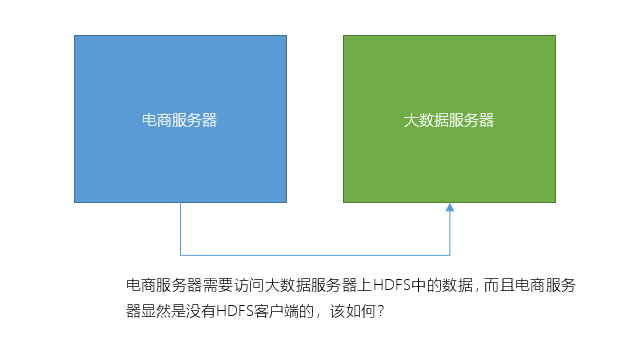
接下来,我们将学习几种基于HTTP协议的客户端,HTTP是跨平台的,它不要求客户端上必须安装Hadoop,就可以直接操作HDFS。
WebHDFS
简介
WebHDFS其实是HDFS提供的HTTP RESTFul API接口,并且它是独立于Hadoop的版本的,它支持HDFS的完整FileSystem / FileContext接口。它可以让客户端发送http请求的方式来操作HDFS,而无需安装Hadoop。
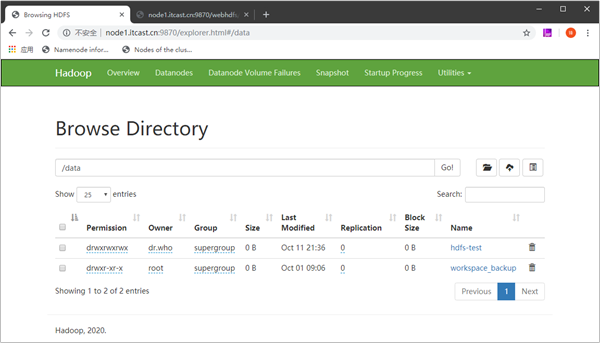
在我们经常使用的HDFS Web UI,它就是基于webhdfs来操作HDFS的。
关于RESTful
REST

- REST(表现层状态转换,英语:Representational State Transfer)是Roy Thomas Fielding博士于2000年在博士论文中提出来的一种万维网软件架构风格,目的是便于不同软件/程序在网络(例如互联网)中互相传递信息。
- REST是基于超文本传输协议(HTTP)之上而确定的一组约束和属性,是一种设计提供万维网络服务的软件构建风格。符合或兼容于这种架构风格(简称为 REST 或 RESTful)的网络服务,允许客户端发出以统一资源标识符访问和操作网络资源的请求,而与预先定义好的无状态操作集一致化。
- 因此REST提供了在互联网络的计算系统之间,彼此资源可交互使用的协作性质(interoperability)。相对于其它种类的网络服务,例如SOAP服务,则是以本身所定义的操作集,来访问网络上的资源。
- 目前在三种主流的Web服务实现方案中,因为REST模式与复杂的SOAP和XML-RPC相比更加简洁,越来越多的Web服务开始采用REST风格设计和实现。例如,Amazon.com提供接近REST风格的Web服务运行图书查询;雅虎提供的Web服务也是REST风格的。
- 需要注意的是,REST是设计风格而不是标准。REST通常基于HTTP、URI、XML以及HTML这些现有的广泛流行的协议和标准。
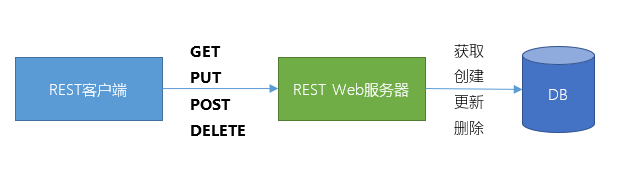
- 资源是由URI来指定。
- 对资源的操作包括获取、创建、修改和删除,这些操作正好对应HTTP协议提供的GET、POST、PUT和DELETE方法。
- 通过操作资源的表现形式来操作资源。
- 资源的表现形式则是XML或者HTML,取决于读者是机器还是人、是消费Web服务的客户软件还是Web浏览器。当然也可以是任何其他的格式,例如JSON。
RESTFul API
- 符合REST设计风格的Web API称为RESTful API。它从以下三个方面资源进行定义:
- 直观简短的资源地址:URI,比如:http://example.com/resources。
- 传输的资源:Web服务接受与返回的互联网媒体类型,比如:JSON,XML,YAML等。
- 对资源的操作:Web服务在该资源上所支持的一系列请求方法(比如:POST,GET,PUT或DELETE)。
| 资源 | GET | PUT | POST | DELETE |
|---|---|---|---|---|
| 一组资源的URI,比如 https://example.com/resources | 列出URI,以及该资源组中每个资源的详细信息。 | 使用给定的一组资源替换当前整组资源。 | 在本组资源中创建/追加一个新的资源。该操作往往返回新资源的URL。 | 删除整组资源。 |
| 单个资源的URI,比如https://example.com/resources/142 | 获取指定的资源的详细信息,格式可以自选一个合适的网络媒体类型(比如:XML、JSON等) | 替换/创建指定的资源。并将其追加到相应的资源组中。 | 把指定的资源当做一个资源组,并在其下创建/追加一个新的元素,使其隶属于当前资源。 | 删除指定的元素。 |
- PUT和DELETE方法是幂等方法
- GET方法是安全方法(不会对服务器端有修改,因此当然也是幂等的)
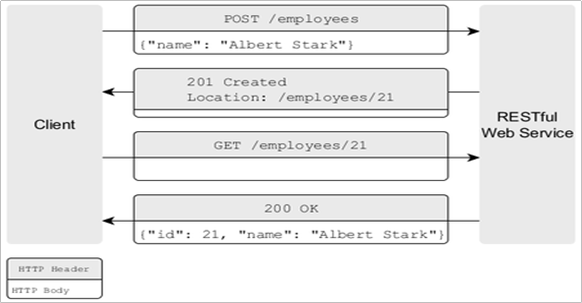
PUT请求类型和POST请求类型的区别
- PUT和POST均可用于创建或者更新某个资源(例如:添加一个用户、添加一个文件),用哪种请求方式取决我们自己。
- 我们主要使用是否需要有幂等性来判断到底用PUT、还是POST。PUT是幂等的,也就是将一个对象进行两次PUT操作,是不会起作用的。而如果使用POST,会同时收到两个请求。
HDFS HTTP RESTFUL API
HDFS HTTP RESTFUL API它支持以下操作:
HTTP GET
- OPEN (等同于FileSystem.open)
- GETFILESTATUS (等同于FileSystem.getFileStatus)
- LISTSTATUS (等同于FileSystem.listStatus)
- LISTSTATUS_BATCH (等同于FileSystem.listStatusIterator)
- GETCONTENTSUMMARY (等同于FileSystem.getContentSummary)
- GETQUOTAUSAGE (等同于FileSystem.getQuotaUsage)
- GETFILECHECKSUM (等同于FileSystem.getFileChecksum)
- GETHOMEDIRECTORY (等同于FileSystem.getHomeDirectory)
- GETDELEGATIONTOKEN (等同于FileSystem.getDelegationToken)
- GETTRASHROOT (等同于FileSystem.getTrashRoot)
- GETXATTRS (等同于FileSystem.getXAttr)
- GETXATTRS (等同于FileSystem.getXAttrs)
- GETXATTRS (等同于FileSystem.getXAttrs)
- LISTXATTRS (等同于FileSystem.listXAttrs)
- CHECKACCESS (等同于FileSystem.access)
- GETALLSTORAGEPOLICY (等同于FileSystem.getAllStoragePolicies)
- GETSTORAGEPOLICY (等同于FileSystem.getStoragePolicy)
- GETSNAPSHOTDIFF
- GETSNAPSHOTTABLEDIRECTORYLIST
- GETECPOLICY (等同于HDFSErasureCoding.getErasureCodingPolicy)
- GETFILEBLOCKLOCATIONS (等同于FileSystem.getFileBlockLocations)
HTTP PUT
- CREATE (等同于FileSystem.create)
- MKDIRS (等同于FileSystem.mkdirs)
- CREATESYMLINK (等同于FileContext.createSymlink)
- RENAME (等同于FileSystem.rename)
- SETREPLICATION (等同于FileSystem.setReplication)
- SETOWNER (等同于FileSystem.setOwner)
- SETPERMISSION (等同于FileSystem.setPermission)
- SETTIMES (等同于FileSystem.setTimes)
- RENEWDELEGATIONTOKEN (等同于DelegationTokenAuthenticator.renewDelegationToken)
- CANCELDELEGATIONTOKEN (等同于DelegationTokenAuthenticator.cancelDelegationToken)
- CREATESNAPSHOT (等同于FileSystem.createSnapshot)
- RENAMESNAPSHOT (等同于FileSystem.renameSnapshot)
- SETXATTR (等同于FileSystem.setXAttr)
- REMOVEXATTR (等同于FileSystem.removeXAttr)
- SETSTORAGEPOLICY (等同于FileSystem.setStoragePolicy)
- ENABLEECPOLICY (等同于HDFSErasureCoding.enablePolicy)
- DISABLEECPOLICY (等同于HDFSErasureCoding.disablePolicy)
- SETECPOLICY (等同于HDFSErasureCoding.setErasureCodingPolicy)
HTTP POST
- APPEND (等同于FileSystem.append)
- CONCAT (等同于FileSystem.concat)
- TRUNCATE (等同于FileSystem.truncate)
- UNSETSTORAGEPOLICY (等同于FileSystem.unsetStoragePolicy)
- UNSETECPOLICY (等同于HDFSErasureCoding.unsetErasureCodingPolicy)
HTTP DELETE
- DELETE (等同于FileSystem.delete)
- DELETESNAPSHOT (等同于FileSystem.deleteSnapshot)
文件系统URL和HTTP URL
WebHDFS的文件系统schema是webhdfs://。WebHDFS文件系统URI具有以下格式。
webhdfs://<HOST>:<HTTP_PORT>/<PATH>
上面的WebHDFS URI对应于下面的HDFS URI。
hdfs://<HOST>:<RPC_PORT>/<PATH>
在RESTAPI中,在路径中插入前缀“/webhdfs/v1”,并在末尾追加一个查询。因此,对应的HTTPURL具有以下格式。
http://<HOST>:<HTTP_PORT>/webhdfs/v1/<PATH>?op=...
安装Postman进行测试:
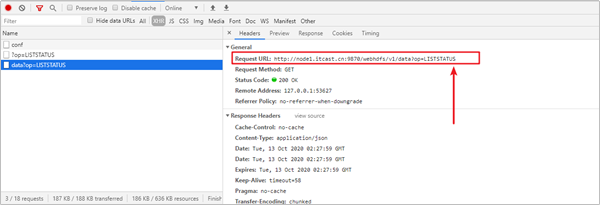
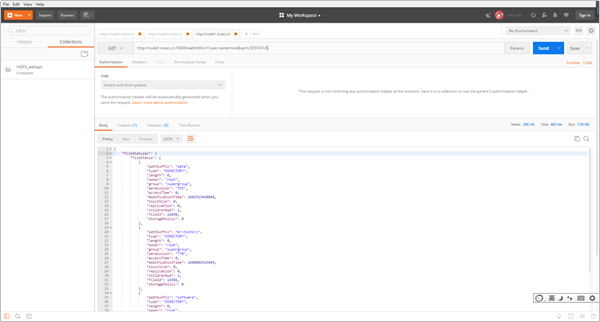
请求URL:http://node1.itcast.cn:9870/webhdfs/v1/?op=LISTSTATUS
该操作表示要查看根目录下的所有文件以及目录,相当于 hdfs dfs -ls /
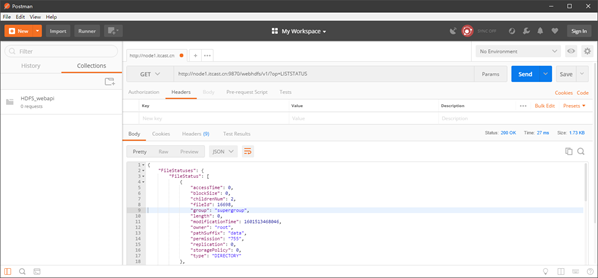
我们可以在Postman中看到,HDFS给我们返回了以下信息:
{
"FileStatuses": {
"FileStatus": [
{
"accessTime": 0,
"blockSize": 0,
"childrenNum": 2,
"fileId": 16698,
"group": "supergroup",
"length": 0,
"modificationTime": 1601513468046,
"owner": "root",
"pathSuffix": "data",
"permission": "755",
"replication": 0,
"storagePolicy": 0,
"type": "DIRECTORY"
},
{
"accessTime": 0,
"blockSize": 0,
"childrenNum": 2,
"fileId": 16386,
"group": "supergroup",
"length": 0,
"modificationTime": 1600886915849,
"owner": "root",
"pathSuffix": "mr-history",
"permission": "770",
"replication": 0,
"storagePolicy": 0,
"type": "DIRECTORY"
},
...
]
}
}使用WebHDFS创建并写入到一个文件
创建文件
提交HTTP PUT请求,而不会自动跟随重定向,也不会发送文件数据。
curl -i -X PUT "http://<HOST>:<PORT>/webhdfs/v1/<PATH>?op=CREATE
[&overwrite=<true |false>][&blocksize=<LONG>][&replication=<SHORT>]
[&permission=<OCTAL>][&buffersize=<INT>][&noredirect=<true|false>]"通常,请求被重定向到要写入文件数据的DataNode。
HTTP/1.1 307 TEMPORARY_REDIRECT
Location: http://<DATANODE>:<PORT>/webhdfs/v1/<PATH>?op=CREATE...
Content-Length: 0如果不希望自动重定向,则可以设置noredirected标志。
HTTP/1.1 200 OK
Content-Type: application/json
{"Location":"http://<DATANODE>:<PORT>/webhdfs/v1/<PATH>?op=CREATE..."}示例:
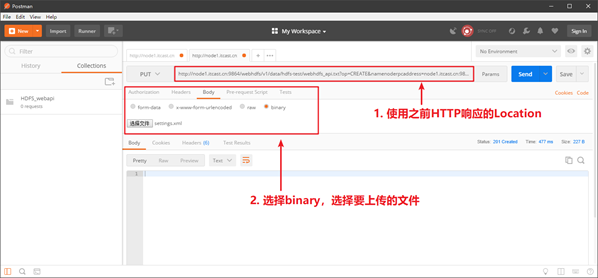
在/data/hdfs-test目录中创建一个名字为webhdfs_api.txt文件,并写入内容。
使用postman创建一个请求,设置请求方式为PUT,请求url为:
http://node1.itcast.cn:9870/webhdfs/v1/data/hdfs-test/webhdfs_api.txt?op=CREATE&overwrite=true&replication=2&noredirect=trueHTTP会响应一个用于上传数据的URL链接:
{
"Location": "http://node1.itcast.cn:9864/webhdfs/v1/data/hdfs-test/webhdfs_api.txt?op=CREATE&namenoderpcaddress=node1.itcast.cn:9820&createflag=&createparent=true&overwrite=true&replication=2"
}写入数据
使用Location标头中的URL提交另一个HTTP PUT请求(如果指定了noredirect,则返回返回的响应),并写入要写入的文件数据。
curl -i -X PUT -T <LOCAL_FILE> "http://<DATANODE>:<PORT>/webhdfs/v1/<PATH>?op=CREATE..."
客户端接收到一个201创建的响应,该响应的内容长度为零,位置头中文件的WebHDFS URI为:
HTTP/1.1 201 Created
Location: webhdfs://<HOST>:<PORT>/<PATH>
Content-Length: 0示例:
使用postman基于之前返回的http响应,上传文件。
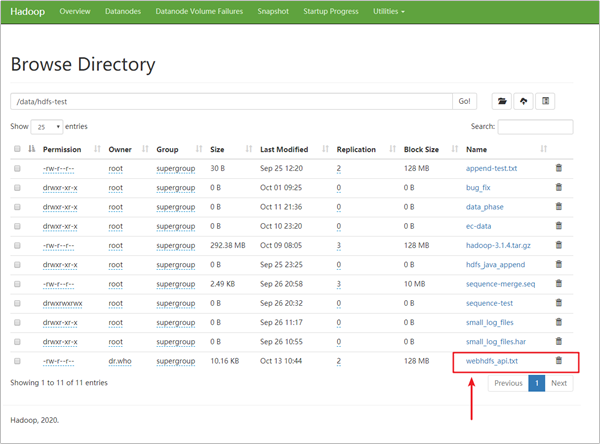
我们打开WebUI,发现文件已经上传成功。
更多操作请参考:
HttpFS
HttpHDFS本质上和WebHDFS是一样的,都是提供HTTP REST API功能,但它们的区别是HttpHDFS是HttpFS是一个独立于HadoopNameNode的服务,它本身就是Java JettyWeb应用程序。
因为是可以独立部署的,所以可以对HttpHDFS设置防火墙,而避免NameNode暴露在墙外,对一些安全性要求比较高的系统,HttpHDFS会更好些。
HttpFS是一种服务器,它提供REST HTTP网关,支持所有HDFS文件系统操作(读和写)。并且它可以与WebhdfsREST HTTPAPI。
HttpFS可用于在运行不同版本Hadoop(克服RPC版本控制问题)的集群之间传输数据,例如使用HadoopDiscreCP。
- HttpFS可用于在防火墙后面的集群上访问HDFS中的数据(HttpFS服务器充当网关,是允许跨越防火墙进入集群的唯一系统)。
- HttpFS可以使用HTTP实用程序(例如curl和wget)和来自Java以外的其他语言的HTTP库Perl来访问HDFS中的数据。
- 这个Webhdfs客户端文件系统实现可以使用Hadoop文件系统命令访问HttpFS(hdfs dfs)行工具以及使用Hadoop文件系统JavaAPI的Java应用程序。
- HttpFS内置了支持Hadoop伪身份验证和HTTP、SPNEGO Kerberos和其他可插拔身份验证机制的安全性。它还提供Hadoop代理用户支持。
HttpFS是如何工作的
- HttpFS是一个独立于HadoopNameNode的服务。
- HttpFS本身就是Java JettyWeb应用程序。
- HttpFS HTTP Web服务API调用是HTTPREST调用,映射到HDFS文件系统操作。例如,使用
curl/Unix命令:
$curl ‘http://httpfs-host:14000/webhdfs/v1/user/foo/README.txt?op=OPEN&user.name=foo’
返回HDFS的内容/user/foo/README.txt档案。
$curl ‘http://httpfs-host:14000/webhdfs/v1/user/foo?op=LISTSTATUS&user.name=foo’
返回HDFS的内容/user/foo目录中的JSON格式。
$curl ‘http://httpfs-host:14000/webhdfs/v1/user/foo?op=GETTRASHROOT&user.name=foo’
返回路径/user/foo/.trash,如果/是加密区域,则返回路径。/.Trash/Foo。看见更多细节关于加密区域中的垃圾路径。
$curl -X POST‘http://httpfs-host:14000/webhdfs/v1/user/foo/bar?op=MKDIRS&user.name=foo’
创建HDFS/user/foo/bar目录。- HttpFS默认端口号为14000
配置Hadoop
编辑Hadoop的core-site.xml,并将运行HttpFS服务器的Unix用户定义为proxyuser。例如:
<property>
<name>hadoop.proxyuser.#HTTPFSUSER#.hosts</name>
<value>httpfs-host.foo.com</value>
</property>
<property>
<name>hadoop.proxyuser.#HTTPFSUSER#.groups</name>
<value>*</value>
</property>重要:替换#HTTPFSUSER#使用将启动HttpFS服务器的Unix用户。
例如:
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>重启Hadoop
重启Hadoop,并激活代理用户配置
启动HttpFS
hdfs --daemon start httpfs
测试HttpFS工作
http://node1.itcast.cn:14000/webhdfs/v1?user.name=root&op=LISTSTATUS
HTTP默认服务
| Name | Description |
|---|---|
| /conf | Display configuration properties |
| /jmx | Java JMX management interface |
| /logLevel | Get or set log level per class |
| /logs | Display log files |
| /stacks | Display JVM stacks |
| /static/index.html | The static home page |
http://node1.itcast.cn:14000/conf?user.name=root
Hadoop常用文件存储格式
传统系统常见文件存储格式
在Windows有很多种文件格式,例如:JPEG文件用来存储图片、MP3文件用来存储音乐、DOC文件用来存储WORD文档。每一种文件存储某一类的数据,例如:我们不会用文本来存储音乐、不会用文本来存储图片。windows上支持的存储格式是非常的多。

文件系统块大小
- 在服务器/电脑上,有多种块设备(Block Device),例如:硬盘、CDROM、软盘等等。
- 每个文件系统都需要将一个分区拆分为多个块,用来存储文件。不同的文件系统块大小不同。
[root@node1 ~]# stat -f .
File: "."
ID: fd0000000000 Namelen: 255 Type: xfs
Block size: 4096 Fundamental block size: 4096
Blocks: Total: 15144730 Free: 11924333 Available: 11924333
Inodes: Total: 30304256 Free: 30139006例如:我们看到该文件系统的块大小为:4096字节 = 4KB。如果我们需要在磁盘中存储5个字节的数据,也会占据4096字节的空间。
Hadoop中文件存储格式
接下来,我们要讲解的是在Hadoop中的数据存储格式。Hadoop上的文件存储格式,肯定不会像Windows这么丰富,因为目前我们用Hadoop来存储、处理数据。我们不会用Hadoop来听歌、看电影、或者打游戏。

- 文件格式是定义数据文件系统中存储的一种方式,可以在文件中存储各种数据结构,特别是Row、Map,数组以及字符串,数字等。
- 在Hadoop中,没有默认的文件格式,格式的选择取决于其用途。而选择一种优秀、适合的数据存储格式是非常重要的。
- 后续我们要学习的,使用HDFS的应用程序(例如MapReduce或Spark)性能中的最大问题、瓶颈是在特定位置查找数据的时间和写入到另一个位置的时间,而且管理大量数据的处理和存储也很复杂(例如:数据的格式会不断变化,原来一行有12列,后面要存储20列)。
- Hadoop文件格式发展了好一段时间,这些文件存储格式可以解决大部分问题。我们在开发大数据中,选择合适的文件格式可能会带来一些明显的好处:
可以保证写入的速度
可以保证读取的速度
文件是可被切分的
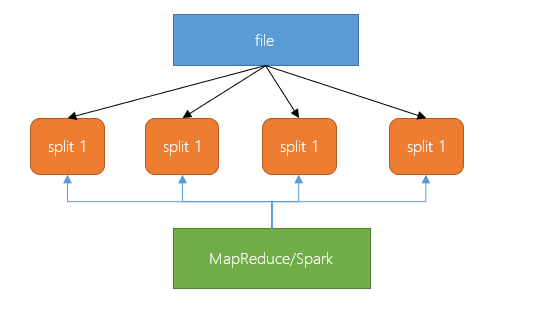
对压缩支持友好
支持schema的更改
某些文件格式是为通用设计的(如MapReduce或Spark),而其他文件则是针对更特定的场景,有些在设计时考虑了特定的数据特征。因此,确实有很多选择。
每种格式都有优点和缺点,数据处理的不同阶段可以使用不同的格式才会更有效率。通过选择一种格式,最大程度地发挥该存储格式的优势,最小化劣势。
BigData File Viewer工具
介绍
- 一个跨平台(Windows,MAC,Linux)桌面应用程序,用于查看常见的大数据二进制格式,例如Parquet,ORC,AVRO等。支持本地文件系统,HDFS,AWS S3等。
github地址:https://github.com/Eugene-Mark/bigdata-file-viewer
功能清单
- 打开并查看本地目录中的Parquet,ORC和AVRO,HDFS,AWS S3等。
- 将二进制格式的数据转换为文本格式的数据,例如CSV。
- 支持复杂的数据类型,例如数组,映射,结构等。
- 支持Windows,MAC和Linux等多种平台。
- 代码可扩展以涉及其他数据格式。
Hadoop丰富的存储格式
Text File

简介
- 文本文件在非Hadoop领域很常见,在Hadoop领域也很常见。
- 数据一行一行到排列,每一行都是一条记录。以典型的UNIX方式以换行符【\n】终止。
- 文本文件是可以被切分的,但如果对文本文件进行压缩,则必须使用支持切分文件的压缩编解码器,例如BZIP2。因为这些文件只是文本文件,压缩时会对所有内容进行编码。
- 可以将每一行成为JSON文档,可以让数据带有结构。
应用场景
仅在需要从Hadoop中直接提取数据,或直接从文件中加载大量数据的情况下,才建议使用纯文本格式或CSV。
结构
优点
简单易读、轻量级
缺点
- 读写速度慢。
- 不支持块压缩,在Hadoop中对文本文件进行压缩/解压缩会有较高的读取成本,因为需要将整个文件全部压缩或者解压缩。
- 无法切分压缩文件(会导致较大的map task)。
Sequence File
简介
- Sequence最初是为MapReduce设计的,因此和MapReduce集成很好。
- 在Sequence File中,每个数据都是以一个key和一个value进行序列化存储,仅此而已。
- Sequence File中的数据是以二进制格式存储,这种格式所需的存储空间小于文本的格式。与文本文件一样,Sequence File内部也不支持对键和值的结构指定格式编码。
应用场景
通常把Sequence file作为中间数据存储格式。例如:将大量小文件合并放入到一个SequenceFIle中。
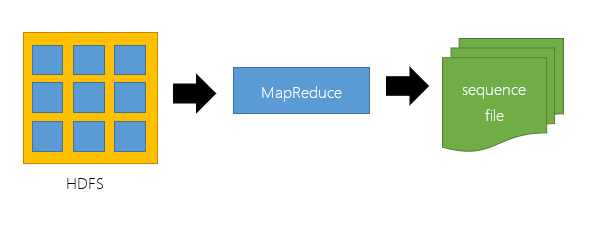
结构
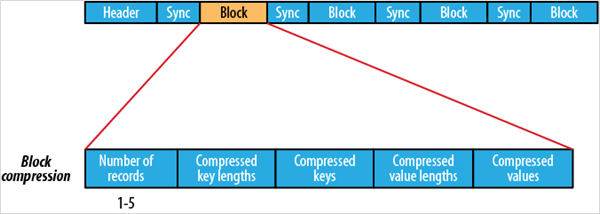
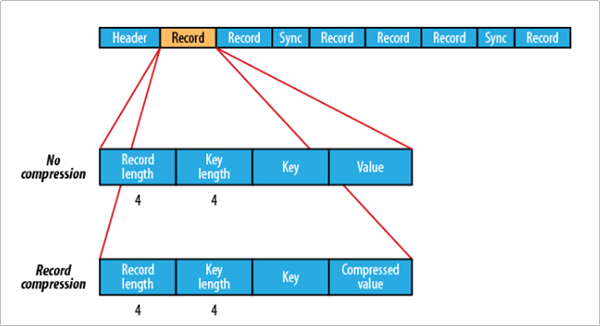
优点
- 与文本文件相比更紧凑,支持块级压缩
- 压缩文件内容的同时,支持将文件切分。
- 序列文件在Hadoop和许多其他支持HDFS的项目支持很好,例如:Spark。
- 它是让我们摆脱文本文件迈出第一步。
- 它可以作为大量小文件的容器
缺点
- 对于具有SQL类型的Hive支持不好,需要读取和解压缩所有字段
- 不存储元数据,并且对schema扩展中的唯一方式是在末尾添加新字段。
Avro File

简介
- Apache Avro是与语言无关的序列化系统,由Hadoop创始人 Doug Cutting开发。
- Avro是基于行的存储格式,它在每个文件中都包含JSON格式的schema定义,从而提高了互操作性并允许schema的变化(删除列、添加列)。 除了支持可切分以外,还支持块压缩。
- Avro是一种自描述格式,它将数据的schema直接编码存储在文件中,可以用来存储复杂结构的数据。
- Avro可以进行快速序列化,生成的序列化数据也比较小。
应用场景
- 适合于一次性需要将大量的列(数据比较宽)、写入频繁的场景。
- 随着更多存储格式的发展,常用于Kafka和Druid中。
结构
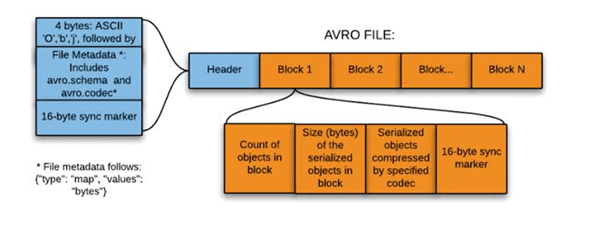
直接将一行数据序列化在一个block中
优点
- Avro是与语言无关的数据序列化系统。
- Avro将schema存储在header中,数据是自描述的。
- 序列化和反序列化速度很快。
- Avro文件是可切分的、可压缩的,非常适合在Hadoop生态系统中进行数据存储。
缺点
- 如果我们只需要对数据文件中的少数列进行操作,行式存储效率较低。例如:我们读取15列中的2列数据,基于行式存储就需要读取数百万行的15列。而列式存储就会比行式存储方式高效。
- 列式存储因为是将同一列(类)的数据存储在一起,压缩率要比方式存储高。
RCFile
简介
- RCFile是为基于MapReduce的数据仓库系统设计的数据存储结构。它结合了行存储和列存储的优点,可以满足快速数据加载和查询,有效利用存储空间以及适应高负载的需求。
- RCFile是由二进制键/值对组成的flat文件,它与sequence file有很多相似之处。
- 在数仓中执行分析时,这种面向列的存储非常有用。当我们使用面向列的存储类型时,执行分析很容易。
Hive Tip:
无法将数据直接加载到RCFILE中。首先需要将数据加载到另一个表中,然后将其覆盖写入到新创建的RCFile中。
应用场景
- 常用在Hive中
结构
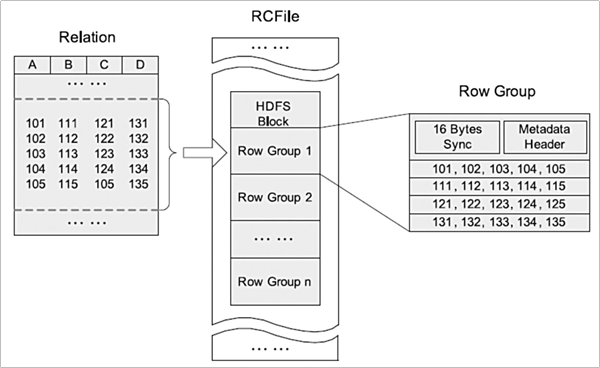
- RCFile可将数据分为几组行,并且在其中将数据存储在列中。
- RCFile首先将行水平划分为行拆分(Row Group),然后以列方式垂直划分每个行拆分(Columns)。
- RCFile将行拆分的元数据存储为record的key,并将行拆分的所有数据存储value。
- 作为行存储,RCFile保证同一行中的数据位于同一节点中。
- 作为列存储,RCFile可以利用列数据压缩,并跳过不必要的列读取。
优点
- 基于列式的存储,更好的压缩比。
- 利用元数据存储来支持数据类型。
- 支持Split。
缺点
- RC不支持schema扩展,如果要添加新的列,则必须重写文件,这会降低操作效率。
ORC File

简介
- Apache ORC(Optimized Row Columnar,优化行列)是Apache Hadoop生态系统面向列的开源数据存储格式,它与Hadoop环境中的大多数计算框架兼容。
- ORC代表“优化行列”,它以比RC更为优化的方式存储数据,提供了一种非常有效的方式来存储关系数据,然后存储RC文件。
- ORC将原始数据的大小最多减少75%,数据处理的速度也提高了 。
应用场景
- 常用在Hive中
结构

优点
- 比TextFile,Sequence File和RC File具备更好的的性能。
- 列数据单独存储。
- 带类型的数据存储格式,使用类型专用的编码器。
- 轻量级索引。
缺点
- 与RC文件一样,ORC也是不支持列扩展的。
Parquet File

简介
- Parquet File是另一种列式存储的结构,来自于Hadoop的创始人Doug Cutting的Trevni项目。
- 和ORCFile一样,Parquet也是基于列的二进制存储格式,可以存储嵌套的数据结构。
- 当指定要使用列进行操作时,磁盘输入/输出操效率很高。
- Parquet与Cloudera Impala兼容很好,并做了大量优化。
- 支持块压缩。
- 与RC和ORC文件不同,Parquet serdes支持有限的schema扩展。在Parquet中,可以在结构的末尾添加新列。
Hive Tip:
关于Hive对Parquet文件的支持的一个注意事项:Parquet列名必须小写,这一点非常重要。如果Parquet文件包含大小写混合的列名,则Hive将无法读取该列
结构

优点
- 和ORC文件一样,它非常适合进行压缩,具有出色的查询性能,尤其是从特定列查询数据时,效率很高。
缺点
- 与RC和ORC一样,Parquet也具有压缩和查询性能方面的优点,与非列文件格式相比,写入速度通常较慢。
Parquet VS ORC
- ORC文件格式压缩比parquet要高,parquet文件的数据格式schema要比ORC复杂,占用的空间也就越高。
- ORC文件格式的读取效率要比parquet文件格式高。
- 如果数据中有嵌套结构的数据,则Parquet会更好。
- Hive对ORC的支持更好,对parquet支持不好,ORC与Hive关联紧密。
- ORC还可以支持ACID、Update操作等。
- Spark对parquet支持较好,对ORC支持不好。
- 为了数据能够兼容更多的查询引擎,Parquet也是一种较好的选择。
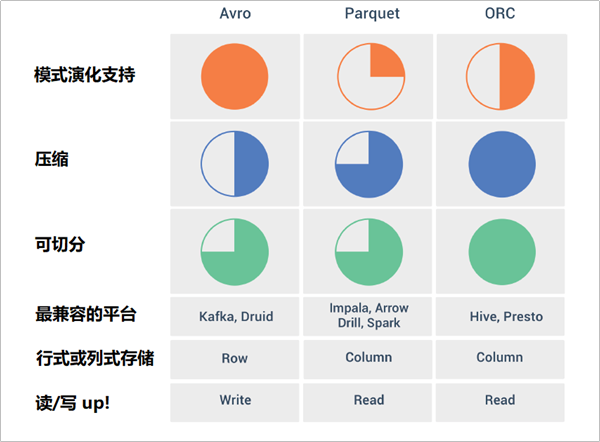
ProtoBuf和Thrift
由于Protobuf和Thrift是不可split的,因此它们在HDFS中并不流行
扩展:新一代的存储格式Apache Arrow

Arrow简介
- Apache Arrow是一个跨语言平台,是一种列式内存数据结构,主要用于构建数据系统。Apache Arrow在2016年2月17日作为顶级Apache项目引入。
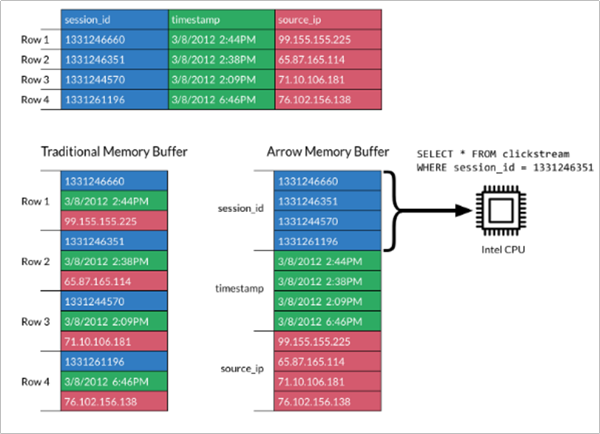
- Apache Arrow发展非常迅速,并且在未来会有更好的发展空间。 它可以在系统之间进行高效且快速的数据交换,而无需进行序列化,而这些成本已与其他系统(例如Thrift,Avro和Protocol Buffers)相关联。
- 每一个系统实现,它的方法(method)都有自己的内存存储格式,在开发中,70%-80%的时间浪费在了序列化和反序列化上。
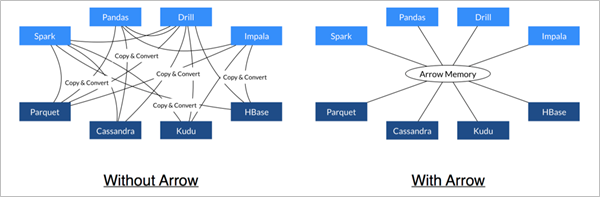
- Arrow促进了许多组件之间的通信。 例如,使用Python(pandas)读取复杂的文件并将其转换为Spark DataFrame。
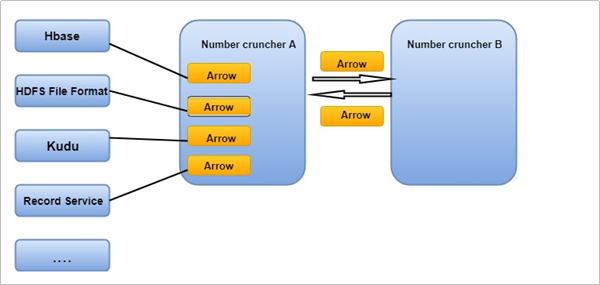
Arrow是如何提升数据移动性能的
- 利用Arrow作为内存中数据表示的两个过程可以将数据从一种方法“重定向”到另一种方法,而无需序列化或反序列化。 例如,Spark可以使用Python进程发送Arrow数据来执行用户定义的函数。
- 无需进行反序列化,可以直接从启用了Arrow的数据存储系统中接收Arrow数据。 例如,Kudu可以将Arrow数据直接发送到Impala进行分析。
- Arrow的设计针对嵌套结构化数据(例如在Impala或Spark Data框架中)的分析性能进行了优化。
文件压缩格式
在Hadoop中,一般存储着非常大的文件,以及在存储HDFS块或运行MapReduce任务时,Hadoop集群中节点之间的存在大量数据传输。 如果条件允许时,尽量减少文件大小,这将有助于减少存储需求以及减少网络上的数据传输。
文件压缩测试
在资料中有一份数据random_data.zip,里面每一个数据文件都是不一样的,而且文件都是通过大量随机函数生成的。我们上传到Linux,使用gzip方式压缩,测试以下压缩比。
cd /export/software/
rz
# 解压ZIP文件
unzip random_data.zip
# 查看原始文件大小
[root@node1 ~]# du -d 0 -h random_data
49M random_data
# 使用gz方式进行压缩
tar -cvzf random_data.tar.gz random_data
# 我们看到压缩后大约40M左右
-rw-r--r-- 1 root root 40M Sep 26 09:54 random_data.tar.gz在资料中还有一份数据集,名为hbase-logs.zip,这个压缩包中存储了大量重复的一些日志。我们
同样上传到Linux,测试压缩比。
cd /export/software/
rz
# 解压日志文件
unzip hbase-logs.zip
ll
# 未压缩之前为69M
du -d 0 -h logs/
69M logs/
# 压缩之后为6.5M
tar -cvzf hbase_logs.tar.gz logs
ll -h
-rw-r--r-- 1 root root 6.5M Sep 26 10:08 hbase_logs.tar.gzHadoop支持的压缩算法
Haodop对文件压缩均实现org.apache.hadoop.io.compress.CompressionCodec接口,所有的实现类都在org.apache.hadoop.io.compress包下。
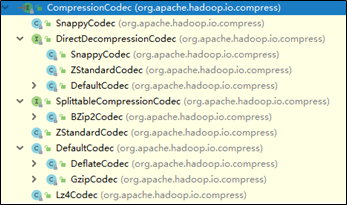
压缩算法比较
有不少的压缩算法可以应用到Hadoop中,但不同压缩算法有各自的特点。
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 | 对应的编码/解码器 |
|---|---|---|---|---|---|
| DEFAULT | 无 | DEFAULT | .deflate | 否 | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | gzip | DEFAULT | .gz | 否 | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | lzop | LZO | .lzo | 是(索引) | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | 无 | LZ4 | .lz4 | 否 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | 无 | Snappy | .snappy | 否 | org.apache.hadoop.io.compress.SnappyCodec |
存放数据到HDFS中,可以选择指定的压缩方式,在MapReduce程序读取时,会根据扩展名自动解压。例如:如果文件扩展名为.snappy,Hadoop框架将自动使用SnappyCodec解压缩文件。
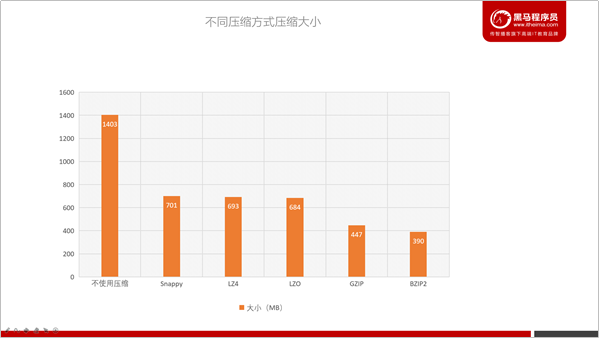
通过上图,我们可以看到哪些压缩算法压缩比更高。
整体排序如下:
Snappy < LZ4 < LZO < GZIP < BZIP2,但压缩比越高,压缩的时间也会更长。以下是部分参考数据:
| 压缩算法 | 压缩后占比 | 压缩 | 解压缩 |
|---|---|---|---|
| GZIP | 13.4% | 21 MB/s | 118 MB/s |
| LZO | 20.5% | 135 MB/s | 410 MB/s |
| Zippy/Snappy | 22.2% | 172 MB/s | 409 MB/s |
HDFS压缩如何抉择
既然压缩能够节省空间、而且可以提升IO效率,那么能否将所有数据都以压缩格式存储在HDFS中呢?例如:bzip2,而且文件是支持切分的。
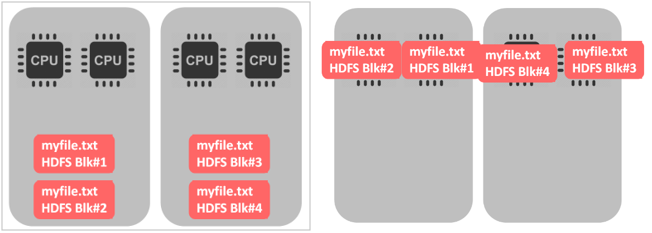
如果选择GZIP,就会出现以下情况:
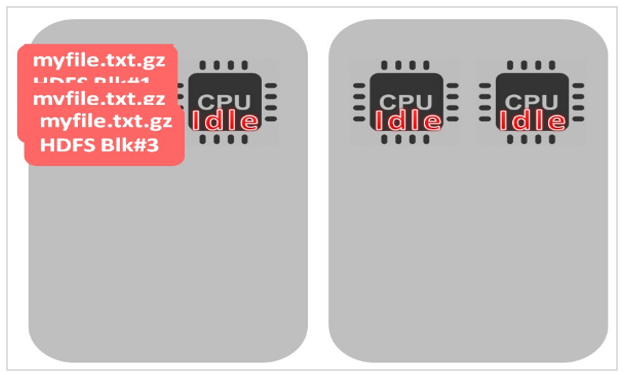
- 如果文件是不可切分的,只有一个CPU在处理所有的文件,其他的CPU都是空闲的。如果HDFS中的block和文件大小差不多还好,一个文件、一个块、一个CPU。如果是一个很大的文件就会出现问题了。
- bzip2在压缩和解压缩数据方面实际上平均比Gzip差3倍,这对性能是有一定的影响的。如果我们需要频繁地查询数据,数据压缩一定会影响查询效率。
- 如果不关心查询性能(没有任何SLA)并且很少选择此数据,则bzip2可能是不错的选择。最好是对自己的数据进行基准测试,然后再做决定。
HDFS存储类型和存储策略
介绍
- Archive存储(档案存储)是一种将增长的存储容量与计算容量解耦的解决方案。
- 可以将一些需要存储、但计算需求很少的数据放在低成本的存储节点中,这些节点用于集群中冷数据的存储。
- 根据策略,热数据可以转移到冷节点存储。在冷区域中加入更多的节点可以使存储与集群中的计算容量无关。
- 异构存储和归档存储提供的框架将HDFS体系结构概括为包括其他类型的存储介质,包括:SSD和内存。用户可以选择将数据存储在SSD或内存中以获得更好的性能。
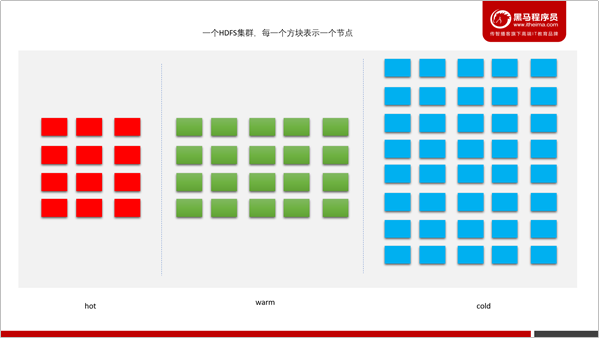
存储类型和存储策略
多种多样的存储类型
大家考虑一个问题:我们可以将数据保存在什么样的存储类型中呢?

- 硬盘
- SSD
- SATA
内存
NAS
速率对比
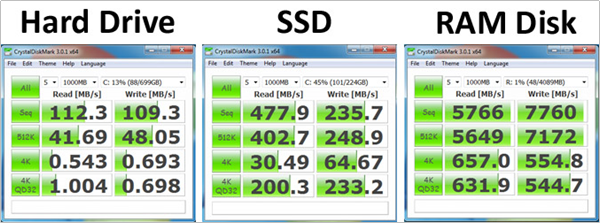
RAM比SSD快几个数量级。普通的磁盘大致的速度为30-150MB,比较快的SSD可以实现500MB /秒的实际写入速度。 RAM的理论上最大速度可以达到SSD实际性能的30倍。
以下是一个实际对比图:
存储类型
之前在hdfs-site.xml中配置,是将数据保存在Linux中的本地磁盘。
<property>
<name>dfs.datanode.data.dir</name>
<value>/export/server/hadoop-3.1.4/data/datanode</value>
<description>DataNode存储名称空间和事务日志的本地文件系统上的路径</description>
</property>以上配置跟下面的配置是一样的:
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]:/export/server/hadoop-3.1.4/data/datanode</value>
<description>DataNode存储名称空间和事务日志的本地文件系统上的路径</description>
</property>在HDFS中,可以给不同的存储介质分配不同的存储类型:
- DISK:默认的存储类型,磁盘存储。
- ARCHIVE:具有存储密度高(PB级),但计算能力小的特点,可用于支持档案存储。
- SSD:固态硬盘。
- RAM_DISK:DataNode中的内存空间。
存储策略介绍
HDFS中提供热、暖、冷、ALL_SSD、One_SSD、Lazy_Persistence等存储策略。为了根据不同的存储策略将文件存储在不同的存储类型中,引入了一种新的存储策略概念。HDFS支持以下存储策略:
热(hot)
- 用于大量存储和计算。
- 当数据经常被使用,将保留在此策略中。
- 当block是hot时,所有副本都存储在磁盘中。
冷(cold)
- 仅仅用于存储,只有非常有限的一部分数据用于计算。
- 不再使用的数据或需要存档的数据将从热存储转移到冷存储中。
- 当block是cold时,所有副本都存储在Archive中。
温(warm)
- 部分热,部分冷。
- 当一个块是warm时,它的一些副本存储在磁盘中,其余的副本存储在Archive中。
单SSD
在SSD中存储一个副本,其余的副本存储在磁盘中。
懒持久
用于编写内存中只有一个副本的块。副本首先写在RAM_Disk中,然后惰性地保存在磁盘中。
HDFS中的存储策略
HDFS存储策略由以下字段组成:
策略ID(Policy ID)
策略名称(Policy Name)
块放置的存储类型列表(Block Placement)
用于创建文件的后备存储类型列表(Fallback storages for creation)
用于副本的后备存储类型列表(Fallback storages for replication)
当有足够的空间时,块副本将根据#3中指定的存储类型列表存储。当列表#3中的某些存储类型耗尽时,将分别使用#4和#5中指定的后备存储类型列表来替换空间外存储类型,以便进行文件创建和副本。
以下是一个典型的存储策略表格:
| Policy ID | Policy Name | Block Placement (n replicas) | Fallback storages for creation | Fallback storages for replication |
|---|---|---|---|---|
| 15 | Lazy_Persist | RAM_DISK: 1, DISK: n-1 | DISK | DISK |
| 12 | All_SSD | SSD: n | DISK | DISK |
| 10 | One_SSD | SSD: 1, DISK: n-1 | SSD, DISK | SSD, DISK |
| 7 | Hot (default) | DISK: n | <none> |
ARCHIVE |
| 5 | Warm | DISK: 1, ARCHIVE: n-1 | ARCHIVE, DISK | ARCHIVE, DISK |
| 2 | Cold | ARCHIVE: n | <none> |
<none> |
| 1 | Provided | PROVIDED: 1, DISK: n-1 | PROVIDED, DISK | PROVIDED, DISK |
注意事项:
Lazy_Persistence策略仅对单个副本块有用。对于具有多个副本的块,所有副本都将被写入磁盘,因为只将一个副本写入RAM_Disk并不能提高总体性能。
对于带条带的擦除编码文件,合适的存储策略是ALL_SSD、HOST、CORD。因此,如果用户为EC文件设置除上述之外的策略,在创建或移动块时不会遵循该策略。
存储策略方案
- 创建文件或目录时,其存储策略为未指定状态。可以使用:
storagepolicies -setStoragePolicy
命令指定
- 文件或目录的有效存储策略由以下规则解析:
- 如果使用存储策略指定了文件或目录,则返回该文件或目录。
- 对于未指定的文件或目录,如果是根目录,则返回默认存储策略。否则,返回其父级的有效存储策略。
- 可以使用storagepolicies –getStoragePolicy命令获取有效的存储策略。
配置
dfs.storage.policy.enabled
启用/禁用存储策略功能。默认值是true
dfs.datanode.data.dir
在每个数据节点上,应当用逗号分隔的存储位置标记它们的存储类型。这允许存储策略根据策略将块放置在不同的存储类型上。
磁盘上的DataNode存储位置/grid/dn/disk 0应该配置为[DISK]file:///grid/dn/disk0
SSD上的DataNode存储位置/grid/dn/ssd 0应该配置为 [SSD]file:///grid/dn/ssd0
存档上的DataNode存储位置/grid/dn/Archive 0应该配置为 [ARCHIVE]file:///grid/dn/archive0
将RAM_磁盘上的DataNode存储位置/grid/dn/ram0配置为[RAM_DISK]file:///grid/dn/ram0
如果DataNode存储位置没有显式标记存储类型,它的默认存储类型将是磁盘。存储策略命令
列出存储策略
列出所有存储策略。
命令:
[root@node1 Examples]# hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}hdfs storagepolicies -listPolicies
设置存储策略
给一个文件或目录设置存储策略
hdfs storagepolicies -setStoragePolicy -path <path> -policy <policy>
参数:

取消存储策略
取消文件或目录的存储策略。在执行unset命令之后,将应用当前目录最近的祖先存储策略,如果没有任何祖先的策略,则将应用默认的存储策略。
hdfs storagepolicies -unsetStoragePolicy -path <path>
参数:

获取存储策略
获取文件或目录的存储策略。
hdfs storagepolicies -getStoragePolicy -path <path>

冷热温三阶段数据存储
为了更加充分的利用存储资源,我们可以将数据分为冷、热、温三个阶段来存储。
| /data/hdfs-test/data_phase/warm | 温阶段数据 |
| /data/hdfs-test/data_phase/cold | 冷阶段数据 |
| /data/hdfs-test/data_phase/hot | 热阶段数据 |
配置DataNode存储目录
为了能够支撑不同类型的数据,我们需要在hdfs-site.xml中配置不同存储类型数据的位置。
- 进入到Hadoop配置目录,编辑hdfs-site.xml
cd /export/server/hadoop-3.1.4/etc/hadoop
vim hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file:///export/server/hadoop-3.1.4/data/datanode,[ARCHIVE]file:///export/server/hadoop-3.1.4/data/archive</value>
<description>DataNode存储名称空间和事务日志的本地文件系统上的路径</description>
</property>2.分发到不同另外两个节点中
scp hdfs-site.xml node2.itcast.cn:$PWD
scp hdfs-site.xml node3.itcast.cn:$PWD- 重启HDFS集群
stop-dfs.sh
start-dfs.sh配置好后,我们在WebUI的Datanodes页面中点击任意一个DataNode节点。

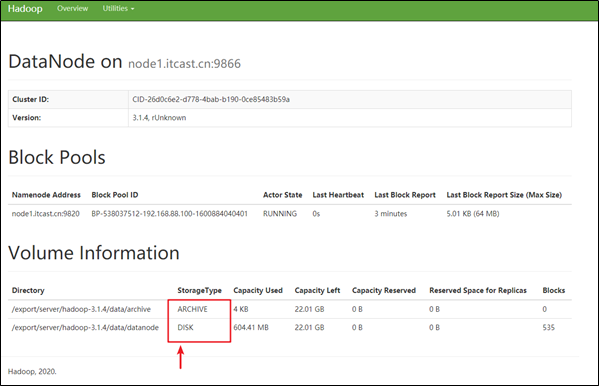
可以看到,现在配置的是两个目录,一个StorageType为ARCHIVE、一个Storage为DISK。
配置策略
- 创建测试目录结构
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/hot
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/warm
hdfs dfs -mkdir -p /data/hdfs-test/data_phase/cold- 查看当前HDFS支持的存储策略
[root@node1 Examples]# hdfs storagepolicies -listPolicies
Block Storage Policies:
BlockStoragePolicy{PROVIDED:1, storageTypes=[PROVIDED, DISK], creationFallbacks=[PROVIDED, DISK], replicationFallbacks=[PROVIDED, DISK]}
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
BlockStoragePolicy{ONE_SSD:10, storageTypes=[SSD, DISK], creationFallbacks=[SSD, DISK], replicationFallbacks=[SSD, DISK]}
BlockStoragePolicy{ALL_SSD:12, storageTypes=[SSD], creationFallbacks=[DISK], replicationFallbacks=[DISK]}
BlockStoragePolicy{LAZY_PERSIST:15, storageTypes=[RAM_DISK, DISK], creationFallbacks=[DISK], replicationFallbacks=[DISK]}3.分别设置三个目录的存储策略
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/hot -policy HOT
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/warm -policy WARM
hdfs storagepolicies -setStoragePolicy -path /data/hdfs-test/data_phase/cold -policy COLD4.查看三个目录的存储策略
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/hot
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/warm
hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/cold [root@node1 Examples]# hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/hot
The storage policy of /data/hdfs-test/data_phase/hot:
BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}
[root@node1 Examples]# hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/warm
The storage policy of /data/hdfs-test/data_phase/warm:
BlockStoragePolicy{WARM:5, storageTypes=[DISK, ARCHIVE], creationFallbacks=[DISK, ARCHIVE], replicationFallbacks=[DISK, ARCHIVE]}
[root@node1 Examples]# hdfs storagepolicies -getStoragePolicy -path /data/hdfs-test/data_phase/cold
The storage policy of /data/hdfs-test/data_phase/cold:
BlockStoragePolicy{COLD:2, storageTypes=[ARCHIVE], creationFallbacks=[], replicationFallbacks=[]}上传测试
- 分别上传文件到三个目录中测试
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/hot
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/warm
hdfs dfs -put /etc/profile /data/hdfs-test/data_phase/cold- 查看不同存储策略文件的block位置
[root@node1 hadoop]# hdfs fsck /data/hdfs-test/data_phase/hot/profile -files -blocks -locations
Connecting to namenode via http://node1.itcast.cn:9870/fsck?ugi=root&files=1&blocks=1&locations=1&path=%2Fdata%2Fhdfs-test%2Fdata_phase%2Fhot%2Fprofile
FSCK started by root (auth:SIMPLE) from /192.168.88.100 for path /data/hdfs-test/data_phase/hot/profile at Sun Oct 11 22:03:05 CST 2020
/data/hdfs-test/data_phase/hot/profile 3158 bytes, replicated: replication=3, 1 block(s): OK
0. BP-538037512-192.168.88.100-1600884040401:blk_1073742535_1750 len=3158 Live_repl=3 [DatanodeInfoWithStorage[192.168.88.101:9866,DS-96feb29a-5dfd-4692-81ea-9e7f100166fe,DISK], DatanodeInfoWithStorage[192.168.88.100:9866,DS-79739be9-5f9b-4f96-a005-aa5b507899f5,DISK], DatanodeInfoWithStorage[192.168.88.102:9866,DS-e28af2f2-21ae-4aa6-932e-e376dd04ddde,DISK]]
hdfs fsck /data/hdfs-test/data_phase/warm/profile -files -blocks -locations
/data/hdfs-test/data_phase/warm/profile 3158 bytes, replicated: replication=3, 1 block(s): OK
0. BP-538037512-192.168.88.100-1600884040401:blk_1073742536_1751 len=3158 Live_repl=3 [DatanodeInfoWithStorage[192.168.88.102:9866,DS-636f34a0-682c-4d1b-b4ee-b4c34e857957,ARCHIVE], DatanodeInfoWithStorage[192.168.88.101:9866,DS-ff6970f8-43e0-431f-9041-fc440a44fdb0,ARCHIVE], DatanodeInfoWithStorage[192.168.88.100:9866,DS-79739be9-5f9b-4f96-a005-aa5b507899f5,DISK]]
hdfs fsck /data/hdfs-test/data_phase/cold/profile -files -blocks -locations
/data/hdfs-test/data_phase/cold/profile 3158 bytes, replicated: replication=3, 1 block(s): OK
0. BP-538037512-192.168.88.100-1600884040401:blk_1073742537_1752 len=3158 Live_repl=3 [DatanodeInfoWithStorage[192.168.88.102:9866,DS-636f34a0-682c-4d1b-b4ee-b4c34e857957,ARCHIVE], DatanodeInfoWithStorage[192.168.88.101:9866,DS-ff6970f8-43e0-431f-9041-fc440a44fdb0,ARCHIVE], DatanodeInfoWithStorage[192.168.88.100:9866,DS-ca9759a0-f6f0-4b8b-af38-d96f603bca93,ARCHIVE]]我们可以看到:
- hot目录中的block,3个block都在DISK磁盘。
- warm目录中的block,1个block在DISK磁盘,另外两个在archive磁盘。
- cold目录中的block,3个block都在archive磁盘。
HDFS中的内存存储支持
介绍
- HDFS支持写入由DataNode管理的堆外内存。
- DataNode异步地将内存中数据刷新到磁盘,从而减少代价较高的磁盘IO操作,这种写入称之为懒持久写入。
- HDFS为懒持久化写做了较大的持久性保证。在将副本保存到磁盘之前,如果节点重新启动,有非常小的几率会出现数据丢失。应用程序可以选择使用懒持久化写,以减少写入延迟。
该特性从ApacheHadoop 2.6.0开始支持。
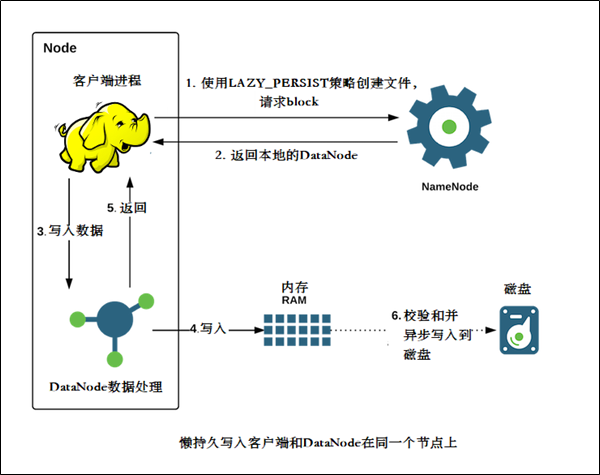
- 比较适用于,当应用程序需要往HDFS中以低延迟的方式写入相对较低数据量(从几GB到十几GB(取决于可用内存)的数据量时。
- 内存存储适用于在集群内运行,且运行的客户端与HDFS DataNode处于同一节点的应用程序。使用内存存储可以减少网络传输的开销。
- 如果内存不足或未配置,使用懒持久化写入的应用程序将继续工作,会继续使用磁盘存储。
配置内存存储支持
接下来,我们来了解下在HDFS中使用该功能,需要有哪些操作。
设置能够使用的内存空间
确定用于存储在内存中的副本内存量
- 在指定DataNode的hdfs-site.xml设置dfs.datanode.max.locked.memory。
- DataNode将确保懒持久化的内存不超过dfs.datanode.max.locked.memory
- 例如,为内存中的副本预留32 GB
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>34359738368</value>
</property>在设置此值时,请记住,还需要内存中的空间来处理其他事情,例如数据节点和应用程序JVM堆以及操作系统页缓存。如果在与数据节点相同的节点上运行YARN节点管理器进程,则还需要YARN容器的内存。
DataNode设置基于内存的存储
在每个DataNode节点上初始化一个RAM磁盘。
通过选择RAM磁盘,可以在DataNode进程重新启动时保持更好的数据持久性。
下面的设置可以在大多数Linux发行版上运行,目前不支持在其他平台上使用RAM磁盘。
选择tmpfs(VS ramfs)
- Linux支持使用两种类型的RAM磁盘-tmpfs和ramfs。
- tmpfs的大小受linux内核的限制,而ramfs可以使用所有系统可用的内存。
- tmpfs可以在内存不足情况下交换到磁盘上。但是,许多对性能要求很高的应用运行时都禁用内存磁盘交换。
- HDFS当前支持tmpfs分区,而对ramfs的支持正在开发中。
挂载RAM磁盘
使用Linux中的mount命令来挂载内存磁盘。例如:挂载32GB的tmpfs分区在
/mnt/dn-tmpfs。sudo mount -t tmpfs -o size=32g tmpfs /mnt/dn-tmpfs/。建议在/etc/fstab创建一个入口,在DataNode节点重新启动时,将自动重新创建RAM磁盘。
另一个可选项是使用
/dev/shm下面的子目录。这是tmpfs默认在大多数Linux发行版上都可以安装。确保挂载的大小大于或等于
dfs.datanode.max.locked.memory,或者写入到/etc /fstab。不建议使用多个tmpfs对懒持久化写入的每个DataNode节点进行分区。
设置RAM_DISK存储类型tmpfs标签
- 标记tmpfs目录中具有RAM_磁盘存储类型的目录。
- 在hdfs-site.xml中配置dfs.datanode.data.dir。例如,在具有三个硬盘卷的DataNode上,/grid /0, /grid /1以及 /grid /2和一个tmpfs挂载在 /mnt/dn-tmpfs, dfs.datanode.data.dir必须设置如下:
<property>
<name>dfs.datanode.data.dir</name>
<value>/grid/0,/grid/1,/grid/2,[RAM_DISK]/mnt/dn-tmpfs</value>
</property>- 这一步至关重要。如果没有RAM_DISK标记,HDFS将把tmpfs卷作为非易失性存储,数据将不会保存到持久存储,重新启动节点时将丢失数据。
确保启用存储策略
确保全局设置中的存储策略是已启用的。默认情况下,此设置是打开的。
使用内存存储
使用懒持久化存储策略
指定HDFS使用LAZY_PERSIST策略,可以对文件使用懒持久化写入
可以通过以下三种方式之一进行设置:
在目录上执行hdfs storagepolicies命令
- 在目录上设置㽾策略,将使其对目录中的所有新文件生效
- 这个HDFS存储策略命令可以用于设置策略.
hdfs storagepolicies -setStoragePolicy -path <path> -policy LAZY_PERSIST
在目录上执行setStoragePolicy方法
Apache Hadoop 2.8.0后,应用程序可以通过编程方式将存储策略设置FileSystem.setStoragePolicy。
fs.setStoragePolicy(path, "LAZY_PERSIST");
创建文件的时候指定CreateFlag
当创建文件时,应用程序调用FileSystem.create方法,传递CreateFlag#LAZY_PERSIST实现。
FSDataOutputStream fos =
fs.create(
path,
FsPermission.getFileDefault(),
EnumSet.of(CreateFlag.CREATE, CreateFlag.LAZY_PERSIST),
bufferLength,
replicationFactor,
blockSize,
null);银行海量转账数据分层案例
银行每一天都有大量的转账、交易需要保存、处理。用户每进行一笔交易或者转账,银行都需要将用户转账的所有相关信息保存下来。
四大银行:

银行有非常多的用户,四大银行拥有数10亿的用户。要保存的数据量可想而知。如果说有的数据,都同等对待,为了保证使用数据的性能,采用的是高性能存储,这将是一笔不小的资源浪费。实际上,超过一定时间的数据,数据访问的频率要低得多。例如:用户查询5年前的转账记录、要比查询1年类的转账记录频率要低得多。
所以,为了能够更好地利用资源,需要对数据进行分层。也就是不同时间范围的数据,放在不同的层(冷热温)中。
存储分层策略
按照以下配置,在HDFS的source目录中创建以下几个文件夹:
| 文件夹路径 | 存储策略 | 说明 |
|---|---|---|
/source/bank/transfer/log_lte1y |
DISK | 存储一年以内采集的数据 |
/source/bank/transfer/log_gt1y |
ARCHIVE | 存储1年以上的数据 |
测试
# 创建文件夹
hdfs dfs -mkdir -p /source/bank/transfer/log_lte1y
hdfs dfs -mkdir -p /source/bank/transfer/log_gt1y
# 指定存储策略
hdfs storagepolicies -setStoragePolicy -path /source/bank/transfer/log_lte1y -policy HOT
hdfs storagepolicies -setStoragePolicy -path /source/bank/transfer/log_gt1y -policy COLD
# 查看存储策略
hdfs storagepolicies -getStoragePolicy -path /source/bank/transfer/log_lte1y
hdfs storagepolicies -getStoragePolicy -path /source/bank/transfer/log_gt1y
# 上传文件测试
# 上传文件到linux
rz
# 一年
hdfs dfs -put /root/bank_record.csv /source/bank/transfer/log_lte1y/bank_record_2020_9.csv
# 五年
hdfs dfs -put /root/bank_record.csv /source/bank/transfer/log_gt1y/bank_record_2015_9.csv
# 假设现在到了2021年10年,我们可以将之前的数据移动到log_gt1y
hdfs dfs -mv /source/bank/transfer/log_lte1y/bank_record_2020_9.csv /source/bank/transfer/log_gt1y/bank_record_2020_9.csv 微信
微信 支付宝
支付宝







