Docker文件系统
基础知识
Linux 的 rootfs 和 bootfs
一个典型的 Linux 系统要能运行的话,它至少需要两个文件系统FS: bootfs + rbootfs

bootfs
boot file system:包含 boot loader 和 kernel。用户不会修改这个文件系统。实际上,在启动(boot)过程完成后,整个内核都会被加载进内存,此时 bootfs 会被卸载掉从而释放出所占用的内存。同时也可以看出,对于同样内核版本的不同的 Linux 发行版的 bootfs 都是一致的。
rootfs
root file system:包含典型的目录结构,包括 /dev, /proc, /bin, /etc, /lib, /usr, and /tmp 等再加上要运行用户应用所需要的所有配置文件,二进制文件和库文件。这个文件系统在不同的Linux 发行版中是不同的。而且用户可以对这个文件进行修改。
Linux 系统在启动时,roofs 首先会被挂载为只读模式,然后在启动完成后被修改为读写模式,随后它们就可以被修改了。
AUFS
AUFS 是一种 Union File System(联合文件系统),又叫 Another UnionFS,后来叫Alternative UnionFS,再后来叫成高大上的 Advance UnionFS,所谓 UnionFS,就是把不同物理位置的目录合并mount到同一个目录中。UnionFS的一个最主要的应用是,把一张CD/DVD和一个硬盘目录给联合 mount在一起,然后,你就可以对这个只读的CD/DVD上的文件进行修改(当然,修改的文件存于硬盘上的目录里)。
最主要的功能是将多个不同的目录联合挂载到同一个目录下
$ tree
.
├── A
│ ├── a
│ └── x
└── B
├── b
└── x执行 挂载命令
mount -t aufs -o dirs=./A:./B none ./CA 和 B 目录将被合并
AUFS 的特点
- AUFS 是一种联合文件系统,它把若干目录按照顺序和权限 mount 为一个目录并呈现出来
- 默认情况下,只有第一层(第一个目录)是可写的,其余层是只读的。
- 增加文件:默认情况下,新增的文件都会被放在最上面的可写层中。
- 删除文件:因为底下各层都是只读的,当需要删除这些层中的文件时,AUFS 使用 whiteout 机制,它的实现是通过在上层的可写的目录下建立对应的whiteout隐藏文件来实现的。
- 修改文件:AUFS 利用其 CoW (copy-on-write)特性来修改只读层中的文件。AUFS 工作在文件层面,因此,只要有对只读层中的文件做修改,不管修改数据的量的多少,在第一次修改时,文件都会被拷贝到可写层然后再被修改。
- 节省空间:AUFS 的 CoW 特性能够允许在多个容器之间共享分层,从而减少物理空间占用。
- 查找文件:AUFS 的查找性能在层数非常多时会出现下降,层数越多,查找性能越低,因此,在制作 Docker 镜像时要注意层数不要太多。
- 性能:AUFS 的 CoW 特性在写入大型文件时第一次会出现延迟。
Docker文件系统
Docker 镜像的 rootfs
前面基础知识部分谈到过,同一个内核版本的所有 Linux 系统的 bootfs 是相同的,而 rootfs 则是不同的。在 Docker 中,基础镜像中的 roofs 会一直保持只读模式,Docker 会利用 union mount 来在这个 rootfs 上增加更多的只读文件系统,最后它们看起来就像一个文件系统即容器的 rootfs。
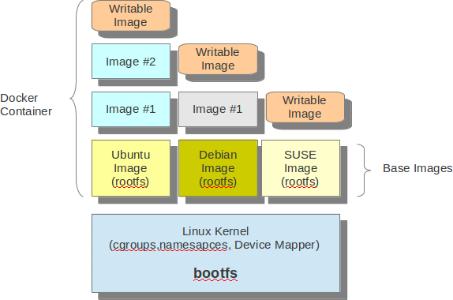
可见在一个Linux 系统之中
- 所有 Docker 容器都共享主机系统的 bootfs 即 Linux 内核
- 每个容器有自己的 rootfs,它来自不同的 Linux 发行版的基础镜像,包括 Ubuntu,Debian 和 SUSE 等
- 所有基于一种基础镜像的容器都共享这种 rootfs
查看文件结构
以 training/webapp 镜像为例
docker history training/webapp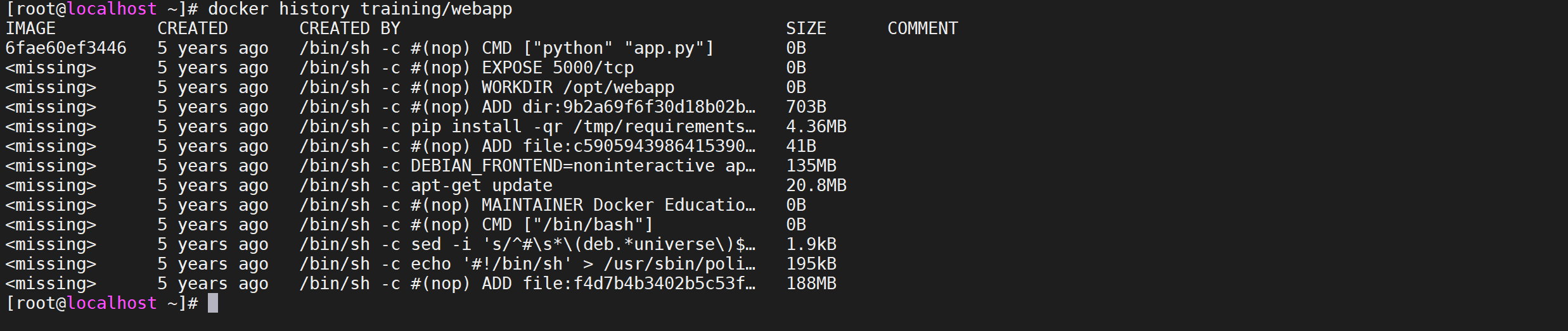
Docker的三种文件系统
对于Docker来说,联合文件系统可以说是其镜像和容器的基础。联文件系统可以使得Docker把镜像做成分层结构,从而使得镜像的每一层都可以被共享。从而节省大量的存储空间。
联合文件系统更多的是一种概念或者标准,真正实现联合文件系统才是关键,当前Docker中常见的联合文件系统有三种:AUFS、Devicemapper和OverlayFS。
AUFS
AUFS如何存储数据
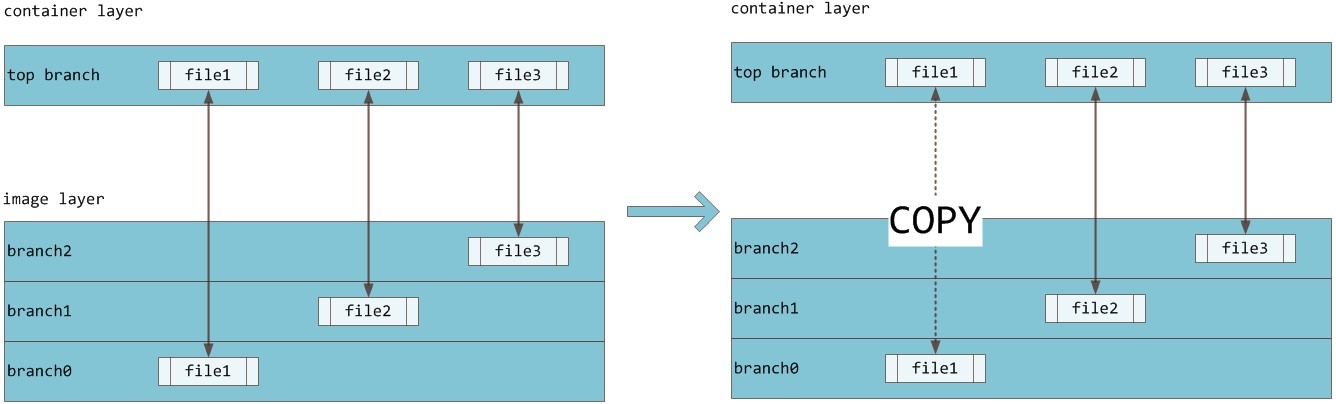
AUFS 是联合文件系统,意味着它在主机上使用多层目录存储,每一个目录在 AUFS 中都叫作分支,而在 Docker 中则称之为层(layer),但最终呈现给用户的则是一个普通单层的文件系统,我们把多层以单一层的方式呈现出来的过程叫作联合挂载。
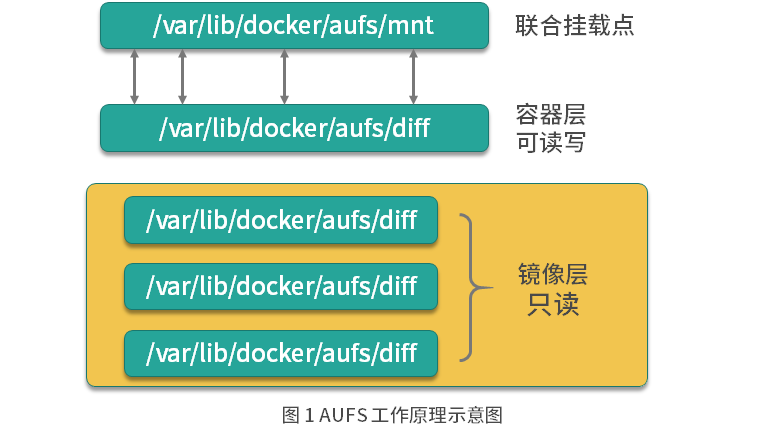
每一个镜像层和容器层都是 /var/lib/docker 下的一个子目录,镜像层和容器层都在 aufs/diff 目录下,每一层的目录名称是镜像或容器的 ID 值,联合挂载点在 aufs/mnt 目录下,mnt 目录是真正的容器工作目录。
创建镜像
创建整个容器过程中,aufs文件夹的变化
当一个镜像未生成容器时
- diff文件夹:存储镜像内容,每一层都存储在镜像层ID命名的子文件夹中。
- layers文件夹:存储镜像层关系的元数据,在diff文件夹下的每一个镜像层在这里都会有一个文件,文件的内容为该层镜像的父级镜像的ID
- mnt文件夹:联合挂载点目录,未生成容器时,该目录为空
当一个镜像生成容器后
- diff文件夹:当容器运行时会在diff文件夹下生成容器层
- layers文件夹:增加容器相关的元数据
- mnt文件夹:容器的联合挂载点,这和容器中看到的文件内容一致
AUFS如何工作
读取文件
- 文件在容器层中存在时:当文件存在于容器层时,直接从容器层读取。
- 当文件在容器层中不存在时:当容器运行时需要读取某个文件,如果容器层中不存在时,则从镜像层查找该文件,然后读取文件内容。
- 文件既存在于镜像层,又存在于容器层:当我们读取的文件既存在于镜像层,又存在于容器层时,将会从容器层读取该文件。
修改文件
- 第一次修改文件:当我们第一次在容器中修改某个文件时,AUFS 会触发写时复制操作,AUFS 首先从镜像层复制文件到容器层,然后再执行对应的修改操作。
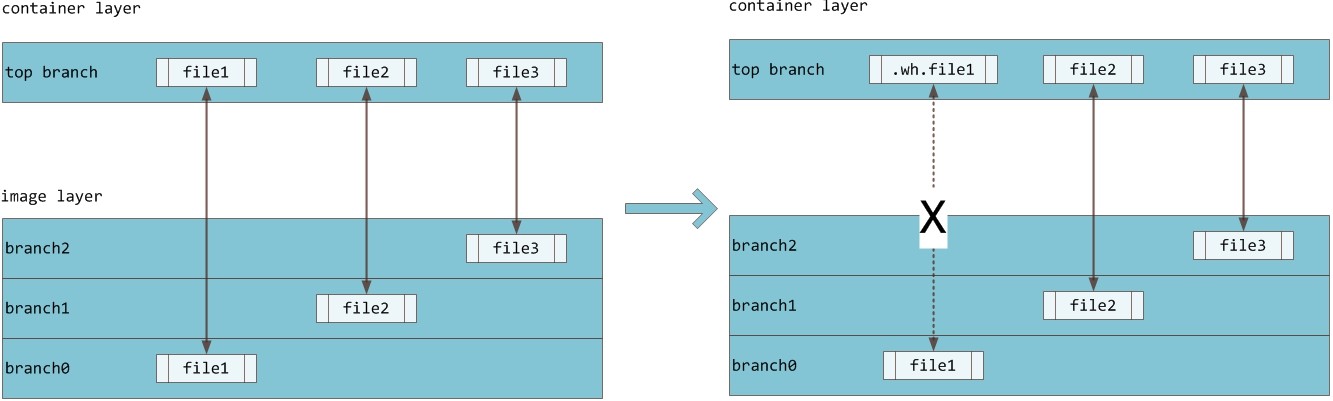
- 删除文件或目录:当文件或目录被删除时,AUFS 并不会真正从镜像中删除它,因为镜像层是只读的,AUFS 会创建一个特殊的文件或文件夹,这种特殊的文件或文件夹会阻止容器的访问。
Devicemapper
Devicemapper 是 Linux 内核提供的框架,从 Linux 内核 2.6.9 版本开始引入,Devicemapper 与 AUFS 不同,AUFS 是一种文件系统,而Devicemapper 是一种映射块设备的技术框架。
工作机制
Devicemapper 的工作机制主要围绕三个核心概念。
- 映射设备(mapped device):即对外提供的逻辑设备,它是由 Devicemapper 模拟的一个虚拟设备,并不是真正存在于宿主机上的物理设备。
- 目标设备(target device):目标设备是映射设备对应的物理设备或者物理设备的某一个逻辑分段,是真正存在于物理机上的设备。
映射表(map table):映射表记录了映射设备到目标设备的映射关系,它记录了映射设备在目标设备的起始地址、范围和目标设备的类型等变量。
映射设备通过映射表关联到具体的物理目标设备。事实上,映射设备不仅可以通过映射表关联到物理目标设备,也可以关联到虚拟目标设备,然后虚拟目标设备再通过映射表关联到物理目标设备。
镜像分层与共享
Devicemapper 使用专用的块设备实现镜像的存储,并且像 AUFS 一样使用了写时复制的技术来保障最大程度节省存储空间,所以 Devicemapper 的镜像分层也是依赖快照来是实现的。
Devicemapper的优点
Devicemapper 的每一镜像层都是其下一层的快照,最底层的镜像层是我们的瘦供给池,通过这种方式实现镜像分层有以下优点:
- 相同的镜像层,仅在磁盘上存储一次。例如,我有 10 个运行中的 busybox 容器,底层都使用了 busybox 镜像,那么 busybox 镜像只需要在磁盘上存储一次即可。
- 快照是写时复制策略的实现,也就是说,当我们需要对文件进行修改时,文件才会被复制到读写层。
- 相比对文件系统加锁的机制,Devicemapper 工作在块级别,因此可以实现同时修改和读写层中的多个块设备,比文件系统效率更高。
读写数据
当我们需要读取数据时,如果数据存在底层快照中,则向底层快照查询数据并读取。当我们需要写数据时,则向瘦供给池动态申请存储空间生成读写层,然后把数据复制到读写层进行修改。Devicemapper 默认每次申请的大小是 64K 或者 64K 的倍数,因此每次新生成的读写层的大小都是 64K 或者 64K 的倍数。
OverlayFS
OverlayFS 的发展分为两个阶段,2014 年,OverlayFS 第一个版本被合并到 Linux 内核 3.18 版本中,此时的 OverlayFS 在 Docker 中被称为overlay文件驱动。由于第一版的overlay文件系统存在很多弊端(例如运行一段时间后Docker 会报 “too many links problem” 的错误), Linux 内核在 4.0 版本对overlay做了很多必要的改进,此时的 OverlayFS 被称之为overlay2。
工作原理
overlay2 和 AUFS 类似,它将所有目录称之为层(layer),overlay2 的目录是镜像和容器分层的基础,而把这些层统一展现到同一的目录下的过程称为联合挂载(union mount)。overlay2 把目录的下一层叫作lowerdir,上一层叫作upperdir,联合挂载后的结果叫作merged。
读写数据
读取数据
容器内进程读取文件分为以下三种情况。
- 文件在容器层中存在:当文件存在于容器层并且不存在于镜像层时,直接从容器层读取文件;
- 当文件在容器层中不存在:当容器中的进程需要读取某个文件时,如果容器层中不存在该文件,则从镜像层查找该文件,然后读取文件内容;
- 文件既存在于镜像层,又存在于容器层:当我们读取的文件既存在于镜像层,又存在于容器层时,将会从容器层读取该文件。
写入数据
overlay2 对文件的修改采用的是写时复制的工作机制,这种工作机制可以最大程度节省存储空间。具体的文件操作机制如下。
- 第一次修改文件:当我们第一次在容器中修改某个文件时,overlay2 会触发写时复制操作,overlay2 首先从镜像层复制文件到容器层,然后在容器层执行对应的文件修改操作。
- 删除文件或目录:当文件或目录被删除时,overlay2 并不会真正从镜像中删除它,因为镜像层是只读的,overlay2 会创建一个特殊的文件或目录,这种特殊的文件或目录会阻止容器的访问。
文件系统结构
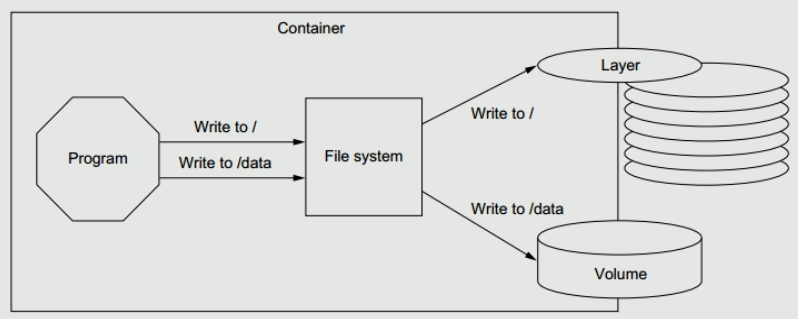
Docker镜像由多个只读层叠加而成,启动容器时,docker会加载只读镜像层并在镜像栈顶部加一个读写层;
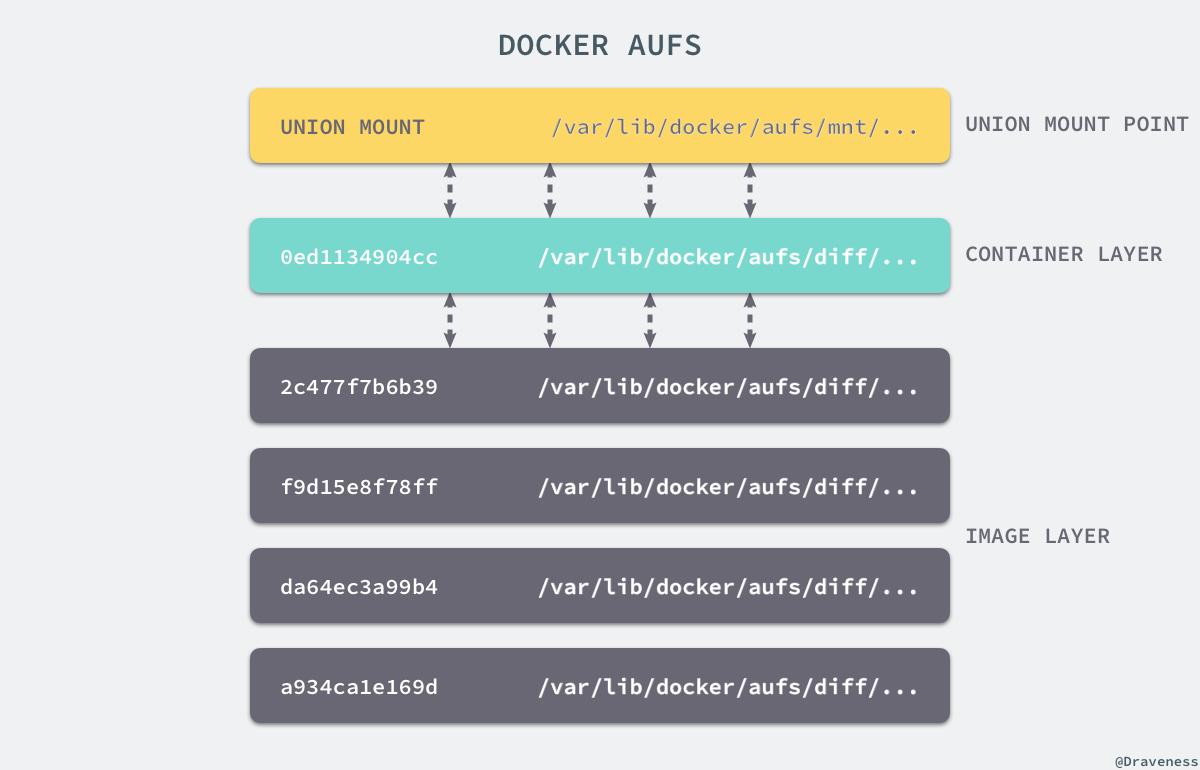
如果运行中的容器修改了现有的一个已经存在的文件,那该文件将会从读写层下面的只读层复制到读写层,该文件版本仍然存在,只是已经被读写层中该文件的副本所隐藏,此即“写时复制(COW)”机制。
如果一个文件在最底层是可见的,如果在layer1上标记为删除,最高的层是用户看到的Layer2的层,在layer0上的文件,在layer2上可以删除,但是只是标记删除,用户是不可见的,总之在到达最顶层之前,把它标记来删除,对于最上层的用户是不可见的,当标记一删除,只有用户在最上层建一个同名一样的文件,才是可见的。
存在的问题
对于修改类的操作,修改删除等,一般效率非常低,如果对一于I/O要求比较高的应用,如redis在实现持化存储时,是在底层存储时的性能要求比较高。
假设底层运行一个存储库mysql,mysql本来对于I/O的要求就比较高,如果mysql又是运行在容器中自己的文件系统之上时,也就是容器在停止时,就意味着删除,其实现数据存取时效率比较低,要避免这个限制要使用存储卷来实现。
在默认情况下,当用户退出容器而容器中又没有非守护进程在运行时,容器会进入关闭状态,同时,数据的修改会保留在最上层的可写文件系统内。当用户需要重新开启一个容器时,是无法访问原来所做的修改的,而是恢复到镜像的初始化状态。为了解决数据持久化的问题,Docker提供了数据卷。
文件系统缺点
- 存储于联合文件系统中,不易于宿主机访问;
- 容器间数据共享不便
- 删除容器其数据会丢失
存储卷
存储卷简介
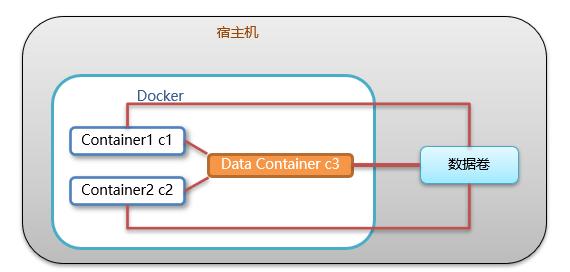
“卷”是容器上的一个或多个“目录”,此类目录可绕过联合文件系统,与宿主机上的某个目录“绑定(关联)”;
类似于挂载一样,宿主机的/data/web目录与容器中的/container/data/web目录绑定关系,然后容器中的进程向这个目录中写数据时,是直接写在宿主机的目录上的,绕过容器文件系统与宿主机的文件系统建立关联关系,使得可以在宿主机和容器内共享数据库内容,让容器直接访问宿主机中的内容,也可以宿主机向容器供集内容,两者是同步的。
mount名称空间本来是隔离的,可以让两个本来是隔离的文件系统,在某个子路径上建立一定程度的绑定关系,从而使得在两个容器之间的文件系统的某个子路径上不再是隔离的,实现一定程度上共享的效果。
在宿主机上能够被共享的目录(可以是文件)就被称为volume。
存储卷作用
优点是容器中进程所生成的数据,都保存在存储卷上,从而脱离容器文件系统自身后,当容器被关闭甚至被删除时,都不用担心数据被丢失,实现数据可以脱离容器生命周期而持久,当再次重建容器时,如果可以让它使用到或者关联到同一个存储卷上时,再创建容器,虽然不是之前的容器,但是数据还是那个数据,特别类似于进程的运行逻辑,进程本身不保存任何的数据,数据都在进程之外的文件系统上,或者是专业的存储服务之上,所以进程每次停止,只是保存程序文件,对于容器也是一样;容器就是一个有生命周期的动态对象来使用,容器关闭就是容器删除的时候,但是它底层的镜像文件还是存在的,可以基于镜像再重新启动容器。
但是容器有一个问题,一般与进程的启动不太一样,就是容器启动时选项比较多,如果下次再启动时,很容器会忘记它启动时的选项,所以最好有一个文件来保存容器的启动,这就是容器编排工具的作用。一般情况下,是使用命令来启动操作docker,但是可以通过文件来读,也就读文件来启动,读所需要的存储卷等,但是它也只是操作一个容器,这也是需要专业的容器编排工具的原因。
另一个优势就是容器就可以不置于启动在那台主机之上了,如几台主机后面挂载一个NFS,在各自主机上创建容器,而容器上通过关联到宿主机的某个目录上,而这个目录也是NFS所挂载的目录中,这样容器如果停止或者是删除都可以不限制于只能在原先的宿主机上启动才可以,可以实现全集群范围内调试容器的使用,当再分配存储、计算资源时,就不会再局限于单机之上,可以在集群范围内建立起来,基本各种docker的编排工具都能实现此功能,但是后面严重依赖于共享存储的使用。
应用状态分析
考虑到容器应用是需要持久存储数据的,可能是有状态的,如果考虑使用NFS做反向代理是没必要存储数据的,应用可以分为有状态和无状态,有状态是当前这次连接请求处理一定此前的处理是有关联的,无状态是前后处理是没有关联关系的,大多数有状态应用都是数据持久存储的,如mysql,redis有状态应用,在持久存储,如nginx作为反向代理是无状态应用,tomcat可以是有状态的,但是它有可能不需要持久存储数据,因为它的session都是保存在内存中就可以的,会导致节点宕机而丢失session,如果有必要应该让它持久,这也算是有状态的。
应用状态象限
是否有状态或无状态,是否需要持久存储,可以定立一个正轴坐标系,第一象限中是那些有状态需要存储的,像mysql,redis等服务,有些有有状态但是无需进行存储的,像tomcat把会话保存在内存中时,无状态也无需要存储的数据,如各种反向代理服务器nginx,lvs请求连接都是当作一个独立的连接来调度,本地也不需要保存数据,第四象限是无状态,但是需要存储数据是比较少见。
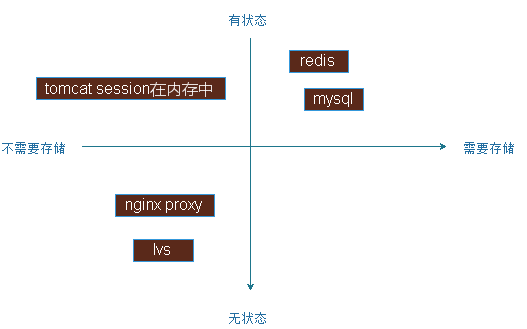
运维起来比较难的是有状态且需要持久的,需要大量的运维经验和大量的操作步骤才能操作起来的,如做一个Mysql主从需要运维知识、经验整合进去才能实现所谓的部署,扩展或缩容,出现问题后修复,必须要了解集群的规模有多大,有多少个主节点,有多少个从节点,主节点上有多少个库,这些都要一清二楚,才能修复故障,这些就强依赖于运维经验,无状态的如nginx一安装就可以了,并不复杂,对于无状态的应用可以迅速的实现复制,在运维上实现自动化是很容易的,对于有状态的现状比较难脱离运维人员来管理,即使是k8s在使用上也暂时没有成熟的工具来实现。
对于有状态的应用的数据,不使用存储卷,只能放在容器本地,效率比较低,而导致一个很严重问题就是无法迁移使用,而且随着容器生命周期的停止,还不能把它删除,只能等待下次再启动状态才可以,如果删除了数据就可能没了,因为它的可写层是随着容器的生命周期而存在的,所以只要持久存储数据,存储卷就是必需的。
对于docker存储卷运行起来并不太麻烦,如果不自己借助额外的体系来维护,它本身并没有这么强大,因为docker存储卷是使用其所在的宿主机上的本地文件系统目录,也就是宿主机有一块磁盘,这块磁盘并没有共享给其他的docker主要,然后容器所使用的目录,只是关联到宿主机磁盘上的某个目录而已,也就是容器在这宿主机上停止或删除,是可以重新再创建的,但是不能调度到其他的主机上,这也是docker本身没有解决的问题,所以docker存储卷默认就是docker所在主机的本地,但是自己搭建一个共享的NFS来存储docker存储的数据,也可以实现,但是这个过程强依赖于运维人员的能力。
存储卷原理
volume于容器初始化之时会创建,由base image提供的卷中的数据会于此期间完成复制
volume的初意是独立于容器的生命周期实现数据持久化,因此删除容器之时既不会删除卷,也不会对哪怕未被引用的卷做垃圾回收操作
存储卷的理解
卷为docker提供了独立于容器的数据管理机制
可以把“镜像”想像成静态文件,例如“程序”,把卷类比为动态内容,例如“数据”,于是,镜像可以重用,而卷可以共享
卷实现了“程序(镜像)”和”数据(卷)“分离,以及”程序(镜像)“和”制作镜像的主机”分离,用记制作镜像时无须考虑镜像运行在容器所在的主机的环境
存储卷分类
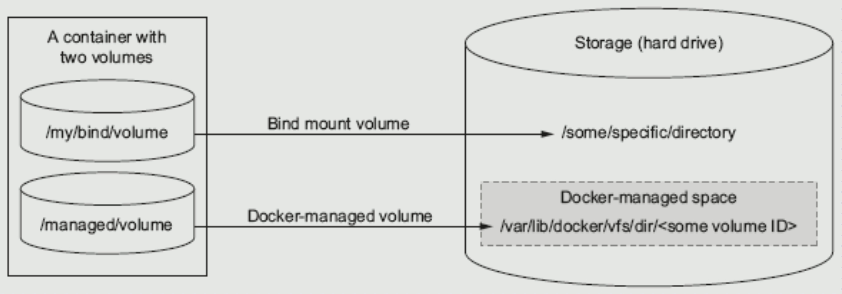
Docker有两种类型的卷,每种类型都在容器中存在一个挂载点,但其在宿主机上位置有所不同;
绑定挂载卷
Bind mount volume(绑定挂载卷):在宿主机上的路径要人工的指定一个特定的路径,在容器中也需要指定一个特定的路径,两个已知的路径建立关联关系
docker管理卷
Docker-managed volume(docker管理卷): 只需要在容器内指定容器的挂载点是什么,而被绑定宿主机下的那个目录,是由容器引擎daemon自行创建一个空的目录,或者使用一个已经存在的目录,与存储卷建立存储关系,这种方式极大解脱用户在使用卷时的耦合关系,缺陷是用户无法指定那些使用目录,临时存储比较适合;
 微信
微信 支付宝
支付宝






