YARN监控管理与资源管理

Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
可以把Hadoop YARN理解为相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序,YARN为这些程序提供运算所需的资源(内存、cpu等)。
YARN WebUI 服务
YARN提供WEB UI服务,在Hadoop 2.9.0版本中,提供新WebUI V2服务,可提供对运行在YARN框架上的应用程序的可视化。
WebUI V1 使用
与HDFS一样,YARN也提供了一个WebUI服务,可以使用YARN Web用户界面监视集群、队列、应用程序、服务、流活动和节点信息。还可以查看集群详细配置的信息,检查各种应用程序和服务的日志。
首页
浏览器输入http://node2.itcast.cn:8088/访问YARN WebUI服务,页面打开后,以列表形式展示已经运行完成的各种应用程序,如MapReduce应用、Spark应用、Flink应用等,与点击页面左侧Application栏目红线框Applications链接显示的内容一致。
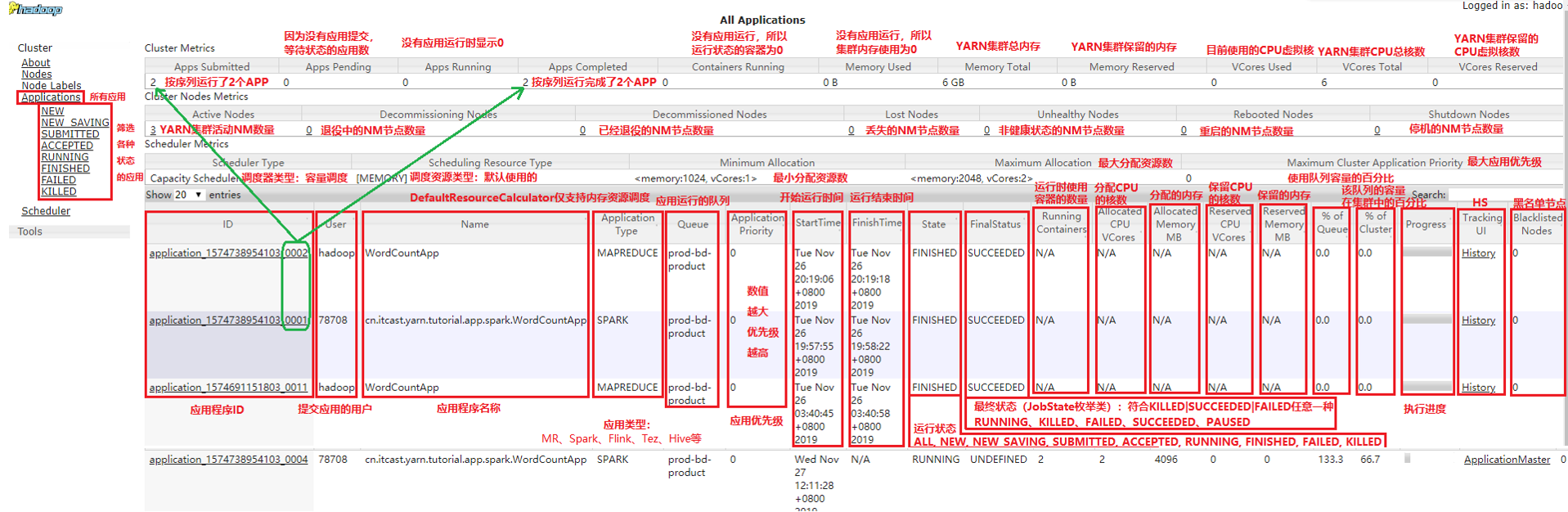
应用程序分析
当点击任意一个应用程序时,会打开一个新页面,并展示这个应用程序的运行信息。以MR应用为例,如果应用程序正在运行,打开的页面如图10-1-2所示;如果应用程序已经运行完成,打开的页面如下图所示。
- 正在运行的MR应用程序
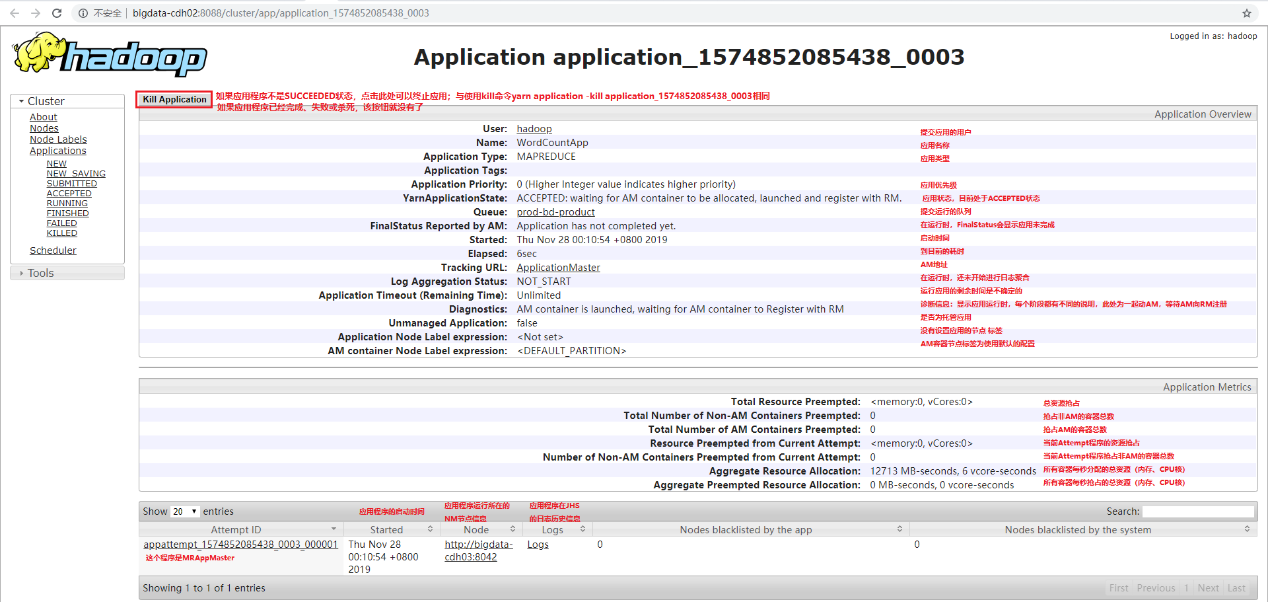
- 运行完成的MR应用程序

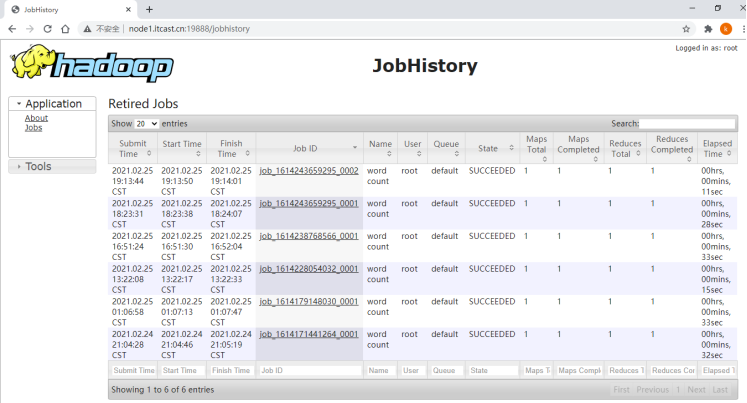
HistoryServer 服务
YARN中提供了一个叫做JobHistoryServer的守护进程,它属于YARN集群的一项系统服务,仅存储已经运行完成的MapReduce应用程序的作业历史信息,并不会存储其他类型(如Spark、Flink等)应用程序的作业历史信息。
当启用JobHistoryServer服务时,仍需要开启日志聚合功能,否则每个Container的运行日志是存储在NodeManager节点本地,查看日志时需要访问各个NodeManager节点,不利于统一管理和分析。
当开启日志聚合功能后AM会自动收集每个Container的日志,并在应用程序完成后将这些日志移动到文件系统,例如HDFS。然后通过JHS的WebUI服务来提供用户使用和应用恢复。
启用 JHS 服务
在【mapred-site.xml】文件中配置指定JobHistoryServer服务地址和端口号,具体操作如下。
编辑文件:
[root@node1 ~]# vim /export/server/hadoop/etc/hadoop/mapred-site.xm添加属性配置:
<property> <name>mapreduce.jobhistory.address</name> <value>node1.itcast.cn:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1.itcast.cn:19888</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/mr-history/intermediate</value> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/mr-history/done</value> </property>同步mapred-site.xml文件到集群其他机器,命令如下:
[root@node1 ~]# cd /export/server/hadoop/etc/hadoop [root@node1 hadoop]# scp -r mapred-site.xml root@node2.itcast.cn:$PWD [root@node1 hadoop]# scp -r mapred-site.xml root@node3.itcast.cn:$PWD
启用日志聚合
首先配置运行在YARN上应用的日志聚集功能,当应用运行完成,将日志相关信息上传至HDFS文件系统,编辑文件【yarn-site.xml】和添加属性配置。
编辑文件:
[root@node1 ~]# vim /export/server/hadoop/etc/hadoop/yarn-site.xml添加属性配置:
<property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/app-logs</value> </property> <property> <name>yarn.log.server.url</name> <value>http://node1.itcast.cn:19888/jobhistory/logs</value> </property>同步yarn-site.xml文件到集群其他机器,命令如下:
[root@node1 ~]# cd /export/server/hadoop/etc/hadoop [root@node1 hadoop]# scp -r yarn-site.xml root@node2.itcast.cn:$PWD [root@node1 hadoop]# scp -r yarn-site.xml root@node3.itcast.cn:$PWD
启动 JHS 服务
在上述配置中指定的JHS服务位于【node1.itcast.cn】节点上,在【node1.itcast.cn】节点中启动JobHistoryServer服务。
- 启动命令如下:
[root@node1 ~]# mr-jobhistory-daemon.sh start historyserver或者如下命令:
[root@node1 ~]# mapred --daemon start historyserver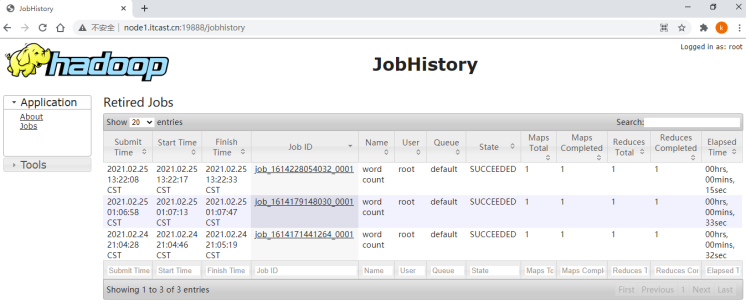
JHS 管理 MR 应用
当提交运行MapReduce程序在YARN上运行完成以后,将应用运行日志数据上传到HDFS上,此时JobHistoryServer服务可以从HDFS上读取运行信息,在WebUI进行展示,具体流程如下。
提交MR应用程序
使用yarn jar提交运行官方自带词频统计WordCount程序到YARN上运行,命令如下:
[root@node1 ~]# yarn jar \
/export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \
wordcount \
/datas/input.data /datas/output运行MR程序显示日志信息:
2021-02-25 19:13:43,059 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
2021-02-25 19:13:43,278 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1614243659295_0002
2021-02-25 19:13:43,518 INFO input.FileInputFormat: Total input files to process : 1
2021-02-25 19:13:43,619 INFO mapreduce.JobSubmitter: number of splits:1
2021-02-25 19:13:43,816 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1614243659295_0002
2021-02-25 19:13:43,818 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-02-25 19:13:44,007 INFO conf.Configuration: resource-types.xml not found
2021-02-25 19:13:44,008 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-02-25 19:13:44,077 INFO impl.YarnClientImpl: Submitted application application_1614243659295_0002
2021-02-25 19:13:44,136 INFO mapreduce.Job: The url to track the job: http://node3.itcast.cn:8088/proxy/application_1614243659295_0002/
2021-02-25 19:13:44,137 INFO mapreduce.Job: Running job: job_1614243659295_0002
2021-02-25 19:13:51,321 INFO mapreduce.Job: Job job_1614243659295_0002 running in uber mode : false
2021-02-25 19:13:51,322 INFO mapreduce.Job: map 0% reduce 0%
2021-02-25 19:13:57,474 INFO mapreduce.Job: map 100% reduce 0%
2021-02-25 19:14:02,544 INFO mapreduce.Job: map 100% reduce 100%
2021-02-25 19:14:03,564 INFO mapreduce.Job: Job job_1614243659295_0002 completed successfully
2021-02-25 19:14:03,687 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=65
FILE: Number of bytes written=446779
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=205
HDFS: Number of bytes written=39
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3439
Total time spent by all reduces in occupied slots (ms)=3085
Total time spent by all map tasks (ms)=3439
Total time spent by all reduce tasks (ms)=3085
Total vcore-milliseconds taken by all map tasks=3439
Total vcore-milliseconds taken by all reduce tasks=3085
Total megabyte-milliseconds taken by all map tasks=3521536
Total megabyte-milliseconds taken by all reduce tasks=3159040
Map-Reduce Framework
Map input records=3
Map output records=16
Map output bytes=160
Map output materialized bytes=65
Input split bytes=109
Combine input records=16
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=65
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=100
CPU time spent (ms)=2170
Physical memory (bytes) snapshot=506044416
Virtual memory (bytes) snapshot=5578981376
Total committed heap usage (bytes)=360185856
Peak Map Physical memory (bytes)=280317952
Peak Map Virtual memory (bytes)=2785366016
Peak Reduce Physical memory (bytes)=225726464
Peak Reduce Virtual memory (bytes)=2793615360
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=96
File Output Format Counters
Bytes Written=39MR运行历史信息
MR应用程序在运行时,是通过AM(MRAppMaster类)将日志写到HDFS中,会生成.jhist、.summary和_conf.xml文件。其中.jhist文件是MR程序的计数信息,.summary文件是作业的摘要信息,_conf.xml文件是MR程序的配置信息。
- MR应用程序启动时的资源信息
MR应用程序启动时,会把作业信息存储到${yarn.app.mapreduce.am.staging-dir}/${user}/.staging/${job_id}目录下。
yarn.app.mapreduce.am.staging-dir:/tmp/hadoop-yarn/staging(默认)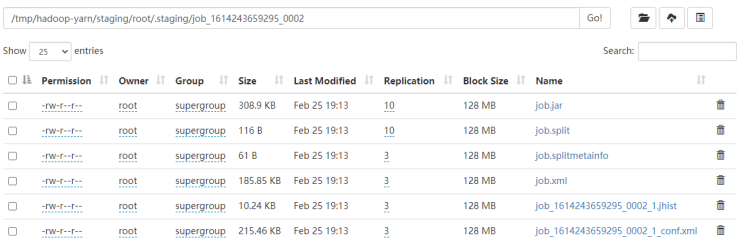
- MR应用程序运行完成时生成的信息
MR应用程序运行完成后,作业信息会被临时移动到${mapreduce.jobhistory.intermediate-done-dir}/${user}目录下。
mapreduce.jobhistory.intermediate-done-dir:/mr-history/intermediate(配置)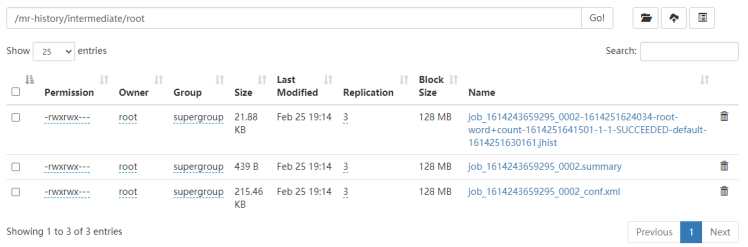
- MR应用程序最终的作业信息
等待${mapreduce.jobhistory.move.interval-ms}配置项的值(默认180000毫秒=3分钟)后,会把${mapreduce.jobhistory.intermediate-done-dir}/${user}下的作业数据移动到${mapreduce.jobhistory.done-dir}/${year}/${month}/${day}/${serialPart}目录下。此时.summary文件会被删除,因为.jhist文件提供了更详细的作业历史信息。
JHS服务中的作业历史信息不是永久存储的,在默认情况下,作业历史清理程序默认按照86400000毫秒(一天)的频率去检查要删除的文件,只有在文件早于mapreduce.jobhistory.max-age-ms(一天)时才进行删除。JHS的历史文件的移动和删除操作由HistoryFileManager类完成。
JHS 运行流程
客户端提交MR应用程序到RM;
在
/tmp/logs/<user>/logs/application_timestamp_xxxx中创建应用程序文件夹;MR作业在群集上的YARN中运行;
MR作业完成,在提交作业的作业客户上报告作业计数器;
将计数器信息(.jhist文件)和job_conf.xml文件写入
/user/history/done_intermediate/<user>/job_timestamp_xxxx然后将.jist文件和job_conf.xml从
/user/history/done_intermediate/<user>/移动到/user/history/done目录下;来自每个NM的Container日志汇总到
/tmp/logs/<用户ID>/logs/application_timestamp_xxxx;
JHS WebUI
JobHistoryServer服务WebUI界面相关说明:
首页
浏览器输入:http://node1.itcast.cn:19888 访问JHS服务,页面打开后,以列表形式展示已经运行完成的MR应用程序,与点击页面左侧Application栏目红线框jobs链接显示的内容一致。
JHS 构建说明
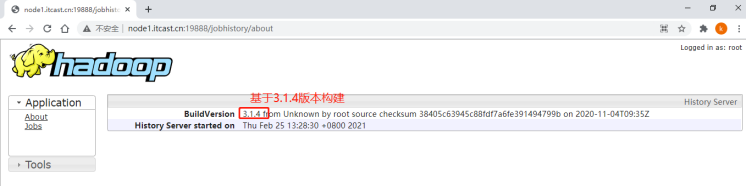
浏览器输入 http://node1.itcast.cn:19888/jobhistory/about 地址或者在点击页面左侧Application栏目下红线框about链接后会展示JHS服务的构建版本信息和启动时间。
MR应用程序查看
在JHS作业列表点击任意一个作业:
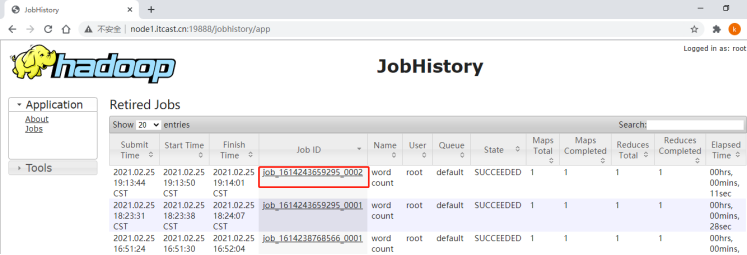
作业信息查看:
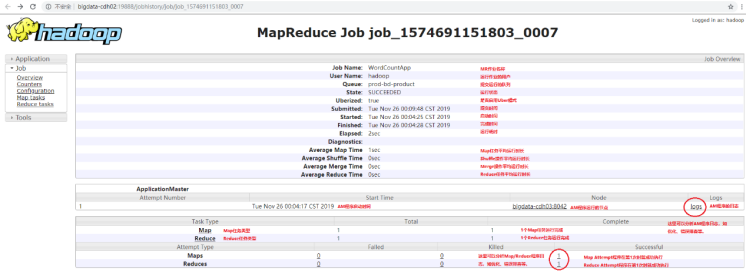
JHS 配置
浏览器输入 http://node1.itcast.cn:19888/conf 或点击页面左侧Tools栏目中的红线框configuration链接会打开JHS的所需配置页面,在配置页面中,主要有集群自定义配置(core-site.xml、hdfs-site.xml、yarn-site.xml和mapred-site.xml)和集群默认配置(core-default.xml、hdfs-default.xml、yarn-default.xml和mapred-default.xml)两种。配置页面中的配置项较多,截图为部分展示。
JHS 本地日志
浏览器输入 http://node1.itcast.cn:19888/logs/ 地址或点击页面左侧Tools栏目中的红线框local logs链接会打开JHS服务的所在节点的log文件列表页面。
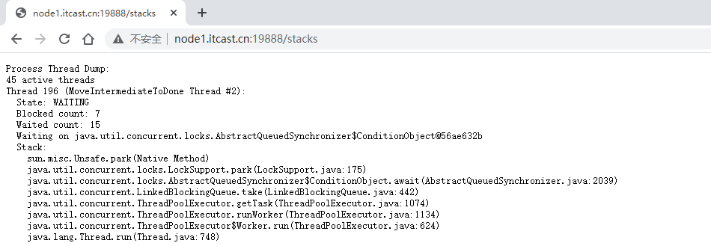
JHS 堆栈信息
浏览日输入 http://node1.itcast.cn:19888/stacks 地址或点击页面左侧Tools栏目中的红线框Server stacks链接会打开JHS服务的堆栈转储信息。stacks功能会统计JHS服务的后台线程数、每个线程的运行状态和详情。这些线程有MoveIntermediateToDone线程、JHS的10020 RPC线程、JHS的10033 Admin接口线程、HDFS的StatisticsDataReferenceCleaner线程、JHS服务度量系统的计时器线程、DN的Socket输入流缓存线程和JvmPauseMonitor线程等。
TimelineServer 服务
由于Job History Server仅对MapReduce应用程序提供历史信息支持,其他应用程序的历史信息需要分别提供单独的HistoryServer才能查询和检索。例如Spark的Application需要通过Spark自己提供的org.apache.spark.deploy.history.HistoryServer来解决应用历史信息。
为了解决这个问题,YARN新增了Timeline Server组件,以通用的方式存储和检索应用程序当前和历史信息。
到目前,有V1、V1.5和V2共三个版本,V1仅限于写入器/读取器和存储的单个实例,无法很好地扩展到小型群集之外;V2还处于alpha状态,所以在本章以V1.5进行讲解。
| 版本 | 说明 |
|---|---|
| V1 | 基于LevelDB实现。 |
| V1.5 | 在V1的基础上改进了扩展性。 |
| V2 | 1.使用更具扩展性的分布式写入器体系结构和可扩展的后端存储。2.将数据的收集(写入)与数据的提供(读取)分开。它使用分布式收集器,每个YARN应用程序实质上是一个收集器。读取器是专用于通过REST API服务查询的单独实例。3.使用HBase作为主要的后备存储,因为Apache HBase可以很好地扩展到较大的大小,同时保持良好的读写响应时间。4.支持在流级别汇总指标。 |
官方文档:
http://hadoop.apache.org/docs/r3.1.4/hadoop-yarn/hadoop-yarn-site/TimelineServer.html
http://hadoop.apache.org/docs/r3.1.4/hadoop-yarn/hadoop-yarn-site/TimelineServiceV2.html
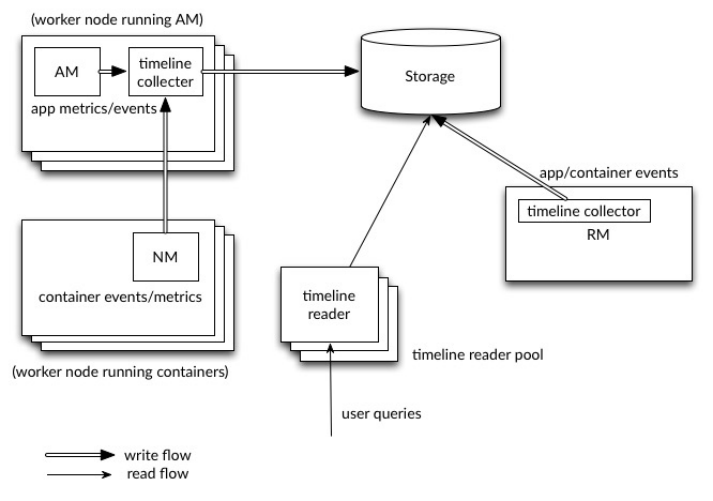
YARN Timeline Service v.2 服务架构图如下:
启用 Timeline 服务
在【yarn-site.xml】配置文件中添加如下属性,启动Timeline Server服务功能:
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>node2.itcast.cn</value>
<description>设置YARN Timeline服务地址</description>
</property>
<property>
<name>yarn.timeline-service.address</name>
<value>node2.itcast.cn:10200</value>
<description>设置YARN Timeline服务启动RPC服务器的地址,默认端口10200</description>
</property>
<property>
<name>yarn.timeline-service.webapp.address</name>
<value>node2.itcast.cn:8188</value>
<description>设置YARN Timeline服务WebUI地址</description>
</property>
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
<description>设置RM是否发布信息到Timeline服务器</description>
</property>
<property>
<name>yarn.timeline-service.generic-application-history.enabled</name>
<value>true</value>
<description>设置是否Timelinehistory-servic中获取常规信息,如果为否,则是通过RM获取</description>
</property>同步yarn-site.xml文件到集群其他机器,命令如下:
[root@node1 ~]# cd /export/server/hadoop/etc/hadoop
[root@node1 hadoop]# scp -r yarn-site.xml root@node2.itcast.cn:$PWD
[root@node1 hadoop]# scp -r yarn-site.xml root@node3.itcast.cn:$PWD重启YARN服务,命令如下所示:
[root@node2 ~]# stop-yarn.sh
[root@node2 ~]# start-yarn.sh启动 Timeline 服务
在上述配置中指定的Timeline服务位于【node2.itcast.cn】节点上,需要在【node2.itcast.cn】节点的shell客户端中启动,如果在非【node2.itcast.cn】节点上启动时会报错。
启动命令如下:
[root@node2 ~]# yarn --daemon start timelineserver在浏览器中输入:http://node2.itcast.cn:8188/applicationhistory
YARN 命令使用
YARN命令:${HADOOP_HOME}/bin/yarn,在不带任何参数的情况下运行yarn脚本会打印所有命令的描述,命令分为用户命令和管理命令。
[root@node3 ~]# yarn
Usage: yarn [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or yarn [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
--buildpaths attempt to add class files from build tree
--config dir Hadoop config directory
--daemon (start|status|stop) operate on a daemon
--debug turn on shell script debug mode
--help usage information
--hostnames list[,of,host,names] hosts to use in worker mode
--hosts filename list of hosts to use in worker mode
--loglevel level set the log4j level for this command
--workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
daemonlog get/set the log level for each daemon
node prints node report(s)
rmadmin admin tools
scmadmin SharedCacheManager admin tools
Client Commands:
app|application prints application(s) report/kill application/manage long running application
applicationattempt prints applicationattempt(s) report
classpath prints the class path needed to get the hadoop jar and the required libraries
cluster prints cluster information
container prints container(s) report
envvars display computed Hadoop environment variables
jar <jar> run a jar file
logs dump container logs
queue prints queue information
schedulerconf Updates scheduler configuration
timelinereader run the timeline reader server
top view cluster information
version print the version
Daemon Commands:
nodemanager run a nodemanager on each worker
proxyserver run the web app proxy server
registrydns run the registry DNS server
resourcemanager run the ResourceManager
router run the Router daemon
sharedcachemanager run the SharedCacheManager daemon
timelineserver run the timeline server用户命令
用户命令主要包括对Application、ApplicationAttempt、Classpath、Container、Jar、Logs、Node、Queue和Version的使用。
application
使用方式:
[root@node3 ~]# yarn application [options]- 查看帮助
[root@node3 ~]# yarn application | yarn application --help
- 查看所有的Application
[root@node3 ~]# yarn application -list仅显示状态为SUBMITTED、ACCEPTED、RUNNING应用。
- 杀死某一个Application
[root@node3 ~]# yarn application -kill application_1573364048641_0004- 查看某一个Application的统计报告
[root@node3 ~]# yarn application -status application_1614179148030_0001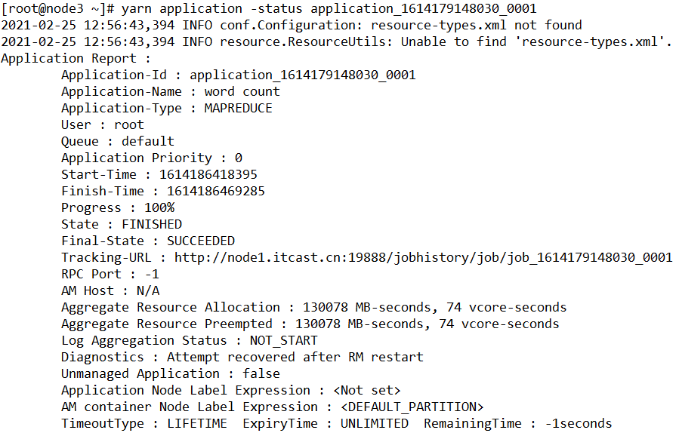
- 查看状态为ALL的Application列表
[root@node3 ~]# yarn application -list -appStates ALL
- 查看类型为MAPREDUCE的Application列表
[root@node3 ~]# yarn application -list -appTypes MAPREDUCE- 移动一个Application到default队列
[root@node3 ~]# yarn application -movetoqueue application_1573364048641_0004 -queue default注意:如果使用FairScheduler时,使用此命令移动应用程序从A队列到B队列时,出于公平考虑,它在A队列所分配的资源会在B队列中重新资源分配。如果加入被移动的应用程序的资源超出B队列的maxRunningApps 或者maxResources 限制,会导致移动失败。
- 修改一个Application的优先级
[root@node3 ~]# yarn application -updatePriority 0 -appId application_1573364048641_0006注意:整数值越高则优先级越高
jar
使用方式:
[root@node3 ~]# yarn jar x.jar [mainClass] args...使用yarn jar提交运行MapReduce应用,命令如下所示:
[root@node3 ~]# yarn jar \
> /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \
> wordcount \
> /datas/input.data /datas/output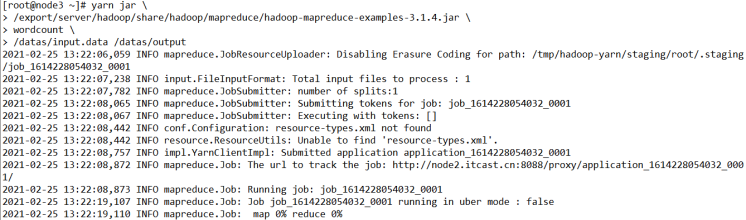
applicationattempt
使用方式:
[root@node3 ~]# yarn applicationattempt [options]- 查看帮助
[root@node3 ~]# yarn applicationattempt -help
- 标记applicationattempt失败
[root@node3 ~]# yarn applicationattempt -fail appattempt_1573364048641_0004_000001- 查看某个应用所有的attempt
[root@node3 ~]# yarn applicationattempt -list application_1614179148030_0001
- 查看具体某一个applicationattemp的报告
[root@node3 ~]# yarn applicationattempt -status appattempt_1614179148030_0001_000001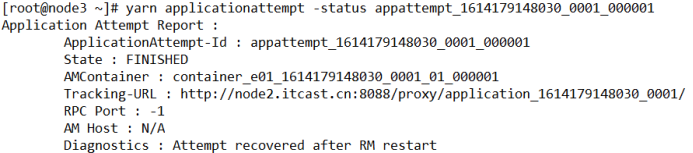
container
使用方式:
[root@node3 ~]# yarn container [options]- 查看帮助
[root@node3 ~]# yarn container -help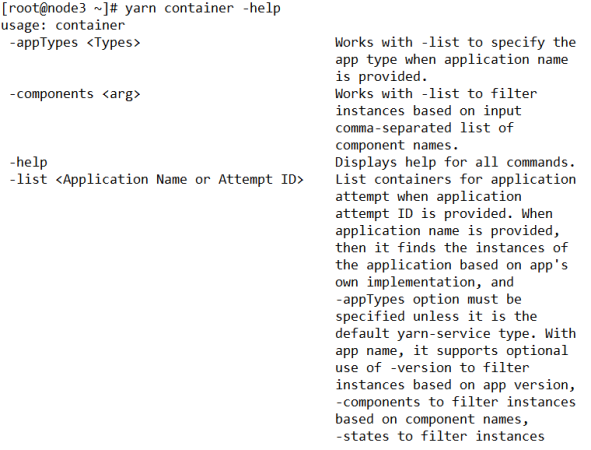
- 查看某一个applicationattempt下所有的container
[root@node3 ~]# yarn container -list appattempt_1614179148030_0001_000001备注:应用在YARN时,才能够查看出Contanier容器信息。
logs
使用方式:
[root@node3 ~]# yarn logs -applicationId <application ID> [options]- 查看帮助
[root@node3 ~]# yarn logs -help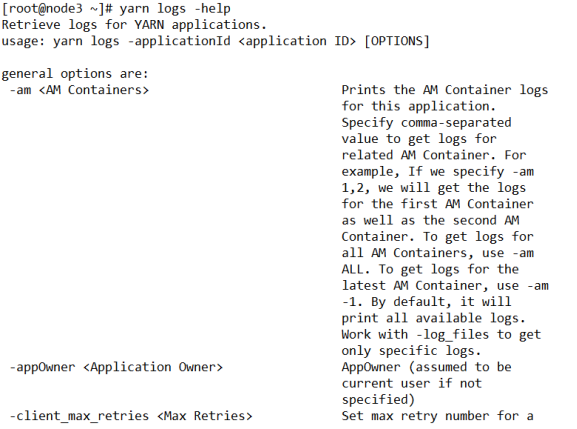
- 查看应用程序所有的logs
[root@node3 ~]# yarn logs -applicationId application_1614179148030_0001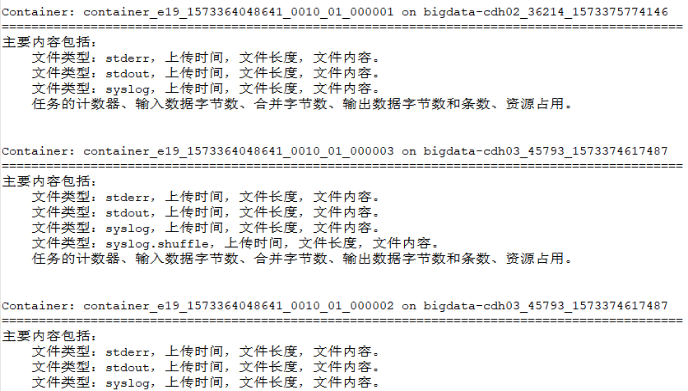
- 查看应用程序某个container运行所在节点的log
[root@node3 ~]# yarn logs -applicationId application_1614179148030_0001 -containerId container_e01_1614179148030_0001_01_000001
classpath
获取yarn的类路径,执行命令,显示如下结果:
[root@node3 ~]# yarn classpath
/export/server/hadoop/etc/hadoop:/export/server/hadoop/share/hadoop/common/lib/*:/export/server/hadoop/share/hadoop/common/*:/export/server/hadoop/share/hadoop/hdfs:/export/server/hadoop/share/hadoop/hdfs/lib/*:/export/server/hadoop/share/hadoop/hdfs/*:/export/server/hadoop/share/hadoop/mapreduce/lib/*:/export/server/hadoop/share/hadoop/mapreduce/*:/export/server/hadoop/share/hadoop/yarn/lib/*:/export/server/hadoop/share/hadoop/yarn/*queue
使用方式:
[root@node3 ~]# yarn queue [options]- 查看帮助
[root@node3 ~]# yarn queue -help
- 查看某个queue的状态
[root@node3 ~]# yarn queue -status default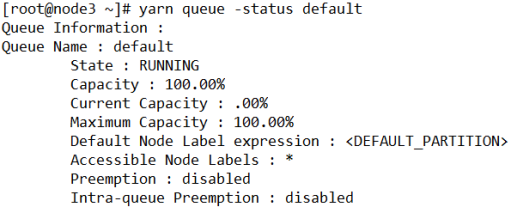
node
使用方式:
[root@node3 ~]# yarn node [options]- 查看帮助
[root@node3 ~]# yarn node -help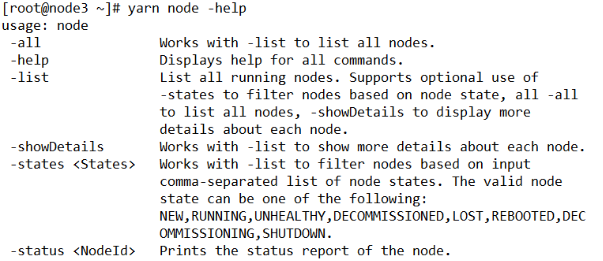
- 查看yarn所有从节点
[root@node3 ~]# yarn node -list -all
- 查看yarn所有节点的详情
[root@node3 ~]# yarn node -list -showDetails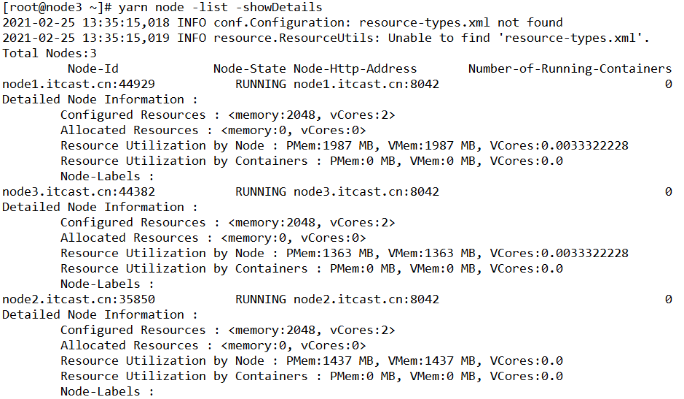
- 查看yarn所有正在运行的节点
[root@node3 ~]# yarn node -list -states RUNNING
- 查看yarn某一个节点的报告
[root@node3 ~]# yarn node -status node1.itcast.cn:44929 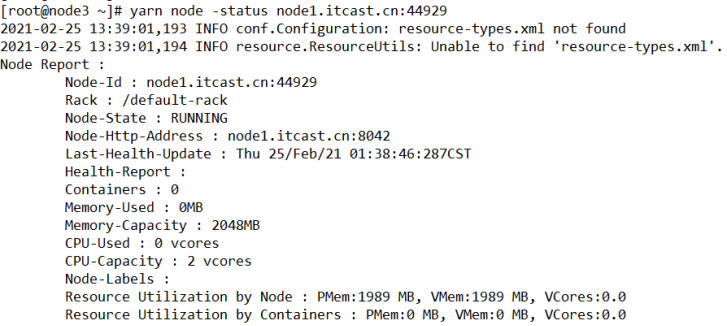
version
使用方式:
[root@node3 ~]# yarn version
管理命令
对于Hadoop集群的管理员使用的相关命令,主要包括daemonlog、nodemanager、proxymanager、resourcemanager、rmadmin、scmadmin、sharedcachemanager和timelineserver命令。
resourcemanager
使用方式:
[root@node3 ~]# yarn resourcemanager [options]- 启动某个节点的resourcemanager
[root@node3 ~]# yarn resourcemanager - 格式化resourcemanager的RMStateStore
清除RMStateStore,如果不再需要以前的应用程序,则将非常有用。只有在ResourceManager没有运行时才能使用此命令。
[root@node3 ~]# yarn resourcemanager -format-state-store删除RMStateStore中的Application
从RMStateStore删除该应用程序,只有在ResourceManager没有运行时才能使用此命令。
[root@node3 ~]# yarn resourcemanager -remove-application-from-state-store <appId> nodemanager
启动某个节点的nodemanager,命令如下:
[root@node3 ~]# yarn nodemanagerproxyserver
启动某个节点的proxyserver,命令如下:
[root@node3 ~]# yarn proxyserver如果启动YARN ProxyServer服务,需要在yarn-site.xml文件中配置如下属性:
<property>
<name>yarn.web-proxy.address</name>
<value>node3.itcast.cn:8089</value>
</property>daemonlog
使用方式:
[root@node3 ~]# yarn daemonlog -getlevel <host:httpport> <classname>[root@node3 ~]# yarn daemonlog -setlevel <host:httpport> <classname> <level>查看帮助
[root@node3 ~]# yarn daemonlog

- 查看RMAppImpl的日志级别
[root@node3 ~]# yarn daemonlog -getlevel \
node2.itcast.cn:8088 org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl 
- 设置RMAppImpl的日志级别
[root@node3 ~]# yarn daemonlog -setlevel \
node2.itcast.cn:8088 org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl DEBUG
rmadmin
使用方式:
[root@node3 ~]# yarn rmadmin [options]- 查看帮助
[root@node3 ~]# yarn rmadmin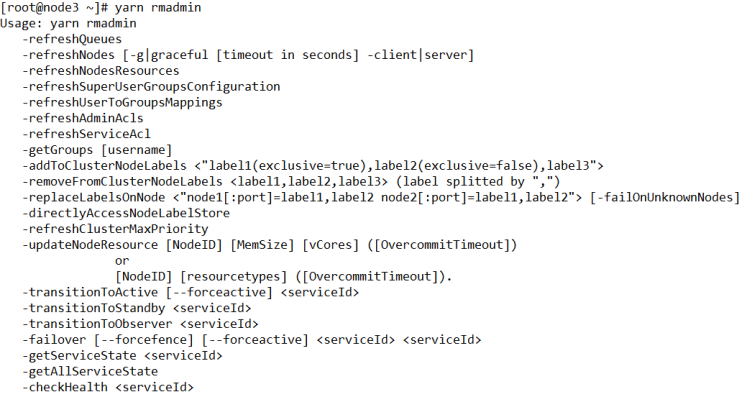
重新加载mapred-queues配置文件
重新加载队列的ACL,状态和调度程序特定的属性,ResourceManager将重新加载mapred-queues配置文件。
[root@node3 ~]# yarn rmadmin -refreshQueues- 刷新ResourceManager的主机信息
[root@node3 ~]# yarn rmadmin -refreshNodes- 在ResourceManager上刷新NodeManager的资源
[root@node3 ~]# yarn rmadmin -refreshNodesResources- 刷新超级用户代理组映射
[root@node3 ~]# yarn rmadmin -refreshSuperUserGroupsConfiguration- 刷新ACL以管理ResourceManager
[root@node3 ~]# yarn rmadmin -refreshAdminAcls获取ResourceManager服务的Active/Standby状态
获取所有RM状态
[root@node3 ~]# yarn rmadmin -getAllServiceState获取rm1的状态
[root@node3 ~]# yarn rmadmin -getServiceState rm1获取rm2的状态
[root@node3 ~]# yarn rmadmin -getServiceState rm2

ResourceManager服务执行健康检查
请求ResourceManager服务执行健康检查,如果检查失败,RMAdmin工具将使用非零退出码退出。
[root@node3 ~]# yarn rmadmin -checkHealth rm1 [root@node3 ~]# yarn rmadmin -checkHealth rm2
timelineserver
启动TimelineServer服务,命令如下:
[root@node3 ~]# yarn-daemon.sh start timelineserver启动完成以后,提供WEB UI端口号:8188,访问地址:http://node3.itcast.cn:8188
scmadmin
scmadmin是ShareCacheManager(共享缓存管理)的管理客户端,使用方式:
[root@node3 ~]# yarn scmadmin [options]查看帮助
[root@node3 ~]# yarn scmadmin

执行清理任务
[root@node3 ~]# yarn scmadmin -runCleanerTask
先启动SCM服务(SharedCacheManager服务)
[root@node3 ~]# yarn-daemon.sh start sharedcachemanager资源调度与隔离
在YARN中,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负责资源的分配,而NodeManager则负责资源的供给和隔离。
- 资源调度:ResourceManager将某个NodeManager上资源分配给任务;
- 资源隔离:NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证;
Hadoop YARN同时支持内存和CPU两种资源的调度,先品味一下内存和CPU这两种资源的特点,这是两种性质不同的资源。内存资源的多少会会决定任务的生死,如果内存不够,任务可能会运行失败;相比之下,CPU资源则不同,它只会决定任务运行的快慢,不会对生死产生影响。
Memory 资源
YARN允许用户配置每个节点上可用的物理内存资源,注意,这里是“可用的”,因为一个节点上的内存会被若干个服务共享,比如一部分给YARN,一部分给HDFS,一部分给HBase等,YARN配置的只是自己可以使用的,配置参数如下:
参数一:yarn.nodemanager.resource.memory-mb
- 该节点上YARN可使用的物理内存总量,默认是8192(MB);
- 如果设置为-1,并且yarn.nodemanager.resource.detect-hardware-capabilities 为true时,将会自动计算操作系统内存进行设置。
参数二:yarn.nodemanager.vmem-pmem-ratio
- 任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1
- 参数三:yarn.nodemanager.pmem-check-enabled
- 是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
- 参数四:yarn.nodemanager.vmem-check-enabled
- 是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
- 参数五:yarn.scheduler.minimum-allocation-mb
- 单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
- 参数六:yarn.scheduler.maximum-allocation-mb
- 单个任务可申请的最多物理内存量,默认是8192(MB)。
- 默认情况下,YARN采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。由于Cgroups对内存的控制缺乏灵活性(即任务任何时刻不能超过内存上限,如果超过,则直接将其杀死或者报OOM),而Java进程在创建瞬间内存将翻倍,之后骤降到正常值,这种情况下,采用线程监控的方式更加灵活(当发现进程树内存瞬间翻倍超过设定值时,可认为是正常现象,不会将任务杀死),因此YARN未提供Cgroups内存隔离机制。
CPU 资源
在YARN中,CPU资源的组织方式仍在探索中,当前只是非常粗粒度的实现方式。CPU被划分成虚拟CPU(CPU virtual Core),此处的虚拟CPU是YARN自己引入的概念,初衷是,考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力也是不一样的,比如某个物理CPU的计算能力可能是另外一个物理CPU的2倍,此时可以通过为第一个物理CPU多配置几个虚拟CPU弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟CPU个数。
- 参数一:yarn.nodemanager.resource.cpu-vcores
- 该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设值为与物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值。
- 如果设置为-1,并且yarn.nodemanager.resource.detect-hardware-capabilities为true时,将会自动计算操作系统CPU 核数进行设置。
- 参数二:yarn.scheduler.minimum-allocation-vcores
- 单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。
- 参数三:yarn.scheduler.maximum-allocation-vcores
- 单个任务可申请的最多虚拟CPU个数,默认是4。
- 由于CPU资源的独特性,目前这种CPU分配方式仍然是粗粒度的。
资源调度器
概述
在YARN中,负责给应用分配资源的就是Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。为此,YARN提供了多种调度器和可配置的策略供选择。
在YARN中有三种调度器可以选择:FIFO Scheduler(先进先出调度器) ,Capacity Scheduler(容量调度器),Fair Scheduler(公平调度器)。

默认情况下,Apache版本YARN使用的是Capacity调度器。如果需要使用其他的调度器,可以在yarn-site.xml中的yarn.resourcemanager.scheduler.class进行配置,具体的配置方式如下:

在YARN WebUI界面:http://node2.itcast.cn:8088/cluster
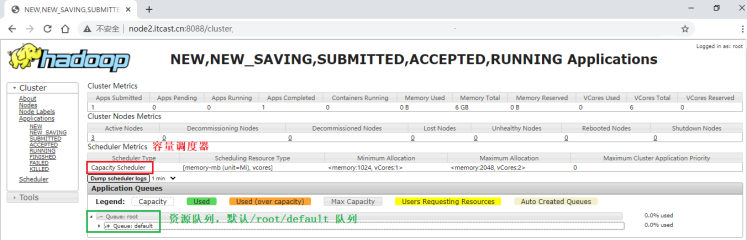
在YARN中,有层级队列组织方法,它们构成一个树结构,且根队列叫做root。所有的应用都运行在叶子队列中(即树结构中的非叶子节点只是逻辑概念,本身并不能运行应用)。对于任何一个应用,都可以显式地指定它属于的队列,也可以不指定从而使用username或者default队列。下图就是一个队列的结构:
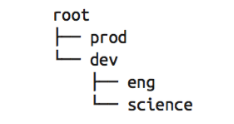
FIFO Scheduler(先进先出调度器)
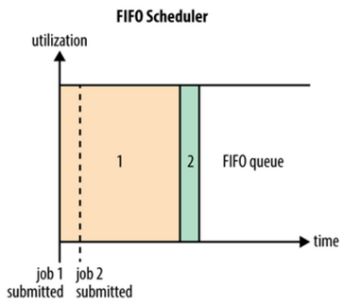
FifoScheduler是MRv1中JobTracker原有的调度器实现,此调度器在YARN中保留了下来。FifoScheduler是一个先进先出的思想,即先来的Application先运行。调度工作不考虑优先级和范围,适用于负载较低的小规模集群。当使用大型共享集群时,它的效率较低且会导致一些问题。
FifoScheduler拥有一个控制全局的队列queue,默认queue名称为default,该调度器会获取当前集群上所有的资源信息作用于这个全局的queue。
FifoScheduler将所有的Application按照提交时候的顺序来执行,只有当上一个Job执行完成之后后面的Job才会按照队列的顺序依次被执行。虽然单一的FIFO调度实现简单,但是对于很多实际的场景并不能满足要求,催发了Capacity调度器和Fair调度器的出现。
Capacity Scheduler(容量调度器)
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。

Capacity调度器可以理解成一个个的资源队列,这个资源队列是用户自己去分配的。队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
什么是Capacity Scheduler
Capacity Scheduler调度器以队列为单位划分资源。简单通俗点来说,就是一个个队列有独立的资源,队列的结构和资源是可以进行配置的,如下图:
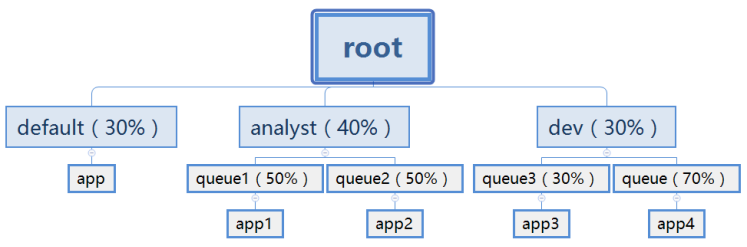
default队列占30%资源,analyst和dev分别占40%和30%资源;类似的,analyst和dev各有两个子队列,子队列在父队列的基础上再分配资源。
- 队列里的应用以FIFO方式调度,每个队列可设定一定比例的资源最低保证和使用上限;
- 每个用户也可以设定一定的资源使用上限以防止资源滥用;
- 而当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
调度器特性
CapacityScheduler是一个可插拔调度程序,它被设计为以队列为单位划分资源、易于操作的方式在多租户模式下安全的共享大型集群,同时能保证每个组所需资源的保证,当容量不够用时还可以使用其他组多余的容量。这种方式最大程度地提高集群的吞吐量和利用率,以便在分配的容量约束下及时为其应用程序分配资源。CapacityScheduler的特性如下:
层次化的队列设计(Hierarchical Queues)
层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。
容量保证(Capacity Guarantees)
队列上都会设置一个资源的占比,可以保证每个队列都不会占用整个集群的资源。
安全(Security )
每个队列又严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。
弹性分配(Elasticity )
空闲的资源可以被分配给任何队列。当多个队列出现争用的时候,则会按照比例进行平衡。
多租户租用(Multi-tenancy)
通过队列的容量限制,多个用户就可以共享同一个集群,同事保证每个队列分配到自己的容量,提高利用率。
操作性(Operability)
Yarn支持动态修改调整容量、权限等的分配,可以在运行时直接修改;
提供管理员界面,显示当前的队列状况;管理员可以在运行时,添加一个队列;但是不能删除一个队列;
管理员可以在运行时暂停某个队列,可以保证当前的队列在执行过程中,集群不会接收其他的任务。如果一个队列被设置成了stopped,那么就不能向它或者子队列上提交任务了。
基于资源的调度(Resource-based Scheduling)
协调不同资源需求的应用程序,比如内存、CPU、磁盘等等。
基于用户/组的队列隐射(Queue Mapping based on User or Group)
允许用户基于用户或者组去映射一个作业到特定队列。
调度器配置
CapacityScheduler的配置项包括两部分,其中一部分在yarn-site.xml中,主要用于配置YARN集群使用的调度器;另一部分在capacity-scheduler.xml配置文件中,主要用于配置各个队列的资源量、权重等信息。
一、开启调度器
在ResourceManager中配置使用的调度器,修改HADOOP_CONF/yarn-site.xml,设置属性:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>二、配置队列
调度器的核心就是**队列的分配和使用,修改HADOOP_CONF/capacity-scheduler.xml可以配
置队列。Capacity调度器默认有一个预定义的队列:root,所有的队列都是它的子队列。队列的分配支持层次化的配置,使用.来进行分割,比如:

案例:root下面有三个子队列

三、队列属性
- 队列的资源容量占比(百分比):

系统繁忙时,每个队列都应该得到设置的量的资源;当系统空闲时,该队列的资源则可以被其他的队列使用。同一层的所有队列加起来必须是100%。
- 队列资源的使用上限

系统空闲时,队列可以使用其他的空闲资源,因此最多使用的资源量则是该参数控制。默认是-1,即禁用。
- 每个任务占用的最少资源

比如,设置成25%。那么如果有两个用户提交任务,那么每个任务资源不超过50%。如果3个用户提交任务,那么每个任务资源不超过33%。如果4个用户提交任务,那么每个任务资源不超过25%。如果5个用户提交任务,那么第五个用户需要等待才能提交。默认是100,即不去做限制。
- 每个用户最多使用的队列资源占比

如果设置为50,那么每个用户使用的资源最多就是50%。
四、运行和提交应用限制
- 设置系统中可以同时运行和等待的应用数量,默认是10000。

- 设置有多少资源可以用来运行app master,即控制当前激活状态的应用,默认是10%。

五、队列管理
- 队列的状态,可以使RUNNING或者STOPPED

如果队列是STOPPED状态,那么新应用不会提交到该队列或者子队列。同样,如果root被设置成STOPPED,那么整个集群都不能提交任务了。现有的应用可以等待完成,因此队列可以优雅的退出关闭。
- 访问控制列表ACL:控制谁可以向该队列提交任务

限定哪些Linux用户/用户组可向给定队列中提交应用程序。如果一个用户可以向该队列提交,那么也可以提交任务到它的子队列。配置该属性时,用户之间或用户组之间用“,”分割,用户和用户组之间用空格分割,比如“user1, user2 group1,group2”。
- 设置队列的管理员的ACL控制

为队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等。同样,该属性具有继承性,如果一个用户可以向某个队列中提交应用程序,则它可以向它的所有子队列中提交应用程序。
六、基于用户/组的队列映射
- 映射单个用户或者用户组到一个队列
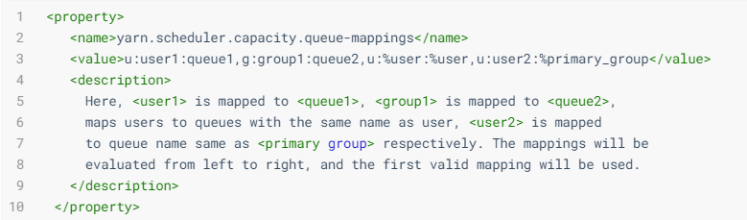
语法:[u or g]:[name]:[queue_name][,next_mapping]*,列表可以多个,之间以逗号分隔。%user放在[name]部分,表示已经提交应用的用户。如果队列名称和用户一样,那可以使用%user表示队列。如果队列名称和用户主组一样,可以使用%primary_group表示队列。u:%user:%user 表示-已经提交应用的用户,映射到和用户名称一样的队列上。 u:user2:%primary_group表示user2提交的应用映射到user2主组名称一样的队列上。如果用户组并不多,队列也不多,建议还是使用简单的语法,而不要使用带%的。
- 定义针对特定用户的队列是否可以被覆盖,默认值为false。

七、其他属性
- 资源计算方法

默认是org.apache.hadoop.yarn.util.resource.DefaultResourseCalculator,它只会计算内存。DominantResourceCalculator则会计算内存和CPU。
- 调度器尝试进行调度的次数

节点局部性延迟,在容器企图调度本地机栈容器后(失败),还可以错过错过多少次的调度次数。一般都是跟集群的节点数量有关。默认40(一个机架上的节点数)一旦设置完这些队列属性,就可以在web ui上看到了。
八、修改队列配置
如果想要修改队列或者调度器的配置,可以修改HADOOP_CONF_DIR/capacity-scheduler.xml,修改完成后,需要执行下面的命令:
HADOOP_YARN_HOME/bin/yarn rmadmin -refreshQueues注意事项:
- 队列不能被删除,只能新增;
- 更新队列的配置需要是有效的值;
- 同层级的队列容量限制相加需要等于100%;
- 在MapReduce中,可以通过
mapreduce.job.queuename属性指定要用的队列。如果队列不存在,在提交任务时就会收到错误。如果没有定义任何队列,所有的应用将会放在一个default队列中。
案例:Capacity调度器配置
假设有如下层次的队列:
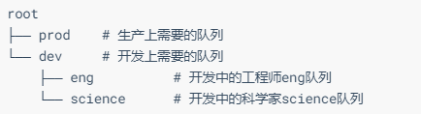
step1、Capacity Scheduler 配置
上图中队列的一个调度器配置文件HADOOP_CONF/capacity-scheduler.xml:
<?xml version="1.0"?>
<configuration>
<!-- 分为两个队列,分别为prod和dev -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<!-- dev继续分为两个队列,分别为eng和science -->
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>eng,science</value>
</property>
<!-- 设置prod队列40% -->
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<!-- 设置dev队列60% -->
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<!-- 设置dev队列可使用的资源上限为75% -->
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<!-- 设置eng队列50% -->
<property>
<name>yarn.scheduler.capacity.root.dev.eng.capacity</name>
<value>50</value>
</property>
<!-- 设置science队列50% -->
<property>
<name>yarn.scheduler.capacity.root.dev.science.capacity</name>
<value>50</value>
</property>
</configuration>相关属性说明如下所示:
- dev队列又被分成了eng和science两个相同容量的子队列;
- dev的maximum-capacity属性被设置成了75%,所以即使prod队列完全空闲dev也不会占用全部集群资源,也就是说,prod队列仍有25%的可用资源用来应急;
- eng和science两个队列没有设置maximum-capacity属性,也就是说eng或science队列中的job可能会用到整个dev队列的所有资源(最多为集群的75%);
- 而类似的,prod由于没有设置maximum-capacity属性,它有可能会占用集群全部资源。
- 对于Capacity调度器,队列名必须是队列树中的最后一部分,如果使用队列树则不会被识别。比如,在上面配置中,使用prod和eng作为队列名是可以的,但是如果用root.dev.eng或者dev.eng是无效的。
step2、测试运行
上述配置队列形式如下所示:
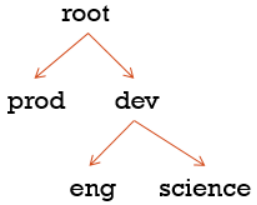
启动ResouceManager,打开8088页面:
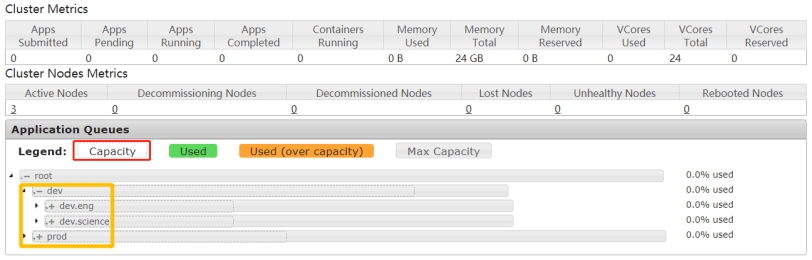
运行MapReduce中WordCount程序,指定运行队列prod
HADOOP_HOME=/export/server/hadoop
${HADOOP_HOME}/bin/yarn jar \
${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \
wordcount \
-Dmapreduce.job.queuename=prod \
datas/input.data /datas/output查看8088界面如下所示:
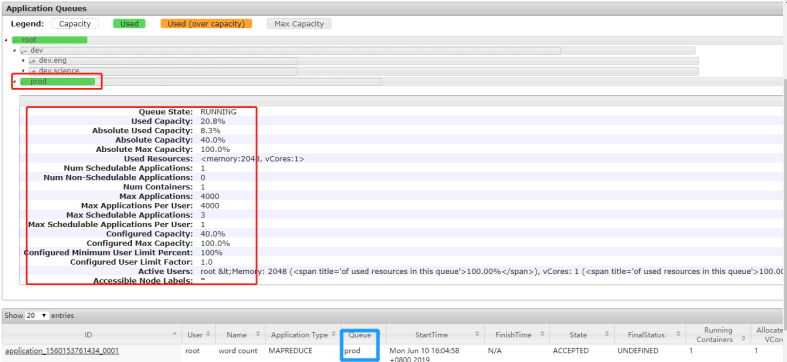
不指定运行队列,默认运行在default队列,如果找不到default队列将会报如下错误。
HADOOP_HOME=/export/server/hadoop
${HADOOP_HOME}/bin/yarn jar \
${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \
wordcount \
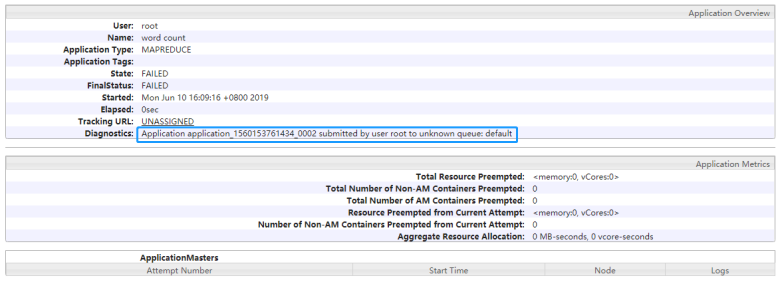
datas/input.data /datas/output2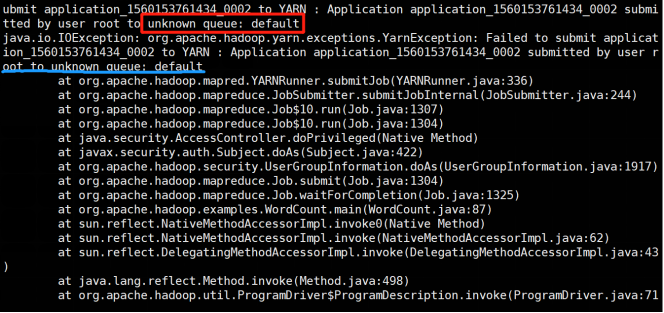
查看8088界面如下所示:
Capacity官方默认配置
在HADOOP 安装目录中,官方自带默认配置HADOOP_CONF/capacity-scheduler.xml:
<configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
<description>
Maximum number of applications that can be pending and running.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
<description>
Maximum percent of resources in the cluster which can be used to run
application masters i.e. controls number of concurrent running
applications.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
<description>
The ResourceCalculator implementation to be used to compare
Resources in the scheduler.
The default i.e. DefaultResourceCalculator only uses Memory while
DominantResourceCalculator uses dominant-resource to compare
multi-dimensional resources such as Memory, CPU etc.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>100</value>
<description>Default queue target capacity.</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
<description>
Default queue user limit a percentage from 0.0 to 1.0.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
<description>
The maximum capacity of the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>
The state of the default queue. State can be one of RUNNING or STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
<description>
The ACL of who can submit jobs to the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>
The ACL of who can administer jobs on the default queue.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
<description>
Number of missed scheduling opportunities after which the CapacityScheduler
attempts to schedule rack-local containers.
Typically this should be set to number of nodes in the cluster, By default is setting
approximately number of nodes in one rack which is 40.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value></value>
<description>
A list of mappings that will be used to assign jobs to queues
The syntax for this list is [u|g]:[name]:[queue_name][,next mapping]*
Typically this list will be used to map users to queues,
for example, u:%user:%user maps all users to queues with the same name
as the user.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings-override.enable</name>
<value>false</value>
<description>
If a queue mapping is present, will it override the value specified
by the user? This can be used by administrators to place jobs in queues
that are different than the one specified by the user.
The default is false.
</description>
</property>
</configuration>Fair Scheduler(公平调度器)
FairScheduler是Hadoop可插拔的调度程序,提供了YARN应用程序公平地共享大型集群中资源的另一种方式。FairScheduler是一个将资源公平的分配给应用程序的方法,使所有应用在平均情况下随着时间的流逝可以获得相等的资源份额。
什么是Fair Scheduler
Fair Scheduler 设计目标是为所有的应用分配公平的资源(对公平的定义通过参数来设置)。公平调度是一个分配资源给所有application的方法,平均来看,是随着时间的进展平等分享资源的。
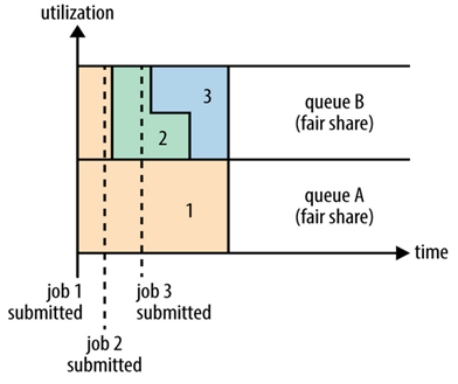
公平调度可以在多个队列间工作。如上图所示,假设有两个用户A和B,分别拥有一个队列:
- 当A启动一个job而B没有任务时,A会获得全部集群资源;
- 当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。
如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会各自使用四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。FairScheduler将应用组织到队列中,并在这些队列之间公平地共享资源。默认情况下,所有用户共享一个名为default的队列。如果应用明确在容器资源请求中指定了队列,则该请求将提交到指定的队列。可以通过配置,根据请求中包含的用户名或组分配队列。在每个队列中,使用调度策略在运行的应用程序之间共享资源。默认设置是基于内存的公平共享,但是也可以配置具有优势资源公平性的FIFO和多资源。
分层队列:队列可以按层次结构排列以划分资源,并可以配置权重以按特定比例共享集群。
- 基于用户或组的队列映射:可以根据提交任务的用户名或组来分配队列。如果任务指定了一个队列,则在该队列中提交任务。
- 资源抢占:根据应用的配置,抢占和分配资源可以是友好的或是强制的。默认不启用资源抢占。
- 保证最小配额:可以设置队列最小资源,允许将保证的最小份额分配给队列,保证用户可以启动任务。当队列不能满足最小资源时,可以从其它队列抢占。当队列资源使用不完时,可以给其它队列使用。这对于确保某些用户、组或生产应用始终获得足够的资源。
- 允许资源共享:即当一个应用运行时,如果其它队列没有任务执行,则可以使用其它队列,当其它队列有应用需要资源时再将占用的队列释放出来。所有的应用都从资源队列中分配资源。
- 默认不限制每个队列和用户可以同时运行应用的数量。可以配置来限制队列和用户并行执行的应用数量。限制并行执行应用数量不会导致任务提交失败,超出的应用会在队列中等待。
启用 Fair Scheduler
要使用Fair Scheduler,首先在yarn-site.xml配置文件进配置:
<property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value></property>资源配置文件
Fair Scheduler的配置文件,位于类路径下,默认文件名fair-scheduler.xml,通过属性指定:
<!-- Path to allocation file, the file is searched for on the classpath -->
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<!-- 如果不指定全路径,表示在HADOOP_CONF路径下;通常指定全路径 -->
<value>fair-scheduler.xml</value>
</property>若没有fair-scheduler.xml这个配置文件,Fair Scheduler采用的分配策略:调度器会在用户提交第一个应用时为其自动创建一个队列,队列的名字就是用户名,所有的应用都会被分配到相应的用户队列中。
Fair Scheduler 配置
定制Fair Scheduler涉及到2个文件。首先,scheduler有关的选项可以在yarn-site.xml中配置。此外,多数情况,用户需要创建一个“allocation”文件来列举存在的queues和它们相应的weights和capacities。这个“allocation”文件每隔10秒钟加载一次,更新的配置可以更快的生效。
调度器级别的参数
在HADOOP_CONF/yarn-site.xml中,主要用于配置调度器级别的参数。
- 属性一:是否将与allocation有关的username作为默认的queue name,当queue name没有指定的时候。如果设置成false(且没有指定queue name) 或者没有设定,所有的jobs将共享“default” queue。

- 属性二:是否使用“preemption”(优先权,抢占),默认为fasle

- 属性三:启动抢占后的资源利用率阈值。利用率是计算所有资源中容量使用的最大比率。 默认值是0.8f。

- 属性四:在一个队列内部分配资源时,默认情况下,采用公平轮询的方法将资源分配各个应用程序,而该参数则提供了另外一种资源分配方式:按照应用程序资源需求数目分配资源,即需求资源数量越多,分配的资源越多。默认情况下,该参数值为false。

- 属性五:是在允许在一个心跳中,发送多个container分配信息

- 属性六:如果assignmultuple为true,在一次心跳中,最多发送分配container的个数。默认为-1,无限制。

- 属性七:一个float值,在0~1之间,表示在等待获取满足node-local条件的containers时,最多放弃不满足node-local的container的机会次数,放弃的nodes个数为集群的大小的比例。默认值为-1.0表示不放弃任何调度的机会。

- 属性八:当应用程序请求某个机架上资源时,它可以接受的可跳过的最大资源调度机会。

- 属性九:是否根据application的大小(job的个数)作为权重。默认为false,如果为true,那么复杂的application将获取更多的资源。

- 属性十:如果设置为true,application提交时可以创建新的队列,要么是application指定了队列,或者是按照user-as-default-queue放置到相应队列。如果设置为false,任何时间一个app要放置到一个未在分配文件中指定的队列,都将被放置到“default”队列。默认是true。如果一个队列放置策略已经在分配文件中指定,本属性将会被忽略。

- 属性十一:默认值500ms,锁住调度器重新进行计算作业所需资源的间隔

分配文件队列的参数
可以在分配(allocation)文件中配置每一个队列,并且可以像Capacity Scheduler一样分层次配置队列,分配文件每10秒重载一次,因此允许在运行时进行修改。
- 简单配置案例

队列的层次
通过嵌套
<queue>元素实现的。所有的队列都是root队列的孩子,即使没有配到<root>元素里。在这个配置中,把dev队列有分成了eng和science两个队列。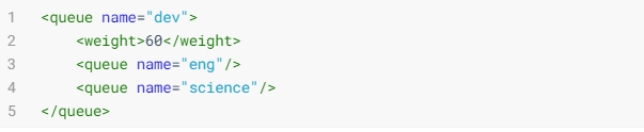
Fair Scheduler中的队列有一个权重属性(权重就是对公平的定义),并把这个属性作为公平调度的依据。在每个资源池的配置项中,有个weight属性(默认为1),标记了资源池的权重,当资源池中有任务等待,并且集群中有空闲资源时候,每个资源池可以根据权重获得不同比例的集群空闲资源。
例子中,当调度器分配集群40:60资源给prod和dev时便视作公平,eng和science队列没有定义权重,则会被平均分配。
权重并不是百分比,把上面的40和60分别替换成2和3,效果也是一样的。注意,对于在没有配置文件时,按用户自动创建的队列,它们仍有权重并且权重值为1。
比如,资源池businessA和businessB的权重分别为2和1,这两个资源池中的资源都已经跑满了,并且还有任务在排队,此时集群中有30个Container的空闲资源,那么,businessA将会额外获得20个Container的资源,businessB会额外获得10个Container的资源。
队列的默认调度策略(整体)
通过顶级元素
<defaultQueueSchedulingPolicy>进行配置,如果没有配置,默认采用公平调度。每个队列内部仍可以有不同的调度策略。
针对Apache Hadoop来说,Fair Scheduler默认的调度策略(scheduling policy)是基于内存
CDH版本的YARN默认采用的调度策略是Fair Scheduler的DRF策略,即基于vcore和内存的策略,而不是只基于内存的调度策略。

每个队列的调度策略
尽管是Fair Scheduler,其仍支持在队列级别进行FIFO Schedule。每个队列的调度策略可以被其内部的
<schedulingPolicy>元素覆盖。
例子中,
prod队列就被指定采用FIFO进行调度,所以,对于提交到prod队列的任务就可以按照FIFO规则顺序的执行了。需要注意,prod和dev之间的调度仍然是公平调度,同样eng和science也是公平调度。
队列的设置
Fair Scheduler采用了一套基于规则的系统来确定应用应该放到哪个队列。
例子中,
<queuePlacementPolicy>元素定义了一个规则列表,其中的每个规则会被逐个尝试直到匹配成功。
所有Rule接受
create参数,用于表明该规则是否能够创建新队列。create默认值为true;如果设置为false并且Rule要放置app到一个allocations file没有配置的队列,那么继续应用下一个Rule;上例第一个规则specified,则会把应用放到它指定的队列中,若这个应用没有指定队列名或队列名不存在,则说明不匹配这个规则,然后尝试下一个规则;
primaryGroup规则会尝试把应用放在以用户所在的Unix组名命名的队列中,如果没有这个队列,不创建队列转而尝试下一个规则;
当前面所有规则不满足时,则触发
default规则,把应用放在dev.eng队列中;可以不配置
queuePlacementPolicy规则,调度器则默认采用如下规则:
简单的配置策略:使得所有的应用放入同一个队列(default),这样就可以让所有应用之间平等共享集群而不是在用户之间。

运行Apps数量限制及AM资源限制
对特定用户可以运行的apps的数量限制

设置任意用户(没有特定限制的用户)运行app的默认最大数量限制

设置队列的默认运行app数量限制,可以被任一队列的
maxRunningApps元素覆盖
设置队列的默认AM共享资源限制;可以被任一队列的maxAMShare 元素覆盖

抢占(Preemption)
当一个job提交到一个繁忙集群中的空队列时,job并不会马上执行,而是阻塞直到正在运行的job释放系统资源。为了使提交job的执行时间更具预测性(可以设置等待的超时时间),Fair调度器支持抢占。
抢占就是允许调度器杀掉占用超过其应占份额资源队列的containers,这些containers资源便可被分配到应该享有这些份额资源的队列中。需要注意抢占会降低集群的执行效率,因为被终止的containers需要被重新执行。
通过设置一个全局的参数yarn.scheduler.fair.preemption=true来启用抢占功能。此外,还有两个参数用来控制抢占的过期时间(这两个参数默认没有配置,需要至少配置一个来允许抢占Container):
公平共享抢占的默认阈值
配置文件中的顶级元素
<defaultFairSharePreemptionThreshold>为所有队列配置这个阈值;还可在<queue>元素内配置<fairSharePreemptionThreshold>元素来为某个队列指定超阈值,默认是0.5。
公平共享抢占的默认超时时间
配置文件中的顶级元素
<defaultMinSharePreemptionTimeout>为所有队列配置这个超时时间;还可在<queue>元素内配置<minSharePreemptionTimeout>元素来为某个队列指定超时时间。
如果队列在
fair share preemption timeout指定时间内未获得平等的资源的一半(这个比例可以配置),调度器则会进行抢占containers。默认最小共享抢占超时时间
配置文件中的顶级元素
<defaultFairSharePreemptionTimeout>为所有队列配置这个超时时间;还可在<queue>元素内配置<fairSharePreemptionTimeout>元素来为某个队列指定超时时间。
如果队列在
minimum share preemption timeout指定的时间内未获得最小的资源保障,调度器就会抢占containers。哪些情况下会发生抢占
最小资源抢占, 当前queue的资源无法保障时,而又有apps运行,需要向外抢占;
公平调度抢占, 当前queue的资源为达到max,而又有apps运行,需要向外抢占;
最小最大资源设置
资源设置格式:X 表示内存,单位为MB;Y 表示虚拟CPU Core核数;注意分隔符

最小资源保证:
在每个资源池中,允许配置该资源池的最小资源,这是为了防止把空闲资源共享出去还未回收的时候,该资源池有任务需要运行时候的资源保证。
比如,资源池businessA中配置了最小资源为(5vCPU,5GB),那么即使没有任务运行,Yarn也会为资源池businessA预留出最小资源,一旦有任务需要运行,而集群中已经没有其他空闲资源的时候,最小资源也可以保证资源池businessA中的任务可以先运行起来,随后再从集群中获取资源。

如果一个队列的最小共享未能得到满足,那么它将会在相同parent下其他队列之前获得可用资源。在单一资源公平策略下,一个队列如果它的内存使用量低于最小内存值则认为是未满足的。
- 在DRF策略下,如果一个队列的主资源是低于最小共享的话则认为是未满足的。如果有多个队列未满足的情况,资源分配给相关资源使用量和最小值之间比率最小的队列。
- 注意一点,有可能一个队列处于最小资源之下,但是在它提交application时不会立刻达到最小资源,因为已经在运行的job会使用这些资源。
最大资源限制
最多可以使用的资源量,fair scheduler会保证每个队列使用的资源量不会超过该队列的最多可使用资源量。

对于单一资源公平策略,vcores的值会被忽略。一个队列永远不会分配资源总量超过这个限制。
资源调度分配案例一
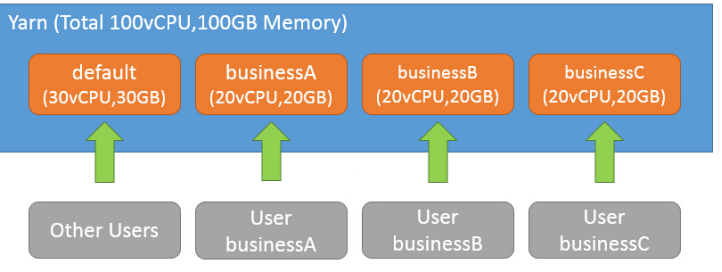
根据用户组分配资源池 ,假设在生产环境Yarn中,总共有四类用户需要使用集群,开发用户、测试用户、业务1用户、业务2用户。为了使其提交的任务不受影响,在Yarn上规划配置了五个资源池,分别为 dev_group(开发用户组资源池)、test_group(测试用户组资源池)、business1_group(业务1用户组资源池)、business2_group(业务2用户组资源池)、default(只分配了极少资源)。并根据实际业务情况,为每个资源池分配了相应的资源及优先级等。
相关配置如下:
<?xml version="1.0"?>
<allocations>
<!-- 设置每个用户提交运行应用的最大数量为30 -->
<userMaxAppsDefault>30</userMaxAppsDefault>
<!-- 全局设置各个队列中资源调度策略为DRF,同时对内存和CPU进行调度 -->
<defaultQueueSchedulingPolicy>drf</defaultQueueSchedulingPolicy>
<!-- 根队列root下所包含的子队列设置 -->
<queue name="root">
<!-- 全局设置root队列下的应用提交与管理ACL用户和用户组,值为任意用户和任意组 -->
<aclSubmitApps> </aclSubmitApps>
<aclAdministerApps> </aclAdministerApps>
<!-- 默认队列default,分配较少资源,最多运行一个应用 -->
<queue name="default">
<minResources>2000 mb, 1 vcores</minResources>
<maxResources>10000 mb, 1 vcores</maxResources>
<maxRunningApps>1</maxRunningApps>
<schedulingMode>fifo</schedulingMode>
<weight>0.5</weight>
<aclSubmitApps>*</aclSubmitApps>
</queue>
<!-- 开发用户组资源池的队列,最小资源设置较大,采用DRF调度策略,仅仅dev_group组用户提交 -->
<queue name="dev_group">
<minResources>200000 mb, 33 vcores</minResources>
<maxResources>300000 mb, 90 vcores</maxResources>
<maxRunningApps>150</maxRunningApps>
<schedulingMode>drf</schedulingMode>
<weight>2.5</weight>
<aclSubmitApps> dev_group</aclSubmitApps>
<aclAdministerApps> hadoop,dev_group</aclAdministerApps>
</queue>
<queue name="test_group">
<minResources>70000 mb, 20 vcores</minResources>
<maxResources>95000 mb, 25 vcores</maxResources>
<maxRunningApps>60</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1</weight>
<aclSubmitApps> test_group</aclSubmitApps>
<aclAdministerApps> hadoop,test_group</aclAdministerApps>
</queue>
<queue name="business1_group">
<minResources>75000 mb, 15 vcores</minResources>
<maxResources>100000 mb, 20 vcores</maxResources>
<maxRunningApps>80</maxRunningApps>
<schedulingMode>drf</schedulingMode>
<weight>1</weight>
<aclSubmitApps> business1_group</aclSubmitApps>
<aclAdministerApps> hadoop,business1_group</aclAdministerApps>
</queue>
<queue name="business2_group">
<minResources>75000 mb, 15 vcores</minResources>
<maxResources>102400 mb, 20 vcores</maxResources>
<maxRunningApps>80</maxRunningApps>
<schedulingMode>drf</schedulingMode>
<weight>1</weight>
<aclSubmitApps> business2_group</aclSubmitApps>
<aclAdministerApps> hadoop,business2_group</aclAdministerApps>
</queue>
</queue>
<queuePlacementPolicy>
<rule name="primaryGroup" create="false"/>
<!-- 提交用户所属的secondary group名称相匹配的队列 -->
<rule name="secondaryGroupExistingQueue" create="false"/>
<rule name="default"/>
</queuePlacementPolicy>
</allocations>资源调度分配案例二
由于公司的hadoop集群的计算资源不是很充足,需要开启yarn资源队列的资源抢占。
- 只有一个队列的资源小于设置的 最小资源时,才有可能启动资源抢占。
- 只要所有的资源队列的最小资源之和小于等于集群的资源总量就都是合理的。如果最小资源之和大于集群的资源总量,同时又开启了资源抢占模式,那么资源调度就会不停的处于资源抢占的模式(这样的逻辑当然是不合理的了)。
- 所有队列的最大资源配置之和可以大于集群的资源总量是合理的
- 每个队列的最大资源配置 只要小于等于集群的资源总量 就也是合理的。
<?xml version="1.0"?>
<allocations>
<defaultQueueSchedulingPolicy>drf</defaultQueueSchedulingPolicy>
<defaultMinSharePreemptionTimeout>300</defaultMinSharePreemptionTimeout>
<pool name="default">
<maxResources>0 mb, 0 vcores</maxResources>
<maxRunningApps>0</maxRunningApps>
<weight>0.0</weight>
</pool>
<pool name="online">
<minResources>24000 mb, 12 vcores</minResources>
<maxResources>48000 mb, 24 vcores</maxResources>
<maxRunningApps>12</maxRunningApps>
<weight>3.0</weight>
</pool>
<pool name="develop">
<minResources>12000 mb, 6 vcores</minResources>
<maxResources>24000mb, 12 vcores</maxResources>
<maxRunningApps>6</maxRunningApps>
<weight>2.0</weight>
</pool>
<pool name="bi">
<minResources>12000 mb, 6 vcores</minResources>
<maxResources>24000 mb, 12 vcores</maxResources>
<maxRunningApps>6</maxRunningApps>
<weight>1.0</weight>
</pool>
<!-- 与pool里的选择策略是:遇小选小 -->
<userMaxAppsDefault>5</userMaxAppsDefault>
<!-- 具体指定(specified):应用程序被放置到它要求队列中。如果应用程序要求没有队列,也就是说,它指定了: default
用户(user):应用程序被放置到一个与谁提交它的用户的名称队列
primaryGroup:应用程序被放置到一个队列,谁提交它的用户的主组的名称
secondaryGroupExistingQueue:应用程序被放置到一个有一个与谁提交了用户的次要组名的队列。符合配置的队列中的第一次要组将被选中
默认(default):应用程序被放置到一个名为default的队列
拒绝(reject):应用程序被拒绝
-->
<queuePlacementPolicy>
<!--<rule name="specified" create="false" /> 暂不启用: 用户提交任务时指定队列将无效-->
<rule name="user" create="false" />
<rule name="primaryGroup" create="false" />
<!--<rule name="secondaryGroupExistingQueue" create="false" /> 暂不启用: 尚未指定次要组 -->
<rule name="secondaryGroupExistingQueue" create="false" />
<!-- <rule name="reject"/> -->
<rule name="default" queue="develop"/>
</queuePlacementPolicy>
</allocations>- 第一:三个资源队列default,online,develop,bi四个队列;集群的共有24core,48G内存

该示例的最小资源之和是100%,最大资源之和可以大于资源总量,最大值可以根据实际中的情况来划分。例如在线上要优先保证线上资源,所以online队列的最小资源比例为70%,最大为100%;develop,和bi的最小资源都是可以为0的,这样才能保证在紧急情况下online可以抢占100%的资源。

- 第二:queuePlacementPolicy

演示Fair Scheduler
下面以三台机器为例,进行初步设置,运行程序MapReduce或Spark程序演示。
- 开启Fair Scheduler,相关参数配置,添加到
HADOOP_CONF/yarn-site.xml中
<!-- 设置使用公平调度器FairScheduler -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!-- 指定全公平调度器资源配置文件 -->
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>fair-scheduler.xml</value>
</property>
<!-- 当应用不指定运行的队列时,默认运行在default队列中 -->
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
</property>
<!-- 不允许应用创建与指定名称相同的队列 -->
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
</property>- 资源队列配置,文件
HADOOP_CONF/fair-scheduler.xml,内容如下:
<?xml version="1.0"?>
<allocations>
<defaultQueueSchedulingPolicy>drf</defaultQueueSchedulingPolicy>
<queue name="batch_mr">
<weight>30</weight>
<schedulingPolicy>fair</schedulingPolicy>
</queue>
<queue name="engin_spark">
<weight>55</weight>
<queue name="etl"/>
<queue name="ml"/>
</queue>
<queue name="default">
<weight>15</weight>
<schedulingPolicy>fifo</schedulingPolicy>
</queue>
<queuePlacementPolicy>
<rule name="specified" create="false"/>
<rule name="primaryGroup" create="false"/>
<rule name="default" queue="default"/>
</queuePlacementPolicy>
</allocations>- 启动ResouceManager,打开8088页面

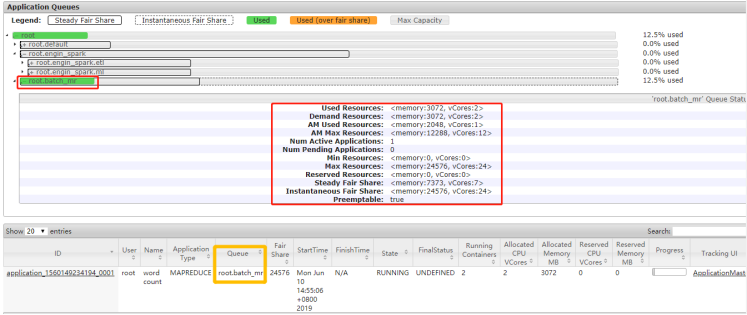
运行MapReduce中WordCount程序,指定运行队列batch_mr
HADOOP_HOME=/export/server/hadoop ${HADOOP_HOME}/bin/yarn jar \ ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \ wordcount \ -Dmapreduce.job.queuename=batch_mr \ datas/input.data /datas/output
不指定运行队列,默认运行在default队列
HADOOP_HOME=/export/server/hadoop ${HADOOP_HOME}/bin/yarn jar \ ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \ wordcount \ datas/input.data /datas/output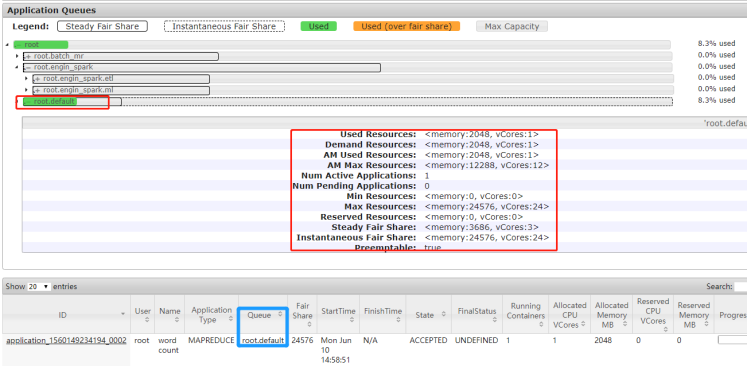
Fair Scheduler 整体结构
公平调度器的运行流程就是RM去启动FairScheduler,SchedulerDispatcher两个服务,这两个服务各自负责update线程,handle线程。
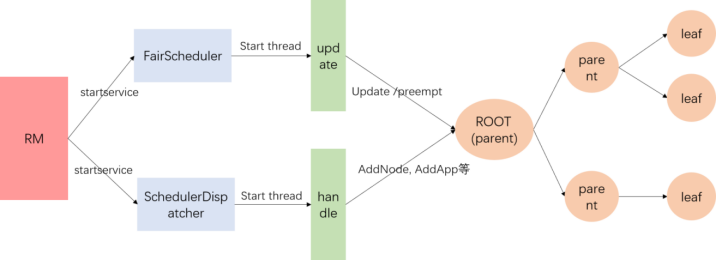
update线程有两个任务:
(1)更新各个队列的资源(Instantaneous Fair Share)
(2)判断各个leaf队列是否需要抢占资源(如果开启抢占功能);
handle线程主要是处理一些事件响应,比如集群增加节点,队列增加APP,队列删除APP,APP更新container等。
YARN 核心参数
在实际项目生产环境,需要调整配置YARN相关核心参数的值,才能更好的管理资源、调度任务执行及使用资源。
RM 核心参数
针对ResourceManager主节点来说,需要设置调度器类型及请求线程数据量:
参数一:yarn.resourcemanager.scheduler.class
设置YARN使用调度器,默认值:(不同版本YARN,值不一样)
Apache 版本 YARN ,默认值为容量调度器;org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
CDH 版本 YARN ,默认值为公平调度器;org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
参数二:yarn.resourcemanager.scheduler.client.thread-count
- ResourceManager处理调度器请求的线程数量,默认50,如果YARN运行任务Job比较多,可以将值调整大一下。
NM 核心参数
NodeManager运行在每台机器上,负责具体的资源管理
参数一:
yarn.nodemanager.resource.detect-hardware-capabilities- 是否让yarn自己检测硬件进行配置,默认false,如果设置为true,那么就会自动探测NodeManager所在主机的内存和CPU。
参数二:
yarn.nodemanager.resource.count-logical-processors-as-cores- 是否将虚拟核数当作CPU核数,默认false。
参数三:
yarn.nodemanager.resource.pcores-vcores-multiplier- 虚拟核数和物理核数乘数,例如:4核8线程,该参数就应设为2,默认1.0。
参数四:
yarn.nodemanager.resource.memory-mb- NodeManager使用内存,默认8G
参数五:
yarn.nodemanager.resource.system-reserved-memory-mb- 此参数,仅仅当上述参数一为true和参数四为-1时,设置才生效;
- 默认值:20% of (system memory - 2*HADOOP_HEAPSIZE)
参数六:
yarn.nodemanager.resource.cpu-vcores- NodeManager使用CPU核数,默认8个。
参数七:其他参数,使用默认值即可
- 参数:yarn.nodemanager.pmem-check-enabled,是否开启物理内存检查限制container,默认打开;
- 参数:yarn.nodemanager.vmem-check-enabled,是否开启虚拟内存检查限制container,默认打开;
- 参数:yarn.nodemanager.vmem-pmem-ratio,虚拟内存物理内存比例,默认2.1;
Contanier 核心参数
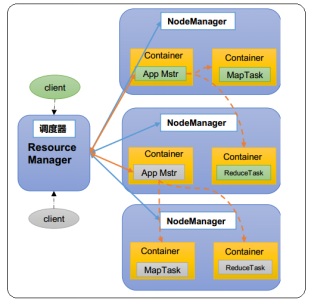
当应用程序提交运行至YARN上时,无论是AppMaster运行,还是Task(MapReduce框架)或Executor(Spark框架)或TaskManager(Flink框架)运行,NodeManager将资源封装在Contanier容器中,以便管理和监控,核心配置参数如下所示:
参数一:
yarn.scheduler.minimum-allocation-mb- 单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
参数二:
yarn.scheduler.maximum-allocation-mb- 单个任务可申请的最多物理内存量,默认是8192(MB)。
参数三:
yarn.scheduler.minimum-allocation-vcores- 单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。
参数四:
yarn.scheduler.maximum-allocation-vcores- 单个任务可申请的最多虚拟CPU个数,默认是4。
YARN Resource 资源配置
YARN支持可扩展的资源模型。默认情况下,YARN会跟踪所有节点,应用程序和队列的CPU和内存,但资源定义可以扩展为包含任意“countable”资源。可数资源是在容器运行时消耗的资源,但之后会释放,CPU和内存都是可数资源。
此外,YARN还支持使用“resource profiles”,允许用户通过单个配置文件指定多个资源请求,例如,“large”可能意味着8个虚拟内核和16GB RAM。
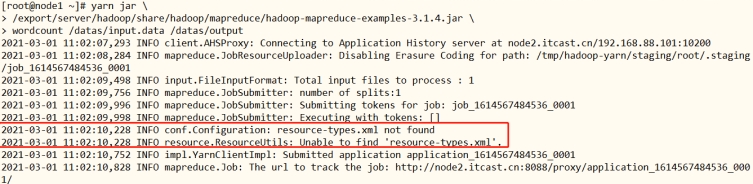
默认情况,提交MapReduce程序运行至YARN集群时,日志信息中显示出【resource-types.xml】资源类型配置文件未到,原因在于没有进行YARN Resource配置。
资源配置参数
如果进行YARN Resource配置,相关参数说明如下:
启动资源配置:
yarn-site.xml- 参数:
yarn.resourcemanager.resource-profiles.enabled,是否启用资源配置文件支持,默认为false。
- 参数:
资源类型配置:
resource-types.xml- 参数:
yarn.resource-types,逗号分隔的附加资源列表。 - 参数:
yarn.resource-types.<resource>.units,指定资源类型的默认单位。 - 参数:
yarn.resource-types.<resource>.minimum-allocation,指定资源类型的最小请求。 - 参数:
yarn.resource-types.<resource>.minimum-allocation,指定资源类型的最大请求。
- 参数:
- 节点资源配置:
node-resource.xml- 参数:
yarn.nodemanager.resource-type.<resource>,节点管理器中可用的指定资源的数量。
- 参数:
注意,如果使用resource-types.xml和node-resources.xml文件,则还需要将它们放在与yarn-site.xml相同的配置目录【$HADOOP_HOME/etc/hadoop】中,或者将属性放入yarn-site.xml文件中。
YARN 资源模型
具体看一看YARN是如何进行资源模型设置与管理,分为2个方面:ResourceManager和NodeManager设置。
Resource Manager
资源管理器是跟踪集群中哪些资源的最终仲裁者。资源管理器从XML配置文件加载其资源定义。例如,要定义除CPU和内存之外的新资源,应配置以下属性:
<property>
<name>yarn.resource-types</name>
<value>resource1,resource2</value>
<description>The resources to be used for scheduling. Use resource-types.xml to specify details about the individual resource types. </description>
</property>对于定义的每个新资源类型,可以添加可选的单元属性以设置资源类型的默认单位,及具有可选的最小和最大属性。可以定义yarn-site.xml文件或在一个文件名为 resource-types.xml中。
<configuration>
<property>
<name>yarn.resource-types</name>
<value>resource1, resource2</value>
</property>
<property>
<name>yarn.resource-types.resource1.units</name>
<value>G</value>
</property>
<property>
<name>yarn.resource-types.resource2.minimum-allocation</name>
<value>1</value>
</property>
<property>
<name>yarn.resource-types.resource2.maximum-allocation</name>
<value>1024</value>
</property>
</configuration>Node Manager
每个节点管理器独立定义该节点可用的资源。资源定义是通过为每个可用资源设置属性来完成的,可以放在通常的yarn-site.xml文件或名为noderesources.xml的文件中。属性的值应该是节点提供的资源量。例如:
<configuration>
<property>
<name>yarn.nodemanager.resource-type.resource1</name>
<value>5G</value>
</property>
<property>
<name>yarn.nodemanager.resource-type.resource2</name>
<value>2m</value>
</property>
</configuration>注意,此处资源的单位不需要与资源管理器持有的定义匹配,如果单位不匹配,会自动进行转换。
MapReduce 使用 Resource
MapReduce从YARN请求三种不同类型的容器:master container, map containers, 和 reduce containers 。对于每种容器类型,都有一组相应的属性可用于设置所请求的资源。
在MapReduce中设置资源请求的属性是:
| 属性 | 描述 |
|---|---|
yarn.app.mapreduce.am.resource.memory-mb |
将应用程序主容器请求的内存设置为以MB为单位的值。默认为1536。 |
yarn.app.mapreduce.am.resource.vcores |
将应用程序 master container 请求的CPU设置为该值。默认为1。 |
yarn.app.mapreduce.am.resource .<resource> |
将应用程序master container 的<resource>请求的数量设置为该值。 |
mapreduce.map.resource.memory-mb |
将所有 map master container请求的内存设置为以MB为单位的值。默认为1024。 |
mapreduce.map.resource.vcores |
将所有映射map master container 请求的CPU设置为该值。默认为1。 |
mapreduce.map.resource. <resource> |
将所有map master container 的<resource>请求的数量设置为该值。 |
mapreduce.reduce.resource.memory-mb |
将所有educe task container请求的内存设置为以MB为单位的值。默认为1024。 |
mapreduce.reduce.resource. <resource> |
将所有educe task container 的<resource>请求的数量设置为该值。 |
注意,YARN可以修改这些资源请求以满足配置的最小和最大资源值,或者是配置增量的倍数。
 微信
微信 支付宝
支付宝








